Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391
|
|
|
- Marianna Hicks
- 5 years ago
- Views:
Transcription


1 Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391
2 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2
3 Big Data In information technology, big data is a collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications. 3

 experiments represent about 150 million sensors delivering data 40 million times per second.")

4 Big Data Examples Astronomy atmospheric science satellite imagery medical records Genomics biological Biogeochemical social networks social data web logs photography archives video archives Internet text and documents Internet search indexing web server logs sensor networks RFID call detail records large-scale e- commerce traffic flow sensors Industry Marketing banking transactions scans of government documents, military surveillance The Large Hadron Collider (LHC) experiments represent about 150 million sensors delivering data 40 million times per second. this is equivalent to 500 quintillion ( ) bytes per day. Decoding the human genome originally took 10 years to process; now it can be achieved in one week. The NASA Center for Climate Simulation (NCCS) stores 32 petabytes of climate observations and simulations. 4

5 Social Media 5

6 Facebook 6
7 Facebook Facebook Announces Monthly Active Users Were At 1.01 Billion As Of September 30 th An Increase Of 26% Year-Over-Year 7


8 Facebook 8


9 Twitter 9
10 General Internet statistics 2012 In one day on the Internet: Enough information is consumed to fill 168 million DVDs 294 billion s are sent 2 million blog posts are written (enough posts to fill TIME magazine for 770 million years) 250 million photos are uploaded 864,000 hours of video are uploaded to YouTube 4.7 billion minutes are spent on Facebook 532 million statuses are updated 22 million hours of tv and movies are watched on Netflix More than 35 million apps are downloaded More iphones are sold than people are born 172 million people visit Facebook 40 million visit Twitter 22 million visit LinkedIn 20 million visit Google+ 17 million visit Pinterest 10
11 The three Vs of Big Data Are commonly used to characterize different aspects of big data: Volume Processing large amounts of information is the main attraction of big data analytics The most immediate challenge to conventional IT structures It calls for scalable storage, and a distributed approach to querying Velocity Industry terminology for such fast-moving data tends to be either streaming data, or complex event processing. There are two main reasons to consider streaming processing when the input data are too fast to store in their entirety where the application mandates immediate response to the data Variety A common theme in big data systems is that the source data is diverse, and doesn t fall into neat relational structures text from social networks, image data, a raw feed directly from a sensor source 11
12 Challenges with traditional storage They work very well, but since they are vertically scaled, as the amount of data / users increases, the performance quickly degrades. In order to increase performance: either very expensive software and hardware have to be bought, or some of RDBMS advantages have to be dropped. Big Data solutions were born to solve 2 issues classic databases were not able to: Being really very scalable at low cost Being able to work with non-modeled and non-structured data (i.e. internet data originally) 12

13 non-structured data 13

14 To design this new family of solutions, the word NoSQL has been invented and used for the first time in NoSQL doesn t mean No SQL, but Not only SQL! And the SQL word represents the relational databases, not the SQL language. Using the No SQL expression may be confusing, but it sounds really good, and this is why it is still used today. is a broad class of database management systems. NoSQL databases are not built primarily on tables, and generally do not use SQL for data manipulation. read/write latency of a NoSQL database like Cassandra can be up to 30 times faster than that of an equivalent relational database like MySQL when both databases are loaded with 50+GB of data
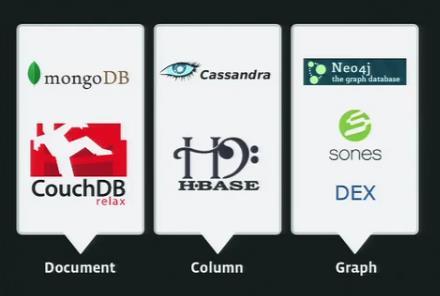
15 NOSQL IMPLEMENTATIONS 15

16 The most well known technology used for Big Data is Hadoop 16
17 The Solution for the Big Data We are looking at newer programming models Supporting algorithms and data structures h 17

18 History Google's MapReduce and Google File System (GFS) papers, and Hadoop is derived from these papers 18

 (HDFS) The two major components of")
19 The Solution for the Big Data But those are not open source So Doug Cutting created the open source version named Hadoop programming models A programming model called MapReduce Google's for processing MapReduce big-data Supporting algorithms and data structures A supporting file system called HadoopGoogle Distributed File System File System (GFS) (HDFS) The two major components of Hadoop h 19

20 Storage: HDFS 20

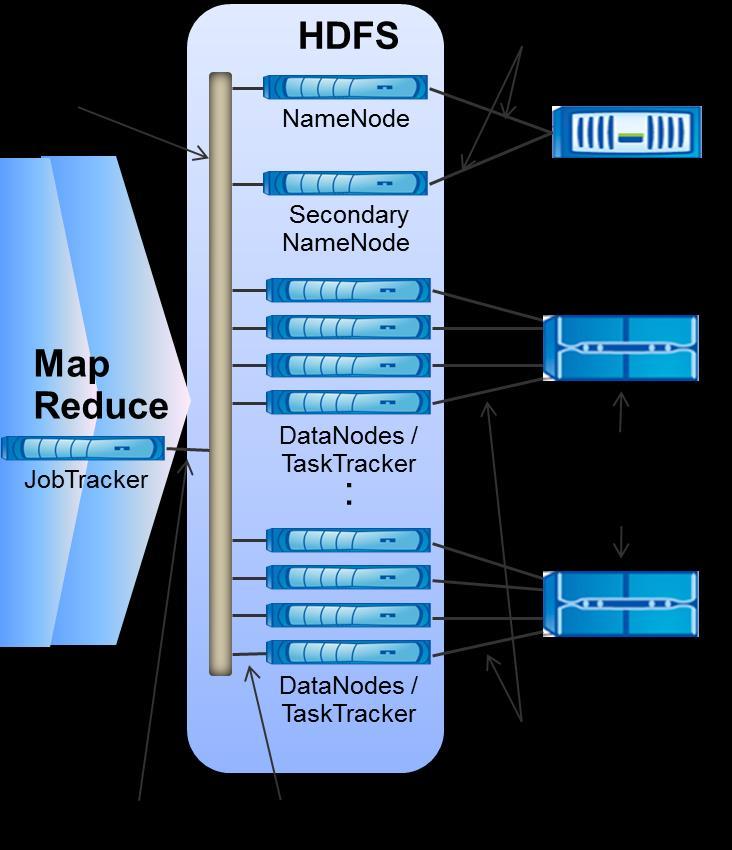
21 Hadoop Distributed File System is a distributed file system designed to run on commodity hardware Is designed to store very large data sets reliably Is self-healing, rebalances files across cluster Is scalable, just by adding new nodes is highly fault-tolerant when nodes fail HDFS stores file system metadata and application data separately Blocks are replicated to handle hardware failure (Block oriented) Namenode (Only one per cluster) Secondary namenode (Checkpoint node) (Only one per cluster) Datanodes (Many per cluster) 21
22 HDFS Blocks Blocks in disks: Minimum amount of data that can be read or written. (~ 512 bytes) Filesystem blocks: Abstraction over disk blocks. (~ few kilobytes) HDFS block: Abstraction over Filesystem blocks, to facilitate distribution over network and other requirements of Hadoop. Usually 64 MB or 128 MB. Block abstraction keeps the design simple. e.g, replication is at block level rather than file level. File is split into blocks for storing in HDFS. Blocks of the same file can reside on multiple machines in the cluster. Each block is stored as a file in the Local FS of the DataNode. Block size does not refer to size on disk. 1 MB file will not take up 64 MB on disk. 22

23 Processing: MapReduce 23
24 What is MapReduce? It is a framework to......automatically partition jobs that have large input data sets into simpler work units or tasks, distribute them in the nodes of a cluster (map) and......combine the intermediate results of those tasks (reduce) in a way to produce the required results. Run on key/value pairs Moves computation to data 24

25 Simple Example Mapped data on Node 1 Result Input data Mapped data on Node 2 25
26 What is MapReduce? Parallel programming model meant for large clusters User implements Map() and Reduce() Parallel computing framework Parallelization Fault Tolerance Data Distribution Load Balancing Status and monitoring Simplify the parallelization and distribution of large-scale computations in clusters MapReduce library does most of the hard work for us! Used extensively on many applications inside Google and Yahoo that......require simple processing tasks......but have large input data sets 26
27 Word Count Execution Input Map Shuffle & Sort Reduce Output the quick brown fox the fox ate the mouse how now brown cow Map Map Map the, 1 brown, 1 fox, 1 the, 1 fox, 1 the, 1 how, 1 now, 1 brown, 1 ate, 1 mouse, 1 cow, 1 quick, 1 Reduce Reduce brown, 2 fox, 2 how, 1 now, 1 the, 3 ate, 1 cow, 1 mouse, 1 quick, 1 27
:")
28 An Optimization: The Combiner Local reduce function for repeated keys produced by same map For associative ops. like sum, count, max Decreases amount of intermediate data Example: local counting for Word Count: def combiner(key, values): output(key, sum(values)) 28
29 Word Count with Combiner Input Map Shuffle & Sort Reduce Output the quick brown fox the fox ate the mouse how now brown cow Map Map Map the, 2 fox, 1 how, 1 now, 1 brown, 1 the, 1 brown, 1 fox, 1 ate, 1 mouse, 1 cow, 1 quick, 1 Reduce Reduce brown, 2 fox, 2 how, 1 now, 1 the, 3 ate, 1 cow, 1 mouse, 1 quick, 1 29
30 Programming Model Input & Output Each one is a set of key/value pairs Map: Processes input key/value pairs Compute a set of intermediate key/value pairs map (in_key, in_value) -> list(int_key, intermediate_value) Reduce: Combine all the intermediate values that share the same key Produces a set of merged output values (usually just one per key) reduce(int_key, list(intermediate_value)) -> list(out_value) 30
31 Example: Count # of Each Letter in a Big File Big File 640MB a t b o m a p r r e d u c e g o o o g l e a p i m a c a c a b r a a r r o z f e i j a o t o m a t e c r u i m e s s o l (There are 26 different keys 1) Split File into 10 pieces of 64MB letters in the range [a..z]) Master Worker Worker Idle Idle Worker Idle Worker Idle Worker Idle Worker Idle Worker Worker Idle Idle 31
32 Example: Count # of Each Letter in a Big File Big File 640MB a t b o m a p r r e d u c e g o o o g l e a p i m a c a c a b r a a r r o z f e i j a o t o m a t e c r u i m e s s o l 2) Assign map and reduce tasks Master Mappers Reducers Worker Worker Idle Idle Worker Idle Worker Idle Worker Idle Worker Idle Worker Worker Idle Idle 32
33 Example: Count # of Each Letter in a Big File Big File 640MB a t b o m a p r r e d u c e g o o o g l e a p i m a c a c a b r a a r r o z f e i j a o t o m a t e c r u i m e s s o l 3) Read the split data Map T. In progress Map T. In progress Map T. In progress Map T. In progress Master Reduce T. Idle Reduce T. Idle Reduce T. Idle Reduce T. Idle 33
34 Example: Count # of Each Letter in a Big File Big File 640MB a y b o m a p r r e d u c e g o o o g l e a p i m a c a c a b r a a r r o z f e i j a o t o m a t e c r u i m e s s o l 4) Process data (in memory) Machine 1 Partition Function (used to map the letters in regions): Map T.1 In-Progress a b c d e f g h i j k l m n n o p q r s t v w x y z R1 R2 R3 R4 Simulating the execution in memory (a,1) (b,1) (a,1) (m1) (o,1) (p,1) (r, 1) (y,1) R1 R2 R3 R4 34
35 Example: Count # of Each Letter in a Big File Big File 640MB a t b o m a p r r e d u c e g o o o g l e a p i m a c a c a b r a a r r o z f e i j a o t o m a t e c r u i m e s s o l 5) Apply combiner function Machine 1 Map T.1 In-Progress Simulating the execution in memory (a,1) (a,2) (b,1) (b,1) (a,1) (m1) (o,1) (p,1) (r, 1) (y,1) R1 R2 R3 R4 35
36 Example: Count # of Each Letter in a Big File Big File 640MB a t b o m a p r r e d u c e g o o o g l e a p i m a c a c a b r a a r r o z f e i j a o t o m a t e c r u i m e s s o l 6) Store results on disk Machine 1 Map T.1 In-Progress Master Memory (a,2) (b,1) (m1) (o,1) (p,1) (r, 1) (y,1) R1 R2 R3 R4 Disk 36
37 Example: Count # of Each Letter in a Big File Big File 640MB a t b o m a p r r e d u c e g o o o g l e a p i m a c a c a b r a a r r o z f e i j a o t o m a t e c r u i m e s s o l 7) Inform the master about the position of the intermediate results in local disk Machine 1 Map T.1 In-Progress MT1 Results Location MT1 Results Master (a,2) (b,1) (m1) (o,1) (p,1) (r, 1) (y,1) R1 R2 R3 R4 37
38 Example: Count # of Each Letter in a Big File Big File 640MB a t b o m a p r r e d u c e g o o o g l e a p i m a c a c a b r a a r r o z f e i j a o t o m a t e c r u i m e s s o l 8) The Master assigns the next task (Map Task 5) to the Worker recently free Data for Map Task 5 Machine 1 Worker In-Progress T1 Results Master Task 5 (a,2) (b,1) (m1) (o,1) (p,1) (r, 1) (y,1) R1 R2 R3 R4 38
39 Example: Count # of Each Letter in a Big File Big File 640MB a t b o m a p r r e d u c e g o o o g l e a p i m a c a c a b r a a r r o z f e i j a o t o m a t e c r u i m e s s o l 9) The Master forwards the location of the intermediate results of Map Task 1 to reducers Machine 1 Map T.5 In-Progress Master MT1 Results MT1 Results Location (R1) MT1 Results Location (Rx) (a,2) (b,1) (m1) (o,1) (p,1) (r, 1) (y,1) R1 R2 R3 R4 Reduce T.1 Idle... An Introduction to MapReduce 39
40 Example: Count # of Each Letter in a Big File Big File 640MB a t b o m a p r r e d u c e g o o o g l e a p i m a c a c a b r a a r r o z f e i j a o t o m a t e c r u i m e s s o l (a, 2) (b,1) (e, 1) (d, 1) (c, 1) (e, 1) (g, 1) (e, 1) (a, 3) (c, 1) (c, 1) (a, 1) (b,1) (a, 2) (f, 1) (e, 1) (a, 2) (e, 1)(c, 1) (e, 1) Letters in Region 1: a b c d e f g Reduce T.1 Idle R1 40
41 Example: Count # of Each Letter in a Big File 10) The RT 1 reads the data in R=1 from each MT Machine N Reduce T.1 In-Progress (a, 2) (b,1) (e, 1) (d, 1) (c, 1) (e, 1) (g, 1) (e, 1) (a, 3) (c, 1) (c, 1) (a, 1) (b,1) (a, 2) (f, 1) (e, 1) (a, 2) (e, 1)(c, 1) (e, 1) Data read from each Map Task stored in region 1 41
42 Example: Count # of Each Letter in a Big File 11) The reduce task 1 sorts the data Machine N Reduce T.1 In-Progress (a, 2) (a, 3) (a, 1) (a, 2) (a, 2) (b,1) (b,1) (c, 1) (c, 1) (c, 1) (c, 1) (d, 1) (e, 1) (e, 1) (e, 1) (e, 1) (e, 1) (e, 1) (f, 1) (g, 1) 42
43 Example: Count # of Each Letter in a Big File 12) Then it passes the key and the corresponding set of intermediate data to the user's reduce function Machine N Reduce T.1 In-Progress (a, 2) (a, 3) (a, 1) (a, 2) (a, 2) (b,1) (b,1) (c, 1) (c, 1) (c, 1) (c, 1) (d, 1) (e, 1) (e, 1) (e, 1) (e, 1) (e, 1) (e, 1) (f, 1) (g, 1) (a, {2,3,1,2,2}) (b, {1,1}) (c, {1,1,1,1}) (d,{1}) (e, {1,1,1,1,1,1}) (f, {1}) (g, {1}) 43
44 Example: Count # of Each Letter in a Big File 12) Finally, generates the output file 1 of R, after executing the user's reduce Machine N Reduce T.1 In-Progress (a, {2,3,1,2,2}) (b, {1,1}) (c, {1,1,1,1}) (d,{1}) (e, {1,1,1,1,1,1}) (f, {1}) (g, {1}) (a, 10) (b, 2) (c, 4) (d, 1) (e, 6) (f, 1) (g, 1) 44
45 MapReduce Characteristics Very large scale data: peta, exa bytes Write once and read many data: allows for parallelism without mutexes Map and Reduce are the main operations: simple code There are other supporting operations such as combine All the map should be completed before reduce operation starts. Number of map tasks and reduce tasks are configurable. Operations are provisioned near the data. Commodity hardware and storage. Runtime takes care of splitting and moving data for operations. 45
46 Hadoop Architecture 46
47 HDFS Architecture 47
48 Namenode The "master" node Maintains the HDFS namespace, filesystem tree and metadata. Maintains the mapping from each file to the list of blocks where the file is. Maintains in memory the locations of each block. (Block to datanode mapping) Issues instructions to datanode to create/replicate/delete blocks Single point of failure 48
49 Datanodes The "slaves" Serve as storage for data blocks No metadata Report all blocks to namenode (BlockReport) Sends periodic "heartbeat" to Namenode Serves read, write requests, performs block creation, deletion, and replication upon instruction from Namenode. User data never flows through the NameNode. 49
50 Block reports and heartbeats A block report contains the block id, the length for each block replica The first is sent immediately after the DataNode registration Subsequent block reports are sent every hour. During normal operation DataNodes send heartbeats to the NameNode to confirm that the DataNode is operating and the block replicas it hosts are available. Heartbeats from a DataNode also carry information about: Total storage capacity Fraction of storage in use The default heartbeat interval is three seconds 50

51 MapReduce Architecture 51
52 MapReduce: JobTracker & TaskTracker Master-Slave architecture JobTracker Accepts jobs submitted by users Assigns Map and Reduce tasks to Tasktrackers Makes all scheduling decisions Schedules tasks on nodes close to data Monitors task and tasktracker status, re-executes tasks upon failure TaskTracker Asks for new tasks, executes, monitors, reports status Run Map and Reduce tasks upon instruction from the Jobtracker Manage storage and transmission of intermediate output
53 Other Features: Failures Re-execution is the main mechanism for fault-tolerance Worker failures: Master detect Worker failures via periodic heartbeats The master drives the re-execution of tasks Completed and in-progress map tasks are re-executed In-progress reduce tasks are re-executed Master failure: The initial implementation did not support failures of the master Robust: lost 1600 of 1800 machines once, but finished fine 53
54 Hadoop Characteristics Commodity HW + Horizontal scaling Add inexpensive servers Storage servers and their disks are not assumed to be highly reliable and available Can add/upgrade servers over time Use replication across servers to deal with unreliable storage/servers Support for moving computation close to data i.e. servers have 2 purposes: data storage and computation Metadata-data separation - simple design Storage scales horizontally Metadata scales vertically Automatic re-execution on failure/distribution 54
55 Real world Hadoop Facebook In 2010 Facebook claimed that they had the largest Hadoop cluster in the world with 21 PB of storage On July 27, 2011 they announced the data had grown to 30 PB On June 13, 2012 they announced the data had grown to 100 PB On November 8, 2012 they announced the warehouse grows by roughly half a PB per day the world s largest Hadoop cluster, which spans more than 100 petabytes of data, and it analyzes about 105 terabytes every 30 minutes. Yahoo June 15, 2012, It stores 140 petabytes in Hadoop. Since Hadoop keeps all data sets in triplicate, over 400 petabytes of storage are needed to sustain its systems. 55

56 Thank you 56
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
Map Reduce & Hadoop Recommended Text:
 Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Advanced Database Technologies NoSQL: Not only SQL
 Advanced Database Technologies NoSQL: Not only SQL Christian Grün Database & Information Systems Group NoSQL Introduction 30, 40 years history of well-established database technology all in vain? Not at
Advanced Database Technologies NoSQL: Not only SQL Christian Grün Database & Information Systems Group NoSQL Introduction 30, 40 years history of well-established database technology all in vain? Not at
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Distributed Systems CS6421
 Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Big Data - Some Words BIG DATA 8/31/2017. Introduction
 BIG DATA Introduction Big Data - Some Words Connectivity Social Medias Share information Interactivity People Business Data Data mining Text mining Business Intelligence 1 What is Big Data Big Data means
BIG DATA Introduction Big Data - Some Words Connectivity Social Medias Share information Interactivity People Business Data Data mining Text mining Business Intelligence 1 What is Big Data Big Data means
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
Overview. Why MapReduce? What is MapReduce? The Hadoop Distributed File System Cloudera, Inc.
 MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Cloud Computing. Hwajung Lee. Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University
 Cloud Computing Hwajung Lee Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University Cloud Computing Cloud Introduction Cloud Service Model Big Data Hadoop MapReduce HDFS (Hadoop Distributed
Cloud Computing Hwajung Lee Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University Cloud Computing Cloud Introduction Cloud Service Model Big Data Hadoop MapReduce HDFS (Hadoop Distributed
Top 25 Big Data Interview Questions And Answers
 Top 25 Big Data Interview Questions And Answers By: Neeru Jain - Big Data The era of big data has just begun. With more companies inclined towards big data to run their operations, the demand for talent
Top 25 Big Data Interview Questions And Answers By: Neeru Jain - Big Data The era of big data has just begun. With more companies inclined towards big data to run their operations, the demand for talent
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
A Glimpse of the Hadoop Echosystem
 A Glimpse of the Hadoop Echosystem 1 Hadoop Echosystem A cluster is shared among several users in an organization Different services HDFS and MapReduce provide the lower layers of the infrastructures Other
A Glimpse of the Hadoop Echosystem 1 Hadoop Echosystem A cluster is shared among several users in an organization Different services HDFS and MapReduce provide the lower layers of the infrastructures Other
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Distributed Computations MapReduce. adapted from Jeff Dean s slides
 Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
I am a Data Nerd and so are YOU!
 I am a Data Nerd and so are YOU! Not This Type of Nerd Data Nerd Coffee Talk We saw Cloudera as the lone open source champion of Hadoop and the EMC/Greenplum/MapR initiative as a more closed and
I am a Data Nerd and so are YOU! Not This Type of Nerd Data Nerd Coffee Talk We saw Cloudera as the lone open source champion of Hadoop and the EMC/Greenplum/MapR initiative as a more closed and
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
UNIT-IV HDFS. Ms. Selva Mary. G
 UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
Performance Enhancement of Data Processing using Multiple Intelligent Cache in Hadoop
 Performance Enhancement of Data Processing using Multiple Intelligent Cache in Hadoop K. Senthilkumar PG Scholar Department of Computer Science and Engineering SRM University, Chennai, Tamilnadu, India
Performance Enhancement of Data Processing using Multiple Intelligent Cache in Hadoop K. Senthilkumar PG Scholar Department of Computer Science and Engineering SRM University, Chennai, Tamilnadu, India
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Hadoop Distributed File System(HDFS)
") Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
STATS Data Analysis using Python. Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns
 STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
Big Data for Engineers Spring Resource Management
 Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
CCA-410. Cloudera. Cloudera Certified Administrator for Apache Hadoop (CCAH)
") Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Programming Models MapReduce
 Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب
 Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب 1391 زمستان Outlines Introduction DataModel Architecture HBase vs. RDBMS HBase users 2 Why Hadoop? Datasets are growing to Petabytes Traditional datasets
Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب 1391 زمستان Outlines Introduction DataModel Architecture HBase vs. RDBMS HBase users 2 Why Hadoop? Datasets are growing to Petabytes Traditional datasets
BIG DATA TESTING: A UNIFIED VIEW
 http://core.ecu.edu/strg BIG DATA TESTING: A UNIFIED VIEW BY NAM THAI ECU, Computer Science Department, March 16, 2016 2/30 PRESENTATION CONTENT 1. Overview of Big Data A. 5 V s of Big Data B. Data generation
http://core.ecu.edu/strg BIG DATA TESTING: A UNIFIED VIEW BY NAM THAI ECU, Computer Science Department, March 16, 2016 2/30 PRESENTATION CONTENT 1. Overview of Big Data A. 5 V s of Big Data B. Data generation
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Big Data Analytics. Rasoul Karimi
 Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
Nowcasting. D B M G Data Base and Data Mining Group of Politecnico di Torino. Big Data: Hype or Hallelujah? Big data hype?
 Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
TP1-2: Analyzing Hadoop Logs
 TP1-2: Analyzing Hadoop Logs Shadi Ibrahim January 26th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
TP1-2: Analyzing Hadoop Logs Shadi Ibrahim January 26th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
Big Data 7. Resource Management
 Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]
![Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]](/thumbs/96/126854374.jpg "Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ]") s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
s@lm@n Cloudera Exam CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Version: 7.5 [ Total Questions: 97 ] Question No : 1 Which two updates occur when a client application opens a stream
The MapReduce Framework
 The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
CS 655 Advanced Topics in Distributed Systems
 Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
HDFS Federation. Sanjay Radia Founder and Hortonworks. Page 1
 HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423