CS5412: DIVING IN: INSIDE THE DATA CENTER
|
|
|
- Briana Moody
- 5 years ago
- Views:
Transcription
1 1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman
2 We ve seen one cloud service 2 Inside a cloud, Dynamo is an example of a service used to make sure that cloud-hosted applications can scale at low cost It offers a very scalable key-value way to store and fetch data, and this model is very important and popular, probably the single most important idea in all of cloud computing! But it isn t the only example of a cloud service we should know about
3 Data centers 3 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to a tier one computer (one of many) hosting the proper services Each hosted company has its own domain but also runs inside a kind of virtual enterprise: looks like a private network, with its own IP addresses etc. These can make use of shared services provided by the cloud provider, like file system services
4 Tier two and Inner Tiers 4 If tier one faces the user and constructs responses, what lives in tier two? Caching services are very common (many flavors) Other kinds of rapidly responsive lightweight services that are massively scaled Inner tier services might still have online roles, but tend to live on smaller numbers of nodes: maybe tens rather than hundreds or thousands
5 Tier two and Inner Tiers 5 Tiers one and two soak up the load This reduces load on the inner tiers, and in fact there may be further layers of caching to soak up load outside the data center (Akamai, Facebook edge, etc.) Many services use asynchronous streams of updates Send updates down towards inner services but don t wait and don t hold locks! Notifications percolate up, often showing up much later. Meanwhile, tier one runs with potentially out-of-data cached data. Tier 1 Service Tier 1 Tier 1 Service Service Tier 1 Service Tier 1 Service Backend DB
6 Contrast with Back office 6 A term often used for services and systems that don t play online roles In some sense the whole cloud has an outward facing side, handling users in real-time, and an inward side, doing offline tasks Still can have immense numbers of nodes involved but the programming model has more of a batch feel to it For example, MapReduce (Hadoop)
7 Some interesting services we ll consider 7 Memcached: In-memory caching subsystem Dynamo: Amazon s shopping cart BigTable: A sparse table for structured data GFS: Google File System Chubby: Google s locking service Zookeeper: File system with locking, strong semantics TAO: Used by Facebook to track relationships such as Friends and Likes MapReduce: Functional computing for big datasets
8 Connection to DHT concept 8 Last time we focused on a P2P style of DHT These services are mostly built as layers over a data center DHT deployment Same idea and similar low-level functionality But inside the data center we can avoid costly indirect routing. We ll discuss that next time.
9 Memcached 9 Very simple concept: High performance distributed in-memory caching service that manages objects Key-value API has become an accepted standard Many implementations Simplest versions: just a library that manages a list or a dictionary Fanciest versions: distributed services implemented using a cluster of machines
10 Memcached API 10 Memcached defines a standard API Defines the calls the application can issue to the library or the server (either way, it looks like library) In theory, this means an application can be coded and tested using one version of memcached, then migrated to a different one function get_foo(foo_id) foo = memcached_get("foo:". foo_id) if foo!= null return foo foo = fetch_foo_from_database(foo_id) memcached_set("foo:". foo_id, foo) return foo end
11 A single memcached server is easy 11 Today s tools make it trivial to build a server Build a program Designate some of its methods as ones that expose service APIs Tools will create stubs: library procedures that automate binding to the service Now run your service at a suitable place and register it in the local registry Applications can do remote procedure calls, and these code paths are heavily optimized: quite fast
12 12 Can one use a cluster to host a scalable version of Memcached? This is what Amazon s Dynamo service does! Built over a version of Chord DHT Basic idea is to offer a key-value API, like memcached But now we ll have thousands of service instances Used for shopping cart: a very high-load application Basic innovation? To speed things up (think BASE), Dynamo sometimes puts data at the wrong place Idea is that if the right nodes can t be reached, put the data somewhere in the DHT, then allow repair mechanisms to migrate the information to the right place asynchronously
13 Dynamo in practice 13 Suppose key should map to N56 Dynamo replicates data on neighboring nodes (N1 here) Will also save key,value on subsequent nodes if targets don t respond Data migrates to correct location eventually
14 Dynamo in practice 14 When Amazon rolled Dynamo out, there was a huge need for scalable key-value storage, and Dynamo responded to this (e.g. shopping cart) But in fact it wasn t popular with people more familiar with database APIs Eventually Amazon introduced Dynamo-DB which has a NoSQL API: SQL but with weak consistency. This has been far more successful for many uses.
