Jure Leskovec Including joint work with Y. Perez, R. Sosič, A. Banarjee, M. Raison, R. Puttagunta, P. Shah
|
|
|
- Dwayne Alexander
- 6 years ago
- Views:
Transcription


1 Jure Leskovec Including joint work with Y. Perez, R. Sosič, A. Banarjee, M. Raison, R. Puttagunta, P. Shah


2 2 My research group at Stanford: Mining and modeling large social and information networks Problems motivated by the Web and on-line media, large scale data We work with networks from FB, Yahoo, Twitter, LinkedIn, Wikimedia, StackOverflow This talk: Feedback appreciated!




3 3 Posts Select Select Python Questions Answers Join Python Q&A Construct Graph Hits Algorithm Provenance script Experts Join Scores Users
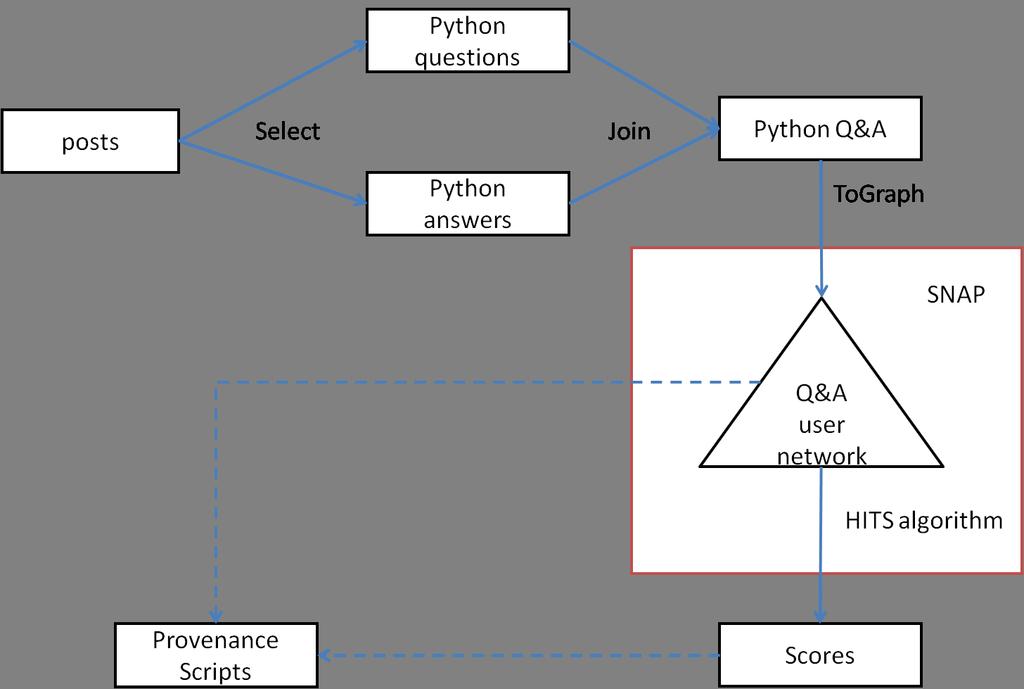
4 4
5 Graphs are almost never given but they have to be constructed from input data! (graph constructions is a part of modeling/discovery process) Examples: Facebook graphs: Friend, Communication, Poke, Co-Tag, Co-location, Co-Event Cellphone/ graphs: How many calls? Biology: P2P, Gene interaction networks 12/14/2014 Jure Leskovec (@jure), Stanford University 5
6 6 Graph construction operations Graph analytics Hadoop MapReduce Big data storage Relational tables Graphs and networks
7 7 Easy to use front-end Common high-level programming language Fast execution times Interactive use (as opposed to batch use) Ability to process large networks Tens of billions of edges Support for several representations Transformations between tables and graphs Large number of graph algorithms Straightforward to use Workflow management and reproducibility Provenance
8 Two observations: (1) Most graphs are not that large (2) Big-memory machines are here: 4x Intel CPU, 64 cores, 1TB RAM, $35K 12/14/2014 Jure Leskovec Stanford University Number of Edges Number of Graphs <0.1M M 1M 25 1M 10M 17 10M 100M 7 100M 1B 5 > 1B 1 Stanford Large Network Collection 71 graphs 8
9 9 Option 1 Option 2 Standard SQL database Separate systems for tables and graphs Single representation for tables and graphs Distributed system Disk based structures Custom representations Integrated system for tables and graphs Separate table and graph representations Single machine system In-memory structures
10 10 Option 1 Option 2 Standard SQL database Separate systems for tables and graphs Single representation for tables and graphs Distributed system Disk based structures Custom representations Integrated system for tables and graphs Separate table and graph representations Single machine system In-memory structures Ringo
11 12 Unstructured data (a) Specify entities Relational tables (b) Specify relationships Tabular networks (c) Optimize representation Network representation (e) Integrate the results (d) Perform analytic reasoning and inference Results Ringo
")



12 13 Ringo (Python) code for executing finding the StackOverflow example
 Provenance Script")

13 14 High-Level Language User Front-End Interface with Graph Processing Engine Metadata (Provenance) Provenance Script In-memory Graph Processing Engine Filters Graph Methods Graph Containers Graph, Table Conversions Table Objects Secondary Storage
14 16 Input data must be manipulated and transformed into graphs Src Dst v1 v2 v2 v3 v3 v4 v1 v3 v1 v4 v2 v1 v3 v4 Table data structure Graph data structure
15 17 Four ways to create a graph: The data already contains edges as source and destination pairs Nodes are connected based on their similarity Nodes are connected based on a temporal order Nodes are connected based on grouping and aggregation
16 18 Use case: In a forum, connect users that post to similar topics: Distance metrics Euclidean, Haversine, Jaccard distance Connect similar nodes SimJoin, connect if closer than the threshold Quadratic complexity Locality sensitive hashing
17 19 Use case: In a Web log, connect pages in a temporal order as clicked by the users Connect a node with its successors Events selected per user, ordered by timestamps NextK, connect K successors
18 20 Use case: In a Web log, measure the activity level of different user groups Edge creation Partition users to groups Identify interactions within each group Compute a score for each group based on interactions Treat groups as super-nodes in a graph
19 21 generation manipulation analytics Methods graphs networks Containers Several graph containers are supported Over 200 graph algorithms (provided via SNAP)
20 22 Requirements: Fast processing Efficient traversal of nodes and edges Dynamic structure Quickly add/remove nodes and edges Create subgraphs, dynamic graphs, How to achieve good balance?
21 23 Nodes table Sorted vector of neighbors
22 24 Nodes table Sorted vectors of in and out neighbors
23 25 Nodes table Sorted vectors of in and out edges Edges table


24 26 Column based store Persistent row identifier Lots of tricks: Implicit select, String pools Standard table operations Select, join, project, group, aggregate Graph construction operations Explicit pairs Distance based edges, SimJoin Time based edges, NextK
25 27 Src Dst v1 v2 v2 v3 v3 v4 v1 v3 v2 v1 v3 v4 v1 v4 Src Dst v1 v2 v3 v4 v1 v2 v3 v1 v1 v2 v3 v4 v3 v4 v2 v3 v4 v3 v1 v4 v1 v1 v2 v3
26 28 Make two copies of pairs of (Src,Dst) columns (Paralle Sort first copy by Src, second copy by Dst (Parallel) Merge column Src from the first copy and Dst from the second copy (Sequential) Count the number of unique values in the merged column to get the number of nodes in the graph (S) Allocate the node hash table For each node, build vectors of neighbors (Parallel)
27 31 High-level front end Python module Based on Snap.py, uses SWIG for C++ interface High-performance graph engine C++ based on SNAP Multi-core support OpenMP to parallelize loops Fast, concurrent hash table, vector operations
28 32 Dataset LiveJournal Twitter2010 Nodes 4.8M 42M Edges 69M 1.5B Text Size 1.1GB 26.2GB Graph Size 0.7GB 13.2GB Table Size 1.1GB 23.5GB
29 33 Algorithm Graph PageRank LiveJournal PageRank Twitter2010 Triangles LiveJournal Triangles Twitter2010 Giraph 45.6s 439.3s N/A N/A GraphX 56.0s s - GraphChi 54.0s 595.3s 66.5s - PowerGrap h 27.5s 251.7s 5.4s 706.8s Ringo 2.6s 72.0s 13.7s 284.1s Hardware: 4x Intel CPU, 64 cores, 1TB RAM, $35K
30 34 System Hosts CPUs host Host Configuration Time GraphChi 1 4 8x core AMD, 64GB RAM 158s TurboGraph 1 1 6x core Intel, 12GB RAM 30s Spark s GraphX X core Intel, 68GB RAM 15s PowerGraph x hyper Intel, 23GB RAM 3.6s Ringo x hyper Intel, 1TB RAM 6.0s Twitter2010, one iteration of PageRank
