Multiprocessors continued
|
|
|
- Holly O’Brien’
- 6 years ago
- Views:
Transcription
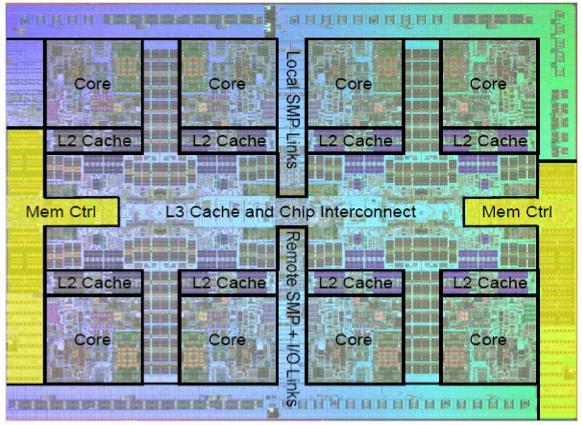

1 Multiprocessors continued IBM's Power7 with eight cores and 32 Mbytes edram Quad-core Kentsfield package
2 Quick overview Why do we have multi-processors? What type of programs will work well? What type work poorly?
3 Overview of today s lecture Performance expectations Amdahl s law. Review Shared memory vs. message passing Interconnection networks Thread-level parallelism Context Bandwidth Coherence Snoopy-bus consistency protocols. Consistency Strong (sequential consistency), Weak (relaxed consistency) Locking mechanisms Test and Set; Load lock/store conditional
4 Let s start at the top: Performance Expectations Amdahl's Law: If a fraction P of your program can be sped up by a factor of S, then your performance is: So if P=0.3 and S=2 we get (1/(.7+.15)) 1/.85 which is about Question: If you have a program in which 10% can t be done in parallel (i.e. must be serial) and you ve got 64 processors, what s the best speed up you could hope for? ( 1 1 P) P S
5 TLP Review: Thread-Level Parallelism struct acct_t { int bal; }; shared struct acct_t accts[max_acct]; int id,amt; if (accts[id].bal >= amt) { accts[id].bal -= amt; spew_cash(); } 0: addi r1,accts,r3 1: ld 0(r3),r4 2: blt r4,r2,6 3: sub r4,r2,r4 4: st r4,0(r3) 5: call spew_cash 6: Thread-level parallelism (TLP) Collection of asynchronous tasks: not started and stopped together Data shared loosely, dynamically Example: database/web server (each query is a thread) accts is shared, can t register allocate 1 even if it were scalar id and amt are private variables, register allocated to r1, r2 1 Keyword in C is volatile
6 TLP Thread level parallelism (TLP) We exploited parallelism at the instruction level (ILP) Hardware can t find TLP. Complier/programmer needs to find it (we lack the window size) Compilers getting better at this. But hardware can take advantage of TLP Run on multiple cores If data is shared, provide rules to the software about what it can assume about shared data.
7 Shared memory vs. message passing Review: Pluses: Why Shared Memory? For applications looks like multitasking uniprocessor For OS only evolutionary extensions required Easy to do communication without OS Software can worry about correctness first then performance Minuses: Result: Proper synchronization is complex Communication is implicit so harder to optimize Hardware designers must implement Traditionally bus-based Symmetric Multiprocessors (SMPs), and now the CMPs are the most success parallel machines ever And the first with multi-billion-dollar markets
8 Shared memory vs. message passing Alternative to shared memory? Explicit message passing Rather difficult to code We ll not be doing anything with it But while not a 470 topic, it is important. Graduate level parallel programming class covers this in detail.
9 Shared memory vs. message passing But shared memory systems have their Two in particular own problems Cache coherence Memory consistency model Different solutions depending on interconnect So let s do interconnect now, and jump back to these two later.
10 Interconnect Review: Interconnect There are many ways to connect processors. Shared network Bus-based Crossbar Point-to-point More topologies than I want to think about Mesh (in any amount of dimensionality) Torus (in any amount of dimensionality) ncube Tree etc. etc. etc. etc.
11 Interconnect Shared vs. Point-to-Point Networks Shared network: e.g., bus (left) + Low latency Low bandwidth: doesn t scale beyond ~8 processors + Shared property simplifies cache coherence protocols (later) Point-to-point network: e.g., mesh or ring (right) Longer latency: may need multiple hops to communicate + Higher bandwidth: scales to 1000s of processors Cache coherence protocols are complex Mem R Mem R Mem R Mem R Mem R R Mem Mem R R Mem
12 Interconnect Organizing Point-To-Point Networks Network topology: organization of network Tradeoff performance (connectivity, latency, bandwidth) cost Router chips Networks that require separate router chips are indirect Networks that use processor/memory/router packages are direct + Fewer components, Glueless MP Point-to-point network examples Indirect tree (left) Direct mesh or ring (right) R R R Mem R R Mem Mem R Mem R Mem R Mem R Mem R R Mem
13 Interconnect Implementation #1: Snooping Bus MP Mem Mem Mem Mem Two basic implementations Bus-based systems Typically small: 2 8 (maybe 16) processors Typically processors split from memories (UMA) Sometimes multiple processors on single chip (CMP) Symmetric multiprocessors (SMPs) Common, I use one everyday
14 Interconnect Implementation #2: Scalable MP Mem R R Mem Mem R R Mem General point-to-point network-based systems Typically processor/memory/router blocks (NUMA) Glueless MP: no need for additional glue chips Can be arbitrarily large: 1000 s of processors Massively parallel processors (MPPs)
15 Bandwidth Context: Bandwidth As in the uniprocessor we need caches To reduce average memory latency. But recall caches are also important for reducing bandwidth. And now we ve got (say) 4x as many requests We ve probably got a bandwidth problem. It s important that caches work well! Mem R Mem R Mem R Mem R
16 Next: Shared data It s easy without a cache! Just make all accesses go to memory. But we need a cache, both for latency and bandwidth reasons. With caches, two different processors might see an incoherent view of the same memory location. Let s quickly see why.
