Path-based Keyword Search over XML Streams
|
|
|
- Ashlee Taylor
- 5 years ago
- Views:
Transcription
1 DEIM Forum 2014 A1-5 Abstract Path-based Keyword Search over XML Streams Savong BOU, Toshiyuki AMAGASA, and Hiroyuki KITAGAWA Graduate School of Systems and Information Engineering, University of Tsukuba Tennodai, Tsukuba, Ibaraki , Japan Faculty of Engineering, Information and Systems, University of Tsukuba Tennodai, Tsukuba, Ibaraki , Japan Recently, a great deal of attention has been focusing on processing keyword search over XML and XML streams. The keyword search is simple and provides a user-friendly way of retrieving required data from an XML data. Though its popularity, there is a concern over its efficiency. For this reason, several methods have been proposed to enable keyword search over XML streams. However, most of them primarily aim at processing pure keyword search where only keywords are allowed as a query. However, in many cases, there is a demand to combine keyword search and path-based query. To address this problem, we propose a method to integrate XPath and keyword search so that we can combine XPath- and keyword-based query, thereby making users possible to express their search demands in more specific ways. The experimental results show that the proposed scheme can process queries over XML streams practically. Key words XML Streams, Keyword Search, XPath, XQuery 1. Introduction Extensible Markup Language (XML) [1] is a standard for representing semi-structured data. XML has been used in various applications, because it is powerful and versatile while it is simple. In many applications, information represented using XML is exchanged in real-time. This kind of information is called XML streams [9]. Several applications of XML streams have emerged recently, such as web services, sensor networks, etc. In such applications, it is often required to filter necessary data out of incoming XML streams, and, typically, such requests are represented in terms of XPath expressions [9]. In the meantime, a large number of web services, such as blogs, news sites, and podcast hosts, are currently disseminating their contents in the form of streaming XML data. The variability and heterogeneity of those sources make the usage of traditional querying schemes, which are based on path-based query language [9], cumbersome for end users, because those languages require precise knowledge about the underlying schemas of XML data being queried in order to formulate meaningful queries. On the other hand, keyword search [4, 6 8, 10, 12 14], where only few keywords are used to query XML data, provides a simple and effective query paradigm. For example, if one wishes to retrieve partial XML data related to XML query processing, he only needs to put three keywords, XML, query and processing rather than a complicated XPath-based query. For this reason, keyword search over XML data has been studied well, and many XML database systems support such functionality. However, those engines support keyword search over XML data, which are permanently stored and can be indexed for efficient retrieval, and few research works address keyword search over XML data in streaming environments [6, 8, 13]. In [8, 13], they proposed a scheme to process multiple keyword-based queries over XML streams. It offers a good compromise between performance and memory usage, which makes it the best choice in real world scenarios. Besides, [6] proposed a technique based on refining a keyword query to a query graph being a sub-graph of corresponding DTD document so that their stack-based algorithm can process XML stream and manage the buffer of search results in a single pass efficiently using their new search heuristic. It is worth to mention that, in many application scenarios, there is a strong need to make keyword search against some specific parts of XML data whose structures constantly change and are unknown or little known. Taking a bibliographic XML data for example, one may make a query only on abstract, but not to elsewhere. However, since keywords in keyword search can appear either as label(xml element) or textual value, and can carry multiple and different meanings, it is hard to express the exact search intention only with keywords. In particular, it is hard to specify which parts of XML data the keyword search should be applied to.


2 The above problem can be solved by combining XPathbased query with keyword search. The XPath-based query will be used as a mean to specify which part of XML data the keyword search should be applied to, and the keywords are used to specify the user s demand for the query results. It should be noticed that the combination of XPath- and keyword-based queries is beneficial to the users, because they can exploit the benefits from both query styles, that is, one does not need to fully understand the structure of the documents being queried, while having the freedom to limit the parts of the documents to be retrieved in terms of an XPath expression. However, to the best of authors knowledge, no research has been made on this type of query in a streaming setting so far. To address this problem, we propose a scheme to process XPath queries combined with keyword search over XML streams. More precisely, we extend NFA model to support XPath-based keyword search. We also extend NFA-based YFilter [5] with the method used in CKStream [8]. source, which is shown in Figure 1. From this data source, if a user wants to retrieve information on any publication which is written by author "Porter" and has type "Novel", he may issue a keyword search, q 1, with two keywords as "author::porter type:novel". Similarly, the user may issue a query, q 2, "author::porter War" if he wants to know any publication which is about "War" and written by author "Porter". Note that, in this data source, we observe that the word "book" appears as both XML element and textual value. Therefore, if the user issues keyword search, q 3, "book author::hiroki", the keyword book matches both XML element "book" whose ID is 2 and textual value of XML element "title" whose ID is 8 because this keyword is in the form of k as mentioned above. 2. Preliminaries First, we would like to explain some preliminaries related to our work. XPath XML Path Language (XPath) [9] is an expression language that allows us to locate specific XML fragments in a given piece of XML data. More precisely, an XPath expression, P, is defined as the following grammar [9]: P ::= /N //N PP N ::= E A text(s) * Here, E, A, and S are an element label, an attribute label, and a string constant, respectively, and * is the wild card. The function text(s) matches a text node whose value is the string S. XML Keyword Search is a style of XML data search, where a set of keywords are given as the input, and the set of ranked XML fragments that match with the query specification is returned as the query result. In [4, 8, 13], the syntax of keyword search is defined as follows. Definition 1 An XML keyword search Q is a set of search terms (t 1,..,t m). Each query term is of the form: l::k, l::, ::k, or k, where l is a node label and k a keyword. A node n i satises a query term of the form: l::k if n i s label equals l and the tokenized textual content of n i contains the word k. l:: if n i s label equals label l. ::k if the textual content of n i contains the word k. k if either n i s label is k or the tokenized textual content of n i contains the word k. To better illustrate the concept of keyword search, we present an example with a fragment of bibliography data Fig. 1: An example of XML data Combining XPath with keyword search: it is natural to extend XPath so that it can deal with keywordbased queries. More precisely, keyword search can be used to specify a query predicate in an XPath expression. In fact, XQuery and XPath Full Text 1.0 [2] is a W3C standard for that purpose. Since our objective is to combine keyword search with XPath-based queries, we partially borrow the syntax from it. Here is the basic syntax. /XPath[ftcontains(keyword-search query)] where XPath is an XPath expression and ftcontains is a dedicated function to specify a keyword search query according to [4,8,13]. Note that the XPath and keyword-search query are connected by a descendant axis. Node Relatedness Heuristics in XML keyword search, for a set of given keywords, it is essential to decide which XML fragments are most eligible to be query results. For this reason, many heuristics have been proposed [4,10,12,14]. Among these, LCA (Lowest Common Ancestor) is known to be the fundamental method, where the lowest XML fragments that subsume the entire keyword set and the fragments are identified. Subsequently, to improve LCA, many variants have been proposed. Definition 2 SLCA (Smallest Lowest Common Ancestor) [14]: two nodes n 1 and n 2 that belong to the same XML data d i are meaningfully related if there are no nodes n 3 d i and n 4 d i such that LCA(n 3, n 4 ) descendant of LCA(n 1, n 2 ).
3 Node v d i, such that v LCA(n 1, n 2), v SLCA(n 1, n 2). However, there are some criticisms against SLCA heuristic, for its answer is too compact, and the smallest subtree is not always the correct answer of keyword search. As a result, some accurate answers are discarded. For example, we have a keyword search "author::porter title::", which is to search for the title of any publication written by author "Porter". Based on SLCA heuristic, the subtree rooted at node chapter ID 6 is returned. However, the subtree rooted at node book ID 2 is not returned as answer eventhough it is also the correct result of this query. To complement such loopholes, MLCA heuristic [11] has been proposed. MLCA heuristic takes the relationship between pairs of all keywords in the query into consideration; consequently, each result under MLCA heuristic is a pattern match, in which every two nodes are meaningfully related. Therefore, with MLCA heuristic, the answers of the above query are sets of all matched nodes in subtrees rooted at node chapter ID 6 and book ID 2. MLCA is defined as follow: Definition 3 MLCA (Meaningful Lowest Common Ancestor) [11]: Let the set of nodes in an XML data be N. Two nodes are of the same type if and only if they have the same tag name. Given A, B N, where A is comprised of nodes of type α, and B is comprised of nodes of type β, the MLCA set C N of A and B satisfies the following conditions: c k C, a i A, b j B, such that c k = LCA(a i, b j). c k is denoted as MLCA(a i, b j). a i A, b j B, if d ij = LCA(a i, b j) and d ij / C, then c k C, c k is descendant of d ij. Then set C is denoted as MLCASET (A, B). Figure 2 shows the NFA fragments of basic location steps. There is a transition from one state to another state via a directed edge representing a transition. The symbol on an edge represents the incoming XML element that triggers the transition. The special symbol "*" matches any element. The symbol " " is used to denote an epsilon-transition. Fig. 3: XPath queries and a corresponding NFA Figure 3 shows an example of such a Non-deterministic Finite Automation (NFA) corresponding to five XPath queries. A circle denotes a state. Circles with double lines denote accepting states, marked by the IDs of accepted queries. When processing an XML data, it is parsed with a SAX parser, which is an event-based XML parser; whenever it reads a new XML constructs, such as start- and end-tags, text content, etc., it raises a corresponding event and is notified to the application program. When YFilter receives a start element events, it triggers a state transitions in the FSMs, while an end element event is received, YFilter must backtrack to previous states. A run-time stack is used to track the active and previously processed states. 3. Existing Approaches 3. 1 YFilter YFilter [5] is an XML filtering system that provides realtime, fast matching of large numbers of queries, containing constraints on both structure and content, against both static XML data and XML streams. The key innovation in YFilter is that it generates a single Nondeterministic Finite Automation (NFA) from all the input-queries. YFilter also provides better structure matching and additional benefits including a relatively small number of machine states, incremental machine construction, and ease of maintenance. Fig. 2: Basic NFA Location Step Fig. 4: An example of query processing in YFilter Figure 4 shows a running example of the run-time stack, which process queries in Figure 3 by XML data in Figure 1. The content of stack is a set of active state ID. When receiving a start element event, it follows all matching transitions from the currently active states. First, if a transition marked by the incoming element name exists, the next state is added to the set of new active states. A transition marked by the "*" symbol is checked in the same way. Then, the state itself is added to the set. Finally, if an " "-transition exists, the state after the " "-transition is processed immediately according to these same rules CKStream CKStream [8] is an algorithm to process multiple keyword
4 search over XML streams. It relies on parsing stacks and query indexes specially designed to allow the simultaneous matching of terms from different queries. CKStream also relies on a SAX parser. Parsing Stack: when parsing an XML stream, each visited XML node, e.g., element or text, is associated with an entry in a stack, and that entry handles the following information: (1) the label of the element of the entry; (2) a bitmap called CAN BE SLCA, which contains one bit for each query being evaluated, (3) a set used queries containing the IDs of the queries whose terms include keywords and (4) keywords. Each entry is popped from the stack when its corresponding node and all its descendants have been visited. Query Index: To efficiently deal with a large number of queries, the algorithms exploits query indexes for efficient query look up. Each index entry represents a query term and refers to queries in which this term occurs. It also differentiates between structural (label) and non-structural (value) query terms. A sample query index created from queries q 1, q 2, and q 3 above is shown in Figure 5. Fig. 5: Example of Query Index Query Bitmap: Stores information about which keywords from each query have occurred in an XML node, which is kept using a bitmap stored on the stack entry corresponding to such a node. This bitmap is called query bitmap and each of its bits is associated with one unique search term from each query. The information stored in query bitmap is similar to that of query index, but they are used differently. A sample of query bitmap from queries q 1, q 2, and q 3 above is shown in Figure Proposed Scheme 4. 1 Proposal Overview We extend NFA-based YFilter [5] with keyword-based CK- Stream [8] in an attempt to make the filtering engine supports XPath query, keyword search query, and XPath-based keyword search. More precisely, we extend the NFA-based finite state machine in YFilter by adding the data structures in CKStream, such as a set of used queries and query bitmap, thereby combining the keyword-search capability of CKStream and the path-based filtering of YFilter. In addition, we use MLCA heuristic to generate query results, whereas SLCA is used in CKStream, because it gives more related and compact results than other heuristics [12]. MLCA returns a set of nodes that match queries Extension of NFA Model in YFilter In YFilter, a state transition occurs only when an XML element is read, but, to support keyword search, a state transition is also needed for text content. For this reason, we modify the NFA model as follows. The edges with the labels of the form "text() con" represent state transitions corresponding to text nodes, that are enabled when text node contains the specified keywords. In addition, each accepting state in the extended NFA contains the position of bit inside the query bitmap. Queries are matched by checking if all bits corresponding to their respective queries are matched. The basic extended-nfa location steps are shown in Figure 7. Fig. 6: An Example of Query Bitmap When a startelement(tag) comes, it searches the query index for the current node s label, obtaining the positions associated with the entry corresponding to this label. It sets to true the bit position associated with this occurrence in the query bitmap of the new stack entry. Similarly, when character() comes, it searches the query index and sets true to the corresponding bits. Notice that terms of the form l::k are handled in this function and receive a specic treatment. Finally, when an endelement(tag) comes, it looks for complete queries, i.e., those in which all search terms are satised by the node being processed (or by its decedents). Fig. 7: Basic Extended-NFA Location Step 4. 3 Combining YFilter and CKStream By using the extended NFA model, our proposed work constructs an extended-nfa corresponding to a set of XPathbased keyword search. Similar to YFilter and CKStream, the proposed scheme based on SAX parser. In addition, two data structures, query bitmap and used query, are borrowed from CKStream to process keyword queries; they are used whenever there is a push of an entry into the stack. When there is a trigger to pop an entry from stack, queries are evaluated to be matched or not by looking at bits in query bitmap corresponding to each used queries from set used query.