31 35 Dataset LiveJournal Twitter2010 Table to graph Graph to table 8.5s 13.0 MEdges/s 1.5s 46.0 MEdges/s 81.0s 18.0 MEdges/s 29.2s 50.4 MEdges/s Hardware: 4x Intel CPU, 80 cores, 1TB RAM, $35K
32 Dataset LiveJournal Twitter2010 Select 10K Select All- 10K Join 10K Join All-10K <0.2s MRows/s <0.1s MRows/s 0.6s MRows/s 3.1s 44.5 MRows/s 1.6s MRows/s 1.6s MRows/s 4.2s MRows/s 29.7s 98.8 MRows/s 12/14/2014 Jure Leskovec Stanford University 36
33 37 Algorithm Runtime 3-core 31.0s Single source shortest path Strongly connected component 7.4s 18.0s LiveJournal, 1 core
34 38 Dataset LiveJournal Twitter2010 Load graph 5.2s 76.6s Save graph 3.5s 69.0s Load table 6.0s 114.3s Save table 4.3s 100.2s
35 39 Big-memory machines are here: 1TB RAM, 100 Cores a small cluster No overheads of distributed systems Easy to program Most useful datasets fit in memory Big-memory machines present a viable solution for analysis of all-but-thelargest networks
36 graph construction operations graph analytics Relational tables Graphs and networks Ringo: Network science & exploration In-memory graph analytics Processing of tables and graphs Fast and scalable 12/14/2014 Jure Leskovec Stanford University 40
37 12/14/2014 Jure Leskovec Stanford University 41 Get your own 1TB RAM server! And download RINGO/SNAP



38 42
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
GridGraph: Large-Scale Graph Processing on a Single Machine Using 2-Level Hierarchical Partitioning. Xiaowei ZHU Tsinghua University
 GridGraph: Large-Scale Graph Processing on a Single Machine Using -Level Hierarchical Partitioning Xiaowei ZHU Tsinghua University Widely-Used Graph Processing Shared memory Single-node & in-memory Ligra,
GridGraph: Large-Scale Graph Processing on a Single Machine Using -Level Hierarchical Partitioning Xiaowei ZHU Tsinghua University Widely-Used Graph Processing Shared memory Single-node & in-memory Ligra,
Graph Data Management
 Graph Data Management Analysis and Optimization of Graph Data Frameworks presented by Fynn Leitow Overview 1) Introduction a) Motivation b) Application for big data 2) Choice of algorithms 3) Choice of
Graph Data Management Analysis and Optimization of Graph Data Frameworks presented by Fynn Leitow Overview 1) Introduction a) Motivation b) Application for big data 2) Choice of algorithms 3) Choice of
Graph Analytics in the Big Data Era
 Graph Analytics in the Big Data Era Yongming Luo, dr. George H.L. Fletcher Web Engineering Group What is really hot? 19-11-2013 PAGE 1 An old/new data model graph data Model entities and relations between
Graph Analytics in the Big Data Era Yongming Luo, dr. George H.L. Fletcher Web Engineering Group What is really hot? 19-11-2013 PAGE 1 An old/new data model graph data Model entities and relations between
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu HITS (Hypertext Induced Topic Selection) Is a measure of importance of pages or documents, similar to PageRank
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu HITS (Hypertext Induced Topic Selection) Is a measure of importance of pages or documents, similar to PageRank
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Why do we need graph processing?
 Why do we need graph processing? Community detection: suggest followers? Determine what products people will like Count how many people are in different communities (polling?) Graphs are Everywhere Group
Why do we need graph processing? Community detection: suggest followers? Determine what products people will like Count how many people are in different communities (polling?) Graphs are Everywhere Group
Tools for Social Networking Infrastructures
 Tools for Social Networking Infrastructures 1 Cassandra - a decentralised structured storage system Problem : Facebook Inbox Search hundreds of millions of users distributed infrastructure inbox changes
Tools for Social Networking Infrastructures 1 Cassandra - a decentralised structured storage system Problem : Facebook Inbox Search hundreds of millions of users distributed infrastructure inbox changes
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
RStream:Marrying Relational Algebra with Streaming for Efficient Graph Mining on A Single Machine
 RStream:Marrying Relational Algebra with Streaming for Efficient Graph Mining on A Single Machine Guoqing Harry Xu Kai Wang, Zhiqiang Zuo, John Thorpe, Tien Quang Nguyen, UCLA Nanjing University Facebook
RStream:Marrying Relational Algebra with Streaming for Efficient Graph Mining on A Single Machine Guoqing Harry Xu Kai Wang, Zhiqiang Zuo, John Thorpe, Tien Quang Nguyen, UCLA Nanjing University Facebook
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Mosaic: Processing a Trillion-Edge Graph on a Single Machine
 Mosaic: Processing a Trillion-Edge Graph on a Single Machine Steffen Maass, Changwoo Min, Sanidhya Kashyap, Woonhak Kang, Mohan Kumar, Taesoo Kim Georgia Institute of Technology Best Student Paper @ EuroSys
Mosaic: Processing a Trillion-Edge Graph on a Single Machine Steffen Maass, Changwoo Min, Sanidhya Kashyap, Woonhak Kang, Mohan Kumar, Taesoo Kim Georgia Institute of Technology Best Student Paper @ EuroSys
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Apache Giraph: Facebook-scale graph processing infrastructure. 3/31/2014 Avery Ching, Facebook GDM
 Apache Giraph: Facebook-scale graph processing infrastructure 3/31/2014 Avery Ching, Facebook GDM Motivation Apache Giraph Inspired by Google s Pregel but runs on Hadoop Think like a vertex Maximum value
Apache Giraph: Facebook-scale graph processing infrastructure 3/31/2014 Avery Ching, Facebook GDM Motivation Apache Giraph Inspired by Google s Pregel but runs on Hadoop Think like a vertex Maximum value
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
G(B)enchmark GraphBench: Towards a Universal Graph Benchmark. Khaled Ammar M. Tamer Özsu
enchmark GraphBench: Towards a Universal Graph Benchmark. Khaled Ammar M. Tamer Özsu") G(B)enchmark GraphBench: Towards a Universal Graph Benchmark Khaled Ammar M. Tamer Özsu Bioinformatics Software Engineering Social Network Gene Co-expression Protein Structure Program Flow Big Graphs o
G(B)enchmark GraphBench: Towards a Universal Graph Benchmark Khaled Ammar M. Tamer Özsu Bioinformatics Software Engineering Social Network Gene Co-expression Protein Structure Program Flow Big Graphs o
Big Data Analytics: What is Big Data? Stony Brook University CSE545, Fall 2016 the inaugural edition
 Big Data Analytics: What is Big Data? Stony Brook University CSE545, Fall 2016 the inaugural edition What s the BIG deal?! 2011 2011 2008 2010 2012 What s the BIG deal?! (Gartner Hype Cycle) What s the
Big Data Analytics: What is Big Data? Stony Brook University CSE545, Fall 2016 the inaugural edition What s the BIG deal?! 2011 2011 2008 2010 2012 What s the BIG deal?! (Gartner Hype Cycle) What s the
GraphCEP Real-Time Data Analytics Using Parallel Complex Event and Graph Processing
 Institute of Parallel and Distributed Systems () Universitätsstraße 38 D-70569 Stuttgart GraphCEP Real-Time Data Analytics Using Parallel Complex Event and Graph Processing Ruben Mayer, Christian Mayer,
Institute of Parallel and Distributed Systems () Universitätsstraße 38 D-70569 Stuttgart GraphCEP Real-Time Data Analytics Using Parallel Complex Event and Graph Processing Ruben Mayer, Christian Mayer,
Harp-DAAL for High Performance Big Data Computing
 Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
The Stratosphere Platform for Big Data Analytics
 The Stratosphere Platform for Big Data Analytics Hongyao Ma Franco Solleza April 20, 2015 Stratosphere Stratosphere Stratosphere Big Data Analytics BIG Data Heterogeneous datasets: structured / unstructured
The Stratosphere Platform for Big Data Analytics Hongyao Ma Franco Solleza April 20, 2015 Stratosphere Stratosphere Stratosphere Big Data Analytics BIG Data Heterogeneous datasets: structured / unstructured
Antonio Fernández Anta
 Antonio Fernández Anta Joint work with Luis F. Chiroque, Héctor Cordobés, Rafael A. García Leiva, Philippe Morere, Lorenzo Ornella, Fernando Pérez, and Agustín Santos Recommendation Engines (RE) suggest
Antonio Fernández Anta Joint work with Luis F. Chiroque, Héctor Cordobés, Rafael A. García Leiva, Philippe Morere, Lorenzo Ornella, Fernando Pérez, and Agustín Santos Recommendation Engines (RE) suggest
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem
 I J C T A, 9(41) 2016, pp. 1235-1239 International Science Press Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem Hema Dubey *, Nilay Khare *, Alind Khare **
I J C T A, 9(41) 2016, pp. 1235-1239 International Science Press Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem Hema Dubey *, Nilay Khare *, Alind Khare **
CS / Cloud Computing. Recitation 3 September 9 th & 11 th, 2014
 CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
Graph-Processing Systems. (focusing on GraphChi)
") Graph-Processing Systems (focusing on GraphChi) Recall: PageRank in MapReduce (Hadoop) Input: adjacency matrix H D F S (a,[c]) (b,[a]) (c,[a,b]) (c,pr(a) / out (a)), (a,[c]) (a,pr(b) / out (b)), (b,[a])
Graph-Processing Systems (focusing on GraphChi) Recall: PageRank in MapReduce (Hadoop) Input: adjacency matrix H D F S (a,[c]) (b,[a]) (c,[a,b]) (c,pr(a) / out (a)), (a,[c]) (a,pr(b) / out (b)), (b,[a])
Resource and Performance Distribution Prediction for Large Scale Analytics Queries
 Resource and Performance Distribution Prediction for Large Scale Analytics Queries Prof. Rajiv Ranjan, SMIEEE School of Computing Science, Newcastle University, UK Visiting Scientist, Data61, CSIRO, Australia
Resource and Performance Distribution Prediction for Large Scale Analytics Queries Prof. Rajiv Ranjan, SMIEEE School of Computing Science, Newcastle University, UK Visiting Scientist, Data61, CSIRO, Australia
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
MapReduce: Recap. Juliana Freire & Cláudio Silva. Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec
 MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Pregel. Ali Shah
 Pregel Ali Shah s9alshah@stud.uni-saarland.de 2 Outline Introduction Model of Computation Fundamentals of Pregel Program Implementation Applications Experiments Issues with Pregel 3 Outline Costs of Computation
Pregel Ali Shah s9alshah@stud.uni-saarland.de 2 Outline Introduction Model of Computation Fundamentals of Pregel Program Implementation Applications Experiments Issues with Pregel 3 Outline Costs of Computation
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
GraFBoost: Using accelerated flash storage for external graph analytics
 GraFBoost: Using accelerated flash storage for external graph analytics Sang-Woo Jun, Andy Wright, Sizhuo Zhang, Shuotao Xu and Arvind MIT CSAIL Funded by: 1 Large Graphs are Found Everywhere in Nature
GraFBoost: Using accelerated flash storage for external graph analytics Sang-Woo Jun, Andy Wright, Sizhuo Zhang, Shuotao Xu and Arvind MIT CSAIL Funded by: 1 Large Graphs are Found Everywhere in Nature
Cluster Computing Architecture. Intel Labs
 Intel Labs Legal Notices INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED
Intel Labs Legal Notices INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED
Apache Spark Graph Performance with Memory1. February Page 1 of 13
 Apache Spark Graph Performance with Memory1 February 2017 Page 1 of 13 Abstract Apache Spark is a powerful open source distributed computing platform focused on high speed, large scale data processing
Apache Spark Graph Performance with Memory1 February 2017 Page 1 of 13 Abstract Apache Spark is a powerful open source distributed computing platform focused on high speed, large scale data processing
Apache Giraph. for applications in Machine Learning & Recommendation Systems. Maria Novartis
 Apache Giraph for applications in Machine Learning & Recommendation Systems Maria Stylianou @marsty5 Novartis Züri Machine Learning Meetup #5 June 16, 2014 Apache Giraph for applications in Machine Learning
Apache Giraph for applications in Machine Learning & Recommendation Systems Maria Stylianou @marsty5 Novartis Züri Machine Learning Meetup #5 June 16, 2014 Apache Giraph for applications in Machine Learning
CSC 261/461 Database Systems Lecture 24. Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101
 CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
A New Parallel Algorithm for Connected Components in Dynamic Graphs. Robert McColl Oded Green David Bader
 A New Parallel Algorithm for Connected Components in Dynamic Graphs Robert McColl Oded Green David Bader Overview The Problem Target Datasets Prior Work Parent-Neighbor Subgraph Results Conclusions Problem
A New Parallel Algorithm for Connected Components in Dynamic Graphs Robert McColl Oded Green David Bader Overview The Problem Target Datasets Prior Work Parent-Neighbor Subgraph Results Conclusions Problem
Analyzing Big Data with Microsoft R
 Analyzing Big Data with Microsoft R 20773; 3 days, Instructor-led Course Description The main purpose of the course is to give students the ability to use Microsoft R Server to create and run an analysis
Analyzing Big Data with Microsoft R 20773; 3 days, Instructor-led Course Description The main purpose of the course is to give students the ability to use Microsoft R Server to create and run an analysis
Automatic Scaling Iterative Computations. Aug. 7 th, 2012
 Automatic Scaling Iterative Computations Guozhang Wang Cornell University Aug. 7 th, 2012 1 What are Non-Iterative Computations? Non-iterative computation flow Directed Acyclic Examples Batch style analytics
Automatic Scaling Iterative Computations Guozhang Wang Cornell University Aug. 7 th, 2012 1 What are Non-Iterative Computations? Non-iterative computation flow Directed Acyclic Examples Batch style analytics
FPGP: Graph Processing Framework on FPGA
 FPGP: Graph Processing Framework on FPGA Guohao DAI, Yuze CHI, Yu WANG, Huazhong YANG E.E. Dept., TNLIST, Tsinghua University dgh14@mails.tsinghua.edu.cn 1 Big graph is widely used Big graph is widely
FPGP: Graph Processing Framework on FPGA Guohao DAI, Yuze CHI, Yu WANG, Huazhong YANG E.E. Dept., TNLIST, Tsinghua University dgh14@mails.tsinghua.edu.cn 1 Big graph is widely used Big graph is widely
One Trillion Edges. Graph processing at Facebook scale
 One Trillion Edges Graph processing at Facebook scale Introduction Platform improvements Compute model extensions Experimental results Operational experience How Facebook improved Apache Giraph Facebook's
One Trillion Edges Graph processing at Facebook scale Introduction Platform improvements Compute model extensions Experimental results Operational experience How Facebook improved Apache Giraph Facebook's
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Principal Software Engineer Red Hat Emerging Technology June 24, 2015
 USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
Big Data Analytics. Rasoul Karimi
 Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
modern database systems lecture 10 : large-scale graph processing
 modern database systems lecture 1 : large-scale graph processing Aristides Gionis spring 18 timeline today : homework is due march 6 : homework out april 5, 9-1 : final exam april : homework due graphs
modern database systems lecture 1 : large-scale graph processing Aristides Gionis spring 18 timeline today : homework is due march 6 : homework out april 5, 9-1 : final exam april : homework due graphs
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
A Fast and High Throughput SQL Query System for Big Data
 A Fast and High Throughput SQL Query System for Big Data Feng Zhu, Jie Liu, and Lijie Xu Technology Center of Software Engineering, Institute of Software, Chinese Academy of Sciences, Beijing, China 100190
A Fast and High Throughput SQL Query System for Big Data Feng Zhu, Jie Liu, and Lijie Xu Technology Center of Software Engineering, Institute of Software, Chinese Academy of Sciences, Beijing, China 100190
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU
 Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
On Fast Parallel Detection of Strongly Connected Components (SCC) in Small-World Graphs
 in Small-World Graphs") On Fast Parallel Detection of Strongly Connected Components (SCC) in Small-World Graphs Sungpack Hong 2, Nicole C. Rodia 1, and Kunle Olukotun 1 1 Pervasive Parallelism Laboratory, Stanford University
On Fast Parallel Detection of Strongly Connected Components (SCC) in Small-World Graphs Sungpack Hong 2, Nicole C. Rodia 1, and Kunle Olukotun 1 1 Pervasive Parallelism Laboratory, Stanford University
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Graph Analytics using Vertica Relational Database
 Graph Analytics using ertica Relational Database Alekh Jindal* Samuel Madden Malú Castellanos Meichun Hsu Microsoft MIT ertica ertica * work done while at MIT Motivation for graphs on DB Data anyways in
Graph Analytics using ertica Relational Database Alekh Jindal* Samuel Madden Malú Castellanos Meichun Hsu Microsoft MIT ertica ertica * work done while at MIT Motivation for graphs on DB Data anyways in
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/25/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 In many data mining
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/25/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 In many data mining
Overview. Audience profile. At course completion. Course Outline. : 20773A: Analyzing Big Data with Microsoft R. Course Outline :: 20773A::
 Module Title Duration : 20773A: Analyzing Big Data with Microsoft R : 3 days Overview The main purpose of the course is to give students the ability to use Microsoft R Server to create and run an analysis
Module Title Duration : 20773A: Analyzing Big Data with Microsoft R : 3 days Overview The main purpose of the course is to give students the ability to use Microsoft R Server to create and run an analysis
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Graph Analytics and Machine Learning A Great Combination Mark Hornick
 Graph Analytics and Machine Learning A Great Combination Mark Hornick Oracle Advanced Analytics and Machine Learning November 3, 2017 Safe Harbor Statement The following is intended to outline our research
Graph Analytics and Machine Learning A Great Combination Mark Hornick Oracle Advanced Analytics and Machine Learning November 3, 2017 Safe Harbor Statement The following is intended to outline our research
Social Network Analytics on Cray Urika-XA
 Social Network Analytics on Cray Urika-XA Mike Hinchey, mhinchey@cray.com Technical Solutions Architect Cray Inc, Analytics Products Group April, 2015 Agenda 1. Introduce platform Urika-XA 2. Technology
Social Network Analytics on Cray Urika-XA Mike Hinchey, mhinchey@cray.com Technical Solutions Architect Cray Inc, Analytics Products Group April, 2015 Agenda 1. Introduce platform Urika-XA 2. Technology
Prototyping Data Intensive Apps: TrendingTopics.org
 Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
4th National Conference on Electrical, Electronics and Computer Engineering (NCEECE 2015)
") 4th National Conference on Electrical, Electronics and Computer Engineering (NCEECE 2015) Benchmark Testing for Transwarp Inceptor A big data analysis system based on in-memory computing Mingang Chen1,2,a,
4th National Conference on Electrical, Electronics and Computer Engineering (NCEECE 2015) Benchmark Testing for Transwarp Inceptor A big data analysis system based on in-memory computing Mingang Chen1,2,a,
New Challenges in Big Data: Technical Perspectives. Hwanjo Yu POSTECH
 New Challenges in Big Data: Technical Perspectives Hwanjo Yu POSTECH http:/hwanjoyu.org Over 1 Billion SNS users!! Viral Marketing Word-of-Mouth Effect > TV advertising......... Influence Maximization
New Challenges in Big Data: Technical Perspectives Hwanjo Yu POSTECH http:/hwanjoyu.org Over 1 Billion SNS users!! Viral Marketing Word-of-Mouth Effect > TV advertising......... Influence Maximization
Extreme-scale Graph Analysis on Blue Waters
 Extreme-scale Graph Analysis on Blue Waters 2016 Blue Waters Symposium George M. Slota 1,2, Siva Rajamanickam 1, Kamesh Madduri 2, Karen Devine 1 1 Sandia National Laboratories a 2 The Pennsylvania State
Extreme-scale Graph Analysis on Blue Waters 2016 Blue Waters Symposium George M. Slota 1,2, Siva Rajamanickam 1, Kamesh Madduri 2, Karen Devine 1 1 Sandia National Laboratories a 2 The Pennsylvania State
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics
 Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
BIG DATA TESTING: A UNIFIED VIEW
 http://core.ecu.edu/strg BIG DATA TESTING: A UNIFIED VIEW BY NAM THAI ECU, Computer Science Department, March 16, 2016 2/30 PRESENTATION CONTENT 1. Overview of Big Data A. 5 V s of Big Data B. Data generation
http://core.ecu.edu/strg BIG DATA TESTING: A UNIFIED VIEW BY NAM THAI ECU, Computer Science Department, March 16, 2016 2/30 PRESENTATION CONTENT 1. Overview of Big Data A. 5 V s of Big Data B. Data generation
FlashGraph: Processing Billion-Node Graphs on an Array of Commodity SSDs
 FlashGraph: Processing Billion-Node Graphs on an Array of Commodity SSDs Da Zheng, Disa Mhembere, Randal Burns Department of Computer Science Johns Hopkins University Carey E. Priebe Department of Applied
FlashGraph: Processing Billion-Node Graphs on an Array of Commodity SSDs Da Zheng, Disa Mhembere, Randal Burns Department of Computer Science Johns Hopkins University Carey E. Priebe Department of Applied
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/6/2012 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 In many data mining
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/6/2012 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 In many data mining
CS 655 Advanced Topics in Distributed Systems
 Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Graphs / Networks CSE 6242/ CX Centrality measures, algorithms, interactive applications. Duen Horng (Polo) Chau Georgia Tech
 Chau Georgia Tech") CSE 6242/ CX 4242 Graphs / Networks Centrality measures, algorithms, interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John
CSE 6242/ CX 4242 Graphs / Networks Centrality measures, algorithms, interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John
Nowcasting. D B M G Data Base and Data Mining Group of Politecnico di Torino. Big Data: Hype or Hallelujah? Big data hype?
 Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
Functionality, Challenges and Architecture of Social Networks
 Functionality, Challenges and Architecture of Social Networks INF 5370 Outline Social Network Services Functionality Business Model Current Architecture and Scalability Challenges Conclusion 1 Social Network
Functionality, Challenges and Architecture of Social Networks INF 5370 Outline Social Network Services Functionality Business Model Current Architecture and Scalability Challenges Conclusion 1 Social Network
Bigtable. Presenter: Yijun Hou, Yixiao Peng
 Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
RAMCloud. Scalable High-Performance Storage Entirely in DRAM. by John Ousterhout et al. Stanford University. presented by Slavik Derevyanko
 RAMCloud Scalable High-Performance Storage Entirely in DRAM 2009 by John Ousterhout et al. Stanford University presented by Slavik Derevyanko Outline RAMCloud project overview Motivation for RAMCloud storage:
RAMCloud Scalable High-Performance Storage Entirely in DRAM 2009 by John Ousterhout et al. Stanford University presented by Slavik Derevyanko Outline RAMCloud project overview Motivation for RAMCloud storage:
Databricks, an Introduction
 Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Flash Storage Complementing a Data Lake for Real-Time Insight
 Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 10. Graph databases Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Graph Databases Basic
NDBI040 Big Data Management and NoSQL Databases Lecture 10. Graph databases Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Graph Databases Basic
Graph Algorithms using Map-Reduce. Graphs are ubiquitous in modern society. Some examples: The hyperlink structure of the web
 Graph Algorithms using Map-Reduce Graphs are ubiquitous in modern society. Some examples: The hyperlink structure of the web Graph Algorithms using Map-Reduce Graphs are ubiquitous in modern society. Some
Graph Algorithms using Map-Reduce Graphs are ubiquitous in modern society. Some examples: The hyperlink structure of the web Graph Algorithms using Map-Reduce Graphs are ubiquitous in modern society. Some
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Popularity of Twitter Accounts: PageRank on a Social Network
 Popularity of Twitter Accounts: PageRank on a Social Network A.D-A December 8, 2017 1 Problem Statement Twitter is a social networking service, where users can create and interact with 140 character messages,
Popularity of Twitter Accounts: PageRank on a Social Network A.D-A December 8, 2017 1 Problem Statement Twitter is a social networking service, where users can create and interact with 140 character messages,
TI2736-B Big Data Processing. Claudia Hauff
 TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Pig Design Patterns Hadoop Ctd. Graphs Giraph Spark Zoo Keeper Spark Learning objectives Implement
TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Pig Design Patterns Hadoop Ctd. Graphs Giraph Spark Zoo Keeper Spark Learning objectives Implement
HaLoop Efficient Iterative Data Processing on Large Clusters
 HaLoop Efficient Iterative Data Processing on Large Clusters Yingyi Bu, Bill Howe, Magdalena Balazinska, and Michael D. Ernst University of Washington Department of Computer Science & Engineering Presented
HaLoop Efficient Iterative Data Processing on Large Clusters Yingyi Bu, Bill Howe, Magdalena Balazinska, and Michael D. Ernst University of Washington Department of Computer Science & Engineering Presented
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Revolver: Vertex-centric Graph Partitioning Using Reinforcement Learning
 Revolver: Vertex-centric Graph Partitioning Using Reinforcement Learning Mohammad Hasanzadeh Mofrad 1, Rami Melhem 1 and Mohammad Hammoud 2 1 University of Pittsburgh 2 Carnegie Mellon University Qatar
Revolver: Vertex-centric Graph Partitioning Using Reinforcement Learning Mohammad Hasanzadeh Mofrad 1, Rami Melhem 1 and Mohammad Hammoud 2 1 University of Pittsburgh 2 Carnegie Mellon University Qatar
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
custinger - Supporting Dynamic Graph Algorithms for GPUs Oded Green & David Bader
 custinger - Supporting Dynamic Graph Algorithms for GPUs Oded Green & David Bader What we will see today The first dynamic graph data structure for the GPU. Scalable in size Supports the same functionality
custinger - Supporting Dynamic Graph Algorithms for GPUs Oded Green & David Bader What we will see today The first dynamic graph data structure for the GPU. Scalable in size Supports the same functionality
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
New Developments in Spark
 New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level