Advanced Database Systems
|
|
|
- Chloe Hill
- 6 years ago
- Views:
Transcription
1 Lecture IV Query Processing Kyumars Sheykh Esmaili

2 Basic Steps in Query Processing 2
3 Query Optimization Many equivalent execution plans Choosing the best one Based on Heuristics, Cost Will be discussed separately Today: Measure query costs Algorithms for evaluating (main) relational algebra operations Combine algorithms for individual operations in order to evaluate a complete expression 3
4 Measures of Query Cost Cost is generally measured as total elapsed time for answering query Many factors contribute to time cost disk accesses, CPU, or even network communication Typically disk access is the predominant cost, and is also relatively easy to estimate. Measured by taking into account Number of seeks Number of blocks read The cost of a seek is usually much higher than that of a block transfer read or write (one order of magnitude) 4
5 Measures of Query Cost (Cont.) For simplicity we just use the number of block transfers from disk and the number of seeks as the cost measures t T time to transfer one block t S time for one seek Cost for b block transfers plus S seeks b * t T + S * t S We do not include cost to writing output to disk in the cost formulae We ignore CPU costs for simplicity, as they tend to be much lower Real systems do take CPU cost into account, but they are clearly less significant 5
6 Outline Selection Operation Sorting Join Operation Other Operations Evaluation of Expressions 6
7 Selection Operator
8 Algorithms for Selection Operation File scan search algorithms that locate and retrieve records that fulfill a selection condition. Algorithm A1 (linear search). Scan each file block and test all records to see whether they satisfy the selection condition. Cost estimate = b r * block transfers + 1 seek b r denotes number of blocks containing records from relation r If selection is on a key attribute, can stop on finding record cost = (b r /2) * block transfers + 1 seek This linear search can be always applied, regardless of: selection condition or ordering of records in the file, or availability of indices 8
9 Algorithms for Selection (Cont.) A2 (binary search). Applicable only if the selection is an equality comparison on the attribute on which file is ordered. Assumes that the blocks of a relation are stored contiguously Cost estimate (number of disk blocks to be scanned): cost of locating the first tuple by a binary search on the blocks o log 2 (b r ) * (t T + t S ) If there are multiple records satisfying selection o Add transfer cost of the number of blocks containing records that satisfy selection condition If b r is not too big, then most likely binary search doesn t pay off 9
10 Selections Using Indices Index scan search algorithms that use an index selection condition must be on search-key of index. A3 (primary index on candidate key, equality). Retrieve a single record that satisfies the corresponding equality condition Cost = (h i + 1) * (t T + t S ) where h i denotes the height of the index Recall that the height of a B+-tree index is log n/2 (K), where n is the number of index entries per node and K is the number of search keys. E.g. for a relation r with different search key, and with 100 index entries per node, h i = 4 Unless the relation is really small, this algorithms always pays off when indexes are available 10
11 Selections Using Indices (cont) A4 (primary index on nonkey, equality) Retrieve multiple records. Records will be on consecutive blocks Let b = number of blocks containing matching records Cost = h i * (t T + t S ) + t S + t T * b A5 (equality on search-key of secondary index). Retrieve a single record if the search-key is a candidate key Cost = (h i + 1) * (t T + t S ) Retrieve multiple records if search-key is not a candidate key each of n matching records may be on a different block Cost = (h i + n) * (t T + t S ) o Can be very expensive if n is big! Note that it multiplies the time for seeks by n. 11
12 Selections Involving Comparisons One can implement selections of the form σ A V (r) or σ A V (r) by using a linear file scan or binary search just as before, or by using indices in the following ways: A6 (primary index, comparison). For σ A V (r) use index to find first tuple v and scan relation sequentially from there For σ A V (r) just scan relation sequentially till first tuple > v; o Using the index would be useless, and would requires extra seeks on the index file A7 (secondary index, comparison). For σ A V (r) use index to find first index entry v and scan index sequentially from there, to find pointers to records. For σ A V (r) just scan leaf pages of index finding pointers to records, till first entry > v In either case, retrieve records that are pointed to o requires an I/O for each record (a lot!) o Linear file scan may be much cheaper!!!! 12
13 Complex Selections Conjunction: σ θ1 θ2... θn (r) A8 (conjunctive selection using one index). Select a combination of θ i and algorithms A1-A7 that results in the least cost for σ θi (r). Test other conditions on tuple after fetching it into memory buffer. In this case the choice of the first condition is crucial! One must use estimates to know which one is better 13
14 Complex Selections Algorithms Disjunction:σ θ1 θ2... θn (r). A9 (disjunctive selection by union of identifiers). Applicable only if all conditions have available indices. Otherwise use linear scan. Use corresponding index for each condition, and take union of all the obtained sets of record pointers. Then fetch records from file 14
15 Sort Operator
16 Sorting Sorting algorithms are important in query processing at least for two reasons: The query itself may require sorting (order by clause) Some algorithms for other operations, like join, set operations and aggregation, require that relation are previously sorted To sort a relation: We may build an index on the relation, and then use the index to read the relation in sorted order. This only sorts the relation logically, not physically May lead to one disk block access for each tuple. For relations that fit in memory sorting algorithms that you ve studied before, like quicksort, can be used. For relations that don t fit in memory special algorithms are required, that take into account the measures in terms of disc transfers and seeks. 16
17 External Sort-Merge It is a sorting algorithm to be used when the whole relation does not fit in memory. Let M denote memory size (in pages). 1. Create sorted runs. Let i be 0 initially. Repeatedly do the following till the end of the relation: (a) Read M blocks of relation into memory (b) Sort the in-memory blocks (with your favorite sorting algorithm) (c) Write sorted data to run R i ; increment i. Let the final value of i be N 2. Merge the runs (next slide).. 17
18 External Sort-Merge (Cont.) 2. Merge the runs (N-way merge). We assume (for now) that N < M. 1. Use N blocks of memory to buffer input runs, and 1 block to buffer output. Read the first block of each run into its buffer page 2. repeat 1. Select the first record (in sort order) among all buffer pages 2. Write the record to the output buffer. If the output buffer is full write it to disk. 3. Delete the record from its input buffer page. If the buffer page becomes empty then read the next block (if any) of the run into the buffer. 3. until all input buffer pages are empty: 18
19 External Sort-Merge (Cont.) If N M, several merge passes are required. In each pass, contiguous groups of M - 1 runs are merged. A pass reduces the number of runs by a factor of M -1, and creates runs longer by the same factor. E.g. If M=11, and there are 90 runs, one pass reduces the number of runs to 9, each 10 times the size of the initial runs Repeated passes are performed till all runs have been merged into one. 19



20 Example: External Sorting Using Sort-Merge 20
21 External Merge Sort Transfer Cost Cost analysis: Total number of merge passes required: log M 1 (b r /M). Block transfers for initial run creation as well as in each pass is 2b r for final pass, we don t count write cost o we ignore final write cost for all operations since the output of an operation may be sent to the parent operation without being written to disk Thus total number of block transfers for external sorting: b r ( 2 log M 1 (b r / M) + 1) 21
22 External Merge Sort Seek Cost Cost of seeks During run generation: one seek to read each run and one seek to write each run 2 b r / M During the merge phase Buffer size: b b (read/write b b blocks at a time) Need 2 b r / b b seeks for each merge pass o except the final one which does not require a write Total number of seeks: 2 b r / M + b r / b b (2 log M 1 (b r / M) -1) 22
