CS6200 Information Retrieval. David Smith College of Computer and Information Science Northeastern University
|
|
|
- Stewart Griffin
- 5 years ago
- Views:
Transcription
1 CS6200 Information Retrieval David Smith College of Computer and Information Science Northeastern University

2 Indexing Process!2
3 Indexes Storing document information for faster queries Indexes Index Compression Index Construction Query Processing!3
4 Indexes Indexes are data structures designed to make search faster The main goal is to store whatever we need in order to minimize processing at query time Text search has unique requirements, which leads to unique data structures Most common data structure is inverted index A forward index stores the terms for each document As seen in the back of a book An inverted index stores the documents for each term Similar to a concordance!4

5 A Shakespeare Concordance!5
6 Indexes and Ranking Indexes are designed to support search faster response time, supports updates Text search engines use a particular form of search: ranking documents are retrieved in sorted order according to a score computing using the document representation, the query, and a ranking algorithm What is a reasonable abstract model for ranking? This will allow us to discuss indexes without deciding the details of the retrieval model!6
7 Abstract Model of Ranking!7
8 More Concrete Model!8
9 Inverted Index Each index term is associated with an inverted list Contains lists of documents, or lists of word occurrences in documents, and other information Each entry is called a posting The part of the posting that refers to a specific document or location is called a pointer Each document in the collection is given a unique number Lists are usually document-ordered (sorted by document number)!9
10 Example Collection!10
11 Simple Inverted Index!11
12 Inverted Index with counts! supports better ranking algorithms!!12
13 Inverted Index with positions! supports proximity matches!13
14 Proximity Matches Matching phrases or words within a window e.g., "tropical fish", or find tropical within 5 words of fish Word positions in inverted lists make these types of query features efficient e.g.,!14
15 Fields and Extents Document structure is useful in search field restrictions e.g., date, from:, etc. some fields more important e.g., title Options: separate inverted lists for each field type add information about fields to postings use extent lists!15
16 Extent Lists An extent is a contiguous region of a document represent extents using word positions inverted list records all extents for a given field type e.g., extent list!16
17 Other Issues Precomputed scores in inverted list e.g., list for fish [(1:3.6), (3:2.2)], where 3.6 is total feature value for document 1 improves speed but reduces flexibility Score-ordered lists query processing engine can focus only on the top part of each inverted list, where the highest-scoring documents are recorded very efficient for single-word queries!17
18 Index Compression Managing index size efficiently Indexes Index Compression Index Construction Query Processing!18
19 Compression Inverted lists are very large e.g., 25-50% of collection for TREC collections using Indri search engine Much higher if n-grams are indexed Compression of indexes saves disk and/or memory space Typically have to decompress lists to use them Best compression techniques have good compression ratios and are easy to decompress Lossless compression no information lost!19
20 Compression Basic idea: Common data elements use short codes while uncommon data elements use longer codes Example: coding numbers! number sequence:! possible encoding:! encode 0 using a single 0:! only 10 bits, but...!20
21 Compression Example Ambiguous encoding not clear how to decode another decoding:! which represents:! use unambiguous code:! which gives:!21


22 Compression and Entropy Entropy measures randomness Inverse of compressability!!! n H(X) p(x = x i )log 2 p(x = x i ) i=1 Log2: measured in bits Upper bound: log n Example curve for binomial!22
23 Compression and Entropy Entropy bounds compression rate Theorem: H(X) E[ encoded(x) ] Recall: H(X) log(n) n is the size of the domain of X Standard binary encoding of integers optimizes for the worst case where choice of numbers is completely unpredictable It turns out, we can do better. At best: H(X) E[ encoded(x) ] < H(X) + 1 Bound achieved by Huffman codes!23
24 Delta Encoding Word count data is good candidate for compression many small numbers and few larger numbers encode small numbers with small codes Document numbers are less predictable but differences between numbers in an ordered list are smaller and more predictable Delta encoding: encoding differences between document numbers (d-gaps) makes the posting list more compressible!24
25 Delta Encoding Inverted list (without counts)! Differences between adjacent numbers! Differences for a high-frequency word are easier to compress, e.g.,! Differences for a low-frequency word are large, e.g.,!25
26 Bit-Aligned Codes Breaks between encoded numbers can occur after any bit position Unary code Encode k by k 1s followed by 0 0 at end makes code unambiguous!26
27 Unary and Binary Codes Unary is very efficient for small numbers such as 0 and 1, but quickly becomes very expensive 1023 can be represented in 10 binary bits, but requires 1024 bits in unary Binary is more efficient for large numbers, but it may be ambiguous!27
28 Elias-γ Code More efficient when smaller numbers are more common Can handle very large integers To encode a number k, compute!! k d is number of binary digits, encoded in unary!28
29 Elias-δ Code Elias-γ code uses no more bits than unary, many fewer for k > takes 19 bits instead of 1024 bits using unary In general, takes 2 log 2 k +1 bits To improve coding of large numbers, use Elias-δ code Instead of encoding k d in unary, we encode k d + 1 using Elias-γ Takes approximately 2 log 2 log 2 k + log 2 k bits!29
30 Split k d into: Elias-δ Code!! encode k dd in unary, k dr in binary, and k r in binary!30
31 !31
32 Byte-Aligned Codes Variable-length bit encodings can be a problem on processors that process bytes v-byte is a popular byte-aligned code Similar to Unicode UTF-8 Shortest v-byte code is 1 byte Numbers are 1 to 4 bytes, with high bit 1 in the last byte, 0 otherwise!32
33 V-Byte Encoding!33
34 V-Byte Encoder!34
35 V-Byte Decoder!35
36 Compression Example Consider inverted list with counts & positions (doc, count, positions)! Delta encode document numbers and positions:! Compress using v-byte:!36
37 Skipping Search involves comparison of inverted lists of different lengths Finding a particular doc is very inefficient Skipping ahead to check document numbers is much better Compression makes this difficult Variable size, only d-gaps stored Skip pointers are additional data structure to support skipping!37
38 Skip Pointers A skip pointer (d, p) contains a document number d and a byte (or bit) position p Means there is an inverted list posting that starts at position p, and the posting before it was for document d skip pointers Inverted list!38
39 Skip Pointers Example Inverted list of doc numbers! D-gaps! Skip pointers!39
40 Auxiliary Structures Inverted lists often stored together in a single file for efficiency Inverted file Vocabulary or lexicon Contains a lookup table from index terms to the byte offset of the inverted list in the inverted file Either hash table in memory or B-tree for larger vocabularies Term statistics stored at start of inverted lists Collection statistics stored in separate file For very large indexes, distributed filesystems are used instead.!40
