Chapter 17 Indexing Structures for Files and Physical Database Design
|
|
|
- Nelson Small
- 6 years ago
- Views:
Transcription
1 Chapter 17 Indexing Structures for Files and Physical Database Design We assume that a file already exists with some primary organization unordered, ordered or hash. The index provides alternate ways to access the records without affecting the existing placement of records on the disk. Each indexing approach have a particular data structure to speed up the search. A variety of indexing techniques are studied here. Types of Single-Level Ordered Indexes - Concept of indexes is similar to an index of terms in a book - Index access structure is usually a single field of a file called indexing field - The index stores each value of the field along with all disk blocks that contain records with this field - The values in the index are ordered so that a binary search can be done - Both the index and data files are ordered, but index file is smaller Several types of ordered indexes: - Primary index specified on a key field - Clustering index, ordering field is not a key field; the data file is called clustered file - A file can have at most one physical ordering field; it can have one primary index, or one clustering index but not both 1

2 - Secondary index can be specified on any non-ordering field of a file; a data file can have several secondary indexes in addition to the primary access method Primary Indexes - Ordered file with 2 fields, PK field and data ptr. PK is the primary key of the data file. Ptr is the pointer to a disk block; PK is the value for the first record in the block - Each block in the data file has one entry in the index file - The two fields <K(i), P(i)>; P(i) is the pointer for the block in data file - In general the two fields are: <K(i), X>: o X may be the physical address of a block (or page) 2
3 Fig o X may be the record address made up of a block address and a record id (for offset) with in the block o X may be a logical address of the block or of the record within the file and is a relative number that would be mapped to physical address - First record in each block of the data file is called an block anchor or anchor record - Indexes can be dense or parse - A dense index has an entry for every search key value; a parse index has index entries for only for some of the search values - To retrieve a record given the value of its PK field, we do a binary search on the index file to find appropriate entry I, and then retrieve the data field block whose address is P(i). 3
4 4
5 Example 1. Ordered file with records r = Disk block size = B = 4096 bytes File records are fixed size and unspanned Record length = R = 100 bytes Blocking factor bfr = [B/R] (lower ceiling) = 4096/100 = 40 records per block The number of blocks needed for the file = [r/bfr] (upper ceiling) 5 = /40 = 7500 blocks A binary search on the data file = log 2 (7500) (upper ceiling) = 13 Let ordering key field is 9 bytes, block pointer is 6 bytes; total 15 bytes in each entry of index file bfr for index file is 4095/15 (lower ceiling) = 273 total number of index entries = total no of blocks The number of index blocks = [7500/273] (upper ceiling) = 28 To perform binary search on index file: log 2 (28) (upper ceiling) = 5 To search for a record, we need one additional access to read the data block, thus we need 5+1 = 6 block accesses using a binary search Whereas, we need 13 block accesses without an index file Problems with Primary Index - Insertion o Inserting in correct position (make space, change index entries) o Move records to make space for new records
6 o Move will change anchor records of some blocks o Use linked list or overflow records - Deletion o Use delete markers Clustering Indexes - Ordered on a non-key field (no distinct values), clustering field - The data field is ordered on a non-key field called a clustered file - Seed up retrieval of all records that have the same value for the clustering field - Includes one index entry for each distinct value of the field, the index entry points to the first data block that contains records with the field value - Another example of non-dense (or parse) index - Insertion and deletion problems (reserve one or more blocks for each value of the clustering field); Example 2: r = records B = 4096 bytes It is ordered by zip codes; there are 1000 zip codes in the file Average 300 records per zip code (assume even distribution) The index 1000 index entries, 5 bytes zip code, 6 bytes block no, 11 bytes total in each entry; bfr = 4096/11 (lower ceiling) = 372 index entries per block The number of index blocks = 1000/372 (upper ceiling) = 3 6
7 Binary search on index file would require log 2 (3) = 2 block accesses The index is loaded in main memory 1000*11 = bytes. 7
8 8
9 Secondary Indexes - The data field records could be unordered, ordered, or hashed - A secondary index provides a secondary means of accessing a file for which some primary access already exists - The secondary index may be on a field which is a candidate key and has a unique value in every record, or a non-key with duplicate values - The index is an ordered file with two fields: o The first field is of the same data type as some non-ordering field of the data file that is an indexing field o The second field is either a block or record pointer o There can be many secondary indexes (and hence, indexing fields) for the same file; each represents an additional means of accessing that file based on some specific field - Includes one entry for each record in the data file; hence it is a dense index (records of the data file are not physically ordered by secondary key) - A secondary index needs more storage space and longer search time than primary index, because of its longer number of entries - Search time is improved as there is no need to do linear search on records in a data file (records are directly accessed) 9
10 10
11 Example 3: r = records size R = 100 bytes block size B = 4096 bytes no of records per block bfr = 4096/100 = 40 no of blocks for the data file = b = /40 = 7500 suppose we want to search for a record with a specific value for the secondary key.a non-ordering key with 9 bytes value without a secondary index; to do a linear search on the file would require: b/2 searches (7500/2 = 3750) block accesses suppose that we construct a secondary index on the nonordering key field of the file; 9+6 = 15 byte entry value; the blocking factor for the index: 4096/15 = 273 entries per block in a dense secondary index; total number of index entries is equal to the number of records; the number of blocks needed for the secondary index = /273 (upper ceiling) = 1099 blocks A binary search on this secondary index needs log 2 b = log 2 (1099) = 11 block accesses To search for a record using the index, we need 1 additional block access to the data file 11+1 = 12 block accesses (compared to 3750 block accesses) 11
12 We can also create a secondary index on a non-key, non-ordering field. Numerous records in the data file can have the same value for the indexing field. There are several options: 1. Include duplicate index entries with the same K(i) value, one for each record. Dense index. 2. Have variable length records for the index entries, with a repeating field for the pointer. Keep a list of pointers <P(i, 1), P(i, 2),,P(i, k) in the index entry K(i). 3. Create an extra level of indirection to handle the multiple pointers. Fig If one block of indirection is not enough, a cluster can be used. 12
13 13
14 Multilevel Indexes We covered ordered index file techniques. A binary search is needed to locate pointers for disk blocks or records. A binary search requires log 2 b i block accesses for an index with b i blocks. Each step of the binary search reduces the file by 2. The idea of multilevel index is to reduce the part of the index that we continue to search by bfr i. the blocking factor for the index, which is larger than 2. The search space is reduced much faster. The value bfr i is called fan-out (fo). Multilevel index requires log fo b i block accesses. With a 4096 byte block size, 9 byte key (SSN) and 4 byte pointer (13 bytes total index entry) bfr i = 4096/13 (lower ceiling) = 315. In multilevel index, the index file is the first level (base) of multilevel index, as an ordered file with distinct values for each K(i). We can create a primary index for the first level is called the second level multilevel index. The second level has one entry for each block, as it is a primary index (we can use block anchors) The process repeats for 3 rd level and so on until all entries fit in one disk block for the top level. -problems: insertion and deletion; leave some space in each of its blocks called dynamic multilevel index 14
15 Example 4 r = fixed length records B = 4096 bytes Record size R = 100 bytes bfr = 4096/100 (lower ceiling) = 40 records per block number of blocks = /40 (upper ceiling) = 7500 blocks Number of bytes in each index entry = = 15 bfr i = 4096/15 (lower ceiling) = 273 = fo of the multilevel index number of blocks needed for the index = /273 (upper ceiling) = b1 = 1099 blocks (number of first level blocks) (n th level n-1 level. 1 st level) in multilevel structure The number of 2 nd level blocks = b2 = b1/fo (upper ceiling) = 1099/273 = 5 blocks The number of 3 rd level blocks = b3 = b2/fo (upper ceiling) = 5/273 = 1 block Hence, the third level is the top level (for multilevel index), t = 3 To access a record by searching a multilevel index, we must access one block at each level plus 1 block from the data file = 3+1 = 4 blocks (in a single level it was 12 blocks) 15
16 16
17 Dynamic Multilevel Indexes Using B-Tree and B + Trees Tree Structure: - A tree is formed of nodes - Each node except the root, has one parent node and 0 or more child nodes - The root node has no parent - A node with no child nodes is a leaf node - A nonleaf node is an internal node - The level of node is always one higher than its parent - The level of root node is 0 - A subtree of a node consists of that node and all its descendant nodes - If the leaf nodes are at different levels, it is an unbalanced tree - B-tree nodes are kept % full - Pointers to the data blocks are stored at internal and leaf nodes for B-trees - Pointers to the data blocks are stored at leaf nodes for B + trees Search Trees A search tree is a special type of tree used to guide the search for a record given the value of one of the record s fields. Fig A search tree of order p is a tree such that each node contains p-1 search values and p pointers. <P1, K1, P2, K2,.P q-1, K q-1, P q > Each P i is a pointer to a child node or null 17
18 We can use search tree as a mechanism to search for records on disk. Two constraints must hold all the time: 1. Within each node K1 < K2 < K3 <..K q-1 2. For all values of X in the subtree pointed at by P i We have; K i-1 < X < K i 18
19 19
20 - Search field is same as the index field - Algorithms needed to insert and delete - May result in unbalanced tree - Make sure nodes are evenly distributed - Make search speed uniform - Minimize number of levels; also make sure it does not require restructuring many times B-Trees B-Tree solves the above problems: - Tree is always balanced - Space wasted by deletion, if any, will not be excessive - Insertion and deletion algorithms are complex A B-Tree of order p, when used as an access structure on a key field to search for records in a data file can be defined as follows: 1. Each internal node in the B-Tree is of the form: <P 1, <K 1, Pr 1 >, P 2, <K 2, Pr 2 >,.P q-1, <K q-1,pr q-1 >, Pq> Where, q <= p, each Pi is a tree pointer a pointer to the record, whose search key field value is equal to Ki (or the data field value containing that record) 2. Within each node K 1 < K 2 < <K q-1 3. For all search key field values X in the subtree pointed at by Pi, we have K i-1 < X< K i for 1 < I <q; X < K i for i = 1; K i-1 < X for i=q 4. Each node has at most p tree pointers 20
21 5. Each node, except the root and leaf nodes, has at least [p/2] (upper ceiling) pointers; the root node has at least two tree pointers unless it is the only node in the tree 6. A node with q tree pointers, q <=p, has q-1 search key field values and hence has q-1 data pointers 7. All the leaf nodes are at the same level. Leaf nodes have same structure as the internal nodes, except they have null pointers. 21
22 - Fig (b) illustrate a B-Tree with p = 3. All search key values are unique, as it is a key field - If we use a B-Tree on a nonkey field, we must change the file pointer Pr i to point to a block or a cluster of blocks that contain the pointers to the records. - The B-Tree starts with a single root node (which is also a leaf node) at level 0 - Once the root node is full with p-1 search key values, we attempt to insert another entry in the tree; the root node splits into two nodes at level 1. Only the middle value is kept at the root node, the rest of the values are split evenly on other nodes - When a nonroot node is full, and a new entry is inserted into it, that node is split into two nodes at the same level, and the middle entry is moved into the parent node, along with two pointers to the newly split nodes. - Read deletion from p/621 - SKIP Example 5 B-Tree (order p) - No node has more than p children - Every node except the root and terminal nodes has at least [p/2] (upper ceiling) children - The root has at least two children, unless the tree has only one node - All terminal nodes appear on the same level, i.e., same distance from the root - A non-terminal node with k children contains k-1 records; a terminal node contains at least ([p/2] 1) records (upper ceiling) and at most p-1 records - The largest number of records allowed in a node is p-1 22
23 B-Tree Insertion: - New records are always inserted into terminal nodes - Every null pointer represents an insertion pointer, where a new record might go - To determine the insertion point, searching for a new record as if it were already in the tree - Problems with inserting is that nodes can overflow because there is upper bound p-1 records - If the node into which we have inserted a record now exceeds the max size, then redistribute or split on overflow - The node is split into three parts - Splitting on overfull node with p records, the middle record is passed upward and inserted into its parent B-Tree Exmples: (perform it on the B-Tree, p=3) (1) Insert 13 (2) Insert 10 (3) Insert 16 23
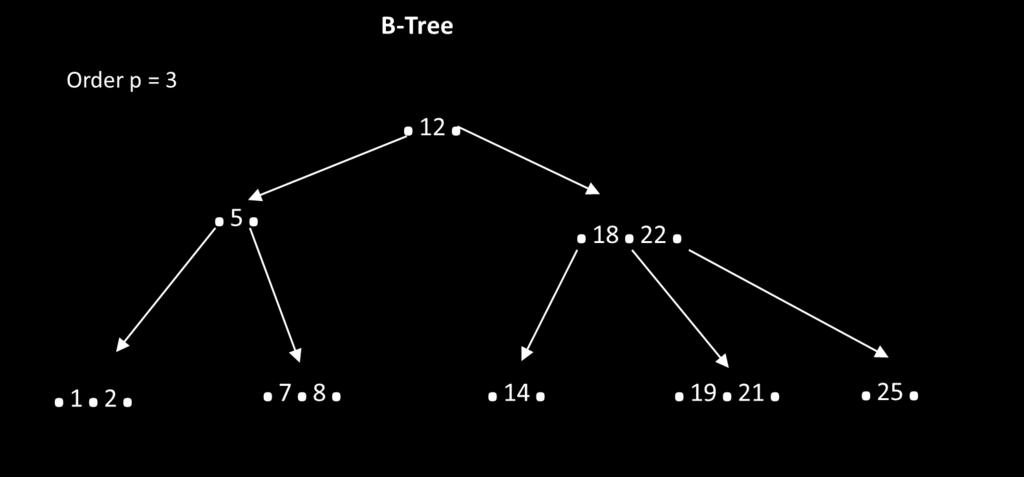
24 24
25 B-Tree Deletion - Start the delete operation at the lowest level of the tree - Replace it by a copy of its successor, the record with the next highest key, the successor will be at the lowest level (predecessor will also work as well) - We may have an underflow after deletion (node may be smaller than the minimum size) - Use redistribution or concatenation to solve underflow B-Tree Examples: p=5 Delete 10 Delete 13 Delete 18 25
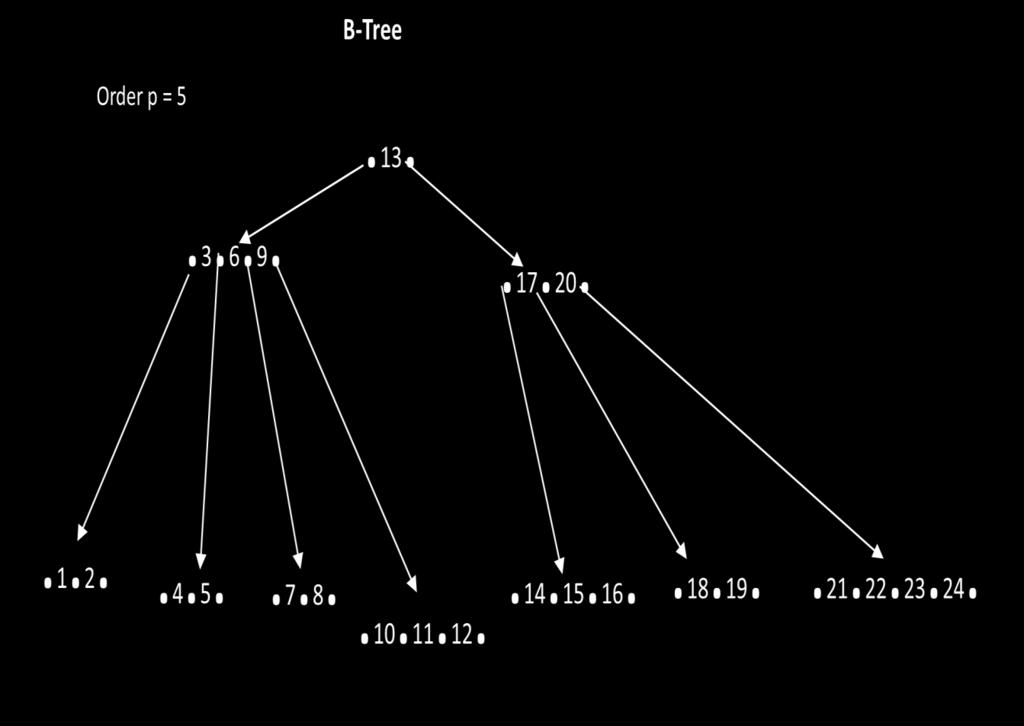
26 26
27 B+ Trees Knuth proposed a variation on B trees. - Records on a B+ tree are held only on the terminal nodes - The terminal nodes are linked together to facilitate sequential processing of the records and are termed the sequential set - No need for terminal nodes to have tree pointers - Terminal nodes have different structure than non-terminal nodes Each internal node is of the form: 1. <P 1, K 1, P 2, K 2,.P q-1, K q-1, Pq>, Where, q p, each Pi is a tree pointer 2. Within each node K 1 < K 2 < <K q-1 3. For all search filed values X in the subtree pointed at by Pi, we have K i-1 < X K i for 1 <i<q, X K i for i=1; and K i -1 < X for i=q 4. Each internal node has at most p tree pointers 5. Each internal node, except the root, has at least ᴦp/2 tree pointers; the root node has at least two tree pointers if it is an internal node (ᴦp/2 to p) 6. An internal node with q pointers, q p, has q-1 search fields values (Notice that there is no K q as this pointer will lead to another subtree, it is simply a pointer, no need for a key) The structure of the lead nodes of B+ tree of order p is as follows: 1. <<K 1,Pr 1 >, <K 2, Pr 2 >,.,<K q-1, Pr q-1 >, P next > where q p, each Pr i is a data pointer, and P next points to the next leaf node 27
28 2. Within each leaf node K 1 < K 2 < <K q-1, q p 3. Each Pr i is a data pointer that points to the record whose search field value is K i or to a file block containing the record (or to a block of record pointers that point to records whose search field value is K i, if the search field is not a key) 4. Each leaf node has at least ᴦp/2 values 5. All leaf nodes are at the same level - By starting at the left most leaf node, it is possible to traverse leaf nodes as a linked list using P next pointers - Provides ordered access to the data records - A P previous can also be included - As the structures for internal and leaf nodes are different, their order can be different; order p for internal nodes, and order p leaf for leaf nodes. Example 6: Search key field is V = 9 bytes Block size is B = 512 bytes Record pointer is Pr = 7 bytes Block pointer/tree pointer is P = 6 bytes An internal node can have up to p tree pointers and p-1 key fields, these must fit in a single block Thus, p * P + (p-1) * V B p*6+(p-1)
29 15p 521 P 34 for intermediate nodes The leaf nodes have the same number of values and pointers, except they are data pointers and next pointer. The order of p leaf can be calculated as follows: P leaf * (Pr+V) + P 512 P leaf * (7+9) P leaf * P leaf * P leaf 31 Example 7: Construct a B+ tree on example 6 - Assume each node is 69% full - p = 34, p leaf = 31 - On the average, each internal node have 0.69 * 34 ~ 23 pointers and 22 key values - On the average leaf node has 0.69 * 31 ~ 21 data record pointers Root 1 node 22 key entries (22+1=23) ptrs Level1 23 nodes 23*22 (506) (506+23=529) ptrs Level2 23*23(529) 528*22(11638) ( =12167) Leaf 529*23(12167) 12167*21 (255507) data record ptrs 29
30 30
31 B+ Tree Example 31
32 B+ Tree Insertion 1. If an index node has to split, the algorithm is same as B tree. 2. If the node splits when we insert record into a terminal node, we put a copy of the key of the central record in TOOBIG into the index. Thus the central record will also be one of the two halves after splitting, B+ Tree Deletion 1. When a record is deleted from B+ tree, no distribution or concatenation is needed 2. No changes are made to the index, even if the key of the record to be deleted appears in the record, it can be left as a separator Use the following B+ tree for deletion. 32
33 33
34 Indexes on Multiple Keys So far, we have considered single attributes as search attributes. However, in real world, multiple attributes are used to search records. EMPLOYEE ssn, dno, age, street, city, zip, salary, skill-code Query: List the employees in department number 4, where age is 59. Both attributes department number and age are non-key attributes, that is, a search value for either of these will point to multiple records. Ordered index on multiple attributes: - Create an index on a search key field that is a combination of <dno, age>. The search key is a pair of values, <4, 59> in this example. - In general, <A1, A2,, An> attributes result in values <v1, v2,,vn> - <3, n> precedes <4,m> in this ordering. The ascending order for dno keys will be <4,18>, <4,19>,.etc..The composite attribute indexing can be used to access data Partitioned Hashing For a key consisting of n components, the hash function is designed to produce a result with n separate hash addresses. For example, <Dno, Age> search key; suppose Dno=4 has a hash function 010 and Age=59 has a hash function Then, the search value goes to Just to search with employees with Age=59, it will be go through all 8 buckets of combinations resulting in , ,.searches. This approach is only good for equality search, not range searches. 34
35 Grid Files Organize records as a grid file. <Dno, Age> has a 2 dimensional grid. n dimensional grid can be formed with n attributes, which is hard to construct and maintain. The scales are made in a way to achieve uniform distribution. Dn0=4 and Age=59 falls into grid (1,5). Each cell or cluster of cells can point to one bucket pool. This is suitable for range queries. 35
36 SKIP 17.5 General Issues Concerning Indexing - When physical index changes, then index entry needs to change; thus one can use a logical address to cope with this problem; it causes another level of indirect mapping of addresses and more overhead and maintenance - Index creation: many RDBMS have commands for creating index CREATE [UNIQUE] INDEX <index-name> ON <table-name> (<column-name> [<order>] )[CKUSTER]; CREATE INDEX DnoIndex ON EMPLOYEE (Dno) CLUSTER; - Index creation process: index is not part of the data file, but can be created and discarded dynamically (called access structure) - Whenever we expect to access a file frequently based on some search condition involving a particular attribute, we can request the DBMS to create an index - Usually, a secondary index is created to avoid reordering of records on the disk - Secondary index can be created with any primary record organization - Insertion of a large number of entries into index is called bulk loading the index - Indexing of strings cause problem as the strings vary in size; prefix compression is used to reduce the size of strings to short fields - Tuning indexes: The initial choice of indexes may have to be revisted for the following reasons: 36
37 o Certain queries may take too long to run for the lack of an index o Certain indexes may not be utilized at all o Certain indexes may undergo too much updating due to frequent changes - Some indexes may be dropped, some new ones created; trace facility shows the usage of indexes - Rebuilding the index: to improve performance and restructure the tree - It is common to use an index to enforce a key constraint on an attribute; while inserting a record, it can be checked to see if another record exists with the same key attribute (key integrity constraint) - If an index is created on a nonkey field, duplicates occur; data records for the duplicate may contain in the same block or span across many blocks; some systems use row-id with the record, so that records with duplicates have their own unique identifiers - Inverted file: a file that has a secondary index on every one of its fields is called a fully inverted file. The data file itself is an unordered file. - Using indexing hints on queries: provision for allowing hints in queries that are suggested alternatives or indicators to the query process and optimization process for expediting query execution SELECT /*+ INDEX (EMPLOYEE emp_dno_index)*/ Emp_ssn, Salary, Dno FROM EMPLOYEE WHERE Dno < 10; - Column-based storage of relations 37
38 o Vertically partitioning the table column by column, thus a two column table can be constructed, only the needed columns can be accessed (index value, data value) o Using materialized views to support queries on multiple columns Physical database design in Relational Databases The goal of the physical design is to provide appropriate structuring of data to provide optimal performance. Factors that influence physical database design: (a) Analyze the database queries and transactions: intended use of the database by defining high level form of queries and transactions that will run; for each retrieval query the following information would be needed: i. The files (relations accessed by the query) ii. Attributes on which selection condition is specified iii. Selection condition is equality, inequality or a range iv. Join and multiple tables and attributes v. The attributes whose value is retrieved by queries For each update operation or transaction, the following information will be needed: i. The files that will be updated ii. Type of operation (insert, update or delete) iii. Attributes on selection iv. Attributes that will be changed (b) Analyze the expected frequency of invocation of queries and transactions (80% processing and 20% querying rule) 38
