Map Reduce. Yerevan.
|
|
|
- Shona Cole
- 5 years ago
- Views:
Transcription

1 Map Reduce Yerevan dacosta@irit.fr

2 Divide and conquer at PaaS 100 % //
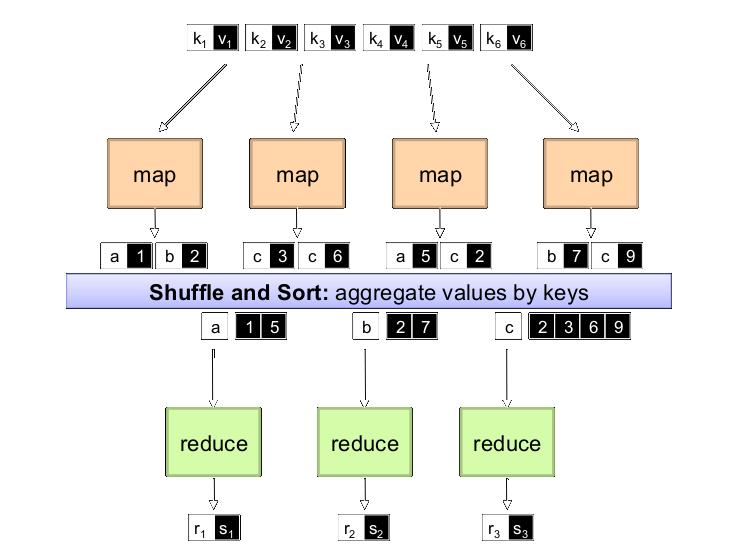
3 Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate results Aggregate intermediate results Generate final output MAP Reduce Key idea: functional abstraction for these two operations
4 Folding
5 Difficulties? Huge amount of data Do not fit into memory Access patterns are broad Most data not accessed frequently Complex data links between data or treatment Same data can be treated in different ways No pre-processing Example : crawling through internet data

6 "Map" step: The master node takes the input, divides it into smaller subproblems, and distributes them to worker nodes "Reduce" step: The master node then collects the answers to all the subproblems and combines them in some way to form the output Principle
7 Programmers specify two functions: map (k, v) <k, v >* reduce (k, v ) <k, v >* All values with the same key are reduced together Usually, programmers also specify: partition (k, number of partitions ) partition for k Often a simple hash of the key, e.g. hash(k ) mod n Allows reduce operations for different keys in parallel combine(k,v ) <k,v > Mini-reducers that run in memory after the map phase Optimizes to reduce network traffic & disk writes Implementations: Google has a proprietary implementation in C++ Hadoop is an open source implementation in Java MapReduce
8
9 Word count
10 Exemple : Average For 1 million entry Batch of of them Output of Map Range Reduce : Batch of 1 Y 102 of them Treat 1000's Output 102 values number of contract by Age
11 MapReduce Runtime Handles scheduling Assigns workers to map and reduce tasks Handles data distribution Moves the process to the data Handles synchronization Gathers, sorts, and shuffles intermediate data Handles faults Detects worker failures and restarts Everything happens on top of a distributed FS (later)
12

13 What's the problem here? How do we get data to the workers Classical cluster vision
14 Distributed File System Don t move data to workers... Move workers to the data! Store data on the local disks for nodes in the cluster Start up the workers on the node that has the data local Why? Not enough RAM to hold all the data in memory Disk access is slow, disk throughput is good A distributed file system is the answer GFS (Google File System) HDFS for Hadoop (= GFS clone)
15 GFS: Assumptions Commodity hardware over exotic hardware High component failure rates Inexpensive commodity components fail all the time Modest number of HUGE files Files are write-once, mostly appended to Perhaps concurrently Large streaming reads over random access High sustained throughput over low latency
16 GFS: Design Decisions Files stored as chunks Fixed size (64MB) Reliability through replication Each chunk replicated across 3+ chunkservers Single master to coordinate access, keep metadata Simple centralized management No data caching Little benefit due to large data sets, streaming reads Simplify the API Push some of the issues onto the client
