7680: Distributed Systems
|
|
|
- Gertrude Rose
- 5 years ago
- Views:
Transcription

1 Cristina Nita-Rotaru 7680: Distributed Systems BigTable. Hbase.Spanner.
2 1: BigTable
3 Acknowledgement } Slides based on material from course at UMichigan, U Washington, and the authors of BigTable and Spanner. 3
4 REQUIRED READING } Bigtable: A Distributed Storage System for Structured Data ACM Trans. Comput. Syst. 26, 2 (Jun. 2008), 1-26 } Spanner, Google s globally distributed database. OSDI
5 BigTable } Distributed storage system for managing structured data such as: } URLs: contents, crawl metadata, links, anchors, pagerank } Per-user data: user preference settings, recent queries/search results } Geographic locations: physical entities (shops, restaurants, etc.), roads, satellite image data, user annotations, } Designed to scale to a very large size: petabytes of data distributed across thousands of servers } Used for many Google applications 5 } Web indexing, Personalized Search, Google Earth, Google Analytics, Google Finance, and more
6 Why BigTable? } Scalability requirements not met by existent commercial systems: } Millions of machines } Hundreds of millions of users } Billions of URLs, many versions/page } Thousands or queries/sec } 100TB+ of satellite image data } Low-level storage optimization helps performance significantly 6
7 Goals } Simpler model that supports dynamic control over data and layout format } Want asynchronous processes to be continuously updating different pieces of data: access to most current data at any time } Examine data changes over time: e.g. contents of a web page over multiple crawls } Support for: } Very high read/write rates (millions ops per second) } Efficient scans over all or subsets of data } Efficient joins of large one-to-one and one-to-many datasets 7
8 Design Overview } Distributed multi-level map } Fault-tolerant, persistent } Scalable } Thousands of servers } Terabytes of in-memory data } Petabyte of disk-based data } Millions of reads/writes per second, efficient scans } Self-managing } Servers can be added/removed dynamically } Servers adjust to load imbalance 8

9 Typical Google Cluster Shared pool of machines that also run other distributed applications 9
10 Building Blocks } Google File System (GFS) } Stores persistent data (SSTable file format) } Scheduler } Schedules jobs onto machines } Chubby } Lock service: distributed lock manager, master election, location bootstrapping } MapReduce (optional) } Data processing } Read/write BigTable data 10
11 Chubby } {lock/file/name} service } Coarse-grained locks } Provides a namespace that consists of directories and small files. } Each of the directories or files can be used as a lock. } Each client has a session with Chubby } The session expires if it is unable to renew its session lease within the lease expiration time. } 5 replicas Paxos, need a majority vote to be active 11
12 Data Model } A sparse, distributed persistent multi-dimensional sorted map } Rows, column are arbitrary strings } (row, column, timestamp) -> cell contents 12
13 Data Model: Rows } Arbitrary string } Access to data in a row is atomic } Row creation is implicit upon storing data } Ordered lexicographically 13
14 Rows (cont.) } Rows close together lexicographically usually on one or a small number of machines } Reads of short row ranges are efficient and typically require communication with a small number of machines } Can exploit lexicographic order by selecting row keys so they get good locality for data access } Example: } math.gatech.edu, math.uga.edu, phys.gatech.edu, phys.uga.edu } VS } edu.gatech.math, edu.gatech.phys, edu.uga.math, edu.uga.phys 14
15 Data Model: Columns } Two-level name structure: family: qualifier } Column family: } Is the unit of access control } Has associated type information } Qualifier gives unbounded columns } Additional levels of indexing, if desired 15
16 Data Model: Timestamps (64bit integers) Store different versions of data in a cell: } New writes default to current time, but timestamps for writes can also be set explicitly by clients } Lookup options } Return most recent K values } Return all values } Column families can be marked w/ attributes: } Retain most recent K values in a cell } Keep values until they are older than K seconds 16
17 Data Model: Tablet } The row range for a table is dynamically partitioned } Each row range is called a tablet (typically bytes) } Tablet is the unit for distribution and load balancing 17
18 Storage: SSTable } Immutable, sorted file of key-value pairs } Optionally, SSTable can be completely mapped into memory } Chunks of data plus an index } Index is of block ranges, not values } Index is loaded into memory when SSTable is open 64K block 64K block 64K block SSTable Index 18
