An Introduction to Parallel Programming
|
|
|
- Arlene Powell
- 6 years ago
- Views:
Transcription
1 An Introduction to Parallel Programming Ing. Andrea Marongiu Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe and Dr. Rodric Rabbah and from Parallel Programming for Multicore course at UC Berkeley, by prof Kathy Yelick

 predicted in 1965 that the transistor density of")
2 Technology Trends: Microprocessor Capacity Moore s Law 2X transistors/chip Every 1.5 years Called Moore s Law Microprocessors have become smaller, denser, and more powerful. Gordon Moore (co-founder of Intel) predicted in 1965 that the transistor density of semiconductor chips would double roughly every 18 months. Slide source: Jack Dongarra
3 How to make effective use of transistors? Make the processor go faster Give it a faster clock (more operations per second) Give the processor more ability E.g., exploit instruction-level parallelism But It gets very expensive to keep doing this
4 How to make effective use of transistors? More instruction-level parallelism hard to find Very complex designs needed.. Take longer to design and debug..for small gains Clock frequency scaling is slowing drastically Too much power and heat when pushing the envelope Cannot communicate across chip fast enough Better to design small local units with short paths Difficult and very expensive for memory speed to keep up
5 How to make effective use of transistors? INTRODUCE MULTIPLE PROCESSORS Advantages: Effective use of billion of transistors Easier to reuse a basic unit many times Potential for very easy scaling Just keep adding cores for higher (peak) performance Each individual processor can be less powerful Which means it s cheaper to buy and run (less power)
6 How to make effective use of transistors? INTRODUCE MULTIPLE PROCESSORS Disadvantages Parallelization is not a limitless way to infinite performance! Algorithms and computer hardware give limits on performance One task many processors We need to think about how to share the task amongst them We need to co-ordinate carefully We need a new way of writing our programs


7 Vocabulary in the multi-era AMP (Asymmetric MP) Each processor has local memory Tasks statically allocated to one processor SMP (Symmetric MP) Processors share memory Tasks dynamically scheduled to any processor

8 Vocabulary in the multi-era Heterogeneous: Specialization among processors Often different instruction sets Usually AMP design Homogeneous: All processors have the same instruction set Processors can run any task Usually SMP design





9 Modern many-cores Locally homogeneous Globally heterogeneous
10 Multicore design paradigm Two primary patterns of multicore architecture design Shared memory - One copy of data shared among many cores - Atomicity, locking and synchronization essential for correctness - Many scalability issues Distributed memory - Cores primarily access local memory - Explicit data exchange between cores - Data distribution and communication orchestration is essential for performance
11 Shared Memory Programming Processor 1..n ask for X There is only one place to look Communication through shared variables Race conditions possible Use synchronization to protect from conflicts Change how data is stored to minimize synchronization

