Data Mining. 3.2 Decision Tree Classifier. Fall Instructor: Dr. Masoud Yaghini. Chapter 5: Decision Tree Classifier
|
|
|
- Lucy Hodge
- 5 years ago
- Views:
Transcription
1 Data Mining 3.2 Decision Tree Classifier Fall 2008 Instructor: Dr. Masoud Yaghini
2 Outline Introduction Basic Algorithm for Decision Tree Induction Attribute Selection Measures Information Gain Gain Ratio Gini Index Tree Pruning Scalable Decision Tree Induction Methods References
3 Introduction
4 Decision Tree Induction Decision tree induction is the learning of decision trees from class-labeled training tuples. A decision tree is a flowchart-like tree structure, where each internal node (non-leaf node) denotes a test on an attribute each branch represents an outcome of the test each leaf node (or terminal node) holds a class label. The topmost node in a tree is the root node.
5 An example This example represents the concept buys _computer, that is, it predicts whether a customer at AllElectronics is likely to purchase a computer.
6 An example: Training Dataset
7 An example: A Decision Tree for buys_computer
8 Decision Tree Induction How are decision trees used for classification? Given a tuple, X, for which the associated class label is unknown, The attribute values of the tuple are tested against the decision tree A path is traced from the root to a leaf node, which holds the class prediction for that tuple.
9 Decision Tree Induction Advantages of decision tree The construction of decision tree classifiers does not require any domain knowledge or parameter setting. Decision trees can handle high dimensional data. Easy to interpret for small-sized trees The learning and classification steps of decision tree induction are simple and fast. Accuracy is comparable to other classification techniques for many simple data sets
10 Decision Tree Induction Decision tree induction algorithms have been used for classification in many application areas, such as: Medicine Manufacturing and production Financial analysis Astronomy Molecular biology.
11 Decision Tree Induction Attribute selection measures During tree construction, attribute selection measures are used to select the attribute that best partitions the tuples into distinct classes. Tree pruning When decision trees are built, many of the branches may reflect noise or outliers in the training data. Tree pruning attempts to identify and remove such branches, with the goal of improving classification accuracy on unseen data. Scalability Scalability issues related to the induction of decision trees from large databases.
12 Decision Tree Induction Algorithms ID3 (Iterative Dichotomiser) algorithm Developed by J. Ross Quinlan During the late 1970s and early 1980s C4.5 algorithm Quinlan later presented C4.5 (a successor of ID3) Became a benchmark to which newer supervised learning algorithms are often compared. Commercial successor: C5.0 CART (Classification and Regression Trees) algorithm The generation of binary decision trees Developed by a group of statisticians
13 Decision Tree Induction Algorithms ID3, C4.5, and CART adopt a greedy (i.e., nonbacktracking) approach in which decision trees are constructed in a top-down recursive divide-and-conquer manner. Most algorithms for decision tree induction also follow such a top-down approach, which starts with a training set of tuples and their associated class labels. The training set is recursively partitioned into smaller subsets as the tree is being built.
14 Basic Algorithm for Decision Tree Induction
15 Basic Algorithm for Decision Tree Induction Basic algorithm (a greedy algorithm) Tree is constructed in a top-down recursive divideand-conquer manner At start, all the training examples are at the root Attributes are categorical (if continuous-valued, they are discretized in advance) Examples are partitioned recursively based on selected attributes Test attributes are selected on the basis of a heuristic or statistical measure (e.g., information gain)
16 Basic Algorithm for Decision Tree Induction Conditions for stopping partitioning All samples for a given node belong to the same class There are no remaining attributes for further partitioning majority voting is employed for classifying the leaf There are no samples left
17 Basic Algorithm for Decision Tree Induction
18 Basic Algorithm - Method
19 Basic Algorithm for Decision Tree Induction Step 1 The tree starts as a single node, N, representing the training tuples in D Steps 2 and 3 If the tuples in D are all of the same class, then node N becomes a leaf and is labeled with that class. Steps 4 and 5 steps 4 and 5 are terminating conditions. Allof the terminating conditions are explained at the end of the algorithm.
20 Basic Algorithm for Decision Tree Induction Step 6 the algorithm calls Attribute_selection_method to determine the splitting criterion. The splitting criterion tells us which attribute to test at node N by determining the best way to separate or partition the tuples in D into individual classes The splitting criterion is determined so that, ideally, the resulting partitions at each branch are as pure as possible.
21 Basic Algorithm for Decision Tree Induction Step 7 The node N is labeled with the splitting criterion, which serves as a test at the node Steps 10 to 11 A branch is grown from node N for each of the outcomes of the splitting criterion. The tuples in D are partitioned accordingly
22 Basic Algorithm for Decision Tree Induction Different ways of handling continuous attributes Discretization to form an ordinal categorical attribute Binary Decision: (A < v) or (A v) consider all possible splits and finds the best cut can be more compute intensive
23 Basic Algorithm for Decision Tree Induction Let A be the splitting attribute. A has v distinct values, {a 1, a 2, : : :, a v }, based on the training data. There are three possible scenario for partitioning tuples based on the splitting criterion: a. A is discrete-valued b. A is continuous-valued c. A is discrete-valued and a binary tree must be produced
24 Basic Algorithm for Decision Tree Induction
25 Basic Algorithm for Decision Tree Induction In scenario a (A is discrete-valued ) the outcomes of the test at node N correspond directly to the known values of A. Because all of the tuples in a given partition have the same value for A, then A need not be considered in any future partitioning of the tuples. Therefore, it is removed from attribute_list (steps 8 to 9).
26 Basic Algorithm for Decision Tree Induction Step 14 The algorithm uses the same process recursively to form a decision tree for the tuples at each resulting partition, Dj, of D. Step 15 The resulting decision tree is returned.
27 Basic Algorithm for Decision Tree Induction The recursive partitioning stops only when any one of the following terminating conditions is true: 1. All of the tuples in partition D (represented at node N) belong to the same class (steps 2 and 3) 2. There are no remaining attributes on which the tuples may be further partitioned (step 4). In this case, majority voting is employed (step 5). This involves converting node N into a leaf and labeling it with the most common class in D. 3. There are no tuples for a given branch, that is, a partition Dj is empty (step 12). In this case, a leaf is created with the majority class in D (step 13).
28 Decision Tree Induction Differences in decision tree algorithms include: how the attributes are selected in creating the tree and the mechanisms used for pruning
29 Attribute Selection Measures
30 Attribute Selection Measures Which is the best attribute? Want to get the smallest tree choose the attribute that produces the purest nodes Attribute selection measure An attribute selection measure is a heuristic for selecting the splitting criterion that best separates a given data partition, D, of class-labeled training tuples into individual classes. If we were to split D into smaller partitions according to the outcomes of the splitting criterion, ideally each partition would be pure (i.e., all of the tuples that fall into a given partition would belong to the same class).
