Interactive keyword-based access to large-scale structured datasets
|
|
|
- Clifton Tyler
- 6 years ago
- Views:
Transcription



1 Interactive keyword-based access to large-scale structured datasets 2 nd Keystone Summer School 20 July 2016 Dr. Elena Demidova University of Southampton 1
2 Overview Keyword-based access to structured data Usability and expressiveness Preparation of data for keyword-based access Indexing structured data Interactive query construction Building structured queries with user input 2
3 Keyword-based access to structured data Usability and expressiveness 3





4 Keyword-based access to structured data Using structure we could refine the results: London What do you mean? A book title? An author? 39 4
5 Access to structured data: Search vs. query Example: DBLP as a relational database containing paper-author relations Keyword query: K = {Michelle, XML} Structured query: Q = σ michelle name (Author) Write σ xml title (Paper) (Example from [Yu et. al 2009]) 5
6 Complicated Easy to use adapted from: [Tata et. al 2008] Database queries: Expressiveness vs. usability Usability Keyword search possibly imprecise results BANKS, DBXPlorer, Discover ( 02) Goal: Expressive AND Easy to use Structured queries language, schema (SQL, SPARQL, XQuery) QBE ( 75), NLQ ( 99) Less expressive Expressiveness More expressive 6
7 Database queries: Expressiveness vs. usability Database queries: knowledge of database schema knowledge of query language syntax Keyword search: Easy-to-use but imprecise Ambiguous: unclear information need Keyword query interpretation: Automatically translate keyword query in a (most likely) structured query (-ies) 7
8 Preparation of data for keyword-based access Indexing structured data at the example of relational databases 8
9 Keyword query semantics A l-keyword query K = {k 1, k 2,, k l } a set of keywords of size l. K semantics (typically): search for interconnected tuples that jointly contain {k 1, k 2,, k l }. How can we find the tuples containing {k 1, k 2,, k l } in a database? 9
10 Full-text search on a specific database attribute Full-text search on specific attribute is supported by major databases, e.g. using contains predicate: contains (R.A, k i ) the predicate selecting all tuples from a relation R that contain keyword k i in the text attribute R.A. SELECT * FROM Author WHERE contains(author.name, Michelle ); String comparison operators (e.g. like): SELECT * FROM Author WHERE Author.Name LIKE '%michelle%'; Problem: need to search in each attribute separately 10
11 DB indexing for keyword search Inverted index using Lucene, Solr, Elasticsearch Granularity: Tuple level: Dictionary Postings Michelle -> Author.a 3 Paper.p 1... XML -> Paper.p 2 Paper.p 3 Attribute level: Dictionary Postings Michelle -> Author.Name Paper.Title... XML -> Paper.Title Differences? 11
12 SQL full-text search vs. indexing Built-in full-text search capabilities are database dependent Contains predicate can use indexes but is neither flexible, nor not generally available String comparison operators can require sequential scan (e.g. like operator if the prefix is undefined) Each textual attribute needs to be queried separately In the global full-text index, the list of attributes is immediately available Index construction cost Storage cost (depends on the index granularity) 12
13 Query construction as a way to improve query expressiveness Building structured queries from keywords 13
14 From keywords to structured queries: An example DPLP example and definitions from: [Yu et. al 2009] K = {Michelle, XML} 1. Identify tuples / attributes containing keywords σ michelle name (Author): michelle σ xml title (Paper): xml σ michelle title (Paper): michelle 2. Identify join paths to connect all keywords in the query Q = michelle name (Author) Write σ xml title(paper) Other paths? 14
15 From keywords to structured queries: An example K = {Michelle, XML} Q = michelle name (Author) Write σ xml title(paper) The translation K - > Q requires: 1. Knowledge of the schema graph (tables, attributes, join paths) 2. Knowledge of keyword occurrences 3. Efficient algorithms 15
16 Definitions and notations: The schema graph Schema graph: a directed graph G s (V,E) V the set of relation schemas {R 1, R 2,, R n }. An instance of a relation schema is a set of tuples (i.e. a database table). E - the set of edges R i -> R j between two relation schemas. An edge is a primary key to foreign key relation. TID primary key attribute (i.e. tuple identifier). Text attribute an attribute allowing full-text search. 16
17 An example: The DBLP schema graph Author TID Name Write TID AID PID Paper TID Title Cite TID PID1 PID2 A simplified representation of the schema graph: Author Write Paper PID1 Cite AID PID PID2 17
18 Definitions and notations: The database graph The database graph: a directed graph G D (V t, E t ) on the schema graph Gs. V t the set of tuples {t 1, t 2,, t n }. E t - the set of edges between tuples. Two tuples t i and t j are connected if there exists a foreign key (fk) reference t i -> t j or t j -> t i. Two tuples t i, t j are reachable if there exists a sequence of connections between them, e.g. t i -> t 1,., t n -> t j. The distance between two tuples dis(t i, t j ) is the minimum number of connections between t i, t j. 18
19 An example: The DPLP database graph The distance between two tuples dis(t i, t j ) is the minimum number of connections between t i, t j. dis (a1, p4)? 19
20 Interconnecting keywords: MTJNT An answer to a l-keyword query is a Minimal Total Joining Network of Tuples (MTJNT). JNT (Joining Network of Tuples) a connected tree of tuples. Every two adjacent tuples t i, t j in JNT an be joined based on the fk-reference in the schema i.e. either R i -> R j or R j -> R i (ignoring direction). TJNT (Total JNT) w.r.t. a l-keyword query K if it contains all keywords of K. MTJNT (Minimal TJNT) if no tuple can be removed such that JNT remains total. T max a size control parameter to define the maximum number of tuples in MTJNT. 20
21 Keyword query answers: MTJNT examples K = {Michelle, XML} T max = 5 contains (a 3, Michelle ) contains (p 1, Michelle ) contains (p 2, XML ) contains (p 3, XML ) MTJNTs: 21
22 MTJNT issues Size and scalability: The data graph is potentially very large, i.e. search is very costly The search space increases exponentially by adding new data entries Results semantics and presentation The results are heterogeneous in terms of structure, i.e. difficult to present and understand Aggregation / summarization is needed Generation of structured queries: Schema graph is much smaller Structured queries naturally aggregate MTJNTs 22
23 Structured queries: Candidate Network (CN) A keyword relation: a subset R i {K } of relation R i that contains a subset K of keywords from K (and no other keywords from K). The subset can be empty R i { }. A Candidate Network (CN) is a connected tree of keyword relations. Every two adjacent keyword relations R i, R j in CN are joined based on the fk-reference in the schema G s. CN is total w.r.t. a l-keyword query K if its keyword relations jointly contain all keywords of K. CN is minimal if no keyword relation can be removed such that CN remains total. T max a size control parameter to define the maximum number of keyword relations in CN. A CN can produce a set of possibly empty MTJNTs. One MTJNTs can be generated by exactly one CN. 23
24 CN examples CNs: K = {Michelle, XML}, T max = 5, P{Michelle}, P{XML}, A{Michelle} 24
25 CN examples CNs: K = {Michelle, XML}, T max = 5, P{Michelle}, P{XML}, A{Michelle} MTJNTs: Which MTJNTs are generated by which CNs? 25
26 CN generation algorithms Given are: 1. Keyword query K = {k 1, k 2,, k l } 2. Schema graph G s 3. The nodes of G s containing each keyword k i in K The Problem: Find the path(s) connecting all {k 1, k 2,, k l } in G s (i.e. the structured query(-ies)) Example: K = {Michelle, XML} Author Write Paper PID1 Cite Michelle AID PID XML Michelle PID2 26
27 CN generation algorithms Complexity: similar to the Steiner tree problem - find the shortest interconnect for a given set of objects: NP-complete. Approximation algorithms: Iteratively explore the schema graph to construct the paths BFS/DFS Author Write Paper PID1 Cite Michelle AID Data structures? PID XML Michelle PID2 27
28 Search algorithms and data structures: BFS Search on the schema graph G s (with keyword relations) Breadth-First-Search (BFS): queue Step i: V 1 V 2 V 4 V 5 V 3 V 6. dequeue V 1 Step i+1: V 1 V 3 enqueue. V 1 V 2 28
29 Search algorithms and data structures: BFS Search on the schema graph G s (with keyword relations) Breadth-First-Search (BFS): queue Step j: V 1 V 2 V 4 V 5 V 3 V 6. dequeue V 1 V 2 Step j+1: V 1 V 2 V 5 enqueue. V 1 V 2 V 4 29
30 Search algorithms and data structures: DFS Search on the schema graph G s (with keyword relations) Depth First Search (DFS) for top-k generation: Stack V 1 V 2 V 4 V 5 V 3 V 6 V 1 pop push V 1 V 2 pop V 1 V 2 V 1 V 2 V 4 push 30
31 algorithm from [Hristidis et. al. 2002] CN generation algorithm (BFS-based): Discover Notation: here Q is a keyword query! Rule 1: duplicate elim. Rule 2: minimality Rule 3: avoid cycles 31