12 Example Data parallel Perform same computation but operate on different data A single process can fork multiple concurrent threads Each thread encapsulates its own execution path Each thread has local state and shared resources Threads communicate through shared resources such as global memory
13 Pthreads
;")
14 Types of Parallelism Data parallelism Perform same computation but operate on different data Task (control) parallelism Perform different functions pthread_create(/* thread id */ /* attributes */ /* any function */ /* args to function */);
15 Distributed Memory Programming Processor 1..n ask for X There are n places to look Each processor s memory has its own X Xs may vary For Processor 1 to look at Processor s 2 s X Processor 1 has to request X from Processor 2 Processor 2 sends a copy of its own X to Processor 1 Processor 1 receives the copy Processor 1 stores the copy in its own memory
16 Message Passing Architectures with distributed memories use explicit communication to exchange data Data exchange requires synchronization (cooperation) between senders and receivers
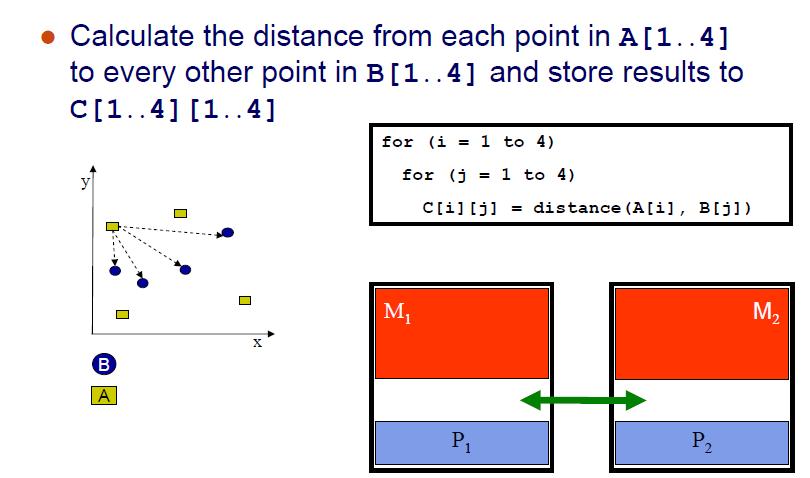
17 Example
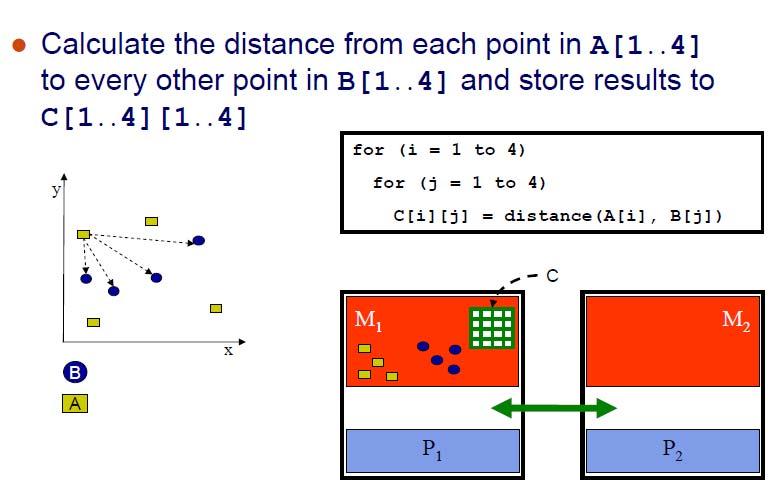
18 Example
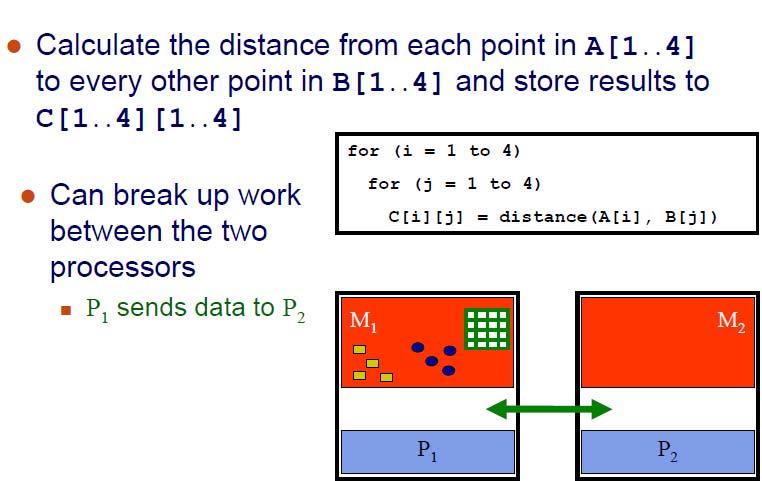
19 Example
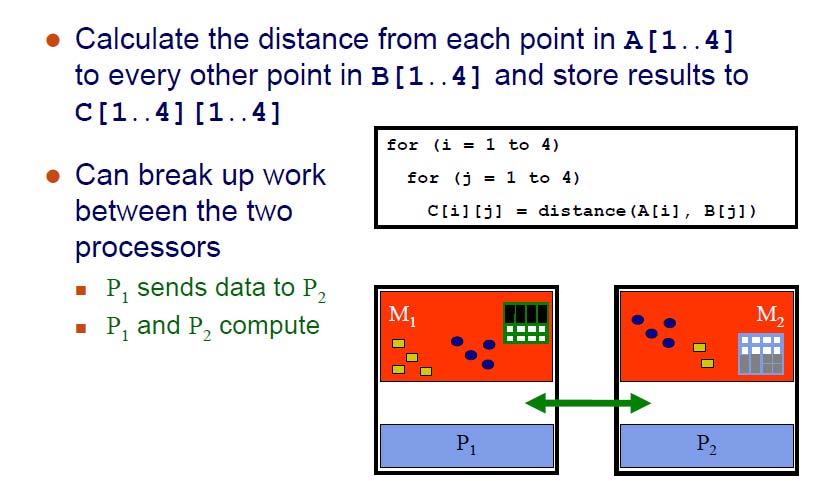
20 Example
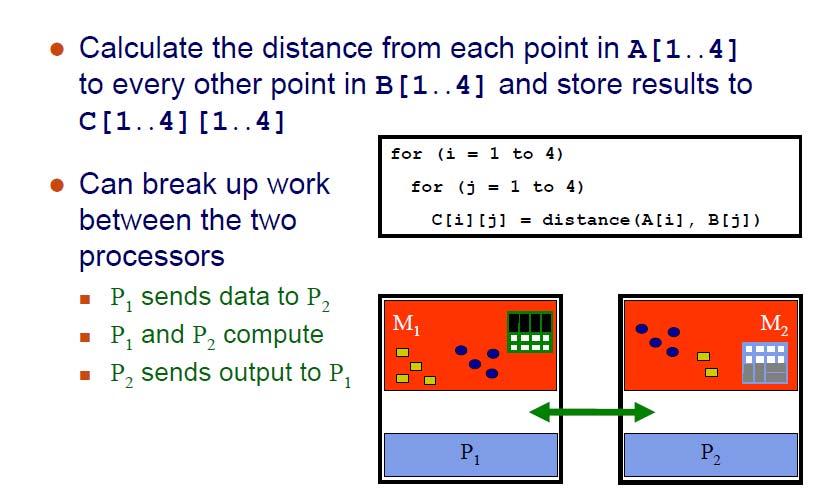
21 Example
22 Example
23 Understanding Performance What factors affect performance of parallel programs? Coverage or extent of parallelism in algorithm Granularity of partitioning among processors Locality of computation and communication
24 Coverage Not all programs are embarassingly parallel Programs have sequential parts and parallel parts
25 Amdahl's Law Amdahl s Law: The performance improvement to be gained from using some faster mode of execution is limited by the fraction of the time the faster mode can be used

26 Amdahl's Law Potential program speedup is defined by the fraction of code that can be parallelized
27 Amdahl's Law Speedup = old running time / new running time = 100 seconds / 60 seconds = 1.67 (parallel version is 1.67 times faster)
28 Amdahl's Law
29 Amdahl's Law S Suppose that 75% of a program can be parallelized. What is the speedup that could be achieved with 256 processors? o,, And for processors? o,, 3,95!!!!!!
30 Amdahl's Law S Suppose that n=32. Which p is required for S=12,55? o o o o o ,, 1, 1 %!!!!!
31 Amdahl's Law S If the portion of the program that can be parallelized is small, then the speedup is limited The non-parallel portion limits the performance
32 Amdahl's Law Speedup tends to 1/(1-p) as number of processors tends to infinity Parallel programming is worthwhile when programs have a lot of work that is parallel in nature Overhead
33 Overhead of parallelism Given enough parallel work, this is the biggest barrier to getting desired speedup Parallelism overheads include: cost of starting a thread or process cost of communicating shared data cost of synchronizing extra (redundant) computation Each of these can take a very large amount of time if a parallel program is not carefully designed Tradeoff: Algorithm needs sufficiently large units of work to run fast in parallel (I.e. large granularity), but not so large that there is not enough parallel work
34 Understanding Performance Coverage or extent of parallelism in algorithm Granularity of partitioning among processors Locality of computation and communication
35 Granularity Granularity is a qualitative measure of the ratio of computation to communication Computation stages are typically separated from periods of communication by synchronization events

36 Granularity Fine-grain Parallelism Low computation to communication ratio Small amounts of computational work between communication stages Less opportunity for performance enhancement High communication overhead Coarse-grain Parallelism High computation to communication ratio Large amounts of computational work between communciation events More opportunity for performance increase Harder to load balance efficiently
37 Load Balancing Processors that finish early have to wait for the processor with the largest amount of work to complete Leads to idle time, lowers utilization Particularly urgent with barrier synchronization P 1 P 2 P 3 P 4 P 1 P 2 P 3 P 4 Slowest core dictates overall execution time

38 Static Load Balancing Programmer make decisions and assigns a fixed amount of work to each processing core a priori Works well for homogeneous multicores All core are the same Each core has an equal amount of work Not so well for heterogeneous multicores Some cores may be faster than others Work distribution is uneven

39 Dynamic Load Balancing When one core finishes its allocated work, it takes on work from core with the heaviest workload Ideal for codes where work is uneven, and in heterogeneous multicore P 1 P 2 P 3 P 4
40 Communication and Synchronization In parallel programming processors need to communicate partial results on data or synchronize for correct processing In shared memory systems Communication takes place implicitly by concurrently operating on shared variables Synchronization primitives must be explicitly inserted in the code In distributed memory systems Communication primitives (send/receive) must be explicitly inserted in the code Synchronization is implicitly achieved through message exchange
41 Communication Cost Model
42 Types of Communication Cores exchange data or control messages example: DMA Control messages are often short Data messages are relatively much larger

43 Overlapping messages and computation Computation and communication concurrency can be achieved with pipelining Think instruction pipelining in superscalars CPU is idle MEM is idle

44 Overlapping messages and computation Computation and communication concurrency can be achieved with pipelining Think instruction pipelining in superscalars Essential for performance on Cell and similar distributed memory multicores
45 Understanding Performance Coverage or extent of parallelism in algorithm Granularity of partitioning among processors Locality of computation and communication

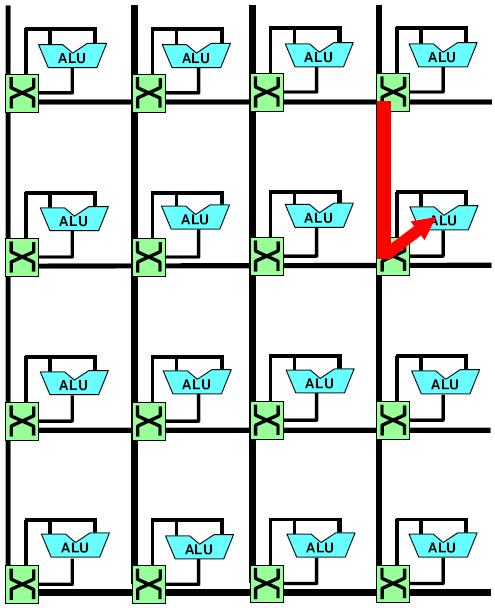
46 Locality in communication (message passing)

