Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
|
|
|
- Derick Montgomery
- 6 years ago
- Views:
Transcription
1 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko

2 What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines is hard

3 What Are The Problems? Data volumes are expanding dramatically Needs to scale out Managing hundreds of machines is hard Increasing incidence of faults and stragglers Why Is It Hard? High scale increase possibility of faults and stragglers Complicate parallel design

4 What Are The Problems? Data volumes are expanding dramatically Needs to scale out Managing hundreds of machines is hard Increasing incidence of faults and stragglers Complicate parallel design Data analysis becomes more complex Why Is It Hard? Database systems need to handle statistical methods beyond their simple roll-up, drill-down capability

5 What Are The Problems? Data volumes are expanding dramatically Needs to scale out Managing hundreds of machines is hard Increasing incidence of faults and stragglers Complicate parallel design Data analysis becomes more complex Databases have to handle complex algorithm efficiently Users expect to query at interactive speeds Why Is It Hard? The increase of scale and complexity makes it hard
6 Existing Solutions -Class AMapReduce-based Systems Hive, Dryad, etc.
7 Why don t they work? Although they have: Scalability Fine-grained fault tolerance Allows complex statistical analysis (e.g. ML) But: Slow SQL query processing latency
8 Existing Solutions -Class BMassive Parallel Processing Databases Vertica, Teradata, etc.
9 Why don t they work? Although they have: Fast parallel SQL query processing But: Not scalable Expensive/impossible complex analysis (e.g. UDFS, ML) Coarse-grained fault tolerance
10 Shark: A Hybrid Approach - Class A+B MapReduce parallel query processing + RDBS data processing + =
11 Features of Shark Build on top of Spark using RDD Dynamic Query Optimization (PDE) Supports low-latency, interactive SQL queries Support efficient complex analytics such as ML Compatibility with Apache Hive, Metastores, HiveQL, etc.
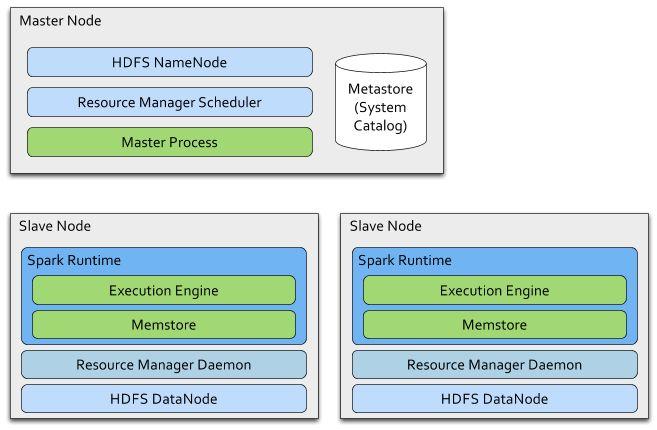
12 Shark Architecture
13 Example: SQL on RDD Step 1: User submits a query Step 2 : Hive query compiler parses the query Abstract syntax tree Query SELECT id, price FROM Customer, Transactions JOIN Customer ON customer_id.id=transaction.buyer_id WHERE Transaction.price > 100
14 Example: SQL on RDD Step 3: Turns syntax tree into logical plan (Basic logical optimization) Abstract syntax tree Logical execution plan
15 Example: SQL on RDD Step 4: Create physical plan (i.e. RDD transformation) (Additional optimization) Logical execution plan Physical execution plan
 or derived from applying operators to other RDDs.")
16 RDD RDD is a small partition of records Each RDD is either created from external FS (e.g. HDFS) or derived from applying operators to other RDDs. Each RDD is immutable, and deterministic Lineage of the RDDs are used for fault recovery
17 What are the benefits of RDDs?
18 What Does Hive Do Instead? Step 4: Create physical plan (MapReduce stages) Logical execution plan Physical execution plan
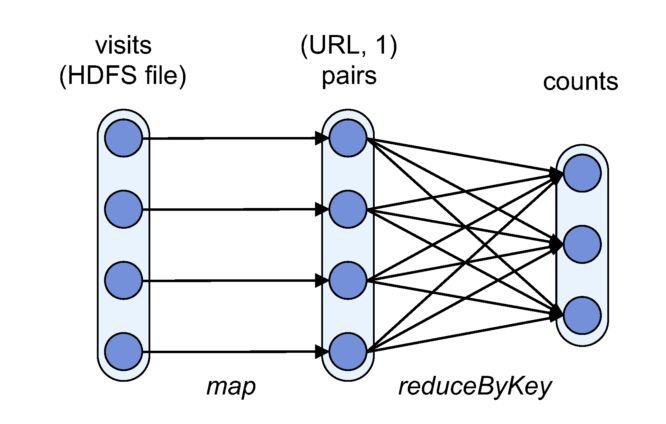
19 Diff(MapReduce, Spark RDD)

