MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
|
|
|
- Paul Malone
- 6 years ago
- Views:
Transcription
1 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming
2 Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance Growth in data-intensive applications Increasing desktop performance relatively unimportant Effectiveness of multiprocessors for server applications Leveraging design investment by replication 2
3 Flynn s Classification of Parallel Architectures SISD: Single Instruction Single Data stream uniprocessors SIMD: Single Instruction Multiple Data streams suitable for data parallelism Intel s multimedia extensions, vector processors growing popularity in graphics applications MISD: Multiple instruction Single Data stream no commercial multiprocessor to date MIMD: Multiple Instruction Multiple Data streams suitable for thread-level parallelism 3
4 MIMD Architecture of choice for general-purpose multiprocessors Offers flexibility Can leverage the design investment in uniprocessors Can use off-the-shelf processors COTS (Commercial, Off-The-Shelf) processors Examples Clusters commodity and custom clusters Multicores 4
5 Shared-Memory Multiprocessors 5
6 Distributed-Memory Multiprocessors 6
7 Models for Memory and Communication Memory architecture shared memory Uniform Memory Access (UMA) Symmetric (Shared-Memory) Multiprocessors (SMPs) distributed memory Non-Uniform Memory Access (NUMA) Communication architecture (programming) shared memory message-passing 7

8 Other Ways to Categorize Parallel Programming threads vs producer-consumer client-sever vs p-to-p / master-slave vs symm. course vs fine grained SPMD vs MPMD tightly vs loosely coupled Parallel Programs recursive vs iterative shared mem vs msg passing data vs task parallel synch. vs asynch. 8
9 CACHES
10 Terminology cache virtual memory memory stall cycles direct mapped valid bit block address write through instruction cache average memory access time cache hit page miss penalty fully associative dirty bit block offset write back data cache hit time cache miss page fault miss rate n-way set associative least-recently used tag field write allocate unified cache misses per instruction block locality address trace set random replacement index field no-write allocate write buffer write stall 10
11 Memory Hierarchy 11
12 Four Memory-Hierarchy Questions Where can a block be placed in the upper level? block placement How is a block found if it is in the upper level? block indentification Which block should be replaced on a miss? block replacement What happens on a write? write strategy 12
13 Where Can a Block Be Placed in a Cache? Only one place for each block direct mapped Anywhere in the cache fully associative Restricted set of places set associative (Block address) MOD (Number of blocks in cache) (Block address) MOD (Number of sets in cache) 13
14 Example 14
15 How is a Block Found if it is in Cache? Tags in each cache block gives the block address all possible tags searched in parallel (associative memory) valid bit tells whether a tag match valid Fields in a memory address No index field in fully associative caches 15
16 Which Block Should be Replaced on a Miss? Random easy to implement Least-recently used (LRU) idea: rely on the past to predict the future replace the block unused for the longest time First in, First out (FIFO) approximates LRU (oldest, rather than least recently used) simpler to implement 16
17 Comparison of Replacement Policies Data cache misses per 1000 instructions on five SPECint2000 and five SPECfp2000 benchmarks 17
18 Reads dominate What Happens on a Write? 7% of the overall memory traffic are writes 28% of the data cache traffic are writes Write takes longer reading cache line and validity check can be parallel reads can read the whole line, write must modify only the specified bytes 18
19 Handling Writes Write strategy write through write to cache block and to the block in the lower-level memory write back write only to cache block, update the lower-level memory when block replaced Block allocation strategy write allocate allocate a block on cache miss no-write allocate do not allocate, no affect on cache 19
20 Example: Opteron Data Cache 20
21 Terminology cache virtual memory memory stall cycles direct mapped valid bit block address write through instruction cache average memory access time cache hit page miss penalty fully associative dirty bit block offset write back data cache hit time cache miss page fault miss rate n-way set associative least-recently used tag field write allocate unified cache misses per instruction block locality address trace set random replacement index field no-write allocate write buffer write stall 21
22 SYMMETRIC SHARED-MEMORY: CACHE COHERENCE
23 Quotes 23
