BIG DATA & HDFS. Anuradha Bhatia, Big Data & HDFS, NoSQL 1
|
|
|
- Justina McDowell
- 6 years ago
- Views:
Transcription
1 BIG DATA & HDFS 1
2 OUTLINE Big Data Characteristics of Big Data Traditional v/s Streaming Data Hadoop Hadoop Architecture 2
3 BIG DATA 3 Big data is a collection of both structured and unstructured data that is too large, fast and distinct to be managed by traditional database management tools or traditional data processing applications. For e.g., Data managed by e-commerce websites for request search, consumer/customer recommendations, current trend and merchandising Data managed by social media for providing a social network platform Data managed by real-time auction / bidding in online environment






4 IMPLEMENTATION Natural Systems Wildfire management Water management Water Water 4 Stock market Impact of weather on securities prices 5 million messages per second, trade in 150 microseconds Law Enforcement Real-time multimodal surveillance Transportation Intelligent traffic management Global air traffic management Manufacturing Process control for microchip fabrication Health & Life Sciences Neonatal ICU monitoring Epidemic early warning system Remote healthcare monitoring Fraud prevention Detecting multi-party fraud Real time fraud prevention Radio Astronomy Detection of transient events

5 BIG DATA USES 5

6 BIG DATA CONSISTS OF 6


7 WHICH PLATFORM DO YOU CHOOSE? 7 Hadoop Analytic Database General Purpose RDBMS Structured Semi-Structured Unstructured
8 CHARACTERISTICS OF BIG DATA 8 Volume System/Users generating TeraBtes, PetaBytes and ZetaBytes of data Storage Velocity System generated streams of data Multiple sources feeding data for one system Processing Variety Structured data Unstructured data-blogs, Images, Audio etc. Presentation
9 VALUE CHAIN OF BIG DATA 9 Data Generation Source of data e.g., Users, Enterprises, Systems etc Data Collection Companies, Tools, Sites aggregating data e.g, IMS Data Analysis Research and Analytics Firms e.g., MuSigms, etc. Application of Insights Management consulting firms, MNC s
10 TRADITIONAL COMPUTING Historical fact finding with data-at-rest Batch paradigm, pull model Query-driven: submits queries to static data Relies on Databases, Data Warehouses 10 Queries Data Results a) static data


11 STREAM COMPUTING Real time analysis of data-in-motion Streaming data A stream of structured or unstructured data-inmotion Stream Computing Analytic operations on streaming data in real-time 11

 Very low latency Low usefulness density Complex analytics Event needs to be detected High volume (TB/sec)")
12 STREAM COMPUTING EVENTS 12 Large Spectrum of Events/Data Structured data RFID click streams financial data network packet traces text and transactional data ATM transactions pervasive sensor data Unstructured data phone conversations satellite data instant messages Unknown data/signal web searches news broadcasting digital audio, video and image data High usefulness density Simple analytics Well defined event High speed (million events per sec) Very low latency Low usefulness density Complex analytics Event needs to be detected High volume (TB/sec) Low latency

13 HADOOP 13 Ecosystem of open source projects Hosted by Apache Foundation Google developed concepts and shared Distributed file system that scales out on commodity servers with direct attached storage and automatic failover.

