MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
|
|
|
- Myles Conley
- 5 years ago
- Views:
Transcription
1 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia
2 What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft, Viewstamp Transactional Online processing distributed transactions Today: Offline batch processing
3 Why distributed computations? How long to sort 1 TB on one computer? One computer can read ~50MB from disk Takes 5.5 hours! Google indexes 60 trillion web pages 60 * 10^12 pages * 10KB/page = 600 PB Large Hadron Collider is expected to produce 15 PB every year!
4 Solution: use many nodes! Data Centers at Amazon/Facebook/Google Hundreds of thousands of PCs connected by high speed LANs Cloud computing Any programmer can rent nodes in Data Centers for cheap The promise: 1000 nodes è 1000X speedup
5 Distributed computations are difficult to program Sending data to/from nodes Coordinating among nodes Recovering from node failure Optimizing for locality Debugging Same for all problems
6 The world before MapReduce comes along Dominant philosophy in systems research programming many machines should be the same that of a single multi-core machine distributed shared memory automatic parallelization of existing programs MPI for high performance computing a collection of communication/synchronization primitives to simplify message passing No systems handle failures
7 MapReduce A programming model for large-scale computations Process large amounts of input, produce output No side-effects or persistent state (unlike file system) MapReduce is implemented as a runtime library: automatic parallelization load balancing locality optimization handling of machine failures
8 MapReduce design Input data is partitioned into M splits Map: extract information on each split Each Map produces R partitions Shuffle and sort Bring M partitions to the same reducer Reduce: aggregate, summarize, filter or transform Output is in R result files
9 More specifically Programmer specifies two methods: map(k, v) <k', v'>* reduce(k', <v'>*) <k', v'>* All v' with same k' are reduced together Usually also specify: partition(k, total partitions) -> partition for k often a simple hash of the key allows reduce operations for different k to be parallelized
10 Example: Count word frequencies in web pages Input is files with one doc per record Map parses documents into words key = document URL value = document contents Output of map: doc1, to be or not to be to, 1 be, 1 or, 1
11 Example: word frequencies Reduce: computes sum for a key key = be values = 1, 1 key = not values = 1 key = or values = 1 key = to values = 1, Output of reduce saved 2 be, 2 not, 1 or, 1 to, 2
12 Example: Pseudo-code Map(String input_key, String input_value): //input_key: document name //input_value: document contents for each word w in input_values: EmitIntermediate(w, "1"); Reduce(String key, Iterator intermediate_values): //key: a word, same for input and output //intermediate_values: a list of counts int result = 0; for each v in intermediate_values: result += ParseInt(v); Emit(AsString(result));
13 MapReduce is widely applicable Distributed grep Document clustering Web link graph reversal Detecting duplicate web pages
14 MapReduce implementation Input data is partitioned into M splits Map: extract information on each split Each Map produces R partitions Shuffle and sort Bring M partitions to the same reducer Reduce: aggregate, summarize, filter or transform Output is in R result files, stored in a replicated, distributed file system (GFS).
15 MapReduce scheduling One master, many workers Input data split into M map tasks R reduce tasks Tasks are assigned to workers dynamically
16 MapReduce scheduling Master assigns a map task to a free worker Prefers close-by workers when assigning task Worker reads task input (often from local disk!) Worker produces R local files containing intermediate k/v pairs Master assigns a reduce task to a free worker Worker reads intermediate k/v pairs from map workers Worker sorts & applies user s Reduce op to produce the output




17 Parallel MapReduce Input data Map Map Map Map Master Shuffle Shuffle Shuffle Reduce Reduce Reduce Partitioned output
18 WordCount Internals Input data is split into M map jobs Each map job generates in R local partitions doc1, to be or not to be to, 1 be, 1 or, 1 not, 1 to, 1 partionfunction to, 1, 1 be, 1 not, 1 or, 1 R local partitions doc234, do not be silly do, 1 not, 1 be, 1 silly, 1 do, 1 not, 1 be, 1 R local partitions

19 WordCount Internals Shuffle brings same partitions to same reducer to, 1, 1 be, 1 not, 1 or, 1 R local partitions do, 1 to, 1, 1 be, 1, 1 do, 1 be, 1 not, 1 R local partitions not, 1, 1 or, 1
20 WordCount Internals Reduce aggregates sorted key values pairs do, 1 to, 1, 1 do, 1 to, 2 be, 1, 1 be, 2 not, 1, 1 or, 1 not, 2 or, 1
21 The importance of partition function partition(k, total partitions) -> partition for k e.g. hash(k ) % R What is the partition function for sort?

22 Load Balance and Pipelining Fine granularity tasks: many more map tasks than machines Minimizes time for fault recovery Can pipeline shuffling with map execution Better dynamic load balancing Often use 200,000 map/5000 reduce tasks w/ 2000 machines
23 Fault tolerance What are the potential failure cases? Lost packets Temporary network disconnect Servers crash and rebooted Servers fail permanently (disk wipe)
24 Fault tolerance via re-execution On master failure: Lab3 does not require handing master failure On worker failure: Re-execute in-progress map tasks Re-execute in-progress reduce tasks Task completion committed through master Is it possible a task is executed twice?
25 How to handle stragglers Ideal speedup on N Machines? Why no ideal speedup in practice? Straggler: Slow workers drastically increase completion time Other jobs consuming resources on machine Bad disks with soft errors transfer data very slowly Weird things: processor caches disabled (!!) An unusually large reduce partition Solution: Near end of phase, spawn backup copies of tasks Whichever one finishes first "wins"
26 MapReduce Sort Performance 1TB (100-byte record) data to be sorted 1700 machines M=15000 R=4000
27 MapReduce Sort Performance When can shuffle start? When can reduce start?
28 Big Data Computation Storm Spark-Streaming Naid Pregel GraphLab GraphX Map Reduce Hadoop Dryad LINQ Spark Hive Dremel Shark
29 Spark s motivation More Complex Analytics multi-stage processing iterative machine learning iterative graph processing Better performance lots of application s dataset can fit in the aggregate memory of many machines
30 What MapReduce lacks Efficient data sharing primitive for multistaging processing output of the previous stage is stored on GFS input of the current stage is read from GFS

31 Multi-stage MapReduce job
32 Spark s goal
33 Spark s solution Restricted form of distributed shared memory Immutable, partitioned collections of records Can only be built through coarse-grained deterministic transformations (map, filter, join,...) Efficient fault recovery using lineage Log one operation to apply to many elements Recompute lost partitions on failure
34 RDD recovery re-run

35 Spark API DryadLINQ-like API in Scala language

36 Example: log mining

37 Fault recovery
38 Another example: PageRank
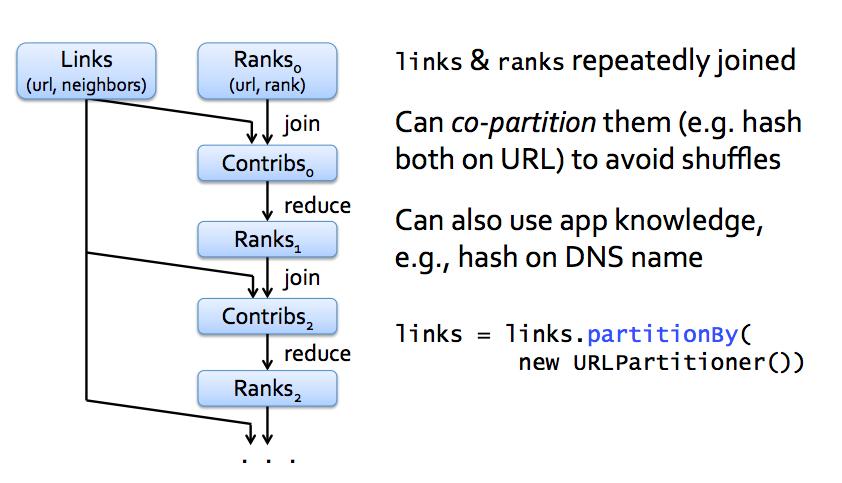
39 Optimizing Placement
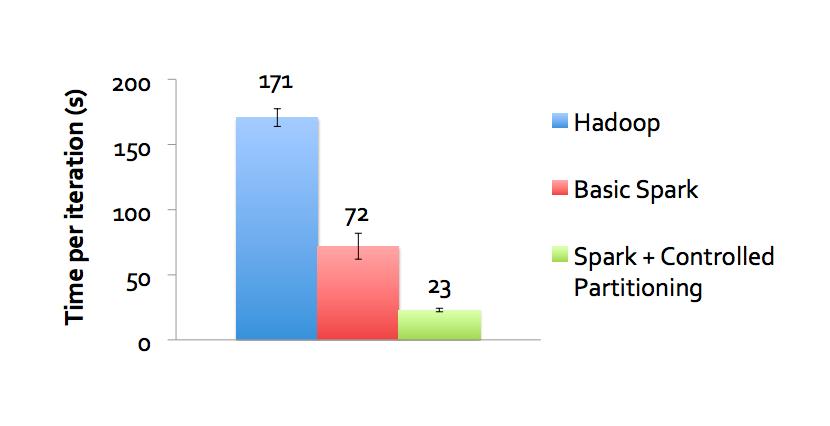
40 PageRank Optimization
41 Summary MapReduce The interface Map + Reduce let programmers write applications that can be automatically parallelized/distributed Re-execution to handle failure / stragglers Spark Enable multi-stage MR jobs to pass data via memory RDD handles fault-tolerance at a coarsegranularity by tracking lineage.
Distributed Computations MapReduce. adapted from Jeff Dean s slides
 Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
MapReduce: Simplified Data Processing on Large Clusters
 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
MapReduce & Resilient Distributed Datasets. Yiqing Hua, Mengqi(Mandy) Xia
 Xia") MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Google: A Computer Scientist s Playground
 Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Outline Mission, data, and scaling Systems infrastructure Parallel programming model: MapReduce Googles
Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Outline Mission, data, and scaling Systems infrastructure Parallel programming model: MapReduce Googles
Google: A Computer Scientist s Playground
 Outline Mission, data, and scaling Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Systems infrastructure Parallel programming model: MapReduce Googles
Outline Mission, data, and scaling Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Systems infrastructure Parallel programming model: MapReduce Googles
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Cloud Programming. Programming Environment Oct 29, 2015 Osamu Tatebe
 Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Fall 2016 1 HW8 is out Last assignment! Get Amazon credits now (see instructions) Spark with Hadoop Due next wed CSE 344 - Fall 2016
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing. Lecture 6: MapReduce in Parallel Computing
 ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
Motivation. Map in Lisp (Scheme) Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters
 Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters") Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Parallel Programming Concepts
 Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
Agenda. Request- Level Parallelism. Agenda. Anatomy of a Web Search. Google Query- Serving Architecture 9/20/10
 Agenda CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instructors: Randy H. Katz David A. PaHerson hhp://inst.eecs.berkeley.edu/~cs61c/fa10 Request and Data Level Parallelism Administrivia
Agenda CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instructors: Randy H. Katz David A. PaHerson hhp://inst.eecs.berkeley.edu/~cs61c/fa10 Request and Data Level Parallelism Administrivia
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
L22: SC Report, Map Reduce
 L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
L22: SC Report, Map Reduce November 23, 2010 Map Reduce What is MapReduce? Example computing environment How it works Fault Tolerance Debugging Performance Google version = Map Reduce; Hadoop = Open source
CSE Lecture 11: Map/Reduce 7 October Nate Nystrom UTA
 CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Spark: A Brief History. https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf
 Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Today s content. Resilient Distributed Datasets(RDDs) Spark and its data model
 Spark and its data model") Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Part II: Software Infrastructure in Data Centers: Distributed Execution Engines
 CSE 6350 File and Storage System Infrastructure in Data centers Supporting Internet-wide Services Part II: Software Infrastructure in Data Centers: Distributed Execution Engines 1 MapReduce: Simplified
CSE 6350 File and Storage System Infrastructure in Data centers Supporting Internet-wide Services Part II: Software Infrastructure in Data Centers: Distributed Execution Engines 1 MapReduce: Simplified
Concurrency for data-intensive applications
 Concurrency for data-intensive applications Dennis Kafura CS5204 Operating Systems 1 Jeff Dean Sanjay Ghemawat Dennis Kafura CS5204 Operating Systems 2 Motivation Application characteristics Large/massive
Concurrency for data-intensive applications Dennis Kafura CS5204 Operating Systems 1 Jeff Dean Sanjay Ghemawat Dennis Kafura CS5204 Operating Systems 2 Motivation Application characteristics Large/massive
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
1. Introduction to MapReduce
 Processing of massive data: MapReduce 1. Introduction to MapReduce 1 Origins: the Problem Google faced the problem of analyzing huge sets of data (order of petabytes) E.g. pagerank, web access logs, etc.
Processing of massive data: MapReduce 1. Introduction to MapReduce 1 Origins: the Problem Google faced the problem of analyzing huge sets of data (order of petabytes) E.g. pagerank, web access logs, etc.
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CSE 344 MAY 2 ND MAP/REDUCE
 CSE 344 MAY 2 ND MAP/REDUCE ADMINISTRIVIA HW5 Due Tonight Practice midterm Section tomorrow Exam review PERFORMANCE METRICS FOR PARALLEL DBMSS Nodes = processors, computers Speedup: More nodes, same data
CSE 344 MAY 2 ND MAP/REDUCE ADMINISTRIVIA HW5 Due Tonight Practice midterm Section tomorrow Exam review PERFORMANCE METRICS FOR PARALLEL DBMSS Nodes = processors, computers Speedup: More nodes, same data
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Discretized Streams. An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters
 Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
6.830 Lecture Spark 11/15/2017
 6.830 Lecture 19 -- Spark 11/15/2017 Recap / finish dynamo Sloppy Quorum (healthy N) Dynamo authors don't think quorums are sufficient, for 2 reasons: - Decreased durability (want to write all data at
6.830 Lecture 19 -- Spark 11/15/2017 Recap / finish dynamo Sloppy Quorum (healthy N) Dynamo authors don't think quorums are sufficient, for 2 reasons: - Decreased durability (want to write all data at
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Principles of Data Management. Lecture #16 (MapReduce & DFS for Big Data)
") Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
MapReduce: A Programming Model for Large-Scale Distributed Computation
 CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
The MapReduce Framework
 The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
In the news. Request- Level Parallelism (RLP) Agenda 10/7/11
 Agenda 10/7/11") In the news "The cloud isn't this big fluffy area up in the sky," said Rich Miller, who edits Data Center Knowledge, a publicaeon that follows the data center industry. "It's buildings filled with servers
In the news "The cloud isn't this big fluffy area up in the sky," said Rich Miller, who edits Data Center Knowledge, a publicaeon that follows the data center industry. "It's buildings filled with servers
Overview. Why MapReduce? What is MapReduce? The Hadoop Distributed File System Cloudera, Inc.
 MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
CS 138: Google. CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
CS 138: Google. CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
MapReduce: Recap. Juliana Freire & Cláudio Silva. Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec
 MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce: Recap Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec MapReduce: Recap Sequentially read a lot of data Why? Map: extract something we care about map (k, v)
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
SparkStreaming. Large scale near- realtime stream processing. Tathagata Das (TD) UC Berkeley UC BERKELEY
 UC Berkeley UC BERKELEY") SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database System Architectures Parallel DBs, MapReduce, ColumnStores
 Database System Architectures Parallel DBs, MapReduce, ColumnStores CMPSCI 445 Fall 2010 Some slides courtesy of Yanlei Diao, Christophe Bisciglia, Aaron Kimball, & Sierra Michels- Slettvet Motivation:
Database System Architectures Parallel DBs, MapReduce, ColumnStores CMPSCI 445 Fall 2010 Some slides courtesy of Yanlei Diao, Christophe Bisciglia, Aaron Kimball, & Sierra Michels- Slettvet Motivation:
CS MapReduce. Vitaly Shmatikov
 CS 5450 MapReduce Vitaly Shmatikov BackRub (Google), 1997 slide 2 NEC Earth Simulator, 2002 slide 3 Conventional HPC Machine ucompute nodes High-end processors Lots of RAM unetwork Specialized Very high
CS 5450 MapReduce Vitaly Shmatikov BackRub (Google), 1997 slide 2 NEC Earth Simulator, 2002 slide 3 Conventional HPC Machine ucompute nodes High-end processors Lots of RAM unetwork Specialized Very high
Cloud Computing CS
 Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Part A: MapReduce. Introduction Model Implementation issues
 Part A: Massive Parallelism li with MapReduce Introduction Model Implementation issues Acknowledgements Map-Reduce The material is largely based on material from the Stanford cources CS246, CS345A and
Part A: Massive Parallelism li with MapReduce Introduction Model Implementation issues Acknowledgements Map-Reduce The material is largely based on material from the Stanford cources CS246, CS345A and
Utah Distributed Systems Meetup and Reading Group - Map Reduce and Spark
 Utah Distributed Systems Meetup and Reading Group - Map Reduce and Spark JT Olds Space Monkey Vivint R&D January 19 2016 Outline 1 Map Reduce 2 Spark 3 Conclusion? Map Reduce Outline 1 Map Reduce 2 Spark
Utah Distributed Systems Meetup and Reading Group - Map Reduce and Spark JT Olds Space Monkey Vivint R&D January 19 2016 Outline 1 Map Reduce 2 Spark 3 Conclusion? Map Reduce Outline 1 Map Reduce 2 Spark
Distributed Computing with Spark and MapReduce
 Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
Parallel Nested Loops
 Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Nested Loops For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on (S 1,T 1 ), (S 1,T 2 ),
Parallel Partition-Based. Parallel Nested Loops. Median. More Join Thoughts. Parallel Office Tools 9/15/2011
 Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Parallel Nested Loops Parallel Partition-Based For each tuple s i in S For each tuple t j in T If s i =t j, then add (s i,t j ) to output Create partitions S 1, S 2, T 1, and T 2 Have processors work on
Large-Scale GPU programming
 Large-Scale GPU programming Tim Kaldewey Research Staff Member Database Technologies IBM Almaden Research Center tkaldew@us.ibm.com Assistant Adjunct Professor Computer and Information Science Dept. University
Large-Scale GPU programming Tim Kaldewey Research Staff Member Database Technologies IBM Almaden Research Center tkaldew@us.ibm.com Assistant Adjunct Professor Computer and Information Science Dept. University
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
MapReduce. Kiril Valev LMU Kiril Valev (LMU) MapReduce / 35
 MapReduce / 35") MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Shark: SQL and Rich Analytics at Scale. Yash Thakkar ( ) Deeksha Singh ( )
 Deeksha Singh ( )") Shark: SQL and Rich Analytics at Scale Yash Thakkar (2642764) Deeksha Singh (2641679) RDDs as foundation for relational processing in Shark: Resilient Distributed Datasets (RDDs): RDDs can be written at
Shark: SQL and Rich Analytics at Scale Yash Thakkar (2642764) Deeksha Singh (2641679) RDDs as foundation for relational processing in Shark: Resilient Distributed Datasets (RDDs): RDDs can be written at
Advanced Data Management Technologies
 ADMT 2017/18 Unit 16 J. Gamper 1/53 Advanced Data Management Technologies Unit 16 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
ADMT 2017/18 Unit 16 J. Gamper 1/53 Advanced Data Management Technologies Unit 16 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
MapReduce. Simplified Data Processing on Large Clusters (Without the Agonizing Pain) Presented by Aaron Nathan
 Presented by Aaron Nathan") MapReduce Simplified Data Processing on Large Clusters (Without the Agonizing Pain) Presented by Aaron Nathan The Problem Massive amounts of data >100TB (the internet) Needs simple processing Computers
MapReduce Simplified Data Processing on Large Clusters (Without the Agonizing Pain) Presented by Aaron Nathan The Problem Massive amounts of data >100TB (the internet) Needs simple processing Computers
Flat Datacenter Storage. Edmund B. Nightingale, Jeremy Elson, et al. 6.S897
 Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Advanced Database Technologies NoSQL: Not only SQL
 Advanced Database Technologies NoSQL: Not only SQL Christian Grün Database & Information Systems Group NoSQL Introduction 30, 40 years history of well-established database technology all in vain? Not at
Advanced Database Technologies NoSQL: Not only SQL Christian Grün Database & Information Systems Group NoSQL Introduction 30, 40 years history of well-established database technology all in vain? Not at
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Putting it together. Data-Parallel Computation. Ex: Word count using partial aggregation. Big Data Processing. COS 418: Distributed Systems Lecture 21
 Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
L3: Spark & RDD. CDS Department of Computational and Data Sciences. Department of Computational and Data Sciences
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Parallel Data Processing with Hadoop/MapReduce. CS140 Tao Yang, 2014
 Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example