20 Partial DAG Execution
21 Columnar Memory Store What are the benefits?
22 Distributed Data Loading Tracking metadata to customize data compression of each RDD

23 Data Co-partitioning Each partition of the parent RDD is used by at most one partition of the child RDD partition Schema-aware for faster join operations

24 Partition Statistics & Map Pruning Avoid scanning irrelevant part of the data
25 Experiments Pavlo et al. Benchmark (2.1TB data) TPC-H Dataset (100GB/1TB data) Real Hive Warehouse (1.7TB dara) Machine Learning Dataset (100GB data)





26 Experiment Setup 100 m2.4xlarge nodes 8 virtual cores each node 68GB memory each node 1.6TB local storage each node
27 Result Summary Up to 100X faster than Hive for SQL More than 100X faster than Hadoop for ML Comparable performance to MPP databases Even faster than MPP in some cases
 FROM uservisits GROUP BY")
28 Aggregation Queries SELECT sourceip, SUM (adrevenue) FROM uservisits GROUP BY sourceip

29 Join Query Effects of data co-partitioning Effects of dynamic query optimization

30 Fault Tolerance Measuring Shark performance in presence of node failures

31 Real Hive Warehouse


32 Machine Learning Logistic regression per iteration runtime (seconds) K-means clustering per iteration runtime (seconds)
33 Next Steps? Implement optimizations promised in the paper (e.g. bytecode compilation of expression evaluators) Exploit specialized data structures for more compact data representations and better cache behavior More benchmark experiment should be conducted after optimization for comparison
Shark: SQL and Rich Analytics at Scale. Yash Thakkar ( ) Deeksha Singh ( )
 Deeksha Singh ( )") Shark: SQL and Rich Analytics at Scale Yash Thakkar (2642764) Deeksha Singh (2641679) RDDs as foundation for relational processing in Shark: Resilient Distributed Datasets (RDDs): RDDs can be written at
Shark: SQL and Rich Analytics at Scale Yash Thakkar (2642764) Deeksha Singh (2641679) RDDs as foundation for relational processing in Shark: Resilient Distributed Datasets (RDDs): RDDs can be written at
Shark: SQL and Rich Analytics at Scale. Reynold Xin UC Berkeley
 Shark: SQL and Rich Analytics at Scale Reynold Xin UC Berkeley Challenges in Modern Data Analysis Data volumes expanding. Faults and stragglers complicate parallel database design. Complexity of analysis:
Shark: SQL and Rich Analytics at Scale Reynold Xin UC Berkeley Challenges in Modern Data Analysis Data volumes expanding. Faults and stragglers complicate parallel database design. Complexity of analysis:
Hive and Shark. Amir H. Payberah. Amirkabir University of Technology (Tehran Polytechnic)
") Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Shark: SQL and Rich Analytics at Scale
 Shark: SQL and Rich Analytics at Scale Reynold Xin, Josh Rosen, Matei Zaharia, Michael J. Franklin, Scott Shenker, Ion Stoica AMPLab, EECS, UC Berkeley {rxin, joshrosen, matei, franklin, shenker, istoica}@cs.berkeley.edu
Shark: SQL and Rich Analytics at Scale Reynold Xin, Josh Rosen, Matei Zaharia, Michael J. Franklin, Scott Shenker, Ion Stoica AMPLab, EECS, UC Berkeley {rxin, joshrosen, matei, franklin, shenker, istoica}@cs.berkeley.edu
Shark: SQL and Rich Analytics at Scale
 Shark: SQL and Rich Analytics at Scale Reynold Shi Xin Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2015-24 http://www.eecs.berkeley.edu/pubs/techrpts/2015/eecs-2015-24.html
Shark: SQL and Rich Analytics at Scale Reynold Shi Xin Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2015-24 http://www.eecs.berkeley.edu/pubs/techrpts/2015/eecs-2015-24.html
April Copyright 2013 Cloudera Inc. All rights reserved.
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09. Presented by: Daniel Isaacs
 Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09 Presented by: Daniel Isaacs It all starts with cluster computing. MapReduce Why
Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09 Presented by: Daniel Isaacs It all starts with cluster computing. MapReduce Why
Evolution From Shark To Spark SQL:
 Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
The Stratosphere Platform for Big Data Analytics
 The Stratosphere Platform for Big Data Analytics Hongyao Ma Franco Solleza April 20, 2015 Stratosphere Stratosphere Stratosphere Big Data Analytics BIG Data Heterogeneous datasets: structured / unstructured
The Stratosphere Platform for Big Data Analytics Hongyao Ma Franco Solleza April 20, 2015 Stratosphere Stratosphere Stratosphere Big Data Analytics BIG Data Heterogeneous datasets: structured / unstructured
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Data Storage Infrastructure at Facebook
 Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Shark: Hive on Spark
 Optional Reading (additional material) Shark: Hive on Spark Prajakta Kalmegh Duke University 1 What is Shark? Port of Apache Hive to run on Spark Compatible with existing Hive data, metastores, and queries
Optional Reading (additional material) Shark: Hive on Spark Prajakta Kalmegh Duke University 1 What is Shark? Port of Apache Hive to run on Spark Compatible with existing Hive data, metastores, and queries
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Today s Papers. Architectural Differences. EECS 262a Advanced Topics in Computer Systems Lecture 17
 EECS 262a Advanced Topics in Computer Systems Lecture 17 Comparison of Parallel DB, CS, MR and Jockey October 30 th, 2013 John Kubiatowicz and Anthony D. Joseph Electrical Engineering and Computer Sciences
EECS 262a Advanced Topics in Computer Systems Lecture 17 Comparison of Parallel DB, CS, MR and Jockey October 30 th, 2013 John Kubiatowicz and Anthony D. Joseph Electrical Engineering and Computer Sciences
GLADE: A Scalable Framework for Efficient Analytics. Florin Rusu (University of California, Merced) Alin Dobra (University of Florida)
 Alin Dobra (University of Florida)") DE: A Scalable Framework for Efficient Analytics Florin Rusu (University of California, Merced) Alin Dobra (University of Florida) Big Data Analytics Big Data Storage is cheap ($100 for 1TB disk) Everything
DE: A Scalable Framework for Efficient Analytics Florin Rusu (University of California, Merced) Alin Dobra (University of Florida) Big Data Analytics Big Data Storage is cheap ($100 for 1TB disk) Everything
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads
 HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads Azza Abouzeid, Kamil Bajda-Pawlikowski, Daniel J. Abadi, Alexander Rasin and Avi Silberschatz Presented by
HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads Azza Abouzeid, Kamil Bajda-Pawlikowski, Daniel J. Abadi, Alexander Rasin and Avi Silberschatz Presented by
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Parallel Processing Spark and Spark SQL
 Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
HadoopDB: An open source hybrid of MapReduce
 HadoopDB: An open source hybrid of MapReduce and DBMS technologies Azza Abouzeid, Kamil Bajda-Pawlikowski Daniel J. Abadi, Avi Silberschatz Yale University http://hadoopdb.sourceforge.net October 2, 2009
HadoopDB: An open source hybrid of MapReduce and DBMS technologies Azza Abouzeid, Kamil Bajda-Pawlikowski Daniel J. Abadi, Avi Silberschatz Yale University http://hadoopdb.sourceforge.net October 2, 2009
MapR Enterprise Hadoop
 2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Today s content. Resilient Distributed Datasets(RDDs) Spark and its data model
 Spark and its data model") Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Fault Tolerance in K3. Ben Glickman, Amit Mehta, Josh Wheeler
 Fault Tolerance in K3 Ben Glickman, Amit Mehta, Josh Wheeler Outline Background Motivation Detecting Membership Changes with Spread Modes of Fault Tolerance in K3 Demonstration Outline Background Motivation
Fault Tolerance in K3 Ben Glickman, Amit Mehta, Josh Wheeler Outline Background Motivation Detecting Membership Changes with Spread Modes of Fault Tolerance in K3 Demonstration Outline Background Motivation
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
HAWQ: A Massively Parallel Processing SQL Engine in Hadoop
 HAWQ: A Massively Parallel Processing SQL Engine in Hadoop Lei Chang, Zhanwei Wang, Tao Ma, Lirong Jian, Lili Ma, Alon Goldshuv Luke Lonergan, Jeffrey Cohen, Caleb Welton, Gavin Sherry, Milind Bhandarkar
HAWQ: A Massively Parallel Processing SQL Engine in Hadoop Lei Chang, Zhanwei Wang, Tao Ma, Lirong Jian, Lili Ma, Alon Goldshuv Luke Lonergan, Jeffrey Cohen, Caleb Welton, Gavin Sherry, Milind Bhandarkar
CIS 601 Graduate Seminar. Dr. Sunnie S. Chung Dhruv Patel ( ) Kalpesh Sharma ( )
 Kalpesh Sharma ( )") Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin. Presented by: Suhua Wei Yong Yu
 CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Spark: A Brief History. https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf
 Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Actian Vector Benchmarks. Cloud Benchmarking Summary Report
 Actian Vector Benchmarks Cloud Benchmarking Summary Report April 2018 The Cloud Database Performance Benchmark Executive Summary The table below shows Actian Vector as evaluated against Amazon Redshift,
Actian Vector Benchmarks Cloud Benchmarking Summary Report April 2018 The Cloud Database Performance Benchmark Executive Summary The table below shows Actian Vector as evaluated against Amazon Redshift,
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
GLADE: A Scalable Framework for Efficient Analytics. Florin Rusu University of California, Merced
 GLADE: A Scalable Framework for Efficient Analytics Florin Rusu University of California, Merced Motivation and Objective Large scale data processing Map-Reduce is standard technique Targeted to distributed
GLADE: A Scalable Framework for Efficient Analytics Florin Rusu University of California, Merced Motivation and Objective Large scale data processing Map-Reduce is standard technique Targeted to distributed
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData
 Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
CS Spark. Slides from Matei Zaharia and Databricks
 CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
DRIZZLE: FAST AND Adaptable STREAM PROCESSING AT SCALE
 DRIZZLE: FAST AND Adaptable STREAM PROCESSING AT SCALE Shivaram Venkataraman, Aurojit Panda, Kay Ousterhout, Michael Armbrust, Ali Ghodsi, Michael Franklin, Benjamin Recht, Ion Stoica STREAMING WORKLOADS
DRIZZLE: FAST AND Adaptable STREAM PROCESSING AT SCALE Shivaram Venkataraman, Aurojit Panda, Kay Ousterhout, Michael Armbrust, Ali Ghodsi, Michael Franklin, Benjamin Recht, Ion Stoica STREAMING WORKLOADS
a Spark in the cloud iterative and interactive cluster computing
 a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Hive SQL over Hadoop
 Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018
: Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018") Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018 K. Zhang (pic source: mapr.com/blog) Copyright BUDT 2016 758 Where
Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018 K. Zhang (pic source: mapr.com/blog) Copyright BUDT 2016 758 Where
Shark: SQL and Analytics with Cost-Based Query Optimization on Coarse-Grained Distributed Memory
 Shark: SQL and Analytics with Cost-Based Query Optimization on Coarse-Grained Distributed Memory Antonio Lupher Electrical Engineering and Computer Sciences University of California at Berkeley Technical
Shark: SQL and Analytics with Cost-Based Query Optimization on Coarse-Grained Distributed Memory Antonio Lupher Electrical Engineering and Computer Sciences University of California at Berkeley Technical
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Apache Hive for Oracle DBAs. Luís Marques
 Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 29, 2013 UC BERKELEY Stage 0:M ap-shuffle-reduce M apper(row ) { fields = row.split("\t") em it(fields[0],fields[1]); } Reducer(key,values)
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 29, 2013 UC BERKELEY Stage 0:M ap-shuffle-reduce M apper(row ) { fields = row.split("\t") em it(fields[0],fields[1]); } Reducer(key,values)
Spark & Spark SQL. High- Speed In- Memory Analytics over Hadoop and Hive Data. Instructor: Duen Horng (Polo) Chau
 Chau") CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Discretized Streams. An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters
 Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Big Data Infrastructures & Technologies. SQL on Big Data
 Big Data Infrastructures & Technologies SQL on Big Data THE DEBATE: DATABASE SYSTEMS VS MAPREDUCE A major step backwards? MapReduce is a step backward in database access Schemas are good Separation of
Big Data Infrastructures & Technologies SQL on Big Data THE DEBATE: DATABASE SYSTEMS VS MAPREDUCE A major step backwards? MapReduce is a step backward in database access Schemas are good Separation of
Large-Scale Data Engineering
 Large-Scale Data Engineering SQL on Big Data THE DEBATE: DATABASE SYSTEMS VS MAPREDUCE A major step backwards? MapReduce is a step backward in database access Schemas are good Separation of the schema
Large-Scale Data Engineering SQL on Big Data THE DEBATE: DATABASE SYSTEMS VS MAPREDUCE A major step backwards? MapReduce is a step backward in database access Schemas are good Separation of the schema
Delft University of Technology Parallel and Distributed Systems Report Series
 Delft University of Technology Parallel and Distributed Systems Report Series An Empirical Performance Evaluation of Distributed SQL Query Engines: Extended Report Stefan van Wouw, José Viña, Alexandru
Delft University of Technology Parallel and Distributed Systems Report Series An Empirical Performance Evaluation of Distributed SQL Query Engines: Extended Report Stefan van Wouw, José Viña, Alexandru
Practical Big Data Processing An Overview of Apache Flink
 Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
SparkStreaming. Large scale near- realtime stream processing. Tathagata Das (TD) UC Berkeley UC BERKELEY
 UC Berkeley UC BERKELEY") SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
Tatsuhiro Chiba, Takeshi Yoshimura, Michihiro Horie and Hiroshi Horii IBM Research
 Tatsuhiro Chiba, Takeshi Yoshimura, Michihiro Horie and Hiroshi Horii IBM Research IBM Research 2 IEEE CLOUD 2018 / Towards Selecting Best Combination of SQL-on-Hadoop Systems and JVMs à à Application
Tatsuhiro Chiba, Takeshi Yoshimura, Michihiro Horie and Hiroshi Horii IBM Research IBM Research 2 IEEE CLOUD 2018 / Towards Selecting Best Combination of SQL-on-Hadoop Systems and JVMs à à Application
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Hadoop course content
 course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Impala. A Modern, Open Source SQL Engine for Hadoop. Yogesh Chockalingam
 Impala A Modern, Open Source SQL Engine for Hadoop Yogesh Chockalingam Agenda Introduction Architecture Front End Back End Evaluation Comparison with Spark SQL Introduction Why not use Hive or HBase?
Impala A Modern, Open Source SQL Engine for Hadoop Yogesh Chockalingam Agenda Introduction Architecture Front End Back End Evaluation Comparison with Spark SQL Introduction Why not use Hive or HBase?
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Resource and Performance Distribution Prediction for Large Scale Analytics Queries
 Resource and Performance Distribution Prediction for Large Scale Analytics Queries Prof. Rajiv Ranjan, SMIEEE School of Computing Science, Newcastle University, UK Visiting Scientist, Data61, CSIRO, Australia
Resource and Performance Distribution Prediction for Large Scale Analytics Queries Prof. Rajiv Ranjan, SMIEEE School of Computing Science, Newcastle University, UK Visiting Scientist, Data61, CSIRO, Australia
Importing and Exporting Data Between Hadoop and MySQL
 Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Activator Library. Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success.
 Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Tutorial Outline. Map/Reduce vs. DBMS. MR vs. DBMS [DeWitt and Stonebraker 2008] Acknowledgements. MR is a step backwards in database access
![Tutorial Outline. Map/Reduce vs. DBMS. MR vs. DBMS [DeWitt and Stonebraker 2008] Acknowledgements. MR is a step backwards in database access](/thumbs/92/110435840.jpg "Tutorial Outline. Map/Reduce vs. DBMS. MR vs. DBMS [DeWitt and Stonebraker 2008] Acknowledgements. MR is a step backwards in database access") Map/Reduce vs. DBMS Sharma Chakravarthy Information Technology Laboratory Computer Science and Engineering Department The University of Texas at Arlington, Arlington, TX 76009 Email: sharma@cse.uta.edu
Map/Reduce vs. DBMS Sharma Chakravarthy Information Technology Laboratory Computer Science and Engineering Department The University of Texas at Arlington, Arlington, TX 76009 Email: sharma@cse.uta.edu
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Shark: Fast Data Analysis Using Coarse-grained Distributed Memory
 Shark: Fast Data Analysis Using Coarse-grained Distributed Memory Clifford Engle Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2013-35
Shark: Fast Data Analysis Using Coarse-grained Distributed Memory Clifford Engle Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2013-35
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
SparkSQL 11/14/2018 1
 SparkSQL 11/14/2018 1 Where are we? Pig Latin HiveQL Pig Hive??? Hadoop MapReduce Spark RDD HDFS 11/14/2018 2 Where are we? Pig Latin HiveQL SQL Pig Hive??? Hadoop MapReduce Spark RDD HDFS 11/14/2018 3
SparkSQL 11/14/2018 1 Where are we? Pig Latin HiveQL Pig Hive??? Hadoop MapReduce Spark RDD HDFS 11/14/2018 2 Where are we? Pig Latin HiveQL SQL Pig Hive??? Hadoop MapReduce Spark RDD HDFS 11/14/2018 3
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/22/2018 Week 10-A Sangmi Lee Pallickara. FAQs.
 10/22/2018 - FALL 2018 W10.A.0.0 10/22/2018 - FALL 2018 W10.A.1 FAQs Term project: Proposal 5:00PM October 23, 2018 PART 1. LARGE SCALE DATA ANALYTICS IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
10/22/2018 - FALL 2018 W10.A.0.0 10/22/2018 - FALL 2018 W10.A.1 FAQs Term project: Proposal 5:00PM October 23, 2018 PART 1. LARGE SCALE DATA ANALYTICS IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Achieving Horizontal Scalability. Alain Houf Sales Engineer
 Achieving Horizontal Scalability Alain Houf Sales Engineer Scale Matters InterSystems IRIS Database Platform lets you: Scale up and scale out Scale users and scale data Mix and match a variety of approaches
Achieving Horizontal Scalability Alain Houf Sales Engineer Scale Matters InterSystems IRIS Database Platform lets you: Scale up and scale out Scale users and scale data Mix and match a variety of approaches
Lightning Fast Cluster Computing. Michael Armbrust Reflections Projections 2015 Michast
 Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based