32 CN generation: An example Author Write Paper PID1 Cite Michelle AID Keyword relations: P{Michelle}, P{XML}, A{Michelle} PID XML Michelle PID2 enqueue: P{Michelle}, P{XML}, A{Michelle} dequeue: T 1 <- A{Michelle} expand: T 2 <- A{Michelle} W{} enqueue: T 2 dequeue: T 2 <- A{Michelle} W{} expand: T 3 <- A{Michelle} W{} P{XML} enqueue: T 3 dequeue: T 3, check if T 3 is minimal and total, add T 3 to the result 32
33 CN generation: Complexity and optimizations Complexity factors: Size of the schema graph G s the number of nodes and edges Maximum number of joins (T max ) Size of the keyword query (l) The number of CNs grows exponentially with these factors. Algorithm optimizations: Avoid generation of duplicate CNs by defining the expansion order Generate only the top-k CNs 33
34 CN and MTJNT ranking factors Ranking can be performed at CN and MTJNT levels Typical ranking factors include: Size of the CN / tuple tree preference to the short paths IR-Style factors Frequency-based keyword weights Keyword selectivity (IDF) Length normalizations Global attribute weight in a database (PageRank / ObjectRank) Typically, the factors are combined 34
35 Ranking query interpretations: An example Rank the following CNs using the size factor: 35
36 Interactive query construction Building structured queries with user input 36

37 Query construction for large scale databases Freebase: 22 millions entities, more than 350 millions facts more than 7,500 relational tables about 100 domains Wikipedia, MusicBrainz, part of the LOD cloud Goal: Enable efficient and scalable query construction solutions for large scale data 37




38 A film adaptation starring Tom Hanks was attempted [ ] after the actor's performances in The Terminal (2004) An article in Entertainment Weekly did a comparison to the Tom Hanks film The Terminal Feng Zhenghu has been likened to the Tom Hanks character in The Terminal Tom Hanks' character Viktor Navorski is stuck at New York's JFK airport in the United terminal in The Terminal 38
39 Structured MQL query for Tom Hanks Terminal [{ "!pd:/film/actor/film": [{ "name": "Tom Hanks" "type": "/film/actor"}], "film":[{ "name" : "The Terminal" "type" : "/film/film"}], "character":{ "name" : null } "type": "/film/performance" }] Requires prior knowledge of: Schema: above 1000 entity types (relational tables) Specialized query language: MQL 39
40 Query interpretation techniques Automatic keyword query interpretation: Automatically translate keyword query in the (most likely) structured query (-ies) No one size fits all no perfect ranking for every query and every user If ranking fails, navigation cost can be inacceptable too many interpretations / search results Interactive query refinement Goal: Enable users to incrementally refine a keyword query into the intended interpretation on the target database in a minimal number of interactions 40
41 Query interpretation A query interpretation consists of: A set of keyword interpretations I that map a keyword to a value of an attribute (also interpretations as an attribute or table name are possible) σ 2001 year (Movie):2001 σ hanks name (Actor):hanks σ cruise name (Actor):cruise A query template T T= σ? name (Actor) Acts σ? year (Movie) Acts σ? name (Actor) 41
 = Q = σ hanks name (Actor) Acts σ 2001 year (Movie) Acts σ cruise name (Actor) partial interpretation of K, sub-query of Q complete interpretation of K (structured query)")
42 Query interpretation K= hanks cruise 2001 σ hanks name (Actor):hanks σ cruise name (Actor):cruise + σ 2001 year (Movie):2001 T= σ? name (Actor) Acts σ? year (Movie) Acts σ? name (Actor) = Q = σ hanks name (Actor) Acts σ 2001 year (Movie) Acts σ cruise name (Actor) partial interpretation of K, sub-query of Q complete interpretation of K (structured query) interpretation space of K 42

43 Query hierarchy K = Tom Hanks
44 Query construction options (QCO) Idea: use partial interpretations (sub-queries) as user interaction items (QCO) Problem: large number of queries and sub-queries (QCOs) σ 2001 year (Movie):2001 σ hanks name (Actor):hanks Q = σ hanks name (Actor) Acts σ 2001 year (Movie) σ cruise name (Actor):cruise σ 2001 year (Movie) Acts σ cruise name (Actor) How to select a QCO to present to the user? 44
45 Query construction plan (QCP) as a binary tree Idea: use sub-query relations to organize the options in a (binary) tree structure The root node is the entire interpretation space Remove queries conflicting with QCO 1 Yes QCO 1 : σ hanks name (Actor):hanks No Remove queries that subsume QCO 1 Yes QCO 2 : σ 2001 year (Movie):2001 No QCO σ hanks name (Actor) Acts σ 2001 year(movie) Acts σ cruise name (Actor) QCO A leaf node is a single complete query interpretation Problem: How to find an optimal QCP? 45
46 Defining a cost function for QCP Idea: define a cost function Take query probability into account Construction of the most likely queries should not incur much cost Cost ( QCP) depth( leaf ) P( leaf ) leaf QCP Given a keyword query K, how to compute the probability of leaf nodes (i.e. complete query interpretations of K)? K (a keyword query) = {hanks, 2001, cruise} Q (a leaf node of QCP) = σ hanks name (Actor) Acts σ 2001 year (Movie) Acts σ cruise name (Actor) P(leaf) = P(Q K): the conditional probability that, given K, Q is the user intended complete interpretation of K. 46
47 Query interpretation: assumptions Assumption 1 (Keyword Independence): Assume that the interpretation of each keyword in a keyword query is independent from the other keywords. Assumption 2 (Keyword Interpretation Independence): Assume that the probability of a keyword interpretation is independent from the part of the query interpretation the keyword is not interpreted to. 47
:hanks T= σ? name (Actor) Acts σ? year (Movie) Acts σ? name (Actor) P( Q K) P i i i T ki K A : k A P( ) Estimates for P(T) and P(A i :k i A i )?")
48 Probability of a query interpretation P ( Q K) P I, T K I is the set of keyword interpretations {A i :k i } in Q σ 2001 year (Movie):2001 σ cruise name (Actor):cruise T is the template of Q σ hanks name (Actor):hanks T= σ? name (Actor) Acts σ? year (Movie) Acts σ? name (Actor) P( Q K) P i i i T ki K A : k A P( ) Estimates for P(T) and P(A i :k i A i )? 48
49 Probability of a keyword interpretation We model the formation of a query interpretation as a random process. For an attribute A i, this process randomly picks one of its instances a j and randomly picks a keyword k i from that instance to form the expression σ ki A i. Then, the probability of P(σ ki A i σ? A i ) is the probability that σ ki A is formed through this random process. Example: T= σ? name (Actor) Acts σ? year (Movie) Acts σ? name (Actor) Q = σ hanks name (Actor) Acts σ 2001 year (Movie) Acts σ cruise name (Actor) P(σ hanks name (Actor) σ? name (Actor)) 49
50 Probability of a keyword interpretation P(σ ki A i σ? A i ) can be estimated using Attribute Term Frequency (ATF): ATF (k i, A i ) = (TF(k i, A i )+ɑ) / (N Ai +ɑ*b) ATF(k i, A i ) - the normalized keyword frequency of k i in A i N Ai the number of keywords in A i ɑ - a smoothing parameter (typically ɑ =1: Laplace smoothing) B the vocabulary size 50
51 Probability of a query template P(T) = (#occurences(t) +ɑ) / (N + ɑ*b) #occurences(t) - number of queries in the log using T as a template N - total number of queries in the log α - smoothing parameter, typically set to 1 B a constant When the query log is absent or is not sufficient, we assume that all query templates are equally probable. 51
52 Challenges in query interpretation Inefficient QCOs Too many keyword interpretations A keyword interpretation subsumes a small proportion of the I- space, more general QCOs are needed Very large interpretation space The number of subgraphs of the schema graph grows very sharply with the size of the schema graph. The occurrences of keywords are more numerous in a larger database. Too many query interpretations. Existing query interpretation approaches rely on a completely materialized interpretation space. This is no longer feasible. Need to enable incremental materialization of the interpretation space 52
53 Query construction algorithm - Query hierarchy can become very large - Use greedy algorithms - Expand query hierarchy incrementally - Use a threshold to restrict the size of the top level - Select the QCO to be presented to the user based on Information Gain (IG) - IG can be computed using probability of query interpretation 53
54 Query-based QCOs Keyword as schema terms or attribute values actor.name: hanks (Hanks is in the actor s name) hanks actor.name director.name. terminal film.name company.nam e location.name Joins using pk-fk relationships in the schema graph actor.name: hanks acts film.name: terminal acts acto r film 54
55 Ontology-based QCOs Freebase domain hierarchy Arts & Entertainment, Society External ontologies E.g. YAGO+F mapping between YAGO and Freebase Person, Location, Object Person: [hanks] Object: [hanks] Actor [hanks] Deceased Person [hanks] Organization [hanks] TV Episode [hanks] 55
56 FreeQ query hierarchy example Ontology-based QCOs: Arts & Entertainment: Tom Hanks Society: Tom Hanks.. Actor: Tom Hanks Query-based QCOs: Actor Name:Tom Hanks Acts Celebrity: Tom Hanks Award Nomination Award Nominee: Tom Hanks Nominated For: Terminal Film Name:Terminal. The arrows represent sub-query relationship 56
