MapR Enterprise Hadoop
|
|
|
- Gladys Doyle
- 6 years ago
- Views:
Transcription

1 2014 MapR Technologies 2014 MapR Technologies 1
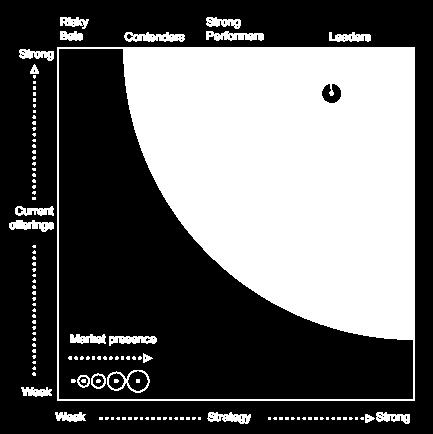









2 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2







3 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS & BUSINESS INTELLIGENCE DATA WAREHOUSE & INTEGRATION INFRASTRUCTURE & CLOUD CONSULTANTS & INTEGRATORS 2014 MapR Technologies 3

4 MapR Distribution for Hadoop MapR MapR Technologies Technologies 4


5 MANAGEMENT MANAGEMENT Hadoop Distributions Distribution A Distribution C Open Source Open Source Open Source ARCHITECTURAL INNOVATIONS 2014 MapR Technologies 5
6 Architecture Matters for Success FOUNDATION 2014 MapR Technologies 6
7 Architecture Matters for Success NEW APPLICATIONS SLAs TRUSTED INFORMATION LOWER TCO Data protection & security Multi-tenancy Open standards for integration High performance Workload management FOUNDATION 2014 MapR Technologies 7
8 CLI REST API GUI MapR Control System (Management and Monitoring) MapR Distribution for Apache Hadoop APACHE HADOOP AND OSS ECOSYSTEM Batch Tez* ML, Graph SQL NoSQL & Search Streaming Data Integration & Access Security Workflow & Data Governance Provisioning & Coordination Spark Drill* Cascading GraphX Shark Accumulo* Hue Savannah* Pig MLLib Impala Solr Storm* HttpFS Juju MapReduc e v1 & v2 Mahout Hive HBase Spark Streaming Flume Knox* Falcon* Whirr YARN Sqoop Sentry* Oozie ZooKeeper EXECUTION ENGINES DATA GOVERNANCE AND OPERATIONS NFS HDFS API HBase API JSON API MapR-FS (POSIX) MapR Data Platform (Random Read/Write) MapR-DB (High-Performance NoSQL) Enterprise Grade Data Hub Operational 2014 MapR Technologies 8
9 Business Continuity MapR MapR Technologies Technologies 9
10 Business Continuity High Availability Data Protection Disaster Recovery What are your requirements? What do you have for your enterprise storage, databases and data warehouses? 2014 MapR Technologies 10
11 AVAILABILITY 1 High Availability Everywhere No NameNode architecture MapReduce/YARN HA NFS HA Instant recovery Rolling upgrades HA is built in Distributed metadata can self-heal No practical limit on # of files Jobs are not impacted by failures Meet your data processing SLAs High throughput and resilience for NFS-based data ingestion, import/export and multi-client access Files and tables are accessible within seconds of a node failure or cluster restart Upgrade the software with no downtime No special configuration to enable HA All MapR customers operate with HA 2014 MapR Technologies 11
 At least one replica on a different rack C3 C7 C4 C7 C1 C4 C4 C2 C6 C5 C7 C3 C5 C3 C6 Snapshots Protect from user and application errors Point-in-time recovery No data duplication No")
12 DATA PROTECTION 2 Data Protection: Replication and Snapshots Replication C1 C2 C1 C2 C5 C6 Protect from hardware failures File chunks, table regions and metadata are automatically replicated (3x by default) At least one replica on a different rack C3 C7 C4 C7 C1 C4 C4 C2 C6 C5 C7 C3 C5 C3 C6 Snapshots Protect from user and application errors Point-in-time recovery No data duplication No performance or scale impact Read files and tables directly from snapshot ₁ 2014 MapR Technologies 12