17 Processor 0 0: addi r1,accts,r3 1: ld 0(r3),r4 2: blt r4,r2,6 3: sub r4,r2,r4 4: st r4,0(r3) 5: call spew_cash An Example Execution Processor 1 0: addi r1,accts,r3 1: ld 0(r3),r4 2: blt r4,r2,6 3: sub r4,r2,r4 4: st r4,0(r3) 5: call spew_cash CPU0 CPU1 Mem Two $100 withdrawals from account #241 at two ATMs Each transaction maps to thread on different processor Track accts[241].bal (address is in r3)
18 No-Cache, No-Problem Processor 0 0: addi r1,accts,r3 1: ld 0(r3),r4 2: blt r4,r2,6 3: sub r4,r2,r4 4: st r4,0(r3) 5: call spew_cash Processor 1 0: addi r1,accts,r3 1: ld 0(r3),r4 2: blt r4,r2,6 3: sub r4,r2,r4 4: st r4,0(r3) 5: call spew_cash Scenario I: processors have no caches No problem
19 Processor 0 0: addi r1,accts,r3 1: ld 0(r3),r4 2: blt r4,r2,6 3: sub r4,r2,r4 4: st r4,0(r3) 5: call spew_cash Cache Incoherence Processor 1 0: addi r1,accts,r3 1: ld 0(r3),r4 2: blt r4,r2,6 3: sub r4,r2,r4 4: st r4,0(r3) 5: call spew_cash 500 V: D: D:400 V: D:400 D: Scenario II: processors have write-back caches Potentially 3 copies of accts[241].bal: memory, p0$, p1$ Can get incoherent (inconsistent)
20 D$ tags D$ data Hardware Cache Coherence CPU Coherence controller: CC Examines bus traffic (addresses and data) Executes coherence protocol bus What to do with local copy when you see different things happening on bus
21 Snooping Cache-Coherence Protocols Bus provides serialization point Each cache controller snoops all bus transactions take action to ensure coherence invalidate update supply value depends on state of the block and the protocol
22 Snooping Design Choices Controller updates state of blocks in response to processor and snoop events and generates bus xactions Often have duplicate cache tags Snoopy protocol set of states state-transition diagram actions Basic Choices write-through vs. write-back invalidate vs. update Processor ld/st Cache State Tag... Data Snoop (observed bus transaction)
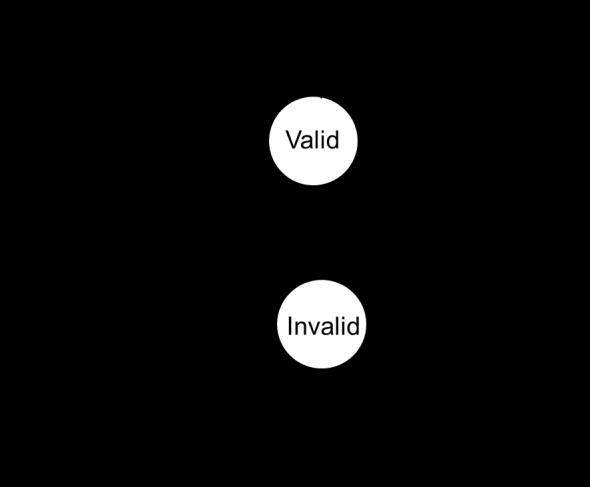
23 Simple bus-based scheme Write through/no write allocate with invalidate protocol. Either have the data or don t (Valid or Invalid) Bus just supports read and write. When anyone else does a write, we go to I. Could go with an update protocol. How would that be different? What are the 4C s of caching now?
24 The Simple Invalidate Snooping Protocol PrRd / -- PrWr / BusWr Write-through, nowrite-allocate cache PrRd / BusRd Valid Invalid BusWr Inputs: PrRd, PrWr, BusRd, BusWr Outputs: BusRd, BusWr PrWr / BusWr Yes, that s confusing!

25 Example time Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar. Wenisch Processor 1 Processor 2 Bus Processor Transaction Read A Read A Write A Write A Cache State Processor Transaction Read A Read A Write A : PrRd, PrWr, BusRd, BusWr Cache State
26 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar. Wenisch More Generally: MOESI [Sweazey & Smith ISCA86] M - Modified (dirty) O - Owned (dirty but shared) WHY? E - Exclusive (clean unshared) only copy, not dirty S - Shared I - Invalid Variants MSI MESI MOSI MOESI S O M E I ownership validity exclusiveness
27 MESI Write Back/Write allocate/invalidate Cache line is in one of 4 states Modified (dirty) Exclusive (clean unshared) only copy, not dirty Shared Invalid Can issue 4 transactions on the bus (Read, Write, Read and Invalidate, Invalidate. Each processor snoops it s own cache and checks to see if it has the data. If so announces if it has it clean (HIT) or dirty (HITM)
28 Actions: PrRd, PrWr, BRL Bus Read Line (BusRd) BWL Bus Write Line (BusWr) BRIL Bus Read and Invalidate BIL Bus Invalidate Line MESI example Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar. Wenisch Processor 1 Processor 2 Bus Processor Transaction Read A Read A Write A Write A Cache State Processor Transaction Read A Read A Write A Cache State M - Modified (dirty) E - Exclusive (clean unshared) only copy, not dirty S - Shared I - Invalid