57 A measure of QCO efficiency Entropy of the query interpretation space: Expected information gain of a QCO as entropy reduction: Entropy of O computed using P(O): 57
58 Probability estimation for QCOs Probability of a QCO using probabilities of the subsumed query interpretations: Estimation of QCO probability using materialized part of the query hierarchy: 58
59 Efficient hierarchy traversal Query initialization: Path indexing: for each table, index all paths leading to keywords within radius r/2 (bi-directional): Is independent of keyword query length User interaction: Use path index to materialize QCOs and query interpretations incrementally by BF-k and DF-k Start expansion with the most probable QCOs Thresholds, time limits 59

![2013] 60](/docs-images/75/72716011/images/60-2.jpg)
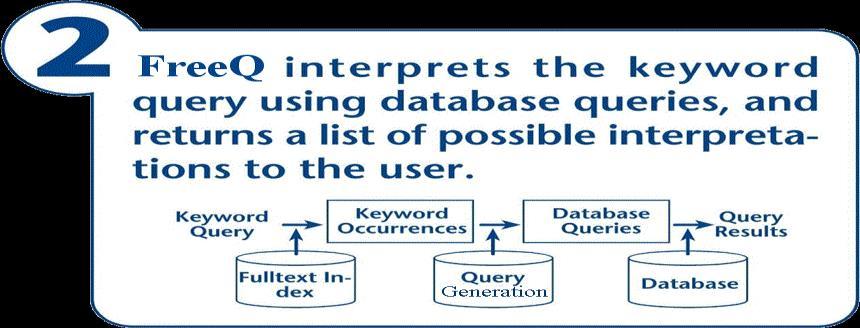
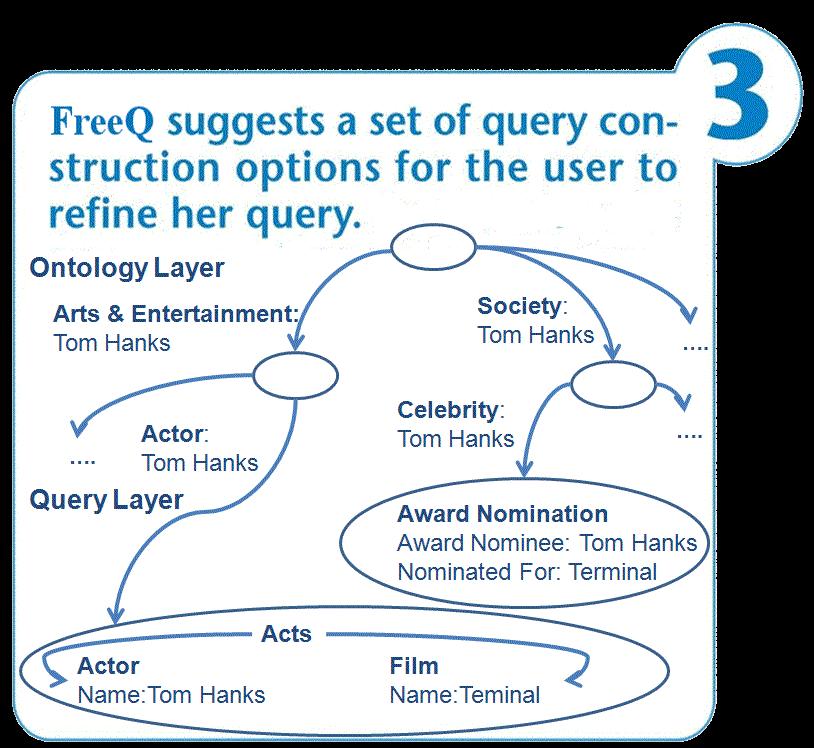
60 [Demidova et. al 2013] 60
61 Discussion Interactive query construction can enable efficient and scalable query solutions for large scale data It can involve ontologies to summarize and enrich database schema using abstract concepts (e.g. using YAGO ontology) Query interpretation space on large scale data can and should be materialized incrementally 61
62 References [Yu et. al 2009] Jeffrey Xu Yu, Lu Qin, Lijun Chang. Keyword Search in Databases. Synthesis Lectures on Data Management. Morgan & Claypool Publishers (Chapter 2.) [Qin et. al 2009] Lu Qin, Jeffrey Xu Yu, and Lijun Chang. Keyword search in databases: the power of RDBMS. In Proc. of the 2009 ACM SIGMOD [Hristidis et. al 2002] Vagelis Hristidis and Yannis Papakonstantinou. Discover: keyword search in relational databases. In Proc. of VLDB [Demidova et. al 2012] Elena Demidova, Xuan Zhou, Wolfgang Nejdl: A Probabilistic Scheme for Keyword-Based Incremental Query Construction. IEEE Trans. Knowl. Data Eng. 24(3): (2012). [Demidova et. al 2013] Elena Demidova, Xuan Zhou, and Wolfgang Nejdl Efficient query construction for large scale data. In Proc. of the ACM SIGIR
63 Further reading [Tata et. al 2008] Sandeep Tata and Guy M. Lohman. SQAK: doing more with keywords. In Proc. of the 2008 ACM SIGMOD. [Nandi et. al 2009] Nandi, A., Jagadish, H.V.: Qunits: queried units in database search. In CIDR (2009). [Jayapandian et. al 2008] Magesh Jayapandian and H. V. Jagadish Expressive query specification through form customization. In Proc. of the EDBT [Chu et. al 2009] Eric Chu, Akanksha Baid, Xiaoyong Chai, AnHai Doan, and Jeffrey Naughton Combining keyword search and forms for ad hoc querying of databases. In Proc. of the 2009 ACM SIGMOD. 63
64 Questions, Comments? Dr. Elena Demidova Web and Internet Science Group University of Southampton 64
Keyword query interpretation over structured data
 Keyword query interpretation over structured data Advanced Methods of IR Elena Demidova Materials used in the slides: Jeffrey Xu Yu, Lu Qin, Lijun Chang. Keyword Search in Databases. Synthesis Lectures
Keyword query interpretation over structured data Advanced Methods of IR Elena Demidova Materials used in the slides: Jeffrey Xu Yu, Lu Qin, Lijun Chang. Keyword Search in Databases. Synthesis Lectures
Refinement of keyword queries over structured data with ontologies and users
 Refinement of keyword queries over structured data with ontologies and users Advanced Methods of IR Elena Demidova SS 2014 Materials used in the slides: Sandeep Tata and Guy M. Lohman. SQAK: doing more
Refinement of keyword queries over structured data with ontologies and users Advanced Methods of IR Elena Demidova SS 2014 Materials used in the slides: Sandeep Tata and Guy M. Lohman. SQAK: doing more
Keyword query interpretation over structured data
 Keyword query interpretation over structured data Advanced Methods of Information Retrieval Elena Demidova SS 2018 Elena Demidova: Advanced Methods of Information Retrieval SS 2018 1 Recap Elena Demidova:
Keyword query interpretation over structured data Advanced Methods of Information Retrieval Elena Demidova SS 2018 Elena Demidova: Advanced Methods of Information Retrieval SS 2018 1 Recap Elena Demidova:
Keyword search in relational databases. By SO Tsz Yan Amanda & HON Ka Lam Ethan
 Keyword search in relational databases By SO Tsz Yan Amanda & HON Ka Lam Ethan 1 Introduction Ubiquitous relational databases Need to know SQL and database structure Hard to define an object 2 Query representation
Keyword search in relational databases By SO Tsz Yan Amanda & HON Ka Lam Ethan 1 Introduction Ubiquitous relational databases Need to know SQL and database structure Hard to define an object 2 Query representation
Supporting Fuzzy Keyword Search in Databases
 I J C T A, 9(24), 2016, pp. 385-391 International Science Press Supporting Fuzzy Keyword Search in Databases Jayavarthini C.* and Priya S. ABSTRACT An efficient keyword search system computes answers as
I J C T A, 9(24), 2016, pp. 385-391 International Science Press Supporting Fuzzy Keyword Search in Databases Jayavarthini C.* and Priya S. ABSTRACT An efficient keyword search system computes answers as
Keyword Search over Hybrid XML-Relational Databases
 SICE Annual Conference 2008 August 20-22, 2008, The University Electro-Communications, Japan Keyword Search over Hybrid XML-Relational Databases Liru Zhang 1 Tadashi Ohmori 1 and Mamoru Hoshi 1 1 Graduate
SICE Annual Conference 2008 August 20-22, 2008, The University Electro-Communications, Japan Keyword Search over Hybrid XML-Relational Databases Liru Zhang 1 Tadashi Ohmori 1 and Mamoru Hoshi 1 1 Graduate
Diversification of Query Interpretations and Search Results
 Diversification of Query Interpretations and Search Results Advanced Methods of IR Elena Demidova Materials used in the slides: Charles L.A. Clarke, Maheedhar Kolla, Gordon V. Cormack, Olga Vechtomova,
Diversification of Query Interpretations and Search Results Advanced Methods of IR Elena Demidova Materials used in the slides: Charles L.A. Clarke, Maheedhar Kolla, Gordon V. Cormack, Olga Vechtomova,
Top-k Keyword Search Over Graphs Based On Backward Search
 Top-k Keyword Search Over Graphs Based On Backward Search Jia-Hui Zeng, Jiu-Ming Huang, Shu-Qiang Yang 1College of Computer National University of Defense Technology, Changsha, China 2College of Computer
Top-k Keyword Search Over Graphs Based On Backward Search Jia-Hui Zeng, Jiu-Ming Huang, Shu-Qiang Yang 1College of Computer National University of Defense Technology, Changsha, China 2College of Computer
Keyword search in databases: the power of RDBMS
 Keyword search in databases: the power of RDBMS 1 Introduc
Keyword search in databases: the power of RDBMS 1 Introduc
A Survey on Keyword Diversification Over XML Data
 ISSN (Online) : 2319-8753 ISSN (Print) : 2347-6710 International Journal of Innovative Research in Science, Engineering and Technology An ISO 3297: 2007 Certified Organization Volume 6, Special Issue 5,
ISSN (Online) : 2319-8753 ISSN (Print) : 2347-6710 International Journal of Innovative Research in Science, Engineering and Technology An ISO 3297: 2007 Certified Organization Volume 6, Special Issue 5,
IJESRT. Scientific Journal Impact Factor: (ISRA), Impact Factor: 2.114
, Impact Factor: 2.114") [Saranya, 4(3): March, 2015] ISSN: 2277-9655 IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY A SURVEY ON KEYWORD QUERY ROUTING IN DATABASES N.Saranya*, R.Rajeshkumar, S.Saranya
[Saranya, 4(3): March, 2015] ISSN: 2277-9655 IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY A SURVEY ON KEYWORD QUERY ROUTING IN DATABASES N.Saranya*, R.Rajeshkumar, S.Saranya
Effective Top-k Keyword Search in Relational Databases Considering Query Semantics
 Effective Top-k Keyword Search in Relational Databases Considering Query Semantics Yanwei Xu 1,2, Yoshiharu Ishikawa 1, and Jihong Guan 2 1 Graduate School of Information Science, Nagoya University, Japan
Effective Top-k Keyword Search in Relational Databases Considering Query Semantics Yanwei Xu 1,2, Yoshiharu Ishikawa 1, and Jihong Guan 2 1 Graduate School of Information Science, Nagoya University, Japan
Effective Keyword Search in Relational Databases for Lyrics
 Effective Keyword Search in Relational Databases for Lyrics Navin Kumar Trivedi Assist. Professor, Department of Computer Science & Information Technology Divya Singh B.Tech (CSe) Scholar Pooja Pandey
Effective Keyword Search in Relational Databases for Lyrics Navin Kumar Trivedi Assist. Professor, Department of Computer Science & Information Technology Divya Singh B.Tech (CSe) Scholar Pooja Pandey
Volume 2, Issue 11, November 2014 International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 11, November 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online at: www.ijarcsms.com
Volume 2, Issue 11, November 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online at: www.ijarcsms.com
AN INTERACTIVE FORM APPROACH FOR DATABASE QUERIES THROUGH F-MEASURE
 http:// AN INTERACTIVE FORM APPROACH FOR DATABASE QUERIES THROUGH F-MEASURE Parashurama M. 1, Doddegowda B.J 2 1 PG Scholar, 2 Associate Professor, CSE Department, AMC Engineering College, Karnataka, (India).
