Overview. Why MapReduce? What is MapReduce? The Hadoop Distributed File System Cloudera, Inc.
|
|
|
- Milo Daniels
- 5 years ago
- Views:
Transcription
1 MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents:
2 Overview Why MapReduce? What is MapReduce? The Hadoop Distributed File System
3 How MapReduce is Structured Functional programming meets distributed computing A batch data processing system Factors out many reliability concerns from application logic
4 MapReduce Provides: Automatic parallelization & distribution Fault-tolerance Status and monitoring tools A clean abstraction for programmers
5 Programming Model Borrows from functional programming Users implement interface of two functions: map (in_key, in_value) -> (out_key, intermediate_value) list reduce (out_key, intermediate_value list) -> out_value list
6 map Records from the data source (lines out of files, rows of a database, etc) are fed into the map function as key*value pairs: e.g., (filename, line). map() produces one or more intermediate values along with an output key from the input.
7 map map (in_key, in_value) -> (out_key, intermediate_value) list
8 Example: Upper-case Mapper let map(k, v) = emit(k.toupper(), v.toupper()) ( foo, bar ) ( FOO, BAR ) ( Foo, other ) ( FOO, OTHER ) ( key2, data ) ( KEY2, DATA )
9 Example: Explode Mapper let map(k, v) = foreach char c in v: emit(k, c) ( A, cats ) ( A, c ), ( A, a ), ( A, t ), ( A, s ) ( B, hi ) ( B, h ), ( B, i )
10 Example: Filter Mapper let map(k, v) = if (isprime(v)) then emit(k, v) ( foo, 7) ( foo, 7) ( test, 10) (nothing)
11 Example: Changing Keyspaces let map(k, v) = emit(v.length(), v) ( hi, test ) (4, test ) ( x, quux ) (4, quux ) ( y, abracadabra ) (10, abracadabra )
12 reduce After the map phase is over, all the intermediate values for a given output key are combined together into a list reduce() combines those intermediate values into one or more final values for that same output key (in practice, usually only one final value per key)
13 reduce reduce (out_key, intermediate_value list) -> out_value list
14 Example: Sum Reducer let reduce(k, vals) = sum = 0 foreach int v in vals: sum += v emit(k, sum) ( A, [42, 100, 312]) ( A, 454) ( B, [12, 6, -2]) ( B, 16)
15 Example: Identity Reducer let reduce(k, vals) = foreach v in vals: emit(k, v) ( A, [42, 100, 312]) ( A, 42), ( A, 100), ( A, 312) ( B, [12, 6, -2]) ( B, 12), ( B, 6), ( B, -2)

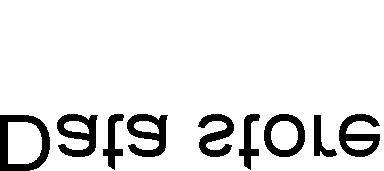

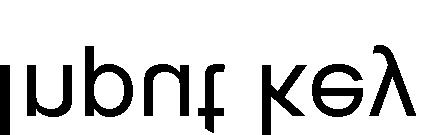
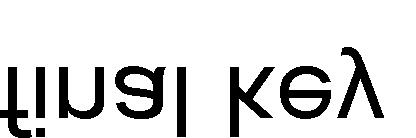
16
17 Parallelism map() functions run in parallel, creating different intermediate values from different input data sets reduce() functions also run in parallel, each working on a different output key All values are processed independently Bottleneck: reduce phase can t start until map phase is completely finished.
18 Example: Count word occurrences map(string input_key, String input_value): // input_key: document name // input_value: document contents for each word w in input_value: emit(w, 1); reduce(string output_key, Iterator<int> intermediate_values): // output_key: a word // output_values: a list of counts int result = 0; for each v in intermediate_values: result += v; emit(output_key, result);
19 Combining Phase Run on mapper nodes after map phase Mini-reduce, only on local map output Used to save bandwidth before sending data to full reducer Reducer can be combiner if commutative & associative e.g., SumReducer
20 Combiner, graphically
21 WordCount Redux map(string input_key, String input_value): // input_key: document name // input_value: document contents for each word w in input_value: emit(w, 1); reduce(string output_key, Iterator<int> intermediate_values): // output_key: a word // output_values: a list of counts int result = 0; for each v in intermediate_values: result += v; emit(output_key, result);
22 MapReduce Conclusions MapReduce has proven to be a useful abstraction in many areas Greatly simplifies large-scale computations Functional programming paradigm can be applied to large-scale applications You focus on the real problem, library deals with messy details
23 HDFS Some slides designed by Alex Moschuk, University of Washington Redistributed under the Creative Commons Attribution 3.0 license
24 HDFS: Motivation Based on Google s GFS Redundant storage of massive amounts of data on cheap and unreliable computers Why not use an existing file system? Different workload and design priorities Handles much bigger dataset sizes than other filesystems
25 Assumptions High component failure rates Inexpensive commodity components fail all the time Modest number of HUGE files Just a few million Each is 100MB or larger; multi-gb files typical Files are write-once, mostly appended to Perhaps concurrently Large streaming reads High sustained throughput favored over low latency
26 HDFS Design Decisions Files stored as blocks Much larger size than most filesystems (default is 64MB) Reliability through replication Each block replicated across 3+ DataNodes Single master (NameNode) coordinates access, metadata Simple centralized management No data caching Little benefit due to large data sets, streaming reads Familiar interface, but customize the API Simplify the problem; focus on distributed apps
27 HDFS Client Block Diagram $" " ###!!
28 Based on GFS Architecture Figure from The Google File System, Ghemawat et. al., SOSP 2003
29 Metadata Single NameNode stores all metadata Filenames, locations on DataNodes of each file Maintained entirely in RAM for fast lookup DataNodes store opaque file contents in block objects on underlying local filesystem
30 HDFS Conclusions HDFS supports large-scale processing workloads on commodity hardware designed to tolerate frequent component failures optimized for huge files that are mostly appended and read filesystem interface is customized for the job, but still retains familiarity for developers simple solutions can work (e.g., single master) Reliably stores several TB in individual clusters
31
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Database System Architectures Parallel DBs, MapReduce, ColumnStores
 Database System Architectures Parallel DBs, MapReduce, ColumnStores CMPSCI 445 Fall 2010 Some slides courtesy of Yanlei Diao, Christophe Bisciglia, Aaron Kimball, & Sierra Michels- Slettvet Motivation:
Database System Architectures Parallel DBs, MapReduce, ColumnStores CMPSCI 445 Fall 2010 Some slides courtesy of Yanlei Diao, Christophe Bisciglia, Aaron Kimball, & Sierra Michels- Slettvet Motivation:
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
ILO3:Algorithms and Programming Patterns for Cloud Applications (Hadoop)
") DISTRIBUTED RESEARCH ON EMERGING APPLICATIONS & MACHINES dream-lab.in Indian Institute of Science, Bangalore DREAM:Lab SE252:Lecture 13-14, Feb 24/25 ILO3:Algorithms and Programming Patterns for Cloud
DISTRIBUTED RESEARCH ON EMERGING APPLICATIONS & MACHINES dream-lab.in Indian Institute of Science, Bangalore DREAM:Lab SE252:Lecture 13-14, Feb 24/25 ILO3:Algorithms and Programming Patterns for Cloud
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
HDFS: Hadoop Distributed File System. Sector: Distributed Storage System
 GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Parallel Data Processing with Hadoop/MapReduce. CS140 Tao Yang, 2014
 Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
MapReduce: Simplified Data Processing on Large Clusters
 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Distributed Systems. CS422/522 Lecture17 17 November 2014
 Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
Practice and Applications of Data Management CMPSCI 345. Lecture 18: Big Data, Hadoop, and MapReduce
 Practice and Applications of Data Management CMPSCI 345 Lecture 18: Big Data, Hadoop, and MapReduce Why Big Data, Hadoop, M-R? } What is the connec,on with the things we learned? } What about SQL? } What
Practice and Applications of Data Management CMPSCI 345 Lecture 18: Big Data, Hadoop, and MapReduce Why Big Data, Hadoop, M-R? } What is the connec,on with the things we learned? } What about SQL? } What
Advanced Database Technologies NoSQL: Not only SQL
 Advanced Database Technologies NoSQL: Not only SQL Christian Grün Database & Information Systems Group NoSQL Introduction 30, 40 years history of well-established database technology all in vain? Not at
Advanced Database Technologies NoSQL: Not only SQL Christian Grün Database & Information Systems Group NoSQL Introduction 30, 40 years history of well-established database technology all in vain? Not at
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Hadoop Distributed File System(HDFS)
") Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
Distributed Computations MapReduce. adapted from Jeff Dean s slides
 Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Parallel Processing - MapReduce and FlumeJava. Amir H. Payberah 14/09/2018
 Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
MapReduce. Simplified Data Processing on Large Clusters (Without the Agonizing Pain) Presented by Aaron Nathan
 Presented by Aaron Nathan") MapReduce Simplified Data Processing on Large Clusters (Without the Agonizing Pain) Presented by Aaron Nathan The Problem Massive amounts of data >100TB (the internet) Needs simple processing Computers
MapReduce Simplified Data Processing on Large Clusters (Without the Agonizing Pain) Presented by Aaron Nathan The Problem Massive amounts of data >100TB (the internet) Needs simple processing Computers
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
Principles of Data Management. Lecture #16 (MapReduce & DFS for Big Data)
") Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Informa)on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies
on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies") Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
MapReduce & BigTable
 CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Map Reduce.
 Map Reduce dacosta@irit.fr Divide and conquer at PaaS Second Third Fourth 100 % // Fifth Sixth Seventh Cliquez pour 2 Typical problem Second Extract something of interest from each MAP Third Shuffle and
Map Reduce dacosta@irit.fr Divide and conquer at PaaS Second Third Fourth 100 % // Fifth Sixth Seventh Cliquez pour 2 Typical problem Second Extract something of interest from each MAP Third Shuffle and
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Google File System. Arun Sundaram Operating Systems
 Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
MapReduce and Hadoop
 Università degli Studi di Roma Tor Vergata MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference Big Data stack High-level Interfaces Data Processing
Università degli Studi di Roma Tor Vergata MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference Big Data stack High-level Interfaces Data Processing
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
Mixing and matching virtual and physical HPC clusters. Paolo Anedda
 Mixing and matching virtual and physical HPC clusters Paolo Anedda paolo.anedda@crs4.it HPC 2010 - Cetraro 22/06/2010 1 Outline Introduction Scalability Issues System architecture Conclusions & Future
Mixing and matching virtual and physical HPC clusters Paolo Anedda paolo.anedda@crs4.it HPC 2010 - Cetraro 22/06/2010 1 Outline Introduction Scalability Issues System architecture Conclusions & Future
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
In the news. Request- Level Parallelism (RLP) Agenda 10/7/11
 Agenda 10/7/11") In the news "The cloud isn't this big fluffy area up in the sky," said Rich Miller, who edits Data Center Knowledge, a publicaeon that follows the data center industry. "It's buildings filled with servers
In the news "The cloud isn't this big fluffy area up in the sky," said Rich Miller, who edits Data Center Knowledge, a publicaeon that follows the data center industry. "It's buildings filled with servers
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Tutorial Outline. Map/Reduce. Data Center as a computer [Patterson, cacm 2008] Acknowledgements
![Tutorial Outline. Map/Reduce. Data Center as a computer [Patterson, cacm 2008] Acknowledgements](/thumbs/89/98108012.jpg "Tutorial Outline. Map/Reduce. Data Center as a computer [Patterson, cacm 2008] Acknowledgements") Tutorial Outline Map/Reduce Map/reduce Hadoop Sharma Chakravarthy Information Technology Laboratory Computer Science and Engineering Department The University of Texas at Arlington, Arlington, TX 76009
Tutorial Outline Map/Reduce Map/reduce Hadoop Sharma Chakravarthy Information Technology Laboratory Computer Science and Engineering Department The University of Texas at Arlington, Arlington, TX 76009
Laarge-Scale Data Engineering
 Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391
 Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
CSE 344 MAY 2 ND MAP/REDUCE
 CSE 344 MAY 2 ND MAP/REDUCE ADMINISTRIVIA HW5 Due Tonight Practice midterm Section tomorrow Exam review PERFORMANCE METRICS FOR PARALLEL DBMSS Nodes = processors, computers Speedup: More nodes, same data
CSE 344 MAY 2 ND MAP/REDUCE ADMINISTRIVIA HW5 Due Tonight Practice midterm Section tomorrow Exam review PERFORMANCE METRICS FOR PARALLEL DBMSS Nodes = processors, computers Speedup: More nodes, same data
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Warehouse-Scale Computing, MapReduce, and Spark
 Warehouse-Scale Computing, MapReduce, and Spark") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Warehouse-Scale Computing, MapReduce, and Spark Instructors: Bernard Boser & Randy H. Katz http://inst.eecs.berkeley.edu/~cs61c/ 11/11/16
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Warehouse-Scale Computing, MapReduce, and Spark Instructors: Bernard Boser & Randy H. Katz http://inst.eecs.berkeley.edu/~cs61c/ 11/11/16
Google: A Computer Scientist s Playground
 Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Outline Mission, data, and scaling Systems infrastructure Parallel programming model: MapReduce Googles
Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Outline Mission, data, and scaling Systems infrastructure Parallel programming model: MapReduce Googles
Google: A Computer Scientist s Playground
 Outline Mission, data, and scaling Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Systems infrastructure Parallel programming model: MapReduce Googles
Outline Mission, data, and scaling Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Systems infrastructure Parallel programming model: MapReduce Googles
Introduction to MapReduce
 Introduction to MapReduce Jacqueline Chame CS503 Spring 2014 Slides based on: MapReduce: Simplified Data Processing on Large Clusters. Jeffrey Dean and Sanjay Ghemawat. OSDI 2004. MapReduce: The Programming
Introduction to MapReduce Jacqueline Chame CS503 Spring 2014 Slides based on: MapReduce: Simplified Data Processing on Large Clusters. Jeffrey Dean and Sanjay Ghemawat. OSDI 2004. MapReduce: The Programming
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
L1:Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung ACM SOSP, 2003
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan18 (3:1) L1:Google File System Sanjay Ghemawat, Howard Gobioff, and
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan18 (3:1) L1:Google File System Sanjay Ghemawat, Howard Gobioff, and
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani
 The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
Google Cluster Computing Faculty Training Workshop
 Google Cluster Computing Faculty Training Workshop Module VI: Distributed Filesystems This presentation includes course content University of Washington Some slides designed by Alex Moschuk, University
Google Cluster Computing Faculty Training Workshop Module VI: Distributed Filesystems This presentation includes course content University of Washington Some slides designed by Alex Moschuk, University
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Software Infrastructure in Data Centers: Distributed File Systems 1 Permanently stores data Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Software Infrastructure in Data Centers: Distributed File Systems 1 Permanently stores data Filesystems
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
Google File System and BigTable. and tiny bits of HDFS (Hadoop File System) and Chubby. Not in textbook; additional information
 and Chubby. Not in textbook; additional information") Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
L2,3:Programming for Large Datasets MapReduce
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan17 (3:1) L2,3:Programming for Large Datasets MapReduce Yogesh Simmhan
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan17 (3:1) L2,3:Programming for Large Datasets MapReduce Yogesh Simmhan
Distributed Systems. Lec 10: Distributed File Systems GFS. Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung
 Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing. Lecture 6: MapReduce in Parallel Computing
 ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
Tutorial Outline. Map/Reduce. Data Center as a computer [Patterson, cacm 2008] Acknowledgements
![Tutorial Outline. Map/Reduce. Data Center as a computer [Patterson, cacm 2008] Acknowledgements](/thumbs/76/74027101.jpg "Tutorial Outline. Map/Reduce. Data Center as a computer [Patterson, cacm 2008] Acknowledgements") Tutorial Outline Map/Reduce Sharma Chakravarthy Information Technology Laboratory Computer Science and Engineering Department The University of Texas at Arlington, Arlington, TX 76009 Email: sharma@cse.uta.edu
Tutorial Outline Map/Reduce Sharma Chakravarthy Information Technology Laboratory Computer Science and Engineering Department The University of Texas at Arlington, Arlington, TX 76009 Email: sharma@cse.uta.edu
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016