23 Join Operator
24 Join Operation Several different algorithms to implement joins exist (not counting with the ones involving parallelism) Nested-loop join Block nested-loop join Indexed nested-loop join Merge-join Hash-join As for selection, the choice is based on cost estimate Examples in next slides use the following information Number of records of customer: depositor: Number of blocks of customer: 400 depositor:
25 Nested-Loop Join The simplest join algorithms, that can be used independently of everything (like the linear search for selection) To compute the theta join r θ s for each tuple t r in r do begin for each tuple t s in s do begin test pair (t r,t s ) to see if they satisfy the join condition θ if they do, add t r t s to the result. end end r is called the outer relation and s the inner relation of the join. Quite expensive in general, since it requires to examine every pair of tuples in the two relations. 25
26 Nested-Loop Join (Cont.) In the worst case, if there is enough memory only to hold one block of each relation, the estimated cost is n r b s + b r block transfers, plus n r + b r seeks If the smaller relation fits entirely in memory, use that as the inner relation. Reduces cost to b r + b s block transfers and 2 seeks In general, it is much better to have the smaller relation as the outer relation The number of block transfers is multiplied by the number of blocks of the inner relation However, if the smaller relation is small enough to fit in memory, one should use it as the inner relation! The choice of the inner and outer relation strongly depends on the estimate of the size of each relation 26
27 Nested-Loop Join Cost in Example Assuming worst case memory availability cost estimate is with depositor as outer relation: = block transfers, = 5100 seeks with customer as the outer relation = block transfers, seeks If smaller relation (depositor) fits entirely in memory, the cost estimate will be 500 block transfers and 2 seeks Instead of iterating over records, one could iterate over blocks. This way, instead of n r b s + b r we would have b r b s + b r block transfers This is the basis of the block nested-loops algorithm (next slide). 27
28 Block Nested-Loop Join Variant of nested-loop join in which every block of inner relation is paired with every block of outer relation. for each block B r of r do begin for each block B s of s do begin for each tuple t r in B r do begin for each tuple t s in B s do begin Check if (t r,t s ) satisfy the join condition if they do, add t r t s to the result. end end end end 28
29 Block Nested-Loop Join Cost Worst case estimate: b r b s + b r block transfers and 2 * b r seeks Each block in the inner relation s is read once for each block in the outer relation (instead of once for each tuple in the outer relation Best case (when smaller relation fits into memory): b r + b s block transfers plus 2 seeks. Some improvements to nested loop and block nested loop algorithms can be made: Scan inner loop forward and backward alternately, to make use of the blocks remaining in buffer (with LRU replacement) Use index on inner relation if available to faster get the tuples which match the tuple of the outer relation at hands 29
30 Indexed Nested-Loop Join Index lookups can replace file scans if join is an equi-join or natural join and an index is available on the inner relation s join attribute In some cases, it pays to construct an index just to compute a join. For each tuple t r in the outer relation r, use the index on s to look up tuples in s that satisfy the join condition with tuple t r. Worst case: buffer has space for only one page of r, and, for each tuple in r, we perform an index lookup on s. Cost of the join: b r (t T + t S ) + n r c Where c is the cost of traversing index and fetching all matching s tuples for one tuple or r c can be estimated as cost of a single selection on s using the join condition (usually quite low, when compared to the join) If indices are available on join attributes of both r and s, use the relation with fewer tuples as the outer relation. 30
31 Example of Nested-Loop Join Costs Compute depositor customer, with depositor as the outer relation. Let customer have a primary B + -tree index on the join attribute customer-name, which contains 20 entries in each index node. Since customer has tuples, the height of the tree is 4, and one more access is needed to find the actual data depositor has tuples For nested loop: block transfers and seeks Cost of block nested loops join 400* = block transfers + 2 * 100 = 200 seeks Cost of indexed nested loops join * 5 = block transfers and seeks. CPU cost likely to be less than that for block nested loops join However in terms of time for transfers and seeks, in this case using the index doesn t pay (this is specially so because the relations are small) 31

32 Merge-Join 1. Sort both relations on their join attribute (if not already sorted on the join attributes). 2. Merge the sorted relations to join them 1. Join step is similar to the merge stage of the sort-merge algorithm. 2. Main difference is handling of duplicate values in join attribute every pair with same value on join attribute must be matched 32
33 Merge-Join (Cont.) Can be used only for equi-joins and natural joins Each block needs to be read only once (assuming that all tuples for any given value of the join attributes fit in memory) Thus the cost of merge join is (where b b is the number of blocks in allocated in memory): b r + b s block transfers + b r / b b + b s / b b seeks + the cost of sorting if relations are unsorted. hybrid merge-join: If one relation is sorted, and the other has a secondary B + -tree index on the join attribute Merge the sorted relation with the leaf entries of the B + -tree. Sort the result on the addresses of the unsorted relation s tuples Scan the unsorted relation in physical address order and merge with previous result, to replace addresses by the actual tuples Sequential scan more efficient than random lookup 33
34 Hash-Join Also only applicable for equi-joins and natural joins. A hash function h is used to partition tuples of both relations h maps JoinAttrs values to {0, 1,..., n}, where JoinAttrs denotes the common attributes of r and s used in the natural join. r 0, r 1,..., r n denote partitions of r tuples Each tuple t r r is put in partition r i where i = h(t r [JoinAttrs]). s 0, s 1..., s n denotes partitions of s tuples Each tuple t s s is put in partition s i, where i = h(t s [JoinAttrs]). General idea: Partition the relations according to this Then perform the join on each partition r i and s i There is no need to compute the join between different partitions since an r tuple and an s tuple that satisfy the join condition will have the same value for the join attributes. If that value is hashed to some value i, the r tuple has to be in r i and the s tuple in s i. 34

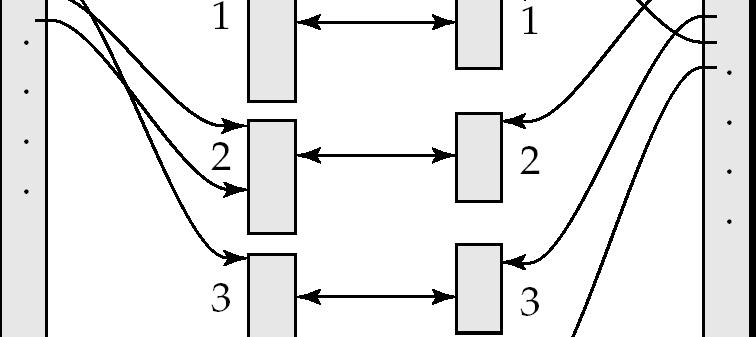
35 Hash-Join (Cont.) 35
36 Hash-Join Algorithm The hash-join of r and s is computed as follows. 1. Partition the relation s using hashing function h. When partitioning a relation, one block of memory is reserved as the output buffer for each partition. 2. Partition r similarly. 3. For each i: (a) Load s i into memory and build an in-memory hash Relation s is called the build input and r is called the probe input. index on it using the join attribute. This hash index uses a different hash function than the earlier one h. (b) Read the tuples in r i from the disk one by one. For each tuple t r locate each matching tuple t s in s i using the inmemory hash index. Output the concatenation of their attributes. 36
37 Hash-Join algorithm (Cont.) The number of partitions n for the hash function h is chosen such that each s i should fit in memory. Typically n is chosen as b s/m * f where f is a fudge factor, typically around 1.2, to avoid overflows The probe relation partitions r i need not fit in memory Recursive partitioning required if number of partitions n is greater than number of pages M of memory. instead of partitioning n ways, use M 1 partitions for s Further partition the M 1 partitions using a different hash function Use same partitioning method on r Rarely required: e.g., recursive partitioning not needed for relations of 1GB or less with memory size of 2MB, with block size of 4KB. So is not further considered here (see the book for details on the associated costs) 37