19 Tablet vs. SSTable } Tablet is built out of multiple SSTables Tablet Start:aardvark End:apple 64K block 64K block 64K block SSTable 64K block 64K block 64K block SSTable Index Index 19
20 Table vs. Tablet vs. SSTable } Multiple tablets make up the table } SSTables can be shared } Tablets do not overlap, SSTables can overlap Tablet Tablet aardvark apple apple_two_e boat SSTable SSTable SSTable SSTable 20
21 Example: WebTable } Want to keep copy of a large collection of web pages and related information } Use URLs as row keys } Various aspects of web page as column names } Store contents of web pages in the contents: column under the timestamps when they were fetched. 21
22 Implementation } Library linked into every client } One master server responsible for: } Assigning tablets to tablet servers } Detecting addition and expiration of tablet servers } Balancing tablet-server load } Garbage collection } Handling schema changes such as table and column family creation } Many tablet servers, each of them: } Handles read and write requests to its table } Splits tablets that have grown too large } Clients communicate directly with tablet servers for reads and writes. 22
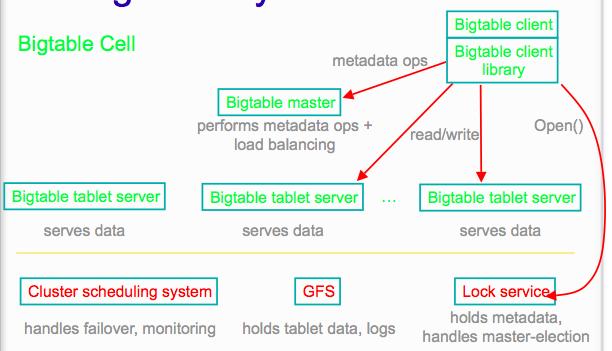
23 Deployment 23
24 More about Tablets } Serving machine responsible for } Usually about 100 tablets } Fast recovery: } 100 machines each pick up 1 tablet for failed machine } Fine-grained load balancing: } Migrate tablets away from overloaded machine } Master makes load-balancing decisions 24
25 Tablet Location } Since tablets move around from server to server, given a row, how do clients find the right machine } Find tablet whose row range covers the target row } METADATA: Key: table id + end row, Data: location } Aggressive caching and prefetching at client side 25
26 Tablet Assignment } Each tablet is assigned to one tablet server at a time. } Master server } Keeps track of the set of live tablet servers and current assignments of tablets to servers. } Keeps track of unassigned tablets. } When a tablet is unassigned, master assigns the tablet to a tablet server with sufficient room. } It uses Chubby to monitor health of tablet servers, and restart/replace failed servers. 26
27 Tablet Assignment: Chubby } Tablet server registers itself with Chubby by getting a lock in a specific directory of Chubby } Chubby gives lease on lock, must be renewed periodically } Server loses lock if it gets disconnected } Master monitors this directory to find which servers exist/are alive } If server not contactable/has lost lock, master grabs lock and reassigns tablets } GFS replicates data. Prefer to start tablet server on same machine that the data is already at 27
28 API } Metadata operations } Create/delete tables, column families, change metadata } Writes (atomic) } Set(): write cells in a row } DeleteCells(): delete cells in a row } DeleteRow(): delete all cells in a row } Reads } Scanner: read arbitrary cells in a bigtable } Each row read is atomic } Can restrict returned rows to a particular range } Can ask for just data from 1 row, all rows, etc. 28 } Can ask for all columns, just certain column families, or specific columns
29 Refinements: Locality Groups } Can group multiple column families into a locality group } Separate SSTable is created for each locality group in each tablet. } Segregating columns families that are not typically accessed together enables more efficient reads. } In WebTable, page metadata can be in one group and contents of the page in another group. 29
30 Refinements: Compression } Many opportunities for compression } Similar values in the same row/column at different timestamps } Similar values in different columns } Similar values across adjacent rows } Two-pass custom compressions scheme } First pass: compress long common strings across a large window } Second pass: look for repetitions in small window } Speed emphasized, but good space reduction (10-to-1) 30
31 Refinements: Bloom Filters } Read operation has to read from disk when desired SSTable is not in memory } Reduce number of accesses by specifying a Bloom filter: } Allows to ask if a SSTable might contain data for a specified row/column pair. } Small amount of memory for Bloom filters drastically reduces the number of disk seeks for read operations } Results in most lookups for non-existent rows or columns not needing to touch disk 31
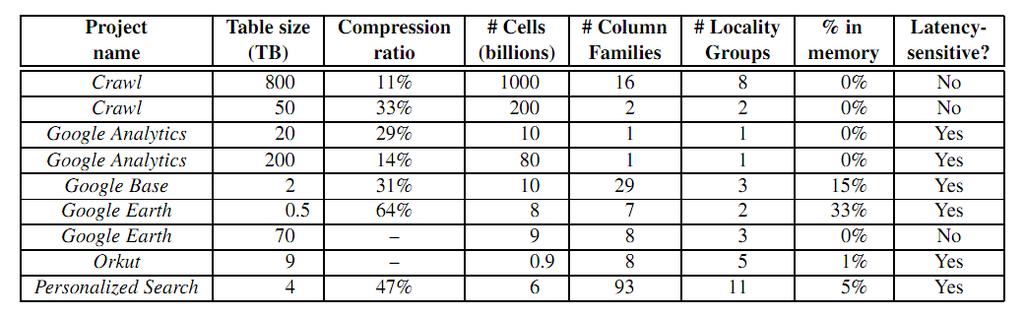
32 Real Applications 32
33 Limitations } No transactions supported } Does not support full relational data model } Achieved throughput is limited by GFS 33
34 Lessons Learnt } Large distributed systems vulnerable to many type of failures } Memory and network corruption } Large clock skew } Hung machines } Extended and asymmetric network partitions } Bugs in other systems } Proper system-level monitoring critical } Simple design better } Do not add new features before they are needed 34
35 2: HBase
36 HBase } Open-source, distributed, versioned, column-oriented data store, modeled after Google's Bigtable } Random, real time read/write access to large data: } Billions of rows, millions of columns } Distributed across clusters of commodity hardware 36
37 History } } Google releases paper on BigTable } } Initial HBase prototype created as Hadoop contrib. } } First useable HBase } } Hadoop become Apache top-level project and HBase becomes subproject } Current stable release 0.98.x 37
38 HBase Is Not } Tables have one primary index, the row key. } No join operators. } Scans and queries can select a subset of available columns. } There are three types of lookups: } Fast lookup using row key and optional timestamp. } Full table scan } Range scan from region start to end. 38
39 HBase Is Not (2) } Limited atomicity and transaction support. } HBase supports multiple batched mutations of single rows only. } Data is unstructured and untyped. } No accessed or manipulated via SQL. } Programmatic access via Java, REST, or Thrift APIs. } Scripting via JRuby. 39
40 3: Spanner
41 Limitations of BigTable } Difficult to use for applications that } have complex, evolving schemas, } want strong consistency in the presence of wide-area replication 41
42 What is Spanner } Scalable, multi-version, globally- distributed, and synchronously-replicated database } Distribute data at global scale and support externallyconsistent distributed transactions. } Features: } non- blocking reads in the past } lock-free read-only transactions, } atomic schema changes } Scale up to } millions of machines } hundreds of datacenters } trillions of database rows 42
43 What is Spanner } Applications can control replication configurations for data } Applications can specify constraints } to control which datacenters contain which data, how far data is from its users (to control read latency) } how far replicas are from each other (to control write latency) } how many replicas are maintained (to control durability, availability, and read performance). } Data can also be dynamically and transparently moved between datacenters by the system to balance resource usage across datacenters 43
44 Spanner key idea } Consistent reads and writes } How: } use global commit timestamps to transactions, even though transactions may be distributed. } timestamps represent serialization order. } provide such guarantees at global scale } How to get the global timestamps: TrueTime } Relies on existing algorithms as Paxos and 2PC 44
45 Architecture } Instance it s called universe; examples: test, deployment, production } Universe master } Placement master } handles automated movement of data across zones on the timescale of minutes } periodically communicates with the spanservers to find data that needs to be moved, either to meet updated replication constraints or to balance load. } Universe consists of zones } Denotes physical isolation } Several zones can be in a datacenter 45
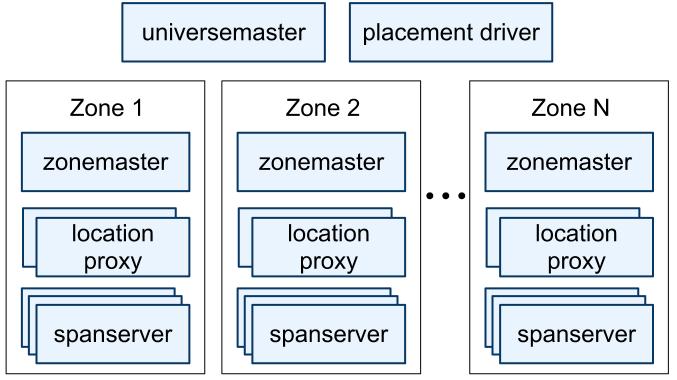
46 Architecture 46
47 Zones } Zonemaster } assigns the data to span servers } Spanservers } hundreds to thousands } store data } responsible for between 100 and 1000 instances of a data structure called a tablet (different from the BigTable tablet) } each data has a timestamp } Location proxies } used by clients to locate the spanservers assigned to serve their data 47
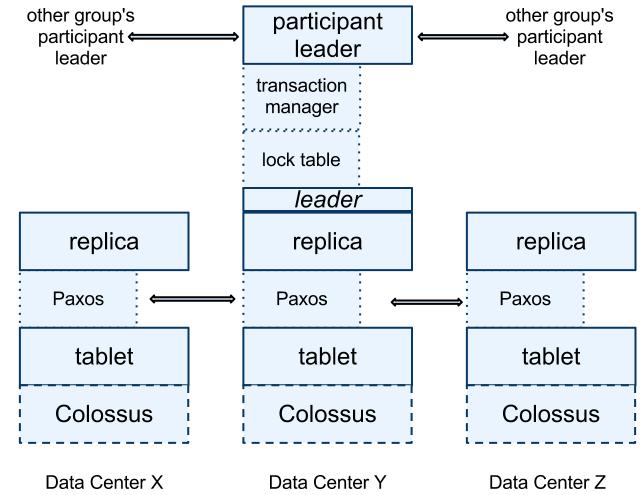
48 Replication 48
49 More about replication } Directory analogous to bucket in BigTable } Smallest unit of data placement } Smallest unit to define replication properties } 2PC and Paxos-based replication } Back End: Colossus (successor to GFS) } Paxos State Machine on top of each tablet stores meta data and logs of the tablet. } Leader among replicas in a Paxos group is chosen and all write requests for replicas in that group initiate at leader. } Transaction Leader } Is Paxos Leader if transaction involves one Paxos group 49
50 TrueTime } Leverages hardware features like GPS and Atomic Clocks } Implemented via TrueTime API } Key method being now() which not only returns current system time but also another value (ε) which tells the maximum uncertainty in the time returned } Set of time master server per datacenters and time slave daemon per machines } Majority of time masters are GPS fitted and few others are atomic clock fitted (Armageddon masters) } Daemon polls variety of masters and reaches a consensus about correct timestamp 50
51 TrueTime } TrueTime uses both GPS and Atomic clocks since they are different failure rates and scenarios } Two other boolean methods in API are } After(t) returns TRUE if t is definitely passed } Before(t) returns TRUE if t is definitely not arrived } TrueTime uses these methods in concurrency control and t serialize transactions 51
52 TrueTime } After() is used for Paxos Leader Leases } Uses after(smax) to check if Smax is passed so that Paxos Leader can abdicate its slaves. } Paxos Leaders can not assign timestamps(si) greater than Smax for transactions(ti) and clients can not see the data commited by transaction Ti till after(si) is true. } After(t) returns TRUE if t is definitely passed } Before(t) returns TRUE if t is definitely not arrived } Replicas maintain a timestamp tsafe which is the maximum timestamp at which that replica is up to date. 52
53 TrueTime } Read-Write requires lock. } Read-Only lock free. } Requires declaration before start of transaction. } Reads information that is up to date } Snapshot Read Read information from past by specifying a timestamp or bound } Use specifies specific timestamp from past or timestamp bound so that data till that point will be read. 53
54 Applications } Google advertising backend application F1 } Replicated across 5 datacenters spread across US 54
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis
 Slides adapted by Tyler Davis") BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612
 Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
BigTable: A Distributed Storage System for Structured Data
 BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
Distributed Systems [Fall 2012]
![Distributed Systems [Fall 2012]](/thumbs/75/71557798.jpg "Distributed Systems [Fall 2012]") Distributed Systems [Fall 2012] Lec 20: Bigtable (cont ed) Slide acks: Mohsen Taheriyan (http://www-scf.usc.edu/~csci572/2011spring/presentations/taheriyan.pptx) 1 Chubby (Reminder) Lock service with a
Distributed Systems [Fall 2012] Lec 20: Bigtable (cont ed) Slide acks: Mohsen Taheriyan (http://www-scf.usc.edu/~csci572/2011spring/presentations/taheriyan.pptx) 1 Chubby (Reminder) Lock service with a
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
CSE 444: Database Internals. Lectures 26 NoSQL: Extensible Record Stores
 CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
Big Table. Google s Storage Choice for Structured Data. Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla
 Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
Bigtable. Presenter: Yijun Hou, Yixiao Peng
 Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
BigTable. CSE-291 (Cloud Computing) Fall 2016
 Fall 2016") BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
BigTable A System for Distributed Structured Storage
 BigTable A System for Distributed Structured Storage Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber Adapted
BigTable A System for Distributed Structured Storage Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber Adapted
References. What is Bigtable? Bigtable Data Model. Outline. Key Features. CSE 444: Database Internals
 References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
Google big data techniques (2)
") Google big data techniques (2) Lecturer: Jiaheng Lu Fall 2016 10.12.2016 1 Outline Google File System and HDFS Relational DB V.S. Big data system Google Bigtable and NoSQL databases 2016/12/10 3 The Google
Google big data techniques (2) Lecturer: Jiaheng Lu Fall 2016 10.12.2016 1 Outline Google File System and HDFS Relational DB V.S. Big data system Google Bigtable and NoSQL databases 2016/12/10 3 The Google
BigTable: A System for Distributed Structured Storage
 BigTable: A System for Distributed Structured Storage Jeff Dean Joint work with: Mike Burrows, Tushar Chandra, Fay Chang, Mike Epstein, Andrew Fikes, Sanjay Ghemawat, Robert Griesemer, Bob Gruber, Wilson
BigTable: A System for Distributed Structured Storage Jeff Dean Joint work with: Mike Burrows, Tushar Chandra, Fay Chang, Mike Epstein, Andrew Fikes, Sanjay Ghemawat, Robert Griesemer, Bob Gruber, Wilson
MapReduce & BigTable
 CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
Bigtable: A Distributed Storage System for Structured Data. Andrew Hon, Phyllis Lau, Justin Ng
 Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
CS5412: OTHER DATA CENTER SERVICES
 1 CS5412: OTHER DATA CENTER SERVICES Lecture V Ken Birman Tier two and Inner Tiers 2 If tier one faces the user and constructs responses, what lives in tier two? Caching services are very common (many
1 CS5412: OTHER DATA CENTER SERVICES Lecture V Ken Birman Tier two and Inner Tiers 2 If tier one faces the user and constructs responses, what lives in tier two? Caching services are very common (many
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable References Bigtable: A Distributed Storage System for Structured Data. Fay Chang et. al. OSDI
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable References Bigtable: A Distributed Storage System for Structured Data. Fay Chang et. al. OSDI
DIVING IN: INSIDE THE DATA CENTER
 1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
Outline. Spanner Mo/va/on. Tom Anderson
 Spanner Mo/va/on Tom Anderson Outline Last week: Chubby: coordina/on service BigTable: scalable storage of structured data GFS: large- scale storage for bulk data Today/Friday: Lessons from GFS/BigTable
Spanner Mo/va/on Tom Anderson Outline Last week: Chubby: coordina/on service BigTable: scalable storage of structured data GFS: large- scale storage for bulk data Today/Friday: Lessons from GFS/BigTable
CS5412: DIVING IN: INSIDE THE DATA CENTER
 1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs
1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs
CA485 Ray Walshe NoSQL
 NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
Introduction Data Model API Building Blocks SSTable Implementation Tablet Location Tablet Assingment Tablet Serving Compactions Refinements
 Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. M. Burak ÖZTÜRK 1 Introduction Data Model API Building
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. M. Burak ÖZTÜRK 1 Introduction Data Model API Building
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Extreme Computing. NoSQL.
 Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Lessons Learned While Building Infrastructure Software at Google
 Lessons Learned While Building Infrastructure Software at Google Jeff Dean jeff@google.com Google Circa 1997 (google.stanford.edu) Corkboards (1999) Google Data Center (2000) Google Data Center (2000)
Lessons Learned While Building Infrastructure Software at Google Jeff Dean jeff@google.com Google Circa 1997 (google.stanford.edu) Corkboards (1999) Google Data Center (2000) Google Data Center (2000)
Structured Big Data 1: Google Bigtable & HBase Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC
 CSIE, NDHU, Taiwan, ROC") Structured Big Data 1: Google Bigtable & HBase Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei Liao
Structured Big Data 1: Google Bigtable & HBase Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei Liao
Spanner: Google's Globally-Distributed Database* Huu-Phuc Vo August 03, 2013
 Spanner: Google's Globally-Distributed Database* Huu-Phuc Vo August 03, 2013 *OSDI '12, James C. Corbett et al. (26 authors), Jay Lepreau Best Paper Award Outline What is Spanner? Features & Example Structure
Spanner: Google's Globally-Distributed Database* Huu-Phuc Vo August 03, 2013 *OSDI '12, James C. Corbett et al. (26 authors), Jay Lepreau Best Paper Award Outline What is Spanner? Features & Example Structure
Corbett et al., Spanner: Google s Globally-Distributed Database
 Corbett et al., : Google s Globally-Distributed Database MIMUW 2017-01-11 ACID transactions ACID transactions SQL queries ACID transactions SQL queries Semi-relational data model ACID transactions SQL
Corbett et al., : Google s Globally-Distributed Database MIMUW 2017-01-11 ACID transactions ACID transactions SQL queries ACID transactions SQL queries Semi-relational data model ACID transactions SQL
Distributed Systems. GFS / HDFS / Spanner
 15-440 Distributed Systems GFS / HDFS / Spanner Agenda Google File System (GFS) Hadoop Distributed File System (HDFS) Distributed File Systems Replication Spanner Distributed Database System Paxos Replication
15-440 Distributed Systems GFS / HDFS / Spanner Agenda Google File System (GFS) Hadoop Distributed File System (HDFS) Distributed File Systems Replication Spanner Distributed Database System Paxos Replication
Spanner : Google's Globally-Distributed Database. James Sedgwick and Kayhan Dursun
 Spanner : Google's Globally-Distributed Database James Sedgwick and Kayhan Dursun Spanner - A multi-version, globally-distributed, synchronously-replicated database - First system to - Distribute data
Spanner : Google's Globally-Distributed Database James Sedgwick and Kayhan Dursun Spanner - A multi-version, globally-distributed, synchronously-replicated database - First system to - Distribute data
Spanner: Google's Globally-Distributed Database. Presented by Maciej Swiech
 Spanner: Google's Globally-Distributed Database Presented by Maciej Swiech What is Spanner? "...Google's scalable, multi-version, globallydistributed, and synchronously replicated database." What is Spanner?
Spanner: Google's Globally-Distributed Database Presented by Maciej Swiech What is Spanner? "...Google's scalable, multi-version, globallydistributed, and synchronously replicated database." What is Spanner?
CSE-E5430 Scalable Cloud Computing Lecture 9
 CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
CS5412: DIVING IN: INSIDE THE DATA CENTER
 1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman We ve seen one cloud service 2 Inside a cloud, Dynamo is an example of a service used to make sure that cloud-hosted applications can scale
1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman We ve seen one cloud service 2 Inside a cloud, Dynamo is an example of a service used to make sure that cloud-hosted applications can scale
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems. 19. Spanner. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 19. Spanner Paul Krzyzanowski Rutgers University Fall 2017 November 20, 2017 2014-2017 Paul Krzyzanowski 1 Spanner (Google s successor to Bigtable sort of) 2 Spanner Take Bigtable and
Distributed Systems 19. Spanner Paul Krzyzanowski Rutgers University Fall 2017 November 20, 2017 2014-2017 Paul Krzyzanowski 1 Spanner (Google s successor to Bigtable sort of) 2 Spanner Take Bigtable and
Google File System and BigTable. and tiny bits of HDFS (Hadoop File System) and Chubby. Not in textbook; additional information
 and Chubby. Not in textbook; additional information") Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
BigTable. Chubby. BigTable. Chubby. Why Chubby? How to do consensus as a service
 BigTable BigTable Doug Woos and Tom Anderson In the early 2000s, Google had way more than anybody else did Traditional bases couldn t scale Want something better than a filesystem () BigTable optimized
BigTable BigTable Doug Woos and Tom Anderson In the early 2000s, Google had way more than anybody else did Traditional bases couldn t scale Want something better than a filesystem () BigTable optimized
Distributed Data Management. Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig
 Distributed Data Management Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Sommerfest! Distributed Data Management Christoph Lofi IfIS TU
Distributed Data Management Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Sommerfest! Distributed Data Management Christoph Lofi IfIS TU
big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures
 mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures") Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Google Data Management
 Google Data Management Vera Goebel Department of Informatics, University of Oslo 2009 Google Technology Kaizan: continuous developments and improvements Grid computing: Google data centers and messages
Google Data Management Vera Goebel Department of Informatics, University of Oslo 2009 Google Technology Kaizan: continuous developments and improvements Grid computing: Google data centers and messages
DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.
![DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.](/thumbs/86/93978710.jpg "DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.") CHALLENGES Transparency: Slide 1 DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems ➀ Introduction ➁ NFS (Network File System) ➂ AFS (Andrew File System) & Coda ➃ GFS (Google File System)
CHALLENGES Transparency: Slide 1 DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems ➀ Introduction ➁ NFS (Network File System) ➂ AFS (Andrew File System) & Coda ➃ GFS (Google File System)
Bigtable: A Distributed Storage System for Structured Data
 Bigtable: A Distributed Storage System for Structured Data Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber {fay,jeff,sanjay,wilsonh,kerr,m3b,tushar,fikes,gruber}@google.com
Bigtable: A Distributed Storage System for Structured Data Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber {fay,jeff,sanjay,wilsonh,kerr,m3b,tushar,fikes,gruber}@google.com
Big Data Processing Technologies. Chentao Wu Associate Professor Dept. of Computer Science and Engineering
 Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
Distributed Database Case Study on Google s Big Tables
 Distributed Database Case Study on Google s Big Tables Anjali diwakar dwivedi 1, Usha sadanand patil 2 and Vinayak D.Shinde 3 1,2,3 Computer Engineering, Shree l.r.tiwari college of engineering Abstract-
Distributed Database Case Study on Google s Big Tables Anjali diwakar dwivedi 1, Usha sadanand patil 2 and Vinayak D.Shinde 3 1,2,3 Computer Engineering, Shree l.r.tiwari college of engineering Abstract-
Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database.
 Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database. Presented by Kewei Li The Problem db nosql complex legacy tuning expensive
Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database. Presented by Kewei Li The Problem db nosql complex legacy tuning expensive
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Ghislain Fourny. Big Data 5. Wide column stores
 Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Bigtable: A Distributed Storage System for Structured Data
 Bigtable: A Distributed Storage System for Structured Data Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber ~Harshvardhan
Bigtable: A Distributed Storage System for Structured Data Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber ~Harshvardhan
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
Recap. CSE 486/586 Distributed Systems Google Chubby Lock Service. Recap: First Requirement. Recap: Second Requirement. Recap: Strengthening P2
 Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Recap. CSE 486/586 Distributed Systems Google Chubby Lock Service. Paxos Phase 2. Paxos Phase 1. Google Chubby. Paxos Phase 3 C 1
 Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
The Google File System
 The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
The Google File System By Ghemawat, Gobioff and Leung Outline Overview Assumption Design of GFS System Interactions Master Operations Fault Tolerance Measurements Overview GFS: Scalable distributed file
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Bigtable: A Distributed Storage System for Structured Data
 4 Bigtable: A Distributed Storage System for Structured Data FAY CHANG, JEFFREY DEAN, SANJAY GHEMAWAT, WILSON C. HSIEH, DEBORAH A. WALLACH, MIKE BURROWS, TUSHAR CHANDRA, ANDREW FIKES, and ROBERT E. GRUBER
4 Bigtable: A Distributed Storage System for Structured Data FAY CHANG, JEFFREY DEAN, SANJAY GHEMAWAT, WILSON C. HSIEH, DEBORAH A. WALLACH, MIKE BURROWS, TUSHAR CHANDRA, ANDREW FIKES, and ROBERT E. GRUBER
Spanner: Google s Globally- Distributed Database
 Spanner: Google s Globally- Distributed Database Google, Inc. OSDI 2012 Presented by: Karen Ouyang Problem Statement Distributed data system with high availability Support external consistency! Key Ideas
Spanner: Google s Globally- Distributed Database Google, Inc. OSDI 2012 Presented by: Karen Ouyang Problem Statement Distributed data system with high availability Support external consistency! Key Ideas
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
From Google File System to Omega: a Decade of Advancement in Big Data Management at Google
 2015 IEEE First International Conference on Big Data Computing Service and Applications From Google File System to Omega: a Decade of Advancement in Big Data Management at Google Jade Yang Department of
2015 IEEE First International Conference on Big Data Computing Service and Applications From Google File System to Omega: a Decade of Advancement in Big Data Management at Google Jade Yang Department of
Google Spanner - A Globally Distributed,
 Google Spanner - A Globally Distributed, Synchronously-Replicated Database System James C. Corbett, et. al. Feb 14, 2013. Presented By Alexander Chow For CS 742 Motivation Eventually-consistent sometimes
Google Spanner - A Globally Distributed, Synchronously-Replicated Database System James C. Corbett, et. al. Feb 14, 2013. Presented By Alexander Chow For CS 742 Motivation Eventually-consistent sometimes
Programming model and implementation for processing and. Programs can be automatically parallelized and executed on a large cluster of machines
 A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs
A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs
Lecture: The Google Bigtable
 Lecture: The Google Bigtable h#p://research.google.com/archive/bigtable.html 10/09/2014 Romain Jaco3n romain.jaco7n@orange.fr Agenda Introduc3on Data model API Building blocks Implementa7on Refinements
Lecture: The Google Bigtable h#p://research.google.com/archive/bigtable.html 10/09/2014 Romain Jaco3n romain.jaco7n@orange.fr Agenda Introduc3on Data model API Building blocks Implementa7on Refinements
Distributed Systems. Fall 2017 Exam 3 Review. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems Fall 2017 Exam 3 Review Paul Krzyzanowski Rutgers University Fall 2017 December 11, 2017 CS 417 2017 Paul Krzyzanowski 1 Question 1 The core task of the user s map function within a
Distributed Systems Fall 2017 Exam 3 Review Paul Krzyzanowski Rutgers University Fall 2017 December 11, 2017 CS 417 2017 Paul Krzyzanowski 1 Question 1 The core task of the user s map function within a
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Goal of the presentation is to give an introduction of NoSQL databases, why they are there.
 1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
Distributed Data Management. Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig
 Distributed Data Management Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Exams 25 minutes oral examination 20.-24.02.2012 19.-23.03.2012
Distributed Data Management Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Exams 25 minutes oral examination 20.-24.02.2012 19.-23.03.2012
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
11 Storage at Google Google Google Google Google 7/2/2010. Distributed Data Management
 11 Storage at Google Distributed Data Management 11.1 Google Bigtable 11.2 Google File System 11. Bigtable Implementation Wolf-Tilo Balke Christoph Lofi Institut für Informationssysteme Technische Universität
11 Storage at Google Distributed Data Management 11.1 Google Bigtable 11.2 Google File System 11. Bigtable Implementation Wolf-Tilo Balke Christoph Lofi Institut für Informationssysteme Technische Universität
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
Scaling Up HBase. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up HBase Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up HBase Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
How do we build TiDB. a Distributed, Consistent, Scalable, SQL Database
 How do we build TiDB a Distributed, Consistent, Scalable, SQL Database About me LiuQi ( 刘奇 ) JD / WandouLabs / PingCAP Co-founder / CEO of PingCAP Open-source hacker / Infrastructure software engineer
How do we build TiDB a Distributed, Consistent, Scalable, SQL Database About me LiuQi ( 刘奇 ) JD / WandouLabs / PingCAP Co-founder / CEO of PingCAP Open-source hacker / Infrastructure software engineer
Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب
 Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب 1391 زمستان Outlines Introduction DataModel Architecture HBase vs. RDBMS HBase users 2 Why Hadoop? Datasets are growing to Petabytes Traditional datasets
Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب 1391 زمستان Outlines Introduction DataModel Architecture HBase vs. RDBMS HBase users 2 Why Hadoop? Datasets are growing to Petabytes Traditional datasets
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Integrity in Distributed Databases
 Integrity in Distributed Databases Andreas Farella Free University of Bozen-Bolzano Table of Contents 1 Introduction................................................... 3 2 Different aspects of integrity.....................................
Integrity in Distributed Databases Andreas Farella Free University of Bozen-Bolzano Table of Contents 1 Introduction................................................... 3 2 Different aspects of integrity.....................................
Design & Implementation of Cloud Big table
 Design & Implementation of Cloud Big table M.Swathi 1,A.Sujitha 2, G.Sai Sudha 3, T.Swathi 4 M.Swathi Assistant Professor in Department of CSE Sri indu College of Engineering &Technolohy,Sheriguda,Ibrahimptnam
Design & Implementation of Cloud Big table M.Swathi 1,A.Sujitha 2, G.Sai Sudha 3, T.Swathi 4 M.Swathi Assistant Professor in Department of CSE Sri indu College of Engineering &Technolohy,Sheriguda,Ibrahimptnam
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
Exam 2 Review. October 29, Paul Krzyzanowski 1
 Exam 2 Review October 29, 2015 2013 Paul Krzyzanowski 1 Question 1 Why did Dropbox add notification servers to their architecture? To avoid the overhead of clients polling the servers periodically to check
Exam 2 Review October 29, 2015 2013 Paul Krzyzanowski 1 Question 1 Why did Dropbox add notification servers to their architecture? To avoid the overhead of clients polling the servers periodically to check
Beyond TrueTime: Using AugmentedTime for Improving Spanner
 Beyond TrueTime: Using AugmentedTime for Improving Spanner Murat Demirbas University at Buffalo, SUNY demirbas@cse.buffalo.edu Sandeep Kulkarni Michigan State University, sandeep@cse.msu.edu Spanner [1]
Beyond TrueTime: Using AugmentedTime for Improving Spanner Murat Demirbas University at Buffalo, SUNY demirbas@cse.buffalo.edu Sandeep Kulkarni Michigan State University, sandeep@cse.msu.edu Spanner [1]
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
Applications of Paxos Algorithm
 Applications of Paxos Algorithm Gurkan Solmaz COP 6938 - Cloud Computing - Fall 2012 Department of Electrical Engineering and Computer Science University of Central Florida - Orlando, FL Oct 15, 2012 1
Applications of Paxos Algorithm Gurkan Solmaz COP 6938 - Cloud Computing - Fall 2012 Department of Electrical Engineering and Computer Science University of Central Florida - Orlando, FL Oct 15, 2012 1
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
CS 655 Advanced Topics in Distributed Systems
 Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
W b b 2.0. = = Data Ex E pl p o l s o io i n
 Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static