Workloads Programmierung Paralleler und Verteilter Systeme (PPV)
|
|
|
- Gilbert Fisher
- 6 years ago
- Views:
Transcription
1 Workloads Programmierung Paralleler und Verteilter Systeme (PPV) Sommer 2015 Frank Feinbube, M.Sc., Felix Eberhardt, M.Sc., Prof. Dr. Andreas Polze
2 Workloads 2 Hardware / software execution environment are typically designed and optimized for specific workload task parallel workload Different tasks being performed at the same time Might originate from the same or different programs data parallel workload Parallel execution of the same task on disjoint data sets Sometimes also flow parallelism added Overlapping work on data stream Examples: Pipelines, assembly line model Task / data size can be coarse-grained or fine-grained Decision of algorithm design and / or configuration No common semantics for these terms
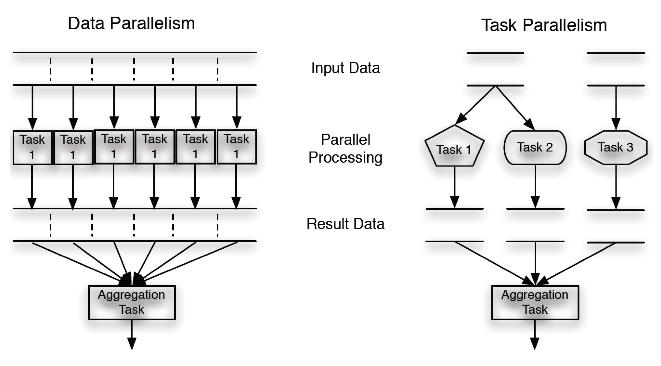
3 Workloads





4 Workloads 4 Data Parallelism [4] 2013 SMU HPC Summer Workshop [5] Parallel Computing Tutorial Functional Parallelism
 Single Instruction, Multiple Data")
5 Execution Environment Mapping 5 Multiple Instruction, Multiple Data (MIMD) Single Instruction, Multiple Data (SIMD)

6 Execution Environment Mapping 6 Data Parallel SIMD Task Parallel MIMD Shared Memory (SM) Shared Nothing / Distributed Memory (DM) SM-SIMD systems: GPU, Cell, SSE, AltiVec Vector processor DM-SIMD systems: processor-array systems systolic arrays Hadoop... SM-MIMD systems: ManyCore/SMP system... DM-MIMD systems: cluster systems MPP systems... Task parallel workload is a MIMD problem Data parallel workload is a SIMD problem Execution environments are optimized for one kind of workload, event though they can also the other one
7 The Parallel Programming Problem 7 Configuration Type Flexible Parallel Application Match? Execution Environment
![Designing Parallel Algorithms [Foster] 8 Map workload problem on an execution environment Concurrency for speedup Data locality for speedup Scalability Best parallel solution typically differs](/docs-images/80/80608545/images/8-0.jpg "massively from the sequential version of an algorithm Foster defines four distinct stages of a methodological approach We will use this as a guide in the upcoming discussions Note: Foster talks about")
8 Designing Parallel Algorithms [Foster] 8 Map workload problem on an execution environment Concurrency for speedup Data locality for speedup Scalability Best parallel solution typically differs massively from the sequential version of an algorithm Foster defines four distinct stages of a methodological approach We will use this as a guide in the upcoming discussions Note: Foster talks about communication, we use the term synchronization instead Example: Parallel Sum

9 Example: Parallel Reduction 9 Reduce a set of elements into one, given an operation Example: Sum
10 Example: All Prefix Sums 10 Input: Ordered set [a 0, a 1,, a n ] Output: Ordered set [a 0, (a 0 + a 1 ),, (a 0 + a a n )] + is an arbitrary operation Multiple use cases Lexically comparison of strings Add multi-precision numbers that do not fit into one word Implementation of quick sort Delete marked elements from an array Search for regular expressions Serial version is trivial, and demands O(n) steps
11 Designing Parallel Algorithms [Foster] 11 A) Search for concurrency and scalability Partitioning Decompose computation and data into small tasks Communication Define necessary coordination of task execution B) Search for locality and other performance-related issues Agglomeration Consider performance and implementation costs Mapping Maximize processor utilization, minimize communication Might require backtracking or parallel investigation of steps
12 Partitioning 12 Expose opportunities for parallel execution fine-grained decomposition Good partition keeps computation and data together Data partitioning leads to data parallelism Computation partitioning leads task parallelism Complementary approaches, can lead to different algorithms Reveal hidden structures of the algorithm that have potential Investigate complementary views on the problem Avoid replication of either computation or data, can be revised later to reduce communication overhead Step results in multiple candidate solutions





13 Partitioning - Decomposition Types 13 Domain Decomposition Define small data fragments Specify computation for them Different phases of computation on the same data are handled separately Rule of thumb: First focus on large or frequently used data structures Functional Decomposition Split up computation into disjoint tasks, ignore the data accessed for the moment With significant data overlap, domain decomposition is more appropriate
14 Partitioning - Checklist 14 Checklist for resulting partitioning scheme Order of magnitude more tasks than processors? -> Keeps flexibility for next steps Avoidance of redundant computation and storage requirements? -> Scalability for large problem sizes Tasks of comparable size? -> Goal to allocate equal work to processors Does number of tasks scale with the problem size? -> Algorithm should be able to solve larger tasks with more processors Resolve bad partitioning by estimating performance behavior, and eventually reformulating the problem
15 Communication Step 15 Specify links between data consumers and data producers Specify kind and number of messages on these links Domain decomposition problems might have tricky communication infrastructures, due to data dependencies Communication in functional decomposition problems can easily be modeled from the data flow between the tasks Categorization of communication patterns Local communication (few neighbors) vs. global communication Structured communication (e.g. tree) vs. unstructured communication Static vs. dynamic communication structure Synchronous vs. asynchronous communication
16 Communication - Hints 16 Distribute computation and communication, don t centralize algorithm Bad example: Central manager for parallel summation Divide-and-conquer helps as mental model to identify concurrency Unstructured communication is hard to agglomerate, better avoid it Checklist for communication design Do all tasks perform the same amount of communication? -> Distribute or replicate communication hot spots Does each task performs only local communication? Can communication happen concurrently? Can computation happen concurrently?
17 Ghost Cells 17 Domain decomposition might lead to chunks that demand data from each other for their computation Solution 1: Copy necessary portion of data (,ghost cells ) Feasible if no synchronization is needed after update Data amount and frequency of update influences resulting overhead and efficiency Additional memory consumption Solution 2: Access relevant data,remotely as needed Delays thread coordination until the data is really needed Correctness ( old data vs. new data) must be considered on parallel progress
18 Agglomeration Step 18 Algorithm so far is correct, but not specialized for some execution environment Check again partitioning and communication decisions Agglomerate tasks for efficient execution on some machine Replicate data and / or computation for efficiency reasons Resulting number of tasks can still be greater than the number of processors Three conflicting guiding decisions Reduce communication costs by coarser granularity of computation and communication Preserve flexibility with respect to later mapping decisions Reduce software engineering costs (serial -> parallel version)

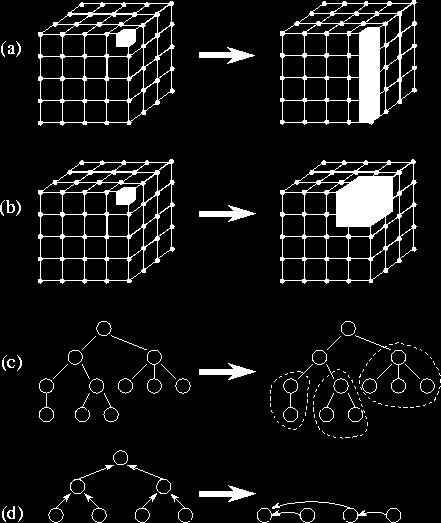
19 19 Agglomeration [Foster]
20 Agglomeration Granularity vs. Flexibility 20 Reduce communication costs by coarser granularity Sending less data Sending fewer messages (per-message initialization costs) Agglomerate, especially if tasks cannot run concurrently Reduces also task creation costs Replicate computation to avoid communication (helps also with reliability) Preserve flexibility Flexible large number of tasks still prerequisite for scalability Define granularity as compile-time or run-time parameter
21 Agglomeration - Checklist 21 Communication costs reduced by increasing locality? Does replicated computation outweighs its costs in all cases? Does data replication restrict the range of problem sizes / processor counts? Does the larger tasks still have similar computation / communication costs? Does the larger tasks still act with sufficient concurrency? Does the number of tasks still scale with the problem size? How much can the task count decrease, without disturbing load balancing, scalability, or engineering costs? Is the transition to parallel code worth the engineering costs?
22 Mapping Step 22 Only relevant for shared-nothing systems, since shared memory systems typically perform automatic task scheduling Minimize execution time by Place concurrent tasks on different nodes Place tasks with heavy communication on the same node Conflicting strategies, additionally restricted by resource limits In general, NP-complete bin packing problem Set of sophisticated (dynamic) heuristics for load balancing Preference for local algorithms that do not need global scheduling state
23 Partitioning Strategies [Breshears] 23 Produce at least as many tasks as there will be threads / cores But: Might be more effective to use only fraction of the cores (granularity) Computation must pay-off with respect to overhead Avoid synchronization, since it adds up as overhead to serial execution time Patterns for data decomposition By element (one-dimensional) By row, by column group, by block (multi-dimensional) Influenced by ratio of computation and synchronization
24 Surface-To-Volume Effect [Foster, Breshears] 24 Visualize the data to be processed (in parallel) as sliced 3D cube Synchronization requirements of a task Proportional to the surface of the data slice it operates upon Visualized by the amount of,borders of the slice Computation work of a task Proportional to the volume of the data slice it operates upon Represents the granularity of decomposition Ratio of synchronization and computation High synchronization, low computation, high ratio à bad Low synchronization, high computation, low ratio à good Ratio decreases for increasing data size per task Coarse granularity by agglomerating tasks in all dimensions For given volume, the surface then goes down à good
")
25 Surface-To-Volume Effect [Foster, Breshears] 25 (C) nicerweb.com