5 The details of our proposed algorithm are shown in Algorithm 1 below. There are 3 main functions: Callback Function Start of Element, Callback Function Text, Callback Function End of Element. Callback Function Start of Element: When the startelement(tag) is called, this function is invoked. All bits in the query bitmap are set to false by default. Then startelement(tag) is processed against the single extended- NFA. Then all the newly-active states are checked one by one. If any of those states are accepting states, the query IDs and the positions of bits in the query bitmap will be obtained. The query IDs are put in the set of used queries and the bits of the query bitmap are set to true at the obtained bit positions. If no accepting state exists, all bits in the query bitmap remain false and the set of used queries is blank. Finally, the set of active states, query bitmap, and set of used queries are inserted into an entry, which later pushes into the stack. Callback Function Text: When the character() event is called, textual content is split into tokens. Then each token is processed by the single extended-nfa. Following the same procedure as mentioned in Callback Function Start of Element, the information that is obtained from the accepting states are used to update the entry at the top of the stack (the entry of parent nodes in the stack). In Callback Function Text, no new query bitmap nor new set of used queries are created; and therefore, no new entry is pushed into the stack. Callback Function End of Element: When an endelement(tag) is called, the entry is popped out from the stack. Then all query IDs in the set of used queries in the popped entry are checked one by one. For each query ID being processed, all bits in the query bitmap of the corresponding query are checked. If they are all true, the corresponding query matches, and the results are returned. If not all bits of the corresponding query are true, then that corresponding query IDs is added to the set of used queries of the top entry of the stack and all bits in the query bitmap of the popped entry are used to update the query bitmap of the top entry by using "OR" operator. We show how our proposed method works by running the two queries below against the XML data shown in Figure 1. The detail run is shown in Figure 9. Q1: //book[ftcontains(author::porter type::novel)] Q2: /bib/book/chapter[ftcontains(author::porter War)] These queries contain three unique keywords, so the query bitmap will be of size 3 where t 1, t 2 and t 3 are the position of each keyword in the query bitmap. By using the extended-nfa model, from the two queries, a single NFA is constructed as shown in Figure 8. Algorithm 1 The Proposed Method Callback Functions Callback Function Start of Element Input: Parsing stack S, the XML node e being processed 1: initialization 2: Push(sn) {create new stack entry} 3: Process e against extended-nfa 4: Add the newly active states to the stack 5: N := number of distinct terms in all queries being processed 6: sn.query bitmap[0,,n-1] :=false 7: while each newly active state do 8: if sn.state is accepting state then 9: p := get position of query bitmap 10: q := get query ID of keyword matched 11: Add q to sn.used queries 12: sn.query bitmap[p] :=true 13: end if 14: end while Callback Function Text Input: Parsing stack S, the XML node e being processed 1: initialization 2: sn := *top(s) {sn points to the top entry in the stack} 3: K := set of tokens in node e 4: while all k K do 5: Process k against extended-nfa 6: Add the newly active states to the stack 7: while each newly active state do 8: if sn.state is accepting state then 9: p := get position of query bitmap of term l::k 10: q := get query ID of keyword matched 11: Add q to sn.used queries 12: sn.query bitmap[p] :=true 13: end if 14: end while 15: end while Callback Function End of Element Input: Parsing stack S, the XML node e being processed 1: initialization 2: sn := pop(s) {pops the top entry in the stack to sn} 3: tn := *top(s) tn points to the top entry in the stack 4: while q sn.used queries do 5: let j 1,, j N be the positions of the bits corresponding to terms from query q in query bitmap 6: COMPLETE := sn.query bitmap[j 1 ] and... and sn.query bitmap[j N] 7: if sn.state is accepting state then 8: q.results := q.results sn 9: else 10: Add sn.used queries to tn.used queries 11: tn.query bitmap := sn.query bitmap or tn.query bitmap 12: end if 13: end while
, the system follows the same rule as that in YFilter to get the next states and pushes into the stack.")


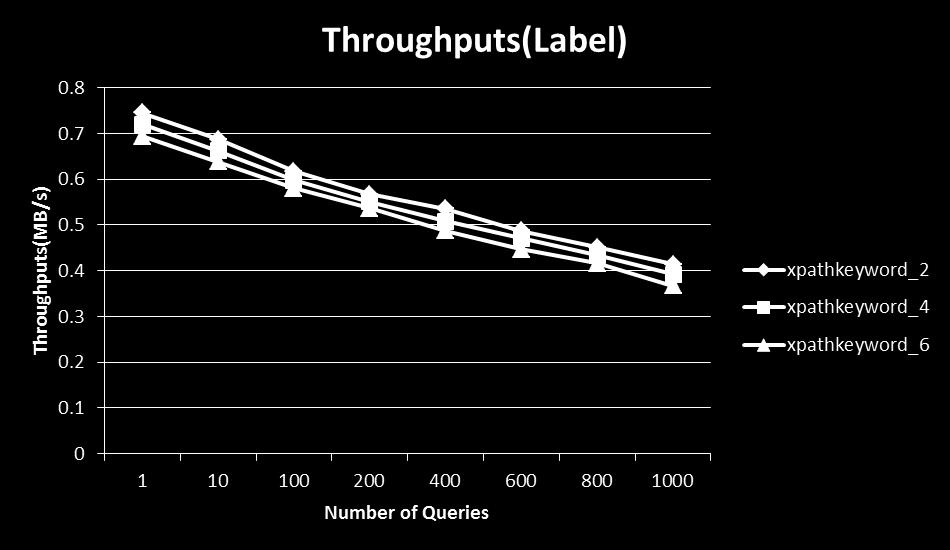
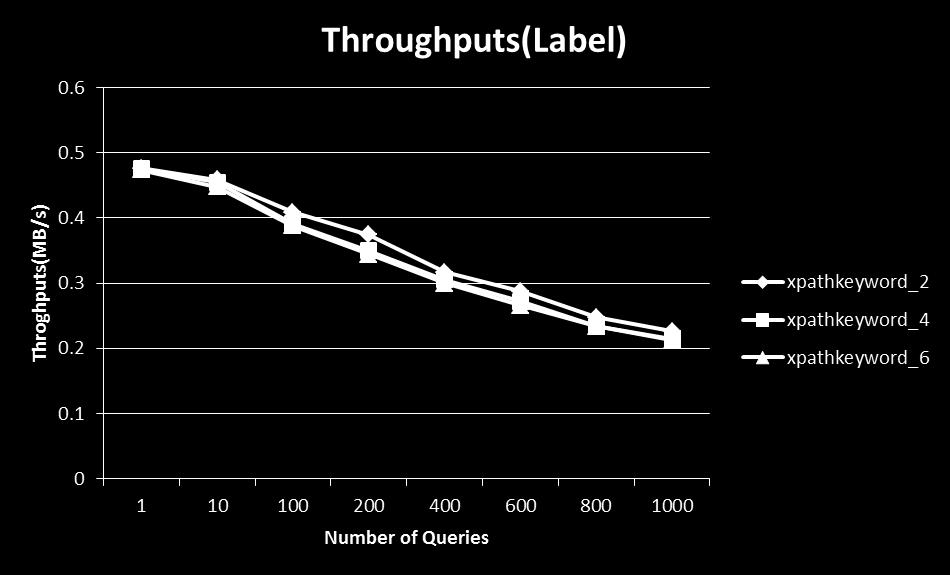
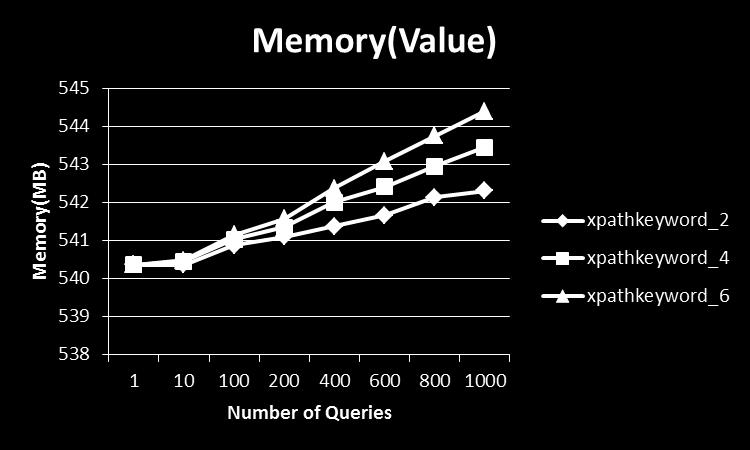
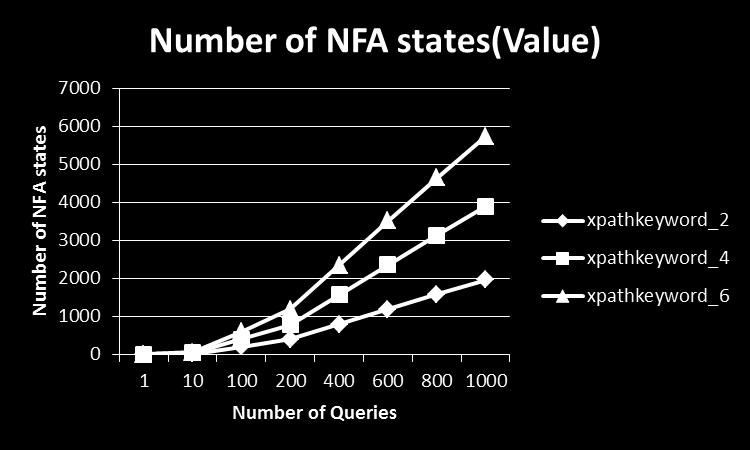
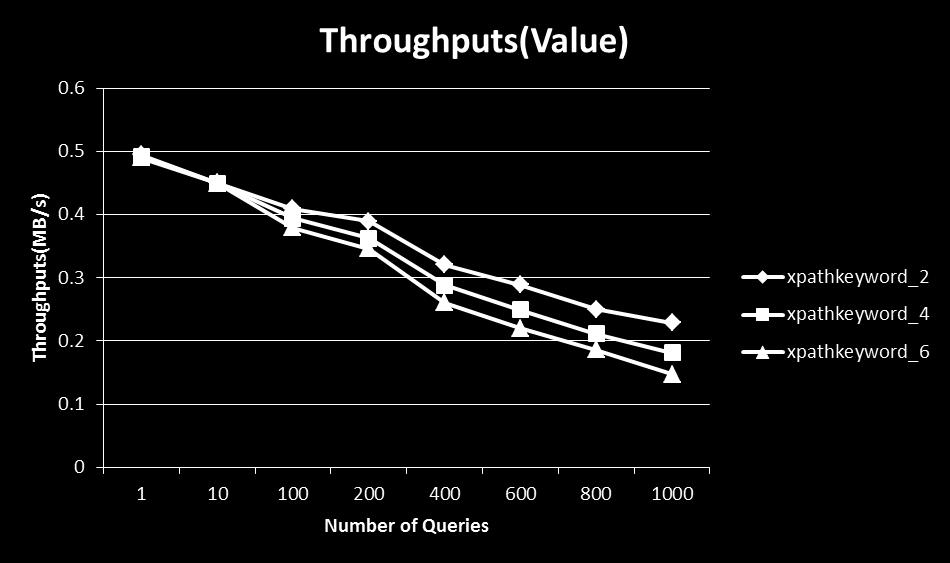
6 As shown in Figure 9, when new XML data, startdocument(), comes, the initial state is initialized and pushed into the stack. When receiving an event startelement(tag), the system follows the same rule as that in YFilter to get the next states and pushes into the stack. If the element is associated with textual content, on receiving character() event, the system follows the same procedure to get the newly active states. If none of the newly-active states are accepting states, ablank query bitmap and set used query are created. If one or more newly-active states are accepting states, the positions of the bitmap are obtained, and bitmaps of the newlycreated query bitmap are set to true to the corresponding obtained positions. The IDs of queries obtained from the accepting states are added to the set used query. Then a new entry is pushed into the stack. Fig. 8: A Single NFA Fig. 9: A Running Example Proposed Method When receiving an event endelement(tag), the entry is popped of the stack. Then it checks the set used query of the popped entry. If the used query is not empty, IDs of each query are used and it checks the bitmaps of the corresponding queries in the query bitmap of the popped entry. If all bitmaps of any queries are true, the respective queries match. Otherwise, they do not match. If none of queries match, all bitmaps of the query bitmap are sent and combined with entry of the top stack by using "OR" operator. The set used query of the popped entry is added up to that of the top entry. 5. Experimental Evaluation 5. 1 Setup The algorithm is implemented using Java on the existing YFilter [5] and the SAX API from Xerces Java Parser in an Intel Core 2.33GHz computer with 2GB of memory in Windows XP Service Pack 2. All data structures, query bitmaps and sets of used queries, are kept entirely in memory. We use two types of datasets, synthetic data and real data. Our synthetic data is generated by the xmlgen of XMark [3]. Our real datasets are DBLP-biographic information on major computer science journals and proceedings, Mondial-world geographic database integrated from the CIA World Factbook, the International Atlas, and the TERRA database. Details of the datasets are presented in Table 1. Table 1: All datasets used in the experiments Dataset Element Attributes Max-depth Avg-depth XMark 333 millions 333 millions 5 3 DBLP 3,332, , Mondial 22,423 47, We generate XPath-based keyword search from the above datasets. Since there is a performance impact when searching for different kinds of keywords in our system, we separately generate sets of queries which contains only keywords in the forms of l::, l, l::k, ::k and mixed of the four forms. For example, we could generate: //regions[ftcontains(::begin ::caius)], whose keywords are in the form of ::k from XMark dataset. Moreover, since the same keywords can appear in different queries, we devide our sets of queries into two categories, sets of queries in which the same keywords can appear in different queries and sets of queries in which the same keywords cannot appear in different queries. We measure the elapsed time, average memory usage, and number of extended-nfa states for processing all XML data on a given stream. This includes the time spent to create the NFA, query bitmaps, and the set of used queries Varying the Number of Queries We vary the number of queries from 1, 10, 100, 200, 400, 600, 800, and 1000 and investigate the impact on the performance of our algorithm. We observe that as the number of queries increases, the memory usage increases, and the number of NFA states also increases while the throughputs constantly decrease. As shown in Figures 10, 11, 12, 13, 14, and 15. This is because the system needs to process each single query and output the result of each queries. Figure 10 shows that the number of NFA states increases when the number of queries increases from 1 to 100, but when the number of queries increases from 100 to 1000, the number of NFA states becomes constant at 31 because same keywords
7 appear at different queries very frequently and the number of unique labels is only 31 in DBLP. Such cases also happen to Mondial and XMark dataset as shown in Figures 11, and 12. We could not generate more than 100 queries in which the same keyword appears only once in a particular query in the same set of queries. As a result, the increasse of memory usage and the decrease of throughputs do not change much when the number of queries increases Varying the Number of Query Terms We investigate the impact on the performance of our algorithm when we increase the number of keywords from 2, 4, and 6. 6 keywords are a reasonable limit when one uses to specify the query [8]. We randomly generate sets of queries whose same keywords can appear in more than one query. With these sets of queries, we observed that though the number of keywords increase, the memory usage, number of extended-nfa states and throughputs do not change much between 2, 4, and 6 keywords. These cause by the more frequency that same keywords appear at different queries as shown in Figures 10, 11, and 12. Next we generate sets of queries in which the same keywords appear at only one query in the same sets. Then we investigate the impact that the increase in unique keywords in the queries on the performance of the algorithm. As expected, as the number of unique keywords increase, the number of NFA states also increase. As a result, the memory usage increases and the thoughputs decrease significantly as shown in Figures 13, 14, and 15. Though memory usage and throughputs of the algorithm have some degradation when the number of queries and the number of keyword words increase, the algorithm scales well with such increase. 6. Related Works XML Keyword Search: Using keywords to query XML databases has been extensively studied. XSEarch [4] adopts an intuitive concept of meaningfully related sets of nodes based on the relationship of the nodes with its ancestors. XRANK [10] presents an adaptation of Google s PageRank to XML data for computing a ranking score for the answer trees. The work in [8] and [13] took the first steps towards processing keyword-based queries over XML streams. XML Streams: Recent research on XML streams (dissemination, ltering and routing) aims at building large-scale, distributed systems [4, 5, 8, 9]. Most of those are concerned with performance aspects and optimize the ltering process [9], the message delivering and the routing network. YFilter [5] uses NFA-based implementation to improve structure matching and number of machine states are small. In order to deal with multiple XML schemas, two approaches are very common: to use query rewriting [15] and global schemas [11]. 7. Conclusion In this paper, we have developed a filtering system that supports XPath-based keyword search over XML streams. The NFA model is extended so that it supports XPath-based keyword search query. The above extended-nfa is used to integrate the method in YFilter with that of CKStream. We evaluate them by some experiments on both synthetic and real datasets. The experimental results show that our proposed method works well with acceptable throughputs, less memory usage, and good efficiency and utility. For our future work, we are going to apply our proposed method, XPath-based keyword search, to multiple XML streams, which useful information can be obtained when informations from different sources are combined at real-time. Acknowledgement This work is partly supported by the collaborative research (Fujitsu Lab. Ltd., CPE25149), the Okawa Foundation research grant, and JSPS KAKENHI ( ). References [1] Extensible markup language [2] S. Amer-Yahia, E. Curtmola, and A. Deutsch. Flexible and efficient xml search with complex full-text predicates. In SIGMOD, pages , ACM New York, NY, USA, [3] R. Busse, M. Carey, D. Florescu, M. Kersten, I. Manolescu, A. Schmidt, and F. Wass. Xmark-an xml benchmark project [4] S. Cohen, J. Mamou, Y. Kanza, and Y. Sagiv. Xsearch: a semantic search engine for xml. In In Proc. Of VLDB, volume 29, pages 45 56, [5] Y. Diao and M. J. Franklin. High-performance xml filtering: An overview of yfilter. In IEEE, pages 41 48, [6] M. Gawinecki, F. Mandreoli, and G. Cabri. Keyword search over xml streams: Addressing time-stamping and understanding results. pages , U. of Modena, [7] V. Hristidis and N. Koudas. Keyword proximity search in xml trees. IEEE Trans., 18: , [8] C. Hummel, S. da Silva, M. Moro, and Laender H.F. Multiple keyword-based queries over xml streams. In ACM, pages , ACM New York, NY, USA, [9] A. Gupta J. Green and M. Onozuka. Processing xml stream with deterministic automata and stream indexes. ACM, 29: , [10] F. Shao L. Guo, C. Botev, and J. S. Xrank: ranked keyword search over xml documents. In In Proc. Of SIGMOD Conf., pages 16 27, ACM New York, NY, USA, [11] Y. Li, C. Yu, and H. V. Jagadish. Schema-free xquery. In VLDB, volume 30, pages 72 83, [12] Z. Vagena, L. S. Colby, F. Ozcan, A. Balmin, and Q. Li. On the Effectiveness of Flexible Querying Heuristics for XML Data, volume [13] Z. Vagena and M. Moro. Semantic search over xml document streams. In DATAX, [14] Y. Xu and Y. Papakonstantinou. Efcient keyword search for smallest lcas in xml databases. In In Proc. of SIGMOD Conf., pages , ACM New York, NY, USA, [15] C. Yu and L. Popa. Constraint-based xml query rewriting for data integration. In In Proc. of SIGMOD Conf., pages , ACM New York, NY, USA, 2004.