31 Attribute Selection Measures Attribute selection measures are also known as splitting rules because they determine how the tuples at a given node are to be split.
32 Attribute Selection Measures The attribute selection measure provides a ranking for each attribute describing the given training tuples. The attribute having the best score for the measure is chosen as the splitting attribute for the given tuples. If the splitting attribute is continuous-valued or if we are restricted to binary trees then, respectively, either a split point or a splitting subset must also be determined as part of the splitting criterion.
33 Attribute Selection Measures This section describes three popular attribute selection measures: Information gain Gain ratio Gini index
34 Attribute Selection Measures The notation used herein is as follows. Let D, the data partition, be a training set of classlabeled tuples. Suppose the class label attribute has m distinct values defining m distinct classes, C i (for i = 1,, m) Let C i,d be the set of tuples of class C i in D. Let D and C i,d denote the number of tuples in D and C i,d, respectively.
35 Information Gain

36 Which attribute to select? Information Gain
37 Information Gain
38 Information Gain Need a measure of node impurity: Non-homogeneous, High degree of impurity Homogeneous, Low degree of impurity
39 Attribute Selection Measures ID3 uses information gain as its attribute selection measure. Let node N represent or hold the tuples of partition D. The attribute with the highest information gain is chosen as the splitting attribute for node N. This attribute minimizes the information needed to classify the tuples in the resulting partitions and reflects impurity in these partitions.
40 Attribute Selection Measures Let p i be the probability that an arbitrary tuple in D belongs to class C i, estimated by C i, D / D Expected information (entropy) needed to classify a tuple in D: Info( D) = p i log 2 ( p m i=11 Info(D) is just the average amount of information needed to identify the class label of a tuple in D. The smaller information required, the greater the purity. The information we have is based solely on the proportions of tuples of each class. A log function to the base 2 is used, because the information is encoded in bits (It is measured in bits). i )
41 Attribute Selection Measures High Entropy means X is from a uniform (boring) distribution Low Entropy means X is from a varied (peaks and valleys) distribution
42 Attribute Selection Measures Information needed (after using A to split D) to classify D: v Dj Info A( D) = Info( D D j= 1 Attribute A can be used to split D into v partitions or subsets, {D1, D2,, Dv}, where Dj contains those tuples in D that have outcome aj of A. This measure tell us how much more information would we still need (after the partitioning) in order to arrive at an exact classification The smaller the expected information (still) required, the greater the purity of the partitions. j )
43 Attribute Selection Measures Information gained by branching on attribute A Gain(A) = Info(D) Info (D) A Information gain increases with the average purity of the subsets Information gain: information needed before splitting information needed after splitting
44 Example: AllElectronics This table presents a training set, D.
45 Example: AllElectronics The class label attribute, buys_computer, has two distinct values (namely, {yes, no}); therefore, there are two distinct classes (that is, m = 2). Let class C1 correspond to yes and class C2 correspond to no. The expected information needed to classify a tuple in D: Info ( D) = I (9,5) = log ( ) log ( ) 14 2 = 0.940
46 Example: AllElectronics Next, we need to compute the expected information requirement for each attribute. Let s start with the attribute age. We need to look at the distribution of yes and no tuples for each category of age. For the age category youth, there are two yes tuples and threeno tuples. For the category middle_aged, there are four yes tuples and zero no tuples. For the category senior, there are three yes tuples and two no tuples.
47 Example: AllElectronics The expected information needed to classify a tuple in D if the tuples are partitioned according to age is Info age ( D) = I (2,3) + I (4,0) + I (3,2)
48 Example: AllElectronics The gain in information from such a partitioning would be Gain( age) = Info( D) Infoage ( D) = = Similarly Gain ( income ) = Gain( student) = Gain( credit _ rating) = bits Because age has the highest information gain among the attributes, it is selected as the splitting attribute.
49 Example: AllElectronics Branches are grown for each outcome of age. The tuples are shown partitioned accordingly.
50 Example: AllElectronics Notice that the tuples falling into the partition for age = middle_aged all belong to the same class. Because they all belong to class yes, a leaf should therefore be created at the end of this branch and labeled with yes.
51 Example: AllElectronics The final decision tree returned by the algorithm
52 Example: Weather Problem

53 Example: Weather Problem
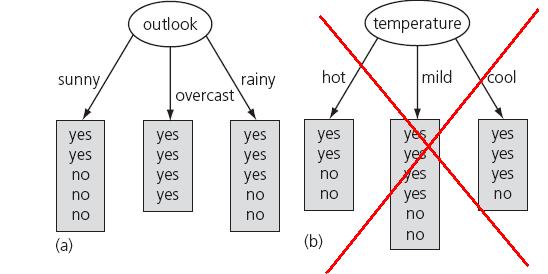
54 Example: Weather Problem attribute Outlook: Info outlook ( D) = I (2,3) + I (4,0) + I (3,2) = Info ( D) = I (9,5) = log ( ) log ( ) 14 2 = 0.940
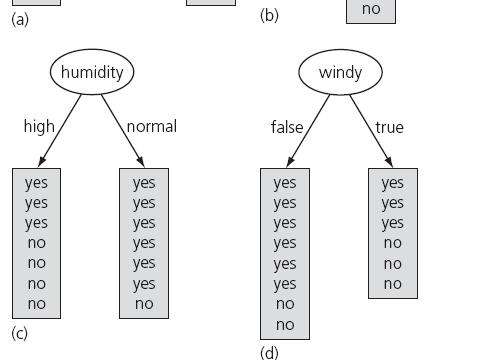
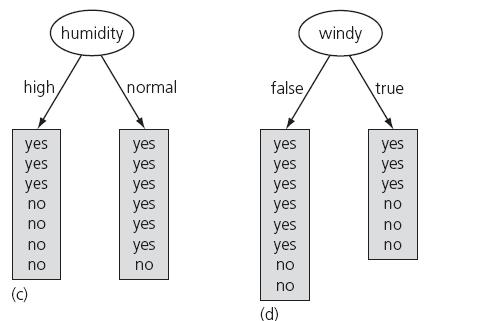
55 Example: Weather Problem Information gain: information before splitting information after splitting: gain(outlook ) = = bits Information gain for attributes from weather data: gain(outlook ) gain(temperature ) gain(humidity ) gain(windy ) = bits = bits = bits = bits
56 Example: Weather Problem Continuing to split

57 Example: Weather Problem Continuing to split

58 Example: Weather Problem Final decision tree
59 Continuous-Value Attributes Let attribute A be a continuous-valued attribute Standard method: binary splits Must determine the best split point for A Sort the value A in increasing order Typically, the midpoint between each pair of adjacent values is considered as a possible split point (a i +a i+1 )/2 is the midpoint between the values of a i and a i+1 Therefore, given v values of A, then v-1 possible splits are evaluated. The point with the minimum expected information requirement for A is selected as the split-point for A
60 Continuous-Value Attributes Split: D1 is the set of tuples in D satisfying A split-point, and D2 is the set of tuples in D satisfying A > splitpoint Split on temperature attribute: E.g. temperature < 71.5: yes/4, no/2 temperature 71.5: yes/5, no/3 Info = 6/14 info([4,2]) + 8/14 info([5,3]) = bits
61 Gain Ratio
62 Problem: Gain ratio When there are attributes with a large number of values Information gain measure is biased towards attributes with a large number of values This may result in selection of an attribute that is nonoptimal for prediction
63 Gain ratio Weather data with ID code
64 Gain ratio Information gain is maximal for ID code (namely bits)
65 Gain ratio Gain ratio a modification of the information gain C4.5 uses gain ratio to overcome the problem Gain ratio applies a kind of normalization to information gain using a split information SplitInfo v D j D j D) = log ( ) j 1 D D A ( 2 = The attribute with the maximum gain ratio is selected as the splitting attribute.
66 Example Gain ratio Computation of gain ratio for the attribute income. A test on income splits the data into three partitions, namely low, medium, and high, containing four, six, and four tuples, respectively. Computation of the gain ratio of income: SplitInfo A ( D) = log ( ) log 2 ( ) log ( ) 14 2 = Gain(income) = GainRatio(income) = 0.029/0.926 = 0.031
67 Gain ratio Gain ratios for weather data
68 Gini Index
69 Gini index Gini Index The Gini index is used in CART. The Gini index measures the impurity of D The Gini index considers a binary split for each attribute. If a data set D contains examples from m classes, gini index, gini(d) is defined as where p i is the relative frequency of class i in D gini ( D) m = 1 p 2 i i= 1
70 Gini Index When considering a binary split, we compute a weighted sum of the impurity of each resulting partition. If a data set D is split on A into two subsets D 1 and D 2, the gini index gini(d) is defined as D 1 D 2 gini A ( D) = gini ( D 1) + gini ( D 2 ) D D The subset that gives the minimum gini index for that attribute is selected as its splitting subset.
71 Gini Index To determine the best binary split on A, we examine all of the possible subsets that can be formed using known values of A. Given a tuple, this test is satisfied if the value of A for the tuple is among the values listed in S A. If A is a discrete-valued attribute having v distinct values, then there are 2 v possible subsets. For continuous-valued attributes, each possible split-point must be considered. The strategy is similar to that described for information gain.
72 Gini Index The reduction in impurity that would be incurred by a binary split on attribute A is gini( A) = gini( D) gini ( D) The attribute that maximizes the reduction in impurity (or, equivalently, has the minimum Gini index) is selected as the splitting attribute. A
73 Example: Gini Index D has 9 tuples in buys_computer = yes and 5 in no The impurity of D: 9 gini( D) = Suppose the attribute income partitions D into 10 in D 1 : {low, medium} and 4 in D =
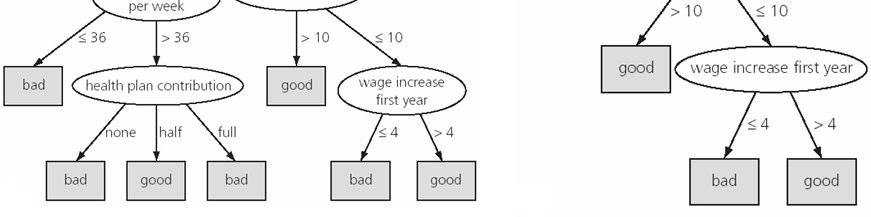
74 Gini Index The attribute income and splitting subset {medium, high} give the minimum gini index overall, with a reduction in impurity of = For continuous-valued attributes May need other tools, e.g., clustering, to get the possible split values Can be modified for categorical attributes
75 Other Attribute Selection Measures Other Attribute Selection Measures CHAID C-SEP G-statistics Which attribute selection measure is the best? Most give good results, none is significantly superior than others
76 Tree Pruning
77 Tree Pruning Overfitting: An induced tree may overfit the training data Too many branches, some may reflect anomalies due to noise or outliers Poor accuracy for unseen samples Tree Pruning To prevent overfitting to noise in the data Pruned trees tend to be smaller and less complex and, thus, easier to comprehend. They are usually faster and better at correctly classifying independent test data.
78 Tree Pruning An unpruned decision tree and a pruned version of it.
79 Tree Pruning Two approaches to avoid overfitting Postpruning take a fully-grown decision tree and remove unreliable branches Postpruning preferred in practice Prepruning stop growing a branch when information becomes unreliable
80 Prepruning Based on statistical significance test Stop growing the tree when there is no statistically significant association between any attribute and the class at a particular node Most popular test: chi-squared test ID3 used chi-squared test in addition to information gain Only statistically significant attributes were allowed to be selected by information gain procedure
81 Postpruning Postpruning: First, build full tree & Then, prune it Two pruning operations: Subtree replacement: Bottom-up To select some subtrees and replace them with single leaves Subtree raising Delete node, Redistribute instances Slower than subtree replacement Possible strategies: error estimation, significance testing,
82 Subtree replacement

83 Subtree raising
84 Scalable Decision Tree Induction Methods
85 Scalable Decision Tree Induction Methods The efficiency of existing decision tree algorithms, such as ID3, C4.5, and CART, has been well established for relatively small data sets. Efficiency becomes an issue of concern when these algorithms are applied to the mining of very large real-world databases. The pioneering decision tree algorithms that we have discussed so far have the restriction that the training tuples should reside in memory.
86 Scalable Decision Tree Induction Methods Algorithms for the induction of decision trees from very large training sets: SLIQ (EDBT 96 Mehta et al.) Builds an index for each attribute and only class list and the current attribute list reside in memory SPRINT (VLDB 96 J. Shafer et al.) Constructs an attribute list data structure PUBLIC (VLDB 98 Rastogi & Shim) Integrates tree splitting and tree pruning: stop growing the tree earlier RainForest (VLDB 98 Gehrke, Ramakrishnan & Ganti) Builds an AVC-list (attribute, value, class label) BOAT (PODS 99 Gehrke, Ganti, Ramakrishnan & Loh) Uses bootstrapping to create several small samples
87 References
88 References J. Han, M. Kamber, Data Mining: Concepts and Techniques, Elsevier Inc. (2006). (Chapter 6) I. H. Witten and E. Frank, Data Mining: Practical Machine Learning Tools and Techniques, 2nd Edition, Elsevier Inc., (Chapter 6)
89 The end
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3
 Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
COMP 465: Data Mining Classification Basics
 Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Extra readings beyond the lecture slides are important:
 1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
Classification with Decision Tree Induction
 Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
Data Mining. 3.3 Rule-Based Classification. Fall Instructor: Dr. Masoud Yaghini. Rule-Based Classification
 Data Mining 3.3 Fall 2008 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rules With Exceptions Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Data Mining 3.3 Fall 2008 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rules With Exceptions Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.4. Spring 2010 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Data Mining Part 5. Prediction 5.4. Spring 2010 Instructor: Dr. Masoud Yaghini Outline Using IF-THEN Rules for Classification Rule Extraction from a Decision Tree 1R Algorithm Sequential Covering Algorithms
Data Mining Practical Machine Learning Tools and Techniques
 Decision trees Extending previous approach: Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank to permit numeric s: straightforward
Decision trees Extending previous approach: Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank to permit numeric s: straightforward
CSE4334/5334 DATA MINING
 CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
Data Mining. Part 2. Data Understanding and Preparation. 2.4 Data Transformation. Spring Instructor: Dr. Masoud Yaghini. Data Transformation
 Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Decision Trees Dr. G. Bharadwaja Kumar VIT Chennai
 Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
Decision Trees Decision Tree Decision Trees (DTs) are a nonparametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target
Machine Learning in Real World: C4.5
 Machine Learning in Real World: C4.5 Industrial-strength algorithms For an algorithm to be useful in a wide range of realworld applications it must: Permit numeric attributes with adaptive discretization
Machine Learning in Real World: C4.5 Industrial-strength algorithms For an algorithm to be useful in a wide range of realworld applications it must: Permit numeric attributes with adaptive discretization
Classification. Instructor: Wei Ding
 Classification Decision Tree Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Preliminaries Each data record is characterized by a tuple (x, y), where x is the attribute
Classification Decision Tree Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Preliminaries Each data record is characterized by a tuple (x, y), where x is the attribute
CS Machine Learning
 CS 60050 Machine Learning Decision Tree Classifier Slides taken from course materials of Tan, Steinbach, Kumar 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K
CS 60050 Machine Learning Decision Tree Classifier Slides taken from course materials of Tan, Steinbach, Kumar 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K
Classification: Basic Concepts, Decision Trees, and Model Evaluation
 Classification: Basic Concepts, Decision Trees, and Model Evaluation Data Warehousing and Mining Lecture 4 by Hossen Asiful Mustafa Classification: Definition Given a collection of records (training set
Classification: Basic Concepts, Decision Trees, and Model Evaluation Data Warehousing and Mining Lecture 4 by Hossen Asiful Mustafa Classification: Definition Given a collection of records (training set
Part I. Instructor: Wei Ding
 Classification Part I Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Classification: Definition Given a collection of records (training set ) Each record contains a set
Classification Part I Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Classification: Definition Given a collection of records (training set ) Each record contains a set
Lecture outline. Decision-tree classification
 Lecture outline Decision-tree classification Decision Trees Decision tree A flow-chart-like tree structure Internal node denotes a test on an attribute Branch represents an outcome of the test Leaf nodes
Lecture outline Decision-tree classification Decision Trees Decision tree A flow-chart-like tree structure Internal node denotes a test on an attribute Branch represents an outcome of the test Leaf nodes
Data Mining Classification - Part 1 -
 Data Mining Classification - Part 1 - Universität Mannheim Bizer: Data Mining I FSS2019 (Version: 20.2.2018) Slide 1 Outline 1. What is Classification? 2. K-Nearest-Neighbors 3. Decision Trees 4. Model
Data Mining Classification - Part 1 - Universität Mannheim Bizer: Data Mining I FSS2019 (Version: 20.2.2018) Slide 1 Outline 1. What is Classification? 2. K-Nearest-Neighbors 3. Decision Trees 4. Model
Classification: Decision Trees
 Metodologie per Sistemi Intelligenti Classification: Decision Trees Prof. Pier Luca Lanzi Laurea in Ingegneria Informatica Politecnico di Milano Polo regionale di Como Lecture outline What is a decision
Metodologie per Sistemi Intelligenti Classification: Decision Trees Prof. Pier Luca Lanzi Laurea in Ingegneria Informatica Politecnico di Milano Polo regionale di Como Lecture outline What is a decision
Example of DT Apply Model Example Learn Model Hunt s Alg. Measures of Node Impurity DT Examples and Characteristics. Classification.
 lassification-decision Trees, Slide 1/56 Classification Decision Trees Huiping Cao lassification-decision Trees, Slide 2/56 Examples of a Decision Tree Tid Refund Marital Status Taxable Income Cheat 1
lassification-decision Trees, Slide 1/56 Classification Decision Trees Huiping Cao lassification-decision Trees, Slide 2/56 Examples of a Decision Tree Tid Refund Marital Status Taxable Income Cheat 1
Decision Tree Learning
 Decision Tree Learning Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata August 25, 2014 Example: Age, Income and Owning a flat Monthly income (thousand rupees) 250 200 150
Decision Tree Learning Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata August 25, 2014 Example: Age, Income and Owning a flat Monthly income (thousand rupees) 250 200 150
Classification and Prediction
 Objectives Introduction What is Classification? Classification vs Prediction Supervised and Unsupervised Learning D t P Data Preparation ti Classification Accuracy ID3 Algorithm Information Gain Bayesian
Objectives Introduction What is Classification? Classification vs Prediction Supervised and Unsupervised Learning D t P Data Preparation ti Classification Accuracy ID3 Algorithm Information Gain Bayesian
Data Mining in Bioinformatics Day 1: Classification
 Data Mining in Bioinformatics Day 1: Classification Karsten Borgwardt February 18 to March 1, 2013 Machine Learning & Computational Biology Research Group Max Planck Institute Tübingen and Eberhard Karls
Data Mining in Bioinformatics Day 1: Classification Karsten Borgwardt February 18 to March 1, 2013 Machine Learning & Computational Biology Research Group Max Planck Institute Tübingen and Eberhard Karls
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018
![MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018](/thumbs/77/76295965.jpg "MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018") MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
7. Decision or classification trees
 7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
Decision tree learning
 Decision tree learning Andrea Passerini passerini@disi.unitn.it Machine Learning Learning the concept Go to lesson OUTLOOK Rain Overcast Sunny TRANSPORTATION LESSON NO Uncovered Covered Theoretical Practical
Decision tree learning Andrea Passerini passerini@disi.unitn.it Machine Learning Learning the concept Go to lesson OUTLOOK Rain Overcast Sunny TRANSPORTATION LESSON NO Uncovered Covered Theoretical Practical
Machine Learning. Decision Trees. Le Song /15-781, Spring Lecture 6, September 6, 2012 Based on slides from Eric Xing, CMU
 Machine Learning 10-701/15-781, Spring 2008 Decision Trees Le Song Lecture 6, September 6, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 1.6, CB & Chap 3, TM Learning non-linear functions f:
Machine Learning 10-701/15-781, Spring 2008 Decision Trees Le Song Lecture 6, September 6, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 1.6, CB & Chap 3, TM Learning non-linear functions f:
Data Mining. 3.5 Lazy Learners (Instance-Based Learners) Fall Instructor: Dr. Masoud Yaghini. Lazy Learners
 Fall Instructor: Dr. Masoud Yaghini. Lazy Learners") Data Mining 3.5 (Instance-Based Learners) Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction k-nearest-neighbor Classifiers References Introduction Introduction Lazy vs. eager learning Eager
Data Mining 3.5 (Instance-Based Learners) Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction k-nearest-neighbor Classifiers References Introduction Introduction Lazy vs. eager learning Eager
Credit card Fraud Detection using Predictive Modeling: a Review
 February 207 IJIRT Volume 3 Issue 9 ISSN: 2396002 Credit card Fraud Detection using Predictive Modeling: a Review Varre.Perantalu, K. BhargavKiran 2 PG Scholar, CSE, Vishnu Institute of Technology, Bhimavaram,
February 207 IJIRT Volume 3 Issue 9 ISSN: 2396002 Credit card Fraud Detection using Predictive Modeling: a Review Varre.Perantalu, K. BhargavKiran 2 PG Scholar, CSE, Vishnu Institute of Technology, Bhimavaram,
Analysis of Various Decision Tree Algorithms for Classification in Data Mining
 Volume 163 No 8, April 017 Analysis of Various Decision Tree Algorithms for Classification in Data Mining Bhumika Gupta, PhD Assistant Professor, C.S.E.D Arpit Arora Aditya Rawat Naresh Dhami Akshay Jain
Volume 163 No 8, April 017 Analysis of Various Decision Tree Algorithms for Classification in Data Mining Bhumika Gupta, PhD Assistant Professor, C.S.E.D Arpit Arora Aditya Rawat Naresh Dhami Akshay Jain
Implementierungstechniken für Hauptspeicherdatenbanksysteme Classification: Decision Trees
 Implementierungstechniken für Hauptspeicherdatenbanksysteme Classification: Decision Trees Dominik Vinan February 6, 2018 Abstract Decision Trees are a well-known part of most modern Machine Learning toolboxes.
Implementierungstechniken für Hauptspeicherdatenbanksysteme Classification: Decision Trees Dominik Vinan February 6, 2018 Abstract Decision Trees are a well-known part of most modern Machine Learning toolboxes.
Decision Tree CE-717 : Machine Learning Sharif University of Technology
 Decision Tree CE-717 : Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Some slides have been adapted from: Prof. Tom Mitchell Decision tree Approximating functions of usually discrete
Decision Tree CE-717 : Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Some slides have been adapted from: Prof. Tom Mitchell Decision tree Approximating functions of usually discrete
Basic Data Mining Technique
 Basic Data Mining Technique What is classification? What is prediction? Supervised and Unsupervised Learning Decision trees Association rule K-nearest neighbor classifier Case-based reasoning Genetic algorithm
Basic Data Mining Technique What is classification? What is prediction? Supervised and Unsupervised Learning Decision trees Association rule K-nearest neighbor classifier Case-based reasoning Genetic algorithm
Decision trees. Decision trees are useful to a large degree because of their simplicity and interpretability
 Decision trees A decision tree is a method for classification/regression that aims to ask a few relatively simple questions about an input and then predicts the associated output Decision trees are useful
Decision trees A decision tree is a method for classification/regression that aims to ask a few relatively simple questions about an input and then predicts the associated output Decision trees are useful
Lecture 7: Decision Trees
 Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand).
.") http://waikato.researchgateway.ac.nz/ Research Commons at the University of Waikato Copyright Statement: The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand). The thesis
http://waikato.researchgateway.ac.nz/ Research Commons at the University of Waikato Copyright Statement: The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand). The thesis
CLASSIFICATION OF C4.5 AND CART ALGORITHMS USING DECISION TREE METHOD
 CLASSIFICATION OF C4.5 AND CART ALGORITHMS USING DECISION TREE METHOD Khin Lay Myint 1, Aye Aye Cho 2, Aye Mon Win 3 1 Lecturer, Faculty of Information Science, University of Computer Studies, Hinthada,
CLASSIFICATION OF C4.5 AND CART ALGORITHMS USING DECISION TREE METHOD Khin Lay Myint 1, Aye Aye Cho 2, Aye Mon Win 3 1 Lecturer, Faculty of Information Science, University of Computer Studies, Hinthada,
Data Mining Lecture 8: Decision Trees
 Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
ISSUES IN DECISION TREE LEARNING
 ISSUES IN DECISION TREE LEARNING Handling Continuous Attributes Other attribute selection measures Overfitting-Pruning Handling of missing values Incremental Induction of Decision Tree 1 DECISION TREE
ISSUES IN DECISION TREE LEARNING Handling Continuous Attributes Other attribute selection measures Overfitting-Pruning Handling of missing values Incremental Induction of Decision Tree 1 DECISION TREE
PUBLIC: A Decision Tree Classifier that Integrates Building and Pruning
 Data Mining and Knowledge Discovery, 4, 315 344, 2000 c 2000 Kluwer Academic Publishers. Manufactured in The Netherlands. PUBLIC: A Decision Tree Classifier that Integrates Building and Pruning RAJEEV
Data Mining and Knowledge Discovery, 4, 315 344, 2000 c 2000 Kluwer Academic Publishers. Manufactured in The Netherlands. PUBLIC: A Decision Tree Classifier that Integrates Building and Pruning RAJEEV
Classification/Regression Trees and Random Forests
 Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
Data Mining Practical Machine Learning Tools and Techniques. Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank
 Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank Implementation: Real machine learning schemes Decision trees Classification
Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank Implementation: Real machine learning schemes Decision trees Classification
Additive Models, Trees, etc. Based in part on Chapter 9 of Hastie, Tibshirani, and Friedman David Madigan
 Additive Models, Trees, etc. Based in part on Chapter 9 of Hastie, Tibshirani, and Friedman David Madigan Predictive Modeling Goal: learn a mapping: y = f(x;θ) Need: 1. A model structure 2. A score function