![Surface-to-Volume Effect [Foster] 26 Computation on 8x8](/docs-images/80/80608545/images/26-0.jpg "grid (a): 64 tasks, one point each 64x4=256")

26 Surface-to-Volume Effect [Foster] 26 Computation on 8x8 grid (a): 64 tasks, one point each 64x4=256 synchronizations 256 data values are transferred (b): 4 tasks, 16 points each 4x4=16 synchronizations 16x4=64 data values are transferred
27 Designing Parallel Algorithms [Breshears] 27 Parallel solution must keep sequential consistency property Mentally simulate the execution of parallel streams Check critical parts of the parallelized sequential application Amount of computation per parallel task Always introduced by moving from serial to parallel code Speedup must offset the parallelization overhead (Amdahl) Granularity: Amount of parallel computation done before synchronization is needed Fine-grained granularity overhead vs. coarse-grained granularity concurrency Iterative approach of finding the right granularity Decision might be only correct only for the execution host under test
Parallel Programming Concepts. Parallel Algorithms. Peter Tröger
 Parallel Programming Concepts Parallel Algorithms Peter Tröger Sources: Ian Foster. Designing and Building Parallel Programs. Addison-Wesley. 1995. Mattson, Timothy G.; S, Beverly A.; ers,; Massingill,
Parallel Programming Concepts Parallel Algorithms Peter Tröger Sources: Ian Foster. Designing and Building Parallel Programs. Addison-Wesley. 1995. Mattson, Timothy G.; S, Beverly A.; ers,; Massingill,
IN5050: Programming heterogeneous multi-core processors Thinking Parallel
 IN5050: Programming heterogeneous multi-core processors Thinking Parallel 28/8-2018 Designing and Building Parallel Programs Ian Foster s framework proposal develop intuition as to what constitutes a good
IN5050: Programming heterogeneous multi-core processors Thinking Parallel 28/8-2018 Designing and Building Parallel Programs Ian Foster s framework proposal develop intuition as to what constitutes a good
Parallel Programming Concepts. Parallel Algorithms. Peter Tröger. Sources:
 Parallel Programming Concepts Parallel Algorithms Peter Tröger Sources: Ian Foster. Designing and Building Parallel Programs. Addison-Wesley. 1995. Mattson, Timothy G.; S, Beverly A.; ers,; Massingill,
Parallel Programming Concepts Parallel Algorithms Peter Tröger Sources: Ian Foster. Designing and Building Parallel Programs. Addison-Wesley. 1995. Mattson, Timothy G.; S, Beverly A.; ers,; Massingill,
COMP/CS 605: Introduction to Parallel Computing Topic: Parallel Computing Overview/Introduction
 COMP/CS 605: Introduction to Parallel Computing Topic: Parallel Computing Overview/Introduction Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University
COMP/CS 605: Introduction to Parallel Computing Topic: Parallel Computing Overview/Introduction Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University
Parallel Computing. Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides)
, A Grama book (chapter 3 slides)") Parallel Computing 2012 Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides) Parallel Algorithm Design Outline Computational Model Design Methodology Partitioning Communication
Parallel Computing 2012 Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides) Parallel Algorithm Design Outline Computational Model Design Methodology Partitioning Communication
Parallel Algorithm Design. Parallel Algorithm Design p. 1
 Parallel Algorithm Design Parallel Algorithm Design p. 1 Overview Chapter 3 from Michael J. Quinn, Parallel Programming in C with MPI and OpenMP Another resource: http://www.mcs.anl.gov/ itf/dbpp/text/node14.html
Parallel Algorithm Design Parallel Algorithm Design p. 1 Overview Chapter 3 from Michael J. Quinn, Parallel Programming in C with MPI and OpenMP Another resource: http://www.mcs.anl.gov/ itf/dbpp/text/node14.html
An Introduction to Parallel Programming
 An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
CS4961 Parallel Programming. Lecture 5: Data and Task Parallelism, cont. 9/8/09. Administrative. Mary Hall September 8, 2009.
 CS4961 Parallel Programming Lecture 5: Data and Task Parallelism, cont. Administrative Homework 2 posted, due September 10 before class - Use the handin program on the CADE machines - Use the following
CS4961 Parallel Programming Lecture 5: Data and Task Parallelism, cont. Administrative Homework 2 posted, due September 10 before class - Use the handin program on the CADE machines - Use the following
High Performance Computing
 The Need for Parallelism High Performance Computing David McCaughan, HPC Analyst SHARCNET, University of Guelph dbm@sharcnet.ca Scientific investigation traditionally takes two forms theoretical empirical
The Need for Parallelism High Performance Computing David McCaughan, HPC Analyst SHARCNET, University of Guelph dbm@sharcnet.ca Scientific investigation traditionally takes two forms theoretical empirical
A Pattern-supported Parallelization Approach
 A Pattern-supported Parallelization Approach Ralf Jahr, Mike Gerdes, Theo Ungerer University of Augsburg, Germany The 2013 International Workshop on Programming Models and Applications for Multicores and
A Pattern-supported Parallelization Approach Ralf Jahr, Mike Gerdes, Theo Ungerer University of Augsburg, Germany The 2013 International Workshop on Programming Models and Applications for Multicores and
Introduction to Parallel Programming
 Introduction to Parallel Programming David Lifka lifka@cac.cornell.edu May 23, 2011 5/23/2011 www.cac.cornell.edu 1 y What is Parallel Programming? Using more than one processor or computer to complete
Introduction to Parallel Programming David Lifka lifka@cac.cornell.edu May 23, 2011 5/23/2011 www.cac.cornell.edu 1 y What is Parallel Programming? Using more than one processor or computer to complete
Scalable Algorithmic Techniques Decompositions & Mapping. Alexandre David
 Scalable Algorithmic Techniques Decompositions & Mapping Alexandre David 1.2.05 adavid@cs.aau.dk Introduction Focus on data parallelism, scale with size. Task parallelism limited. Notion of scalability
Scalable Algorithmic Techniques Decompositions & Mapping Alexandre David 1.2.05 adavid@cs.aau.dk Introduction Focus on data parallelism, scale with size. Task parallelism limited. Notion of scalability
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Parallel Programming Concepts. Summary. Dr. Peter Tröger M.Sc. Frank Feinbube
 1 Parallel Programming Concepts Summary Dr. Peter Tröger M.Sc. Frank Feinbube Course Topics 3 The Parallelization Problem Power wall, memory wall, Moore s law Terminology and metrics Shared Memory Parallelism
1 Parallel Programming Concepts Summary Dr. Peter Tröger M.Sc. Frank Feinbube Course Topics 3 The Parallelization Problem Power wall, memory wall, Moore s law Terminology and metrics Shared Memory Parallelism
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
High Performance Computing. Introduction to Parallel Computing
 High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Introduction to High Performance Computing
 Introduction to High Performance Computing Gregory G. Howes Department of Physics and Astronomy University of Iowa Iowa High Performance Computing Summer School University of Iowa Iowa City, Iowa 25-26
Introduction to High Performance Computing Gregory G. Howes Department of Physics and Astronomy University of Iowa Iowa High Performance Computing Summer School University of Iowa Iowa City, Iowa 25-26
Data parallel algorithms 1
 Data parallel algorithms (Guy Steele): The data-parallel programming style is an approach to organizing programs suitable for execution on massively parallel computers. In this lecture, we will characterize
Data parallel algorithms (Guy Steele): The data-parallel programming style is an approach to organizing programs suitable for execution on massively parallel computers. In this lecture, we will characterize
Designing Parallel Programs. This review was developed from Introduction to Parallel Computing
 Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
CS 475: Parallel Programming Introduction
 CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 14 Parallelism in Software I
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 14 Parallelism in Software I") EE382 (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 14 Parallelism in Software I Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality, Spring 2015
EE382 (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 14 Parallelism in Software I Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality, Spring 2015
Introduction to Parallel Programming
 Introduction to Parallel Programming Linda Woodard CAC 19 May 2010 Introduction to Parallel Computing on Ranger 5/18/2010 www.cac.cornell.edu 1 y What is Parallel Programming? Using more than one processor
Introduction to Parallel Programming Linda Woodard CAC 19 May 2010 Introduction to Parallel Computing on Ranger 5/18/2010 www.cac.cornell.edu 1 y What is Parallel Programming? Using more than one processor
Parallel Computing. Parallel Algorithm Design
 Parallel Computing Parallel Algorithm Design Task/Channel Model Parallel computation = set of tasks Task Program Local memory Collection of I/O ports Tasks interact by sending messages through channels
Parallel Computing Parallel Algorithm Design Task/Channel Model Parallel computation = set of tasks Task Program Local memory Collection of I/O ports Tasks interact by sending messages through channels
Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload)
") Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Analyzing a 3D Graphics Workload Where is most of the work done? Memory Vertex
Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Analyzing a 3D Graphics Workload Where is most of the work done? Memory Vertex
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES. Cliff Woolley, NVIDIA
 HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
Review: Creating a Parallel Program. Programming for Performance
 Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
Parallelization Principles. Sathish Vadhiyar
 Parallelization Principles Sathish Vadhiyar Parallel Programming and Challenges Recall the advantages and motivation of parallelism But parallel programs incur overheads not seen in sequential programs
Parallelization Principles Sathish Vadhiyar Parallel Programming and Challenges Recall the advantages and motivation of parallelism But parallel programs incur overheads not seen in sequential programs