41 Index Construction Algorithms for indexing Indexes Index Compression Index Construction Query Processing!41
42 Index Construction Simple in-memory indexer!42
43 Merging Merging addresses limited memory problem Build the inverted list structure until memory runs out Then write the partial index to disk, start making a new one At the end of this process, the disk is filled with many partial indexes, which are merged Partial lists must be designed so they can be merged in small pieces e.g., storing in alphabetical order!43

44 Merging!44
45 Distributed Indexing Distributed processing driven by need to index and analyze huge amounts of data (i.e., the Web) Large numbers of inexpensive servers used rather than larger, more expensive machines MapReduce is a distributed programming tool designed for indexing and analysis tasks!45
46 Example Given a large text file that contains data about credit card transactions Each line of the file contains a credit card number and an amount of money Determine the number of unique credit card numbers Could use hash table memory problems counting is simple with sorted file Similar with distributed approach sorting and placement are crucial!46
47 MapReduce Distributed programming framework that focuses on data placement and distribution Mapper Generally, transforms a list of items into another list of items of the same length Reducer Transforms a list of items into a single item Definitions not so strict in terms of number of outputs Many mapper and reducer tasks on a cluster of machines!47
48 MapReduce Basic process Map stage which transforms data records into pairs, each with a key and a value Shuffle uses a hash function so that all pairs with the same key end up next to each other and on the same machine Reduce stage processes records in batches, where all pairs with the same key are processed at the same time Idempotence of Mapper and Reducer provides fault tolerance multiple operations on same input gives same output!48

49 MapReduce!49
50 Example!50
51 Indexing Example!51
52 Result Merging Index merging is a good strategy for handling updates when they come in large batches For small updates this is very inefficient instead, create separate index for new documents, merge results from both searches could be in-memory, fast to update and search Deletions handled using delete list Modifications done by putting old version on delete list, adding new version to new documents index!52
53 Query Processing Using the index to search efficiently Indexes Index Compression Index Construction Query Processing!53
54 Query Processing Document-at-a-time Calculates complete scores for documents by processing all term lists, one document at a time Term-at-a-time Accumulates scores for documents by processing term lists one at a time Both approaches have optimization techniques that significantly reduce time required to generate scores!54
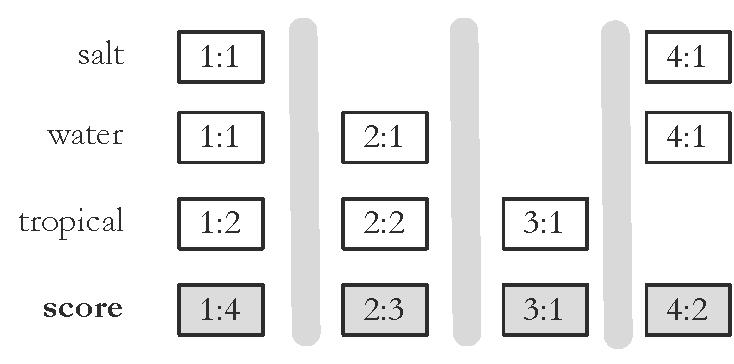
55 Document-At-A-Time!55
56 Pseudocode Function Descriptions getcurrentdocument() Returns the document number of the current posting of the inverted list. skipforwardtodocument(d) Moves forward in the inverted list until getcurrentdocument() <= d. This function may read to the end of the list. movepastdocument(d) Moves forward in the inverted list until getcurrentdocument() < d. movetonextdocument() Moves to the next document in the list. Equivalent to movepastdocument(getcurrentdocument()). getnextaccumulator(d) returns the first document number d' >= d that has already has an accumulator. removeaccumulatorsbetween(a, b) Removes all accumulators for documents numbers between a and b. A d will be removed iff a < d < b.!56
57 Document-At-A-Time Get best k documents for query Q from index I, with query score function g() and document score function f(). Process one document at a time.!57
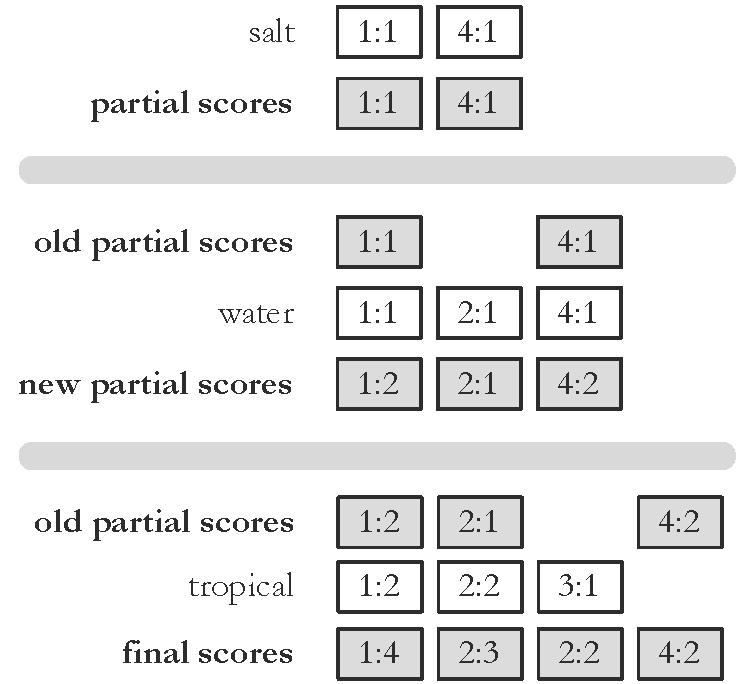
58 Term-At-A-Time!58
59 Term-At-A-Time Get best k documents for query Q from index I, with query score function g() and document score function f(). Process one term at a time.!59
60 Optimization Techniques Term-at-a-time uses more memory for accumulators, but accesses disk more efficiently Two classes of optimization Read less data from inverted lists e.g., skip lists better for simple feature functions Calculate scores for fewer documents e.g., conjunctive processing better for complex feature functions!60
61 Conjunctive Term-at-a-Time!61
62 Conjunctive Document-at-a-Time!62
63 Threshold Methods Threshold methods use the number of topranked documents needed (k) to optimize query processing for most applications, k is small For any query, there is a minimum score that each document needs to reach before it can be shown to the user score of the kth-highest scoring document gives threshold τ optimization methods estimate τ to ignore documents!63
64 Threshold Methods Example: find the top 2 documents Query term weights: [0.7, 0.1, 0.2] Doc term weights are between 0 and 1 Ranker uses dot product of query and doc weights Doc 1 term weights: [0.3, 0.4, 0.5] Score: 0.3* * *0.2 = 0.35 Doc 2 term weights: [0.5, 0.1, 0.1] Score: 0.5* * *0.2 = 0.38 Doc 3 term weights: [0.01, 1, 1] Score: 0.01*0.7 +1* *0.2 = We know from the first term that doc 3 can t possibly get a high enough score to beat docs 1 and 2 We can discard the document after looking at just one term!64
65 Threshold Methods For document-at-a-time processing, use score of lowest-ranked document so far for τ for term-at-a-time, have to use kth-largest score in the accumulator table MaxScore method compares the maximum score that remaining documents could have to τ uses the maximum score observed in term posting lists to estimate the best possible document score safe optimization in that ranking will be the same without optimization (cf. A* search)!65
66 MaxScore Example Indexer computes µ tree maximum score any document got for term tree Assume k =3, τ is lowest score for entire query after first three docs Likely that τ > µ tree because of additional terms τ is the score of a document that contains both query terms Can safely skip over all gray postings, which have scores < µ tree!66
67 Other Approaches Early termination of query processing ignore high-frequency word lists in term-at-atime ignore documents at end of lists in doc-at-a-time unsafe optimization List ordering order inverted lists by quality metric (e.g., PageRank) or by partial score makes unsafe (and fast) optimizations more likely to produce good documents!67
68 Structured Queries Query language can support specification of complex features similar to SQL for database systems query translator converts the user s input into the structured query representation Galago query language is the example used here e.g., Galago query:!68
69 Evaluation Tree for Structured Query!69
70 Distributed Evaluation Basic process All queries sent to a director machine Director then sends messages to many index servers Each index server does some portion of the query processing Director organizes the results and returns them to the user Two main approaches Document distribution by far the most popular Term distribution!70
71 Distributed Evaluation Document distribution each index server acts as a search engine for a small fraction of the total collection director sends a copy of the query to each of the index servers, each of which returns the top-k results results are merged into a single ranked list by the director Collection statistics should be shared for effective ranking!71
72 Distributed Evaluation Term distribution Single index is built for the whole cluster of machines Each inverted list in that index is then assigned to one index server in most cases the data to process a query is not stored on a single machine One of the index servers is chosen to process the query usually the one holding the longest inverted list Other index servers send information to that server Final results sent to director!72
73 Caching Query distributions similar to Zipf About ½ each day are unique, but some are very popular Caching can significantly improve effectiveness Cache popular query results Cache common inverted lists Inverted list caching can help with unique queries Cache must be refreshed to prevent stale data!73
CS6200 Informa.on Retrieval. David Smith College of Computer and Informa.on Science Northeastern University
 CS6200 Informa.on Retrieval David Smith College of Computer and Informa.on Science Northeastern University Indexing Process Indexes Indexes are data structures designed to make search faster Text search
CS6200 Informa.on Retrieval David Smith College of Computer and Informa.on Science Northeastern University Indexing Process Indexes Indexes are data structures designed to make search faster Text search
Search Engines. Informa1on Retrieval in Prac1ce. Annotations by Michael L. Nelson
 Search Engines Informa1on Retrieval in Prac1ce Annotations by Michael L. Nelson All slides Addison Wesley, 2008 Indexes Indexes are data structures designed to make search faster Text search has unique
Search Engines Informa1on Retrieval in Prac1ce Annotations by Michael L. Nelson All slides Addison Wesley, 2008 Indexes Indexes are data structures designed to make search faster Text search has unique
Indexing. UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze
 Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
Indexing. CS6200: Information Retrieval. Index Construction. Slides by: Jesse Anderton
 Indexing Index Construction CS6200: Information Retrieval Slides by: Jesse Anderton Motivation: Scale Corpus Terms Docs Entries A term incidence matrix with V terms and D documents has O(V x D) entries.
Indexing Index Construction CS6200: Information Retrieval Slides by: Jesse Anderton Motivation: Scale Corpus Terms Docs Entries A term incidence matrix with V terms and D documents has O(V x D) entries.
Chapter IR:IV. IV. Indexing. Abstract Model of Ranking Inverted Indexes Compression Auxiliary Structures Index Construction Query Processing
 Chapter IR:IV IV. Indexing Abstract Model of Ranking Inverted Indexes Compression Auxiliary Structures Index Construction Query Processing IR:IV-276 Indexing HAGEN/POTTHAST/STEIN 2017 Inverted Indexes
Chapter IR:IV IV. Indexing Abstract Model of Ranking Inverted Indexes Compression Auxiliary Structures Index Construction Query Processing IR:IV-276 Indexing HAGEN/POTTHAST/STEIN 2017 Inverted Indexes
Administrative. Distributed indexing. Index Compression! What I did last summer lunch talks today. Master. Tasks
 Administrative Index Compression! n Assignment 1? n Homework 2 out n What I did last summer lunch talks today David Kauchak cs458 Fall 2012 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt
Administrative Index Compression! n Assignment 1? n Homework 2 out n What I did last summer lunch talks today David Kauchak cs458 Fall 2012 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt
Query Processing and Alternative Search Structures. Indexing common words
 Query Processing and Alternative Search Structures CS 510 Winter 2007 1 Indexing common words What is the indexing overhead for a common term? I.e., does leaving out stopwords help? Consider a word such
Query Processing and Alternative Search Structures CS 510 Winter 2007 1 Indexing common words What is the indexing overhead for a common term? I.e., does leaving out stopwords help? Consider a word such
Introduction to Information Retrieval (Manning, Raghavan, Schutze)
") Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
Information Retrieval
 Information Retrieval Suan Lee - Information Retrieval - 05 Index Compression 1 05 Index Compression - Information Retrieval - 05 Index Compression 2 Last lecture index construction Sort-based indexing
Information Retrieval Suan Lee - Information Retrieval - 05 Index Compression 1 05 Index Compression - Information Retrieval - 05 Index Compression 2 Last lecture index construction Sort-based indexing
V.2 Index Compression
 V.2 Index Compression Heap s law (empirically observed and postulated): Size of the vocabulary (distinct terms) in a corpus E[ distinct terms in corpus] n with total number of term occurrences n, and constants,
V.2 Index Compression Heap s law (empirically observed and postulated): Size of the vocabulary (distinct terms) in a corpus E[ distinct terms in corpus] n with total number of term occurrences n, and constants,
Architecture and Implementation of Database Systems (Summer 2018)
") Jens Teubner Architecture & Implementation of DBMS Summer 2018 1 Architecture and Implementation of Database Systems (Summer 2018) Jens Teubner, DBIS Group jens.teubner@cs.tu-dortmund.de Summer 2018 Jens
Jens Teubner Architecture & Implementation of DBMS Summer 2018 1 Architecture and Implementation of Database Systems (Summer 2018) Jens Teubner, DBIS Group jens.teubner@cs.tu-dortmund.de Summer 2018 Jens
Efficient Implementation of Postings Lists
 Efficient Implementation of Postings Lists Inverted Indices Query Brutus AND Calpurnia J. Pei: Information Retrieval and Web Search -- Efficient Implementation of Postings Lists 2 Skip Pointers J. Pei:
Efficient Implementation of Postings Lists Inverted Indices Query Brutus AND Calpurnia J. Pei: Information Retrieval and Web Search -- Efficient Implementation of Postings Lists 2 Skip Pointers J. Pei:
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 5: Index Compression Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-17 1/59 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 5: Index Compression Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-17 1/59 Overview
Efficient query processing
 Efficient query processing Efficient scoring, distributed query processing Web Search 1 Ranking functions In general, document scoring functions are of the form The BM25 function, is one of the best performing:
Efficient query processing Efficient scoring, distributed query processing Web Search 1 Ranking functions In general, document scoring functions are of the form The BM25 function, is one of the best performing:
Information Retrieval. Lecture 3 - Index compression. Introduction. Overview. Characterization of an index. Wintersemester 2007
 Information Retrieval Lecture 3 - Index compression Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Dictionary and inverted index:
Information Retrieval Lecture 3 - Index compression Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Dictionary and inverted index:
Information Retrieval
 Introduction to Information Retrieval CS3245 Information Retrieval Lecture 6: Index Compression 6 Last Time: index construction Sort- based indexing Blocked Sort- Based Indexing Merge sort is effective
Introduction to Information Retrieval CS3245 Information Retrieval Lecture 6: Index Compression 6 Last Time: index construction Sort- based indexing Blocked Sort- Based Indexing Merge sort is effective
Text Analytics. Index-Structures for Information Retrieval. Ulf Leser
 Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Efficiency. Efficiency: Indexing. Indexing. Efficiency Techniques. Inverted Index. Inverted Index (COSC 488)
") Efficiency Efficiency: Indexing (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Difficult to analyze sequential IR algorithms: data and query dependency (query selectivity). O(q(cf max )) -- high estimate-
Efficiency Efficiency: Indexing (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Difficult to analyze sequential IR algorithms: data and query dependency (query selectivity). O(q(cf max )) -- high estimate-
Text Analytics. Index-Structures for Information Retrieval. Ulf Leser
 Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
IN4325 Indexing and query processing. Claudia Hauff (WIS, TU Delft)
") IN4325 Indexing and query processing Claudia Hauff (WIS, TU Delft) The big picture Information need Topic the user wants to know more about The essence of IR Query Translation of need into an input for
IN4325 Indexing and query processing Claudia Hauff (WIS, TU Delft) The big picture Information need Topic the user wants to know more about The essence of IR Query Translation of need into an input for
Index Compression. David Kauchak cs160 Fall 2009 adapted from:
 Index Compression David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt Administrative Homework 2 Assignment 1 Assignment 2 Pair programming?
Index Compression David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt Administrative Homework 2 Assignment 1 Assignment 2 Pair programming?
Static Pruning of Terms In Inverted Files
 In Inverted Files Roi Blanco and Álvaro Barreiro IRLab University of A Corunna, Spain 29th European Conference on Information Retrieval, Rome, 2007 Motivation : to reduce inverted files size with lossy
In Inverted Files Roi Blanco and Álvaro Barreiro IRLab University of A Corunna, Spain 29th European Conference on Information Retrieval, Rome, 2007 Motivation : to reduce inverted files size with lossy
Recap: lecture 2 CS276A Information Retrieval
 Recap: lecture 2 CS276A Information Retrieval Stemming, tokenization etc. Faster postings merges Phrase queries Lecture 3 This lecture Index compression Space estimation Corpus size for estimates Consider
Recap: lecture 2 CS276A Information Retrieval Stemming, tokenization etc. Faster postings merges Phrase queries Lecture 3 This lecture Index compression Space estimation Corpus size for estimates Consider
Course work. Today. Last lecture index construc)on. Why compression (in general)? Why compression for inverted indexes?
on. Why compression (in general)? Why compression for inverted indexes?") Course work Introduc)on to Informa(on Retrieval Problem set 1 due Thursday Programming exercise 1 will be handed out today CS276: Informa)on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan
Course work Introduc)on to Informa(on Retrieval Problem set 1 due Thursday Programming exercise 1 will be handed out today CS276: Informa)on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan
CS60092: Informa0on Retrieval
 Introduc)on to CS60092: Informa0on Retrieval Sourangshu Bha1acharya Last lecture index construc)on Sort- based indexing Naïve in- memory inversion Blocked Sort- Based Indexing Merge sort is effec)ve for
Introduc)on to CS60092: Informa0on Retrieval Sourangshu Bha1acharya Last lecture index construc)on Sort- based indexing Naïve in- memory inversion Blocked Sort- Based Indexing Merge sort is effec)ve for
Information Retrieval. Chap 7. Text Operations
 Information Retrieval Chap 7. Text Operations The Retrieval Process user need User Interface 4, 10 Text Text logical view Text Operations logical view 6, 7 user feedback Query Operations query Indexing
Information Retrieval Chap 7. Text Operations The Retrieval Process user need User Interface 4, 10 Text Text logical view Text Operations logical view 6, 7 user feedback Query Operations query Indexing
Query Evaluation Strategies
 Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Research (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa
Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Research (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa
COMP6237 Data Mining Searching and Ranking
 COMP6237 Data Mining Searching and Ranking Jonathon Hare jsh2@ecs.soton.ac.uk Note: portions of these slides are from those by ChengXiang Cheng Zhai at UIUC https://class.coursera.org/textretrieval-001
COMP6237 Data Mining Searching and Ranking Jonathon Hare jsh2@ecs.soton.ac.uk Note: portions of these slides are from those by ChengXiang Cheng Zhai at UIUC https://class.coursera.org/textretrieval-001
Information Retrieval
 Information Retrieval Suan Lee - Information Retrieval - 04 Index Construction 1 04 Index Construction - Information Retrieval - 04 Index Construction 2 Plan Last lecture: Dictionary data structures Tolerant
Information Retrieval Suan Lee - Information Retrieval - 04 Index Construction 1 04 Index Construction - Information Retrieval - 04 Index Construction 2 Plan Last lecture: Dictionary data structures Tolerant
Web Information Retrieval. Lecture 4 Dictionaries, Index Compression
 Web Information Retrieval Lecture 4 Dictionaries, Index Compression Recap: lecture 2,3 Stemming, tokenization etc. Faster postings merges Phrase queries Index construction This lecture Dictionary data
Web Information Retrieval Lecture 4 Dictionaries, Index Compression Recap: lecture 2,3 Stemming, tokenization etc. Faster postings merges Phrase queries Index construction This lecture Dictionary data
Corso di Biblioteche Digitali
 Corso di Biblioteche Digitali Vittore Casarosa casarosa@isti.cnr.it tel. 050-315 3115 cell. 348-397 2168 Ricevimento dopo la lezione o per appuntamento Valutazione finale 70-75% esame orale 25-30% progetto
Corso di Biblioteche Digitali Vittore Casarosa casarosa@isti.cnr.it tel. 050-315 3115 cell. 348-397 2168 Ricevimento dopo la lezione o per appuntamento Valutazione finale 70-75% esame orale 25-30% progetto
modern database systems lecture 4 : information retrieval
 modern database systems lecture 4 : information retrieval Aristides Gionis Michael Mathioudakis spring 2016 in perspective structured data relational data RDBMS MySQL semi-structured data data-graph representation
modern database systems lecture 4 : information retrieval Aristides Gionis Michael Mathioudakis spring 2016 in perspective structured data relational data RDBMS MySQL semi-structured data data-graph representation
Outline of the course
 Outline of the course Introduction to Digital Libraries (15%) Description of Information (30%) Access to Information (30%) User Services (10%) Additional topics (15%) Buliding of a (small) digital library
Outline of the course Introduction to Digital Libraries (15%) Description of Information (30%) Access to Information (30%) User Services (10%) Additional topics (15%) Buliding of a (small) digital library
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 45/65 43/63 (Winter 08) Part 3: Analyzing Text (/) January 30, 08 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides are
Data-Intensive Distributed Computing CS 45/65 43/63 (Winter 08) Part 3: Analyzing Text (/) January 30, 08 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides are
Natural Language Processing
 Natural Language Processing Language Models Language models are distributions over sentences N gram models are built from local conditional probabilities Language Modeling II Dan Klein UC Berkeley, The
Natural Language Processing Language Models Language models are distributions over sentences N gram models are built from local conditional probabilities Language Modeling II Dan Klein UC Berkeley, The
MG4J: Managing Gigabytes for Java. MG4J - intro 1
 MG4J: Managing Gigabytes for Java MG4J - intro 1 Managing Gigabytes for Java Schedule: 1. Introduction to MG4J framework. 2. Exercitation: try to set up a search engine on a particular collection of documents.
MG4J: Managing Gigabytes for Java MG4J - intro 1 Managing Gigabytes for Java Schedule: 1. Introduction to MG4J framework. 2. Exercitation: try to set up a search engine on a particular collection of documents.
Information Retrieval 6. Index compression
 Ghislain Fourny Information Retrieval 6. Index compression Picture copyright: donest /123RF Stock Photo What we have seen so far 2 Boolean retrieval lawyer AND Penang AND NOT silver query Input Set of
Ghislain Fourny Information Retrieval 6. Index compression Picture copyright: donest /123RF Stock Photo What we have seen so far 2 Boolean retrieval lawyer AND Penang AND NOT silver query Input Set of
3-2. Index construction. Most slides were adapted from Stanford CS 276 course and University of Munich IR course.
 3-2. Index construction Most slides were adapted from Stanford CS 276 course and University of Munich IR course. 1 Ch. 4 Index construction How do we construct an index? What strategies can we use with
3-2. Index construction Most slides were adapted from Stanford CS 276 course and University of Munich IR course. 1 Ch. 4 Index construction How do we construct an index? What strategies can we use with
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
Inverted Indexes. Indexing and Searching, Modern Information Retrieval, Addison Wesley, 2010 p. 5
 Inverted Indexes Indexing and Searching, Modern Information Retrieval, Addison Wesley, 2010 p. 5 Basic Concepts Inverted index: a word-oriented mechanism for indexing a text collection to speed up the
Inverted Indexes Indexing and Searching, Modern Information Retrieval, Addison Wesley, 2010 p. 5 Basic Concepts Inverted index: a word-oriented mechanism for indexing a text collection to speed up the
EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling
 EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling Doug Downey Based partially on slides by Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze Announcements Project progress report
EECS 395/495 Lecture 3 Scalable Indexing, Searching, and Crawling Doug Downey Based partially on slides by Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze Announcements Project progress report
Using Graphics Processors for High Performance IR Query Processing
 Using Graphics Processors for High Performance IR Query Processing Shuai Ding Jinru He Hao Yan Torsten Suel Polytechnic Inst. of NYU Polytechnic Inst. of NYU Polytechnic Inst. of NYU Yahoo! Research Brooklyn,
Using Graphics Processors for High Performance IR Query Processing Shuai Ding Jinru He Hao Yan Torsten Suel Polytechnic Inst. of NYU Polytechnic Inst. of NYU Polytechnic Inst. of NYU Yahoo! Research Brooklyn,
Information Retrieval
 Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Query Evaluation Strategies
 Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Labs (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa Research
Introduction to Search Engine Technology Term-at-a-Time and Document-at-a-Time Evaluation Ronny Lempel Yahoo! Labs (Many of the following slides are courtesy of Aya Soffer and David Carmel, IBM Haifa Research
David Rappaport School of Computing Queen s University CANADA. Copyright, 1996 Dale Carnegie & Associates, Inc.
 David Rappaport School of Computing Queen s University CANADA Copyright, 1996 Dale Carnegie & Associates, Inc. Data Compression There are two broad categories of data compression: Lossless Compression
David Rappaport School of Computing Queen s University CANADA Copyright, 1996 Dale Carnegie & Associates, Inc. Data Compression There are two broad categories of data compression: Lossless Compression
More Bits and Bytes Huffman Coding
 More Bits and Bytes Huffman Coding Encoding Text: How is it done? ASCII, UTF, Huffman algorithm ASCII C A T Lawrence Snyder, CSE UTF-8: All the alphabets in the world Uniform Transformation Format: a variable-width
More Bits and Bytes Huffman Coding Encoding Text: How is it done? ASCII, UTF, Huffman algorithm ASCII C A T Lawrence Snyder, CSE UTF-8: All the alphabets in the world Uniform Transformation Format: a variable-width
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Variable Length Integers for Search
 7:57:57 AM Variable Length Integers for Search Past, Present and Future Ryan Ernst A9.com 7:57:59 AM Overview About me Search and inverted indices Traditional encoding (Vbyte) Modern encodings Future work
7:57:57 AM Variable Length Integers for Search Past, Present and Future Ryan Ernst A9.com 7:57:59 AM Overview About me Search and inverted indices Traditional encoding (Vbyte) Modern encodings Future work
Logistics. CSE Case Studies. Indexing & Retrieval in Google. Review: AltaVista. BigTable. Index Stream Readers (ISRs) Advanced Search
 Advanced Search") CSE 454 - Case Studies Indexing & Retrieval in Google Some slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Logistics For next class Read: How to implement PageRank Efficiently Projects
CSE 454 - Case Studies Indexing & Retrieval in Google Some slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Logistics For next class Read: How to implement PageRank Efficiently Projects
Search Engines Information Retrieval in Practice
 Search Engines Information Retrieval in Practice W. BRUCE CROFT University of Massachusetts, Amherst DONALD METZLER Yahoo! Research TREVOR STROHMAN Google Inc. ----- PEARSON Boston Columbus Indianapolis
Search Engines Information Retrieval in Practice W. BRUCE CROFT University of Massachusetts, Amherst DONALD METZLER Yahoo! Research TREVOR STROHMAN Google Inc. ----- PEARSON Boston Columbus Indianapolis
ΕΠΛ660. Ανάκτηση µε το µοντέλο διανυσµατικού χώρου
 Ανάκτηση µε το µοντέλο διανυσµατικού χώρου Σηµερινό ερώτηµα Typically we want to retrieve the top K docs (in the cosine ranking for the query) not totally order all docs in the corpus can we pick off docs
Ανάκτηση µε το µοντέλο διανυσµατικού χώρου Σηµερινό ερώτηµα Typically we want to retrieve the top K docs (in the cosine ranking for the query) not totally order all docs in the corpus can we pick off docs
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 6 Information Retrieval: Crawling & Indexing Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 6 Information Retrieval: Crawling & Indexing Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains
Information Retrieval
 Introduction to Information Retrieval Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden mo
Introduction to Information Retrieval Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden mo
Query Answering Using Inverted Indexes
 Query Answering Using Inverted Indexes Inverted Indexes Query Brutus AND Calpurnia J. Pei: Information Retrieval and Web Search -- Query Answering Using Inverted Indexes 2 Document-at-a-time Evaluation
Query Answering Using Inverted Indexes Inverted Indexes Query Brutus AND Calpurnia J. Pei: Information Retrieval and Web Search -- Query Answering Using Inverted Indexes 2 Document-at-a-time Evaluation
HICAMP Bitmap. A Space-Efficient Updatable Bitmap Index for In-Memory Databases! Bo Wang, Heiner Litz, David R. Cheriton Stanford University DAMON 14
 HICAMP Bitmap A Space-Efficient Updatable Bitmap Index for In-Memory Databases! Bo Wang, Heiner Litz, David R. Cheriton Stanford University DAMON 14 Database Indexing Databases use precomputed indexes
HICAMP Bitmap A Space-Efficient Updatable Bitmap Index for In-Memory Databases! Bo Wang, Heiner Litz, David R. Cheriton Stanford University DAMON 14 Database Indexing Databases use precomputed indexes
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO Lecture 6: Information Retrieval I. Aidan Hogan
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 6: Information Retrieval I Aidan Hogan aidhog@gmail.com Postponing MANAGING TEXT DATA Information Overload If we didn t have search Contains all
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 6: Information Retrieval I Aidan Hogan aidhog@gmail.com Postponing MANAGING TEXT DATA Information Overload If we didn t have search Contains all
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 6: Index Compression Paul Ginsparg Cornell University, Ithaca, NY 15 Sep
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 6: Index Compression Paul Ginsparg Cornell University, Ithaca, NY 15 Sep
Analyzing the performance of top-k retrieval algorithms. Marcus Fontoura Google, Inc
 Analyzing the performance of top-k retrieval algorithms Marcus Fontoura Google, Inc This talk Largely based on the paper Evaluation Strategies for Top-k Queries over Memory-Resident Inverted Indices, VLDB
Analyzing the performance of top-k retrieval algorithms Marcus Fontoura Google, Inc This talk Largely based on the paper Evaluation Strategies for Top-k Queries over Memory-Resident Inverted Indices, VLDB
CSE 454. Index Compression Alta Vista PageRank
 CSE 454 Index Compression Alta Vista PageRank 1 Review t 1 d i q Vector Space Representation Dot Product as Similarity Metric d j t 2 TF-IDF for Computing Weights w ij = f(i,j) * log(n/n i ) Where q =
CSE 454 Index Compression Alta Vista PageRank 1 Review t 1 d i q Vector Space Representation Dot Product as Similarity Metric d j t 2 TF-IDF for Computing Weights w ij = f(i,j) * log(n/n i ) Where q =
Indexing and Searching
 Indexing and Searching Introduction How to retrieval information? A simple alternative is to search the whole text sequentially Another option is to build data structures over the text (called indices)
Indexing and Searching Introduction How to retrieval information? A simple alternative is to search the whole text sequentially Another option is to build data structures over the text (called indices)
Lossless Compression Algorithms
 Multimedia Data Compression Part I Chapter 7 Lossless Compression Algorithms 1 Chapter 7 Lossless Compression Algorithms 1. Introduction 2. Basics of Information Theory 3. Lossless Compression Algorithms
Multimedia Data Compression Part I Chapter 7 Lossless Compression Algorithms 1 Chapter 7 Lossless Compression Algorithms 1. Introduction 2. Basics of Information Theory 3. Lossless Compression Algorithms
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 07) Week 4: Analyzing Text (/) January 6, 07 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 07) Week 4: Analyzing Text (/) January 6, 07 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These slides
Index Construction. Dictionary, postings, scalable indexing, dynamic indexing. Web Search
 Index Construction Dictionary, postings, scalable indexing, dynamic indexing Web Search 1 Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Index Construction Dictionary, postings, scalable indexing, dynamic indexing Web Search 1 Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Information Retrieval II
 Information Retrieval II David Hawking 30 Sep 2010 Machine Learning Summer School, ANU Session Outline Ranking documents in response to a query Measuring the quality of such rankings Case Study: Tuning
Information Retrieval II David Hawking 30 Sep 2010 Machine Learning Summer School, ANU Session Outline Ranking documents in response to a query Measuring the quality of such rankings Case Study: Tuning
MILC: Inverted List Compression in Memory
 MILC: Inverted List Compression in Memory Yorrick Müller Garching, 3rd December 2018 Yorrick Müller MILC: Inverted List Compression In Memory 1 Introduction Inverted Lists Inverted list := Series of sorted
MILC: Inverted List Compression in Memory Yorrick Müller Garching, 3rd December 2018 Yorrick Müller MILC: Inverted List Compression In Memory 1 Introduction Inverted Lists Inverted list := Series of sorted
Stanford University Computer Science Department Solved CS347 Spring 2001 Mid-term.
 Stanford University Computer Science Department Solved CS347 Spring 2001 Mid-term. Question 1: (4 points) Shown below is a portion of the positional index in the format term: doc1: position1,position2
Stanford University Computer Science Department Solved CS347 Spring 2001 Mid-term. Question 1: (4 points) Shown below is a portion of the positional index in the format term: doc1: position1,position2
Desktop Crawls. Document Feeds. Document Feeds. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Web crawlers Retrieving web pages Crawling the web» Desktop crawlers» Document feeds File conversion Storing the documents Removing noise Desktop Crawls! Used
Information Retrieval INFO 4300 / CS 4300! Web crawlers Retrieving web pages Crawling the web» Desktop crawlers» Document feeds File conversion Storing the documents Removing noise Desktop Crawls! Used
Introduc)on to. CS60092: Informa0on Retrieval
on to. CS60092: Informa0on Retrieval") Introduc)on to CS60092: Informa0on Retrieval Ch. 4 Index construc)on How do we construct an index? What strategies can we use with limited main memory? Sec. 4.1 Hardware basics Many design decisions in
Introduc)on to CS60092: Informa0on Retrieval Ch. 4 Index construc)on How do we construct an index? What strategies can we use with limited main memory? Sec. 4.1 Hardware basics Many design decisions in
1 o Semestre 2007/2008
 Efficient Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Outline 1 2 3 4 5 6 7 Outline 1 2 3 4 5 6 7 Text es An index is a mechanism to locate a given term in
Efficient Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Outline 1 2 3 4 5 6 7 Outline 1 2 3 4 5 6 7 Text es An index is a mechanism to locate a given term in
Real-time Text Queries with Tunable Term Pair Indexes
 Real-time Text Queries with Tunable Term Pair Indexes Andreas Broschart Ralf Schenkel MPI I 2010 5-006 October 2010 Authors Addresses Andreas Broschart Max-Planck-Institut für Informatik und Universität
Real-time Text Queries with Tunable Term Pair Indexes Andreas Broschart Ralf Schenkel MPI I 2010 5-006 October 2010 Authors Addresses Andreas Broschart Max-Planck-Institut für Informatik und Universität
Cluster based Mixed Coding Schemes for Inverted File Index Compression
 Cluster based Mixed Coding Schemes for Inverted File Index Compression Jinlin Chen 1, Ping Zhong 2, Terry Cook 3 1 Computer Science Department Queen College, City University of New York USA jchen@cs.qc.edu
Cluster based Mixed Coding Schemes for Inverted File Index Compression Jinlin Chen 1, Ping Zhong 2, Terry Cook 3 1 Computer Science Department Queen College, City University of New York USA jchen@cs.qc.edu
Efficiency vs. Effectiveness in Terabyte-Scale IR
 Efficiency vs. Effectiveness in Terabyte-Scale Information Retrieval Stefan Büttcher Charles L. A. Clarke University of Waterloo, Canada November 17, 2005 1 2 3 4 5 6 What is Wumpus? Multi-user file system
Efficiency vs. Effectiveness in Terabyte-Scale Information Retrieval Stefan Büttcher Charles L. A. Clarke University of Waterloo, Canada November 17, 2005 1 2 3 4 5 6 What is Wumpus? Multi-user file system
MASSACHUSETTS INSTITUTE OF TECHNOLOGY Database Systems: Fall 2008 Quiz II
 Department of Electrical Engineering and Computer Science MASSACHUSETTS INSTITUTE OF TECHNOLOGY 6.830 Database Systems: Fall 2008 Quiz II There are 14 questions and 11 pages in this quiz booklet. To receive
Department of Electrical Engineering and Computer Science MASSACHUSETTS INSTITUTE OF TECHNOLOGY 6.830 Database Systems: Fall 2008 Quiz II There are 14 questions and 11 pages in this quiz booklet. To receive
EE67I Multimedia Communication Systems Lecture 4
 EE67I Multimedia Communication Systems Lecture 4 Lossless Compression Basics of Information Theory Compression is either lossless, in which no information is lost, or lossy in which information is lost.
EE67I Multimedia Communication Systems Lecture 4 Lossless Compression Basics of Information Theory Compression is either lossless, in which no information is lost, or lossy in which information is lost.
8 Integer encoding. scritto da: Tiziano De Matteis
 8 Integer encoding scritto da: Tiziano De Matteis 8.1 Unary code... 8-2 8.2 Elias codes: γ andδ... 8-2 8.3 Rice code... 8-3 8.4 Interpolative coding... 8-4 8.5 Variable-byte codes and (s,c)-dense codes...
8 Integer encoding scritto da: Tiziano De Matteis 8.1 Unary code... 8-2 8.2 Elias codes: γ andδ... 8-2 8.3 Rice code... 8-3 8.4 Interpolative coding... 8-4 8.5 Variable-byte codes and (s,c)-dense codes...
Optimized Top-K Processing with Global Page Scores on Block-Max Indexes
 Optimized Top-K Processing with Global Page Scores on Block-Max Indexes Dongdong Shan 1 Shuai Ding 2 Jing He 1 Hongfei Yan 1 Xiaoming Li 1 Peking University, Beijing, China 1 Polytechnic Institute of NYU,
Optimized Top-K Processing with Global Page Scores on Block-Max Indexes Dongdong Shan 1 Shuai Ding 2 Jing He 1 Hongfei Yan 1 Xiaoming Li 1 Peking University, Beijing, China 1 Polytechnic Institute of NYU,
SIGNAL COMPRESSION Lecture Lempel-Ziv Coding
 SIGNAL COMPRESSION Lecture 5 11.9.2007 Lempel-Ziv Coding Dictionary methods Ziv-Lempel 77 The gzip variant of Ziv-Lempel 77 Ziv-Lempel 78 The LZW variant of Ziv-Lempel 78 Asymptotic optimality of Ziv-Lempel
SIGNAL COMPRESSION Lecture 5 11.9.2007 Lempel-Ziv Coding Dictionary methods Ziv-Lempel 77 The gzip variant of Ziv-Lempel 77 Ziv-Lempel 78 The LZW variant of Ziv-Lempel 78 Asymptotic optimality of Ziv-Lempel
Index construction CE-324: Modern Information Retrieval Sharif University of Technology
 Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Index construction CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch.
Processing of Very Large Data
 Processing of Very Large Data Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Software Development Technologies Master studies, first
Processing of Very Large Data Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Software Development Technologies Master studies, first
Lecture 24: Image Retrieval: Part II. Visual Computing Systems CMU , Fall 2013
 Lecture 24: Image Retrieval: Part II Visual Computing Systems Review: K-D tree Spatial partitioning hierarchy K = dimensionality of space (below: K = 2) 3 2 1 3 3 4 2 Counts of points in leaf nodes Nearest
Lecture 24: Image Retrieval: Part II Visual Computing Systems Review: K-D tree Spatial partitioning hierarchy K = dimensionality of space (below: K = 2) 3 2 1 3 3 4 2 Counts of points in leaf nodes Nearest
230 Million Tweets per day
 Tweets per day Queries per day Indexing latency Avg. query response time Earlybird - Realtime Search @twitter Michael Busch @michibusch michael@twitter.com buschmi@apache.org Earlybird - Realtime Search
Tweets per day Queries per day Indexing latency Avg. query response time Earlybird - Realtime Search @twitter Michael Busch @michibusch michael@twitter.com buschmi@apache.org Earlybird - Realtime Search
An Asymmetric, Semi-adaptive Text Compression Algorithm
 An Asymmetric, Semi-adaptive Text Compression Algorithm Harry Plantinga Department of Computer Science University of Pittsburgh Pittsburgh, PA 15260 planting@cs.pitt.edu Abstract A new heuristic for text
An Asymmetric, Semi-adaptive Text Compression Algorithm Harry Plantinga Department of Computer Science University of Pittsburgh Pittsburgh, PA 15260 planting@cs.pitt.edu Abstract A new heuristic for text
CS/COE 1501
 CS/COE 1501 www.cs.pitt.edu/~nlf4/cs1501/ Compression What is compression? Represent the same data using less storage space Can get more use out a disk of a given size Can get more use out of memory E.g.,
CS/COE 1501 www.cs.pitt.edu/~nlf4/cs1501/ Compression What is compression? Represent the same data using less storage space Can get more use out a disk of a given size Can get more use out of memory E.g.,
Announcement. Reading Material. Overview of Query Evaluation. Overview of Query Evaluation. Overview of Query Evaluation 9/26/17
 Announcement CompSci 516 Database Systems Lecture 10 Query Evaluation and Join Algorithms Project proposal pdf due on sakai by 5 pm, tomorrow, Thursday 09/27 One per group by any member Instructor: Sudeepa
Announcement CompSci 516 Database Systems Lecture 10 Query Evaluation and Join Algorithms Project proposal pdf due on sakai by 5 pm, tomorrow, Thursday 09/27 One per group by any member Instructor: Sudeepa
Chapter 6: Information Retrieval and Web Search. An introduction
 Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
CS307 Operating Systems Main Memory
 CS307 Main Memory Fan Wu Department of Computer Science and Engineering Shanghai Jiao Tong University Spring 2018 Background Program must be brought (from disk) into memory and placed within a process
CS307 Main Memory Fan Wu Department of Computer Science and Engineering Shanghai Jiao Tong University Spring 2018 Background Program must be brought (from disk) into memory and placed within a process
File Systems. OS Overview I/O. Swap. Management. Operations CPU. Hard Drive. Management. Memory. Hard Drive. CSI3131 Topics. Structure.
 File Systems I/O Management Hard Drive Management Virtual Memory Swap Memory Management Storage and I/O Introduction CSI3131 Topics Process Management Computing Systems Memory CPU Peripherals Processes
File Systems I/O Management Hard Drive Management Virtual Memory Swap Memory Management Storage and I/O Introduction CSI3131 Topics Process Management Computing Systems Memory CPU Peripherals Processes
Information Retrieval
 Introduction to Information Retrieval Lecture 4: Index Construction Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards This time: Spell correction Soundex Index construction Index
Introduction to Information Retrieval Lecture 4: Index Construction Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards This time: Spell correction Soundex Index construction Index
Indexing Web pages. Web Search: Indexing Web Pages. Indexing the link structure. checkpoint URL s. Connectivity Server: Node table
 Indexing Web pages Web Search: Indexing Web Pages CPS 296.1 Topics in Database Systems Indexing the link structure AltaVista Connectivity Server case study Bharat et al., The Fast Access to Linkage Information
Indexing Web pages Web Search: Indexing Web Pages CPS 296.1 Topics in Database Systems Indexing the link structure AltaVista Connectivity Server case study Bharat et al., The Fast Access to Linkage Information
Kathleen Durant PhD Northeastern University CS Indexes
 Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Lecture 5: Information Retrieval using the Vector Space Model
 Lecture 5: Information Retrieval using the Vector Space Model Trevor Cohn (tcohn@unimelb.edu.au) Slide credits: William Webber COMP90042, 2015, Semester 1 What we ll learn today How to take a user query
Lecture 5: Information Retrieval using the Vector Space Model Trevor Cohn (tcohn@unimelb.edu.au) Slide credits: William Webber COMP90042, 2015, Semester 1 What we ll learn today How to take a user query
Lecture 3 Index Construction and Compression. Many thanks to Prabhakar Raghavan for sharing most content from the following slides
 Lecture 3 Index Construction and Compression Many thanks to Prabhakar Raghavan for sharing most content from the following slides Recap of the previous lecture Tokenization Term equivalence Skip pointers
Lecture 3 Index Construction and Compression Many thanks to Prabhakar Raghavan for sharing most content from the following slides Recap of the previous lecture Tokenization Term equivalence Skip pointers
Logistics. CSE Case Studies. Indexing & Retrieval in Google. Design of Alta Vista. Course Overview. Google System Anatomy
 CSE 454 - Case Studies Indexing & Retrieval in Google Slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Design of Alta Vista Based on a talk by Mike Burrows Group Meetings Starting Tomorrow
CSE 454 - Case Studies Indexing & Retrieval in Google Slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Design of Alta Vista Based on a talk by Mike Burrows Group Meetings Starting Tomorrow
CS377: Database Systems Text data and information. Li Xiong Department of Mathematics and Computer Science Emory University
 CS377: Database Systems Text data and information retrieval Li Xiong Department of Mathematics and Computer Science Emory University Outline Information Retrieval (IR) Concepts Text Preprocessing Inverted
CS377: Database Systems Text data and information retrieval Li Xiong Department of Mathematics and Computer Science Emory University Outline Information Retrieval (IR) Concepts Text Preprocessing Inverted
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable References Bigtable: A Distributed Storage System for Structured Data. Fay Chang et. al. OSDI
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2009 Lecture 12 Google Bigtable References Bigtable: A Distributed Storage System for Structured Data. Fay Chang et. al. OSDI
CS347. Lecture 2 April 9, Prabhakar Raghavan
 CS347 Lecture 2 April 9, 2001 Prabhakar Raghavan Today s topics Inverted index storage Compressing dictionaries into memory Processing Boolean queries Optimizing term processing Skip list encoding Wild-card
CS347 Lecture 2 April 9, 2001 Prabhakar Raghavan Today s topics Inverted index storage Compressing dictionaries into memory Processing Boolean queries Optimizing term processing Skip list encoding Wild-card
Amusing algorithms and data-structures that power Lucene and Elasticsearch. Adrien Grand
 Amusing algorithms and data-structures that power Lucene and Elasticsearch Adrien Grand Agenda conjunctions regexp queries numeric doc values compression cardinality aggregation How are conjunctions implemented?
Amusing algorithms and data-structures that power Lucene and Elasticsearch Adrien Grand Agenda conjunctions regexp queries numeric doc values compression cardinality aggregation How are conjunctions implemented?
Crawler. Crawler. Crawler. Crawler. Anchors. URL Resolver Indexer. Barrels. Doc Index Sorter. Sorter. URL Server
 Authors: Sergey Brin, Lawrence Page Google, word play on googol or 10 100 Centralized system, entire HTML text saved Focused on high precision, even at expense of high recall Relies heavily on document
Authors: Sergey Brin, Lawrence Page Google, word play on googol or 10 100 Centralized system, entire HTML text saved Focused on high precision, even at expense of high recall Relies heavily on document
Today s topics CS347. Inverted index storage. Inverted index storage. Processing Boolean queries. Lecture 2 April 9, 2001 Prabhakar Raghavan
 Today s topics CS347 Lecture 2 April 9, 2001 Prabhakar Raghavan Inverted index storage Compressing dictionaries into memory Processing Boolean queries Optimizing term processing Skip list encoding Wild-card
Today s topics CS347 Lecture 2 April 9, 2001 Prabhakar Raghavan Inverted index storage Compressing dictionaries into memory Processing Boolean queries Optimizing term processing Skip list encoding Wild-card