Additive Models, Trees, etc. Based in part on Chapter 9 of Hastie, Tibshirani, and Friedman David Madigan Predictive Modeling Goal: learn a mapping: y = f(x;θ) Need: 1. A model structure 2. A score function
Nearest neighbor classification DSE 220
 Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Notes based on: Data Mining for Business Intelligence
 Chapter 9 Classification and Regression Trees Roger Bohn April 2017 Notes based on: Data Mining for Business Intelligence 1 Shmueli, Patel & Bruce 2 3 II. Results and Interpretation There are 1183 auction
Chapter 9 Classification and Regression Trees Roger Bohn April 2017 Notes based on: Data Mining for Business Intelligence 1 Shmueli, Patel & Bruce 2 3 II. Results and Interpretation There are 1183 auction
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Classification (Basic Concepts) Huan Sun, CSE@The Ohio State University 09/12/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han Classification: Basic Concepts
CSE 5243 INTRO. TO DATA MINING Classification (Basic Concepts) Huan Sun, CSE@The Ohio State University 09/12/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han Classification: Basic Concepts
Classification and Regression Trees
 Classification and Regression Trees Matthew S. Shotwell, Ph.D. Department of Biostatistics Vanderbilt University School of Medicine Nashville, TN, USA March 16, 2018 Introduction trees partition feature
Classification and Regression Trees Matthew S. Shotwell, Ph.D. Department of Biostatistics Vanderbilt University School of Medicine Nashville, TN, USA March 16, 2018 Introduction trees partition feature
Data Warehousing & Data Mining
 Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Summary Last week: Sequence Patterns: Generalized
Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Summary Last week: Sequence Patterns: Generalized
Lecture 5: Decision Trees (Part II)
") Lecture 5: Decision Trees (Part II) Dealing with noise in the data Overfitting Pruning Dealing with missing attribute values Dealing with attributes with multiple values Integrating costs into node choice
Lecture 5: Decision Trees (Part II) Dealing with noise in the data Overfitting Pruning Dealing with missing attribute values Dealing with attributes with multiple values Integrating costs into node choice
Decision Tree Learning
 Decision Tree Learning 1 Simple example of object classification Instances Size Color Shape C(x) x1 small red circle positive x2 large red circle positive x3 small red triangle negative x4 large blue circle
Decision Tree Learning 1 Simple example of object classification Instances Size Color Shape C(x) x1 small red circle positive x2 large red circle positive x3 small red triangle negative x4 large blue circle
Chapter ML:III. III. Decision Trees. Decision Trees Basics Impurity Functions Decision Tree Algorithms Decision Tree Pruning
 Chapter ML:III III. Decision Trees Decision Trees Basics Impurity Functions Decision Tree Algorithms Decision Tree Pruning ML:III-67 Decision Trees STEIN/LETTMANN 2005-2017 ID3 Algorithm [Quinlan 1986]
Chapter ML:III III. Decision Trees Decision Trees Basics Impurity Functions Decision Tree Algorithms Decision Tree Pruning ML:III-67 Decision Trees STEIN/LETTMANN 2005-2017 ID3 Algorithm [Quinlan 1986]
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Model Evaluation
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Model Evaluation
Ensemble Methods, Decision Trees
 CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
9/6/14. Our first learning algorithm. Comp 135 Introduction to Machine Learning and Data Mining. knn Algorithm. knn Algorithm (simple form)
") Comp 135 Introduction to Machine Learning and Data Mining Our first learning algorithm How would you classify the next example? Fall 2014 Professor: Roni Khardon Computer Science Tufts University o o o
Comp 135 Introduction to Machine Learning and Data Mining Our first learning algorithm How would you classify the next example? Fall 2014 Professor: Roni Khardon Computer Science Tufts University o o o
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Classification: Decision Trees
 Classification: Decision Trees IST557 Data Mining: Techniques and Applications Jessie Li, Penn State University 1 Decision Tree Example Will a pa)ent have high-risk based on the ini)al 24-hour observa)on?
Classification: Decision Trees IST557 Data Mining: Techniques and Applications Jessie Li, Penn State University 1 Decision Tree Example Will a pa)ent have high-risk based on the ini)al 24-hour observa)on?
Introduction to Machine Learning
 Introduction to Machine Learning Decision Tree Example Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short} Class: Country = {Gromland, Polvia} CS4375 --- Fall 2018 a
Introduction to Machine Learning Decision Tree Example Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short} Class: Country = {Gromland, Polvia} CS4375 --- Fall 2018 a
Chapter 4: Algorithms CS 795
 Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
Supervised Learning. Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression...
 Supervised Learning Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression... Supervised Learning y=f(x): true function (usually not known) D: training
Supervised Learning Decision trees Artificial neural nets K-nearest neighbor Support vectors Linear regression Logistic regression... Supervised Learning y=f(x): true function (usually not known) D: training
Classification and Regression
 Classification and Regression Announcements Study guide for exam is on the LMS Sample exam will be posted by Monday Reminder that phase 3 oral presentations are being held next week during workshops Plan
Classification and Regression Announcements Study guide for exam is on the LMS Sample exam will be posted by Monday Reminder that phase 3 oral presentations are being held next week during workshops Plan
8. Tree-based approaches
 Foundations of Machine Learning École Centrale Paris Fall 2015 8. Tree-based approaches Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr
Foundations of Machine Learning École Centrale Paris Fall 2015 8. Tree-based approaches Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr
BITS F464: MACHINE LEARNING
 BITS F464: MACHINE LEARNING Lecture-16: Decision Tree (contd.) + Random Forest Dr. Kamlesh Tiwari Assistant Professor Department of Computer Science and Information Systems Engineering, BITS Pilani, Rajasthan-333031
BITS F464: MACHINE LEARNING Lecture-16: Decision Tree (contd.) + Random Forest Dr. Kamlesh Tiwari Assistant Professor Department of Computer Science and Information Systems Engineering, BITS Pilani, Rajasthan-333031
International Journal of Software and Web Sciences (IJSWS)
") International Association of Scientific Innovation and Research (IASIR) (An Association Unifying the Sciences, Engineering, and Applied Research) ISSN (Print): 2279-0063 ISSN (Online): 2279-0071 International
International Association of Scientific Innovation and Research (IASIR) (An Association Unifying the Sciences, Engineering, and Applied Research) ISSN (Print): 2279-0063 ISSN (Online): 2279-0071 International
Outline. RainForest A Framework for Fast Decision Tree Construction of Large Datasets. Introduction. Introduction. Introduction (cont d)
") Outline RainForest A Framework for Fast Decision Tree Construction of Large Datasets resented by: ov. 25, 2004 1. 2. roblem Definition 3. 4. Family of Algorithms 5. 6. 2 Classification is an important
Outline RainForest A Framework for Fast Decision Tree Construction of Large Datasets resented by: ov. 25, 2004 1. 2. roblem Definition 3. 4. Family of Algorithms 5. 6. 2 Classification is an important
A Systematic Overview of Data Mining Algorithms
 A Systematic Overview of Data Mining Algorithms 1 Data Mining Algorithm A well-defined procedure that takes data as input and produces output as models or patterns well-defined: precisely encoded as a
A Systematic Overview of Data Mining Algorithms 1 Data Mining Algorithm A well-defined procedure that takes data as input and produces output as models or patterns well-defined: precisely encoded as a
Business Club. Decision Trees
 Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Advanced learning algorithms
 Advanced learning algorithms Extending decision trees; Extraction of good classification rules; Support vector machines; Weighted instance-based learning; Design of Model Tree Clustering Association Mining
Advanced learning algorithms Extending decision trees; Extraction of good classification rules; Support vector machines; Weighted instance-based learning; Design of Model Tree Clustering Association Mining
Lars Schmidt-Thieme, Information Systems and Machine Learning Lab (ISMLL), University of Hildesheim, Germany
, University of Hildesheim, Germany") Syllabus Fri. 27.10. (1) 0. Introduction A. Supervised Learning: Linear Models & Fundamentals Fri. 3.11. (2) A.1 Linear Regression Fri. 10.11. (3) A.2 Linear Classification Fri. 17.11. (4) A.3 Regularization
Syllabus Fri. 27.10. (1) 0. Introduction A. Supervised Learning: Linear Models & Fundamentals Fri. 3.11. (2) A.1 Linear Regression Fri. 10.11. (3) A.2 Linear Classification Fri. 17.11. (4) A.3 Regularization
Chapter 4: Algorithms CS 795
 Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
Chapter 4: Algorithms CS 795 Inferring Rudimentary Rules 1R Single rule one level decision tree Pick each attribute and form a single level tree without overfitting and with minimal branches Pick that
Induction of Decision Trees
 Induction of Decision Trees Blaž Zupan and Ivan Bratko magixfriuni-ljsi/predavanja/uisp An Example Data Set and Decision Tree # Attribute Class Outlook Company Sailboat Sail? 1 sunny big small yes 2 sunny
Induction of Decision Trees Blaž Zupan and Ivan Bratko magixfriuni-ljsi/predavanja/uisp An Example Data Set and Decision Tree # Attribute Class Outlook Company Sailboat Sail? 1 sunny big small yes 2 sunny
Machine Learning. Decision Trees. Manfred Huber
 Machine Learning Decision Trees Manfred Huber 2015 1 Decision Trees Classifiers covered so far have been Non-parametric (KNN) Probabilistic with independence (Naïve Bayes) Linear in features (Logistic
Machine Learning Decision Trees Manfred Huber 2015 1 Decision Trees Classifiers covered so far have been Non-parametric (KNN) Probabilistic with independence (Naïve Bayes) Linear in features (Logistic
Data Mining. Decision Tree. Hamid Beigy. Sharif University of Technology. Fall 1396
 Data Mining Decision Tree Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 24 Table of contents 1 Introduction 2 Decision tree
Data Mining Decision Tree Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 24 Table of contents 1 Introduction 2 Decision tree
What Is Data Mining? CMPT 354: Database I -- Data Mining 2
 Data Mining What Is Data Mining? Mining data mining knowledge Data mining is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data CMPT
Data Mining What Is Data Mining? Mining data mining knowledge Data mining is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data CMPT
Improved Post Pruning of Decision Trees
 IJSRD - International Journal for Scientific Research & Development Vol. 3, Issue 02, 2015 ISSN (online): 2321-0613 Improved Post Pruning of Decision Trees Roopa C 1 A. Thamaraiselvi 2 S. Preethi Lakshmi
IJSRD - International Journal for Scientific Research & Development Vol. 3, Issue 02, 2015 ISSN (online): 2321-0613 Improved Post Pruning of Decision Trees Roopa C 1 A. Thamaraiselvi 2 S. Preethi Lakshmi
ARTIFICIAL INTELLIGENCE (CS 370D)
") Princess Nora University Faculty of Computer & Information Systems ARTIFICIAL INTELLIGENCE (CS 370D) (CHAPTER-18) LEARNING FROM EXAMPLES DECISION TREES Outline 1- Introduction 2- know your data 3- Classification
Princess Nora University Faculty of Computer & Information Systems ARTIFICIAL INTELLIGENCE (CS 370D) (CHAPTER-18) LEARNING FROM EXAMPLES DECISION TREES Outline 1- Introduction 2- know your data 3- Classification
(Classification and Prediction)
") Tamkang University Big Data Mining Tamkang University (Classification and Prediction) 1062DM04 MI4 (M2244) (2995) Wed, 9, 10 (16:10-18:00) (B206) Min-Yuh Day Assistant Professor Dept. of Information Management,
Tamkang University Big Data Mining Tamkang University (Classification and Prediction) 1062DM04 MI4 (M2244) (2995) Wed, 9, 10 (16:10-18:00) (B206) Min-Yuh Day Assistant Professor Dept. of Information Management,
Performance Analysis of Classifying Unlabeled Data from Multiple Data Sources
 Performance Analysis of Classifying Unlabeled Data from Multiple Data Sources M.JEEVAN BABU, K. SUVARNA VANI * Department of Computer Science and Engineering V. R. Siddhartha Engineering College, Vijayawada,
Performance Analysis of Classifying Unlabeled Data from Multiple Data Sources M.JEEVAN BABU, K. SUVARNA VANI * Department of Computer Science and Engineering V. R. Siddhartha Engineering College, Vijayawada,
Data Preprocessing. Slides by: Shree Jaswal
 Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
A Systematic Overview of Data Mining Algorithms. Sargur Srihari University at Buffalo The State University of New York
 A Systematic Overview of Data Mining Algorithms Sargur Srihari University at Buffalo The State University of New York 1 Topics Data Mining Algorithm Definition Example of CART Classification Iris, Wine
A Systematic Overview of Data Mining Algorithms Sargur Srihari University at Buffalo The State University of New York 1 Topics Data Mining Algorithm Definition Example of CART Classification Iris, Wine
Artificial Intelligence. Programming Styles
 Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Nesnelerin İnternetinde Veri Analizi
 Nesnelerin İnternetinde Veri Analizi Bölüm 3. Classification in Data Streams w3.gazi.edu.tr/~suatozdemir Supervised vs. Unsupervised Learning (1) Supervised learning (classification) Supervision: The training
Nesnelerin İnternetinde Veri Analizi Bölüm 3. Classification in Data Streams w3.gazi.edu.tr/~suatozdemir Supervised vs. Unsupervised Learning (1) Supervised learning (classification) Supervision: The training
An introduction to random forests
 An introduction to random forests Eric Debreuve / Team Morpheme Institutions: University Nice Sophia Antipolis / CNRS / Inria Labs: I3S / Inria CRI SA-M / ibv Outline Machine learning Decision tree Random
An introduction to random forests Eric Debreuve / Team Morpheme Institutions: University Nice Sophia Antipolis / CNRS / Inria Labs: I3S / Inria CRI SA-M / ibv Outline Machine learning Decision tree Random
Machine Learning. A. Supervised Learning A.7. Decision Trees. Lars Schmidt-Thieme
 Machine Learning A. Supervised Learning A.7. Decision Trees Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany 1 /
Machine Learning A. Supervised Learning A.7. Decision Trees Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany 1 /
Exam Advanced Data Mining Date: Time:
 Exam Advanced Data Mining Date: 11-11-2010 Time: 13.30-16.30 General Remarks 1. You are allowed to consult 1 A4 sheet with notes written on both sides. 2. Always show how you arrived at the result of your
Exam Advanced Data Mining Date: 11-11-2010 Time: 13.30-16.30 General Remarks 1. You are allowed to consult 1 A4 sheet with notes written on both sides. 2. Always show how you arrived at the result of your
MIT Samberg Center Cambridge, MA, USA. May 30 th June 2 nd, by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA
 Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
What is Learning? CS 343: Artificial Intelligence Machine Learning. Raymond J. Mooney. Problem Solving / Planning / Control.