http:// AN INTERACTIVE FORM APPROACH FOR DATABASE QUERIES THROUGH F-MEASURE Parashurama M. 1, Doddegowda B.J 2 1 PG Scholar, 2 Associate Professor, CSE Department, AMC Engineering College, Karnataka, (India).
Effective Keyword Search over (Semi)-Structured Big Data Mehdi Kargar
-Structured Big Data Mehdi Kargar") Effective Keyword Search over (Semi)-Structured Big Data Mehdi Kargar School of Computer Science Faculty of Science University of Windsor How Big is this Big Data? 40 Billion Instagram Photos 300 Hours
Effective Keyword Search over (Semi)-Structured Big Data Mehdi Kargar School of Computer Science Faculty of Science University of Windsor How Big is this Big Data? 40 Billion Instagram Photos 300 Hours
Querying Wikipedia Documents and Relationships
 Querying Wikipedia Documents and Relationships Huong Nguyen Thanh Nguyen Hoa Nguyen Juliana Freire School of Computing and SCI Institute, University of Utah {huongnd,thanhh,thanhhoa,juliana}@cs.utah.edu
Querying Wikipedia Documents and Relationships Huong Nguyen Thanh Nguyen Hoa Nguyen Juliana Freire School of Computing and SCI Institute, University of Utah {huongnd,thanhh,thanhhoa,juliana}@cs.utah.edu
Keyword Search in Databases
 + Databases and Information Retrieval Integration TIETS42 Keyword Search in Databases Autumn 2016 Kostas Stefanidis kostas.stefanidis@uta.fi http://www.uta.fi/sis/tie/dbir/index.html http://people.uta.fi/~kostas.stefanidis/dbir16/dbir16-main.html
+ Databases and Information Retrieval Integration TIETS42 Keyword Search in Databases Autumn 2016 Kostas Stefanidis kostas.stefanidis@uta.fi http://www.uta.fi/sis/tie/dbir/index.html http://people.uta.fi/~kostas.stefanidis/dbir16/dbir16-main.html
PathStack : A Holistic Path Join Algorithm for Path Query with Not-predicates on XML Data
 PathStack : A Holistic Path Join Algorithm for Path Query with Not-predicates on XML Data Enhua Jiao, Tok Wang Ling, Chee-Yong Chan School of Computing, National University of Singapore {jiaoenhu,lingtw,chancy}@comp.nus.edu.sg
PathStack : A Holistic Path Join Algorithm for Path Query with Not-predicates on XML Data Enhua Jiao, Tok Wang Ling, Chee-Yong Chan School of Computing, National University of Singapore {jiaoenhu,lingtw,chancy}@comp.nus.edu.sg
Roadmap. Roadmap. Ranking Web Pages. PageRank. Roadmap. Random Walks in Ranking Query Results in Semistructured Databases
 Roadmap Random Walks in Ranking Query in Vagelis Hristidis Roadmap Ranking Web Pages Rank according to Relevance of page to query Quality of page Roadmap PageRank Stanford project Lawrence Page, Sergey
Roadmap Random Walks in Ranking Query in Vagelis Hristidis Roadmap Ranking Web Pages Rank according to Relevance of page to query Quality of page Roadmap PageRank Stanford project Lawrence Page, Sergey
Query Segmentation Using Conditional Random Fields
 Query Segmentation Using Conditional Random Fields Xiaohui Yu and Huxia Shi York University Toronto, ON, Canada, M3J 1P3 xhyu@yorku.ca,huxiashi@cse.yorku.ca ABSTRACT A growing mount of available text data
Query Segmentation Using Conditional Random Fields Xiaohui Yu and Huxia Shi York University Toronto, ON, Canada, M3J 1P3 xhyu@yorku.ca,huxiashi@cse.yorku.ca ABSTRACT A growing mount of available text data
Extending Keyword Search to Metadata in Relational Database
 DEWS2008 C6-1 Extending Keyword Search to Metadata in Relational Database Jiajun GU Hiroyuki KITAGAWA Graduate School of Systems and Information Engineering Center for Computational Sciences University
DEWS2008 C6-1 Extending Keyword Search to Metadata in Relational Database Jiajun GU Hiroyuki KITAGAWA Graduate School of Systems and Information Engineering Center for Computational Sciences University
Toward Scalable Keyword Search over Relational Data
 Toward Scalable Keyword Search over Relational Data Akanksha Baid, Ian Rae, Jiexing Li, AnHai Doan, and Jeffrey Naughton University of Wisconsin, Madison {baid, ian, jxli, anhai, naughton}@cs.wisc.edu
Toward Scalable Keyword Search over Relational Data Akanksha Baid, Ian Rae, Jiexing Li, AnHai Doan, and Jeffrey Naughton University of Wisconsin, Madison {baid, ian, jxli, anhai, naughton}@cs.wisc.edu
Implementation of Skyline Sweeping Algorithm
 Implementation of Skyline Sweeping Algorithm BETHINEEDI VEERENDRA M.TECH (CSE) K.I.T.S. DIVILI Mail id:veeru506@gmail.com B.VENKATESWARA REDDY Assistant Professor K.I.T.S. DIVILI Mail id: bvr001@gmail.com
Implementation of Skyline Sweeping Algorithm BETHINEEDI VEERENDRA M.TECH (CSE) K.I.T.S. DIVILI Mail id:veeru506@gmail.com B.VENKATESWARA REDDY Assistant Professor K.I.T.S. DIVILI Mail id: bvr001@gmail.com
Searching SNT in XML Documents Using Reduction Factor
 Searching SNT in XML Documents Using Reduction Factor Mary Posonia A Department of computer science, Sathyabama University, Tamilnadu, Chennai, India maryposonia@sathyabamauniversity.ac.in http://www.sathyabamauniversity.ac.in
Searching SNT in XML Documents Using Reduction Factor Mary Posonia A Department of computer science, Sathyabama University, Tamilnadu, Chennai, India maryposonia@sathyabamauniversity.ac.in http://www.sathyabamauniversity.ac.in
International Journal of Advance Engineering and Research Development. Performance Enhancement of Search System
 Scientific Journal of Impact Factor(SJIF): 3.134 International Journal of Advance Engineering and Research Development Volume 2,Issue 7, July -2015 Performance Enhancement of Search System Ms. Uma P Nalawade
Scientific Journal of Impact Factor(SJIF): 3.134 International Journal of Advance Engineering and Research Development Volume 2,Issue 7, July -2015 Performance Enhancement of Search System Ms. Uma P Nalawade
Jianyong Wang Department of Computer Science and Technology Tsinghua University
 Jianyong Wang Department of Computer Science and Technology Tsinghua University jianyong@tsinghua.edu.cn Joint work with Wei Shen (Tsinghua), Ping Luo (HP), and Min Wang (HP) Outline Introduction to entity
Jianyong Wang Department of Computer Science and Technology Tsinghua University jianyong@tsinghua.edu.cn Joint work with Wei Shen (Tsinghua), Ping Luo (HP), and Min Wang (HP) Outline Introduction to entity
Keywords Machine learning, Pattern matching, Query processing, NLP
 Volume 7, Issue 3, March 2017 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Ratatta: Chatbot
Volume 7, Issue 3, March 2017 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Ratatta: Chatbot
Open Access The Three-dimensional Coding Based on the Cone for XML Under Weaving Multi-documents
 Send Orders for Reprints to reprints@benthamscience.ae 676 The Open Automation and Control Systems Journal, 2014, 6, 676-683 Open Access The Three-dimensional Coding Based on the Cone for XML Under Weaving
Send Orders for Reprints to reprints@benthamscience.ae 676 The Open Automation and Control Systems Journal, 2014, 6, 676-683 Open Access The Three-dimensional Coding Based on the Cone for XML Under Weaving
SPARK: Top-k Keyword Query in Relational Database
 SPARK: Top-k Keyword Query in Relational Database Wei Wang University of New South Wales Australia 20/03/2007 1 Outline Demo & Introduction Ranking Query Evaluation Conclusions 20/03/2007 2 Demo 20/03/2007
SPARK: Top-k Keyword Query in Relational Database Wei Wang University of New South Wales Australia 20/03/2007 1 Outline Demo & Introduction Ranking Query Evaluation Conclusions 20/03/2007 2 Demo 20/03/2007
Keyword Search over RDF Graphs. Elisa Menendez
 Elisa Menendez emenendez@inf.puc-rio.br Summary Motivation Keyword Search over RDF Process Challenges Example QUIOW System Next Steps Motivation Motivation Keyword search is an easy way to retrieve information
Elisa Menendez emenendez@inf.puc-rio.br Summary Motivation Keyword Search over RDF Process Challenges Example QUIOW System Next Steps Motivation Motivation Keyword search is an easy way to retrieve information
ISSN Vol.05,Issue.07, July-2017, Pages:
 WWW.IJITECH.ORG ISSN 2321-8665 Vol.05,Issue.07, July-2017, Pages:1320-1324 Efficient Prediction of Difficult Keyword Queries over Databases KYAMA MAHESH 1, DEEPTHI JANAGAMA 2, N. ANJANEYULU 3 1 PG Scholar,
