Distributed Graph Storage. Veronika Molnár, UZH
|
|
|
- Crystal Cannon
- 5 years ago
- Views:
Transcription
1 Distributed Graph Storage Veronika Molnár, UZH
2 Overview Graphs and Social Networks Criteria for Graph Processing Systems Current Systems Storage Computation Large scale systems Comparison / Best systems Questions 2
 Social Network graph (image source : thenextweb.")
3 Graphs and Social Networks 1 Graph = collection of nodes + edges connecting nodes to each other Social Network = collection of individuals and social relations Social Network is also a Graph! (node = person, edge = relation) Social Network graph (image source : thenextweb.com) 3
4 Graphs and Social Networks 2 Social Network graph properties (SNA = Social Network Analysis) Limited number of connections at each node (person) e.g. Facebook: max 5000 Distribution not uniform Most people: an average number of connections But: a few people have a lot of connections (Power law distribution) Small degree of separation = Small World (length of shortest paths) Centrality Constantly changing, but very large graph! (7 billion people = 7 billion nodes) 4

5 Graphs and Social Networks Shortest Path 3 Centrality VM BP Betweenness Closeness PageRank Degree 5

6 Graphs and Social Networks 4 Social Network can be Facebook s Mailing lists Academic networks 6
7 Criteria for Graph Processing Systems 1 Modes: Distributed processing Research and industry use Interactive and noninteractive modes Storage of static and dynamic information connectivity graph 7 (image source: research.microsoft.com)
 Speed Features: SNA (Social Network Analysis) metrics: PageRank, Centrality, Shortest paths,.")
8 Criteria for Graph Processing Systems Properties: 2 Scalability (social networks are large!) Speed Features: SNA (Social Network Analysis) metrics: PageRank, Centrality, Shortest paths,... Extensibility connectivity graph 8 (image source: research.microsoft.com)
9 Current Systems 1 Storage: Apache Hive (and Hadoop) Titan Graph Database Neo4j 9
10 Current Systems Storage 2 Apache Hive (and Hadoop) Hadoop: Map/Reduce architecture Hive: Highlevel operations on large data sets HiveQL (similar to SQL) Converted to MapReduce jobs Not graphspecific Supports custom data formats Can be used as a backend for other systems 10
11 Current Systems Storage 3 Titan Graph Database Store and Query large graphs Graph schemas Gremlin query language edge and vertex labels transactional query model high level operations Two backends: Cassandra and HBase 11
12 Current Systems Storage 4 Neo4j Cost: 12K for startups (more for large companies), free for personal use Graph Database Management ACID compliant (Atomicity, Consistency, Isolation, Durability) Graphs are stored as Edges, Nodes, Attributes Focus on finding and querying data Graph analytics with igraph or GraphX Community! 12
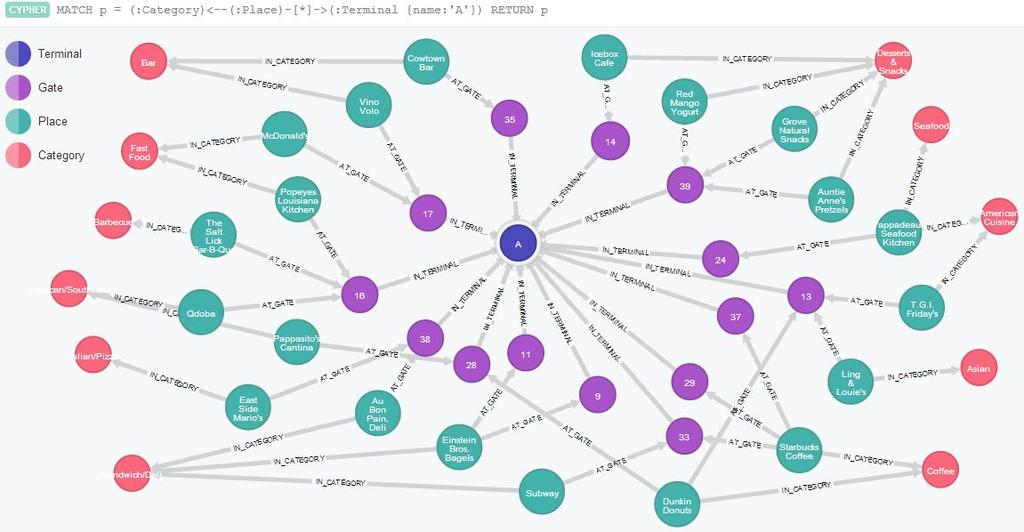
13 Neo4j 13
14 Current Systems 5 Computation: igraph Spark GraphX GraphLab 14
15 Current Systems Computation 6 igraph Network analysis / network research Portable and efficient Python, R, C, C++ Builtin, optimized SNA metrics (centrality, diameter, connected components) Standalone or Grid Extensible, 3 layer API 15
16 Current Systems Computation 7 Spark GraphX Graphs and parallel graph computations Userdefined parallel operations stored inmemory for faster processing very good endtoend performance graphs are immutable; all operations create a new graph Prebuilt graph algorithms, e.g. PageRank 16
17 Current Systems Computation 8 GraphLab Cost: $4,000/machine/year, or free 1 year student subscription Graph computations: processing & analytics Visualization (GraphLab Canvas) Machine learning Common graph algorithms + API 17

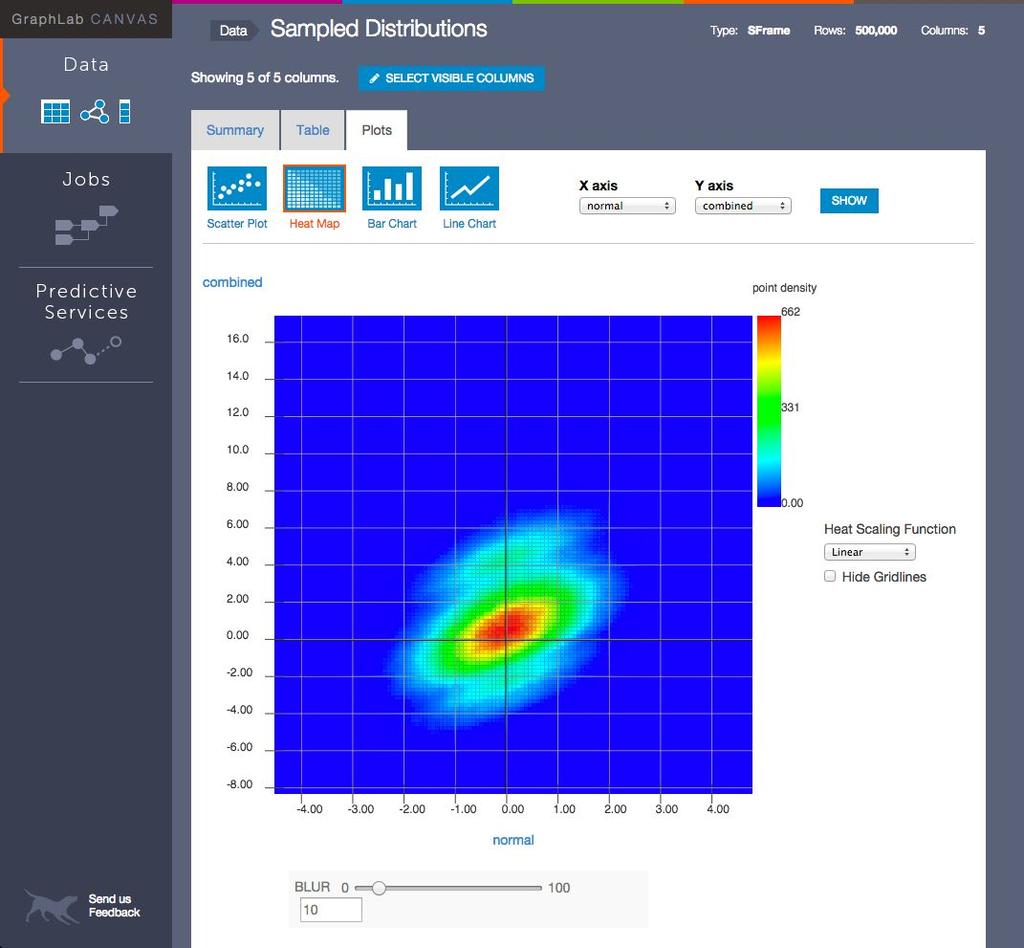
18 GraphLab 18
19 Current Systems 9 Used by Facebook/Google: Pregel/Pregelix Apache Giraph 19
