Department of Computer Science San Marcos, TX Report Number TXSTATE-CS-TR Clustering in the Cloud. Xuan Wang
|
|
|
- Daniella Lindsey
- 5 years ago
- Views:
Transcription

1 Department of Computer Science San Marcos, TX Report Number TXSTATE-CS-TR Clustering in the Cloud Xuan Wang
2 !"#$%&'()*+()+%,&+!"-#. + /+!"#$%&'()*+0"*-'(%,1$+0.23%(-)+% &.#8&+9'21&:-'; Xuan Wang Advisor: Anne Hee Hiong Ngu Independent Study Report Spring 2010
3 !!-)%&)%$! Table of figures...3! 1.! Introduction...4! 1.1! Apache Hadoop...4! 1.2! MapReduce...4! 1.3! Project motivation...4! 2.! Methodology...5! 2.1! K-Means Clustering...5! 2.1.1! Original Algorithm...5! 2.1.2! K-Means adaption to MapReduce framework...6! 2.2! Divisive hierarchical clustering in MapReduce...7! 3.! Results...8! 4.! Conclusion...9! 5.! Future work...9! 6.! Appendix -- screen shots...10! 7.! References...13!
4 "#$%&!'(!()*+,&-! Figure 1 - MapReduce illustration...4! Figure 2 - Original K-Means clustering algorithm illustration...6! Figure 3 - MapReduce K-Means algorithm illustration...7! Figure 4 - Divisive clustering concept illustration...8! Figure 5 - Dendrogram showing divisive clustering...8!

5 ./ 012,'3+42)'1!./. 56#47&!8#3''6! Inspired by a series of Google s MapReduce papers, Apache Hadoop is a Java-based software framework that enables data-intensive application in a distributed environment. It is released under the free license Apache License Version 2.0. Hadoop enables applications to work with thousands of nodes and terabyte of data, without concerning the user with too much detail on the allocation and distribution of data and calculation../9 :#6;&3+4&! Google introduced and patented MapReduce- a software framework to support distributed computing on large data sets on clusters of computers. The name MapReduce and the inspiration came from map and reduce functions in functional programming. In MapReduce, the Map function processes the input in the form of key/value pairs to generate intermediate key/value pairs, and the Reduce function processes all intermediate values associated with the same intermediate key generated by the Map function, as shown in the figure below. Figure 1 - MapReduce illustration The MapReduce framework automatically parallelizes and executes on a large cluster of machines. Partitioning the input data, scheduling the program's execution across a set of machines, handling faults, and managing the required inter-machine communication are all handled by the run-time system. This enables programmers with no experience with parallel and distributed systems to easily utilize the resources of a large distributed system../< =,'>&42!?'2)@#2)'1! Currently, many well established MapReduce implementations, such as Inverted Indexing, and sorting algorithms are very intuitively MapReduce-able. For instance, in Inverted Indexing, content
6 from all documents is parsed into tokens by map function, and relayed to the reducer function in the form of key-value pairs, with the key being the token (normally a word), and the integer 1 as the key. Recall in Map/Reduce framework, all values with the same key will be sent the same Reducer. So in the reduce function, for each word, there are the number of its occurrence key-value pairs. The reduce function simply adds all 1 s up, and the result is the appearance count of this word in the collection. This process fits perfectly in the MapReduce framework, because token as key and frequency as value to construct key-value pairs are intuitive. As a matter of fact, the MapReduce framework was first designed to help indexing the internet for web search engine. As the popularity of cloud computing keeps growing, and as Hadoop being one of the most influential cloud computing framework (and free too), researchers from more and more disciplines who need to deal with large quantity of data processing are attracted to cloud computing with the Hadoop framework. The question remains: How applicable is Hadoop, or essentially the MapReduce framework, to my own area of work? Can my applications be converted to the MapReduce style? This independent study, besides familiarizing the author with the framework, explores the applicability of the MapReduce paradigm to areas of high-volume data computing, specifically data mining. Two algorithms are studies and successfully converted into MapReduce programs. An attempt was made to evaluate the efficiency gain with the framework. In this study, Hadoop s stand-alone distribution was used for development, and Amazon s Elastic Cloud was used as the experiment set up as a real distributed environment. 9/ :&27'3'%'*A! 9/. BC:-!D%+-2&,)1*! K-Means clustering is a method of cluster analysis which aims to partition dataset (or entries, observations) into k clusters in which each data point belongs to the cluster with the nearest mean. The choice of K-Means is mostly because of its simplicity. 9/./. E,)*)1#%!5%*',)27?! As shown in Figure 2, the algorithm works as follows: 1. Randomly generate K points (call them cluster centers), K being the number of clusters desired. 2. Calculate the distance between each of the data points to each of the centers, and assign each point to the closest center. 3. Among each collection of points that have been assigned to the same center, and also calculate the new center (coordinates, or values). 4. With the new centers, repeat step 2. If the assignment of cluster for the data points changes, repeat 3 & 4. If cluster formation didn t change, the clustering has finished.
 are randomly selected from the input data file as initial cluster centers. 1.")
7 Figure 2 - Original K-Means clustering algorithm illustration 9/./9 BC:-!#3#62)'1!2'!:#6;&3+4&!(,#?&F',G! As shown in Figure 3, the MapReduce adaption of the algorithms works as follows: 0. To simplify the work, K points (K is the number of the clusters we wish to get out of the input dataset) are randomly selected from the input data file as initial cluster centers. 1. Input data set (through a data file) is partitioned into N parts (controlled by the run-time system, not your program). Each part is sent to a mapper. 2. In the map function, the distance between each point and each cluster center is calculated, and each point is labeled with the center index to which the distance is the smallest. Mapper outputs the key-value pairs of label assigned to each point, and the coordinates of the point. 3. All data points of the same current cluster (based on the current cluster centers) are sent to a single reducer. In the reduce function, new cluster center coordinates are easily computed. The output of the reducer is consequently the cluster index and its new coordinates. 4. The new cluster coordinates are compared to the original ones. If the difference is within a preset threshold, then program terminates, and we have found the clusters. If not, use the newly generated cluster centers and repeat step 2 to 4.

8 Figure 3 - MapReduce K-Means algorithm illustration! 9/9 H)@)-)@&!7)&,#,47)4#%!4%+-2&,)1*!)1!:#6;&3+4&! The idea of divisive clustering (A.K.A. Diana) is pretty straightforward, as shown in Figure 4. The initial cluster is split into two partitions. Then each of the sub clusters is split into two clusters, one after another. The process continues until each of the data point forms a cluster of just itself. Any number of clusters can be achieved by selecting a proper cut-off height (or depth). (Refer to the dendrogram in Figure 5) The MapReduce adaption of the divisive clustering algorithm is inspired by the previously explained K-Means clustering algorithm: the former could be implemented as simple iterations of the latter, with cluster number K set to be 2 for each iteration.



9 Figure 4 - Divisive clustering concept illustration! </ ;&-+%2-! Figure 5 - Dendrogram showing divisive clustering The author generated 36K two-dimensional data points as the input dataset. The following results and conclusions are based on this data set. Correct clustering result (KMeans, Divisive Clustering)
10 The MapReduce version of both the KMeans and the Divisive Clustering algorithms give the correct the results, as verified both visually with plot and by other clustering tools. Minor performance gain on experiment dataset Both programs were verified on Amazon s cloud with multiple parameters setup (2, 5, or 10 clusters nodes launched). There is only very minor performance gain on the 2 cluster nodes setup, compared to running on the sudo-distributed system on a single machine (1 min 36 sec compared to 1 min 45 sec). There is no performance gain in 5 cluster nodes and 10 cluster nodes setups. Analysis! Possibly due to small size of dataset. The normally recommended block size is 100MB. So it s very likely that the sample dataset was not big enough to have the efficiency gain by parallel computing overweigh the overhead between split partitions.! Further optimization needed. During the process of developing the two algorithms discussed above, the author noticed that there exist some potential optimizations that can increase efficiency. For instance, weighted local cluster centers can be produced by each map function, and the output could be maximally the number of clusters, instead of the data points, which should reduce a lot of data traffic between the mapper and reducer. I/ D'14%+-)'1! Clustering algorithms can adapt to M/R framework w/. linked multiple M/R jobs The single most important finding of this independent study is that some more complex (than inverted indexing) data intensive applications can be adapted to the MapReduce framework. The key point is to identify the distributable portion, which should also be the most data intensive and consequently the bottleneck of program efficiency improvement). And then write those portions into inter-linkable MapReduce jobs, with the appropriate intermediate results between jobs to relay the calculation results down. J/ K+2+,&!F',G-! Optimization of converted algorithms As mentioned in part 3, the algorithms can be further optimized in a couple of ways. More efficient data passing alternatives between linked jobs Hadoop is aware of the need to custom outputs of mapper function and reducer functions. There is more efficient data format that the intermediate results can be stored as (such as sequence file format), etc. These options will enable faster read and write. Use available packages to build your own algorithms
 L/ 566&13)M!CC!-'?&!-4,&&1!-7'2-!")
11 A series of commercially available packages (Analytics1305 as mentioned in the reference being one of them) with optimized MapReduce implementation of some universal algorithms such as K-Means, etc. If applicable, complex algorithms can be built on top of those packages. Hadoop framework on TXSTATE SunGrid clusters (instead of paying Amazon, etc) L/ 566&13)M!CC!-'?&!-4,&&1!-7'2-! Launching instances from Amazon EC2 UI: Running instances

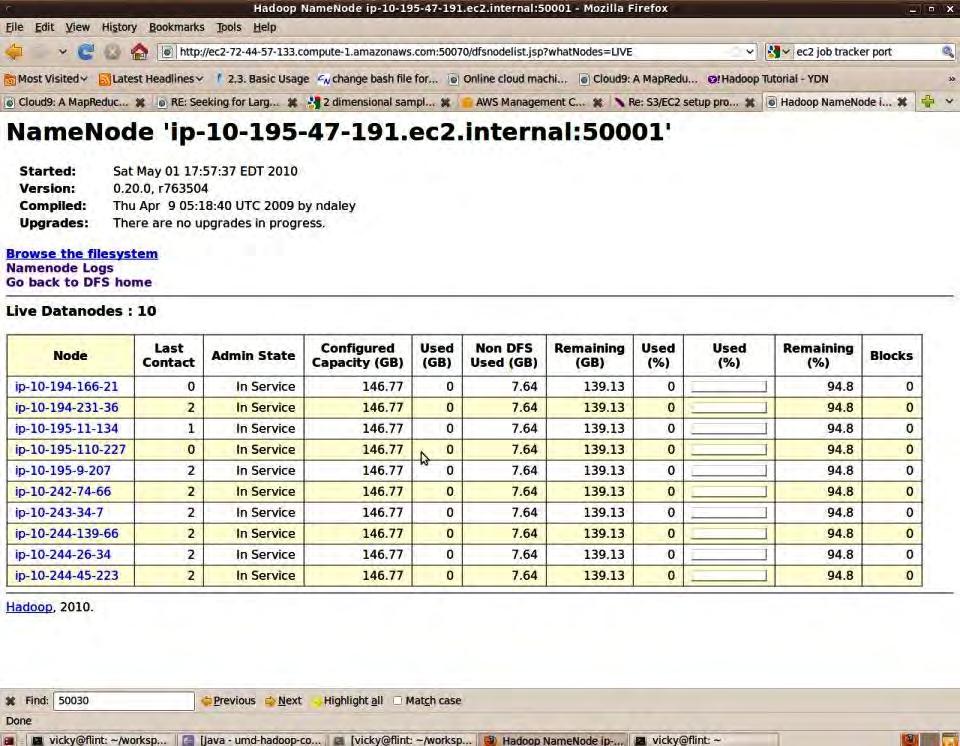
12 Name node tracker (port 50070)
13 Connection to master node
14 N/ ;&(&,&14&-! Analytics1305. (2010). Integrated solutions for large scale data analysis. Retrieved from Integrated solutions for large scale data analysis: Apache. (2010, Feb 19). Apache Hadoop Quick Start. Retrieved Mar 2010, from Apache Hadoop: Berry, M. (2008, Feb 9). MapReduce and K-Means Clustering. Retrieved Mar 2010, from Data Miners Blog: Cloudera. (2010). Hadoop Training. Retrieved 2010, from Cloudera: Apache Hadoop for the Enterprise: GoogleCodeUniversity. (2007, Jul). Google: Cluster Computing and MapReduce. Retrieved Mar 2010, from Google Code: Lin, J. (2010, Apr). Data-Intensive Information Processing Applications Course(Spring 2010). Retrieved Apr 2010, from University of Maryland: Spring/index.html LLC, A. W. (2009, Nov 30). Get Started with EC2. Retrieved Mar 2010, from Amazon Elastic Compute Cloud, Getting Started Guide: Yahoo! (n.d.). Yahoo! Hadoop Tutorial. Retrieved Jan-Apr 2010, from Yahoo! Developer Network:
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
The MapReduce Framework
 The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
A Comparative study of Clustering Algorithms using MapReduce in Hadoop
 A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering
A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering
Data Analysis Using MapReduce in Hadoop Environment
 Data Analysis Using MapReduce in Hadoop Environment Muhammad Khairul Rijal Muhammad*, Saiful Adli Ismail, Mohd Nazri Kama, Othman Mohd Yusop, Azri Azmi Advanced Informatics School (UTM AIS), Universiti
Data Analysis Using MapReduce in Hadoop Environment Muhammad Khairul Rijal Muhammad*, Saiful Adli Ismail, Mohd Nazri Kama, Othman Mohd Yusop, Azri Azmi Advanced Informatics School (UTM AIS), Universiti
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets
 2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets Tao Xiao Chunfeng Yuan Yihua Huang Department
2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets Tao Xiao Chunfeng Yuan Yihua Huang Department
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
MATE-EC2: A Middleware for Processing Data with Amazon Web Services
 MATE-EC2: A Middleware for Processing Data with Amazon Web Services Tekin Bicer David Chiu* and Gagan Agrawal Department of Compute Science and Engineering Ohio State University * School of Engineering
MATE-EC2: A Middleware for Processing Data with Amazon Web Services Tekin Bicer David Chiu* and Gagan Agrawal Department of Compute Science and Engineering Ohio State University * School of Engineering
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
CATEGORIZATION OF THE DOCUMENTS BY USING MACHINE LEARNING
 CATEGORIZATION OF THE DOCUMENTS BY USING MACHINE LEARNING Amol Jagtap ME Computer Engineering, AISSMS COE Pune, India Email: 1 amol.jagtap55@gmail.com Abstract Machine learning is a scientific discipline
CATEGORIZATION OF THE DOCUMENTS BY USING MACHINE LEARNING Amol Jagtap ME Computer Engineering, AISSMS COE Pune, India Email: 1 amol.jagtap55@gmail.com Abstract Machine learning is a scientific discipline
MapReduce Design Patterns
 MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
MapReduce Design Patterns MapReduce Restrictions Any algorithm that needs to be implemented using MapReduce must be expressed in terms of a small number of rigidly defined components that must fit together
Frequent Item Set using Apriori and Map Reduce algorithm: An Application in Inventory Management
 Frequent Item Set using Apriori and Map Reduce algorithm: An Application in Inventory Management Kranti Patil 1, Jayashree Fegade 2, Diksha Chiramade 3, Srujan Patil 4, Pradnya A. Vikhar 5 1,2,3,4,5 KCES
Frequent Item Set using Apriori and Map Reduce algorithm: An Application in Inventory Management Kranti Patil 1, Jayashree Fegade 2, Diksha Chiramade 3, Srujan Patil 4, Pradnya A. Vikhar 5 1,2,3,4,5 KCES
Programming model and implementation for processing and. Programs can be automatically parallelized and executed on a large cluster of machines
 A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs
A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
An improved MapReduce Design of Kmeans for clustering very large datasets
 An improved MapReduce Design of Kmeans for clustering very large datasets Amira Boukhdhir Laboratoire SOlE Higher Institute of management Tunis Tunis, Tunisia Boukhdhir _ amira@yahoo.fr Oussama Lachiheb
An improved MapReduce Design of Kmeans for clustering very large datasets Amira Boukhdhir Laboratoire SOlE Higher Institute of management Tunis Tunis, Tunisia Boukhdhir _ amira@yahoo.fr Oussama Lachiheb
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Scalable Web Programming. CS193S - Jan Jannink - 2/25/10
 Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Locality Aware Fair Scheduling for Hammr
 Locality Aware Fair Scheduling for Hammr Li Jin January 12, 2012 Abstract Hammr is a distributed execution engine for data parallel applications modeled after Dryad. In this report, we present a locality
Locality Aware Fair Scheduling for Hammr Li Jin January 12, 2012 Abstract Hammr is a distributed execution engine for data parallel applications modeled after Dryad. In this report, we present a locality
Improved MapReduce k-means Clustering Algorithm with Combiner
 2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation Improved MapReduce k-means Clustering Algorithm with Combiner Prajesh P Anchalia Department Of Computer Science and Engineering
2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation Improved MapReduce k-means Clustering Algorithm with Combiner Prajesh P Anchalia Department Of Computer Science and Engineering
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
ML from Large Datasets
 10-605 ML from Large Datasets 1 Announcements HW1b is going out today You should now be on autolab have a an account on stoat a locally-administered Hadoop cluster shortly receive a coupon for Amazon Web
10-605 ML from Large Datasets 1 Announcements HW1b is going out today You should now be on autolab have a an account on stoat a locally-administered Hadoop cluster shortly receive a coupon for Amazon Web
Map Reduce & Hadoop Recommended Text:
 Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
Uday Kumar Sr 1, Naveen D Chandavarkar 2 1 PG Scholar, Assistant professor, Dept. of CSE, NMAMIT, Nitte, India. IJRASET 2015: All Rights are Reserved
 Implementation of K-Means Clustering Algorithm in Hadoop Framework Uday Kumar Sr 1, Naveen D Chandavarkar 2 1 PG Scholar, Assistant professor, Dept. of CSE, NMAMIT, Nitte, India Abstract Drastic growth
Implementation of K-Means Clustering Algorithm in Hadoop Framework Uday Kumar Sr 1, Naveen D Chandavarkar 2 1 PG Scholar, Assistant professor, Dept. of CSE, NMAMIT, Nitte, India Abstract Drastic growth
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Large-Scale GPU programming
 Large-Scale GPU programming Tim Kaldewey Research Staff Member Database Technologies IBM Almaden Research Center tkaldew@us.ibm.com Assistant Adjunct Professor Computer and Information Science Dept. University
Large-Scale GPU programming Tim Kaldewey Research Staff Member Database Technologies IBM Almaden Research Center tkaldew@us.ibm.com Assistant Adjunct Professor Computer and Information Science Dept. University
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Comparative Analysis of K means Clustering Sequentially And Parallely
 Comparative Analysis of K means Clustering Sequentially And Parallely Kavya D S 1, Chaitra D Desai 2 1 M.tech, Computer Science and Engineering, REVA ITM, Bangalore, India 2 REVA ITM, Bangalore, India
Comparative Analysis of K means Clustering Sequentially And Parallely Kavya D S 1, Chaitra D Desai 2 1 M.tech, Computer Science and Engineering, REVA ITM, Bangalore, India 2 REVA ITM, Bangalore, India
Keywords Hadoop, Map Reduce, K-Means, Data Analysis, Storage, Clusters.
 Volume 6, Issue 3, March 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue
Volume 6, Issue 3, March 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Improving the MapReduce Big Data Processing Framework
 Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
MAPREDUCE FOR BIG DATA PROCESSING BASED ON NETWORK TRAFFIC PERFORMANCE Rajeshwari Adrakatti
 International Journal of Computer Engineering and Applications, ICCSTAR-2016, Special Issue, May.16 MAPREDUCE FOR BIG DATA PROCESSING BASED ON NETWORK TRAFFIC PERFORMANCE Rajeshwari Adrakatti 1 Department
International Journal of Computer Engineering and Applications, ICCSTAR-2016, Special Issue, May.16 MAPREDUCE FOR BIG DATA PROCESSING BASED ON NETWORK TRAFFIC PERFORMANCE Rajeshwari Adrakatti 1 Department
Parallelizing Structural Joins to Process Queries over Big XML Data Using MapReduce
 Parallelizing Structural Joins to Process Queries over Big XML Data Using MapReduce Huayu Wu Institute for Infocomm Research, A*STAR, Singapore huwu@i2r.a-star.edu.sg Abstract. Processing XML queries over
Parallelizing Structural Joins to Process Queries over Big XML Data Using MapReduce Huayu Wu Institute for Infocomm Research, A*STAR, Singapore huwu@i2r.a-star.edu.sg Abstract. Processing XML queries over
CS / Cloud Computing. Recitation 3 September 9 th & 11 th, 2014
 CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
ABSTRACT I. INTRODUCTION
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISS: 2456-3307 Hadoop Periodic Jobs Using Data Blocks to Achieve
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISS: 2456-3307 Hadoop Periodic Jobs Using Data Blocks to Achieve
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
Parallel Nested Loops
 Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Partition-Based. Parallel Nested Loops. Median. More Join Thoughts. Parallel Office Tools 9/15/2011
 Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
732A54/TDDE31 Big Data Analytics
 732A54/TDDE31 Big Data Analytics Lecture 10: Machine Learning with MapReduce Jose M. Peña IDA, Linköping University, Sweden 1/27 Contents MapReduce Framework Machine Learning with MapReduce Neural Networks
732A54/TDDE31 Big Data Analytics Lecture 10: Machine Learning with MapReduce Jose M. Peña IDA, Linköping University, Sweden 1/27 Contents MapReduce Framework Machine Learning with MapReduce Neural Networks
A Novel Parallel Hierarchical Community Detection Method for Large Networks
 A Novel Parallel Hierarchical Community Detection Method for Large Networks Ping Lu Shengmei Luo Lei Hu Yunlong Lin Junyang Zou Qiwei Zhong Kuangyan Zhu Jian Lu Qiao Wang Southeast University, School of
A Novel Parallel Hierarchical Community Detection Method for Large Networks Ping Lu Shengmei Luo Lei Hu Yunlong Lin Junyang Zou Qiwei Zhong Kuangyan Zhu Jian Lu Qiao Wang Southeast University, School of
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Global Journal of Engineering Science and Research Management
 A FUNDAMENTAL CONCEPT OF MAPREDUCE WITH MASSIVE FILES DATASET IN BIG DATA USING HADOOP PSEUDO-DISTRIBUTION MODE K. Srikanth*, P. Venkateswarlu, Ashok Suragala * Department of Information Technology, JNTUK-UCEV
A FUNDAMENTAL CONCEPT OF MAPREDUCE WITH MASSIVE FILES DATASET IN BIG DATA USING HADOOP PSEUDO-DISTRIBUTION MODE K. Srikanth*, P. Venkateswarlu, Ashok Suragala * Department of Information Technology, JNTUK-UCEV
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
MapReduce: A Programming Model for Large-Scale Distributed Computation
 CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
MapReduce: Simplified Data Processing on Large Clusters
 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian ZHENG 1, Mingjiang LI 1, Jinpeng YUAN 1
 International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Mitigating Data Skew Using Map Reduce Application
 Ms. Archana P.M Mitigating Data Skew Using Map Reduce Application Mr. Malathesh S.H 4 th sem, M.Tech (C.S.E) Associate Professor C.S.E Dept. M.S.E.C, V.T.U Bangalore, India archanaanil062@gmail.com M.S.E.C,
Ms. Archana P.M Mitigating Data Skew Using Map Reduce Application Mr. Malathesh S.H 4 th sem, M.Tech (C.S.E) Associate Professor C.S.E Dept. M.S.E.C, V.T.U Bangalore, India archanaanil062@gmail.com M.S.E.C,
MapReduce Algorithms
 Large-scale data processing on the Cloud Lecture 3 MapReduce Algorithms Satish Srirama Some material adapted from slides by Jimmy Lin, 2008 (licensed under Creation Commons Attribution 3.0 License) Outline
Large-scale data processing on the Cloud Lecture 3 MapReduce Algorithms Satish Srirama Some material adapted from slides by Jimmy Lin, 2008 (licensed under Creation Commons Attribution 3.0 License) Outline
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Master-Worker pattern
 COSC 6397 Big Data Analytics Master Worker Programming Pattern Edgar Gabriel Spring 2017 Master-Worker pattern General idea: distribute the work among a number of processes Two logically different entities:
COSC 6397 Big Data Analytics Master Worker Programming Pattern Edgar Gabriel Spring 2017 Master-Worker pattern General idea: distribute the work among a number of processes Two logically different entities:
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
MapReduce programming model
 MapReduce programming model technology basics for data scientists Spring - 2014 Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN Warning! Slides are only for presenta8on guide We will discuss+debate
MapReduce programming model technology basics for data scientists Spring - 2014 Jordi Torres, UPC - BSC www.jorditorres.eu @JordiTorresBCN Warning! Slides are only for presenta8on guide We will discuss+debate
Analysis in the Big Data Era
 Analysis in the Big Data Era Massive Data Data Analysis Insight Key to Success = Timely and Cost-Effective Analysis 2 Hadoop MapReduce Ecosystem Popular solution to Big Data Analytics Java / C++ / R /
Analysis in the Big Data Era Massive Data Data Analysis Insight Key to Success = Timely and Cost-Effective Analysis 2 Hadoop MapReduce Ecosystem Popular solution to Big Data Analytics Java / C++ / R /
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
EXTRACT DATA IN LARGE DATABASE WITH HADOOP
 International Journal of Advances in Engineering & Scientific Research (IJAESR) ISSN: 2349 3607 (Online), ISSN: 2349 4824 (Print) Download Full paper from : http://www.arseam.com/content/volume-1-issue-7-nov-2014-0
International Journal of Advances in Engineering & Scientific Research (IJAESR) ISSN: 2349 3607 (Online), ISSN: 2349 4824 (Print) Download Full paper from : http://www.arseam.com/content/volume-1-issue-7-nov-2014-0
Performance Evaluation of Cloud Centers with High Degree of Virtualization to provide MapReduce as Service
 Int. J. Advance Soft Compu. Appl, Vol. 8, No. 3, December 2016 ISSN 2074-8523 Performance Evaluation of Cloud Centers with High Degree of Virtualization to provide MapReduce as Service C. N. Sahoo 1, Veena
Int. J. Advance Soft Compu. Appl, Vol. 8, No. 3, December 2016 ISSN 2074-8523 Performance Evaluation of Cloud Centers with High Degree of Virtualization to provide MapReduce as Service C. N. Sahoo 1, Veena
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
Distributed Systems CS6421
 Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Research Article Apriori Association Rule Algorithms using VMware Environment
 Research Journal of Applied Sciences, Engineering and Technology 8(2): 16-166, 214 DOI:1.1926/rjaset.8.955 ISSN: 24-7459; e-issn: 24-7467 214 Maxwell Scientific Publication Corp. Submitted: January 2,
Research Journal of Applied Sciences, Engineering and Technology 8(2): 16-166, 214 DOI:1.1926/rjaset.8.955 ISSN: 24-7459; e-issn: 24-7467 214 Maxwell Scientific Publication Corp. Submitted: January 2,
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
CS 534: Computer Vision Segmentation and Perceptual Grouping
 CS 534: Computer Vision Segmentation and Perceptual Grouping Spring 2005 Ahmed Elgammal Dept of Computer Science CS 534 Segmentation - 1 Where are we? Image Formation Human vision Cameras Geometric Camera
CS 534: Computer Vision Segmentation and Perceptual Grouping Spring 2005 Ahmed Elgammal Dept of Computer Science CS 534 Segmentation - 1 Where are we? Image Formation Human vision Cameras Geometric Camera
Cloud Computing CS
 Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
An Indian Journal FULL PAPER ABSTRACT KEYWORDS. Trade Science Inc. The study on magnanimous data-storage system based on cloud computing
 [Type text] [Type text] [Type text] ISSN : 0974-7435 Volume 10 Issue 11 BioTechnology 2014 An Indian Journal FULL PAPER BTAIJ, 10(11), 2014 [5368-5376] The study on magnanimous data-storage system based
[Type text] [Type text] [Type text] ISSN : 0974-7435 Volume 10 Issue 11 BioTechnology 2014 An Indian Journal FULL PAPER BTAIJ, 10(11), 2014 [5368-5376] The study on magnanimous data-storage system based
2/26/2017. For instance, consider running Word Count across 20 splits
 Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
Based on the slides of prof. Pietro Michiardi Hadoop Internals https://github.com/michiard/disc-cloud-course/raw/master/hadoop/hadoop.pdf Job: execution of a MapReduce application across a data set Task:
Hadoop Map Reduce 10/17/2018 1
 Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
CLUSTERING BIG DATA USING NORMALIZATION BASED k-means ALGORITHM
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 5.258 IJCSMC,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 5.258 IJCSMC,
Homework 3: Map-Reduce, Frequent Itemsets, LSH, Streams (due March 16 th, 9:30am in class hard-copy please)
") Virginia Tech. Computer Science CS 5614 (Big) Data Management Systems Spring 2017, Prakash Homework 3: Map-Reduce, Frequent Itemsets, LSH, Streams (due March 16 th, 9:30am in class hard-copy please) Reminders:
Virginia Tech. Computer Science CS 5614 (Big) Data Management Systems Spring 2017, Prakash Homework 3: Map-Reduce, Frequent Itemsets, LSH, Streams (due March 16 th, 9:30am in class hard-copy please) Reminders:
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Aggregation on the Fly: Reducing Traffic for Big Data in the Cloud
 Aggregation on the Fly: Reducing Traffic for Big Data in the Cloud Huan Ke, Peng Li, Song Guo, and Ivan Stojmenovic Abstract As a leading framework for processing and analyzing big data, MapReduce is leveraged
Aggregation on the Fly: Reducing Traffic for Big Data in the Cloud Huan Ke, Peng Li, Song Guo, and Ivan Stojmenovic Abstract As a leading framework for processing and analyzing big data, MapReduce is leveraged
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 7: Parallel Computing Cho-Jui Hsieh UC Davis May 3, 2018 Outline Multi-core computing, distributed computing Multi-core computing tools
STA141C: Big Data & High Performance Statistical Computing Lecture 7: Parallel Computing Cho-Jui Hsieh UC Davis May 3, 2018 Outline Multi-core computing, distributed computing Multi-core computing tools
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
A computational model for MapReduce job flow
 A computational model for MapReduce job flow Tommaso Di Noia, Marina Mongiello, Eugenio Di Sciascio Dipartimento di Ingegneria Elettrica e Dell informazione Politecnico di Bari Via E. Orabona, 4 70125
A computational model for MapReduce job flow Tommaso Di Noia, Marina Mongiello, Eugenio Di Sciascio Dipartimento di Ingegneria Elettrica e Dell informazione Politecnico di Bari Via E. Orabona, 4 70125
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Dis Commodity Clusters Web data sets can be ery large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Dis Commodity Clusters Web data sets can be ery large Tens to hundreds of terabytes
Introduction to MapReduce
 Introduction to MapReduce April 19, 2012 Jinoh Kim, Ph.D. Computer Science Department Lock Haven University of Pennsylvania Research Areas Datacenter Energy Management Exa-scale Computing Network Performance
Introduction to MapReduce April 19, 2012 Jinoh Kim, Ph.D. Computer Science Department Lock Haven University of Pennsylvania Research Areas Datacenter Energy Management Exa-scale Computing Network Performance