24 Quotes We are dedicating all of our future product development to multicore designs. We believe this is a key inflection point for the industry. Intel President Paul Otellini, describing Intelʼs future direction at the Intel Developers Forum in
25 Quotes The turning away from conventional organization came in the middle 1960s, when the law of diminishing returns began to take effect in the effort to increase the operational speed of a computer... Electronic circuits are ultimately limited in their speed of operation by the speed of light... and many of the circuits were already operating in the nanosecond range. W. Jack Bouknight et al. The Illiac IV System (1972) We are dedicating all of our future product development to multicore designs. We believe this is a key inflection point for the industry. Intel President Paul Otellini, describing Intelʼs future direction at the Intel Developers Forum in
26 Multiprocessor Cache Coherence X is not in any cache initially. The caches are write-through. 24
27 Multiprocessor Cache Coherence X is not in any cache initially. The caches are write-through. Proposed definition: Memory system is coherent if any read of a data item returns the most recently written value of that data item. 24

28 Multiprocessor Cache Coherence X is not in any cache initially. The caches are write-through. Proposed definition: Memory system is coherent if any read of a data item returns the most recently written value of that data item. Too simplistic! 24
29 Coherency: Take 2 A memory system is coherent if: 25
30 Coherency: Take 2 A memory system is coherent if: 1. Writes and Reads by one processor P x M P x M 25
31 Coherency: Take 2 A memory system is coherent if: 1. Writes and Reads by one processor 2. Writes and Reads by two processors P x M P1 x M P x M P2 x M 25
32 Coherency: Take 2 A memory system is coherent if: 1. Writes and Reads by one processor 2. Writes and Reads by two processors 3. Writes by two processors (serialization) P x M P1 x M P1 x M P3 x M P x M P2 x M P2 y M P3 y M 25
33 Coherence vs Consistency Coherence defines the behavior of reads and writes to the same memory location Consistency defines the behavior of reads and writes with respect to accesses to other memory locations we will return to consistency later Working assumptions: a write does not complete until all processors have seen the effect of that write processor does not change the order of an write with respect to any other memory access 26
34 What Needs to Happen for Coherence? Migration data can move to local cache, when needed Replication data may be replicated in local cache, when needed Need a protocol to maintain the coherence property specialized hardware 27
35 Directory based Coherence Protocols central location (directory) maintains the sharing state of a block of physical memory slightly higher implementation cost scalable most used for distributed-memory multiprocessors Snooping each cache maintains sharing state of the blocks it contains shared broadcast medium (e.g., bus) each cache snoops on the medium to determine whether they a copy of the block that is requested most used for shared-memory multiprocessors 28
36 Snooping Protocols: Handling Writes Write invalidate write requires exclusive access any copy held by the reading processor is invalidated if two processors attempt to write, one wins the race Write update (or write broadcast) update all the cached copies of a data item when written consumes substantially more bandwidth than invalidatingbased protocol not used in recent multiprocessors 29
37 Example of Invalidation Protocol Write-back caches 30
38 Write Invalidate Protocol: Observations Serialization through access to the broadcast medium Need to locate data item upon miss simple on write-through caches write-buffers may complicate this write-through increases the memory bandwidth requirement more complex on write-back caches caches snoop for read addresses, supply matching dirty block no need to write back dirty block if cached elsewhere preferred approach on most modern multiprocessors, due to lower memory bandwidth requirements Cache tags and valid bits can do double duty Additional bit to indicate whether block shared Desirable to reduce contention on cache between processor and snooping 31
39 Invalidation-Based Coherence Protocol for Write-Back Caches with Allocate on Write 32
40 Invalidation-Based Coherence Protocol for Write-Back Caches with Allocate on Write Idea: Shared read, exclusive write 32
41 Invalidation-Based Coherence Protocol for Write-Back Caches with Allocate on Write Idea: Shared read, exclusive write Read Hit: get from local cache Miss: get from memory or another processor s cache; writeback existing block if needed 32