Parallel Algorithm Design. CS595, Fall 2010
 Parallel Algorithm Design CS595, Fall 2010 1 Programming Models The programming model o determines the basic concepts of the parallel implementation and o abstracts from the hardware as well as from the
Parallel Algorithm Design CS595, Fall 2010 1 Programming Models The programming model o determines the basic concepts of the parallel implementation and o abstracts from the hardware as well as from the
Principles of Parallel Algorithm Design: Concurrency and Mapping
 Principles of Parallel Algorithm Design: Concurrency and Mapping John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 422/534 Lecture 3 17 January 2017 Last Thursday
Principles of Parallel Algorithm Design: Concurrency and Mapping John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 422/534 Lecture 3 17 January 2017 Last Thursday
Thinking parallel. Decomposition. Thinking parallel. COMP528 Ways of exploiting parallelism, or thinking parallel
 COMP528 Ways of exploiting parallelism, or thinking parallel www.csc.liv.ac.uk/~alexei/comp528 Alexei Lisitsa Dept of computer science University of Liverpool a.lisitsa@.liverpool.ac.uk Thinking parallel
COMP528 Ways of exploiting parallelism, or thinking parallel www.csc.liv.ac.uk/~alexei/comp528 Alexei Lisitsa Dept of computer science University of Liverpool a.lisitsa@.liverpool.ac.uk Thinking parallel
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448. The Greed for Speed
 Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
COSC 462. Parallel Algorithms. The Design Basics. Piotr Luszczek
 COSC 462 Parallel Algorithms The Design Basics Piotr Luszczek September 18, 2017 1/16 Levels of Abstraction 2/16 Concepts Tools Algorithms: partitioning, communication, agglomeration, mapping Domain, channel,
COSC 462 Parallel Algorithms The Design Basics Piotr Luszczek September 18, 2017 1/16 Levels of Abstraction 2/16 Concepts Tools Algorithms: partitioning, communication, agglomeration, mapping Domain, channel,
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 11 Parallelism in Software II
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 11 Parallelism in Software II") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 11 Parallelism in Software II Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality, Fall 2011 --
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 11 Parallelism in Software II Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality, Fall 2011 --
A Study of High Performance Computing and the Cray SV1 Supercomputer. Michael Sullivan TJHSST Class of 2004
 A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
--Introduction to Culler et al. s Chapter 2, beginning 192 pages on software
 CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Parallel Programming (Chapters 2, 3, & 4) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived from
CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Parallel Programming (Chapters 2, 3, & 4) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived from
Parallel Computing Introduction
 Parallel Computing Introduction Bedřich Beneš, Ph.D. Associate Professor Department of Computer Graphics Purdue University von Neumann computer architecture CPU Hard disk Network Bus Memory GPU I/O devices
Parallel Computing Introduction Bedřich Beneš, Ph.D. Associate Professor Department of Computer Graphics Purdue University von Neumann computer architecture CPU Hard disk Network Bus Memory GPU I/O devices
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
18-447: Computer Architecture Lecture 30B: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013
 18-447: Computer Architecture Lecture 30B: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013 Readings: Multiprocessing Required Amdahl, Validity of the single processor
18-447: Computer Architecture Lecture 30B: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013 Readings: Multiprocessing Required Amdahl, Validity of the single processor
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Scalable GPU Graph Traversal!
 Scalable GPU Graph Traversal Duane Merrill, Michael Garland, and Andrew Grimshaw PPoPP '12 Proceedings of the 17th ACM SIGPLAN symposium on Principles and Practice of Parallel Programming Benwen Zhang
Scalable GPU Graph Traversal Duane Merrill, Michael Garland, and Andrew Grimshaw PPoPP '12 Proceedings of the 17th ACM SIGPLAN symposium on Principles and Practice of Parallel Programming Benwen Zhang
Principle Of Parallel Algorithm Design (cont.) Alexandre David B2-206
 Alexandre David B2-206") Principle Of Parallel Algorithm Design (cont.) Alexandre David B2-206 1 Today Characteristics of Tasks and Interactions (3.3). Mapping Techniques for Load Balancing (3.4). Methods for Containing Interaction
Principle Of Parallel Algorithm Design (cont.) Alexandre David B2-206 1 Today Characteristics of Tasks and Interactions (3.3). Mapping Techniques for Load Balancing (3.4). Methods for Containing Interaction
Design of Parallel Algorithms. Models of Parallel Computation
 + Design of Parallel Algorithms Models of Parallel Computation + Chapter Overview: Algorithms and Concurrency n Introduction to Parallel Algorithms n Tasks and Decomposition n Processes and Mapping n Processes
+ Design of Parallel Algorithms Models of Parallel Computation + Chapter Overview: Algorithms and Concurrency n Introduction to Parallel Algorithms n Tasks and Decomposition n Processes and Mapping n Processes
Concurrency for data-intensive applications
 Concurrency for data-intensive applications Dennis Kafura CS5204 Operating Systems 1 Jeff Dean Sanjay Ghemawat Dennis Kafura CS5204 Operating Systems 2 Motivation Application characteristics Large/massive
Concurrency for data-intensive applications Dennis Kafura CS5204 Operating Systems 1 Jeff Dean Sanjay Ghemawat Dennis Kafura CS5204 Operating Systems 2 Motivation Application characteristics Large/massive
Programming as Successive Refinement. Partitioning for Performance
 Programming as Successive Refinement Not all issues dealt with up front Partitioning often independent of architecture, and done first View machine as a collection of communicating processors balancing
Programming as Successive Refinement Not all issues dealt with up front Partitioning often independent of architecture, and done first View machine as a collection of communicating processors balancing