17 Grid Computing by the fathers of the Grid
18 Master s Responsibilities Metadata storage Namespace management/locking Periodic communication with chunkservers Chunk creation, replication, rebalancing Garbage collection
19 Exemple : Inverted Indexing

20 Architecture of IR Systems
21 How do we represent text? Bag of words Treat all the words in a document as index terms for that document Assign a weight to each term based on importance Disregard order, structure, meaning, etc. of the words Simple, yet effective! Assumptions Term occurrence is independent Document relevance is independent Words are well-defined
22 Sample Document McDonald's slims down spuds Fast-food chain to reduce certain types of fat in its french fries with new cooking oil. Bag of Words NEW YORK (CNN/Money) - McDonald's Corp. is cutting the amount of "bad" fat in its french fries nearly in half, the fast-food chain said Tuesday as it moves to make all its fried menu items healthier. But does that mean the popular shoestring frieswon't taste the same? The company says no. "It's a win-win for our customers because they are getting the same great french-fry taste along with an even healthier nutrition profile," said Mike Roberts, president of McDonald's USA. But others are not so sure. McDonald's will not specifically discuss the kind of oil it plans to use, but at least one nutrition expert says playing with the formula could mean a different taste.... Bag of Words 16 said 14 McDonalds 12 fat 11 fries 8 new 6 company, french, nutrition 5 food, oil, percent, reduce, taste, Tuesday...
23 Representing Documents

24 Inverted Index
25 To execute a Boolean query: Build query syntax tree Boolean Retrieval For each clause, look up postings Traverse postings and apply Boolean operator Efficiency analysis Postings traversal is linear (assuming sorted postings) Start with shortest posting first

26 Term Weighting
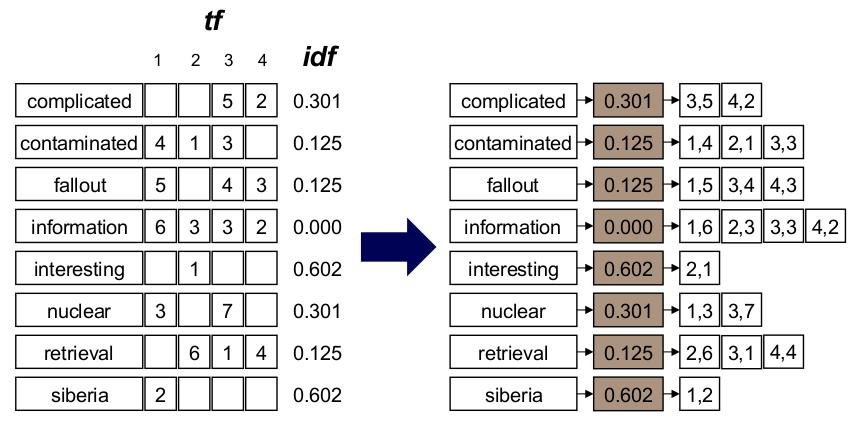
27
28 MapReduce it? The indexing problem Must be relatively fast, but need not be real time For Web, incremental updates are important Crawling is a challenge itself! The retrieval problem Must have sub-second response For Web, only need relatively few results
29 Indexing: Performance Analysis Fundamentally, a large sorting problem Terms usually fit in memory Postings usually don t How is it done on a single machine? How large is the inverted index? Size of vocabulary Size of postings
30 Map over all documents Emit term as key, (docid, tf) as value MapReduce: Index Construction Emit other information as necessary (e.g., term position) Reduce Trivial: each value represents a posting! Might want to sort the postings (e.g., by docid or tf) MapReduce does all the heavy lifting!
31 Query Execution MapReduce is meant for large-data batch processing Not suitable for lots of real time operations requiring low latency The solution: the secret sauce Most likely involves document partitioning Lots of system engineering: e.g., caching, load balancing, etc.
32 MapReduce Algorithm Design
33 Managing Dependencies Remember: Mappers run in isolation You have no idea in what order the mappers run You have no idea on what node the mappers run You have no idea when each mapper finishes Tools for synchronization: Ability to hold state in reducer across multiple key-value pairs Sorting function for keys Partitioner Cleverly-constructed data structures
34 For the programmer Input reader Reads data from stable storage and generates key/value pairs. Map function Takes a series of key/value pairs, processes each, and generates zero or more output key/value pairs Partition function Each Map function output is allocated to a particular reducer by the application's partition function Compare function Reduce function Called once for each unique key in the sorted order Output writer Writes the output of the Reduce to the stable storage

35 Input Map Copy/Sort Reduce Output
36 Use cases Word count, a little less naive! Before : 1 message per word in the text Here 1 message per different word in the text
37 Co-occurence Count the number of co-occurence of n elements in sets Exemple Words appears in same sentence Customer who buy this also buy that If there are N elements Report occurrence of NxN couples On a single node, quite simple Foreach set Foreach i in set Foreach j in set Res[i][j]++ Map Reduce version?
38 Pairs approach Too many intermediary keys Easy and strayforward implementation Optimize using local accumulation of counts of [i,j] Easy optimization Only few improvement (large space)
39 Stripes Approach Faster, lower number of intermediate keys Can lead to memory problems More complex implementation
40 Other exemples Grep 10^ byte records Seek a rare 3 letters word 1800 machines Peak performance : 30 GB/s with 1764 workers 150s 1 minute startup Sort Same environment and dataset 50 lines of code 891 seconds
41 Characteristics Manage well failure Just send the keys again Heavy on the file system Need dedicated and adapted filesystem Scale well In term of data, workflow Easy to use Some translation tools from SQL are available Middleware manages data- and computing-locality
42 Some users Google They normalized it They use it internally large-scale machine learning problems, clustering problems for the Google News and Froogle products, extracting data to produce reports of popular queries (e.g. Google Zeitgeist and Google Trends), extracting properties of Web pages for new experiments and products (e.g. extraction of geographical locations from a large corpus of Web pages for localized search), processing of satellite imagery data, language model processing for statistical machine translation, and large-scale graph computations.
43 Facebook Hadoop Now use Corona (own implementation) Yahoo More than 100,000 CPUs in more than 40,000 computers Hadoop Linkedin 5000 servers on hadoop Ebay 532 nodes cluster (8 * 532 cores, 5.3PB) Other users
44 Some links Google MapReduce: Simplified Data Processing on Large Clusters by Jeffrey Dean and Sanjay Ghemawat Technical report Apache Hadoop: The definitive guide Book Microsoft Google s MapReduce Programming Model Revisited Technical report
Map Reduce.
 Map Reduce dacosta@irit.fr Divide and conquer at PaaS Second Third Fourth 100 % // Fifth Sixth Seventh Cliquez pour 2 Typical problem Second Extract something of interest from each MAP Third Shuffle and
Map Reduce dacosta@irit.fr Divide and conquer at PaaS Second Third Fourth 100 % // Fifth Sixth Seventh Cliquez pour 2 Typical problem Second Extract something of interest from each MAP Third Shuffle and
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Developing MapReduce Programs
 Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
Cloud Computing Developing MapReduce Programs Dell Zhang Birkbeck, University of London 2017/18 MapReduce Algorithm Design MapReduce: Recap Programmers must specify two functions: map (k, v) * Takes
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Information Retrieval Processing with MapReduce
 Information Retrieval Processing with MapReduce Based on Jimmy Lin s Tutorial at the 32nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2009) This
Information Retrieval Processing with MapReduce Based on Jimmy Lin s Tutorial at the 32nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2009) This
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 2: MapReduce Algorithm Design (2/2) January 14, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
CMSC 723: Computational Linguistics I Session #12 MapReduce and Data Intensive NLP. University of Maryland. Wednesday, November 18, 2009
 CMSC 723: Computational Linguistics I Session #12 MapReduce and Data Intensive NLP Jimmy Lin and Nitin Madnani University of Maryland Wednesday, November 18, 2009 Three Pillars of Statistical NLP Algorithms
CMSC 723: Computational Linguistics I Session #12 MapReduce and Data Intensive NLP Jimmy Lin and Nitin Madnani University of Maryland Wednesday, November 18, 2009 Three Pillars of Statistical NLP Algorithms
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Informa)on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies
on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies") Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 2: MapReduce Algorithm Design (2/2) January 12, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
Overview. Why MapReduce? What is MapReduce? The Hadoop Distributed File System Cloudera, Inc.
 MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
MapReduce Algorithms
 Large-scale data processing on the Cloud Lecture 3 MapReduce Algorithms Satish Srirama Some material adapted from slides by Jimmy Lin, 2008 (licensed under Creation Commons Attribution 3.0 License) Outline
Large-scale data processing on the Cloud Lecture 3 MapReduce Algorithms Satish Srirama Some material adapted from slides by Jimmy Lin, 2008 (licensed under Creation Commons Attribution 3.0 License) Outline
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
Hadoop Distributed File System(HDFS)
") Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
HDFS: Hadoop Distributed File System. Sector: Distributed Storage System
 GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
GFS: Google File System Google C/C++ HDFS: Hadoop Distributed File System Yahoo Java, Open Source Sector: Distributed Storage System University of Illinois at Chicago C++, Open Source 2 System that permanently
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 1: MapReduce Algorithm Design (4/4) January 16, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 1: MapReduce Algorithm Design (4/4) January 16, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Outline. Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins
 MapReduce 1 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins 2 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce
MapReduce 1 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce Algorithm Evaluation Computing Joins 2 Outline Distributed File System Map-Reduce The Computational Model Map-Reduce
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
Map-Reduce. John Hughes
 Map-Reduce John Hughes The Problem 850TB in 2006 The Solution? Thousands of commodity computers networked together 1,000 computers 850GB each How to make them work together? Early Days Hundreds of ad-hoc
Map-Reduce John Hughes The Problem 850TB in 2006 The Solution? Thousands of commodity computers networked together 1,000 computers 850GB each How to make them work together? Early Days Hundreds of ad-hoc
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Cloud Programming. Programming Environment Oct 29, 2015 Osamu Tatebe
 Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Laarge-Scale Data Engineering
 Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
Laarge-Scale Data Engineering The MapReduce Framework & Hadoop Key premise: divide and conquer work partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 result combine Parallelisation challenges How
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
with MapReduce The ischool University of Maryland JHU Summer School on Human Language Technology Wednesday, June 17, 2009
 Data-Intensive Text Processing with MapReduce Jimmy Lin The ischool University of Maryland JHU Summer School on Human Language Technology Wednesday, June 17, 2009 This work is licensed under a Creative
Data-Intensive Text Processing with MapReduce Jimmy Lin The ischool University of Maryland JHU Summer School on Human Language Technology Wednesday, June 17, 2009 This work is licensed under a Creative
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google* 정학수, 최주영 1 Outline Introduction Design Overview System Interactions Master Operation Fault Tolerance and Diagnosis Conclusions
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin. Presented by: Suhua Wei Yong Yu
 CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
Distributed Systems. 18. MapReduce. Paul Krzyzanowski. Rutgers University. Fall 2015
 Distributed Systems 18. MapReduce Paul Krzyzanowski Rutgers University Fall 2015 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Credit Much of this information is from Google: Google Code University [no
Distributed Systems 18. MapReduce Paul Krzyzanowski Rutgers University Fall 2015 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Credit Much of this information is from Google: Google Code University [no
CSE Lecture 11: Map/Reduce 7 October Nate Nystrom UTA
 CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Dis Commodity Clusters Web data sets can be ery large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Dis Commodity Clusters Web data sets can be ery large Tens to hundreds of terabytes
Index Construction. Dictionary, postings, scalable indexing, dynamic indexing. Web Search
 Index Construction Dictionary, postings, scalable indexing, dynamic indexing Web Search 1 Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Index Construction Dictionary, postings, scalable indexing, dynamic indexing Web Search 1 Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
CS /5/18. Paul Krzyzanowski 1. Credit. Distributed Systems 18. MapReduce. Simplest environment for parallel processing. Background.
 Credit Much of this information is from Google: Google Code University [no longer supported] http://code.google.com/edu/parallel/mapreduce-tutorial.html Distributed Systems 18. : The programming model
Credit Much of this information is from Google: Google Code University [no longer supported] http://code.google.com/edu/parallel/mapreduce-tutorial.html Distributed Systems 18. : The programming model
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
FLAT DATACENTER STORAGE. Paper-3 Presenter-Pratik Bhatt fx6568
 FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
FLAT DATACENTER STORAGE Paper-3 Presenter-Pratik Bhatt fx6568 FDS Main discussion points A cluster storage system Stores giant "blobs" - 128-bit ID, multi-megabyte content Clients and servers connected
Introduction to MapReduce
 Introduction to MapReduce Based on slides by Juliana Freire Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Required Reading! Data-Intensive Text Processing with MapReduce,
Introduction to MapReduce Based on slides by Juliana Freire Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Required Reading! Data-Intensive Text Processing with MapReduce,
Map-Reduce (PFP Lecture 12) John Hughes
 John Hughes") Map-Reduce (PFP Lecture 12) John Hughes The Problem 850TB in 2006 The Solution? Thousands of commodity computers networked together 1,000 computers 850GB each How to make them work together? Early Days
Map-Reduce (PFP Lecture 12) John Hughes The Problem 850TB in 2006 The Solution? Thousands of commodity computers networked together 1,000 computers 850GB each How to make them work together? Early Days
Clustering Documents. Document Retrieval. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April, 2017 Sham Kakade 2017 1 Document Retrieval n Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April, 2017 Sham Kakade 2017 1 Document Retrieval n Goal: Retrieve
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Software Infrastructure in Data Centers: Distributed File Systems 1 Permanently stores data Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Software Infrastructure in Data Centers: Distributed File Systems 1 Permanently stores data Filesystems
Engineering Goals. Scalability Availability. Transactional behavior Security EAI... CS530 S05
 Engineering Goals Scalability Availability Transactional behavior Security EAI... Scalability How much performance can you get by adding hardware ($)? Performance perfect acceptable unacceptable Processors
Engineering Goals Scalability Availability Transactional behavior Security EAI... Scalability How much performance can you get by adding hardware ($)? Performance perfect acceptable unacceptable Processors
STATS Data Analysis using Python. Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns
 STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
Principles of Data Management. Lecture #16 (MapReduce & DFS for Big Data)
") Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
CS 138: Google. CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Clustering Documents. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 21 th, 2015 Sham Kakade 2016 1 Document Retrieval Goal: Retrieve
Case Study 2: Document Retrieval Clustering Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 21 th, 2015 Sham Kakade 2016 1 Document Retrieval Goal: Retrieve
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani
 The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
The Authors : Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung Presentation by: Vijay Kumar Chalasani CS5204 Operating Systems 1 Introduction GFS is a scalable distributed file system for large data intensive
Distributed Systems. 05r. Case study: Google Cluster Architecture. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 05r. Case study: Google Cluster Architecture Paul Krzyzanowski Rutgers University Fall 2016 1 A note about relevancy This describes the Google search cluster architecture in the mid
Distributed Systems 05r. Case study: Google Cluster Architecture Paul Krzyzanowski Rutgers University Fall 2016 1 A note about relevancy This describes the Google search cluster architecture in the mid
CS-2510 COMPUTER OPERATING SYSTEMS
 CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
CS-2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application Functional
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Introduction to MapReduce
 Introduction to MapReduce Based on slides by Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec How much data? Google processes 20 PB a day (2008) Internet Archive Wayback Machine has 3 PB + 100
Introduction to MapReduce Based on slides by Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec How much data? Google processes 20 PB a day (2008) Internet Archive Wayback Machine has 3 PB + 100
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
MapReduce Algorithm Design
 MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
MapReduce Algorithm Design Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul Big
CS 138: Google. CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides