arxiv: v1 [cs.cv] 24 Nov 2016
|
|
|
- Joseph Scott
- 6 years ago
- Views:
Transcription
1 Recalling Holistic Information for Semantic Segmentation arxiv: v1 [cs.cv] 24 Nov 2016 Hexiang Hu UCLA Los Angeles, CA Abstract Fei Sha UCLA Los Angeles, CA Semantic segmentation requires a detailed labeling of image pixels by object category. Information derived from local image patches is necessary to describe the detailed shape of individual objects. However, this information is ambiguous and can result in noisy labels. Global inference of image content can instead capture the general semantic concepts present. We advocate that high-recall holistic inference of image concepts provides valuable information for detailed pixel labeling. We build a two-stream neural network architecture that facilitates information flow from holistic information to local pixels, while keeping common image features shared among the low-level layers of both the holistic analysis and segmentation branches. We empirically evaluate our network on four standard semantic segmentation datasets. Our network obtains state-of-the-art performance on PASCAL-Context and NYUDv2, and ablation studies verify its effectiveness on ADE20K and SIFT- Flow. 1. Introduction Image analysis is a fundamental problem in computer vision. The task can be framed at different levels of granularity. At a fine scale, semantic segmentation labels each pixel to depict semantic elements by detailed shapes and contours. However, detailed semantic segmentation is challenging there exists significant ambiguity in fine-scale image patches that can result in noisy semantic segmentation outputs. The main focus of this paper is utilizing holistic information derived from analyzing entire images to filter equal contribution. Zhiwei Deng Simon Fraser University Burnaby, BC, Canada zhiweid@sfu.ca Greg Mori Simon Fraser University Burnaby, BC, Canada mori@cs.sfu.ca Guang-Tong Zhou Oracle Labs Vancouver, BC, Canada zhouguangtong@gmail.com Holistic Analysis Semantic Segmentation pixel labels bicycle motorbike holistic Info. Holistic Filtering car bicycle person motorbike refined pixel labels bicycle motorbike Figure 1. An example showing the usage of holistic information in semantic segmentation. We obtain holistic information about the contents of the entire image, and leverage this to filter out noisy pixel predictions to improve semantic segmentation. In our example, the noisy pixel label (i.e., bicycle) is removed after holistic filtering since it is not recalled as a likely label via the holistic analysis. noisy low-level semantic segmentation. Holistic information about the content of an image is highly valuable for semantic segmentation on local pixels essentially, the existence, non-existence and co-existence information on semantic classes provides a strong cue in determining the local pixel labels (see Figure 1). State-of-the-art methods for semantic segmentation leverage the successes of Convolutional Neural Networks (CNNs) [18]. CNNs have transformed the field of image classification, especially since the development of AlexNet [16]. There have been many follow-up CNN architectures to further boost image classification, including VGGNet [28], Google Inception [29], ResNet [11], etc. Semantic segmentation utilizes these network structures, combined with dense output structures to label image pixels by semantic categories. A representative work is the Fully Convolutional Network (FCN) [26] that leverages skip features of CNNs to produce a detailed pixel labeling. Another 1
2 example is the DeepLab [3] framework, which augments FCN with dilated convolution [32], atrous spatial pyramid pooling and Conditional Random Fields (CRFs), and obtains state-of-art semantic segmentation performance. Common among these previous methods is a focus on (layers of) low-level pixel analysis leading to semantic segmentation. State-of-the-art techniques combine this with sophisticated graphical model-style techniques (CRF) and pooling structures to obtain high accuracy. The role of these additional components is to smooth out the noisy pixel labelings that result from the direct CNN analysis. However, we believe that a simpler approach to incorporate this information is via a holistic analysis that globally suggests category labels that are likely to be present in the image. To make use of holistic information in semantic segmentation, we leverage it to filter out noisy pixel predictions if the holistic information suggests a semantic category is unlikely to be present, then pixels should be unlikely to be predicted as that label. Of course, holistic image analysis is imperfect. We conduct a detailed problem analysis in Section 3 to study how and when the holistic information can help. We utilize these observations to propose a novel neural network architecture that unifies a holistic branch and a detailed semantic segmentation branch. The two branches share common image features in low-level layers of convolution and pooling. In the holistic branch, we then recall information about semantic categories by aggregating over a grid of image patches. In the segmentation branch, we pipe in holistic information to guide segmentation by filtering out noisy pixel predictions. Our network is end-to-end trainable towards the goal of high-quality semantic segmentation. Contribution. We summarize our main contributions as: First, we advocate to leverage holistic image analysis to guide semantic segmentation, and provide empirical analysis to support our intuition. Second, we invent holistic filtering that enables us to filter out noisy pixel predictions with the guidance of holistic information. Third, we propose a two-stream neural network architecture for semantic segmentation. We implement a holistic branch and a segmentation branch, which facilitate the flow of global image information to the segmentation branch. Our approach is general, and could be incorporated into a variety of CNN-based semantic segmentation architectures. Finally, we evaluate our proposed network on PASCAL-Context [23], ADE20K [35], NYUDv2 [27] and SIFT-Flow [20]. Experimental results show that the proposed network improves upon state-of-the-art semantic segmentation models such as FCN [26] and DeepLab [3]. 