Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
|
|
|
- Judith Palmer
- 6 years ago
- Views:
Transcription

1 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam

2 Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer, public speaker, and a senior consultant for over 18 years Oracle ACE Associate Part of iloug Israel Oracle User Group Involved with Big Data projects since 2011 Blogger and 2












3 About Brillix We offer complete, integrated end-to-end solutions based on best-ofbreed innovations in database, security and big data technologies We provide complete end-to-end 24x7 expert remote database services We offer professional customized on-site trainings, delivered by our top-notch world recognized instructors 3

4 Some of Our Customers 4
5 Agenda What is the Big Data challenge? A Big Data Solution: Apache Hadoop HDFS MapReduce and YARN Hadoop Ecosystem: HBase, Sqoop, Hive, Pig and other tools Another Big Data Solution: Apache Spark Where does the DBA fits in? 5
6 The Challenge 6

7 The Big Data Challenge 7
8 Volume Big data comes in one size: Big. Size is measured in Terabyte (10 12 ), Petabyte (10 15 ), Exabyte (10 18 ), Zettabyte (10 21 ) The storing and handling of the data becomes an issue Producing value out of the data in a reasonable time is an issue 8
9 Variety Big Data extends beyond structured data, including semi-structured and unstructured information: logs, text, audio and videos Wide variety of rapidly evolving data types requires highly flexible stores and handling Un-Structured Objects Flexible Structure Unknown Textual and Binary Structured Tables Columns and Rows Predefined Structure Mostly Textual 9
10 Velocity The speed in which data is being generated and collected Streaming data and large volume data movement High velocity of data capture requires rapid ingestion Might cause a backlog problem 10
11 Value Big data is not about the size of the data, It s about the value within the data 11
12 So, We Define Big Data Problem When the data is too big or moves too fast to handle in a sensible amount of time When the data doesn t fit any conventional database structure When we think that we can still produce value from that data and want to handle it When the technical solution to the business need becomes part of the problem 12
13 How to do Big Data 13

14 14
15 Big Data in Practice Big data is big: technological framework and infrastructure solutions are needed Big data is complicated: We need developers to manage handling of the data We need devops to manage the clusters We need data analysts and data scientists to produce value 15
16 Possible Solutions: Scale Up Older solution: using a giant server with a lot of resources (scale up: more cores, faster processers, more memory) to handle the data Process everything on a single server with hundreds of CPU cores Use lots of memory (1+ TB) Have a huge data store on high end storage solutions Data needs to be copied to the processes in real time, so it s no good for high amounts of data (Terabytes to Petabytes) 16
17 Another Solution: Distributed Systems A scale-out solution: let s use distributed systems: use multiple machine for a single job/application More machines means more resources CPU Memory Storage But the solution is still complicated: infrastructure and frameworks are needed 17
18 Distributed Infrastructure Challenges We need Infrastructure that is built for: Large-scale Linear scale out ability Data-intensive jobs that spread the problem across clusters of server nodes Storage: efficient and cost-effective enough to capture and store terabytes, if not petabytes, of data Network infrastructure that can quickly import large data sets and then replicate it to various nodes for processing High-end hardware is too expensive - we need a solution that uses cheaper hardware 18
19 Distributed System/Frameworks Challenges How do we distribute our workload across the system? Programming complexity keeping the data in sync What to do with faults and redundancy? How do we handle security demands to protect highly-distributed infrastructure and data? 19
20 A Big Data Solution: Apache Hadoop 20

21 Apache Hadoop Open source project run by Apache Foundation (2006) Hadoop brings the ability to cheaply process large amounts of data, regardless of its structure It Is has been the driving force behind the growth of the big data industry Get the public release from: 21