20 Current Systems Large Scale 10 Pregel/Pregelix Pregel: Googleonly, Pregelix: opensource BSP (bulk synchronous processing) model Extremely large graphs User defined edge, vertex, message types Supersteps inmemory/outofcore operation models Vertexbased API, libraries with graph algorithms 20
21 Current Systems Large Scale 11 Apache Giraph BSP model Graphwide metrics via global operations Built on Hadoop, 526 times faster than Hive Highly parallel, keeps all data in memory Scales linearly with number of edges, can make efficient use of large clusters Used for PageRank, popularity rank, shortest paths No builtin graph metrics 21
22 Comparison Focus Scalability SNA Extensibility Used for Hive parallel computations any size no Java generic Titan storage ~100 B no Python, Java graph queries Neo4j transactional DB ~1 B yes Java, Python, R recommender systems igraph efficiency, portability ~1 M yes R, Python, C++ research GraphX parallel computations ~1 B yes Java, Python, R graph processing GraphLab processing, analytics ~1 B yes C++ recommender systems Giraph large scale, BSP any size no Java, Python Facebook Pregel(ix) large scale, BSP any size yes Java Google 22
23 Which is the best? Depends on the network and intended use.. Very large Social Networks: Research: igraph and GraphX support R and Python integration Analysis and Visualisation of Social Networks Highperformance, customizable systems, such as Pregelix GraphLab with builtin interactive analysis and plotting features Neo4j contains vast amounts of community resources for these tasks Custom use cases... Existing systems might not support these Instead: use Hadoop/Hive and write the rest yourself! 23
24 Thank You! aaaaaand Stay for some questions 24
25 Questions 1 Why do we analyse social data? What are the possible uses of analysing social data? 25
26 Questions 2 Can visualisation help to understand graphs? (connections can be viewed, subset of graph can be analysed, ) 26
27 Questions 3 Have you ever used such a system? Which one? 27
28 Questions 4 What are the advantages and disadvantages of distributed graph processing? What is the value of graph processing? 28
29 Questions 5 How can social metric calculations deal with fake accounts? 29


30 The End... 30
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
One Trillion Edges. Graph processing at Facebook scale
 One Trillion Edges Graph processing at Facebook scale Introduction Platform improvements Compute model extensions Experimental results Operational experience How Facebook improved Apache Giraph Facebook's
One Trillion Edges Graph processing at Facebook scale Introduction Platform improvements Compute model extensions Experimental results Operational experience How Facebook improved Apache Giraph Facebook's
Webinar Series TMIP VISION
 Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
TI2736-B Big Data Processing. Claudia Hauff
 TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Ctd. Graphs Pig Design Patterns Hadoop Ctd. Giraph Zoo Keeper Spark Spark Ctd. Learning objectives
TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Ctd. Graphs Pig Design Patterns Hadoop Ctd. Giraph Zoo Keeper Spark Spark Ctd. Learning objectives
Turning NoSQL data into Graph Playing with Apache Giraph and Apache Gora
 Turning NoSQL data into Graph Playing with Apache Giraph and Apache Gora Team Renato Marroquín! PhD student: Interested in: Information retrieval. Distributed and scalable data management. Apache Gora:
Turning NoSQL data into Graph Playing with Apache Giraph and Apache Gora Team Renato Marroquín! PhD student: Interested in: Information retrieval. Distributed and scalable data management. Apache Gora:
A Highly Efficient Runtime and Graph Library for Large Scale Graph Analytics
 A Highly Efficient Runtime and Graph Library for Large Scale Graph Analytics Ilie Gabriel Tanase Research Staff Member, IBM TJ Watson Yinglong Xia, Yanbin Liu, Wei Tan, Jason Crawford, Ching-Yung Lin IBM
A Highly Efficient Runtime and Graph Library for Large Scale Graph Analytics Ilie Gabriel Tanase Research Staff Member, IBM TJ Watson Yinglong Xia, Yanbin Liu, Wei Tan, Jason Crawford, Ching-Yung Lin IBM
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Apache Giraph. for applications in Machine Learning & Recommendation Systems. Maria Novartis
 Apache Giraph for applications in Machine Learning & Recommendation Systems Maria Stylianou @marsty5 Novartis Züri Machine Learning Meetup #5 June 16, 2014 Apache Giraph for applications in Machine Learning
Apache Giraph for applications in Machine Learning & Recommendation Systems Maria Stylianou @marsty5 Novartis Züri Machine Learning Meetup #5 June 16, 2014 Apache Giraph for applications in Machine Learning
CISC 7610 Lecture 4 Approaches to multimedia databases. Topics: Document databases Graph databases Metadata Column databases
 CISC 7610 Lecture 4 Approaches to multimedia databases Topics: Document databases Graph databases Metadata Column databases NoSQL architectures: different tradeoffs for different workloads Already seen:
CISC 7610 Lecture 4 Approaches to multimedia databases Topics: Document databases Graph databases Metadata Column databases NoSQL architectures: different tradeoffs for different workloads Already seen:
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
modern database systems lecture 10 : large-scale graph processing
 modern database systems lecture 1 : large-scale graph processing Aristides Gionis spring 18 timeline today : homework is due march 6 : homework out april 5, 9-1 : final exam april : homework due graphs
modern database systems lecture 1 : large-scale graph processing Aristides Gionis spring 18 timeline today : homework is due march 6 : homework out april 5, 9-1 : final exam april : homework due graphs
CISC 7610 Lecture 4 Approaches to multimedia databases. Topics: Graph databases Neo4j syntax and examples Document databases
 CISC 7610 Lecture 4 Approaches to multimedia databases Topics: Graph databases Neo4j syntax and examples Document databases NoSQL architectures: different tradeoffs for different workloads Already seen:
CISC 7610 Lecture 4 Approaches to multimedia databases Topics: Graph databases Neo4j syntax and examples Document databases NoSQL architectures: different tradeoffs for different workloads Already seen:
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 60 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Pregel: A System for Large-Scale Graph Processing
ECE 60 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Pregel: A System for Large-Scale Graph Processing
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
PREGEL AND GIRAPH. Why Pregel? Processing large graph problems is challenging Options
 Data Management in the Cloud PREGEL AND GIRAPH Thanks to Kristin Tufte 1 Why Pregel? Processing large graph problems is challenging Options Custom distributed infrastructure Existing distributed computing
Data Management in the Cloud PREGEL AND GIRAPH Thanks to Kristin Tufte 1 Why Pregel? Processing large graph problems is challenging Options Custom distributed infrastructure Existing distributed computing
CIB Session 12th NoSQL Databases Structures
 CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
RAMCloud. Scalable High-Performance Storage Entirely in DRAM. by John Ousterhout et al. Stanford University. presented by Slavik Derevyanko
 RAMCloud Scalable High-Performance Storage Entirely in DRAM 2009 by John Ousterhout et al. Stanford University presented by Slavik Derevyanko Outline RAMCloud project overview Motivation for RAMCloud storage:
RAMCloud Scalable High-Performance Storage Entirely in DRAM 2009 by John Ousterhout et al. Stanford University presented by Slavik Derevyanko Outline RAMCloud project overview Motivation for RAMCloud storage:
PROFESSIONAL. NoSQL. Shashank Tiwari WILEY. John Wiley & Sons, Inc.
 PROFESSIONAL NoSQL Shashank Tiwari WILEY John Wiley & Sons, Inc. Examining CONTENTS INTRODUCTION xvil CHAPTER 1: NOSQL: WHAT IT IS AND WHY YOU NEED IT 3 Definition and Introduction 4 Context and a Bit
PROFESSIONAL NoSQL Shashank Tiwari WILEY John Wiley & Sons, Inc. Examining CONTENTS INTRODUCTION xvil CHAPTER 1: NOSQL: WHAT IT IS AND WHY YOU NEED IT 3 Definition and Introduction 4 Context and a Bit
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Stages of Data Processing
 Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
E6895 Advanced Big Data Analytics Lecture 4:
 E6895 Advanced Big Data Analytics Lecture 4: Data Store Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Chief Scientist, Graph Computing, IBM Watson Research
E6895 Advanced Big Data Analytics Lecture 4: Data Store Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Chief Scientist, Graph Computing, IBM Watson Research
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Efficient and Scalable Friend Recommendations
 Efficient and Scalable Friend Recommendations Comparing Traditional and Graph-Processing Approaches Nicholas Tietz Software Engineer at GraphSQL nicholas@graphsql.com January 13, 2014 1 Introduction 2
Efficient and Scalable Friend Recommendations Comparing Traditional and Graph-Processing Approaches Nicholas Tietz Software Engineer at GraphSQL nicholas@graphsql.com January 13, 2014 1 Introduction 2
Big Data com Hadoop. VIII Sessão - SQL Bahia. Impala, Hive e Spark. Diógenes Pires 03/03/2018
 Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem
 I J C T A, 9(41) 2016, pp. 1235-1239 International Science Press Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem Hema Dubey *, Nilay Khare *, Alind Khare **
I J C T A, 9(41) 2016, pp. 1235-1239 International Science Press Parallel HITS Algorithm Implemented Using HADOOP GIRAPH Framework to resolve Big Data Problem Hema Dubey *, Nilay Khare *, Alind Khare **
SQT03 Big Data and Hadoop with Azure HDInsight Andrew Brust. Senior Director, Technical Product Marketing and Evangelism
 Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Apache Hadoop Goes Realtime at Facebook. Himanshu Sharma
 Apache Hadoop Goes Realtime at Facebook Guide - Dr. Sunny S. Chung Presented By- Anand K Singh Himanshu Sharma Index Problem with Current Stack Apache Hadoop and Hbase Zookeeper Applications of HBase at
Apache Hadoop Goes Realtime at Facebook Guide - Dr. Sunny S. Chung Presented By- Anand K Singh Himanshu Sharma Index Problem with Current Stack Apache Hadoop and Hbase Zookeeper Applications of HBase at
Management and Analysis of Big Graph Data: Current Systems and Open Challenges
 Management and Analysis of Big Graph Data: Current Systems and Open Challenges Martin Junghanns 1, André Petermann 1, Martin Neumann 2 and Erhard Rahm 1 1 Leipzig University, Database Research Group 2
Management and Analysis of Big Graph Data: Current Systems and Open Challenges Martin Junghanns 1, André Petermann 1, Martin Neumann 2 and Erhard Rahm 1 1 Leipzig University, Database Research Group 2
A Hierarchical Synchronous Parallel Model for Wide-Area Graph Analytics
 A Hierarchical Synchronous Parallel Model for Wide-Area Graph Analytics Shuhao Liu*, Li Chen, Baochun Li, Aiden Carnegie University of Toronto April 17, 2018 Graph Analytics What is Graph Analytics? 2
A Hierarchical Synchronous Parallel Model for Wide-Area Graph Analytics Shuhao Liu*, Li Chen, Baochun Li, Aiden Carnegie University of Toronto April 17, 2018 Graph Analytics What is Graph Analytics? 2
Distributed Systems. 21. Graph Computing Frameworks. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 21. Graph Computing Frameworks Paul Krzyzanowski Rutgers University Fall 2016 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Can we make MapReduce easier? November 21, 2016 2014-2016
Distributed Systems 21. Graph Computing Frameworks Paul Krzyzanowski Rutgers University Fall 2016 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Can we make MapReduce easier? November 21, 2016 2014-2016
Cassandra, MongoDB, and HBase. Cassandra, MongoDB, and HBase. I have chosen these three due to their recent
 Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
Introduction to NoSQL by William McKnight
 Introduction to NoSQL by William McKnight All rights reserved. Reproduction in whole or part prohibited except by written permission. Product and company names mentioned herein may be trademarks of their
Introduction to NoSQL by William McKnight All rights reserved. Reproduction in whole or part prohibited except by written permission. Product and company names mentioned herein may be trademarks of their
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
A Review Paper on Big data & Hadoop
 A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
MapReduce and Friends
 MapReduce and Friends Craig C. Douglas University of Wyoming with thanks to Mookwon Seo Why was it invented? MapReduce is a mergesort for large distributed memory computers. It was the basis for a web
MapReduce and Friends Craig C. Douglas University of Wyoming with thanks to Mookwon Seo Why was it invented? MapReduce is a mergesort for large distributed memory computers. It was the basis for a web
Presented by Sunnie S Chung CIS 612
 By Yasin N. Silva, Arizona State University Presented by Sunnie S Chung CIS 612 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. See http://creativecommons.org/licenses/by-nc-sa/4.0/
By Yasin N. Silva, Arizona State University Presented by Sunnie S Chung CIS 612 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. See http://creativecommons.org/licenses/by-nc-sa/4.0/
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES
 1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
A Glimpse of the Hadoop Echosystem
 A Glimpse of the Hadoop Echosystem 1 Hadoop Echosystem A cluster is shared among several users in an organization Different services HDFS and MapReduce provide the lower layers of the infrastructures Other
A Glimpse of the Hadoop Echosystem 1 Hadoop Echosystem A cluster is shared among several users in an organization Different services HDFS and MapReduce provide the lower layers of the infrastructures Other
Graph Analytics in the Big Data Era
 Graph Analytics in the Big Data Era Yongming Luo, dr. George H.L. Fletcher Web Engineering Group What is really hot? 19-11-2013 PAGE 1 An old/new data model graph data Model entities and relations between
Graph Analytics in the Big Data Era Yongming Luo, dr. George H.L. Fletcher Web Engineering Group What is really hot? 19-11-2013 PAGE 1 An old/new data model graph data Model entities and relations between
Distributed Databases: SQL vs NoSQL
 Distributed Databases: SQL vs NoSQL Seda Unal, Yuchen Zheng April 23, 2017 1 Introduction Distributed databases have become increasingly popular in the era of big data because of their advantages over
Distributed Databases: SQL vs NoSQL Seda Unal, Yuchen Zheng April 23, 2017 1 Introduction Distributed databases have become increasingly popular in the era of big data because of their advantages over
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Processing Unstructured Data. Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd.
 Processing Unstructured Data Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd. http://dinesql.com / Dinesh Priyankara @dinesh_priya Founder/Principal Architect dinesql Pvt Ltd. Microsoft Most
Processing Unstructured Data Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd. http://dinesql.com / Dinesh Priyankara @dinesh_priya Founder/Principal Architect dinesql Pvt Ltd. Microsoft Most
Processing big data with modern applications: Hadoop as DWH backend at Pro7. Dr. Kathrin Spreyer Big data engineer
 Processing big data with modern applications: Hadoop as DWH backend at Pro7 Dr. Kathrin Spreyer Big data engineer GridKa School Karlsruhe, 02.09.2014 Outline 1. Relational DWH 2. Data integration with
Processing big data with modern applications: Hadoop as DWH backend at Pro7 Dr. Kathrin Spreyer Big data engineer GridKa School Karlsruhe, 02.09.2014 Outline 1. Relational DWH 2. Data integration with
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Big Data Infrastructures & Technologies Hadoop Streaming Revisit.
 Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source
 Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Pregel: A System for Large- Scale Graph Processing. Written by G. Malewicz et al. at SIGMOD 2010 Presented by Chris Bunch Tuesday, October 12, 2010
 Pregel: A System for Large- Scale Graph Processing Written by G. Malewicz et al. at SIGMOD 2010 Presented by Chris Bunch Tuesday, October 12, 2010 1 Graphs are hard Poor locality of memory access Very
Pregel: A System for Large- Scale Graph Processing Written by G. Malewicz et al. at SIGMOD 2010 Presented by Chris Bunch Tuesday, October 12, 2010 1 Graphs are hard Poor locality of memory access Very
Authors: Malewicz, G., Austern, M. H., Bik, A. J., Dehnert, J. C., Horn, L., Leiser, N., Czjkowski, G.
 Authors: Malewicz, G., Austern, M. H., Bik, A. J., Dehnert, J. C., Horn, L., Leiser, N., Czjkowski, G. Speaker: Chong Li Department: Applied Health Science Program: Master of Health Informatics 1 Term
Authors: Malewicz, G., Austern, M. H., Bik, A. J., Dehnert, J. C., Horn, L., Leiser, N., Czjkowski, G. Speaker: Chong Li Department: Applied Health Science Program: Master of Health Informatics 1 Term
COSC 416 NoSQL Databases. NoSQL Databases Overview. Dr. Ramon Lawrence University of British Columbia Okanagan
 COSC 416 NoSQL Databases NoSQL Databases Overview Dr. Ramon Lawrence University of British Columbia Okanagan ramon.lawrence@ubc.ca Databases Brought Back to Life!!! Image copyright: www.dragoart.com Image
COSC 416 NoSQL Databases NoSQL Databases Overview Dr. Ramon Lawrence University of British Columbia Okanagan ramon.lawrence@ubc.ca Databases Brought Back to Life!!! Image copyright: www.dragoart.com Image
DATABASE DESIGN II - 1DL400
 DATABASE DESIGN II - 1DL400 Fall 2016 A second course in database systems http://www.it.uu.se/research/group/udbl/kurser/dbii_ht16 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATABASE DESIGN II - 1DL400 Fall 2016 A second course in database systems http://www.it.uu.se/research/group/udbl/kurser/dbii_ht16 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
Introduction to Big Data. NoSQL Databases. Instituto Politécnico de Tomar. Ricardo Campos
 Instituto Politécnico de Tomar Introduction to Big Data NoSQL Databases Ricardo Campos Mestrado EI-IC Análise e Processamento de Grandes Volumes de Dados Tomar, Portugal, 2016 Part of the slides used in
Instituto Politécnico de Tomar Introduction to Big Data NoSQL Databases Ricardo Campos Mestrado EI-IC Análise e Processamento de Grandes Volumes de Dados Tomar, Portugal, 2016 Part of the slides used in
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Apache Giraph: Facebook-scale graph processing infrastructure. 3/31/2014 Avery Ching, Facebook GDM
 Apache Giraph: Facebook-scale graph processing infrastructure 3/31/2014 Avery Ching, Facebook GDM Motivation Apache Giraph Inspired by Google s Pregel but runs on Hadoop Think like a vertex Maximum value
Apache Giraph: Facebook-scale graph processing infrastructure 3/31/2014 Avery Ching, Facebook GDM Motivation Apache Giraph Inspired by Google s Pregel but runs on Hadoop Think like a vertex Maximum value
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Social Network Analytics on Cray Urika-XA
 Social Network Analytics on Cray Urika-XA Mike Hinchey, mhinchey@cray.com Technical Solutions Architect Cray Inc, Analytics Products Group April, 2015 Agenda 1. Introduce platform Urika-XA 2. Technology
Social Network Analytics on Cray Urika-XA Mike Hinchey, mhinchey@cray.com Technical Solutions Architect Cray Inc, Analytics Products Group April, 2015 Agenda 1. Introduce platform Urika-XA 2. Technology
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Distributed Graph Algorithms
 Distributed Graph Algorithms Alessio Guerrieri University of Trento, Italy 2016/04/26 This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. Contents 1 Introduction
Distributed Graph Algorithms Alessio Guerrieri University of Trento, Italy 2016/04/26 This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. Contents 1 Introduction
Analyzing Flight Data
 IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
Databases and Big Data Today. CS634 Class 22
 Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Apache Spark and Hadoop Based Big Data Processing System for Clinical Research
 Apache Spark and Hadoop Based Big Data Processing System for Clinical Research Sreekanth Rallapalli 1,*, Gondkar R R 2 1 Research Scholar, R&D Centre, Bharathiyar University, Coimbatore, Tamilnadu, India.