14 HADOOP SYSTEM 14 Source: Hortonworks
15 HADOOP DISTRIBUTED FILE SYSTEM - HDFS 15 Hadoop Distributed File System (HDFS) HDFS is the implementation of Hadoop file system, the java abstract class org.apache.hadoop.fs.filesystem that represents a file system in Hadoop. HDFS is designed to work efficiently in conjunction with MapReduce. Definition A distributed file system that provides big data storage solution through high-throughput access to application data. When data can potentially outgrow the storage capacity of a single machine, portioning it across a number of separate machines is necessary for storage of processing. This is achieved using a distributed file systems. Potential Challenges: Ensuring data integrity Data retention in case of nodes failure Integration across multiple nodes and systems
16 HADOOP DISTRIBUTED FILE SYSTEM - HDFS 16 Hadoop Distributed File System (HDFS) HDFS is designed for storing very large files with streaming data access patterns, running on clusters of commodity hardware Very Large Files Very large means files that are hundred of MB, GB, TB or PB in size. Streaming Data Access: HDFS implements write-once, read-many-times pattern. Data is copied from source for analysis over time. Each analysis involves a large portion of the dataset, so that time to read the whole dataset is more important than the latency in reading the first record. Commodity Hardware: Hadoop runs on clusters of commodity hardware (commodity available hardware) HDFS is designed to carry on working without a noticeable interruption to the user in the case of node failure.
17 HADOOP DISTRIBUTED FILE SYSTEM - HDFS 17 Where HDFS doesn t work well: HDFS is not designed for the following scenarios Low-Latency Data Access: HDFS is optimised for delivering a high throughput of data, and this may be at the expense of latency Lots of Small Files: File system metadata is stored in memory, hence the limit to the number of files in a file system is governed by the amount of memory on the namenode. As rule of thumb, each file, directory, and block takes about 150 bytes. Multiple Updates in the File: Files in HDFS may be written to by a single writer at the end of the file. There is no support for multiple writers, or for modifications at arbitrary offsets in the file.
18 HADOOP DISTRIBUTED FILE SYSTEM - CONCEPT Blocks NameNode DataNodes HDFS Federation HDFS High Availablity 18
19 HADOOP DISTRIBUTED FILE SYSTEM - BLOCKS 19 Files in HDFS are broken into blocks of 64 MB (default) and stored as independent units. Files in HDFS that is smaller than a single block does not occupy a full block s storage HDFS blocks are large compared to disk blocks to minimize the cost of seeks. Map tasks in MapReduce operate on one block at a time Block as a unit of abstraction rather than a file simplifies the storage subsystem which takes the metadata information Blocks fit well with replication for providing fault tolerance and availability HDFS s fsck command understands blocks For example, command to list the blocks that make up each file in the system: % hadoop fsck / -files -blocks
20 HDFS NAMENODES & DATANODES HDFS cluster consists of NameNodes DataNodes 20














21 HDFS NAMENODES & DATANODES 21 Client DFS 2-Get block location Namenode FSData InputStream Datanode Datanode Datanode
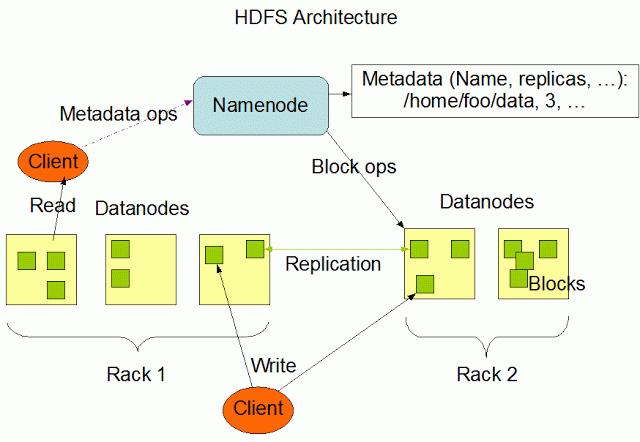
22 HDFS ARCHITECTURE 22