22 Original Hadoop Components HDFS (Hadoop Distributed File System) distributed file system that runs in clustered environments MapReduce programming paradigm for running processes over clustered environments Hadoop main idea: let s distribute the data to many servers, and then bring the program to the data 22
23 Hadoop Benefits Designed for scale out Reliable solution based on unreliable hardware Load data first, structure later Designed for storing large files Designed to maximize throughput of large scans Designed to leverage parallelism Solution Ecosystem 23
24 What Hadoop Is Not? Hadoop is not a database it does not a replacement for DW, or for other relational databases Hadoop is not for OLTP/real-time systems Very good for large amounts, not so much for smaller sets Designed for clusters there is no Hadoop monster server (single server) 24
25 Hadoop Limitations Hadoop is scalable but it s not fast Some assembly may be required Batteries are not included (DIY mindset) some features needs to be developed if they re not available Open source license limitations apply Technology is changing very rapidly 25
26 Hadoop under the Hood 26



27 Original Hadoop 1.0 Components HDFS (Hadoop Distributed File System) distributed file system that runs in a clustered environment MapReduce programming technique for running processes over a clustered environment 27

28 Hadoop 2.0 Hadoop 2.0 changed the Hadoop conception and introduced a better resource management concept: Hadoop Common HDFS YARN Multiple data processing frameworks including MapReduce, Spark and others 28
29 HDFS is... A distributed file system Designed to reliably store data using commodity hardware Designed to expect hardware failures and still stay resilient Intended for larger files Designed for batch inserts and appending data (no updates) 29
30 Files and Blocks Files are split into 128MB blocks (single unit of storage) Managed by NameNode and stored on DataNodes Transparent to users Replicated across machines at load time Same block is stored on multiple machines Good for fault-tolerance and access Default replication factor is 3 30
31 HDFS is Good for... Storing large files Terabytes, Petabytes, etc... Millions rather than billions of files 128MB or more per file Streaming data Write once and read-many times patterns Optimized for streaming reads rather than random reads 32
32 HDFS is Not So Good For... Low-latency reads / Real-time application High-throughput rather than low latency for small chunks of data HBase addresses this issue Large amount of small files Better for millions of large files instead of billions of small files Multiple Writers Single writer per file Writes at the end of files, no-support for arbitrary offset 33

33 Using HDFS in Command Line 34
34 How Does HDFS Look Like (GUI) 35

35 Interfacing with HDFS 36
36 MapReduce is... A programming model for expressing distributed computations at a massive scale An execution framework for organizing and performing such computations MapReduce can be written in Java, Scala, C, Payton, Ruby and others Concept: Bring the code to the data, not the data to the code 37
37 The MapReduce Paradigm Imposes key-value input/output We implement two main functions: MAP - Takes a large problem and divides into sub problems and performs the same function on all sub-problems Map(k1, v1) -> list(k2, v2) REDUCE - Combine the output from all sub-problems (each key goes to the same reducer) Reduce(k2, list(v2)) -> list(v3) Framework handles everything else (almost) 38

38 Divide and Conquer 39
39 YARN Takes care of distributed processing and coordination Scheduling Jobs are broken down into smaller chunks called tasks These tasks are scheduled to run on data nodes Task Localization with Data Framework strives to place tasks on the nodes that host the segment of data to be processed by that specific task Code is moved to where the data is 40
40 YARN Error Handling Failures are an expected behavior so tasks are automatically re-tried on other machines Data Synchronization Shuffle and Sort barrier re-arranges and moves data between machines Input and output are coordinated by the framework 41
41 Submitting a Job Yarn script with a class argument command launches a JVM and executes the provided Job $ yarn jar HadoopSamples.jar mr.wordcount.startswithcountjob \ /user/sample/hamlet.txt \ /user/sample/wordcount/ 42