42 Invalidation-Based Coherence Protocol for Write-Back Caches with Allocate on Write Idea: Shared read, exclusive write Read Hit: get from local cache Miss: get from memory or another processor s cache; writeback existing block if needed Write Hit: write in cache, mark the block exclusive (invalidate copies at other processors) Miss: get from memory or another processor s cache; writeback existing block if needed 32
43 Cache Coherence Mechanism (MESI or MOESI) 33
44 Write Invalidate Cache Coherence Protocol for Write-Back Caches 34
45 Write Invalidate Cache Coherence Protocol for Write-Back Caches 35
46 Interconnection Network, Instead of Bus 36
47 SYMMETRIC SHARED-MEMORY: PERFORMANCE
48 Performance Issues Cache misses capacity compulsory conflict Cache coherence true-sharing misses false-sharing 38
49 Performance Issues Cache misses capacity compulsory conflict Cache coherence true-sharing misses false-sharing 38
50 Machine Performance: Alpha-Server Alpha-Server 4100, 4 processors: processor Alpha (four issue) Three-level cache L1: 8KB direct-mapped, separate instruction and data, 32- byte block size, write through, on-chip L2: 96KB 3-way set-associative, unified, 32-byte block size, write back, on-chip L3: 2MB direct-mapped, unified, 64-byte block size, write back, off-chip Latencies L2: 7 cycles, L3: 21 cycles, memory: 80 cycles 39
51 Performance: Commercial Workload Online Transaction-Processing (OLTP) modeled after TPC-B client-server Decision Support System (DSS) modeled after TPC-D long-running queries against large complex data structures (obsoleted) Web index search AltaVista, using 200 GB memory-mapped database I/O time ignored (substantial for these applications) 40

52 Execution Time Breakdown 41

53 OLTP with Different Cache Sizes 42

54 OLTP: Contributing Causes of L3 Cycles 43

55 OLTP Mem. Access Cycles with Processor Count 44

56 OLPT Misses with L3 Cache Block Size 45
57 Multiprogramming and OS Workload Models user and OS activities Andrew benchmark, emulates software development compiling installing object files in a library removing object files Memory hierarchy L1 instruction cache: 32KB, 2-way set-associative, 64-byte block; L1 data cache: 32KB 2-way set-associative, 32-byte block L2: 1MB unified, 2-way set assoc., 128-byte block Memory: 100 clock cycles access 46
58 Distribution of Execution Time 47

59 L1 Size and L1 Block Size 48
60 Kernel Data Cache Miss Rates 49

61 Memory Traffic Per Data Reference 50
62 DISTRIBUTED SHARED-MEMORY: DIRECTORY-BASED COHERENCE
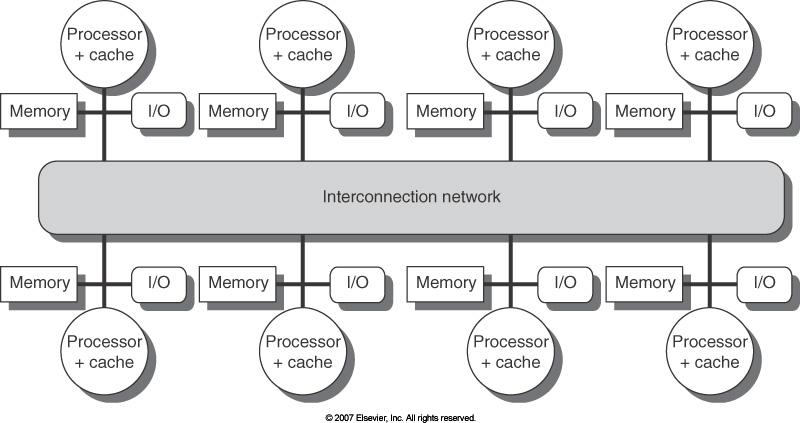
63 Distributed Memory 52
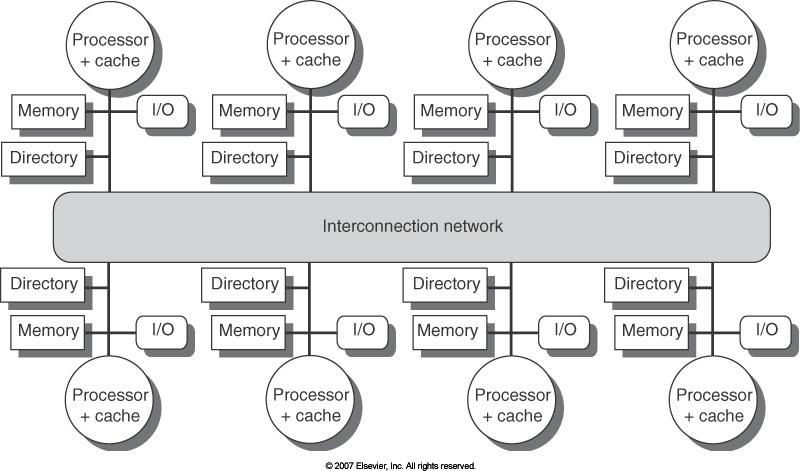
64 Distributed Memory+Directories 53
65 Directory-Based Protocol States Shared one or more processors have the block cached memory has up to date value Uncached no processor has a copy of the cache block Modified exactly one processor has a copy of the cache block memory copy is out of date the processor with the copy is the block s owner 54
66 Possible Messages 55
67 States for Individual Caches 56
68 States for Directories 57
69 SYNCHRONIZATION
70 Basic Idea Hardware support for atomically reading and writing a memory location enables software to implement locks a variety of synchronizations possible with locks Multiple (equivalent) approaches possible Synchronization libraries on top of hardware primitives 59
71 Some Examples Atomic exchange exchange a register and memory value atomically return the register value if failed, memory value if succeeded Test-and-set test a memory location and set its value if the test passed Fetch-and-increment 60
72 Paired Instructions Problems with single atomic operations complicates coherence Alternative: pair of special load and store instructions load linked or load locked store conditional can implement atomic exchange with the pair 61
73 Other Primitives can also be built Atomic exchange Fetch-and-increment Implemented with a link register to track the address of LL instruction 62

74 Implementing Spin Locks: Uncached 63
75 Implementing Spin Locks: Cached 64
76 Cache Coherence Steps 65

77 Implementing Spin Locks: Linked Load/Store 66
78 MEMORY CONSISTENCY
79 Memory Consistency Related to accesses to multiple shared memory locations coherence deals with accesses to a shared location P1: A = 0;... A = 1; L1: if (B == 0)... P2: B = 0;... B = 1; L2: if (A == 0)... 68
80 Memory Consistency Related to accesses to multiple shared memory locations coherence deals with accesses to a shared location P1: A = 0;... A = 1; L1: if (B == 0)... P2: B = 0;... B = 1; L2: if (A == 0)... Sequential Consistency 68
81 Programmer s View Sequential consistency easy to reason about Most real programs use synchronization synchronization primitives usually implemented in libraries not using synchronization data races Allowing sequential consistency for synchronization variables ensure correctness can implement relaxed consistency for the rest 69