29 A wrong FSM for MESI It is actually not so much wrong as different (well, some of both)
30 Let s draw a better one.
31 Two processors, each have a 2-line direct-mapped cache with each line consisting of 16 bytes. R, W, R&I, I are the transactions. Fill in the tables. Processor Address Read/Write Bus transaction(s) Hit/Miss HIT/ HITM 4C miss type (if any) 1 0x100 Read 1 0x100 Write 1 0x210 Read 1 0x220 Read 2 0x210 Read 2 0x220 Write 1 0x220 Read Proc 1 Proc 2 Address State Address State Set 0 Set 0 Set 1 Set 1
32 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Scalability problems of Snoopy Coherence Prohibitive bus bandwidth Required bandwidth grows with # CPUS but available BW per bus is fixed Adding busses makes serialization/ordering hard Prohibitive processor snooping bandwidth All caches do tag lookup when ANY processor accesses memory Inclusion limits this to L2, but still lots of lookups Upshot: bus-based coherence doesn t scale beyond 8 16 CPUs
33 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Scalable Cache Coherence Scalable cache coherence: two part solution Part I: bus bandwidth Replace non-scalable bandwidth substrate (bus) with scalable bandwidth one (point-to-point network, e.g., mesh) Part II: processor snooping bandwidth Interesting: most snoops result in no action Replace non-scalable broadcast protocol (spam everyone) with scalable directory protocol (only spam processors that care)
34 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Directory Coherence Protocols Observe: physical address space statically partitioned + Can easily determine which memory module holds a given line That memory module sometimes called home Can t easily determine which processors have line in their caches Bus-based protocol: broadcast events to all processors/caches ± Simple and fast, but non-scalable Directories: non-broadcast coherence protocol Extend memory to track caching information For each physical cache line whose home this is, track: Owner: which processor has a dirty copy (I.e., M state) Sharers: which processors have clean copies (I.e., S state) Processor sends coherence event to home directory Home directory only sends events to processors that care
35 Read Processing Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Node #1 Directory Node #2 Read A (miss) A: Shared, #1
36 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Write Processing Node #1 Directory Node #2 Read A (miss) A: Shared, #1 A: Mod., #2 Trade-offs: Longer accesses (3-hop between Processor, directory, other Processor) Lower bandwidth no snoops necessary Makes sense either for CMPs (lots of L1 miss traffic) or large-scale servers (shared-memory MP > 32 nodes)
37 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Serialization and Ordering Let A and flag be 0 P1 P2 A += 5 while (flag == 0) flag = 1 print A Assume A and flag are in different cache blocks What happens? How do you implement it correctly?
38 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Coherence vs. Consistency Intuition says loads should return latest value what is latest? Coherence concerns only one memory location Consistency concerns apparent ordering for all locations A Memory System is Coherent if can serialize all operations to that location such that, operations performed by any processor appear in program order program order = order defined program text or assembly code value returned by a read is value written by last store to that location
39 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Why Coherence!= Consistency /* initial A = B = flag = 0 */ P1 P2 A = 1; while (flag == 0); /* spin */ B = 1; print A; flag = 1; print B; Intuition says printed A = B = 1 Coherence doesn t say anything. Why? Your uniprocessor ordering mechanisms (ld/st queue) hurts here. Why?
40 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Sequential Consistency (SC) processors issue memory ops in program order P1 P2 P3 switch randomly set after each memory op provides single sequential order among all operations Memory
41 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Sufficient Conditions for SC Every proc. issues memory ops in program order Memory ops happen (start and end) atomically must wait for store to complete before issuing next memory op after load, issuing proc waits for load to complete, before issuing next op Easily implemented with a shared bus
42 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Relaxed Memory Models Motivation with Directory Protocols Misses have longer latency (do cache hits to get to next miss) Collecting acknowledgements can take even longer Recall SC has Each processor generates at total order of its reads and writes (R-->R, R-->W, W-->W, & W-->R) That are interleaved into a global total order Example Relaxed Models PC: Relax ordering from writes to (other proc s) reads RC: Relax all read/write orderings (but add fences )
43 Locks Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch
44 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Lock-based Mutual Exclusion xfer Crit. sec release wait xfer Crit. sec release wait xfer Crit. sec Acquire starts No contention: Want low latency Synchronization period Acquire done Release starts Contention: Want low period Low traffic Fairness Release done
; lock_variable = 1 Context switch!")
45 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch How Not to Implement Locks LOCK while (lock_variable == 1); lock_variable = 1 Context switch! UNLOCK lock_variable = 0;
46 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Solution: Atomic Read-Modify-Write Test&Set(r,x) {r=m[x]; m[x]=1;} r is register m[x] is memory location x Fetch&Op(r1,r2,x,op) {r1=m[x]; m[x]=op(r1,r2);} Swap(r,x) {temp=m[x]; m[x]=r; r=temp;} Compare&Swap(r1,r2,x) {temp=r2; r2=m[x]; if r1==r2 then m[x]=temp;}
47 Lock: Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Write a lock and unlock with test-and-set unlock:
48 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Implementing RMWs Bus-based systems: Hold bus and issue load/store operations without any intervening accesses by other processors Scalable systems Acquire exclusive ownership via cache coherence Perform load/store operations without allowing external coherence requests
49 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Load-Locked Store-Conditional Load-locked Issues a normal load and sets a flag and address field Store-conditional Checks that flag is set and address matches If so, performs store and sets store register to 1. Otherwise sets store register to 0. Flag is cleared by Invalidation Cache eviction Context switch lock: lda r2, #1 ll r1, lock_variable sc lock_variable, r2 beqz r2, lock neqz r1, lock unlock:st lock_variable, #0 // branch not equal to zero
50 Brehob Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar, Wenisch Test-and-Set Spin Lock (T&S) Lock is acquire, Unlock is release acquire(lock_ptr): while (true): // Perform test-and-set old = compare_and_swap(lock_ptr, UNLOCKED, LOCKED) if (old == UNLOCKED): break // lock acquired! // keep spinning, back to top of while loop release(lock_ptr): store[lock_ptr] <- UNLOCKED Performance problem CAS is both a read and write; spinning causes lots of invalidations
Multiprocessors continued
 Multiprocessors continued IBM's Power7 with eight cores and 32 Mbytes edram Quad-core Kentsfield package Quick overview Why do we have multi-processors? What type of programs will work well? What type
Multiprocessors continued IBM's Power7 with eight cores and 32 Mbytes edram Quad-core Kentsfield package Quick overview Why do we have multi-processors? What type of programs will work well? What type
On Power and Multi-Processors
 Brehob -- Portions Brooks, Dutta, Mudge & Wenisch On Power and Multi-Processors Finishing up power issues and how those issues have led us to multi-core processors. Introduce multi-processor systems. Brehob
Brehob -- Portions Brooks, Dutta, Mudge & Wenisch On Power and Multi-Processors Finishing up power issues and how those issues have led us to multi-core processors. Introduce multi-processor systems. Brehob
On Power and Multi-Processors
 Brehob 2014 -- Portions Brooks, Dutta, Mudge & Wenisch On Power and Multi-Processors Finishing up power issues and how those issues have led us to multi-core processors. Introduce multi-processor systems.
Brehob 2014 -- Portions Brooks, Dutta, Mudge & Wenisch On Power and Multi-Processors Finishing up power issues and how those issues have led us to multi-core processors. Introduce multi-processor systems.
Wenisch Portions Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, Vijaykumar. Prof. Thomas Wenisch. Lecture 23 EECS 470.
 Multiprocessors Fall 2007 Prof. Thomas Wenisch www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth Shen, Smith, Sohi, and Vijaykumar of Carnegie
Multiprocessors Fall 2007 Prof. Thomas Wenisch www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth Shen, Smith, Sohi, and Vijaykumar of Carnegie
EECS 470. Lecture 17 Multiprocessors I. Fall 2018 Jon Beaumont
 Lecture 17 Multiprocessors I Fall 2018 Jon Beaumont www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth Shen, Smith, Sohi, and Vijaykumar of
Lecture 17 Multiprocessors I Fall 2018 Jon Beaumont www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth Shen, Smith, Sohi, and Vijaykumar of
Today s Outline: Shared Memory Review. Shared Memory & Concurrency. Concurrency v. Parallelism. Thread-Level Parallelism. CS758: Multicore Programming
 CS758: Multicore Programming Today s Outline: Shared Memory Review Shared Memory & Concurrency Introduction to Shared Memory Thread-Level Parallelism Shared Memory Prof. David A. Wood University of Wisconsin-Madison
CS758: Multicore Programming Today s Outline: Shared Memory Review Shared Memory & Concurrency Introduction to Shared Memory Thread-Level Parallelism Shared Memory Prof. David A. Wood University of Wisconsin-Madison
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Shared-Memory Multi-Processors Shared-Memory Multiprocessors Multiple threads use shared memory (address space) SysV Shared Memory or Threads in software Communication implicit
CSE 502: Computer Architecture Shared-Memory Multi-Processors Shared-Memory Multiprocessors Multiple threads use shared memory (address space) SysV Shared Memory or Threads in software Communication implicit
CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 1 (Chapter 5)
 Symmetric Multiprocessors Part 1 (Chapter 5)") CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 1 (Chapter 5) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived
CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Symmetric Multiprocessors Part 1 (Chapter 5) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Thread-Level Parallelism. Shared Memory. This Unit: Shared Memory Multiprocessors. U. Wisconsin CS/ECE 752 Advanced Computer Architecture I
 U. Wisconsin CS/ECE 752 Advanced Computer Architecture I Prof. David A. Wood Unit 12: Shared-ory Multiprocessors Slides developed by Amir Roth of University of Pennsylvania with sources that included University
U. Wisconsin CS/ECE 752 Advanced Computer Architecture I Prof. David A. Wood Unit 12: Shared-ory Multiprocessors Slides developed by Amir Roth of University of Pennsylvania with sources that included University
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming Cache design review Let s say your code executes int x = 1; (Assume for simplicity x corresponds to the address 0x12345604
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Computer Architecture
 18-447 Computer Architecture CSCI-564 Advanced Computer Architecture Lecture 29: Consistency & Coherence Lecture 20: Consistency and Coherence Bo Wu Prof. Onur Mutlu Colorado Carnegie School Mellon University
18-447 Computer Architecture CSCI-564 Advanced Computer Architecture Lecture 29: Consistency & Coherence Lecture 20: Consistency and Coherence Bo Wu Prof. Onur Mutlu Colorado Carnegie School Mellon University
EECS 570 Lecture 9. Snooping Coherence. Winter 2017 Prof. Thomas Wenisch h6p://www.eecs.umich.edu/courses/eecs570/
 Snooping Coherence Winter 2017 Prof. Thomas Wenisch h6p://www.eecs.umich.edu/courses/eecs570/ Slides developed in part by Profs. Falsafi, Hardavellas, Nowatzyk, and Wenisch of EPFL, Northwestern, CMU,
Snooping Coherence Winter 2017 Prof. Thomas Wenisch h6p://www.eecs.umich.edu/courses/eecs570/ Slides developed in part by Profs. Falsafi, Hardavellas, Nowatzyk, and Wenisch of EPFL, Northwestern, CMU,
ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols CA SMP and cache coherence
 Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University
 EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
Lecture 24: Multiprocessing Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 24: Multiprocessing Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Most of the rest of this
Systems Group Department of Computer Science ETH Zürich Lecture 24: Multiprocessing Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Most of the rest of this
PARALLEL MEMORY ARCHITECTURE
 PARALLEL MEMORY ARCHITECTURE Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 6 is due tonight n The last
PARALLEL MEMORY ARCHITECTURE Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 6 is due tonight n The last
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Cache Coherence. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Page 1. SMP Review. Multiprocessors. Bus Based Coherence. Bus Based Coherence. Characteristics. Cache coherence. Cache coherence
 SMP Review Multiprocessors Today s topics: SMP cache coherence general cache coherence issues snooping protocols Improved interaction lots of questions warning I m going to wait for answers granted it
SMP Review Multiprocessors Today s topics: SMP cache coherence general cache coherence issues snooping protocols Improved interaction lots of questions warning I m going to wait for answers granted it
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Goldibear and the 3 Locks. Programming With Locks Is Tricky. More Lock Madness. And To Make It Worse. Transactional Memory: The Big Idea
 Programming With Locks s Tricky Multicore processors are the way of the foreseeable future thread-level parallelism anointed as parallelism model of choice Just one problem Writing lock-based multi-threaded
Programming With Locks s Tricky Multicore processors are the way of the foreseeable future thread-level parallelism anointed as parallelism model of choice Just one problem Writing lock-based multi-threaded
Multiprocessors 1. Outline
 Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence
 1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
Processor Architecture
 Processor Architecture Shared Memory Multiprocessors M. Schölzel The Coherence Problem s may contain local copies of the same memory address without proper coordination they work independently on their