42 Resource Manage: UI 43
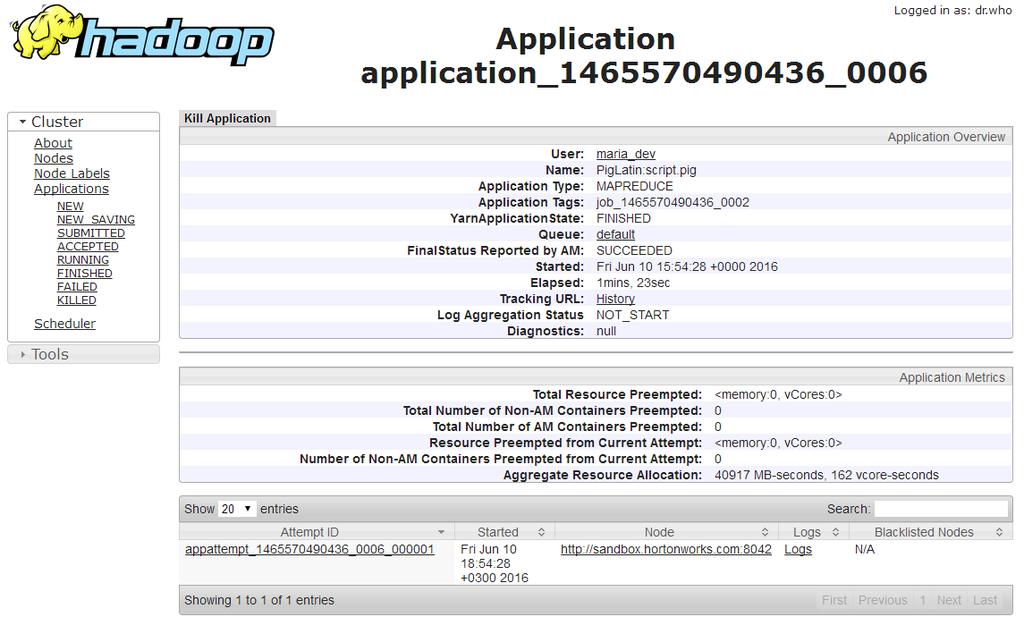
43 Application View 44
44 Hadoop Main Problems Hadoop MapReduce Framework (not MapReduce paradigm) had some major problems: Developing MapReduce was complicated there was more than just business logics to develop Transferring data between stages requires the intermediate data to be written to disk (and than read by the next step) Multi-step needed orchestration and abstraction solutions Initial resource management was very painful MapReduce framework was based on resource slots 45
45 Extending Hadoop The Hadoop Ecosystem

46 Improving Hadoop: Distributions Core Hadoop is complicated so some tools and solution frameworks were added to make things easier There are over 80 different Apache projects for big data solution which uses Hadoop (and growing!) Hadoop Distributions collects some of these tools and release them as a complete integrated package Cloudera HortonWorks MapR Amazon EMR 47

47 Common HADOOP 2.0 Technology Eco System 48
48 Improving Programmability MapReduce code in Java is sometime tedious, so different solutions came to the rescue Pig: Programming language that simplifies Hadoop actions: loading, transforming and sorting data Hive: enables Hadoop to operate as data warehouse using SQL-like syntax Spark and other frameworks 49
49 Pig Pig is an abstraction on top of Hadoop Provides high level programming language designed for data processing Scripts converted into MapReduce code, and executed on the Hadoop Clusters Makes ETL/ELT processing and other simple MapReduce easier without writing MapReduce code Pig was widely accepted and used by Yahoo!, Twitter, Netflix, and others Often replaced by more up-to-date tools like Apache Spark 50

50 Hive Data Warehousing Solution built on top of Hadoop Provides SQL-like query language named HiveQL Minimal learning curve for people with SQL expertise Data analysts are target audience Early Hive development work started at Facebook in 2007 Hive is an Apache top level project under Hadoop 51
51 Hive Provides Ability to bring structure to various data formats Simple interface for ad hoc querying, analyzing and summarizing large amounts of data Access to files on various data stores such as HDFS and HBase Also see: Apache Impala (mainly in Cloudera) 52
52 Databases and DB Connectivity HBase: Online NoSQL Key/Value wide-column oriented datastore that is native to HDFS Sqoop: a tool designed to import data from and export data to relational databases (HDFS, Hbase, or Hive) Sqoop2: Sqoop centralized service (GUI, WebUI, REST) 53



53 HBase HBase is the closest thing we had to database in the early Hadoop days Distributed key/value with wide-column oriented NoSQL database, built on top of HDFS Providing Big Table-like capabilities Does not have a query language: only get, put, and scan commands Often compared with Cassandra (non-hadoop native Apache project) 54
54 When Do We Use HBase? Huge volumes of randomly accessed data HBase is at its best when it s accessed in a distributed fashion by many clients (high consistency) Consider HBase when we are loading data by key, searching data by key (or range), serving data by key, querying data by key or when storing data by row that doesn t conform well to a schema. 55
55 When NOT To Use HBase HBase doesn t use SQL, don t have an optimizer, doesn t support transactions or joins HBase doesn t have data types See project Apache Phoenix for better data structure and query language when using HBase 56
56 Sqoop and Sqoop2 Sqoop is a command line tool for moving data from RDBMS to Hadoop. Sqoop2 is a centralized tool for running sqoop. Uses MapReduce load the data from relational database to HDFS Can also export data from HBase to RDBMS Comes with connectors to MySQL, PostgreSQL, Oracle, SQL Server and DB2. $bin/sqoop import --connect 'jdbc:sqlserver:// ;username=dbuser;password=dbpasswd;database=tpch' \ --table lineitem --hive-import $bin/sqoop export --connect 'jdbc:sqlserver:// ;username=dbuser;password=dbpasswd;database=tpch' \ --table lineitem --export-dir /data/lineitemdata 57
57 Improving Hadoop More Useful Tools For improving coordination: Zookeeper For improving scheduling/orchestration: Oozie Data Storing in memory: Apache Impala For Improving log collection: Flume Text Search and Data Discovery: Solr For Improving UI and Dashboards: Hue and Ambari 58
58 Improving Hadoop More Useful Tools (2) Data serialization: Avro and Parquet Data governance: Atlas Security: Knox and Ranger Data Replication: Falcon Machine Learning: Mahout Performance Improvement: Tez And there are more 59
59 60
60 Is Hadoop the Only Big Data Solution? No There are other solutions: Apache Spark and Apache Mesos frameworks NoSQL systems (Apache Cassandra, CouchBase, MongoDB and many others) Stream analysis (Apache Kafka, Apache Storm, Apache Flink) Machine learning (Apache Mahout, Spark MLlib) Some can be integrated with Hadoop, but some are independent 61
61 Another Big Data Solution: Apache Spark Apache Spark is a fast, general engine for large-scale data processing on a cluster Originally developed by UC Berkeley in 2009 as a research project, and is now an open source Apache top level project Main idea: use the memory resources of the cluster for better performance It is now one of the most fast-growing project today 62

62 The Spark Stack 63
63 Okay, So Where Does the DBA Fits In? Big Data solutions are not databases. Databases are probably not going to disappear, but we feel the change even today: DBA s must be ready for the change DBA s are the perfect candidates to transition into Big Data Experts: Have system (OS, disk, memory, hardware) experience Can understand data easily DBA s are used to work with developers and other data users 64
64 What DBAs Needs Now? DBA s will need to know more programming: Java, Scala, Python, R or any other popular language in the Big Data world will do DBA s needs to understand the position shifts, and the introduction of DevOps, Data Scientists, CDO etc. Big Data is changing daily: we need to learn, read, and be involved before we are left behind 65
65 Q&A 66
66 Summary Big Data is here it s complicated and RDBMS does not fit anymore Big Data solutions are evolving Hadoop is an example for such a solution Spark is very popular Big Data solution DBA s need to be ready for the change: Big Data solutions are not databases and we make ourselves ready 67