39 (c) Analyzing the time constraints on the queries and transactions (min of 4 seconds and max of 20 seconds) (d) Analyzing the expected frequency of update operations; slow down the operation (e) Analyzing the uniqueness constraints on attributes; checking uniqueness constraints during inserts will slow the process Physical database design decisions: - Most relational databases represent each base relation as a physical database file - The access path options include individual or composite attributes for primary file organization (keys) - At most one of the indexes on each file may be a primary or clustering index. Any number of secondary indexes can be created - The performance largely depends upon which indexes or hashing schemes exist to expedite the processing of selections and joins - The physical design decisions for indexing fall into the following categories: o Whether to index an attribute (used in a query) o What attribute or attributes to index on (one or more) o Whether to set up a clustered index (primary index, key; clustered index, non-key; which one depends on ordering of the table on that attribute or attributes) o Whether to use a hash or tree index (B+ trees support equality and range queries; hash do not support range queires; most commonly used are tree index (B+ tree) o Whether to use dynamic hashing (files that grow and shrink often; not commonly used). 39
Indexing Methods. Lecture 9. Storage Requirements of Databases
 Indexing Methods Lecture 9 Storage Requirements of Databases Need data to be stored permanently or persistently for long periods of time Usually too big to fit in main memory Low cost of storage per unit
Indexing Methods Lecture 9 Storage Requirements of Databases Need data to be stored permanently or persistently for long periods of time Usually too big to fit in main memory Low cost of storage per unit
Remember. 376a. Database Design. Also. B + tree reminders. Algorithms for B + trees. Remember
 376a. Database Design Dept. of Computer Science Vassar College http://www.cs.vassar.edu/~cs376 Class 14 B + trees, multi-key indices, partitioned hashing and grid files B and B + -trees are used one implementation
376a. Database Design Dept. of Computer Science Vassar College http://www.cs.vassar.edu/~cs376 Class 14 B + trees, multi-key indices, partitioned hashing and grid files B and B + -trees are used one implementation
Database Systems. File Organization-2. A.R. Hurson 323 CS Building
 File Organization-2 A.R. Hurson 323 CS Building Indexing schemes for Files The indexing is a technique in an attempt to reduce the number of accesses to the secondary storage in an information retrieval
File Organization-2 A.R. Hurson 323 CS Building Indexing schemes for Files The indexing is a technique in an attempt to reduce the number of accesses to the secondary storage in an information retrieval
Chapter 18. Indexing Structures for Files. Chapter Outline. Indexes as Access Paths. Primary Indexes Clustering Indexes Secondary Indexes
 Chapter 18 Indexing Structures for Files Chapter Outline Types of Single-level Ordered Indexes Primary Indexes Clustering Indexes Secondary Indexes Multilevel Indexes Dynamic Multilevel Indexes Using B-Trees
Chapter 18 Indexing Structures for Files Chapter Outline Types of Single-level Ordered Indexes Primary Indexes Clustering Indexes Secondary Indexes Multilevel Indexes Dynamic Multilevel Indexes Using B-Trees
Chapter 12: Indexing and Hashing. Basic Concepts
 Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
Chapter 12: Indexing and Hashing
 Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Physical Level of Databases: B+-Trees
 Physical Level of Databases: B+-Trees Adnan YAZICI Computer Engineering Department METU (Fall 2005) 1 B + -Tree Index Files l Disadvantage of indexed-sequential files: performance degrades as file grows,
Physical Level of Databases: B+-Trees Adnan YAZICI Computer Engineering Department METU (Fall 2005) 1 B + -Tree Index Files l Disadvantage of indexed-sequential files: performance degrades as file grows,
Index Structures for Files
 University of Dublin Trinity College Index Structures for Files Owen.Conlan@scss.tcd.ie Why do we index in the physical world? The last few pages of many books contain an index Such an index is a table
University of Dublin Trinity College Index Structures for Files Owen.Conlan@scss.tcd.ie Why do we index in the physical world? The last few pages of many books contain an index Such an index is a table
Chapter 18 Indexing Structures for Files. Indexes as Access Paths
 Chapter 18 Indexing Structures for Files Indexes as Access Paths A single-level index is an auxiliary file that makes it more efficient to search for a record in the data file. The index is usually specified
Chapter 18 Indexing Structures for Files Indexes as Access Paths A single-level index is an auxiliary file that makes it more efficient to search for a record in the data file. The index is usually specified
Database Technology. Topic 7: Data Structures for Databases. Olaf Hartig.
 Topic 7: Data Structures for Databases Olaf Hartig olaf.hartig@liu.se Database System 2 Storage Hierarchy Traditional Storage Hierarchy CPU Cache memory Main memory Primary storage Disk Tape Secondary
Topic 7: Data Structures for Databases Olaf Hartig olaf.hartig@liu.se Database System 2 Storage Hierarchy Traditional Storage Hierarchy CPU Cache memory Main memory Primary storage Disk Tape Secondary
Chapter 12: Indexing and Hashing
 Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Copyright 2007 Ramez Elmasri and Shamkant B. Navathe. Slide 14-1
 Slide 14-1 Chapter 14 Indexing Structures for Files Chapter Outline Types of Single-level Ordered Indexes Primary Indexes Clustering Indexes Secondary Indexes Multilevel Indexes Dynamic Multilevel Indexes
Slide 14-1 Chapter 14 Indexing Structures for Files Chapter Outline Types of Single-level Ordered Indexes Primary Indexes Clustering Indexes Secondary Indexes Multilevel Indexes Dynamic Multilevel Indexes
Indexes as Access Paths
 Chapter 18 Indexing Structures for Files Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Indexes as Access Paths A single-level index is an auxiliary file that makes it more
Chapter 18 Indexing Structures for Files Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Indexes as Access Paths A single-level index is an auxiliary file that makes it more
Database files Organizations Indexing B-tree and B+ tree. Copyright 2011 Ramez Elmasri and Shamkant Navathe
 Database files Organizations Indexing B-tree and B+ tree Outline Type of Single-Level Ordered Indexes Multilevel Indexes Dynamic Multilevel Indexes Using B-Trees and B + -Trees Indexes on Multiple Keys
Database files Organizations Indexing B-tree and B+ tree Outline Type of Single-Level Ordered Indexes Multilevel Indexes Dynamic Multilevel Indexes Using B-Trees and B + -Trees Indexes on Multiple Keys
CSIT5300: Advanced Database Systems
 CSIT5300: Advanced Database Systems L08: B + -trees and Dynamic Hashing Dr. Kenneth LEUNG Department of Computer Science and Engineering The Hong Kong University of Science and Technology Hong Kong SAR,
CSIT5300: Advanced Database Systems L08: B + -trees and Dynamic Hashing Dr. Kenneth LEUNG Department of Computer Science and Engineering The Hong Kong University of Science and Technology Hong Kong SAR,
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing" Chapter 11: Indexing and Hashing"
 Chapter 11: Indexing and Hashing" Database System Concepts, 6 th Ed.! Silberschatz, Korth and Sudarshan See www.db-book.com for conditions on re-use " Chapter 11: Indexing and Hashing" Basic Concepts!
Chapter 11: Indexing and Hashing" Database System Concepts, 6 th Ed.! Silberschatz, Korth and Sudarshan See www.db-book.com for conditions on re-use " Chapter 11: Indexing and Hashing" Basic Concepts!
amiri advanced databases '05
 More on indexing: B+ trees 1 Outline Motivation: Search example Cost of searching with and without indices B+ trees Definition and structure B+ tree operations Inserting Deleting 2 Dense ordered index
More on indexing: B+ trees 1 Outline Motivation: Search example Cost of searching with and without indices B+ trees Definition and structure B+ tree operations Inserting Deleting 2 Dense ordered index
Indexing: B + -Tree. CS 377: Database Systems
 Indexing: B + -Tree CS 377: Database Systems Recap: Indexes Data structures that organize records via trees or hashing Speed up search for a subset of records based on values in a certain field (search
Indexing: B + -Tree CS 377: Database Systems Recap: Indexes Data structures that organize records via trees or hashing Speed up search for a subset of records based on values in a certain field (search
CSE 530A. B+ Trees. Washington University Fall 2013
 CSE 530A B+ Trees Washington University Fall 2013 B Trees A B tree is an ordered (non-binary) tree where the internal nodes can have a varying number of child nodes (within some range) B Trees When a key
CSE 530A B+ Trees Washington University Fall 2013 B Trees A B tree is an ordered (non-binary) tree where the internal nodes can have a varying number of child nodes (within some range) B Trees When a key
Database System Concepts, 6 th Ed. Silberschatz, Korth and Sudarshan See for conditions on re-use
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files Static
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files Static
Intro to DB CHAPTER 12 INDEXING & HASHING
 Intro to DB CHAPTER 12 INDEXING & HASHING Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing
Intro to DB CHAPTER 12 INDEXING & HASHING Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing
Indexing. Week 14, Spring Edited by M. Naci Akkøk, , Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel
 Indexing Week 14, Spring 2005 Edited by M. Naci Akkøk, 5.3.2004, 3.3.2005 Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel Overview Conventional indexes B-trees Hashing schemes
Indexing Week 14, Spring 2005 Edited by M. Naci Akkøk, 5.3.2004, 3.3.2005 Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel Overview Conventional indexes B-trees Hashing schemes
CS143: Index. Book Chapters: (4 th ) , (5 th ) , , 12.10
 , (5 th ) , , 12.10") CS143: Index Book Chapters: (4 th ) 12.1-3, 12.5-8 (5 th ) 12.1-3, 12.6-8, 12.10 1 Topics to Learn Important concepts Dense index vs. sparse index Primary index vs. secondary index (= clustering index
CS143: Index Book Chapters: (4 th ) 12.1-3, 12.5-8 (5 th ) 12.1-3, 12.6-8, 12.10 1 Topics to Learn Important concepts Dense index vs. sparse index Primary index vs. secondary index (= clustering index
Topics to Learn. Important concepts. Tree-based index. Hash-based index
 CS143: Index 1 Topics to Learn Important concepts Dense index vs. sparse index Primary index vs. secondary index (= clustering index vs. non-clustering index) Tree-based vs. hash-based index Tree-based
CS143: Index 1 Topics to Learn Important concepts Dense index vs. sparse index Primary index vs. secondary index (= clustering index vs. non-clustering index) Tree-based vs. hash-based index Tree-based
Advances in Data Management Principles of Database Systems - 2 A.Poulovassilis
 1 Advances in Data Management Principles of Database Systems - 2 A.Poulovassilis 1 Storing data on disk The traditional storage hierarchy for DBMSs is: 1. main memory (primary storage) for data currently
1 Advances in Data Management Principles of Database Systems - 2 A.Poulovassilis 1 Storing data on disk The traditional storage hierarchy for DBMSs is: 1. main memory (primary storage) for data currently
Chapter 17. Disk Storage, Basic File Structures, and Hashing. Records. Blocking
 Chapter 17 Disk Storage, Basic File Structures, and Hashing Records Fixed and variable length records Records contain fields which have values of a particular type (e.g., amount, date, time, age) Fields
Chapter 17 Disk Storage, Basic File Structures, and Hashing Records Fixed and variable length records Records contain fields which have values of a particular type (e.g., amount, date, time, age) Fields
Introduction to Query Processing and Query Optimization Techniques. Copyright 2011 Ramez Elmasri and Shamkant Navathe
 Introduction to Query Processing and Query Optimization Techniques Outline Translating SQL Queries into Relational Algebra Algorithms for External Sorting Algorithms for SELECT and JOIN Operations Algorithms
Introduction to Query Processing and Query Optimization Techniques Outline Translating SQL Queries into Relational Algebra Algorithms for External Sorting Algorithms for SELECT and JOIN Operations Algorithms
Database System Concepts, 5th Ed. Silberschatz, Korth and Sudarshan See for conditions on re-use
 Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
CSC 261/461 Database Systems Lecture 17. Fall 2017
 CSC 261/461 Database Systems Lecture 17 Fall 2017 Announcement Quiz 6 Due: Tonight at 11:59 pm Project 1 Milepost 3 Due: Nov 10 Project 2 Part 2 (Optional) Due: Nov 15 The IO Model & External Sorting Today
CSC 261/461 Database Systems Lecture 17 Fall 2017 Announcement Quiz 6 Due: Tonight at 11:59 pm Project 1 Milepost 3 Due: Nov 10 Project 2 Part 2 (Optional) Due: Nov 15 The IO Model & External Sorting Today
Indexing: Overview & Hashing. CS 377: Database Systems
 Indexing: Overview & Hashing CS 377: Database Systems Recap: Data Storage Data items Records Memory DBMS Blocks blocks Files Different ways to organize files for better performance Disk Motivation for
Indexing: Overview & Hashing CS 377: Database Systems Recap: Data Storage Data items Records Memory DBMS Blocks blocks Files Different ways to organize files for better performance Disk Motivation for
(2,4) Trees Goodrich, Tamassia. (2,4) Trees 1
 Trees Goodrich, Tamassia. (2,4) Trees 1") (2,4) Trees 9 2 5 7 10 14 (2,4) Trees 1 Multi-Way Search Tree ( 9.4.1) A multi-way search tree is an ordered tree such that Each internal node has at least two children and stores d 1 key-element items
(2,4) Trees 9 2 5 7 10 14 (2,4) Trees 1 Multi-Way Search Tree ( 9.4.1) A multi-way search tree is an ordered tree such that Each internal node has at least two children and stores d 1 key-element items
Material You Need to Know
 Review Quiz 2 Material You Need to Know Normalization Storage and Disk File Layout Indexing B-trees and B+ Trees Extensible Hashing Linear Hashing Decomposition Goals: Lossless Joins, Dependency preservation
Review Quiz 2 Material You Need to Know Normalization Storage and Disk File Layout Indexing B-trees and B+ Trees Extensible Hashing Linear Hashing Decomposition Goals: Lossless Joins, Dependency preservation
Chapter 3. Algorithms for Query Processing and Optimization
 Chapter 3 Algorithms for Query Processing and Optimization Chapter Outline 1. Introduction to Query Processing 2. Translating SQL Queries into Relational Algebra 3. Algorithms for External Sorting 4. Algorithms
Chapter 3 Algorithms for Query Processing and Optimization Chapter Outline 1. Introduction to Query Processing 2. Translating SQL Queries into Relational Algebra 3. Algorithms for External Sorting 4. Algorithms
Algorithms for Query Processing and Optimization. 0. Introduction to Query Processing (1)
") Chapter 19 Algorithms for Query Processing and Optimization 0. Introduction to Query Processing (1) Query optimization: The process of choosing a suitable execution strategy for processing a query. Two
Chapter 19 Algorithms for Query Processing and Optimization 0. Introduction to Query Processing (1) Query optimization: The process of choosing a suitable execution strategy for processing a query. Two
 Ordered Indices To gain fast random access to records in a file, we can use an index structure. Each index structure is associated with a particular search key. Just like index of a book, library catalog,
Ordered Indices To gain fast random access to records in a file, we can use an index structure. Each index structure is associated with a particular search key. Just like index of a book, library catalog,
Tree-Structured Indexes
 Introduction Tree-Structured Indexes Chapter 10 As for any index, 3 alternatives for data entries k*: Data record with key value k
Introduction Tree-Structured Indexes Chapter 10 As for any index, 3 alternatives for data entries k*: Data record with key value k
Kathleen Durant PhD Northeastern University CS Indexes
 Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Indexing and Hashing
 C H A P T E R 1 Indexing and Hashing This chapter covers indexing techniques ranging from the most basic one to highly specialized ones. Due to the extensive use of indices in database systems, this chapter
C H A P T E R 1 Indexing and Hashing This chapter covers indexing techniques ranging from the most basic one to highly specialized ones. Due to the extensive use of indices in database systems, this chapter
Module 4: Index Structures Lecture 13: Index structure. The Lecture Contains: Index structure. Binary search tree (BST) B-tree. B+-tree.
 B-tree. B+-tree.") The Lecture Contains: Index structure Binary search tree (BST) B-tree B+-tree Order file:///c /Documents%20and%20Settings/iitkrana1/My%20Documents/Google%20Talk%20Received%20Files/ist_data/lecture13/13_1.htm[6/14/2012
The Lecture Contains: Index structure Binary search tree (BST) B-tree B+-tree Order file:///c /Documents%20and%20Settings/iitkrana1/My%20Documents/Google%20Talk%20Received%20Files/ist_data/lecture13/13_1.htm[6/14/2012
CS127: B-Trees. B-Trees
 CS127: B-Trees B-Trees 1 Data Layout on Disk Track: one ring Sector: one pie-shaped piece. Block: intersection of a track and a sector. Disk Based Dictionary Structures Use a disk-based method when the
CS127: B-Trees B-Trees 1 Data Layout on Disk Track: one ring Sector: one pie-shaped piece. Block: intersection of a track and a sector. Disk Based Dictionary Structures Use a disk-based method when the
Access Methods. Basic Concepts. Index Evaluation Metrics. search key pointer. record. value. Value
 Access Methods This is a modified version of Prof. Hector Garcia Molina s slides. All copy rights belong to the original author. Basic Concepts search key pointer Value record? value Search Key - set of
Access Methods This is a modified version of Prof. Hector Garcia Molina s slides. All copy rights belong to the original author. Basic Concepts search key pointer Value record? value Search Key - set of
Physical Database Design: Outline
 Physical Database Design: Outline File Organization Fixed size records Variable size records Mapping Records to Files Heap Sequentially Hashing Clustered Buffer Management Indexes (Trees and Hashing) Single-level
Physical Database Design: Outline File Organization Fixed size records Variable size records Mapping Records to Files Heap Sequentially Hashing Clustered Buffer Management Indexes (Trees and Hashing) Single-level
Tree-Structured Indexes
 Tree-Structured Indexes Chapter 9 Database Management Systems, R. Ramakrishnan and J. Gehrke 1 Introduction As for any index, 3 alternatives for data entries k*: ➀ Data record with key value k ➁
Tree-Structured Indexes Chapter 9 Database Management Systems, R. Ramakrishnan and J. Gehrke 1 Introduction As for any index, 3 alternatives for data entries k*: ➀ Data record with key value k ➁
Physical Disk Structure. Physical Data Organization and Indexing. Pages and Blocks. Access Path. I/O Time to Access a Page. Disks.
 Physical Disk Structure Physical Data Organization and Indexing Chapter 11 1 4 Access Path Refers to the algorithm + data structure (e.g., an index) used for retrieving and storing data in a table The
Physical Disk Structure Physical Data Organization and Indexing Chapter 11 1 4 Access Path Refers to the algorithm + data structure (e.g., an index) used for retrieving and storing data in a table The
Database index structures
 Database index structures From: Database System Concepts, 6th edijon Avi Silberschatz, Henry Korth, S. Sudarshan McGraw- Hill Architectures for Massive DM D&K / UPSay 2015-2016 Ioana Manolescu 1 Chapter
Database index structures From: Database System Concepts, 6th edijon Avi Silberschatz, Henry Korth, S. Sudarshan McGraw- Hill Architectures for Massive DM D&K / UPSay 2015-2016 Ioana Manolescu 1 Chapter
Indexing. Chapter 8, 10, 11. Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1
 Indexing Chapter 8, 10, 11 Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Tree-Based Indexing The data entries are arranged in sorted order by search key value. A hierarchical search
Indexing Chapter 8, 10, 11 Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Tree-Based Indexing The data entries are arranged in sorted order by search key value. A hierarchical search
Extra: B+ Trees. Motivations. Differences between BST and B+ 10/27/2017. CS1: Java Programming Colorado State University
 Extra: B+ Trees CS1: Java Programming Colorado State University Slides by Wim Bohm and Russ Wakefield 1 Motivations Many times you want to minimize the disk accesses while doing a search. A binary search
Extra: B+ Trees CS1: Java Programming Colorado State University Slides by Wim Bohm and Russ Wakefield 1 Motivations Many times you want to minimize the disk accesses while doing a search. A binary search
Indexing. Jan Chomicki University at Buffalo. Jan Chomicki () Indexing 1 / 25
 Indexing 1 / 25") Indexing Jan Chomicki University at Buffalo Jan Chomicki () Indexing 1 / 25 Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow (nanosec) (10 nanosec) (millisec) (sec) Very small Small
Indexing Jan Chomicki University at Buffalo Jan Chomicki () Indexing 1 / 25 Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow (nanosec) (10 nanosec) (millisec) (sec) Very small Small
Database Systems. Session 8 Main Theme. Physical Database Design, Query Execution Concepts and Database Programming Techniques
 Database Systems Session 8 Main Theme Physical Database Design, Query Execution Concepts and Database Programming Techniques Dr. Jean-Claude Franchitti New York University Computer Science Department Courant
Database Systems Session 8 Main Theme Physical Database Design, Query Execution Concepts and Database Programming Techniques Dr. Jean-Claude Franchitti New York University Computer Science Department Courant
File Structures and Indexing
 File Structures and Indexing CPS352: Database Systems Simon Miner Gordon College Last Revised: 10/11/12 Agenda Check-in Database File Structures Indexing Database Design Tips Check-in Database File Structures
File Structures and Indexing CPS352: Database Systems Simon Miner Gordon College Last Revised: 10/11/12 Agenda Check-in Database File Structures Indexing Database Design Tips Check-in Database File Structures
COMP 430 Intro. to Database Systems. Indexing
 COMP 430 Intro. to Database Systems Indexing How does DB find records quickly? Various forms of indexing An index is automatically created for primary key. SQL gives us some control, so we should understand
COMP 430 Intro. to Database Systems Indexing How does DB find records quickly? Various forms of indexing An index is automatically created for primary key. SQL gives us some control, so we should understand
Chapter 18 Indexing Structures for Files
 Chapter 18 Indexing Structures for Files Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Disk I/O for Read/ Write Unit for Disk I/O for Read/ Write: Chapter 18 One Buffer for
Chapter 18 Indexing Structures for Files Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Disk I/O for Read/ Write Unit for Disk I/O for Read/ Write: Chapter 18 One Buffer for
Storage hierarchy. Textbook: chapters 11, 12, and 13
 Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow Very small Small Bigger Very big (KB) (MB) (GB) (TB) Built-in Expensive Cheap Dirt cheap Disks: data is stored on concentric circular
Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow Very small Small Bigger Very big (KB) (MB) (GB) (TB) Built-in Expensive Cheap Dirt cheap Disks: data is stored on concentric circular
More B-trees, Hash Tables, etc. CS157B Chris Pollett Feb 21, 2005.
 More B-trees, Hash Tables, etc. CS157B Chris Pollett Feb 21, 2005. Outline B-tree Domain of Application B-tree Operations Hash Tables on Disk Hash Table Operations Extensible Hash Tables Multidimensional
More B-trees, Hash Tables, etc. CS157B Chris Pollett Feb 21, 2005. Outline B-tree Domain of Application B-tree Operations Hash Tables on Disk Hash Table Operations Extensible Hash Tables Multidimensional
Find the block in which the tuple should be! If there is free space, insert it! Otherwise, must create overflow pages!
 Professor: Pete Keleher! keleher@cs.umd.edu! } Keep sorted by some search key! } Insertion! Find the block in which the tuple should be! If there is free space, insert it! Otherwise, must create overflow
Professor: Pete Keleher! keleher@cs.umd.edu! } Keep sorted by some search key! } Insertion! Find the block in which the tuple should be! If there is free space, insert it! Otherwise, must create overflow
Announcements. Reading Material. Recap. Today 9/17/17. Storage (contd. from Lecture 6)
") CompSci 16 Intensive Computing Systems Lecture 7 Storage and Index Instructor: Sudeepa Roy Announcements HW1 deadline this week: Due on 09/21 (Thurs), 11: pm, no late days Project proposal deadline: Preliminary
CompSci 16 Intensive Computing Systems Lecture 7 Storage and Index Instructor: Sudeepa Roy Announcements HW1 deadline this week: Due on 09/21 (Thurs), 11: pm, no late days Project proposal deadline: Preliminary
Question Bank Subject: Advanced Data Structures Class: SE Computer
 Question Bank Subject: Advanced Data Structures Class: SE Computer Question1: Write a non recursive pseudo code for post order traversal of binary tree Answer: Pseudo Code: 1. Push root into Stack_One.
Question Bank Subject: Advanced Data Structures Class: SE Computer Question1: Write a non recursive pseudo code for post order traversal of binary tree Answer: Pseudo Code: 1. Push root into Stack_One.
CSE 562 Database Systems
 Goal of Indexing CSE 562 Database Systems Indexing Some slides are based or modified from originals by Database Systems: The Complete Book, Pearson Prentice Hall 2 nd Edition 08 Garcia-Molina, Ullman,
Goal of Indexing CSE 562 Database Systems Indexing Some slides are based or modified from originals by Database Systems: The Complete Book, Pearson Prentice Hall 2 nd Edition 08 Garcia-Molina, Ullman,
CS 245 Midterm Exam Winter 2014
 CS 245 Midterm Exam Winter 2014 This exam is open book and notes. You can use a calculator and your laptop to access course notes and videos (but not to communicate with other people). You have 70 minutes
CS 245 Midterm Exam Winter 2014 This exam is open book and notes. You can use a calculator and your laptop to access course notes and videos (but not to communicate with other people). You have 70 minutes
Chapter 12: Query Processing. Chapter 12: Query Processing
 Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Query Processing Overview Measures of Query Cost Selection Operation Sorting Join
Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Query Processing Overview Measures of Query Cost Selection Operation Sorting Join
B-Trees. Introduction. Definitions
 1 of 10 B-Trees Introduction A B-tree is a specialized multiway tree designed especially for use on disk. In a B-tree each node may contain a large number of keys. The number of subtrees of each node,
1 of 10 B-Trees Introduction A B-tree is a specialized multiway tree designed especially for use on disk. In a B-tree each node may contain a large number of keys. The number of subtrees of each node,
B-Trees & its Variants
 B-Trees & its Variants Advanced Data Structure Spring 2007 Zareen Alamgir Motivation Yet another Tree! Why do we need another Tree-Structure? Data Retrieval from External Storage In database programs,
B-Trees & its Variants Advanced Data Structure Spring 2007 Zareen Alamgir Motivation Yet another Tree! Why do we need another Tree-Structure? Data Retrieval from External Storage In database programs,
System Structure Revisited
 System Structure Revisited Naïve users Casual users Application programmers Database administrator Forms DBMS Application Front ends DML Interface CLI DDL SQL Commands Query Evaluation Engine Transaction
System Structure Revisited Naïve users Casual users Application programmers Database administrator Forms DBMS Application Front ends DML Interface CLI DDL SQL Commands Query Evaluation Engine Transaction
(i) It is efficient technique for small and medium sized data file. (ii) Searching is comparatively fast and efficient.
 It is efficient technique for small and medium sized data file. (ii) Searching is comparatively fast and efficient.") INDEXING An index is a collection of data entries which is used to locate a record in a file. Index table record in a file consist of two parts, the first part consists of value of prime or non-prime attributes
INDEXING An index is a collection of data entries which is used to locate a record in a file. Index table record in a file consist of two parts, the first part consists of value of prime or non-prime attributes
Trees can be used to store entire records from a database, serving as an in-memory representation of the collection of records in a file.
 Large Trees 1 Trees can be used to store entire records from a database, serving as an in-memory representation of the collection of records in a file. Trees can also be used to store indices of the collection
Large Trees 1 Trees can be used to store entire records from a database, serving as an in-memory representation of the collection of records in a file. Trees can also be used to store indices of the collection
Lecture 8 Index (B+-Tree and Hash)
") CompSci 516 Data Intensive Computing Systems Lecture 8 Index (B+-Tree and Hash) Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 HW1 due tomorrow: Announcements Due on 09/21 (Thurs),
CompSci 516 Data Intensive Computing Systems Lecture 8 Index (B+-Tree and Hash) Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 HW1 due tomorrow: Announcements Due on 09/21 (Thurs),
QUIZ: Buffer replacement policies
 QUIZ: Buffer replacement policies Compute join of 2 relations r and s by nested loop: for each tuple tr of r do for each tuple ts of s do if the tuples tr and ts match do something that doesn t require
QUIZ: Buffer replacement policies Compute join of 2 relations r and s by nested loop: for each tuple tr of r do for each tuple ts of s do if the tuples tr and ts match do something that doesn t require
ACCESS METHODS: FILE ORGANIZATIONS, B+TREE
 ACCESS METHODS: FILE ORGANIZATIONS, B+TREE File Storage How to keep blocks of records on disk files but must support operations: scan all records search for a record id ( RID ) insert new records delete
ACCESS METHODS: FILE ORGANIZATIONS, B+TREE File Storage How to keep blocks of records on disk files but must support operations: scan all records search for a record id ( RID ) insert new records delete
Introduction to Indexing 2. Acknowledgements: Eamonn Keogh and Chotirat Ann Ratanamahatana
 Introduction to Indexing 2 Acknowledgements: Eamonn Keogh and Chotirat Ann Ratanamahatana Indexed Sequential Access Method We have seen that too small or too large an index (in other words too few or too
Introduction to Indexing 2 Acknowledgements: Eamonn Keogh and Chotirat Ann Ratanamahatana Indexed Sequential Access Method We have seen that too small or too large an index (in other words too few or too
CPS352 Lecture - Indexing
 Objectives: CPS352 Lecture - Indexing Last revised 2/25/2019 1. To explain motivations and conflicting goals for indexing 2. To explain different types of indexes (ordered versus hashed; clustering versus
Objectives: CPS352 Lecture - Indexing Last revised 2/25/2019 1. To explain motivations and conflicting goals for indexing 2. To explain different types of indexes (ordered versus hashed; clustering versus
Database System Concepts
 Chapter 13: Query Processing s Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2008/2009 Slides (fortemente) baseados nos slides oficiais do livro c Silberschatz, Korth
Chapter 13: Query Processing s Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2008/2009 Slides (fortemente) baseados nos slides oficiais do livro c Silberschatz, Korth
Chapter 12: Indexing and Hashing (Cnt(
 Chapter 12: Indexing and Hashing (Cnt( Cnt.) Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition
Chapter 12: Indexing and Hashing (Cnt( Cnt.) Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition
Chapter 5: Physical Database Design. Designing Physical Files
 Chapter 5: Physical Database Design Designing Physical Files Technique for physically arranging records of a file on secondary storage File Organizations Sequential (Fig. 5-7a): the most efficient with
Chapter 5: Physical Database Design Designing Physical Files Technique for physically arranging records of a file on secondary storage File Organizations Sequential (Fig. 5-7a): the most efficient with
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2009 Lecture 6 - Storage and Indexing
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 6 - Storage and Indexing References Generalized Search Trees for Database Systems. J. M. Hellerstein, J. F. Naughton
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 6 - Storage and Indexing References Generalized Search Trees for Database Systems. J. M. Hellerstein, J. F. Naughton
Problem. Indexing with B-trees. Indexing. Primary Key Indexing. B-trees: Example. B-trees. primary key indexing
 15-82 Advanced Topics in Database Systems Performance Problem Given a large collection of records, Indexing with B-trees find similar/interesting things, i.e., allow fast, approximate queries 2 Indexing
15-82 Advanced Topics in Database Systems Performance Problem Given a large collection of records, Indexing with B-trees find similar/interesting things, i.e., allow fast, approximate queries 2 Indexing
PART IV. Given 2 sorted arrays, What is the time complexity of merging them together?
 General Questions: PART IV Given 2 sorted arrays, What is the time complexity of merging them together? Array 1: Array 2: Sorted Array: Pointer to 1 st element of the 2 sorted arrays Pointer to the 1 st
General Questions: PART IV Given 2 sorted arrays, What is the time complexity of merging them together? Array 1: Array 2: Sorted Array: Pointer to 1 st element of the 2 sorted arrays Pointer to the 1 st
Motivation for B-Trees
 1 Motivation for Assume that we use an AVL tree to store about 20 million records We end up with a very deep binary tree with lots of different disk accesses; log2 20,000,000 is about 24, so this takes
1 Motivation for Assume that we use an AVL tree to store about 20 million records We end up with a very deep binary tree with lots of different disk accesses; log2 20,000,000 is about 24, so this takes
Index Tuning. Index. An index is a data structure that supports efficient access to data. Matching records. Condition on attribute value
 Index Tuning AOBD07/08 Index An index is a data structure that supports efficient access to data Condition on attribute value index Set of Records Matching records (search key) 1 Performance Issues Type
Index Tuning AOBD07/08 Index An index is a data structure that supports efficient access to data Condition on attribute value index Set of Records Matching records (search key) 1 Performance Issues Type
Chapter 12: Query Processing
 Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Overview Chapter 12: Query Processing Measures of Query Cost Selection Operation Sorting Join
Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Overview Chapter 12: Query Processing Measures of Query Cost Selection Operation Sorting Join
Query Processing. Debapriyo Majumdar Indian Sta4s4cal Ins4tute Kolkata DBMS PGDBA 2016
 Query Processing Debapriyo Majumdar Indian Sta4s4cal Ins4tute Kolkata DBMS PGDBA 2016 Slides re-used with some modification from www.db-book.com Reference: Database System Concepts, 6 th Ed. By Silberschatz,
Query Processing Debapriyo Majumdar Indian Sta4s4cal Ins4tute Kolkata DBMS PGDBA 2016 Slides re-used with some modification from www.db-book.com Reference: Database System Concepts, 6 th Ed. By Silberschatz,
Background: disk access vs. main memory access (1/2)
") 4.4 B-trees Disk access vs. main memory access: background B-tree concept Node structure Structural properties Insertion operation Deletion operation Running time 66 Background: disk access vs. main memory
4.4 B-trees Disk access vs. main memory access: background B-tree concept Node structure Structural properties Insertion operation Deletion operation Running time 66 Background: disk access vs. main memory
Overview of Storage and Indexing
 Overview of Storage and Indexing UVic C SC 370 Dr. Daniel M. German Department of Computer Science July 2, 2003 Version: 1.1.1 7 1 Overview of Storage and Indexing (1.1.1) CSC 370 dmgerman@uvic.ca Overview
Overview of Storage and Indexing UVic C SC 370 Dr. Daniel M. German Department of Computer Science July 2, 2003 Version: 1.1.1 7 1 Overview of Storage and Indexing (1.1.1) CSC 370 dmgerman@uvic.ca Overview
Chapter 18 Strategies for Query Processing. We focus this discussion w.r.t RDBMS, however, they are applicable to OODBS.
 Chapter 18 Strategies for Query Processing We focus this discussion w.r.t RDBMS, however, they are applicable to OODBS. 1 1. Translating SQL Queries into Relational Algebra and Other Operators - SQL is
Chapter 18 Strategies for Query Processing We focus this discussion w.r.t RDBMS, however, they are applicable to OODBS. 1 1. Translating SQL Queries into Relational Algebra and Other Operators - SQL is
Data on External Storage
 Advanced Topics in DBMS Ch-1: Overview of Storage and Indexing By Syed khutubddin Ahmed Assistant Professor Dept. of MCA Reva Institute of Technology & mgmt. Data on External Storage Prg1 Prg2 Prg3 DBMS
Advanced Topics in DBMS Ch-1: Overview of Storage and Indexing By Syed khutubddin Ahmed Assistant Professor Dept. of MCA Reva Institute of Technology & mgmt. Data on External Storage Prg1 Prg2 Prg3 DBMS
Lecture 13. Lecture 13: B+ Tree
 Lecture 13 Lecture 13: B+ Tree Lecture 13 Announcements 1. Project Part 2 extension till Friday 2. Project Part 3: B+ Tree coming out Friday 3. Poll for Nov 22nd 4. Exam Pickup: If you have questions,
Lecture 13 Lecture 13: B+ Tree Lecture 13 Announcements 1. Project Part 2 extension till Friday 2. Project Part 3: B+ Tree coming out Friday 3. Poll for Nov 22nd 4. Exam Pickup: If you have questions,
Chapter 12: Query Processing
 Chapter 12: Query Processing Overview Catalog Information for Cost Estimation $ Measures of Query Cost Selection Operation Sorting Join Operation Other Operations Evaluation of Expressions Transformation
Chapter 12: Query Processing Overview Catalog Information for Cost Estimation $ Measures of Query Cost Selection Operation Sorting Join Operation Other Operations Evaluation of Expressions Transformation
CARNEGIE MELLON UNIVERSITY DEPT. OF COMPUTER SCIENCE DATABASE APPLICATIONS
 CARNEGIE MELLON UNIVERSITY DEPT. OF COMPUTER SCIENCE 15-415 DATABASE APPLICATIONS C. Faloutsos Indexing and Hashing 15-415 Database Applications http://www.cs.cmu.edu/~christos/courses/dbms.s00/ general
CARNEGIE MELLON UNIVERSITY DEPT. OF COMPUTER SCIENCE 15-415 DATABASE APPLICATIONS C. Faloutsos Indexing and Hashing 15-415 Database Applications http://www.cs.cmu.edu/~christos/courses/dbms.s00/ general
I think that I shall never see A billboard lovely as a tree. Perhaps unless the billboards fall I ll never see a tree at all.
 9 TREE-STRUCTURED INDEXING I think that I shall never see A billboard lovely as a tree. Perhaps unless the billboards fall I ll never see a tree at all. Ogden Nash, Song of the Open Road We now consider
9 TREE-STRUCTURED INDEXING I think that I shall never see A billboard lovely as a tree. Perhaps unless the billboards fall I ll never see a tree at all. Ogden Nash, Song of the Open Road We now consider
CS 525: Advanced Database Organization 04: Indexing
 CS 5: Advanced Database Organization 04: Indexing Boris Glavic Part 04 Indexing & Hashing value record? value Slides: adapted from a course taught by Hector Garcia-Molina, Stanford InfoLab CS 5 Notes 4
CS 5: Advanced Database Organization 04: Indexing Boris Glavic Part 04 Indexing & Hashing value record? value Slides: adapted from a course taught by Hector Garcia-Molina, Stanford InfoLab CS 5 Notes 4
Module 4: Tree-Structured Indexing
 Module 4: Tree-Structured Indexing Module Outline 4.1 B + trees 4.2 Structure of B + trees 4.3 Operations on B + trees 4.4 Extensions 4.5 Generalized Access Path 4.6 ORACLE Clusters Web Forms Transaction
Module 4: Tree-Structured Indexing Module Outline 4.1 B + trees 4.2 Structure of B + trees 4.3 Operations on B + trees 4.4 Extensions 4.5 Generalized Access Path 4.6 ORACLE Clusters Web Forms Transaction
B-Trees. Disk Storage. What is a multiway tree? What is a B-tree? Why B-trees? Insertion in a B-tree. Deletion in a B-tree
 B-Trees Disk Storage What is a multiway tree? What is a B-tree? Why B-trees? Insertion in a B-tree Deletion in a B-tree Disk Storage Data is stored on disk (i.e., secondary memory) in blocks. A block is
B-Trees Disk Storage What is a multiway tree? What is a B-tree? Why B-trees? Insertion in a B-tree Deletion in a B-tree Disk Storage Data is stored on disk (i.e., secondary memory) in blocks. A block is
Data Organization B trees
 Data Organization B trees Data organization and retrieval File organization can improve data retrieval time SELECT * FROM depositors WHERE bname= Downtown 100 blocks 200 recs/block Query returns 150 records
Data Organization B trees Data organization and retrieval File organization can improve data retrieval time SELECT * FROM depositors WHERE bname= Downtown 100 blocks 200 recs/block Query returns 150 records
Tree-Structured Indexes. Chapter 10
 Tree-Structured Indexes Chapter 10 1 Introduction As for any index, 3 alternatives for data entries k*: Data record with key value k 25, [n1,v1,k1,25] 25,
Tree-Structured Indexes Chapter 10 1 Introduction As for any index, 3 alternatives for data entries k*: Data record with key value k 25, [n1,v1,k1,25] 25,
CS 350 Algorithms and Complexity
 CS 350 Algorithms and Complexity Winter 2019 Lecture 12: Space & Time Tradeoffs. Part 2: Hashing & B-Trees Andrew P. Black Department of Computer Science Portland State University Space-for-time tradeoffs
CS 350 Algorithms and Complexity Winter 2019 Lecture 12: Space & Time Tradeoffs. Part 2: Hashing & B-Trees Andrew P. Black Department of Computer Science Portland State University Space-for-time tradeoffs
Chapter 13: Query Processing
 Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Data Structure. IBPS SO (IT- Officer) Exam 2017
 Exam 2017") Data Structure IBPS SO (IT- Officer) Exam 2017 Data Structure: In computer science, a data structure is a way of storing and organizing data in a computer s memory so that it can be used efficiently. Data
Data Structure IBPS SO (IT- Officer) Exam 2017 Data Structure: In computer science, a data structure is a way of storing and organizing data in a computer s memory so that it can be used efficiently. Data