23 WHAT DOES IT DO? 23 Hadoop implements Google s MapReduce, using HDFS HDFS creates multiple replicas of data blocks for reliability, placing them on compute nodes around the cluster. MapReduce can then process the data where it is located. Hadoop s target is to run on clusters of the order of 10,000-nodes.
24 DATA CHARACTERISTICS 24 Batch processing rather than interactive user access. Large data sets and files: gigabytes to terabytes size High aggregate data bandwidth Scale to hundreds of nodes in a cluster Tens of millions of files in a single instance Write-once-read-many: a file once created, written and closed need not be changed this assumption simplifies coherency A map-reduce application or web-crawler application fits perfectly with this model.
25 DATA BLOCKS 25 HDFS support write-once-read-many with reads at streaming speeds. A typical block size is 64MB (or even 128 MB). A file is chopped into 64MB chunks and stored.
26 FILESYSTEM NAMESPACE 26 Hierarchical file system with directories and files Create, remove, move, rename etc. Namenode maintains the file system Any meta information changes to the file system recorded by the Namenode. An application can specify the number of replicas of the file needed: replication factor of the file. This information is stored in the Namenode.
27 FS SHELL, ADMIN AND BROWSER INTERFACE 27 HDFS organizes its data in files and directories. It provides a command line interface called the FS shell that lets the user interact with data in the HDFS. The syntax of the commands is similar to bash and csh. Example: to create a directory /foodir/bin/hadoop dfs mkdir /foodir There is also DFSAdmin interface available Browser interface is also available to view the namespace.
28 Steps for HDFS 28 BLOCKS REPLICATION STAGING
29 DATA REPLICATION 29 HDFS is designed to store very large files across machines in a large cluster. Each file is a sequence of blocks. All blocks in the file except the last are of the same size. Blocks are replicated for fault tolerance. Block size and replicas are configurable per file. The Namenode receives a Heartbeat and a BlockReport from each DataNode in the cluster. BlockReport contains all the blocks on a Datanode.
30 REPLICA PLACEMENT 30 The placement of the replicas is critical to HDFS reliability and performance. Optimizing replica placement distinguishes HDFS from other distributed file systems. Rack-aware replica placement: Replicas are placed: one on a node in a local rack, one on a different node in the local rack and one on a node in a different rack. 1/3 of the replica on a node, 2/3 on a rack and 1/3 distributed evenly across remaining racks.
31 REPLICA SELECTION 31 Replica selection for READ operation: HDFS tries to minimize the bandwidth consumption and latency. If there is a replica on the Reader node then that is preferred. HDFS cluster may span multiple data centers: replica in the local data center is preferred over the remote one.
32 STAGING 32 A client request to create a file does not reach Namenode immediately. HDFS client caches the data into a temporary file. When the data reached a HDFS block size the client contacts the Namenode. Namenode inserts the filename into its hierarchy and allocates a data block for it. The Namenode responds to the client with the identity of the Datanode and the destination of the replicas (Datanodes) for the block. Then the client flushes it from its local memory.
33 STAGING 33 The client sends a message that the file is closed. Namenode proceeds to commit the file for creation operation into the persistent store. If the Namenode dies before file is closed, the file is lost. This client side caching is required to avoid network congestion.
34 SAFEMODE STARTUP 34 On startup Namenode enters Safemode. Replication of data blocks do not occur in Safemode. Each DataNode checks in with Heartbeat and BlockReport. Namenode verifies that each block has acceptable number of replicas After a configurable percentage of safely replicated blocks check in with the Namenode, Namenode exits Safemode. It then makes the list of blocks that need to be replicated. Namenode then proceeds to replicate these blocks to other Datanodes.
35 NAMENODE 35 Keeps image of entire file system namespace and file Blockmap in memory. 8GB of local RAM is sufficient to support the above data structures that represent the huge number of files and directories. When the Namenode starts up it gets the FsImage and Editlog from its local file system, update FsImage with EditLog information and then stores a copy of the FsImage on the filesytstem as a checkpoint. Periodic checkpointing is done. So that the system can recover back to the last checkpointed state in case of a crash.
36 FILESYSTEM METADATA 36 The HDFS namespace is stored by Namenode. Namenode uses a transaction log called the EditLog to record every change that occurs to the filesystem meta data. o o o For example, creating a new file. Change replication factor of a file EditLog is stored in the Namenode s local filesystem Entire filesystem namespace including mapping of blocks to files and file system properties is stored in a file FsImage. Stored in Namenode s local filesystem.
37 DATANODE A Datanode stores data in files in its local file system. Datanode has no knowledge about HDFS filesystem It stores each block of HDFS data in a separate file. Datanode does not create all files in the same directory. It uses heuristics to determine optimal number of files per directory and creates directories appropriately: Research issue? When the filesystem starts up it generates a list of all HDFS blocks and send this report to Namenode: Blockreport. 37
38 NAMENODES & DATANODES 38 Master/slave architecture HDFS cluster consists of a single Namenode, a master server that manages the file system namespace and regulates access to files by clients. There are a number of DataNodes usually one per node in a cluster. The DataNodes manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. A file is split into one or more blocks and set of blocks are stored in DataNodes. DataNodes: serves read, write requests, performs block creation, deletion, and replication upon instruction from Namenode.
39 NAMENODES & DATANODES 39 NameNode Manages the file namespace operation like opening, creating, renaming etc. File name to list blocks + location mapping File metadata Authorization and authentication Collect block reports from DataNodes on block locations Replicate missing blocks Keeps ALL namespace in memory plus checkpoints & journal
40 NAMENODES & DATANODES 40 DataNode Handles block storage on multiple volumes and data integrity. Clients access the blocks directly from data nodes for read and write Data nodes periodically send block reports to NameNode Block creation, deletion and replication upon instruction from the NameNode
41 CLIENT 41
42 FAULT TOLERANCE 42 Failure is the norm rather than exception A HDFS instance may consist of thousands of low end machines, each storing part of the file system s data. Since we have huge number of components and that each component has non-trivial probability of failure means that there is always some component that is non-functional. Detection of faults and quick, automatic recovery from them is a core architectural goal of HDFS.
43 DATANODE FAILURE & HEARTBEAT 43 A network partition can cause a subset of Datanodes to lose connectivity with the Namenode. Namenode detects this condition by the absence of a Heartbeat message. Namenode marks Datanodes without Hearbeat and does not send any IO requests to them. Any data registered to the failed Datanode is not available to the HDFS. Also the death of a Datanode may cause replication factor of some of the blocks to fall below their specified value.
44 RE-REPLICATION The necessity for re-replication may arise due to: 44 o A Datanode may become unavailable, o A replica may become corrupted, o A hard disk on a Datanode may fail, or o The replication factor on the block may be increased.
45 HDFS FAULT TOLERANCE 45 The input data (on HDFS) is stored on the local disks of the machines in the cluster. HDFS divides each file into 64 MB blocks, and stores several copies of each block (typically 3 copies) on different machines. Worker Failure: The master pings every worker periodically. If no response is received from a worker in a certain amount of time, the master marks the worker as failed. Any map tasks completed by the worker are reset back to their initial idle state, and therefore become eligible for scheduling on other workers. Similarly, any map task or reduce task in progress on a failed worker is also reset to idle and becomes eligible for rescheduling. Master Failure: It is easy to make the master write periodic checkpoints of the master data structures described above. If the master task dies, a new copy can be started from the last check-pointed state. However, in most cases, the user restarts the job.
46 CLUSTER - REBALANCING 46 HDFS architecture is compatible with data rebalancing schemes. A scheme might move data from one Datanode to another if the free space on a Datanode falls below a certain threshold. In the event of a sudden high demand for a particular file, a scheme might dynamically create additional replicas and rebalance other data in the cluster.
47 DATA INTEGRITY 47 Consider a situation: a block of data fetched from Datanode arrives corrupted. This corruption may occur because of faults in a storage device, network faults, or buggy software. A HDFS client creates the checksum of every block of its file and stores it in hidden files in the HDFS namespace. When a clients retrieves the contents of file, it verifies that the corresponding checksums match. If does not match, the client can retrieve the block from a replica.
48 METADATA DISK FAILURE 48 FsImage and EditLog are central data structures of HDFS. A corruption of these files can cause a HDFS instance to be nonfunctional. For this reason, a Namenode can be configured to maintain multiple copies of the FsImage and EditLog. Multiple copies of the FsImage and EditLog files are updated synchronously. Meta-data is not data-intensive. The Namenode could be single point failure: automatic failover is NOT supported!
49 BACKUP 49
50 SAFEMODE 50 On startup NameNode enters SafeMode Replication of data blocks do not occur in SafeMode Each DataNode checks in with HeartBeat and BlockReport NameNode verifies that each block has acceptable number of replicas After a configurable percentage of safely replicated blocks check in with the NameNode, NameNode exists in SafeMode It then makes the list of blocks that need to be replicated NameNode then proceeds to replicate these blocks to other DataNodes
51 APPLICATION PROGRAMMING INTERFACE 51 HDFS provides Java API for application to use. Python access is also used in many applications. A C language wrapper for Java API is also available. A HTTP browser can be used to browse the files of a HDFS instance.
52 SPACE RECLAMATION 52 When a file is deleted by a client, HDFS renames file to a file in be the /trash directory for a configurable amount of time. A client can request for an undelete in this allowed time. After the specified time the file is deleted and the space is reclaimed. When the replication factor is reduced, the Namenode selects excess replicas that can be deleted. Next heartbeat(?) transfers this information to the Datanode that clears the blocks for use.
53 HADOOP ECOSYSTEM HDFS is the file system 53 MR is the job which runs on file system The MR job helps the user to ask question from HDFS files Pig and Hive are two projects built to replace coding the map reduce Pig and Hive interpreter turns the script and sql queries "INTO" MR job To save the map and reduce only dependency to be able to query on HDFS - Impala and Hive Impala Optimized for high latency queries-near real time Hive optimized for batch processing job Sqoop: Can put data from a relation DB to Hadoop ecosystem Flume can send data generated from external system to move to HDFS- Apt for high volume logging Hue: Graphical frontend to cluster Oozie: Workflow management tool Mahout : Machine learning Library
54 HADOOP ECOSYSTEM 54 PIG HIVE Select * from MR IMPALA HBASE HDFS HUE, OOZIE, MAHOUT CDH SQOOP FLUME CLOUDERA