47 Locality of memory accesses (shared memory)

48 Locality of memory accesses (shared memory)
49 Memory access latency in shared memory architectures Uniform Memory Access (UMA) Centrally located memory All processors are equidistant (access times) Non-Uniform Access (NUMA) Physically partitioned but accessible by all Processors have the same address space Placement of data affects performance
50 Distributed Shared Memory A.k.a. Partitioned Global Address Space (PGAS) Each processor has a local memory node, globally visible by every processor in the system Local accesses are fast, remote accesses are slow (NUMA)
51 Distributed Shared Memory Concurrent threads with a partitioned shared space Similar to the shared memory Memory partition Mi has affinity to thread Th i Helps exploiting locality Legend Simple statements as SM Synchronization
52 Summary Coverage or extent of parallelism in algorithm Granularity of partitioning among processors Locality of computation and communication so how do I parallelize my program?
53 4 common steps to creating a parallel program
54 Decomposition Identify concurrency and decide at what level to exploit it Break upon computation into tasks to be divided among processors Tasks may become available dynamically Number of tasks may vary with time Enough tasks to keep processors busy Number of tasks available at a time is upper bound on achievable speedup
55 Guidelines for TASK decomposition Algorithms start with a good understanding of the problem being solved Programs often naturally decomposes into tasks Two common decompositions are Function calls and Distinct loop iterations Easier to start with many tasks and later fuse them, rather than too few tasks and later try to split them
56 Guidelines for TASK decomposition Flexibility Program design should afford flexibility in the number and size of tasks generated Tasks should not be tied to a specific architecture Fixed tasks vs. parameterized tasks Efficiency Tasks should have enough work to amortize the cost of creating and managing them Tasks should be sufficiently independent so that managing dependencies does not become the bottleneck Simplicity The code has to remain readable and easy to understand, and debug
57 Guidelines for DATA decomposition Data decomposition is often implied by task decomposition Programmers need to address task and data decomposition to create a parallel program Which decomposition to start with? Data decomposition is a good starting point when Main computation is organized around manipulation of a large data structure Similar operations are applied to different parts of the data structure

58 Common DATA decompositions Array data structures Decomposition of arrays along rows, columns, blocks Recursive data structures Example: decomposition of trees into sub-trees
59 Algorithmic Considerations Determine which tasks can be done in parallel with each other, and which must be done in some order Conceptualize a decomposition as a task dependency graph: A directed graph with Nodes corresponding to tasks sqr (A[0])sqr(A[1]) sqr(a[2]) Edges indicating dependencies, that the result of one task is required for processing the next. sum A given problem may be decomposed into tasks in many different ways. Tasks may be of same, different, or indeterminate sizes. sqr(a[n])
60 Where's the parallelism?
61 Where's the parallelism?
62 Where's the parallelism?