38 Cost of Hash-Join The cost of hash join is 3(b r + b s ) +4 n h block transfers + 2( b r / b b + b s / b b ) seeks If the entire build input can be kept in main memory no partitioning is required Cost estimate goes down to b r + b s. For the running example, assume that memory size is 20 blocks b depositor = 100 and b customer = 400. depositor is to be used as build input. Partition it into five partitions, each of size 20 blocks. This partitioning can be done in one pass. Similarly, partition customer into five partitions, each of size 80. This is also done in one pass. Therefore total cost, ignoring cost of writing partially filled blocks: 3( ) = block transfers + 2( 100/ /3 ) = 336 seeks The best we had up to here was block transfers plus 200 seeks (for block nested loop) or 25,100 block transfers and seeks (for index nested loop) 38
39 Other Operators
40 Other Operations Duplicate elimination can be implemented via hashing or sorting. On sorting duplicates will come adjacent to each other, and all but one set of duplicates can be deleted. Optimization: duplicates can be deleted during run generation as well as at intermediate merge steps in external sort-merge. Hashing is similar duplicates will come into the same bucket. Projection: perform projection on each tuple followed by duplicate elimination. 40
41 Other Operations : Aggregation Aggregation can be implemented in similarly to duplicate elimination. Sorting or hashing can be used to bring tuples in the same group together, and then the aggregate functions can be applied on each group. Optimization: combine tuples in the same group during run generation and intermediate merges, by computing partial aggregate values For count, min, max, sum: keep aggregate values on tuples found so far in the group. o When combining partial aggregate for count, add up the aggregates For avg, keep sum and count, and divide sum by count at the end 41
42 Other Operations : Set Operations Set operations (, and ): can either use variant of merge-join after sorting, or variant of hash-join. E.g., Set operations using hashing: 1. Partition both relations using the same hash function 2. Process each partition i as follows. 1. Using a different hashing function, build an in-memory hash index on r i. 2. Process s i as follows r s: 1. Add tuples in s i to the hash index if they are not already in it. 2. At end of s i add the tuples in the hash index to the result. r s: 1. output tuples in s i to the result if they are already there in the hash index r s: 1. for each tuple in s i, if it is there in the hash index, delete it from the index. 2. At end of s i add remaining tuples in the hash index to the result. 42
43 Evaluation of Expressions
44 Evaluation of Expressions So far we have seen algorithms for individual operations These have then to be combined to evaluate complex expressions, with several operations Alternatives for evaluating an entire expression tree Materialization: generate results of an expression whose inputs are relations or are already computed, materialize (store) it on disk. Repeat. Pipelining: pass on tuples to parent operations even as an operation is being executed 44
45 Materialization Evaluate one operation at a time starting at the lowest-level Use intermediate results materialized into temporary relations to evaluate next-level operations 45
46 Materialization at Work Application scan scan scan R S T 46
47 Materialization at Work Application Results of Scanning R scan scan scan R S T 47
48 Materialization at Work Application Results of Scanning R Results of Scanning S scan scan scan R S T 48
49 Materialization at Work Application Results of Joining R and S Results of Scanning R Results of Scanning S scan scan scan R S T 49
50 Materialization at Work Application Results of Joining R and S Results of Scanning R Results of Scanning S scan scan scan Results of Scanning T R S T 50
51 Materialization at Work Application Final Results Results of Joining R and S Results of Scanning R Results of Scanning S scan scan scan Results of Scanning T R S T 51
52 Materialization Summary Advantages Materialized evaluation is always applicable Disadvantages It may require considerable storage space cost of writing results to disk and reading them back can be quite high 52
53 Pipelining Pipelined evaluation : evaluate several operations simultaneously, passing the results of one operation on to the next. It is much cheaper than materialization: there is no need to store a temporary relation to disk. Pipelining may not always be possible e.g., sort and hash-join where a preliminary phase is required over the whole relations Pipelines can be executed in two ways: demand driven and producer driven 53
54 Pipelining (Cont.) In producer-driven (or eager or push) pipelining Operators produce tuples eagerly and pass them up to their parents Buffer maintained between operators, child puts tuples in buffer, parent removes tuples from buffer if buffer is full, child waits till there is space in the buffer, and then generates more tuples In demand driven (or lazy, or pull) evaluation system repeatedly requests next tuple from top level operation Each operation requests next tuple from children operations as required, in order to output its next tuple In between calls, operation has to maintain state so it knows what to return next 54
55 Pipelining (Cont.) Implementation of pull pipelining Each operation is implemented as an iterator implementing the following operations open() o E.g. file scan: initialize file scan state: pointer to beginning of file o E.g. merge join: sort relations; state: pointers to beginning of sorted relations next() o E.g. for file scan: Output next tuple, and advance and store file pointer o E.g. for merge join: continue with merge from earlier state till next output tuple is found. Save pointers as iterator state. close() 55
56 Iterator Model at Work Application scan scan scan R S T 56
57 Iterator Model at Work JDBC: execute() Application scan scan scan R S T 57
58 Iterator Model at Work JDBC: execute() Application open() scan scan scan R S T 58
59 Iterator Model at Work JDBC: execute() Application open() open() open() scan scan scan R S T 59
60 Iterator Model at Work JDBC: execute() Application open() open() scan open/close for scan scan each R tuple R S T 60
61 Iterator Model at Work JDBC: execute() Application open() scan scan open/close for scan each R,S tuple R S T 61
62 Iterator Model at Work JDBC: next() Application next() next() next() scan scan scan R S T 62
63 Iterator Model at Work JDBC: next() Application next() next() r1 scan scan scan R S T 63
64 Iterator Model at Work JDBC: next() Application next() next() r1 scan open() scan scan R S T 64
65 Iterator Model at Work JDBC: next() Application next() next() r1 scan next() scan scan R S T 65
66 Iterator Model at Work JDBC: next() Application next() next() r1 scan s1 scan scan R S T 66
67 Iterator Model at Work JDBC: next() Application next() next() r1 scan next() scan scan R S T 67
68 Iterator Model at Work JDBC: next() Application next() next() r1 scan s2 scan scan R S T 68
69 Iterator Model at Work JDBC: next() Application next() r1, s2 scan scan scan R S T 69
70 Iterator Model at Work JDBC: next() Application next() r1, s2 scan scan open() scan R S T 70
71 Iterator Model at Work JDBC: next() Application next() r1, s2 scan scan next() scan R S T 71
72 Iterator Model at Work JDBC: next() Application next() r1, s2 scan scan t1 scan R S T 72
73 Iterator Model at Work JDBC: next() Application r1, s2, t1 scan scan scan R S T r2, r3, s3, s4, t2, t3, 73 73
74 Iterator Model Summary Advantages generic interface for all operators: great information hiding easy to implement iterators (clear what to do in any phase) works well with JDBC and embedded SQL no overheads in terms of main memory Disadvantages Not applicable to all cases Blocking operators (e.g. Sort) high overhead of method calls poor instruction cache locality 74
Chapter 12: Query Processing
 Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Overview Chapter 12: Query Processing Measures of Query Cost Selection Operation Sorting Join
Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Overview Chapter 12: Query Processing Measures of Query Cost Selection Operation Sorting Join
Chapter 13: Query Processing
 Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Chapter 12: Query Processing. Chapter 12: Query Processing
 Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Query Processing Overview Measures of Query Cost Selection Operation Sorting Join
Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Query Processing Overview Measures of Query Cost Selection Operation Sorting Join
! A relational algebra expression may have many equivalent. ! Cost is generally measured as total elapsed time for
 Chapter 13: Query Processing Basic Steps in Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 1. Parsing and
