Clustering from Data Streams
|
|
|
- Rosa Lindsey
- 6 years ago
- Views:
Transcription
1 Clustering from Data Streams João Gama LIAAD-INESC Porto, University of Porto, Portugal
2 1 Introduction 2 Clustering Micro Clustering 3 Clustering Time Series Growing the Structure Adapting to Change Properties of ODAC 4 References
3 Outline 1 Introduction 2 Clustering Micro Clustering 3 Clustering Time Series Growing the Structure Adapting to Change Properties of ODAC 4 References
4 Clustering What is cluster analysis? Grouping a set of data objects into a set of clusters, the intra-cluster similarity is high and the inter-cluster similarity is low The quality of a clustering result depends on both the similarity measure used The quality of a clustering method is also measured by its ability to discover some or all of the hidden patterns

5 Illustrative Example: K-means MacQueen 67: Each cluster is represented by the center of the cluster
6 K-Means for Streaming Data


7 Illustrative Example: Hierarchical Clustering Bottom-Up Initial State: Each object is a group. Iteratively join two groups in a single one. Top-Down Initial State: Single Group with all the objects. Iteratively divide each group into two groups.
8 Major Clustering Approaches Partitioning algorithms: Construct various partitions and then evaluate them by some criterion E.g., k-means, k-medoids, etc. Hierarchy algorithms: Create a hierarchical decomposition of the set of data (or objects) using some criterion. Often needs to integrate with other clustering methods, e.g., BIRCH Density-based: based on connectivity and density functions Finding clusters of arbitrary shapes, e.g., DBSCAN, OPTICS, etc. Grid-based: based on a multiple-level granularity structure View space as grid structures, e.g., STING, CLIQUE Model-based: find the best fit of the model to all the clusters Good for conceptual clustering, e.g., COBWEB, SOM
9 Learning Algorithms: Desirable Properties Processing each example: Small constant time Fixed amount of main memory Single scan of the data Without (or reduced) revisit old records. Processing examples at the speed they arrive Decision Models at anytime Ideally, produce a model equivalent to the one that would be obtained by a batch data-mining algorithm Ability to detect and react to concept drift
10 Clustering Data Streams New requirements in stream clustering Generate high-quality clusters in one scan High quality, efficient incremental clustering Analysis should take care of multi-dimensional space Analysis for different time granularity Tracking the evolution of clusters Clustering: A stream data reduction technique
11 Outline 1 Introduction 2 Clustering Micro Clustering 3 Clustering Time Series Growing the Structure Adapting to Change Properties of ODAC 4 References

 2 Constant space irrespective to the")
12 Cluster Feature Vector Birch: Balanced Iterative Reducing and Clustering using Hierarchies, by Zhang, Ramakrishnan, Livny 1996 Cluster Feature Vector: CF = (N, LS, SS) N: Number of data points LS: N 1 x i SS: N 1 ( x i) 2 Constant space irrespective to the number of examples!
13 Micro clusters The sufficient statistics of a cluster A are CF A = (N, LS, SS). N, the number of data objects, LS, the linear sum of the data objects, SS, the sum of squared the data objects. Properties: Centroid = LS/N Radius = SS/N (LS/N) 2 Diameter = 2 N SS 2 LS 2 N (N 1)
14 Micro clusters Given the sufficient statistics of a cluster A, CF A = (N A, LS A, SS A ). Updates are: Incremental: a point x is added to the cluster: LS A LS A + x; SS A SS A + x 2 ; N A N A + 1 Additive: merging clusters A and B: LS C LS A + LS B ; SS C SS A + SS B ; N C N A + N B Subtractive: CF (C 1 C 2 ) = CF (C 1 ) FV (C 2 )
15 CluStream CluStream: A Framework for Clustering Evolving Data Streams (VLDB03) Divide the clustering process into online and offline components Online: periodically stores summary statistics about the stream data Micro-clustering: better quality than k-means Incremental, online processing and maintenance Offline: answers various user queries based on the stored summary statistics Tilted time frame work: register dynamic changes With limited overhead to achieve high efficiency, scalability, quality of results and power of evolution/change detection
16 CluStream: Online Phase Inputs: Maximum micro-cluster diameter D max For each x in the stream: Find the nearest micro-cluster M i IF the diameter of (M i x) < D max THEN assign x to that micro-cluster M i M i x ELSE Start a new micro-cluster based on x
