TIE Data-intensive Programming. Dr. Timo Aaltonen Department of Pervasive Computing
|
|
|
- Sheena Morgan
- 6 years ago
- Views:
Transcription
1 TIE Data-intensive Programming Dr. Timo Aaltonen Department of Pervasive Computing
2 Data-Intensive Programming Lecturer: Timo Aaltonen Assistants Adnan Mushtaq MSc Antti Luoto MSc Antti Kallonen
3 Lecturer University Lecturer Doctoral degree in Software Engineering, TUT, Software Engineering, 2005 Work history Various positions, TUT, Principal Researcher, System Software Engineering, Nokia Research Center, University lecturer, TUT
4 Working at the course Lectures on Fridays Weekly exercises beginning from the week #2 Course work announced next Friday Communication Exam
5 Weekly Exercises Linux class TC217 In the beginning of the course hands-on training In the end of the course reception for problems with the course work Enrolment is open Not compulsory, no credit points Two more instances will be added
6 Course Work Using Hadoop tools and framework to solve typical Big Data problem (in Java) Groups of three Hardware Your own laptop with self-installed Hadoop Your own laptop with VirtualBox 5.1 and Ubuntu VM A TUT virtual machine
7 Exam Electronic exam after the course Tests rather understanding than exact syntax Use pseudocode to write a MapReduce program which General questions on Hadoop and related technologies
8 Today Big data Data Science Hadoop HDFS Apache Flume
9 1: Big Data World is drowning in data click stream data is collected by web servers NYSE generates 1 TB trade data every day MTC collects 5000 attributes for each call Smart marketers collect purchasing habits More data usually beats better algorithms
10 Three Vs of Big Data Volume: amount of data Transaction data stored through the years, unstructured data streaming in from social media, increasing amounts of sensor and machine-tomachine data Velocity: speed of data in and out streaming data from RFID, sensors, Variety: range of data types and sources structured, unstructured
11 Big Data Variability Data flows can be highly inconsistent with periodic peaks Complexity Data comes from multiple sources. linking, matching, cleansing and transforming data across systems is a complex task
12 Data Science Definition: Data science is an activity to extracts insights from messy data Facebook analyzes location data to identify global migration patterns to find out the fanbases to different sport teams A retailer might track purchases both online and in-store to targeted marketing

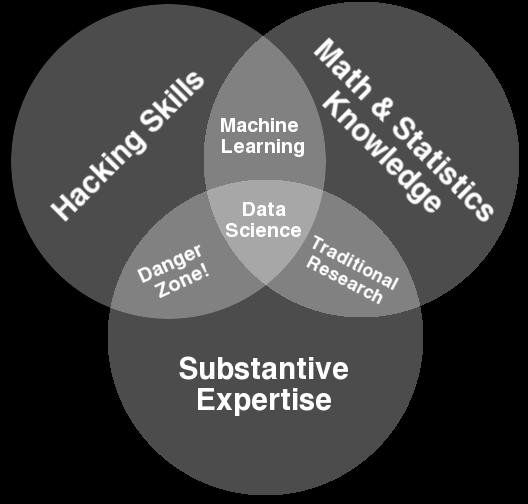
13 Data Science
14 New Challenges Compute-intensiveness raw computing power Challenges of data intensiveness amount of data complexity of data speed in which data is changing
15 Data Storage Analysis Hard drive from 1990 store 1,370 MB speed 4.4 MB/s Hard drive 2010s store 1 TB speed 100 MB/s
16 Scalability Grows without requiring developers to rearchitect their algorithms/application Horizontal scaling Vertical scaling
17 Parallel Approach Reading from multiple disks in parallel 100 drives having 1/100 of the data => 1/100 reading time Problem: Hardware failures replication Problem: Most analysis tasks need to be able to combine data in some way MapReduce Hadoop
18 2: Apache Hadoop Hadoop is a frameworks of tools libraries and methodologies Operates on large unstructured datasets Open source (Apache License) Simple programming model Scalable
19 Hadoop A scalable fault-tolerant distributed system for data storage and processing (open source under the Apache license) Core Hadoop has two main systems: Hadoop Distributed File System: self-healing highbandwidth clustered storage MapReduce: distributed fault-tolerant resource management and scheduling coupled with a scalable data programming abstraction
20 Hadoop Administrators Installation Monitor/Manage Systems Tune Systems End Users Design MapReduce Applications Import and export data Work with various Hadoop Tools
21 Hadoop Developed by Doug Cutting and Michael J. Cafarella Based on Google MapReduce technology Designed to handle large amounts of data and be robust Donated to Apache Foundation in 2006 by Yahoo
22 Hadoop Design Principles Moving computation is cheaper than moving data Hardware will fail Hide execution details from the user Use streaming data access Use simple file system coherency model Hadoop is not a replacement for SQL, always fast and efficient quick ad-hoc querying
23 Hadoop MapReduce MapReduce (MR) is the original programming model for Hadoop Collocate data with compute node data access is fast since its local (data locality) Network bandwidth is the most precious resource in the data center MR implementations explicit model the network topology
24 Hadoop MapReduce MR operates at a high level of abstraction programmer thinks in terms of functions of key and value pairs MR is a shared-nothing architecture tasks do not depend on each other failed tasks can be rescheduled by the system MR was introduced by Google used for producing search indexes applicable to many other problems too
