Building a Scalable Recommender System with Apache Spark, Apache Kafka and Elasticsearch
|
|
|
- Valentine Brooks
- 6 years ago
- Views:
Transcription

1 Nick Pentreath Nov / 14 / 16 Building a Scalable Recommender System with Apache Spark, Apache Kafka and Elasticsearch
2 Principal Engineer, IBM Apache Spark PMC Focused on machine learning Author of Machine Learning with Spark
3 Agenda Recommender systems & the machine learning workflow Data modelling for recommender systems Why Spark, Kafka & Elasticsearch? Kafka & Spark Streaming Spark ML for collaborative filtering Deploying & scoring recommender models with Elasticsearch Monitoring, feedback & re-training Scaling model serving Demo
4 Recommender Systems & the ML Workflow
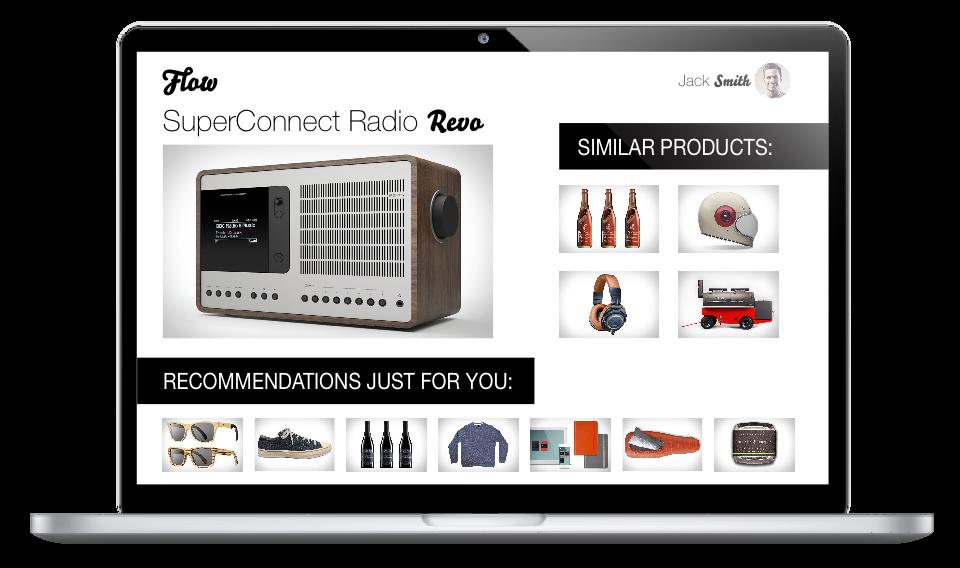
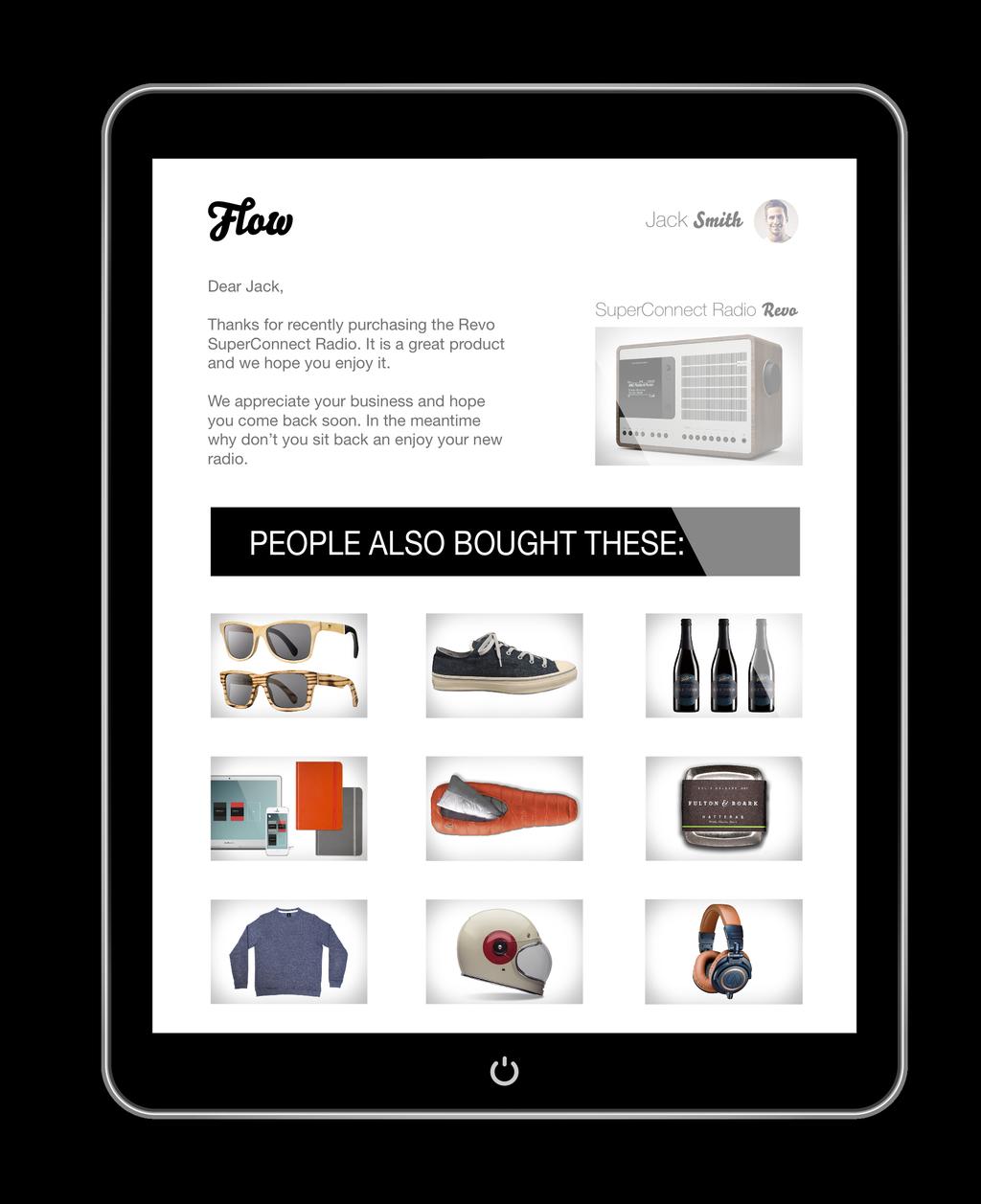

