Countering Spam Using Classification Techniques. Steve Webb Data Mining Guest Lecture February 21, 2008
|
|
|
- Phillip Thornton
- 6 years ago
- Views:
Transcription
1 Countering Spam Using Classification Techniques Steve Webb Data Mining Guest Lecture February 21, 2008

2 Overview Introduction Countering Spam Problem Description Classification History Ongoing Research Countering Web Spam Problem Description Classification History Ongoing Research Conclusions




3 Introduction The Internet has spawned numerous information-rich environments Systems World Wide Web Social Networking Communities Openness facilities information sharing, but it also makes them vulnerable
4 Denial of Information (DoI) Attacks Deliberate insertion of low quality information (or noise) into information-rich environments Information analog to Denial of Service (DoS) attacks Two goals Promotion of ideals by means of deception Denial of access to high quality information Spam is the currently the most prominent example of a DoI attack
5 Overview Introduction Countering Spam Problem Description Classification History Ongoing Research Countering Web Spam Problem Description Classification History Ongoing Research Conclusions

6 Countering Spam Close to 200 billion (yes, billion) s are sent each day Spam accounts for around 90% of that traffic ~2 million spam messages every second

7 Old Spam Examples
8 Problem Description spam detection can be modeled as a binary text classification problem Two classes: spam and legitimate (non-spam) Example of supervised learning Build a model (classifier) based on training data to approximate the target function Construct a function φ: M {spam, legitimate} such that it overlaps Φ: M {spam, legitimate} as much as possible
9 Problem Description (cont.) How do we represent a message? How do we generate features? How do we process features? How do we evaluate performance?
10 How do we represent a message? Classification algorithms require a consistent format Salton s vector space model ( bag of words ) is the most popular representation Each message m is represented as a feature vector f of n features: <f 1, f 2,, f n >

11 How do we generate features? Sources of information SMTP connections Network properties headers Social networks body Textual parts URLs Attachments
12 How do we process features? Feature Tokenization Alphanumeric tokens N-grams Phrases Feature Scrubbing Stemming Stop word removal Feature Selection Simple feature removal Information-theoretic algorithms

13 How do we evaluate performance? Traditional IR metrics Precision vs. Recall False positives vs. False negatives Imbalanced error costs P = d b + d R = c d + d ROC curves FP = a b + b FN = c c + d
14 Classification History Sahami et al. (1998) Used a Naïve Bayes classifier Were the first to apply text classification research to the spam problem Pantel and Lin (1998) Also used a Naïve Bayes classifier Found that Naïve Bayes outperforms RIPPER
15 Classification History (cont.) Drucker et al. (1999) Evaluated Support Vector Machines as a solution to spam Found that SVM is more effective than RIPPER and Rocchio Hidalgo and Lopez (2000) Found that decision trees (C4.5) outperform Naïve Bayes and k-nn
16 Classification History (cont.) Up to this point, private corpora were used exclusively in spam research Androutsopoulos et al. (2000a) Created the first publicly available spam corpus (Ling-spam) Performed various feature set size, training set size, stemming, and stop-list experiments with a Naïve Bayes classifier
17 Classification History (cont.) Androutsopoulos et al. (2000b) Created another publicly available spam corpus (PU1) Confirmed previous research than Naïve Bayes outperforms a keyword-based filter Carreras and Marquez (2001) Used PU1 to show that AdaBoost is more effective than decision trees and Naïve Bayes
18 Classification History (cont.) Androutsopoulos et al. (2004) Created 3 more publicly available corpora (PU2, PU3, and PUA) Compared Naïve Bayes, Flexible Bayes, Support Vector Machines, and LogitBoost: FB, SVM, and LB outperform NB Zhang et al. (2004) Used Ling-spam, PU1, and the SpamAssassin corpora Compared Naïve Bayes, Support Vector Machines, and AdaBoost: SVM and AB outperform NB
19 Classification History (cont.) CEAS (2004 present) Focuses solely on and anti-spam research Generates a significant amount of academic and industry anti-spam research Klimt and Yang (2004) Published the Enron Corpus the first large-scale corpus of legitimate messages TREC Spam Track (2005 present) Produces new corpora every year Provides a standardized platform to evaluate classification algorithms

20 Ongoing Research Concept Drift New Classification Approaches Adversarial Classification Image Spam
21 Concept Drift Spam content is extremely dynamic Topic drift (e.g., specific scams) Technique drift (e.g., obfuscations) How do we keep up with the Joneses? Batch vs. Online Learning Percentage of Spam Messages OBFUSCATING_COMMENT INTERRUPTUS HTML_FONT_LOW_CONTRAST HTML_TINY_FONT 0 01/03 01/04 01/05 01/06 Month
22 New Classification Approaches Filter Fusion Compression-based Filtering Network behavioral clustering

23 Adversarial Classification Classifiers assume a clear distinction between spam and legitimate features Camouflaged messages Mask spam content with legitimate content Disrupt decision boundaries for classifiers
24 Camouflage Attacks Baseline performance Accuracies consistently higher than 98% Classifiers under attack Accuracies degrade to between 50% and 70% Retrained classifiers Accuracies climb back to between 91% and 99% Weighted Accuracy, Weighted Accuracy, λ = Naive Bayes SVM LogitBoost Number of of Retained Features 640
25 Camouflage Attacks (cont.) Retraining postpones the problem, but it doesn t solve it NaiveBayes SVM LogitBoost We can identify features that are less susceptible to attack, but that s simply Fraction of False Negatives another stalling technique 0 0 0(A) 1 1(A) 2 2(A) 3 3(A) Round Number (A denotes Attack) 4 4(A)




26 Image Spam What happens when an does not contain textual features? OCR is easily defeated Classification using image properties
27 Overview Introduction Countering Spam Problem Description Classification History Ongoing Research Countering Web Spam Problem Description Classification History Ongoing Research Conclusions

28 Countering Web Spam What is web spam? Traditional definition Our definition Between 13.8% and 22.1% of all web pages
 Elaborate entry pages used to deceive")
29 Ad Farms Only contain advertising links (usually ad listings) Elaborate entry pages used to deceive visitors
 Clicking on an entry page link leads to an ad listing Ad syndicators")
30 Ad Farms (cont.) Clicking on an entry page link leads to an ad listing Ad syndicators provide the content Web spammers create the HTML structures
31 Parked Domains Domain parking services Provide place holders for newly registered domains Allow ad listings to be used as place holders to monetize a domain Inevitably, web spammers abused these services
32 Parked Domains (cont.) Functionally equivalent to Ad Farms Both rely on ad syndicators for content Both provide little to no value to their visitors Unique Characteristics Reliance on domain parking services (e.g., apps5.oingo.com, searchportal.information.com, etc.) Typically for sale by owner ( Offer To Buy This Domain )

