Data Storage Infrastructure at Facebook
|
|
|
- Alison Gallagher
- 6 years ago
- Views:
Transcription
1 Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung
2 Outline Strategy of data storage, processing, and log collection Data flow from the source to the data warehouse Storage systems and optimization Data discovery and analysis Challenges in resource sharing
3 Facebook s Architecture

4 Facebook s Architecture Hadoop Hbase HayStack Hive MySQL Memcached PHP HipHop compiler Scribe Thrift
5 Part 1: Strategy for Data Storage, Processing, Log collection Apache Hadoop Apache Hive Scribe
6 Hadoop, Why? Scalability Able to process multi petabyte datasets Fault Tolerance Node failure is expected everyday Number of nodes is not constant High Availability User can access from nearest node Cost Efficiency Open source Use commodity hardware as a node in Hadoop clusters Eliminates particular technology dependency



7 Hadoop Architecture HDFS (Hadoop Distributed File System) Map-Reduce Infrastructure
8 Hive SQL-like analysis tool (HiveQL) on top of Hadoop Dramatically improve the productivity and usage for Hadoop With Hive, users without programming experience can use Hadoop for their work Without Hive, one basic Hadoop data manipulation, like GROUP BY will take >100 lines of Java/Python code Even worse, if the programmer does not have database knowledge, the code will likely use sub-optimal algorithm, often it is pretty sub-optimal
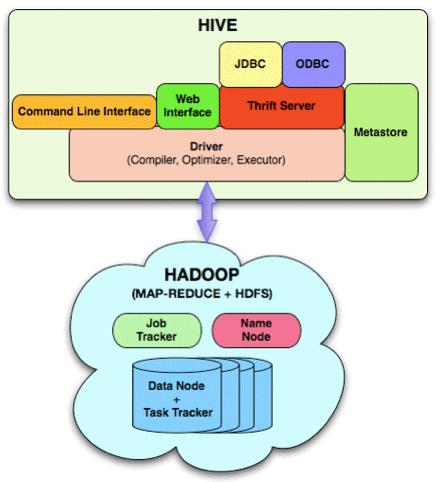
9 Hive Architecture

10 Scribe Scalable Logging System Distributed and scalable logging system Combined with HDFS Aggregate logs from thousands of web servers

11 Part 2: Data Flow Architecture Two Sources of Data Web Server Log data Copy every 5-15 minutes Federated MySQL Information data Copy daily Two different clusters Production Hive-Hadoop cluster Ad-hoc Hive-Hadoop cluster
12 Deal with Data Delivery Latency Even log data copied at 5-15 minutes interval, the loader will only load data into Hive native table at the end of the day Solution at Facebook: Use Hive s external table feature, create table meta data on the raw HDFS files After data loaded into Hive native table at the end of day, remove raw HDFS files from the external table New solutions are needed to enable continuously log data loading
13 Part 3: Storage Optimization All data need to compressed to save space Hadoop allows user specific codecs, Facebook using gzip codec to get compression factor at 6-7 HDFS by default use 3 copies of data to prevent data loss Using erasure codes, 2 copies of data and 2 copies of error correction code, this multiple can be brought down to 2.2 Using Hadoop RAID on older data sets and keeping the newer data sets replicated 3 ways
14 Part 3: Storage Optimization Reduce the memory usage by HDFS NameNode Trade off latency to reduce memory pressure Implement file format to reduce map tasks Data federation Distribute data based on time Data across time boundary will need more join Distribute data based on application Some of the common data have to be replicated
15 Part 4: Data Discovery and Analysis Hive Provide immense scalability to non-engineering users, such as business analysts, product managers Data discovery Internal tool to enable wiki approach for metadata creation Tools to extract lineage information from query log Periodic Batch Jobs For such job, inner job dependencies and ability to schedule such job are critical
16 Part 5: Resource Sharing Support the co-existence of interactive jobs and batch jobs on the same Hadoop cluster Implement Hadoop Fair Share Scheduler Isolate ad-hoc queries and periodic batch queries Implement Scheduler to make it more aware of system resource usage caused by poorly written ad-hoc queries
17 Take Home Message For a data warehouse design What kind of data source, flow architecture What kind of storage architecture What kind of user, what kind of task How to make usage easier How to share the resource between jobs
18 End Thank you
Evolution of Big Data Facebook. Architecture Summit, Shenzhen, August 2012 Ashish Thusoo
 Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Big Data Facebook
 Big Data Architectures@ Facebook QCon London 2012 Ashish Thusoo Outline Big Data @ Facebook - Scope & Scale Evolution of Big Data Architectures @ FB Past, Present and Future Questions Big Data @ FB: Scale