Chapter 13: Query Processing Basic Steps in Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 1. Parsing and
Chapter 13: Query Processing Basic Steps in Query Processing
 Chapter 13: Query Processing Basic Steps in Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 1. Parsing and
Chapter 13: Query Processing Basic Steps in Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 1. Parsing and
Query Processing. Debapriyo Majumdar Indian Sta4s4cal Ins4tute Kolkata DBMS PGDBA 2016
 Query Processing Debapriyo Majumdar Indian Sta4s4cal Ins4tute Kolkata DBMS PGDBA 2016 Slides re-used with some modification from www.db-book.com Reference: Database System Concepts, 6 th Ed. By Silberschatz,
Query Processing Debapriyo Majumdar Indian Sta4s4cal Ins4tute Kolkata DBMS PGDBA 2016 Slides re-used with some modification from www.db-book.com Reference: Database System Concepts, 6 th Ed. By Silberschatz,
Database System Concepts
 Chapter 13: Query Processing s Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2008/2009 Slides (fortemente) baseados nos slides oficiais do livro c Silberschatz, Korth
Chapter 13: Query Processing s Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2008/2009 Slides (fortemente) baseados nos slides oficiais do livro c Silberschatz, Korth
Query Processing & Optimization
 Query Processing & Optimization 1 Roadmap of This Lecture Overview of query processing Measures of Query Cost Selection Operation Sorting Join Operation Other Operations Evaluation of Expressions Introduction
Query Processing & Optimization 1 Roadmap of This Lecture Overview of query processing Measures of Query Cost Selection Operation Sorting Join Operation Other Operations Evaluation of Expressions Introduction
Chapter 12: Query Processing
 Chapter 12: Query Processing Overview Catalog Information for Cost Estimation $ Measures of Query Cost Selection Operation Sorting Join Operation Other Operations Evaluation of Expressions Transformation
Chapter 12: Query Processing Overview Catalog Information for Cost Estimation $ Measures of Query Cost Selection Operation Sorting Join Operation Other Operations Evaluation of Expressions Transformation
Shuigeng Zhou. May 18, 2016 School of Computer Science Fudan University
 Query Processing Shuigeng Zhou May 18, 2016 School of Comuter Science Fudan University Overview Outline Measures of Query Cost Selection Oeration Sorting Join Oeration Other Oerations Evaluation of Exressions
Query Processing Shuigeng Zhou May 18, 2016 School of Comuter Science Fudan University Overview Outline Measures of Query Cost Selection Oeration Sorting Join Oeration Other Oerations Evaluation of Exressions
CMSC424: Database Design. Instructor: Amol Deshpande
 CMSC424: Database Design Instructor: Amol Deshpande amol@cs.umd.edu Databases Data Models Conceptual representa1on of the data Data Retrieval How to ask ques1ons of the database How to answer those ques1ons
CMSC424: Database Design Instructor: Amol Deshpande amol@cs.umd.edu Databases Data Models Conceptual representa1on of the data Data Retrieval How to ask ques1ons of the database How to answer those ques1ons
CSIT5300: Advanced Database Systems
 CSIT5300: Advanced Database Systems L10: Query Processing Other Operations, Pipelining and Materialization Dr. Kenneth LEUNG Department of Computer Science and Engineering The Hong Kong University of Science
CSIT5300: Advanced Database Systems L10: Query Processing Other Operations, Pipelining and Materialization Dr. Kenneth LEUNG Department of Computer Science and Engineering The Hong Kong University of Science
DBMS Y3/S5. 1. OVERVIEW The steps involved in processing a query are: 1. Parsing and translation. 2. Optimization. 3. Evaluation.
 Query Processing QUERY PROCESSING refers to the range of activities involved in extracting data from a database. The activities include translation of queries in high-level database languages into expressions
Query Processing QUERY PROCESSING refers to the range of activities involved in extracting data from a database. The activities include translation of queries in high-level database languages into expressions
Query processing and optimization
 Query processing and optimization These slides are a modified version of the slides of the book Database System Concepts (Chapter 13 and 14), 5th Ed., McGraw-Hill, by Silberschatz, Korth and Sudarshan.
Query processing and optimization These slides are a modified version of the slides of the book Database System Concepts (Chapter 13 and 14), 5th Ed., McGraw-Hill, by Silberschatz, Korth and Sudarshan.
Review. Support for data retrieval at the physical level:
 Query Processing Review Support for data retrieval at the physical level: Indices: data structures to help with some query evaluation: SELECTION queries (ssn = 123) RANGE queries (100
Query Processing Review Support for data retrieval at the physical level: Indices: data structures to help with some query evaluation: SELECTION queries (ssn = 123) RANGE queries (100
Advanced Databases. Lecture 1- Query Processing. Masood Niazi Torshiz Islamic Azad university- Mashhad Branch
 Advanced Databases Lecture 1- Query Processing Masood Niazi Torshiz Islamic Azad university- Mashhad Branch www.mniazi.ir Overview Measures of Query Cost Selection Operation Sorting Join Operation Other
Advanced Databases Lecture 1- Query Processing Masood Niazi Torshiz Islamic Azad university- Mashhad Branch www.mniazi.ir Overview Measures of Query Cost Selection Operation Sorting Join Operation Other
Ch 5 : Query Processing & Optimization
 Ch 5 : Query Processing & Optimization Basic Steps in Query Processing 1. Parsing and translation 2. Optimization 3. Evaluation Basic Steps in Query Processing (Cont.) Parsing and translation translate
Ch 5 : Query Processing & Optimization Basic Steps in Query Processing 1. Parsing and translation 2. Optimization 3. Evaluation Basic Steps in Query Processing (Cont.) Parsing and translation translate
Introduction to Query Processing and Query Optimization Techniques. Copyright 2011 Ramez Elmasri and Shamkant Navathe
 Introduction to Query Processing and Query Optimization Techniques Outline Translating SQL Queries into Relational Algebra Algorithms for External Sorting Algorithms for SELECT and JOIN Operations Algorithms
Introduction to Query Processing and Query Optimization Techniques Outline Translating SQL Queries into Relational Algebra Algorithms for External Sorting Algorithms for SELECT and JOIN Operations Algorithms
Something to think about. Problems. Purpose. Vocabulary. Query Evaluation Techniques for large DB. Part 1. Fact:
 Query Evaluation Techniques for large DB Part 1 Fact: While data base management systems are standard tools in business data processing they are slowly being introduced to all the other emerging data base
Query Evaluation Techniques for large DB Part 1 Fact: While data base management systems are standard tools in business data processing they are slowly being introduced to all the other emerging data base
Announcement. Reading Material. Overview of Query Evaluation. Overview of Query Evaluation. Overview of Query Evaluation 9/26/17
 Announcement CompSci 516 Database Systems Lecture 10 Query Evaluation and Join Algorithms Project proposal pdf due on sakai by 5 pm, tomorrow, Thursday 09/27 One per group by any member Instructor: Sudeepa
Announcement CompSci 516 Database Systems Lecture 10 Query Evaluation and Join Algorithms Project proposal pdf due on sakai by 5 pm, tomorrow, Thursday 09/27 One per group by any member Instructor: Sudeepa
Algorithms for Query Processing and Optimization. 0. Introduction to Query Processing (1)
") Chapter 19 Algorithms for Query Processing and Optimization 0. Introduction to Query Processing (1) Query optimization: The process of choosing a suitable execution strategy for processing a query. Two
Chapter 19 Algorithms for Query Processing and Optimization 0. Introduction to Query Processing (1) Query optimization: The process of choosing a suitable execution strategy for processing a query. Two
Query Processing. Introduction to Databases CompSci 316 Fall 2017
 Query Processing Introduction to Databases CompSci 316 Fall 2017 2 Announcements (Tue., Nov. 14) Homework #3 sample solution posted in Sakai Homework #4 assigned today; due on 12/05 Project milestone #2
Query Processing Introduction to Databases CompSci 316 Fall 2017 2 Announcements (Tue., Nov. 14) Homework #3 sample solution posted in Sakai Homework #4 assigned today; due on 12/05 Project milestone #2
Query Optimization. Query Optimization. Optimization considerations. Example. Interaction of algorithm choice and tree arrangement.