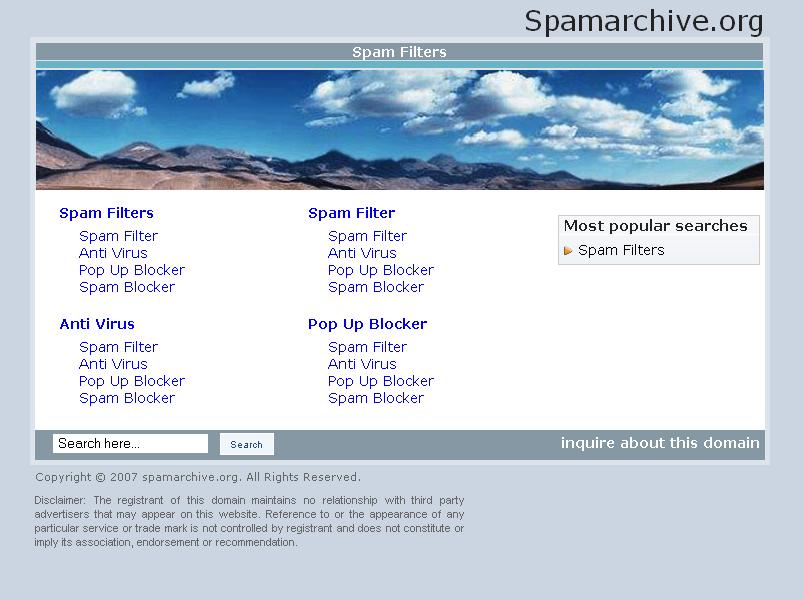
33 Parked Domains (cont.)
34 Advertisements Pages advertising specific products or services Examples of the kinds of pages being advertised in Ad Farms and Parked Domains
35 Problem Description Web spam detection can also be modeled as a binary text classification problem Salton s vector space model is quite common Feature processing and performance evaluation are also quite similar But what about feature generation
36 How do we generate features? Sources of information HTTP connections Hosting IP addresses Session headers HTML content Textual properties Structural properties URL linkage structure PageRank scores Neighbor properties
37 Classification History Davison (2000) Was the first to investigate link-based web spam Built decision trees to successfully identify nepotistic links Becchetti et al. (2005) Revisited the use of decision trees to identify linkbased web spam Used link-based features such as PageRank and TrustRank scores
38 Classification History Drost and Scheffer (2005) Used Support Vector Machines to classify web spam pages Relied on content-based features as well as linkbased features Ntoulas et al. (2006) Built decision trees to classify web spam Used content-based features (e.g., fraction of visible content, compressibility, etc.)
39 Classification History Up to this point, previous web spam research was limited to small (on the order of a few thousand), private data sets Webb et al. (2006) Presented the Webb Spam Corpus a first-of-its-kind large-scale, publicly available web spam corpus (almost 350K web spam pages) Castillo et al. (2006) Presented the WEBSPAM-UK2006 corpus a publicly available web spam corpus (only contains 1,924 web spam pages)
40 Classification History Castillo et al. (2007) Created a cost-sensitive decision tree to identify web spam in the WEBSPAM-UK2006 data set Used link-based features from [Becchetti et al. (2005)] and content-based features from [Ntoulas et al. (2006)] Webb et al. (2008) Compared various classifiers (e.g., SVM, decision trees, etc.) using HTTP session information exclusively Used the Webb Spam Corpus, WebBase data, and the WEBSPAM-UK2006 data set Found that these classifiers are comparable to (and in many cases, better than) existing approaches

41 Ongoing Research Redirection Phishing Social Spam
42 Redirection 144,801 unique redirect chains (1.54 average HTTP redirects) 7% 1% 2% 3% 5% 302 HTTP redirect frame redirect 301 HTTP redirect iframe redirect 43.9% of web spam pages use some form of HTML or JavaScript redirection 8% 11% 14% 49% meta refresh and location.replace() meta refresh meta refresh and location location* Other

43 Phishing Interesting form of deception that affects and web users Another form of adversarial classification



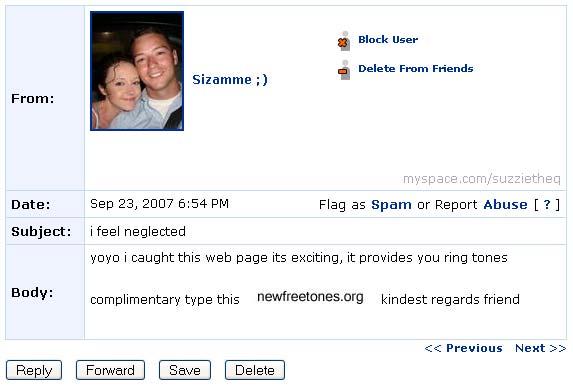
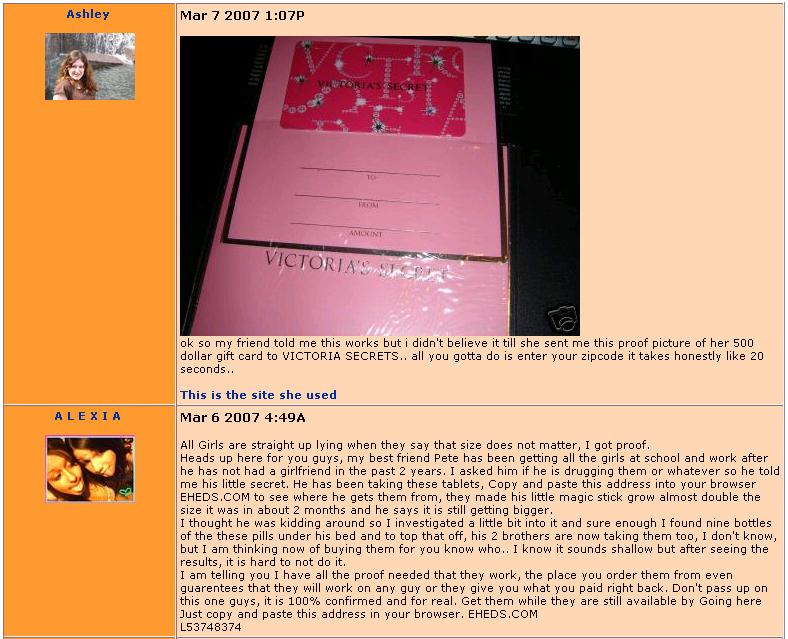
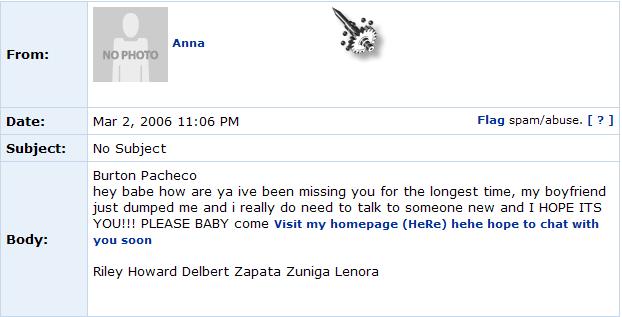
44 Social Spam Comment spam Bulletin spam Message spam
45 Conclusions and web spam are currently two of the largest information security problems Classification techniques offer an effective way to filter this low quality information Spammers are extremely dynamic, generating various areas of important future research