67 Thank You Zohar Elkayam 68
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Configuring and Deploying Hadoop Cluster Deployment Templates
 Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
MapR Enterprise Hadoop
 2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
SQT03 Big Data and Hadoop with Azure HDInsight Andrew Brust. Senior Director, Technical Product Marketing and Evangelism
 Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Cmprssd Intrduction To
 Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor
Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
docs.hortonworks.com
 docs.hortonworks.com : Getting Started Guide Copyright 2012, 2014 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open source platform for storing,
docs.hortonworks.com : Getting Started Guide Copyright 2012, 2014 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open source platform for storing,
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG
 BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
New Approaches to Big Data Processing and Analytics
 New Approaches to Big Data Processing and Analytics Contributing authors: David Floyer, David Vellante Original publication date: February 12, 2013 There are number of approaches to processing and analyzing
New Approaches to Big Data Processing and Analytics Contributing authors: David Floyer, David Vellante Original publication date: February 12, 2013 There are number of approaches to processing and analyzing
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Stages of Data Processing
 Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Introduction to Big-Data
 Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
Big Data Infrastructure at Spotify
 Big Data Infrastructure at Spotify Wouter de Bie Team Lead Data Infrastructure September 26, 2013 2 Who am I? According to ZDNet: "The work they have done to improve the Apache Hive data warehouse system
Big Data Infrastructure at Spotify Wouter de Bie Team Lead Data Infrastructure September 26, 2013 2 Who am I? According to ZDNet: "The work they have done to improve the Apache Hive data warehouse system
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A Review Paper on Big data & Hadoop
 A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
Big Data com Hadoop. VIII Sessão - SQL Bahia. Impala, Hive e Spark. Diógenes Pires 03/03/2018
 Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Hadoop, Yarn and Beyond
 Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Importing and Exporting Data Between Hadoop and MySQL
 Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
The age of Big Data Big Data for Oracle Database Professionals
 The age of Big Data Big Data for Oracle Database Professionals Oracle OpenWorld 2017 #OOW17 SessionID: SUN5698 Tom S. Reddy tom.reddy@datareddy.com About the Speaker COLLABORATE & OpenWorld Speaker IOUG
The age of Big Data Big Data for Oracle Database Professionals Oracle OpenWorld 2017 #OOW17 SessionID: SUN5698 Tom S. Reddy tom.reddy@datareddy.com About the Speaker COLLABORATE & OpenWorld Speaker IOUG
International Journal of Advance Engineering and Research Development. A study based on Cloudera's distribution of Hadoop technologies for big data"
 Scientific Journal of Impact Factor (SJIF): 4.72 International Journal of Advance Engineering and Research Development Volume 4, Issue 8, August -2017 e-issn (O): 2348-4470 p-issn (P): 2348-6406 A study
Scientific Journal of Impact Factor (SJIF): 4.72 International Journal of Advance Engineering and Research Development Volume 4, Issue 8, August -2017 e-issn (O): 2348-4470 p-issn (P): 2348-6406 A study
STATS Data Analysis using Python. Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns
 STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
Hadoop. Introduction to BIGDATA and HADOOP
 Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Introduction to Big Data. Hadoop. Instituto Politécnico de Tomar. Ricardo Campos
 Instituto Politécnico de Tomar Introduction to Big Data Hadoop Ricardo Campos Mestrado EI-IC Análise e Processamento de Grandes Volumes de Dados Tomar, Portugal, 2016 Part of the slides used in this presentation
Instituto Politécnico de Tomar Introduction to Big Data Hadoop Ricardo Campos Mestrado EI-IC Análise e Processamento de Grandes Volumes de Dados Tomar, Portugal, 2016 Part of the slides used in this presentation
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Webinar Series TMIP VISION
 Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Question: 1 You need to place the results of a PigLatin script into an HDFS output directory. What is the correct syntax in Apache Pig?
 Volume: 72 Questions Question: 1 You need to place the results of a PigLatin script into an HDFS output directory. What is the correct syntax in Apache Pig? A. update hdfs set D as./output ; B. store D
Volume: 72 Questions Question: 1 You need to place the results of a PigLatin script into an HDFS output directory. What is the correct syntax in Apache Pig? A. update hdfs set D as./output ; B. store D
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI
 DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI Department of Information Technology IT6701 - INFORMATION MANAGEMENT Anna University 2 & 16 Mark Questions & Answers Year / Semester: IV / VII Regulation: 2013
DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI Department of Information Technology IT6701 - INFORMATION MANAGEMENT Anna University 2 & 16 Mark Questions & Answers Year / Semester: IV / VII Regulation: 2013