 COS 597: Principles of Database and Information Systems Query Optimization Query Optimization Query as expression over relational algebraic operations Get evaluation (parse) tree Leaves: base relations
COS 597: Principles of Database and Information Systems Query Optimization Query Optimization Query as expression over relational algebraic operations Get evaluation (parse) tree Leaves: base relations
Database Applications (15-415)
") Database Applications (15-415) DBMS Internals- Part VI Lecture 14, March 12, 2014 Mohammad Hammoud Today Last Session: DBMS Internals- Part V Hash-based indexes (Cont d) and External Sorting Today s Session:
Database Applications (15-415) DBMS Internals- Part VI Lecture 14, March 12, 2014 Mohammad Hammoud Today Last Session: DBMS Internals- Part V Hash-based indexes (Cont d) and External Sorting Today s Session:
Faloutsos 1. Carnegie Mellon Univ. Dept. of Computer Science Database Applications. Outline
 Carnegie Mellon Univ. Dept. of Computer Science 15-415 - Database Applications Lecture #14: Implementation of Relational Operations (R&G ch. 12 and 14) 15-415 Faloutsos 1 introduction selection projection
Carnegie Mellon Univ. Dept. of Computer Science 15-415 - Database Applications Lecture #14: Implementation of Relational Operations (R&G ch. 12 and 14) 15-415 Faloutsos 1 introduction selection projection
Chapter 12: Indexing and Hashing. Basic Concepts
 Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
University of Waterloo Midterm Examination Sample Solution
 1. (4 total marks) University of Waterloo Midterm Examination Sample Solution Winter, 2012 Suppose that a relational database contains the following large relation: Track(ReleaseID, TrackNum, Title, Length,
1. (4 total marks) University of Waterloo Midterm Examination Sample Solution Winter, 2012 Suppose that a relational database contains the following large relation: Track(ReleaseID, TrackNum, Title, Length,
Query Processing. Solutions to Practice Exercises Query:
 C H A P T E R 1 3 Query Processing Solutions to Practice Exercises 13.1 Query: Π T.branch name ((Π branch name, assets (ρ T (branch))) T.assets>S.assets (Π assets (σ (branch city = Brooklyn )(ρ S (branch)))))
C H A P T E R 1 3 Query Processing Solutions to Practice Exercises 13.1 Query: Π T.branch name ((Π branch name, assets (ρ T (branch))) T.assets>S.assets (Π assets (σ (branch city = Brooklyn )(ρ S (branch)))))
Chapter 12: Indexing and Hashing
 Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Hash-Based Indexing 165
 Hash-Based Indexing 165 h 1 h 0 h 1 h 0 Next = 0 000 00 64 32 8 16 000 00 64 32 8 16 A 001 01 9 25 41 73 001 01 9 25 41 73 B 010 10 10 18 34 66 010 10 10 18 34 66 C Next = 3 011 11 11 19 D 011 11 11 19
Hash-Based Indexing 165 h 1 h 0 h 1 h 0 Next = 0 000 00 64 32 8 16 000 00 64 32 8 16 A 001 01 9 25 41 73 001 01 9 25 41 73 B 010 10 10 18 34 66 010 10 10 18 34 66 C Next = 3 011 11 11 19 D 011 11 11 19
Evaluation of relational operations
 Evaluation of relational operations Iztok Savnik, FAMNIT Slides & Textbook Textbook: Raghu Ramakrishnan, Johannes Gehrke, Database Management Systems, McGraw-Hill, 3 rd ed., 2007. Slides: From Cow Book
Evaluation of relational operations Iztok Savnik, FAMNIT Slides & Textbook Textbook: Raghu Ramakrishnan, Johannes Gehrke, Database Management Systems, McGraw-Hill, 3 rd ed., 2007. Slides: From Cow Book
Introduction Alternative ways of evaluating a given query using
 Query Optimization Introduction Catalog Information for Cost Estimation Estimation of Statistics Transformation of Relational Expressions Dynamic Programming for Choosing Evaluation Plans Introduction
Query Optimization Introduction Catalog Information for Cost Estimation Estimation of Statistics Transformation of Relational Expressions Dynamic Programming for Choosing Evaluation Plans Introduction
Lecture 19 Query Processing Part 1
 CMSC 461, Database Management Systems Spring 2018 Lecture 19 Query Processing Part 1 These slides are based on Database System Concepts 6 th edition book (whereas some quotes and figures are used from
CMSC 461, Database Management Systems Spring 2018 Lecture 19 Query Processing Part 1 These slides are based on Database System Concepts 6 th edition book (whereas some quotes and figures are used from
Chapter 3. Algorithms for Query Processing and Optimization
 Chapter 3 Algorithms for Query Processing and Optimization Chapter Outline 1. Introduction to Query Processing 2. Translating SQL Queries into Relational Algebra 3. Algorithms for External Sorting 4. Algorithms
Chapter 3 Algorithms for Query Processing and Optimization Chapter Outline 1. Introduction to Query Processing 2. Translating SQL Queries into Relational Algebra 3. Algorithms for External Sorting 4. Algorithms
Evaluation of Relational Operations
 Evaluation of Relational Operations Chapter 14 Comp 521 Files and Databases Fall 2010 1 Relational Operations We will consider in more detail how to implement: Selection ( ) Selects a subset of rows from
Evaluation of Relational Operations Chapter 14 Comp 521 Files and Databases Fall 2010 1 Relational Operations We will consider in more detail how to implement: Selection ( ) Selects a subset of rows from
CS122 Lecture 8 Winter Term,
 CS122 Lecture 8 Winter Term, 2014-2015 2 Other Join Algorithms Nested- loops join is generally useful, but slow Most joins involve equality tests against attributes Such joins are called equijoins Two
CS122 Lecture 8 Winter Term, 2014-2015 2 Other Join Algorithms Nested- loops join is generally useful, but slow Most joins involve equality tests against attributes Such joins are called equijoins Two
Implementation of Relational Operations: Other Operations
 Implementation of Relational Operations: Other Operations Module 4, Lecture 2 Database Management Systems, R. Ramakrishnan 1 Simple Selections SELECT * FROM Reserves R WHERE R.rname < C% Of the form σ
Implementation of Relational Operations: Other Operations Module 4, Lecture 2 Database Management Systems, R. Ramakrishnan 1 Simple Selections SELECT * FROM Reserves R WHERE R.rname < C% Of the form σ
Intro to DB CHAPTER 12 INDEXING & HASHING
 Intro to DB CHAPTER 12 INDEXING & HASHING Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing
Intro to DB CHAPTER 12 INDEXING & HASHING Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing
CS 4604: Introduction to Database Management Systems. B. Aditya Prakash Lecture #10: Query Processing
 CS 4604: Introduction to Database Management Systems B. Aditya Prakash Lecture #10: Query Processing Outline introduction selection projection join set & aggregate operations Prakash 2018 VT CS 4604 2
CS 4604: Introduction to Database Management Systems B. Aditya Prakash Lecture #10: Query Processing Outline introduction selection projection join set & aggregate operations Prakash 2018 VT CS 4604 2
CS122 Lecture 15 Winter Term,
 CS122 Lecture 15 Winter Term, 2014-2015 2 Index Op)miza)ons So far, only discussed implementing relational algebra operations to directly access heap Biles Indexes present an alternate access path for
CS122 Lecture 15 Winter Term, 2014-2015 2 Index Op)miza)ons So far, only discussed implementing relational algebra operations to directly access heap Biles Indexes present an alternate access path for
Chapter 14 Query Optimization
 Chapter 14 Query Optimization Chapter 14: Query Optimization! Introduction! Catalog Information for Cost Estimation! Estimation of Statistics! Transformation of Relational Expressions! Dynamic Programming
Chapter 14 Query Optimization Chapter 14: Query Optimization! Introduction! Catalog Information for Cost Estimation! Estimation of Statistics! Transformation of Relational Expressions! Dynamic Programming
Chapter 14 Query Optimization
 Chapter 14 Query Optimization Chapter 14: Query Optimization! Introduction! Catalog Information for Cost Estimation! Estimation of Statistics! Transformation of Relational Expressions! Dynamic Programming
Chapter 14 Query Optimization Chapter 14: Query Optimization! Introduction! Catalog Information for Cost Estimation! Estimation of Statistics! Transformation of Relational Expressions! Dynamic Programming
Chapter 14 Query Optimization
 Chapter 14: Query Optimization Chapter 14 Query Optimization! Introduction! Catalog Information for Cost Estimation! Estimation of Statistics! Transformation of Relational Expressions! Dynamic Programming
Chapter 14: Query Optimization Chapter 14 Query Optimization! Introduction! Catalog Information for Cost Estimation! Estimation of Statistics! Transformation of Relational Expressions! Dynamic Programming
Chapter 12: Query Processing
 Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Basic Steps in Query Processing 1. Parsing and translation 2. Optimization 3. Evaluation 12.2
Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Basic Steps in Query Processing 1. Parsing and translation 2. Optimization 3. Evaluation 12.2