EE382N (20): Computer Architecture - Parallelism and Locality Lecture 10 Parallelism in Software I
: Computer Architecture - Parallelism and Locality Lecture 10 Parallelism in Software I") EE382 (20): Computer Architecture - Parallelism and Locality Lecture 10 Parallelism in Software I Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality (c) Rodric Rabbah, Mattan
EE382 (20): Computer Architecture - Parallelism and Locality Lecture 10 Parallelism in Software I Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality (c) Rodric Rabbah, Mattan
Lecture 4: Principles of Parallel Algorithm Design (part 4)
") Lecture 4: Principles of Parallel Algorithm Design (part 4) 1 Mapping Technique for Load Balancing Minimize execution time Reduce overheads of execution Sources of overheads: Inter-process interaction
Lecture 4: Principles of Parallel Algorithm Design (part 4) 1 Mapping Technique for Load Balancing Minimize execution time Reduce overheads of execution Sources of overheads: Inter-process interaction
Chapter 17: Parallel Databases
 Chapter 17: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of Parallel Systems Database Systems
Chapter 17: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of Parallel Systems Database Systems
Principles of Parallel Algorithm Design: Concurrency and Decomposition
 Principles of Parallel Algorithm Design: Concurrency and Decomposition John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 422/534 Lecture 2 12 January 2017 Parallel
Principles of Parallel Algorithm Design: Concurrency and Decomposition John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 422/534 Lecture 2 12 January 2017 Parallel
ECE 669 Parallel Computer Architecture
 ECE 669 Parallel Computer Architecture Lecture 23 Parallel Compilation Parallel Compilation Two approaches to compilation Parallelize a program manually Sequential code converted to parallel code Develop
ECE 669 Parallel Computer Architecture Lecture 23 Parallel Compilation Parallel Compilation Two approaches to compilation Parallelize a program manually Sequential code converted to parallel code Develop
Parallelization Strategy
 COSC 6374 Parallel Computation Algorithm structure Spring 2008 Parallelization Strategy Finding Concurrency Structure the problem to expose exploitable concurrency Algorithm Structure Supporting Structure
COSC 6374 Parallel Computation Algorithm structure Spring 2008 Parallelization Strategy Finding Concurrency Structure the problem to expose exploitable concurrency Algorithm Structure Supporting Structure
Introduction to Parallel Programming
 Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
Design of Parallel Algorithms. Course Introduction
 + Design of Parallel Algorithms Course Introduction + CSE 4163/6163 Parallel Algorithm Analysis & Design! Course Web Site: http://www.cse.msstate.edu/~luke/courses/fl17/cse4163! Instructor: Ed Luke! Office:
+ Design of Parallel Algorithms Course Introduction + CSE 4163/6163 Parallel Algorithm Analysis & Design! Course Web Site: http://www.cse.msstate.edu/~luke/courses/fl17/cse4163! Instructor: Ed Luke! Office:
Computer Architecture Lecture 27: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015
 18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
CSC630/COS781: Parallel & Distributed Computing
 CSC630/COS781: Parallel & Distributed Computing Algorithm Design Chapter 3 (3.1-3.3) 1 Contents Preliminaries of parallel algorithm design Decomposition Task dependency Task dependency graph Granularity
CSC630/COS781: Parallel & Distributed Computing Algorithm Design Chapter 3 (3.1-3.3) 1 Contents Preliminaries of parallel algorithm design Decomposition Task dependency Task dependency graph Granularity
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Principles of Parallel Algorithm Design: Concurrency and Mapping
 Principles of Parallel Algorithm Design: Concurrency and Mapping John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 422/534 Lecture 3 28 August 2018 Last Thursday Introduction
Principles of Parallel Algorithm Design: Concurrency and Mapping John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 422/534 Lecture 3 28 August 2018 Last Thursday Introduction
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
CS4961 Parallel Programming. Lecture 2: Introduction to Parallel Algorithms 8/31/10. Mary Hall August 26, Homework 1, cont.
 Parallel Programming Lecture 2: Introduction to Parallel Algorithms Mary Hall August 26, 2010 1 Homework 1 Due 10:00 PM, Wed., Sept. 1 To submit your homework: - Submit a PDF file - Use the handin program
Parallel Programming Lecture 2: Introduction to Parallel Algorithms Mary Hall August 26, 2010 1 Homework 1 Due 10:00 PM, Wed., Sept. 1 To submit your homework: - Submit a PDF file - Use the handin program
EE382N (20): Computer Architecture - Parallelism and Locality Lecture 13 Parallelism in Software IV
: Computer Architecture - Parallelism and Locality Lecture 13 Parallelism in Software IV") EE382 (20): Computer Architecture - Parallelism and Locality Lecture 13 Parallelism in Software IV Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality (c) Rodric Rabbah, Mattan
EE382 (20): Computer Architecture - Parallelism and Locality Lecture 13 Parallelism in Software IV Mattan Erez The University of Texas at Austin EE382: Parallelilsm and Locality (c) Rodric Rabbah, Mattan
Introduction to High-Performance Computing
 Introduction to High-Performance Computing Simon D. Levy BIOL 274 17 November 2010 Chapter 12 12.1: Concurrent Processing High-Performance Computing A fancy term for computers significantly faster than
Introduction to High-Performance Computing Simon D. Levy BIOL 274 17 November 2010 Chapter 12 12.1: Concurrent Processing High-Performance Computing A fancy term for computers significantly faster than
Outline. Database Tuning. Ideal Transaction. Concurrency Tuning Goals. Concurrency Tuning. Nikolaus Augsten. Lock Tuning. Unit 8 WS 2013/2014
 Outline Database Tuning Nikolaus Augsten University of Salzburg Department of Computer Science Database Group 1 Unit 8 WS 2013/2014 Adapted from Database Tuning by Dennis Shasha and Philippe Bonnet. Nikolaus
Outline Database Tuning Nikolaus Augsten University of Salzburg Department of Computer Science Database Group 1 Unit 8 WS 2013/2014 Adapted from Database Tuning by Dennis Shasha and Philippe Bonnet. Nikolaus