55 STORAGE OF FILE IN HDFS 55

56 STORAGE OF FILE IN HDFS 56 When a 150MB file is being fed to Hadoop ecosystem it breaks itself in to multiple parts to achieve parallelism It breaks itself in to chunks where default chunk size is 64MB Data node is the demon which takes care of all the happening at an individual node Name node is the one which keeps a track on what goes where and when required how to collect the same group together Now think hard what could be the possible challenges?

57 HDFS APPLICATION 57

58 HDFS APPLICATION 58 Application of HDFS-Moving Data File for Analysis Moving a file in hadoop Moved file in Hadoop ecosystem

59 MAPREDUCE STRUCTURE 59
60 NoSQL 60 What is NoSQL CAP Theorem What is lost Types of NoSQL Data Model Frameworks Demo Wrap-up
61 SCALING UP Issues with scaling up when the dataset is just too big RDBMS were not designed to be distributed Began to look at multi-node database solutions Known as scaling out or horizontal scaling Different approaches include: o Master-slave o Sharding 61
62 Master-Slave RDBMS - MASTER/SLAVE 62 o All writes are written to the master. All reads performed against the replicated slave databases o Critical reads may be incorrect as propagated down writes may not have been o Large data sets can pose problems as master needs to duplicate data to slaves
63 RDBMS - SHARDING Partition or Sharding o Scales well for both reads and writes o Not transparent, application needs to be partition-aware o Can no longer have relationships/joins across partitions o Loss of referential integrity across shards 63
64 SCALING RDBMS Multi-Master replication INSERT only, not UPDATES/DELETES No JOINs, thereby reducing query time o This involves de-normalizing data In-memory databases 64
65 NoSQL 65 Stands for Not Only SQL Class of non-relational data storage systems Usually do not require a fixed table schema nor do they use the concept of joins All NoSQL offerings relax one or more of the ACID properties
66 WHY NoSQL?? 66 For data storage, an RDBMS cannot be the be-all/end-all Just as there are different programming languages, need to have other data storage tools in the toolbox A NoSQL solution is more acceptable to a client now than even a year ago
67 BIG TABLE Three major papers were the seeds of the NoSQL movement o BigTable (Google) o Dynamo (Amazon) Gossip protocol (discovery and error detection) Distributed key-value data store Eventual consistency o CAP Theorem 67
68 CAP THEOREM 68 Three properties of a system: Consistency, Availability and Partitions You can have at most two of these three properties for any shared-data system To scale out, you have to partition. That leaves either consistency or availability to choose from o In almost all cases, you would choose availability over consistency
69 CHARACTERISTICS OF NoSQL NoSQL solutions fall into two major areas: 69 o Key/Value or the big hash table. Amazon S3 (Dynamo) Voldemort Scalaris o Schema-less which comes in multiple flavors, column-based, document-based or graph-based. Cassandra (column-based) CouchDB (document-based) Neo4J (graph-based) HBase (column-based)
70 Pros o Very fast o Very scalable o Simple model o Able to distribute horizontally KEY VALUE 70 Cons o Many data structures (objects) can't be easily modeled as key value pairs
71 Pros SCHEMA- LESS o Schema-less data model is richer than key/value pairs o Eventual consistency o Many are distributed o Still provide excellent performance and scalability 71 Cons o Typically no ACID transactions or joins
72 SQL TO NoSQL 72 Joins Group by Order by ACID transactions SQL as a sometimes frustrating but still powerful query language Easy integration with other applications that support SQL
73 SEARCHING 73 Relational o SELECT `column` FROM `database`,`table` WHERE `id` = key; o SELECT product_name FROM rockets WHERE id = 123; Cassandra (standard) o keyspace.getslice(key, column_family, "column") o keyspace.getslice(123, new ColumnParent( rockets ), getslicepredicate());
74 NoSQL API 74 Basic API access: o get(key) -- Extract the value given a key o put(key, value) -- Create or update the value given its key o delete(key) -- Remove the key and its associated value o execute(key, operation, parameters) -- Invoke an operation to the value (given its key) which is a special data structure (e.g. List, Set, Map... etc).
75 DATA MODEL Within Cassandra data set o Column: smallest data element, a tuple with a name and a value :hadoop, '1' might return: {'name' => Hadoop Model', toon' => Ready Set Zoom', inventoryqty' => 5, producturl => hadoop\1.gif } 75
76 DATA MODEL 76 o ColumnFamily: There s a single structure used to group both the Columns and SuperColumns. Called a ColumnFamily (think table), it has two types, Standard & Super. Column families must be defined at startup o Key: the permanent name of the record o Keyspace: the outer-most level of organization. This is usually the name of the application. For example, Acme' (think database name).
77 HASHING 77 V A B C S D R H M
78 HASHING Partition using consistent hashing 78 o Keys hash to a point on a fixed circular space o Ring is partitioned into a set of ordered slots and servers and keys hashed over these slots Nodes take positions on the circle. A, B, and D exists. o B responsible for AB range. o D responsible for BD range. o A responsible for DA range. C joins. o B, D split ranges. o C gets BC from D.
79 DATA TYPE 79 Columns are always sorted by their name. Sorting supports: o BytesType o UTF8Type o LexicalUUIDType o TimeUUIDType o AsciiType o LongType Each of these options treats the Columns' name as a different data type
80 CASE STUDY 80 Facebook Search MySQL > 50 GB Data o Writes Average : ~300 ms o Reads Average : ~350 ms Rewritten with NoSQL > 50 GB Data o Writes Average : 0.12 ms o Reads Average : 15 ms
81 IMPLEMENTATION OF NoSQL 81 Log Analysis Social Networking Feeds (many firms hooked in through Facebook or Twitter) External feeds from partners (EAI) Data that is not easily analyzed in a RDBMS such as time-based data Large data feeds that need to be massaged before entry into an RDBMS
82 SHARED DATA ARCHITECTURE 82 Shared Data A B C D
83 SHARED NOTHING ARCHITECTURE 83 Shared Nothing A B C D
84 LIST OF NoSQL DATABASES Wide Column Store o Hadoop / Hbase o Cloudera o Cassandra o Hypertable o Accumulo o Amazon Simple DB o Cloudata o MonetDB 84
85 Document Store o OrientDB o MongoDB o Couchbase Server o CouchDB o RavenDB o Marklogic Server o JSON ODM LIST OF NoSQL DATABASES 85
86 Key Value Store o DynamoDB o Azure o Riak o Redis o Aerospike o LevelDB o RocksDB LIST OF NoSQL DATABASES 86
87 Graph Databases o Neo4J o ArangoDB o Infinite Graph o Sparksee o TITAN o InfoGrid o Graph Base LIST OF NoSQL DATABASES 87
88 MapReduce Map Operations Reduce Operations Submitting a MapReduce Job Shuffle Data types 88
89 Map Reduce 89 Map reduce is a programming model for processing and generating large data sets. Use of functional model with user specified Map and reduce operations allows to parallelize large computations. map(k1,v1) list(k2,v2)
90 Map OPERATION The common array operation var a = [1, 2, 3] ; for( i = 0 ; i < a.length ; i++) a[i] = a[i] * 2; The output is var a = [2, 4, 6] 90
91 Map OPERATION When fn is passed as an function argument function map(fn, a) { for( i = 0; i < a.length; i++) a[i] = fn(a[i]); } The map function is invoked as map(function(x) {return x * 2;}, a); 91
92 Reduce FUNCTION Merges together the intermediate key value accepted from the user, I with the set of values from the key. Merges the values to form a smaller set of values. 92 reduce(k2, list(v2)) list(v2)
93 EXECUTION OVERVIEW 93 The Map invocations are distributed across multiple machines by automatically partitioning the input data into a set of M splits. Reduce invocations are distributed by partitioning the intermediate key space into R pieces using a partitioning function. The number of partitions (R) and the partitioning functions are specified by the user.
94 Map FUNCTION FOR WORDCOUNT Key : Document Name Value : Document Contents 94 map ( String key, String value) for each word w in value : EmitIntermediate(w, 1 );
95 Reduce FUNCTION FOR WORDCOUNT Key : A Word Values : A list of counts 95 reduce( String key, Iterator values): int result = 0; for each v in values: result += ParseInt (v); Emit(AsString(result));
96 MapReduce AT HIGH LEVEL 96 MapReduce job submitted by the Client Machine Master Node Job Tracker Slave Node Task Tracker Slave Node Task Tracker Task Instance Task Instance
97 ANATOMY OF MapReduce 97 Partitioning I N P U T D A T A NODE 1 NODE 2 NODE 3 MAP MAP MAP Interim D Interim D Interim D Reduce Reduce Reduce Node to store Output Node to store Output Node to store Output
98 SUMMARY 98 A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, Shuffle the sorted output based on its key and then input to the reduce tasks. The input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