82 Relaxed Consistency Models Idea: allow reads and writes to finish out of order, but use synchronization to enforce ordering Ways to relax consistency (weak consistency) Relaxing W R: processor consistency Relaxing W W: partial store order Relaxing R W and R R: weak ordering, PowerPC consistency, release consistency Two approaches to optimize performance use weak consistency, rely on synchronization for correctness use sequential or processor consistency with speculative execution 70
83 FALLACIES AND PITFALLS
84 Fallacies and Pitfalls Pitfall: Measuring performance of multiprocessors by linear speedup versus execution time sequential vs parallel algorithms superlinear speedups and cache effects strong vs weak scaling Pitfall: Not developing software to take advantage of, or optimize for, a multiprocessor architecture 72
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM (PART 1)
") 1 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM (PART 1) Chapter 5 Appendix F Appendix I OUTLINE Introduction (5.1) Multiprocessor Architecture Challenges in Parallel Processing Centralized Shared Memory
1 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM (PART 1) Chapter 5 Appendix F Appendix I OUTLINE Introduction (5.1) Multiprocessor Architecture Challenges in Parallel Processing Centralized Shared Memory
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Advanced Topics in Computer Architecture
 Advanced Topics in Computer Architecture Lecture 5 Multiprocessors and Thread-Level Parallelism Marenglen Biba Department of Computer Science University of New York Tirana Outline Introduction Symmetric
Advanced Topics in Computer Architecture Lecture 5 Multiprocessors and Thread-Level Parallelism Marenglen Biba Department of Computer Science University of New York Tirana Outline Introduction Symmetric
Lecture 24: Virtual Memory, Multiprocessors
 Lecture 24: Virtual Memory, Multiprocessors Today s topics: Virtual memory Multiprocessors, cache coherence 1 Virtual Memory Processes deal with virtual memory they have the illusion that a very large
Lecture 24: Virtual Memory, Multiprocessors Today s topics: Virtual memory Multiprocessors, cache coherence 1 Virtual Memory Processes deal with virtual memory they have the illusion that a very large
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Parallel Computer Architecture Spring Shared Memory Multiprocessors Memory Coherence
 Parallel Computer Architecture Spring 2018 Shared Memory Multiprocessors Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly Parallel Computer Architecture
Parallel Computer Architecture Spring 2018 Shared Memory Multiprocessors Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly Parallel Computer Architecture
COSC4201 Multiprocessors
 COSC4201 Multiprocessors Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Multiprocessing We are dedicating all of our future product development to multicore
COSC4201 Multiprocessors Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Multiprocessing We are dedicating all of our future product development to multicore
Chapter 5 Thread-Level Parallelism. Abdullah Muzahid
 Chapter 5 Thread-Level Parallelism Abdullah Muzahid 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors is saturating + Modern multiple issue processors are becoming very complex
Chapter 5 Thread-Level Parallelism Abdullah Muzahid 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors is saturating + Modern multiple issue processors are becoming very complex
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Shared Memory Multiprocessors. Symmetric Shared Memory Architecture (SMP) Cache Coherence. Cache Coherence Mechanism. Interconnection Network
 Cache Coherence. Cache Coherence Mechanism. Interconnection Network") Shared Memory Multis Processor Processor Processor i Processor n Symmetric Shared Memory Architecture (SMP) cache cache cache cache Interconnection Network Main Memory I/O System Cache Coherence Cache
Shared Memory Multis Processor Processor Processor i Processor n Symmetric Shared Memory Architecture (SMP) cache cache cache cache Interconnection Network Main Memory I/O System Cache Coherence Cache
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
MEMORY HIERARCHY BASICS. B649 Parallel Architectures and Programming
 MEMORY HIERARCHY BASICS B649 Parallel Architectures and Programming BASICS Why Do We Need Caches? 3 Overview 4 Terminology cache virtual memory memory stall cycles direct mapped valid bit block address
MEMORY HIERARCHY BASICS B649 Parallel Architectures and Programming BASICS Why Do We Need Caches? 3 Overview 4 Terminology cache virtual memory memory stall cycles direct mapped valid bit block address
Chapter 5. Thread-Level Parallelism
 Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
Parallel Computers. CPE 631 Session 20: Multiprocessors. Flynn s Tahonomy (1972) Why Multiprocessors?