Big Data Architectures@ Facebook QCon London 2012 Ashish Thusoo Outline Big Data @ Facebook - Scope & Scale Evolution of Big Data Architectures @ FB Past, Present and Future Questions Big Data @ FB: Scale
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Data Warehousing and Analytics Infrastructure at Facebook
 Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo Zheng Shao Suresh Anthony Dhruba Borthakur Namit Jain Joydeep Sen Sarma Facebook 1 Raghu Murthy Hao Liu 1 The authors can be reached
Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo Zheng Shao Suresh Anthony Dhruba Borthakur Namit Jain Joydeep Sen Sarma Facebook 1 Raghu Murthy Hao Liu 1 The authors can be reached
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Hive and Shark. Amir H. Payberah. Amirkabir University of Technology (Tehran Polytechnic)
") Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Big Data com Hadoop. VIII Sessão - SQL Bahia. Impala, Hive e Spark. Diógenes Pires 03/03/2018
 Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED DATA PLATFORM
 CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin. Presented by: Suhua Wei Yong Yu
 CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
A Review Approach for Big Data and Hadoop Technology
 International Journal of Modern Trends in Engineering and Research www.ijmter.com e-issn No.:2349-9745, Date: 2-4 July, 2015 A Review Approach for Big Data and Hadoop Technology Prof. Ghanshyam Dhomse
International Journal of Modern Trends in Engineering and Research www.ijmter.com e-issn No.:2349-9745, Date: 2-4 July, 2015 A Review Approach for Big Data and Hadoop Technology Prof. Ghanshyam Dhomse
Chase Wu New Jersey Institute of Technology
 CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
The Technology of the Business Data Lake. Appendix
 The Technology of the Business Data Lake Appendix Pivotal data products Term Greenplum Database GemFire Pivotal HD Spring XD Pivotal Data Dispatch Pivotal Analytics Description A massively parallel platform
The Technology of the Business Data Lake Appendix Pivotal data products Term Greenplum Database GemFire Pivotal HD Spring XD Pivotal Data Dispatch Pivotal Analytics Description A massively parallel platform
CIS 601 Graduate Seminar. Dr. Sunnie S. Chung Dhruv Patel ( ) Kalpesh Sharma ( )
 Kalpesh Sharma ( )") Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack. Chief Architect RainStor
 Mark Cusack. Chief Architect RainStor") Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack Chief Architect RainStor Agenda Importance of Hadoop + data compression Data compression techniques Compression,
Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack Chief Architect RainStor Agenda Importance of Hadoop + data compression Data compression techniques Compression,
Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018
: Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018") Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018 K. Zhang (pic source: mapr.com/blog) Copyright BUDT 2016 758 Where
Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018 K. Zhang (pic source: mapr.com/blog) Copyright BUDT 2016 758 Where
Importing and Exporting Data Between Hadoop and MySQL
 Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Processing Unstructured Data. Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd.
 Processing Unstructured Data Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd. http://dinesql.com / Dinesh Priyankara @dinesh_priya Founder/Principal Architect dinesql Pvt Ltd. Microsoft Most
Processing Unstructured Data Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd. http://dinesql.com / Dinesh Priyankara @dinesh_priya Founder/Principal Architect dinesql Pvt Ltd. Microsoft Most
Hive SQL over Hadoop
 Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Processing 11 billions events a day with Spark. Alexander Krasheninnikov
 Processing 11 billions events a day with Spark Alexander Krasheninnikov Badoo facts 46 languages 10M Photos added daily 320M registered users 190 countries 21M daily active users 3000+ servers 2 data-centers
Processing 11 billions events a day with Spark Alexander Krasheninnikov Badoo facts 46 languages 10M Photos added daily 320M registered users 190 countries 21M daily active users 3000+ servers 2 data-centers
Oracle Big Data. A NA LYT ICS A ND MA NAG E MENT.
 Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Apache Hadoop Goes Realtime at Facebook. Himanshu Sharma
 Apache Hadoop Goes Realtime at Facebook Guide - Dr. Sunny S. Chung Presented By- Anand K Singh Himanshu Sharma Index Problem with Current Stack Apache Hadoop and Hbase Zookeeper Applications of HBase at
Apache Hadoop Goes Realtime at Facebook Guide - Dr. Sunny S. Chung Presented By- Anand K Singh Himanshu Sharma Index Problem with Current Stack Apache Hadoop and Hbase Zookeeper Applications of HBase at
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
A Survey on Big Data
 A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
How to Write Data to HDFS
 How to Write Data to HDFS 2014 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise) without prior
How to Write Data to HDFS 2014 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise) without prior
Expert Lecture plan proposal Hadoop& itsapplication
 Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Typical size of data you deal with on a daily basis
 Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
PROFESSIONAL. NoSQL. Shashank Tiwari WILEY. John Wiley & Sons, Inc.
 PROFESSIONAL NoSQL Shashank Tiwari WILEY John Wiley & Sons, Inc. Examining CONTENTS INTRODUCTION xvil CHAPTER 1: NOSQL: WHAT IT IS AND WHY YOU NEED IT 3 Definition and Introduction 4 Context and a Bit
PROFESSIONAL NoSQL Shashank Tiwari WILEY John Wiley & Sons, Inc. Examining CONTENTS INTRODUCTION xvil CHAPTER 1: NOSQL: WHAT IT IS AND WHY YOU NEED IT 3 Definition and Introduction 4 Context and a Bit
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Microsoft. Exam Questions Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo
 Version:Demo") Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Advanced Database Technologies NoSQL: Not only SQL
 Advanced Database Technologies NoSQL: Not only SQL Christian Grün Database & Information Systems Group NoSQL Introduction 30, 40 years history of well-established database technology all in vain? Not at
Advanced Database Technologies NoSQL: Not only SQL Christian Grün Database & Information Systems Group NoSQL Introduction 30, 40 years history of well-established database technology all in vain? Not at
Activator Library. Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success.
 Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
docs.hortonworks.com
 docs.hortonworks.com : Getting Started Guide Copyright 2012, 2014 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open source platform for storing,
docs.hortonworks.com : Getting Started Guide Copyright 2012, 2014 Hortonworks, Inc. Some rights reserved. The, powered by Apache Hadoop, is a massively scalable and 100% open source platform for storing,
Apache Hive for Oracle DBAs. Luís Marques
 Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Cloud Computing Techniques for Big Data and Hadoop Implementation
 Cloud Computing Techniques for Big Data and Hadoop Implementation Nikhil Gupta (Author) Ms. komal Saxena(Guide) Research scholar Assistant Professor AIIT, Amity university AIIT, Amity university NOIDA-UP
Cloud Computing Techniques for Big Data and Hadoop Implementation Nikhil Gupta (Author) Ms. komal Saxena(Guide) Research scholar Assistant Professor AIIT, Amity university AIIT, Amity university NOIDA-UP
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
MAPR TECHNOLOGIES, INC. TECHNICAL BRIEF APRIL 2017 MAPR SNAPSHOTS
 MAPR TECHNOLOGIES, INC. TECHNICAL BRIEF APRIL 2017 MAPR SNAPSHOTS INTRODUCTION The ability to create and manage snapshots is an essential feature expected from enterprise-grade storage systems. This capability
MAPR TECHNOLOGIES, INC. TECHNICAL BRIEF APRIL 2017 MAPR SNAPSHOTS INTRODUCTION The ability to create and manage snapshots is an essential feature expected from enterprise-grade storage systems. This capability