Processor Architecture Shared Memory Multiprocessors M. Schölzel The Coherence Problem s may contain local copies of the same memory address without proper coordination they work independently on their
Fall 2015 :: CSE 610 Parallel Computer Architectures. Cache Coherence. Nima Honarmand
 Cache Coherence Nima Honarmand Cache Coherence: Problem (Review) Problem arises when There are multiple physical copies of one logical location Multiple copies of each cache block (In a shared-mem system)
Cache Coherence Nima Honarmand Cache Coherence: Problem (Review) Problem arises when There are multiple physical copies of one logical location Multiple copies of each cache block (In a shared-mem system)
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy
 EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
EN2910A: Advanced Computer Architecture Topic 05: Coherency of Memory Hierarchy Prof. Sherief Reda School of Engineering Brown University Material from: Parallel Computer Organization and Design by Debois,
Cache Coherence. (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri
 Mainak Chaudhuri") Cache Coherence (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri mainakc@cse.iitk.ac.in 1 Setting Agenda Software: shared address space Hardware: shared memory multiprocessors Cache
Cache Coherence (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri mainakc@cse.iitk.ac.in 1 Setting Agenda Software: shared address space Hardware: shared memory multiprocessors Cache
Lecture 10: Cache Coherence: Part I. Parallel Computer Architecture and Programming CMU /15-618, Spring 2015
 Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
Lecture 10: Cache Coherence: Part I Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Marble House The Knife (Silent Shout) Before starting The Knife, we were working
Cache Coherence and Atomic Operations in Hardware
 Cache Coherence and Atomic Operations in Hardware Previously, we introduced multi-core parallelism. Today we ll look at 2 things: 1. Cache coherence 2. Instruction support for synchronization. And some
Cache Coherence and Atomic Operations in Hardware Previously, we introduced multi-core parallelism. Today we ll look at 2 things: 1. Cache coherence 2. Instruction support for synchronization. And some
Chapter 5. Thread-Level Parallelism
 Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
CS252 Spring 2017 Graduate Computer Architecture. Lecture 12: Cache Coherence
 CS252 Spring 2017 Graduate Computer Architecture Lecture 12: Cache Coherence Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture 11 Memory Systems DRAM
CS252 Spring 2017 Graduate Computer Architecture Lecture 12: Cache Coherence Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time in Lecture 11 Memory Systems DRAM
Beyond ILP In Search of More Parallelism
 Beyond ILP In Search of More Parallelism Instructor: Nima Honarmand Getting More Performance OoO superscalars extract ILP from sequential programs Hardly more than 1-2 IPC on real workloads Although some
Beyond ILP In Search of More Parallelism Instructor: Nima Honarmand Getting More Performance OoO superscalars extract ILP from sequential programs Hardly more than 1-2 IPC on real workloads Although some
Overview: Shared Memory Hardware. Shared Address Space Systems. Shared Address Space and Shared Memory Computers. Shared Memory Hardware
 Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware
 Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
Introduction. Coherency vs Consistency. Lec-11. Multi-Threading Concepts: Coherency, Consistency, and Synchronization
 Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Foundations of Computer Systems
 18-600 Foundations of Computer Systems Lecture 21: Multicore Cache Coherence John P. Shen & Zhiyi Yu November 14, 2016 Prevalence of multicore processors: 2006: 75% for desktops, 85% for servers 2007:
18-600 Foundations of Computer Systems Lecture 21: Multicore Cache Coherence John P. Shen & Zhiyi Yu November 14, 2016 Prevalence of multicore processors: 2006: 75% for desktops, 85% for servers 2007:
EECS 570 Lecture 2. Message Passing & Shared Memory. Winter 2018 Prof. Satish Narayanasamy
 Message Passing & Shared Memory Winter 2018 Prof. Satish Narayanasamy http://www.eecs.umich.edu/courses/eecs570/ Intel Paragon XP/S Slides developed in part by Drs. Adve, Falsafi, Martin, Musuvathi, Narayanasamy,
Message Passing & Shared Memory Winter 2018 Prof. Satish Narayanasamy http://www.eecs.umich.edu/courses/eecs570/ Intel Paragon XP/S Slides developed in part by Drs. Adve, Falsafi, Martin, Musuvathi, Narayanasamy,
Chapter 5 Thread-Level Parallelism. Abdullah Muzahid
 Chapter 5 Thread-Level Parallelism Abdullah Muzahid 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors is saturating + Modern multiple issue processors are becoming very complex
Chapter 5 Thread-Level Parallelism Abdullah Muzahid 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors is saturating + Modern multiple issue processors are becoming very complex
Chapter 8. Multiprocessors. In-Cheol Park Dept. of EE, KAIST
 Chapter 8. Multiprocessors In-Cheol Park Dept. of EE, KAIST Can the rapid rate of uniprocessor performance growth be sustained indefinitely? If the pace does slow down, multiprocessor architectures will
Chapter 8. Multiprocessors In-Cheol Park Dept. of EE, KAIST Can the rapid rate of uniprocessor performance growth be sustained indefinitely? If the pace does slow down, multiprocessor architectures will
Shared Memory Architectures. Approaches to Building Parallel Machines
 Shared Memory Architectures Arvind Krishnamurthy Fall 2004 Approaches to Building Parallel Machines P 1 Switch/Bus P n Scale (Interleaved) First-level $ P 1 P n $ $ (Interleaved) Main memory Shared Cache
Shared Memory Architectures Arvind Krishnamurthy Fall 2004 Approaches to Building Parallel Machines P 1 Switch/Bus P n Scale (Interleaved) First-level $ P 1 P n $ $ (Interleaved) Main memory Shared Cache
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Cache Coherence in Bus-Based Shared Memory Multiprocessors
 Cache Coherence in Bus-Based Shared Memory Multiprocessors Shared Memory Multiprocessors Variations Cache Coherence in Shared Memory Multiprocessors A Coherent Memory System: Intuition Formal Definition