46 Questions
Detecting Malicious Web Links and Identifying Their Attack Types
 Detecting Malicious Web Links and Identifying Their Attack Types Anti-Spam Team Cellopoint July 3, 2013 Introduction References A great effort has been directed towards detection of malicious URLs Blacklisting
Detecting Malicious Web Links and Identifying Their Attack Types Anti-Spam Team Cellopoint July 3, 2013 Introduction References A great effort has been directed towards detection of malicious URLs Blacklisting
An Experimental Evaluation of Spam Filter Performance and Robustness Against Attack
 An Experimental Evaluation of Spam Filter Performance and Robustness Against Attack Steve Webb, Subramanyam Chitti, and Calton Pu {webb, chittis, calton}@cc.gatech.edu College of Computing Georgia Institute
An Experimental Evaluation of Spam Filter Performance and Robustness Against Attack Steve Webb, Subramanyam Chitti, and Calton Pu {webb, chittis, calton}@cc.gatech.edu College of Computing Georgia Institute
Detecting Spam Web Pages
 Detecting Spam Web Pages Marc Najork Microsoft Research Silicon Valley About me 1989-1993: UIUC (home of NCSA Mosaic) 1993-2001: Digital Equipment/Compaq Started working on web search in 1997 Mercator
Detecting Spam Web Pages Marc Najork Microsoft Research Silicon Valley About me 1989-1993: UIUC (home of NCSA Mosaic) 1993-2001: Digital Equipment/Compaq Started working on web search in 1997 Mercator
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p.
 Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Part I: Data Mining Foundations
 Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
An Empirical Performance Comparison of Machine Learning Methods for Spam Categorization
 An Empirical Performance Comparison of Machine Learning Methods for Spam E-mail Categorization Chih-Chin Lai a Ming-Chi Tsai b a Dept. of Computer Science and Information Engineering National University
An Empirical Performance Comparison of Machine Learning Methods for Spam E-mail Categorization Chih-Chin Lai a Ming-Chi Tsai b a Dept. of Computer Science and Information Engineering National University
WEB SPAM IDENTIFICATION THROUGH LANGUAGE MODEL ANALYSIS
 WEB SPAM IDENTIFICATION THROUGH LANGUAGE MODEL ANALYSIS Juan Martinez-Romo and Lourdes Araujo Natural Language Processing and Information Retrieval Group at UNED * nlp.uned.es Fifth International Workshop
WEB SPAM IDENTIFICATION THROUGH LANGUAGE MODEL ANALYSIS Juan Martinez-Romo and Lourdes Araujo Natural Language Processing and Information Retrieval Group at UNED * nlp.uned.es Fifth International Workshop
Naïve Bayes for text classification
 Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
Evolutionary Study of Web Spam: Webb Spam Corpus 2011 versus Webb Spam Corpus 2006
 Evolutionary Study of Web Spam: Webb Spam Corpus 2011 versus Webb Spam Corpus 2006 De Wang, Danesh Irani, and Calton Pu College of Computing Georgia Institute of Technology Atlanta, Georgia 30332-0765
Evolutionary Study of Web Spam: Webb Spam Corpus 2011 versus Webb Spam Corpus 2006 De Wang, Danesh Irani, and Calton Pu College of Computing Georgia Institute of Technology Atlanta, Georgia 30332-0765
A Content Vector Model for Text Classification
 A Content Vector Model for Text Classification Eric Jiang Abstract As a popular rank-reduced vector space approach, Latent Semantic Indexing (LSI) has been used in information retrieval and other applications.
A Content Vector Model for Text Classification Eric Jiang Abstract As a popular rank-reduced vector space approach, Latent Semantic Indexing (LSI) has been used in information retrieval and other applications.
Web Spam. Seminar: Future Of Web Search. Know Your Neighbors: Web Spam Detection using the Web Topology
 Seminar: Future Of Web Search University of Saarland Web Spam Know Your Neighbors: Web Spam Detection using the Web Topology Presenter: Sadia Masood Tutor : Klaus Berberich Date : 17-Jan-2008 The Agenda
Seminar: Future Of Web Search University of Saarland Web Spam Know Your Neighbors: Web Spam Detection using the Web Topology Presenter: Sadia Masood Tutor : Klaus Berberich Date : 17-Jan-2008 The Agenda
Chapter 6: Information Retrieval and Web Search. An introduction
 Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Finding the Linchpins of the Dark Web: A Study on Topologically Dedicated Hosts on Malicious Web Infrastructures
 Finding the Linchpins of the Dark Web: A Study on Topologically Dedicated Hosts on Malicious Web Infrastructures Zhou Li, Indiana University Bloomington Sumayah Alrwais, Indiana University Bloomington
Finding the Linchpins of the Dark Web: A Study on Topologically Dedicated Hosts on Malicious Web Infrastructures Zhou Li, Indiana University Bloomington Sumayah Alrwais, Indiana University Bloomington
Link Analysis in Web Mining
 Problem formulation (998) Link Analysis in Web Mining Hubs and Authorities Spam Detection Suppose we are given a collection of documents on some broad topic e.g., stanford, evolution, iraq perhaps obtained
Problem formulation (998) Link Analysis in Web Mining Hubs and Authorities Spam Detection Suppose we are given a collection of documents on some broad topic e.g., stanford, evolution, iraq perhaps obtained
Bing Liu. Web Data Mining. Exploring Hyperlinks, Contents, and Usage Data. With 177 Figures. Springer
 Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
The Security Role for Content Analysis
 The Security Role for Content Analysis Jim Nisbet Founder, Tablus, Inc. November 17, 2004 About Us Tablus is a 3 year old company that delivers solutions to provide visibility to sensitive information
The Security Role for Content Analysis Jim Nisbet Founder, Tablus, Inc. November 17, 2004 About Us Tablus is a 3 year old company that delivers solutions to provide visibility to sensitive information
Information Retrieval
 Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
Information Retrieval CSC 375, Fall 2016 An information retrieval system will tend not to be used whenever it is more painful and troublesome for a customer to have information than for him not to have
2. Design Methodology
 Content-aware Email Multiclass Classification Categorize Emails According to Senders Liwei Wang, Li Du s Abstract People nowadays are overwhelmed by tons of coming emails everyday at work or in their daily
Content-aware Email Multiclass Classification Categorize Emails According to Senders Liwei Wang, Li Du s Abstract People nowadays are overwhelmed by tons of coming emails everyday at work or in their daily
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Classification and Clustering Classification and clustering are classical pattern recognition / machine learning problems
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Classification and Clustering Classification and clustering are classical pattern recognition / machine learning problems
CS 8803 AIAD Prof Ling Liu. Project Proposal for Automated Classification of Spam Based on Textual Features Gopal Pai
 CS 8803 AIAD Prof Ling Liu Project Proposal for Automated Classification of Spam Based on Textual Features Gopal Pai Under the supervision of Steve Webb Motivations and Objectives Spam, which was until
CS 8803 AIAD Prof Ling Liu Project Proposal for Automated Classification of Spam Based on Textual Features Gopal Pai Under the supervision of Steve Webb Motivations and Objectives Spam, which was until
A Comparison of Text-Categorization Methods applied to N-Gram Frequency Statistics
 A Comparison of Text-Categorization Methods applied to N-Gram Frequency Statistics Helmut Berger and Dieter Merkl 2 Faculty of Information Technology, University of Technology, Sydney, NSW, Australia hberger@it.uts.edu.au
A Comparison of Text-Categorization Methods applied to N-Gram Frequency Statistics Helmut Berger and Dieter Merkl 2 Faculty of Information Technology, University of Technology, Sydney, NSW, Australia hberger@it.uts.edu.au
5 Choosing keywords Initially choosing keywords Frequent and rare keywords Evaluating the competition rates of search
 Seo tutorial Seo tutorial Introduction to seo... 4 1. General seo information... 5 1.1 History of search engines... 5 1.2 Common search engine principles... 6 2. Internal ranking factors... 8 2.1 Web page
Seo tutorial Seo tutorial Introduction to seo... 4 1. General seo information... 5 1.1 History of search engines... 5 1.2 Common search engine principles... 6 2. Internal ranking factors... 8 2.1 Web page
A Semi-Supervised Approach for Web Spam Detection using Combinatorial Feature-Fusion
 A Semi-Supervised Approach for Web Spam Detection using Combinatorial Feature-Fusion Ye Tian, Gary M. Weiss, Qiang Ma Department of Computer and Information Science Fordham University 441 East Fordham
A Semi-Supervised Approach for Web Spam Detection using Combinatorial Feature-Fusion Ye Tian, Gary M. Weiss, Qiang Ma Department of Computer and Information Science Fordham University 441 East Fordham
Chapter 27 Introduction to Information Retrieval and Web Search
 Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Collaborative Filtering. Doug Herbers Master s Oral Defense June 28, 2005
 Collaborative E-Mail Filtering Doug Herbers Master s Oral Defense June 28, 2005 Background Spamming the use of any electronic communications medium to send unsolicited messages in bulk E-Mail is the most
Collaborative E-Mail Filtering Doug Herbers Master s Oral Defense June 28, 2005 Background Spamming the use of any electronic communications medium to send unsolicited messages in bulk E-Mail is the most
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Application of Support Vector Machine Algorithm in Spam Filtering
 Application of Support Vector Machine Algorithm in E-Mail Spam Filtering Julia Bluszcz, Daria Fitisova, Alexander Hamann, Alexey Trifonov, Advisor: Patrick Jähnichen Abstract The problem of spam classification
Application of Support Vector Machine Algorithm in E-Mail Spam Filtering Julia Bluszcz, Daria Fitisova, Alexander Hamann, Alexey Trifonov, Advisor: Patrick Jähnichen Abstract The problem of spam classification
Ranked Retrieval. Evaluation in IR. One option is to average the precision scores at discrete. points on the ROC curve But which points?
 Ranked Retrieval One option is to average the precision scores at discrete Precision 100% 0% More junk 100% Everything points on the ROC curve But which points? Recall We want to evaluate the system, not
Ranked Retrieval One option is to average the precision scores at discrete Precision 100% 0% More junk 100% Everything points on the ROC curve But which points? Recall We want to evaluate the system, not
Spam Classification Documentation
 Spam Classification Documentation What is SPAM? Unsolicited, unwanted email that was sent indiscriminately, directly or indirectly, by a sender having no current relationship with the recipient. Objective:
Spam Classification Documentation What is SPAM? Unsolicited, unwanted email that was sent indiscriminately, directly or indirectly, by a sender having no current relationship with the recipient. Objective:
EVALUATION OF THE HIGHEST PROBABILITY SVM NEAREST NEIGHBOR CLASSIFIER WITH VARIABLE RELATIVE ERROR COST
 EVALUATION OF THE HIGHEST PROBABILITY SVM NEAREST NEIGHBOR CLASSIFIER WITH VARIABLE RELATIVE ERROR COST Enrico Blanzieri and Anton Bryl May 2007 Technical Report # DIT-07-025 Evaluation of the Highest
EVALUATION OF THE HIGHEST PROBABILITY SVM NEAREST NEIGHBOR CLASSIFIER WITH VARIABLE RELATIVE ERROR COST Enrico Blanzieri and Anton Bryl May 2007 Technical Report # DIT-07-025 Evaluation of the Highest
Introduction to Data Mining
 Introduction to Data Mining Lecture #11: Link Analysis 3 Seoul National University 1 In This Lecture WebSpam: definition and method of attacks TrustRank: how to combat WebSpam HITS algorithm: another algorithm
Introduction to Data Mining Lecture #11: Link Analysis 3 Seoul National University 1 In This Lecture WebSpam: definition and method of attacks TrustRank: how to combat WebSpam HITS algorithm: another algorithm
A novel supervised learning algorithm and its use for Spam Detection in Social Bookmarking Systems
 A novel supervised learning algorithm and its use for Spam Detection in Social Bookmarking Systems Anestis Gkanogiannis and Theodore Kalamboukis Department of Informatics Athens University of Economics
A novel supervised learning algorithm and its use for Spam Detection in Social Bookmarking Systems Anestis Gkanogiannis and Theodore Kalamboukis Department of Informatics Athens University of Economics
Information Retrieval (IR) Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.
 Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.") Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
CLOAK OF VISIBILITY : DETECTING WHEN MACHINES BROWSE A DIFFERENT WEB
 CLOAK OF VISIBILITY : DETECTING WHEN MACHINES BROWSE A DIFFERENT WEB CIS 601: Graduate Seminar Prof. S. S. Chung Presented By:- Amol Chaudhari CSU ID 2682329 AGENDA About Introduction Contributions Background
CLOAK OF VISIBILITY : DETECTING WHEN MACHINES BROWSE A DIFFERENT WEB CIS 601: Graduate Seminar Prof. S. S. Chung Presented By:- Amol Chaudhari CSU ID 2682329 AGENDA About Introduction Contributions Background
Vulnerability Disclosure in the Age of Social Media: Exploiting Twitter for Predicting Real-World Exploits
 Vulnerability Disclosure in the Age of Social Media: Exploiting Twitter for Predicting Real-World Exploits Carl Sabottke Octavian Suciu Tudor Dumitraș University of Maryland 2 Problem Increasing number
Vulnerability Disclosure in the Age of Social Media: Exploiting Twitter for Predicting Real-World Exploits Carl Sabottke Octavian Suciu Tudor Dumitraș University of Maryland 2 Problem Increasing number
Chapter-8. Conclusion and Future Scope
 Chapter-8 Conclusion and Future Scope This thesis has addressed the problem of Spam E-mails. In this work a Framework has been proposed. The proposed framework consists of the three pillars which are Legislative
Chapter-8 Conclusion and Future Scope This thesis has addressed the problem of Spam E-mails. In this work a Framework has been proposed. The proposed framework consists of the three pillars which are Legislative
Evaluating Classifiers
 Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
Web Spam Challenge 2008
 Web Spam Challenge 2008 Data Analysis School, Moscow, Russia K. Bauman, A. Brodskiy, S. Kacher, E. Kalimulina, R. Kovalev, M. Lebedev, D. Orlov, P. Sushin, P. Zryumov, D. Leshchiner, I. Muchnik The Data
Web Spam Challenge 2008 Data Analysis School, Moscow, Russia K. Bauman, A. Brodskiy, S. Kacher, E. Kalimulina, R. Kovalev, M. Lebedev, D. Orlov, P. Sushin, P. Zryumov, D. Leshchiner, I. Muchnik The Data
Using AdaBoost and Decision Stumps to Identify Spam
 Using AdaBoost and Decision Stumps to Identify Spam E-mail Tyrone Nicholas June 4, 2003 Abstract An existing spam e-mail filter using the Naive Bayes decision engine was retrofitted with one based on the
Using AdaBoost and Decision Stumps to Identify Spam E-mail Tyrone Nicholas June 4, 2003 Abstract An existing spam e-mail filter using the Naive Bayes decision engine was retrofitted with one based on the
MEASURING AND FINGERPRINTING CLICK-SPAM IN AD NETWORKS
 MEASURING AND FINGERPRINTING CLICK-SPAM IN AD NETWORKS Vacha Dave *, Saikat Guha and Yin Zhang * * The University of Texas at Austin Microsoft Research India Internet Advertising Today 2 Online advertising
MEASURING AND FINGERPRINTING CLICK-SPAM IN AD NETWORKS Vacha Dave *, Saikat Guha and Yin Zhang * * The University of Texas at Austin Microsoft Research India Internet Advertising Today 2 Online advertising
Analyzing and Detecting Review Spam
 Seventh IEEE International Conference on Data Mining Analyzing and Detecting Review Spam Nitin Jindal and Bing Liu Department of Computer Science University of Illinois at Chicago nitin.jindal@gmail.com,
Seventh IEEE International Conference on Data Mining Analyzing and Detecting Review Spam Nitin Jindal and Bing Liu Department of Computer Science University of Illinois at Chicago nitin.jindal@gmail.com,
INCORPORTING KEYWORD-BASED FILTERING TO DOCUMENT CLASSIFICATION FOR SPAMMING
 INCORPORTING KEYWORD-BASED FILTERING TO DOCUMENT CLASSIFICATION FOR EMAIL SPAMMING TAK-LAM WONG, KAI-ON CHOW, FRANZ WONG Department of Computer Science, City University of Hong Kong, 83 Tat Chee Avenue,
INCORPORTING KEYWORD-BASED FILTERING TO DOCUMENT CLASSIFICATION FOR EMAIL SPAMMING TAK-LAM WONG, KAI-ON CHOW, FRANZ WONG Department of Computer Science, City University of Hong Kong, 83 Tat Chee Avenue,
F. Aiolli - Sistemi Informativi 2007/2008. Web Search before Google
 Web Search Engines 1 Web Search before Google Web Search Engines (WSEs) of the first generation (up to 1998) Identified relevance with topic-relateness Based on keywords inserted by web page creators (META
Web Search Engines 1 Web Search before Google Web Search Engines (WSEs) of the first generation (up to 1998) Identified relevance with topic-relateness Based on keywords inserted by web page creators (META
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 08: Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu October 24, 2017 Learnt Prediction and Classification Methods Vector Data
CS145: INTRODUCTION TO DATA MINING 08: Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu October 24, 2017 Learnt Prediction and Classification Methods Vector Data
Classifying Spam using URLs
 Classifying Spam using URLs Di Ai Computer Science Stanford University Stanford, CA diai@stanford.edu CS 229 Project, Autumn 2018 Abstract This project implements support vector machine and random forest
Classifying Spam using URLs Di Ai Computer Science Stanford University Stanford, CA diai@stanford.edu CS 229 Project, Autumn 2018 Abstract This project implements support vector machine and random forest
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Evaluating Classifiers
 Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
Website Report for bangaloregastro.com
 Digi Leader Studios 40th Cross, 10th Main, 5th Block Jayanagar, Bengaluru - India 09845182203 connect@digileader.in https://www.digileader.in Website Report for bangaloregastro.com This report grades your
Digi Leader Studios 40th Cross, 10th Main, 5th Block Jayanagar, Bengaluru - India 09845182203 connect@digileader.in https://www.digileader.in Website Report for bangaloregastro.com This report grades your
Adversarial Web Search. Contents
 Foundations and Trends R in Information Retrieval Vol. 4, No. 5 (2010) 377 486 c 2011 C. Castillo and B. D. Davison DOI: 10.1561/1500000021 Adversarial Web Search By Carlos Castillo and Brian D. Davison
Foundations and Trends R in Information Retrieval Vol. 4, No. 5 (2010) 377 486 c 2011 C. Castillo and B. D. Davison DOI: 10.1561/1500000021 Adversarial Web Search By Carlos Castillo and Brian D. Davison
CS229 Final Project: Predicting Expected Response Times
 CS229 Final Project: Predicting Expected Email Response Times Laura Cruz-Albrecht (lcruzalb), Kevin Khieu (kkhieu) December 15, 2017 1 Introduction Each day, countless emails are sent out, yet the time
CS229 Final Project: Predicting Expected Email Response Times Laura Cruz-Albrecht (lcruzalb), Kevin Khieu (kkhieu) December 15, 2017 1 Introduction Each day, countless emails are sent out, yet the time
Automatic Summarization
 Automatic Summarization CS 769 Guest Lecture Andrew B. Goldberg goldberg@cs.wisc.edu Department of Computer Sciences University of Wisconsin, Madison February 22, 2008 Andrew B. Goldberg (CS Dept) Summarization
Automatic Summarization CS 769 Guest Lecture Andrew B. Goldberg goldberg@cs.wisc.edu Department of Computer Sciences University of Wisconsin, Madison February 22, 2008 Andrew B. Goldberg (CS Dept) Summarization
Text Categorization (I)
") CS473 CS-473 Text Categorization (I) Luo Si Department of Computer Science Purdue University Text Categorization (I) Outline Introduction to the task of text categorization Manual v.s. automatic text categorization
CS473 CS-473 Text Categorization (I) Luo Si Department of Computer Science Purdue University Text Categorization (I) Outline Introduction to the task of text categorization Manual v.s. automatic text categorization
Spam Decisions on Gray using Personalized Ontologies
 Spam Decisions on Gray E-mail using Personalized Ontologies Seongwook Youn Semantic Information Research Laboratory (http://sir-lab.usc.edu) Dept. of Computer Science Univ. of Southern California Los Angeles,
Spam Decisions on Gray E-mail using Personalized Ontologies Seongwook Youn Semantic Information Research Laboratory (http://sir-lab.usc.edu) Dept. of Computer Science Univ. of Southern California Los Angeles,
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
Logistic Regression: Probabilistic Interpretation
 Logistic Regression: Probabilistic Interpretation Approximate 0/1 Loss Logistic Regression Adaboost (z) SVM Solution: Approximate 0/1 loss with convex loss ( surrogate loss) 0-1 z = y w x SVM (hinge),
Logistic Regression: Probabilistic Interpretation Approximate 0/1 Loss Logistic Regression Adaboost (z) SVM Solution: Approximate 0/1 loss with convex loss ( surrogate loss) 0-1 z = y w x SVM (hinge),
STUDYING OF CLASSIFYING CHINESE SMS MESSAGES
 STUDYING OF CLASSIFYING CHINESE SMS MESSAGES BASED ON BAYESIAN CLASSIFICATION 1 LI FENG, 2 LI JIGANG 1,2 Computer Science Department, DongHua University, Shanghai, China E-mail: 1 Lifeng@dhu.edu.cn, 2
STUDYING OF CLASSIFYING CHINESE SMS MESSAGES BASED ON BAYESIAN CLASSIFICATION 1 LI FENG, 2 LI JIGANG 1,2 Computer Science Department, DongHua University, Shanghai, China E-mail: 1 Lifeng@dhu.edu.cn, 2
Identifying Suspended Accounts In Twitter
 University of Windsor Scholarship at UWindsor Electronic Theses and Dissertations 2016 Identifying Suspended Accounts In Twitter Xiutian Cui University of Windsor Follow this and additional works at: https://scholar.uwindsor.ca/etd
University of Windsor Scholarship at UWindsor Electronic Theses and Dissertations 2016 Identifying Suspended Accounts In Twitter Xiutian Cui University of Windsor Follow this and additional works at: https://scholar.uwindsor.ca/etd
Chapter 5: Summary and Conclusion CHAPTER 5 SUMMARY AND CONCLUSION. Chapter 1: Introduction
 CHAPTER 5 SUMMARY AND CONCLUSION Chapter 1: Introduction Data mining is used to extract the hidden, potential, useful and valuable information from very large amount of data. Data mining tools can handle
CHAPTER 5 SUMMARY AND CONCLUSION Chapter 1: Introduction Data mining is used to extract the hidden, potential, useful and valuable information from very large amount of data. Data mining tools can handle
deseo: Combating Search-Result Poisoning Yu USF
 deseo: Combating Search-Result Poisoning Yu Jin @MSCS USF Your Google is not SAFE! SEO Poisoning - A new way to spread malware! Why choose SE? 22.4% of Google searches in the top 100 results > 50% for
deseo: Combating Search-Result Poisoning Yu Jin @MSCS USF Your Google is not SAFE! SEO Poisoning - A new way to spread malware! Why choose SE? 22.4% of Google searches in the top 100 results > 50% for
VECTOR SPACE CLASSIFICATION
 VECTOR SPACE CLASSIFICATION Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press. Chapter 14 Wei Wei wwei@idi.ntnu.no Lecture
VECTOR SPACE CLASSIFICATION Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press. Chapter 14 Wei Wei wwei@idi.ntnu.no Lecture
CHEAP, efficient and easy to use, has become an
 Proceedings of International Joint Conference on Neural Networks, Dallas, Texas, USA, August 4-9, 2013 A Multi-Resolution-Concentration Based Feature Construction Approach for Spam Filtering Guyue Mi,
Proceedings of International Joint Conference on Neural Networks, Dallas, Texas, USA, August 4-9, 2013 A Multi-Resolution-Concentration Based Feature Construction Approach for Spam Filtering Guyue Mi,
Identifying Important Communications
 Identifying Important Communications Aaron Jaffey ajaffey@stanford.edu Akifumi Kobashi akobashi@stanford.edu Abstract As we move towards a society increasingly dependent on electronic communication, our
Identifying Important Communications Aaron Jaffey ajaffey@stanford.edu Akifumi Kobashi akobashi@stanford.edu Abstract As we move towards a society increasingly dependent on electronic communication, our
Karami, A., Zhou, B. (2015). Online Review Spam Detection by New Linguistic Features. In iconference 2015 Proceedings.
. Online Review Spam Detection by New Linguistic Features. In iconference 2015 Proceedings.") Online Review Spam Detection by New Linguistic Features Amir Karam, University of Maryland Baltimore County Bin Zhou, University of Maryland Baltimore County Karami, A., Zhou, B. (2015). Online Review
Online Review Spam Detection by New Linguistic Features Amir Karam, University of Maryland Baltimore County Bin Zhou, University of Maryland Baltimore County Karami, A., Zhou, B. (2015). Online Review
Detecting Spammers with SNARE: Spatio-temporal Network-level Automatic Reputation Engine
 Detecting Spammers with SNARE: Spatio-temporal Network-level Automatic Reputation Engine Shuang Hao, Nadeem Ahmed Syed, Nick Feamster, Alexander G. Gray, Sven Krasser Motivation Spam: More than Just a
Detecting Spammers with SNARE: Spatio-temporal Network-level Automatic Reputation Engine Shuang Hao, Nadeem Ahmed Syed, Nick Feamster, Alexander G. Gray, Sven Krasser Motivation Spam: More than Just a
Fighting Spam, Phishing and Malware With Recurrent Pattern Detection
 Fighting Spam, Phishing and Malware With Recurrent Pattern Detection White Paper September 2017 www.cyren.com 1 White Paper September 2017 Fighting Spam, Phishing and Malware With Recurrent Pattern Detection
Fighting Spam, Phishing and Malware With Recurrent Pattern Detection White Paper September 2017 www.cyren.com 1 White Paper September 2017 Fighting Spam, Phishing and Malware With Recurrent Pattern Detection
Information Retrieval
 Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Measuring Similarity to Detect
 Measuring Similarity to Detect Qualified Links Xiaoguang Qi, Lan Nie, and Brian D. Davison Dept. of Computer Science & Engineering Lehigh University Introduction Approach Experiments Discussion & Conclusion
Measuring Similarity to Detect Qualified Links Xiaoguang Qi, Lan Nie, and Brian D. Davison Dept. of Computer Science & Engineering Lehigh University Introduction Approach Experiments Discussion & Conclusion
Learning to Detect Web Spam by Genetic Programming
 Learning to Detect Web Spam by Genetic Programming Xiaofei Niu 1,3, Jun Ma 1,, Qiang He 1, Shuaiqiang Wang 2, and Dongmei Zhang 1,3 1 School of Computer Science and Technology, Shandong University, Jinan
Learning to Detect Web Spam by Genetic Programming Xiaofei Niu 1,3, Jun Ma 1,, Qiang He 1, Shuaiqiang Wang 2, and Dongmei Zhang 1,3 1 School of Computer Science and Technology, Shandong University, Jinan
Cloak of Visibility. -Detecting When Machines Browse A Different Web. Zhe Zhao
 Cloak of Visibility -Detecting When Machines Browse A Different Web Zhe Zhao Title: Cloak of Visibility -Detecting When Machines Browse A Different Web About Author: Google Researchers Publisher: IEEE
Cloak of Visibility -Detecting When Machines Browse A Different Web Zhe Zhao Title: Cloak of Visibility -Detecting When Machines Browse A Different Web About Author: Google Researchers Publisher: IEEE
Spice UK. Susan Hallam. Susan Hallam Page 1. Spice UK. Agenda for Today
 UK UK www.shcl.co.uk susan@shcl.co.uk Agenda for Today Getting Found in Google Social Media Marketing Adwords Pay Per Click Advertising Promotion Techniques Google Analytics susan@shcl.co.uk Page 1 UK
UK UK www.shcl.co.uk susan@shcl.co.uk Agenda for Today Getting Found in Google Social Media Marketing Adwords Pay Per Click Advertising Promotion Techniques Google Analytics susan@shcl.co.uk Page 1 UK
In this project, I examined methods to classify a corpus of s by their content in order to suggest text blocks for semi-automatic replies.
 December 13, 2006 IS256: Applied Natural Language Processing Final Project Email classification for semi-automated reply generation HANNES HESSE mail 2056 Emerson Street Berkeley, CA 94703 phone 1 (510)
December 13, 2006 IS256: Applied Natural Language Processing Final Project Email classification for semi-automated reply generation HANNES HESSE mail 2056 Emerson Street Berkeley, CA 94703 phone 1 (510)
Data Mining Classification: Alternative Techniques. Imbalanced Class Problem
 Data Mining Classification: Alternative Techniques Imbalanced Class Problem Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Class Imbalance Problem Lots of classification problems
Data Mining Classification: Alternative Techniques Imbalanced Class Problem Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Class Imbalance Problem Lots of classification problems
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Evaluation of different biological data and computational classification methods for use in protein interaction prediction.
 Evaluation of different biological data and computational classification methods for use in protein interaction prediction. Yanjun Qi, Ziv Bar-Joseph, Judith Klein-Seetharaman Protein 2006 Motivation Correctly
Evaluation of different biological data and computational classification methods for use in protein interaction prediction. Yanjun Qi, Ziv Bar-Joseph, Judith Klein-Seetharaman Protein 2006 Motivation Correctly
Information Retrieval. (M&S Ch 15)
") Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
On the automatic classification of app reviews
 Requirements Eng (2016) 21:311 331 DOI 10.1007/s00766-016-0251-9 RE 2015 On the automatic classification of app reviews Walid Maalej 1 Zijad Kurtanović 1 Hadeer Nabil 2 Christoph Stanik 1 Walid: please
Requirements Eng (2016) 21:311 331 DOI 10.1007/s00766-016-0251-9 RE 2015 On the automatic classification of app reviews Walid Maalej 1 Zijad Kurtanović 1 Hadeer Nabil 2 Christoph Stanik 1 Walid: please
Solution 1 (python) Performance: Enron Samples Rate Recall Precision Total Contribution
 Performance: Enron Samples Rate Recall Precision Total Contribution") Summary Each of the ham/spam classifiers has been tested against random samples from pre- processed enron sets 1 through 6 obtained via: http://www.aueb.gr/users/ion/data/enron- spam/, or the entire set
Summary Each of the ham/spam classifiers has been tested against random samples from pre- processed enron sets 1 through 6 obtained via: http://www.aueb.gr/users/ion/data/enron- spam/, or the entire set
Website Report for
 Website Report for www.jgllaw.com This report grades your website on the strength of a range of important factors such as on-page SEO optimization, off-page backlinks, social, performance, security and
Website Report for www.jgllaw.com This report grades your website on the strength of a range of important factors such as on-page SEO optimization, off-page backlinks, social, performance, security and
Discovering Advertisement Links by Using URL Text
 017 3rd International Conference on Computational Systems and Communications (ICCSC 017) Discovering Advertisement Links by Using URL Text Jing-Shan Xu1, a, Peng Chang, b,* and Yong-Zheng Zhang, c 1 School
017 3rd International Conference on Computational Systems and Communications (ICCSC 017) Discovering Advertisement Links by Using URL Text Jing-Shan Xu1, a, Peng Chang, b,* and Yong-Zheng Zhang, c 1 School
CS47300 Web Information Search and Management
 CS47300 Web Information Search and Management Search Engine Optimization Prof. Chris Clifton 31 October 2018 What is Search Engine Optimization? 90% of search engine clickthroughs are on the first page
CS47300 Web Information Search and Management Search Engine Optimization Prof. Chris Clifton 31 October 2018 What is Search Engine Optimization? 90% of search engine clickthroughs are on the first page
New Issues in Near-duplicate Detection
 New Issues in Near-duplicate Detection Martin Potthast and Benno Stein Bauhaus University Weimar Web Technology and Information Systems Motivation About 30% of the Web is redundant. [Fetterly 03, Broder
New Issues in Near-duplicate Detection Martin Potthast and Benno Stein Bauhaus University Weimar Web Technology and Information Systems Motivation About 30% of the Web is redundant. [Fetterly 03, Broder
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
CLASSIFICATION JELENA JOVANOVIĆ. Web:
 CLASSIFICATION JELENA JOVANOVIĆ Email: jeljov@gmail.com Web: http://jelenajovanovic.net OUTLINE What is classification? Binary and multiclass classification Classification algorithms Naïve Bayes (NB) algorithm
CLASSIFICATION JELENA JOVANOVIĆ Email: jeljov@gmail.com Web: http://jelenajovanovic.net OUTLINE What is classification? Binary and multiclass classification Classification algorithms Naïve Bayes (NB) algorithm
CSI5387: Data Mining Project
 CSI5387: Data Mining Project Terri Oda April 14, 2008 1 Introduction Web pages have become more like applications that documents. Not only do they provide dynamic content, they also allow users to play
CSI5387: Data Mining Project Terri Oda April 14, 2008 1 Introduction Web pages have become more like applications that documents. Not only do they provide dynamic content, they also allow users to play
An Introduction to Search Engines and Web Navigation
 An Introduction to Search Engines and Web Navigation MARK LEVENE ADDISON-WESLEY Ал imprint of Pearson Education Harlow, England London New York Boston San Francisco Toronto Sydney Tokyo Singapore Hong
An Introduction to Search Engines and Web Navigation MARK LEVENE ADDISON-WESLEY Ал imprint of Pearson Education Harlow, England London New York Boston San Francisco Toronto Sydney Tokyo Singapore Hong
Splog Detection Using Self-Similarity Analysis on Blog Temporal Dynamics. Yu-Ru Lin, Hari Sundaram, Yun Chi, Junichi Tatemura and Belle Tseng
 Splog Detection Using Self-Similarity Analysis on Blog Temporal Dynamics Yu-Ru Lin, Hari Sundaram, Yun Chi, Junichi Tatemura and Belle Tseng NEC Laboratories America, Cupertino, CA AIRWeb Workshop 2007
Splog Detection Using Self-Similarity Analysis on Blog Temporal Dynamics Yu-Ru Lin, Hari Sundaram, Yun Chi, Junichi Tatemura and Belle Tseng NEC Laboratories America, Cupertino, CA AIRWeb Workshop 2007
On Detecting Deception
 On Detecting Deception Sadia Afroz Privacy, Security and Automation Lab (PSAL) Drexel University What is Deception? Deception: An adversarial behavior that disrupts regular behavior of a system Deception
On Detecting Deception Sadia Afroz Privacy, Security and Automation Lab (PSAL) Drexel University What is Deception? Deception: An adversarial behavior that disrupts regular behavior of a system Deception
Classification Algorithms in Data Mining
 August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER
 VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
Identifying Web Spam With User Behavior Analysis
 Identifying Web Spam With User Behavior Analysis Yiqun Liu, Rongwei Cen, Min Zhang, Shaoping Ma, Liyun Ru State Key Lab of Intelligent Tech. & Sys. Tsinghua University 2008/04/23 Introduction simple math
Identifying Web Spam With User Behavior Analysis Yiqun Liu, Rongwei Cen, Min Zhang, Shaoping Ma, Liyun Ru State Key Lab of Intelligent Tech. & Sys. Tsinghua University 2008/04/23 Introduction simple math
Building Search Applications
 Building Search Applications Lucene, LingPipe, and Gate Manu Konchady Mustru Publishing, Oakton, Virginia. Contents Preface ix 1 Information Overload 1 1.1 Information Sources 3 1.2 Information Management
Building Search Applications Lucene, LingPipe, and Gate Manu Konchady Mustru Publishing, Oakton, Virginia. Contents Preface ix 1 Information Overload 1 1.1 Information Sources 3 1.2 Information Management
Efficacious Spam Filtering and Detection in Social Networks
 Indian Journal of Science and Technology, Vol 7(S7), 180 184, November 2014 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Efficacious Spam Filtering and Detection in Social Networks U. V. Anbazhagu
Indian Journal of Science and Technology, Vol 7(S7), 180 184, November 2014 ISSN (Print) : 0974-6846 ISSN (Online) : 0974-5645 Efficacious Spam Filtering and Detection in Social Networks U. V. Anbazhagu
Tour-Based Mode Choice Modeling: Using An Ensemble of (Un-) Conditional Data-Mining Classifiers
 Conditional Data-Mining Classifiers") Tour-Based Mode Choice Modeling: Using An Ensemble of (Un-) Conditional Data-Mining Classifiers James P. Biagioni Piotr M. Szczurek Peter C. Nelson, Ph.D. Abolfazl Mohammadian, Ph.D. Agenda Background
Tour-Based Mode Choice Modeling: Using An Ensemble of (Un-) Conditional Data-Mining Classifiers James P. Biagioni Piotr M. Szczurek Peter C. Nelson, Ph.D. Abolfazl Mohammadian, Ph.D. Agenda Background
Comment Extraction from Blog Posts and Its Applications to Opinion Mining
 Comment Extraction from Blog Posts and Its Applications to Opinion Mining Huan-An Kao, Hsin-Hsi Chen Department of Computer Science and Information Engineering National Taiwan University, Taipei, Taiwan
Comment Extraction from Blog Posts and Its Applications to Opinion Mining Huan-An Kao, Hsin-Hsi Chen Department of Computer Science and Information Engineering National Taiwan University, Taipei, Taiwan
The Comparative Study of Machine Learning Algorithms in Text Data Classification*
 The Comparative Study of Machine Learning Algorithms in Text Data Classification* Wang Xin School of Science, Beijing Information Science and Technology University Beijing, China Abstract Classification
The Comparative Study of Machine Learning Algorithms in Text Data Classification* Wang Xin School of Science, Beijing Information Science and Technology University Beijing, China Abstract Classification
Self-tuning ongoing terminology extraction retrained on terminology validation decisions
 Self-tuning ongoing terminology extraction retrained on terminology validation decisions Alfredo Maldonado and David Lewis ADAPT Centre, School of Computer Science and Statistics, Trinity College Dublin
Self-tuning ongoing terminology extraction retrained on terminology validation decisions Alfredo Maldonado and David Lewis ADAPT Centre, School of Computer Science and Statistics, Trinity College Dublin
Spam Filtering Using Statistical Data Compression Models
 Journal of Machine Learning Research? (2006)??-?? Submitted 03/06; Published??/?? Spam Filtering Using Statistical Data Compression Models Andrej Bratko Bogdan Filipič Department of Intelligent Systems
Journal of Machine Learning Research? (2006)??-?? Submitted 03/06; Published??/?? Spam Filtering Using Statistical Data Compression Models Andrej Bratko Bogdan Filipič Department of Intelligent Systems
Detecting Spam Bots in Online Social Networking Sites: A Machine Learning Approach
 Detecting Spam Bots in Online Social Networking Sites: A Machine Learning Approach Alex Hai Wang College of Information Sciences and Technology, The Pennsylvania State University, Dunmore, PA 18512, USA
Detecting Spam Bots in Online Social Networking Sites: A Machine Learning Approach Alex Hai Wang College of Information Sciences and Technology, The Pennsylvania State University, Dunmore, PA 18512, USA
Bayesian Spam Detection
 Scholarly Horizons: University of Minnesota, Morris Undergraduate Journal Volume 2 Issue 1 Article 2 2015 Bayesian Spam Detection Jeremy J. Eberhardt University or Minnesota, Morris Follow this and additional
Scholarly Horizons: University of Minnesota, Morris Undergraduate Journal Volume 2 Issue 1 Article 2 2015 Bayesian Spam Detection Jeremy J. Eberhardt University or Minnesota, Morris Follow this and additional
Increasing the Accuracy of a Spam-Detecting Artificial Immune System
 Increasing the Accuracy of a Spam-Detecting Artificial Immune System Terri Oda Carleton University 1125 Colonel By Drive Ottawa, ON K1S 5B6 terri@zone12.com Tony White Carleton University 1125 Colonel
Increasing the Accuracy of a Spam-Detecting Artificial Immune System Terri Oda Carleton University 1125 Colonel By Drive Ottawa, ON K1S 5B6 terri@zone12.com Tony White Carleton University 1125 Colonel