2. Related Work Convolutional neural networks. In the last several years, CNNs have reformed the field of object recognition. The proposal of AlexNet [16], which achieves remarkable performance in ImageNet classification [25] with 8 layers of network, breaks the saturation bottleneck. Later on, Simonyan and Zisserman built VGGNet [28], a deeper network architecture of 19 layers. Recently, He et al. [11] proposed ResNet with over a hundred layers by introducing residual connections for even better classification accuracy and more generalized image features. Semantic segmentation. The significant success of CNNs in object recognition has led the recent new attention on semantic segmentation. A representative work is the Fully Convolutional Network (FCN) [26] that uses skip features of CNNs for detailed pixel labeling. FCN combines multi-level feature descriptors to leverage coarse-tofine local pixel information. In a recent advance, the atrous convolution is introduced by Chen et al. [3] as a technique to retain a large field of view while keeping fewer trainable weights in semantic segmentation networks. The same method termed as dilated convolution was also pursued by Yu and Koltun [32] by a cascading series of dilated convolution layers. Another line of work pushes on refining the detailed shapes and contours of semantic segmentation. A fully connected CRF is proposed by Krähenbühl and Koltun [15] as an efficient dense pixel modeling method. The fully connected pairwise CRF is further adopted by Chen et al. [3] and Zheng et al. [34] on top of FCNs as a further refinement. These methods have achieved considerable improvement on the semantic image segmentation task. Different from the above-mentioned methods, our work leverages image-level holistic information to guide semantic segmentation, and we verify that correctly recalling holistic information is a key to improve the semantic segmentation performance. Global-local information fusion. It has been shown that visual understanding benefits from exploiting and leveraging information of varying granularity. Deng et al. [6] modeled hierarchical and exclusive relations among semantic categories. Jain et al. [14] developed recurrent neural network structures for spatio-temporal inference. Hu et al. [13] proposed a neural graph inference model to propagate information among multiple levels of visual classes, including coarse labels, fine-grained categories as well as attributes. Amer et al. [1] adopted the and-or graph structure to reason about human activities at multiple levels of granularity. Gkioxari et al. [8] exploited contextual cues to improve action recognition. In the realm of semantic segmentation, He et al. [12] proposed to use multi-scale CRFs to capture features at various image resolutions for semantic segmentation. Approaches for modeling object instances and their segmentation have
3 (a). PASCAL-Context pacc macc miu fwiu FCN [26] FCN [26] + Holistic Filter (b). ADE20K pacc macc miu fwiu DilatedNet [35] DilatedNet [35] + Holistic Filter Table 1. Performance comparison of the baseline semantic segmentation methods and their holistic filtering counterparts. Here we use the ground-truth image labels as the holistic information. All measures are reported in percentage. also been developed [17, 31]. Another example of this line improves instance-aware semantic segmentation with detection and classification [5]. In contrast, we propose a framework to exploit holistic analysis for semantic segmentation. 3. Problem Analysis In this section, we would like to understand the effects of holistic information on semantic segmentation. We first design experiments to answer the question Can holistic information help semantic segmentation? With a positive answer, we proceed to discover What makes holistic information helpful? Given the observations, we also provide practical guidance for our network design Can Holistic Information Help? First, we conduct an analysis to determine whether holistic information can help in semantic segmentation. Suppose we knew the ground-truth image-level labels as the holistic information, how much performance gain would there be in semantic segmentation? Addressing this question analyzes how much potential there is for incorporating holistic image-level reasoning into semantic segmentation. We simply represent holistic information by the groundtruth labels assigned to each image, and then use the labels to filter out noisy segmentation outputs. Specifically, when labeling a pixel, we constrain the candidate set of labels to be the set of labels suggested by holistic information, i.e., the ground-truth image labels. As a comparison, the baseline methods uses all possible labels appearing in the dataset as the candidate labels. This simple change provides evidence of how much a holistic filtering could potentially help in semantic segmentation. We apply existing semantic segmentation methods as baselines on two datasets. Specifically, we run FCN (8s) on PASCAL-Context [26] and DilatedNet on ADE20K [35]. We compare the performance of the baselines and their holistic filtering counterparts in Table 1. Please refer to Section 5 for dataset details and the performance metrics. Table 1 shows that the holistic filtering achieves favorable performance gain over baselines that do not use holistic information approximately 33% and 40% relative improvement on PASCAL-Context and ADE20K respectively in terms of mean IU. This is reasonable since the holistic information indicates what to expect in the image, and help to filter out noisy prediction on pixel labels. Beyond leveraging holistic information in the postsegmentation process to filter out noisy pixel predictions, we have also retrained the network weights with the guidance of holistic information. It turns out that retraining brings additional performance gain. We will describe the detailed network design that enables retraining in Section 4, and further analyze our experimental results in Section What Makes Holistic Information Helpful? We now continue to explore the key properties the holistic information should possess in order to help semantic segmentation. This exploration is valuable for practical usage because in a real scenario, we could never assume perfect image labels as the holistic information. We first design a mechanism to contaminate the holistic information. The idea is to start with the set of ground-truth image labels, and then randomly remove some ground-truth labels or add in noisy labels that are not in the ground-truth set. By performing such operations, we could effectively control the precision and recall of the ground-truth labels in the holistic information the precision is degraded when adding in more and more noisy labels, and the recall is degraded when removing more and more ground-truth labels. We have experimented with the holistic filtering methods mentioned in Section 3.1 with various precision and recall settings of ground-truth labels in holistic information (details of the experimental setup are provided in Appendix B). We plot the mean IU performance on PASCAL-Context and ADE20K in Figure 2. The plots clearly show that the precision (of ground-truth labels in holistic information) has minor impact on the semantic segmentation performance the mean IU changes slightly as the precision degrades from 1 to 0.2. On the other hand, however, the recall (of ground-truth labels in holistic information) plays a key role for semantic segmentation the mean IU decreases significantly with respect to degradation of recall. Moreover, the comparison with the baseline methods shows that our holistic filtering method is able to outperform the baselines as long as the recall goes above 0.85 on PASCAL-Context and 0.75 on ADE20K. Here the holistic information is used only in the post segmentation process to filter out noisy pixel predictions the performance of our holistic filtering method is further boosted when retraining the network weights with the guidance of holistic information. The above observations lead us to some practical guide-



4 (a). PASCAL-Context (b). ADE20K Figure 2. The mean IU grids of semantic segmentation with holistic filtering on the PASCAL-Context and ADE20K datasets, with respect to various precisions and recalls. The light yellow plane depicts the baseline performance, i.e., 39.12% of FCN on PASCAL-Context [26] and 32.31% of DilatedNet on ADE20K [35]. lines for designing our semantic segmentation network. Specifically, we should have a holistic branch that recalls ground-truth image labels as much as possible to serve as the holistic information. If necessary, we would rather sacrifice precision in the predicted labels to improve recall. Furthermore, we need a segmentation branch that pipes the holistic information to filter semantic segmentation. The process needs to be differentiable, so that we can jointly train the holistic and segmentation branches end-to-end. Next we describe the details of our network design. 4. Network Design We now present our network design that leverages the guidelines derived from the previous problem analysis. Figure 3 illustrates the general network architecture. In detail, we have a holistic branch to recall holistic information, and a segmentation branch to adopt holistic information to guide the semantic segmentation process. The two branches share a common feature network of convolutional layers and pooling layers. The feature network outputs a feature map of certain feature channels on downsampled images. The feature network can be easily adopted from any existing CNN architecture (like VGGNet [28], ResNet [11], etc.), by removing its top fully-connected layers and keeping the convolutional and pooling layers. This flexibility enables our network to take advantage of the continual improvement in CNN architectures. In our experiments, we use the 152-layer ResNet [11] by default, if not further specified. In the following we describe our holistic branch and segmentation branch, respectively. After that, we will briefly go through our training process Recall-Preserving Holistic Analysis Our holistic branch takes in the feature map as input and suggests image labels, with a focus on recalling groundtruth image labels as much as possible. To preserve high recall, we believe it is critical to conduct location-aware predictions that densely inspect image patches, since a semantic component (i.e., an object or stuff) always takes up a portion of the entire image. We then aggregate the location-aware predictions by max-pooling to compose the final holistic information. Our holistic analysis is unlikely to miss ground-truth image labels via the dense location-aware prediction, and thus preserves high recall. However, it might incur noisy image labels since noisy or background image patches could mislead the max-pooling process. Note that our holistic analysis is different from standard image classification that optimizes both recall and precision, but it serves our purpose as we would rather sacrifice precision to improve recall. In detail, we add in a patch network on top of the feature map to generate a classification map that predicts locationaware image labels using densely sliding image patches. The patch network is composed of three layers. First, we have a dilated convolutional layer [32, 3] to summarize image patch information. We use k k convolutional kernels with a dilation rate of r under d channels. In our experiment, we set the default patch size as 224, k = 3, r = 2 and d = 512, if not further specified. The second layer is a ReLU layer included for non-linearity. Finally, we top up with a one-by-one convolutional layer to predict a classification map of c channels, each represents a semantic class. We then compose the holistic information by a maxpooling over the classification map. The max-pooling results in a c-dimensional vector that describes the confidence scores for each semantic class to appear in the given image.
 Segmentation Branch Feature Network up-sampling Pixel Network (f, h, w) feature map seg. map holistic filtering (c, H, W) seg. map full seg. map Figure 3.")
5 image semantic segmentation Holistic Branch max-pooling Patch Network (c, 1, 1) holistic classif. map information (H, W) Segmentation Branch Feature Network up-sampling Pixel Network (f, h, w) feature map seg. map holistic filtering (c, H, W) seg. map full seg. map Figure 3. Our network architecture for semantic segmentation. Please refer to the text for detailed description of the pipeline. The notations in brackets depict the size of the data. The input image size is H W. After the feature network, the image is down-sampled to h w pixels. Moreover, we use f to denote the number of feature channels, and c to denote the number of pixel/image classes. These are then piped into the segmentation branch to guide semantic segmentation. Here we use soft label confidences to enable gradient back-propagation for end-to-end training Semantic Segmentation with Holistic Filtering Our segmentation branch takes in the feature map and the holistic information to generate a semantic segmentation of the given image. As shown in Figure 3, the branch is composed of three major processes including a pixel network, a holistic filtering and an up-sampling. The pixel network is responsible for generating a segmentation map based on the feature map obtained from the feature network. The network structure can be easily adopted from any state-of-the-art semantic segmentation framework. In our experiments, we have evaluated two variants, FCN [26] and DilatedNet [32, 3] with slight modifications (details in Appendix A). The FCN variant uses decovolution to generate three segmentation maps of various down-sampling rates. The DilatedNet applies dilated convolution to obtain a single segmentation map. The holistic filtering is a key component in our pipeline. It uses the holistic information derived from the holistic branch to actively filter out noisy pixel predictions in a segmentation map. The idea is to use the holistic information to recommend labels for pixel predictions if the holistic information suggests a semantic label is unlikely to be present, then pixels should be unlikely to be predicted as that label as well. Figure 4 illustrates the detailed implementation of the holistic filtering. Note that the holistic information (i.e., the image label confidences) and the segmentation map are both values in the real domain. Therefore, we first apply a sigmoid function to normalize both to [0, 1] a high value indicates a high confidence of observing the corresponding semantic label. Then we multiply the holistic information to each cell of the segmentation map to filter out noisy pixel predictions. In the filtered segmentation map, a cell receives a high value on a label only if both the holistic information and the original pixel prediction are highly confident of predicting that label. Finally, we follow [13] to apply a logit function (i.e., the inverse sigmoid function) to map the segmentation map back to the real domain. Note that all operations in the holistic filtering are differentiable so that the gradient can be back-propagated for end-to-end training. With the filtered segmentation map obtained from holistic filtering, we then apply an up-sampling operation to generate our final output a full semantic segmentation map. The up-sampling is simply done by bi-linear interpolation (following [3]) to increase the resolution to the original image size. We could also switch the order of up-sampling and holistic filtering in the pipeline to adopt holistic information to filter the full segmentation map. This results in slightly better empirical performance, but increases the computational cost significantly. We keep up-sampling after holistic filtering for the sake of efficiency.
6 holistic information (c, 1, 1) [-inf, inf] seg. map [-inf, inf] sigmoid sigmoid holistic information (c, 1, 1) [0, 1] repeat [0, 1] seg. map holistic map element-wise multiplication [0, 1] seg. map [0, 1] Holistic Filtering logit seg. map [-inf, inf] Figure 4. Details of the holistic filtering. The notations in round brackets indicate the size of the data, and the numbers in square brackets show that domain of the data values. All operations are differentiable for end-to-end training Training We optimize both classification and segmentation losses in our end-to-end trainable network. The classification loss is enforced on the patch network in the holistic branch. Each cell of the classification map corresponds to an image patch, and we impose loss on each patch individually for location-aware recognition. Specifically, we derive a ground-truth classification map from the ground-truth pixel labels. A map cell is labeled as 1 if the corresponding image patch has at least one pixel labeled the same as the map cell s semantic label; and 0 otherwise. We first adopt a sigmoid activation layer on the output classification map, and then evaluate a categorical cross-entropy loss. The segmentation loss is enforced on the full segmentation map dumped from the segmentation branch. Following the standard setting of semantic segmentation [26, 3], we first apply a softmax activation layer to the full segmentation map, and then compute a categorical cross-entropy loss for the segmentation task. The balance between the two losses is controlled by a constant multiplier so that both losses have similar order of magnitude. We follow the practice of FCN [26] to train our network optimizing the objective by stochastic gradient descent (SGD) with a small batch size (e.g., 1) and a large momentum (e.g., 0.99). We train our network for approximately 60 epochs and choose the best models through validation. To further clarify our implementation details, we will publicly release our code. 5. Experiments We evaluate our network on four benchmark datasets: the PASCAL-Context dataset [23], the ADE20K dataset [35], the NYUDv2 dataset [27], and the SIFT- Flow dataset [20]. All these datasets contain abundant contextual labels on pixels, and thus are challenging for semantic segmentation tasks. We choose these four datasets as all the pixels are densely labeled with a variety of semantic classes. Baselines. A direct baseline of our network is to keep the segmentation branch and ignore the holistic branch as well as the holistic filtering operation. As stated in Section 4.2, our pixel network in the segmentation branch has two variants modified from FCN [26] and DilatedNet [32, 3], so we call the two resultant baselines FCN + and DilatedNet +. Following this convention, we name our holistic filtering semantic segmentation networks as Holistic FCN + and Holistic DilatedNet +, respectively. Our feature network adopts the 152-layer ResNet [11] by default. We have also evaluated VGGNet [28] as an alternative, and the result is in Appendix D. It shows that our network architecture has flexibility to take various feature networks to improve semantic segmentation. Metrics. Following [26], we evaluate four performance metrics that are commonly used for semantic segmentation tasks. The metrics are variations on pixel accuracy and region intersection over union (IU). Specifically, we denote by n ij the number of pixels of class i predicted to belong to class j, t i = j n ij the total number of pixels of class i, and c the total number of semantic classes. We evaluate: Pixel Accuracy (pacc): i n ii/ i t i Mean Accuracy (macc): (1/c) i n ii/t i Mean IU (miu): (1/c) i n ii/ ( t i + j n ji n ii ) Frequency Weighted IU (fwiu): ( k t k) 1 i t in ii / ( t i + j n ji n ii ) In all the result tables, we highlight the best figures in red and boldfaced, and the second best in blue and underline. Data augmentation. We describe our data augmentation strategy in Appendix C. Visualizations. To smooth paper overflow, we also defer qualitative visualizations to Appendix E PASCAL-Context Dataset. The PASCAL-Context dataset is derived from the PASCAL VOC 2010 dataset with detailed annotations on every pixel [23]. The semantic labels include both objects and stuff present in the image. Following [23, 26], we evaluate our network on the most frequent 59 classes alongside one background class. The training and testing sets contain 4,998 and 5,105 images, respectively. Evaluation. We have compared our holistic filtering networks with our baselines and existing methods in the literature. The evaluation results are reported in Table 2. It clearly shows that the two holistic filtering networks outperform all the other methods, in terms of all four performance metrics. This verifies the effectiveness of the proposed method. It is worth noting that both Holistic FCN + and Holistic DilatedNet + outperform the current state-of-the-art