17 Pyramidal Time Frame The micro-clusters are stored at snapshots. When should we make the snapshot? The snapshots follow a pyramidal pattern:
18 Analysis find the cluster structure in the current window, find the cluster structure over time ranges with granularity confined by the specification of window size and boundary, put different weights on different windows to mine various kinds of weighted cluster structures, mine the evolution of cluster structures based on the changes of their occurrences in a sequence of windows
19 Any Time Stream Clustering Properties of anytime algorithms Deliver a model at any time Improve the model if more time is available Model adaptation whenever an instance arrives Model refinement whenever time permits ClusTree [Kranen et al., 2011] an online component to learn micro-clusters Any variety of online components can be utilized Micro-clusters are subject to exponential aging
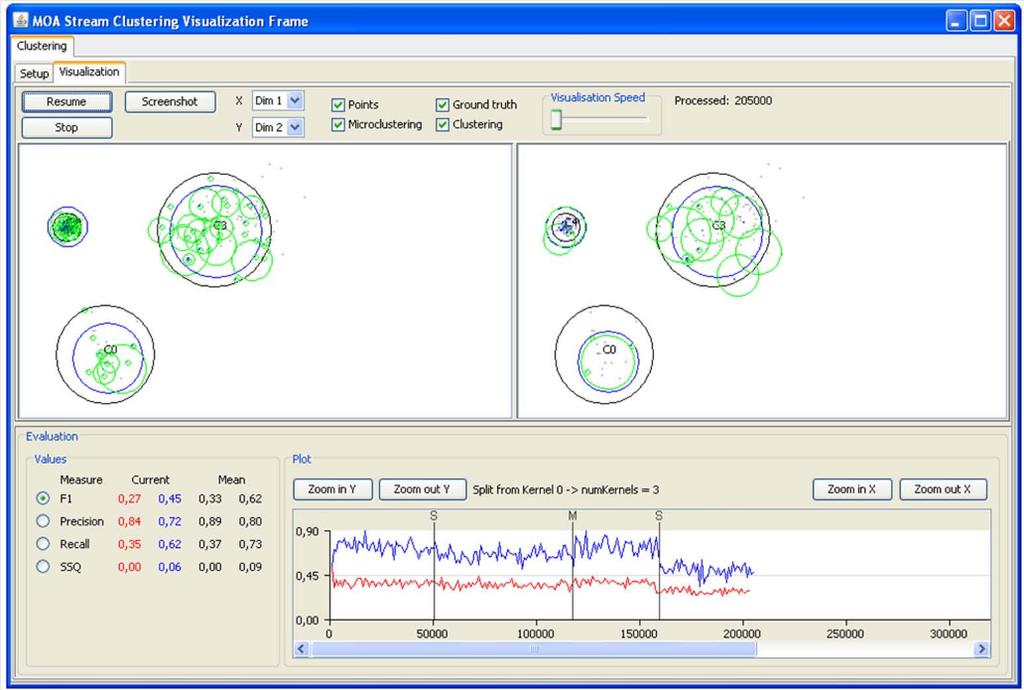
20 MOA
21 Outline 1 Introduction 2 Clustering Micro Clustering 3 Clustering Time Series Growing the Structure Adapting to Change Properties of ODAC 4 References
22 Clustering Time Series Data Streams Goal: Continuously maintain a clustering structure from evolving time series data streams. Ability to Incorporate new Information; Process new Information at the rate it is available. Ability to Detect and React to changes in the Cluster s Structure. Clustering of variables (sensors) not examples! The standard technique of transposing the working-matrix does not work: transpose is a blocking operator!
23 Online Divisive-Agglomerative Clustering Online Divisive-Agglomerative Clustering, Rodrigues & Gama, 2008 Goal: Continuously maintain a hierarchical cluster s structure from evolving time series data streams. Performs hierarchical clustering Continuously monitor the evolution of clusters diameters Two Operators: Splitting: expand the structure more data, more detailed clusters Merge: contract the structure reacting to changes. Splitting and agglomerative criteria are supported by a confidence level given by the Hoeffding bounds.
24 Main Algorithm ForEver Read Next Example For all the clusters Update the sufficient statistics Time to Time Verify Merge Clusters Verify Expand Cluster
25 Feeding ODAC Each example is processed once. Only sufficient statistics at leaves are updated. Sufficient Statistics: a triangular matrix of the correlations between variables in a leaf. Released when a leaf expands to a node.
26 Similarity Distance 1 corr(a,b) 2 Distance between time Series: rnomc(a, b) = where corr(a, b) is the Pearson Correlation coefficient: corr(a, b) = P AB n A 2 A2 n B 2 B2 n The sufficient statistics needed to compute the correlation are easily updated at each time step: A = a i, B = b i, A 2 = a 2 i, B 2 = b 2 i, P = a i b i
27 The Expand Operator: Expanding a Leaf Step 1 Step 2 Step 3 Find Pivots: x j, x k : d(x j, x k ) > d(a, b) a, b j, k If Splitting Criteria applies: Generate two new clusters. Each new cluster attract nearest variables.
28 Splitting Criteria When should we expand a leaf? Let d 1 = d(a, b) the farthest distance d 2 the second farthest distance Question: Is d 1 a stable option? what if we observe more examples? Hoeffding bound: R 2 ln(1/δ) 2n Split if d 1 d 2 > ɛ with ɛ = where R is the range of the random variable; δ is a user confidence level, and n is the number of observed data points.
29 Hoeffding bound Suppose we have made n independent observations of a random variable r whose range is R. The Hoeffding bound states that: With probability 1 δ The true mean of r is in the range r ± ɛ where ɛ = R 2 ln(1/δ) 2n Independent of the probability distribution generating the examples.

 a, b j, k If the Hoeffding")

30 The Expand Operator: Expanding a Leaf Step 1 Step 2 Step 3 Find Pivots: x j, x k : d(x j, x k ) > d(a, b) a, b j, k If the Hoeffding bound applies: Generate two new clusters. Each new cluster attract nearest variables.
 receive examples from different")
31 Multi-Time-Windows A multi-window system: each node (and leaves) receive examples from different time-windows.

32 The Merge Operator: Change Detection Time Series Concept Drift: Changes in the distribution generating the observations. Clustering Concept Drift Changing in the way time series correlate with each other Change in the cluster Structure.
33 The Merge Operator: Change Detection The Splitting Criteria guarantees that cluster s diameters monotonically decrease. Assume Clusters: c j with descendants c k and c s. If diameter(c k ) diameter(c j ) > ɛ OR diameter(c s ) diameter(c j ) > ɛ Change in the correlation structure! Merge clusters c k and c s into c j.

34 Properties of ODAC For stationary data the cluster s diameters monotonically decrease. Constant update time/memory consumption with respect to the number of examples! Every time a split is reported the time to process the next example decreases, and the space used by the new leaves is less than that used by the parent. (a + b) 2 > a 2 + b 2

35 The Electrical Load Demand Problem
36 The Electrical Load Demand Problem
37 Evolution of Processing Speed
38 Evolution of Memory Usage
39 Outline 1 Introduction 2 Clustering Micro Clustering 3 Clustering Time Series Growing the Structure Adapting to Change Properties of ODAC 4 References
40 Master References J. Gama, Knowledge Discovery from Data Streams, CRC Press, S. Muthukrishnan Data Streams: Algorithms and Applications, Foundations & Trends in Theoretical Computer Science, C. Aggarwal (Ed) Data Streams: Models and Algorithms, Springer, 2007 B. Babcock, S. Babu, M. Datar, R. Motwani, and J. Widom. Models and Issues in Data Stream Systems, Proceedings of PODS, Gaber, M, M., Zaslavsky, A., and Krishnaswamy, S., Mining Data Streams: A Review, in ACM SIGMOD Record, Vol. 34, No. 1, J. Silva, E. Faria, R. Barros, E. Hruschka, A. Carvalho, J. Gama: Data stream clustering: A survey. ACM Comput. Surv. 46(1): 13 (2013)
41 Bibliography on Clustering P. Rodrigues, J. Gama and J. P. Pedroso. Hierarchical Clustering of Time Series Data Streams; TKDE, Zhang, Ramakrishnan, Livny; Birch: Balanced Iterative Reducing and Clustering using Hierarchies, SIGMOD Charu Aggarwal, Jiawei Han, J. Wang, P. S. Yu, A Framework for Clustering Evolving Data Streams, by VLDB G. Cormode, S. Muthukrishnan, and W. Zhuang, Conquering the divide: Continuous clustering of distributed data streams. ICDE Kranen, Assent, Baldauf, and Seidl; The ClusTree: indexing micro-clusters for anytime stream mining, Knowl. Inf. Syst. 29, Cormode, Muthu, Zhuang; Conquering the Divide: Continuous Clustering of Distributed Data Streams. ICDE 2007 P. Rodrigues, J. Gama: Clustering Distributed Sensor Data Streams. ECML/PKDD 2008 P. Rodrigues, J. Gama: L2GClust: local-to-global clustering of stream sources. SAC 2011
Anytime Concurrent Clustering of Multiple Streams with an Indexing Tree
 JMLR: Workshop and Conference Proceedings 41:19 32, 2015 BIGMINE 2015 Anytime Concurrent Clustering of Multiple Streams with an Indexing Tree Zhinoos Razavi Hesabi zhinoos.razavi@rmit.edu.au Timos Sellis
JMLR: Workshop and Conference Proceedings 41:19 32, 2015 BIGMINE 2015 Anytime Concurrent Clustering of Multiple Streams with an Indexing Tree Zhinoos Razavi Hesabi zhinoos.razavi@rmit.edu.au Timos Sellis
An Empirical Comparison of Stream Clustering Algorithms
 MÜNSTER An Empirical Comparison of Stream Clustering Algorithms Matthias Carnein Dennis Assenmacher Heike Trautmann CF 17 BigDAW Workshop Siena Italy May 15 18 217 Clustering MÜNSTER An Empirical Comparison
MÜNSTER An Empirical Comparison of Stream Clustering Algorithms Matthias Carnein Dennis Assenmacher Heike Trautmann CF 17 BigDAW Workshop Siena Italy May 15 18 217 Clustering MÜNSTER An Empirical Comparison
Mining Data Streams. Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction. Summarization Methods. Clustering Data Streams
![Mining Data Streams. Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction. Summarization Methods. Clustering Data Streams](/thumbs/85/93020188.jpg "Mining Data Streams. Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction. Summarization Methods. Clustering Data Streams") Mining Data Streams Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction Summarization Methods Clustering Data Streams Data Stream Classification Temporal Models CMPT 843, SFU, Martin Ester, 1-06
Mining Data Streams Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction Summarization Methods Clustering Data Streams Data Stream Classification Temporal Models CMPT 843, SFU, Martin Ester, 1-06
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
A Review on Cluster Based Approach in Data Mining
 A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/10/2017)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Unsupervised Learning Hierarchical Methods
 Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Data Stream Clustering: A Survey
 Data Stream Clustering: A Survey JONATHAN A. SILVA, ELAINE R. FARIA, RODRIGO C. BARROS, EDUARDO R. HRUSCHKA, and ANDRE C. P. L. F. DE CARVALHO University of São Paulo and JOÃO P. GAMA University of Porto
Data Stream Clustering: A Survey JONATHAN A. SILVA, ELAINE R. FARIA, RODRIGO C. BARROS, EDUARDO R. HRUSCHKA, and ANDRE C. P. L. F. DE CARVALHO University of São Paulo and JOÃO P. GAMA University of Porto
What is Cluster Analysis? COMP 465: Data Mining Clustering Basics. Applications of Cluster Analysis. Clustering: Application Examples 3/17/2015
 // What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
// What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
A Framework for Clustering Massive Text and Categorical Data Streams
 A Framework for Clustering Massive Text and Categorical Data Streams Charu C. Aggarwal IBM T. J. Watson Research Center charu@us.ibm.com Philip S. Yu IBM T. J.Watson Research Center psyu@us.ibm.com Abstract
A Framework for Clustering Massive Text and Categorical Data Streams Charu C. Aggarwal IBM T. J. Watson Research Center charu@us.ibm.com Philip S. Yu IBM T. J.Watson Research Center psyu@us.ibm.com Abstract
DATA STREAMS: MODELS AND ALGORITHMS
 DATA STREAMS: MODELS AND ALGORITHMS DATA STREAMS: MODELS AND ALGORITHMS Edited by CHARU C. AGGARWAL IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 Kluwer Academic Publishers Boston/Dordrecht/London
DATA STREAMS: MODELS AND ALGORITHMS DATA STREAMS: MODELS AND ALGORITHMS Edited by CHARU C. AGGARWAL IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 Kluwer Academic Publishers Boston/Dordrecht/London
K-means based data stream clustering algorithm extended with no. of cluster estimation method
 K-means based data stream clustering algorithm extended with no. of cluster estimation method Makadia Dipti 1, Prof. Tejal Patel 2 1 Information and Technology Department, G.H.Patel Engineering College,
K-means based data stream clustering algorithm extended with no. of cluster estimation method Makadia Dipti 1, Prof. Tejal Patel 2 1 Information and Technology Department, G.H.Patel Engineering College,
COMP 465: Data Mining Still More on Clustering
 3/4/015 Exercise COMP 465: Data Mining Still More on Clustering Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Describe each of the following
3/4/015 Exercise COMP 465: Data Mining Still More on Clustering Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Describe each of the following
arxiv: v1 [cs.lg] 3 Oct 2018
![arxiv: v1 [cs.lg] 3 Oct 2018](/thumbs/87/96316720.jpg "arxiv: v1 [cs.lg] 3 Oct 2018") Real-time Clustering Algorithm Based on Predefined Level-of-Similarity Real-time Clustering Algorithm Based on Predefined Level-of-Similarity arxiv:1810.01878v1 [cs.lg] 3 Oct 2018 Rabindra Lamsal Shubham
Real-time Clustering Algorithm Based on Predefined Level-of-Similarity Real-time Clustering Algorithm Based on Predefined Level-of-Similarity arxiv:1810.01878v1 [cs.lg] 3 Oct 2018 Rabindra Lamsal Shubham
Challenges in Ubiquitous Data Mining
 LIAAD-INESC Porto, University of Porto, Portugal jgama@fep.up.pt 1 2 Very-short-term Forecasting in Photovoltaic Systems 3 4 Problem Formulation: Network Data Model Querying Model Query = Q( n i=0 S i)
LIAAD-INESC Porto, University of Porto, Portugal jgama@fep.up.pt 1 2 Very-short-term Forecasting in Photovoltaic Systems 3 4 Problem Formulation: Network Data Model Querying Model Query = Q( n i=0 S i)
Clustering Techniques
 Clustering Techniques Marco BOTTA Dipartimento di Informatica Università di Torino botta@di.unito.it www.di.unito.it/~botta/didattica/clustering.html Data Clustering Outline What is cluster analysis? What
Clustering Techniques Marco BOTTA Dipartimento di Informatica Università di Torino botta@di.unito.it www.di.unito.it/~botta/didattica/clustering.html Data Clustering Outline What is cluster analysis? What
Research on Parallelized Stream Data Micro Clustering Algorithm Ke Ma 1, Lingjuan Li 1, Yimu Ji 1, Shengmei Luo 1, Tao Wen 2
 International Conference on Advances in Mechanical Engineering and Industrial Informatics (AMEII 2015) Research on Parallelized Stream Data Micro Clustering Algorithm Ke Ma 1, Lingjuan Li 1, Yimu Ji 1,
International Conference on Advances in Mechanical Engineering and Industrial Informatics (AMEII 2015) Research on Parallelized Stream Data Micro Clustering Algorithm Ke Ma 1, Lingjuan Li 1, Yimu Ji 1,
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/09/2018)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
CS Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
Data Mining: Concepts and Techniques. Chapter March 8, 2007 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
Data Mining: Concepts and Techniques Chapter 7.1-4 March 8, 2007 Data Mining: Concepts and Techniques 1 1. What is Cluster Analysis? 2. Types of Data in Cluster Analysis Chapter 7 Cluster Analysis 3. A
UNIT V CLUSTERING, APPLICATIONS AND TRENDS IN DATA MINING. Clustering is unsupervised classification: no predefined classes
 UNIT V CLUSTERING, APPLICATIONS AND TRENDS IN DATA MINING What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other
UNIT V CLUSTERING, APPLICATIONS AND TRENDS IN DATA MINING What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Advances in data stream mining
 Mohamed Medhat Gaber Mining data streams has been a focal point of research interest over the past decade. Hardware and software advances have contributed to the significance of this area of research by
Mohamed Medhat Gaber Mining data streams has been a focal point of research interest over the past decade. Hardware and software advances have contributed to the significance of this area of research by
Mining Data Streams. From Data-Streams Management System Queries to Knowledge Discovery from continuous and fast-evolving Data Records.
 DATA STREAMS MINING Mining Data Streams From Data-Streams Management System Queries to Knowledge Discovery from continuous and fast-evolving Data Records. Hammad Haleem Xavier Plantaz APPLICATIONS Sensors
DATA STREAMS MINING Mining Data Streams From Data-Streams Management System Queries to Knowledge Discovery from continuous and fast-evolving Data Records. Hammad Haleem Xavier Plantaz APPLICATIONS Sensors
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Knowledge Discovery in Databases
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Towards Real-Time Feature Tracking Technique using Adaptive Micro-Clusters
 Towards Real-Time Feature Tracking Technique using Adaptive Micro-Clusters Mahmood Shakir Hammoodi, Frederic Stahl, Mark Tennant, Atta Badii Abstract Data streams are unbounded, sequential data instances
Towards Real-Time Feature Tracking Technique using Adaptive Micro-Clusters Mahmood Shakir Hammoodi, Frederic Stahl, Mark Tennant, Atta Badii Abstract Data streams are unbounded, sequential data instances
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Growing Hierarchical Trees for Data Stream Clustering and Visualization
 Growing Hierarchical Trees for Data Stream Clustering and Visualization Nhat-Quang Doan ICT Department University of Science and Technology of Hanoi 18 Hoang Quoc Viet Str, Cau Giay Hanoi, Vietnam Email:
Growing Hierarchical Trees for Data Stream Clustering and Visualization Nhat-Quang Doan ICT Department University of Science and Technology of Hanoi 18 Hoang Quoc Viet Str, Cau Giay Hanoi, Vietnam Email:
Analyzing Outlier Detection Techniques with Hybrid Method
 Analyzing Outlier Detection Techniques with Hybrid Method Shruti Aggarwal Assistant Professor Department of Computer Science and Engineering Sri Guru Granth Sahib World University. (SGGSWU) Fatehgarh Sahib,
Analyzing Outlier Detection Techniques with Hybrid Method Shruti Aggarwal Assistant Professor Department of Computer Science and Engineering Sri Guru Granth Sahib World University. (SGGSWU) Fatehgarh Sahib,
High-Dimensional Incremental Divisive Clustering under Population Drift
 High-Dimensional Incremental Divisive Clustering under Population Drift Nicos Pavlidis Inference for Change-Point and Related Processes joint work with David Hofmeyr and Idris Eckley Clustering Clustering:
High-Dimensional Incremental Divisive Clustering under Population Drift Nicos Pavlidis Inference for Change-Point and Related Processes joint work with David Hofmeyr and Idris Eckley Clustering Clustering:
Knowledge Discovery in Databases II. Lecture 4: Stream clustering
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases II Winter Semester 2012/2013 Lecture 4: Stream
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases II Winter Semester 2012/2013 Lecture 4: Stream
Robust Clustering for Tracking Noisy Evolving Data Streams
 Robust Clustering for Tracking Noisy Evolving Data Streams Olfa Nasraoui Carlos Rojas Abstract We present a new approach for tracking evolving and noisy data streams by estimating clusters based on density,
Robust Clustering for Tracking Noisy Evolving Data Streams Olfa Nasraoui Carlos Rojas Abstract We present a new approach for tracking evolving and noisy data streams by estimating clusters based on density,
Analysis and Extensions of Popular Clustering Algorithms
 Analysis and Extensions of Popular Clustering Algorithms Renáta Iváncsy, Attila Babos, Csaba Legány Department of Automation and Applied Informatics and HAS-BUTE Control Research Group Budapest University
Analysis and Extensions of Popular Clustering Algorithms Renáta Iváncsy, Attila Babos, Csaba Legány Department of Automation and Applied Informatics and HAS-BUTE Control Research Group Budapest University
Clustering Large Dynamic Datasets Using Exemplar Points
 Clustering Large Dynamic Datasets Using Exemplar Points William Sia, Mihai M. Lazarescu Department of Computer Science, Curtin University, GPO Box U1987, Perth 61, W.A. Email: {siaw, lazaresc}@cs.curtin.edu.au
Clustering Large Dynamic Datasets Using Exemplar Points William Sia, Mihai M. Lazarescu Department of Computer Science, Curtin University, GPO Box U1987, Perth 61, W.A. Email: {siaw, lazaresc}@cs.curtin.edu.au
Volume 2, Issue 2, February 2014 International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 2, February 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Paper / Case Study Available online at: www.ijarcsms.com Mining
Volume 2, Issue 2, February 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Paper / Case Study Available online at: www.ijarcsms.com Mining
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Data Stream Clustering Using Micro Clusters
 Data Stream Clustering Using Micro Clusters Ms. Jyoti.S.Pawar 1, Prof. N. M.Shahane. 2 1 PG student, Department of Computer Engineering K. K. W. I. E. E. R., Nashik Maharashtra, India 2 Assistant Professor
Data Stream Clustering Using Micro Clusters Ms. Jyoti.S.Pawar 1, Prof. N. M.Shahane. 2 1 PG student, Department of Computer Engineering K. K. W. I. E. E. R., Nashik Maharashtra, India 2 Assistant Professor
An Efficient Density Based Incremental Clustering Algorithm in Data Warehousing Environment
 An Efficient Density Based Incremental Clustering Algorithm in Data Warehousing Environment Navneet Goyal, Poonam Goyal, K Venkatramaiah, Deepak P C, and Sanoop P S Department of Computer Science & Information
An Efficient Density Based Incremental Clustering Algorithm in Data Warehousing Environment Navneet Goyal, Poonam Goyal, K Venkatramaiah, Deepak P C, and Sanoop P S Department of Computer Science & Information
Dynamic Clustering Of High Speed Data Streams
 www.ijcsi.org 224 Dynamic Clustering Of High Speed Data Streams J. Chandrika 1, Dr. K.R. Ananda Kumar 2 1 Department of CS & E, M C E,Hassan 573 201 Karnataka, India 2 Department of CS & E, SJBIT, Bangalore
www.ijcsi.org 224 Dynamic Clustering Of High Speed Data Streams J. Chandrika 1, Dr. K.R. Ananda Kumar 2 1 Department of CS & E, M C E,Hassan 573 201 Karnataka, India 2 Department of CS & E, SJBIT, Bangalore
Lecture 7 Cluster Analysis: Part A
 Lecture 7 Cluster Analysis: Part A Zhou Shuigeng May 7, 2007 2007-6-23 Data Mining: Tech. & Appl. 1 Outline What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering
Lecture 7 Cluster Analysis: Part A Zhou Shuigeng May 7, 2007 2007-6-23 Data Mining: Tech. & Appl. 1 Outline What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 09: Vector Data: Clustering Basics Instructor: Yizhou Sun yzsun@cs.ucla.edu October 27, 2017 Methods to Learn Vector Data Set Data Sequence Data Text Data Classification
CS145: INTRODUCTION TO DATA MINING 09: Vector Data: Clustering Basics Instructor: Yizhou Sun yzsun@cs.ucla.edu October 27, 2017 Methods to Learn Vector Data Set Data Sequence Data Text Data Classification
Data Stream Mining. Tore Risch Dept. of information technology Uppsala University Sweden
 Data Stream Mining Tore Risch Dept. of information technology Uppsala University Sweden 2016-02-25 Enormous data growth Read landmark article in Economist 2010-02-27: http://www.economist.com/node/15557443/
Data Stream Mining Tore Risch Dept. of information technology Uppsala University Sweden 2016-02-25 Enormous data growth Read landmark article in Economist 2010-02-27: http://www.economist.com/node/15557443/
E-Stream: Evolution-Based Technique for Stream Clustering
 E-Stream: Evolution-Based Technique for Stream Clustering Komkrit Udommanetanakit, Thanawin Rakthanmanon, and Kitsana Waiyamai Department of Computer Engineering, Faculty of Engineering Kasetsart University,
E-Stream: Evolution-Based Technique for Stream Clustering Komkrit Udommanetanakit, Thanawin Rakthanmanon, and Kitsana Waiyamai Department of Computer Engineering, Faculty of Engineering Kasetsart University,
CS Data Mining Techniques Instructor: Abdullah Mueen
 CS 591.03 Data Mining Techniques Instructor: Abdullah Mueen LECTURE 6: BASIC CLUSTERING Chapter 10. Cluster Analysis: Basic Concepts and Methods Cluster Analysis: Basic Concepts Partitioning Methods Hierarchical
CS 591.03 Data Mining Techniques Instructor: Abdullah Mueen LECTURE 6: BASIC CLUSTERING Chapter 10. Cluster Analysis: Basic Concepts and Methods Cluster Analysis: Basic Concepts Partitioning Methods Hierarchical
Mining Data Streams Data Mining and Text Mining (UIC Politecnico di Milano) Daniele Loiacono
 Daniele Loiacono") Mining Data Streams Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann Series in Data
Mining Data Streams Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann Series in Data
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
MAIDS: Mining Alarming Incidents from Data Streams
 MAIDS: Mining Alarming Incidents from Data Streams (Demonstration Proposal) Y. Dora Cai David Clutter Greg Pape Jiawei Han Michael Welge Loretta Auvil Automated Learning Group, NCSA, University of Illinois
MAIDS: Mining Alarming Incidents from Data Streams (Demonstration Proposal) Y. Dora Cai David Clutter Greg Pape Jiawei Han Michael Welge Loretta Auvil Automated Learning Group, NCSA, University of Illinois
Data Stream Clustering Algorithms: A Review
 Int. J. Advance Soft Compu. Appl, Vol. 7, No. 3, November 2015 ISSN 2074-8523 Data Stream Clustering Algorithms: A Review Maryam Mousavi 1, Azuraliza Abu Bakar 1, and Mohammadmahdi Vakilian 1 1 Centre
Int. J. Advance Soft Compu. Appl, Vol. 7, No. 3, November 2015 ISSN 2074-8523 Data Stream Clustering Algorithms: A Review Maryam Mousavi 1, Azuraliza Abu Bakar 1, and Mohammadmahdi Vakilian 1 1 Centre
Keywords Clustering, Goals of clustering, clustering techniques, clustering algorithms.
 Volume 3, Issue 5, May 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Survey of Clustering
Volume 3, Issue 5, May 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Survey of Clustering
Clustering Algorithms for Data Stream
 Clustering Algorithms for Data Stream Karishma Nadhe 1, Prof. P. M. Chawan 2 1Student, Dept of CS & IT, VJTI Mumbai, Maharashtra, India 2Professor, Dept of CS & IT, VJTI Mumbai, Maharashtra, India Abstract:
Clustering Algorithms for Data Stream Karishma Nadhe 1, Prof. P. M. Chawan 2 1Student, Dept of CS & IT, VJTI Mumbai, Maharashtra, India 2Professor, Dept of CS & IT, VJTI Mumbai, Maharashtra, India Abstract:
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Cluster Analysis Reading: Chapter 10.4, 10.6, 11.1.3 Han, Chapter 8.4,8.5,9.2.2, 9.3 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber &
CS570: Introduction to Data Mining Cluster Analysis Reading: Chapter 10.4, 10.6, 11.1.3 Han, Chapter 8.4,8.5,9.2.2, 9.3 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber &
Data mining techniques for data streams mining
 REVIEW OF COMPUTER ENGINEERING STUDIES ISSN: 2369-0755 (Print), 2369-0763 (Online) Vol. 4, No. 1, March, 2017, pp. 31-35 DOI: 10.18280/rces.040106 Licensed under CC BY-NC 4.0 A publication of IIETA http://www.iieta.org/journals/rces
REVIEW OF COMPUTER ENGINEERING STUDIES ISSN: 2369-0755 (Print), 2369-0763 (Online) Vol. 4, No. 1, March, 2017, pp. 31-35 DOI: 10.18280/rces.040106 Licensed under CC BY-NC 4.0 A publication of IIETA http://www.iieta.org/journals/rces
Data Mining. Clustering. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
CHAPTER 7. PAPER 3: EFFICIENT HIERARCHICAL CLUSTERING OF LARGE DATA SETS USING P-TREES
 CHAPTER 7. PAPER 3: EFFICIENT HIERARCHICAL CLUSTERING OF LARGE DATA SETS USING P-TREES 7.1. Abstract Hierarchical clustering methods have attracted much attention by giving the user a maximum amount of
CHAPTER 7. PAPER 3: EFFICIENT HIERARCHICAL CLUSTERING OF LARGE DATA SETS USING P-TREES 7.1. Abstract Hierarchical clustering methods have attracted much attention by giving the user a maximum amount of
A Framework for Clustering Evolving Data Streams
 VLDB 03 Paper ID: 312 A Framework for Clustering Evolving Data Streams Charu C. Aggarwal, Jiawei Han, Jianyong Wang, Philip S. Yu IBM T. J. Watson Research Center & UIUC charu@us.ibm.com, hanj@cs.uiuc.edu,
VLDB 03 Paper ID: 312 A Framework for Clustering Evolving Data Streams Charu C. Aggarwal, Jiawei Han, Jianyong Wang, Philip S. Yu IBM T. J. Watson Research Center & UIUC charu@us.ibm.com, hanj@cs.uiuc.edu,
A Review: Techniques for Clustering of Web Usage Mining
 A Review: Techniques for Clustering of Web Usage Mining Rupinder Kaur 1, Simarjeet Kaur 2 1 Research Fellow, Department of CSE, SGGSWU, Fatehgarh Sahib, Punjab, India 2 Assistant Professor, Department
A Review: Techniques for Clustering of Web Usage Mining Rupinder Kaur 1, Simarjeet Kaur 2 1 Research Fellow, Department of CSE, SGGSWU, Fatehgarh Sahib, Punjab, India 2 Assistant Professor, Department
Table Of Contents: xix Foreword to Second Edition
 Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
d(2,1) d(3,1 ) d (3,2) 0 ( n, ) ( n ,2)......
 d(3,1 ) d (3,2) 0 ( n, ) ( n ,2)......") Data Mining i Topic: Clustering CSEE Department, e t, UMBC Some of the slides used in this presentation are prepared by Jiawei Han and Micheline Kamber Cluster Analysis What is Cluster Analysis? Types
Data Mining i Topic: Clustering CSEE Department, e t, UMBC Some of the slides used in this presentation are prepared by Jiawei Han and Micheline Kamber Cluster Analysis What is Cluster Analysis? Types
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Towards New Heterogeneous Data Stream Clustering based on Density
 , pp.30-35 http://dx.doi.org/10.14257/astl.2015.83.07 Towards New Heterogeneous Data Stream Clustering based on Density Chen Jin-yin, He Hui-hao Zhejiang University of Technology, Hangzhou,310000 chenjinyin@zjut.edu.cn
, pp.30-35 http://dx.doi.org/10.14257/astl.2015.83.07 Towards New Heterogeneous Data Stream Clustering based on Density Chen Jin-yin, He Hui-hao Zhejiang University of Technology, Hangzhou,310000 chenjinyin@zjut.edu.cn
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK REAL TIME DATA SEARCH OPTIMIZATION: AN OVERVIEW MS. DEEPASHRI S. KHAWASE 1, PROF.
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK REAL TIME DATA SEARCH OPTIMIZATION: AN OVERVIEW MS. DEEPASHRI S. KHAWASE 1, PROF.
Classification of evolving data streams with infinitely delayed labels
 Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 21-12 Classification of evolving data streams
Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 21-12 Classification of evolving data streams
Comparative Study of Subspace Clustering Algorithms
 Comparative Study of Subspace Clustering Algorithms S.Chitra Nayagam, Asst Prof., Dept of Computer Applications, Don Bosco College, Panjim, Goa. Abstract-A cluster is a collection of data objects that
Comparative Study of Subspace Clustering Algorithms S.Chitra Nayagam, Asst Prof., Dept of Computer Applications, Don Bosco College, Panjim, Goa. Abstract-A cluster is a collection of data objects that
Mining Frequent Itemsets from Data Streams with a Time- Sensitive Sliding Window
 Mining Frequent Itemsets from Data Streams with a Time- Sensitive Sliding Window Chih-Hsiang Lin, Ding-Ying Chiu, Yi-Hung Wu Department of Computer Science National Tsing Hua University Arbee L.P. Chen
Mining Frequent Itemsets from Data Streams with a Time- Sensitive Sliding Window Chih-Hsiang Lin, Ding-Ying Chiu, Yi-Hung Wu Department of Computer Science National Tsing Hua University Arbee L.P. Chen
Survey Paper on Clustering Data Streams Based on Shared Density between Micro-Clusters
 Survey Paper on Clustering Data Streams Based on Shared Density between Micro-Clusters Dure Supriya Suresh ; Prof. Wadne Vinod ME(Student), ICOER,Wagholi, Pune,Maharastra,India Assit.Professor, ICOER,Wagholi,
Survey Paper on Clustering Data Streams Based on Shared Density between Micro-Clusters Dure Supriya Suresh ; Prof. Wadne Vinod ME(Student), ICOER,Wagholi, Pune,Maharastra,India Assit.Professor, ICOER,Wagholi,
Clustering in the Presence of Concept Drift
 Clustering in the Presence of Concept Drift Richard Hugh Moulton 1, Herna L. Viktor 1, Nathalie Japkowicz 2, and João Gama 3 1 School of Electrical Engineering and Computer Science, University of Ottawa,
Clustering in the Presence of Concept Drift Richard Hugh Moulton 1, Herna L. Viktor 1, Nathalie Japkowicz 2, and João Gama 3 1 School of Electrical Engineering and Computer Science, University of Ottawa,
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Kapitel 4: Clustering
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
C-NBC: Neighborhood-Based Clustering with Constraints
 C-NBC: Neighborhood-Based Clustering with Constraints Piotr Lasek Chair of Computer Science, University of Rzeszów ul. Prof. St. Pigonia 1, 35-310 Rzeszów, Poland lasek@ur.edu.pl Abstract. Clustering is
C-NBC: Neighborhood-Based Clustering with Constraints Piotr Lasek Chair of Computer Science, University of Rzeszów ul. Prof. St. Pigonia 1, 35-310 Rzeszów, Poland lasek@ur.edu.pl Abstract. Clustering is
Contents. Foreword to Second Edition. Acknowledgments About the Authors
 Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
CMPUT 391 Database Management Systems. Data Mining. Textbook: Chapter (without 17.10)
") CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
DESIGNING AN INTEREST SEARCH MODEL USING THE KEYWORD FROM THE CLUSTERED DATASETS
 ISSN: 0976-3104 SPECIAL ISSUE: Emerging Technologies in Networking and Security (ETNS) Ajitha et al. ARTICLE OPEN ACCESS DESIGNING AN INTEREST SEARCH MODEL USING THE KEYWORD FROM THE CLUSTERED DATASETS
ISSN: 0976-3104 SPECIAL ISSUE: Emerging Technologies in Networking and Security (ETNS) Ajitha et al. ARTICLE OPEN ACCESS DESIGNING AN INTEREST SEARCH MODEL USING THE KEYWORD FROM THE CLUSTERED DATASETS
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
Dynamic Optimization of Generalized SQL Queries with Horizontal Aggregations Using K-Means Clustering
 Dynamic Optimization of Generalized SQL Queries with Horizontal Aggregations Using K-Means Clustering Abstract Mrs. C. Poongodi 1, Ms. R. Kalaivani 2 1 PG Student, 2 Assistant Professor, Department of
Dynamic Optimization of Generalized SQL Queries with Horizontal Aggregations Using K-Means Clustering Abstract Mrs. C. Poongodi 1, Ms. R. Kalaivani 2 1 PG Student, 2 Assistant Professor, Department of
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
CS573 Data Privacy and Security. Li Xiong
 CS573 Data Privacy and Security Anonymizationmethods Li Xiong Today Clustering based anonymization(cont) Permutation based anonymization Other privacy principles Microaggregation/Clustering Two steps:
CS573 Data Privacy and Security Anonymizationmethods Li Xiong Today Clustering based anonymization(cont) Permutation based anonymization Other privacy principles Microaggregation/Clustering Two steps:
Coresets for k-means clustering
 Melanie Schmidt, TU Dortmund Resource-aware Machine Learning - International Summer School 02.10.2014 Coresets and k-means Coresets and k-means 75 KB Coresets and k-means 75 KB 55 KB Coresets and k-means
Melanie Schmidt, TU Dortmund Resource-aware Machine Learning - International Summer School 02.10.2014 Coresets and k-means Coresets and k-means 75 KB Coresets and k-means 75 KB 55 KB Coresets and k-means
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
A Comparative Study of Various Clustering Algorithms in Data Mining
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 6.017 IJCSMC,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 6.017 IJCSMC,
Clustering Large Datasets using Data Stream Clustering Techniques
 Clustering Large Datasets using Data Stream Clustering Techniques Matthew Bolaños 1, John Forrest 2, and Michael Hahsler 1 1 Southern Methodist University, Dallas, Texas, USA. 2 Microsoft, Redmond, Washington,
Clustering Large Datasets using Data Stream Clustering Techniques Matthew Bolaños 1, John Forrest 2, and Michael Hahsler 1 1 Southern Methodist University, Dallas, Texas, USA. 2 Microsoft, Redmond, Washington,
[Gidhane* et al., 5(7): July, 2016] ISSN: IC Value: 3.00 Impact Factor: 4.116
![[Gidhane* et al., 5(7): July, 2016] ISSN: IC Value: 3.00 Impact Factor: 4.116](/thumbs/86/94131898.jpg "[Gidhane* et al., 5(7): July, 2016] ISSN: IC Value: 3.00 Impact Factor: 4.116") IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY AN EFFICIENT APPROACH FOR TEXT MINING USING SIDE INFORMATION Kiran V. Gaidhane*, Prof. L. H. Patil, Prof. C. U. Chouhan DOI: 10.5281/zenodo.58632
IJESRT INTERNATIONAL JOURNAL OF ENGINEERING SCIENCES & RESEARCH TECHNOLOGY AN EFFICIENT APPROACH FOR TEXT MINING USING SIDE INFORMATION Kiran V. Gaidhane*, Prof. L. H. Patil, Prof. C. U. Chouhan DOI: 10.5281/zenodo.58632
Hierarchy. No or very little supervision Some heuristic quality guidances on the quality of the hierarchy. Jian Pei: CMPT 459/741 Clustering (2) 1
 1") Hierarchy An arrangement or classification of things according to inclusiveness A natural way of abstraction, summarization, compression, and simplification for understanding Typical setting: organize
Hierarchy An arrangement or classification of things according to inclusiveness A natural way of abstraction, summarization, compression, and simplification for understanding Typical setting: organize