25 Hadoop Components Hadoop Common A set of components and interfaces for distributed file systems and general I/O Hadoop Distributed Filesystem (HDFS) Hadoop YARN a resource-management platform, scheduling Hadoop MapReduce Distributed programming model and execution environment

26 Hadoop Stack Transition
27 Hadoop Ecosystem HBase a scalable data warehouse with support for large tables Hive a data warehouse infrastructure that provides data summarization and ad hoc querying Pig a high-level data-flow language and execution framework for parallel computation Spark a fast and general compute engine for Hadoop data. Wide range of applications ETL, Machine Learning, stream processing, and graph analytics
28 Flexibility: Complex Data Processing 1. Java MapReduce: Most flexibility and performance, but tedious development cycle (the assembly language of Hadoop). 2. Streaming MapReduce (aka Pipes): Allows you to develop in any programming language of your choice, but slightly lower performance and less flexibility than native Java MapReduce. 3. Crunch: A library for multi-stage MapReduce pipelines in Java (modeled After Google s FlumeJava) 4. Pig Latin: A high-level language out of Yahoo, suitable for batch data flow workloads. 5. Hive: A SQL interpreter out of Facebook, also includes a metastore mapping files to their schemas and associated SerDes. 6. Oozie: A workflow engine that enables creating a workflow of jobs composed of any of the above.
29 3: Hadoop Distributed File System Hadoop comes with distributed file system called HDFS (Hadoop Distributed File System) Based on Google s GFS (Google File System) HDFS provides redundant storage for massive amounts of data using commodity hardware Data in HDFS is distributed across all data nodes Efficient for MapReduce processing
30 HDFS Design File system on commodity hardware Survives even with high failure rates of the components Supports lots of large files File size hundreds GB or several TB Main design principles Write once, read many times Rather streaming reads, than frequent random access High throughput is more important than low latency
31 HDFS Architecture HDFS operates on top of existing file system Files are stored as blocks (default size 128 MB, different from file system blocks) File reliability is based on block-based replication Each block of a file is typically replicated across several DataNodes (default replication is 3) NameNode stores metadata, manages replication and provides access to files No data caching (because of large datasets), but direct reading/streaming from DataNode to client
32 HDFS Architecture NameNode stores HDFS metadata filenames, locations of blocks, file attributes Metadata is kept in RAM for fast lookups The number of files in HDFS is limited by the amount of available RAM in the NameNode HDFS NameNode federation can help in RAM issues: several NameNodes, each of which manages a portion of the file system namespace
33 HDFS Architecture DataNode stores file contents as blocks Different blocks of the same file are stored on different DataNodes Same block is typically replicated across several DataNodes for redundancy Periodically sends report of all existing blocks to the NameNode DataNodes exchange heartbeats with the NameNode
34 HDFS Architecture Built-in protection against DataNode failure If NameNode does not receive any heartbeat from a DataNode within certain time period, DataNode is assumed to be lost In case of failing DataNode, block replication is actively maintained NameNode determines which blocks were on the lost DataNode The NameNode finds other copies of these lost blocks and replicates them to other nodes
35 HDFS HDFS Federation Multiple Namenode servers Multiple namespaces High Availability redundant NameNodes Heterogeneous Storage and Archival Storage ARCHIVE, DISK, SSD, RAM_DISK
36 High-Availability (HA) Issues: NameNode Failure NameNode failure corresponds to losing all files on a file system % sudo rm --dont-do-this / For recovery, Hadoop provides two options Backup files that make up the persistent state of the file system Secondary NameNode Also some more advanced techniques exist
37 HA Issues: the secondary NameNode The secondary NameNode is not mirrored NameNode Required memory-intensive administrative functions NameNode keeps metadata in memory and writes changes to an edit log The secondary NameNode periodically combines previous namespace image and the edit log into a new namespace image, preventing the log to become too large Keeps a copy of the merged namespace image, which can be used in the event of the NameNode failure
38 Network Topology HDFS is aware how close two nodes are in the network From closer to further 0: Processes in the same node 2: Different nodes in the same rack 4: Nodes in different racks in the same data center 6: Nodes in different data centers

39 Network Topology