Cache Coherence in Bus-Based Shared Memory Multiprocessors Shared Memory Multiprocessors Variations Cache Coherence in Shared Memory Multiprocessors A Coherent Memory System: Intuition Formal Definition
1. Memory technology & Hierarchy
 1. Memory technology & Hierarchy Back to caching... Advances in Computer Architecture Andy D. Pimentel Caches in a multi-processor context Dealing with concurrent updates Multiprocessor architecture In
1. Memory technology & Hierarchy Back to caching... Advances in Computer Architecture Andy D. Pimentel Caches in a multi-processor context Dealing with concurrent updates Multiprocessor architecture In
Page 1. Outline. Coherence vs. Consistency. Why Consistency is Important
 Outline ECE 259 / CPS 221 Advanced Computer Architecture II (Parallel Computer Architecture) Memory Consistency Models Copyright 2006 Daniel J. Sorin Duke University Slides are derived from work by Sarita
Outline ECE 259 / CPS 221 Advanced Computer Architecture II (Parallel Computer Architecture) Memory Consistency Models Copyright 2006 Daniel J. Sorin Duke University Slides are derived from work by Sarita
Parallel Computer Architecture Lecture 5: Cache Coherence. Chris Craik (TA) Carnegie Mellon University
 Carnegie Mellon University") 18-742 Parallel Computer Architecture Lecture 5: Cache Coherence Chris Craik (TA) Carnegie Mellon University Readings: Coherence Required for Review Papamarcos and Patel, A low-overhead coherence solution
18-742 Parallel Computer Architecture Lecture 5: Cache Coherence Chris Craik (TA) Carnegie Mellon University Readings: Coherence Required for Review Papamarcos and Patel, A low-overhead coherence solution
Lecture 11: Snooping Cache Coherence: Part II. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Lecture 11: Snooping Cache Coherence: Part II CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Assignment 2 due tonight 11:59 PM - Recall 3-late day policy Assignment
Lecture 11: Snooping Cache Coherence: Part II CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Assignment 2 due tonight 11:59 PM - Recall 3-late day policy Assignment
Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley
 Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley Avinash Kodi Department of Electrical Engineering & Computer
Fall 2012 EE 6633: Architecture of Parallel Computers Lecture 4: Shared Address Multiprocessors Acknowledgement: Dave Patterson, UC Berkeley Avinash Kodi Department of Electrical Engineering & Computer
4 Chip Multiprocessors (I) Chip Multiprocessors (ACS MPhil) Robert Mullins
 Chip Multiprocessors (ACS MPhil) Robert Mullins") 4 Chip Multiprocessors (I) Robert Mullins Overview Coherent memory systems Introduction to cache coherency protocols Advanced cache coherency protocols, memory systems and synchronization covered in the
4 Chip Multiprocessors (I) Robert Mullins Overview Coherent memory systems Introduction to cache coherency protocols Advanced cache coherency protocols, memory systems and synchronization covered in the
CMSC Computer Architecture Lecture 15: Memory Consistency and Synchronization. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 15: Memory Consistency and Synchronization Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 5 (multi-core) " Basic requirements: out later today
CMSC 22200 Computer Architecture Lecture 15: Memory Consistency and Synchronization Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 5 (multi-core) " Basic requirements: out later today
Limitations of parallel processing
 Your professor du jour: Steve Gribble gribble@cs.washington.edu 323B Sieg Hall all material in this lecture in Henessey and Patterson, Chapter 8 635-640 645, 646 654-665 11/8/00 CSE 471 Multiprocessors
Your professor du jour: Steve Gribble gribble@cs.washington.edu 323B Sieg Hall all material in this lecture in Henessey and Patterson, Chapter 8 635-640 645, 646 654-665 11/8/00 CSE 471 Multiprocessors
EECS 570 Lecture 11. Directory-based Coherence. Winter 2019 Prof. Thomas Wenisch
 Directory-based Coherence Winter 2019 Prof. Thomas Wenisch http://www.eecs.umich.edu/courses/eecs570/ Slides developed in part by Profs. Adve, Falsafi, Hill, Lebeck, Martin, Narayanasamy, Nowatzyk, Reinhardt,
Directory-based Coherence Winter 2019 Prof. Thomas Wenisch http://www.eecs.umich.edu/courses/eecs570/ Slides developed in part by Profs. Adve, Falsafi, Hill, Lebeck, Martin, Narayanasamy, Nowatzyk, Reinhardt,
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Alewife Messaging. Sharing of Network Interface. Alewife User-level event mechanism. CS252 Graduate Computer Architecture.
 CS252 Graduate Computer Architecture Lecture 18 April 5 th, 2010 ory Consistency Models and Snoopy Bus Protocols Alewife Messaging Send message write words to special network interface registers Execute
CS252 Graduate Computer Architecture Lecture 18 April 5 th, 2010 ory Consistency Models and Snoopy Bus Protocols Alewife Messaging Send message write words to special network interface registers Execute
Parallel Computers. CPE 631 Session 20: Multiprocessors. Flynn s Tahonomy (1972) Why Multiprocessors?
 Why Multiprocessors?") Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Shared Symmetric Memory Systems
 Shared Symmetric Memory Systems Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Shared Symmetric Memory Systems Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Multiprocessors II: CC-NUMA DSM. CC-NUMA for Large Systems
 Multiprocessors II: CC-NUMA DSM DSM cache coherence the hardware stuff Today s topics: what happens when we lose snooping new issues: global vs. local cache line state enter the directory issues of increasing
Multiprocessors II: CC-NUMA DSM DSM cache coherence the hardware stuff Today s topics: what happens when we lose snooping new issues: global vs. local cache line state enter the directory issues of increasing
Other consistency models
 Last time: Symmetric multiprocessing (SMP) Lecture 25: Synchronization primitives Computer Architecture and Systems Programming (252-0061-00) CPU 0 CPU 1 CPU 2 CPU 3 Timothy Roscoe Herbstsemester 2012
Last time: Symmetric multiprocessing (SMP) Lecture 25: Synchronization primitives Computer Architecture and Systems Programming (252-0061-00) CPU 0 CPU 1 CPU 2 CPU 3 Timothy Roscoe Herbstsemester 2012
Lecture 20: Multi-Cache Designs. Spring 2018 Jason Tang
 Lecture 20: Multi-Cache Designs Spring 2018 Jason Tang 1 Topics Split caches Multi-level caches Multiprocessor caches 2 3 Cs of Memory Behaviors Classify all cache misses as: Compulsory Miss (also cold-start
Lecture 20: Multi-Cache Designs Spring 2018 Jason Tang 1 Topics Split caches Multi-level caches Multiprocessor caches 2 3 Cs of Memory Behaviors Classify all cache misses as: Compulsory Miss (also cold-start
Shared Memory Multiprocessors
 Parallel Computing Shared Memory Multiprocessors Hwansoo Han Cache Coherence Problem P 0 P 1 P 2 cache load r1 (100) load r1 (100) r1 =? r1 =? 4 cache 5 cache store b (100) 3 100: a 100: a 1 Memory 2 I/O
Parallel Computing Shared Memory Multiprocessors Hwansoo Han Cache Coherence Problem P 0 P 1 P 2 cache load r1 (100) load r1 (100) r1 =? r1 =? 4 cache 5 cache store b (100) 3 100: a 100: a 1 Memory 2 I/O
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
EN164: Design of Computing Systems Lecture 34: Misc Multi-cores and Multi-processors
 EN164: Design of Computing Systems Lecture 34: Misc Multi-cores and Multi-processors Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Lecture 34: Misc Multi-cores and Multi-processors Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Computer Science 146. Computer Architecture
 Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Module 9: Addendum to Module 6: Shared Memory Multiprocessors Lecture 17: Multiprocessor Organizations and Cache Coherence. The Lecture Contains:
 The Lecture Contains: Shared Memory Multiprocessors Shared Cache Private Cache/Dancehall Distributed Shared Memory Shared vs. Private in CMPs Cache Coherence Cache Coherence: Example What Went Wrong? Implementations
The Lecture Contains: Shared Memory Multiprocessors Shared Cache Private Cache/Dancehall Distributed Shared Memory Shared vs. Private in CMPs Cache Coherence Cache Coherence: Example What Went Wrong? Implementations
Bus-Based Coherent Multiprocessors
 Bus-Based Coherent Multiprocessors Lecture 13 (Chapter 7) 1 Outline Bus-based coherence Memory consistency Sequential consistency Invalidation vs. update coherence protocols Several Configurations for
Bus-Based Coherent Multiprocessors Lecture 13 (Chapter 7) 1 Outline Bus-based coherence Memory consistency Sequential consistency Invalidation vs. update coherence protocols Several Configurations for
Parallel Computer Architecture Spring Distributed Shared Memory Architectures & Directory-Based Memory Coherence
 Parallel Computer Architecture Spring 2018 Distributed Shared Memory Architectures & Directory-Based Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly
Parallel Computer Architecture Spring 2018 Distributed Shared Memory Architectures & Directory-Based Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly
Shared Memory Multiprocessors
 Shared Memory Multiprocessors Jesús Labarta Index 1 Shared Memory architectures............... Memory Interconnect Cache Processor Concepts? Memory Time 2 Concepts? Memory Load/store (@) Containers Time
Shared Memory Multiprocessors Jesús Labarta Index 1 Shared Memory architectures............... Memory Interconnect Cache Processor Concepts? Memory Time 2 Concepts? Memory Load/store (@) Containers Time
Review: Multiprocessor. CPE 631 Session 21: Multiprocessors (Part 2) Potential HW Coherency Solutions. Bus Snooping Topology
 Potential HW Coherency Solutions. Bus Snooping Topology") Review: Multiprocessor CPE 631 Session 21: Multiprocessors (Part 2) Department of Electrical and Computer Engineering University of Alabama in Huntsville Basic issues and terminology Communication: share
Review: Multiprocessor CPE 631 Session 21: Multiprocessors (Part 2) Department of Electrical and Computer Engineering University of Alabama in Huntsville Basic issues and terminology Communication: share
EC 513 Computer Architecture
 EC 513 Computer Architecture Cache Coherence - Directory Cache Coherence Prof. Michel A. Kinsy Shared Memory Multiprocessor Processor Cores Local Memories Memory Bus P 1 Snoopy Cache Physical Memory P
EC 513 Computer Architecture Cache Coherence - Directory Cache Coherence Prof. Michel A. Kinsy Shared Memory Multiprocessor Processor Cores Local Memories Memory Bus P 1 Snoopy Cache Physical Memory P
Computer Architecture
 Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
Multiplying Performance. Application Domains for Multiprocessors. Multicore: Mainstream Multiprocessors. Identifying Parallelism
 CSE 560 Computer Systems Architecture Multicores (Shared Memory Multiprocessors) Multiplying Performance A single processor can only be so fast Limited clock frequency Limited instruction-level parallelism
CSE 560 Computer Systems Architecture Multicores (Shared Memory Multiprocessors) Multiplying Performance A single processor can only be so fast Limited clock frequency Limited instruction-level parallelism
Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol
 Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu
Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu
Lecture 25: Multiprocessors
 Lecture 25: Multiprocessors Today s topics: Virtual memory wrap-up Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 TLB and Cache Is the cache indexed
Lecture 25: Multiprocessors Today s topics: Virtual memory wrap-up Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 TLB and Cache Is the cache indexed
Page 1. Cache Coherence
 Page 1 Cache Coherence 1 Page 2 Memory Consistency in SMPs CPU-1 CPU-2 A 100 cache-1 A 100 cache-2 CPU-Memory bus A 100 memory Suppose CPU-1 updates A to 200. write-back: memory and cache-2 have stale
Page 1 Cache Coherence 1 Page 2 Memory Consistency in SMPs CPU-1 CPU-2 A 100 cache-1 A 100 cache-2 CPU-Memory bus A 100 memory Suppose CPU-1 updates A to 200. write-back: memory and cache-2 have stale
Lecture 11: Cache Coherence: Part II. Parallel Computer Architecture and Programming CMU /15-618, Spring 2015
 Lecture 11: Cache Coherence: Part II Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Bang Bang (My Baby Shot Me Down) Nancy Sinatra (Kill Bill Volume 1 Soundtrack) It
Lecture 11: Cache Coherence: Part II Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Bang Bang (My Baby Shot Me Down) Nancy Sinatra (Kill Bill Volume 1 Soundtrack) It
Cache Coherence. Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T.