Storage hierarchy. Textbook: chapters 11, 12, and 13
 Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow Very small Small Bigger Very big (KB) (MB) (GB) (TB) Built-in Expensive Cheap Dirt cheap Disks: data is stored on concentric circular
Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow Very small Small Bigger Very big (KB) (MB) (GB) (TB) Built-in Expensive Cheap Dirt cheap Disks: data is stored on concentric circular
Fundamentals of Database Systems
 Fundamentals of Database Systems Assignment: 4 September 21, 2015 Instructions 1. This question paper contains 10 questions in 5 pages. Q1: Calculate branching factor in case for B- tree index structure,
Fundamentals of Database Systems Assignment: 4 September 21, 2015 Instructions 1. This question paper contains 10 questions in 5 pages. Q1: Calculate branching factor in case for B- tree index structure,
Query Processing & Optimization. CS 377: Database Systems
 Query Processing & Optimization CS 377: Database Systems Recap: File Organization & Indexing Physical level support for data retrieval File organization: ordered or sequential file to find items using
Query Processing & Optimization CS 377: Database Systems Recap: File Organization & Indexing Physical level support for data retrieval File organization: ordered or sequential file to find items using
Database Applications (15-415)
") Database Applications (15-415) DBMS Internals- Part VI Lecture 17, March 24, 2015 Mohammad Hammoud Today Last Two Sessions: DBMS Internals- Part V External Sorting How to Start a Company in Five (maybe
Database Applications (15-415) DBMS Internals- Part VI Lecture 17, March 24, 2015 Mohammad Hammoud Today Last Two Sessions: DBMS Internals- Part V External Sorting How to Start a Company in Five (maybe
Evaluation of Relational Operations: Other Techniques. Chapter 14 Sayyed Nezhadi
 Evaluation of Relational Operations: Other Techniques Chapter 14 Sayyed Nezhadi Schema for Examples Sailors (sid: integer, sname: string, rating: integer, age: real) Reserves (sid: integer, bid: integer,
Evaluation of Relational Operations: Other Techniques Chapter 14 Sayyed Nezhadi Schema for Examples Sailors (sid: integer, sname: string, rating: integer, age: real) Reserves (sid: integer, bid: integer,
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
What happens. 376a. Database Design. Execution strategy. Query conversion. Next. Two types of techniques
 376a. Database Design Dept. of Computer Science Vassar College http://www.cs.vassar.edu/~cs376 Class 16 Query optimization What happens Database is given a query Query is scanned - scanner creates a list
376a. Database Design Dept. of Computer Science Vassar College http://www.cs.vassar.edu/~cs376 Class 16 Query optimization What happens Database is given a query Query is scanned - scanner creates a list
Advances in Data Management Query Processing and Query Optimisation A.Poulovassilis
 1 Advances in Data Management Query Processing and Query Optimisation A.Poulovassilis 1 General approach to the implementation of Query Processing and Query Optimisation functionalities in DBMSs 1. Parse
1 Advances in Data Management Query Processing and Query Optimisation A.Poulovassilis 1 General approach to the implementation of Query Processing and Query Optimisation functionalities in DBMSs 1. Parse
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Query Optimization. Shuigeng Zhou. December 9, 2009 School of Computer Science Fudan University
 Query Optimization Shuigeng Zhou December 9, 2009 School of Computer Science Fudan University Outline Introduction Catalog Information for Cost Estimation Estimation of Statistics Transformation of Relational
Query Optimization Shuigeng Zhou December 9, 2009 School of Computer Science Fudan University Outline Introduction Catalog Information for Cost Estimation Estimation of Statistics Transformation of Relational
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
! Parallel machines are becoming quite common and affordable. ! Databases are growing increasingly large
 Chapter 20: Parallel Databases Introduction! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems!
Chapter 20: Parallel Databases Introduction! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems!
Chapter 20: Parallel Databases
 Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 20: Parallel Databases. Introduction
 Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 17: Parallel Databases
 Chapter 17: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of Parallel Systems Database Systems
Chapter 17: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of Parallel Systems Database Systems
Indexing. Week 14, Spring Edited by M. Naci Akkøk, , Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel
 Indexing Week 14, Spring 2005 Edited by M. Naci Akkøk, 5.3.2004, 3.3.2005 Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel Overview Conventional indexes B-trees Hashing schemes
Indexing Week 14, Spring 2005 Edited by M. Naci Akkøk, 5.3.2004, 3.3.2005 Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel Overview Conventional indexes B-trees Hashing schemes
CAS CS 460/660 Introduction to Database Systems. Query Evaluation II 1.1
 CAS CS 460/660 Introduction to Database Systems Query Evaluation II 1.1 Cost-based Query Sub-System Queries Select * From Blah B Where B.blah = blah Query Parser Query Optimizer Plan Generator Plan Cost
CAS CS 460/660 Introduction to Database Systems Query Evaluation II 1.1 Cost-based Query Sub-System Queries Select * From Blah B Where B.blah = blah Query Parser Query Optimizer Plan Generator Plan Cost
Announcements. Reading Material. Recap. Today 9/17/17. Storage (contd. from Lecture 6)
") CompSci 16 Intensive Computing Systems Lecture 7 Storage and Index Instructor: Sudeepa Roy Announcements HW1 deadline this week: Due on 09/21 (Thurs), 11: pm, no late days Project proposal deadline: Preliminary
CompSci 16 Intensive Computing Systems Lecture 7 Storage and Index Instructor: Sudeepa Roy Announcements HW1 deadline this week: Due on 09/21 (Thurs), 11: pm, no late days Project proposal deadline: Preliminary
Evaluation of Relational Operations: Other Techniques
 Evaluation of Relational Operations: Other Techniques [R&G] Chapter 14, Part B CS4320 1 Using an Index for Selections Cost depends on #qualifying tuples, and clustering. Cost of finding qualifying data
Evaluation of Relational Operations: Other Techniques [R&G] Chapter 14, Part B CS4320 1 Using an Index for Selections Cost depends on #qualifying tuples, and clustering. Cost of finding qualifying data
Chapter 18: Parallel Databases
 Chapter 18: Parallel Databases Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery
Chapter 18: Parallel Databases Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery
Chapter 18: Parallel Databases. Chapter 18: Parallel Databases. Parallelism in Databases. Introduction
 Chapter 18: Parallel Databases Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of
Chapter 18: Parallel Databases Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of
Overview of Implementing Relational Operators and Query Evaluation
 Overview of Implementing Relational Operators and Query Evaluation Chapter 12 Motivation: Evaluating Queries The same query can be evaluated in different ways. The evaluation strategy (plan) can make orders
Overview of Implementing Relational Operators and Query Evaluation Chapter 12 Motivation: Evaluating Queries The same query can be evaluated in different ways. The evaluation strategy (plan) can make orders
CMSC424: Database Design. Instructor: Amol Deshpande
 CMSC424: Database Design Instructor: Amol Deshpande amol@cs.umd.edu Databases Data Models Conceptual representa1on of the data Data Retrieval How to ask ques1ons of the database How to answer those ques1ons
CMSC424: Database Design Instructor: Amol Deshpande amol@cs.umd.edu Databases Data Models Conceptual representa1on of the data Data Retrieval How to ask ques1ons of the database How to answer those ques1ons
Database System Concepts, 6 th Ed. Silberschatz, Korth and Sudarshan See for conditions on re-use
 Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files Static
Chapter 11: Indexing and Hashing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files Static
Relational Database Systems 2 5. Query Processing
 Relational Database Systems 2 5. Query Processing Silke Eckstein Benjamin Köhncke Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 4 Trees & Advanced Indexes
Relational Database Systems 2 5. Query Processing Silke Eckstein Benjamin Köhncke Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 4 Trees & Advanced Indexes
Chapter 11: Indexing and Hashing" Chapter 11: Indexing and Hashing"
 Chapter 11: Indexing and Hashing" Database System Concepts, 6 th Ed.! Silberschatz, Korth and Sudarshan See www.db-book.com for conditions on re-use " Chapter 11: Indexing and Hashing" Basic Concepts!
Chapter 11: Indexing and Hashing" Database System Concepts, 6 th Ed.! Silberschatz, Korth and Sudarshan See www.db-book.com for conditions on re-use " Chapter 11: Indexing and Hashing" Basic Concepts!
Outline. Query Processing Overview Algorithms for basic operations. Query optimization. Sorting Selection Join Projection
 Outline Query Processing Overview Algorithms for basic operations Sorting Selection Join Projection Query optimization Heuristics Cost-based optimization 19 Estimate I/O Cost for Implementations Count
Outline Query Processing Overview Algorithms for basic operations Sorting Selection Join Projection Query optimization Heuristics Cost-based optimization 19 Estimate I/O Cost for Implementations Count
Database Applications (15-415)
") Database Applications (15-415) DBMS Internals- Part V Lecture 13, March 10, 2014 Mohammad Hammoud Today Welcome Back from Spring Break! Today Last Session: DBMS Internals- Part IV Tree-based (i.e., B+
Database Applications (15-415) DBMS Internals- Part V Lecture 13, March 10, 2014 Mohammad Hammoud Today Welcome Back from Spring Break! Today Last Session: DBMS Internals- Part IV Tree-based (i.e., B+
Implementation of Relational Operations. Introduction. CS 186, Fall 2002, Lecture 19 R&G - Chapter 12
 Implementation of Relational Operations CS 186, Fall 2002, Lecture 19 R&G - Chapter 12 First comes thought; then organization of that thought, into ideas and plans; then transformation of those plans into
Implementation of Relational Operations CS 186, Fall 2002, Lecture 19 R&G - Chapter 12 First comes thought; then organization of that thought, into ideas and plans; then transformation of those plans into
5.3 Parser and Translator. 5.3 Parser and Translator. 5.3 Parser and Translator. 5.3 Parser and Translator. 5.3 Parser and Translator
 5 Query Processing Relational Database Systems 2 5. Query Processing Silke Eckstein Andreas Kupfer Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 5.1 Introduction:
5 Query Processing Relational Database Systems 2 5. Query Processing Silke Eckstein Andreas Kupfer Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 5.1 Introduction:
Advanced Databases. Lecture 4 - Query Optimization. Masood Niazi Torshiz Islamic Azad university- Mashhad Branch
 Advanced Databases Lecture 4 - Query Optimization Masood Niazi Torshiz Islamic Azad university- Mashhad Branch www.mniazi.ir Query Optimization Introduction Transformation of Relational Expressions Catalog
Advanced Databases Lecture 4 - Query Optimization Masood Niazi Torshiz Islamic Azad university- Mashhad Branch www.mniazi.ir Query Optimization Introduction Transformation of Relational Expressions Catalog
Chapter 12: Indexing and Hashing
 Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Introduction to Indexing 2. Acknowledgements: Eamonn Keogh and Chotirat Ann Ratanamahatana
 Introduction to Indexing 2 Acknowledgements: Eamonn Keogh and Chotirat Ann Ratanamahatana Indexed Sequential Access Method We have seen that too small or too large an index (in other words too few or too
Introduction to Indexing 2 Acknowledgements: Eamonn Keogh and Chotirat Ann Ratanamahatana Indexed Sequential Access Method We have seen that too small or too large an index (in other words too few or too
Evaluation of Relational Operations: Other Techniques
 Evaluation of Relational Operations: Other Techniques Chapter 12, Part B Database Management Systems 3ed, R. Ramakrishnan and Johannes Gehrke 1 Using an Index for Selections v Cost depends on #qualifying
Evaluation of Relational Operations: Other Techniques Chapter 12, Part B Database Management Systems 3ed, R. Ramakrishnan and Johannes Gehrke 1 Using an Index for Selections v Cost depends on #qualifying
SQL QUERY EVALUATION. CS121: Relational Databases Fall 2017 Lecture 12
 SQL QUERY EVALUATION CS121: Relational Databases Fall 2017 Lecture 12 Query Evaluation 2 Last time: Began looking at database implementation details How data is stored and accessed by the database Using
SQL QUERY EVALUATION CS121: Relational Databases Fall 2017 Lecture 12 Query Evaluation 2 Last time: Began looking at database implementation details How data is stored and accessed by the database Using
Query Processing Strategies and Optimization
 Query Processing Strategies and Optimization CPS352: Database Systems Simon Miner Gordon College Last Revised: 10/25/12 Agenda Check-in Design Project Presentations Query Processing Programming Project
Query Processing Strategies and Optimization CPS352: Database Systems Simon Miner Gordon College Last Revised: 10/25/12 Agenda Check-in Design Project Presentations Query Processing Programming Project
Kathleen Durant PhD Northeastern University CS Indexes
 Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
DBMS Query evaluation
 Data Management for Data Science DBMS Maurizio Lenzerini, Riccardo Rosati Corso di laurea magistrale in Data Science Sapienza Università di Roma Academic Year 2016/2017 http://www.dis.uniroma1.it/~rosati/dmds/
Data Management for Data Science DBMS Maurizio Lenzerini, Riccardo Rosati Corso di laurea magistrale in Data Science Sapienza Università di Roma Academic Year 2016/2017 http://www.dis.uniroma1.it/~rosati/dmds/
15-415/615 Faloutsos 1
 Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB Applications Lecture #14: Implementation of Relational Operations (R&G ch. 12 and 14) 15-415/615 Faloutsos 1 Outline introduction selection
Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB Applications Lecture #14: Implementation of Relational Operations (R&G ch. 12 and 14) 15-415/615 Faloutsos 1 Outline introduction selection
Data on External Storage
 Advanced Topics in DBMS Ch-1: Overview of Storage and Indexing By Syed khutubddin Ahmed Assistant Professor Dept. of MCA Reva Institute of Technology & mgmt. Data on External Storage Prg1 Prg2 Prg3 DBMS
Advanced Topics in DBMS Ch-1: Overview of Storage and Indexing By Syed khutubddin Ahmed Assistant Professor Dept. of MCA Reva Institute of Technology & mgmt. Data on External Storage Prg1 Prg2 Prg3 DBMS
Administriva. CS 133: Databases. General Themes. Goals for Today. Fall 2018 Lec 11 10/11 Query Evaluation Prof. Beth Trushkowsky
 Administriva Lab 2 Final version due next Wednesday CS 133: Databases Fall 2018 Lec 11 10/11 Query Evaluation Prof. Beth Trushkowsky Problem sets PSet 5 due today No PSet out this week optional practice
Administriva Lab 2 Final version due next Wednesday CS 133: Databases Fall 2018 Lec 11 10/11 Query Evaluation Prof. Beth Trushkowsky Problem sets PSet 5 due today No PSet out this week optional practice
Relational Database Systems 2 5. Query Processing
 Relational Database Systems 2 5. Query Processing Silke Eckstein Andreas Kupfer Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 5 Query Processing 5.1 Introduction:
Relational Database Systems 2 5. Query Processing Silke Eckstein Andreas Kupfer Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 5 Query Processing 5.1 Introduction:
Statistics. Duplicate Elimination
 Query Execution 1. Parse query into a relational algebra expression tree. 2. Optimize relational algebra expression tree and select implementations for the relational algebra operators. (This step involves
Query Execution 1. Parse query into a relational algebra expression tree. 2. Optimize relational algebra expression tree and select implementations for the relational algebra operators. (This step involves
Principles of Data Management. Lecture #9 (Query Processing Overview)
") Principles of Data Management Lecture #9 (Query Processing Overview) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s Notable News v Midterm
Principles of Data Management Lecture #9 (Query Processing Overview) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s Notable News v Midterm
Physical Disk Structure. Physical Data Organization and Indexing. Pages and Blocks. Access Path. I/O Time to Access a Page. Disks.
 Physical Disk Structure Physical Data Organization and Indexing Chapter 11 1 4 Access Path Refers to the algorithm + data structure (e.g., an index) used for retrieving and storing data in a table The
Physical Disk Structure Physical Data Organization and Indexing Chapter 11 1 4 Access Path Refers to the algorithm + data structure (e.g., an index) used for retrieving and storing data in a table The
CMPUT 391 Database Management Systems. Query Processing: The Basics. Textbook: Chapter 10. (first edition: Chapter 13) University of Alberta 1
 University of Alberta 1") CMPUT 391 Database Management Systems Query Processing: The Basics Textbook: Chapter 10 (first edition: Chapter 13) Based on slides by Lewis, Bernstein and Kifer University of Alberta 1 External Sorting
CMPUT 391 Database Management Systems Query Processing: The Basics Textbook: Chapter 10 (first edition: Chapter 13) Based on slides by Lewis, Bernstein and Kifer University of Alberta 1 External Sorting
Implementing Relational Operators: Selection, Projection, Join. Database Management Systems, R. Ramakrishnan and J. Gehrke 1
 Implementing Relational Operators: Selection, Projection, Join Database Management Systems, R. Ramakrishnan and J. Gehrke 1 Readings [RG] Sec. 14.1-14.4 Database Management Systems, R. Ramakrishnan and
Implementing Relational Operators: Selection, Projection, Join Database Management Systems, R. Ramakrishnan and J. Gehrke 1 Readings [RG] Sec. 14.1-14.4 Database Management Systems, R. Ramakrishnan and
Evaluation of Relational Operations
 Evaluation of Relational Operations Yanlei Diao UMass Amherst March 13 and 15, 2006 Slides Courtesy of R. Ramakrishnan and J. Gehrke 1 Relational Operations We will consider how to implement: Selection
Evaluation of Relational Operations Yanlei Diao UMass Amherst March 13 and 15, 2006 Slides Courtesy of R. Ramakrishnan and J. Gehrke 1 Relational Operations We will consider how to implement: Selection
Chapter 14: Query Optimization
 Chapter 14: Query Optimization Database System Concepts 5 th Ed. See www.db-book.com for conditions on re-use Chapter 14: Query Optimization Introduction Transformation of Relational Expressions Catalog
Chapter 14: Query Optimization Database System Concepts 5 th Ed. See www.db-book.com for conditions on re-use Chapter 14: Query Optimization Introduction Transformation of Relational Expressions Catalog
The physical database. Contents - physical database design DATABASE DESIGN I - 1DL300. Introduction to Physical Database Design
 DATABASE DESIGN I - 1DL300 Fall 2011 Introduction to Physical Database Design Elmasri/Navathe ch 16 and 17 Padron-McCarthy/Risch ch 21 and 22 An introductory course on database systems http://www.it.uu.se/edu/course/homepage/dbastekn/ht11
DATABASE DESIGN I - 1DL300 Fall 2011 Introduction to Physical Database Design Elmasri/Navathe ch 16 and 17 Padron-McCarthy/Risch ch 21 and 22 An introductory course on database systems http://www.it.uu.se/edu/course/homepage/dbastekn/ht11
Database Systems. Announcement. December 13/14, 2006 Lecture #10. Assignment #4 is due next week.
 Database Systems ( 料 ) December 13/14, 2006 Lecture #10 1 Announcement Assignment #4 is due next week. 2 1 Overview of Query Evaluation Chapter 12 3 Outline Query evaluation (Overview) Relational Operator
Database Systems ( 料 ) December 13/14, 2006 Lecture #10 1 Announcement Assignment #4 is due next week. 2 1 Overview of Query Evaluation Chapter 12 3 Outline Query evaluation (Overview) Relational Operator
TotalCost = 3 (1, , 000) = 6, 000
 = 6, 000") 156 Chapter 12 HASH JOIN: Now both relations are the same size, so we can treat either one as the smaller relation. With 15 buffer pages the first scan of S splits it into 14 buckets, each containing about
156 Chapter 12 HASH JOIN: Now both relations are the same size, so we can treat either one as the smaller relation. With 15 buffer pages the first scan of S splits it into 14 buckets, each containing about
CSE 530A. B+ Trees. Washington University Fall 2013
 CSE 530A B+ Trees Washington University Fall 2013 B Trees A B tree is an ordered (non-binary) tree where the internal nodes can have a varying number of child nodes (within some range) B Trees When a key
CSE 530A B+ Trees Washington University Fall 2013 B Trees A B tree is an ordered (non-binary) tree where the internal nodes can have a varying number of child nodes (within some range) B Trees When a key
CS122 Lecture 4 Winter Term,
 CS122 Lecture 4 Winter Term, 2014-2015 2 SQL Query Transla.on Last time, introduced query evaluation pipeline SQL query SQL parser abstract syntax tree SQL translator relational algebra plan query plan
CS122 Lecture 4 Winter Term, 2014-2015 2 SQL Query Transla.on Last time, introduced query evaluation pipeline SQL query SQL parser abstract syntax tree SQL translator relational algebra plan query plan
Database System Concepts
 Chapter 14: Optimization Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2007/2008 Slides (fortemente) baseados nos slides oficiais do livro c Silberschatz, Korth and Sudarshan.
Chapter 14: Optimization Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2007/2008 Slides (fortemente) baseados nos slides oficiais do livro c Silberschatz, Korth and Sudarshan.
QUERY EXECUTION: How to Implement Relational Operations?
 QUERY EXECUTION: How to Implement Relational Operations? 1 Introduction We ve covered the basic underlying storage, buffering, indexing and sorting technology Now we can move on to query processing Relational
QUERY EXECUTION: How to Implement Relational Operations? 1 Introduction We ve covered the basic underlying storage, buffering, indexing and sorting technology Now we can move on to query processing Relational