8 Fig. 10: DBLP: Varying the number of queries and keywords of type l:: Fig. 11: Mondial: Varying the number of queries and keywords of type l:: Fig. 12: XMark: Varying the number of queries and keywords of type l:: Fig. 13: DBLP: Varying the number of queries and keywords of type ::k Fig. 14: Mondial: Varying the number of queries and keywords of type ::k Fig. 15: XMark: Varying the number of queries and keywords of type ::k
Improving Data Access Performance by Reverse Indexing
 Improving Data Access Performance by Reverse Indexing Mary Posonia #1, V.L.Jyothi *2 # Department of Computer Science, Sathyabama University, Chennai, India # Department of Computer Science, Jeppiaar Engineering
Improving Data Access Performance by Reverse Indexing Mary Posonia #1, V.L.Jyothi *2 # Department of Computer Science, Sathyabama University, Chennai, India # Department of Computer Science, Jeppiaar Engineering
ISSN: (Online) Volume 2, Issue 3, March 2014 International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 3, March 2014 International Journal of Advance Research in Computer Science and Management Studies") ISSN: 2321-7782 (Online) Volume 2, Issue 3, March 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Paper / Case Study Available online at: www.ijarcsms.com
ISSN: 2321-7782 (Online) Volume 2, Issue 3, March 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Paper / Case Study Available online at: www.ijarcsms.com
An Effective and Efficient Approach for Keyword-Based XML Retrieval. Xiaoguang Li, Jian Gong, Daling Wang, and Ge Yu retold by Daryna Bronnykova
 An Effective and Efficient Approach for Keyword-Based XML Retrieval Xiaoguang Li, Jian Gong, Daling Wang, and Ge Yu retold by Daryna Bronnykova Search on XML documents 2 Why not use google? Why are traditional
An Effective and Efficient Approach for Keyword-Based XML Retrieval Xiaoguang Li, Jian Gong, Daling Wang, and Ge Yu retold by Daryna Bronnykova Search on XML documents 2 Why not use google? Why are traditional
SFilter: A Simple and Scalable Filter for XML Streams
 SFilter: A Simple and Scalable Filter for XML Streams Abdul Nizar M., G. Suresh Babu, P. Sreenivasa Kumar Indian Institute of Technology Madras Chennai - 600 036 INDIA nizar@cse.iitm.ac.in, sureshbabuau@gmail.com,
SFilter: A Simple and Scalable Filter for XML Streams Abdul Nizar M., G. Suresh Babu, P. Sreenivasa Kumar Indian Institute of Technology Madras Chennai - 600 036 INDIA nizar@cse.iitm.ac.in, sureshbabuau@gmail.com,
Top-k Keyword Search Over Graphs Based On Backward Search
 Top-k Keyword Search Over Graphs Based On Backward Search Jia-Hui Zeng, Jiu-Ming Huang, Shu-Qiang Yang 1College of Computer National University of Defense Technology, Changsha, China 2College of Computer
Top-k Keyword Search Over Graphs Based On Backward Search Jia-Hui Zeng, Jiu-Ming Huang, Shu-Qiang Yang 1College of Computer National University of Defense Technology, Changsha, China 2College of Computer
XML Filtering Technologies
 XML Filtering Technologies Introduction Data exchange between applications: use XML Messages processed by an XML Message Broker Examples Publish/subscribe systems [Altinel 00] XML message routing [Snoeren
XML Filtering Technologies Introduction Data exchange between applications: use XML Messages processed by an XML Message Broker Examples Publish/subscribe systems [Altinel 00] XML message routing [Snoeren
Processing XML Keyword Search by Constructing Effective Structured Queries
 Processing XML Keyword Search by Constructing Effective Structured Queries Jianxin Li, Chengfei Liu, Rui Zhou and Bo Ning Email:{jianxinli, cliu, rzhou, bning}@groupwise.swin.edu.au Swinburne University
Processing XML Keyword Search by Constructing Effective Structured Queries Jianxin Li, Chengfei Liu, Rui Zhou and Bo Ning Email:{jianxinli, cliu, rzhou, bning}@groupwise.swin.edu.au Swinburne University
A Survey on Keyword Diversification Over XML Data
 ISSN (Online) : 2319-8753 ISSN (Print) : 2347-6710 International Journal of Innovative Research in Science, Engineering and Technology An ISO 3297: 2007 Certified Organization Volume 6, Special Issue 5,
ISSN (Online) : 2319-8753 ISSN (Print) : 2347-6710 International Journal of Innovative Research in Science, Engineering and Technology An ISO 3297: 2007 Certified Organization Volume 6, Special Issue 5,
SpiderX: Fast XML Exploration System
 SpiderX: Fast XML Exploration System Chunbin Lin, Jianguo Wang Computer Science and Engineering, California, San Diego La Jolla, California, USA chunbinlin@cs.ucsd.edu, csjgwang@cs.ucsd.edu ABSTRACT Keyword
SpiderX: Fast XML Exploration System Chunbin Lin, Jianguo Wang Computer Science and Engineering, California, San Diego La Jolla, California, USA chunbinlin@cs.ucsd.edu, csjgwang@cs.ucsd.edu ABSTRACT Keyword
Integrating Path Index with Value Index for XML data
 Integrating Path Index with Value Index for XML data Jing Wang 1, Xiaofeng Meng 2, Shan Wang 2 1 Institute of Computing Technology, Chinese Academy of Sciences, 100080 Beijing, China cuckoowj@btamail.net.cn
Integrating Path Index with Value Index for XML data Jing Wang 1, Xiaofeng Meng 2, Shan Wang 2 1 Institute of Computing Technology, Chinese Academy of Sciences, 100080 Beijing, China cuckoowj@btamail.net.cn
Symmetrically Exploiting XML
 Symmetrically Exploiting XML Shuohao Zhang and Curtis Dyreson School of E.E. and Computer Science Washington State University Pullman, Washington, USA The 15 th International World Wide Web Conference
Symmetrically Exploiting XML Shuohao Zhang and Curtis Dyreson School of E.E. and Computer Science Washington State University Pullman, Washington, USA The 15 th International World Wide Web Conference
Structural Consistency: Enabling XML Keyword Search to Eliminate Spurious Results Consistently
 Last Modified: 22 Sept. 29 Structural Consistency: Enabling XML Keyword Search to Eliminate Spurious Results Consistently Ki-Hoon Lee, Kyu-Young Whang, Wook-Shin Han, and Min-Soo Kim Department of Computer
Last Modified: 22 Sept. 29 Structural Consistency: Enabling XML Keyword Search to Eliminate Spurious Results Consistently Ki-Hoon Lee, Kyu-Young Whang, Wook-Shin Han, and Min-Soo Kim Department of Computer
Kikori-KS: An Effective and Efficient Keyword Search System for Digital Libraries in XML
 Kikori-KS An Effective and Efficient Keyword Search System for Digital Libraries in XML Toshiyuki Shimizu 1, Norimasa Terada 2, and Masatoshi Yoshikawa 1 1 Graduate School of Informatics, Kyoto University
Kikori-KS An Effective and Efficient Keyword Search System for Digital Libraries in XML Toshiyuki Shimizu 1, Norimasa Terada 2, and Masatoshi Yoshikawa 1 1 Graduate School of Informatics, Kyoto University
A Scheme of Automated Object and Facet Extraction for Faceted Search over XML Data
 IDEAS 2014 A Scheme of Automated Object and Facet Extraction for Faceted Search over XML Data Takahiro Komamizu, Toshiyuki Amagasa, Hiroyuki Kitagawa University of Tsukuba Background Introduction Background
IDEAS 2014 A Scheme of Automated Object and Facet Extraction for Faceted Search over XML Data Takahiro Komamizu, Toshiyuki Amagasa, Hiroyuki Kitagawa University of Tsukuba Background Introduction Background
An Efficient XML Index Structure with Bottom-Up Query Processing
 An Efficient XML Index Structure with Bottom-Up Query Processing Dong Min Seo, Jae Soo Yoo, and Ki Hyung Cho Department of Computer and Communication Engineering, Chungbuk National University, 48 Gaesin-dong,
An Efficient XML Index Structure with Bottom-Up Query Processing Dong Min Seo, Jae Soo Yoo, and Ki Hyung Cho Department of Computer and Communication Engineering, Chungbuk National University, 48 Gaesin-dong,
Tree-Pattern Queries on a Lightweight XML Processor
 Tree-Pattern Queries on a Lightweight XML Processor MIRELLA M. MORO Zografoula Vagena Vassilis J. Tsotras Research partially supported by CAPES, NSF grant IIS 0339032, UC Micro, and Lotus Interworks Outline
Tree-Pattern Queries on a Lightweight XML Processor MIRELLA M. MORO Zografoula Vagena Vassilis J. Tsotras Research partially supported by CAPES, NSF grant IIS 0339032, UC Micro, and Lotus Interworks Outline
Structural consistency: enabling XML keyword search to eliminate spurious results consistently
 The VLDB Journal (2010) 19:503 529 DOI 10.1007/s00778-009-0177-7 REGULAR PAPER Structural consistency: enabling XML keyword search to eliminate spurious results consistently Ki-Hoon Lee Kyu-Young Whang
The VLDB Journal (2010) 19:503 529 DOI 10.1007/s00778-009-0177-7 REGULAR PAPER Structural consistency: enabling XML keyword search to eliminate spurious results consistently Ki-Hoon Lee Kyu-Young Whang
Accelerating XML Structural Matching Using Suffix Bitmaps
 Accelerating XML Structural Matching Using Suffix Bitmaps Feng Shao, Gang Chen, and Jinxiang Dong Dept. of Computer Science, Zhejiang University, Hangzhou, P.R. China microf_shao@msn.com, cg@zju.edu.cn,
Accelerating XML Structural Matching Using Suffix Bitmaps Feng Shao, Gang Chen, and Jinxiang Dong Dept. of Computer Science, Zhejiang University, Hangzhou, P.R. China microf_shao@msn.com, cg@zju.edu.cn,
YFilter: an XML Stream Filtering Engine. Weiwei SUN University of Konstanz
 YFilter: an XML Stream Filtering Engine Weiwei SUN University of Konstanz 1 Introduction Data exchange between applications: use XML Messages processed by an XML Message Broker Examples Publish/subscribe
YFilter: an XML Stream Filtering Engine Weiwei SUN University of Konstanz 1 Introduction Data exchange between applications: use XML Messages processed by an XML Message Broker Examples Publish/subscribe
An Efficient Execution Scheme for Designated Event-based Stream Processing
 DEIM Forum 2014 D3-2 An Efficient Execution Scheme for Designated Event-based Stream Processing Yan Wang and Hiroyuki Kitagawa Graduate School of Systems and Information Engineering, University of Tsukuba
DEIM Forum 2014 D3-2 An Efficient Execution Scheme for Designated Event-based Stream Processing Yan Wang and Hiroyuki Kitagawa Graduate School of Systems and Information Engineering, University of Tsukuba
Efficient Keyword Search over Relational Data Streams
 DEIM Forum 2016 A3-4 Abstract Efficient Keyword Search over Relational Data Streams Savong BOU, Toshiyuki AMAGASA, and Hiroyuki KITAGAWA Graduate School of Systems and Information Engineering, University
DEIM Forum 2016 A3-4 Abstract Efficient Keyword Search over Relational Data Streams Savong BOU, Toshiyuki AMAGASA, and Hiroyuki KITAGAWA Graduate School of Systems and Information Engineering, University
Efficient Keyword Search for Smallest LCAs in XML Databases
 Efficient Keyword Search for Smallest LCAs in XML Databases Yu Xu Department of Computer Science & Engineering University of California San Diego yxu@cs.ucsd.edu Yannis Papakonstantinou Department of Computer
Efficient Keyword Search for Smallest LCAs in XML Databases Yu Xu Department of Computer Science & Engineering University of California San Diego yxu@cs.ucsd.edu Yannis Papakonstantinou Department of Computer
Searching SNT in XML Documents Using Reduction Factor
 Searching SNT in XML Documents Using Reduction Factor Mary Posonia A Department of computer science, Sathyabama University, Tamilnadu, Chennai, India maryposonia@sathyabamauniversity.ac.in http://www.sathyabamauniversity.ac.in
Searching SNT in XML Documents Using Reduction Factor Mary Posonia A Department of computer science, Sathyabama University, Tamilnadu, Chennai, India maryposonia@sathyabamauniversity.ac.in http://www.sathyabamauniversity.ac.in
Extracting Facets from Textual Contents for Faceted Search over XML Data
 iiwas2014 Extracting Facets from Textual Contents for Faceted Search over XML Data Takahiro Komamizu, Toshiyuki Amagasa, Hiroyuki Kitagawa University of Tsukuba, Japan Background XML (Extensible Markup
iiwas2014 Extracting Facets from Textual Contents for Faceted Search over XML Data Takahiro Komamizu, Toshiyuki Amagasa, Hiroyuki Kitagawa University of Tsukuba, Japan Background XML (Extensible Markup
A FRAMEWORK FOR EFFICIENT DATA SEARCH THROUGH XML TREE PATTERNS
 A FRAMEWORK FOR EFFICIENT DATA SEARCH THROUGH XML TREE PATTERNS SRIVANI SARIKONDA 1 PG Scholar Department of CSE P.SANDEEP REDDY 2 Associate professor Department of CSE DR.M.V.SIVA PRASAD 3 Principal Abstract:
A FRAMEWORK FOR EFFICIENT DATA SEARCH THROUGH XML TREE PATTERNS SRIVANI SARIKONDA 1 PG Scholar Department of CSE P.SANDEEP REDDY 2 Associate professor Department of CSE DR.M.V.SIVA PRASAD 3 Principal Abstract:
Chapter 13 XML: Extensible Markup Language
 Chapter 13 XML: Extensible Markup Language - Internet applications provide Web interfaces to databases (data sources) - Three-tier architecture Client V Application Programs Webserver V Database Server
Chapter 13 XML: Extensible Markup Language - Internet applications provide Web interfaces to databases (data sources) - Three-tier architecture Client V Application Programs Webserver V Database Server
Keyword Search over Hybrid XML-Relational Databases
 SICE Annual Conference 2008 August 20-22, 2008, The University Electro-Communications, Japan Keyword Search over Hybrid XML-Relational Databases Liru Zhang 1 Tadashi Ohmori 1 and Mamoru Hoshi 1 1 Graduate
SICE Annual Conference 2008 August 20-22, 2008, The University Electro-Communications, Japan Keyword Search over Hybrid XML-Relational Databases Liru Zhang 1 Tadashi Ohmori 1 and Mamoru Hoshi 1 1 Graduate
TwigINLAB: A Decomposition-Matching-Merging Approach To Improving XML Query Processing
 American Journal of Applied Sciences 5 (9): 99-25, 28 ISSN 546-9239 28 Science Publications TwigINLAB: A Decomposition-Matching-Merging Approach To Improving XML Query Processing Su-Cheng Haw and Chien-Sing
American Journal of Applied Sciences 5 (9): 99-25, 28 ISSN 546-9239 28 Science Publications TwigINLAB: A Decomposition-Matching-Merging Approach To Improving XML Query Processing Su-Cheng Haw and Chien-Sing
Efficient LCA based Keyword Search in XML Data
 Efficient LCA based Keyword Search in XML Data Yu Xu Teradata San Diego, CA yu.xu@teradata.com Yannis Papakonstantinou University of California, San Diego San Diego, CA yannis@cs.ucsd.edu ABSTRACT Keyword
Efficient LCA based Keyword Search in XML Data Yu Xu Teradata San Diego, CA yu.xu@teradata.com Yannis Papakonstantinou University of California, San Diego San Diego, CA yannis@cs.ucsd.edu ABSTRACT Keyword
A Keyword-Based Filtering Technique of Document-Centric XML using NFA Representation
 A Keyword-Based Filtering Technique of Document-Centric XML using NFA Representation Changwoo Byun, Kyounghan Lee, and Seog Park Abstract XML is becoming a de facto standard for online data exchange. Existing
A Keyword-Based Filtering Technique of Document-Centric XML using NFA Representation Changwoo Byun, Kyounghan Lee, and Seog Park Abstract XML is becoming a de facto standard for online data exchange. Existing
Navigation- vs. Index-Based XML Multi-Query Processing
 Navigation- vs. Index-Based XML Multi-Query Processing Nicolas Bruno, Luis Gravano Columbia University {nicolas,gravano}@cs.columbia.edu Nick Koudas, Divesh Srivastava AT&T Labs Research {koudas,divesh}@research.att.com
Navigation- vs. Index-Based XML Multi-Query Processing Nicolas Bruno, Luis Gravano Columbia University {nicolas,gravano}@cs.columbia.edu Nick Koudas, Divesh Srivastava AT&T Labs Research {koudas,divesh}@research.att.com
A New Way of Generating Reusable Index Labels for Dynamic XML
 A New Way of Generating Reusable Index Labels for Dynamic XML P. Jayanthi, Dr. A. Tamilarasi Department of CSE, Kongu Engineering College, Perundurai 638 052, Erode, Tamilnadu, India. Abstract XML now
A New Way of Generating Reusable Index Labels for Dynamic XML P. Jayanthi, Dr. A. Tamilarasi Department of CSE, Kongu Engineering College, Perundurai 638 052, Erode, Tamilnadu, India. Abstract XML now
An Extended Byte Carry Labeling Scheme for Dynamic XML Data
 Available online at www.sciencedirect.com Procedia Engineering 15 (2011) 5488 5492 An Extended Byte Carry Labeling Scheme for Dynamic XML Data YU Sheng a,b WU Minghui a,b, * LIU Lin a,b a School of Computer
Available online at www.sciencedirect.com Procedia Engineering 15 (2011) 5488 5492 An Extended Byte Carry Labeling Scheme for Dynamic XML Data YU Sheng a,b WU Minghui a,b, * LIU Lin a,b a School of Computer
INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN EFFECTIVE KEYWORD SEARCH OF FUZZY TYPE IN XML
 INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN 2320-7345 EFFECTIVE KEYWORD SEARCH OF FUZZY TYPE IN XML Mr. Mohammed Tariq Alam 1,Mrs.Shanila Mahreen 2 Assistant Professor
INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN 2320-7345 EFFECTIVE KEYWORD SEARCH OF FUZZY TYPE IN XML Mr. Mohammed Tariq Alam 1,Mrs.Shanila Mahreen 2 Assistant Professor
A Schema Extraction Algorithm for External Memory Graphs Based on Novel Utility Function
 DEIM Forum 2018 I5-5 Abstract A Schema Extraction Algorithm for External Memory Graphs Based on Novel Utility Function Yoshiki SEKINE and Nobutaka SUZUKI Graduate School of Library, Information and Media
DEIM Forum 2018 I5-5 Abstract A Schema Extraction Algorithm for External Memory Graphs Based on Novel Utility Function Yoshiki SEKINE and Nobutaka SUZUKI Graduate School of Library, Information and Media
PathStack : A Holistic Path Join Algorithm for Path Query with Not-predicates on XML Data
 PathStack : A Holistic Path Join Algorithm for Path Query with Not-predicates on XML Data Enhua Jiao, Tok Wang Ling, Chee-Yong Chan School of Computing, National University of Singapore {jiaoenhu,lingtw,chancy}@comp.nus.edu.sg
PathStack : A Holistic Path Join Algorithm for Path Query with Not-predicates on XML Data Enhua Jiao, Tok Wang Ling, Chee-Yong Chan School of Computing, National University of Singapore {jiaoenhu,lingtw,chancy}@comp.nus.edu.sg
Reasoning with Patterns to Effectively Answer XML Keyword Queries
 Noname manuscript No. (will be inserted by the editor) Reasoning with Patterns to Effectively Answer XML Keyword Queries Cem Aksoy Aggeliki Dimitriou Dimitri Theodoratos the date of receipt and acceptance
Noname manuscript No. (will be inserted by the editor) Reasoning with Patterns to Effectively Answer XML Keyword Queries Cem Aksoy Aggeliki Dimitriou Dimitri Theodoratos the date of receipt and acceptance
Security Based Heuristic SAX for XML Parsing
 Security Based Heuristic SAX for XML Parsing Wei Wang Department of Automation Tsinghua University, China Beijing, China Abstract - XML based services integrate information resources running on different
Security Based Heuristic SAX for XML Parsing Wei Wang Department of Automation Tsinghua University, China Beijing, China Abstract - XML based services integrate information resources running on different
XML Data Stream Processing: Extensions to YFilter
 XML Data Stream Processing: Extensions to YFilter Shaolei Feng and Giridhar Kumaran January 31, 2007 Abstract Running XPath queries on XML data steams is a challenge. Current approaches that store the
XML Data Stream Processing: Extensions to YFilter Shaolei Feng and Giridhar Kumaran January 31, 2007 Abstract Running XPath queries on XML data steams is a challenge. Current approaches that store the
Published by: PIONEER RESEARCH & DEVELOPMENT GROUP ( ) 1
 1") A Conventional Query Processing using Wireless XML Broadcasting Subhashini.G 1, Kavitha.M 2 1 M.E II Year, Department of Computer Science and Engineering, Sriram Engineering College, Perumalpattu 602 024
A Conventional Query Processing using Wireless XML Broadcasting Subhashini.G 1, Kavitha.M 2 1 M.E II Year, Department of Computer Science and Engineering, Sriram Engineering College, Perumalpattu 602 024
CHAPTER 3 LITERATURE REVIEW
 20 CHAPTER 3 LITERATURE REVIEW This chapter presents query processing with XML documents, indexing techniques and current algorithms for generating labels. Here, each labeling algorithm and its limitations
20 CHAPTER 3 LITERATURE REVIEW This chapter presents query processing with XML documents, indexing techniques and current algorithms for generating labels. Here, each labeling algorithm and its limitations
Data Presentation and Markup Languages
 Data Presentation and Markup Languages MIE456 Tutorial Acknowledgements Some contents of this presentation are borrowed from a tutorial given at VLDB 2000, Cairo, Agypte (www.vldb.org) by D. Florescu &.
Data Presentation and Markup Languages MIE456 Tutorial Acknowledgements Some contents of this presentation are borrowed from a tutorial given at VLDB 2000, Cairo, Agypte (www.vldb.org) by D. Florescu &.
Answering XML Twig Queries with Automata
 Answering XML Twig Queries with Automata Bing Sun, Bo Zhou, Nan Tang, Guoren Wang, Ge Yu, and Fulin Jia Northeastern University, Shenyang, China {sunb,wanggr,yuge,dbgroup}@mail.neu.edu.cn Abstract. XML
Answering XML Twig Queries with Automata Bing Sun, Bo Zhou, Nan Tang, Guoren Wang, Ge Yu, and Fulin Jia Northeastern University, Shenyang, China {sunb,wanggr,yuge,dbgroup}@mail.neu.edu.cn Abstract. XML
Retrieving Meaningful Relaxed Tightest Fragments for XML Keyword Search
 Retrieving Meaningful Relaxed Tightest Fragments for XML Keyword Search Lingbo Kong, Rémi Gilleron, Aurélien Lemay Mostrare, INRIA Futurs, Villeneuve d Ascq, Lille, 59650 FRANCE mlinking@gmail.com, {remi.gilleron,
Retrieving Meaningful Relaxed Tightest Fragments for XML Keyword Search Lingbo Kong, Rémi Gilleron, Aurélien Lemay Mostrare, INRIA Futurs, Villeneuve d Ascq, Lille, 59650 FRANCE mlinking@gmail.com, {remi.gilleron,
Massively Parallel XML Twig Filtering Using Dynamic Programming on FPGAs
 Massively Parallel XML Twig Filtering Using Dynamic Programming on FPGAs Roger Moussalli, Mariam Salloum, Walid Najjar, Vassilis J. Tsotras University of California Riverside, California 92521, USA (rmous,msalloum,najjar,tsotras)@cs.ucr.edu
Massively Parallel XML Twig Filtering Using Dynamic Programming on FPGAs Roger Moussalli, Mariam Salloum, Walid Najjar, Vassilis J. Tsotras University of California Riverside, California 92521, USA (rmous,msalloum,najjar,tsotras)@cs.ucr.edu
Huayu Wu, and Zhifeng Bao National University of Singapore
 Huayu Wu, and Zhifeng Bao National University of Singapore Outline Introduction Motivation Our Approach Experiments Conclusion Introduction XML Keyword Search Originated from Information Retrieval (IR)
Huayu Wu, and Zhifeng Bao National University of Singapore Outline Introduction Motivation Our Approach Experiments Conclusion Introduction XML Keyword Search Originated from Information Retrieval (IR)
Massively Parallel XML Twig Filtering Using Dynamic Programming on FPGAs
 Massively Parallel XML Twig Filtering Using Dynamic Programming on FPGAs Roger Moussalli, Mariam Salloum, Walid Najjar, Vassilis J. Tsotras University of California Riverside, California 92521, USA (rmous,msalloum,najjar,tsotras)@cs.ucr.edu
Massively Parallel XML Twig Filtering Using Dynamic Programming on FPGAs Roger Moussalli, Mariam Salloum, Walid Najjar, Vassilis J. Tsotras University of California Riverside, California 92521, USA (rmous,msalloum,najjar,tsotras)@cs.ucr.edu
Full-Text and Structural XML Indexing on B + -Tree
 Full-Text and Structural XML Indexing on B + -Tree Toshiyuki Shimizu 1 and Masatoshi Yoshikawa 2 1 Graduate School of Information Science, Nagoya University shimizu@dl.itc.nagoya-u.ac.jp 2 Information
Full-Text and Structural XML Indexing on B + -Tree Toshiyuki Shimizu 1 and Masatoshi Yoshikawa 2 1 Graduate School of Information Science, Nagoya University shimizu@dl.itc.nagoya-u.ac.jp 2 Information
High-Performance Holistic XML Twig Filtering Using GPUs. Ildar Absalyamov, Roger Moussalli, Walid Najjar and Vassilis Tsotras
 High-Performance Holistic XML Twig Filtering Using GPUs Ildar Absalyamov, Roger Moussalli, Walid Najjar and Vassilis Tsotras Outline! Motivation! XML filtering in the literature! Software approaches! Hardware
High-Performance Holistic XML Twig Filtering Using GPUs Ildar Absalyamov, Roger Moussalli, Walid Najjar and Vassilis Tsotras Outline! Motivation! XML filtering in the literature! Software approaches! Hardware
TERM BASED WEIGHT MEASURE FOR INFORMATION FILTERING IN SEARCH ENGINES
 TERM BASED WEIGHT MEASURE FOR INFORMATION FILTERING IN SEARCH ENGINES Mu. Annalakshmi Research Scholar, Department of Computer Science, Alagappa University, Karaikudi. annalakshmi_mu@yahoo.co.in Dr. A.
TERM BASED WEIGHT MEASURE FOR INFORMATION FILTERING IN SEARCH ENGINES Mu. Annalakshmi Research Scholar, Department of Computer Science, Alagappa University, Karaikudi. annalakshmi_mu@yahoo.co.in Dr. A.
A Framework for Processing Complex Document-centric XML with Overlapping Structures Ionut E. Iacob and Alex Dekhtyar
 A Framework for Processing Complex Document-centric XML with Overlapping Structures Ionut E. Iacob and Alex Dekhtyar ABSTRACT Management of multihierarchical XML encodings has attracted attention of a
A Framework for Processing Complex Document-centric XML with Overlapping Structures Ionut E. Iacob and Alex Dekhtyar ABSTRACT Management of multihierarchical XML encodings has attracted attention of a
A New Indexing Strategy for XML Keyword Search
 2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery (FSKD 2010) A New Indexing Strategy for XML Keyword Search Yongqing Xiang, Zhihong Deng, Hang Yu, Sijing Wang, Ning Gao Key
2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery (FSKD 2010) A New Indexing Strategy for XML Keyword Search Yongqing Xiang, Zhihong Deng, Hang Yu, Sijing Wang, Ning Gao Key
Design of Index Schema based on Bit-Streams for XML Documents
 Design of Index Schema based on Bit-Streams for XML Documents Youngrok Song 1, Kyonam Choo 3 and Sangmin Lee 2 1 Institute for Information and Electronics Research, Inha University, Incheon, Korea 2 Department
Design of Index Schema based on Bit-Streams for XML Documents Youngrok Song 1, Kyonam Choo 3 and Sangmin Lee 2 1 Institute for Information and Electronics Research, Inha University, Incheon, Korea 2 Department
A BFS-BASED SIMILAR CONFERENCE RETRIEVAL FRAMEWORK
 A BFS-BASED SIMILAR CONFERENCE RETRIEVAL FRAMEWORK Qing Guo 1, 2 1 Nanyang Technological University, Singapore 2 SAP Innovation Center Network,Singapore ABSTRACT Literature review is part of scientific
A BFS-BASED SIMILAR CONFERENCE RETRIEVAL FRAMEWORK Qing Guo 1, 2 1 Nanyang Technological University, Singapore 2 SAP Innovation Center Network,Singapore ABSTRACT Literature review is part of scientific
Efficient, Effective and Flexible XML Retrieval Using Summaries
 Efficient, Effective and Flexible XML Retrieval Using Summaries M. S. Ali, Mariano Consens, Xin Gu, Yaron Kanza, Flavio Rizzolo, and Raquel Stasiu University of Toronto {sali, consens, xgu, yaron, flavio,
Efficient, Effective and Flexible XML Retrieval Using Summaries M. S. Ali, Mariano Consens, Xin Gu, Yaron Kanza, Flavio Rizzolo, and Raquel Stasiu University of Toronto {sali, consens, xgu, yaron, flavio,
Evaluating XPath Queries
 Chapter 8 Evaluating XPath Queries Peter Wood (BBK) XML Data Management 201 / 353 Introduction When XML documents are small and can fit in memory, evaluating XPath expressions can be done efficiently But
Chapter 8 Evaluating XPath Queries Peter Wood (BBK) XML Data Management 201 / 353 Introduction When XML documents are small and can fit in memory, evaluating XPath expressions can be done efficiently But
Module 3. XML Processing. (XPath, XQuery, XUpdate) Part 5: XQuery + XPath Fulltext
 Part 5: XQuery + XPath Fulltext") Module 3 XML Processing (XPath, XQuery, XUpdate) Part 5: XQuery + XPath Fulltext 21.12.2011 Outline Motivation Challenges XQuery Full-Text Language XQuery Full-Text Semantics and Data Model Motivation
Module 3 XML Processing (XPath, XQuery, XUpdate) Part 5: XQuery + XPath Fulltext 21.12.2011 Outline Motivation Challenges XQuery Full-Text Language XQuery Full-Text Semantics and Data Model Motivation
Distributed Structural and Value XML Filtering
 Distributed Structural and Value XML Filtering Iris Miliaraki Dept. of Informatics and Telecommunications National and Kapodistrian University of Athens Athens, Greece iris@di.uoa.gr Manolis Koubarakis
Distributed Structural and Value XML Filtering Iris Miliaraki Dept. of Informatics and Telecommunications National and Kapodistrian University of Athens Athens, Greece iris@di.uoa.gr Manolis Koubarakis
Semantics based Buffer Reduction for Queries over XML Data Streams
 Semantics based Buffer Reduction for Queries over XML Data Streams Chi Yang Chengfei Liu Jianxin Li Jeffrey Xu Yu and Junhu Wang Faculty of Information and Communication Technologies Swinburne University
Semantics based Buffer Reduction for Queries over XML Data Streams Chi Yang Chengfei Liu Jianxin Li Jeffrey Xu Yu and Junhu Wang Faculty of Information and Communication Technologies Swinburne University
Keyword query interpretation over structured data
 Keyword query interpretation over structured data Advanced Methods of Information Retrieval Elena Demidova SS 2018 Elena Demidova: Advanced Methods of Information Retrieval SS 2018 1 Recap Elena Demidova:
Keyword query interpretation over structured data Advanced Methods of Information Retrieval Elena Demidova SS 2018 Elena Demidova: Advanced Methods of Information Retrieval SS 2018 1 Recap Elena Demidova:
Improving the Performance of Search Engine With Respect To Content Mining Kr.Jansi, L.Radha
 Improving the Performance of Search Engine With Respect To Content Mining Kr.Jansi, L.Radha 1 Asst. Professor, Srm University, Chennai 2 Mtech, Srm University, Chennai Abstract R- Google is a dedicated
Improving the Performance of Search Engine With Respect To Content Mining Kr.Jansi, L.Radha 1 Asst. Professor, Srm University, Chennai 2 Mtech, Srm University, Chennai Abstract R- Google is a dedicated
Performance Evaluation on XML Schema Retrieval by Using XSPath
 Performance Evaluation on XML Schema Retrieval by Using Trupti N. Mahale Prof. Santosh Kumar Abstract The contents and structure of the XML document can be retrieved using schemas. As schemas are complex
Performance Evaluation on XML Schema Retrieval by Using Trupti N. Mahale Prof. Santosh Kumar Abstract The contents and structure of the XML document can be retrieved using schemas. As schemas are complex
Parallelizing Structural Joins to Process Queries over Big XML Data Using MapReduce
 Parallelizing Structural Joins to Process Queries over Big XML Data Using MapReduce Huayu Wu Institute for Infocomm Research, A*STAR, Singapore huwu@i2r.a-star.edu.sg Abstract. Processing XML queries over
Parallelizing Structural Joins to Process Queries over Big XML Data Using MapReduce Huayu Wu Institute for Infocomm Research, A*STAR, Singapore huwu@i2r.a-star.edu.sg Abstract. Processing XML queries over
A Study on Reverse Top-K Queries Using Monochromatic and Bichromatic Methods
 A Study on Reverse Top-K Queries Using Monochromatic and Bichromatic Methods S.Anusuya 1, M.Balaganesh 2 P.G. Student, Department of Computer Science and Engineering, Sembodai Rukmani Varatharajan Engineering
A Study on Reverse Top-K Queries Using Monochromatic and Bichromatic Methods S.Anusuya 1, M.Balaganesh 2 P.G. Student, Department of Computer Science and Engineering, Sembodai Rukmani Varatharajan Engineering
IJSER 1 INTRODUCTION. Sathiya G. In this paper, proposed a novel, energy and latency. efficient wireless XML streaming scheme supporting twig
 International Journal of Scientific & Engineering Research, Volume 5, Issue 4, April-2014 127 WIRELESS XML STREAMING USING LINEAGE ENCODING Sathiya G Abstract - With the rapid development of wireless network
International Journal of Scientific & Engineering Research, Volume 5, Issue 4, April-2014 127 WIRELESS XML STREAMING USING LINEAGE ENCODING Sathiya G Abstract - With the rapid development of wireless network
Scalable Filtering and Matching of XML Documents in Publish/Subscribe Systems for Mobile Environment
 Scalable Filtering and Matching of XML Documents in Publish/Subscribe Systems for Mobile Environment Yi Yi Myint, Hninn Aye Thant Abstract The number of applications using XML data representation is growing
Scalable Filtering and Matching of XML Documents in Publish/Subscribe Systems for Mobile Environment Yi Yi Myint, Hninn Aye Thant Abstract The number of applications using XML data representation is growing
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 Rashmi Gadbail,, 2013; Volume 1(8): 783-791 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK EFFECTIVE XML DATABASE COMPRESSION
Rashmi Gadbail,, 2013; Volume 1(8): 783-791 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK EFFECTIVE XML DATABASE COMPRESSION
Effective Top-k Keyword Search in Relational Databases Considering Query Semantics
 Effective Top-k Keyword Search in Relational Databases Considering Query Semantics Yanwei Xu 1,2, Yoshiharu Ishikawa 1, and Jihong Guan 2 1 Graduate School of Information Science, Nagoya University, Japan
Effective Top-k Keyword Search in Relational Databases Considering Query Semantics Yanwei Xu 1,2, Yoshiharu Ishikawa 1, and Jihong Guan 2 1 Graduate School of Information Science, Nagoya University, Japan
Keyword query interpretation over structured data
 Keyword query interpretation over structured data Advanced Methods of IR Elena Demidova Materials used in the slides: Jeffrey Xu Yu, Lu Qin, Lijun Chang. Keyword Search in Databases. Synthesis Lectures
Keyword query interpretation over structured data Advanced Methods of IR Elena Demidova Materials used in the slides: Jeffrey Xu Yu, Lu Qin, Lijun Chang. Keyword Search in Databases. Synthesis Lectures
Schema-Free XQuery. Yunyao Li Cong Yu H. V. Jagadish. Abstract. 1 Introduction
 Schema-Free XQuery Yunyao Li Cong Yu H. V. Jagadish Department of EECS, University of Michigan Ann Arbor, MI 9, USA {yunyaol, congy, jag}@eecs.umich.edu Abstract The widespread adoption of XML holds out
Schema-Free XQuery Yunyao Li Cong Yu H. V. Jagadish Department of EECS, University of Michigan Ann Arbor, MI 9, USA {yunyaol, congy, jag}@eecs.umich.edu Abstract The widespread adoption of XML holds out
Mining XML data: A clustering approach
 Mining XML data: A clustering approach Saraee, MH and Aljibouri, J Title Authors Type URL Published Date 2005 Mining XML data: A clustering approach Saraee, MH and Aljibouri, J Conference or Workshop Item
Mining XML data: A clustering approach Saraee, MH and Aljibouri, J Title Authors Type URL Published Date 2005 Mining XML data: A clustering approach Saraee, MH and Aljibouri, J Conference or Workshop Item
A New Method of Generating Index Label for Dynamic XML Data
 Journal of Computer Science 7 (3): 421-426, 2011 ISSN 1549-3636 2011 Science Publications A New Method of Generating Index Label for Dynamic XML Data Jayanthi Paramasivam and Tamilarasi Angamuthu Department
Journal of Computer Science 7 (3): 421-426, 2011 ISSN 1549-3636 2011 Science Publications A New Method of Generating Index Label for Dynamic XML Data Jayanthi Paramasivam and Tamilarasi Angamuthu Department
Automata Approach to XML Data Indexing
 information Article Automata Approach to XML Data Indexing Eliška Šestáková, * ID and Jan Janoušek Faculty of Information Technology, Czech Technical University in Prague, Thákurova 9, 160 00 Praha 6,
information Article Automata Approach to XML Data Indexing Eliška Šestáková, * ID and Jan Janoušek Faculty of Information Technology, Czech Technical University in Prague, Thákurova 9, 160 00 Praha 6,
Integrated Usage of Heterogeneous Databases for Novice Users
 International Journal of Networked and Distributed Computing, Vol. 3, No. 2 (April 2015), 109-118 Integrated Usage of Heterogeneous Databases for Novice Users Ayano Terakawa Dept. of Information Science,
International Journal of Networked and Distributed Computing, Vol. 3, No. 2 (April 2015), 109-118 Integrated Usage of Heterogeneous Databases for Novice Users Ayano Terakawa Dept. of Information Science,
Semistructured Data Store Mapping with XML and Its Reconstruction
 Semistructured Data Store Mapping with XML and Its Reconstruction Enhong CHEN 1 Gongqing WU 1 Gabriela Lindemann 2 Mirjam Minor 2 1 Department of Computer Science University of Science and Technology of
Semistructured Data Store Mapping with XML and Its Reconstruction Enhong CHEN 1 Gongqing WU 1 Gabriela Lindemann 2 Mirjam Minor 2 1 Department of Computer Science University of Science and Technology of
Mining XML Functional Dependencies through Formal Concept Analysis
 Mining XML Functional Dependencies through Formal Concept Analysis Viorica Varga May 6, 2010 Outline Definitions for XML Functional Dependencies Introduction to FCA FCA tool to detect XML FDs Finding XML
Mining XML Functional Dependencies through Formal Concept Analysis Viorica Varga May 6, 2010 Outline Definitions for XML Functional Dependencies Introduction to FCA FCA tool to detect XML FDs Finding XML
XML RETRIEVAL. Introduction to Information Retrieval CS 150 Donald J. Patterson
 Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Manning, Raghavan, and Schütze http://www.informationretrieval.org OVERVIEW Introduction Basic XML Concepts Challenges
Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Manning, Raghavan, and Schütze http://www.informationretrieval.org OVERVIEW Introduction Basic XML Concepts Challenges
Compression of the Stream Array Data Structure
 Compression of the Stream Array Data Structure Radim Bača and Martin Pawlas Department of Computer Science, Technical University of Ostrava Czech Republic {radim.baca,martin.pawlas}@vsb.cz Abstract. In
Compression of the Stream Array Data Structure Radim Bača and Martin Pawlas Department of Computer Science, Technical University of Ostrava Czech Republic {radim.baca,martin.pawlas}@vsb.cz Abstract. In
Web Data Management. Tree Pattern Evaluation. Philippe Rigaux CNAM Paris & INRIA Saclay
 http://webdam.inria.fr/ Web Data Management Tree Pattern Evaluation Serge Abiteboul INRIA Saclay & ENS Cachan Ioana Manolescu INRIA Saclay & Paris-Sud University Philippe Rigaux CNAM Paris & INRIA Saclay
http://webdam.inria.fr/ Web Data Management Tree Pattern Evaluation Serge Abiteboul INRIA Saclay & ENS Cachan Ioana Manolescu INRIA Saclay & Paris-Sud University Philippe Rigaux CNAM Paris & INRIA Saclay
A Structural Numbering Scheme for XML Data
 A Structural Numbering Scheme for XML Data Alfred M. Martin WS2002/2003 February/March 2003 Based on workout made during the EDBT 2002 Workshops Dao Dinh Khal, Masatoshi Yoshikawa, and Shunsuke Uemura
A Structural Numbering Scheme for XML Data Alfred M. Martin WS2002/2003 February/March 2003 Based on workout made during the EDBT 2002 Workshops Dao Dinh Khal, Masatoshi Yoshikawa, and Shunsuke Uemura
One of the main selling points of a database engine is the ability to make declarative queries---like SQL---that specify what should be done while