63 Where's the parallelism?
64 Further readings (online resource)
6.189 IAP Lecture 5. Parallel Programming Concepts. Dr. Rodric Rabbah, IBM IAP 2007 MIT
 6.189 IAP 2007 Lecture 5 Parallel Programming Concepts 1 6.189 IAP 2007 MIT Recap Two primary patterns of multicore architecture design Shared memory Ex: Intel Core 2 Duo/Quad One copy of data shared among
6.189 IAP 2007 Lecture 5 Parallel Programming Concepts 1 6.189 IAP 2007 MIT Recap Two primary patterns of multicore architecture design Shared memory Ex: Intel Core 2 Duo/Quad One copy of data shared among
MIT OpenCourseWare Multicore Programming Primer, January (IAP) Please use the following citation format:
 Please use the following citation format:") MIT OpenCourseWare http://ocw.mit.edu 6.189 Multicore Programming Primer, January (IAP) 2007 Please use the following citation format: Rodric Rabbah, 6.189 Multicore Programming Primer, January (IAP) 2007.
MIT OpenCourseWare http://ocw.mit.edu 6.189 Multicore Programming Primer, January (IAP) 2007 Please use the following citation format: Rodric Rabbah, 6.189 Multicore Programming Primer, January (IAP) 2007.
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 14 Parallelism in Software I
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 14 Parallelism in Software I") EE382 (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 14 Parallelism in Software I Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality, Spring 2015
EE382 (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 14 Parallelism in Software I Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality, Spring 2015
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 11 Parallelism in Software II
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 11 Parallelism in Software II") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 11 Parallelism in Software II Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality, Fall 2011 --
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 11 Parallelism in Software II Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality, Fall 2011 --
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
CMSC Computer Architecture Lecture 12: Multi-Core. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
Patterns for! Parallel Programming!
 Lecture 4! Patterns for! Parallel Programming! John Cavazos! Dept of Computer & Information Sciences! University of Delaware!! www.cis.udel.edu/~cavazos/cisc879! Lecture Overview Writing a Parallel Program
Lecture 4! Patterns for! Parallel Programming! John Cavazos! Dept of Computer & Information Sciences! University of Delaware!! www.cis.udel.edu/~cavazos/cisc879! Lecture Overview Writing a Parallel Program
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
EE382N (20): Computer Architecture - Parallelism and Locality Lecture 10 Parallelism in Software I
: Computer Architecture - Parallelism and Locality Lecture 10 Parallelism in Software I") EE382 (20): Computer Architecture - Parallelism and Locality Lecture 10 Parallelism in Software I Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality (c) Rodric Rabbah, Mattan
EE382 (20): Computer Architecture - Parallelism and Locality Lecture 10 Parallelism in Software I Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality (c) Rodric Rabbah, Mattan
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Review: Creating a Parallel Program. Programming for Performance
 Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
Designing Parallel Programs. This review was developed from Introduction to Parallel Computing
 Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Trends and Challenges in Multicore Programming
 Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
CS 31: Intro to Systems Threading & Parallel Applications. Kevin Webb Swarthmore College November 27, 2018
 CS 31: Intro to Systems Threading & Parallel Applications Kevin Webb Swarthmore College November 27, 2018 Reading Quiz Making Programs Run Faster We all like how fast computers are In the old days (1980
CS 31: Intro to Systems Threading & Parallel Applications Kevin Webb Swarthmore College November 27, 2018 Reading Quiz Making Programs Run Faster We all like how fast computers are In the old days (1980
Workloads Programmierung Paralleler und Verteilter Systeme (PPV)
") Workloads Programmierung Paralleler und Verteilter Systeme (PPV) Sommer 2015 Frank Feinbube, M.Sc., Felix Eberhardt, M.Sc., Prof. Dr. Andreas Polze Workloads 2 Hardware / software execution environment
Workloads Programmierung Paralleler und Verteilter Systeme (PPV) Sommer 2015 Frank Feinbube, M.Sc., Felix Eberhardt, M.Sc., Prof. Dr. Andreas Polze Workloads 2 Hardware / software execution environment
Computer Architecture: Parallel Processing Basics. Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Parallel Processing Basics Prof. Onur Mutlu Carnegie Mellon University Readings Required Hill, Jouppi, Sohi, Multiprocessors and Multicomputers, pp. 551-560 in Readings in Computer
Computer Architecture: Parallel Processing Basics Prof. Onur Mutlu Carnegie Mellon University Readings Required Hill, Jouppi, Sohi, Multiprocessors and Multicomputers, pp. 551-560 in Readings in Computer
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computer Architecture Lecture 27: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015
 18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
CS 194 Parallel Programming. Why Program for Parallelism?
 CS 194 Parallel Programming Why Program for Parallelism? Katherine Yelick yelick@cs.berkeley.edu http://www.cs.berkeley.edu/~yelick/cs194f07 8/29/2007 CS194 Lecure 1 What is Parallel Computing? Parallel
CS 194 Parallel Programming Why Program for Parallelism? Katherine Yelick yelick@cs.berkeley.edu http://www.cs.berkeley.edu/~yelick/cs194f07 8/29/2007 CS194 Lecure 1 What is Parallel Computing? Parallel
Moore s Law. Computer architect goal Software developer assumption
 Moore s Law The number of transistors that can be placed inexpensively on an integrated circuit will double approximately every 18 months. Self-fulfilling prophecy Computer architect goal Software developer
Moore s Law The number of transistors that can be placed inexpensively on an integrated circuit will double approximately every 18 months. Self-fulfilling prophecy Computer architect goal Software developer
18-447: Computer Architecture Lecture 30B: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013
 18-447: Computer Architecture Lecture 30B: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013 Readings: Multiprocessing Required Amdahl, Validity of the single processor