40 File Block Placement Clients always read from the closest node Default placement strategy One replica in the same local node as client Second replica in a different rack Third replica in different, randomly selected, node in the same rack as the second replica Additional (3+) replicas are random
41 Balancing Hadoop works best when blocks are evenly spread out Support for DataNodes of different size In optimal case the disk usage percentage in all DataNodes approximately the same level Hadoop provides balancer daemon Re-distributes blocks Should be run when new DataNodes are added
42 Running Hadoop Three configurations standalone pseudo-distributed fully-distributed
43 Configuring HDFS Variable HADOOP_CONF_DIR defines the directory for the Hadoop configuration files core-site.xml <configuration> <property> <name>fs.defaultfs</name> <value>hdfs://localhost:9001</value> </property> </configuration>
44 hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/nn/hadoop/namenode</value> </property> <property> <name>dfs.datanode.name.dir</name> <value>file:///home/nn/hadoop/datanode</value> </property> </configuration>
45 Accessing Data Data can be accessed using various methods Java API C API Command line / POSIX (FUSE mount) Command line / HDFS client: Demo HTTP Various tools
46 HDFS URI All HDFS (CLI) commands take path URIs as arguments URI example hdfs://localhost:9000/user/hduser/log-data/file1.log The scheme and authority are optional /user/hduser/log-data/file1.log Home directory log-data/file1.log
47 RDBMS vs HDFS Schema-on-Write (RDBMS) Schema must be created before any data can be loaded An explicit load operation which transforms data to DB internal structure New columns must be added explicitly before new data for such columns can be loaded into the DB Schema-on-Read (HDFS) Data is simply copied to the file store, no transformation is needed A SerDe (Serializer /Deserlizer) is applied during read time to extract the required columns (late binding) New data can start flowing anytime and will appear retroactively once the SerDe is updated to parse it
48 Conclusions Pros Support for very large files Designed for streaming data Commodity hardware Cons Not designed for low-latency data access Architecture does not support lots of small files No support for multiple writers / arbitrary file modifications (Writes always at the end of the file)

49 Reading data
50 Flume
51 4: Data Modeling HDFS is a Schema-on-read system allows storing all of your raw data Still following must be considered Data storage formats Multitenancy Schema design Metadata management
52 Data Storage Options No standard data storage format Hadoop allows storing of data in any format Major considerations for data storage include File format (e.g. plain text, SequenceFile or more complex but more functionally rich options, such as Avro and Parquet) Compression (splittability) Data storage system (HDFS, HBase, Hive, Impala)
53 File Formats: Text File Common use case: web logs and server logs comes in many formats Organization of the files in the filesystem Text files consume space -> compression Overhead for conversion ( 123 ->123) Structured text data XML and JSON present challenges to HADOOP hard to split Dedicated libraries exist
54 File Formats: Binary Data Hadoop can be used to process binary files e.g. images Container format is preferred e.g. SequenceFile If the splittable unit of binary data is larger than 64 MB, you may consider putting the data in its own file, without using a container format
55 Hadoop File Types Hadoop-specific file formats are specifically created to work well with MapReduce file-based data structures such as sequence files, serialization formats like Avro, and columnar formats such as RCFile and Parquet Splittable compression These formats support common compression formats and are also splittable Agnostic compression codec is stored in the header metadata of the file format - > the file can be compressed with any compression codec, without readers having to know the codec
56 File-Based Data Structures SequenceFile format is one of the most commonly used file-based formats in Hadoop other formats: MapFiles, SetFiles, ArrayFiles, BloomMapFiles, stores data as binary key-value pairs three formats available for records: uncompressed, record-compressed, blockcompressed

57 Sequence File Header metadata compression codec, key and value class names, userdefined metadata, randomly generated sync marker Often used a container for smaller files
58 Compression Also for speeding MapReduce Not only for reducing storage requirements Compression must be splittable MapReduce framework splits data for input to multiple tasks
59 HDFS Schema Design Hadoop is often a data hub for the entire organization data is shared by many departments and teams Carefully structured and organized repository has several benefits standard directory structure makes it easier to share data between teams allows for enforcing access rights and quota conventions regarding e.g. staging data lead less errors code reuse Hadoop tools make assumptions of the data placement