15 Lessons learned? 15 Notice that we started with Chord: a DHT for big P2P uses. But nobody has big P2P systems! Dynamo was initially just Chord adapted for use inside a data-center, as a service, adjusted to deal with the peculiar failure patterns seen at Amazon. But ultimately, with Dynamo-DB, Amazon was forced to change the model to bridge to developers.
16 BigTable 16 Yet another key-value store! Built by Google over their GFS file system and Chubby lock service Idea is to create a flexible kind of table that can be expanded as needed dynamically Like Dynamo-DB, starts with a DHT idea but then grew to become a specialized solution with many features
17 Data model: a big map <Row, Column, Timestamp> triple for key Arbitrary columns on a row-by-row basis Column family:qualifier. Family is heavyweight, qualifier lightweight Column-oriented physical store- rows are sparse! Does not support a relational model No table-wide integrity constraints No multirow transactions 17
18 API 18 Metadata operations Create/delete tables, column families, change metadata Writes (atomic) Set(): write cells in a row DeleteCells(): delete cells in a row DeleteRow(): delete all cells in a row Reads Scanner: read arbitrary cells in a bigtable Each row read is atomic Can restrict returned rows to a particular range Can ask for just data from 1 row, all rows, etc. Can ask for all columns, just certain column families, or specific columns
19 Versions 19 Data has associated version numbers To perform a transaction, create a set of pages all using some new version number Then can atomically install them For reads can let BigTable select the version or can tell it which one to access
20 How did they build it 20 We ll skim very lightly over the main data structures but you don t need to learn the details Idea is just to have a feeling for how it works And how does it work? They map BigTable down to a kind of key-value system!
21 SSTable Immutable, sorted file of key-value pairs Chunks of data plus an index Index is of block ranges, not values 64K block 64K block 64K block SSTable Index 21
22 Tablet Contains some range of rows of the table Built out of multiple SSTables Tablet Start:aardvark End:apple 64K block 64K block 64K block SSTable 64K block 64K block 64K block SSTable Index Index 22
23 Table Multiple tablets make up the table SSTables can be shared Tablets do not overlap, SSTables can overlap Tablet aardvark apple Tablet apple_two_e boat SSTable SSTable SSTable SSTable 23
24 Finding a tablet Stores: Key: table id + end row, Data: location Cached at clients, which may detect data to be incorrect in which case, lookup on hierarchy performed Also prefetched (for range queries) 24
25 Finding a tablet 25 Stepping back, can you see how this is a bit like using a DHT in two layers? To look for something, you use the row and column information as a key, and that key lets you find the metadata on the tablet server, and then you can track down the actual data So the DHT (key-value) concept can be turned into this very fancy infinitely large table!
26 Programming model 26 Application reads information Uses it to create a group of updates Then uses group commit to install them atomically Conflicts? One wins and the other fails, or perhaps both attempts fail But this ensures that data moves in a predictable manner version by version: a form of the ACID model! Thus BigTable offers strong consistency, up to a limit There are failure cases they deliberately don t cover
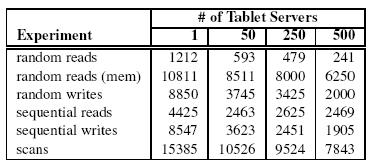
27 Microbenchmarks 27
28 Performance 28

29 Application at Google 29
30 So where does this table live? 30 Google actually stores the table inside its global file system or GFS GFS is a kind of DHT too! It has a name node service where you can find a list of data nodes and a key-value mapping from file name to data nodes that host that file (actually, chunks of that file, because Google s files are huge) Sort of the same idea as we just saw for BigTable
31 GFS and Chubby 31 GFS file system used under the surface for storage Has a master and a set of chunk servers To access a file, ask master it directs you to some chunk server and provides a capability That server sends you the data Chubby lock server Implements locks with varying levels of durability Implemented over Paxos, a protocol we ll look at a few lectures from now
32 GFS Architecture 32
33 Write Algorithm is trickier Application originates write request. 2. GFS client translates request from (filename, data) -> (filename, chunk index), and sends it to master. 3. Master responds with chunk handle and (primary + secondary) replica locations. 4. Client pushes write data to all locations. Data is stored in chunkservers internal buffers. 5. Client sends write command to primary.
34 Write Algorithm is trickier Primary determines serial order for data instances stored in its buffer and writes the instances in that order to the chunk. 7. Primary sends serial order to the secondaries and tells them to perform the write. 8. Secondaries respond to the primary. 9. Primary responds back to client. Note: If write fails at one of chunkservers, client is informed and retries the write.
35 Write Algorithm is trickier 35
36 Write Algorithm is trickier 36
37 We ve only scratched the surface 37 We ve focused on scalable storage But there are many other major, important services What are some examples? We don t have time for deep dives but can at least mention a few
38 Zookeeper 38 Created at Yahoo! Integrates locking and storage into a file system Files play the role of locks Also has a way to create unique version or sequence numbers But basic API is just like a Linux file system Implemented using virtual synchrony protocols (we ll study those too, when we talk about Paxos) Extremely popular, widely used
, A tracks updates by B (and B sends updates to A) This involves a whole collection of graphs TAO is a fancy file system like GFS or Zookeeper but specialized to track")
39 TAO 39 At Facebook the need is sort of different from Google or Yahoo Facebook is concerned mostly with the relationships between people and companies or other things A likes B (and B likes A), A friends B (and B friends A), A tracks updates by B (and B sends updates to A) This involves a whole collection of graphs TAO is a fancy file system like GFS or Zookeeper but specialized to track these kinds of graphs

40 TAO 40 Some TAO ideas One is to try and use key-value caching at the edge to be super fast even at risk of using stale data for a little while Updates flow in a huge pipeline towards the core of the cloud, are done in a batched way, then cacheupdates flow back out. Every layer has redundancy and backup options if the layer below it is broken temporarily We ll study TAO more carefully later
41 What about MapReduce (Hadoop) 41 So famous that people have heard of it as often as TCP/IP or XML This is an example of a service that lives deeper in the cloud and isn t used while processing requests from clients Instead, MapReduce is useful for offline tasks
42 MapReduce 42 Used for functional style of computing with massive numbers of machines and huge data sets Works in a series of stages Map takes some operations and maps it on a set of servers so that each does some part The operations are functional: they don t modify the data they read and can be reissued if needed Result: a large number of partial results, each from running the function on some part of the data Reduce combines these partial results to obtain a smaller set of result files (perhaps just one, perhaps a few) Often iterates with further map/reduce stages


43 Hadoop 43 Open source MapReduce Has many refinements and improvements Widely popular and used even at Google! Challenges Dealing with variable sets of worker nodes Computation is functional; hard to accommodate adaptive events such as changing parameter values based on rate of convergence of a computation
44 Classic MapReduce examples 44 Make a list of terms appearing in some set of web pages, counting the frequency Find common misspellings for a word Sort a very large data set via a partitioning merge sort Nice features: Relatively easy to program Automates parallelism, failure handling, data management tasks
45 MapReduce debate 45 The database community dislikes MapReduce Databases can do the same things In fact can do far more things And database queries can be compiled automatically into MapReduce patterns; this is done in big parallel database products all the time! Counter-argument: Easy to customize MapReduce for a new application Hadoop is free, parallel databases not so much
46 Summary 46 We ve touched upon a series of examples of cloud computing infrastructure components Each really could have had a whole lecture They aren t simple systems and many were very hard to implement! Hard to design hard to build hard to optimize for stable and high quality operation at scale Major teams and huge resource investments Design decisions that may sound simple often required very careful thought and much debate and experimentation!
47 Summary 47 Some recurring themes Data replication using (key,value) tuples Anticipated update rates, sizes, scalability drive design Use of multicast mechanisms: Paxos, virtual synchrony Need to plan adaptive behaviors if nodes come and go, or crash, while system is running High value for latency tolerant solutions Extremely asynchronous structures Parallel: work gets done out there Many offer strong consistency guarantees, but not necessarily for every aspect. Selective guarantees.
DIVING IN: INSIDE THE DATA CENTER
 1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
CS5412: DIVING IN: INSIDE THE DATA CENTER
 1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs
1 CS5412: DIVING IN: INSIDE THE DATA CENTER Lecture V Ken Birman Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs
CS5412: OTHER DATA CENTER SERVICES
 1 CS5412: OTHER DATA CENTER SERVICES Lecture V Ken Birman Tier two and Inner Tiers 2 If tier one faces the user and constructs responses, what lives in tier two? Caching services are very common (many
1 CS5412: OTHER DATA CENTER SERVICES Lecture V Ken Birman Tier two and Inner Tiers 2 If tier one faces the user and constructs responses, what lives in tier two? Caching services are very common (many
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
CSE 444: Database Internals. Lectures 26 NoSQL: Extensible Record Stores
 CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
References. What is Bigtable? Bigtable Data Model. Outline. Key Features. CSE 444: Database Internals
 References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis
 Slides adapted by Tyler Davis") BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
CS5412: ANATOMY OF A CLOUD
 1 CS5412: ANATOMY OF A CLOUD Lecture VIII Ken Birman How are cloud structured? 2 Clients talk to clouds using web browsers or the web services standards But this only gets us to the outer skin of the cloud
1 CS5412: ANATOMY OF A CLOUD Lecture VIII Ken Birman How are cloud structured? 2 Clients talk to clouds using web browsers or the web services standards But this only gets us to the outer skin of the cloud
Goal of the presentation is to give an introduction of NoSQL databases, why they are there.
 1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Extreme Computing. NoSQL.
 Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
7680: Distributed Systems
 Cristina Nita-Rotaru 7680: Distributed Systems BigTable. Hbase.Spanner. 1: BigTable Acknowledgement } Slides based on material from course at UMichigan, U Washington, and the authors of BigTable and Spanner.
Cristina Nita-Rotaru 7680: Distributed Systems BigTable. Hbase.Spanner. 1: BigTable Acknowledgement } Slides based on material from course at UMichigan, U Washington, and the authors of BigTable and Spanner.
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
MapReduce & BigTable
 CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
CPSC 426/526 MapReduce & BigTable Ennan Zhai Computer Science Department Yale University Lecture Roadmap Cloud Computing Overview Challenges in the Clouds Distributed File Systems: GFS Data Process & Analysis:
big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures
 mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures") Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
BigTable. CSE-291 (Cloud Computing) Fall 2016
 Fall 2016") BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
CA485 Ray Walshe NoSQL
 NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
BigTable: A Distributed Storage System for Structured Data
 BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612
 Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Big Table. Google s Storage Choice for Structured Data. Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla
 Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
Big Table Google s Storage Choice for Structured Data Presented by Group E - Dawei Yang - Grace Ramamoorthy - Patrick O Sullivan - Rohan Singla Bigtable: Introduction Resembles a database. Does not support
Distributed Systems [Fall 2012]
![Distributed Systems [Fall 2012]](/thumbs/75/71557798.jpg "Distributed Systems [Fall 2012]") Distributed Systems [Fall 2012] Lec 20: Bigtable (cont ed) Slide acks: Mohsen Taheriyan (http://www-scf.usc.edu/~csci572/2011spring/presentations/taheriyan.pptx) 1 Chubby (Reminder) Lock service with a
Distributed Systems [Fall 2012] Lec 20: Bigtable (cont ed) Slide acks: Mohsen Taheriyan (http://www-scf.usc.edu/~csci572/2011spring/presentations/taheriyan.pptx) 1 Chubby (Reminder) Lock service with a
Outline. Spanner Mo/va/on. Tom Anderson
 Spanner Mo/va/on Tom Anderson Outline Last week: Chubby: coordina/on service BigTable: scalable storage of structured data GFS: large- scale storage for bulk data Today/Friday: Lessons from GFS/BigTable
Spanner Mo/va/on Tom Anderson Outline Last week: Chubby: coordina/on service BigTable: scalable storage of structured data GFS: large- scale storage for bulk data Today/Friday: Lessons from GFS/BigTable
Big Data Processing Technologies. Chentao Wu Associate Professor Dept. of Computer Science and Engineering
 Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
Big Data Processing Technologies Chentao Wu Associate Professor Dept. of Computer Science and Engineering wuct@cs.sjtu.edu.cn Schedule (1) Storage system part (first eight weeks) lec1: Introduction on
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2015 Lecture 14 NoSQL
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2015 Lecture 14 NoSQL References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No.
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2015 Lecture 14 NoSQL References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No.
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
Programming model and implementation for processing and. Programs can be automatically parallelized and executed on a large cluster of machines
 A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs
A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs
Cassandra, MongoDB, and HBase. Cassandra, MongoDB, and HBase. I have chosen these three due to their recent
 Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
Tanton Jeppson CS 401R Lab 3 Cassandra, MongoDB, and HBase Introduction For my report I have chosen to take a deeper look at 3 NoSQL database systems: Cassandra, MongoDB, and HBase. I have chosen these
Indexing Large-Scale Data
 Indexing Large-Scale Data Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook November 16, 2010
Indexing Large-Scale Data Serge Abiteboul Ioana Manolescu Philippe Rigaux Marie-Christine Rousset Pierre Senellart Web Data Management and Distribution http://webdam.inria.fr/textbook November 16, 2010
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Dynamo: Key-Value Cloud Storage
 Dynamo: Key-Value Cloud Storage Brad Karp UCL Computer Science CS M038 / GZ06 22 nd February 2016 Context: P2P vs. Data Center (key, value) Storage Chord and DHash intended for wide-area peer-to-peer systems
Dynamo: Key-Value Cloud Storage Brad Karp UCL Computer Science CS M038 / GZ06 22 nd February 2016 Context: P2P vs. Data Center (key, value) Storage Chord and DHash intended for wide-area peer-to-peer systems
Rule 14 Use Databases Appropriately
 Rule 14 Use Databases Appropriately Rule 14: What, When, How, and Why What: Use relational databases when you need ACID properties to maintain relationships between your data. For other data storage needs
Rule 14 Use Databases Appropriately Rule 14: What, When, How, and Why What: Use relational databases when you need ACID properties to maintain relationships between your data. For other data storage needs
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
CS5412 CLOUD COMPUTING: PRELIM EXAM Open book, open notes. 90 minutes plus 45 minutes grace period, hence 2h 15m maximum working time.
 CS5412 CLOUD COMPUTING: PRELIM EXAM Open book, open notes. 90 minutes plus 45 minutes grace period, hence 2h 15m maximum working time. SOLUTION SET In class we often used smart highway (SH) systems as
CS5412 CLOUD COMPUTING: PRELIM EXAM Open book, open notes. 90 minutes plus 45 minutes grace period, hence 2h 15m maximum working time. SOLUTION SET In class we often used smart highway (SH) systems as
Google File System and BigTable. and tiny bits of HDFS (Hadoop File System) and Chubby. Not in textbook; additional information
 and Chubby. Not in textbook; additional information") Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable References Bigtable: A Distributed Storage System for Structured Data. Fay Chang et. al. OSDI
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable References Bigtable: A Distributed Storage System for Structured Data. Fay Chang et. al. OSDI
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Tools for Social Networking Infrastructures
 Tools for Social Networking Infrastructures 1 Cassandra - a decentralised structured storage system Problem : Facebook Inbox Search hundreds of millions of users distributed infrastructure inbox changes
Tools for Social Networking Infrastructures 1 Cassandra - a decentralised structured storage system Problem : Facebook Inbox Search hundreds of millions of users distributed infrastructure inbox changes
CS /15/16. Paul Krzyzanowski 1. Question 1. Distributed Systems 2016 Exam 2 Review. Question 3. Question 2. Question 5.
 Question 1 What makes a message unstable? How does an unstable message become stable? Distributed Systems 2016 Exam 2 Review Paul Krzyzanowski Rutgers University Fall 2016 In virtual sychrony, a message
Question 1 What makes a message unstable? How does an unstable message become stable? Distributed Systems 2016 Exam 2 Review Paul Krzyzanowski Rutgers University Fall 2016 In virtual sychrony, a message
CSE-E5430 Scalable Cloud Computing Lecture 9
 CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
Distributed Data Store
 Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
CS 655 Advanced Topics in Distributed Systems
 Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Introduction Data Model API Building Blocks SSTable Implementation Tablet Location Tablet Assingment Tablet Serving Compactions Refinements
 Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. M. Burak ÖZTÜRK 1 Introduction Data Model API Building
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. M. Burak ÖZTÜRK 1 Introduction Data Model API Building
Google is Really Different.
 COMP 790-088 -- Distributed File Systems Google File System 7 Google is Really Different. Huge Datacenters in 5+ Worldwide Locations Datacenters house multiple server clusters Coming soon to Lenior, NC
COMP 790-088 -- Distributed File Systems Google File System 7 Google is Really Different. Huge Datacenters in 5+ Worldwide Locations Datacenters house multiple server clusters Coming soon to Lenior, NC
CS5412: TRANSACTIONS (I)
") 1 CS5412: TRANSACTIONS (I) Lecture XVII Ken Birman Transactions 2 A widely used reliability technology, despite the BASE methodology we use in the first tier Goal for this week: in-depth examination of
1 CS5412: TRANSACTIONS (I) Lecture XVII Ken Birman Transactions 2 A widely used reliability technology, despite the BASE methodology we use in the first tier Goal for this week: in-depth examination of
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
CS5412: THE BASE METHODOLOGY VERSUS THE ACID MODEL
 1 CS5412: THE BASE METHODOLOGY VERSUS THE ACID MODEL Lecture VIII Ken Birman Today s lecture will be a bit short 2 We have a guest with us today: Kate Jenkins from Akamai The world s top content hosting
1 CS5412: THE BASE METHODOLOGY VERSUS THE ACID MODEL Lecture VIII Ken Birman Today s lecture will be a bit short 2 We have a guest with us today: Kate Jenkins from Akamai The world s top content hosting
Distributed Systems. Lec 10: Distributed File Systems GFS. Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung
 Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Bigtable. Presenter: Yijun Hou, Yixiao Peng
 Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
NoSQL systems. Lecture 21 (optional) Instructor: Sudeepa Roy. CompSci 516 Data Intensive Computing Systems
 Instructor: Sudeepa Roy. CompSci 516 Data Intensive Computing Systems") CompSci 516 Data Intensive Computing Systems Lecture 21 (optional) NoSQL systems Instructor: Sudeepa Roy Duke CS, Spring 2016 CompSci 516: Data Intensive Computing Systems 1 Key- Value Stores Duke CS,
CompSci 516 Data Intensive Computing Systems Lecture 21 (optional) NoSQL systems Instructor: Sudeepa Roy Duke CS, Spring 2016 CompSci 516: Data Intensive Computing Systems 1 Key- Value Stores Duke CS,
DrRobert N. M. Watson
 Distributed systems Lecture 15: Replication, quorums, consistency, CAP, and Amazon/Google case studies DrRobert N. M. Watson 1 Last time General issue of consensus: How to get processes to agree on something
Distributed systems Lecture 15: Replication, quorums, consistency, CAP, and Amazon/Google case studies DrRobert N. M. Watson 1 Last time General issue of consensus: How to get processes to agree on something
Horizontal or vertical scalability? Horizontal scaling is challenging. Today. Scaling Out Key-Value Storage
 Horizontal or vertical scalability? Scaling Out Key-Value Storage COS 418: Distributed Systems Lecture 8 Kyle Jamieson Vertical Scaling Horizontal Scaling [Selected content adapted from M. Freedman, B.
Horizontal or vertical scalability? Scaling Out Key-Value Storage COS 418: Distributed Systems Lecture 8 Kyle Jamieson Vertical Scaling Horizontal Scaling [Selected content adapted from M. Freedman, B.
Distributed Architectures & Microservices. CS 475, Spring 2018 Concurrent & Distributed Systems
 Distributed Architectures & Microservices CS 475, Spring 2018 Concurrent & Distributed Systems GFS Architecture GFS Summary Limitations: Master is a huge bottleneck Recovery of master is slow Lots of success
Distributed Architectures & Microservices CS 475, Spring 2018 Concurrent & Distributed Systems GFS Architecture GFS Summary Limitations: Master is a huge bottleneck Recovery of master is slow Lots of success
Next-Generation Cloud Platform
 Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
Next-Generation Cloud Platform Jangwoo Kim Jun 24, 2013 E-mail: jangwoo@postech.ac.kr High Performance Computing Lab Department of Computer Science & Engineering Pohang University of Science and Technology
CS 138: Google. CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
Bigtable: A Distributed Storage System for Structured Data. Andrew Hon, Phyllis Lau, Justin Ng
 Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
CS5412: TRANSACTIONS (I)
") 1 CS5412: TRANSACTIONS (I) Lecture XVI Ken Birman Transactions 2 A widely used reliability technology, despite the BASE methodology we use in the first tier Goal for this lecture and the next one: in-depth
1 CS5412: TRANSACTIONS (I) Lecture XVI Ken Birman Transactions 2 A widely used reliability technology, despite the BASE methodology we use in the first tier Goal for this lecture and the next one: in-depth
Recap. CSE 486/586 Distributed Systems Google Chubby Lock Service. Recap: First Requirement. Recap: Second Requirement. Recap: Strengthening P2
 Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
10. Replication. Motivation
 10. Replication Page 1 10. Replication Motivation Reliable and high-performance computation on a single instance of a data object is prone to failure. Replicate data to overcome single points of failure
10. Replication Page 1 10. Replication Motivation Reliable and high-performance computation on a single instance of a data object is prone to failure. Replicate data to overcome single points of failure
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.
![DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.](/thumbs/86/93978710.jpg "DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems INTRODUCTION. Transparency: Flexibility: Slide 1. Slide 3.") CHALLENGES Transparency: Slide 1 DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems ➀ Introduction ➁ NFS (Network File System) ➂ AFS (Andrew File System) & Coda ➃ GFS (Google File System)
CHALLENGES Transparency: Slide 1 DISTRIBUTED SYSTEMS [COMP9243] Lecture 9b: Distributed File Systems ➀ Introduction ➁ NFS (Network File System) ➂ AFS (Andrew File System) & Coda ➃ GFS (Google File System)
PNUTS and Weighted Voting. Vijay Chidambaram CS 380 D (Feb 8)
") PNUTS and Weighted Voting Vijay Chidambaram CS 380 D (Feb 8) PNUTS Distributed database built by Yahoo Paper describes a production system Goals: Scalability Low latency, predictable latency Must handle
PNUTS and Weighted Voting Vijay Chidambaram CS 380 D (Feb 8) PNUTS Distributed database built by Yahoo Paper describes a production system Goals: Scalability Low latency, predictable latency Must handle
CS5412: THE BASE METHODOLOGY VERSUS THE ACID MODEL IN AN OVERLAY
 1 CS5412: THE BASE METHODOLOGY VERSUS THE ACID MODEL IN AN OVERLAY Lecture IX Ken Birman Recall the overlay network idea 2 For example, Dynamo, Chord, etc Basically, a key-value storage system spread over
1 CS5412: THE BASE METHODOLOGY VERSUS THE ACID MODEL IN AN OVERLAY Lecture IX Ken Birman Recall the overlay network idea 2 For example, Dynamo, Chord, etc Basically, a key-value storage system spread over
Distributed Data Management. Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig
 Distributed Data Management Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Exams 25 minutes oral examination 20.-24.02.2012 19.-23.03.2012
Distributed Data Management Christoph Lofi Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de Exams 25 minutes oral examination 20.-24.02.2012 19.-23.03.2012
CS 138: Google. CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
A Survey Paper on NoSQL Databases: Key-Value Data Stores and Document Stores
 A Survey Paper on NoSQL Databases: Key-Value Data Stores and Document Stores Nikhil Dasharath Karande 1 Department of CSE, Sanjay Ghodawat Institutes, Atigre nikhilkarande18@gmail.com Abstract- This paper
A Survey Paper on NoSQL Databases: Key-Value Data Stores and Document Stores Nikhil Dasharath Karande 1 Department of CSE, Sanjay Ghodawat Institutes, Atigre nikhilkarande18@gmail.com Abstract- This paper
Recap. CSE 486/586 Distributed Systems Google Chubby Lock Service. Paxos Phase 2. Paxos Phase 1. Google Chubby. Paxos Phase 3 C 1
 Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
Recap CSE 486/586 Distributed Systems Google Chubby Lock Service Steve Ko Computer Sciences and Engineering University at Buffalo Paxos is a consensus algorithm. Proposers? Acceptors? Learners? A proposer
CPS 512 midterm exam #1, 10/7/2016
 CPS 512 midterm exam #1, 10/7/2016 Your name please: NetID: Answer all questions. Please attempt to confine your answers to the boxes provided. If you don t know the answer to a question, then just say
CPS 512 midterm exam #1, 10/7/2016 Your name please: NetID: Answer all questions. Please attempt to confine your answers to the boxes provided. If you don t know the answer to a question, then just say
BigTable A System for Distributed Structured Storage
 BigTable A System for Distributed Structured Storage Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber Adapted
BigTable A System for Distributed Structured Storage Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber Adapted
CIB Session 12th NoSQL Databases Structures
 CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
Distributed Systems. Fall 2017 Exam 3 Review. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems Fall 2017 Exam 3 Review Paul Krzyzanowski Rutgers University Fall 2017 December 11, 2017 CS 417 2017 Paul Krzyzanowski 1 Question 1 The core task of the user s map function within a
Distributed Systems Fall 2017 Exam 3 Review Paul Krzyzanowski Rutgers University Fall 2017 December 11, 2017 CS 417 2017 Paul Krzyzanowski 1 Question 1 The core task of the user s map function within a
11 Storage at Google Google Google Google Google 7/2/2010. Distributed Data Management
 11 Storage at Google Distributed Data Management 11.1 Google Bigtable 11.2 Google File System 11. Bigtable Implementation Wolf-Tilo Balke Christoph Lofi Institut für Informationssysteme Technische Universität
11 Storage at Google Distributed Data Management 11.1 Google Bigtable 11.2 Google File System 11. Bigtable Implementation Wolf-Tilo Balke Christoph Lofi Institut für Informationssysteme Technische Universität
CS 138: Dynamo. CS 138 XXIV 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Dynamo CS 138 XXIV 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Dynamo Highly available and scalable distributed data store Manages state of services that have high reliability and
CS 138: Dynamo CS 138 XXIV 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Dynamo Highly available and scalable distributed data store Manages state of services that have high reliability and
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems. 29. Distributed Caching Paul Krzyzanowski. Rutgers University. Fall 2014
 Distributed Systems 29. Distributed Caching Paul Krzyzanowski Rutgers University Fall 2014 December 5, 2014 2013 Paul Krzyzanowski 1 Caching Purpose of a cache Temporary storage to increase data access
Distributed Systems 29. Distributed Caching Paul Krzyzanowski Rutgers University Fall 2014 December 5, 2014 2013 Paul Krzyzanowski 1 Caching Purpose of a cache Temporary storage to increase data access
Large-Scale Data Stores and Probabilistic Protocols
 Distributed Systems 600.437 Large-Scale Data Stores & Probabilistic Protocols Department of Computer Science The Johns Hopkins University 1 Large-Scale Data Stores and Probabilistic Protocols Lecture 11
Distributed Systems 600.437 Large-Scale Data Stores & Probabilistic Protocols Department of Computer Science The Johns Hopkins University 1 Large-Scale Data Stores and Probabilistic Protocols Lecture 11
Structured Big Data 1: Google Bigtable & HBase Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC
 CSIE, NDHU, Taiwan, ROC") Structured Big Data 1: Google Bigtable & HBase Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei Liao
Structured Big Data 1: Google Bigtable & HBase Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei Liao
Distributed systems. Lecture 6: distributed transactions, elections, consensus and replication. Malte Schwarzkopf
 Distributed systems Lecture 6: distributed transactions, elections, consensus and replication Malte Schwarzkopf Last time Saw how we can build ordered multicast Messages between processes in a group Need
Distributed systems Lecture 6: distributed transactions, elections, consensus and replication Malte Schwarzkopf Last time Saw how we can build ordered multicast Messages between processes in a group Need
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Systems. 16. Distributed Lookup. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 16. Distributed Lookup Paul Krzyzanowski Rutgers University Fall 2017 1 Distributed Lookup Look up (key, value) Cooperating set of nodes Ideally: No central coordinator Some nodes can
Distributed Systems 16. Distributed Lookup Paul Krzyzanowski Rutgers University Fall 2017 1 Distributed Lookup Look up (key, value) Cooperating set of nodes Ideally: No central coordinator Some nodes can
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Google big data techniques (2)
") Google big data techniques (2) Lecturer: Jiaheng Lu Fall 2016 10.12.2016 1 Outline Google File System and HDFS Relational DB V.S. Big data system Google Bigtable and NoSQL databases 2016/12/10 3 The Google
Google big data techniques (2) Lecturer: Jiaheng Lu Fall 2016 10.12.2016 1 Outline Google File System and HDFS Relational DB V.S. Big data system Google Bigtable and NoSQL databases 2016/12/10 3 The Google
Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database.
 Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database. Presented by Kewei Li The Problem db nosql complex legacy tuning expensive
Megastore: Providing Scalable, Highly Available Storage for Interactive Services & Spanner: Google s Globally- Distributed Database. Presented by Kewei Li The Problem db nosql complex legacy tuning expensive
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/96/128755699.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [DYNAMO & GOOGLE FILE SYSTEM] Frequently asked questions from the previous class survey What s the typical size of an inconsistency window in most production settings? Dynamo?
CS 555: DISTRIBUTED SYSTEMS [DYNAMO & GOOGLE FILE SYSTEM] Frequently asked questions from the previous class survey What s the typical size of an inconsistency window in most production settings? Dynamo?
CISC 7610 Lecture 5 Distributed multimedia databases. Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL
 CISC 7610 Lecture 5 Distributed multimedia databases Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL Motivation YouTube receives 400 hours of video per minute That is 200M hours
CISC 7610 Lecture 5 Distributed multimedia databases Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL Motivation YouTube receives 400 hours of video per minute That is 200M hours
Fusion iomemory PCIe Solutions from SanDisk and Sqrll make Accumulo Hypersonic
 WHITE PAPER Fusion iomemory PCIe Solutions from SanDisk and Sqrll make Accumulo Hypersonic Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Executive
WHITE PAPER Fusion iomemory PCIe Solutions from SanDisk and Sqrll make Accumulo Hypersonic Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Executive