Section 8. Pig Latin
|
|
|
- Clyde Shelton
- 5 years ago
- Views:
Transcription
1 Section 8 Pig Latin
2 Outline Based on Pig Latin: A not-so-foreign language for data processing, by Olston, Reed, Srivastava, Kumar, and Tomkins,
3 Pig Engine Overview Data model = loosely typed nested relations Query model = a sql-like, dataflow language Execution model: Option 1: run locally on your machine Option 2: compile into sequence of map/reduce, run on a cluster supporting Hadoop Main idea: use Opt1 to debug, Opt2 to execute 3
4 Example Input: a table of urls: (url, category, pagerank) Compute the average pagerank of all sufficiently high pageranks, for each category Return the answers only for categories with sufficiently many such pages 4
5 First in SQL SELECT category, AVG(pagerank) FROM urls WHERE pagerank > 0.2 GROUP By category HAVING COUNT(*) >
6 then in Pig-Latin good_urls = FILTER urls BY pagerank > 0.2 groups = GROUP good_urls BY category big_groups = FILTER groups BY COUNT(good_urls) > 10 6 output = FOREACH big_groups GENERATE category, AVG(good_urls.pagerank) Pig Latin combines high-level declarative querying in the spirit of SQL, and low-level, procedural programming a la map-reduce. 6
7 Types in Pig-Latin Atomic: string or number, e.g. Alice or 55 Tuple: ( Alice, 55, salesperson ) Bag: {( Alice, 55, salesperson ), ( Betty,44, manager ), } Maps: we will try not to use these 7
8 Types in Pig-Latin Bags can be nested! {( a, {1,4,3}), ( c,{ }), ( d, {2,2,5,3,2})} Tuple components can be referenced by number $0, $1, $2, 8
9 9
10 Loading data Input data = FILES! Heard that before? The LOAD command parses an input file into a bag of records Both parser (= deserializer ) and output type are provided by user 10


11 Loading data queries = LOAD query_log.txt USING myload( ) AS (userid, querystring, timestamp) 11
12 Loading data USING userfuction( ) -- is optional Default deserializer expects tab-delimited file AS type is optional Default is a record with unnamed fields; refer to them as $0, $1, The return value of LOAD is just a handle to a bag The actual reading is done in pull mode, or parallelized 12

13 FOREACH expanded_queries = FOREACH queries GENERATE userid, expandquery(querystring) expandquery( ) is a UDF that produces likely expansions Note: it returns a bag, hence expanded_queries is a nested bag 13
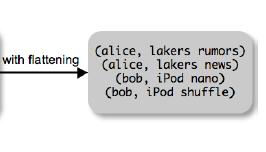
) Now we get a flat collection")
14 FOREACH expanded_queries = FOREACH queries GENERATE userid, flatten(expandquery(querystring)) Now we get a flat collection 14

15 15
16 FLATTEN Note that it is NOT a first class function! First class FLATTEN: FLATTEN({{2,3},{5},{},{4,5,6}}) = {2,3,5,4,5,6} Type: {{T}} {T} Pig-latin FLATTEN FLATTEN({4,5,6}) = 4, 5, 6 Type: {T} T, T, T,, T????? 16
17 FILTER Remove all queries from Web bots: real_queries = FILTER queries BY userid neq bot Better: use a complex UDF to detect Web bots: real_queries = FILTER queries BY NOT isbot(userid) 17
18 JOIN results: revenue: {(querystring, url, position)} {(querystring, adslot, amount)} join_result = JOIN results BY querystring revenue BY querystring join_result : {(querystring, url, position, adslot, amount)} 18

19 19

 AS totalrevenue grouped_revenue: {(querystring, {(adslot,")
20 GROUP BY revenue: {(querystring, adslot, amount)} grouped_revenue = GROUP revenue BY querystring query_revenues = FOREACH grouped_revenue GENERATE querystring, SUM(revenue.amount) AS totalrevenue grouped_revenue: {(querystring, {(adslot, amount)})} query_revenues: {(querystring, totalrevenue)} 20
21 Cogroup A generic way to group tuples from two datasets together 21
}, revenue:{(adslot, amount)})} What is the output type in general?")
22 Co-Group Dataset 1 results: {(querystring, url, position)} Dataset 2 revenue: {(querystring, adslot, amount)} grouped_data = COGROUP results BY querystring, revenue BY querystring; grouped_data: {(querystring, results:{(url, position)}, revenue:{(adslot, amount)})} What is the output type in general? {group_id, bag dataset 1, bag dataset 2} 22

23 Co-Group 23
24 Co-Group grouped_data: {(querystring, results:{(url, position)}, revenue:{(adslot, amount)})} url_revenues = FOREACH grouped_data GENERATE FLATTEN(distributeRevenue(results, revenue)); distributerevenue is a UDF that accepts search results and revenue information for a query string at a time, and outputs a bag of urls and the revenue attributed to them. 24
}, revenue:{(adslot, amount)})} grouped_data = COGROUP results BY querystring,")
25 Co-Group v.s. Join grouped_data: {(querystring, results:{(url, position)}, revenue:{(adslot, amount)})} grouped_data = COGROUP results BY querystring, revenue BY querystring; join_result = FOREACH grouped_data GENERATE FLATTEN(results), FLATTEN(revenue); Result is the same as JOIN 25
26 Asking for Output: STORE STORE query_revenues INTO `myoutput' USING mystore(); Meaning: write query_revenues to the file myoutput This is when the entire query is finally executed! 26

27 First in SQL SELECT category, AVG(pagerank) FROM urls WHERE pagerank > 0.2 GROUP By category HAVING COUNT(*) >
 > 10 6 output = FOREACH big_groups GENERATE category, AVG(good_urls.")
28 then in Pig-Latin good_urls = FILTER urls BY pagerank > 0.2 groups = GROUP good_urls BY category big_groups = FILTER groups BY COUNT(good_urls) > 10 6 output = FOREACH big_groups GENERATE category, AVG(good_urls.pagerank) Pig Latin combines high-level declarative querying in the spirit of SQL, and low-level, procedural programming a la map-reduce. 28
29 Another Example raw (from, to, amount date) raw2 (name, phonenumber) In Pig, how would we write SELECT from, SUM(amount) * FROM transactions * GROUP BY from
30 SQL SELECT from, SUM(amount) * FROM transactions * GROUP BY from PIG grouped = GROUP raw BY from; grouped2 = FOREACH grouped GENERATE $0 as from, SUM(raw.amount) as total;
31 Another Example Extended In Pig, how would we write SELECT from, SUM(amount) * FROM transactions * GROUP BY from HAVING SUM(amount) >= 150 * ORDER BY SUM(amount) DESC;
32 grouped = GROUP raw BY from; grouped2 = FOREACH grouped GENERATE $0 as from, SUM(raw.amount) as total; grouped3 = FILTER grouped2 BY (total >= 150); grouped4 = ORDER grouped3 BY total DESC;
33 Implementation Over Hadoop! Parse query: All between LOAD and STORE one logical plan Logical plan ensemble of MapReduce jobs Each (CO)Group becomes a MapReduce job Other ops merged into Map or Reduce operators 33

34 Implementation 34

35 Query Processing Steps Pig Latin program
Lecture 23: Supplementary slides for Pig Latin. Friday, May 28, 2010
 Lecture 23: Supplementary slides for Pig Latin Friday, May 28, 2010 1 Outline Based entirely on Pig Latin: A not-so-foreign language for data processing, by Olston, Reed, Srivastava, Kumar, and Tomkins,
Lecture 23: Supplementary slides for Pig Latin Friday, May 28, 2010 1 Outline Based entirely on Pig Latin: A not-so-foreign language for data processing, by Olston, Reed, Srivastava, Kumar, and Tomkins,
Introduction to Database Systems CSE 444. Lecture 22: Pig Latin
 Introduction to Database Systems CSE 444 Lecture 22: Pig Latin Outline Based entirely on Pig Latin: A not-so-foreign language for data processing, by Olston, Reed, Srivastava, Kumar, and Tomkins, 2008
Introduction to Database Systems CSE 444 Lecture 22: Pig Latin Outline Based entirely on Pig Latin: A not-so-foreign language for data processing, by Olston, Reed, Srivastava, Kumar, and Tomkins, 2008
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 27: Map Reduce and Pig Latin CSE 344 - Fall 214 1 Announcements HW8 out now, due last Thursday of the qtr You should have received AWS credit code via email.
Introduction to Data Management CSE 344 Lecture 27: Map Reduce and Pig Latin CSE 344 - Fall 214 1 Announcements HW8 out now, due last Thursday of the qtr You should have received AWS credit code via email.
"Big Data" Open Source Systems. CS347: Map-Reduce & Pig. Motivation for Map-Reduce. Building Text Index - Part II. Building Text Index - Part I
 "Big Data" Open Source Systems CS347: Map-Reduce & Pig Hector Garcia-Molina Stanford University Infrastructure for distributed data computations Map-Reduce, S4, Hyracks, Pregel [Storm, Mupet] Components
"Big Data" Open Source Systems CS347: Map-Reduce & Pig Hector Garcia-Molina Stanford University Infrastructure for distributed data computations Map-Reduce, S4, Hyracks, Pregel [Storm, Mupet] Components
Outline. MapReduce Data Model. MapReduce. Step 2: the REDUCE Phase. Step 1: the MAP Phase 11/29/11. Introduction to Data Management CSE 344
 Outline Introduction to Data Management CSE 344 Review of MapReduce Introduction to Pig System Pig Latin tutorial Lecture 23: Pig Latin Some slides are courtesy of Alan Gates, Yahoo!Research 1 2 MapReduce
Outline Introduction to Data Management CSE 344 Review of MapReduce Introduction to Pig System Pig Latin tutorial Lecture 23: Pig Latin Some slides are courtesy of Alan Gates, Yahoo!Research 1 2 MapReduce
Pig Latin: A Not-So-Foreign Language for Data Processing
 Pig Latin: A Not-So-Foreign Language for Data Processing Christopher Olston, Benjamin Reed, Utkarsh Srivastava, Ravi Kumar, Andrew Tomkins (Yahoo! Research) Presented by Aaron Moss (University of Waterloo)
Pig Latin: A Not-So-Foreign Language for Data Processing Christopher Olston, Benjamin Reed, Utkarsh Srivastava, Ravi Kumar, Andrew Tomkins (Yahoo! Research) Presented by Aaron Moss (University of Waterloo)
Pig Latin. Dominique Fonteyn Wim Leers. Universiteit Hasselt
 Pig Latin Dominique Fonteyn Wim Leers Universiteit Hasselt Pig Latin...... is an English word game in which we place the rst letter of a word at the end and add the sux -ay. Pig Latin becomes igpay atinlay
Pig Latin Dominique Fonteyn Wim Leers Universiteit Hasselt Pig Latin...... is an English word game in which we place the rst letter of a word at the end and add the sux -ay. Pig Latin becomes igpay atinlay
Data Management in the Cloud PIG LATIN AND HIVE. The Google Stack. Sawzall. Map/Reduce. Bigtable GFS
 Data Management in the Cloud PIG LATIN AND HIVE 191 The Google Stack Sawzall Map/Reduce Bigtable GFS 192 The Hadoop Stack SQUEEQL! ZZZZZQL! EXCUSEZ- MOI?!? Pig/Pig Latin Hive REALLY!?! Hadoop HDFS At your
Data Management in the Cloud PIG LATIN AND HIVE 191 The Google Stack Sawzall Map/Reduce Bigtable GFS 192 The Hadoop Stack SQUEEQL! ZZZZZQL! EXCUSEZ- MOI?!? Pig/Pig Latin Hive REALLY!?! Hadoop HDFS At your
Data-intensive computing systems
 Data-intensive computing systems High-Level Languages University of Verona Computer Science Department Damiano Carra Acknowledgements! Credits Part of the course material is based on slides provided by
Data-intensive computing systems High-Level Languages University of Verona Computer Science Department Damiano Carra Acknowledgements! Credits Part of the course material is based on slides provided by
1.2 Why Not Use SQL or Plain MapReduce?
 1. Introduction The Pig system and the Pig Latin programming language were first proposed in 2008 in a top-tier database research conference: Christopher Olston, Benjamin Reed, Utkarsh Srivastava, Ravi
1. Introduction The Pig system and the Pig Latin programming language were first proposed in 2008 in a top-tier database research conference: Christopher Olston, Benjamin Reed, Utkarsh Srivastava, Ravi
Pig Latin: A Not-So-Foreign Language for Data Processing
 Pig Latin: A Not-So-Foreign Language for Data Processing Christopher Olston Yahoo! Research Ravi Kumar Yahoo! Research Benjamin Reed Yahoo! Research Andrew Tomkins Yahoo! Research Utkarsh Srivastava Yahoo!
Pig Latin: A Not-So-Foreign Language for Data Processing Christopher Olston Yahoo! Research Ravi Kumar Yahoo! Research Benjamin Reed Yahoo! Research Andrew Tomkins Yahoo! Research Utkarsh Srivastava Yahoo!
Motivation: Building a Text Index. CS 347 Distributed Databases and Transaction Processing Distributed Data Processing Using MapReduce
 Motivation: Building a Text Index CS 347 Distributed Databases and Transaction Processing Distributed Data Processing Using MapReduce Hector Garcia-Molina Zoltan Gyongyi Web page stream 1 rat dog 2 dog
Motivation: Building a Text Index CS 347 Distributed Databases and Transaction Processing Distributed Data Processing Using MapReduce Hector Garcia-Molina Zoltan Gyongyi Web page stream 1 rat dog 2 dog
Going beyond MapReduce
 Going beyond MapReduce MapReduce provides a simple abstraction to write distributed programs running on large-scale systems on large amounts of data MapReduce is not suitable for everyone MapReduce abstraction
Going beyond MapReduce MapReduce provides a simple abstraction to write distributed programs running on large-scale systems on large amounts of data MapReduce is not suitable for everyone MapReduce abstraction
The Hadoop Stack, Part 1 Introduction to Pig Latin. CSE Cloud Computing Fall 2018 Prof. Douglas Thain University of Notre Dame
 The Hadoop Stack, Part 1 Introduction to Pig Latin CSE 40822 Cloud Computing Fall 2018 Prof. Douglas Thain University of Notre Dame Three Case Studies Workflow: Pig Latin A dataflow language and execution
The Hadoop Stack, Part 1 Introduction to Pig Latin CSE 40822 Cloud Computing Fall 2018 Prof. Douglas Thain University of Notre Dame Three Case Studies Workflow: Pig Latin A dataflow language and execution
Declarative MapReduce 10/29/2018 1
 Declarative Reduce 10/29/2018 1 Reduce Examples Filter Aggregate Grouped aggregated Reduce Reduce Equi-join Reduce Non-equi-join Reduce 10/29/2018 2 Declarative Languages Describe what you want to do not
Declarative Reduce 10/29/2018 1 Reduce Examples Filter Aggregate Grouped aggregated Reduce Reduce Equi-join Reduce Non-equi-join Reduce 10/29/2018 2 Declarative Languages Describe what you want to do not
Pig A language for data processing in Hadoop
 Pig A language for data processing in Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Apache Pig: Introduction Tool for querying data on Hadoop
Pig A language for data processing in Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Apache Pig: Introduction Tool for querying data on Hadoop
The Pig Experience. A. Gates et al., VLDB 2009
 The Pig Experience A. Gates et al., VLDB 2009 Why not Map-Reduce? Does not directly support complex N-Step dataflows All operations have to be expressed using MR primitives Lacks explicit support for processing
The Pig Experience A. Gates et al., VLDB 2009 Why not Map-Reduce? Does not directly support complex N-Step dataflows All operations have to be expressed using MR primitives Lacks explicit support for processing
Distributed Data Management Summer Semester 2013 TU Kaiserslautern
 Distributed Data Management Summer Semester 2013 TU Kaiserslautern Dr.- Ing. Sebas4an Michel smichel@mmci.uni- saarland.de Distributed Data Management, SoSe 2013, S. Michel 1 Lecture 4 PIG/HIVE Distributed
Distributed Data Management Summer Semester 2013 TU Kaiserslautern Dr.- Ing. Sebas4an Michel smichel@mmci.uni- saarland.de Distributed Data Management, SoSe 2013, S. Michel 1 Lecture 4 PIG/HIVE Distributed
Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09. Presented by: Daniel Isaacs
 Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09 Presented by: Daniel Isaacs It all starts with cluster computing. MapReduce Why
Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09 Presented by: Daniel Isaacs It all starts with cluster computing. MapReduce Why
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 28: Map Reduce Wrapup, slides on Pig Latin CSE 344 - Fall 2013 1 Announcements HW8 due on Friday Message from Daseul: don t use PARALLEL Final exam: 12/11/2013,
Introduction to Data Management CSE 344 Lecture 28: Map Reduce Wrapup, slides on Pig Latin CSE 344 - Fall 2013 1 Announcements HW8 due on Friday Message from Daseul: don t use PARALLEL Final exam: 12/11/2013,
Hadoop is supplemented by an ecosystem of open source projects IBM Corporation. How to Analyze Large Data Sets in Hadoop
 Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Big Data for Oracle DBAs. Arup Nanda
 Big Data for Oracle DBAs Arup Nanda fcrawler.looksmart.com - - [26/Apr/2000:00:00:12-0400] "GET /contacts.html HTTP/1.0" 200 4595 "-" "FAST-WebCrawler/2.1-pre2 (ashen@looksmart.net)" fcrawle fcrawler.looksmart.com
Big Data for Oracle DBAs Arup Nanda fcrawler.looksmart.com - - [26/Apr/2000:00:00:12-0400] "GET /contacts.html HTTP/1.0" 200 4595 "-" "FAST-WebCrawler/2.1-pre2 (ashen@looksmart.net)" fcrawle fcrawler.looksmart.com
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2014/15
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2014/15 Hadoop Evolution and Ecosystem Hadoop Map/Reduce has been an incredible success, but not everybody is happy with it 3 DB
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2014/15 Hadoop Evolution and Ecosystem Hadoop Map/Reduce has been an incredible success, but not everybody is happy with it 3 DB
Dr. Chuck Cartledge. 18 Feb. 2015
 CS-495/595 Pig Lecture #6 Dr. Chuck Cartledge 18 Feb. 2015 1/18 Table of contents I 1 Miscellanea 2 The Book 3 Chapter 11 4 Conclusion 5 References 2/18 Corrections and additions since last lecture. Completed
CS-495/595 Pig Lecture #6 Dr. Chuck Cartledge 18 Feb. 2015 1/18 Table of contents I 1 Miscellanea 2 The Book 3 Chapter 11 4 Conclusion 5 References 2/18 Corrections and additions since last lecture. Completed
this is so cumbersome!
 Pig Arend Hintze this is so cumbersome! Instead of programming everything in java MapReduce or streaming: wouldn t it we wonderful to have a simpler interface? Problem: break down complex MapReduce tasks
Pig Arend Hintze this is so cumbersome! Instead of programming everything in java MapReduce or streaming: wouldn t it we wonderful to have a simpler interface? Problem: break down complex MapReduce tasks
Scaling Up Pig. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
International Journal of Computer Engineering and Applications, BIG DATA ANALYTICS USING APACHE PIG Prabhjot Kaur
 Prabhjot Kaur Department of Computer Engineering ME CSE(BIG DATA ANALYTICS)-CHANDIGARH UNIVERSITY,GHARUAN kaurprabhjot770@gmail.com ABSTRACT: In today world, as we know data is expanding along with the
Prabhjot Kaur Department of Computer Engineering ME CSE(BIG DATA ANALYTICS)-CHANDIGARH UNIVERSITY,GHARUAN kaurprabhjot770@gmail.com ABSTRACT: In today world, as we know data is expanding along with the
Data Cleansing some important elements
 1 Kunal Jain, Praveen Kumar Tripathi Dept of CSE & IT (JUIT) Data Cleansing some important elements Genoveva Vargas-Solar CR1, CNRS, LIG-LAFMIA Genoveva.Vargas@imag.fr http://vargas-solar.com, Montevideo,
1 Kunal Jain, Praveen Kumar Tripathi Dept of CSE & IT (JUIT) Data Cleansing some important elements Genoveva Vargas-Solar CR1, CNRS, LIG-LAFMIA Genoveva.Vargas@imag.fr http://vargas-solar.com, Montevideo,
Scaling Up Pig. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Actian Vector Benchmarks. Cloud Benchmarking Summary Report
 Actian Vector Benchmarks Cloud Benchmarking Summary Report April 2018 The Cloud Database Performance Benchmark Executive Summary The table below shows Actian Vector as evaluated against Amazon Redshift,
Actian Vector Benchmarks Cloud Benchmarking Summary Report April 2018 The Cloud Database Performance Benchmark Executive Summary The table below shows Actian Vector as evaluated against Amazon Redshift,
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
GLADE: A Scalable Framework for Efficient Analytics. Florin Rusu (University of California, Merced) Alin Dobra (University of Florida)
 Alin Dobra (University of Florida)") DE: A Scalable Framework for Efficient Analytics Florin Rusu (University of California, Merced) Alin Dobra (University of Florida) Big Data Analytics Big Data Storage is cheap ($100 for 1TB disk) Everything
DE: A Scalable Framework for Efficient Analytics Florin Rusu (University of California, Merced) Alin Dobra (University of Florida) Big Data Analytics Big Data Storage is cheap ($100 for 1TB disk) Everything
Beyond Hive Pig and Python
 Beyond Hive Pig and Python What is Pig? Pig performs a series of transformations to data relations based on Pig Latin statements Relations are loaded using schema on read semantics to project table structure
Beyond Hive Pig and Python What is Pig? Pig performs a series of transformations to data relations based on Pig Latin statements Relations are loaded using schema on read semantics to project table structure
Programming and Debugging Large- Scale Data Processing Workflows
 Programming and Debugging Large- Scale Data Processing Workflows Christopher Olston Google Research (work done at Yahoo! Research, with many colleagues) Big- Data AnalyHcs @ Yahoo: Use Cases web search
Programming and Debugging Large- Scale Data Processing Workflows Christopher Olston Google Research (work done at Yahoo! Research, with many colleagues) Big- Data AnalyHcs @ Yahoo: Use Cases web search
Pig Latin Reference Manual 1
 Table of contents 1 Overview.2 2 Pig Latin Statements. 2 3 Multi-Query Execution 5 4 Specialized Joins..10 5 Optimization Rules. 13 6 Memory Management15 7 Zebra Integration..15 1. Overview Use this manual
Table of contents 1 Overview.2 2 Pig Latin Statements. 2 3 Multi-Query Execution 5 4 Specialized Joins..10 5 Optimization Rules. 13 6 Memory Management15 7 Zebra Integration..15 1. Overview Use this manual
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Hadoop ecosystem. Nikos Parlavantzas
 1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
1 Hadoop ecosystem Nikos Parlavantzas Lecture overview 2 Objective Provide an overview of a selection of technologies in the Hadoop ecosystem Hadoop ecosystem 3 Hadoop ecosystem 4 Outline 5 HBase Hive
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
International Journal of Advance Research in Engineering, Science & Technology
 Impact Factor (SJIF): 3.632 International Journal of Advance Research in Engineering, Science & Technology e-issn: 2393-9877, p-issn: 2394-2444 Volume 3, Issue 2, February-2016 A SURVEY ON HADOOP PIG SYSTEM
Impact Factor (SJIF): 3.632 International Journal of Advance Research in Engineering, Science & Technology e-issn: 2393-9877, p-issn: 2394-2444 Volume 3, Issue 2, February-2016 A SURVEY ON HADOOP PIG SYSTEM
MAP-REDUCE ABSTRACTIONS
 MAP-REDUCE ABSTRACTIONS 1 Abstractions On Top Of Hadoop We ve decomposed some algorithms into a map- reduce work9low (series of map- reduce steps) naive Bayes training naïve Bayes testing phrase scoring
MAP-REDUCE ABSTRACTIONS 1 Abstractions On Top Of Hadoop We ve decomposed some algorithms into a map- reduce work9low (series of map- reduce steps) naive Bayes training naïve Bayes testing phrase scoring
Index. Symbols A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
 Symbols A B C D E F G H I J K L M N O P Q R S T U V W X Y Z Symbols + addition operator?: bincond operator /* */ comments - multi-line -- comments - single-line # deference operator (map). deference operator
Symbols A B C D E F G H I J K L M N O P Q R S T U V W X Y Z Symbols + addition operator?: bincond operator /* */ comments - multi-line -- comments - single-line # deference operator (map). deference operator
Pig on Spark project proposes to add Spark as an execution engine option for Pig, similar to current options of MapReduce and Tez.
 Pig on Spark Mohit Sabharwal and Xuefu Zhang, 06/30/2015 Objective The initial patch of Pig on Spark feature was delivered by Sigmoid Analytics in September 2014. Since then, there has been effort by a
Pig on Spark Mohit Sabharwal and Xuefu Zhang, 06/30/2015 Objective The initial patch of Pig on Spark feature was delivered by Sigmoid Analytics in September 2014. Since then, there has been effort by a
Query processing on raw files. Vítor Uwe Reus
 Query processing on raw files Vítor Uwe Reus Outline 1. Introduction 2. Adaptive Indexing 3. Hybrid MapReduce 4. NoDB 5. Summary Outline 1. Introduction 2. Adaptive Indexing 3. Hybrid MapReduce 4. NoDB
Query processing on raw files Vítor Uwe Reus Outline 1. Introduction 2. Adaptive Indexing 3. Hybrid MapReduce 4. NoDB 5. Summary Outline 1. Introduction 2. Adaptive Indexing 3. Hybrid MapReduce 4. NoDB
Hadoop Ecosystem. Why an ecosystem
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Hadoop Ecosystem Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini Why an
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Hadoop Ecosystem Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini Why an
Large Scale OLAP. Yifu Huang. 2014/11/4 MAST Scientific English Writing Report
 Large Scale OLAP Yifu Huang 2014/11/4 MAST612117 Scientific English Writing Report 2014 1 Preliminaries OLAP On-Line Analytical Processing Traditional solutions: data warehouses built by parallel databases
Large Scale OLAP Yifu Huang 2014/11/4 MAST612117 Scientific English Writing Report 2014 1 Preliminaries OLAP On-Line Analytical Processing Traditional solutions: data warehouses built by parallel databases
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica. Hadoop Ecosystem
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Hadoop Ecosystem Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini Why an
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Hadoop Ecosystem Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini Why an
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 4: Apache Pig Aidan Hogan aidhog@gmail.com HADOOP: WRAPPING UP 0. Reading/Writing to HDFS Creates a file system for default configuration Check
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 4: Apache Pig Aidan Hogan aidhog@gmail.com HADOOP: WRAPPING UP 0. Reading/Writing to HDFS Creates a file system for default configuration Check
Yahoo! manages more than 42,000 Hadoop nodes holding 200 PBs. more than 22 organizations are running PB-scale Hadoop clusters
 An Optimization Framework for Map-Reduce Queries Leonidas Fegaras Chengkai Li Upa Gupta University of Texas at Arlington http://lambda.uta.edu/mrql/ Alternatives to MR Compared to a parallel RDB, the MR
An Optimization Framework for Map-Reduce Queries Leonidas Fegaras Chengkai Li Upa Gupta University of Texas at Arlington http://lambda.uta.edu/mrql/ Alternatives to MR Compared to a parallel RDB, the MR
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Fault Tolerance in K3. Ben Glickman, Amit Mehta, Josh Wheeler
 Fault Tolerance in K3 Ben Glickman, Amit Mehta, Josh Wheeler Outline Background Motivation Detecting Membership Changes with Spread Modes of Fault Tolerance in K3 Demonstration Outline Background Motivation
Fault Tolerance in K3 Ben Glickman, Amit Mehta, Josh Wheeler Outline Background Motivation Detecting Membership Changes with Spread Modes of Fault Tolerance in K3 Demonstration Outline Background Motivation
Getting Started. Table of contents. 1 Pig Setup Running Pig Pig Latin Statements Pig Properties Pig Tutorial...
 Table of contents 1 Pig Setup... 2 2 Running Pig... 3 3 Pig Latin Statements... 6 4 Pig Properties... 8 5 Pig Tutorial... 9 1. Pig Setup 1.1. Requirements Mandatory Unix and Windows users need the following:
Table of contents 1 Pig Setup... 2 2 Running Pig... 3 3 Pig Latin Statements... 6 4 Pig Properties... 8 5 Pig Tutorial... 9 1. Pig Setup 1.1. Requirements Mandatory Unix and Windows users need the following:
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Templates for Supporting Sequenced Temporal Semantics in Pig Latin
 Utah State University DigitalCommons@USU All Graduate Plan B and other Reports Graduate Studies 5-2011 Templates for Supporting Sequenced Temporal Semantics in Pig Latin Dhaval Deshpande Utah State University
Utah State University DigitalCommons@USU All Graduate Plan B and other Reports Graduate Studies 5-2011 Templates for Supporting Sequenced Temporal Semantics in Pig Latin Dhaval Deshpande Utah State University
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
POS: A High-Level System to Simplify Real-Time Stream Application Development on Storm
 Data Sci. Eng. DOI 10.1007/s41019-015-0002-9 REGULAR PAPER POS: A High-Level System to Simplify Real-Time Stream Application Development on Storm Bin Cui 1 Jie Jiang 2 Quanlong Huang 1 Ying Xu 1 Yanjun
Data Sci. Eng. DOI 10.1007/s41019-015-0002-9 REGULAR PAPER POS: A High-Level System to Simplify Real-Time Stream Application Development on Storm Bin Cui 1 Jie Jiang 2 Quanlong Huang 1 Ying Xu 1 Yanjun
MRBench : A Benchmark for Map-Reduce Framework
 MRBench : A Benchmark for Map-Reduce Framework Kiyoung Kim, Kyungho Jeon, Hyuck Han, Shin-gyu Kim, Hyungsoo Jung, Heon Y. Yeom School of Computer Science and Engineering Seoul National University Seoul
MRBench : A Benchmark for Map-Reduce Framework Kiyoung Kim, Kyungho Jeon, Hyuck Han, Shin-gyu Kim, Hyungsoo Jung, Heon Y. Yeom School of Computer Science and Engineering Seoul National University Seoul
Apache Pig Releases. Table of contents
 Table of contents 1 Download...3 2 News... 3 2.1 19 June, 2017: release 0.17.0 available...3 2.2 8 June, 2016: release 0.16.0 available...3 2.3 6 June, 2015: release 0.15.0 available...3 2.4 20 November,
Table of contents 1 Download...3 2 News... 3 2.1 19 June, 2017: release 0.17.0 available...3 2.2 8 June, 2016: release 0.16.0 available...3 2.3 6 June, 2015: release 0.15.0 available...3 2.4 20 November,
IN ACTION. Chuck Lam SAMPLE CHAPTER MANNING
 IN ACTION Chuck Lam SAMPLE CHAPTER MANNING Hadoop in Action by Chuck Lam Chapter 10 Copyright 2010 Manning Publications brief contents PART I HADOOP A DISTRIBUTED PROGRAMMING FRAMEWORK... 1 1 Introducing
IN ACTION Chuck Lam SAMPLE CHAPTER MANNING Hadoop in Action by Chuck Lam Chapter 10 Copyright 2010 Manning Publications brief contents PART I HADOOP A DISTRIBUTED PROGRAMMING FRAMEWORK... 1 1 Introducing
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Hive Cloudera, Inc.
 Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
Big Data and Hadoop. Course Curriculum: Your 10 Module Learning Plan. About Edureka
 Course Curriculum: Your 10 Module Learning Plan Big Data and Hadoop About Edureka Edureka is a leading e-learning platform providing live instructor-led interactive online training. We cater to professionals
Course Curriculum: Your 10 Module Learning Plan Big Data and Hadoop About Edureka Edureka is a leading e-learning platform providing live instructor-led interactive online training. We cater to professionals
Scaling Up 1 CSE 6242 / CX Duen Horng (Polo) Chau Georgia Tech. Hadoop, Pig
 Chau Georgia Tech. Hadoop, Pig") CSE 6242 / CX 4242 Scaling Up 1 Hadoop, Pig Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
CSE 6242 / CX 4242 Scaling Up 1 Hadoop, Pig Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads
 HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads Azza Abouzeid, Kamil Bajda-Pawlikowski, Daniel J. Abadi, Alexander Rasin and Avi Silberschatz Presented by
HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads Azza Abouzeid, Kamil Bajda-Pawlikowski, Daniel J. Abadi, Alexander Rasin and Avi Silberschatz Presented by
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
A Review Paper on Big data & Hadoop
 A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
KAMD: A Progress Estimator for MapReduce Pipelines
 KAMD: A Progress Estimator for MapReduce Pipelines Kristi Morton, Abe Friesen University of Washington Seattle, WA {kmorton,afriesen}@cs.washington.edu ABSTRACT Limited user-feedback exists in cluster
KAMD: A Progress Estimator for MapReduce Pipelines Kristi Morton, Abe Friesen University of Washington Seattle, WA {kmorton,afriesen}@cs.washington.edu ABSTRACT Limited user-feedback exists in cluster
RAPID: Enabling Scalable Ad-Hoc Analytics on the Semantic Web
 RAPID: Enabling Scalable Ad-Hoc Analytics on the Semantic Web Radhika Sridhar, Padmashree Ravindra, Kemafor Anyanwu North Carolina State University {rsridha, pravind2, kogan}@ncsu.edu Abstract. As the
RAPID: Enabling Scalable Ad-Hoc Analytics on the Semantic Web Radhika Sridhar, Padmashree Ravindra, Kemafor Anyanwu North Carolina State University {rsridha, pravind2, kogan}@ncsu.edu Abstract. As the
COSC 6339 Big Data Analytics. Hadoop MapReduce Infrastructure: Pig, Hive, and Mahout. Edgar Gabriel Fall Pig
 COSC 6339 Big Data Analytics Hadoop MapReduce Infrastructure: Pig, Hive, and Mahout Edgar Gabriel Fall 2018 Pig Pig is a platform for analyzing large data sets abstraction on top of Hadoop Provides high
COSC 6339 Big Data Analytics Hadoop MapReduce Infrastructure: Pig, Hive, and Mahout Edgar Gabriel Fall 2018 Pig Pig is a platform for analyzing large data sets abstraction on top of Hadoop Provides high
MapReduce-II. September 2013 Alberto Abelló & Oscar Romero 1
 MapReduce-II September 2013 Alberto Abelló & Oscar Romero 1 Knowledge objectives 1. Enumerate the different kind of processes in the MapReduce framework 2. Explain the information kept in the master 3.
MapReduce-II September 2013 Alberto Abelló & Oscar Romero 1 Knowledge objectives 1. Enumerate the different kind of processes in the MapReduce framework 2. Explain the information kept in the master 3.
Data Warehousing. Jens Teubner, TU Dortmund Winter 2014/15. Jens Teubner Data Warehousing Winter 2014/15 1
 Jens Teubner Data Warehousing Winter 2014/15 1 Data Warehousing Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Winter 2014/15 Jens Teubner Data Warehousing Winter 2014/15 180 Part VII MapReduce
Jens Teubner Data Warehousing Winter 2014/15 1 Data Warehousing Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Winter 2014/15 Jens Teubner Data Warehousing Winter 2014/15 180 Part VII MapReduce
data parallelism Chris Olston Yahoo! Research
 data parallelism Chris Olston Yahoo! Research set-oriented computation data management operations tend to be set-oriented, e.g.: apply f() to each member of a set compute intersection of two sets easy
data parallelism Chris Olston Yahoo! Research set-oriented computation data management operations tend to be set-oriented, e.g.: apply f() to each member of a set compute intersection of two sets easy
Getting Started. Table of contents. 1 Pig Setup Running Pig Pig Latin Statements Pig Properties Pig Tutorial...
 Table of contents 1 Pig Setup... 2 2 Running Pig... 3 3 Pig Latin Statements... 6 4 Pig Properties... 8 5 Pig Tutorial... 9 1 Pig Setup 1.1 Requirements Mandatory Unix and Windows users need the following:
Table of contents 1 Pig Setup... 2 2 Running Pig... 3 3 Pig Latin Statements... 6 4 Pig Properties... 8 5 Pig Tutorial... 9 1 Pig Setup 1.1 Requirements Mandatory Unix and Windows users need the following:
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
DATA MINING II - 1DL460
 DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
Practical Big Data Processing An Overview of Apache Flink
 Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
1. Stratified sampling is advantageous when sampling each stratum independently.
 Quiz 1. 1. Stratified sampling is advantageous when sampling each stratum independently. 2. All outliers within a dataset are invalid observations. 3. Consider a dataset comprising a set of (single value)
Quiz 1. 1. Stratified sampling is advantageous when sampling each stratum independently. 2. All outliers within a dataset are invalid observations. 3. Consider a dataset comprising a set of (single value)
Today s Papers. Architectural Differences. EECS 262a Advanced Topics in Computer Systems Lecture 17
 EECS 262a Advanced Topics in Computer Systems Lecture 17 Comparison of Parallel DB, CS, MR and Jockey October 30 th, 2013 John Kubiatowicz and Anthony D. Joseph Electrical Engineering and Computer Sciences
EECS 262a Advanced Topics in Computer Systems Lecture 17 Comparison of Parallel DB, CS, MR and Jockey October 30 th, 2013 John Kubiatowicz and Anthony D. Joseph Electrical Engineering and Computer Sciences
Introduction to Apache Pig ja Hive
 Introduction to Apache Pig ja Hive Pelle Jakovits 30 September, 2014, Tartu Outline Why Pig or Hive instead of MapReduce Apache Pig Pig Latin language Examples Architecture Hive Hive Query Language Examples
Introduction to Apache Pig ja Hive Pelle Jakovits 30 September, 2014, Tartu Outline Why Pig or Hive instead of MapReduce Apache Pig Pig Latin language Examples Architecture Hive Hive Query Language Examples
Carnegie Mellon Univ. Dept. of Computer Science /615 - DB Applications. Administrivia Final Exam. Administrivia Final Exam
 Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB Applications C. Faloutsos A. Pavlo Lecture#28: Modern Database Systems Administrivia Final Exam Who: You What: R&G Chapters 15-22 When: Tuesday
Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB Applications C. Faloutsos A. Pavlo Lecture#28: Modern Database Systems Administrivia Final Exam Who: You What: R&G Chapters 15-22 When: Tuesday
Techno Expert Solutions An institute for specialized studies!
 Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
OLTP vs. OLAP Carnegie Mellon Univ. Dept. of Computer Science /615 - DB Applications
 OLTP vs. OLAP Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB Applications C. Faloutsos A. Pavlo Lecture#25: OldSQL vs. NoSQL vs. NewSQL On-line Transaction Processing: Short-lived txns.
OLTP vs. OLAP Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB Applications C. Faloutsos A. Pavlo Lecture#25: OldSQL vs. NoSQL vs. NewSQL On-line Transaction Processing: Short-lived txns.
Compile-Time Code Generation for Embedded Data-Intensive Query Languages
 Compile-Time Code Generation for Embedded Data-Intensive Query Languages Leonidas Fegaras University of Texas at Arlington http://lambda.uta.edu/ Outline Emerging DISC (Data-Intensive Scalable Computing)
Compile-Time Code Generation for Embedded Data-Intensive Query Languages Leonidas Fegaras University of Texas at Arlington http://lambda.uta.edu/ Outline Emerging DISC (Data-Intensive Scalable Computing)
Shell and Utility Commands
 Table of contents 1 Shell Commands... 2 2 Utility Commands...3 1. Shell Commands 1.1. fs Invokes any FsShell command from within a Pig script or the Grunt shell. 1.1.1. Syntax fs subcommand subcommand_parameters
Table of contents 1 Shell Commands... 2 2 Utility Commands...3 1. Shell Commands 1.1. fs Invokes any FsShell command from within a Pig script or the Grunt shell. 1.1.1. Syntax fs subcommand subcommand_parameters
Query Processing and Advanced Queries. Query Optimization (4)
") Query Processing and Advanced Queries Query Optimization (4) Two-Pass Algorithms Based on Hashing R./S If both input relations R and S are too large to be stored in the buffer, hash all the tuples of both
Query Processing and Advanced Queries Query Optimization (4) Two-Pass Algorithms Based on Hashing R./S If both input relations R and S are too large to be stored in the buffer, hash all the tuples of both
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
GLADE: A Scalable Framework for Efficient Analytics
 DE: A Scalable Framework for Efficient Analytics Florin Rusu University of California, Merced 52 N Lake Road Merced, CA 95343 frusu@ucmerced.edu Alin Dobra University of Florida PO Box 11612 Gainesville,
DE: A Scalable Framework for Efficient Analytics Florin Rusu University of California, Merced 52 N Lake Road Merced, CA 95343 frusu@ucmerced.edu Alin Dobra University of Florida PO Box 11612 Gainesville,
Tutorial Outline. Map/Reduce vs. DBMS. MR vs. DBMS [DeWitt and Stonebraker 2008] Acknowledgements. MR is a step backwards in database access
![Tutorial Outline. Map/Reduce vs. DBMS. MR vs. DBMS [DeWitt and Stonebraker 2008] Acknowledgements. MR is a step backwards in database access](/thumbs/92/110435840.jpg "Tutorial Outline. Map/Reduce vs. DBMS. MR vs. DBMS [DeWitt and Stonebraker 2008] Acknowledgements. MR is a step backwards in database access") Map/Reduce vs. DBMS Sharma Chakravarthy Information Technology Laboratory Computer Science and Engineering Department The University of Texas at Arlington, Arlington, TX 76009 Email: sharma@cse.uta.edu
Map/Reduce vs. DBMS Sharma Chakravarthy Information Technology Laboratory Computer Science and Engineering Department The University of Texas at Arlington, Arlington, TX 76009 Email: sharma@cse.uta.edu
Dremel: Interac-ve Analysis of Web- Scale Datasets
 Dremel: Interac-ve Analysis of Web- Scale Datasets Google Inc VLDB 2010 presented by Arka BhaEacharya some slides adapted from various Dremel presenta-ons on the internet The Problem: Interactive data
Dremel: Interac-ve Analysis of Web- Scale Datasets Google Inc VLDB 2010 presented by Arka BhaEacharya some slides adapted from various Dremel presenta-ons on the internet The Problem: Interactive data
Impala. A Modern, Open Source SQL Engine for Hadoop. Yogesh Chockalingam
 Impala A Modern, Open Source SQL Engine for Hadoop Yogesh Chockalingam Agenda Introduction Architecture Front End Back End Evaluation Comparison with Spark SQL Introduction Why not use Hive or HBase?
Impala A Modern, Open Source SQL Engine for Hadoop Yogesh Chockalingam Agenda Introduction Architecture Front End Back End Evaluation Comparison with Spark SQL Introduction Why not use Hive or HBase?
SQL-to-MapReduce Translation for Efficient OLAP Query Processing
 , pp.61-70 http://dx.doi.org/10.14257/ijdta.2017.10.6.05 SQL-to-MapReduce Translation for Efficient OLAP Query Processing with MapReduce Hyeon Gyu Kim Department of Computer Engineering, Sahmyook University,
, pp.61-70 http://dx.doi.org/10.14257/ijdta.2017.10.6.05 SQL-to-MapReduce Translation for Efficient OLAP Query Processing with MapReduce Hyeon Gyu Kim Department of Computer Engineering, Sahmyook University,
Distributed Computing
 Distributed Computing Web Data Management http://webdam.inria.fr/jorge/ S. Abiteboul, I. Manolescu, P. Rigaux, M.-C. Rousset, P. Senellart July 19, 2011 Outline MapReduce Introduction The MapReduce Computing
Distributed Computing Web Data Management http://webdam.inria.fr/jorge/ S. Abiteboul, I. Manolescu, P. Rigaux, M.-C. Rousset, P. Senellart July 19, 2011 Outline MapReduce Introduction The MapReduce Computing
Evolution From Shark To Spark SQL:
 Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
RESTORE: REUSING RESULTS OF MAPREDUCE JOBS. Presented by: Ahmed Elbagoury
 RESTORE: REUSING RESULTS OF MAPREDUCE JOBS Presented by: Ahmed Elbagoury Outline Background & Motivation What is Restore? Types of Result Reuse System Architecture Experiments Conclusion Discussion Background
RESTORE: REUSING RESULTS OF MAPREDUCE JOBS Presented by: Ahmed Elbagoury Outline Background & Motivation What is Restore? Types of Result Reuse System Architecture Experiments Conclusion Discussion Background
Expert Lecture plan proposal Hadoop& itsapplication
 Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
DryadLINQ. Distributed Computation. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India
 Dryad Distributed Computation Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Distributed Batch Processing 1/34 Outline Motivation 1 Motivation
Dryad Distributed Computation Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Distributed Batch Processing 1/34 Outline Motivation 1 Motivation