99 QUESTIONS 99
100 100
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
CS-580K/480K Advanced Topics in Cloud Computing. NoSQL Database
 CS-580K/480K dvanced Topics in Cloud Computing NoSQL Database 1 1 Where are we? Cloud latforms 2 VM1 VM2 VM3 3 Operating System 4 1 2 3 Operating System 4 1 2 Virtualization Layer 3 Operating System 4
CS-580K/480K dvanced Topics in Cloud Computing NoSQL Database 1 1 Where are we? Cloud latforms 2 VM1 VM2 VM3 3 Operating System 4 1 2 3 Operating System 4 1 2 Virtualization Layer 3 Operating System 4
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
CIB Session 12th NoSQL Databases Structures
 CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
UNIT-IV HDFS. Ms. Selva Mary. G
 UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop & Big Data Analytics Complete Practical & Real-time Training
 An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
NoSQL systems. Lecture 21 (optional) Instructor: Sudeepa Roy. CompSci 516 Data Intensive Computing Systems
 Instructor: Sudeepa Roy. CompSci 516 Data Intensive Computing Systems") CompSci 516 Data Intensive Computing Systems Lecture 21 (optional) NoSQL systems Instructor: Sudeepa Roy Duke CS, Spring 2016 CompSci 516: Data Intensive Computing Systems 1 Key- Value Stores Duke CS,
CompSci 516 Data Intensive Computing Systems Lecture 21 (optional) NoSQL systems Instructor: Sudeepa Roy Duke CS, Spring 2016 CompSci 516: Data Intensive Computing Systems 1 Key- Value Stores Duke CS,
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Data Intensive Computing
 Data Intensive Computing B. Ramamurthy This work is Partially Supported by NSF DUE Grant#: 0737243, 0920335 1 Topics for discussion Problem Space: explosion of data Solution space: emergence of multi core,
Data Intensive Computing B. Ramamurthy This work is Partially Supported by NSF DUE Grant#: 0737243, 0920335 1 Topics for discussion Problem Space: explosion of data Solution space: emergence of multi core,
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
CS 655 Advanced Topics in Distributed Systems
 Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]
![Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]](/thumbs/96/126854374.jpg "Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]") s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY
 NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY WHAT IS NOSQL? Stands for No-SQL or Not Only SQL. Class of non-relational data storage systems E.g.
NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY WHAT IS NOSQL? Stands for No-SQL or Not Only SQL. Class of non-relational data storage systems E.g.
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
7680: Distributed Systems
 Cristina Nita-Rotaru 7680: Distributed Systems GFS. HDFS Required Reading } Google File System. S, Ghemawat, H. Gobioff and S.-T. Leung. SOSP 2003. } http://hadoop.apache.org } A Novel Approach to Improving
Cristina Nita-Rotaru 7680: Distributed Systems GFS. HDFS Required Reading } Google File System. S, Ghemawat, H. Gobioff and S.-T. Leung. SOSP 2003. } http://hadoop.apache.org } A Novel Approach to Improving
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Improving the MapReduce Big Data Processing Framework
 Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391
 Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Google File System and BigTable. and tiny bits of HDFS (Hadoop File System) and Chubby. Not in textbook; additional information
 and Chubby. Not in textbook; additional information") Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
A Survey on Big Data
 A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
NoSQL Databases MongoDB vs Cassandra. Kenny Huynh, Andre Chik, Kevin Vu
 NoSQL Databases MongoDB vs Cassandra Kenny Huynh, Andre Chik, Kevin Vu Introduction - Relational database model - Concept developed in 1970 - Inefficient - NoSQL - Concept introduced in 1980 - Related
NoSQL Databases MongoDB vs Cassandra Kenny Huynh, Andre Chik, Kevin Vu Introduction - Relational database model - Concept developed in 1970 - Inefficient - NoSQL - Concept introduced in 1980 - Related
New Approaches to Big Data Processing and Analytics
 New Approaches to Big Data Processing and Analytics Contributing authors: David Floyer, David Vellante Original publication date: February 12, 2013 There are number of approaches to processing and analyzing
New Approaches to Big Data Processing and Analytics Contributing authors: David Floyer, David Vellante Original publication date: February 12, 2013 There are number of approaches to processing and analyzing
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
Jargons, Concepts, Scope and Systems. Key Value Stores, Document Stores, Extensible Record Stores. Overview of different scalable relational systems
 Jargons, Concepts, Scope and Systems Key Value Stores, Document Stores, Extensible Record Stores Overview of different scalable relational systems Examples of different Data stores Predictions, Comparisons
Jargons, Concepts, Scope and Systems Key Value Stores, Document Stores, Extensible Record Stores Overview of different scalable relational systems Examples of different Data stores Predictions, Comparisons
Cmprssd Intrduction To
 Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor
Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
COSC 416 NoSQL Databases. NoSQL Databases Overview. Dr. Ramon Lawrence University of British Columbia Okanagan
 COSC 416 NoSQL Databases NoSQL Databases Overview Dr. Ramon Lawrence University of British Columbia Okanagan ramon.lawrence@ubc.ca Databases Brought Back to Life!!! Image copyright: www.dragoart.com Image
COSC 416 NoSQL Databases NoSQL Databases Overview Dr. Ramon Lawrence University of British Columbia Okanagan ramon.lawrence@ubc.ca Databases Brought Back to Life!!! Image copyright: www.dragoart.com Image
10 Million Smart Meter Data with Apache HBase
 10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
Big Data Analytics. Rasoul Karimi
 Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
BIG DATA TECHNOLOGIES: WHAT EVERY MANAGER NEEDS TO KNOW ANALYTICS AND FINANCIAL INNOVATION CONFERENCE JUNE 26-29,
 BIG DATA TECHNOLOGIES: WHAT EVERY MANAGER NEEDS TO KNOW ANALYTICS AND FINANCIAL INNOVATION CONFERENCE JUNE 26-29, 2016 1 OBJECTIVES ANALYTICS AND FINANCIAL INNOVATION CONFERENCE JUNE 26-29, 2016 2 WHAT
BIG DATA TECHNOLOGIES: WHAT EVERY MANAGER NEEDS TO KNOW ANALYTICS AND FINANCIAL INNOVATION CONFERENCE JUNE 26-29, 2016 1 OBJECTIVES ANALYTICS AND FINANCIAL INNOVATION CONFERENCE JUNE 26-29, 2016 2 WHAT
Chase Wu New Jersey Institute of Technology
 CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Cassandra, MongoDB, and HBase. Cassandra, MongoDB, and HBase. I have chosen these three due to their recent
 Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
BIG DATA TESTING: A UNIFIED VIEW
 http://core.ecu.edu/strg BIG DATA TESTING: A UNIFIED VIEW BY NAM THAI ECU, Computer Science Department, March 16, 2016 2/30 PRESENTATION CONTENT 1. Overview of Big Data A. 5 V s of Big Data B. Data generation
http://core.ecu.edu/strg BIG DATA TESTING: A UNIFIED VIEW BY NAM THAI ECU, Computer Science Department, March 16, 2016 2/30 PRESENTATION CONTENT 1. Overview of Big Data A. 5 V s of Big Data B. Data generation
Sources. P. J. Sadalage, M Fowler, NoSQL Distilled, Addison Wesley
 Big Data and NoSQL Sources P. J. Sadalage, M Fowler, NoSQL Distilled, Addison Wesley Very short history of DBMSs The seventies: IMS end of the sixties, built for the Apollo program (today: Version 15)
Big Data and NoSQL Sources P. J. Sadalage, M Fowler, NoSQL Distilled, Addison Wesley Very short history of DBMSs The seventies: IMS end of the sixties, built for the Apollo program (today: Version 15)
STATS Data Analysis using Python. Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns
 STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Chapter 24 NOSQL Databases and Big Data Storage Systems
 Chapter 24 NOSQL Databases and Big Data Storage Systems - Large amounts of data such as social media, Web links, user profiles, marketing and sales, posts and tweets, road maps, spatial data, email - NOSQL
Chapter 24 NOSQL Databases and Big Data Storage Systems - Large amounts of data such as social media, Web links, user profiles, marketing and sales, posts and tweets, road maps, spatial data, email - NOSQL
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to the Hadoop Ecosystem - 1
 Hello and welcome to this online, self-paced course titled Administering and Managing the Oracle Big Data Appliance (BDA). This course contains several lessons. This lesson is titled Introduction to the
Hello and welcome to this online, self-paced course titled Administering and Managing the Oracle Big Data Appliance (BDA). This course contains several lessons. This lesson is titled Introduction to the
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component