60 Recommended Locations of Files /user/<username> data, JARs, and config files of a specific user /etl data in all phases of an ETL workflow /etl/<group>/<application>/<process>/{input, processing, output, bad} /tmp temporary data
61 Recommended Locations of Files /data datasets shared across organization data is written by automated ETL processes read-only for users subdirectories for each data set /app JARs, Oozie workflow definitions, Hive HQL files, /app/<group>/<application>/<version>/<artifact directory>/<artifact>
62 Recommended Locations of Files /metadata the metadata required by some tools
63 Partitioning HDFS has no indexes pro: fast to ingest data con: might lead to full table scan (FTC), even when only a portion of data is needed Solution: break data set into smaller subsets (partitions) a HDFS subdirectory for each partition allows queries to read only the specific partitions
64 Partitioning: Example Assume data sets for all orders for various pharmacies Without partitioning checking order history for just one physician over the past three months leads to full table scan medication_orders/date= /{order1.csv, order2.csv} only 90 directories must be scanned
65 5: Data Movement File system client for simple usage Common data sources for Hadoop include traditional data management systems such as relational databases and mainframes logs, machine-generated data, and other forms of event data files being imported from existing enterprise data storage systems
66 Data Movement: Considerations Timeliness of data ingestion and accessibility What are the requirements around how often data needs to be ingested? How soon does data need to be available to downstream processing? Incremental updates How will new data be added? Does it need to be appended to existing data? Or overwrite existing data?
67 Data Movement: Considerations Data access and processing Will the data be used in processing? If so, will it be used in batch processing jobs? Or is random access to the data required? Source system and data structure Where is the data coming from? A relational database? Logs? Is it structured, semistructured, or unstructured data?
68 Data Movement: Considerations Partitioning and splitting of data How should data be partitioned after ingest? Does the data need to be ingested into multiple target systems (e.g., HDFS and HBase)? Storage format What format will the data be stored in? Data transformation Does the data need to be transformed in flight?
69 Timeliness of Data Ingestion Time lag from when data is available for ingestion to when it s accessible in Hadoop Classifications ingestion requirements: Macro batch anything over 15 minutes to hours, or even a daily job. Micro batch fired off every 2 minutes or so, but no more than 15 minutes in total. Near-Real-Time Decision Support immediately actionable by the recipient of the information delivered in less than 2 minutes but greater than 2 seconds. Near-Real-Time Event Processing under 2 seconds, and can be as fast as a 100-millisecond range. Real Time anything under 100 milliseconds.
70 Incremental Updates Data is either appended to an existing data set or it is modified HDFS works fine for append only implementations. The downside to HDFS is the inability to do appends or random writes to files after they re created HDFS is optimized for large files If the requirements call for a two-minute append process that ends up producing lots of small files, then a periodic process to combine smaller files will be required to get the benefits from larger files
71 Original Source System and Data Original file type Structure any format: delimited, XML, JSON, Avro, fixed length, variable length, copybooks, Hadoop can accept any file format not all formats are optimal for particular use cases not all file formats can work with all tools in the Hadoop ecosystem, example: variable-length files
72 Compression Pro transferring a compressed file over the network requires less I/O and network bandwidth Con most compression codecs applied outside of Hadoop are not splittable (e.g., Gzip)
73 Misc RDBMS Tool: Sqoop Streaming Data Twitter feeds, a Java Message Service (JMS) queue, events firing from a web application server Tools: Flume or Kafka Logfiles an anti-pattern is to read the logfiles from disk as they are written because this is almost impossible to implement without losing data The correct way of ingesting logfiles is to stream the logs directly to a tool like Flume or Kafka, which will write directly to Hadoop instead
74 Transformations modifications on incoming data, distributing the data into partitions or buckets, sending the data to more than one store or location Transformation: XML or JSON is converted to delimited data Partitioning: incoming data is stock trade data and partitioning by ticker is required Splitting: The data needs to land in HDFS and HBasefor different access patterns.
75 Data Ingestion Options file transfers Tools like Flume, Sqoop, and Kafka
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Introduction to Big-Data
 Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
The New World of Big Data is The Phenomenon of Our Time
 Compliments of PREVIEW EDITION Hadoop Application Architectures DESIGNING REAL WORLD BIG DATA APPLICATIONS Mark Grover, Ted Malaska, Jonathan Seidman & Gwen Shapira The New World of Big Data is The Phenomenon
Compliments of PREVIEW EDITION Hadoop Application Architectures DESIGNING REAL WORLD BIG DATA APPLICATIONS Mark Grover, Ted Malaska, Jonathan Seidman & Gwen Shapira The New World of Big Data is The Phenomenon
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Hadoop & Big Data Analytics Complete Practical & Real-time Training
 An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
MapR Enterprise Hadoop
 2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Configuring and Deploying Hadoop Cluster Deployment Templates
 Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation)
 (Development, Administration & REAL TIME Projects Implementation)") HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
The Evolving Apache Hadoop Ecosystem What it means for Storage Industry
 The Evolving Apache Hadoop Ecosystem What it means for Storage Industry Sanjay Radia Architect/Founder, Hortonworks Inc. All Rights Reserved Page 1 Outline Hadoop (HDFS) and Storage Data platform drivers
The Evolving Apache Hadoop Ecosystem What it means for Storage Industry Sanjay Radia Architect/Founder, Hortonworks Inc. All Rights Reserved Page 1 Outline Hadoop (HDFS) and Storage Data platform drivers
Flash Storage Complementing a Data Lake for Real-Time Insight
 Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler
 The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
April Copyright 2013 Cloudera Inc. All rights reserved.
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop. Introduction to BIGDATA and HADOOP
 Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Chase Wu New Jersey Institute of Technology
 CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics
 Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics Cy Erbay Senior Director Striim Executive Summary Striim is Uniquely Qualified to Solve the Challenges of Real-Time
Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics Cy Erbay Senior Director Striim Executive Summary Striim is Uniquely Qualified to Solve the Challenges of Real-Time
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Oracle GoldenGate for Big Data
 Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Cmprssd Intrduction To
 Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor
Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
A Survey on Big Data
 A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
Expert Lecture plan proposal Hadoop& itsapplication
 Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
docs.hortonworks.com
 docs.hortonworks.com : Getting Started Guide Copyright 2012, 2014 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open source platform for storing,
docs.hortonworks.com : Getting Started Guide Copyright 2012, 2014 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open source platform for storing,
Hadoop: The Definitive Guide
 THIRD EDITION Hadoop: The Definitive Guide Tom White Q'REILLY Beijing Cambridge Farnham Köln Sebastopol Tokyo labte of Contents Foreword Preface xv xvii 1. Meet Hadoop 1 Daw! 1 Data Storage and Analysis
THIRD EDITION Hadoop: The Definitive Guide Tom White Q'REILLY Beijing Cambridge Farnham Köln Sebastopol Tokyo labte of Contents Foreword Preface xv xvii 1. Meet Hadoop 1 Daw! 1 Data Storage and Analysis
Hadoop Online Training
 Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Nowcasting. D B M G Data Base and Data Mining Group of Politecnico di Torino. Big Data: Hype or Hallelujah? Big data hype?
 Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia,
 Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Hadoop Overview. Lars George Director EMEA Services
 Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
Evolution of Big Data Facebook. Architecture Summit, Shenzhen, August 2012 Ashish Thusoo
 Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Techno Expert Solutions An institute for specialized studies!
 Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
CIS 601 Graduate Seminar. Dr. Sunnie S. Chung Dhruv Patel ( ) Kalpesh Sharma ( )
 Kalpesh Sharma ( )") Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
Top 25 Big Data Interview Questions And Answers
 Top 25 Big Data Interview Questions And Answers By: Neeru Jain - Big Data The era of big data has just begun. With more companies inclined towards big data to run their operations, the demand for talent
Top 25 Big Data Interview Questions And Answers By: Neeru Jain - Big Data The era of big data has just begun. With more companies inclined towards big data to run their operations, the demand for talent
Hadoop, Yarn and Beyond
 Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
This is a brief tutorial that explains how to make use of Sqoop in Hadoop ecosystem.
 About the Tutorial Sqoop is a tool designed to transfer data between Hadoop and relational database servers. It is used to import data from relational databases such as MySQL, Oracle to Hadoop HDFS, and
About the Tutorial Sqoop is a tool designed to transfer data between Hadoop and relational database servers. It is used to import data from relational databases such as MySQL, Oracle to Hadoop HDFS, and
Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack. Chief Architect RainStor
 Mark Cusack. Chief Architect RainStor") Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack Chief Architect RainStor Agenda Importance of Hadoop + data compression Data compression techniques Compression,
Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack Chief Architect RainStor Agenda Importance of Hadoop + data compression Data compression techniques Compression,
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to