Mastering The Behavior of Multi-Core Systems to Match Avionics Requirements
|
|
|
- Leslie Freeman
- 6 years ago
- Views:
Transcription

1 Mastering The Behavior of Multi-Core Systems to Match Avionics Requirements Hicham AGROU, Marc GATTI, Pascal SAINRAT, Patrice TOILLON {hicham.agrou,marc-j.gatti,

2 Summary Introduction
3 Summary Introduction Multi-Core Architectures State of Art Academic Processor, COTS Architecture,
4 Summary Introduction Multi-Core Architectures State of Art Academic Processor, COTS Architecture, Evaluation of QorIQ Platform (P4080) from Freescale Procedures Results
5 Summary Introduction Multi-Core Architectures State of Art Academic Processor, COTS Architecture, Evaluation of QorIQ Platform (P4080) from Freescale Procedures Results THALES Avionics AMISIS Concept First performance Results
6 INTRODUCTION
7 Evolution of Avionic Embedded Computers
8 Pre-IMA Generation Evolution of Avionic Embedded Computers











9 Evolution of Avionic Embedded Computers 90 s A330/A340 1 unit = 1 function Intel, DSP 80 s A300/A320/B737 1 unit = 1 function Intel, Pre-IMA Generation 70 s Concorde 1 unit = 1 function Analog only
10 IMA Generation Evolution of Avionic Embedded Computers


11 Evolution of Avionic Embedded Computers 2000/2010 0/2010 A380/B to 5 functions/unit PowerPC, A653+RTOS Generalization of IMA PowerPC ISA s Legacy IMA Generation ~1995 B777 2 to 3 functions/unit AMD st Generation of IMA

12 Evolution of Avionic Embedded Computers Next generation: IMA on Multicore? 10 or more functions/unit IMA Generation

 Partition scheduling Package Driver Processor")
13 Current Avionics requirements Safety Certification Determinism Level Failure Condition Failure Rate A Catastrophic <1 in 10 9 hours of flight B Hazardous <1 in 10 7 hours of flight C Major <1 in 10 5 hours of flight D Minor <1 in 10 3 hours of flight No Effect E Partitioning Spatial Time & Space isolation Temporal Application #1 Application #2 Application Application #N Application Programing Interface (ARINC 653) Communication, synchronisation services Time, fault, and task management Operating System Layer (ARINC 653) Partition scheduling Package Driver Processor Hardware






14 Future Avionics Requirements Increase Performance Host more functions per unit Improvement ratio Performance / Watts Reduce Environmental Footprint Less energy consumption Reduce number of units
15 Future Avionics Requirements Increase Performance Host more functions per unit Improvement ratio Performance / Watts Reduce Environmental Footprint Less energy consumption Reduce number of units Smaller Modules More embedded functions per chip MULTI-CORE seems to be the solution
16 Academic & COTS Architectures MULTI-CORE ARCHITECTURES STATE OF ART
: Best cache policy")
, Ring protocols, CoreNet, & Data Path Accelerator")

17 Multi-Core Architectures State of The Art Academic Predictable Multi-core Processor: MERASA & PRET processors COTS architecture: IBM Cell, Freescale s MPC8641D & QorIQ Platform Local memories (scratchpads & caches): Best cache policy (for analyzability), Cache Analysis (optimization to reduce cache pollution), Shared Cache Strategy to reduce interferences Interconnect Element: Shared Bus (bounding access time), Ring protocols, CoreNet, & Data Path Accelerator Architecture Hicham Agrou, Marc Gatti, Pascal Sainrat, Patrice Toillon. A Design Approach for Predictable and Efficient Multi-Core for Avionics. In: Digital Avionics Systems Conference (DASC 2011), Seattle, 16/10/ /10/2011, Vol. 7D3, IEEE, p. 1-11; October 2011.
18 Multi-Core Architectures State of The Art Academic Predictable Multi-core Processor: MERASA & PRET processors COTS architecture: IBM Cell, Freescale s MPC8641D & QorIQ Platform Local memories (scratchpads & caches): Best cache policy (for analyzability), Cache Analysis (optimization to reduce cache pollution), Shared Cache Strategy to reduce interferences Interconnect Element: Shared Bus (bounding access time), Ring protocols, CoreNet, & Data Path Accelerator Architecture Lack of studies for multicore architecture in avionics Focus on core level & local memory evolutions At interconnect level, no partitioning warranty is given
: Best cache policy (for analyzability), Cache Analysis (optimization to reduce cache pollution), Shared Cache Strategy to reduce interferences")

19 Multi-Core Architectures State of The Art Academic Predictable Multi-core Processor: MERASA & PRET processors COTS architecture: IBM Cell, Freescale s MPC8641D & QorIQ Platform Local memories (scratchpads & caches): Best cache policy (for analyzability), Cache Analysis (optimization to reduce cache pollution), Shared Cache Strategy to reduce interferences Interconnect Element: Shared Bus (bounding access time), Ring protocols, CoreNet, & Data Path Accelerator Architecture Our approach is to focus on a smart interconnect to manage all transactions in a multi-core system Lack of studies for multicore architecture in avionics Focus on core level & local memory evolutions At interconnect level, no partitioning warranty is given
20 Procedure & Results EVALUATION OF A QORIQ PLATFORM (P4080)

 A(x,n) Our")

21 Evaluation of a QorIQ Platform (P4080) from Freescale Objective Definition of usage profiles compatible with temporal aspects of avionics constraints Procedure To find thresholds of transaction density beyond which CoreNet TM introduces low-performance or/and an abnormal behavior A(0,1) A(x,n) Our Procedure A(0) A(n) OS(0) OS(x) OS OR Hypervisor (s) Stress Application HW HW HW SMP Configuration AMP or AMP+SMP Configuration Bare-metal Configuration