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
This is a brief tutorial that explains how to make use of Sqoop in Hadoop ecosystem.
 About the Tutorial Sqoop is a tool designed to transfer data between Hadoop and relational database servers. It is used to import data from relational databases such as MySQL, Oracle to Hadoop HDFS, and
About the Tutorial Sqoop is a tool designed to transfer data between Hadoop and relational database servers. It is used to import data from relational databases such as MySQL, Oracle to Hadoop HDFS, and
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
A Survey on Big Data
 A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
Introduction into Big Data analytics Lecture 3 Hadoop ecosystem. Janusz Szwabiński
 Introduction into Big Data analytics Lecture 3 Hadoop ecosystem Janusz Szwabiński Outlook of today s talk Apache Hadoop Project Common use cases Getting started with Hadoop Single node cluster Further
Introduction into Big Data analytics Lecture 3 Hadoop ecosystem Janusz Szwabiński Outlook of today s talk Apache Hadoop Project Common use cases Getting started with Hadoop Single node cluster Further
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Department of Information Technology, St. Joseph s College (Autonomous), Trichy, TamilNadu, India
, Trichy, TamilNadu, India") International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 5 ISSN : 2456-3307 A Survey on Big Data and Hadoop Ecosystem Components
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 5 ISSN : 2456-3307 A Survey on Big Data and Hadoop Ecosystem Components
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
MapReduce and Hadoop
 Università degli Studi di Roma Tor Vergata MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference Big Data stack High-level Interfaces Data Processing
Università degli Studi di Roma Tor Vergata MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference Big Data stack High-level Interfaces Data Processing
Chase Wu New Jersey Institute of Technology
 CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Oracle Big Data Fundamentals Ed 2
 Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Oracle GoldenGate for Big Data
 Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
Oracle GoldenGate for Big Data The Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It streamlines
Hortonworks Data Platform
 Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Data Storage Infrastructure at Facebook
 Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Hortonworks and The Internet of Things
 Hortonworks and The Internet of Things Dr. Bernhard Walter Solutions Engineer About Hortonworks Customer Momentum ~700 customers (as of November 4, 2015) 152 customers added in Q3 2015 Publicly traded
Hortonworks and The Internet of Things Dr. Bernhard Walter Solutions Engineer About Hortonworks Customer Momentum ~700 customers (as of November 4, 2015) 152 customers added in Q3 2015 Publicly traded
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Getting Started with Hadoop and BigInsights
 Getting Started with Hadoop and BigInsights Alan Fischer e Silva Hadoop Sales Engineer Nov 2015 Agenda! Intro! Q&A! Break! Hands on Lab 2 Hadoop Timeline 3 In a Big Data World. The Technology exists now
Getting Started with Hadoop and BigInsights Alan Fischer e Silva Hadoop Sales Engineer Nov 2015 Agenda! Intro! Q&A! Break! Hands on Lab 2 Hadoop Timeline 3 In a Big Data World. The Technology exists now
Top 25 Big Data Interview Questions And Answers
 Top 25 Big Data Interview Questions And Answers By: Neeru Jain - Big Data The era of big data has just begun. With more companies inclined towards big data to run their operations, the demand for talent
Top 25 Big Data Interview Questions And Answers By: Neeru Jain - Big Data The era of big data has just begun. With more companies inclined towards big data to run their operations, the demand for talent
Hadoop Overview. Lars George Director EMEA Services
 Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation)
 (Development, Administration & REAL TIME Projects Implementation)") HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Techno Expert Solutions An institute for specialized studies!
 Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Introduction to HDFS and MapReduce
 Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Processing Unstructured Data. Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd.
 Processing Unstructured Data Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd. http://dinesql.com / Dinesh Priyankara @dinesh_priya Founder/Principal Architect dinesql Pvt Ltd. Microsoft Most
Processing Unstructured Data Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd. http://dinesql.com / Dinesh Priyankara @dinesh_priya Founder/Principal Architect dinesql Pvt Ltd. Microsoft Most
BIG DATA COURSE CONTENT
 BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
Department of Digital Systems. Digital Communications and Networks. Master Thesis
 Department of Digital Systems Digital Communications and Networks Master Thesis Study of technologies/research systems for big scientific data analytics Surname/Name: Petsas Konstantinos Registration Number:
Department of Digital Systems Digital Communications and Networks Master Thesis Study of technologies/research systems for big scientific data analytics Surname/Name: Petsas Konstantinos Registration Number: