Cloud Computing. Big Data. Dell Zhang Birkbeck, University of London 2017/18
|
|
|
- April Anastasia Wood
- 5 years ago
- Views:
Transcription
1 Cloud Computing Big Data Dell Zhang Birkbeck, University of London 2017/18

2 The Challenges and Opportunities of Big Data

3 Why Big Data? 640K ought to be enough for anybody.



4 Big Data Everywhere! Lots of data are being collected and warehoused Web data, e-commerce Purchases at department/ grocery stores Bank/Credit Card transactions Social Network
5 Big Data Challenges (3Vs) Big Volume the quantity of generated and stored data Big Velocity the speed at which the data is generated and processed Big Variety the type and nature of the data

6
7 How Much Data? Google processes 20 PB a day (2008) Wayback Machine has 3 PB TB/month (3/2009) Facebook has 2.5 PB of user data + 15 TB/day (4/2009) ebay has 6.5 PB of user data + 50 TB/day (5/2009) CERN s Large Hydron Collider (LHC) generates 15 PB a year
8

9 Maximilien Brice, CERN The Large Hadron Collider

10 The Earthscope Project

11 The PRISM
12 Boundless Informant It is a big data analysis and data visualization system used by the United States National Security Agency (NSA). [Wikipedia] According to published slides, Boundless Informant leverages Free and Open Source Software and is therefore "available to all NSA developers and corporate services hosted in the cloud. The tool uses HDFS, MapReduce, and Accumulo (formerly Cloudbase) for data processing.
13 Structured Data What Kinds of Data? Tables/Transactions/Legacy Data, Semi-Structured Data XML, Unstructured Data Text Data: the Web, Graph Data: Social Networks,
14 What to Do with Big Data? Aggregation and Statistics Data Warehouse and OLAP Indexing, Searching, and Querying Keyword based Search Pattern Matching (XML/RDF) Knowledge Discovery Data Mining Statistical Modeling
15 What to Do with Big Data? Example: Answering factoid questions Pattern matching on the Web Works amazingly well Who shot Abraham Lincoln? search * shot Abraham Lincoln (Brill et al., TREC 2001; Lin, ACM TOIS 2007)
16 What to Do with Big Data? Example: Learning relations Start with seed instances Search for patterns on the Web Using patterns to find more instances Wolfgang Amadeus Mozart ( ) Einstein was born in 1879 Birthday-of(Mozart, 1756) Birthday-of(Einstein, 1879) PERSON (DATE PERSON was born in DATE (Agichtein and Gravano, DL 2000; Ravichandran and Hovy, ACL 2002; )

17 IBM s Watson
18 No Data Like More Data! s/knowledge/data/g; (Banko and Brill, ACL 2001) (Brants et al., EMNLP 2007) How do we get here if we re not Google?
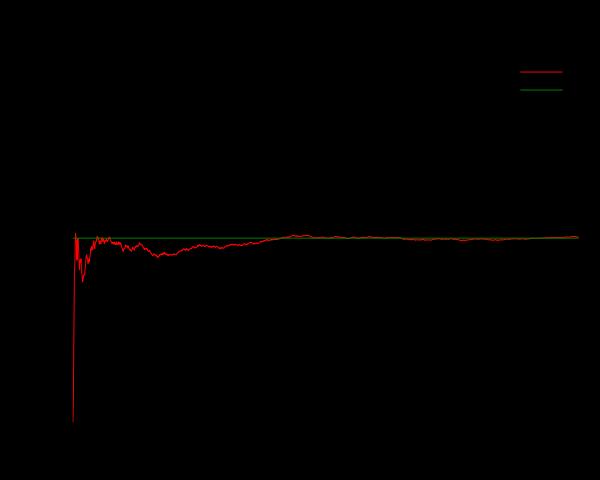
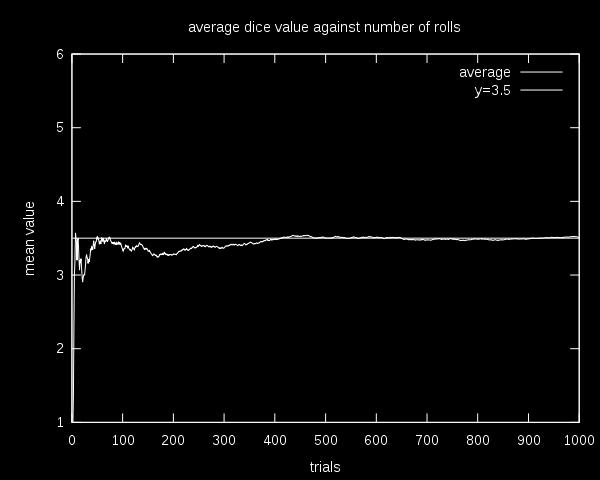
19 The Law of Large Numbers In probability theory, the law of large numbers (LLN) is a theorem that describes the result of performing the same experiment a large number of times. According to the law, the average of the results obtained from a large number of trials should be close to the expected value, and will tend to become closer as more trials are performed. [Wikipedia]


20
21
22
23 Meaningfulness of Answers A big data-mining risk is that you may discover patterns that are meaningless Bonferroni s principle: (roughly) if you look in more places for interesting patterns than your amount of data will support, you are bound to find crap.
24 Meaningfulness of Answers Example: Rhine Paradox Joseph Rhine was a parapsychologist in the 1950 s who hypothesized that some people had Extra- Sensory Perception (ESP) He devised an experiment where subjects were asked to guess 10 hidden cards: red or blue He discovered that almost 1 in 1000 had ESP: they were able to get all 10 right!
25 Meaningfulness of Answers Example: Rhine Paradox He told these people they had ESP and called them in for another test of the same type Alas, he discovered that almost all of them had lost their ESP What did he conclude?
26 How do we get data for computation? NAS Compute Nodes SAN What s the problem here?
27 How do we get data for computation? Don t move data to computation, move computation to the data! Store data on the local disks of nodes in the cluster Start up the programs on the node that has the data local Why? Not enough RAM to hold all the data in memory Disk access is slow, but disk throughput is reasonable
28 Distributed File Systems A Distributed File System (that provides global file namespace) is the answer GFS (Google File System) for Google s MapReduce HDFS (Hadoop Distributed File System) for Hadoop HDFS = GFS clone (same basic ideas) Typical usage pattern Huge files (100s of GB to TB) Data is rarely updated in place Reads and appends are common