18-447: Computer Architecture Lecture 30B: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013 Readings: Multiprocessing Required Amdahl, Validity of the single processor
I-1 Introduction. I-0 Introduction. Objectives:
 I-0 Introduction Objectives: Explain necessity of parallel/multithreaded algorithms. Describe different forms of parallel processing. Present commonly used architectures. Introduce a few basic terms. Comments:
I-0 Introduction Objectives: Explain necessity of parallel/multithreaded algorithms. Describe different forms of parallel processing. Present commonly used architectures. Introduce a few basic terms. Comments:
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 1 Introduction Li Jiang 1 Course Details Time: Tue 8:00-9:40pm, Thu 8:00-9:40am, the first 16 weeks Location: 东下院 402 Course Website: TBA Instructor:
CS427 Multicore Architecture and Parallel Computing Lecture 1 Introduction Li Jiang 1 Course Details Time: Tue 8:00-9:40pm, Thu 8:00-9:40am, the first 16 weeks Location: 东下院 402 Course Website: TBA Instructor:
CSC 447: Parallel Programming for Multi- Core and Cluster Systems
 CSC 447: Parallel Programming for Multi- Core and Cluster Systems Why Parallel Computing? Haidar M. Harmanani Spring 2017 Definitions What is parallel? Webster: An arrangement or state that permits several
CSC 447: Parallel Programming for Multi- Core and Cluster Systems Why Parallel Computing? Haidar M. Harmanani Spring 2017 Definitions What is parallel? Webster: An arrangement or state that permits several
Chapter 18 - Multicore Computers
 Chapter 18 - Multicore Computers Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ Luis Tarrataca Chapter 18 - Multicore Computers 1 / 28 Table of Contents I 1 2 Where to focus your study Luis Tarrataca
Chapter 18 - Multicore Computers Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ Luis Tarrataca Chapter 18 - Multicore Computers 1 / 28 Table of Contents I 1 2 Where to focus your study Luis Tarrataca
740: Computer Architecture Memory Consistency. Prof. Onur Mutlu Carnegie Mellon University
 740: Computer Architecture Memory Consistency Prof. Onur Mutlu Carnegie Mellon University Readings: Memory Consistency Required Lamport, How to Make a Multiprocessor Computer That Correctly Executes Multiprocess
740: Computer Architecture Memory Consistency Prof. Onur Mutlu Carnegie Mellon University Readings: Memory Consistency Required Lamport, How to Make a Multiprocessor Computer That Correctly Executes Multiprocess
Multiprocessing and Scalability. A.R. Hurson Computer Science and Engineering The Pennsylvania State University
 A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
COMP 322: Fundamentals of Parallel Programming
 COMP 322: Fundamentals of Parallel Programming! Lecture 1: The What and Why of Parallel Programming; Task Creation & Termination (async, finish) Vivek Sarkar Department of Computer Science, Rice University
COMP 322: Fundamentals of Parallel Programming! Lecture 1: The What and Why of Parallel Programming; Task Creation & Termination (async, finish) Vivek Sarkar Department of Computer Science, Rice University
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448. The Greed for Speed
 Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
High Performance Computing
 The Need for Parallelism High Performance Computing David McCaughan, HPC Analyst SHARCNET, University of Guelph dbm@sharcnet.ca Scientific investigation traditionally takes two forms theoretical empirical
The Need for Parallelism High Performance Computing David McCaughan, HPC Analyst SHARCNET, University of Guelph dbm@sharcnet.ca Scientific investigation traditionally takes two forms theoretical empirical
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
A Study of High Performance Computing and the Cray SV1 Supercomputer. Michael Sullivan TJHSST Class of 2004
 A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
Parallel Programming Concepts. Parallel Algorithms. Peter Tröger
 Parallel Programming Concepts Parallel Algorithms Peter Tröger Sources: Ian Foster. Designing and Building Parallel Programs. Addison-Wesley. 1995. Mattson, Timothy G.; S, Beverly A.; ers,; Massingill,
Parallel Programming Concepts Parallel Algorithms Peter Tröger Sources: Ian Foster. Designing and Building Parallel Programs. Addison-Wesley. 1995. Mattson, Timothy G.; S, Beverly A.; ers,; Massingill,
Parallel and Distributed Systems. Hardware Trends. Why Parallel or Distributed Computing? What is a parallel computer?
 Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Why do we care about parallel?
 Threads 11/15/16 CS31 teaches you How a computer runs a program. How the hardware performs computations How the compiler translates your code How the operating system connects hardware and software The
Threads 11/15/16 CS31 teaches you How a computer runs a program. How the hardware performs computations How the compiler translates your code How the operating system connects hardware and software The
27. Parallel Programming I
 760 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
760 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano
 Prof. Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Multilevel Memories. Joel Emer Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
CS 475: Parallel Programming Introduction
 CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology
 Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology September 19, 2007 Markus Levy, EEMBC and Multicore Association Enabling the Multicore Ecosystem Multicore
Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology September 19, 2007 Markus Levy, EEMBC and Multicore Association Enabling the Multicore Ecosystem Multicore
Computer Architecture Crash course
 Computer Architecture Crash course Frédéric Haziza Department of Computer Systems Uppsala University Summer 2008 Conclusions The multicore era is already here cost of parallelism is dropping
Computer Architecture Crash course Frédéric Haziza Department of Computer Systems Uppsala University Summer 2008 Conclusions The multicore era is already here cost of parallelism is dropping
High Performance Computing. Introduction to Parallel Computing
 High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
Claude TADONKI. MINES ParisTech PSL Research University Centre de Recherche Informatique
 Got 2 seconds Sequential 84 seconds Expected 84/84 = 1 second!?! Got 25 seconds MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Séminaire MATHEMATIQUES
Got 2 seconds Sequential 84 seconds Expected 84/84 = 1 second!?! Got 25 seconds MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Séminaire MATHEMATIQUES