Parallel FFT Program Optimizations on Heterogeneous Computers
 Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Database Management and Tuning
 Database Management and Tuning Concurrency Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 8 May 10, 2012 Acknowledgements: The slides are provided by Nikolaus
Database Management and Tuning Concurrency Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 8 May 10, 2012 Acknowledgements: The slides are provided by Nikolaus
CS4961 Parallel Programming. Lecture 4: Data and Task Parallelism 9/3/09. Administrative. Mary Hall September 3, Going over Homework 1
 CS4961 Parallel Programming Lecture 4: Data and Task Parallelism Administrative Homework 2 posted, due September 10 before class - Use the handin program on the CADE machines - Use the following command:
CS4961 Parallel Programming Lecture 4: Data and Task Parallelism Administrative Homework 2 posted, due September 10 before class - Use the handin program on the CADE machines - Use the following command:
Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload)
") Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Today Finishing up from last time Brief discussion of graphics workload metrics
Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Today Finishing up from last time Brief discussion of graphics workload metrics
Lecture Topics. Announcements. Today: Advanced Scheduling (Stallings, chapter ) Next: Deadlock (Stallings, chapter
 Next: Deadlock (Stallings, chapter") Lecture Topics Today: Advanced Scheduling (Stallings, chapter 10.1-10.4) Next: Deadlock (Stallings, chapter 6.1-6.6) 1 Announcements Exam #2 returned today Self-Study Exercise #10 Project #8 (due 11/16)
Lecture Topics Today: Advanced Scheduling (Stallings, chapter 10.1-10.4) Next: Deadlock (Stallings, chapter 6.1-6.6) 1 Announcements Exam #2 returned today Self-Study Exercise #10 Project #8 (due 11/16)
Optimization solutions for the segmented sum algorithmic function
 Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
! Parallel machines are becoming quite common and affordable. ! Databases are growing increasingly large
 Chapter 20: Parallel Databases Introduction! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems!
Chapter 20: Parallel Databases Introduction! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems!
Chapter 20: Parallel Databases
 Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 20: Parallel Databases. Introduction
 Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Lect. 2: Types of Parallelism
 Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Introduction to Parallel Computing
 Introduction to Parallel Computing Bootcamp for SahasraT 7th September 2018 Aditya Krishna Swamy adityaks@iisc.ac.in SERC, IISc Acknowledgments Akhila, SERC S. Ethier, PPPL P. Messina, ECP LLNL HPC tutorials
Introduction to Parallel Computing Bootcamp for SahasraT 7th September 2018 Aditya Krishna Swamy adityaks@iisc.ac.in SERC, IISc Acknowledgments Akhila, SERC S. Ethier, PPPL P. Messina, ECP LLNL HPC tutorials
Huge market -- essentially all high performance databases work this way
 11/5/2017 Lecture 16 -- Parallel & Distributed Databases Parallel/distributed databases: goal provide exactly the same API (SQL) and abstractions (relational tables), but partition data across a bunch
11/5/2017 Lecture 16 -- Parallel & Distributed Databases Parallel/distributed databases: goal provide exactly the same API (SQL) and abstractions (relational tables), but partition data across a bunch
16/10/2008. Today s menu. PRAM Algorithms. What do you program? What do you expect from a model? Basic ideas for the machine model
 Today s menu 1. What do you program? Parallel complexity and algorithms PRAM Algorithms 2. The PRAM Model Definition Metrics and notations Brent s principle A few simple algorithms & concepts» Parallel
Today s menu 1. What do you program? Parallel complexity and algorithms PRAM Algorithms 2. The PRAM Model Definition Metrics and notations Brent s principle A few simple algorithms & concepts» Parallel
ELE 455/555 Computer System Engineering. Section 4 Parallel Processing Class 1 Challenges
 ELE 455/555 Computer System Engineering Section 4 Class 1 Challenges Introduction Motivation Desire to provide more performance (processing) Scaling a single processor is limited Clock speeds Power concerns
ELE 455/555 Computer System Engineering Section 4 Class 1 Challenges Introduction Motivation Desire to provide more performance (processing) Scaling a single processor is limited Clock speeds Power concerns
Introduction to GPU programming with CUDA
 Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
HPX. High Performance ParalleX CCT Tech Talk Series. Hartmut Kaiser
 HPX High Performance CCT Tech Talk Hartmut Kaiser (hkaiser@cct.lsu.edu) 2 What s HPX? Exemplar runtime system implementation Targeting conventional architectures (Linux based SMPs and clusters) Currently,
HPX High Performance CCT Tech Talk Hartmut Kaiser (hkaiser@cct.lsu.edu) 2 What s HPX? Exemplar runtime system implementation Targeting conventional architectures (Linux based SMPs and clusters) Currently,
Analytical Modeling of Parallel Programs
 2014 IJEDR Volume 2, Issue 1 ISSN: 2321-9939 Analytical Modeling of Parallel Programs Hardik K. Molia Master of Computer Engineering, Department of Computer Engineering Atmiya Institute of Technology &
2014 IJEDR Volume 2, Issue 1 ISSN: 2321-9939 Analytical Modeling of Parallel Programs Hardik K. Molia Master of Computer Engineering, Department of Computer Engineering Atmiya Institute of Technology &
PowerVR Hardware. Architecture Overview for Developers
 Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
MPI Casestudy: Parallel Image Processing
 MPI Casestudy: Parallel Image Processing David Henty 1 Introduction The aim of this exercise is to write a complete MPI parallel program that does a very basic form of image processing. We will start by
MPI Casestudy: Parallel Image Processing David Henty 1 Introduction The aim of this exercise is to write a complete MPI parallel program that does a very basic form of image processing. We will start by
COMP 308 Parallel Efficient Algorithms. Course Description and Objectives: Teaching method. Recommended Course Textbooks. What is Parallel Computing?
 COMP 308 Parallel Efficient Algorithms Course Description and Objectives: Lecturer: Dr. Igor Potapov Chadwick Building, room 2.09 E-mail: igor@csc.liv.ac.uk COMP 308 web-page: http://www.csc.liv.ac.uk/~igor/comp308
COMP 308 Parallel Efficient Algorithms Course Description and Objectives: Lecturer: Dr. Igor Potapov Chadwick Building, room 2.09 E-mail: igor@csc.liv.ac.uk COMP 308 web-page: http://www.csc.liv.ac.uk/~igor/comp308
Introduction to Parallel Programming Models
 Introduction to Parallel Programming Models Tim Foley Stanford University Beyond Programmable Shading 1 Overview Introduce three kinds of parallelism Used in visual computing Targeting throughput architectures
Introduction to Parallel Programming Models Tim Foley Stanford University Beyond Programmable Shading 1 Overview Introduce three kinds of parallelism Used in visual computing Targeting throughput architectures
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Chapter 18: Parallel Databases
 Chapter 18: Parallel Databases Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery
Chapter 18: Parallel Databases Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery
Chapter 18: Parallel Databases. Chapter 18: Parallel Databases. Parallelism in Databases. Introduction
 Chapter 18: Parallel Databases Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of
Chapter 18: Parallel Databases Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of
Design of Parallel Programs Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Design of Parallel Programs Algoritmi e Calcolo Parallelo Web: home.dei.polimi.it/loiacono Email: loiacono@elet.polimi.it References q The material in this set of slide is taken from two tutorials by Blaise
Design of Parallel Programs Algoritmi e Calcolo Parallelo Web: home.dei.polimi.it/loiacono Email: loiacono@elet.polimi.it References q The material in this set of slide is taken from two tutorials by Blaise
High Performance Computing in C and C++
 High Performance Computing in C and C++ Rita Borgo Computer Science Department, Swansea University Announcement No change in lecture schedule: Timetable remains the same: Monday 1 to 2 Glyndwr C Friday
High Performance Computing in C and C++ Rita Borgo Computer Science Department, Swansea University Announcement No change in lecture schedule: Timetable remains the same: Monday 1 to 2 Glyndwr C Friday
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Parallel FEM Computation and Multilevel Graph Partitioning Xing Cai
 Parallel FEM Computation and Multilevel Graph Partitioning Xing Cai Simula Research Laboratory Overview Parallel FEM computation how? Graph partitioning why? The multilevel approach to GP A numerical example
Parallel FEM Computation and Multilevel Graph Partitioning Xing Cai Simula Research Laboratory Overview Parallel FEM computation how? Graph partitioning why? The multilevel approach to GP A numerical example
Contents. Preface xvii Acknowledgments. CHAPTER 1 Introduction to Parallel Computing 1. CHAPTER 2 Parallel Programming Platforms 11
 Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Homework # 2 Due: October 6. Programming Multiprocessors: Parallelism, Communication, and Synchronization
 ECE669: Parallel Computer Architecture Fall 2 Handout #2 Homework # 2 Due: October 6 Programming Multiprocessors: Parallelism, Communication, and Synchronization 1 Introduction When developing multiprocessor
ECE669: Parallel Computer Architecture Fall 2 Handout #2 Homework # 2 Due: October 6 Programming Multiprocessors: Parallelism, Communication, and Synchronization 1 Introduction When developing multiprocessor
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Patterns for! Parallel Programming!
 Lecture 4! Patterns for! Parallel Programming! John Cavazos! Dept of Computer & Information Sciences! University of Delaware!! www.cis.udel.edu/~cavazos/cisc879! Lecture Overview Writing a Parallel Program
Lecture 4! Patterns for! Parallel Programming! John Cavazos! Dept of Computer & Information Sciences! University of Delaware!! www.cis.udel.edu/~cavazos/cisc879! Lecture Overview Writing a Parallel Program
Computer Architecture
 Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
HPC Algorithms and Applications
 HPC Algorithms and Applications Dwarf #5 Structured Grids Michael Bader Winter 2012/2013 Dwarf #5 Structured Grids, Winter 2012/2013 1 Dwarf #5 Structured Grids 1. dense linear algebra 2. sparse linear
HPC Algorithms and Applications Dwarf #5 Structured Grids Michael Bader Winter 2012/2013 Dwarf #5 Structured Grids, Winter 2012/2013 1 Dwarf #5 Structured Grids 1. dense linear algebra 2. sparse linear