22 P4080 Processor : test perimeter P4080 DS Cores : 1,2 GHz DDR3 # 1 :1200 MHz P4080 CoreNet : 600 MHz



23 Procedure This core performs a transaction and measures its duration


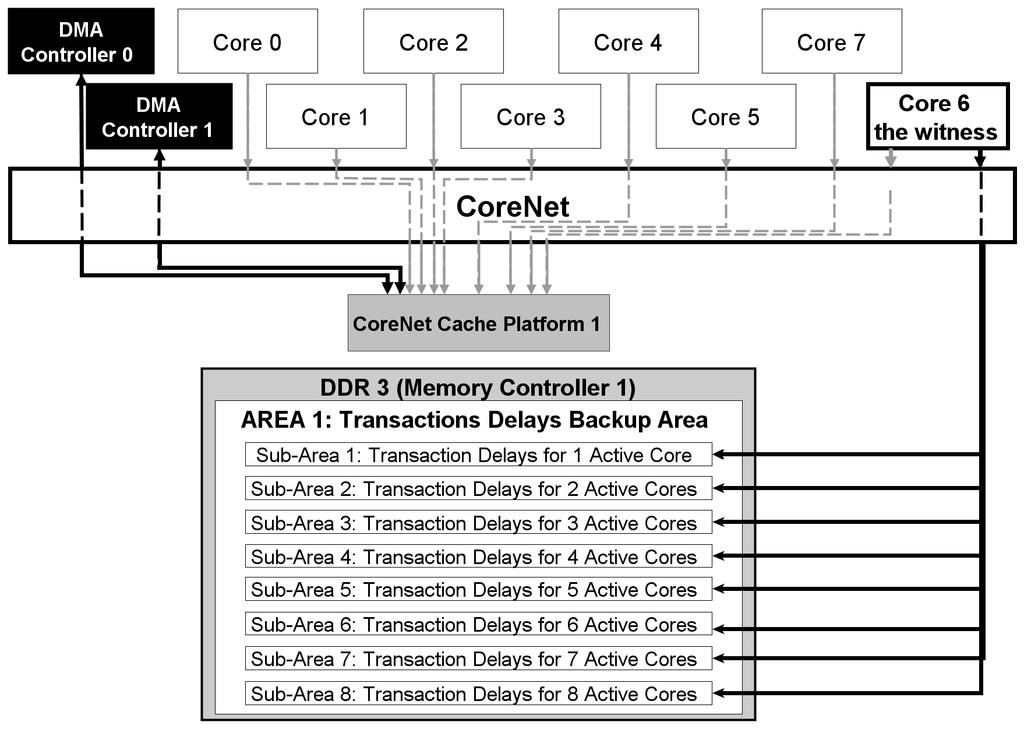
24 Procedure > The Implemented Transaction Initiators DMA Controllers Flooding Cores Each measure is in AREA 1 of DDR 3
25 Test Perimeter > The Implemented Memories
26 Procedure
27 Procedure > Platform s Initialisation 1
28 Procedure > Transactions of Flooding Cores Flooding Core 2
29 Procedure > Direct Memory Accesses 3 2
30 Procedure > Transaction of the Witness 3 2 4
31 Procedure > Storage of the Transaction Duration 5 If 0 Flooding Core in step 2
32 Procedure > Storage of the Transaction Duration 5 If 1 Flooding Core in step 2
33 Procedure > Storage of the Transaction Duration 5 If 2 Flooding Cores in step 2
34 Procedure > Storage of the Transaction Duration 5 If 3 Flooding Cores in step 2
35 Procedure > Storage of the Transaction Duration 5 If 4 Flooding Cores in step 2
36 Procedure > Storage of the Transaction Duration 5 If 5 Flooding Cores in step 2
37 Procedure > Storage of the Transaction Duration 5 If 6 Flooding Cores in step 2
38 Procedure > Storage of the Transaction Duration 5 If 7 Flooding Cores in step 2



39 Scenario 1
40 Scenario 1 Similar results when testing With no/1/2 DMA controller(s) 1 to 8 active cores Parameters 512 sizes of transaction (witness core) have been tested ~ 16 hours of test for each scenario Each test is repeated ~ times

41 Scenario 1




42 Scenario 2
43 Scenario 1 & 2 > Results Scenario 1 Scenario 2
 can increase transaction latency of the witness core in CPC 1")
44 Scenario 1 & 2 > Results Scenario 1 Scenario 2 These results show that DMAs in DDR3 (memory controller 1) can increase transaction latency of the witness core in CPC 1


45 Scenario 3 DMA Load & Store transactions
46 Scenario 3 > Results

47 Scenario 3 > Results Several transaction durations of 7-core configuration are not saved



48 Scenario 4 All transaction initiators perform their transactions in DDR3 (AREA 2)
49 Scenario 4 > Results
50 Scenario 4 > Results All transaction durations are saved in DDR 3 (memory controller 1) and their values increase


51 Scenario 5 All transaction initiators perform their transactions in DDR3 s AREA 1
52 Scenario 5 > Results

53 Scenario 5 > Results Several transaction durations are not saved in DDR3 and their value have globally decreased
54 Scenario 6




55 Scenario 6




56 Scenario 6 : Delaying the backup of each measure 0 µs 3,3 µs 4,3 µs 5 µs
 makes the phenomenon")
57 Scenario 6 : Delaying the measure storage 0 µs 3,3 µs 4,3 µs 5 µs Delaying the measure storage into AREA 1 (DDR3 of memory controller 1) makes the phenomenon disappear


58 Concept, Features & First Performance Results THALES AVIONICS AMISIS
59 AMISIS Architecture Avionics Multi-core Interconnect for Scalable Integrated System Concept Mastering temporal and spatial behavior of each transaction initiator, Ensuring that each transaction initiator will respect an insertion contract Implementation of Hardware Services Maximal Transaction Delay Measure(Max-TDM) t t Maximal Technology Transaction Delay Minimal Technology Transaction Delay Minimal Transaction Delay Measure (Min-TDM) COTS Black Box Approach t CUSTOM White Box Approach
60 AMISIS Architecture Avionics Multi-core Interconnect for Scalable Integrated System Concept Mastering temporal and spatial behavior of each transaction initiator, Ensuring that each transaction initiator will respect an insertion contract Implementing Hardware Services Experimentation s Implementation Objective : Definition of temporal impacts of AMISIS in transaction durations Procedure : Design of AMISIS units in FPGA Measure of AMISIS units temporal impacts
61 First Performance Results of AMISIS AMISIS 125 MHz Memory 400 MHz Load 08 Load 16 Load 32
62 First Performance Results of AMISIS 1 cycle 2 cycles AMISIS 125 MHz Memory 400 MHz
63 First Performance Results of AMISIS AMISIS 125 MHz Memory 400 MHz


64 First Performance Results of AMISIS AMISIS 125 MHz Memory 400 MHz 1 cycle 2 cycles
65 CONCLUSION
66 Conclusion Processing Elements use embedded hardware features that worsen Worst Case Execution Time Estimation
67 Conclusion Processing Elements use embedded hardware features that worsen Worst Case Execution Time Estimation
68 Conclusion Processing Elements use embedded hardware features that worsen Worst Case Execution Time Estimation Dynamic Branch Prediction Out-Of-Order Speculative Execution Larger Pipelines More Ways Policy Replacement : PLRU, FIFO, Round Robin







69 Conclusion Processing Elements use embedded hardware features that worsen Worst Case Execution Time Estimation Mastered Dynamic Branch Prediction Out-Of-Order Speculative Execution Larger Pipelines More Ways Policy Replacement : PLRU, FIFO, Round Robin
70 Conclusion Processing Elements use embedded hardware features that worsen Worst Case Execution Time Estimation Multi-core context implies concurrent accesses that require management to ensure proper spatial and temporal partitioning
71 Conclusion Processing Elements use embedded hardware features that worsen Worst Case Execution Time Estimation Multi-core context implies concurrent accesses that require management to ensure proper spatial and temporal partitioning Scenario 2 shows that increasing the number of shared resources sometimes increases transaction durations Scenario 1 Scenario 2

