Data Warehousing. Syllabus. An Introduction to Oracle Warehouse Builder. Index
|
|
|
- Della Casey
- 5 years ago
- Views:
Transcription
1 Data Warehousing Syllabus Unit-I Unit-II Unit-III Unit-IV Unit-V Unit-VI Introduction to Data Warehousing Data Warehousing Design Consideration and Dimensional Modeling An Introduction to Oracle Warehouse Builder Defining and Importing Source Data Structures Designing the Target Structure Creating the Target Structure in OWB Extract, Transform, and Load Basics Designing and building an ETL mapping ETL: Transformations and Other Operators Validating, Generating, Deploying, and Executing Objects Extra Features Data warehousing and OLAP Index Sr. No Topic Page No 1 Introduction to Data Warehousing Data Warehousing Design Consideration and Dimensional Modeling An Introduction to Oracle Warehouse Builder Defining and Importing Source Data Structures 3 Designing the Target Structure 41- Creating the Target Structure in OWB 4 Extract, Transform, and Load Basics Designing and building an ETL mapping 5 ETL: Transformations and Other Operators Validating, Generating, Deploying, and Executing Objects 6 Extra Features Data warehousing and OLAP
2 Unit-I Topics: Introduction to D.W D.W Design Consideration and Dimensional Modelling
3 Q1. What is data warehouse? List and explain the characteristics of data warehouse. Answer: Data Warehouse: It is a central managed and integrated database containing data from the operational sources in an organization. A data warehouse is a powerful database model that significantly enhances the user s ability to quickly analyze large multidimensional data sets. It cleanses and organizes data to allow users to make business decisions based on facts. And so, the data in data warehouse must have strong analytical characteristics. Data warehouse is a decisional database system. Data Warehouse Delivers Enhanced Business Intelligence. Data Warehouse Saves Time. Data Warehouse Enhances Data Quality and Consistency. Data Warehouse Provides Historical Intelligence. Knowledge Discovery and Decision Support Characteristics of Data Warehouse: Following are different characteristics of data warehousing as follows: Subject Oriented Data: - A data warehouse is organized around major subjects, such as customer, vendor, product, and Sales. It focuses on the modeling and analysis of data rather than day-to-day business operations. Integrated Data: -A data warehouse is constructed by integrating data from multiple heterogeneous data sources. Time Referenced Data: - A data warehouse is a repository of historical data. It gives the view of the data for a designated time frame. Non Volatile Data: - A data warehouse is always a physically separate store of data transformed from the application data found in the operational environment. Due to this separation, a data warehouse does not require transaction processing, recovery, and concurrency control mechanisms. The non-volatility of data enables users to dig deep into history and arrive at specific business decision based on facts.
4 Q2. What are operational databases? Explain the characteristics of a data warehouse. Operational Database:- The Operational databases are often used for on-line transaction processing (OLTP). It deals with day-to-day operations such as banking, purchasing, manufacturing, registration, accounting, etc. These systems typically get data into the database. Each transaction processes information about a single entity. Following are some examples of OLTP queries: What is the price of 2GB Kingston Pen drive? What is the address of the president? The purpose of these queries is to support business operations. Characteristics of Data Warehouse: Following are different characteristics of data warehousing as follows: Subject-oriented: A data warehouse is organized around major subjects, such as customer, vendor, product, and Sales. It focuses on the modeling and analysis of data rather than day-to-day business operations. Integrated: A data warehouse is constructed by integrating data from multiple heterogeneous data sources. Time variant: A data warehouse is a repository of historical data. It gives the view of the data for a designated time frame. Non-volatile: A data warehouse is always a physically separate store of data transformed from the application data found in the operational environment. Due to this separation, a data warehouse does not require transaction processing, recovery, and concurrency control mechanisms. Q3. Draw and explain data warehouse architecture. Or Explain the framework of data warehouse. Data Warehouse Architecture:-

5 A Data Warehouse Architecture (DWA) is a way of representing the overall structure of data, communication, processing and presentation that exists for end-user computing within the enterprise. The architecture is made up of a number of interconnected parts as follows: Source System Source data transport layer Data Quality control and data profiling layer Metadata management layer Data integration layer Data processing layer End user reporting layer Below figure shows architecture of data warehouse which consist of various layer interconnected each other. Source System Operational systems process data to support critical operational needs. In order to do this, operational databases have been historically created to provide an efficient processing structure for a relatively small number of well-defined business transactions. The goal of data warehousing is to free the information locked up in the operational systems and to combine it with information from other external sources of data. Large organizations are acquiring additional data from outside databases. This information includes demographic, econometric, competitive and purchasing trends.
6 Source data transport layer The data transport layer of the DWA, largely constitutes data trafficking. It particularly represents the tools and processes involved in transporting data from the source systems to the enterprise warehouse system. Data Quality control and data profiling layer Data quality causes the most concern in any data warehousing solution. Incomplete and inaccurate data will jeopardize the success of the data warehouse. Data warehouses do not generate their own data; rather they rely on the input data from the various source systems. Metadata management layer Metadata is the information about data within the enterprise. In order to have a fully functional warehouse, it is necessary to have a variety of metadata available as also facts about the end-user views of data and information about the operational databases. Data integration layer The data integration layer is involved in scheduling the various tasks that must be accomplished to integrate data acquired from various source systems. A lot of formatting and cleansing activities happen in this layer so that the data is consistent across the enterprise. Data processing layer This layer consists of data staging and enterprise warehouse. Data staging often involves complex programming, but increasingly warehousing tools are being created that help in this process. Staging may also involve data quality analysis programs and filters that identify patterns and structures within existing operational data. End user reporting layer Success of a data warehouse implementation largely depends upon ease of access to valuable information. Based on the business needs, there can be several types of reporting architectures and data access layers. Q4. Write any five significant differences between OLTP database and Data warehouse database.


7 Q5. Differentiate between operational system & informational system. Operational System Current value is the data content Data structure is optimized for transaction. Access frequency is high Data access type is read, update and delete Uses are predictable and are repetitive Response time is in sub-seconds Large number of users E.g. Current data of sales Informational Systems Data is achieved, derived and summarized Data structure is optimized by complex queries Access frequency is medium to low Data access type is only read Usage is ad-hoc and random Response time is in several seconds to minutes Relatively small numbers of users E.g. Old data of sales Q6. What are the various levels of data redundancy in data warehouse? Or Describe virtual data warehouse and central data warehouse There are three levels of redundancy,

8 Virtual Data Warehouses:- End users are allowed to get operational databases directly using whatever tools are enabling to data access network. That is it provides on-the-fly data for decision support purposes. This approach is flexible and has minimum amount of redundant data. This approach can put the unplanned query load on operational systems. The advantages of this approach are: Flexibility No data redundancy Provides end-users with the most current corporate information Virtual data warehouses often provide a starting point for organizations to learn what end users are really looking for. Central Data Warehouses:- It is a single physical repository that contains all data for a specific functional area, department division or enterprise. A central data warehouse may contain information from multiple operational systems. A central data warehouse contains time variant data. The advantages of this approach are Security Ease of management The disadvantages are Performance implications Expansion is expensive At times

9 Distributed data warehouse:- Certain components are distributed across a number of different physical locations. Large organizations are pushing decision making down to LAN or local computer serving local decision makers. Q7. Write a short note on Granularity of facts. Granularity of Facts:- The granularity of a fact is the level of detail at which it is recorded. If data is to be analyzed effectively, it must be all at the same level of granularity. The more granular the data, the more we can do with it. Excessive granularity brings needless space consumption and increases complexity. We can always aggregate details. Granularity is not absolute or universal across industries. This has two implications. First, grains are not predetermined; second, what is granular to one business may be summarized for another. Granularity is determined by: Number of parts to a key Granularity of those parts Adding elements to an existing key always increases the granularity of the data; removing any part of an existing key decreases its granularity. Granularity is also determined by the inherent cardinality of the entities participating in the primary key. Data at the order level is more granular than data at the customer level, and data at the customer level is more granular than data at the organization level. Q8. Explain the various types of additivity of facts with examples. A fact is something that is measurable and is typically numerical values that can be aggregated. Following are the three types of facts:
 The Sales_Amount can be summed up over all of the dimensions (Time,")
10 Additive:- Facts that are additive across all dimensions are referred as Full Additive or Additive. Example of Additive Fact:- The Sales_Amount can be summed up over all of the dimensions (Time, Customer, Item, Location, Branch) The Sales_Amount can be summed up over all of the dimensions (Time, Customer, Item, Location, Branch) Semi-Additive: Facts those are additive across some of the dimensions, but not all are referred as Semi- Additive. Example of Semi-Additive Fact:- Suppose a Bank stores current balance by account by end of each day. The Balance cannot be summed up across Time dimension. It does not make sense if we sum the current balance by date.

11 Non-Additive:- Facts those are not additive across any dimension are referred as Non-Additive. Non-additive facts are usually the result of ratio or other calculations. Example of Non-Additive Fact:- The Price cannot be summed up across any dimension. Percentages and ratios are non-additive. Q9. Explain dimensional model with the help of diagram. Dimensional Model:- The purpose of dimensional model is to improve performance by matching data structures to queries. Users query the data warehouse looking for data like: Total sales in volume and revenue for the NE region for product XYZ for a certain period this year compared to the same period last year. The central theme of a dimensional model is the star schema, which consists of a central fact table, containing measures, surrounded by qualifiers or descriptors called dimensions table. Dimension Table A dimension table consists of tuple of attribute of the dimension. Fact Table A fact table contains the data and dimension identify each tuple in that data In a star schema, if a dimension is complex and contains relationships such as hierarchies, it is compressed or flattened to a single dimension. Another version of star schema is a snowflake schema. In a snowflake schema complex dimensions are normalized. Here, dimensions maintain relationships with other levels of the same dimension. The dimension tables are usually highly non-normalized structures. These tables can be normalized to reduce their physical size and eliminate redundancy which will result in a snowflake schema. Most dimensions are hierarchic.
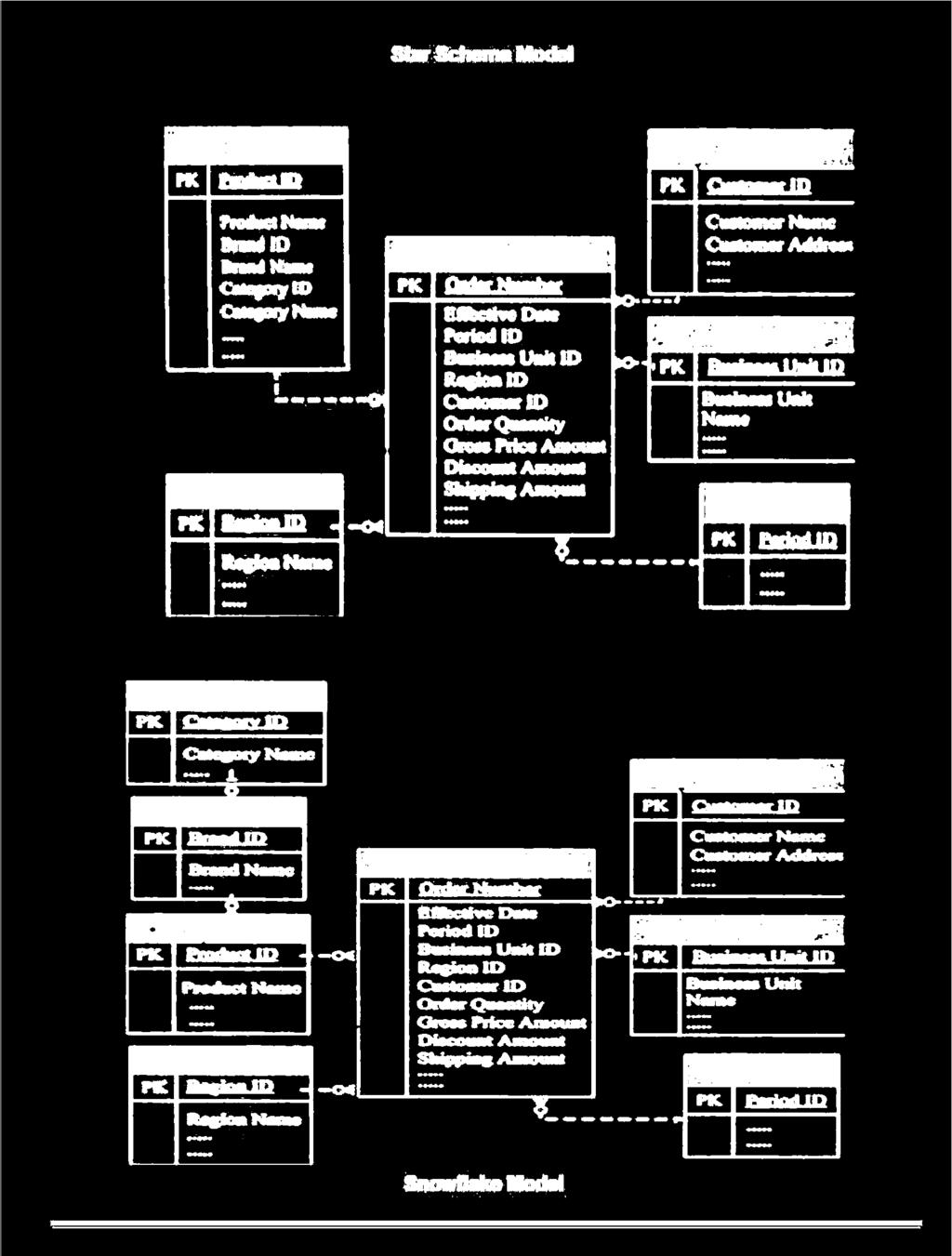
12

13 Q10. Explain star schema model with the help of diagram. The relational implementation of dimensional model is done using star schema. It represents multidimensional data. A star schema consists of a central fact table containing measures and a set of dimension tables. Dimension table:-a dimension table consists of tuple of attribute of the dimension. Fact table: - A fact table contains the data and dimension identify each tuple in that data In star schema model a fact table is at the center of the star and the dimension tables as points of the star. A star schema represents one central set of facts. The dimension tables contain descriptions about each of the aspects. Say for example a warehouse that store sales data, there is a sales fact table stores facts about sales while dimension tables store data about location, clients, items, times, branches. Examples of sales facts are unit sales, dollar sales, sale cost etc. Facts are numeric values which enable users to query and understand business performance metrics by summarizing data.
14 Q11. Differentiate between star schema and snowflake schema. Characteristics Star Schema Snowflake Schema Ease of maintenance / Has redundant data and No redundancy and hence change hence less easy to more easy to maintain and maintain/change change Ease of Use More complex queries and Less complex queries and hence less easy to easy to understand understand Less no. of foreign keys and Moreforeignkeys-and Query Performance hence lesser query execution hence more query execution time time Good for DataMart Good with to use for data warehouse core to simplify Type of Data warehouse simple relationships (1:1 or complex relationships 1:many) (many: many) Joins Fewer Joins Higher number of Joins Contains only single It may have more than one Dimension table dimension table for each dimension table for each dimension dimension When dimension When table dimension table is relatively big in size, snow When to use contains less number of rows, flaking is better as it reduces we can go for Star schema. space. Dimension Tables are in Both Dimension and Fact Normalization/ De- Normalized form but Fact Tables are in De-Normalized Normalization Table is still in Deform Normalized form Q12. Short note on Helper Table. Helper tables usually take one of two forms: Help for multi-valued dimensions Helper tables for complex hierarchies Multi-Valued Dimensions:- Take a situation where a household can own many insurance policies, yet any policy could be owned by multiple households. The simple approach to this is the traditional resolution of the many-to-many relationship, called an associative entity.
 and bill of materials relationships (M: M).")
")
15 Complex Hierarchies:- A hierarchy is a tree structure, such as an organization chart. Hierarchies can involve some form of recursive relationship. Recursive relationships come in two forms self relationships (1: M) and bill of materials relationships (M: M). A self-relationship involves one table whereas a bill of materials involves two. These structures have been handled in ER modeling from its inception. They are generally supported as a self-relating entity or as an associative entity in which an associate entity (containing parent-child relationships) has dual relationships to a primary entity.
16 Unit-II Topics: An Introduction to O.W.B Defining and Importing Source Data Structures

 to begin the installation Step1:- Asks your email address and oracle support password to configure security")
17 Q1. Explain the various steps involved in installing oracle database software. Following steps are used to install oracle database software:- Download the appropriate install file from Oracle web site Unzip the install files into a folder to begin the installation Run the setup.exe file from that folder to launch the Oracle Universal Installer program (OUI) to begin the installation Step1:- Asks your address and oracle support password to configure security updates. Step2:- Following are the installation options create and configure a database install database software only Upgrade an existing database Step3:- Here you can select the type of installation you want to perform. The following are the installation types: Single Instance database installation
 Step4:- To select the")



18 Real Application Cluster database installation (RAC) Step4:- To select the language in which your product will run. Step5:- We can choose the edition of the database to install, Enterprise, Standard, Standard Edition One, or Personal Edition. Step6:- This step asks us to specify the installation location for storing Oracle configuration files and software files.


19 Step7:- In this step oracle will checks the environment to see whether it meets the requirements for successful installation. The prerequisite checks include checking of operating system, physical memory, swap space, network configuration etc. Step8 Shows the installation summary. Step9 The actual installation happens in step 9. A progress bar proceeds to the right as the installation happens and steps for Prepare, Copy Files, and Setup Files are checked off as they are done. Step10 Shows the success or failure of database installation. Q2. What are the hardware and software requirements for installing oracle warehouse builder? Following are the Databases which support OWB: Oracle Database 12c R1 Standard Edition Oracle Database 12c R1 Enterprise Edition Oracle Database 11g R2 Standard Edition Oracle Database 11g R2 Enterprise Edition Oracle Database 11g R1 Standard Edition Oracle Database 11g R1 Enterprise Edition

20 The enterprise edition of the database gives you the power to use full features of the data warehouse. But the standard edition does not support all warehouse features. The OWB with the standard edition allows us to deploy only limited types of objects. Following are hardware Requirements: Intel Core 2 duo or higher processor 1 GB RAM 10GB to 15GB Hard disk space Operating System Requirements It support UNIX or Windows Platform Windows Support (Windows Vista (Business Edition/Enterprise Edition/Ultimate Edition) / Windows XP / Windows Server 2003 / Windows 7) Q3. What is a listener? How is it configured? Listener:- The Listener is a named process which runs on the Oracle Server. The listener process runs constantly in the background on the database server computer waiting for requests from clients to connect to the Oracle database. It receives connection requests from the client and manages the traffic of these requests to the database server. Configuring Listener:- Run Net Configuration Assistant to configure a listener. Step1:- The first screen is a welcome screen. Select Listener Configuration option from it and then click next button.


21 Step 2:- The second screen allows you to add, reconfigure, delete or rename a listener. Choose Add from the given option to configure a new listener and click next. Step3:- The third screen asks you to enter a name for the listener. The default name is LISTENER. Enter a new name or continue with the default and then click next button to proceed.

22 Step4:- The fourth screen is the protocol selection screen. By default the TCP protocol is selected in this screen. TCP is the standard communication protocol for internet and most local networks. Select the protocol and click next. Step5:- The fifth and final screen asks the TCP/IP port number for the listener to run. The default port number is 1521 and continues with the default port number. It will ask us if we want to configure another listener. Select no to finish the listener configuration.




23 Then click on Next Button. Q4. Explain various steps used for creating database. Following steps are used in creation database:- Run Database Configuration Assistant to create database. Step1:- The first step is to specify what action to take. Since we do not have a database created, we'll select the Create a Database option. Step2:- This step will offer the following three options for a database template to select: General Purpose or Transaction Processing Custom Database Data Warehouse We are going to choose the Data Warehouse option for our purposes

24 Step3:- This step of the database creation will ask for a database name. Prove data warehouse name as ACMEDW. As the database name is typed in, the SID is automatically filled in to match it. Step4:- This step of the database creation process asks whether we want to configure Enterprise Manager. The box is checked by default and leaves it. Step5:- Click on the option to Use the Same Administrative Password for All Accounts and enter a password. Step6:- This step is about storage. We'll leave it at the default of File System for storage management. Step7:- This step is for specifying the locations where database files are to be created. This can be left at the default for simplicity Step8:- The next screen is for configuring recovery options. We would want to make sure to use the Flash Recovery option and to enable archiving. Step9:- This step is where we can have the installation program create some sample schemas in the database for our reference, and specify any custom scripts to run. Step10:- The next screen is for Initialization Parameters. These are the settings that are put in place to define various options for the database such as Memory options. Step11:- This step is automatic maintenance and we'll deselect that option and move on, since we don't need that additional functionality. Step12:- The next step is the Database Storage screen referred to earlier. Here the locations of the pre-built data and control files can be changed if needed. On the final Database Configuration Screen, there is a button in the lower right corner labeled Password Management. We ll scroll down until we see the OWBSYS schema and click on the check box to uncheck it (indicating we want it unlocked) and then type in a password and confirm it as shown in the following image:

25 Q5. Explain OWB components and architecture with diagram. OWB Architecture: Below diagram show the architecture of Oracle Warehouse Builder (OWB).It consist of 2 parts i.e. OWB Client and OWB Server. Following are the client side components: Design Center Repository Browser. Following are the server side components: Control Center Service Repository Target Schema. Design Center:- The Design Center is the primary graphical user interface for designing a logical design of the data warehouse. Design Center is used to: import source objects design ETL processes Define the integration solution. Control Center Manager:- It is a part of the design center. It manages communication between target schema and design center. As soon as we define a new object in the Design Center, the object is listed in the Control Center Manager under its deployment location. Repository Browser:-


26 It is another user interface used to browse design metadata. The Target Schema is where OWB will deploy the object to, and where the execution of ETL processes that load our data warehouse will take place. Target Schema:- The target schema is the target to which we load our data and the data objects that we designed in the Design Center such as cubes, dimensions, views, and mappings. The target schema contains Warehouse Builder components such as synonyms that enable the ETL mappings to access the audit/service packages in the repository. Warehouse Builder Repository:- The repository schema stores metadata definitions for all the sources, targets, and ETL processes that constitute our design metadata. In addition to containing design metadata, a repository can also contain the runtime data generated by the Control Center Manager and Control Center Service. Workspaces:- In defining the repository, we create one or more workspaces, with each workspace corresponding to a set of users working on related projects. Q6.What is the relationship between OWBSYS and Oracle Warehouse Builder? Oracle configures its databases with most of the pre-installed schemas locked, and so users cannot access them. It is necessary to unlock them specifically, and assign our own passwords to them if we need to use them. One of them is the OWBSYS schema. This is the schema that the installation program automatically installs to support the Warehouse Builder. We will be making use of it when we start running OWB. So under Password Management we see the OWBSYS schema and click on the check box to uncheck it (indicating we want it unlocked) and then type in a password and confirm it. Q7. Explain various steps used for configuring repository and workspaces. Following steps are used in creation database:- Run Repository Assistant under Warehouse Builder Administration. The steps for configuration are as follows:
27 The Repository Assistant application on the server and the first step it is going to ask us for the database connection information:- Host Name, Port Number, and Oracle Service Name for a SQL*Net connection. The Host Name, Port Number, and Oracle Service name option as follows: The Host Name is the name assigned to the computer on which we've installed the database, and we can just leave it at LOCALHOST. The Port Number is the one we assigned to the listener back when we had installed it. It defaults to the standard Oracle Service Name is name of database i.e. ACMEDW Q8. What is design center? Explain the functions of project explorer and connection explorer windows. Design Center:- The Design Center is the main graphical interface used for the logical design of the data warehouse. Through Design Center we define our sources and targets and design our ETL processes to load the target from the source. The logical design will be stored in a workspace in the Repository on the server. Below diagram shows the Design Center which consist of Project Explorer Connection Explorer and Global Explorer. Project Explorer:- Project Explorer window we can create objects that are relevant to our project. It has nodes for each of the design objects we'll be able to create. We need to design an object under the Databases node to model the source database. If we expand the Databases node in the tree, we will notice that it includes both Oracle and Non-Oracle databases. It also has option to pull data from flat files. The Project Explorer can also be used for defining the target structure. Connection Explorer:- The Connection Explorer is where the connections are defined to our various objects in the Project Explorer. The workspace has to know how to connect to the various databases, files, and applications we may have defined in our Project Explorer. As we begin creating modules in the Project Explorer, it will ask for connection information and this information will be stored and be accessible from the Connection Explorer window. Connection information can also be created explicitly from within the Connection Explorer. Global Explorer The Global Explorer is used to manage these objects. It includes objects such as Public Transformations or Public Data Rules. A transformation is a function, procedure, or package defined in the database in Oracle's procedural SQL language called PL/SQL. Data rules are rules that can be implemented to enforce certain formats in our data.

28 Q9. Write a procedure to create new project in OWB. What is difference between a module and a project? Following steps are used to create new project in OWB. Step1: Launch the Design Center Step2: Right-click on the project name in the Project Explorer and select Rename from the resulting pop-up menu. Alternatively, we can select the project name, then click on the Edit menu entry, and then on Rename. Module: Modules are grouping mechanisms in the Projects Navigator that correspond to locations in the Locations Navigator. A single location can correspond to one or more modules. However, a given module can correspond to only one metadata location and data location at a time. The association of a module to a location enables you to perform certain actions more easily in Oracle Warehouse Builder. For example, group actions such as creating snapshots, copying, validating, generating, deploying, and so on, can be performed on all the objects in a module by choosing an action on the context menu when the module is selected Project:- Project contains one or more a module(s).there are 2 types of module. One is Oracle and second one is Non-Oracle.
29 All modules, including their source and target objects, must have locations associated with them before they can be deployed. We cannot view source data or deploy target objects unless there is a location defined for the associated module. Q10. Explain the procedure for defining source metadata manually with Data Object Editor Following steps are used to create metadata manually with Data Object Editor. Suppose in below example:- Project: ACME_DW_PROJECT Module: ACME_POS We are going to define source metadata for the following table columns ITEMS_KEY number(22) ITEM_NAME varchar2(50) ITEM_CATEGORY varchar2(50) ITEM_VENDOR number(22) ITEM_SKU varchar2(50) ITEM_BRAND varchar2(50) ITEM_LIST_PRICE number(6,2) ITEM_DEPT varchar2(50) Before we can continue building our data warehouse, we must have all our source table metadata created. It is not a particularly difficult task. However, attention to detail is important to make sure what we manually define in the Warehouse Builder actually matches the source tables we're defining. The tool the Warehouse Builder provides for creating source metadata is the Data Object Editor, which is the tool we can use to create any object in the Warehouse Builder that holds data such as database tables. The steps to manually define the source metadata using Data Object Editor are: 1. To start building our source tables for the POS transactional SQL Server database, let's launch the OWB Design Center if it's not already running. Expand the ACME_DW_PROJECT node and take a look at where we're going to create these new tables. We have imported the source metadata into the SQL Server ODBC module so that is where we will create the tables. Navigate to the Databases Non-Oracle ODBC node, and then select the ACME_POS module under this node. We will create our source tables under the Tables node, so let's right-click on this node and select New, from the popup menu. As no wizard is available for creating a table, we are using the Data Object Editor to do this. 2. Upon selecting New, we are presented with the Data Object Editor screen. It's a clean slate that we get to fill in, and will look similar to the following screenshot: There are a number of facets to this interface but we will cover just what we need now in order to create our source tables. Later on, we'll get a chance to explore some of the other aspects of this interface for viewing and editing a data object. The fields to be edited in this Data Object Editor are as follows:

30 The first tab it presents to us is the Name tab where we'll give a name to the first table we're creating. We should not make up table names here, but use the actual name of the table in the SQL Server database. Let's starts with the Items table. We'll just enter its name into the Name field replacing the default, TABLE_1, which it suggested for us. The Warehouse Builder will automatically capitalize everything we enter for consistency, so there is no need to worry about whether we type it in uppercase or lowercase. Let's click on the Columns tab next and enter the information that describes the columns of the Items table. How do we know what to fill in here? Well, that is easy because the names must all match the existing names as found in the source POS transactional SQL Server database. For sizes and types, we just have to match the SQL Server types that each field is defined as, making allowances for slight differences between SQL Server data types and the corresponding Oracle data types. Q11. Explain the steps for importing the metadata for a flat file. Use the Import Metadata Wizard to import metadata definitions into modules. The steps involved in creating the module and importing the metadata for a flat file are: 1. The first task we need to create a new module to contain our file definition. If we look in the Project Explorer under our project, we'll see that there is a Files node right below the Databases node. Right-click on the Files node and select New from the pop-up menu to launch the wizard.


31 2. When we click on the Next button on the Welcome screen, we notice a slight difference already. The Step 1 of the Create Module wizard only asks for a name and description. The other options we had for databases above are not applicable for file modules. We'll enter a name of ACME_FILES and click on the Next button to move to Step We need to edit the connection in Step 2. So we'll click on the Edit button, we see in the following image, it only asks us for a name, a description, and the path to the folder where the files are. 4. The Name field is prefilled with the suggested name based on the module name. As it did for the database module location names, it adds that number 1 to the end. So, we'll just edit it to remove the number and leave it set to ACME_FILES_LOCATION. 5. Notice the Type drop-down menu. It has two entries: General and FTP. If we select FTP (File Transfer Protocol used for getting a file over the network), it will ask us for slightly more information. 6. The simplest option is to store the file on the same computer on which we are running the database. This way, all we have to do is enter the path to the folder that contains the file. We should have a standard path we can use for any files we might need to import in the future. So we create a folder called Getting Started with OWB_files, which we'll put in the D: drive. Choose any available drive with enough space and just substitute the appropriate drive letter. We'll click on the Browse button on the Edit File System Location dialog box, choose the file path, and click on the OK button. 7. We'll then check the box for Import after finish and click on the Finish button. That's it for the Create Module Wizard for files Q12. Explain the steps for creating oracle database module. To create an Oracle Database module, right-click on the Databases Oracle node in the Project Explorer of Warehouse Builder and select New... from the pop-up menu. The first screen that will appear is the Welcome screen, so just click on the Next button to continue. Then we have the following two steps:


32 Step1:- In this step we give our new module a name, a status, and a description that is optional. On the next window after the Welcome screen, type in a name for the module. The module status is a way of associating our module with a particular phase of the process, and we'll leave it at Development and Click on the Next button to proceed. Step2:- The screen starts by suggesting a connection name based on the name we gave the module. Click on the Edit button beside the Name field to fill in the details. This will display the following screen: Q13. What is the significance of HS parameters in the heterogeneous service configuration file? Answer: The file named initdg4odbc.ora is the default init file for using ODBC connections. This file contains the HS parameters that are needed for the Database Gateway for ODBC Following are two parameters used in initdg4odbc.ora file: HS_FDS_CONNECT_INFO = <odbc data_source_name> HS_FDS_TRACE_LEVEL = <trace_level> First Parameter is used for:
33 The HS_FDS_CONNECT_INFO line is where we specify the ODBC DSN. So replace the <odbc data_source_ name> string with the name of the Data Source, which is for example ACME_POS. Second Parameter is used for: The HS_FDS_TRACE_LEVEL line is for setting a trace level for the connection. The trace level determines how much detail gets logged by the service and it is OK to set the default as 0 (zero).
34 Unit-III Topics: Designing the Target Structure Creating the Target Structure in OWB


35 Q1. Short note on cube and dimensions. Cube:- Here, sales indicate data about products sold and to be sold in a company. The dimensions become the business characteristics about the sales, for example: A time dimension users can look back in time and check various time periods A store dimension information can be retrieved by store and location A product dimension various products for sale can be broken out Think of the dimensions as the edges of a cube, and the intersection of the dimensions as the measure we are interested in for that particular combination of time, store, and product. A picture is worth a thousand words, so let's look at what we're talking about in the following image: Think of the width of the cube, or a row going across, as the product dimension. Every piece of information or measure in the same row refers to the same product, so there are as many rows in the cube as there are products. Think of the height of the cube, or a column going up and down, as the store dimension. Every piece of information in a column represents one single store, so there are as many columns as there are stores. Finally, think of the depth of the cube as the time dimension, so any piece of information in the rows and columns at the same depth represent the same point in time. The intersection of each of these three dimensions locates a single individual cube in the big cube, and that represents the measure amount we're interested in. In this case, it's dollar sales for a single product in a single store at a single point in time. Q2. Explain implementation of dimensional model. There are two options: a relational implementation and a multidimensional implementation. The relational implementation, which is the most common for a data warehouse structure, is implemented in the database with tables and foreign keys.
:- The term relational is used because the tables in it relate to each other in some way.")

36 The multidimensional implementation requires a special feature in a database that allows defining cubes directly as objects in the database. Relational implementation (Star Schema):- The term relational is used because the tables in it relate to each other in some way. For a relational data warehouse design, the relational characteristics are retained between tables. A data warehouse dimensional design that is represented relationally in the database will have one main table to hold the primary facts, or measures we want to store, such as count of items sold or dollar amount of sales. The ER diagram of such an implementation would be shaped somewhat like a star, and thus the term star schema is used to refer to this kind of an implementation. The main table in the middle is referred to as the fact table because it holds the facts, or measures. The tables surrounding the fact table are known as dimension tables. These are the dimensions of our cube. These tables contain descriptive information, which places the facts in a context that makes them understandable. Multidimensional implementation (Star Schema):- A multidimensional implementation or OLAP (Online Analytical Processing) requires a database with special features that allow it to store cubes as actual objects in the database, and not just tables that are used to represent a cube and dimensions. It also provides advanced calculation and analytic content built into the database to facilitate advanced analytic querying. The Oracle Database Enterprise Edition has an additional feature that can be licensed called OLAP that embeds a full-featured OLAP server directly in an Oracle database. These kinds of analytic databases are well suited to providing the end user with increased capability to perform highly optimized analytical queries of information. Q3. Explain multidimensional implementation of data warehouse. The multidimensional implementation requires a special feature in a database that allows defining cubes directly as objects in the database. In relational implementation data is organized into dimension tables, fact tables and materialized views. A multidimensional implementation requires a database with special features that allow it to store cubes as actual objects in the database.
37 It also provides advanced calculation and analytic content built into the database to facilitate advanced analytic querying. These analytic databases are quite frequently utilized to build a highly specialized data mart, or a subset of the data warehouse, for a particular user community. MOLAP uses array-based multidimensional storage instead of relational database. MOLAP tools generally utilize a pre-calculated data set referred to as data cube. The data required for the analysis is extracted from relational data warehouse or other data sources and loaded in a multidimensional database which looks like a hypercube. Hypercube is a cube with many dimensions. Q4. What is module? Explain source module and target module. Module: Modules are grouping mechanisms in the Projects Navigator that correspond to locations in the Locations Navigator. A single location can correspond to one or more modules. However, a given module can correspond to only one metadata location and data location at a time. The association of a module to a location enables you to perform certain actions more easily in Oracle Warehouse Builder. For example, group actions such as creating snapshots, copying, validating, generating, deploying, and so on, can be performed on all the objects in a module by choosing an action on the context menu when the module is selected All modules, including their source and target objects, must have locations associated with them before they can be deployed. You cannot view source data or deploy target objects unless there is a location defined for the associated module. Source Module:- A source module is composed of source statements in the assembler language. It accepts a no input from the data stream because they are used at the start of a workflow. It is a place where data are stores. Target Module:- A target module is composed of target statements in the assembler language It accepts input from the data stream. It is place where data are extracts. Q5. List and explain the functionalities that can be performed by OWB in order to create data warehouse. The Oracle Warehouse Builder is a tool provided by Oracle, which can be used at every stage of the implementation of a data warehouse, from initial design and creation of the table structure to the ETL process and data-quality auditing. So, the answer to the question of where it fits in is everywhere.
38 We can choose to use any or all of the features as needed for our project, so we do not need to use every feature. Simple data warehouse implementations will use a subset of the features and as the data warehouse grows in complexity, the tool provides more features that can be implemented. It is flexible enough to provide us a number of options for implementing our data warehouse. List of Functions: Data modeling Extraction, Transformation, and Load (ETL) Data profiling and data quality Metadata management Business-level integration of ERP application data Integration with Oracle business intelligence tools for reporting purposes Vii. Advanced data lineage and impact analysis Oracle Warehouse Builder is also an extensible data integration and data quality solutions platform. Oracle Warehouse Builder can be extended to manage metadata specific to any application, and can integrate with new data source and target types, and implement support for new data access mechanisms and platforms, enforce your organization's best practices, and foster the reuse of components across solutions. Q6. What is a target schema? How is a target module created? Target schema:- A target schema contains the data objects that contain your data warehouse data. The target schema is going to be the main location for the data warehouse. When we talk about our "data warehouse" after we have it all constructed and implemented, the target schema is what we will be referring to. You can design a relational target schema or a dimensional target schema. Every target module must be mapped to a target schema. Creation of target module Launch Design Center. Right-click on the Databases Oracle node in the Project Explorer. Select New... from the pop-up menu. Welcome screen appears. Click next Step1 Enter module name and select the module status as Development Select the module type as Data Warehouse Target Step2

39 Specify location name, user name, password, and host, port and service name Click finish Q7. What is time dimension? Discuss various steps involved in creating a time dimension using time dimension wizard. The Time/Date dimension provides the time series information to describe warehouse data. Most of the data warehouses include a time dimension. Also the information it contains is very similar from warehouse to warehouse. It has levels such as days, weeks, months, etc. The Time dimension enables the warehouse users to retrieve data by time period. Creation of Time dimension Launch Design Center Expand the Databases node under any project where you want create a Time dimension Then right-click on the Dimensions node, and select New Using Time Wizard... to launch the Time Dimension Wizard. The first screen is a welcome screen which shows various steps involved in creation of a time dimension. Step1: Provide name and description Step2: Set the storage type Step3: Define the range of data stored in the time dimension Step4: Choose the levels Step5: Summary of Time Dimension before creation of the Sequence and Map Step6: Progress Status Q8. Explain various characteristics of a dimension. A dimension has the following four characteristics:
40 Levels Each dimension has one or more levels. It defines the levels where aggregation takes place or data can be summed. The OWB supports the following levels for Time dimension: Day Fiscal week Calendar week Fiscal month Calendar month Fiscal quarter Calendar quarter Fiscal year Calendar year Dimension Attributes The Attributes are actual data items that are stored in the dimension that can be found at more than one level. Say for example the time dimension has following attributes in each level: id (identifies that level), Start and end date (designate time period of that level), time span (number of days in the time period), description etc. Level Attributes Each level has Level Attributes associated with it that provide descriptive information about the value in that level. For example, Day level has level attributes such as day of week, day of month, day of quarter, day of year etc. Hierarchies It is composed of certain levels in order. There can be one or more hierarchies in a dimension. The month, quarter and year can be a hierarchy. The data can be viewed at each of these levels, and the next level Q9. Write notes on the following 1. Slowly changing dimension 2. Surrogate keys Slowly Changing Dimension Slowly Changing Dimension (SCD) refers to the fact that dimension values will change over time. Although this doesn't happen often, they will change and hence the "slowly" designation It can also be defined as dimensions that change slowly over time are known as slowly changing dimensions. These changes need to be tracked in order to report historical data. The OWB allows the following options for slowly changing dimensions. Type 1 - Do not keep a history. This means we basically do not care what the old value was and just change it.
41 Type 2 - Store the complete change history. This means we definitely care about keeping that change along with any change that has ever taken place in the dimension. Type 3 - Store only the previous value. This means we only care about seeing what the previous value might have been, but don't care what it was before that. Surrogate Keys:- Surrogate keys are artificial keys that are used as a substitute for source system primary keys. They are generated and maintained within the data warehouse. A Surrogate Key is a NUMBER type column and is generated using a Sequence. The management of surrogate keys is the responsibility of the data warehouse. The Surrogate Keys are used to uniquely identify each record in a dimension. Example:- The source tables have columns such as AIRPORT_NAME or CITY_NAME which are stated as the primary keys (according to the business users) but, these can change and we could consider creating a surrogate key called, say, AIRPORT_ID. This would be internal to the warehouse system and as far as the client is concerned you may display only the AIRPORT_NAME. Surrogate keys are numeric values and hence Indexing is faster.
42 Unit-IV Extract, Transform, and Load Basics Designing and building an ETL mapping
43 Q1. What is ETL? Explain the importance of source target map. ETL stands for extract transform and load. The ETL process transforms the data from an application-oriented structure into a corporate data structure. Once the source and target structures defined, we can move on to the following activities in constructing a data warehouse. Work on extracting data from sources Perform any transformations on the data Load into target data warehouse structure The data warehouse architect builds a source to-target data map before ETL processing starts. The source target map specifies: What data must be placed in the data warehouse environment? Where that data comes from (known as source or system of record) The logic or calculation or data reformatting that must be done to the data. The data mapping is the input needed to feed the ETL process. Mappings are visual representations of the flow of data from source to target and the operations that need to be performed on the data. Q2. What is staging? What are its benefits? Explain the situation where staging is essential. Staging:- Staging is the process of copying the source data temporarily into tables in target database. The purpose is to perform any cleaning and transformations before loading the source data into the final target tables. Staging stores the results of each logical step of transformation in staging tables. The idea is that in case of any failure you can restart your ETL from the last successful staging step. Staging make sense in the following case:- Large amount of data to load Many transformations to perform on that data while loading. Pulling data from non-oracle databases This process will take a lot longer if we directly access the remote database to pull and transform data. We'll also be doing all of the manipulations and transformations in memory and if anything fails; we'll have to start all over again. Benefits:- Source database connection can be freed immediately after copying the data to the staging area. The formatting and restructuring of the data happens later with data in the staging area. If the ETL process needs to be restarted, there is no need to go back to disturb the source system to retrieve the data.
44 It provides you a single platform even though you have heterogeneous source systems. This is the layer where the cleansed and transformed data is temporarily stored. Once the data is ready to be loaded to the warehouse, we load it in the staging database. The advantage of using the staging database is that we add a point in the ETL flow where we can restart the load from. The other advantages of using staging database is that we can directly utilize the bulk load utilities provided by the databases and ETL tools while loading the data in the warehouse/mart, and provide a point in the data flow where we can audit the data. In the absence of a staging area, the data load will have to go from the OLTP system to the OLAP system directly, which in fact will severely hamper the performance of the OLTP system. This is the primary reason for the existence of a staging area. Without applying any business rule, pushing data into staging will take less time because there are no business rules or transformation applied on it. Disadvantages: It takes more space in database and it may not be cost effective for client. Disadvantage of staging is disk space as we have to dump data into a local area. Q3. Write the steps for building staging area table using Data Object Editor. It is explained here with example. STEP 1:-Navigate to the Databases Oracle ACME_DATA WAREHOUSE module. We will create our staging table under the Tables node, so let s right-click on that node and select New... from the popup menu. STEP 2:-Upon selecting New... we are presented with the Data Object Editor screen. However, instead of looking at an object that s been created already, we re starting with a brand-new one. STEP 3:-The first tab is Name tab where we ll give our new table a name. Let s call it POS_TRANS_STAGE for Point-of-Sale transaction staging table. We ll just enter the name into the Name field, replacing the default TABLE_1 that it suggested for us. STEP 4:-Let s click on the Columns tab next and enter the information that describes the columns of our new table. We have listed the key data elements that we will need for creating the columns. We didn t specify any properties of those data elements other than the name, so we ll need to figure that out. Q4. What are mapping operators? Explain any two source target mapping operators in detail. Mapping operators These are the basic design elements to construct an ETL mapping. Used to represent sources and targets in the data flow. Also used to represent how to transform the data from source to target. Following is list of source target mapping operator: Cube Operator-An operator that represents a cube. This operator will be used to represent cube in our mapping.
45 Dimension Operator-An operator that represents dimensions. This operator will be used in our mapping to represent them. External Table Operator-This operator are used to access data stored in flat files as if they were tables. Table Operator-It represents a table in the database. Constant- Represent constant values that are needed. Produces a single output view that can contain one or more constant attributes. View Operator-Represent a database view. Sequence Operator-It represents database sequence which is an automatic generator of sequential unit number & it is mostly used for populating a primary key field. Construct Object-This operator can be used to actually construct an object in our mapping. Q5. List and explain the use of various windows available in mapping editor. Mapping-The mapping window is the main working area on the right where we will design the mapping. This window is also referred as canvas. Explorer-This window is similar to project explorer in design center. It has two tabs that is available object tab & selected object tab. Mapping properties-the Mapping properties window display various property that can be set for objects in our mapping. When an object is selected in the canvas its property will be display in this window. Palette-This palette contains each of the objects that can be used in our mapping. We can click on the object we want to place in the mapping and drag it onto the canvas. Bird s Eye View-This window display miniature version of entire canvas & allows us to store around the canvas without using scroll bar. Q.6 Explain the various OWB operators. There are 3 types of operator in Oracle Warehouse Builder as follows: Source and Target Operator Data Flow Operator Pre\Post Processing Operator Source and Target Operator: The Warehouse Builder provides operators that we will use to represent the sources of our data and the targets into which we will load data. Following are some of the operators: Cube Operator: An operator that represents a cube. This operator will be used to represent cube in our mapping. Dimension Operator: An operator that represents dimensions. This operator will be used in our mapping to represent them.
46 External Table Operator: This operator is used to access data stored in flat files as if they were tables. Table Operator: It represents a table in the database. Constant: Represent constant values that are needed. Produces a single output view that can contain one or more constant attributes. View Operator: Represent a database view. Sequence Operator: It represents database sequence which is an automatic generator of sequential unit number & it is mostly used for populating a primary key field. Data Flow Operator: The true power of a data warehouse lies in the restructuring of the source data into a format that greatly facilitates the querying of large amounts of data over different time periods. For this, we need to transform the source data into a new structure. That is the purpose of the data flow operators. Following are some of the operators: Aggregator: When we need to sum the data up to a higher level, or apply some other aggregation type function such as an average function. This is the purpose of the Aggregator operator Deduplicator: Sometimes our data records will contain duplicate combinations that we want to weed out so we're loading only unique combinations of data. The Deduplicator operator will do this for us. Filter: This will limit the rows from an output set to criteria that we specify. It is generally implemented in a where clause in SQL to restrict the rows that are returned. Joiner: This operator will implement an SQL join on two or more input sets of data. A join takes records from one source and combines them with the records from another source using some combination of values that are common between the two. Set Operation: This operator will allow us to perform an SQL set operation on our data such as a union (returning all rows from each of two sources, either ignoring the duplicates or including the duplicates) or intersect (which will return common rows from two sources). Pre\Post Processing Operator There is a small group of operators that allow us to perform operations before the mapping process begins, or after the mapping process ends. These are the pre- and post-processing operators. Mapping Input Parameter: This operator allows us to pass a parameter(s) into a mapping process. Mapping Output Parameter: This is similar to the Mapping Input Parameter operator; but provides a value as output from our mapping. Post-Mapping Process: Allows us to invoke a function or procedure after the mapping completes its processing. Pre-Mapping Process: It allows us to invoke a function or procedure before the mapping process begins. Q7. Briefly explain the functions of filter and joiner operators.
47 Filter This will limit the rows from an output set to criteria that we specify. It is generally implemented in a where clause in SQL to restrict the rows that are returned. We can connect a filter to a source object, specify the filter criteria, and get only those records that we want in the output. It has Filter Condition property to specify the filter criteria. Joiner This operator will implement an SQL join on two or more input sets of data, and produces a single output row set. That is it combines data from multiple input sources into one. A join takes records from one source and combines them with the records from another source using some combination of values that are common between the two. It has a property called Q8. What are data flow operators? Explain the concept of pivot operator with example. Data flow operators A data warehouse requires restructuring of the source data into a format that is congenial for the analysis of data. The data flow operators are used for this purpose. These operators are dragged and dropped into our mapping between our sources and targets. Then they are connected to those sources and targets to indicate the flow of data and the transformations that will occur on that data as it is being pulled from the source and loaded into the target structure. Pivot The pivot operator enables you to transform a single row of attributes into multiple rows. Suppose we have source records of sales data for the year that contain a column YEAR Q1_sales Q2_sales Q3_sales Q4_sales We wish to transform the data set to the following with a row for each quarter: YEAR QTR SALES Q Q Q Q
48 Q9. What is expression operator? Explain the mapping of a date field SALE_DATE to a numeric field DAY_CODE by applying TO_CHAR() and TO_NUMBER() functions through expression operator. The string format for TO_CHAR() function is YYYMMDD'. Answer: The expression operator represents an SQL expression that can be applied to the output to produce the desired result. Any valid SQL code for an expression can be used, and we can reference input attributes to include them as well as functions. Drag the Expression operator onto the mapping. It has two groups defined an input group, INGRP1 and an output group, OUTGRP1. Link the SALE_DATE attribute of source table to the INGRP1 of the EXPRESSION operator. Right-click on OUTGRP1 and select Open Details... from the pop-up menu. This will display the Expression Editor window for the expression. Click on the Output Attributes tab and add a new output attribute OUTPUT1 of number type and click OK. Click on OUTPUT1 output attribute in the EXPRESSION operator and turn our attention to the property window of the Mapping Editor. The Properly Window shows Expression as its first property. Click the blank space after the label Expression. This shows a button with three dots. Q10. Explain the Indexes and Partitions tab in the Table Editor. Indexer Tab: An index can greatly facilitate rapid access to a particular record. It is generally useful for permanent tables that will be repeatedly accessed in a random manner by certain known columns of data in the table. It is not desirable to go through the effort of creating an index on a staging table, which will only be accessed for a short amount of time during a data load. Also, it is not really useful to create an index on a staging table that will be accessed sequentially to pull all the data rows at one time. An index is best used in situations where data is pulled randomly from large tables, but doesn't provide any benefit in speed if you have to pull every record of the table. Partition Tab: A partition is a way of breaking down the data stored in a table into subsets that are stored separately. This can greatly speed up data access for retrieving random records, as the database will know the partition that contains the record being searched for based on the partitioning scheme used. It can directly home in on a particular partition to fetch the record by completely ignoring all the other partitions that it knows won't contain the record.
49 Unit-V ETL: Transformations and Other Operators Validating, Generating, Deploying, and Executing Objects
50 Q1. Short note on ETL transformation. The process of extracting data from source systems and bringing it into the data warehouse is commonly called ETL, which stands for extraction, transformation, and loading. ETL functions that are combined into one tool to pull data out of one database and place it into another database. Extract is the process of reading data from a database. During extraction, the desired data is identified and extracted from many different sources, including database systems and applications. Very often, it is not possible to identify the specific subset of interest; therefore more data than necessary has to be extracted, so the identification of the relevant data will be done at a later point in time. Depending on the source system's capabilities (for example, operating system resources), some transformations may take place during this extraction process. The size of the extracted data varies from hundreds of kilobytes up to gigabytes, depending on the source system and the business situation. The same is true for the time delta between two (logically) identical extractions: the time span may vary between days/hours and minutes to near real-time. Web server log files, for example, can easily grow to hundreds of megabytes in a very short period of time Transform is the process of converting the extracted data from its previous form into the form it needs to be in so that it can be placed into another database. Transformation occurs by using rules or lookup tables or by combining the data with other data. After data is extracted, it has to be physically transported to the target system or to an intermediate system for further processing. Load is the process of writing the data into the target database. ETL is used to migrate data from one database to another, to form data marts and data warehouses Q2. What is the purpose of main attribute group in a cube? Discuss about dimension attributes and measures in the cube. The first group represents main attributes for the cube and contains data elements to which we will need to map. Other groups represent the dimensions that are linked to the cube. As far as the dimensions are concerned we make separate map for them prior to cube mapping. The data we map for the dimensions will be to attributes in the main cube group, which will indicate to the cube which record is applicable from each of the dimensions. Cube has attributes for surrogate and business identifiers defined for each dimension of the cube. All business identifiers are prefixed with the name of the dimension The name of a dimension is used as the surrogate identifier for that dimension. Say for example, if SKU and NAME are two business identifiers in PRODUCT dimension, then the main attribute group will have three PRODUCT related identifiers; PRODUCT_SKU, PRODUCT_NAME, PRODUCT.
51 Apart from surrogate and business identifiers, the main attribute group also contains the measures we have defined for the cube. Q3. Write the steps to add primary key for a columns of a table in Data Object Editor with suitable example? Here, table name is COUNTIES_LOOKUP To add a primary key, we'll perform the following steps: 1. In the Design Center, open the COUNTIES_LOOKUP table in the Data Object Editor by double-clicking on it under the Tables node. 2. Click on the Constraints tab. 3. Click on the Add Constraint button. 4. Type PK_COUNTIES_LOOKUP (or any other naming convention we might choose) in the Name column. 5. In the Type column, click on the drop-down menu and select Primary Key. 6. Click on the Local Columns column, and then click on the Add Local Column button. 7. Click on the drop-down menu that appears and select the ID column. 8. Close the Data Object Editor. Q4. Short note on Control Center Manager Control Center Manager: The Control Center Manager is the interface the Warehouse Builder provides for interacting with the target schema. This is where the deployment of objects and subsequent execution of generated code takes place. The Design Center is for manipulating metadata only on the repository. Deployment and execution take place in the target schema through the Control Center Service. The Control Center Manager is our interface into the process where we can deploy objects and mappings, check on the status of previous deployments, and execute the generated code in the target schema. We launch the Control Center Manager from the Tools menu of the Design Center main menu. We click on the very first menu entry, which says Control Center Manager. This will open up a new window to run the Control Center Manager, which will look similar to the following

52 Q5. What are the two ways of validating repository objects in object editor? Following are the two ways to validate an object from Data Object Editor: Right-click on the object displayed on the Canvas and select Validate from the pop-up menu Select the object displayed on the canvas and then click on the Validate icon from the toolbar. Deploy Action: Following are the actions Create: Create the object; if an object with the same name already exists, this can generate an error upon deployment Upgrade: Upgrade the object in place, preserving data Drop: Delete the object Replace: Delete and recreate the object; this option does not preserve data Q6. Explain the concept of validating and generating objects. Validating Objects The process of validation is all about making sure the objects and mappings we've defined in the Warehouse Builder have no obvious errors in design. Oracle Warehouse Builder runs a series of validation tests to ensure that data object definitions are complete and that scripts can be generated and deployed. When these tests are complete, the results are displayed. Oracle Warehouse Builder enables you to open object editors and correct any invalid objects before continuing. Validating objects and mapping can be done with the help of Design Center. Validation of repository objects can be done with the help of Data Object Editor. Validation of mapping can be done through Mapping Editor.

53 Generating Objects Generation deals with creating the code that will be executed to create the objects and run the mapping With the generation step in the Warehouse Builder, we can generate the code that we need to use to build and load our data warehouse. The objects dimensions, cube, tables, and so on will have SQL Data Definition Language (or DDL) statements produced, which when executed will build the objects in the database. The mappings will have the PL/SQL code produced that when it's run, will load the objects. Like validation, generation also can be done with the help of Data Object Editor and Mapping Editor. Q7. Write the steps for validating and generating in Data Object Editor (I) Validating in the Data Object Editor: Consider, we have POS_TRANS_STAGE table i.e. staging table defined. Let's double-click on the POS_TRANS_STAGE table name in the Design Center to launch the Data Object Editor so that we can discuss validation in the editor. We can right-click on the object displayed on the Canvas and select Validate from the pop-up menu (ii) We can select Validate from the Object menu on the main editor menu bar. (iii) To validate every object currently loaded into our Data Object Editor. It is to select Validate All from the Diagram menu entry on the main editor menu bar. We can also press the validate icon on the General Toolbar, which is circled in the following image of the toolbar icons: When validating from the Design Center. Here we get another window created in the editor, the Generation window, which appears below the Canvas window. When we validate from the Data Object Editor, it is on an object-by-object basis for objects appearing in the editor canvas. But when we validate a mapping in the Mapping editor, the mapping as a whole is validated all at once. Let's close the Data Object Editor and move on to discuss validating in the Mapping Editor.

Generating in the Data Object Editor: Data Object Editor and open our POS_TRANS_STAGE table in the editor by double-clicking on it in the Design Center.")
54 But as with the generation from the Design Center, we'll have the additional information available. The procedure for generating from the editors is the same as for validation, but the contents of the results window will be slightly different depending on whether we're in the Data Object Editor or the Mapping Editor. Let's discuss each individually as we previously did. (II)Generating in the Data Object Editor: Data Object Editor and open our POS_TRANS_STAGE table in the editor by double-clicking on it in the Design Center. To review the options we have for generating, there is the (i) Generate... menu entry under the Object main menu, OR (ii) The Generate entry on the pop-up menu when we right-click on an object, (iii)generate icon on the general toolbar right next to the Validate icon as shown in the following image: Result: Q8. What is object deployment? Explain the functions of control center manager. Deployment is the process of creating physical objects in the target schema based on the logical definitions created using the Design Center.

55 The process of deploying is where the database objects are actually created and PL/SQL code is actually loaded and compiled in the target database. During initial stages of design no physical objects have been created in the target schema. The operations such as importing metadata for tables, defining objects, mapping and so on and do forth are performed with respect to OWB Design Center client. These objects are created as Warehouse Builder repository objects. So for the actual deployment of object in the target database, we have to use Control Center Service, which must be running for the deployments to function. The Design Center creates a logical design of the data warehouse. The logical design will be stored in a workspace in the Repository on the server. The Control Center Manager is used for the creation of physical objects into the target schema by deploying the logical design. The Control Center Manager is used to execute the design by running the code associated with the ETL that we have designed. The Control Center Manager interacts with the Control Center Service, which runs on the server. The Target Schema is where OWB will deploy the object to, and where the execution of the ETL processes that load our data warehouse will take place. Q9. Explain full and intermediate generation styles. Full and intermediate generation styles The generation style has two options we can choose from, full or intermediate. The Full option will display the code for all operators in the complete mapping for the operating mode selected. The Intermediate option allows us to investigate code for subsets of the full mapping option. It displays code at the attribute group level of an individual operator. If no attribute group is selected when we select the intermediate option in the drop-down menu, we'll immediately get a message in the Script tab saying the following: Please select an attribute group. When we click on an attribute group in any operator on the mapping, the Script window immediately displays the code for setting the values of that attribute group. When we selected the Intermediate generation style, the drop-down menu and buttons on the right-hand side of the window became active. We have a number of options for further investigation of the code that is generated,
56 Unit-VI Extra Features Data warehousing and OLAP
57 Q1. Explain Metadata Change Management. Metadata Change Management:- Metadata change management includes keeping a track of different versions of an object or mapping as we make changes to it, and comparing objects to see what has changed. It is always a good idea to save a working copy of objects and mappings when they are complete and function correctly. If we need to make modifications later and something goes wrong, or we just want to reproduce a system from an earlier point in time, we have a ready-made copy available for use. We won't have to try to manually back out of any changes we might have made. We would also be able to make comparisons between that saved version of the object and the current version to see what has been changed. The Warehouse Builder has a feature called the Recycle Bin for storing deleted objects and mappings for a later retrieval. It allows us to make copies of objects by including a clipboard for copying and pasting to and from, which is similar to an operating system clipboard. It also has a feature called Snapshots, which allows us to make a copy (or snapshot) of our objects at any point during the cycle of developing our data warehouse that can later be used for comparisons. Q2. What is recycling bin? Describe the features of warehouse builder recycle bin window. Recycle Bin The Recycle Bin in OWB is similar to recycle bin in operating systems. OWB keeps deleted objects in the recycle bin. The deleted objects can be restored from the Recycle Bin. To undo a deletion select an object from the Recycle Bin and click restore.. If Put in Recycle Bin check box is checked while deleting, then the object will be send to the Recycle Bin. Warehouse Builder Recycle Bin The Warehouse Builder Recycle Bin window can be opened by clicking on Tools menu and selecting Recycle Bin option from the pop-up menu This window has a content area which shows all deleted objects. The content shown with Object Parent as well as Time Deleted information. The Object Parent means the project from which it was deleted from and the Time Deleted is when we deleted the object. Below the content area it has two buttons: o One for restoring a deleted object o Another for emptying the content of recycle bin

58 Q3. What is a snapshot? Explain full snapshot and signature snapshot. Snapshot A snapshot is a point in time version of an object. The snapshot of an object captures all the metadata information about that object at the time when the snapshot is taken. It enables you to compare the current object with a previously taken snapshot. Since objects can be restored from snapshots, it can be used as a backup mechanism. There are two types of snapshot as follows:- Full Snapshots: Full snapshots provide complete metadata of an object that you can use to restore it later. So it is suitable for making backups of objects. Full snapshots take longer time to create and require more storage space than signature snapshots. Signature Snapshots: It captures only the signature of an object. A signature contains enough information about the selected metadata component to detect changes when compared with another snapshot or the current object definition. Signature snapshots are small and can be created quickly. Q4. What are the different operations that can be performed on a snapshot of an object that is created? We can perform following operation on snapshot of object: Restore: We can restore a snapshot from here, which will copy the snapshot objects back to their place in the project, overwriting any changes that might have been made. It is a way to get back to a previously known good version of an object if, for example, some future change should break it for whatever reason. Delete: If we do not need a snapshot anymore, we can delete it. However, be careful as there is no recycle bin for deleted snapshots. Once it's deleted, it's gone forever. It will ask us if we are sure before actually deleting it.

59 Convert to Signature: This option will convert a full snapshot to a signature snapshot. Export: We can export full snapshots like we can export regular workspace objects. This will save the metadata in a file on disk for backup or for importing later. Compare: This option will let us compare two snapshots to each other to see what the differences are. Q4. Explain the export feature of Metadata Loader. Metadata Loader (MDL):- The workspace objects can be exported and save them to a file. We can export anything from an entire project down to a single data object or mapping. Following are the benefits of Metadata Loader exports and imports Backup To transport metadata definitions to another repository for loading If we choose an entire project or a collection such as a node or module, it will export all objects contained within it. If we choose any subset, it will also export the context of the objects so that it will remember where to put them on import. Say for example if we export a table, the metadata also contains the definition for: The module in which it resides The project the module is in. We can also choose to export any dependencies on the object being exported if they exist. Following steps are used to export object in Design Center:- Select the project by clicking on it and then select Design Export Warehouse Builder Metadata from the main menu. Accept the default file names and locations, and click on the Export button.
60 Q5. Short note on 1. Metadata Snapshots 2. The Import Metadata Wizard Metadata Snapshots:- A snapshot captures all the metadata information about the selected objects and their relationships at a given point in time. While an object can only have one current definition in a workspace, it can have multiple snapshots that describe it at various points in time. Snapshots are stored in the Oracle Database, in contrast to Metadata Loader exports, which are stored as separate disk files. You can, however, export snapshots to disk files. Snapshots are also used to support the recycle bin, providing the information needed to restore a deleted metadata object. When you take a snapshot, you capture the metadata of all or specific objects in your workspace at a given point in time. You can use a snapshot to detect and report changes in your metadata. You can create snapshots of any objects that you can access from the Projects Navigator. A snapshot of a collection is not a snapshot of just the shortcuts in the collection but a snapshot of the actual objects. Import Metadata Wizard:- The Import Metadata Wizard automates importing metadata from a database into a module in Oracle Warehouse Builder. You can import metadata from Oracle Database and non-oracle databases. Each module type that stores source or target data structures has an associated Import Wizard, which automates the process of importing the metadata to describe the data structures. Importing metadata saves time and avoids keying errors, for example, by bringing metadata definitions of existing database objects into Oracle Warehouse Builder. The Welcome page of the Import Metadata Wizard lists the steps for importing metadata from source applications into the appropriate module. The Import Metadata Wizard for Oracle Database supports importing of tables, views, materialized views, dimensions, cubes, external tables, sequences, user-defined types, and PL/SQL transformations directly or through object lookups using synonyms. When you import an external table, Oracle Warehouse Builder also imports the associated location and directory information for any associated flat files.
61 Q6. What are the matching strategies for synchronizing workspace objects with its mapping operator? Explain inbound and outbound synchronization. Synchronizing means maintaining consistency between workspace object with its mapping operator. It can be achieved with the help of:- Inbound Synchronization Outbound Synchronization Inbound Synchronization:- Inbound uses the specified repository object to update the operator in our mapping for matching. It means that the changes in workspace object will be reflected in mapping operator. Outbound Synchronization:- Outbound option would update the workspace object with the changes we've made to the operator in the mapping. It means that the changes in mapping operator will be reflected in workspace object Following are the three matching strategies:- Match by Object Identifier Each source attribute is identified with a uniquely created ID internal to the Warehouse Builder metadata. The unique ID stored in the operator for each attribute is exactly same as that of the corresponding attribute in the workspace object to which the operator is synchronized with. This matching strategy compares the unique object identifier of an operator attribute with that of a workspace object. Match by Object Name This strategy matches the bound names of the operator attributes to the physical names of the workspace object attributes. Match by Object Position This strategy match s operator attributes with attributes of the selected workspace object by position. The first attribute of the operator is synchronized with the first attribute of the workspace object, the second with the second, and so on. Q7. Explain OLAP Terminologies. OLAP Terminologies: Cube:- Data in OLAP databases is stored in cubes. Cubes are made up of dimensions and measures. A cube may have many dimensions. Dimensions:- In an OLAP database cube categories of information are called dimensions. Some dimensions could be Location, Products, Stores, and Time.

62 Measures:- Measures are the numeric values in an OLAP database cube that are available for analysis. The measures could be margin; cost of goods sold, unit sales, budget amount, and so on. Multidimensional:- Multidimensional databases create cubes of aggregated data that anticipate how users think about business models. These cubes also deliver this information efficiently and quickly. Cubes consist of dimensions and measures. Dimensions are categories of information. For example, locations, stores and products are typical dimensions. Measures are the content values in a database that are available for analysis. Members:- In a OLAP database cube, members are the content values for a dimension. In the location dimension, they could be Mumbai, Thane, Mulund and so on. These are all values for location. Q8. Explain multidimensional database architecture with suitable diagram. One of the design objectives of the multidimensional server is to provide fast, linear access to data regardless of the way the data is being requested. The simplest request is a two-dimensional slice of data from an n-dimensional hypercube. The objective is to retrieve the data equally fast, regardless of the requested dimensions. The requested data is a compound slice in which two or more dimensions are nested as rows or columns The second role of the server is to provide calculated results. By far the most common calculation is aggregation; but more complex calculations, such as ratios and allocations, are also required. In fact, the design goal should be to offer a complete algebraic ability where any cell in the hypercube can be derived from any of the others, using all standard business and statistical functions, including conditional logic. Q9. Explain MOLAP and its advantages and disadvantages. MOLAP (Multi-dimensional Online Analytical Processing):-

63 MOLAP stands for Multi-dimensional Online Analytical Processing. MOLAP is the most used storage type. It is designed to offer maximum query performance to the users. The data and aggregations are stored in a multidimensional format, compressed and optimized for performance. When a cube with MOLAP storage is processed, the data is pulled from the relational database, the aggregations are performed, and the data is stored in the AS database in the form of binary files. The data inside the cube will refresh only when the cube is processed, so latency is high. Advantages: The data is stored on the OLAP server in optimized format; queries (even complex calculations) are faster than ROLAP. The data is compressed so it takes up less space. The data is stored on the OLAP server; we don t need to keep the connection to the relational database. Cube browsing is fastest using MOLAP. Disadvantages: This doesn t support REAL TIME i.e. newly inserted data will not be available for analysis until the cube is processed. Q10. Explain ROLAP and its advantages and disadvantages. ROLAP stands for Relational Online Analytical Processing. They provide a multidimensional view of this data. Below diagram show the architecture of ROLAP. All of the relational OLAP vendors store the data in a special way known as a star or snowflake schema. The most common form of these stores the data values in table known as the fact table. One dimension is selected as the fact dimension and this dimension forms the columns of the fact table. The other dimensions are stored in additional tables with the hierarchy defined by childparent columns.

64 The dimension tables are then relationally joined with the fact table to allow multidimensional queries. The data is retrieved from the relational database into the client tool by SQL queries. Since SQL was designed as an access language to relational databases, it is not necessarily optimal for multidimensional queries. The vast majority of ROLAP applications are for simple analysis of large volumes of information. Retail sales analysis is the most common one. The complexity of setup and maintenance has resulted in relatively few applications of ROLAP to financial data warehousing applications such as financial reporting or budgeting. Q11. Explain RAP (Real-Time Analytical Processing). Real-Time Analytical Processing (RAP):- RAP takes the approach that derived values should be calculated on demand, not pre-calculated. This avoids both the long calculation time and the data explosion that occur with the precalculation approach used by most OLAP vendors. In order to calculate on demand quickly enough to provide fast response, data must be stored in memory. This greatly speeds calculation and results in very fast response to the vast majority of requests. Another refinement of this would be to calculate numbers when they are requested but to retain the calculations (as long as they are still valid) so as to support future requests. This has two compelling advantages. First, only those aggregations which are needed are ever performed. In a database with a growth factor of 1,000 or more, many of the possible aggregations may never be requested. Second, in a dynamic, interactive update environment, budgeting being a common example, calculations is always up to date. There is no waiting for a required pre-calculation after each incremental data change. It is important to note that since RAP does not pre-calculate, the RAP database is typically 10 per cent to 25 per cent the size of the data source.

65 This is because the data source typically requires something like bytes per record and possibly more. Generally, the data source stores one number per record that will be input into the multidimensional database. Since RAP stores one number (plus indexes) in approximately 12 bytes, the size ratio between RAP and the data source is typically between 12 / 100=12% and 12 / 50=24%. Q12. Explain Data Explosion & Data Sparsity. Data Explosion:- Following example demonstrate the concept of data explosion in data warehousing. Consider what happens when a 200 MB source file explodes to 10 GB. The database no longer fits on any laptop for mobile computing. When a 1 GB source file explodes to 50 GB it cannot be accommodated on typical desktop servers. In both cases, the time to pre-calculate the model for every incremental data change will likely be many hours. So even though disk space is cheap, the full cost of pre-calculation can be unexpectedly large. Therefore it is critically important to understand what data sparsity and data explosion are, what causes these, and how these can be avoided for, the consequences of ignoring data explosion can be very costly and, in most cases, result in project failure. There are three main factors that contribute to data explosion. Sparsely populated base data increases the likelihood of data explosion Many dimensions in a model increase the likelihood of data explosion, and A high number of calculated levels in each dimension increase the likelihood of data explosion Data Sparsity:- Input data or base data in OLAP applications is typically sparse (not densely populated). Also, as the number of dimensions increase, data will typically become sparser (less dense). Data explosion is the phenomenon that occurs in multidimensional models where the derived or calculated values significantly exceed the base values. Q13. Differentiate between ROLAP and MOLAP
III. Answer any two of the following: 10
 (2½ Hours) [Max Marks: 60 N. B.: (1) All questions are compulsory. (2) Make suitable assumptions wherever necessary and state the assumptions made. (3) Answers to the same question must be written together.
(2½ Hours) [Max Marks: 60 N. B.: (1) All questions are compulsory. (2) Make suitable assumptions wherever necessary and state the assumptions made. (3) Answers to the same question must be written together.
1. Attempt any two of the following: 10 a. State and justify the characteristics of a Data Warehouse with suitable examples.
 Instructions to the Examiners: 1. May the Examiners not look for exact words from the text book in the Answers. 2. May any valid example be accepted - example may or may not be from the text book 1. Attempt
Instructions to the Examiners: 1. May the Examiners not look for exact words from the text book in the Answers. 2. May any valid example be accepted - example may or may not be from the text book 1. Attempt
Unit 2.
 Unit 2 DATAWAREHOUSING UNIT 2 CHAPTER 1,2 1.An Introduction to Oracle Warehouse Builder Installation of the database and OWB, About hardware and operating systems, Installing Oracle database software,
Unit 2 DATAWAREHOUSING UNIT 2 CHAPTER 1,2 1.An Introduction to Oracle Warehouse Builder Installation of the database and OWB, About hardware and operating systems, Installing Oracle database software,
Importing source database objects from a database
 Importing source database objects from a database We are now at the point where we can finally import our source database objects, source database objects. We ll walk through the process of importing from
Importing source database objects from a database We are now at the point where we can finally import our source database objects, source database objects. We ll walk through the process of importing from
This tutorial will help computer science graduates to understand the basic-to-advanced concepts related to data warehousing.
 About the Tutorial A data warehouse is constructed by integrating data from multiple heterogeneous sources. It supports analytical reporting, structured and/or ad hoc queries and decision making. This
About the Tutorial A data warehouse is constructed by integrating data from multiple heterogeneous sources. It supports analytical reporting, structured and/or ad hoc queries and decision making. This
Roll No: Subject: Dataware Housing Date:
 Installation steps of Oracle database 11g Release 2. In this post I will describe the installation steps of Oracle database 11g Release 2 (32-bit) on Windows Server 2007 (32-bit). --------------------------------------
Installation steps of Oracle database 11g Release 2. In this post I will describe the installation steps of Oracle database 11g Release 2 (32-bit) on Windows Server 2007 (32-bit). --------------------------------------
Fig 1.2: Relationship between DW, ODS and OLTP Systems
 1.4 DATA WAREHOUSES Data warehousing is a process for assembling and managing data from various sources for the purpose of gaining a single detailed view of an enterprise. Although there are several definitions
1.4 DATA WAREHOUSES Data warehousing is a process for assembling and managing data from various sources for the purpose of gaining a single detailed view of an enterprise. Although there are several definitions
UNIT
 UNIT 3.1 DATAWAREHOUSING UNIT 3 CHAPTER 1 1.Designing the Target Structure: Data warehouse design, Dimensional design, Cube and dimensions, Implementation of a dimensional model in a database, Relational
UNIT 3.1 DATAWAREHOUSING UNIT 3 CHAPTER 1 1.Designing the Target Structure: Data warehouse design, Dimensional design, Cube and dimensions, Implementation of a dimensional model in a database, Relational
Creating a target user and module
 The Warehouse Builder contains a number of objects, which we can use in designing our data warehouse, that are either relational or dimensional. OWB currently supports designing a target schema only in
The Warehouse Builder contains a number of objects, which we can use in designing our data warehouse, that are either relational or dimensional. OWB currently supports designing a target schema only in
Data Integration and ETL with Oracle Warehouse Builder
 Oracle University Contact Us: 1.800.529.0165 Data Integration and ETL with Oracle Warehouse Builder Duration: 5 Days What you will learn Participants learn to load data by executing the mappings or the
Oracle University Contact Us: 1.800.529.0165 Data Integration and ETL with Oracle Warehouse Builder Duration: 5 Days What you will learn Participants learn to load data by executing the mappings or the
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 01 Databases, Data warehouse Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro
Data Mining Concepts & Techniques Lecture No. 01 Databases, Data warehouse Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology Jamshoro
1 Dulcian, Inc., 2001 All rights reserved. Oracle9i Data Warehouse Review. Agenda
 Agenda Oracle9i Warehouse Review Dulcian, Inc. Oracle9i Server OLAP Server Analytical SQL Mining ETL Infrastructure 9i Warehouse Builder Oracle 9i Server Overview E-Business Intelligence Platform 9i Server:
Agenda Oracle9i Warehouse Review Dulcian, Inc. Oracle9i Server OLAP Server Analytical SQL Mining ETL Infrastructure 9i Warehouse Builder Oracle 9i Server Overview E-Business Intelligence Platform 9i Server:
A Novel Approach of Data Warehouse OLTP and OLAP Technology for Supporting Management prospective
 A Novel Approach of Data Warehouse OLTP and OLAP Technology for Supporting Management prospective B.Manivannan Research Scholar, Dept. Computer Science, Dravidian University, Kuppam, Andhra Pradesh, India
A Novel Approach of Data Warehouse OLTP and OLAP Technology for Supporting Management prospective B.Manivannan Research Scholar, Dept. Computer Science, Dravidian University, Kuppam, Andhra Pradesh, India
CHAPTER 3 Implementation of Data warehouse in Data Mining
 CHAPTER 3 Implementation of Data warehouse in Data Mining 3.1 Introduction to Data Warehousing A data warehouse is storage of convenient, consistent, complete and consolidated data, which is collected
CHAPTER 3 Implementation of Data warehouse in Data Mining 3.1 Introduction to Data Warehousing A data warehouse is storage of convenient, consistent, complete and consolidated data, which is collected
Data Warehouses Chapter 12. Class 10: Data Warehouses 1
 Data Warehouses Chapter 12 Class 10: Data Warehouses 1 OLTP vs OLAP Operational Database: a database designed to support the day today transactions of an organization Data Warehouse: historical data is
Data Warehouses Chapter 12 Class 10: Data Warehouses 1 OLTP vs OLAP Operational Database: a database designed to support the day today transactions of an organization Data Warehouse: historical data is
Designing the staging area contents
 We are going to design and build our very first ETL mapping in OWB, but where do we get started? We know we have to pull data from the acme_pos transactional database as we saw back in topic 2. The source
We are going to design and build our very first ETL mapping in OWB, but where do we get started? We know we have to pull data from the acme_pos transactional database as we saw back in topic 2. The source
Unit 1.
 Unit 1 1 UNIT 1 Introduction to Data Warehousing: Introduction, Necessity, Framework of the datawarehouse, options, developing datawarehouses, end points. Data Warehousing Design Consideration and Dimensional
Unit 1 1 UNIT 1 Introduction to Data Warehousing: Introduction, Necessity, Framework of the datawarehouse, options, developing datawarehouses, end points. Data Warehousing Design Consideration and Dimensional
DATA MINING TRANSACTION
 DATA MINING Data Mining is the process of extracting patterns from data. Data mining is seen as an increasingly important tool by modern business to transform data into an informational advantage. It is
DATA MINING Data Mining is the process of extracting patterns from data. Data mining is seen as an increasingly important tool by modern business to transform data into an informational advantage. It is
Data Warehousing. Overview
 Data Warehousing Overview Basic Definitions Normalization Entity Relationship Diagrams (ERDs) Normal Forms Many to Many relationships Warehouse Considerations Dimension Tables Fact Tables Star Schema Snowflake
Data Warehousing Overview Basic Definitions Normalization Entity Relationship Diagrams (ERDs) Normal Forms Many to Many relationships Warehouse Considerations Dimension Tables Fact Tables Star Schema Snowflake
CS614 - Data Warehousing - Midterm Papers Solved MCQ(S) (1 TO 22 Lectures)
 (1 TO 22 Lectures)") CS614- Data Warehousing Solved MCQ(S) From Midterm Papers (1 TO 22 Lectures) BY Arslan Arshad Nov 21,2016 BS110401050 BS110401050@vu.edu.pk Arslan.arshad01@gmail.com AKMP01 CS614 - Data Warehousing - Midterm
CS614- Data Warehousing Solved MCQ(S) From Midterm Papers (1 TO 22 Lectures) BY Arslan Arshad Nov 21,2016 BS110401050 BS110401050@vu.edu.pk Arslan.arshad01@gmail.com AKMP01 CS614 - Data Warehousing - Midterm
Call: SAS BI Course Content:35-40hours
 SAS BI Course Content:35-40hours Course Outline SAS Data Integration Studio 4.2 Introduction * to SAS DIS Studio Features of SAS DIS Studio Tasks performed by SAS DIS Studio Navigation to SAS DIS Studio
SAS BI Course Content:35-40hours Course Outline SAS Data Integration Studio 4.2 Introduction * to SAS DIS Studio Features of SAS DIS Studio Tasks performed by SAS DIS Studio Navigation to SAS DIS Studio
Data warehouse architecture consists of the following interconnected layers:
 Architecture, in the Data warehousing world, is the concept and design of the data base and technologies that are used to load the data. A good architecture will enable scalability, high performance and
Architecture, in the Data warehousing world, is the concept and design of the data base and technologies that are used to load the data. A good architecture will enable scalability, high performance and
Basics of Dimensional Modeling
 Basics of Dimensional Modeling Data warehouse and OLAP tools are based on a dimensional data model. A dimensional model is based on dimensions, facts, cubes, and schemas such as star and snowflake. Dimension
Basics of Dimensional Modeling Data warehouse and OLAP tools are based on a dimensional data model. A dimensional model is based on dimensions, facts, cubes, and schemas such as star and snowflake. Dimension
Syllabus. Syllabus. Motivation Decision Support. Syllabus
 Presentation: Sophia Discussion: Tianyu Metadata Requirements and Conclusion 3 4 Decision Support Decision Making: Everyday, Everywhere Decision Support System: a class of computerized information systems
Presentation: Sophia Discussion: Tianyu Metadata Requirements and Conclusion 3 4 Decision Support Decision Making: Everyday, Everywhere Decision Support System: a class of computerized information systems
OLAP Introduction and Overview
 1 CHAPTER 1 OLAP Introduction and Overview What Is OLAP? 1 Data Storage and Access 1 Benefits of OLAP 2 What Is a Cube? 2 Understanding the Cube Structure 3 What Is SAS OLAP Server? 3 About Cube Metadata
1 CHAPTER 1 OLAP Introduction and Overview What Is OLAP? 1 Data Storage and Access 1 Benefits of OLAP 2 What Is a Cube? 2 Understanding the Cube Structure 3 What Is SAS OLAP Server? 3 About Cube Metadata
Getting Started enterprise 88. Oracle Warehouse Builder 11gR2: operational data warehouse. Extract, Transform, and Load data to
 Oracle Warehouse Builder 11gR2: Getting Started 2011 Extract, Transform, and Load data to operational data warehouse build a dynamic, Bob Griesemer 1 enterprise 88 orotessionol expertise distilled PUBLISHING
Oracle Warehouse Builder 11gR2: Getting Started 2011 Extract, Transform, and Load data to operational data warehouse build a dynamic, Bob Griesemer 1 enterprise 88 orotessionol expertise distilled PUBLISHING
SAS Data Integration Studio 3.3. User s Guide
 SAS Data Integration Studio 3.3 User s Guide The correct bibliographic citation for this manual is as follows: SAS Institute Inc. 2006. SAS Data Integration Studio 3.3: User s Guide. Cary, NC: SAS Institute
SAS Data Integration Studio 3.3 User s Guide The correct bibliographic citation for this manual is as follows: SAS Institute Inc. 2006. SAS Data Integration Studio 3.3: User s Guide. Cary, NC: SAS Institute
Deccansoft Software Services Microsoft Silver Learning Partner. SSAS Syllabus
 Overview: Analysis Services enables you to analyze large quantities of data. With it, you can design, create, and manage multidimensional structures that contain detail and aggregated data from multiple
Overview: Analysis Services enables you to analyze large quantities of data. With it, you can design, create, and manage multidimensional structures that contain detail and aggregated data from multiple
DATA MINING AND WAREHOUSING
 DATA MINING AND WAREHOUSING Qno Question Answer 1 Define data warehouse? Data warehouse is a subject oriented, integrated, time-variant, and nonvolatile collection of data that supports management's decision-making
DATA MINING AND WAREHOUSING Qno Question Answer 1 Define data warehouse? Data warehouse is a subject oriented, integrated, time-variant, and nonvolatile collection of data that supports management's decision-making
INTRODUCTION. Chris Claterbos, Vlamis Software Solutions, Inc. REVIEW OF ARCHITECTURE
 BUILDING AN END TO END OLAP SOLUTION USING ORACLE BUSINESS INTELLIGENCE Chris Claterbos, Vlamis Software Solutions, Inc. claterbos@vlamis.com INTRODUCTION Using Oracle 10g R2 and Oracle Business Intelligence
BUILDING AN END TO END OLAP SOLUTION USING ORACLE BUSINESS INTELLIGENCE Chris Claterbos, Vlamis Software Solutions, Inc. claterbos@vlamis.com INTRODUCTION Using Oracle 10g R2 and Oracle Business Intelligence
1. Analytical queries on the dimensionally modeled database can be significantly simpler to create than on the equivalent nondimensional database.
 1. Creating a data warehouse involves using the functionalities of database management software to implement the data warehouse model as a collection of physically created and mutually connected database
1. Creating a data warehouse involves using the functionalities of database management software to implement the data warehouse model as a collection of physically created and mutually connected database
Oracle 1Z0-515 Exam Questions & Answers
 Oracle 1Z0-515 Exam Questions & Answers Number: 1Z0-515 Passing Score: 800 Time Limit: 120 min File Version: 38.7 http://www.gratisexam.com/ Oracle 1Z0-515 Exam Questions & Answers Exam Name: Data Warehousing
Oracle 1Z0-515 Exam Questions & Answers Number: 1Z0-515 Passing Score: 800 Time Limit: 120 min File Version: 38.7 http://www.gratisexam.com/ Oracle 1Z0-515 Exam Questions & Answers Exam Name: Data Warehousing
Pentaho Aggregation Designer User Guide
 Pentaho Aggregation Designer User Guide This document is copyright 2012 Pentaho Corporation. No part may be reprinted without written permission from Pentaho Corporation. All trademarks are the property
Pentaho Aggregation Designer User Guide This document is copyright 2012 Pentaho Corporation. No part may be reprinted without written permission from Pentaho Corporation. All trademarks are the property
Sql Fact Constellation Schema In Data Warehouse With Example
 Sql Fact Constellation Schema In Data Warehouse With Example Data Warehouse OLAP - Learn Data Warehouse in simple and easy steps using Multidimensional OLAP (MOLAP), Hybrid OLAP (HOLAP), Specialized SQL
Sql Fact Constellation Schema In Data Warehouse With Example Data Warehouse OLAP - Learn Data Warehouse in simple and easy steps using Multidimensional OLAP (MOLAP), Hybrid OLAP (HOLAP), Specialized SQL
Guide Users along Information Pathways and Surf through the Data
 Guide Users along Information Pathways and Surf through the Data Stephen Overton, Overton Technologies, LLC, Raleigh, NC ABSTRACT Business information can be consumed many ways using the SAS Enterprise
Guide Users along Information Pathways and Surf through the Data Stephen Overton, Overton Technologies, LLC, Raleigh, NC ABSTRACT Business information can be consumed many ways using the SAS Enterprise
Oracle Warehouse Builder 10g: New Features
 Oracle Warehouse Builder 10g: New Features Volume I - Student Guide D44808GC10 Edition 1.0 July 2006 D46761 Author Richard Green Technical Contributors and Reviewers David Allan Herbert Bradbury Sharath
Oracle Warehouse Builder 10g: New Features Volume I - Student Guide D44808GC10 Edition 1.0 July 2006 D46761 Author Richard Green Technical Contributors and Reviewers David Allan Herbert Bradbury Sharath
1 DATAWAREHOUSING QUESTIONS by Mausami Sawarkar
 1 DATAWAREHOUSING QUESTIONS by Mausami Sawarkar 1) What does the term 'Ad-hoc Analysis' mean? Choice 1 Business analysts use a subset of the data for analysis. Choice 2: Business analysts access the Data
1 DATAWAREHOUSING QUESTIONS by Mausami Sawarkar 1) What does the term 'Ad-hoc Analysis' mean? Choice 1 Business analysts use a subset of the data for analysis. Choice 2: Business analysts access the Data
Q1) Describe business intelligence system development phases? (6 marks)
 Describe business intelligence system development phases? (6 marks)") BUISINESS ANALYTICS AND INTELLIGENCE SOLVED QUESTIONS Q1) Describe business intelligence system development phases? (6 marks) The 4 phases of BI system development are as follow: Analysis phase Design
BUISINESS ANALYTICS AND INTELLIGENCE SOLVED QUESTIONS Q1) Describe business intelligence system development phases? (6 marks) The 4 phases of BI system development are as follow: Analysis phase Design
Cognos also provides you an option to export the report in XML or PDF format or you can view the reports in XML format.
 About the Tutorial IBM Cognos Business intelligence is a web based reporting and analytic tool. It is used to perform data aggregation and create user friendly detailed reports. IBM Cognos provides a wide
About the Tutorial IBM Cognos Business intelligence is a web based reporting and analytic tool. It is used to perform data aggregation and create user friendly detailed reports. IBM Cognos provides a wide
Chris Claterbos, Vlamis Software Solutions, Inc.
 ORACLE WAREHOUSE BUILDER 10G AND OLAP WHAT S NEW Chris Claterbos, Vlamis Software Solutions, Inc. INTRODUCTION With the use of the new features found in recently updated Oracle s Warehouse Builder (OWB)
ORACLE WAREHOUSE BUILDER 10G AND OLAP WHAT S NEW Chris Claterbos, Vlamis Software Solutions, Inc. INTRODUCTION With the use of the new features found in recently updated Oracle s Warehouse Builder (OWB)
Question Bank. 4) It is the source of information later delivered to data marts.
 It is the source of information later delivered to data marts.") Question Bank Year: 2016-2017 Subject Dept: CS Semester: First Subject Name: Data Mining. Q1) What is data warehouse? ANS. A data warehouse is a subject-oriented, integrated, time-variant, and nonvolatile
Question Bank Year: 2016-2017 Subject Dept: CS Semester: First Subject Name: Data Mining. Q1) What is data warehouse? ANS. A data warehouse is a subject-oriented, integrated, time-variant, and nonvolatile
Data Strategies for Efficiency and Growth
 Data Strategies for Efficiency and Growth Date Dimension Date key (PK) Date Day of week Calendar month Calendar year Holiday Channel Dimension Channel ID (PK) Channel name Channel description Channel type
Data Strategies for Efficiency and Growth Date Dimension Date key (PK) Date Day of week Calendar month Calendar year Holiday Channel Dimension Channel ID (PK) Channel name Channel description Channel type
Handout 12 Data Warehousing and Analytics.
 Handout 12 CS-605 Spring 17 Page 1 of 6 Handout 12 Data Warehousing and Analytics. Operational (aka transactional) system a system that is used to run a business in real time, based on current data; also
Handout 12 CS-605 Spring 17 Page 1 of 6 Handout 12 Data Warehousing and Analytics. Operational (aka transactional) system a system that is used to run a business in real time, based on current data; also
IT DATA WAREHOUSING AND DATA MINING UNIT-2 BUSINESS ANALYSIS
 PART A 1. What are production reporting tools? Give examples. (May/June 2013) Production reporting tools will let companies generate regular operational reports or support high-volume batch jobs. Such
PART A 1. What are production reporting tools? Give examples. (May/June 2013) Production reporting tools will let companies generate regular operational reports or support high-volume batch jobs. Such
Information Management course
 Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 05(b) : 23/10/2012 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 05(b) : 23/10/2012 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
SSAS 2008 Tutorial: Understanding Analysis Services
 Departamento de Engenharia Informática Sistemas de Informação e Bases de Dados Online Analytical Processing (OLAP) This tutorial has been copied from: https://www.accelebrate.com/sql_training/ssas_2008_tutorial.htm
Departamento de Engenharia Informática Sistemas de Informação e Bases de Dados Online Analytical Processing (OLAP) This tutorial has been copied from: https://www.accelebrate.com/sql_training/ssas_2008_tutorial.htm
SAS/Warehouse Administrator Usage and Enhancements Terry Lewis, SAS Institute Inc., Cary, NC
 SAS/Warehouse Administrator Usage and Enhancements Terry Lewis, SAS Institute Inc., Cary, NC ABSTRACT SAS/Warehouse Administrator software makes it easier to build, maintain, and access data warehouses
SAS/Warehouse Administrator Usage and Enhancements Terry Lewis, SAS Institute Inc., Cary, NC ABSTRACT SAS/Warehouse Administrator software makes it easier to build, maintain, and access data warehouses
Full file at
 Chapter 2 Data Warehousing True-False Questions 1. A real-time, enterprise-level data warehouse combined with a strategy for its use in decision support can leverage data to provide massive financial benefits
Chapter 2 Data Warehousing True-False Questions 1. A real-time, enterprise-level data warehouse combined with a strategy for its use in decision support can leverage data to provide massive financial benefits
A Multi-Dimensional Data Model
 A Multi-Dimensional Data Model A Data Warehouse is based on a Multidimensional data model which views data in the form of a data cube A data cube, such as sales, allows data to be modeled and viewed in
A Multi-Dimensional Data Model A Data Warehouse is based on a Multidimensional data model which views data in the form of a data cube A data cube, such as sales, allows data to be modeled and viewed in
Aggregating Knowledge in a Data Warehouse and Multidimensional Analysis
 Aggregating Knowledge in a Data Warehouse and Multidimensional Analysis Rafal Lukawiecki Strategic Consultant, Project Botticelli Ltd rafal@projectbotticelli.com Objectives Explain the basics of: 1. Data
Aggregating Knowledge in a Data Warehouse and Multidimensional Analysis Rafal Lukawiecki Strategic Consultant, Project Botticelli Ltd rafal@projectbotticelli.com Objectives Explain the basics of: 1. Data
Analytic Workspace Manager and Oracle OLAP 10g. An Oracle White Paper November 2004
 Analytic Workspace Manager and Oracle OLAP 10g An Oracle White Paper November 2004 Analytic Workspace Manager and Oracle OLAP 10g Introduction... 3 Oracle Database Incorporates OLAP... 4 Oracle Business
Analytic Workspace Manager and Oracle OLAP 10g An Oracle White Paper November 2004 Analytic Workspace Manager and Oracle OLAP 10g Introduction... 3 Oracle Database Incorporates OLAP... 4 Oracle Business
Question: 1 What are some of the data-related challenges that create difficulties in making business decisions? Choose three.
 Question: 1 What are some of the data-related challenges that create difficulties in making business decisions? Choose three. A. Too much irrelevant data for the job role B. A static reporting tool C.
Question: 1 What are some of the data-related challenges that create difficulties in making business decisions? Choose three. A. Too much irrelevant data for the job role B. A static reporting tool C.
Teiid Designer User Guide 7.5.0
 Teiid Designer User Guide 1 7.5.0 1. Introduction... 1 1.1. What is Teiid Designer?... 1 1.2. Why Use Teiid Designer?... 2 1.3. Metadata Overview... 2 1.3.1. What is Metadata... 2 1.3.2. Editing Metadata
Teiid Designer User Guide 1 7.5.0 1. Introduction... 1 1.1. What is Teiid Designer?... 1 1.2. Why Use Teiid Designer?... 2 1.3. Metadata Overview... 2 1.3.1. What is Metadata... 2 1.3.2. Editing Metadata
CHAPTER 8 DECISION SUPPORT V2 ADVANCED DATABASE SYSTEMS. Assist. Prof. Dr. Volkan TUNALI
 CHAPTER 8 DECISION SUPPORT V2 ADVANCED DATABASE SYSTEMS Assist. Prof. Dr. Volkan TUNALI Topics 2 Business Intelligence (BI) Decision Support System (DSS) Data Warehouse Online Analytical Processing (OLAP)
CHAPTER 8 DECISION SUPPORT V2 ADVANCED DATABASE SYSTEMS Assist. Prof. Dr. Volkan TUNALI Topics 2 Business Intelligence (BI) Decision Support System (DSS) Data Warehouse Online Analytical Processing (OLAP)
collection of data that is used primarily in organizational decision making.
 Data Warehousing A data warehouse is a special purpose database. Classic databases are generally used to model some enterprise. Most often they are used to support transactions, a process that is referred
Data Warehousing A data warehouse is a special purpose database. Classic databases are generally used to model some enterprise. Most often they are used to support transactions, a process that is referred
An Oracle White Paper March Oracle Warehouse Builder 11gR2: Feature Groups, Licensing and Feature Usage Management
 An Oracle White Paper March 2011 Oracle Warehouse Builder 11gR2: Feature Groups, Licensing and Feature Usage Management Introduction... 1 Warehouse Builder 11gR2: Feature Groups Overview... 3 Enterprise
An Oracle White Paper March 2011 Oracle Warehouse Builder 11gR2: Feature Groups, Licensing and Feature Usage Management Introduction... 1 Warehouse Builder 11gR2: Feature Groups Overview... 3 Enterprise
Data Mining & Data Warehouse
 Data Mining & Data Warehouse Associate Professor Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology (1) 2016 2017 1 Points to Cover Why Do We Need Data Warehouses?
Data Mining & Data Warehouse Associate Professor Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology (1) 2016 2017 1 Points to Cover Why Do We Need Data Warehouses?
Website: Contact: / Classroom Corporate Online Informatica Syllabus
 Designer Guide: Using the Designer o Configuring Designer Options o Using Toolbars o Navigating the Workspace o Designer Tasks o Viewing Mapplet and Mapplet Reports Working with Sources o Working with
Designer Guide: Using the Designer o Configuring Designer Options o Using Toolbars o Navigating the Workspace o Designer Tasks o Viewing Mapplet and Mapplet Reports Working with Sources o Working with
Data Warehouse and Mining
 Data Warehouse and Mining 1. is a subject-oriented, integrated, time-variant, nonvolatile collection of data in support of management decisions. A. Data Mining. B. Data Warehousing. C. Web Mining. D. Text
Data Warehouse and Mining 1. is a subject-oriented, integrated, time-variant, nonvolatile collection of data in support of management decisions. A. Data Mining. B. Data Warehousing. C. Web Mining. D. Text
EMC Ionix ControlCenter (formerly EMC ControlCenter) 6.0 StorageScope
 6.0 StorageScope") EMC Ionix ControlCenter (formerly EMC ControlCenter) 6.0 StorageScope Best Practices Planning Abstract This white paper provides advice and information on practices that will enhance the flexibility of
EMC Ionix ControlCenter (formerly EMC ControlCenter) 6.0 StorageScope Best Practices Planning Abstract This white paper provides advice and information on practices that will enhance the flexibility of
Course Number : SEWI ZG514 Course Title : Data Warehousing Type of Exam : Open Book Weightage : 60 % Duration : 180 Minutes
 Birla Institute of Technology & Science, Pilani Work Integrated Learning Programmes Division M.S. Systems Engineering at Wipro Info Tech (WIMS) First Semester 2014-2015 (October 2014 to March 2015) Comprehensive
Birla Institute of Technology & Science, Pilani Work Integrated Learning Programmes Division M.S. Systems Engineering at Wipro Info Tech (WIMS) First Semester 2014-2015 (October 2014 to March 2015) Comprehensive
DATA WAREHOUSE EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY
 DATA WAREHOUSE EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY CHARACTERISTICS Data warehouse is a central repository for summarized and integrated data
DATA WAREHOUSE EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY CHARACTERISTICS Data warehouse is a central repository for summarized and integrated data
A Star Schema Has One To Many Relationship Between A Dimension And Fact Table
 A Star Schema Has One To Many Relationship Between A Dimension And Fact Table Many organizations implement star and snowflake schema data warehouse The fact table has foreign key relationships to one or
A Star Schema Has One To Many Relationship Between A Dimension And Fact Table Many organizations implement star and snowflake schema data warehouse The fact table has foreign key relationships to one or
Oracle 1Z0-640 Exam Questions & Answers
 Oracle 1Z0-640 Exam Questions & Answers Number: 1z0-640 Passing Score: 800 Time Limit: 120 min File Version: 28.8 http://www.gratisexam.com/ Oracle 1Z0-640 Exam Questions & Answers Exam Name: Siebel7.7
Oracle 1Z0-640 Exam Questions & Answers Number: 1z0-640 Passing Score: 800 Time Limit: 120 min File Version: 28.8 http://www.gratisexam.com/ Oracle 1Z0-640 Exam Questions & Answers Exam Name: Siebel7.7
REPORTING AND QUERY TOOLS AND APPLICATIONS
 Tool Categories: REPORTING AND QUERY TOOLS AND APPLICATIONS There are five categories of decision support tools Reporting Managed query Executive information system OLAP Data Mining Reporting Tools Production
Tool Categories: REPORTING AND QUERY TOOLS AND APPLICATIONS There are five categories of decision support tools Reporting Managed query Executive information system OLAP Data Mining Reporting Tools Production
MICROSOFT BUSINESS INTELLIGENCE
 SSIS MICROSOFT BUSINESS INTELLIGENCE 1) Introduction to Integration Services Defining sql server integration services Exploring the need for migrating diverse Data the role of business intelligence (bi)
SSIS MICROSOFT BUSINESS INTELLIGENCE 1) Introduction to Integration Services Defining sql server integration services Exploring the need for migrating diverse Data the role of business intelligence (bi)
This download file shows detailed view for all updates from BW 7.5 SP00 to SP05 released from SAP help portal.
 This download file shows detailed view for all updates from BW 7.5 SP00 to SP05 released from SAP help portal. (1) InfoObject (New) As of BW backend version 7.5 SPS00, it is possible to model InfoObjects
This download file shows detailed view for all updates from BW 7.5 SP00 to SP05 released from SAP help portal. (1) InfoObject (New) As of BW backend version 7.5 SPS00, it is possible to model InfoObjects
Benefits of Automating Data Warehousing
 Benefits of Automating Data Warehousing Introduction Data warehousing can be defined as: A copy of data specifically structured for querying and reporting. In most cases, the data is transactional data
Benefits of Automating Data Warehousing Introduction Data warehousing can be defined as: A copy of data specifically structured for querying and reporting. In most cases, the data is transactional data
Data Mining. Data warehousing. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Data warehousing Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 22 Table of contents 1 Introduction 2 Data warehousing
Data Mining Data warehousing Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 22 Table of contents 1 Introduction 2 Data warehousing
Analytics: Server Architect (Siebel 7.7)
") Analytics: Server Architect (Siebel 7.7) Student Guide June 2005 Part # 10PO2-ASAS-07710 D44608GC10 Edition 1.0 D44917 Copyright 2005, 2006, Oracle. All rights reserved. Disclaimer This document contains
Analytics: Server Architect (Siebel 7.7) Student Guide June 2005 Part # 10PO2-ASAS-07710 D44608GC10 Edition 1.0 D44917 Copyright 2005, 2006, Oracle. All rights reserved. Disclaimer This document contains
Oracle Warehouse Builder 10g Runtime Environment, an Update. An Oracle White Paper February 2004
 Oracle Warehouse Builder 10g Runtime Environment, an Update An Oracle White Paper February 2004 Runtime Environment, an Update Executive Overview... 3 Introduction... 3 Runtime in warehouse builder 9.0.3...
Oracle Warehouse Builder 10g Runtime Environment, an Update An Oracle White Paper February 2004 Runtime Environment, an Update Executive Overview... 3 Introduction... 3 Runtime in warehouse builder 9.0.3...
Hands-On Lab. Lab: Developing BI Applications. Lab version: Last updated: 2/23/2011
 Hands-On Lab Lab: Developing BI Applications Lab version: 1.0.0 Last updated: 2/23/2011 CONTENTS OVERVIEW... 3 EXERCISE 1: USING THE CHARTING WEB PARTS... 5 EXERCISE 2: PERFORMING ANALYSIS WITH EXCEL AND
Hands-On Lab Lab: Developing BI Applications Lab version: 1.0.0 Last updated: 2/23/2011 CONTENTS OVERVIEW... 3 EXERCISE 1: USING THE CHARTING WEB PARTS... 5 EXERCISE 2: PERFORMING ANALYSIS WITH EXCEL AND
Chapter 3. The Multidimensional Model: Basic Concepts. Introduction. The multidimensional model. The multidimensional model
 Chapter 3 The Multidimensional Model: Basic Concepts Introduction Multidimensional Model Multidimensional concepts Star Schema Representation Conceptual modeling using ER, UML Conceptual modeling using
Chapter 3 The Multidimensional Model: Basic Concepts Introduction Multidimensional Model Multidimensional concepts Star Schema Representation Conceptual modeling using ER, UML Conceptual modeling using
FROM A RELATIONAL TO A MULTI-DIMENSIONAL DATA BASE
 FROM A RELATIONAL TO A MULTI-DIMENSIONAL DATA BASE David C. Hay Essential Strategies, Inc In the buzzword sweepstakes of 1997, the clear winner has to be Data Warehouse. A host of technologies and techniques
FROM A RELATIONAL TO A MULTI-DIMENSIONAL DATA BASE David C. Hay Essential Strategies, Inc In the buzzword sweepstakes of 1997, the clear winner has to be Data Warehouse. A host of technologies and techniques
1Z0-526
 1Z0-526 Passing Score: 800 Time Limit: 4 min Exam A QUESTION 1 ABC's Database administrator has divided its region table into several tables so that the west region is in one table and all the other regions
1Z0-526 Passing Score: 800 Time Limit: 4 min Exam A QUESTION 1 ABC's Database administrator has divided its region table into several tables so that the west region is in one table and all the other regions
COGNOS (R) 8 GUIDELINES FOR MODELING METADATA FRAMEWORK MANAGER. Cognos(R) 8 Business Intelligence Readme Guidelines for Modeling Metadata
 8 GUIDELINES FOR MODELING METADATA FRAMEWORK MANAGER. Cognos(R) 8 Business Intelligence Readme Guidelines for Modeling Metadata") COGNOS (R) 8 FRAMEWORK MANAGER GUIDELINES FOR MODELING METADATA Cognos(R) 8 Business Intelligence Readme Guidelines for Modeling Metadata GUIDELINES FOR MODELING METADATA THE NEXT LEVEL OF PERFORMANCE
COGNOS (R) 8 FRAMEWORK MANAGER GUIDELINES FOR MODELING METADATA Cognos(R) 8 Business Intelligence Readme Guidelines for Modeling Metadata GUIDELINES FOR MODELING METADATA THE NEXT LEVEL OF PERFORMANCE
to-end Solution Using OWB and JDeveloper to Analyze Your Data Warehouse
 An End-to to-end Solution Using OWB and JDeveloper to Analyze Your Data Warehouse Presented at ODTUG 2003 Dan Vlamis dvlamis@vlamis.com Vlamis Software Solutions, Inc. (816) 781-2880 http://www.vlamis.com
An End-to to-end Solution Using OWB and JDeveloper to Analyze Your Data Warehouse Presented at ODTUG 2003 Dan Vlamis dvlamis@vlamis.com Vlamis Software Solutions, Inc. (816) 781-2880 http://www.vlamis.com
Outline. Managing Information Resources. Concepts and Definitions. Introduction. Chapter 7
 Outline Managing Information Resources Chapter 7 Introduction Managing Data The Three-Level Database Model Four Data Models Getting Corporate Data into Shape Managing Information Four Types of Information
Outline Managing Information Resources Chapter 7 Introduction Managing Data The Three-Level Database Model Four Data Models Getting Corporate Data into Shape Managing Information Four Types of Information
Database design View Access patterns Need for separate data warehouse:- A multidimensional data model:-
 UNIT III: Data Warehouse and OLAP Technology: An Overview : What Is a Data Warehouse? A Multidimensional Data Model, Data Warehouse Architecture, Data Warehouse Implementation, From Data Warehousing to
UNIT III: Data Warehouse and OLAP Technology: An Overview : What Is a Data Warehouse? A Multidimensional Data Model, Data Warehouse Architecture, Data Warehouse Implementation, From Data Warehousing to
C_HANAIMP142
 C_HANAIMP142 Passing Score: 800 Time Limit: 4 min Exam A QUESTION 1 Where does SAP recommend you create calculated measures? A. In a column view B. In a business layer C. In an attribute view D. In an
C_HANAIMP142 Passing Score: 800 Time Limit: 4 min Exam A QUESTION 1 Where does SAP recommend you create calculated measures? A. In a column view B. In a business layer C. In an attribute view D. In an
Teradata Aggregate Designer
 Data Warehousing Teradata Aggregate Designer By: Sam Tawfik Product Marketing Manager Teradata Corporation Table of Contents Executive Summary 2 Introduction 3 Problem Statement 3 Implications of MOLAP
Data Warehousing Teradata Aggregate Designer By: Sam Tawfik Product Marketing Manager Teradata Corporation Table of Contents Executive Summary 2 Introduction 3 Problem Statement 3 Implications of MOLAP
Microsoft SQL Server Training Course Catalogue. Learning Solutions
 Training Course Catalogue Learning Solutions Querying SQL Server 2000 with Transact-SQL Course No: MS2071 Two days Instructor-led-Classroom 2000 The goal of this course is to provide students with the
Training Course Catalogue Learning Solutions Querying SQL Server 2000 with Transact-SQL Course No: MS2071 Two days Instructor-led-Classroom 2000 The goal of this course is to provide students with the
Accurate study guides, High passing rate! Testhorse provides update free of charge in one year!
 Accurate study guides, High passing rate! Testhorse provides update free of charge in one year! http://www.testhorse.com Exam : 70-467 Title : Designing Business Intelligence Solutions with Microsoft SQL
Accurate study guides, High passing rate! Testhorse provides update free of charge in one year! http://www.testhorse.com Exam : 70-467 Title : Designing Business Intelligence Solutions with Microsoft SQL
Summary of Last Chapter. Course Content. Chapter 2 Objectives. Data Warehouse and OLAP Outline. Incentive for a Data Warehouse
 Principles of Knowledge Discovery in bases Fall 1999 Chapter 2: Warehousing and Dr. Osmar R. Zaïane University of Alberta Dr. Osmar R. Zaïane, 1999 Principles of Knowledge Discovery in bases University
Principles of Knowledge Discovery in bases Fall 1999 Chapter 2: Warehousing and Dr. Osmar R. Zaïane University of Alberta Dr. Osmar R. Zaïane, 1999 Principles of Knowledge Discovery in bases University
SIEBEL ANALYTICS SERVER ADMINISTRATION GUIDE
 SIEBEL ANALYTICS SERVER ADMINISTRATION GUIDE VERSION 7.5.3 JULY 2003 12-FRKILT Siebel Systems, Inc., 2207 Bridgepointe Parkway, San Mateo, CA 94404 Copyright 2003 Siebel Systems, Inc. All rights reserved.
SIEBEL ANALYTICS SERVER ADMINISTRATION GUIDE VERSION 7.5.3 JULY 2003 12-FRKILT Siebel Systems, Inc., 2207 Bridgepointe Parkway, San Mateo, CA 94404 Copyright 2003 Siebel Systems, Inc. All rights reserved.
Data Warehousing and Decision Support. Introduction. Three Complementary Trends. [R&G] Chapter 23, Part A
![Data Warehousing and Decision Support. Introduction. Three Complementary Trends. [R&G] Chapter 23, Part A](/thumbs/75/72474087.jpg "Data Warehousing and Decision Support. Introduction. Three Complementary Trends. [R&G] Chapter 23, Part A") Data Warehousing and Decision Support [R&G] Chapter 23, Part A CS 432 1 Introduction Increasingly, organizations are analyzing current and historical data to identify useful patterns and support business
Data Warehousing and Decision Support [R&G] Chapter 23, Part A CS 432 1 Introduction Increasingly, organizations are analyzing current and historical data to identify useful patterns and support business
This tutorial has been prepared for computer science graduates to help them understand the basic-to-advanced concepts related to data mining.
 About the Tutorial Data Mining is defined as the procedure of extracting information from huge sets of data. In other words, we can say that data mining is mining knowledge from data. The tutorial starts
About the Tutorial Data Mining is defined as the procedure of extracting information from huge sets of data. In other words, we can say that data mining is mining knowledge from data. The tutorial starts
Data Warehousing and OLAP
 Data Warehousing and OLAP INFO 330 Slides courtesy of Mirek Riedewald Motivation Large retailer Several databases: inventory, personnel, sales etc. High volume of updates Management requirements Efficient
Data Warehousing and OLAP INFO 330 Slides courtesy of Mirek Riedewald Motivation Large retailer Several databases: inventory, personnel, sales etc. High volume of updates Management requirements Efficient
Data Warehousing (1)
") ICS 421 Spring 2010 Data Warehousing (1) Asst. Prof. Lipyeow Lim Information & Computer Science Department University of Hawaii at Manoa 3/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 1 Motivation
ICS 421 Spring 2010 Data Warehousing (1) Asst. Prof. Lipyeow Lim Information & Computer Science Department University of Hawaii at Manoa 3/18/2010 Lipyeow Lim -- University of Hawaii at Manoa 1 Motivation
This module presents the star schema, an alternative to 3NF schemas intended for analytical databases.
 Topic 3.3: Star Schema Design This module presents the star schema, an alternative to 3NF schemas intended for analytical databases. Star Schema Overview The star schema is a simple database architecture
Topic 3.3: Star Schema Design This module presents the star schema, an alternative to 3NF schemas intended for analytical databases. Star Schema Overview The star schema is a simple database architecture
COURSE 20466D: IMPLEMENTING DATA MODELS AND REPORTS WITH MICROSOFT SQL SERVER
 ABOUT THIS COURSE The focus of this five-day instructor-led course is on creating managed enterprise BI solutions. It describes how to implement multidimensional and tabular data models, deliver reports
ABOUT THIS COURSE The focus of this five-day instructor-led course is on creating managed enterprise BI solutions. It describes how to implement multidimensional and tabular data models, deliver reports
Proceedings of the IE 2014 International Conference AGILE DATA MODELS
 AGILE DATA MODELS Mihaela MUNTEAN Academy of Economic Studies, Bucharest mun61mih@yahoo.co.uk, Mihaela.Muntean@ie.ase.ro Abstract. In last years, one of the most popular subjects related to the field of
AGILE DATA MODELS Mihaela MUNTEAN Academy of Economic Studies, Bucharest mun61mih@yahoo.co.uk, Mihaela.Muntean@ie.ase.ro Abstract. In last years, one of the most popular subjects related to the field of
Oracle Warehouse Builder. Oracle Warehouse Builder. Quick Start Guide. Jean-Pierre Dijcks, Igor Machin, March 9, 2004
 Oracle Warehouse Builder Quick Start Guide Jean-Pierre Dijcks, Igor Machin, March 9, 2004 What Can You Expect from this Starter Kit? First and foremost, you can expect a helping hand in navigating through
Oracle Warehouse Builder Quick Start Guide Jean-Pierre Dijcks, Igor Machin, March 9, 2004 What Can You Expect from this Starter Kit? First and foremost, you can expect a helping hand in navigating through
MICROSOFT BUSINESS INTELLIGENCE (MSBI: SSIS, SSRS and SSAS)
") MICROSOFT BUSINESS INTELLIGENCE (MSBI: SSIS, SSRS and SSAS) Microsoft's Business Intelligence (MSBI) Training with in-depth Practical approach towards SQL Server Integration Services, Reporting Services
MICROSOFT BUSINESS INTELLIGENCE (MSBI: SSIS, SSRS and SSAS) Microsoft's Business Intelligence (MSBI) Training with in-depth Practical approach towards SQL Server Integration Services, Reporting Services
CT75 DATA WAREHOUSING AND DATA MINING DEC 2015
 Q.1 a. Briefly explain data granularity with the help of example Data Granularity: The single most important aspect and issue of the design of the data warehouse is the issue of granularity. It refers
Q.1 a. Briefly explain data granularity with the help of example Data Granularity: The single most important aspect and issue of the design of the data warehouse is the issue of granularity. It refers
The strategic advantage of OLAP and multidimensional analysis
 IBM Software Business Analytics Cognos Enterprise The strategic advantage of OLAP and multidimensional analysis 2 The strategic advantage of OLAP and multidimensional analysis Overview Online analytical
IBM Software Business Analytics Cognos Enterprise The strategic advantage of OLAP and multidimensional analysis 2 The strategic advantage of OLAP and multidimensional analysis Overview Online analytical
What is a Data Warehouse?
 What is a Data Warehouse? COMP 465 Data Mining Data Warehousing Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Defined in many different ways,
What is a Data Warehouse? COMP 465 Data Mining Data Warehousing Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Defined in many different ways,
Evolution of Database Systems
 Evolution of Database Systems Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies, second
Evolution of Database Systems Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies, second
SQL Server Analysis Services
 DataBase and Data Mining Group of DataBase and Data Mining Group of Database and data mining group, SQL Server 2005 Analysis Services SQL Server 2005 Analysis Services - 1 Analysis Services Database and
DataBase and Data Mining Group of DataBase and Data Mining Group of Database and data mining group, SQL Server 2005 Analysis Services SQL Server 2005 Analysis Services - 1 Analysis Services Database and
Audience BI professionals BI developers
 Applied Microsoft BI The Microsoft Data Platform empowers BI pros to implement organizational BI solutions delivering a single version of the truth across the enterprise. A typical organizational solution
Applied Microsoft BI The Microsoft Data Platform empowers BI pros to implement organizational BI solutions delivering a single version of the truth across the enterprise. A typical organizational solution