5 Recommender Systems Overview


6 The Machine Perception Learning Workflow Data??? Machine Learning??? $$$




7 The Machine Reality Learning Workflow Spark ML Missing piece Various Spark DataFrames??? Data Ingest Data Processing Model Training Deploy Live System Historical Streaming Feature transformation & engineering Model selection & evaluation Pipelines, not just models Versioning Predict given new data Monitoring & live evaluation Feedback Loop Stream (Kafka)


8 The Machine Recommender Version Learning Workflow Spark ML Elasticsearch Spark DataFrames Elasticsearch Data Ingest Data Processing Model Training Deploy Live System User & Item Metadata Events Aggregation Handle implicit data ALS Ranking-style evaluation Model size & complexity User & item recommendations Monitoring, filters Feedback => another Event Type Stream (Kafka)
9 Data Modeling for Recommender Systems
10 User and Item Data model Metadata



11 User and Item System Requirements Metadata Filtering & Grouping Business Rules



12 Anatomy of a User Interactions User Event User interactions Implicit preference data Intent data Page view ecommerce - cart, purchase Media preview, watch, listen Search query Explicit preference data Social network interactions Rating Review Like Share Follow
13 Anatomy of a Data model User Event
14 Anatomy of a How to handle implicit feedback? User Event
15 Why Kafka, Spark & Elasticsearch?
16 Why Kafka? Scalability De facto standard for a centralized enterprise message / event queue Integration Integrates with just about every storage & processing system Good Spark Streaming integration 1 st class citizen Including for Structured Streaming (but still very new & rough)
17 Why Spark? DataFrames Events & metadata are lightly structured data Suited to DataFrames Pluggable external data source support Spark ML Spark ML pipelines including scalable ALS model for collaborative filtering Implicit feedback & NMF in ALS Cross-validation Custom transformers & algorithms
18 Why Elasticsearch? Storage Native JSON Scalable Good support for time-series / event data Kibana for data visualisation Integration with Spark DataFrames Scoring Full-text search Filtering Aggregations (grouping) Search ~== recommendation (more later)
19 Kafka for Recommender Systems
20 Event Data Pipeline User analytics & aggregation Kafka Spark Streaming Event store Dashboards Item analytics & aggregation
21 Write to Event Store Event store Spark Streaming

22 Kibana Dashboards Spark Streaming Dashboards


23 Item Metadata Analytics Spark Streaming Aggregated activity metrics Item analytics & aggregation



24 User Metadata Analytics User analytics & aggregation Spark Streaming Aggregated activity metrics & item exclusions
25 Structured Status Streaming Still early days Initial Kafka support in Spark No ES support yet not clear if it will be a full-blown datasource or ForeachWriter For now, you can create a custom ForeachWriter for your needs
26 Spark ML for Collaborative Filtering
27 Collaborative Matrix Factorization Filtering

28 Collaborative Prediction Filtering
29 Collaborative Loading Data in Spark ML Filtering


30 Alternating Least Implicit Preference Data Squares
31 Deploying & Scoring Recommendation Models
32 Prelude: Search Analysis cat videos Full-text Search & Similarity Scoring Term vectors cat 0 1 videos 1 Ranking 0 Similarity Sort results


33 Recommendation Can we use the same machinery?? Analysis Term vectors Scoring Ranking User (or item) vector Dot product & cosine similarity the same as we need for recommendations 0.3 Similarity Sort results
34 Elasticsearch Delimited Payload Filter Term Vectors Raw vector Custom analyzer Term vector with payloads
, retrieve payload score += payload * query(i) Normalizes with query vector norm and document vector norm for cosine")
35 Elasticsearch Custom scoring function Scoring Native script (Java), compiled for speed Scoring function computes dot product by: For each document vector index ( term ), retrieve payload score += payload * query(i) Normalizes with query vector norm and document vector norm for cosine similarity
36 Recommendation Can we use the same machinery? Analysis Term vectors Scoring Ranking User (or item) vector Delimited payload filter 0.3 Custom scoring function Sort results
37 Elasticsearch We get search engine functionality for free Scoring

38 Alternating Least Deploying to Elasticsearch Squares
39 Monitoring & Feedback
40 System Events Logging Recommendations Served
41 System Events Logging Recommendation Actions
42 Tracking Performance Performance monitoring & alerts Event store Kafka Spark Streaming Dashboards Impression capping / fatigue
43 Scaling Model Scoring
44 Scoring Performance k=20 k=50 k=100 Scoring time per query, by factor dimension & number of items Time (ms) ,000 1,000,000 Size of item set *3x nodes, 30x shards
45 Scoring Increasing number of shards Performance Time (ms) Scoring time per query, by number of shards & number of items 10 shards 30 shards 60 shards 90 shards 100,000 1,000,000 Size of item set *3x nodes, k=50
46 Scoring Locality Sensitive Hashing Performance LSH hashes each input vector into L hash tables. Each table contains a hash signature created by applying k hash functions. Standard for cosine similarity is Sign Random Projections At indexing time, create a bucket by combining hash table id and hash signature Store buckets as part of item model metadata At scoring time, filter candidate set using term filter on buckets of query item Tune LSH parameters to trade off speed / accuracy LSH coming soon to Spark ML SPARK-5992
47 Scoring Locality Sensitive Hashing Performance 250 Scoring time per query - brute force vs LSH 200 Time (ms) Brute force LSH *3x nodes, 30x shards, k=50, 1,000,000 items
48 Scoring Comparison to score then search Performance 250 Score Sort Search Scoring time per query LSH vs score-then-search 200 Time (ms) Brute force LSH Score-then-search *3x nodes, 30x shards, k=50, 1,000,000 items
49 Demo


50 Future Work
51 Future Work Apache Solr version of scoring plugin (any takers?) Investigate ways to improve Elasticsearch scoring performance Performance for LSH-filtered scoring should be better Can we dig deep into ES scoring internals to combine efficiency of matrix-vector math with ES search & filter capabilities? Investigate more complex models Factorization machines & other contextual recommender models Scoring performance Spark Structured Streaming with Kafka, Elasticsearch & Kibana Continuous recommender application including data, model training, analytics & monitoring
52 References Elasticsearch Elasticsearch Spark Integration Spark ML ALS for Collaborative Filtering Collaborative Filtering for Implicit Feedback Datasets Factorization Machines Elasticsearch Term Vectors & Payloads Delimited Payload Filter Vector Scoring Plugin Kafka & Spark Streaming Kibana

53 Thanks
Creating a Recommender System. An Elasticsearch & Apache Spark approach
 Creating a Recommender System An Elasticsearch & Apache Spark approach My Profile SKILLS Álvaro Santos Andrés Big Data & Analytics Solution Architect in Ericsson with more than 12 years of experience focused
Creating a Recommender System An Elasticsearch & Apache Spark approach My Profile SKILLS Álvaro Santos Andrés Big Data & Analytics Solution Architect in Ericsson with more than 12 years of experience focused
Deploying Machine Learning Models in Practice
 Deploying Machine Learning Models in Practice Nick Pentreath Principal Engineer @MLnick About @MLnick on Twitter & Github Principal Engineer, IBM CODAIT - Center for Open-Source Data & AI Technologies
Deploying Machine Learning Models in Practice Nick Pentreath Principal Engineer @MLnick About @MLnick on Twitter & Github Principal Engineer, IBM CODAIT - Center for Open-Source Data & AI Technologies
Practical Machine Learning Agenda
 Practical Machine Learning Agenda Starting From Log Management Moving To Machine Learning PunchPlatform team Thales Challenges Thanks 1 Starting From Log Management 2 Starting From Log Management Data
Practical Machine Learning Agenda Starting From Log Management Moving To Machine Learning PunchPlatform team Thales Challenges Thanks 1 Starting From Log Management 2 Starting From Log Management Data
Multi-domain Predictive AI. Correlated Cross-Occurrence with Apache Mahout and GPUs
 Multi-domain Predictive AI Correlated Cross-Occurrence with Apache Mahout and GPUs Pat Ferrel ActionML, Chief Consultant Apache Mahout, PMC & Committer Apache PredictionIO, PMC & Committer pat@apache.org
Multi-domain Predictive AI Correlated Cross-Occurrence with Apache Mahout and GPUs Pat Ferrel ActionML, Chief Consultant Apache Mahout, PMC & Committer Apache PredictionIO, PMC & Committer pat@apache.org
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
WHITEPAPER. MemSQL Enterprise Feature List
 WHITEPAPER MemSQL Enterprise Feature List 2017 MemSQL Enterprise Feature List DEPLOYMENT Provision and deploy MemSQL anywhere according to your desired cluster configuration. On-Premises: Maximize infrastructure
WHITEPAPER MemSQL Enterprise Feature List 2017 MemSQL Enterprise Feature List DEPLOYMENT Provision and deploy MemSQL anywhere according to your desired cluster configuration. On-Premises: Maximize infrastructure
Kibana, Grafana and Zeppelin on Monitoring data
 Kibana, Grafana and Zeppelin on Monitoring data Internal group presentaion Ildar Nurgaliev OpenLab Summer student Presentation structure About IT-CM-MM Section and myself Visualisation with Kibana 4 and
Kibana, Grafana and Zeppelin on Monitoring data Internal group presentaion Ildar Nurgaliev OpenLab Summer student Presentation structure About IT-CM-MM Section and myself Visualisation with Kibana 4 and
Search Engines and Time Series Databases
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Search Engines and Time Series Databases Corso di Sistemi e Architetture per Big Data A.A. 2017/18
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Search Engines and Time Series Databases Corso di Sistemi e Architetture per Big Data A.A. 2017/18
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Activator Library. Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success.
 Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Application monitoring with BELK. Nishant Sahay, Sr. Architect Bhavani Ananth, Architect
 Application monitoring with BELK Nishant Sahay, Sr. Architect Bhavani Ananth, Architect Why logs Business PoV Input Data Analytics User Interactions /Behavior End user Experience/ Improvements 2017 Wipro
Application monitoring with BELK Nishant Sahay, Sr. Architect Bhavani Ananth, Architect Why logs Business PoV Input Data Analytics User Interactions /Behavior End user Experience/ Improvements 2017 Wipro
1 Big Data Hadoop. 1. Introduction About this Course About Big Data Course Logistics Introductions
 Big Data Hadoop Architect Online Training (Big Data Hadoop + Apache Spark & Scala+ MongoDB Developer And Administrator + Apache Cassandra + Impala Training + Apache Kafka + Apache Storm) 1 Big Data Hadoop
Big Data Hadoop Architect Online Training (Big Data Hadoop + Apache Spark & Scala+ MongoDB Developer And Administrator + Apache Cassandra + Impala Training + Apache Kafka + Apache Storm) 1 Big Data Hadoop
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Ingest. Aaron Mildenstein, Consulting Architect Tokyo Dec 14, 2017
 Ingest Aaron Mildenstein, Consulting Architect Tokyo Dec 14, 2017 Data Ingestion The process of collecting and importing data for immediate use 2 ? Simple things should be simple. Shay Banon Elastic{ON}
Ingest Aaron Mildenstein, Consulting Architect Tokyo Dec 14, 2017 Data Ingestion The process of collecting and importing data for immediate use 2 ? Simple things should be simple. Shay Banon Elastic{ON}
Ingest. David Pilato, Developer Evangelist Paris, 31 Janvier 2017
 Ingest David Pilato, Developer Evangelist Paris, 31 Janvier 2017 Data Ingestion The process of collecting and importing data for immediate use in a datastore 2 ? Simple things should be simple. Shay Banon
Ingest David Pilato, Developer Evangelist Paris, 31 Janvier 2017 Data Ingestion The process of collecting and importing data for immediate use in a datastore 2 ? Simple things should be simple. Shay Banon
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Fluentd + MongoDB + Spark = Awesome Sauce
 Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Crossing the AI Chasm. What We Learned from building Apache PredictionIO (incubating)
") Crossing the AI Chasm What We Learned from building Apache PredictionIO (incubating) Simon Chan Sr. Director, Product Management, Salesforce Co-founder, PredictionIO PhD, University College London simon@salesforce.com
Crossing the AI Chasm What We Learned from building Apache PredictionIO (incubating) Simon Chan Sr. Director, Product Management, Salesforce Co-founder, PredictionIO PhD, University College London simon@salesforce.com
ADVANCED DATABASES CIS 6930 Dr. Markus Schneider. Group 5 Ajantha Ramineni, Sahil Tiwari, Rishabh Jain, Shivang Gupta
 ADVANCED DATABASES CIS 6930 Dr. Markus Schneider Group 5 Ajantha Ramineni, Sahil Tiwari, Rishabh Jain, Shivang Gupta WHAT IS ELASTIC SEARCH? Elastic Search Elasticsearch is a search engine based on Lucene.
ADVANCED DATABASES CIS 6930 Dr. Markus Schneider Group 5 Ajantha Ramineni, Sahil Tiwari, Rishabh Jain, Shivang Gupta WHAT IS ELASTIC SEARCH? Elastic Search Elasticsearch is a search engine based on Lucene.
BIG DATA COURSE CONTENT
 BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
Introduction to the Europeana SIP CREATOR
 Introduction to the Europeana SIP CREATOR Alicia Ackerman alicia.ackerman@kb.nl Development at Europeana Labs with Serkan Demirel serkan@blackbuilt.nl, Initial development by Gerald De Jong Collaboration
Introduction to the Europeana SIP CREATOR Alicia Ackerman alicia.ackerman@kb.nl Development at Europeana Labs with Serkan Demirel serkan@blackbuilt.nl, Initial development by Gerald De Jong Collaboration
Advanced ecommerce Monitoring one tool does it all
 Advanced ecommerce Monitoring one tool does it all No ecommerce platform can be operated without a proper monitoring solution in place. In fact monitoring or analytics alone isn t enough. If you are serious
Advanced ecommerce Monitoring one tool does it all No ecommerce platform can be operated without a proper monitoring solution in place. In fact monitoring or analytics alone isn t enough. If you are serious
Thales PunchPlatform Agenda
 Thales PunchPlatform Agenda What It Does Building Blocks PunchPlatform team Deployment & Operations Typical Setups Customers and Use Cases RoadMap 1 What It Does Compose Arbitrary Industrial Data Processing
Thales PunchPlatform Agenda What It Does Building Blocks PunchPlatform team Deployment & Operations Typical Setups Customers and Use Cases RoadMap 1 What It Does Compose Arbitrary Industrial Data Processing
Real-time Streaming Applications on AWS Patterns and Use Cases
 Real-time Streaming Applications on AWS Patterns and Use Cases Paul Armstrong - Solutions Architect (AWS) Tom Seddon - Data Engineering Tech Lead (Deliveroo) 28 th June 2017 2016, Amazon Web Services,
Real-time Streaming Applications on AWS Patterns and Use Cases Paul Armstrong - Solutions Architect (AWS) Tom Seddon - Data Engineering Tech Lead (Deliveroo) 28 th June 2017 2016, Amazon Web Services,
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Turbocharge your MySQL analytics with ElasticSearch. Guillaume Lefranc Data & Infrastructure Architect, Productsup GmbH Percona Live Europe 2017
 Turbocharge your MySQL analytics with ElasticSearch Guillaume Lefranc Data & Infrastructure Architect, Productsup GmbH Percona Live Europe 2017 About the Speaker Guillaume Lefranc Data Architect at Productsup
Turbocharge your MySQL analytics with ElasticSearch Guillaume Lefranc Data & Infrastructure Architect, Productsup GmbH Percona Live Europe 2017 About the Speaker Guillaume Lefranc Data Architect at Productsup
Search Quality Evaluation Tools and Techniques
 Search Quality Evaluation Tools and Techniques Alessandro Benedetti, Software Engineer Andrea Gazzarini, Software Engineer 2 nd October 2018 Who we are Alessandro Benedetti Search Consultant R&D Software
Search Quality Evaluation Tools and Techniques Alessandro Benedetti, Software Engineer Andrea Gazzarini, Software Engineer 2 nd October 2018 Who we are Alessandro Benedetti Search Consultant R&D Software
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Microservice Layout in Netflix
 Microservice Layout in Netflix Polyglot Persistence Powering Microservices Roopa Tangirala Engineering Manager Netflix Agenda 5 Use Cases Challenges Current Approach Takeaway AWS S3 CDE Search,
Microservice Layout in Netflix Polyglot Persistence Powering Microservices Roopa Tangirala Engineering Manager Netflix Agenda 5 Use Cases Challenges Current Approach Takeaway AWS S3 CDE Search,
Goal of this document: A simple yet effective
 INTRODUCTION TO ELK STACK Goal of this document: A simple yet effective document for folks who want to learn basics of ELK (Elasticsearch, Logstash and Kibana) without any prior knowledge. Introduction:
INTRODUCTION TO ELK STACK Goal of this document: A simple yet effective document for folks who want to learn basics of ELK (Elasticsearch, Logstash and Kibana) without any prior knowledge. Introduction:
Overview of Data Services and Streaming Data Solution with Azure
 Overview of Data Services and Streaming Data Solution with Azure Tara Mason Senior Consultant tmason@impactmakers.com Platform as a Service Offerings SQL Server On Premises vs. Azure SQL Server SQL Server
Overview of Data Services and Streaming Data Solution with Azure Tara Mason Senior Consultant tmason@impactmakers.com Platform as a Service Offerings SQL Server On Premises vs. Azure SQL Server SQL Server
Table 1 The Elastic Stack use cases Use case Industry or vertical market Operational log analytics: Gain real-time operational insight, reduce Mean Ti
 Solution Overview Cisco UCS Integrated Infrastructure for Big Data with the Elastic Stack Cisco and Elastic deliver a powerful, scalable, and programmable IT operations and security analytics platform
Solution Overview Cisco UCS Integrated Infrastructure for Big Data with the Elastic Stack Cisco and Elastic deliver a powerful, scalable, and programmable IT operations and security analytics platform
Open Source Search. Andreas Pesenhofer. max.recall information systems GmbH Künstlergasse 11/1 A-1150 Wien Austria
 Open Source Search Andreas Pesenhofer max.recall information systems GmbH Künstlergasse 11/1 A-1150 Wien Austria max.recall information systems max.recall is a software and consulting company enabling
Open Source Search Andreas Pesenhofer max.recall information systems GmbH Künstlergasse 11/1 A-1150 Wien Austria max.recall information systems max.recall is a software and consulting company enabling
Kafka Connect the Dots
 Kafka Connect the Dots Building Oracle Change Data Capture Pipelines With Kafka Mike Donovan CTO Dbvisit Software Mike Donovan Chief Technology Officer, Dbvisit Software Multi-platform DBA, (Oracle, MSSQL..)
Kafka Connect the Dots Building Oracle Change Data Capture Pipelines With Kafka Mike Donovan CTO Dbvisit Software Mike Donovan Chief Technology Officer, Dbvisit Software Multi-platform DBA, (Oracle, MSSQL..)
Putting together the platform: Riak, Redis, Solr and Spark. Bryan Hunt
 Putting together the platform: Riak, Redis, Solr and Spark Bryan Hunt 1 $ whoami Bryan Hunt Client Services Engineer @binarytemple 2 Minimum viable product - the ideologically correct doctrine 1. Start
Putting together the platform: Riak, Redis, Solr and Spark Bryan Hunt 1 $ whoami Bryan Hunt Client Services Engineer @binarytemple 2 Minimum viable product - the ideologically correct doctrine 1. Start
Down the event-driven road: Experiences of integrating streaming into analytic data platforms
 Down the event-driven road: Experiences of integrating streaming into analytic data platforms Dr. Dominik Benz, Head of Machine Learning Engineering, inovex GmbH Confluent Meetup Munich, 8.10.2018 Integrate
Down the event-driven road: Experiences of integrating streaming into analytic data platforms Dr. Dominik Benz, Head of Machine Learning Engineering, inovex GmbH Confluent Meetup Munich, 8.10.2018 Integrate
Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink
 Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink Rajesh Bordawekar IBM T. J. Watson Research Center bordaw@us.ibm.com Pidad D Souza IBM Systems pidsouza@in.ibm.com 1 Outline
Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink Rajesh Bordawekar IBM T. J. Watson Research Center bordaw@us.ibm.com Pidad D Souza IBM Systems pidsouza@in.ibm.com 1 Outline
Hortonworks DataFlow Sam Lachterman Solutions Engineer
 Hortonworks DataFlow Sam Lachterman Solutions Engineer 1 Hortonworks Inc. 2011 2017. All Rights Reserved Disclaimer This document may contain product features and technology directions that are under development,
Hortonworks DataFlow Sam Lachterman Solutions Engineer 1 Hortonworks Inc. 2011 2017. All Rights Reserved Disclaimer This document may contain product features and technology directions that are under development,
Deploying, Managing and Reusing R Models in an Enterprise Environment
 Deploying, Managing and Reusing R Models in an Enterprise Environment Making Data Science Accessible to a Wider Audience Lou Bajuk-Yorgan, Sr. Director, Product Management Streaming and Advanced Analytics
Deploying, Managing and Reusing R Models in an Enterprise Environment Making Data Science Accessible to a Wider Audience Lou Bajuk-Yorgan, Sr. Director, Product Management Streaming and Advanced Analytics
Modern Data Warehouse The New Approach to Azure BI
 Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Analytics Platform for ATLAS Computing Services
 Analytics Platform for ATLAS Computing Services Ilija Vukotic for the ATLAS collaboration ICHEP 2016, Chicago, USA Getting the most from distributed resources What we want To understand the system To understand
Analytics Platform for ATLAS Computing Services Ilija Vukotic for the ATLAS collaboration ICHEP 2016, Chicago, USA Getting the most from distributed resources What we want To understand the system To understand
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Dissemination Web Service. Programmatic access to Eurostat data & metadata
 Dissemination Web Service Programmatic access to Eurostat data & metadata Session 7: capacity building technical stream 1 Agenda Context 1 2 3 Main features Live demo Getting started Questions & answers
Dissemination Web Service Programmatic access to Eurostat data & metadata Session 7: capacity building technical stream 1 Agenda Context 1 2 3 Main features Live demo Getting started Questions & answers
PNDA.io: when BGP meets Big-Data
 PNDA.io: when BGP meets Big-Data Let s go back in time 26 th April 2017 The Internet is very much alive Millions of BGP events occurring every day 15 Routers Monitored 410 active peers (both IPv4 and IPv6)
PNDA.io: when BGP meets Big-Data Let s go back in time 26 th April 2017 The Internet is very much alive Millions of BGP events occurring every day 15 Routers Monitored 410 active peers (both IPv4 and IPv6)
TIBCO Complex Event Processing Evaluation Guide
 TIBCO Complex Event Processing Evaluation Guide This document provides a guide to evaluating CEP technologies. http://www.tibco.com Global Headquarters 3303 Hillview Avenue Palo Alto, CA 94304 Tel: +1
TIBCO Complex Event Processing Evaluation Guide This document provides a guide to evaluating CEP technologies. http://www.tibco.com Global Headquarters 3303 Hillview Avenue Palo Alto, CA 94304 Tel: +1
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Integrating New Visualizations with Pentaho Using the Viz API
 Integrating New Visualizations with Pentaho Using the Viz API Nick Keune, Pentaho Embedded & Advanced Analytics SE, Hitachi Vantara Ben Hopkins Pentaho Senior Product Manager, Hitachi Vantara Agenda In
Integrating New Visualizations with Pentaho Using the Viz API Nick Keune, Pentaho Embedded & Advanced Analytics SE, Hitachi Vantara Ben Hopkins Pentaho Senior Product Manager, Hitachi Vantara Agenda In
LIFERAY IOT EXPERIENCE The platform that makes Liferay ready for Industry 4.0
 LIFERAY IOT EXPERIENCE The platform that makes Liferay ready for Industry 4.0 Mauro Mariuzzo Chief Software Architect, SMC Treviso #redhatosd INDUSTRY 4.0 We are in the forth industrial revolution For
LIFERAY IOT EXPERIENCE The platform that makes Liferay ready for Industry 4.0 Mauro Mariuzzo Chief Software Architect, SMC Treviso #redhatosd INDUSTRY 4.0 We are in the forth industrial revolution For
E l a s t i c s e a r c h F e a t u r e s. Contents
 Elasticsearch Features A n Overview Contents Introduction... 2 Location Based Search... 2 Search Social Media(Twitter) data from Elasticsearch... 4 Query Boosting in Elasticsearch... 4 Machine Learning
Elasticsearch Features A n Overview Contents Introduction... 2 Location Based Search... 2 Search Social Media(Twitter) data from Elasticsearch... 4 Query Boosting in Elasticsearch... 4 Machine Learning
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
SCALABLE, LOW LATENCY MODEL SERVING AND MANAGEMENT WITH VELOX
 THE MISSING PIECE IN COMPLEX ANALYTICS: SCALABLE, LOW LATENCY MODEL SERVING AND MANAGEMENT WITH VELOX Daniel Crankshaw, Peter Bailis, Joseph Gonzalez, Haoyuan Li, Zhao Zhang, Ali Ghodsi, Michael Franklin,
THE MISSING PIECE IN COMPLEX ANALYTICS: SCALABLE, LOW LATENCY MODEL SERVING AND MANAGEMENT WITH VELOX Daniel Crankshaw, Peter Bailis, Joseph Gonzalez, Haoyuan Li, Zhao Zhang, Ali Ghodsi, Michael Franklin,
Migrate from Netezza Workload Migration
 Migrate from Netezza Automated Big Data Open Netezza Source Workload Migration CASE SOLUTION STUDY BRIEF Automated Netezza Workload Migration To achieve greater scalability and tighter integration with
Migrate from Netezza Automated Big Data Open Netezza Source Workload Migration CASE SOLUTION STUDY BRIEF Automated Netezza Workload Migration To achieve greater scalability and tighter integration with
Data Science Training
 Data Science Training R, Predictive Modeling, Machine Learning, Python, Bigdata & Spark 9886760678 Introduction: This is a comprehensive course which builds on the knowledge and experience a business analyst
Data Science Training R, Predictive Modeling, Machine Learning, Python, Bigdata & Spark 9886760678 Introduction: This is a comprehensive course which builds on the knowledge and experience a business analyst
Flash Storage Complementing a Data Lake for Real-Time Insight
 Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Distributed Time Travel for Feature Generation. Prasanna Padmanabhan DB Tsai Mohammad H. Taghavi
 Distributed Time Travel for Feature Generation Prasanna Padmanabhan DB Tsai Mohammad H. Taghavi Turn on Netflix, and the absolute best content for you would automatically start playing Everything is a
Distributed Time Travel for Feature Generation Prasanna Padmanabhan DB Tsai Mohammad H. Taghavi Turn on Netflix, and the absolute best content for you would automatically start playing Everything is a
Benchmarking Spark ML using BigBench. Sweta Singh TPCTC 2016
 Benchmarking Spark ML using BigBench Sweta Singh singhswe@us.ibm.com TPCTC 2016 Motivation Study the performance of Machine Learning use cases on large data warehouses in context of assessing Alternate
Benchmarking Spark ML using BigBench Sweta Singh singhswe@us.ibm.com TPCTC 2016 Motivation Study the performance of Machine Learning use cases on large data warehouses in context of assessing Alternate
Oracle Big Data Discovery
 Oracle Big Data Discovery Turning Data into Business Value Harald Erb Oracle Business Analytics & Big Data 1 Safe Harbor Statement The following is intended to outline our general product direction. It
Oracle Big Data Discovery Turning Data into Business Value Harald Erb Oracle Business Analytics & Big Data 1 Safe Harbor Statement The following is intended to outline our general product direction. It
Big Data Analytics Tools. Applied to ATLAS Event Data
 Big Data Analytics Tools Applied to ATLAS Event Data Ilija Vukotic University of Chicago CHEP 2016, San Francisco Idea Big Data technologies have proven to be very useful for storage, visualization and
Big Data Analytics Tools Applied to ATLAS Event Data Ilija Vukotic University of Chicago CHEP 2016, San Francisco Idea Big Data technologies have proven to be very useful for storage, visualization and
Is Elasticsearch the Answer?
 High-Performance Big-Data Computation Solution Is Elasticsearch the Answer? Yoav Melamed Navigation The need Optional solutions What is Elasticsearch Not out of the box Shard limitations and capabilities
High-Performance Big-Data Computation Solution Is Elasticsearch the Answer? Yoav Melamed Navigation The need Optional solutions What is Elasticsearch Not out of the box Shard limitations and capabilities
Deep dive into analytics using Aggregation. Boaz
 Deep dive into analytics using Aggregation Boaz Leskes @bleskes Elasticsearch an end-to-end search and analytics platform. full text search highlighted search snippets search-as-you-type did-you-mean suggestions
Deep dive into analytics using Aggregation Boaz Leskes @bleskes Elasticsearch an end-to-end search and analytics platform. full text search highlighted search snippets search-as-you-type did-you-mean suggestions
SQL Server Machine Learning Marek Chmel & Vladimir Muzny
 SQL Server Machine Learning Marek Chmel & Vladimir Muzny @VladimirMuzny & @MarekChmel MCTs, MVPs, MCSEs Data Enthusiasts! vladimir@datascienceteam.cz marek@datascienceteam.cz Session Agenda Machine learning
SQL Server Machine Learning Marek Chmel & Vladimir Muzny @VladimirMuzny & @MarekChmel MCTs, MVPs, MCSEs Data Enthusiasts! vladimir@datascienceteam.cz marek@datascienceteam.cz Session Agenda Machine learning
Apache Spark Tutorial
 Apache Spark Tutorial Reynold Xin @rxin BOSS workshop at VLDB 2017 Apache Spark The most popular and de-facto framework for big data (science) APIs in SQL, R, Python, Scala, Java Support for SQL, ETL,
Apache Spark Tutorial Reynold Xin @rxin BOSS workshop at VLDB 2017 Apache Spark The most popular and de-facto framework for big data (science) APIs in SQL, R, Python, Scala, Java Support for SQL, ETL,
Understanding the workplace of the future. Artificial Intelligence series
 Understanding the workplace of the future Artificial Intelligence series Konica Minolta Inc. 02 Cognitive Hub and the Semantic Platform Within today s digital workplace, there is a growing need for different
Understanding the workplace of the future Artificial Intelligence series Konica Minolta Inc. 02 Cognitive Hub and the Semantic Platform Within today s digital workplace, there is a growing need for different
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Latest from the Lab: What's New Machine Learning Sam Buhler - Machine Learning Product/Offering Manager
 Latest from the Lab: What's New Machine Learning Sam Buhler - Machine Learning Product/Offering Manager Please Note IBM s statements regarding its plans, directions, and intent are subject to change or
Latest from the Lab: What's New Machine Learning Sam Buhler - Machine Learning Product/Offering Manager Please Note IBM s statements regarding its plans, directions, and intent are subject to change or
Monitoring MySQL with Prometheus & Grafana
 Monitoring MySQL with Prometheus & Grafana Julien Pivotto (@roidelapluie) Percona University Belgium June 22nd, 2017 SELECT USER(); Julien "roidelapluie" Pivotto @roidelapluie Sysadmin at inuits Automation,
Monitoring MySQL with Prometheus & Grafana Julien Pivotto (@roidelapluie) Percona University Belgium June 22nd, 2017 SELECT USER(); Julien "roidelapluie" Pivotto @roidelapluie Sysadmin at inuits Automation,
Real-time data processing with Apache Flink
 Real-time data processing with Apache Flink Gyula Fóra gyfora@apache.org Flink committer Swedish ICT Stream processing Data stream: Infinite sequence of data arriving in a continuous fashion. Stream processing:
Real-time data processing with Apache Flink Gyula Fóra gyfora@apache.org Flink committer Swedish ICT Stream processing Data stream: Infinite sequence of data arriving in a continuous fashion. Stream processing:
Search and Time Series Databases
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Search and Time Series Databases Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Search and Time Series Databases Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
17/05/2017. What we ll cover. Who is Greg? Why PaaS and SaaS? What we re not discussing: IaaS
 What are all those Azure* and Power* services and why do I want them? Dr Greg Low SQL Down Under greg@sqldownunder.com Who is Greg? CEO and Principal Mentor at SDU Data Platform MVP Microsoft Regional
What are all those Azure* and Power* services and why do I want them? Dr Greg Low SQL Down Under greg@sqldownunder.com Who is Greg? CEO and Principal Mentor at SDU Data Platform MVP Microsoft Regional
Personalizing Netflix with Streaming datasets
 Personalizing Netflix with Streaming datasets Shriya Arora Senior Data Engineer Personalization Analytics @shriyarora What is this talk about? Helping you decide if a streaming pipeline fits your ETL problem
Personalizing Netflix with Streaming datasets Shriya Arora Senior Data Engineer Personalization Analytics @shriyarora What is this talk about? Helping you decide if a streaming pipeline fits your ETL problem
Semantic Web Company. PoolParty - Server. PoolParty - Technical White Paper.
 Semantic Web Company PoolParty - Server PoolParty - Technical White Paper http://www.poolparty.biz Table of Contents Introduction... 3 PoolParty Technical Overview... 3 PoolParty Components Overview...
Semantic Web Company PoolParty - Server PoolParty - Technical White Paper http://www.poolparty.biz Table of Contents Introduction... 3 PoolParty Technical Overview... 3 PoolParty Components Overview...
Microsoft SharePoint 2010 The business collaboration platform for the Enterprise and the Web. We have a new pie!
 Microsoft SharePoint 2010 The business collaboration platform for the Enterprise and the Web We have a new pie! 2 Introduction Key Session Objectives Agenda More Scalable More Flexible More Features Intranet
Microsoft SharePoint 2010 The business collaboration platform for the Enterprise and the Web We have a new pie! 2 Introduction Key Session Objectives Agenda More Scalable More Flexible More Features Intranet
Homework: Building an Apache-Solr based Search Engine for DARPA XDATA Employment Data Due: November 10 th, 12pm PT
 Homework: Building an Apache-Solr based Search Engine for DARPA XDATA Employment Data Due: November 10 th, 12pm PT 1. Overview This assignment picks up where the last one left off. You will take your JSON
Homework: Building an Apache-Solr based Search Engine for DARPA XDATA Employment Data Due: November 10 th, 12pm PT 1. Overview This assignment picks up where the last one left off. You will take your JSON
mimacom & LiferayDXP Campaign
 mimacom & LiferayDXP Campaign www.mimacom.sk/liferay-dxp-cee About me Gustav Novotný CEO Software Engineer Liferay Consultant gustav.novotny@mimacom.com Mobile: +420 605466614 Development & Consulting
mimacom & LiferayDXP Campaign www.mimacom.sk/liferay-dxp-cee About me Gustav Novotný CEO Software Engineer Liferay Consultant gustav.novotny@mimacom.com Mobile: +420 605466614 Development & Consulting
Lambda Architecture for Batch and Stream Processing. October 2018
 Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
HDInsight > Hadoop. October 12, 2017
 HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk
 Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk Raanan Dagan and Rohit Pujari September 25, 2017 Washington, DC Forward-Looking Statements During the course of this presentation, we may
Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk Raanan Dagan and Rohit Pujari September 25, 2017 Washington, DC Forward-Looking Statements During the course of this presentation, we may
Apache Griffin Data Quality Solution for both streaming and batch
 Apache Griffin Data Quality Solution for both streaming and batch 郭跃鹏 ebay 资深主任工程师 数据服务部门 guoyp@apache.org Agenda About us Apache Griffin Demo What is coming How to contribute Q/A ebay Marketplace at a
Apache Griffin Data Quality Solution for both streaming and batch 郭跃鹏 ebay 资深主任工程师 数据服务部门 guoyp@apache.org Agenda About us Apache Griffin Demo What is coming How to contribute Q/A ebay Marketplace at a
Enhancing applications with Cognitive APIs IBM Corporation
 Enhancing applications with Cognitive APIs After you complete this section, you should understand: The Watson Developer Cloud offerings and APIs The benefits of commonly used Cognitive services 2 Watson
Enhancing applications with Cognitive APIs After you complete this section, you should understand: The Watson Developer Cloud offerings and APIs The benefits of commonly used Cognitive services 2 Watson
Technical Sheet NITRODB Time-Series Database
 Technical Sheet NITRODB Time-Series Database 10X Performance, 1/10th the Cost INTRODUCTION "#$#!%&''$!! NITRODB is an Apache Spark Based Time Series Database built to store and analyze 100s of terabytes
Technical Sheet NITRODB Time-Series Database 10X Performance, 1/10th the Cost INTRODUCTION "#$#!%&''$!! NITRODB is an Apache Spark Based Time Series Database built to store and analyze 100s of terabytes
CS535 Big Data Fall 2017 Colorado State University 10/10/2017 Sangmi Lee Pallickara Week 8- A.
 CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
Collaborative Filtering
 Collaborative Filtering Final Report 5/4/16 Tianyi Li, Pranav Nakate, Ziqian Song Information Storage and Retrieval (CS 5604) Department of Computer Science Blacksburg, Virginia 24061 Dr. Edward A. Fox
Collaborative Filtering Final Report 5/4/16 Tianyi Li, Pranav Nakate, Ziqian Song Information Storage and Retrieval (CS 5604) Department of Computer Science Blacksburg, Virginia 24061 Dr. Edward A. Fox
Regain control thanks to Prometheus. Guillaume Lefevre, DevOps Engineer, OCTO Technology Etienne Coutaud, DevOps Engineer, OCTO Technology
 Regain control thanks to Prometheus Guillaume Lefevre, DevOps Engineer, OCTO Technology Etienne Coutaud, DevOps Engineer, OCTO Technology About us Guillaume Lefevre DevOps Engineer, OCTO Technology @guillaumelfv
Regain control thanks to Prometheus Guillaume Lefevre, DevOps Engineer, OCTO Technology Etienne Coutaud, DevOps Engineer, OCTO Technology About us Guillaume Lefevre DevOps Engineer, OCTO Technology @guillaumelfv
Apache Ignite and Apache Spark Where Fast Data Meets the IoT
 Apache Ignite and Apache Spark Where Fast Data Meets the IoT Denis Magda GridGain Product Manager Apache Ignite PMC http://ignite.apache.org #apacheignite #denismagda Agenda IoT Demands to Software IoT
Apache Ignite and Apache Spark Where Fast Data Meets the IoT Denis Magda GridGain Product Manager Apache Ignite PMC http://ignite.apache.org #apacheignite #denismagda Agenda IoT Demands to Software IoT
Performance and Scalability Overview
 Performance and Scalability Overview This guide provides an overview of some of the performance and scalability capabilities of the Pentaho Business Anlytics platform PENTAHO PERFORMANCE ENGINEERING TEAM
Performance and Scalability Overview This guide provides an overview of some of the performance and scalability capabilities of the Pentaho Business Anlytics platform PENTAHO PERFORMANCE ENGINEERING TEAM
Realtime visitor analysis with Couchbase and Elasticsearch
 Realtime visitor analysis with Couchbase and Elasticsearch Jeroen Reijn @jreijn #nosql13 About me Jeroen Reijn Software engineer Hippo @jreijn http://blog.jeroenreijn.com About Hippo Visitor Analysis OneHippo
Realtime visitor analysis with Couchbase and Elasticsearch Jeroen Reijn @jreijn #nosql13 About me Jeroen Reijn Software engineer Hippo @jreijn http://blog.jeroenreijn.com About Hippo Visitor Analysis OneHippo
YOU SUN JEONG DATA ANALYTICS WITH DRUID
 YOU SUN JEONG DATA ANALYTICS WITH DRUID 2 WHO AM I? Senior Software Engineer of SK Telecom Commercial Products Big Data Discovery Solution (~ 16) Hadoop DW (~ 15) PaaS(CloudFoundry) (~ 13) Iaas (OpenStack)
YOU SUN JEONG DATA ANALYTICS WITH DRUID 2 WHO AM I? Senior Software Engineer of SK Telecom Commercial Products Big Data Discovery Solution (~ 16) Hadoop DW (~ 15) PaaS(CloudFoundry) (~ 13) Iaas (OpenStack)
Is NiFi compatible with Cloudera, Map R, Hortonworks, EMR, and vanilla distributions?
 Kylo FAQ General What is Kylo? Capturing and processing big data isn't easy. That's why Apache products such as Spark, Kafka, Hadoop, and NiFi that scale, process, and manage immense data volumes are so
Kylo FAQ General What is Kylo? Capturing and processing big data isn't easy. That's why Apache products such as Spark, Kafka, Hadoop, and NiFi that scale, process, and manage immense data volumes are so
Big Data Integrator Platform Platform Architecture and Features Dr. Hajira Jabeen Technical Team Leader-BDE University of Bonn
 Big Data Integrator Platform Platform Architecture and Features Dr. Hajira Jabeen Technical Team Leader-BDE University of Bonn BDE Presentation, EBDVF, 17 BigDataEurope 2 Making Big Data Accessible 3 How
Big Data Integrator Platform Platform Architecture and Features Dr. Hajira Jabeen Technical Team Leader-BDE University of Bonn BDE Presentation, EBDVF, 17 BigDataEurope 2 Making Big Data Accessible 3 How
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Lenses 2.1 Enterprise Features PRODUCT DATA SHEET
 Lenses 2.1 Enterprise Features PRODUCT DATA SHEET 1 OVERVIEW DataOps is the art of progressing from data to value in seconds. For us, its all about making data operations as easy and fast as using the
Lenses 2.1 Enterprise Features PRODUCT DATA SHEET 1 OVERVIEW DataOps is the art of progressing from data to value in seconds. For us, its all about making data operations as easy and fast as using the
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Intelligent Services Serving Machine Learning
 Intelligent Services Serving Machine Learning Joseph E. Gonzalez jegonzal@cs.berkeley.edu; Assistant Professor @ UC Berkeley joseph@dato.com; Co-Founder @ Dato Inc. Contemporary Learning Systems Big Data
Intelligent Services Serving Machine Learning Joseph E. Gonzalez jegonzal@cs.berkeley.edu; Assistant Professor @ UC Berkeley joseph@dato.com; Co-Founder @ Dato Inc. Contemporary Learning Systems Big Data
Talend Big Data Sandbox. Big Data Insights Cookbook
 Overview Pre-requisites Setup & Configuration Hadoop Distribution Download Demo (Scenario) Overview Pre-requisites Setup & Configuration Hadoop Distribution Demo (Scenario) About this cookbook What is
Overview Pre-requisites Setup & Configuration Hadoop Distribution Download Demo (Scenario) Overview Pre-requisites Setup & Configuration Hadoop Distribution Demo (Scenario) About this cookbook What is
iway iway Big Data Integrator New Features Bulletin and Release Notes Version DN
 iway iway Big Data Integrator New Features Bulletin and Release Notes Version 1.5.0 DN3502232.1216 Active Technologies, EDA, EDA/SQL, FIDEL, FOCUS, Information Builders, the Information Builders logo,
iway iway Big Data Integrator New Features Bulletin and Release Notes Version 1.5.0 DN3502232.1216 Active Technologies, EDA, EDA/SQL, FIDEL, FOCUS, Information Builders, the Information Builders logo,