72 Conclusion Processing Elements use embedded hardware features that worsen Worst Case Execution Time Estimation Multi-core context implies concurrent accesses that require management to ensure proper spatial and temporal partitioning Scenario 2 shows that increasing the number of shared resources sometimes increases transaction durations Scenario 3 and 5 show that unexpected phenomena may appear
73 Conclusion Processing Elements use embedded hardware features that worsen Worst Case Execution Time Estimation Multi-core context implies concurrent accesses that require management to ensure proper spatial and temporal partitioning Scenario 2 shows that increasing the number of shared resources sometimes increases transaction durations Scenario 3 and 5 show that unexpected phenomena may appear First performance results of THALES Avionics AMISIS show that the temporal impact of its controls is negligible
74 Thank You for Your Attention
Overview of Potential Software solutions making multi-core processors predictable for Avionics real-time applications
 Overview of Potential Software solutions making multi-core processors predictable for Avionics real-time applications Marc Gatti, Thales Avionics Sylvain Girbal, Xavier Jean, Daniel Gracia Pérez, Jimmy
Overview of Potential Software solutions making multi-core processors predictable for Avionics real-time applications Marc Gatti, Thales Avionics Sylvain Girbal, Xavier Jean, Daniel Gracia Pérez, Jimmy
Integration of Mixed Criticality Systems on MultiCores: Limitations, Challenges and Way ahead for Avionics
 Integration of Mixed Criticality Systems on MultiCores: Limitations, Challenges and Way ahead for Avionics TecDay 13./14. Oct. 2015 Dietmar Geiger, Bernd Koppenhöfer 1 COTS HW Evolution - Single-Core Multi-Core
Integration of Mixed Criticality Systems on MultiCores: Limitations, Challenges and Way ahead for Avionics TecDay 13./14. Oct. 2015 Dietmar Geiger, Bernd Koppenhöfer 1 COTS HW Evolution - Single-Core Multi-Core
AUTOBEST: A microkernel-based system (not only) for automotive applications. Marc Bommert, Alexander Züpke, Robert Kaiser.
 for automotive applications. Marc Bommert, Alexander Züpke, Robert Kaiser.") AUTOBEST: A microkernel-based system (not only) for automotive applications Marc Bommert, Alexander Züpke, Robert Kaiser vorname.name@hs-rm.de Outline Motivation AUTOSAR ARINC 653 AUTOBEST Architecture
AUTOBEST: A microkernel-based system (not only) for automotive applications Marc Bommert, Alexander Züpke, Robert Kaiser vorname.name@hs-rm.de Outline Motivation AUTOSAR ARINC 653 AUTOBEST Architecture
Applying MILS to multicore avionics systems
 Applying MILS to multicore avionics systems Eur Ing Paul Parkinson FIET Principal Systems Architect, A&D EuroMILS Workshop, Prague, 19 th January 2016 2016 Wind River. All Rights Reserved. Agenda A Brief
Applying MILS to multicore avionics systems Eur Ing Paul Parkinson FIET Principal Systems Architect, A&D EuroMILS Workshop, Prague, 19 th January 2016 2016 Wind River. All Rights Reserved. Agenda A Brief
Design and Analysis of Time-Critical Systems Introduction
 Design and Analysis of Time-Critical Systems Introduction Jan Reineke @ saarland university ACACES Summer School 2017 Fiuggi, Italy computer science Structure of this Course 2. How are they implemented?
Design and Analysis of Time-Critical Systems Introduction Jan Reineke @ saarland university ACACES Summer School 2017 Fiuggi, Italy computer science Structure of this Course 2. How are they implemented?
Managing Memory for Timing Predictability. Rodolfo Pellizzoni
 Managing Memory for Timing Predictability Rodolfo Pellizzoni Thanks This work would not have been possible without the following students and collaborators Zheng Pei Wu*, Yogen Krish Heechul Yun* Renato
Managing Memory for Timing Predictability Rodolfo Pellizzoni Thanks This work would not have been possible without the following students and collaborators Zheng Pei Wu*, Yogen Krish Heechul Yun* Renato
Evaluating Multicore Architectures for Application in High Assurance Systems
 Evaluating Multicore Architectures for Application in High Assurance Systems Ryan Bradetich, Paul Oman, Jim Alves-Foss, and Theora Rice Center for Secure and Dependable Systems University of Idaho Contact:
Evaluating Multicore Architectures for Application in High Assurance Systems Ryan Bradetich, Paul Oman, Jim Alves-Foss, and Theora Rice Center for Secure and Dependable Systems University of Idaho Contact:
RAMP-White / FAST-MP
 RAMP-White / FAST-MP Hari Angepat and Derek Chiou Electrical and Computer Engineering University of Texas at Austin Supported in part by DOE, NSF, SRC,Bluespec, Intel, Xilinx, IBM, and Freescale RAMP-White
RAMP-White / FAST-MP Hari Angepat and Derek Chiou Electrical and Computer Engineering University of Texas at Austin Supported in part by DOE, NSF, SRC,Bluespec, Intel, Xilinx, IBM, and Freescale RAMP-White
CNES requirements w.r.t. Next Generation General Purpose Microprocessor
 Round-table on Next Generation Microprocessors for Space Applications : CNES requirements w.r.t. Next Generation General Purpose Microprocessor ESA/ESTEC september 12th 2006 G.Moury, J.Bertrand, M.Pignol
Round-table on Next Generation Microprocessors for Space Applications : CNES requirements w.r.t. Next Generation General Purpose Microprocessor ESA/ESTEC september 12th 2006 G.Moury, J.Bertrand, M.Pignol
Challenges in Future Avionic Systems on Multi-core Platforms
 2014 IEEE International Symposium on Software Reliability Engineering Workshops Challenges in Future Avionic Systems on Multi-core Platforms Andreas Löfwenmark Avionics Equipment Saab Aeronautics Linköping,
2014 IEEE International Symposium on Software Reliability Engineering Workshops Challenges in Future Avionic Systems on Multi-core Platforms Andreas Löfwenmark Avionics Equipment Saab Aeronautics Linköping,
Ensuring Schedulability of Spacecraft Flight Software
 Ensuring Schedulability of Spacecraft Flight Software Flight Software Workshop 7-9 November 2012 Marek Prochazka & Jorge Lopez Trescastro European Space Agency OUTLINE Introduction Current approach to
Ensuring Schedulability of Spacecraft Flight Software Flight Software Workshop 7-9 November 2012 Marek Prochazka & Jorge Lopez Trescastro European Space Agency OUTLINE Introduction Current approach to
Distributed IMA with TTEthernet
 Distributed IMA with thernet ARINC 653 Integration of thernet Georg Gaderer, Product Manager Georg.Gaderer@tttech.com October 30, 2012 Copyright TTTech Computertechnik AG. All rights reserved. Introduction
Distributed IMA with thernet ARINC 653 Integration of thernet Georg Gaderer, Product Manager Georg.Gaderer@tttech.com October 30, 2012 Copyright TTTech Computertechnik AG. All rights reserved. Introduction
Copyright 2016 Xilinx
 Zynq Architecture Zynq Vivado 2015.4 Version This material exempt per Department of Commerce license exception TSU Objectives After completing this module, you will be able to: Identify the basic building
Zynq Architecture Zynq Vivado 2015.4 Version This material exempt per Department of Commerce license exception TSU Objectives After completing this module, you will be able to: Identify the basic building
Towards AADL to SystemC mapping for partitioned systems. Etienne Borde Laurent Pautet Marc Gatti
 Towards AADL to SystemC mapping for partitioned systems Michael Lafaye Etienne Borde Laurent Pautet Marc Gatti Presentation of a First Mapping Prototype: AADL to SystemC for Avionics Partitioned Systems
Towards AADL to SystemC mapping for partitioned systems Michael Lafaye Etienne Borde Laurent Pautet Marc Gatti Presentation of a First Mapping Prototype: AADL to SystemC for Avionics Partitioned Systems
Communication Patterns in Safety Critical Systems for ADAS & Autonomous Vehicles Thorsten Wilmer Tech AD Berlin, 5. March 2018
 Communication Patterns in Safety Critical Systems for ADAS & Autonomous Vehicles Thorsten Wilmer Tech AD Berlin, 5. March 2018 Agenda Motivation Introduction of Safety Components Introduction to ARMv8
Communication Patterns in Safety Critical Systems for ADAS & Autonomous Vehicles Thorsten Wilmer Tech AD Berlin, 5. March 2018 Agenda Motivation Introduction of Safety Components Introduction to ARMv8
An introduction to SDRAM and memory controllers. 5kk73
 An introduction to SDRAM and memory controllers 5kk73 Presentation Outline (part 1) Introduction to SDRAM Basic SDRAM operation Memory efficiency SDRAM controller architecture Conclusions Followed by part
An introduction to SDRAM and memory controllers 5kk73 Presentation Outline (part 1) Introduction to SDRAM Basic SDRAM operation Memory efficiency SDRAM controller architecture Conclusions Followed by part
Memory Hierarchy. Slides contents from:
 Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Freescale QorIQ Program Overview
 August, 2009 Freescale QorIQ Program Overview Multicore processing view Jeffrey Ho Technical Marketing service names are the property of their respective owners. Freescale Semiconductor, Inc. 2009. We
August, 2009 Freescale QorIQ Program Overview Multicore processing view Jeffrey Ho Technical Marketing service names are the property of their respective owners. Freescale Semiconductor, Inc. 2009. We
On-Chip Debugging of Multicore Systems
 Nov 1, 2008 On-Chip Debugging of Multicore Systems PN115 Jeffrey Ho AP Technical Marketing, Networking Systems Division of Freescale Semiconductor, Inc. All other product or service names are the property
Nov 1, 2008 On-Chip Debugging of Multicore Systems PN115 Jeffrey Ho AP Technical Marketing, Networking Systems Division of Freescale Semiconductor, Inc. All other product or service names are the property
Roadrunner. By Diana Lleva Julissa Campos Justina Tandar
 Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
AUTOBEST: A United AUTOSAR-OS And ARINC 653 Kernel. Alexander Züpke, Marc Bommert, Daniel Lohmann
 AUTOBEST: A United AUTOSAR-OS And ARINC 653 Kernel Alexander Züpke, Marc Bommert, Daniel Lohmann alexander.zuepke@hs-rm.de, marc.bommert@hs-rm.de, lohmann@cs.fau.de Motivation Automotive and Avionic industry
AUTOBEST: A United AUTOSAR-OS And ARINC 653 Kernel Alexander Züpke, Marc Bommert, Daniel Lohmann alexander.zuepke@hs-rm.de, marc.bommert@hs-rm.de, lohmann@cs.fau.de Motivation Automotive and Avionic industry
Worst Case Analysis of DRAM Latency in Multi-Requestor Systems. Zheng Pei Wu Yogen Krish Rodolfo Pellizzoni
 orst Case Analysis of DAM Latency in Multi-equestor Systems Zheng Pei u Yogen Krish odolfo Pellizzoni Multi-equestor Systems CPU CPU CPU Inter-connect DAM DMA I/O 1/26 Multi-equestor Systems CPU CPU CPU
orst Case Analysis of DAM Latency in Multi-equestor Systems Zheng Pei u Yogen Krish odolfo Pellizzoni Multi-equestor Systems CPU CPU CPU Inter-connect DAM DMA I/O 1/26 Multi-equestor Systems CPU CPU CPU
MultiChipSat: an Innovative Spacecraft Bus Architecture. Alvar Saenz-Otero
 MultiChipSat: an Innovative Spacecraft Bus Architecture Alvar Saenz-Otero 29-11-6 Motivation Objectives Architecture Overview Other architectures Hardware architecture Software architecture Challenges
MultiChipSat: an Innovative Spacecraft Bus Architecture Alvar Saenz-Otero 29-11-6 Motivation Objectives Architecture Overview Other architectures Hardware architecture Software architecture Challenges
ESE532: System-on-a-Chip Architecture. Today. Message. Real Time. Real-Time Tasks. Real-Time Guarantees. Real Time Demands Challenges
 ESE532: System-on-a-Chip Architecture Day 9: October 1, 2018 Real Time Real Time Demands Challenges Today Algorithms Architecture Disciplines to achieve Penn ESE532 Fall 2018 -- DeHon 1 Penn ESE532 Fall
ESE532: System-on-a-Chip Architecture Day 9: October 1, 2018 Real Time Real Time Demands Challenges Today Algorithms Architecture Disciplines to achieve Penn ESE532 Fall 2018 -- DeHon 1 Penn ESE532 Fall
Challenges for Next Generation Networking AMP Series
 21 June 2011 Freescale, the Freescale logo, AltiVec, C-5, CodeTEST, CodeWarrior, ColdFire, C-Ware, t he Energy Efficient Solutions logo, mobilegt, PowerQUICC, QorIQ, StarCore and Symphony are trademarks
21 June 2011 Freescale, the Freescale logo, AltiVec, C-5, CodeTEST, CodeWarrior, ColdFire, C-Ware, t he Energy Efficient Solutions logo, mobilegt, PowerQUICC, QorIQ, StarCore and Symphony are trademarks
Memory Hierarchy. Slides contents from:
 Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Context. Giorgio Buttazzo. Scuola Superiore Sant Anna. Embedded systems are becoming more complex every day: more functions. higher performance
 Giorgio uttazzo g.buttazzo@sssup.it Scuola Superiore Sant nna Context Embedded systems are becoming more complex every day: more functions higher performance higher efficiency new hardware platforms 2
Giorgio uttazzo g.buttazzo@sssup.it Scuola Superiore Sant nna Context Embedded systems are becoming more complex every day: more functions higher performance higher efficiency new hardware platforms 2
Context. Hardware Performance. Increasing complexity. Software Complexity. And the Result is. Embedded systems are becoming more complex every day:
 Context Embedded systems are becoming more complex every day: Giorgio uttazzo g.buttazzo@sssup.it more functions higher performance higher efficiency Scuola Superiore Sant nna new hardware s Increasing
Context Embedded systems are becoming more complex every day: Giorgio uttazzo g.buttazzo@sssup.it more functions higher performance higher efficiency Scuola Superiore Sant nna new hardware s Increasing
History. PowerPC based micro-architectures. PowerPC ISA. Introduction
 PowerPC based micro-architectures Godfrey van der Linden Presentation for COMP9244 Software view of Processor Architectures 2006-05-25 History 1985 IBM started on AMERICA 1986 Development of RS/6000 1990
PowerPC based micro-architectures Godfrey van der Linden Presentation for COMP9244 Software view of Processor Architectures 2006-05-25 History 1985 IBM started on AMERICA 1986 Development of RS/6000 1990
HEAD HardwarE Accelerated Deduplication
 HEAD HardwarE Accelerated Deduplication Final Report CS710 Computing Acceleration with FPGA December 9, 2016 Insu Jang Seikwon Kim Seonyoung Lee Executive Summary A-Z development of deduplication SW version
HEAD HardwarE Accelerated Deduplication Final Report CS710 Computing Acceleration with FPGA December 9, 2016 Insu Jang Seikwon Kim Seonyoung Lee Executive Summary A-Z development of deduplication SW version
Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology
 Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology September 19, 2007 Markus Levy, EEMBC and Multicore Association Enabling the Multicore Ecosystem Multicore
Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology September 19, 2007 Markus Levy, EEMBC and Multicore Association Enabling the Multicore Ecosystem Multicore
REDUCING CERTIFICATION GRANULARITY TO INCREASE ADAPTABILITY OF AVIONICS SOFTWARE
 REDUCING CERTIFICATION GRANULARITY TO INCREASE ADAPTABILITY OF AVIONICS SOFTWARE Martin Rayrole, David Faura, Marc Gatti, Thales Avionics, Meudon la Forêt, France Abstract A strong certification process
REDUCING CERTIFICATION GRANULARITY TO INCREASE ADAPTABILITY OF AVIONICS SOFTWARE Martin Rayrole, David Faura, Marc Gatti, Thales Avionics, Meudon la Forêt, France Abstract A strong certification process
Optimizing Data Sharing and Address Translation for the Cell BE Heterogeneous CMP
 Optimizing Data Sharing and Address Translation for the Cell BE Heterogeneous CMP Michael Gschwind IBM T.J. Watson Research Center Cell Design Goals Provide the platform for the future of computing 10
Optimizing Data Sharing and Address Translation for the Cell BE Heterogeneous CMP Michael Gschwind IBM T.J. Watson Research Center Cell Design Goals Provide the platform for the future of computing 10
Timing analysis and timing predictability
 Timing analysis and timing predictability Architectural Dependences Reinhard Wilhelm Saarland University, Saarbrücken, Germany ArtistDesign Summer School in China 2010 What does the execution time depends
Timing analysis and timing predictability Architectural Dependences Reinhard Wilhelm Saarland University, Saarbrücken, Germany ArtistDesign Summer School in China 2010 What does the execution time depends
T1042-based Single Board Computer
 T1042-based Single Board Computer High Performance/Low Power DO-254 Certifiable SBC IP Features and Benefits Part of the COTS-D family of safety certifiable modules Single conduction-cooled rugged module
T1042-based Single Board Computer High Performance/Low Power DO-254 Certifiable SBC IP Features and Benefits Part of the COTS-D family of safety certifiable modules Single conduction-cooled rugged module
Leveraging OpenSPARC. ESA Round Table 2006 on Next Generation Microprocessors for Space Applications EDD
 Leveraging OpenSPARC ESA Round Table 2006 on Next Generation Microprocessors for Space Applications G.Furano, L.Messina TEC- OpenSPARC T1 The T1 is a new-from-the-ground-up SPARC microprocessor implementation
Leveraging OpenSPARC ESA Round Table 2006 on Next Generation Microprocessors for Space Applications G.Furano, L.Messina TEC- OpenSPARC T1 The T1 is a new-from-the-ground-up SPARC microprocessor implementation
XPU A Programmable FPGA Accelerator for Diverse Workloads
 XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
Challenges of FSW Schedulability on Multicore Processors
 Challenges of FSW Schedulability on Multicore Processors Flight Software Workshop 27-29 October 2015 Marek Prochazka European Space Agency MULTICORES: WHAT DOES FLIGHT SOFTWARE ENGINEER NEED? Space-qualified
Challenges of FSW Schedulability on Multicore Processors Flight Software Workshop 27-29 October 2015 Marek Prochazka European Space Agency MULTICORES: WHAT DOES FLIGHT SOFTWARE ENGINEER NEED? Space-qualified
Last Time. Making correct concurrent programs. Maintaining invariants Avoiding deadlocks
 Last Time Making correct concurrent programs Maintaining invariants Avoiding deadlocks Today Power management Hardware capabilities Software management strategies Power and Energy Review Energy is power
Last Time Making correct concurrent programs Maintaining invariants Avoiding deadlocks Today Power management Hardware capabilities Software management strategies Power and Energy Review Energy is power
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
The Nios II Family of Configurable Soft-core Processors
 The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
Embedded Systems: Hardware Components (part II) Todor Stefanov
 Todor Stefanov") Embedded Systems: Hardware Components (part II) Todor Stefanov Leiden Embedded Research Center, Leiden Institute of Advanced Computer Science Leiden University, The Netherlands Outline Generic Embedded
Embedded Systems: Hardware Components (part II) Todor Stefanov Leiden Embedded Research Center, Leiden Institute of Advanced Computer Science Leiden University, The Netherlands Outline Generic Embedded
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448. The Greed for Speed
 Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Simplify System Complexity
 1 2 Simplify System Complexity With the new high-performance CompactRIO controller Arun Veeramani Senior Program Manager National Instruments NI CompactRIO The Worlds Only Software Designed Controller
1 2 Simplify System Complexity With the new high-performance CompactRIO controller Arun Veeramani Senior Program Manager National Instruments NI CompactRIO The Worlds Only Software Designed Controller
CellSs Making it easier to program the Cell Broadband Engine processor
 Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
CHAPTER 8: CPU and Memory Design, Enhancement, and Implementation
 CHAPTER 8: CPU and Memory Design, Enhancement, and Implementation The Architecture of Computer Hardware, Systems Software & Networking: An Information Technology Approach 5th Edition, Irv Englander John
CHAPTER 8: CPU and Memory Design, Enhancement, and Implementation The Architecture of Computer Hardware, Systems Software & Networking: An Information Technology Approach 5th Edition, Irv Englander John
Atacama: An Open Experimental Platform for Mixed-Criticality Networking on Top of Ethernet
 Atacama: An Open Experimental Platform for Mixed-Criticality Networking on Top of Ethernet Gonzalo Carvajal 1,2 and Sebastian Fischmeister 1 1 University of Waterloo, ON, Canada 2 Universidad de Concepcion,
Atacama: An Open Experimental Platform for Mixed-Criticality Networking on Top of Ethernet Gonzalo Carvajal 1,2 and Sebastian Fischmeister 1 1 University of Waterloo, ON, Canada 2 Universidad de Concepcion,
Multicore for safety-critical embedded systems: challenges andmarch opportunities 15, / 28
 Multicore for safety-critical embedded systems: challenges and opportunities Giuseppe Lipari CRItAL - Émeraude March 15, 2016 Multicore for safety-critical embedded systems: challenges andmarch opportunities
Multicore for safety-critical embedded systems: challenges and opportunities Giuseppe Lipari CRItAL - Émeraude March 15, 2016 Multicore for safety-critical embedded systems: challenges andmarch opportunities
Controlling Execution Time Variability Using COTS for Safety Critical Systems
 UNIVERSITÉ PARIS-SUD ÉCOLE DOCTORALE : Sciences et Technologie de l Information, des Télécommunications et des Systèmes Institut d Electronique Fondamentale (IEF) Thales Research & Technology - France
UNIVERSITÉ PARIS-SUD ÉCOLE DOCTORALE : Sciences et Technologie de l Information, des Télécommunications et des Systèmes Institut d Electronique Fondamentale (IEF) Thales Research & Technology - France
Computer Systems Architecture I. CSE 560M Lecture 19 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Real-Time Cache Management for Multi-Core Virtualization
 Real-Time Cache Management for Multi-Core Virtualization Hyoseung Kim 1,2 Raj Rajkumar 2 1 University of Riverside, California 2 Carnegie Mellon University Benefits of Multi-Core Processors Consolidation
Real-Time Cache Management for Multi-Core Virtualization Hyoseung Kim 1,2 Raj Rajkumar 2 1 University of Riverside, California 2 Carnegie Mellon University Benefits of Multi-Core Processors Consolidation
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
Applying Multi-core and Virtualization to Industrial and Safety-Related Applications
 White Paper Wind River Hypervisor and Operating Systems Intel Processors for Embedded Computing Applying Multi-core and Virtualization to Industrial and Safety-Related Applications Multi-core and virtualization
White Paper Wind River Hypervisor and Operating Systems Intel Processors for Embedded Computing Applying Multi-core and Virtualization to Industrial and Safety-Related Applications Multi-core and virtualization
System Impact of Distributed Multicore Systems December 5th 2012
 System Impact of Distributed Multicore Systems December 5th 2012 Software Systems Division & Data Systems Division Final Presentation Days Mathieu Patte (Astrium Satellites) Alfons Crespo (UPV) Outline
System Impact of Distributed Multicore Systems December 5th 2012 Software Systems Division & Data Systems Division Final Presentation Days Mathieu Patte (Astrium Satellites) Alfons Crespo (UPV) Outline
High Performance Computing: Blue-Gene and Road Runner. Ravi Patel
 High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
Chapter 5. Introduction ARM Cortex series
 Chapter 5 Introduction ARM Cortex series 5.1 ARM Cortex series variants 5.2 ARM Cortex A series 5.3 ARM Cortex R series 5.4 ARM Cortex M series 5.5 Comparison of Cortex M series with 8/16 bit MCUs 51 5.1
Chapter 5 Introduction ARM Cortex series 5.1 ARM Cortex series variants 5.2 ARM Cortex A series 5.3 ARM Cortex R series 5.4 ARM Cortex M series 5.5 Comparison of Cortex M series with 8/16 bit MCUs 51 5.1
How to Write Fast Code , spring th Lecture, Mar. 31 st
 How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
Hardware-Software Codesign. 1. Introduction
 Hardware-Software Codesign 1. Introduction Lothar Thiele 1-1 Contents What is an Embedded System? Levels of Abstraction in Electronic System Design Typical Design Flow of Hardware-Software Systems 1-2
Hardware-Software Codesign 1. Introduction Lothar Thiele 1-1 Contents What is an Embedded System? Levels of Abstraction in Electronic System Design Typical Design Flow of Hardware-Software Systems 1-2
Computer Architecture!
 Informatics 3 Computer Architecture! Dr. Boris Grot and Dr. Vijay Nagarajan!! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors:!
Informatics 3 Computer Architecture! Dr. Boris Grot and Dr. Vijay Nagarajan!! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors:!
Simplify System Complexity
 Simplify System Complexity With the new high-performance CompactRIO controller Fanie Coetzer Field Sales Engineer Northern South Africa 2 3 New control system CompactPCI MMI/Sequencing/Logging FieldPoint
Simplify System Complexity With the new high-performance CompactRIO controller Fanie Coetzer Field Sales Engineer Northern South Africa 2 3 New control system CompactPCI MMI/Sequencing/Logging FieldPoint
VLSI Design of Multichannel AMBA AHB
 RESEARCH ARTICLE OPEN ACCESS VLSI Design of Multichannel AMBA AHB Shraddha Divekar,Archana Tiwari M-Tech, Department Of Electronics, Assistant professor, Department Of Electronics RKNEC Nagpur,RKNEC Nagpur
RESEARCH ARTICLE OPEN ACCESS VLSI Design of Multichannel AMBA AHB Shraddha Divekar,Archana Tiwari M-Tech, Department Of Electronics, Assistant professor, Department Of Electronics RKNEC Nagpur,RKNEC Nagpur
CONTENTION IN MULTICORE HARDWARE SHARED RESOURCES: UNDERSTANDING OF THE STATE OF THE ART
 CONTENTION IN MULTICORE HARDWARE SHARED RESOURCES: UNDERSTANDING OF THE STATE OF THE ART Gabriel Fernandez 1, Jaume Abella 2, Eduardo Quiñones 2, Christine Rochange 3, Tullio Vardanega 4 and Francisco
CONTENTION IN MULTICORE HARDWARE SHARED RESOURCES: UNDERSTANDING OF THE STATE OF THE ART Gabriel Fernandez 1, Jaume Abella 2, Eduardo Quiñones 2, Christine Rochange 3, Tullio Vardanega 4 and Francisco
Performance comparison between a massive SMP machine and clusters
 Performance comparison between a massive SMP machine and clusters Martin Scarcia, Stefano Alberto Russo Sissa/eLab joint Democritos/Sissa Laboratory for e-science Via Beirut 2/4 34151 Trieste, Italy Stefano
Performance comparison between a massive SMP machine and clusters Martin Scarcia, Stefano Alberto Russo Sissa/eLab joint Democritos/Sissa Laboratory for e-science Via Beirut 2/4 34151 Trieste, Italy Stefano
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
RAD55xx Platform SoC. Dean Saridakis, Richard Berger, Joseph Marshall *** *** *** *** *** *** *** photo courtesy of NASA
 1 RAD55xx Platform SoC Dean Saridakis, Richard Berger, Joseph Marshall *** *** *** *** *** *** *** photo courtesy of NASA 2 Agenda RAD55xx Platform SoC Introduction Processor Core / RAD750 Processor Heritage
1 RAD55xx Platform SoC Dean Saridakis, Richard Berger, Joseph Marshall *** *** *** *** *** *** *** photo courtesy of NASA 2 Agenda RAD55xx Platform SoC Introduction Processor Core / RAD750 Processor Heritage
Multithreading: Exploiting Thread-Level Parallelism within a Processor
 Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
William Stallings Computer Organization and Architecture 8 th Edition. Chapter 18 Multicore Computers
 William Stallings Computer Organization and Architecture 8 th Edition Chapter 18 Multicore Computers Hardware Performance Issues Microprocessors have seen an exponential increase in performance Improved
William Stallings Computer Organization and Architecture 8 th Edition Chapter 18 Multicore Computers Hardware Performance Issues Microprocessors have seen an exponential increase in performance Improved
A Predictable Simultaneous Multithreading Scheme for Hard Real-Time
 A Predictable Simultaneous Multithreading Scheme for Hard Real-Time Jonathan Barre, Christine Rochange, and Pascal Sainrat Institut de Recherche en Informatique de Toulouse, Université detoulouse-cnrs,france
A Predictable Simultaneous Multithreading Scheme for Hard Real-Time Jonathan Barre, Christine Rochange, and Pascal Sainrat Institut de Recherche en Informatique de Toulouse, Université detoulouse-cnrs,france
Hardware-Software Codesign. 1. Introduction
 Hardware-Software Codesign 1. Introduction Lothar Thiele 1-1 Contents What is an Embedded System? Levels of Abstraction in Electronic System Design Typical Design Flow of Hardware-Software Systems 1-2
Hardware-Software Codesign 1. Introduction Lothar Thiele 1-1 Contents What is an Embedded System? Levels of Abstraction in Electronic System Design Typical Design Flow of Hardware-Software Systems 1-2
SUCCESSFULL MULTICORE CERTIFICATION WITH SOFTWARE-PARTITIONING Efficient Implementation for DO-178C, EN 50128, ISO 26262
 Sven Nordhoff, SYSGO AG, Klein-Winternheim, Germany ABSTRACT The usage of multi-core processors (MCPs) in modern systems is state-of-the art and will also come to reality in safetycritical domains like
Sven Nordhoff, SYSGO AG, Klein-Winternheim, Germany ABSTRACT The usage of multi-core processors (MCPs) in modern systems is state-of-the art and will also come to reality in safetycritical domains like
Design and Analysis of Real-Time Systems Predictability and Predictable Microarchitectures
 Design and Analysis of Real-Time Systems Predictability and Predictable Microarcectures Jan Reineke Advanced Lecture, Summer 2013 Notion of Predictability Oxford Dictionary: predictable = adjective, able
Design and Analysis of Real-Time Systems Predictability and Predictable Microarcectures Jan Reineke Advanced Lecture, Summer 2013 Notion of Predictability Oxford Dictionary: predictable = adjective, able
BlueVisor: A Scalable Real-time Hardware Hypervisor for Many-core Embedded System
 BlueVisor: A Scalable eal-time Hardware Hypervisor for Many-core Embedded System Zhe Jiang, Neil C Audsley, Pan Dong eal-time Systems Group Department of Computer Science University of York, United Kingdom
BlueVisor: A Scalable eal-time Hardware Hypervisor for Many-core Embedded System Zhe Jiang, Neil C Audsley, Pan Dong eal-time Systems Group Department of Computer Science University of York, United Kingdom
SMD149 - Operating Systems - Multiprocessing
 SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
Overview. SMD149 - Operating Systems - Multiprocessing. Multiprocessing architecture. Introduction SISD. Flynn s taxonomy
 Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
Gedae cwcembedded.com. The CHAMP-AV6 VPX-REDI. Digital Signal Processing Card. Maximizing Performance with Minimal Porting Effort
 Technology White Paper The CHAMP-AV6 VPX-REDI Digital Signal Processing Card Maximizing Performance with Minimal Porting Effort Introduction The Curtiss-Wright Controls Embedded Computing CHAMP-AV6 is
Technology White Paper The CHAMP-AV6 VPX-REDI Digital Signal Processing Card Maximizing Performance with Minimal Porting Effort Introduction The Curtiss-Wright Controls Embedded Computing CHAMP-AV6 is
Intel CoFluent Studio in Digital Imaging
 Intel CoFluent Studio in Digital Imaging Sensata Technologies Use Case Sensata Technologies www.sensatatechnologies.com Formerly Texas Instruments Sensors & Controls, Sensata Technologies is the world
Intel CoFluent Studio in Digital Imaging Sensata Technologies Use Case Sensata Technologies www.sensatatechnologies.com Formerly Texas Instruments Sensors & Controls, Sensata Technologies is the world
A Closer Look at the Epiphany IV 28nm 64 core Coprocessor. Andreas Olofsson PEGPUM 2013
 A Closer Look at the Epiphany IV 28nm 64 core Coprocessor Andreas Olofsson PEGPUM 2013 1 Adapteva Achieves 3 World Firsts 1. First processor company to reach 50 GFLOPS/W 3. First semiconductor company
A Closer Look at the Epiphany IV 28nm 64 core Coprocessor Andreas Olofsson PEGPUM 2013 1 Adapteva Achieves 3 World Firsts 1. First processor company to reach 50 GFLOPS/W 3. First semiconductor company
ECE 172 Digital Systems. Chapter 15 Turbo Boost Technology. Herbert G. Mayer, PSU Status 8/13/2018
 ECE 172 Digital Systems Chapter 15 Turbo Boost Technology Herbert G. Mayer, PSU Status 8/13/2018 1 Syllabus l Introduction l Speedup Parameters l Definitions l Turbo Boost l Turbo Boost, Actual Performance
ECE 172 Digital Systems Chapter 15 Turbo Boost Technology Herbert G. Mayer, PSU Status 8/13/2018 1 Syllabus l Introduction l Speedup Parameters l Definitions l Turbo Boost l Turbo Boost, Actual Performance
Using a Hypervisor to Manage Multi-OS Systems Cory Bialowas, Product Manager
 Using a Hypervisor to Manage Multi-OS Systems Cory Bialowas, Product Manager cory.bialowas@windriver.com Trends, Disruptions and Opportunity Wasn t life simple? Single-OS: SMP OS OS CPU Single Core Virtualization
Using a Hypervisor to Manage Multi-OS Systems Cory Bialowas, Product Manager cory.bialowas@windriver.com Trends, Disruptions and Opportunity Wasn t life simple? Single-OS: SMP OS OS CPU Single Core Virtualization
M7: Next Generation SPARC. Hotchips 26 August 12, Stephen Phillips Senior Director, SPARC Architecture Oracle
 M7: Next Generation SPARC Hotchips 26 August 12, 2014 Stephen Phillips Senior Director, SPARC Architecture Oracle Safe Harbor Statement The following is intended to outline our general product direction.
M7: Next Generation SPARC Hotchips 26 August 12, 2014 Stephen Phillips Senior Director, SPARC Architecture Oracle Safe Harbor Statement The following is intended to outline our general product direction.
Real-Time Mixed-Criticality Wormhole Networks
 eal-time Mixed-Criticality Wormhole Networks Leandro Soares Indrusiak eal-time Systems Group Department of Computer Science University of York United Kingdom eal-time Systems Group 1 Outline Wormhole Networks
eal-time Mixed-Criticality Wormhole Networks Leandro Soares Indrusiak eal-time Systems Group Department of Computer Science University of York United Kingdom eal-time Systems Group 1 Outline Wormhole Networks
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Design and Analysis of Time-Critical Systems Timing Predictability and Analyzability + Case Studies: PTARM and Kalray MPPA-256
 Design and Analysis of Time-Critical Systems Timing Predictability and Analyzability + Case Studies: PTARM and Kalray MPPA-256 Jan Reineke @ saarland university computer science ACACES Summer School 2017
Design and Analysis of Time-Critical Systems Timing Predictability and Analyzability + Case Studies: PTARM and Kalray MPPA-256 Jan Reineke @ saarland university computer science ACACES Summer School 2017
Lecture 11: SMT and Caching Basics. Today: SMT, cache access basics (Sections 3.5, 5.1)
") Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
High-Performance Real-Time Lab (HiPeRT) Marko Bertogna University of Modena, Italy
 Marko Bertogna University of Modena, Italy") High-Performance Real-Time Lab (HiPeRT) Marko Bertogna University of Modena, Italy marko.bertogna@unimore.it http://hipert.unimore.it/ HiPeRT Lab Research on High-Performance Real-Time Systems ~20 people
High-Performance Real-Time Lab (HiPeRT) Marko Bertogna University of Modena, Italy marko.bertogna@unimore.it http://hipert.unimore.it/ HiPeRT Lab Research on High-Performance Real-Time Systems ~20 people
POWER7: IBM's Next Generation Server Processor
 POWER7: IBM's Next Generation Server Processor Acknowledgment: This material is based upon work supported by the Defense Advanced Research Projects Agency under its Agreement No. HR0011-07-9-0002 Outline
POWER7: IBM's Next Generation Server Processor Acknowledgment: This material is based upon work supported by the Defense Advanced Research Projects Agency under its Agreement No. HR0011-07-9-0002 Outline
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Mobile Processors. Jose R. Ortiz Ubarri
 Mobile Processors Jose R. Ortiz Ubarri Electrical and Computer Engineering Department University of Puerto Rico, Mayagüez Campus Mayagüez, Puerto Rico 00681 5000 Jose.Ortiz@hpcf.upr.edu Introduction While
Mobile Processors Jose R. Ortiz Ubarri Electrical and Computer Engineering Department University of Puerto Rico, Mayagüez Campus Mayagüez, Puerto Rico 00681 5000 Jose.Ortiz@hpcf.upr.edu Introduction While
Computer Architecture
 Informatics 3 Computer Architecture Dr. Vijay Nagarajan Institute for Computing Systems Architecture, School of Informatics University of Edinburgh (thanks to Prof. Nigel Topham) General Information Instructor
Informatics 3 Computer Architecture Dr. Vijay Nagarajan Institute for Computing Systems Architecture, School of Informatics University of Edinburgh (thanks to Prof. Nigel Topham) General Information Instructor
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Exploration of Cache Coherent CPU- FPGA Heterogeneous System
 Exploration of Cache Coherent CPU- FPGA Heterogeneous System Wei Zhang Department of Electronic and Computer Engineering Hong Kong University of Science and Technology 1 Outline ointroduction to FPGA-based
Exploration of Cache Coherent CPU- FPGA Heterogeneous System Wei Zhang Department of Electronic and Computer Engineering Hong Kong University of Science and Technology 1 Outline ointroduction to FPGA-based
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
BREAKING THE MEMORY WALL
 BREAKING THE MEMORY WALL CS433 Fall 2015 Dimitrios Skarlatos OUTLINE Introduction Current Trends in Computer Architecture 3D Die Stacking The memory Wall Conclusion INTRODUCTION Ideal Scaling of power
BREAKING THE MEMORY WALL CS433 Fall 2015 Dimitrios Skarlatos OUTLINE Introduction Current Trends in Computer Architecture 3D Die Stacking The memory Wall Conclusion INTRODUCTION Ideal Scaling of power
Time-Triggered Ethernet
 Time-Triggered Ethernet Chapters 42 in the Textbook Professor: HONGWEI ZHANG CSC8260 Winter 2016 Presented By: Priyank Baxi (fr0630) fr0630@wayne.edu Outline History Overview TTEthernet Traffic Classes
Time-Triggered Ethernet Chapters 42 in the Textbook Professor: HONGWEI ZHANG CSC8260 Winter 2016 Presented By: Priyank Baxi (fr0630) fr0630@wayne.edu Outline History Overview TTEthernet Traffic Classes
Computer Architecture!
 Informatics 3 Computer Architecture! Dr. Boris Grot and Dr. Vijay Nagarajan!! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors
Informatics 3 Computer Architecture! Dr. Boris Grot and Dr. Vijay Nagarajan!! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
A novel way to efficiently simulate complex full systems incorporating hardware accelerators
 ARM Research Summit 2017 Workshop A novel way to efficiently simulate complex full systems incorporating hardware accelerators Nikolaos Tampouratzis Technical University of Crete, Greece Motivation / The
ARM Research Summit 2017 Workshop A novel way to efficiently simulate complex full systems incorporating hardware accelerators Nikolaos Tampouratzis Technical University of Crete, Greece Motivation / The
Computer Architecture!
 Informatics 3 Computer Architecture! Dr. Vijay Nagarajan and Prof. Nigel Topham! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors
Informatics 3 Computer Architecture! Dr. Vijay Nagarajan and Prof. Nigel Topham! Institute for Computing Systems Architecture, School of Informatics! University of Edinburgh! General Information! Instructors
Computer Architecture Crash course
 Computer Architecture Crash course Frédéric Haziza Department of Computer Systems Uppsala University Summer 2008 Conclusions The multicore era is already here cost of parallelism is dropping
Computer Architecture Crash course Frédéric Haziza Department of Computer Systems Uppsala University Summer 2008 Conclusions The multicore era is already here cost of parallelism is dropping