 Why Multiprocessors?") Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
Shared Symmetric Memory Systems
 Shared Symmetric Memory Systems Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Shared Symmetric Memory Systems Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Computer Architecture
 Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence
 1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems
 1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
COSC4201. Multiprocessors and Thread Level Parallelism. Prof. Mokhtar Aboelaze York University
 COSC4201 Multiprocessors and Thread Level Parallelism Prof. Mokhtar Aboelaze York University COSC 4201 1 Introduction Why multiprocessor The turning away from the conventional organization came in the
COSC4201 Multiprocessors and Thread Level Parallelism Prof. Mokhtar Aboelaze York University COSC 4201 1 Introduction Why multiprocessor The turning away from the conventional organization came in the
Chapter 9 Multiprocessors
 ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
Chapter-4 Multiprocessors and Thread-Level Parallelism
 Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
Chapter 8. Multiprocessors. In-Cheol Park Dept. of EE, KAIST
 Chapter 8. Multiprocessors In-Cheol Park Dept. of EE, KAIST Can the rapid rate of uniprocessor performance growth be sustained indefinitely? If the pace does slow down, multiprocessor architectures will
Chapter 8. Multiprocessors In-Cheol Park Dept. of EE, KAIST Can the rapid rate of uniprocessor performance growth be sustained indefinitely? If the pace does slow down, multiprocessor architectures will
Cache Coherence. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 11
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 11
Computer Science 146. Computer Architecture
 Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
CSCI 4717 Computer Architecture
 CSCI 4717/5717 Computer Architecture Topic: Symmetric Multiprocessors & Clusters Reading: Stallings, Sections 18.1 through 18.4 Classifications of Parallel Processing M. Flynn classified types of parallel
CSCI 4717/5717 Computer Architecture Topic: Symmetric Multiprocessors & Clusters Reading: Stallings, Sections 18.1 through 18.4 Classifications of Parallel Processing M. Flynn classified types of parallel
Introduction. Coherency vs Consistency. Lec-11. Multi-Threading Concepts: Coherency, Consistency, and Synchronization
 Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
3/13/2008 Csci 211 Lecture %/year. Manufacturer/Year. Processors/chip Threads/Processor. Threads/chip 3/13/2008 Csci 211 Lecture 8 4
 Outline CSCI Computer System Architecture Lec 8 Multiprocessor Introduction Xiuzhen Cheng Department of Computer Sciences The George Washington University MP Motivation SISD v. SIMD v. MIMD Centralized
Outline CSCI Computer System Architecture Lec 8 Multiprocessor Introduction Xiuzhen Cheng Department of Computer Sciences The George Washington University MP Motivation SISD v. SIMD v. MIMD Centralized
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Aleksandar Milenkovich 1
 Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Memory Consistency and Multiprocessor Performance. Adapted from UCB CS252 S01, Copyright 2001 USB
 Memory Consistency and Multiprocessor Performance Adapted from UCB CS252 S01, Copyright 2001 USB 1 Memory Consistency Model Define memory correctness for parallel execution Execution appears to the that
Memory Consistency and Multiprocessor Performance Adapted from UCB CS252 S01, Copyright 2001 USB 1 Memory Consistency Model Define memory correctness for parallel execution Execution appears to the that
Computer Organization. Chapter 16
 William Stallings Computer Organization and Architecture t Chapter 16 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data
William Stallings Computer Organization and Architecture t Chapter 16 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data
Chapter 18 Parallel Processing
 Chapter 18 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD
Chapter 18 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD
RECAP. B649 Parallel Architectures and Programming
 RECAP B649 Parallel Architectures and Programming RECAP 2 Recap ILP Exploiting ILP Dynamic scheduling Thread-level Parallelism Memory Hierarchy Other topics through student presentations Virtual Machines
RECAP B649 Parallel Architectures and Programming RECAP 2 Recap ILP Exploiting ILP Dynamic scheduling Thread-level Parallelism Memory Hierarchy Other topics through student presentations Virtual Machines
Memory Consistency and Multiprocessor Performance
 Memory Consistency Model Memory Consistency and Multiprocessor Performance Define memory correctness for parallel execution Execution appears to the that of some correct execution of some theoretical parallel
Memory Consistency Model Memory Consistency and Multiprocessor Performance Define memory correctness for parallel execution Execution appears to the that of some correct execution of some theoretical parallel
anced computer architecture CONTENTS AND THE TASK OF THE COMPUTER DESIGNER The Task of the Computer Designer
 Contents advanced anced computer architecture i FOR m.tech (jntu - hyderabad & kakinada) i year i semester (COMMON TO ECE, DECE, DECS, VLSI & EMBEDDED SYSTEMS) CONTENTS UNIT - I [CH. H. - 1] ] [FUNDAMENTALS
Contents advanced anced computer architecture i FOR m.tech (jntu - hyderabad & kakinada) i year i semester (COMMON TO ECE, DECE, DECS, VLSI & EMBEDDED SYSTEMS) CONTENTS UNIT - I [CH. H. - 1] ] [FUNDAMENTALS
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU /15-618, Spring 2015
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor
 EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration I/O MultiProcessor Summary 2 Virtual memory benifits Using physical memory efficiently
EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration I/O MultiProcessor Summary 2 Virtual memory benifits Using physical memory efficiently
Aleksandar Milenkovic, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
1. Memory technology & Hierarchy
 1. Memory technology & Hierarchy Back to caching... Advances in Computer Architecture Andy D. Pimentel Caches in a multi-processor context Dealing with concurrent updates Multiprocessor architecture In
1. Memory technology & Hierarchy Back to caching... Advances in Computer Architecture Andy D. Pimentel Caches in a multi-processor context Dealing with concurrent updates Multiprocessor architecture In
Thread- Level Parallelism. ECE 154B Dmitri Strukov
 Thread- Level Parallelism ECE 154B Dmitri Strukov Introduc?on Thread- Level parallelism Have mul?ple program counters and resources Uses MIMD model Targeted for?ghtly- coupled shared- memory mul?processors
Thread- Level Parallelism ECE 154B Dmitri Strukov Introduc?on Thread- Level parallelism Have mul?ple program counters and resources Uses MIMD model Targeted for?ghtly- coupled shared- memory mul?processors
Multiprocessors - Flynn s Taxonomy (1966)
") Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Multiprocessors 1. Outline
 Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
Flynn s Classification
 Flynn s Classification SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data) No machine is built yet for this type SIMD (Single Instruction Multiple Data) Examples:
Flynn s Classification SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data) No machine is built yet for this type SIMD (Single Instruction Multiple Data) Examples:
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Parallel Processing. Computer Architecture. Computer Architecture. Outline. Multiple Processor Organization
 Computer Architecture Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Parallel Processing http://www.yildiz.edu.tr/~naydin 1 2 Outline Multiple Processor
Computer Architecture Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Parallel Processing http://www.yildiz.edu.tr/~naydin 1 2 Outline Multiple Processor
Organisasi Sistem Komputer
 LOGO Organisasi Sistem Komputer OSK 14 Parallel Processing Pendidikan Teknik Elektronika FT UNY Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple
LOGO Organisasi Sistem Komputer OSK 14 Parallel Processing Pendidikan Teknik Elektronika FT UNY Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple
EEC 581 Computer Architecture. Lec 11 Synchronization and Memory Consistency Models (4.5 & 4.6)
") EEC 581 Computer rchitecture Lec 11 Synchronization and Memory Consistency Models (4.5 & 4.6) Chansu Yu Electrical and Computer Engineering Cleveland State University cknowledgement Part of class notes
EEC 581 Computer rchitecture Lec 11 Synchronization and Memory Consistency Models (4.5 & 4.6) Chansu Yu Electrical and Computer Engineering Cleveland State University cknowledgement Part of class notes
Chapter 5 (Part II) Large and Fast: Exploiting Memory Hierarchy. Baback Izadi Division of Engineering Programs
 Large and Fast: Exploiting Memory Hierarchy. Baback Izadi Division of Engineering Programs") Chapter 5 (Part II) Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Virtual Machines Host computer emulates guest operating system and machine resources Improved isolation of multiple
Chapter 5 (Part II) Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Virtual Machines Host computer emulates guest operating system and machine resources Improved isolation of multiple
Lecture 24: Memory, VM, Multiproc
 Lecture 24: Memory, VM, Multiproc Today s topics: Security wrap-up Off-chip Memory Virtual memory Multiprocessors, cache coherence 1 Spectre: Variant 1 x is controlled by attacker Thanks to bpred, x can
Lecture 24: Memory, VM, Multiproc Today s topics: Security wrap-up Off-chip Memory Virtual memory Multiprocessors, cache coherence 1 Spectre: Variant 1 x is controlled by attacker Thanks to bpred, x can
MULTIPROCESSORS AND THREAD LEVEL PARALLELISM
 UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Chapter 6. Parallel Processors from Client to Cloud Part 2 COMPUTER ORGANIZATION AND DESIGN. Homogeneous & Heterogeneous Multicore Architectures
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Part 2 Homogeneous & Heterogeneous Multicore Architectures Intel XEON 22nm
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Part 2 Homogeneous & Heterogeneous Multicore Architectures Intel XEON 22nm
Lecture 9: MIMD Architecture
 Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
The levels of a memory hierarchy. Main. Memory. 500 By 1MB 4GB 500GB 0.25 ns 1ns 20ns 5ms
 The levels of a memory hierarchy CPU registers C A C H E Memory bus Main Memory I/O bus External memory 500 By 1MB 4GB 500GB 0.25 ns 1ns 20ns 5ms 1 1 Some useful definitions When the CPU finds a requested
The levels of a memory hierarchy CPU registers C A C H E Memory bus Main Memory I/O bus External memory 500 By 1MB 4GB 500GB 0.25 ns 1ns 20ns 5ms 1 1 Some useful definitions When the CPU finds a requested
Multiprocessors and Locking
 Types of Multiprocessors (MPs) Uniform memory-access (UMA) MP Access to all memory occurs at the same speed for all processors. Multiprocessors and Locking COMP9242 2008/S2 Week 12 Part 1 Non-uniform memory-access
Types of Multiprocessors (MPs) Uniform memory-access (UMA) MP Access to all memory occurs at the same speed for all processors. Multiprocessors and Locking COMP9242 2008/S2 Week 12 Part 1 Non-uniform memory-access
UNIT I (Two Marks Questions & Answers)
") UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING UNIT-1
 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
Processor Architecture and Interconnect
 Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Computer Architecture
 Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Computer Science & Engineering. Chapter 5. Memory Hierachy BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 5 Memory Hierachy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic
Computer Architecture Computer Science & Engineering Chapter 5 Memory Hierachy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Chapter Seven. Idea: create powerful computers by connecting many smaller ones
 Chapter Seven Multiprocessors Idea: create powerful computers by connecting many smaller ones good news: works for timesharing (better than supercomputer) vector processing may be coming back bad news:
Chapter Seven Multiprocessors Idea: create powerful computers by connecting many smaller ones good news: works for timesharing (better than supercomputer) vector processing may be coming back bad news:
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano
 Prof. Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Comp. Org II, Spring
 Lecture 11 Parallel Processor Architectures Flynn s taxonomy from 1972 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing (Sta09 Fig 17.1) 2 Parallel
Lecture 11 Parallel Processor Architectures Flynn s taxonomy from 1972 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing (Sta09 Fig 17.1) 2 Parallel
Non-uniform memory access machine or (NUMA) is a system where the memory access time to any region of memory is not the same for all processors.
 is a system where the memory access time to any region of memory is not the same for all processors.") CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
CS654 Advanced Computer Architecture Lec 14 Directory Based Multiprocessors
 CS654 Advanced Computer Architecture Lec 14 Directory Based Multiprocessors Peter Kemper Adapted from the slides of EECS 252 by Prof. David Patterson Electrical Engineering and Computer Sciences University
CS654 Advanced Computer Architecture Lec 14 Directory Based Multiprocessors Peter Kemper Adapted from the slides of EECS 252 by Prof. David Patterson Electrical Engineering and Computer Sciences University
Parallel Processing & Multicore computers
 Lecture 11 Parallel Processing & Multicore computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1)
Lecture 11 Parallel Processing & Multicore computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1)
Interconnect Routing
 Interconnect Routing store-and-forward routing switch buffers entire message before passing it on latency = [(message length / bandwidth) + fixed overhead] * # hops wormhole routing pipeline message through
Interconnect Routing store-and-forward routing switch buffers entire message before passing it on latency = [(message length / bandwidth) + fixed overhead] * # hops wormhole routing pipeline message through
Chapter 05. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 05 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 5.1 Basic structure of a centralized shared-memory multiprocessor based on a multicore chip.
Chapter 05 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 5.1 Basic structure of a centralized shared-memory multiprocessor based on a multicore chip.
Parallel Computer Architecture Spring Distributed Shared Memory Architectures & Directory-Based Memory Coherence
 Parallel Computer Architecture Spring 2018 Distributed Shared Memory Architectures & Directory-Based Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly
Parallel Computer Architecture Spring 2018 Distributed Shared Memory Architectures & Directory-Based Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly
Comp. Org II, Spring
 Lecture 11 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1) Computer
Lecture 11 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1) Computer
Lecture 18: Coherence Protocols. Topics: coherence protocols for symmetric and distributed shared-memory multiprocessors (Sections
 Lecture 18: Coherence Protocols Topics: coherence protocols for symmetric and distributed shared-memory multiprocessors (Sections 4.2-4.4) 1 SMP/UMA/Centralized Memory Multiprocessor Main Memory I/O System
Lecture 18: Coherence Protocols Topics: coherence protocols for symmetric and distributed shared-memory multiprocessors (Sections 4.2-4.4) 1 SMP/UMA/Centralized Memory Multiprocessor Main Memory I/O System
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
CSF Improving Cache Performance. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]
![CSF Improving Cache Performance. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]](/thumbs/76/74076691.jpg "CSF Improving Cache Performance. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]") CSF Improving Cache Performance [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user
CSF Improving Cache Performance [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user
CSC 631: High-Performance Computer Architecture
 CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
Multiprocessor Cache Coherency. What is Cache Coherence?
 Multiprocessor Cache Coherency CS448 1 What is Cache Coherence? Two processors can have two different values for the same memory location 2 1 Terminology Coherence Defines what values can be returned by
Multiprocessor Cache Coherency CS448 1 What is Cache Coherence? Two processors can have two different values for the same memory location 2 1 Terminology Coherence Defines what values can be returned by
Overview: Shared Memory Hardware. Shared Address Space Systems. Shared Address Space and Shared Memory Computers. Shared Memory Hardware
 Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware
 Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
TDT 4260 lecture 3 spring semester 2015
 1 TDT 4260 lecture 3 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU http://research.idi.ntnu.no/multicore 2 Lecture overview Repetition Chap.1: Performance,
1 TDT 4260 lecture 3 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU http://research.idi.ntnu.no/multicore 2 Lecture overview Repetition Chap.1: Performance,
Review: Multiprocessor. CPE 631 Session 21: Multiprocessors (Part 2) Potential HW Coherency Solutions. Bus Snooping Topology
 Potential HW Coherency Solutions. Bus Snooping Topology") Review: Multiprocessor CPE 631 Session 21: Multiprocessors (Part 2) Department of Electrical and Computer Engineering University of Alabama in Huntsville Basic issues and terminology Communication: share
Review: Multiprocessor CPE 631 Session 21: Multiprocessors (Part 2) Department of Electrical and Computer Engineering University of Alabama in Huntsville Basic issues and terminology Communication: share
CS 136: Advanced Architecture. Review of Caches
 1 / 30 CS 136: Advanced Architecture Review of Caches 2 / 30 Why Caches? Introduction Basic goal: Size of cheapest memory... At speed of most expensive Locality makes it work Temporal locality: If you
1 / 30 CS 136: Advanced Architecture Review of Caches 2 / 30 Why Caches? Introduction Basic goal: Size of cheapest memory... At speed of most expensive Locality makes it work Temporal locality: If you
CS3350B Computer Architecture
 CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Intro to Multiprocessors
 The Big Picture: Where are We Now? Intro to Multiprocessors Output Output Datapath Input Input Datapath [dapted from Computer Organization and Design, Patterson & Hennessy, 2005] Multiprocessor multiple
The Big Picture: Where are We Now? Intro to Multiprocessors Output Output Datapath Input Input Datapath [dapted from Computer Organization and Design, Patterson & Hennessy, 2005] Multiprocessor multiple
Page 1. Memory Hierarchies (Part 2)
") Memory Hierarchies (Part ) Outline of Lectures on Memory Systems Memory Hierarchies Cache Memory 3 Virtual Memory 4 The future Increasing distance from the processor in access time Review: The Memory Hierarchy
Memory Hierarchies (Part ) Outline of Lectures on Memory Systems Memory Hierarchies Cache Memory 3 Virtual Memory 4 The future Increasing distance from the processor in access time Review: The Memory Hierarchy