 Coherence Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T. L25-1 Coherence Avoids Stale Data Multicores have multiple private caches for performance Need to provide the illusion
Coherence Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T. L25-1 Coherence Avoids Stale Data Multicores have multiple private caches for performance Need to provide the illusion
Multicore Workshop. Cache Coherency. Mark Bull David Henty. EPCC, University of Edinburgh
 Multicore Workshop Cache Coherency Mark Bull David Henty EPCC, University of Edinburgh Symmetric MultiProcessing 2 Each processor in an SMP has equal access to all parts of memory same latency and bandwidth
Multicore Workshop Cache Coherency Mark Bull David Henty EPCC, University of Edinburgh Symmetric MultiProcessing 2 Each processor in an SMP has equal access to all parts of memory same latency and bandwidth
CS 61C: Great Ideas in Computer Architecture. Amdahl s Law, Thread Level Parallelism
 CS 61C: Great Ideas in Computer Architecture Amdahl s Law, Thread Level Parallelism Instructor: Alan Christopher 07/17/2014 Summer 2014 -- Lecture #15 1 Review of Last Lecture Flynn Taxonomy of Parallel
CS 61C: Great Ideas in Computer Architecture Amdahl s Law, Thread Level Parallelism Instructor: Alan Christopher 07/17/2014 Summer 2014 -- Lecture #15 1 Review of Last Lecture Flynn Taxonomy of Parallel
Lecture 3: Snooping Protocols. Topics: snooping-based cache coherence implementations
 Lecture 3: Snooping Protocols Topics: snooping-based cache coherence implementations 1 Design Issues, Optimizations When does memory get updated? demotion from modified to shared? move from modified in
Lecture 3: Snooping Protocols Topics: snooping-based cache coherence implementations 1 Design Issues, Optimizations When does memory get updated? demotion from modified to shared? move from modified in
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano
 Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
Chapter-4 Multiprocessors and Thread-Level Parallelism
 Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
CS 252 Graduate Computer Architecture. Lecture 11: Multiprocessors-II
 CS 252 Graduate Computer Architecture Lecture 11: Multiprocessors-II Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste http://inst.eecs.berkeley.edu/~cs252
CS 252 Graduate Computer Architecture Lecture 11: Multiprocessors-II Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste http://inst.eecs.berkeley.edu/~cs252
Module 9: "Introduction to Shared Memory Multiprocessors" Lecture 16: "Multiprocessor Organizations and Cache Coherence" Shared Memory Multiprocessors
 Shared Memory Multiprocessors Shared memory multiprocessors Shared cache Private cache/dancehall Distributed shared memory Shared vs. private in CMPs Cache coherence Cache coherence: Example What went
Shared Memory Multiprocessors Shared memory multiprocessors Shared cache Private cache/dancehall Distributed shared memory Shared vs. private in CMPs Cache coherence Cache coherence: Example What went
Module 5: Performance Issues in Shared Memory and Introduction to Coherence Lecture 10: Introduction to Coherence. The Lecture Contains:
 The Lecture Contains: Four Organizations Hierarchical Design Cache Coherence Example What Went Wrong? Definitions Ordering Memory op Bus-based SMP s file:///d /...audhary,%20dr.%20sanjeev%20k%20aggrwal%20&%20dr.%20rajat%20moona/multi-core_architecture/lecture10/10_1.htm[6/14/2012
The Lecture Contains: Four Organizations Hierarchical Design Cache Coherence Example What Went Wrong? Definitions Ordering Memory op Bus-based SMP s file:///d /...audhary,%20dr.%20sanjeev%20k%20aggrwal%20&%20dr.%20rajat%20moona/multi-core_architecture/lecture10/10_1.htm[6/14/2012
SELECTED TOPICS IN COHERENCE AND CONSISTENCY
 SELECTED TOPICS IN COHERENCE AND CONSISTENCY Michel Dubois Ming-Hsieh Department of Electrical Engineering University of Southern California Los Angeles, CA90089-2562 dubois@usc.edu INTRODUCTION IN CHIP
SELECTED TOPICS IN COHERENCE AND CONSISTENCY Michel Dubois Ming-Hsieh Department of Electrical Engineering University of Southern California Los Angeles, CA90089-2562 dubois@usc.edu INTRODUCTION IN CHIP
Page 1. Lecture 12: Multiprocessor 2: Snooping Protocol, Directory Protocol, Synchronization, Consistency. Bus Snooping Topology
 CS252 Graduate Computer Architecture Lecture 12: Multiprocessor 2: Snooping Protocol, Directory Protocol, Synchronization, Consistency Review: Multiprocessor Basic issues and terminology Communication:
CS252 Graduate Computer Architecture Lecture 12: Multiprocessor 2: Snooping Protocol, Directory Protocol, Synchronization, Consistency Review: Multiprocessor Basic issues and terminology Communication:
Cache Coherence. Introduction to High Performance Computing Systems (CS1645) Esteban Meneses. Spring, 2014
 Esteban Meneses. Spring, 2014") Cache Coherence Introduction to High Performance Computing Systems (CS1645) Esteban Meneses Spring, 2014 Supercomputer Galore Starting around 1983, the number of companies building supercomputers exploded:
Cache Coherence Introduction to High Performance Computing Systems (CS1645) Esteban Meneses Spring, 2014 Supercomputer Galore Starting around 1983, the number of companies building supercomputers exploded:
Cache Coherence. Bryan Mills, PhD. Slides provided by Rami Melhem
 Cache Coherence Bryan Mills, PhD Slides provided by Rami Melhem Cache coherence Programmers have no control over caches and when they get updated. x = 2; /* initially */ y0 eventually ends up = 2 y1 eventually
Cache Coherence Bryan Mills, PhD Slides provided by Rami Melhem Cache coherence Programmers have no control over caches and when they get updated. x = 2; /* initially */ y0 eventually ends up = 2 y1 eventually
Lecture 24: Virtual Memory, Multiprocessors
 Lecture 24: Virtual Memory, Multiprocessors Today s topics: Virtual memory Multiprocessors, cache coherence 1 Virtual Memory Processes deal with virtual memory they have the illusion that a very large
Lecture 24: Virtual Memory, Multiprocessors Today s topics: Virtual memory Multiprocessors, cache coherence 1 Virtual Memory Processes deal with virtual memory they have the illusion that a very large
Cache Coherence. Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T.
 Coherence Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T. L5- Coherence Avoids Stale Data Multicores have multiple private caches for performance Need to provide the illusion
Coherence Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T. L5- Coherence Avoids Stale Data Multicores have multiple private caches for performance Need to provide the illusion
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Lecture 25: Multiprocessors. Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization
 Lecture 25: Multiprocessors Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 Snooping-Based Protocols Three states for a block: invalid,
Lecture 25: Multiprocessors Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 Snooping-Based Protocols Three states for a block: invalid,
EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor
 EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration I/O MultiProcessor Summary 2 Virtual memory benifits Using physical memory efficiently
EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration I/O MultiProcessor Summary 2 Virtual memory benifits Using physical memory efficiently
Approaches to Building Parallel Machines. Shared Memory Architectures. Example Cache Coherence Problem. Shared Cache Architectures
 Approaches to Building arallel achines Switch/Bus n Scale Shared ory Architectures (nterleaved) First-level (nterleaved) ain memory n Arvind Krishnamurthy Fall 2004 (nterleaved) ain memory Shared Cache
Approaches to Building arallel achines Switch/Bus n Scale Shared ory Architectures (nterleaved) First-level (nterleaved) ain memory n Arvind Krishnamurthy Fall 2004 (nterleaved) ain memory Shared Cache