 What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
An Information-Theoretic Approach to the Prepruning of Classification Rules
 An Information-Theoretic Approach to the Prepruning of Classification Rules Max Bramer University of Portsmouth, Portsmouth, UK Abstract: Keywords: The automatic induction of classification rules from
An Information-Theoretic Approach to the Prepruning of Classification Rules Max Bramer University of Portsmouth, Portsmouth, UK Abstract: Keywords: The automatic induction of classification rules from
Algorithms: Decision Trees
 Algorithms: Decision Trees A small dataset: Miles Per Gallon Suppose we want to predict MPG From the UCI repository A Decision Stump Recursion Step Records in which cylinders = 4 Records in which cylinders
Algorithms: Decision Trees A small dataset: Miles Per Gallon Suppose we want to predict MPG From the UCI repository A Decision Stump Recursion Step Records in which cylinders = 4 Records in which cylinders
Lecture 19: Decision trees
 Lecture 19: Decision trees Reading: Section 8.1 STATS 202: Data mining and analysis November 10, 2017 1 / 17 Decision trees, 10,000 foot view R2 R5 t4 1. Find a partition of the space of predictors. X2
Lecture 19: Decision trees Reading: Section 8.1 STATS 202: Data mining and analysis November 10, 2017 1 / 17 Decision trees, 10,000 foot view R2 R5 t4 1. Find a partition of the space of predictors. X2
CMPUT 391 Database Management Systems. Data Mining. Textbook: Chapter (without 17.10)
") CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
Data Mining Part 3. Associations Rules
 Data Mining Part 3. Associations Rules 3.2 Efficient Frequent Itemset Mining Methods Fall 2009 Instructor: Dr. Masoud Yaghini Outline Apriori Algorithm Generating Association Rules from Frequent Itemsets
Data Mining Part 3. Associations Rules 3.2 Efficient Frequent Itemset Mining Methods Fall 2009 Instructor: Dr. Masoud Yaghini Outline Apriori Algorithm Generating Association Rules from Frequent Itemsets
Data Science with R. Decision Trees.
 http: // togaware. com Copyright 2014, Graham.Williams@togaware.com 1/46 Data Science with R Decision Trees Graham.Williams@togaware.com Data Scientist Australian Taxation O Adjunct Professor, Australian
http: // togaware. com Copyright 2014, Graham.Williams@togaware.com 1/46 Data Science with R Decision Trees Graham.Williams@togaware.com Data Scientist Australian Taxation O Adjunct Professor, Australian
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Lecture 10 - Classification trees Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey
Knowledge Discovery and Data Mining Lecture 10 - Classification trees Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey
Analytical model A structure and process for analyzing a dataset. For example, a decision tree is a model for the classification of a dataset.
 Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
SOCIAL MEDIA MINING. Data Mining Essentials
 SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
Lecture 2 :: Decision Trees Learning
 Lecture 2 :: Decision Trees Learning 1 / 62 Designing a learning system What to learn? Learning setting. Learning mechanism. Evaluation. 2 / 62 Prediction task Figure 1: Prediction task :: Supervised learning
Lecture 2 :: Decision Trees Learning 1 / 62 Designing a learning system What to learn? Learning setting. Learning mechanism. Evaluation. 2 / 62 Prediction task Figure 1: Prediction task :: Supervised learning
Cse634 DATA MINING TEST REVIEW. Professor Anita Wasilewska Computer Science Department Stony Brook University
 Cse634 DATA MINING TEST REVIEW Professor Anita Wasilewska Computer Science Department Stony Brook University Preprocessing stage Preprocessing: includes all the operations that have to be performed before
Cse634 DATA MINING TEST REVIEW Professor Anita Wasilewska Computer Science Department Stony Brook University Preprocessing stage Preprocessing: includes all the operations that have to be performed before
Classification and Regression Trees
 Classification and Regression Trees David S. Rosenberg New York University April 3, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 April 3, 2018 1 / 51 Contents 1 Trees 2 Regression
Classification and Regression Trees David S. Rosenberg New York University April 3, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 April 3, 2018 1 / 51 Contents 1 Trees 2 Regression
The Curse of Dimensionality
 The Curse of Dimensionality ACAS 2002 p1/66 Curse of Dimensionality The basic idea of the curse of dimensionality is that high dimensional data is difficult to work with for several reasons: Adding more
The Curse of Dimensionality ACAS 2002 p1/66 Curse of Dimensionality The basic idea of the curse of dimensionality is that high dimensional data is difficult to work with for several reasons: Adding more
DATA MINING LECTURE 9. Classification Basic Concepts Decision Trees Evaluation
 DATA MINING LECTURE 9 Classification Basic Concepts Decision Trees Evaluation What is a hipster? Examples of hipster look A hipster is defined by facial hair Hipster or Hippie? Facial hair alone is not
DATA MINING LECTURE 9 Classification Basic Concepts Decision Trees Evaluation What is a hipster? Examples of hipster look A hipster is defined by facial hair Hipster or Hippie? Facial hair alone is not