Apache Spark and Hadoop Based Big Data Processing System for Clinical Research Sreekanth Rallapalli 1,*, Gondkar R R 2 1 Research Scholar, R&D Centre, Bharathiyar University, Coimbatore, Tamilnadu, India.
Distributed Systems. 21. Other parallel frameworks. Paul Krzyzanowski. Rutgers University. Fall 2018
 Distributed Systems 21. Other parallel frameworks Paul Krzyzanowski Rutgers University Fall 2018 1 Can we make MapReduce easier? 2 Apache Pig Why? Make it easy to use MapReduce via scripting instead of
Distributed Systems 21. Other parallel frameworks Paul Krzyzanowski Rutgers University Fall 2018 1 Can we make MapReduce easier? 2 Apache Pig Why? Make it easy to use MapReduce via scripting instead of
CS November 2018
 Distributed Systems 1. Other parallel frameworks Can we make MapReduce easier? Paul Krzyzanowski Rutgers University Fall 018 1 Apache Pig Apache Pig Why? Make it easy to use MapReduce via scripting instead
Distributed Systems 1. Other parallel frameworks Can we make MapReduce easier? Paul Krzyzanowski Rutgers University Fall 018 1 Apache Pig Apache Pig Why? Make it easy to use MapReduce via scripting instead
Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018
: Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018") Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018 K. Zhang (pic source: mapr.com/blog) Copyright BUDT 2016 758 Where
Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018 K. Zhang (pic source: mapr.com/blog) Copyright BUDT 2016 758 Where
Giraph: Large-scale graph processing infrastructure on Hadoop. Qu Zhi
 Giraph: Large-scale graph processing infrastructure on Hadoop Qu Zhi Why scalable graph processing? Web and social graphs are at immense scale and continuing to grow In 2008, Google estimated the number
Giraph: Large-scale graph processing infrastructure on Hadoop Qu Zhi Why scalable graph processing? Web and social graphs are at immense scale and continuing to grow In 2008, Google estimated the number
Large Scale Graph Solutions: Use-cases And Lessons Learnt
 Large Scale Graph Solutions: Use-cases And Lessons Learnt Principal Engineer, AI/Cloud Platforms Abstraction Is The Art Euler s Bridges - Seven Bridges of Königsberg G = (V, E); V(id, attr1, attr2,..);
Large Scale Graph Solutions: Use-cases And Lessons Learnt Principal Engineer, AI/Cloud Platforms Abstraction Is The Art Euler s Bridges - Seven Bridges of Königsberg G = (V, E); V(id, attr1, attr2,..);
Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing
 /34 Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing Zuhair Khayyat 1 Karim Awara 1 Amani Alonazi 1 Hani Jamjoom 2 Dan Williams 2 Panos Kalnis 1 1 King Abdullah University of
/34 Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing Zuhair Khayyat 1 Karim Awara 1 Amani Alonazi 1 Hani Jamjoom 2 Dan Williams 2 Panos Kalnis 1 1 King Abdullah University of
Big Graph Processing. Fenggang Wu Nov. 6, 2016
 Big Graph Processing Fenggang Wu Nov. 6, 2016 Agenda Project Publication Organization Pregel SIGMOD 10 Google PowerGraph OSDI 12 CMU GraphX OSDI 14 UC Berkeley AMPLab PowerLyra EuroSys 15 Shanghai Jiao
Big Graph Processing Fenggang Wu Nov. 6, 2016 Agenda Project Publication Organization Pregel SIGMOD 10 Google PowerGraph OSDI 12 CMU GraphX OSDI 14 UC Berkeley AMPLab PowerLyra EuroSys 15 Shanghai Jiao
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Online Bill Processing System for Public Sectors in Big Data
 IJIRST International Journal for Innovative Research in Science & Technology Volume 4 Issue 10 March 2018 ISSN (online): 2349-6010 Online Bill Processing System for Public Sectors in Big Data H. Anwer
IJIRST International Journal for Innovative Research in Science & Technology Volume 4 Issue 10 March 2018 ISSN (online): 2349-6010 Online Bill Processing System for Public Sectors in Big Data H. Anwer
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
PREGEL: A SYSTEM FOR LARGE- SCALE GRAPH PROCESSING
 PREGEL: A SYSTEM FOR LARGE- SCALE GRAPH PROCESSING G. Malewicz, M. Austern, A. Bik, J. Dehnert, I. Horn, N. Leiser, G. Czajkowski Google, Inc. SIGMOD 2010 Presented by Ke Hong (some figures borrowed from
PREGEL: A SYSTEM FOR LARGE- SCALE GRAPH PROCESSING G. Malewicz, M. Austern, A. Bik, J. Dehnert, I. Horn, N. Leiser, G. Czajkowski Google, Inc. SIGMOD 2010 Presented by Ke Hong (some figures borrowed from
Large-Scale Graph Processing 1: Pregel & Apache Hama Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC
 CSIE, NDHU, Taiwan, ROC") Large-Scale Graph Processing 1: Pregel & Apache Hama Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei
Large-Scale Graph Processing 1: Pregel & Apache Hama Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei
Dynamic Graph Query Support for SDN Management. Ramya Raghavendra IBM TJ Watson Research Center
 Dynamic Graph Query Support for SDN Management Ramya Raghavendra IBM TJ Watson Research Center Roadmap SDN scenario 1: Cloud provisioning Management/Analytics primitives Current Cloud Offerings Limited
Dynamic Graph Query Support for SDN Management Ramya Raghavendra IBM TJ Watson Research Center Roadmap SDN scenario 1: Cloud provisioning Management/Analytics primitives Current Cloud Offerings Limited
Index. bfs() function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225
 function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225") Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
Graph Analytics and Machine Learning A Great Combination Mark Hornick
 Graph Analytics and Machine Learning A Great Combination Mark Hornick Oracle Advanced Analytics and Machine Learning November 3, 2017 Safe Harbor Statement The following is intended to outline our research
Graph Analytics and Machine Learning A Great Combination Mark Hornick Oracle Advanced Analytics and Machine Learning November 3, 2017 Safe Harbor Statement The following is intended to outline our research
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
CS /21/2016. Paul Krzyzanowski 1. Can we make MapReduce easier? Distributed Systems. Apache Pig. Apache Pig. Pig: Loading Data.
 Distributed Systems 1. Graph Computing Frameworks Can we make MapReduce easier? Paul Krzyzanowski Rutgers University Fall 016 1 Apache Pig Apache Pig Why? Make it easy to use MapReduce via scripting instead
Distributed Systems 1. Graph Computing Frameworks Can we make MapReduce easier? Paul Krzyzanowski Rutgers University Fall 016 1 Apache Pig Apache Pig Why? Make it easy to use MapReduce via scripting instead
Data Analytics Job Guarantee Program
 Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Distributed Systems. 20. Other parallel frameworks. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 20. Other parallel frameworks Paul Krzyzanowski Rutgers University Fall 2017 November 20, 2017 2014-2017 Paul Krzyzanowski 1 Can we make MapReduce easier? 2 Apache Pig Why? Make it
Distributed Systems 20. Other parallel frameworks Paul Krzyzanowski Rutgers University Fall 2017 November 20, 2017 2014-2017 Paul Krzyzanowski 1 Can we make MapReduce easier? 2 Apache Pig Why? Make it
CS November 2017
 Distributed Systems 0. Other parallel frameworks Can we make MapReduce easier? Paul Krzyzanowski Rutgers University Fall 017 November 0, 017 014-017 Paul Krzyzanowski 1 Apache Pig Apache Pig Why? Make
Distributed Systems 0. Other parallel frameworks Can we make MapReduce easier? Paul Krzyzanowski Rutgers University Fall 017 November 0, 017 014-017 Paul Krzyzanowski 1 Apache Pig Apache Pig Why? Make
Graph-Parallel Problems. ML in the Context of Parallel Architectures
 Case Study 4: Collaborative Filtering Graph-Parallel Problems Synchronous v. Asynchronous Computation Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox February 20 th, 2014
Case Study 4: Collaborative Filtering Graph-Parallel Problems Synchronous v. Asynchronous Computation Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox February 20 th, 2014
Introduction to NoSQL Databases
 Introduction to NoSQL Databases Roman Kern KTI, TU Graz 2017-10-16 Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 1 / 31 Introduction Intro Why NoSQL? Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 2 / 31 Introduction
Introduction to NoSQL Databases Roman Kern KTI, TU Graz 2017-10-16 Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 1 / 31 Introduction Intro Why NoSQL? Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 2 / 31 Introduction
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Experimental Analysis of Distributed Graph Systems
 Experimental Analysis of Distributed Graph ystems Khaled Ammar, M. Tamer Özsu David R. Cheriton chool of Computer cience University of Waterloo, Waterloo, Ontario, Canada {khaled.ammar, tamer.ozsu}@uwaterloo.ca
Experimental Analysis of Distributed Graph ystems Khaled Ammar, M. Tamer Özsu David R. Cheriton chool of Computer cience University of Waterloo, Waterloo, Ontario, Canada {khaled.ammar, tamer.ozsu}@uwaterloo.ca
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423