29 Distributed File Systems The problem of reliability: if nodes fail, how to store data persistently? Data kept in chunks spread across machines Each chunk replicated on different machines Seamless recovery from disk or machine failure
30 GFS: History Google File System, a paper published in 2003 by Google Labs at OSDI Explains the design and architecture of a distributed system apt for serving very large data files (internally used by Google for storing documents collected from the Web). Open Source versions have been developed at once: Hadoop File System (HDFS), Kosmos File System (KFS).
31 GFS: Motivation Why do we need a distributed file system in the first place? Traditional Network File System (NFS) does not meet scalability requirements What if file1 gets really big? A Large-Scale Distributed File System requires A virtual file namespace Partitioning of files in chunks.
32 GFS: Motivation
33 GFS: Assumptions Commodity hardware over exotic hardware Scale out, not up High component failure rates Inexpensive commodity components fail all the time Modest number of huge files Multi-gigabyte files are common, if not encouraged Files are write-once, mostly appended to Perhaps concurrently Large streaming reads over random access High sustained throughput over low latency
34 GFS: Design Decisions Chunk servers File is split into equal-size contiguous chunks: typically 64MB Each chunk is replicated (default 3x) Try to keep replicas in different racks Master node Stores metadata and coordinates access Simple centralized management Might be replicated
35 GFS: Design Decisions Client library for file access Talks to master node to find chunk servers Connects directly to chunk servers to access data Maintains a cache with the chunks locations (but not the chunks themselves) No data caching: little benefit due to large datasets, streaming reads. Simplify the API: some of the issues are pushed onto the client (e.g., data layout)
36 GFS: Architecture
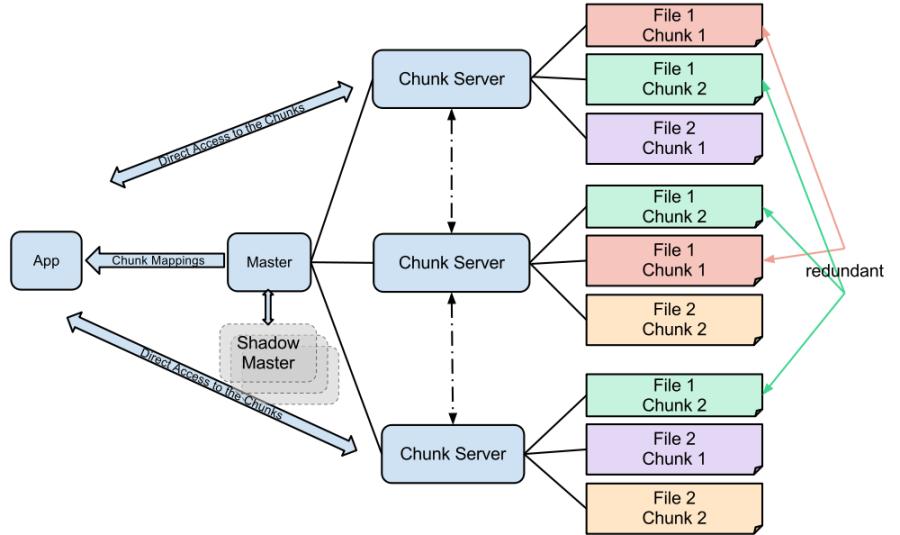
37 GFS Architecture
38 GFS: Technical Details The architecture works best for very large files (e.g., several GBs), divided in large (e.g., 64 MBs) chunks This limits the metadata information served by the Master Each server implements recovery & replication techniques Default: 3 replicas
39 GFS: Technical Details Availability The Master sends heartbeat messages to servers, and initiates a replacement when a failure occurs. Scalability The Master is a potential single point of failure; its protection relies on distributed recovery techniques for all changes that affect the file namespace.
40 Workflow of a write() operation (simplified)

41 Namespace Updates: Distributed Recovery Protocol
42 From GFS to HDFS Terminology differences: GFS master = Hadoop namenode GFS chunkservers = Hadoop datanodes Functional differences: No file appends in HDFS (planned feature) HDFS performance is (likely) slower For the most part, we ll use the Hadoop terminology
 block data datanode state HDFS datanode Linux file system HDFS datanode Linux file system Adapted from (Ghemawat et al.")
43 HDFS: Architecture HDFS namenode Application HDFS Client (file name, block id) (block id, block location) File namespace /foo/bar block 3df2 instructions to datanode (block id, byte range) block data datanode state HDFS datanode Linux file system HDFS datanode Linux file system Adapted from (Ghemawat et al., SOSP 2003)
44
45 HDFS: NameNode Metadata Meta-data in Memory The entire metadata is in main memory No demand paging of meta-data Types of Metadata List of files List of blocks for each file List of DataNodes for each block File attributes, e.g creation time, replication factor A Transaction Log Records file creations, file deletions. etc
46 HDFS: Namenode Responsibilities Managing the file system namespace: Holds file/directory structure, metadata, file-toblock mapping, access permissions, etc. Coordinating file operations: Directs clients to datanodes for reads and writes No data is moved through the namenode Maintaining overall health: Periodic communication with the datanodes Block re-replication and rebalancing Garbage collection
47 HDFS: DataNode Block Server Stores data in the local file system (e.g. ext3) Stores meta-data of a block (e.g. CRC) Serves data and meta-data to Clients Block Report Periodically sends a report of all existing blocks to the NameNode Facilitates Pipelining of Data Forwards data to other specified DataNodes
48 HDFS: Block Placement Current Strategy One replica on local node Second replica on a remote rack Third replica on the same remote rack Additional replicas are randomly placed Clients read from nearest replica Would like to make this policy pluggable
49 HDFS: Data Correctness Use checksums to validate data CRC32 File creation Client computes checksum per 512 byte DataNode stores the checksum File access Client retrieves the data and checksum from DataNode If validation fails, Client tries other replicas
50 HDFS: NameNode Failure A single point of failure Transaction Log stored in multiple directories A directory on the local file system A directory on a remote file system (NFS/CIFS) Need to develop a real high availability solution

51 Distributed Access Structures Indexing Hashing based techniques Consistent Hashing Tree based techniques Distributed B-Tree
52 Indexing We assume a (very) large collection C of pairs (k,v), where k is a key and v is the value of an object (seen as row data). An index on C is a structure that associates the key k with the (physical) address of v.
53 Indexing An index supports dictionary operations: insertion insert(k,v) deletion delete(k) key search search(k): v range search range(k 1, k 2 ): {v} [optional] In a distributed index, one should also consider: (node) leave and (node) join operations
54 Hashing (Centralised)
55
56 Hashing (Distributed) The straightforward idea Everybody uses the same hash function, and buckets are replaced by servers. Issues with distribution Dynamicity: at Web scale, we must be able to add or remove servers at any moment. Inconsistencies: it is very hard to ensure that all participants share an accurate view of the system (e.g., the hash function)
57 Hashing (Distributed) A naïve solution Let N be the number of servers. The function modulo(h(k), N) = i maps a pair (k,v) to server Si. Fact: if N changes, or if a client uses an invalid value for N, the mapping becomes inconsistent.
58 Consistent Hashing With consistent hashing, addition or removal of an instance does not significantly change the mapping of keys to servers. A simple, non-mutable hash function h maps both the keys and the servers IPs to a large address space A (e.g., [0, ]) organized as a ring in clockwise order. If S and S are two adjacent servers on the ring: all the keys in range [h(s),h(s )] are mapped to S.
59
60
61 Some (Really Useful) Refinements What if a server fails? Use replication: put a copy on the next machine (on the ring), then on the next after the next, and so on.
62 Some (Really Useful) Refinements How can we balance the load? Map a server to several points on the ring (virtual nodes) the more points, the more load received by a server; also useful if the server fails: data relocation is more evenly distributed. also useful in case of heterogeneity (the rule in largescale systems).
63
64 Where is the Hash Directory? On a specific ( Master") node, acting as a load balancer (e.g., in caching systems) raises scalability issues Each node records its successor on the ring may require O(N) messages for routing queries: not resilient to failures
65 Where is the Hash Directory? Each node records logn carefully chosen other nodes (e.g., in P2P) ensures O(logN) messages for routing queries convenient trade-off for highly dynamic networks Full duplication of the hash directory at each node (e.g., in Dynamo) ensures 1 message for routing heavy maintenance protocol which can be achieved through gossiping
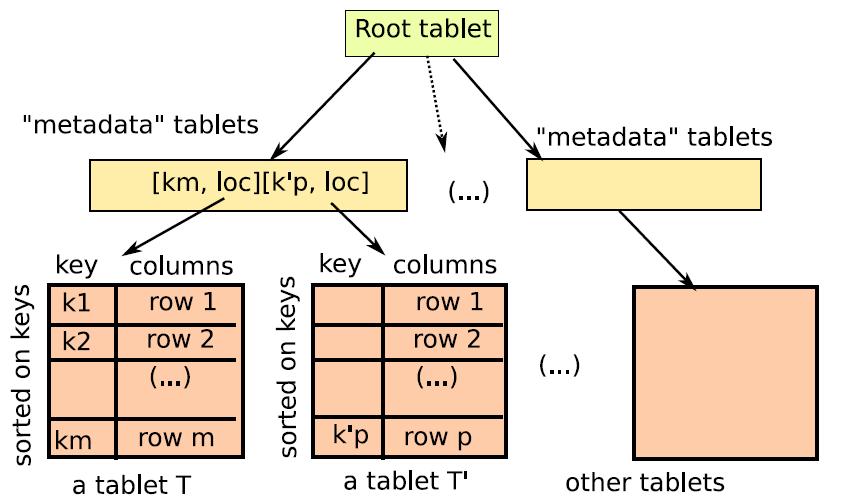
66 Amazon Dynamo A distributed storage system that targets high availability Your shopping cart is stored there! An open-source version: Voldemort It is used by LinkedIn
67 Amazon Dynamo Features Duplicates and maintains the hash directory at each node via gossiping: queries can be routed to the correct server with 1 message. The hosting server replicates N (application parameter) copies of its objects on the N distinct nodes that follow S on the ring. Propagates updates asynchronously: may result in update conflicts, solved by the application at read-time. Use a fully distributed failure detection mechanism: failure are detected by individual nodes when then fail to communicate with others.
68 B-Tree (Centralised)
69 B-Tree (Distributed)
70 B-Tree (Distributed) Issues with distribution All operations follow a top-down path: potential factor of non-scalability Possible solutions caching of the tree structure, or part of it, on the Client node replication of the upper levels of the tree routing tables, stored at each node, enabling horizontal and vertical navigation in the tree
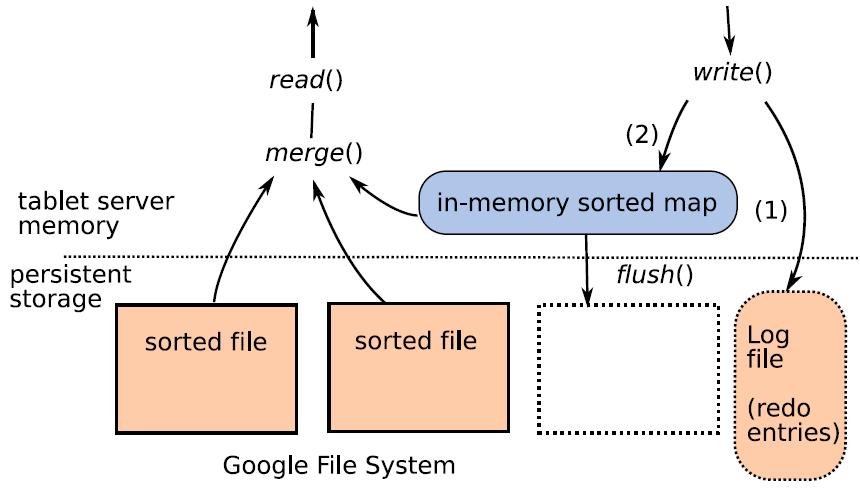
71 BigTable Can be seen as a distributed map structure, with features taken from B-trees non-dense indexed files
72 BigTable Context A controlled environment, with homogeneous servers located in a data centre; A stable organization, with long-term storage of large structured data; A data model (column-oriented tables with versioning)
73 BigTable Design Close to a B-tree, with large capacity leaves Scalability is achieved by a cache maintained by Client nodes
74 BigTable Structure Overview The table is partitioned in tablets Tablets are indexed by upper levels Full tablets are split, with upward adjustment Leaf level: A tablet organized in rows indexed by a key Rows are stored in lexicographic order on the key values
75
76 BigTable Architecture: one Master - many Servers The Master maintains the root node and carries out administrative tasks Scalability is obtained with Client cache that stores a (possibly outdated) image of the tree A Client request may fail, due to an out-of-date image of the tree An adjustment requires at most height(tree) rounds of message
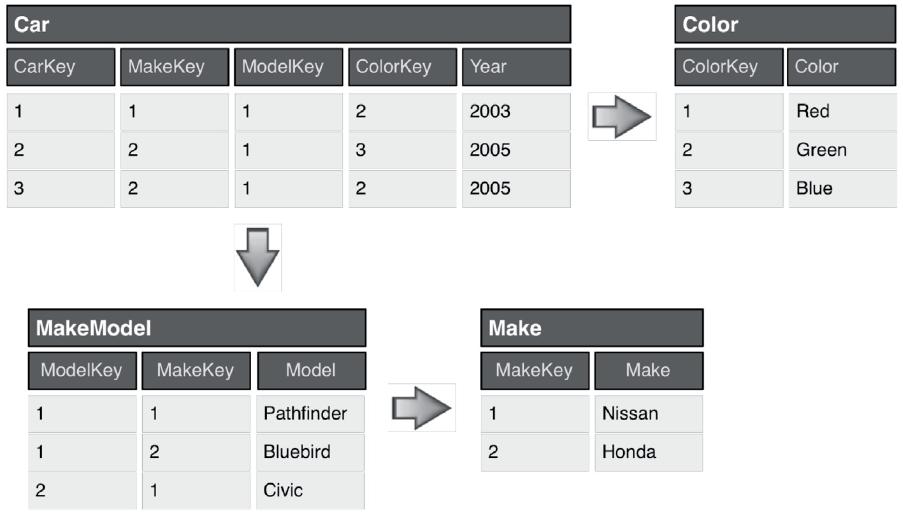
77
78
79 Persistence Management

80 Apache Cassandra BigTable data model + Dynamo infrastructure Initially developed by Facebook Now used by Twitter and Digg, etc.
81 Distributed Access Structures Key points that you should remember Reliability: always be ready to face a failure somewhere Detect failures and deal with it Use replication
82 Distributed Access Structures Key points that you should remember Scalability: no single point of failure; even load distribution over all the nodes. Distribute (and maintain) routing information: trade-off between maintenance cost and operations cost. Cache an image of the structure (e.g., in the Client): design a convergence protocol if the image gets outdated.
83 Distributed Access Structures Key points that you should remember Efficiency: clearly depends on the amount of information replicated at each node or at the Client Stable systems: the structure can be duplicated at each node, and allows O(1) cost low maintenance Highly dynamic systems: very hard to maintain a consistent view of the structure for each participant
 Scaling horizontally: Breaking some of the fundamental guarantees of SQL in order to reach")
84 NoSQL Databases NoSQL ( not only SQL ) is a broad class of database management systems identified by non-adherence to the widely used relational model Relational tables structured storage (typically key-value pairs) Scaling horizontally: Breaking some of the fundamental guarantees of SQL in order to reach massive scale
85 Relational Tables A Relational Database Management System (RDBMS) stores data as a collection of tables, and provides relational operators to manipulate the data in tabular form. All modern commercial relational databases employ SQL as their query language, therefore they are also called SQL databases.
86 Relational Tables
87 Relational Tables The challenge is scalability: SQL databases are hard to be expanded by adding more servers as data have to be replicated across the new servers or partitioned between them Data shipping: time-consuming and expensive Nearly impossible to guarantee maintenance of referential integrity (any field in a table that s declared a foreign key can contain only values from a parent table's primary key or a candidate key)
88 Structured Storage May not require fixed table schemas Usually avoid join operations if a join is needed that depends on shared tables, then replicating the data is hard and blocks easy scaling Often provide weak consistency guarantees such as eventual consistency and transactions restricted to single data items in most cases, you can impose full ACID guarantees by adding a supplementary middleware layer
89 Key-Value Pairs Key-value databases are item-oriented All relevant data relating to an item are stored in that item. Therefore data are commonly duplicated between items in a table A table can contain very different items It radically improves scalability by eliminating the need to join data from multiple tables

90 Key-Value Pairs
91

92 SQL vs NoSQL
93 Take Home Messages The challenges and opportunities of big data Large-scale distributed file systems GFS (HDFS) Large-scale distributed access structures Dynamo (Voldemort), BigTable (HBase) NoSQL databases
Indexing Large-Scale Data
 Indexing Large-Scale Data Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook November 16, 2010
Indexing Large-Scale Data Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook November 16, 2010
Introduction to Distributed Data Systems
 Introduction to Distributed Data Systems Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook January
Introduction to Distributed Data Systems Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook January
Hadoop Distributed File System(HDFS)
") Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
What is this course about?
 Data-Intensive Information Processing Applications! Session #1 Introduction to MapReduce Jordan Boyd-Graber University of Maryland Thursday, February 3, 2011 This work is licensed under a Creative Commons
Data-Intensive Information Processing Applications! Session #1 Introduction to MapReduce Jordan Boyd-Graber University of Maryland Thursday, February 3, 2011 This work is licensed under a Creative Commons
Introduction to MapReduce
 Introduction to MapReduce Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Single-node architecture CPU Memory Data Analysis, Machine Learning, Statistics Disk How much
Introduction to MapReduce Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Single-node architecture CPU Memory Data Analysis, Machine Learning, Statistics Disk How much
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
Introduction to MapReduce
 Introduction to MapReduce Based on slides by Juliana Freire Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Required Reading! Data-Intensive Text Processing with MapReduce,
Introduction to MapReduce Based on slides by Juliana Freire Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Required Reading! Data-Intensive Text Processing with MapReduce,
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
The Google File System
 The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
CS 655 Advanced Topics in Distributed Systems
 Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
Introduction to MapReduce
 Introduction to MapReduce Based on slides by Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec How much data? Google processes 20 PB a day (2008) Internet Archive Wayback Machine has 3 PB + 100
Introduction to MapReduce Based on slides by Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec How much data? Google processes 20 PB a day (2008) Internet Archive Wayback Machine has 3 PB + 100
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Google File System and BigTable. and tiny bits of HDFS (Hadoop File System) and Chubby. Not in textbook; additional information
 and Chubby. Not in textbook; additional information") Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
Distributed System. Gang Wu. Spring,2018
 Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
Distributed System Gang Wu Spring,2018 Lecture7:DFS What is DFS? A method of storing and accessing files base in a client/server architecture. A distributed file system is a client/server-based application
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
Big Data Analytics. Rasoul Karimi
 Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
! Design constraints. " Component failures are the norm. " Files are huge by traditional standards. ! POSIX-like
 Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Google File System. Arun Sundaram Operating Systems
 Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2015 Lecture 14 NoSQL
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2015 Lecture 14 NoSQL References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No.
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2015 Lecture 14 NoSQL References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No.
Bigtable. Presenter: Yijun Hou, Yixiao Peng
 Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
CMSC 723: Computational Linguistics I Session #12 MapReduce and Data Intensive NLP. University of Maryland. Wednesday, November 18, 2009
 CMSC 723: Computational Linguistics I Session #12 MapReduce and Data Intensive NLP Jimmy Lin and Nitin Madnani University of Maryland Wednesday, November 18, 2009 Three Pillars of Statistical NLP Algorithms
CMSC 723: Computational Linguistics I Session #12 MapReduce and Data Intensive NLP Jimmy Lin and Nitin Madnani University of Maryland Wednesday, November 18, 2009 Three Pillars of Statistical NLP Algorithms
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Distributed Systems. Lec 10: Distributed File Systems GFS. Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung
 Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani
 The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
Staggeringly Large Filesystems
 Staggeringly Large Filesystems Evan Danaher CS 6410 - October 27, 2009 Outline 1 Large Filesystems 2 GFS 3 Pond Outline 1 Large Filesystems 2 GFS 3 Pond Internet Scale Web 2.0 GFS Thousands of machines
Staggeringly Large Filesystems Evan Danaher CS 6410 - October 27, 2009 Outline 1 Large Filesystems 2 GFS 3 Pond Outline 1 Large Filesystems 2 GFS 3 Pond Internet Scale Web 2.0 GFS Thousands of machines
Map Reduce.
 Map Reduce dacosta@irit.fr Divide and conquer at PaaS Second Third Fourth 100 % // Fifth Sixth Seventh Cliquez pour 2 Typical problem Second Extract something of interest from each MAP Third Shuffle and
Map Reduce dacosta@irit.fr Divide and conquer at PaaS Second Third Fourth 100 % // Fifth Sixth Seventh Cliquez pour 2 Typical problem Second Extract something of interest from each MAP Third Shuffle and
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/96/128755699.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [DYNAMO & GOOGLE FILE SYSTEM] Frequently asked questions from the previous class survey What s the typical size of an inconsistency window in most production settings? Dynamo?
CS 555: DISTRIBUTED SYSTEMS [DYNAMO & GOOGLE FILE SYSTEM] Frequently asked questions from the previous class survey What s the typical size of an inconsistency window in most production settings? Dynamo?
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Distributed Data Store
 Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
Goal of the presentation is to give an introduction of NoSQL databases, why they are there.
 1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
MapReduce and Friends
 MapReduce and Friends Craig C. Douglas University of Wyoming with thanks to Mookwon Seo Why was it invented? MapReduce is a mergesort for large distributed memory computers. It was the basis for a web
MapReduce and Friends Craig C. Douglas University of Wyoming with thanks to Mookwon Seo Why was it invented? MapReduce is a mergesort for large distributed memory computers. It was the basis for a web
Tools for Social Networking Infrastructures
 Tools for Social Networking Infrastructures 1 Cassandra - a decentralised structured storage system Problem : Facebook Inbox Search hundreds of millions of users distributed infrastructure inbox changes
Tools for Social Networking Infrastructures 1 Cassandra - a decentralised structured storage system Problem : Facebook Inbox Search hundreds of millions of users distributed infrastructure inbox changes
CIB Session 12th NoSQL Databases Structures
 CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Google Disk Farm. Early days
 Google Disk Farm Early days today CS 5204 Fall, 2007 2 Design Design factors Failures are common (built from inexpensive commodity components) Files large (multi-gb) mutation principally via appending
Google Disk Farm Early days today CS 5204 Fall, 2007 2 Design Design factors Failures are common (built from inexpensive commodity components) Files large (multi-gb) mutation principally via appending
4/9/2018 Week 13-A Sangmi Lee Pallickara. CS435 Introduction to Big Data Spring 2018 Colorado State University. FAQs. Architecture of GFS
 W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Outline. Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins
 MapReduce 1 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins 2 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce
MapReduce 1 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins 2 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Google File System. By Dinesh Amatya
 Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
Google File System By Dinesh Amatya Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung designed and implemented to meet rapidly growing demand of Google's data processing need a scalable
CompSci 516 Database Systems
 CompSci 516 Database Systems Lecture 20 NoSQL and Column Store Instructor: Sudeepa Roy Duke CS, Fall 2018 CompSci 516: Database Systems 1 Reading Material NOSQL: Scalable SQL and NoSQL Data Stores Rick
CompSci 516 Database Systems Lecture 20 NoSQL and Column Store Instructor: Sudeepa Roy Duke CS, Fall 2018 CompSci 516: Database Systems 1 Reading Material NOSQL: Scalable SQL and NoSQL Data Stores Rick
DIVING IN: INSIDE THE DATA CENTER
 1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
A Fast and High Throughput SQL Query System for Big Data
 A Fast and High Throughput SQL Query System for Big Data Feng Zhu, Jie Liu, and Lijie Xu Technology Center of Software Engineering, Institute of Software, Chinese Academy of Sciences, Beijing, China 100190
A Fast and High Throughput SQL Query System for Big Data Feng Zhu, Jie Liu, and Lijie Xu Technology Center of Software Engineering, Institute of Software, Chinese Academy of Sciences, Beijing, China 100190
CSE 444: Database Internals. Lectures 26 NoSQL: Extensible Record Stores
 CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
Ghislain Fourny. Big Data 5. Column stores
 Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
High Performance Computing on MapReduce Programming Framework
 International Journal of Private Cloud Computing Environment and Management Vol. 2, No. 1, (2015), pp. 27-32 http://dx.doi.org/10.21742/ijpccem.2015.2.1.04 High Performance Computing on MapReduce Programming
International Journal of Private Cloud Computing Environment and Management Vol. 2, No. 1, (2015), pp. 27-32 http://dx.doi.org/10.21742/ijpccem.2015.2.1.04 High Performance Computing on MapReduce Programming
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Software Infrastructure in Data Centers: Distributed File Systems 1 Permanently stores data Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Software Infrastructure in Data Centers: Distributed File Systems 1 Permanently stores data Filesystems
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
HDFS: Hadoop Distributed File System. Sector: Distributed Storage System
 GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
References. What is Bigtable? Bigtable Data Model. Outline. Key Features. CSE 444: Database Internals
 References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account