Map Reduce & Hadoop Recommended Text:
 Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Configuring and Deploying Hadoop Cluster Deployment Templates
 Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Trafodion Enterprise-Class Transactional SQL-on-HBase
 Trafodion Enterprise-Class Transactional SQL-on-HBase Trafodion Introduction (Welsh for transactions) Joint HP Labs & HP-IT project for transactional SQL database capabilities on Hadoop Leveraging 20+
Trafodion Enterprise-Class Transactional SQL-on-HBase Trafodion Introduction (Welsh for transactions) Joint HP Labs & HP-IT project for transactional SQL database capabilities on Hadoop Leveraging 20+
HCatalog. Table Management for Hadoop. Alan F. Page 1
 HCatalog Table Management for Hadoop Alan F. Gates @alanfgates Page 1 Who Am I? HCatalog committer and mentor Co-founder of Hortonworks Tech lead for Data team at Hortonworks Pig committer and PMC Member
HCatalog Table Management for Hadoop Alan F. Gates @alanfgates Page 1 Who Am I? HCatalog committer and mentor Co-founder of Hortonworks Tech lead for Data team at Hortonworks Pig committer and PMC Member
EXTRACT DATA IN LARGE DATABASE WITH HADOOP
 International Journal of Advances in Engineering & Scientific Research (IJAESR) ISSN: 2349 3607 (Online), ISSN: 2349 4824 (Print) Download Full paper from : http://www.arseam.com/content/volume-1-issue-7-nov-2014-0
International Journal of Advances in Engineering & Scientific Research (IJAESR) ISSN: 2349 3607 (Online), ISSN: 2349 4824 (Print) Download Full paper from : http://www.arseam.com/content/volume-1-issue-7-nov-2014-0
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
RAMCloud. Scalable High-Performance Storage Entirely in DRAM. by John Ousterhout et al. Stanford University. presented by Slavik Derevyanko
 RAMCloud Scalable High-Performance Storage Entirely in DRAM 2009 by John Ousterhout et al. Stanford University presented by Slavik Derevyanko Outline RAMCloud project overview Motivation for RAMCloud storage:
RAMCloud Scalable High-Performance Storage Entirely in DRAM 2009 by John Ousterhout et al. Stanford University presented by Slavik Derevyanko Outline RAMCloud project overview Motivation for RAMCloud storage:
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Lily 2.4 What s New Product Release Notes
 Lily 2.4 What s New Product Release Notes WHAT S NEW IN LILY 2.4 2 Table of Contents Table of Contents... 2 Purpose and Overview of this Document... 3 Product Overview... 4 General... 5 Prerequisites...
Lily 2.4 What s New Product Release Notes WHAT S NEW IN LILY 2.4 2 Table of Contents Table of Contents... 2 Purpose and Overview of this Document... 3 Product Overview... 4 General... 5 Prerequisites...
APACHE HIVE CIS 612 SUNNIE CHUNG
 APACHE HIVE CIS 612 SUNNIE CHUNG APACHE HIVE IS Data warehouse infrastructure built on top of Hadoop enabling data summarization and ad-hoc queries. Initially developed by Facebook. Hive stores data in
APACHE HIVE CIS 612 SUNNIE CHUNG APACHE HIVE IS Data warehouse infrastructure built on top of Hadoop enabling data summarization and ad-hoc queries. Initially developed by Facebook. Hive stores data in
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Understanding NoSQL Database Implementations
 Understanding NoSQL Database Implementations Sadalage and Fowler, Chapters 7 11 Class 07: Understanding NoSQL Database Implementations 1 Foreword NoSQL is a broad and diverse collection of technologies.
Understanding NoSQL Database Implementations Sadalage and Fowler, Chapters 7 11 Class 07: Understanding NoSQL Database Implementations 1 Foreword NoSQL is a broad and diverse collection of technologies.
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG
 BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
Gain Insights From Unstructured Data Using Pivotal HD. Copyright 2013 EMC Corporation. All rights reserved.
 Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
Cloudera Introduction
 Cloudera Introduction Important Notice 2010-2017 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Cloudera Introduction Important Notice 2010-2017 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Hadoop, Yarn and Beyond
 Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Verarbeitung von Vektor- und Rasterdaten auf der Hadoop Plattform DOAG Spatial and Geodata Day 2016
 Verarbeitung von Vektor- und Rasterdaten auf der Hadoop Plattform DOAG Spatial and Geodata Day 2016 Hans Viehmann Product Manager EMEA ORACLE Corporation 12. Mai 2016 Safe Harbor Statement The following
Verarbeitung von Vektor- und Rasterdaten auf der Hadoop Plattform DOAG Spatial and Geodata Day 2016 Hans Viehmann Product Manager EMEA ORACLE Corporation 12. Mai 2016 Safe Harbor Statement The following
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
HBase Solutions at Facebook
 HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
A SURVEY ON SCHEDULING IN HADOOP FOR BIGDATA PROCESSING
 Journal homepage: www.mjret.in ISSN:2348-6953 A SURVEY ON SCHEDULING IN HADOOP FOR BIGDATA PROCESSING Bhavsar Nikhil, Bhavsar Riddhikesh,Patil Balu,Tad Mukesh Department of Computer Engineering JSPM s
Journal homepage: www.mjret.in ISSN:2348-6953 A SURVEY ON SCHEDULING IN HADOOP FOR BIGDATA PROCESSING Bhavsar Nikhil, Bhavsar Riddhikesh,Patil Balu,Tad Mukesh Department of Computer Engineering JSPM s
A Review Paper on Big data & Hadoop
 A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
SURVEY ON BIG DATA TECHNOLOGIES
 SURVEY ON BIG DATA TECHNOLOGIES Prof. Kannadasan R. Assistant Professor Vit University, Vellore India kannadasan.r@vit.ac.in ABSTRACT Rahis Shaikh M.Tech CSE - 13MCS0045 VIT University, Vellore rais137123@gmail.com
SURVEY ON BIG DATA TECHNOLOGIES Prof. Kannadasan R. Assistant Professor Vit University, Vellore India kannadasan.r@vit.ac.in ABSTRACT Rahis Shaikh M.Tech CSE - 13MCS0045 VIT University, Vellore rais137123@gmail.com
Performance Comparison of Hive, Pig & Map Reduce over Variety of Big Data
 Performance Comparison of Hive, Pig & Map Reduce over Variety of Big Data Yojna Arora, Dinesh Goyal Abstract: Big Data refers to that huge amount of data which cannot be analyzed by using traditional analytics
Performance Comparison of Hive, Pig & Map Reduce over Variety of Big Data Yojna Arora, Dinesh Goyal Abstract: Big Data refers to that huge amount of data which cannot be analyzed by using traditional analytics
FROM LEGACY, TO BATCH, TO NEAR REAL-TIME. Marc Sturlese, Dani Solà
 FROM LEGACY, TO BATCH, TO NEAR REAL-TIME Marc Sturlese, Dani Solà WHO ARE WE? Marc Sturlese - @sturlese Backend engineer, focused on R&D Interests: search, scalability Dani Solà - @dani_sola Backend engineer
FROM LEGACY, TO BATCH, TO NEAR REAL-TIME Marc Sturlese, Dani Solà WHO ARE WE? Marc Sturlese - @sturlese Backend engineer, focused on R&D Interests: search, scalability Dani Solà - @dani_sola Backend engineer
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Efficiency at Scale. Sanjeev Kumar Director of Engineering, Facebook
 Efficiency at Scale Sanjeev Kumar Director of Engineering, Facebook International Workshop on Rack-scale Computing, April 2014 Agenda 1 Overview 2 Datacenter Architecture 3 Case Study: Optimizing BLOB
Efficiency at Scale Sanjeev Kumar Director of Engineering, Facebook International Workshop on Rack-scale Computing, April 2014 Agenda 1 Overview 2 Datacenter Architecture 3 Case Study: Optimizing BLOB
HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads
 HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads Azza Abouzeid, Kamil Bajda-Pawlikowski, Daniel J. Abadi, Alexander Rasin and Avi Silberschatz Presented by
HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads Azza Abouzeid, Kamil Bajda-Pawlikowski, Daniel J. Abadi, Alexander Rasin and Avi Silberschatz Presented by