13 DISASTER RECOVERY 3 Disaster Recovery : MapR Mirroring Production Research WAN Datacenter 1 Datacenter 2 Production WAN EC2 Flexible Choose the volumes/directories to mirror You don t need to mirror the entire cluster Active/active Fast No performance impact Block-level (8KB) deltas Automatic compression Safe Point-in-time consistency End-to-end checksums Easy Graceful handling of network issues No third-party software Takes less than two minutes to configure! 2014 MapR Technologies 13
14 SQL Interactive SQL-on-Hadoop: MapR Customers Have Options! Drill 1.0 Hive 0.13 with Tez Impala 1.x Presto 0.56 Shark 0.8 Vertica Latency Low Medium Low Low Medium Low Files Yes (all Hive file formats) Yes (all Hive file formats) Yes (Parquet, Sequence, ) Yes (RC, Sequence, Text) Yes (all Hive file formats) HBase/M7 Yes Yes Various issues No Yes No Schema Hive or schemaless Yes (all Hive file formats) Hive Hive Hive Hive Proprietary or Hive SQL support ANSI SQL HiveQL HiveQL (subset) ANSI SQL HiveQL ANSI SQL + advanced analytics Client support ODBC/JDBC ODBC/JDBC ODBC/JDBC ODBC/JDBC ODBC/JDBC ODBC/JDBC, ADO.NET, Large joins Yes Yes No No No Yes Nested data Yes Limited No Limited Limited Limited Hive UDFs Yes Yes Limited No Yes No Transactions No No No No No Yes Optimizer Limited Limited Limited Limited Limited Yes Concurrency Limited Limited Limited Limited Limited Yes 2014 MapR Technologies 14

15 SQL Benchmark Berkeley AmpLab MapR Technologies 15
16 Apache Open Source Community Projects Q1 Q2 Q3 Q4 Resource management YARN 2.4 Batch MapReduce 2.4 Hive 0.12 Pig 0.11 Cascading 2.5 Spark 0.9 Interactive SQL Drill 1.0 Shark 0.9 Impala Hive on Tez 0.13 Data integration Flume Sqoop HttpFS 1.0 Machine learning Mahout 0.8 MLLib 0.9 GraphX 0.9 Coordination Oozie ZooKeeper Streaming Storm Spark Streaming 0.9 Data management Falcon 0.3 Knox 0.3 Sentry GUI and provisioning Hue 3.5 Savannah 0.4 NoSQL and search HBase 0.94 Solr (LWS 2.6.1) Complete distribution with aggressive roadmap 20 projects in the distribution 10+ new projects in 2014 Monthly update to projects Run multiple versions simultaneously Adopt new project versions w/o upgrading cluster Upgrade cluster without migrating all applications to new project versions Update New 2014 MapR Technologies 16
17 Performance MapR MapR Technologies Technologies 17
18 Time in Seconds Time in Seconds Flux7: Comparative Study of Hadoop Distributions Web Search and Data Analytics Benchmarks Lower is Better IDH CDH 4.3 HDP MapR M Page Rank Hive JOIN Query Source: Flux7 Labs Study, October 2013 Hardware Specs: EC2 on AWS 1 Master: m1.xlarge; 64-bit; 4 vcpu, 8 ECU; 15 GiB RAM; 4x420 GB Storage; 4x Intel Xeon CPU E GHz 4 Slaves: m1.large; 64-bit; 2 vcpu, 4 ECU; 7.5 GiB RAM; 2x420 GB Storage; 2x Intel Xeon CPU 2.66 GHz 2014 MapR Technologies 18
19 MB per Second MB per Second Flux7: Comparative Study of Hadoop Distributions Read and Write Throughput Benchmarks Higher is Better IDH CDH 4.3 HDP 1.3 MapR M DFSIO Read Throughput DFSIO Write Throughput Source: Flux7 Labs Study, October 2013 Hardware Specs: EC2 on AWS 1 Master: m1.xlarge; 64-bit; 4 vcpu, 8 ECU; 15 GiB RAM; 4x420 GB Storage; 4x Intel Xeon CPU E GHz 4 Slaves: m1.large; 64-bit; 2 vcpu, 4 ECU; 7.5 GiB RAM; 2x420 GB Storage; 2x Intel Xeon CPU 2.66 GHz 2014 MapR Technologies 19
20 M7: In-Hadoop Database Operational Applications and Analytics Combined MapR MapR Technologies Technologies 20
21 MapR M7: The Best In-Hadoop Database HBase JVM HDFS NoSQL Columnar Store Apache HBase API Integrated with Hadoop JVM ext3/ext4 Disks Tables/Files Disks Other Distros MapR M7 The most scalable, enterprise-grade, NoSQL database that supports online applications and analytics 2014 MapR Technologies 21
22 HBase Apps: High Performance with Consistent Low Latency M7 (ops/sec) Other HBase (ops/sec) Other HBase latency (usec) M7 Latency (usec) 2014 MapR Technologies 22

23 MapR M7: The Best In-Hadoop Database HBase JVM HDFS NoSQL Columnar Store Apache HBase API Integrated with Hadoop JVM ext3/ext4 Disks Tables/Files Disks Other Distros MapR M7 The most scalable, enterprise-grade, NoSQL database that supports online applications and analytics 2014 MapR Technologies 23




24 MapR Editions Control System NFS Access Performance Unlimited Nodes Free Control System NFS Access Performance High Availability Snapshots & Mirroring 24 X 7 Support Annual Subscription All the Features of M5 Simplified Administration for HBase Increased Performance Consistent Low Latency Unified Snapshots, Mirroring Fastest On-Ramp: MapR Sandbox for Hadoop 2014 MapR Technologies 24
25 Opportunity to Revolutionize Enterprise Data Architecture From Redundant Processing Silos and Data Science Experiments 2014 MapR Technologies 25
26 The Production Enterprise Data Hub to Consolidated Operational and Analytical Workloads 2014 MapR Technologies 26
 for developers Point-and-click tutorials Fully configured in virtual machines Supports VMware and VirtualBox Drag-and-drop data movement 2014 MapR")
27 MapR Sandbox for Hadoop The Fastest On-Ramp to Hadoop Complete MapR distribution for Hadoop Free download Most advanced distribution Tutorials and advanced user interfaces MapR Control System (MCS) for administrators Hadoop User Experience (HUE) for developers Point-and-click tutorials Fully configured in virtual machines Supports VMware and VirtualBox Drag-and-drop data movement 2014 MapR Technologies 27





28 Q & A Engage with maprtech mapr-technologies MapR agoujet@mapr.com maprtech 2014 MapR Technologies 28
Ulf Andreasson. 7 th Oct 2014
 Ulf Andreasson 7 th Oct 2014 1 WWGD what would Google do? 2 Data is doubling in size every two years 3 GFS 4 M/R 5 BigTable 6 Dremel 7 M.C. Srivas, CTO and Co-founder Ran one of the major search infrastructure
Ulf Andreasson 7 th Oct 2014 1 WWGD what would Google do? 2 Data is doubling in size every two years 3 GFS 4 M/R 5 BigTable 6 Dremel 7 M.C. Srivas, CTO and Co-founder Ran one of the major search infrastructure
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Configuring and Deploying Hadoop Cluster Deployment Templates
 Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
April Copyright 2013 Cloudera Inc. All rights reserved.
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Gain Insights From Unstructured Data Using Pivotal HD. Copyright 2013 EMC Corporation. All rights reserved.
 Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
Hortonworks and The Internet of Things
 Hortonworks and The Internet of Things Dr. Bernhard Walter Solutions Engineer About Hortonworks Customer Momentum ~700 customers (as of November 4, 2015) 152 customers added in Q3 2015 Publicly traded
Hortonworks and The Internet of Things Dr. Bernhard Walter Solutions Engineer About Hortonworks Customer Momentum ~700 customers (as of November 4, 2015) 152 customers added in Q3 2015 Publicly traded
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Oracle Big Data Fundamentals Ed 2
 Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
docs.hortonworks.com
 docs.hortonworks.com : Getting Started Guide Copyright 2012, 2014 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open source platform for storing,
docs.hortonworks.com : Getting Started Guide Copyright 2012, 2014 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open source platform for storing,
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
BIG DATA COURSE CONTENT
 BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Copyright 2015 EMC Corporation. All rights reserved. A long time ago
 1 A long time ago AP REDUCE HDFS IN A BLINK OF AN EYE Crunch Mahout YARN MLib PivotalR Hadoop UI Hue Coordination and workflow management Zookeeper Pig Hive MapReduce Tez Giraph Phoenix SolrCloud Flink
1 A long time ago AP REDUCE HDFS IN A BLINK OF AN EYE Crunch Mahout YARN MLib PivotalR Hadoop UI Hue Coordination and workflow management Zookeeper Pig Hive MapReduce Tez Giraph Phoenix SolrCloud Flink
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Automation of Rolling Upgrade for Hadoop Cluster without Data Loss and Job Failures. Hiroshi Yamaguchi & Hiroyuki Adachi
 Automation of Rolling Upgrade for Hadoop Cluster without Data Loss and Job Failures Hiroshi Yamaguchi & Hiroyuki Adachi About Us 2 Hiroshi Yamaguchi Hiroyuki Adachi Hadoop DevOps Engineer Hadoop Engineer
Automation of Rolling Upgrade for Hadoop Cluster without Data Loss and Job Failures Hiroshi Yamaguchi & Hiroyuki Adachi About Us 2 Hiroshi Yamaguchi Hiroyuki Adachi Hadoop DevOps Engineer Hadoop Engineer
HDInsight > Hadoop. October 12, 2017
 HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
The Reality of Qlik and Big Data. Chris Larsen Q3 2016
 The Reality of Qlik and Big Data Chris Larsen Q3 2016 Introduction Chris Larsen Sr Solutions Architect, Partner Engineering @Qlik Based in Lund, Sweden Primary Responsibility Advanced Analytics (and formerly
The Reality of Qlik and Big Data Chris Larsen Q3 2016 Introduction Chris Larsen Sr Solutions Architect, Partner Engineering @Qlik Based in Lund, Sweden Primary Responsibility Advanced Analytics (and formerly
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Cmprssd Intrduction To
 Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor
Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor
Hadoop & Big Data Analytics Complete Practical & Real-time Training
 An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Product Compatibility Matrix
 Compatibility Matrix Important tice (c) 2010-2014, Inc. All rights reserved., the logo, Impala, and any other product or service names or slogans contained in this document are trademarks of and its suppliers
Compatibility Matrix Important tice (c) 2010-2014, Inc. All rights reserved., the logo, Impala, and any other product or service names or slogans contained in this document are trademarks of and its suppliers
Lenovo Big Data Validated Design for Cloudera Enterprise and VMware
 Lenovo Big Data Validated Design for Cloudera Enterprise and VMware Last update: 20 June 2017 Version 1.2 Configuration Reference Number BDACLDRXX63 Describes the reference architecture for Cloudera Enterprise,
Lenovo Big Data Validated Design for Cloudera Enterprise and VMware Last update: 20 June 2017 Version 1.2 Configuration Reference Number BDACLDRXX63 Describes the reference architecture for Cloudera Enterprise,
Oracle Big Data Fundamentals Ed 1
 Oracle University Contact Us: +0097143909050 Oracle Big Data Fundamentals Ed 1 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, learn to use Oracle's Integrated Big Data
Oracle University Contact Us: +0097143909050 Oracle Big Data Fundamentals Ed 1 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, learn to use Oracle's Integrated Big Data
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Chase Wu New Jersey Institute of Technology
 CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
Hadoop Overview. Lars George Director EMEA Services
 Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
Hortonworks Data Platform
 Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Cloudera Introduction
 Cloudera Introduction Important Notice 2010-2017 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Cloudera Introduction Important Notice 2010-2017 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
EsgynDB Enterprise 2.0 Platform Reference Architecture
 EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
EsgynDB Enterprise 2.0 Platform Reference Architecture This document outlines a Platform Reference Architecture for EsgynDB Enterprise, built on Apache Trafodion (Incubating) implementation with licensed
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Hortonworks University. Education Catalog 2018 Q1
 Hortonworks University Education Catalog 2018 Q1 Revised 03/13/2018 TABLE OF CONTENTS About Hortonworks University... 2 Training Delivery Options... 3 Available Courses List... 4 Blended Learning... 6
Hortonworks University Education Catalog 2018 Q1 Revised 03/13/2018 TABLE OF CONTENTS About Hortonworks University... 2 Training Delivery Options... 3 Available Courses List... 4 Blended Learning... 6
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Cloudera Introduction
 Cloudera Introduction Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Cloudera Introduction Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Best Practices for Deploying Hadoop Workloads on HCI Powered by vsan
 Best Practices for Deploying Hadoop Workloads on HCI Powered by vsan Chen Wei, ware, Inc. Paudie ORiordan, ware, Inc. #vmworld HCI2038BU #HCI2038BU Disclaimer This presentation may contain product features
Best Practices for Deploying Hadoop Workloads on HCI Powered by vsan Chen Wei, ware, Inc. Paudie ORiordan, ware, Inc. #vmworld HCI2038BU #HCI2038BU Disclaimer This presentation may contain product features
Cloudera Introduction
 Cloudera Introduction Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Cloudera Introduction Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
SAP VORA 1.4 on AWS - MARKETPLACE EDITION FREQUENTLY ASKED QUESTIONS
 SAP VORA 1.4 on AWS - MARKETPLACE EDITION FREQUENTLY ASKED QUESTIONS 1. What is SAP Vora? SAP Vora is an in-memory, distributed computing solution that helps organizations uncover actionable business insights
SAP VORA 1.4 on AWS - MARKETPLACE EDITION FREQUENTLY ASKED QUESTIONS 1. What is SAP Vora? SAP Vora is an in-memory, distributed computing solution that helps organizations uncover actionable business insights
Cloudera Introduction
 Cloudera Introduction Important Notice 2010-2017 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Cloudera Introduction Important Notice 2010-2017 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Introduction to Database Services
 Introduction to Database Services Shaun Pearce AWS Solutions Architect 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved Today s agenda Why managed database services? A non-relational
Introduction to Database Services Shaun Pearce AWS Solutions Architect 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved Today s agenda Why managed database services? A non-relational
Report on The Infrastructure for Implementing the Mobile Technologies for Data Collection in Egypt
 Report on The Infrastructure for Implementing the Mobile Technologies for Data Collection in Egypt Date: 10 Sep, 2017 Draft v 4.0 Table of Contents 1. Introduction... 3 2. Infrastructure Reference Architecture...
Report on The Infrastructure for Implementing the Mobile Technologies for Data Collection in Egypt Date: 10 Sep, 2017 Draft v 4.0 Table of Contents 1. Introduction... 3 2. Infrastructure Reference Architecture...
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Oracle Big Data. A NA LYT ICS A ND MA NAG E MENT.
 Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
Building an Integrated Big Data & Analytics Infrastructure September 25, 2012 Robert Stackowiak, Vice President Data Systems Architecture Oracle
 Building an Integrated Big Data & Analytics Infrastructure September 25, 2012 Robert Stackowiak, Vice President Data Systems Architecture Oracle Enterprise Solutions Group The following is intended to
Building an Integrated Big Data & Analytics Infrastructure September 25, 2012 Robert Stackowiak, Vice President Data Systems Architecture Oracle Enterprise Solutions Group The following is intended to
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay Mellanox Technologies
 Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData
 Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Question: 1 You need to place the results of a PigLatin script into an HDFS output directory. What is the correct syntax in Apache Pig?
 Volume: 72 Questions Question: 1 You need to place the results of a PigLatin script into an HDFS output directory. What is the correct syntax in Apache Pig? A. update hdfs set D as./output ; B. store D
Volume: 72 Questions Question: 1 You need to place the results of a PigLatin script into an HDFS output directory. What is the correct syntax in Apache Pig? A. update hdfs set D as./output ; B. store D
Data Architectures in Azure for Analytics & Big Data
 Data Architectures in for Analytics & Big Data October 20, 2018 Melissa Coates Solution Architect, BlueGranite Microsoft Data Platform MVP Blog: www.sqlchick.com Twitter: @sqlchick Data Architecture A
Data Architectures in for Analytics & Big Data October 20, 2018 Melissa Coates Solution Architect, BlueGranite Microsoft Data Platform MVP Blog: www.sqlchick.com Twitter: @sqlchick Data Architecture A
Cloudera Introduction
 Cloudera Introduction Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Cloudera Introduction Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Modern Data Warehouse The New Approach to Azure BI
 Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation)
 (Development, Administration & REAL TIME Projects Implementation)") HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
SQT03 Big Data and Hadoop with Azure HDInsight Andrew Brust. Senior Director, Technical Product Marketing and Evangelism
 Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Cisco and Cloudera Deliver WorldClass Solutions for Powering the Enterprise Data Hub alerts, etc. Organizations need the right technology and infrastr
 Solution Overview Cisco UCS Integrated Infrastructure for Big Data and Analytics with Cloudera Enterprise Bring faster performance and scalability for big data analytics. Highlights Proven platform for
Solution Overview Cisco UCS Integrated Infrastructure for Big Data and Analytics with Cloudera Enterprise Bring faster performance and scalability for big data analytics. Highlights Proven platform for
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Cloudera Introduction
 Cloudera Introduction Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Cloudera Introduction Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Backtesting with Spark
 Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Getting Started with Hadoop and BigInsights
 Getting Started with Hadoop and BigInsights Alan Fischer e Silva Hadoop Sales Engineer Nov 2015 Agenda! Intro! Q&A! Break! Hands on Lab 2 Hadoop Timeline 3 In a Big Data World. The Technology exists now
Getting Started with Hadoop and BigInsights Alan Fischer e Silva Hadoop Sales Engineer Nov 2015 Agenda! Intro! Q&A! Break! Hands on Lab 2 Hadoop Timeline 3 In a Big Data World. The Technology exists now
Hadoop, Yarn and Beyond
 Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
SOLUTION TRACK Finding the Needle in a Big Data Innovator & Problem Solver Cloudera
 SOLUTION TRACK Finding the Needle in a Big Data Haystack @EvaAndreasson, Innovator & Problem Solver Cloudera Agenda Problem (Solving) Apache Solr + Apache Hadoop et al Real-world examples Q&A Problem Solving
SOLUTION TRACK Finding the Needle in a Big Data Haystack @EvaAndreasson, Innovator & Problem Solver Cloudera Agenda Problem (Solving) Apache Solr + Apache Hadoop et al Real-world examples Q&A Problem Solving
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Hadoop course content
 course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
Warehouse- Scale Computing and the BDAS Stack
 Warehouse- Scale Computing and the BDAS Stack Ion Stoica UC Berkeley UC BERKELEY Overview Workloads Hardware trends and implications in modern datacenters BDAS stack What is Big Data used For? Reports,
Warehouse- Scale Computing and the BDAS Stack Ion Stoica UC Berkeley UC BERKELEY Overview Workloads Hardware trends and implications in modern datacenters BDAS stack What is Big Data used For? Reports,
Practical Big Data Processing An Overview of Apache Flink
 Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
WITH INTEL TECHNOLOGIES
 WITH INTEL TECHNOLOGIES Commitment Is to Enable The Best Democratize technologies Advance solutions Unleash innovations Intel Xeon Scalable Processor Family Delivers Ideal Enterprise Solutions NEW Intel
WITH INTEL TECHNOLOGIES Commitment Is to Enable The Best Democratize technologies Advance solutions Unleash innovations Intel Xeon Scalable Processor Family Delivers Ideal Enterprise Solutions NEW Intel
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect
 Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
Welcome to. uweseiler
 5.03.014 Welcome to uweseiler 5.03.014 Your Travel Guide Big Data Nerd Hadoop Trainer NoSQL Fan Boy Photography Enthusiast Travelpirate 5.03.014 Your Travel Agency specializes on... Big Data Nerds Agile
5.03.014 Welcome to uweseiler 5.03.014 Your Travel Guide Big Data Nerd Hadoop Trainer NoSQL Fan Boy Photography Enthusiast Travelpirate 5.03.014 Your Travel Agency specializes on... Big Data Nerds Agile
Stages of Data Processing
 Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Lenovo Big Data Reference Architecture for Hortonworks Data Platform Using System x Servers
 Lenovo Big Data Reference Architecture for Hortonworks Data Platform Using System x Last update: 12 December 2017 Version 1.1 Configuration Reference Number: BDAHWKSXX62 Describes the RA for Hortonworks
Lenovo Big Data Reference Architecture for Hortonworks Data Platform Using System x Last update: 12 December 2017 Version 1.1 Configuration Reference Number: BDAHWKSXX62 Describes the RA for Hortonworks
Approaching the Petabyte Analytic Database: What I learned
 Disclaimer This document is for informational purposes only and is subject to change at any time without notice. The information in this document is proprietary to Actian and no part of this document may
Disclaimer This document is for informational purposes only and is subject to change at any time without notice. The information in this document is proprietary to Actian and no part of this document may
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Big Data com Hadoop. VIII Sessão - SQL Bahia. Impala, Hive e Spark. Diógenes Pires 03/03/2018
 Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
MySQL Multi-Site/Multi-Master MySQL High Availability and Disaster Recovery ~~~ Heterogeneous Real-Time Data Replication Oracle Replication
 MySQL Multi-Site/Multi-Master MySQL High Availability and Disaster Recovery ~~~ Heterogeneous Real-Time Data Replication Oracle Replication Continuent Quick Introduction History Products 2004 2009 2014
MySQL Multi-Site/Multi-Master MySQL High Availability and Disaster Recovery ~~~ Heterogeneous Real-Time Data Replication Oracle Replication Continuent Quick Introduction History Products 2004 2009 2014
Introduction into Big Data analytics Lecture 3 Hadoop ecosystem. Janusz Szwabiński
 Introduction into Big Data analytics Lecture 3 Hadoop ecosystem Janusz Szwabiński Outlook of today s talk Apache Hadoop Project Common use cases Getting started with Hadoop Single node cluster Further
Introduction into Big Data analytics Lecture 3 Hadoop ecosystem Janusz Szwabiński Outlook of today s talk Apache Hadoop Project Common use cases Getting started with Hadoop Single node cluster Further
Cloud Analytics and Business Intelligence on AWS
 Cloud Analytics and Business Intelligence on AWS Enterprise Applications Virtual Desktops Sharing & Collaboration Platform Services Analytics Hadoop Real-time Streaming Data Machine Learning Data Warehouse
Cloud Analytics and Business Intelligence on AWS Enterprise Applications Virtual Desktops Sharing & Collaboration Platform Services Analytics Hadoop Real-time Streaming Data Machine Learning Data Warehouse
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Lambda Architecture with Apache Spark
 Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR