Introduction to Apache Spark
|
|
|
- Arron Lewis
- 5 years ago
- Views:
Transcription





1 Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big Data Eğitim ve Araştırma Merkezi Projesi dahilinde gerçekleştirilmiştir. İçerik ile ilgili tek sorumluluk Bahçeşehir Üniversitesi ne ait olup İSTKA veya Kalkınma Bakanlığı nın görüşlerini yansıtmamaktadır.
2 A Major Step Backwards? MapReduce is a step backward in database access: Schemas are good Separation of the schema from the application is good High-level access languages are good MapReduce is poor implementation Brute force and only brute force (no indexes, for example) MapReduce is not novel MapReduce is missing features Bulk loader, indexing, updates, transactions MapReduce is incompatible with DMBS tools Source: Blog post by DeWitt and Stonebraker
3 Need for High-Level Languages MapReduce is great for one-pass computation large-data processing But writing Java programs for everything is verbose and slow Data scientists don t want to write Java But it is inefficient for multi-pass algorithms No efficient primitives for data sharing and iterative tasks State between steps goes to distributed file system Slow due to replication & disk storage
4 Move it onto a cluster In cluster setting, using of Map-Reduce and Hadoop is slow Hadoop writes to disk and complex How to improve this?


5 Example: Iterative Apps Input file system read file system write file system read file system write iter. 1 iter file system read query 1 query 2 result 1 result 2 Input query 3 result 3... Commonly spend 90% of time doing I/O
6 What we need is Resilient Checkpointing Fast, does not always store to disk Replayable Embarrassingly Parallel
7 Scala Scala has many other nice features: A type system that makes sense. Traits. Implicit conversions. Pattern Matching. XML literals, Parser combinators,...
8 Spark: A Brief History 2004 MapReduce paper 2010 Spark paper MapRe Google 2006 Yahoo! Hadoop Summit Apache Spark t op-level 8
9 Why better than hadoop? In-memory as opposed to disk Data can be cached in memory or disk for future use Fast: up to 100 times faster as it is using memory as opposed to disk Easier than Hadoop while being functional, runs a general DAG APIs in Java, Scala, Python, R

10 WordCount MapReduce vs Spark WordCount in 50+ lines of Java MR WordCount in 3 lines of Spark
11 Word Count Example text_file = sc.textfile("hdfs://... wordslist.txt") wordcounts = text_file.flatmap(lambda line: line.split(" ")).map(lambda word:(word, 1 )).reducebykey(lambda x, y : x+y). c o l l e c t ( ) ) ('rat',2),('elephant',1),('cat',2)
12 Disk vs Memory L1 cache reference: L2 cache reference: Mutex lock/unlock: Main memory reference: Disk seek: 0.5 ns 7 ns 100 ns 100 ns 10,000,000 ns
13 Network vs Local Send 2K bytes over 1 Gbps network: Read 1 MB sequentially from memory: Round trip within same datacenter: Read 1 MB sequentially from network: Read 1 MB sequentially from disk: Send packet CA->Netherlands->CA: 20,000 ns 250,000 ns 500,000 ns 10,000,000 ns 30,000,000 ns 150,000,000 ns
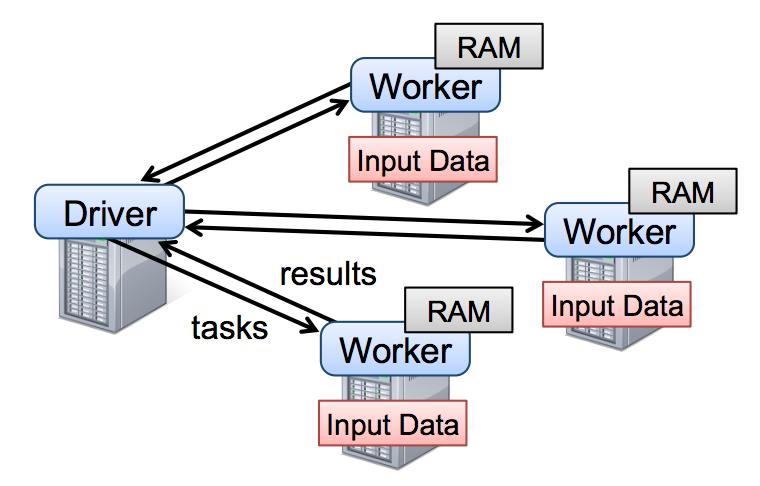
14 Spark Architecture
15 Resilient Distributed Datasets (RDDs) RDD: Spark primitive representing a collection of records Immutable Partitioned (the D in RDD) Transformations operate on an RDD to create another RDD Coarse-grained manipulations only RDDs keep track of lineage Persistence RDDs can be materialized in memory or on disk OOM or machine failures: What happens? Fault tolerance (the R in RDD): RDDs can always be recomputed from stable storage (disk)
16 Resilient Distributed Datasets (RDDs) Resilient: Recover from errors, e.g. node failure, slow processes Track history of each partition, re-run
).reduceByKey(lambda x, y: x + y).")
17 Input file Fault Tolerance RDDs track lineage info to rebuild lost data file.map(lambda rec: (rec.type, 1)).reduceByKey(lambda x, y: x + y).filter(lambda (type, count): count > 10) map reduce filter
18 Input file Fault Tolerance RDDs track lineage info to rebuild lost data file.map(lambda rec: (rec.type, 1)).reduceByKey(lambda x, y: x + y).filter(lambda (type, count): count > 10) map reduce filter
19 Resilient Distributed Datasets (RDDs) Distributed: Distributed across the cluster of machines Divided in partitions, atomic chunks of data
20 Resilient Distributed Datasets (RDDs) Dataset: Data storage created from: HDFS, S3, HBase, JSON, text, Local hierarchy of folders Or created transforming another RDD
21 Resilient Distributed Datasets (RDDs)» Immutable collections of objects, spread across cluster» Statically typed: RDD[T] has objects of type T val sc = new SparkContext() val lines = sc.textfile("log.txt") // RDD[String] // Transform using standard collection operations val errors = lines.filter(_.startswith("error")) val messages = errors.map(_.split( \t )(2)) lazily evaluated messages.saveastextfile("errors.txt") kicks off a computation
22 Spark Driver and Workers driver program SparkContext sqlcontext A Spark program is two programs:» A driver program and a workers program Worker programs run on cluster nodes or in local threads Cluster manager Local threads DataFrames are distributed across workers Worker Spark executor Worker Spark executor Amazon S3, HDFS, or other storage
23 Spark Program 1) Create some input RDDs from external data or parallelize a collection in your driver program. 2) Lazily transform them to define new RDDs using transformations like filter() or map() 3) Ask Spark to cache() any intermediate RDDs that will need to be reused. 4) Launch actions such as count() and collect() to kick off a parallel computation, which is then optimized and executed by Spark.
24 Transformations (lazy): map flatmap filter union/intersection join reducebykey groupbykey Operations on RDDs Actions (actually trigger computations) collect saveastextfile/saveassequencefile

25 Spark with Python
26 Deploying code to the cluster

27 Talking to Cluster Manager Manager can be: YARN Mesos Spark Standalone
28 RDD Stages Tasks RDD Objects DAG Scheduler Task Scheduler Worker DAG TaskSet Cluster manager Task Threads Block manager rdd1.join(rdd2).groupby( ).filter( ) split graph into stages of tasks launch tasks via cluster manager execute tasks build operator DAG submit each stage as ready retry failed or straggling tasks store and serve blocks
29 Where does code run? Local or Distributed?» Locally, in the driver» Distributed at the executors» Both at the driver and the executors» Transformations run at executors» Actions run at executors and driver Your application (driver program) Worker Spark executor Worker Spark executor Important point:» Executors run in parallel» Executors have much more memory
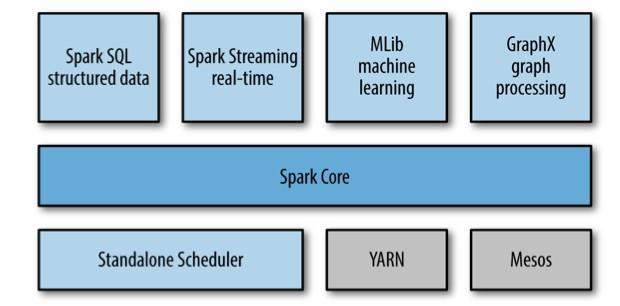
30 Spark Components
31 MLlib algorithms classification: logistic regression, linear SVM, naïve Bayes, classification tree regression: generalized linear models (GLMs), regression tree collaborative filtering: alternating least squares (ALS), non-negative matrix factorization (NMF) clustering: k-means decomposition: SVD, PCA optimization: stochastic gradient descent, L-BFGS
32 Machine Learning Library (MLlib) points = context.sql( select latitude, longitude from tweets ) model = KMeans.train(points, 10) 70+ contributors in past year

33 Spark Streaming Run a streaming computation as a series of very small, deterministic batch jobs Chop up the live stream into batches of X seconds live data stream Spark Streaming Spark treats each batch of data as RDDs and processes them using RDD opera;ons Finally, the processed results of the RDD opera;ons are returned in batches batches of X seconds processed results Spark
34 Spark Streaming Run a streaming computation as a series of very small, deterministic batch jobs Batch sizes as low as ½ second, latency ~ 1 second live data stream Spark Streaming Poten;al for combining batch processing and streaming processing in the same system batches of X seconds processed results Spark
35 MLlib + SQL df = context.sql( select latitude, longitude from tweets ) model = pipeline.fit(df) DataFrames in Spark 1.3 (as of March 2015) Powerful coupled with new pipeline API
36 Spark SQL // Run SQL statements val teenagers = context.sql( "SELECT name FROM people WHERE age >= 13 AND age <= 19") // The results of SQL queries are RDDs of Row objects val names = teenagers.map(t => "Name: " + t(0)).collect()

37 GraphX
38 GraphX General graph processing library Build graph using RDDs of nodes and edges Run standard algorithms such as PageRank
39 MLlib + GraphX
Distributed Computing with Spark and MapReduce
 Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Hadoop Distributed File System(HDFS)
") Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
MapReduce Algorithm Design
 MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Matrix Computations and " Neural Networks in Spark
 Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Machine Learning" on Spark
 Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Programming Essentials
 Spark Programming Essentials Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Spark Programming Essentials Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
15.1 Data flow vs. traditional network programming
 CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Data-intensive computing systems
 Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
MLlib and Distributing the " Singular Value Decomposition. Reza Zadeh
 MLlib and Distributing the " Singular Value Decomposition Reza Zadeh Outline Example Invocations Benefits of Iterations Singular Value Decomposition All-pairs Similarity Computation MLlib + {Streaming,
MLlib and Distributing the " Singular Value Decomposition Reza Zadeh Outline Example Invocations Benefits of Iterations Singular Value Decomposition All-pairs Similarity Computation MLlib + {Streaming,
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Spark and Spark SQL. Amir H. Payberah. SICS Swedish ICT. Amir H. Payberah (SICS) Spark and Spark SQL June 29, / 71
 Spark and Spark SQL June 29, / 71") Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Big Data Infrastructures & Technologies Hadoop Streaming Revisit.
 Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Scaled Machine Learning at Matroid
 Scaled Machine Learning at Matroid Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Machine Learning Pipeline Learning Algorithm Replicate model Data Trained Model Serve Model Repeat entire pipeline Scaling
Scaled Machine Learning at Matroid Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Machine Learning Pipeline Learning Algorithm Replicate model Data Trained Model Serve Model Repeat entire pipeline Scaling
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
08/04/2018. RDDs. RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
Big Data & Hadoop Environment
 Big Data & Hadoop Environment Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Big Data & Hadoop Environment Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Lightning Fast Cluster Computing. Michael Armbrust Reflections Projections 2015 Michast
 Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
2/26/2017. RDDs. RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is used to run an application
are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is used to run an application
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 1 RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application
1 RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application
Apache Spark Internals
 Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
An Overview of Apache Spark
 An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
Spark: A Brief History. https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf
 Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
We consider the general additive objective function that we saw in previous lectures: n F (w; x i, y i ) i=1
 i=1") CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
L3: Spark & RDD. CDS Department of Computational and Data Sciences. Department of Computational and Data Sciences
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Today s content. Resilient Distributed Datasets(RDDs) Spark and its data model
 Spark and its data model") Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
EPL660: Information Retrieval and Search Engines Lab 11
 EPL660: Information Retrieval and Search Engines Lab 11 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Introduction to Apache Spark Fast and general engine for
EPL660: Information Retrieval and Search Engines Lab 11 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Introduction to Apache Spark Fast and general engine for
Beyond MapReduce: Apache Spark Antonino Virgillito
 Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Lecture 4, 04/08/2015. Scribed by Eric Lax, Andreas Santucci, Charles Zheng.
 CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Databricks and Stanford. Lecture 4, 04/08/2015. Scribed by Eric Lax, Andreas Santucci,
CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Databricks and Stanford. Lecture 4, 04/08/2015. Scribed by Eric Lax, Andreas Santucci,
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
Introduction to Apache Spark. Patrick Wendell - Databricks
 Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
CS Spark. Slides from Matei Zaharia and Databricks
 CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
Big Data Analytics. C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark. Lars Schmidt-Thieme
 Big Data Analytics C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer
Big Data Analytics C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
An Introduction to Apache Spark
 An Introduction to Apache Spark Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 1 / 67 Big Data small data big data Amir H. Payberah (SICS) Apache Spark
An Introduction to Apache Spark Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 1 / 67 Big Data small data big data Amir H. Payberah (SICS) Apache Spark
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Parallel Processing Spark and Spark SQL
 Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
Spark & Spark SQL. High- Speed In- Memory Analytics over Hadoop and Hive Data. Instructor: Duen Horng (Polo) Chau
 Chau") CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
Analyzing Flight Data
 IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
Introduction to Spark
 Introduction to Spark Outlines A brief history of Spark Programming with RDDs Transformations Actions A brief history Limitations of MapReduce MapReduce use cases showed two major limitations: Difficulty
Introduction to Spark Outlines A brief history of Spark Programming with RDDs Transformations Actions A brief history Limitations of MapReduce MapReduce use cases showed two major limitations: Difficulty
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
/ Cloud Computing. Recitation 13 April 17th 2018
 15-319 / 15-619 Cloud Computing Recitation 13 April 17th 2018 Overview Last week s reflection Team Project Phase 2 Quiz 11 OLI Unit 5: Modules 21 & 22 This week s schedule Project 4.2 No more OLI modules
15-319 / 15-619 Cloud Computing Recitation 13 April 17th 2018 Overview Last week s reflection Team Project Phase 2 Quiz 11 OLI Unit 5: Modules 21 & 22 This week s schedule Project 4.2 No more OLI modules
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
In-Memory Processing with Apache Spark. Vincent Leroy
 In-Memory Processing with Apache Spark Vincent Leroy Sources Resilient Distributed Datasets, Henggang Cui Coursera IntroducBon to Apache Spark, University of California, Databricks Datacenter OrganizaBon
In-Memory Processing with Apache Spark Vincent Leroy Sources Resilient Distributed Datasets, Henggang Cui Coursera IntroducBon to Apache Spark, University of California, Databricks Datacenter OrganizaBon
Data Analytics and Machine Learning: From Node to Cluster
 Data Analytics and Machine Learning: From Node to Cluster Presented by Viswanath Puttagunta Ganesh Raju Understanding use cases to optimize on ARM Ecosystem Date BKK16-404B March 10th, 2016 Event Linaro
Data Analytics and Machine Learning: From Node to Cluster Presented by Viswanath Puttagunta Ganesh Raju Understanding use cases to optimize on ARM Ecosystem Date BKK16-404B March 10th, 2016 Event Linaro
Lambda Architecture with Apache Spark
 Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
Big Streaming Data Processing. How to Process Big Streaming Data 2016/10/11. Fraud detection in bank transactions. Anomalies in sensor data
 Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
Higher level data processing in Apache Spark
 Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Data Engineering. How MapReduce Works. Shivnath Babu
 Data Engineering How MapReduce Works Shivnath Babu Lifecycle of a MapReduce Job Map function Reduce function Run this program as a MapReduce job Lifecycle of a MapReduce Job Map function Reduce function
Data Engineering How MapReduce Works Shivnath Babu Lifecycle of a MapReduce Job Map function Reduce function Run this program as a MapReduce job Lifecycle of a MapReduce Job Map function Reduce function
Dell In-Memory Appliance for Cloudera Enterprise
 Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
Lecture 09. Spark for batch and streaming processing FREDERICK AYALA-GÓMEZ. CS-E4610 Modern Database Systems
 CS-E4610 Modern Database Systems 05.01.2018-05.04.2018 Lecture 09 Spark for batch and streaming processing FREDERICK AYALA-GÓMEZ PHD STUDENT I N COMPUTER SCIENCE, ELT E UNIVERSITY VISITING R ESEA RCHER,
CS-E4610 Modern Database Systems 05.01.2018-05.04.2018 Lecture 09 Spark for batch and streaming processing FREDERICK AYALA-GÓMEZ PHD STUDENT I N COMPUTER SCIENCE, ELT E UNIVERSITY VISITING R ESEA RCHER,
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Datacenter Simulation Methodologies: Spark
 This work is supported by NSF grants CCF-1149252, CCF-1337215, and STARnet, a Semiconductor Research Corporation Program, sponsored by MARCO and DARPA. Datacenter Simulation Methodologies: Spark Tamara
This work is supported by NSF grants CCF-1149252, CCF-1337215, and STARnet, a Semiconductor Research Corporation Program, sponsored by MARCO and DARPA. Datacenter Simulation Methodologies: Spark Tamara