Thinking parallel. Decomposition. Thinking parallel. COMP528 Ways of exploiting parallelism, or thinking parallel
 COMP528 Ways of exploiting parallelism, or thinking parallel www.csc.liv.ac.uk/~alexei/comp528 Alexei Lisitsa Dept of computer science University of Liverpool a.lisitsa@.liverpool.ac.uk Thinking parallel
COMP528 Ways of exploiting parallelism, or thinking parallel www.csc.liv.ac.uk/~alexei/comp528 Alexei Lisitsa Dept of computer science University of Liverpool a.lisitsa@.liverpool.ac.uk Thinking parallel
27. Parallel Programming I
 The Free Lunch 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism,
The Free Lunch 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism,
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Multiprocessor Systems. Chapter 8, 8.1
 Multiprocessor Systems Chapter 8, 8.1 1 Learning Outcomes An understanding of the structure and limits of multiprocessor hardware. An appreciation of approaches to operating system support for multiprocessor
Multiprocessor Systems Chapter 8, 8.1 1 Learning Outcomes An understanding of the structure and limits of multiprocessor hardware. An appreciation of approaches to operating system support for multiprocessor
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
High Performance Computing Systems
 High Performance Computing Systems Shared Memory Doug Shook Shared Memory Bottlenecks Trips to memory Cache coherence 2 Why Multicore? Shared memory systems used to be purely the domain of HPC... What
High Performance Computing Systems Shared Memory Doug Shook Shared Memory Bottlenecks Trips to memory Cache coherence 2 Why Multicore? Shared memory systems used to be purely the domain of HPC... What
Shared Memory and Distributed Multiprocessing. Bhanu Kapoor, Ph.D. The Saylor Foundation
 Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
27. Parallel Programming I
 771 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
771 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
Programming Models for Supercomputing in the Era of Multicore
 Programming Models for Supercomputing in the Era of Multicore Marc Snir MULTI-CORE CHALLENGES 1 Moore s Law Reinterpreted Number of cores per chip doubles every two years, while clock speed decreases Need
Programming Models for Supercomputing in the Era of Multicore Marc Snir MULTI-CORE CHALLENGES 1 Moore s Law Reinterpreted Number of cores per chip doubles every two years, while clock speed decreases Need
Administration. Coursework. Prerequisites. CS 378: Programming for Performance. 4 or 5 programming projects
 CS 378: Programming for Performance Administration Instructors: Keshav Pingali (Professor, CS department & ICES) 4.126 ACES Email: pingali@cs.utexas.edu TA: Hao Wu (Grad student, CS department) Email:
CS 378: Programming for Performance Administration Instructors: Keshav Pingali (Professor, CS department & ICES) 4.126 ACES Email: pingali@cs.utexas.edu TA: Hao Wu (Grad student, CS department) Email:
Moore s Law. Computer architect goal Software developer assumption
 Moore s Law The number of transistors that can be placed inexpensively on an integrated circuit will double approximately every 18 months. Self-fulfilling prophecy Computer architect goal Software developer
Moore s Law The number of transistors that can be placed inexpensively on an integrated circuit will double approximately every 18 months. Self-fulfilling prophecy Computer architect goal Software developer
Chapter 7. Multicores, Multiprocessors, and Clusters. Goal: connecting multiple computers to get higher performance
 Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Introduction to Parallel Programming
 Introduction to Parallel Programming Linda Woodard CAC 19 May 2010 Introduction to Parallel Computing on Ranger 5/18/2010 www.cac.cornell.edu 1 y What is Parallel Programming? Using more than one processor
Introduction to Parallel Programming Linda Woodard CAC 19 May 2010 Introduction to Parallel Computing on Ranger 5/18/2010 www.cac.cornell.edu 1 y What is Parallel Programming? Using more than one processor
Parallel Programming Concepts. Tom Logan Parallel Software Specialist Arctic Region Supercomputing Center 2/18/04. Parallel Background. Why Bother?
 Parallel Programming Concepts Tom Logan Parallel Software Specialist Arctic Region Supercomputing Center 2/18/04 Parallel Background Why Bother? 1 What is Parallel Programming? Simultaneous use of multiple
Parallel Programming Concepts Tom Logan Parallel Software Specialist Arctic Region Supercomputing Center 2/18/04 Parallel Background Why Bother? 1 What is Parallel Programming? Simultaneous use of multiple
Multicore Hardware and Parallelism
 Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Lecture 27 Programming parallel hardware" Suggested reading:" (see next slide)"
") Lecture 27 Programming parallel hardware" Suggested reading:" (see next slide)" 1" Suggested Readings" Readings" H&P: Chapter 7 especially 7.1-7.8" Introduction to Parallel Computing" https://computing.llnl.gov/tutorials/parallel_comp/"
Lecture 27 Programming parallel hardware" Suggested reading:" (see next slide)" 1" Suggested Readings" Readings" H&P: Chapter 7 especially 7.1-7.8" Introduction to Parallel Computing" https://computing.llnl.gov/tutorials/parallel_comp/"
CS4961 Parallel Programming. Lecture 1: Introduction 08/25/2009. Course Details. Mary Hall August 25, Today s Lecture.
 Parallel Programming Lecture 1: Introduction Mary Hall August 25, 2009 Course Details Time and Location: TuTh, 9:10-10:30 AM, WEB L112 Course Website - http://www.eng.utah.edu/~cs4961/ Instructor: Mary
Parallel Programming Lecture 1: Introduction Mary Hall August 25, 2009 Course Details Time and Location: TuTh, 9:10-10:30 AM, WEB L112 Course Website - http://www.eng.utah.edu/~cs4961/ Instructor: Mary
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Multiprocessors and Locking
 Types of Multiprocessors (MPs) Uniform memory-access (UMA) MP Access to all memory occurs at the same speed for all processors. Multiprocessors and Locking COMP9242 2008/S2 Week 12 Part 1 Non-uniform memory-access
Types of Multiprocessors (MPs) Uniform memory-access (UMA) MP Access to all memory occurs at the same speed for all processors. Multiprocessors and Locking COMP9242 2008/S2 Week 12 Part 1 Non-uniform memory-access
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Parallel Computing Introduction
 Parallel Computing Introduction Bedřich Beneš, Ph.D. Associate Professor Department of Computer Graphics Purdue University von Neumann computer architecture CPU Hard disk Network Bus Memory GPU I/O devices
Parallel Computing Introduction Bedřich Beneš, Ph.D. Associate Professor Department of Computer Graphics Purdue University von Neumann computer architecture CPU Hard disk Network Bus Memory GPU I/O devices
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Administration. Prerequisites. Website. CSE 392/CS 378: High-performance Computing: Principles and Practice
 CSE 392/CS 378: High-performance Computing: Principles and Practice Administration Professors: Keshav Pingali 4.126 ACES Email: pingali@cs.utexas.edu Jim Browne Email: browne@cs.utexas.edu Robert van de
CSE 392/CS 378: High-performance Computing: Principles and Practice Administration Professors: Keshav Pingali 4.126 ACES Email: pingali@cs.utexas.edu Jim Browne Email: browne@cs.utexas.edu Robert van de
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Computer Architecture
 Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Parallel Computing. Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides)
, A Grama book (chapter 3 slides)") Parallel Computing 2012 Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides) Parallel Algorithm Design Outline Computational Model Design Methodology Partitioning Communication
Parallel Computing 2012 Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides) Parallel Algorithm Design Outline Computational Model Design Methodology Partitioning Communication
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Lect. 2: Types of Parallelism
 Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Amdahl's Law in the Multicore Era
 Amdahl's Law in the Multicore Era Explain intuitively why in the asymmetric model, the speedup actually decreases past a certain point of increasing r. The limiting factor of these improved equations and
Amdahl's Law in the Multicore Era Explain intuitively why in the asymmetric model, the speedup actually decreases past a certain point of increasing r. The limiting factor of these improved equations and
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
CS671 Parallel Programming in the Many-Core Era
 CS671 Parallel Programming in the Many-Core Era Lecture 1: Introduction Zheng Zhang Rutgers University CS671 Course Information Instructor information: instructor: zheng zhang website: www.cs.rutgers.edu/~zz124/
CS671 Parallel Programming in the Many-Core Era Lecture 1: Introduction Zheng Zhang Rutgers University CS671 Course Information Instructor information: instructor: zheng zhang website: www.cs.rutgers.edu/~zz124/
The Art of Parallel Processing
 The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Kernel Synchronization I. Changwoo Min
 1 Kernel Synchronization I Changwoo Min 2 Summary of last lectures Tools: building, exploring, and debugging Linux kernel Core kernel infrastructure syscall, module, kernel data structures Process management
1 Kernel Synchronization I Changwoo Min 2 Summary of last lectures Tools: building, exploring, and debugging Linux kernel Core kernel infrastructure syscall, module, kernel data structures Process management
COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence
 1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Concurrency & Parallelism, 10 mi
 The Beauty and Joy of Computing Lecture #7 Concurrency Instructor : Sean Morris Quest (first exam) in 5 days!! In this room! Concurrency & Parallelism, 10 mi up Intra-computer Today s lecture Multiple
The Beauty and Joy of Computing Lecture #7 Concurrency Instructor : Sean Morris Quest (first exam) in 5 days!! In this room! Concurrency & Parallelism, 10 mi up Intra-computer Today s lecture Multiple
Programming at Scale: Concurrency
 Programming at Scale: Concurrency 1 Goal: Building Fast, Scalable Software How do we speed up software? 2 What is scalability? A system is scalable if it can easily adapt to increased (or reduced) demand
Programming at Scale: Concurrency 1 Goal: Building Fast, Scalable Software How do we speed up software? 2 What is scalability? A system is scalable if it can easily adapt to increased (or reduced) demand
Algorithm Engineering with PRAM Algorithms
 Algorithm Engineering with PRAM Algorithms Bernard M.E. Moret moret@cs.unm.edu Department of Computer Science University of New Mexico Albuquerque, NM 87131 Rome School on Alg. Eng. p.1/29 Measuring and
Algorithm Engineering with PRAM Algorithms Bernard M.E. Moret moret@cs.unm.edu Department of Computer Science University of New Mexico Albuquerque, NM 87131 Rome School on Alg. Eng. p.1/29 Measuring and
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Parallelization Principles. Sathish Vadhiyar
 Parallelization Principles Sathish Vadhiyar Parallel Programming and Challenges Recall the advantages and motivation of parallelism But parallel programs incur overheads not seen in sequential programs
Parallelization Principles Sathish Vadhiyar Parallel Programming and Challenges Recall the advantages and motivation of parallelism But parallel programs incur overheads not seen in sequential programs
CS 31: Introduction to Computer Systems : Threads & Synchronization April 16-18, 2019
 CS 31: Introduction to Computer Systems 22-23: Threads & Synchronization April 16-18, 2019 Making Programs Run Faster We all like how fast computers are In the old days (1980 s - 2005): Algorithm too slow?
CS 31: Introduction to Computer Systems 22-23: Threads & Synchronization April 16-18, 2019 Making Programs Run Faster We all like how fast computers are In the old days (1980 s - 2005): Algorithm too slow?
Page 1. Multilevel Memories (Improving performance using a little cash )
") Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
Parallelism in Hardware
 Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Parallelization. Saman Amarasinghe. Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 Spring 2 Parallelization Saman Amarasinghe Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Outline Why Parallelism Parallel Execution Parallelizing Compilers
Spring 2 Parallelization Saman Amarasinghe Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Outline Why Parallelism Parallel Execution Parallelizing Compilers
Parallelism I. John Cavazos. Dept of Computer & Information Sciences University of Delaware
 Parallelism I John Cavazos Dept of Computer & Information Sciences University of Delaware Lecture Overview Thinking in Parallel Flynn s Taxonomy Types of Parallelism Parallelism Basics Design Patterns
Parallelism I John Cavazos Dept of Computer & Information Sciences University of Delaware Lecture Overview Thinking in Parallel Flynn s Taxonomy Types of Parallelism Parallelism Basics Design Patterns