 1 One of the main selling points of a database engine is the ability to make declarative queries---like SQL---that specify what should be done while leaving the engine to choose the best way of fulfilling
1 One of the main selling points of a database engine is the ability to make declarative queries---like SQL---that specify what should be done while leaving the engine to choose the best way of fulfilling
An Analysis of Approaches to XML Schema Inference
 An Analysis of Approaches to XML Schema Inference Irena Mlynkova irena.mlynkova@mff.cuni.cz Charles University Faculty of Mathematics and Physics Department of Software Engineering Prague, Czech Republic
An Analysis of Approaches to XML Schema Inference Irena Mlynkova irena.mlynkova@mff.cuni.cz Charles University Faculty of Mathematics and Physics Department of Software Engineering Prague, Czech Republic
Selectively Storing XML Data in Relations
 Selectively Storing XML Data in Relations Wenfei Fan 1 and Lisha Ma 2 1 University of Edinburgh and Bell Laboratories 2 Heriot-Watt University Abstract. This paper presents a new framework for users to
Selectively Storing XML Data in Relations Wenfei Fan 1 and Lisha Ma 2 1 University of Edinburgh and Bell Laboratories 2 Heriot-Watt University Abstract. This paper presents a new framework for users to
Information Technology Department, PCCOE-Pimpri Chinchwad, College of Engineering, Pune, Maharashtra, India 2
 Volume 5, Issue 5, May 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Adaptive Huffman
Volume 5, Issue 5, May 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Adaptive Huffman
An UML-XML-RDB Model Mapping Solution for Facilitating Information Standardization and Sharing in Construction Industry
 An UML-XML-RDB Model Mapping Solution for Facilitating Information Standardization and Sharing in Construction Industry I-Chen Wu 1 and Shang-Hsien Hsieh 2 Department of Civil Engineering, National Taiwan
An UML-XML-RDB Model Mapping Solution for Facilitating Information Standardization and Sharing in Construction Industry I-Chen Wu 1 and Shang-Hsien Hsieh 2 Department of Civil Engineering, National Taiwan
MAXLCA: A NEW QUERY SEMANTIC MODEL FOR XML KEYWORD SEARCH
 Journal of Web Engineering, Vol. 11, No.2 (2012) 131-145 Rinton Press MAXLCA: A NEW QUERY SEMANTIC MODEL FOR XML KEYWORD SEARCH NING GAO, ZHI-HONG DENG, JIA-JIAN JIANG, HANG YU Key Laboratory of Machine
Journal of Web Engineering, Vol. 11, No.2 (2012) 131-145 Rinton Press MAXLCA: A NEW QUERY SEMANTIC MODEL FOR XML KEYWORD SEARCH NING GAO, ZHI-HONG DENG, JIA-JIAN JIANG, HANG YU Key Laboratory of Machine
Supporting Temporal Queries on XML Keyword Search Engines
 Supporting Temporal Queries on XML Keyword Search Engines Edimar Manica 1,3, Carina F. Dorneles 2, Renata Galante 1 1 Universidade Federal do Rio Grande do Sul, Brazil {edimar.manica, galante}@inf.ufrgs.br
Supporting Temporal Queries on XML Keyword Search Engines Edimar Manica 1,3, Carina F. Dorneles 2, Renata Galante 1 1 Universidade Federal do Rio Grande do Sul, Brazil {edimar.manica, galante}@inf.ufrgs.br
Benchmarking the UB-tree
 Benchmarking the UB-tree Michal Krátký, Tomáš Skopal Department of Computer Science, VŠB Technical University of Ostrava, tř. 17. listopadu 15, Ostrava, Czech Republic michal.kratky@vsb.cz, tomas.skopal@vsb.cz
Benchmarking the UB-tree Michal Krátký, Tomáš Skopal Department of Computer Science, VŠB Technical University of Ostrava, tř. 17. listopadu 15, Ostrava, Czech Republic michal.kratky@vsb.cz, tomas.skopal@vsb.cz
XML: Managing with the Java Platform
 In order to learn which questions have been answered correctly: 1. Print these pages. 2. Answer the questions. 3. Send this assessment with the answers via: a. FAX to (212) 967-3498. Or b. Mail the answers
In order to learn which questions have been answered correctly: 1. Print these pages. 2. Answer the questions. 3. Send this assessment with the answers via: a. FAX to (212) 967-3498. Or b. Mail the answers
Indexing and Searching XML Documents based on Content and Structure Synopses
 Indexing and Searching XML Documents based on Content and Structure Synopses Weimin He, Leonidas Fegaras, and David Levine University of Texas at Arlington, CSE Arlington, TX 76019-0015 {weiminhe,fegaras,levine}@cse.uta.edu
Indexing and Searching XML Documents based on Content and Structure Synopses Weimin He, Leonidas Fegaras, and David Levine University of Texas at Arlington, CSE Arlington, TX 76019-0015 {weiminhe,fegaras,levine}@cse.uta.edu
An Implementation of Tree Pattern Matching Algorithms for Enhancement of Query Processing Operations in Large XML Trees
 An Implementation of Tree Pattern Matching Algorithms for Enhancement of Query Processing Operations in Large XML Trees N. Murugesan 1 and R.Santhosh 2 1 PG Scholar, 2 Assistant Professor, Department of
An Implementation of Tree Pattern Matching Algorithms for Enhancement of Query Processing Operations in Large XML Trees N. Murugesan 1 and R.Santhosh 2 1 PG Scholar, 2 Assistant Professor, Department of
Supporting Fuzzy Keyword Search in Databases
 I J C T A, 9(24), 2016, pp. 385-391 International Science Press Supporting Fuzzy Keyword Search in Databases Jayavarthini C.* and Priya S. ABSTRACT An efficient keyword search system computes answers as
I J C T A, 9(24), 2016, pp. 385-391 International Science Press Supporting Fuzzy Keyword Search in Databases Jayavarthini C.* and Priya S. ABSTRACT An efficient keyword search system computes answers as
QuickStack: A Fast Algorithm for XML Query Matching
 QuickStack: A Fast Algorithm for XML Query Matching Iyad Batal Department of Computer Science University of Pittsburgh iyad@cs.pitt.edu Alexandros Labrinidis Department of Computer Science University of
QuickStack: A Fast Algorithm for XML Query Matching Iyad Batal Department of Computer Science University of Pittsburgh iyad@cs.pitt.edu Alexandros Labrinidis Department of Computer Science University of
Evaluating the Role of Context in Syntax Directed Compression of XML Documents
 Evaluating the Role of Context in Syntax Directed Compression of XML Documents S. Hariharan Priti Shankar Department of Computer Science and Automation Indian Institute of Science Bangalore 60012, India
Evaluating the Role of Context in Syntax Directed Compression of XML Documents S. Hariharan Priti Shankar Department of Computer Science and Automation Indian Institute of Science Bangalore 60012, India
4 SAX. XML Application. SAX Parser. callback table. startelement! startelement() characters! 23
 characters! 23") 4 SAX SAX 23 (Simple API for XML) is, unlike DOM, not a W3C standard, but has been developed jointly by members of the XML-DEV mailing list (ca. 1998). SAX processors use constant space, regardless of
4 SAX SAX 23 (Simple API for XML) is, unlike DOM, not a W3C standard, but has been developed jointly by members of the XML-DEV mailing list (ca. 1998). SAX processors use constant space, regardless of
Cohesiveness Relationships to Empower Keyword Search on Tree Data on the Web
 Cohesiveness Relationships to Empower Keyword Search on Tree Data on the Web Aggeliki Dimitriou School of Electrical and Computer Engineering National Technical University of Athens, Greece angela@dblab.ntua.gr
Cohesiveness Relationships to Empower Keyword Search on Tree Data on the Web Aggeliki Dimitriou School of Electrical and Computer Engineering National Technical University of Athens, Greece angela@dblab.ntua.gr
Aggregate Query Processing of Streaming XML Data
 ggregate Query Processing of Streaming XML Data Yaw-Huei Chen and Ming-Chi Ho Department of Computer Science and Information Engineering National Chiayi University {ychen, s0920206@mail.ncyu.edu.tw bstract
ggregate Query Processing of Streaming XML Data Yaw-Huei Chen and Ming-Chi Ho Department of Computer Science and Information Engineering National Chiayi University {ychen, s0920206@mail.ncyu.edu.tw bstract
Template Extraction from Heterogeneous Web Pages
 Template Extraction from Heterogeneous Web Pages 1 Mrs. Harshal H. Kulkarni, 2 Mrs. Manasi k. Kulkarni Asst. Professor, Pune University, (PESMCOE, Pune), Pune, India Abstract: Templates are used by many
Template Extraction from Heterogeneous Web Pages 1 Mrs. Harshal H. Kulkarni, 2 Mrs. Manasi k. Kulkarni Asst. Professor, Pune University, (PESMCOE, Pune), Pune, India Abstract: Templates are used by many
The Benefits of Utilizing Closeness in XML. Curtis Dyreson Utah State University Shuohao Zhang Microsoft, Marvell Hao Jin Expedia.
 The Benefits of Utilizing Closeness in XML Curtis Dyreson Utah State University Shuohao Zhang Microsoft, Marvell Hao Jin Expedia.com Bozen-Bolzano - September 5, 2008 Outline Motivation Tools Polymorphic
The Benefits of Utilizing Closeness in XML Curtis Dyreson Utah State University Shuohao Zhang Microsoft, Marvell Hao Jin Expedia.com Bozen-Bolzano - September 5, 2008 Outline Motivation Tools Polymorphic
Parser Design. Neil Mitchell. June 25, 2004
 Parser Design Neil Mitchell June 25, 2004 1 Introduction A parser is a tool used to split a text stream, typically in some human readable form, into a representation suitable for understanding by a computer.
Parser Design Neil Mitchell June 25, 2004 1 Introduction A parser is a tool used to split a text stream, typically in some human readable form, into a representation suitable for understanding by a computer.