HBase. Леонид Налчаджи
|
|
|
- Howard Smith
- 5 years ago
- Views:
Transcription
1 HBase Леонид Налчаджи
2 HBase Overview Table layout Architecture Client API Key design 2
3 Overview 3
4 Overview NoSQL Column oriented Versioned 4
5 Overview All rows ordered by row key All cells are uninterpreted arrays of bytes Auto-sharding 5
6 Overview Distributed HDFS based Highly fault tolerant CP/CAP 6
7 Overview Coordinates: <RowKey, CF:CN, Version> Data is grouped by column family Null values for free 7
8 Overview No actual deletes (tombstones) TTL for cells 8
9 Disadvantages No secondary indexes from the box Available through additional table and coprocessors No transactions CAS support, row locks, counters Not good for multiple data centers Master-slave replication No complex query processing 9
10 Table layout 10

11 Table layout 11

12 Table layout 12

13 Table layout 13
14 Architecture 14
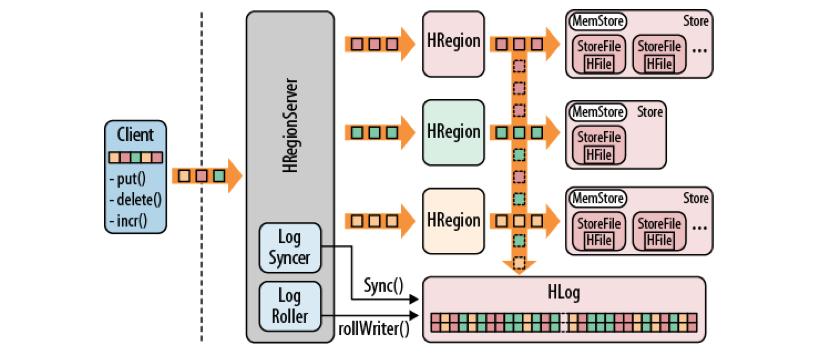
15 Terms Region Region server WAL Memstore StoreFile/HFile 15
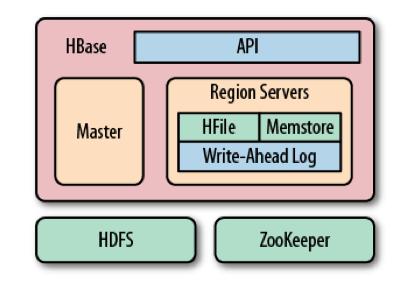
16 Architecture 16
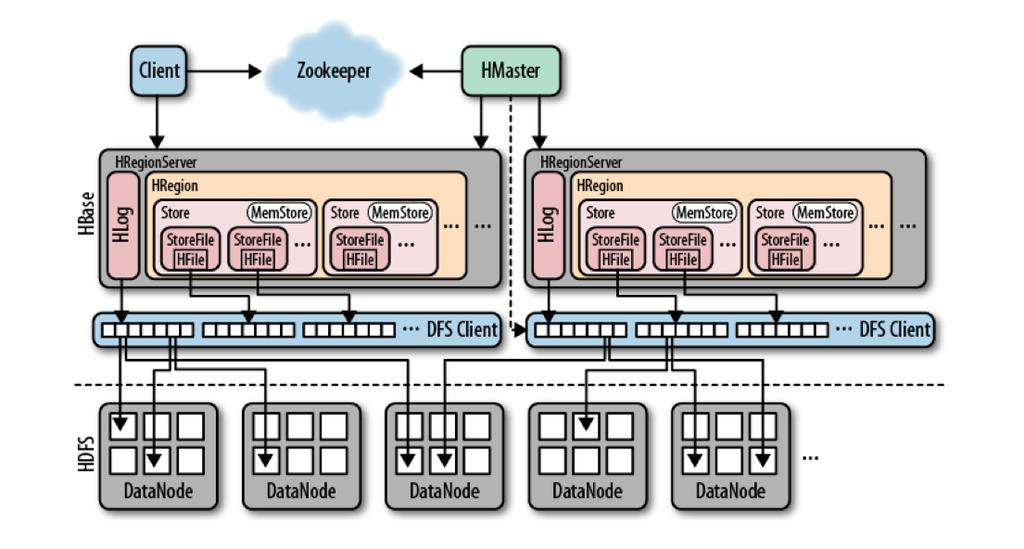
17 17
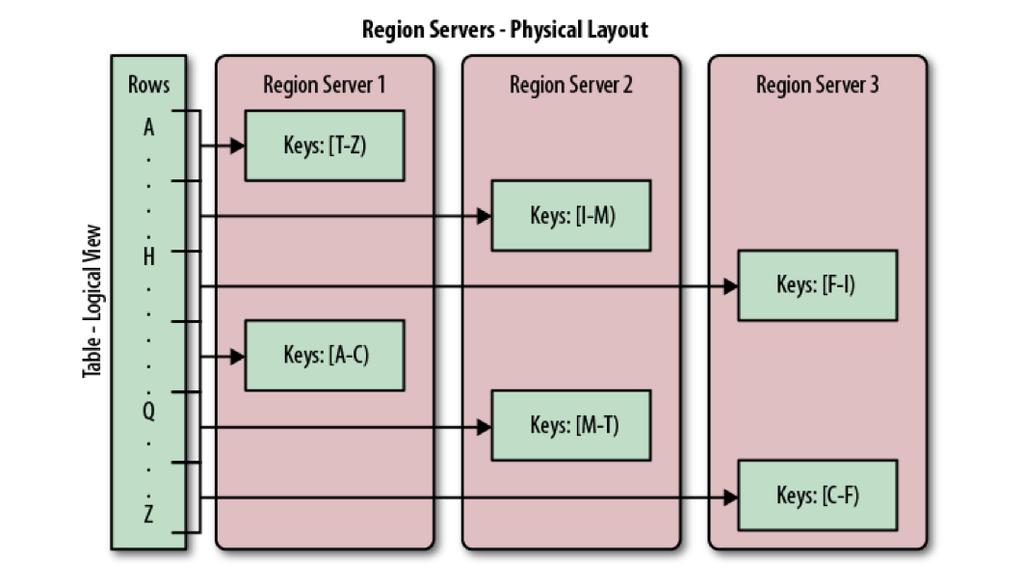
18 Architecture 18
19 Architecture One master (with backup) many slaves (region servers) Very tight integration with ZooKeeper Client calls ZK, RS, Master 19
20 Master Handles schema changes Not SPOF Cluster housekeeping operations Check RS status through ZK 20
21 Region server Stores data in regions HDFS DataNode Region is a container of data Does actual data manipulation 21
22 ZooKeeper Distributed synchronization service FS-like tree structure contains keys Provides primitives to achieve a lot of goals 22
23 Storage Handled by region server 2 types of file WAL log Data storage Memstore: sorted write buffer 23
24 Client connection Ask ZK to get address -ROOT- region From.META. gets the address of RS Cache all these data From -ROOT- gets the RS with.meta. 24
25 Write path Write to HLog (one per RS) Write to Memstore (one per CF) If Memstore is full, flush is requested This request is processed async by another thread 25
26 On Memstore flush On flush Memstore is written to HDFS file The last operation sequence number is stored Memstore is cleared 26
27 Region splits Region is closed Creates directory structure for new regions (multithreaded).meta. is updated (parent and daughters) 27
28 Region splits Master is notified for load balancing All steps are tracked in ZK Parent cleaned up eventually 28
29 Compaction When Memstore is flushed new store file is created Compaction is a housekeeping mechanism which merges store files Come in two varieties: minor and major The type is determined when the compaction check is executed 29
30 Minor compaction Fast Selects files to include Params: max size and min number of files From the oldest to the newest 30
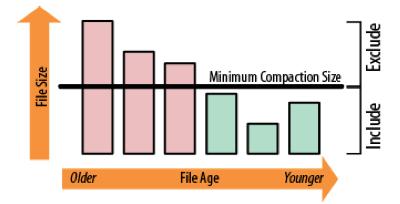
31 Minor compaction 31
32 Major compaction Compact all files into a single file Might be promoted from the minor compaction Starts periodically (each 24 hours by default) Checks tombstone markers and removes data 32

33 HFile format 33
34 HFile format Immutable (trailer is written once) Block size by default 64K Trailer has pointers to other blocks Indexes store offsets to data, metadata Block contains magic and number of key values 34

35 KeyValue format 35
36 Write-Ahead log 36
37 Write-Ahead log One per region server Contains data from several regions Stores data sequentially 37
38 Write-Ahead log Rolled periodically (every hour by default) Applied on cluster restart and on server failure Split is distributed 38
39 Read path There is no single index with logical rows Data is stored in several files and Memstore per column family Gets are the same as scans 39

40 Read path 40
41 Block cache Each region has LRU block cache Based on priorities 1. Single access 2. Multi access priority 3. Catalog CF: ROOT and META 41
42 Block cache Size of cache: number of region servers * heap size * (hfile.block.cache.size) * RS with 1 Gb RAM = 217 Mb 20 RS with 8 Gb RAM = 34 Gb 100 RS with 24 Gb RAM with 0.5 = 1 Tb 42
43 Block cache Always in cache: Catalog tables HFiles indexes Keys (row keys, CF, TS) 43
44 Client API 44
45 CRUD All operations do through HTable object All operations per-row atomic Row lock is available Batch is available Looks like this: HTable table = new HTable("table"); table.put(new Put(...)); 45
46 Put Put(byte[] row) Put(byte[] row, RowLock rowlock) Put(byte[] row, long ts) Put(byte[] row, long ts, RowLock rowlock) 46
47 Put Put add(byte[] family, byte[] qualifier, byte[] value) Put add(byte[] family, byte[] qualifier, long ts, byte[] value) Put add(keyvalue kv) 47
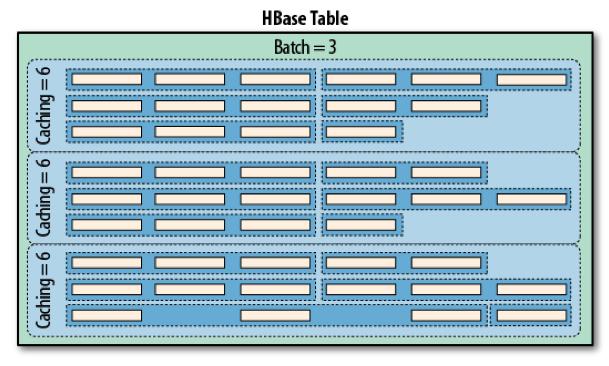
48 Put setwritetowal() heapsize() 48
49 Write buffer There is a client-side write buffer Sorts data by Region Servers 2Mb by default Controlled by: table.setautoflush(false); table.flushcommits(); 49

50 Write buffer 50
51 What else CAS: boolean checkandput(byte[] row, byte[] family, Batch: byte[] qualifier, byte[] value, Put put) throws IOException void put(list<put> puts) throws IOException 51
52 Get Returns strictly one row Result res = table.get(new Get(row)); Can ask if row exists boolean e = table.exist(new Get(row)); Filter can be applied 52
53 Row lock Region server provide a row lock Client can ask for explicit lock: RowLock lockrow(byte[] row) throws IOException; void unlockrow(rowlock rl) throws IOException; Do not use if you do not have to 53
54 Scan Iterator over a number of rows Leased for amount of time Batching and caching is available Can be defined start and end rows 54
55 Scan final Scan scan = new Scan(); scan.addfamily(bytes.tobytes("colfam1")); scan.setbatch(5); scan.setcaching(5); scan.setmaxversions(1); scan.settimestamp(0); scan.setstartrow(bytes.tobytes(0)); scan.setstartrow(bytes.tobytes(1000)); ResultScanner scanner = table.getscanner(scan); for (Result res : scanner) {... } scanner.close(); 55
56 Scan Caching is for rows Batching is for columns Result.next() will return next set of batched cols (more than one for row) 56
57 Scan 57
58 Counters Any column can be treated as counters Atomic increment without locking Can be applied for multiple rows Looks like this: long cnt = table.incrementcolumnvalue(bytes.tobytes(" "), Bytes.toBytes("daily"), Bytes.toBytes("hits"), 1); 58
59 HTable pooling Creating an HTable instance is expensive HTable is not thread safe Should be created on start up and closed on application exit 59
60 HTable pooling Provided pool: HTablePool Thread safe Shares common resources 60
61 HTable pooling HTablePool(Configuration config, int maxsize) HTableInterface gettable(string tablename) void puttable(htableinterface table) void closetablepool(string tablename) 61
62 Key design 62
63 Key design The only index is row key Row keys are sorted Key is uninterpreted array of bytes 63

64 Key design 64
65 example Approach #1: user id is raw key, all messages in one cell <userid> : <cf> : <col> : <ts>:<messages> : data : msgs : : ${msg1}, ${msg2}... 65
66 example Approach #1: user id is raw key, all messages in one cell <userid> : <cf> : <colval> : <messages> All in one request Hard to find anything Users with a lot of messages 66
67 example Approach #2: user id is raw key, message id in column family <userid> : <cf> : <msgid> : <timestamp> : < -message> : data : 5fc38314-e290-ae5da5fc375d : : "Hi,..." : data : 725aae5f-d72e-f90f3f : : "Welcome, and..." : data : cc6775b3-f249-c6dd2b1a7467 : : "To Whom It..." : data : dcbee495-6d5e-6ed c : : "Hi, how are..." 67
68 example Approach #2: user id is raw key, message id in column family <userid> : <cf> : <msgid> : <timestamp> : < -message> Can load data on demand Find anything only with filter Users with a lot of messages 68
69 example Approach #3: raw id is a <userid> <msgid> <userid> - <msgid>: <cf> : <qualifier> : <timestamp> : < -message> fc38314-e290-ae5da5fc375d : data : : : "Hi,..." aae5f-d72e-f90f3f : data : : : "Welcome, and..." cc6775b3-f249-c6dd2b1a7467 : data : : : "To Whom It..." dcbee495-6d5e-6ed c : data : : : "Hi, how are..." 69
70 example Approach #3: raw id is a <userid> <msgid> <userid> - <msgid>: <cf> : <qualifier> : <timestamp> : < -message> Can load data on demand Find message with row key Users with a lot of messages 70
71 example Go further: <userid>-<date>-<messageid>-<attachmentid> 71
72 example Go further: <userid>-<date>-<messageid>-<attachmentid> <userid>-(max_long - <date>)-<messageid> -<attachmentid> 72
73 Performance 73
74 Performance 10 Gb data, 10 parallel clients, 1kb per entry HDFs replication = 3 3 Region servers, 2CPU (24 cores), 48Gb RAM, 10GB for App nobuf, nowal buf:100, nowal buf:1000, nowal nobuf, WAL buf:100, WAL buf:1000, WAL MB/s 12MB/s 53MB/s 48MB/s 5MB/s 11MB/s 31MB/s puts/s 11k rows/s 50k rows/s 45k rows/s 4.7k rows/s 10k rows/s 30k rows/s 74
75 Sources HBase. The defenitive guide (O Reilly) HBase in action (Manning) Official documentation Cloudera articles
76 HBase Леонид Налчаджи
ADVANCED HBASE. Architecture and Schema Design GeeCON, May Lars George Director EMEA Services
 ADVANCED HBASE Architecture and Schema Design GeeCON, May 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer
ADVANCED HBASE Architecture and Schema Design GeeCON, May 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer
Advanced HBase Schema Design. Berlin Buzzwords, June 2012 Lars George
 Advanced HBase Schema Design Berlin Buzzwords, June 2012 Lars George lars@cloudera.com About Me SoluDons Architect @ Cloudera Apache HBase & Whirr CommiIer Author of HBase The Defini.ve Guide Working with
Advanced HBase Schema Design Berlin Buzzwords, June 2012 Lars George lars@cloudera.com About Me SoluDons Architect @ Cloudera Apache HBase & Whirr CommiIer Author of HBase The Defini.ve Guide Working with
Ghislain Fourny. Big Data 5. Column stores
 Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
HBASE INTERVIEW QUESTIONS
 HBASE INTERVIEW QUESTIONS http://www.tutorialspoint.com/hbase/hbase_interview_questions.htm Copyright tutorialspoint.com Dear readers, these HBase Interview Questions have been designed specially to get
HBASE INTERVIEW QUESTIONS http://www.tutorialspoint.com/hbase/hbase_interview_questions.htm Copyright tutorialspoint.com Dear readers, these HBase Interview Questions have been designed specially to get
Ghislain Fourny. Big Data 5. Wide column stores
 Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
BigTable: A Distributed Storage System for Structured Data
 BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Facebook. The Technology Behind Messages (and more ) Kannan Muthukkaruppan Software Engineer, Facebook. March 11, 2011
 Kannan Muthukkaruppan Software Engineer, Facebook. March 11, 2011") HBase @ Facebook The Technology Behind Messages (and more ) Kannan Muthukkaruppan Software Engineer, Facebook March 11, 2011 Talk Outline the new Facebook Messages, and how we got started with HBase quick
HBase @ Facebook The Technology Behind Messages (and more ) Kannan Muthukkaruppan Software Engineer, Facebook March 11, 2011 Talk Outline the new Facebook Messages, and how we got started with HBase quick
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
10 Million Smart Meter Data with Apache HBase
 10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
COSC 6339 Big Data Analytics. NoSQL (II) HBase. Edgar Gabriel Fall HBase. Column-Oriented data store Distributed designed to serve large tables
 HBase. Edgar Gabriel Fall HBase. Column-Oriented data store Distributed designed to serve large tables") COSC 6339 Big Data Analytics NoSQL (II) HBase Edgar Gabriel Fall 2018 HBase Column-Oriented data store Distributed designed to serve large tables Billions of rows and millions of columns Runs on a cluster
COSC 6339 Big Data Analytics NoSQL (II) HBase Edgar Gabriel Fall 2018 HBase Column-Oriented data store Distributed designed to serve large tables Billions of rows and millions of columns Runs on a cluster
COSC 6397 Big Data Analytics. Data Formats (III) HBase: Java API, HBase in MapReduce and HBase Bulk Loading. Edgar Gabriel Spring 2014.
 HBase: Java API, HBase in MapReduce and HBase Bulk Loading. Edgar Gabriel Spring 2014.") COSC 6397 Big Data Analytics Data Formats (III) HBase: Java API, HBase in MapReduce and HBase Bulk Loading Edgar Gabriel Spring 2014 Recap on HBase Column-Oriented data store NoSQL DB Data is stored in
COSC 6397 Big Data Analytics Data Formats (III) HBase: Java API, HBase in MapReduce and HBase Bulk Loading Edgar Gabriel Spring 2014 Recap on HBase Column-Oriented data store NoSQL DB Data is stored in
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
BigTable. Chubby. BigTable. Chubby. Why Chubby? How to do consensus as a service
 BigTable BigTable Doug Woos and Tom Anderson In the early 2000s, Google had way more than anybody else did Traditional bases couldn t scale Want something better than a filesystem () BigTable optimized
BigTable BigTable Doug Woos and Tom Anderson In the early 2000s, Google had way more than anybody else did Traditional bases couldn t scale Want something better than a filesystem () BigTable optimized
Faster HBase queries. Introducing hindex Secondary indexes for HBase. ApacheCon North America Rajeshbabu Chintaguntla
 Security Level: Faster HBase queries Introducing hindex Secondary indexes for HBase ApacheCon North America 2014 www.huawei.com Rajeshbabu Chintaguntla rajeshbabu@apache.org HUAWEI TECHNOLOGIES CO., LTD.
Security Level: Faster HBase queries Introducing hindex Secondary indexes for HBase ApacheCon North America 2014 www.huawei.com Rajeshbabu Chintaguntla rajeshbabu@apache.org HUAWEI TECHNOLOGIES CO., LTD.
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
NoSQL Databases. Amir H. Payberah. Swedish Institute of Computer Science. April 10, 2014
 NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Typical size of data you deal with on a daily basis
 Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
HBase Solutions at Facebook
 HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
Apache Accumulo 1.4 & 1.5 Features
 Apache Accumulo 1.4 & 1.5 Features Inaugural Accumulo DC Meetup Keith Turner What is Accumulo? A re-implementation of Big Table Distributed Database Does not support SQL Data is arranged by Row Column
Apache Accumulo 1.4 & 1.5 Features Inaugural Accumulo DC Meetup Keith Turner What is Accumulo? A re-implementation of Big Table Distributed Database Does not support SQL Data is arranged by Row Column
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
CSE-E5430 Scalable Cloud Computing Lecture 9
 CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
BigTable. CSE-291 (Cloud Computing) Fall 2016
 Fall 2016") BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Cloudera Kudu Introduction
 Cloudera Kudu Introduction Zbigniew Baranowski Based on: http://slideshare.net/cloudera/kudu-new-hadoop-storage-for-fast-analytics-onfast-data What is KUDU? New storage engine for structured data (tables)
Cloudera Kudu Introduction Zbigniew Baranowski Based on: http://slideshare.net/cloudera/kudu-new-hadoop-storage-for-fast-analytics-onfast-data What is KUDU? New storage engine for structured data (tables)
TRANSACTIONS AND ABSTRACTIONS
 TRANSACTIONS AND ABSTRACTIONS OVER HBASE Andreas Neumann @anew68! Continuuity AGENDA Transactions over HBase: Why? What? Implementation: How? The approach Transaction Manager Abstractions Future WHO WE
TRANSACTIONS AND ABSTRACTIONS OVER HBASE Andreas Neumann @anew68! Continuuity AGENDA Transactions over HBase: Why? What? Implementation: How? The approach Transaction Manager Abstractions Future WHO WE
Extreme Computing. NoSQL.
 Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
HBase Java Client API
 2012 coreservlets.com and Dima May HBase Java Client API Basic CRUD operations Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized Hadoop
2012 coreservlets.com and Dima May HBase Java Client API Basic CRUD operations Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized Hadoop
CSE 444: Database Internals. Lectures 26 NoSQL: Extensible Record Stores
 CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
HBase Installation and Configuration
 Aims This exercise aims to get you to: Install and configure HBase Manage data using HBase Shell Manage data using HBase Java API HBase Installation and Configuration 1. Download HBase 1.2.2 $ wget http://apache.uberglobalmirror.com/hbase/1.2.2/hbase-1.2.2-
Aims This exercise aims to get you to: Install and configure HBase Manage data using HBase Shell Manage data using HBase Java API HBase Installation and Configuration 1. Download HBase 1.2.2 $ wget http://apache.uberglobalmirror.com/hbase/1.2.2/hbase-1.2.2-
References. What is Bigtable? Bigtable Data Model. Outline. Key Features. CSE 444: Database Internals
 References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
HBase... And Lewis Carroll! Twi:er,
 HBase... And Lewis Carroll! jw4ean@cloudera.com Twi:er, LinkedIn: @jw4ean 1 Introduc@on 2010: Cloudera Solu@ons Architect 2011: Cloudera TAM/DSE 2012-2013: Cloudera Training focusing on Partners and Newbies
HBase... And Lewis Carroll! jw4ean@cloudera.com Twi:er, LinkedIn: @jw4ean 1 Introduc@on 2010: Cloudera Solu@ons Architect 2011: Cloudera TAM/DSE 2012-2013: Cloudera Training focusing on Partners and Newbies
Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب
 Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب 1391 زمستان Outlines Introduction DataModel Architecture HBase vs. RDBMS HBase users 2 Why Hadoop? Datasets are growing to Petabytes Traditional datasets
Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب 1391 زمستان Outlines Introduction DataModel Architecture HBase vs. RDBMS HBase users 2 Why Hadoop? Datasets are growing to Petabytes Traditional datasets
TRANSACTIONS OVER HBASE
 TRANSACTIONS OVER HBASE Alex Baranau @abaranau Gary Helmling @gario Continuuity WHO WE ARE We ve built Continuuity Reactor: the world s first scale-out application server for Hadoop Fast, easy development,
TRANSACTIONS OVER HBASE Alex Baranau @abaranau Gary Helmling @gario Continuuity WHO WE ARE We ve built Continuuity Reactor: the world s first scale-out application server for Hadoop Fast, easy development,
W b b 2.0. = = Data Ex E pl p o l s o io i n
 Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
Bigtable. Presenter: Yijun Hou, Yixiao Peng
 Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis
 Slides adapted by Tyler Davis") BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
YCSB++ benchmarking tool Performance debugging advanced features of scalable table stores
 YCSB++ benchmarking tool Performance debugging advanced features of scalable table stores Swapnil Patil M. Polte, W. Tantisiriroj, K. Ren, L.Xiao, J. Lopez, G.Gibson, A. Fuchs *, B. Rinaldi * Carnegie
YCSB++ benchmarking tool Performance debugging advanced features of scalable table stores Swapnil Patil M. Polte, W. Tantisiriroj, K. Ren, L.Xiao, J. Lopez, G.Gibson, A. Fuchs *, B. Rinaldi * Carnegie
Bigtable: A Distributed Storage System for Structured Data. Andrew Hon, Phyllis Lau, Justin Ng
 Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Tuning Enterprise Information Catalog Performance
 Tuning Enterprise Information Catalog Performance Copyright Informatica LLC 2015, 2018. Informatica and the Informatica logo are trademarks or registered trademarks of Informatica LLC in the United States
Tuning Enterprise Information Catalog Performance Copyright Informatica LLC 2015, 2018. Informatica and the Informatica logo are trademarks or registered trademarks of Informatica LLC in the United States
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Big Table. Google s Storage Choice for Structured Data. Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla
 Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
Apache HBase Andrew Purtell Committer, Apache HBase, Apache Software Foundation Big Data US Research And Development, Intel
 Apache HBase 0.98 Andrew Purtell Committer, Apache HBase, Apache Software Foundation Big Data US Research And Development, Intel Who am I? Committer on the Apache HBase project Member of the Big Data Research
Apache HBase 0.98 Andrew Purtell Committer, Apache HBase, Apache Software Foundation Big Data US Research And Development, Intel Who am I? Committer on the Apache HBase project Member of the Big Data Research
HBase is not a direct replacement for a classic SQL Database, although recently its performance has improved.
 Relational database managementsystems (RDBMS) have been around since the early 1970s, and they are equally helpful today. But there also seem to be specific problems that do not fit this model very well.
Relational database managementsystems (RDBMS) have been around since the early 1970s, and they are equally helpful today. But there also seem to be specific problems that do not fit this model very well.
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612
 Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Using space-filling curves for multidimensional
 Using space-filling curves for multidimensional indexing Dr. Bisztray Dénes Senior Research Engineer 1 Nokia Solutions and Networks 2014 In medias res Performance problems with RDBMS Switch to NoSQL store
Using space-filling curves for multidimensional indexing Dr. Bisztray Dénes Senior Research Engineer 1 Nokia Solutions and Networks 2014 In medias res Performance problems with RDBMS Switch to NoSQL store
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Percona Live September 21-23, 2015 Mövenpick Hotel Amsterdam
 Percona Live 2015 September 21-23, 2015 Mövenpick Hotel Amsterdam TokuDB internals Percona team, Vlad Lesin, Sveta Smirnova Slides plan Introduction in Fractal Trees and TokuDB Files Block files Fractal
Percona Live 2015 September 21-23, 2015 Mövenpick Hotel Amsterdam TokuDB internals Percona team, Vlad Lesin, Sveta Smirnova Slides plan Introduction in Fractal Trees and TokuDB Files Block files Fractal
CS 550 Operating Systems Spring File System
 1 CS 550 Operating Systems Spring 2018 File System 2 OS Abstractions Process: virtualization of CPU Address space: virtualization of memory The above to allow a program to run as if it is in its own private,
1 CS 550 Operating Systems Spring 2018 File System 2 OS Abstractions Process: virtualization of CPU Address space: virtualization of memory The above to allow a program to run as if it is in its own private,
Indexing. Jan Chomicki University at Buffalo. Jan Chomicki () Indexing 1 / 25
 Indexing 1 / 25") Indexing Jan Chomicki University at Buffalo Jan Chomicki () Indexing 1 / 25 Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow (nanosec) (10 nanosec) (millisec) (sec) Very small Small
Indexing Jan Chomicki University at Buffalo Jan Chomicki () Indexing 1 / 25 Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow (nanosec) (10 nanosec) (millisec) (sec) Very small Small
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
HBASE MOCK TEST HBASE MOCK TEST III
 http://www.tutorialspoint.com HBASE MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to HBase. You can download these sample mock tests at your local machine
http://www.tutorialspoint.com HBASE MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to HBase. You can download these sample mock tests at your local machine
ZooKeeper & Curator. CS 475, Spring 2018 Concurrent & Distributed Systems
 ZooKeeper & Curator CS 475, Spring 2018 Concurrent & Distributed Systems Review: Agreement In distributed systems, we have multiple nodes that need to all agree that some object has some state Examples:
ZooKeeper & Curator CS 475, Spring 2018 Concurrent & Distributed Systems Review: Agreement In distributed systems, we have multiple nodes that need to all agree that some object has some state Examples:
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
HydraFS: a High-Throughput File System for the HYDRAstor Content-Addressable Storage System
 HydraFS: a High-Throughput File System for the HYDRAstor Content-Addressable Storage System Cristian Ungureanu, Benjamin Atkin, Akshat Aranya, Salil Gokhale, Steve Rago, Grzegorz Calkowski, Cezary Dubnicki,
HydraFS: a High-Throughput File System for the HYDRAstor Content-Addressable Storage System Cristian Ungureanu, Benjamin Atkin, Akshat Aranya, Salil Gokhale, Steve Rago, Grzegorz Calkowski, Cezary Dubnicki,
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Distributed PostgreSQL with YugaByte DB
 Distributed PostgreSQL with YugaByte DB Karthik Ranganathan PostgresConf Silicon Valley Oct 16, 2018 1 CHECKOUT THIS REPO: github.com/yugabyte/yb-sql-workshop 2 About Us Founders Kannan Muthukkaruppan,
Distributed PostgreSQL with YugaByte DB Karthik Ranganathan PostgresConf Silicon Valley Oct 16, 2018 1 CHECKOUT THIS REPO: github.com/yugabyte/yb-sql-workshop 2 About Us Founders Kannan Muthukkaruppan,
Voldemort. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Storage hierarchy. Textbook: chapters 11, 12, and 13
 Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow Very small Small Bigger Very big (KB) (MB) (GB) (TB) Built-in Expensive Cheap Dirt cheap Disks: data is stored on concentric circular
Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow Very small Small Bigger Very big (KB) (MB) (GB) (TB) Built-in Expensive Cheap Dirt cheap Disks: data is stored on concentric circular
CA485 Ray Walshe NoSQL
 NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
Outline. Spanner Mo/va/on. Tom Anderson
 Spanner Mo/va/on Tom Anderson Outline Last week: Chubby: coordina/on service BigTable: scalable storage of structured data GFS: large- scale storage for bulk data Today/Friday: Lessons from GFS/BigTable
Spanner Mo/va/on Tom Anderson Outline Last week: Chubby: coordina/on service BigTable: scalable storage of structured data GFS: large- scale storage for bulk data Today/Friday: Lessons from GFS/BigTable
Snapshots and Repeatable reads for HBase Tables
 Snapshots and Repeatable reads for HBase Tables Note: This document is work in progress. Contributors (alphabetical): Vandana Ayyalasomayajula, Francis Liu, Andreas Neumann, Thomas Weise Objective The
Snapshots and Repeatable reads for HBase Tables Note: This document is work in progress. Contributors (alphabetical): Vandana Ayyalasomayajula, Francis Liu, Andreas Neumann, Thomas Weise Objective The
GridGain and Apache Ignite In-Memory Performance with Durability of Disk
 GridGain and Apache Ignite In-Memory Performance with Durability of Disk Dmitriy Setrakyan Apache Ignite PMC GridGain Founder & CPO http://ignite.apache.org #apacheignite Agenda What is GridGain and Ignite
GridGain and Apache Ignite In-Memory Performance with Durability of Disk Dmitriy Setrakyan Apache Ignite PMC GridGain Founder & CPO http://ignite.apache.org #apacheignite Agenda What is GridGain and Ignite
File Systems. Kartik Gopalan. Chapter 4 From Tanenbaum s Modern Operating System
 File Systems Kartik Gopalan Chapter 4 From Tanenbaum s Modern Operating System 1 What is a File System? File system is the OS component that organizes data on the raw storage device. Data, by itself, is
File Systems Kartik Gopalan Chapter 4 From Tanenbaum s Modern Operating System 1 What is a File System? File system is the OS component that organizes data on the raw storage device. Data, by itself, is
Replica Parallelism to Utilize the Granularity of Data
 Replica Parallelism to Utilize the Granularity of Data 1st Author 1st author's affiliation 1st line of address 2nd line of address Telephone number, incl. country code 1st author's E-mail address 2nd Author
Replica Parallelism to Utilize the Granularity of Data 1st Author 1st author's affiliation 1st line of address 2nd line of address Telephone number, incl. country code 1st author's E-mail address 2nd Author
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
CSE 544 Principles of Database Management Systems
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 5 - DBMS Architecture and Indexing 1 Announcements HW1 is due next Thursday How is it going? Projects: Proposals are due
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 5 - DBMS Architecture and Indexing 1 Announcements HW1 is due next Thursday How is it going? Projects: Proposals are due
Course Content MongoDB
 Course Content MongoDB 1. Course introduction and mongodb Essentials (basics) 2. Introduction to NoSQL databases What is NoSQL? Why NoSQL? Difference Between RDBMS and NoSQL Databases Benefits of NoSQL
Course Content MongoDB 1. Course introduction and mongodb Essentials (basics) 2. Introduction to NoSQL databases What is NoSQL? Why NoSQL? Difference Between RDBMS and NoSQL Databases Benefits of NoSQL
Topics. File Buffer Cache for Performance. What to Cache? COS 318: Operating Systems. File Performance and Reliability
 Topics COS 318: Operating Systems File Performance and Reliability File buffer cache Disk failure and recovery tools Consistent updates Transactions and logging 2 File Buffer Cache for Performance What
Topics COS 318: Operating Systems File Performance and Reliability File buffer cache Disk failure and recovery tools Consistent updates Transactions and logging 2 File Buffer Cache for Performance What
Oral Questions and Answers (DBMS LAB) Questions & Answers- DBMS
 Questions & Answers- DBMS") Questions & Answers- DBMS https://career.guru99.com/top-50-database-interview-questions/ 1) Define Database. A prearranged collection of figures known as data is called database. 2) What is DBMS? Database
Questions & Answers- DBMS https://career.guru99.com/top-50-database-interview-questions/ 1) Define Database. A prearranged collection of figures known as data is called database. 2) What is DBMS? Database
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
! Design constraints. " Component failures are the norm. " Files are huge by traditional standards. ! POSIX-like
 Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
Google File System. Arun Sundaram Operating Systems
 Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
Azure-persistence MARTIN MUDRA
 Azure-persistence MARTIN MUDRA Storage service access Blobs Queues Tables Storage service Horizontally scalable Zone Redundancy Accounts Based on Uri Pricing Calculator Azure table storage Storage Account
Azure-persistence MARTIN MUDRA Storage service access Blobs Queues Tables Storage service Horizontally scalable Zone Redundancy Accounts Based on Uri Pricing Calculator Azure table storage Storage Account
HBase Security. Works in Progress Andrew Purtell, an Intel HBase guy
 HBase Security Works in Progress Andrew Purtell, an Intel HBase guy Outline Project Rhino Extending the HBase ACL model to per-cell granularity Introducing transparent encryption I don t always need encryption,
HBase Security Works in Progress Andrew Purtell, an Intel HBase guy Outline Project Rhino Extending the HBase ACL model to per-cell granularity Introducing transparent encryption I don t always need encryption,
Accumulo Extensions to Google s Bigtable Design
 Drivers Extensions to Google s Bigtable National Security Agency Computer and Information Sciences Research Group March 29, 2012 Contents Drivers 1 Drivers 2 3 4 Progress Drivers 1 Drivers 2 3 4 Drivers
Drivers Extensions to Google s Bigtable National Security Agency Computer and Information Sciences Research Group March 29, 2012 Contents Drivers 1 Drivers 2 3 4 Progress Drivers 1 Drivers 2 3 4 Drivers
MyRocks Engineering Features and Enhancements. Manuel Ung Facebook, Inc. Dublin, Ireland Sept th, 2017
 MyRocks Engineering Features and Enhancements Manuel Ung Facebook, Inc. Dublin, Ireland Sept 25 27 th, 2017 Agenda Bulk load Time to live (TTL) Debugging deadlocks Persistent auto-increment values Improved
MyRocks Engineering Features and Enhancements Manuel Ung Facebook, Inc. Dublin, Ireland Sept 25 27 th, 2017 Agenda Bulk load Time to live (TTL) Debugging deadlocks Persistent auto-increment values Improved
Enabling Persistent Memory Use in Java. Steve Dohrmann Sr. Staff Software Engineer, Intel
 Enabling Persistent Memory Use in Java Steve Dohrmann Sr. Staff Software Engineer, Intel Motivation Java is a very popular language on servers, especially for databases, data grids, etc., e.g. Apache projects:
Enabling Persistent Memory Use in Java Steve Dohrmann Sr. Staff Software Engineer, Intel Motivation Java is a very popular language on servers, especially for databases, data grids, etc., e.g. Apache projects:
SQL, NoSQL, MongoDB. CSE-291 (Cloud Computing) Fall 2016 Gregory Kesden
 Fall 2016 Gregory Kesden") SQL, NoSQL, MongoDB CSE-291 (Cloud Computing) Fall 2016 Gregory Kesden SQL Databases Really better called Relational Databases Key construct is the Relation, a.k.a. the table Rows represent records Columns
SQL, NoSQL, MongoDB CSE-291 (Cloud Computing) Fall 2016 Gregory Kesden SQL Databases Really better called Relational Databases Key construct is the Relation, a.k.a. the table Rows represent records Columns
Persistent Storage - Datastructures and Algorithms
 Persistent Storage - Datastructures and Algorithms 1 / 21 L 03: Virtual Memory and Caches 2 / 21 Questions How to access data, when sequential access is too slow? Direct access (random access) file, how
Persistent Storage - Datastructures and Algorithms 1 / 21 L 03: Virtual Memory and Caches 2 / 21 Questions How to access data, when sequential access is too slow? Direct access (random access) file, how
YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores
 YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores Swapnil Patil Milo Polte, Wittawat Tantisiriroj, Kai Ren, Lin Xiao, Julio Lopez, Garth Gibson, Adam Fuchs *, Billie
YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores Swapnil Patil Milo Polte, Wittawat Tantisiriroj, Kai Ren, Lin Xiao, Julio Lopez, Garth Gibson, Adam Fuchs *, Billie
User Perspective. Module III: System Perspective. Module III: Topics Covered. Module III Overview of Storage Structures, QP, and TM
 Module III Overview of Storage Structures, QP, and TM Sharma Chakravarthy UT Arlington sharma@cse.uta.edu http://www2.uta.edu/sharma base Management Systems: Sharma Chakravarthy Module I Requirements analysis
Module III Overview of Storage Structures, QP, and TM Sharma Chakravarthy UT Arlington sharma@cse.uta.edu http://www2.uta.edu/sharma base Management Systems: Sharma Chakravarthy Module I Requirements analysis
CS220 Database Systems. File Organization
 CS220 Database Systems File Organization Slides from G. Kollios Boston University and UC Berkeley 1.1 Context Database app Query Optimization and Execution Relational Operators Access Methods Buffer Management
CS220 Database Systems File Organization Slides from G. Kollios Boston University and UC Berkeley 1.1 Context Database app Query Optimization and Execution Relational Operators Access Methods Buffer Management
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
MyRocks deployment at Facebook and Roadmaps. Yoshinori Matsunobu Production Engineer / MySQL Tech Lead, Facebook Feb/2018, #FOSDEM #mysqldevroom
 MyRocks deployment at Facebook and Roadmaps Yoshinori Matsunobu Production Engineer / MySQL Tech Lead, Facebook Feb/2018, #FOSDEM #mysqldevroom Agenda MySQL at Facebook MyRocks overview Production Deployment
MyRocks deployment at Facebook and Roadmaps Yoshinori Matsunobu Production Engineer / MySQL Tech Lead, Facebook Feb/2018, #FOSDEM #mysqldevroom Agenda MySQL at Facebook MyRocks overview Production Deployment
Research on the Application of Bank Transaction Data Stream Storage based on HBase Xiaoguo Wang*, Yuxiang Liu and Lin Zhang
 International Conference on Engineering Management (Iconf-EM 2016) Research on the Application of Bank Transaction Data Stream Storage based on HBase Xiaoguo Wang*, Yuxiang Liu and Lin Zhang School of
International Conference on Engineering Management (Iconf-EM 2016) Research on the Application of Bank Transaction Data Stream Storage based on HBase Xiaoguo Wang*, Yuxiang Liu and Lin Zhang School of
big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures
 mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures") Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
Who Am I? Chris Larsen
 2.4 and 3.0 Update Who Am I? Chris Larsen Maintainer and author for OpenTSDB since 2013 Software Engineer @ Yahoo Central Monitoring Team Who I m not: A marketer A sales person 2 What Is OpenTSDB? Open
2.4 and 3.0 Update Who Am I? Chris Larsen Maintainer and author for OpenTSDB since 2013 Software Engineer @ Yahoo Central Monitoring Team Who I m not: A marketer A sales person 2 What Is OpenTSDB? Open