WWW.IJITECH.ORG ISSN 2321-8665 Vol.05,Issue.07, July-2017, Pages:1320-1324 Efficient Prediction of Difficult Keyword Queries over Databases KYAMA MAHESH 1, DEEPTHI JANAGAMA 2, N. ANJANEYULU 3 1 PG Scholar,
Information Retrieval Using Keyword Search Technique
 Information Retrieval Using Keyword Search Technique Dhananjay A. Gholap, Dr.Gumaste S. V Department of Computer Engineering, Sharadchandra Pawar College of Engineering, Dumbarwadi, Otur, Pune, India ABSTRACT:
Information Retrieval Using Keyword Search Technique Dhananjay A. Gholap, Dr.Gumaste S. V Department of Computer Engineering, Sharadchandra Pawar College of Engineering, Dumbarwadi, Otur, Pune, India ABSTRACT:
An Appropriate Search Algorithm for Finding Grid Resources
 An Appropriate Search Algorithm for Finding Grid Resources Olusegun O. A. 1, Babatunde A. N. 2, Omotehinwa T. O. 3,Aremu D. R. 4, Balogun B. F. 5 1,4 Department of Computer Science University of Ilorin,
An Appropriate Search Algorithm for Finding Grid Resources Olusegun O. A. 1, Babatunde A. N. 2, Omotehinwa T. O. 3,Aremu D. R. 4, Balogun B. F. 5 1,4 Department of Computer Science University of Ilorin,
Presented by: Dimitri Galmanovich. Petros Venetis, Alon Halevy, Jayant Madhavan, Marius Paşca, Warren Shen, Gengxin Miao, Chung Wu
 Presented by: Dimitri Galmanovich Petros Venetis, Alon Halevy, Jayant Madhavan, Marius Paşca, Warren Shen, Gengxin Miao, Chung Wu 1 When looking for Unstructured data 2 Millions of such queries every day
Presented by: Dimitri Galmanovich Petros Venetis, Alon Halevy, Jayant Madhavan, Marius Paşca, Warren Shen, Gengxin Miao, Chung Wu 1 When looking for Unstructured data 2 Millions of such queries every day
A BFS-BASED SIMILAR CONFERENCE RETRIEVAL FRAMEWORK
 A BFS-BASED SIMILAR CONFERENCE RETRIEVAL FRAMEWORK Qing Guo 1, 2 1 Nanyang Technological University, Singapore 2 SAP Innovation Center Network,Singapore ABSTRACT Literature review is part of scientific
A BFS-BASED SIMILAR CONFERENCE RETRIEVAL FRAMEWORK Qing Guo 1, 2 1 Nanyang Technological University, Singapore 2 SAP Innovation Center Network,Singapore ABSTRACT Literature review is part of scientific
Semantic Search Focus: IR on Structured Data
 Semantic Search Focus: IR on Structured Data 8th European Summer School on Information Retrieval Duc Thanh Tran Institute AIFB, KIT, Germany Tran@aifb.uni-karlsruhe.de http://sites.google.com/site/kimducthanh
Semantic Search Focus: IR on Structured Data 8th European Summer School on Information Retrieval Duc Thanh Tran Institute AIFB, KIT, Germany Tran@aifb.uni-karlsruhe.de http://sites.google.com/site/kimducthanh
AutoJoin: Providing Freedom from Specifying Joins
 AutoJoin: Providing Freedom from Specifying Joins Terrence Mason Iowa Database and Emerging Applications Laboratory, Computer Science University of Iowa Email: terrence-mason, lixin-wang, ramon-lawrence@uiowa.uiowa.edu
AutoJoin: Providing Freedom from Specifying Joins Terrence Mason Iowa Database and Emerging Applications Laboratory, Computer Science University of Iowa Email: terrence-mason, lixin-wang, ramon-lawrence@uiowa.uiowa.edu
A System for Query-Specific Document Summarization
 A System for Query-Specific Document Summarization Ramakrishna Varadarajan, Vagelis Hristidis. FLORIDA INTERNATIONAL UNIVERSITY, School of Computing and Information Sciences, Miami. Roadmap Need for query-specific
A System for Query-Specific Document Summarization Ramakrishna Varadarajan, Vagelis Hristidis. FLORIDA INTERNATIONAL UNIVERSITY, School of Computing and Information Sciences, Miami. Roadmap Need for query-specific
Efficient Subgraph Matching by Postponing Cartesian Products
 Efficient Subgraph Matching by Postponing Cartesian Products Computer Science and Engineering Lijun Chang Lijun.Chang@unsw.edu.au The University of New South Wales, Australia Joint work with Fei Bi, Xuemin
Efficient Subgraph Matching by Postponing Cartesian Products Computer Science and Engineering Lijun Chang Lijun.Chang@unsw.edu.au The University of New South Wales, Australia Joint work with Fei Bi, Xuemin
DivQ: Diversification for Keyword Search over Structured Databases
 DivQ: Diversification for Keyword Search over Structured Databases Elena Demidova, Peter Fankhauser, 2, Xuan Zhou 3 and Wolfgang Nejdl L3S Research Center, Hannover, Germany 2 Fraunhofer IPSI, Darmstadt
DivQ: Diversification for Keyword Search over Structured Databases Elena Demidova, Peter Fankhauser, 2, Xuan Zhou 3 and Wolfgang Nejdl L3S Research Center, Hannover, Germany 2 Fraunhofer IPSI, Darmstadt
Relational Keyword Search System
 Relational Keyword Search System Pradeep M. Ghige #1, Prof. Ruhi R. Kabra *2 # Student, Department Of Computer Engineering, University of Pune, GHRCOEM, Ahmednagar, Maharashtra, India. * Asst. Professor,
Relational Keyword Search System Pradeep M. Ghige #1, Prof. Ruhi R. Kabra *2 # Student, Department Of Computer Engineering, University of Pune, GHRCOEM, Ahmednagar, Maharashtra, India. * Asst. Professor,
CSE 100: GRAPH ALGORITHMS
 CSE 100: GRAPH ALGORITHMS 2 Graphs: Example A directed graph V5 V = { V = E = { E Path: 3 Graphs: Definitions A directed graph V5 V6 A graph G = (V,E) consists of a set of vertices V and a set of edges
CSE 100: GRAPH ALGORITHMS 2 Graphs: Example A directed graph V5 V = { V = E = { E Path: 3 Graphs: Definitions A directed graph V5 V6 A graph G = (V,E) consists of a set of vertices V and a set of edges
CS222P Fall 2017, Final Exam
 STUDENT NAME: STUDENT ID: CS222P Fall 2017, Final Exam Principles of Data Management Department of Computer Science, UC Irvine Prof. Chen Li (Max. Points: 100 + 15) Instructions: This exam has seven (7)
STUDENT NAME: STUDENT ID: CS222P Fall 2017, Final Exam Principles of Data Management Department of Computer Science, UC Irvine Prof. Chen Li (Max. Points: 100 + 15) Instructions: This exam has seven (7)
An Overview of various methodologies used in Data set Preparation for Data mining Analysis
 An Overview of various methodologies used in Data set Preparation for Data mining Analysis Arun P Kuttappan 1, P Saranya 2 1 M. E Student, Dept. of Computer Science and Engineering, Gnanamani College of
An Overview of various methodologies used in Data set Preparation for Data mining Analysis Arun P Kuttappan 1, P Saranya 2 1 M. E Student, Dept. of Computer Science and Engineering, Gnanamani College of
Data Structure Advanced
 Data Structure Advanced 1. Is it possible to find a loop in a Linked list? a. Possilbe at O(n) b. Not possible c. Possible at O(n^2) only d. Depends on the position of loop Solution: a. Possible at O(n)
Data Structure Advanced 1. Is it possible to find a loop in a Linked list? a. Possilbe at O(n) b. Not possible c. Possible at O(n^2) only d. Depends on the position of loop Solution: a. Possible at O(n)
Achieving effective keyword ranked search by using TF-IDF and cosine similarity
 Achieving effective keyword ranked search by using TF-IDF and cosine similarity M.PRADEEPA 1, V.MOHANRAJ 2 1PG scholar department of IT, Sona College of Technology,Tamilnadu,India. pradeepa92.murugan@gmail.com
Achieving effective keyword ranked search by using TF-IDF and cosine similarity M.PRADEEPA 1, V.MOHANRAJ 2 1PG scholar department of IT, Sona College of Technology,Tamilnadu,India. pradeepa92.murugan@gmail.com
KEYWORD SEARCH ON LARGE-SCALE DATA: FROM RELATIONAL AND GRAPH DATA TO OLAP INFRASTRUCTURE
 KEYWORD SEARCH ON LARGE-SCALE DATA: FROM RELATIONAL AND GRAPH DATA TO OLAP INFRASTRUCTURE by Bin Zhou M.Sc., Simon Fraser University, 2007 B.Sc., Fudan University, 2005 a Thesis submitted in partial fulfillment
KEYWORD SEARCH ON LARGE-SCALE DATA: FROM RELATIONAL AND GRAPH DATA TO OLAP INFRASTRUCTURE by Bin Zhou M.Sc., Simon Fraser University, 2007 B.Sc., Fudan University, 2005 a Thesis submitted in partial fulfillment
CS24 Week 8 Lecture 1
 CS24 Week 8 Lecture 1 Kyle Dewey Overview Tree terminology Tree traversals Implementation (if time) Terminology Node The most basic component of a tree - the squares Edge The connections between nodes
CS24 Week 8 Lecture 1 Kyle Dewey Overview Tree terminology Tree traversals Implementation (if time) Terminology Node The most basic component of a tree - the squares Edge The connections between nodes
Improving Data Access Performance by Reverse Indexing
 Improving Data Access Performance by Reverse Indexing Mary Posonia #1, V.L.Jyothi *2 # Department of Computer Science, Sathyabama University, Chennai, India # Department of Computer Science, Jeppiaar Engineering
Improving Data Access Performance by Reverse Indexing Mary Posonia #1, V.L.Jyothi *2 # Department of Computer Science, Sathyabama University, Chennai, India # Department of Computer Science, Jeppiaar Engineering
Graph. Vertex. edge. Directed Graph. Undirected Graph
 Module : Graphs Dr. Natarajan Meghanathan Professor of Computer Science Jackson State University Jackson, MS E-mail: natarajan.meghanathan@jsums.edu Graph Graph is a data structure that is a collection
Module : Graphs Dr. Natarajan Meghanathan Professor of Computer Science Jackson State University Jackson, MS E-mail: natarajan.meghanathan@jsums.edu Graph Graph is a data structure that is a collection
Intranet Search. Exploiting Databases for Document Retrieval. Christoph Mangold Universität Stuttgart
 Intranet Search Exploiting Databases for Document Retrieval Christoph Mangold Universität Stuttgart 2 /6 The Big Picture: Assume. there is a glueing problem with product P7 Has this happened before? Is
Intranet Search Exploiting Databases for Document Retrieval Christoph Mangold Universität Stuttgart 2 /6 The Big Picture: Assume. there is a glueing problem with product P7 Has this happened before? Is
B.H.GARDI COLLEGE OF MASTER OF COMPUTER APPLICATION. Ch. 1 :- Introduction Database Management System - 1
 Basic Concepts :- 1. What is Data? Data is a collection of facts from which conclusion may be drawn. In computer science, data is anything in a form suitable for use with a computer. Data is often distinguished
Basic Concepts :- 1. What is Data? Data is a collection of facts from which conclusion may be drawn. In computer science, data is anything in a form suitable for use with a computer. Data is often distinguished
Evaluating find a path reachability queries
 Evaluating find a path reachability queries Panagiotis ouros and Theodore Dalamagas and Spiros Skiadopoulos and Timos Sellis Abstract. Graphs are used for modelling complex problems in many areas, such
Evaluating find a path reachability queries Panagiotis ouros and Theodore Dalamagas and Spiros Skiadopoulos and Timos Sellis Abstract. Graphs are used for modelling complex problems in many areas, such
Mining XML Functional Dependencies through Formal Concept Analysis
 Mining XML Functional Dependencies through Formal Concept Analysis Viorica Varga May 6, 2010 Outline Definitions for XML Functional Dependencies Introduction to FCA FCA tool to detect XML FDs Finding XML
Mining XML Functional Dependencies through Formal Concept Analysis Viorica Varga May 6, 2010 Outline Definitions for XML Functional Dependencies Introduction to FCA FCA tool to detect XML FDs Finding XML
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 10. Graph databases Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Graph Databases Basic
NDBI040 Big Data Management and NoSQL Databases Lecture 10. Graph databases Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Graph Databases Basic
Processing XML Keyword Search by Constructing Effective Structured Queries
 Processing XML Keyword Search by Constructing Effective Structured Queries Jianxin Li, Chengfei Liu, Rui Zhou and Bo Ning Email:{jianxinli, cliu, rzhou, bning}@groupwise.swin.edu.au Swinburne University
Processing XML Keyword Search by Constructing Effective Structured Queries Jianxin Li, Chengfei Liu, Rui Zhou and Bo Ning Email:{jianxinli, cliu, rzhou, bning}@groupwise.swin.edu.au Swinburne University
arxiv: v5 [cs.db] 29 Mar 2016
![arxiv: v5 [cs.db] 29 Mar 2016](/thumbs/85/91315746.jpg "arxiv: v5 [cs.db] 29 Mar 2016") Effective Keyword Search in Graphs arxiv:52.6395v5 [cs.db] 29 Mar 26 n 5 n n 3 n 4 n 6 n 2 (a) n : n 2 : Laurence Fishburne n 3 : Birth Date (info_type) n 4 : The Matrix ABSTRACT n 7 n 8 Mehdi Kargar n,
Effective Keyword Search in Graphs arxiv:52.6395v5 [cs.db] 29 Mar 26 n 5 n n 3 n 4 n 6 n 2 (a) n : n 2 : Laurence Fishburne n 3 : Birth Date (info_type) n 4 : The Matrix ABSTRACT n 7 n 8 Mehdi Kargar n,
Semantic Entity Retrieval using Web Queries over Structured RDF Data
 Semantic Entity Retrieval using Web Queries over Structured RDF Data Jeff Dalton and Sam Huston CS645 Project Final Report May 11, 2010 Abstract We investigate the problem of performing entity retrieval
Semantic Entity Retrieval using Web Queries over Structured RDF Data Jeff Dalton and Sam Huston CS645 Project Final Report May 11, 2010 Abstract We investigate the problem of performing entity retrieval
Keyword Search on Form Results
 Keyword Search on Form Results Aditya Ramesh (Stanford) * S Sudarshan (IIT Bombay) Purva Joshi (IIT Bombay) * Work done at IIT Bombay Keyword Search on Structured Data Allows queries to be specified without
Keyword Search on Form Results Aditya Ramesh (Stanford) * S Sudarshan (IIT Bombay) Purva Joshi (IIT Bombay) * Work done at IIT Bombay Keyword Search on Structured Data Allows queries to be specified without
A FRAMEWORK FOR PROCESSING KEYWORD-BASED QUERIES IN RELATIONAL DATABASES
 A FRAMEWORK FOR PROCESSING KEYWORD-BASED QUERIES IN RELATIONAL DATABASES 1 EYAS EL-QAWASMEH, 1 OSSAMA ABU-EID, 2 ABDALLAH ALASHQUR 1 Jordan University of Science and Technology, Jordan 2 Applied Science
A FRAMEWORK FOR PROCESSING KEYWORD-BASED QUERIES IN RELATIONAL DATABASES 1 EYAS EL-QAWASMEH, 1 OSSAMA ABU-EID, 2 ABDALLAH ALASHQUR 1 Jordan University of Science and Technology, Jordan 2 Applied Science
CS 564 Final Exam Fall 2015 Answers
 CS 564 Final Exam Fall 015 Answers A: STORAGE AND INDEXING [0pts] I. [10pts] For the following questions, clearly circle True or False. 1. The cost of a file scan is essentially the same for a heap file
CS 564 Final Exam Fall 015 Answers A: STORAGE AND INDEXING [0pts] I. [10pts] For the following questions, clearly circle True or False. 1. The cost of a file scan is essentially the same for a heap file
Effective Semantic Search over Huge RDF Data
 Effective Semantic Search over Huge RDF Data 1 Dinesh A. Zende, 2 Chavan Ganesh Baban 1 Assistant Professor, 2 Post Graduate Student Vidya Pratisthan s Kamanayan Bajaj Institute of Engineering & Technology,
Effective Semantic Search over Huge RDF Data 1 Dinesh A. Zende, 2 Chavan Ganesh Baban 1 Assistant Professor, 2 Post Graduate Student Vidya Pratisthan s Kamanayan Bajaj Institute of Engineering & Technology,
Graph Databases. Guilherme Fetter Damasio. University of Ontario Institute of Technology and IBM Centre for Advanced Studies IBM Corporation
 Graph Databases Guilherme Fetter Damasio University of Ontario Institute of Technology and IBM Centre for Advanced Studies Outline Introduction Relational Database Graph Database Our Research 2 Introduction
Graph Databases Guilherme Fetter Damasio University of Ontario Institute of Technology and IBM Centre for Advanced Studies Outline Introduction Relational Database Graph Database Our Research 2 Introduction
Joint Entity Resolution
 Joint Entity Resolution Steven Euijong Whang, Hector Garcia-Molina Computer Science Department, Stanford University 353 Serra Mall, Stanford, CA 94305, USA {swhang, hector}@cs.stanford.edu No Institute
Joint Entity Resolution Steven Euijong Whang, Hector Garcia-Molina Computer Science Department, Stanford University 353 Serra Mall, Stanford, CA 94305, USA {swhang, hector}@cs.stanford.edu No Institute
Extending In-Memory Relational Database Engines with Native Graph Support
 Extending In-Memory Relational Database Engines with Native Graph Support EDBT 18 Mohamed S. Hassan 1 Tatiana Kuznetsova 1 Hyun Chai Jeong 1 Walid G. Aref 1 Mohammad Sadoghi 2 1 Purdue University West
Extending In-Memory Relational Database Engines with Native Graph Support EDBT 18 Mohamed S. Hassan 1 Tatiana Kuznetsova 1 Hyun Chai Jeong 1 Walid G. Aref 1 Mohammad Sadoghi 2 1 Purdue University West
Hierarchical Result Views for Keyword Queries over Relational Databases
 Hierarchical Result Views for Keyword Queries over Relational Databases Shiyuan Wang Department of Computer Science, UC Santa Barbara Santa Barbara, CA, USA sywang@cs.ucsb.edu Oliver Po NEC Laboratories
Hierarchical Result Views for Keyword Queries over Relational Databases Shiyuan Wang Department of Computer Science, UC Santa Barbara Santa Barbara, CA, USA sywang@cs.ucsb.edu Oliver Po NEC Laboratories
Effici ent Type-Ahead Search on Rel ati onal D ata: a TASTIER Approach
 Effici ent Type-Ahead Search on Rel ati onal D ata: a TASTIER Approach Guoliang Li Shengyue Ji Chen Li Jianhua Feng Department of Computer Science and Technology, Tsinghua National Laboratory for Information
Effici ent Type-Ahead Search on Rel ati onal D ata: a TASTIER Approach Guoliang Li Shengyue Ji Chen Li Jianhua Feng Department of Computer Science and Technology, Tsinghua National Laboratory for Information
Database Technology Introduction. Heiko Paulheim
 Database Technology Introduction Outline The Need for Databases Data Models Relational Databases Database Design Storage Manager Query Processing Transaction Manager Introduction to the Relational Model
Database Technology Introduction Outline The Need for Databases Data Models Relational Databases Database Design Storage Manager Query Processing Transaction Manager Introduction to the Relational Model
Analysis of Algorithms
 Algorithm An algorithm is a procedure or formula for solving a problem, based on conducting a sequence of specified actions. A computer program can be viewed as an elaborate algorithm. In mathematics and
Algorithm An algorithm is a procedure or formula for solving a problem, based on conducting a sequence of specified actions. A computer program can be viewed as an elaborate algorithm. In mathematics and
An Improved Apriori Algorithm for Association Rules
 Research article An Improved Apriori Algorithm for Association Rules Hassan M. Najadat 1, Mohammed Al-Maolegi 2, Bassam Arkok 3 Computer Science, Jordan University of Science and Technology, Irbid, Jordan
Research article An Improved Apriori Algorithm for Association Rules Hassan M. Najadat 1, Mohammed Al-Maolegi 2, Bassam Arkok 3 Computer Science, Jordan University of Science and Technology, Irbid, Jordan
The Relational Data Model and Relational Database Constraints
 CHAPTER 5 The Relational Data Model and Relational Database Constraints Copyright 2017 Ramez Elmasri and Shamkant B. Navathe Slide 1-2 Chapter Outline Relational Model Concepts Relational Model Constraints
CHAPTER 5 The Relational Data Model and Relational Database Constraints Copyright 2017 Ramez Elmasri and Shamkant B. Navathe Slide 1-2 Chapter Outline Relational Model Concepts Relational Model Constraints
Holistic and Compact Selectivity Estimation for Hybrid Queries over RDF Graphs
 Holistic and Compact Selectivity Estimation for Hybrid Queries over RDF Graphs Authors: Andreas Wagner, Veli Bicer, Thanh Tran, and Rudi Studer Presenter: Freddy Lecue IBM Research Ireland 2014 International
Holistic and Compact Selectivity Estimation for Hybrid Queries over RDF Graphs Authors: Andreas Wagner, Veli Bicer, Thanh Tran, and Rudi Studer Presenter: Freddy Lecue IBM Research Ireland 2014 International
Ontology Based Prediction of Difficult Keyword Queries
 Ontology Based Prediction of Difficult Keyword Queries Lubna.C*, Kasim K Pursuing M.Tech (CSE)*, Associate Professor (CSE) MEA Engineering College, Perinthalmanna Kerala, India lubna9990@gmail.com, kasim_mlp@gmail.com
Ontology Based Prediction of Difficult Keyword Queries Lubna.C*, Kasim K Pursuing M.Tech (CSE)*, Associate Professor (CSE) MEA Engineering College, Perinthalmanna Kerala, India lubna9990@gmail.com, kasim_mlp@gmail.com
Efficient Keyword Search over Relational Data Streams
 DEIM Forum 2016 A3-4 Abstract Efficient Keyword Search over Relational Data Streams Savong BOU, Toshiyuki AMAGASA, and Hiroyuki KITAGAWA Graduate School of Systems and Information Engineering, University
DEIM Forum 2016 A3-4 Abstract Efficient Keyword Search over Relational Data Streams Savong BOU, Toshiyuki AMAGASA, and Hiroyuki KITAGAWA Graduate School of Systems and Information Engineering, University
Advanced Data Management Technologies
 ADMT 2017/18 Unit 13 J. Gamper 1/42 Advanced Data Management Technologies Unit 13 DW Pre-aggregation and View Maintenance J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements:
ADMT 2017/18 Unit 13 J. Gamper 1/42 Advanced Data Management Technologies Unit 13 DW Pre-aggregation and View Maintenance J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements:
CSE373: Data Structures & Algorithms Lecture 28: Final review and class wrap-up. Nicki Dell Spring 2014
 CSE373: Data Structures & Algorithms Lecture 28: Final review and class wrap-up Nicki Dell Spring 2014 Final Exam As also indicated on the web page: Next Tuesday, 2:30-4:20 in this room Cumulative but
CSE373: Data Structures & Algorithms Lecture 28: Final review and class wrap-up Nicki Dell Spring 2014 Final Exam As also indicated on the web page: Next Tuesday, 2:30-4:20 in this room Cumulative but
Estimating the Quality of Databases
 Estimating the Quality of Databases Ami Motro Igor Rakov George Mason University May 1998 1 Outline: 1. Introduction 2. Simple quality estimation 3. Refined quality estimation 4. Computing the quality
Estimating the Quality of Databases Ami Motro Igor Rakov George Mason University May 1998 1 Outline: 1. Introduction 2. Simple quality estimation 3. Refined quality estimation 4. Computing the quality
PA3 Design Specification
 PA3 Teaching Data Structure 1. System Description The Data Structure Web application is written in JavaScript and HTML5. It has been divided into 9 pages: Singly linked page, Stack page, Postfix expression
PA3 Teaching Data Structure 1. System Description The Data Structure Web application is written in JavaScript and HTML5. It has been divided into 9 pages: Singly linked page, Stack page, Postfix expression
Evaluation of Keyword Search System with Ranking
 Evaluation of Keyword Search System with Ranking P.Saranya, Dr.S.Babu UG Scholar, Department of CSE, Final Year, IFET College of Engineering, Villupuram, Tamil nadu, India Associate Professor, Department
Evaluation of Keyword Search System with Ranking P.Saranya, Dr.S.Babu UG Scholar, Department of CSE, Final Year, IFET College of Engineering, Villupuram, Tamil nadu, India Associate Professor, Department
Algorithm Design and Analysis
 Algorithm Design and Analysis LECTURE 3 Data Structures Graphs Traversals Strongly connected components Sofya Raskhodnikova L3.1 Measuring Running Time Focus on scalability: parameterize the running time
Algorithm Design and Analysis LECTURE 3 Data Structures Graphs Traversals Strongly connected components Sofya Raskhodnikova L3.1 Measuring Running Time Focus on scalability: parameterize the running time
Web Semantics: Science, Services and Agents on the World Wide Web
 Web Semantics: Science, Services and Agents on the World Wide Web 7 (2009) 189 203 Contents lists available at ScienceDirect Web Semantics: Science, Services and Agents on the World Wide Web journal homepage:
Web Semantics: Science, Services and Agents on the World Wide Web 7 (2009) 189 203 Contents lists available at ScienceDirect Web Semantics: Science, Services and Agents on the World Wide Web journal homepage:
Evaluating XPath Queries
 Chapter 8 Evaluating XPath Queries Peter Wood (BBK) XML Data Management 201 / 353 Introduction When XML documents are small and can fit in memory, evaluating XPath expressions can be done efficiently But
Chapter 8 Evaluating XPath Queries Peter Wood (BBK) XML Data Management 201 / 353 Introduction When XML documents are small and can fit in memory, evaluating XPath expressions can be done efficiently But
Accelerating XML Structural Matching Using Suffix Bitmaps
 Accelerating XML Structural Matching Using Suffix Bitmaps Feng Shao, Gang Chen, and Jinxiang Dong Dept. of Computer Science, Zhejiang University, Hangzhou, P.R. China microf_shao@msn.com, cg@zju.edu.cn,
Accelerating XML Structural Matching Using Suffix Bitmaps Feng Shao, Gang Chen, and Jinxiang Dong Dept. of Computer Science, Zhejiang University, Hangzhou, P.R. China microf_shao@msn.com, cg@zju.edu.cn,
LECTURE 17 GRAPH TRAVERSALS
 DATA STRUCTURES AND ALGORITHMS LECTURE 17 GRAPH TRAVERSALS IMRAN IHSAN ASSISTANT PROFESSOR AIR UNIVERSITY, ISLAMABAD STRATEGIES Traversals of graphs are also called searches We can use either breadth-first
DATA STRUCTURES AND ALGORITHMS LECTURE 17 GRAPH TRAVERSALS IMRAN IHSAN ASSISTANT PROFESSOR AIR UNIVERSITY, ISLAMABAD STRATEGIES Traversals of graphs are also called searches We can use either breadth-first
Department of Computer Engineering, Sharadchandra Pawar College of Engineering, Dumbarwadi, Otur, Pune, Maharashtra, India
 Volume 5, Issue 6, June 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Information Retrieval
Volume 5, Issue 6, June 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Information Retrieval
Estimating Result Size and Execution Times for Graph Queries
 Estimating Result Size and Execution Times for Graph Queries Silke Trißl 1 and Ulf Leser 1 Humboldt-Universität zu Berlin, Institut für Informatik, Unter den Linden 6, 10099 Berlin, Germany {trissl,leser}@informatik.hu-berlin.de
Estimating Result Size and Execution Times for Graph Queries Silke Trißl 1 and Ulf Leser 1 Humboldt-Universität zu Berlin, Institut für Informatik, Unter den Linden 6, 10099 Berlin, Germany {trissl,leser}@informatik.hu-berlin.de
Efficient Prediction of Difficult Keyword Queries over Databases
 Efficient Prediction of Difficult Keyword Queries over Databases Gurramkonda Lakshmi Priyanka P.G. Scholar (M. Tech), Department of CSE, Srinivasa Institute of Technology & Sciences, Ukkayapalli, Kadapa,
Efficient Prediction of Difficult Keyword Queries over Databases Gurramkonda Lakshmi Priyanka P.G. Scholar (M. Tech), Department of CSE, Srinivasa Institute of Technology & Sciences, Ukkayapalli, Kadapa,
DbSurfer: A Search and Navigation Tool for Relational Databases
 DbSurfer: A Search and Navigation Tool for Relational Databases Richard Wheeldon, Mark Levene and Kevin Keenoy School of Computer Science and Information Systems Birkbeck University of London Malet St,
DbSurfer: A Search and Navigation Tool for Relational Databases Richard Wheeldon, Mark Levene and Kevin Keenoy School of Computer Science and Information Systems Birkbeck University of London Malet St,
Department of Computer Science and Technology
 UNIT : Stack & Queue Short Questions 1 1 1 1 1 1 1 1 20) 2 What is the difference between Data and Information? Define Data, Information, and Data Structure. List the primitive data structure. List the
UNIT : Stack & Queue Short Questions 1 1 1 1 1 1 1 1 20) 2 What is the difference between Data and Information? Define Data, Information, and Data Structure. List the primitive data structure. List the
Query Relaxation Using Malleable Schemas. Dipl.-Inf.(FH) Michael Knoppik
 Michael Knoppik") Query Relaxation Using Malleable Schemas Dipl.-Inf.(FH) Michael Knoppik Table Of Contents 1.Introduction 2.Limitations 3.Query Relaxation 4.Implementation Issues 5.Experiments 6.Conclusion Slide 2 1.Introduction
Query Relaxation Using Malleable Schemas Dipl.-Inf.(FH) Michael Knoppik Table Of Contents 1.Introduction 2.Limitations 3.Query Relaxation 4.Implementation Issues 5.Experiments 6.Conclusion Slide 2 1.Introduction
Ranked Keyword Query on Semantic Web Data
 2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery (FSKD 2010) Ranked Keyword Query on Semantic Web Data Huiying Li School of Computer Science and Engineering Southeast University
2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery (FSKD 2010) Ranked Keyword Query on Semantic Web Data Huiying Li School of Computer Science and Engineering Southeast University
CS210 (161) with Dr. Basit Qureshi Final Exam Weight 40%
 with Dr. Basit Qureshi Final Exam Weight 40%") CS210 (161) with Dr. Basit Qureshi Final Exam Weight 40% Name ID Directions: There are 9 questions in this exam. To earn a possible full score, you must solve all questions. Time allowed: 180 minutes Closed
CS210 (161) with Dr. Basit Qureshi Final Exam Weight 40% Name ID Directions: There are 9 questions in this exam. To earn a possible full score, you must solve all questions. Time allowed: 180 minutes Closed
Semantic Optimization of Preference Queries
 Semantic Optimization of Preference Queries Jan Chomicki University at Buffalo http://www.cse.buffalo.edu/ chomicki 1 Querying with Preferences Find the best answers to a query, instead of all the answers.
Semantic Optimization of Preference Queries Jan Chomicki University at Buffalo http://www.cse.buffalo.edu/ chomicki 1 Querying with Preferences Find the best answers to a query, instead of all the answers.
A7-R3: INTRODUCTION TO DATABASE MANAGEMENT SYSTEMS
 A7-R3: INTRODUCTION TO DATABASE MANAGEMENT SYSTEMS NOTE: 1. There are TWO PARTS in this Module/Paper. PART ONE contains FOUR questions and PART TWO contains FIVE questions. 2. PART ONE is to be answered
A7-R3: INTRODUCTION TO DATABASE MANAGEMENT SYSTEMS NOTE: 1. There are TWO PARTS in this Module/Paper. PART ONE contains FOUR questions and PART TWO contains FIVE questions. 2. PART ONE is to be answered
Topics. Trees Vojislav Kecman. Which graphs are trees? Terminology. Terminology Trees as Models Some Tree Theorems Applications of Trees CMSC 302
 Topics VCU, Department of Computer Science CMSC 302 Trees Vojislav Kecman Terminology Trees as Models Some Tree Theorems Applications of Trees Binary Search Tree Decision Tree Tree Traversal Spanning Trees
Topics VCU, Department of Computer Science CMSC 302 Trees Vojislav Kecman Terminology Trees as Models Some Tree Theorems Applications of Trees Binary Search Tree Decision Tree Tree Traversal Spanning Trees
A Graph Method for Keyword-based Selection of the top-k Databases
 This is the Pre-Published Version A Graph Method for Keyword-based Selection of the top-k Databases Quang Hieu Vu 1, Beng Chin Ooi 1, Dimitris Papadias 2, Anthony K. H. Tung 1 hieuvq@nus.edu.sg, ooibc@comp.nus.edu.sg,
This is the Pre-Published Version A Graph Method for Keyword-based Selection of the top-k Databases Quang Hieu Vu 1, Beng Chin Ooi 1, Dimitris Papadias 2, Anthony K. H. Tung 1 hieuvq@nus.edu.sg, ooibc@comp.nus.edu.sg,
KNOWLEDGE GRAPHS. Lecture 1: Introduction and Motivation. TU Dresden, 16th Oct Markus Krötzsch Knowledge-Based Systems
 KNOWLEDGE GRAPHS Lecture 1: Introduction and Motivation Markus Krötzsch Knowledge-Based Systems TU Dresden, 16th Oct 2018 Introduction and Organisation Markus Krötzsch, 16th Oct 2018 Knowledge Graphs slide
KNOWLEDGE GRAPHS Lecture 1: Introduction and Motivation Markus Krötzsch Knowledge-Based Systems TU Dresden, 16th Oct 2018 Introduction and Organisation Markus Krötzsch, 16th Oct 2018 Knowledge Graphs slide
CSE 190D Spring 2017 Final Exam Answers
 CSE 190D Spring 2017 Final Exam Answers Q 1. [20pts] For the following questions, clearly circle True or False. 1. The hash join algorithm always has fewer page I/Os compared to the block nested loop join
CSE 190D Spring 2017 Final Exam Answers Q 1. [20pts] For the following questions, clearly circle True or False. 1. The hash join algorithm always has fewer page I/Os compared to the block nested loop join
Addressed Issue. P2P What are we looking at? What is Peer-to-Peer? What can databases do for P2P? What can databases do for P2P?
 Peer-to-Peer Data Management - Part 1- Alex Coman acoman@cs.ualberta.ca Addressed Issue [1] Placement and retrieval of data [2] Server architectures for hybrid P2P [3] Improve search in pure P2P systems
Peer-to-Peer Data Management - Part 1- Alex Coman acoman@cs.ualberta.ca Addressed Issue [1] Placement and retrieval of data [2] Server architectures for hybrid P2P [3] Improve search in pure P2P systems