7 pacc macc miu fwiu CFM [5] FCN-8s [26] CRF-RNN [34] DeepLab [3] ParseNet [22] BoxSup [4] HO-CRF [2] Context [19] DeepLab + COCO [3] DeepLab + COCO + CRF [3] FCN Holistic FCN DilatedNet Holistic DilatedNet Table 2. Semantic segmentation results on PASCAL-Context. pacc macc miu fwiu FCN-8s [35] DilatedNet [35] DilatedNet Cascade [35] FCN Holistic FCN DilatedNet Holistic DilatedNet Table 3. Semantic segmentation results on the ADE20K validation set, using training and testing images. method, DeepLab + COCO + CRF [3]. However, we did not use extra training data (e.g. the COCO dataset) and domain adaptation to obtain a better model. We applied neither CRFs to smooth the segmentation results, nor multiscale test to refine segmentation at various image granularities. Therefore, we suspect that our network performance can be further boosted once we apply these techniques. Also note that holistic filtering assists in semantic segmentation. For example, the miu values of FCN + and DilatedNet + is improved by 2.85% and 3.51% respectively with holistic filtering. It shows the effectiveness of our twostream network architecture that recalls holistic information for semantic segmentation ADE20K Dataset. ADE20K is a recently released dataset with densely annotated objects and stuff. We learn our model on the training set of 20,210 images, and report performance on the 2,000 validation images. We did not evaluate on the 5,000 test images as the ground-truth annotations have not been made public yet. Following [35], we select the top 150 semantic classes ranked by their total pixel ratios, including 35 object classes and 115 stuff classes. The pixels from the 150 classes occupy 92.75% of all pixels in the dataset. Evaluation. We perform two sets of experiments. The first set follows [35]. We train and test our networks on resized images of 384 by 384 pixels. To evaluate the perforpacc macc miu fwiu ILSVRC 2016 Best w. ResNet ILSVRC 2016 Best w. ResNet FCN Holistic FCN Table 4. Semantic segmentation results on the ADE20K validation set, using full-resolution images for training and testing. We compare with the ILSVRC 2016 best entry [33] using single model and single-scale test. mance against the ground-truth annotations, we re-size the resultant segmentation on each test image from back to the original image size. This experiment enables us to directly compare with those reported in [35], and we apply this setting by default for ADE20K experiments if not further specified. Note that this setting may lead to the loss of image details and object aspect ratios, thus yielding suboptimal performance. We summarize the results in Table 3. Again it shows the utility of holistic filtering networks, which achieve the best performance in all four metrics. The results also verify the usage of holistic filtering it boosts FCN + and DilatedNet + remarkably. The second set of experiments follows the ILSVRC 2016 Scene Parsing Challenge, and uses full-resolution images for both training and testing. We compare our Holistic FCN + with the ILSVRC 2016 best entry [33] (under single model and single-scale test) in Table 4. Holistic DilatedNet + is not included due to the intensive dilated convolution on full-resolution images. Table 4 show that that our method is competitive. Specifically, the miu of Holistic FCN + is 1.73% behind the best result with the same feature network (the 152-layer ResNet), and 2.89% behind the best entry (built on the 269-layer ResNet). Note that we did not investigate all practical techniques to further improve our network performance, such as leveraging extra scene labels, applying deeply supervised training, pre-training with PlaceNet, using a deeper CNN architecture as the feature network, etc NYUDv2 Dataset. NYUDv2 is an RGB-D dataset on indoor scenes collected using Microsoft Kinect. It has 1,449 RGB- D images, with pixel-wise labels that have been coalesced into 40 semantic classes by Gupta et al. [9]. We experiment with the standard split of 795 training images and 654 testing images. Evaluation. We compare our methods with state-ofthe-art approaches, and report the evaluation results in Table 5. Our holistic filtering networks achieve the best performance, especially with Holistic FCN +. Our networks only use the color images for training, ignoring the depth information. We still improve 5.46%
8 pacc macc miu fwiu Gupta et al. [10] FCN-32s + RGB [26] FCN-32s + RGB + D [26] FCN-32s + RGB + HHA [26] FCN Holistic FCN DilatedNet Holistic DilatedNet Table 5. Semantic segmentation results on NYUDv2. pacc macc miu fwiu Liu et al. [21] Exemplar SVM [30] SVM + MRF [30] Multiscale CNN + Natural [7] Multiscale CNN + Balanced [7] Recurrent CNN [24] ParseNet [22] FCN-8s [26] FCN Holistic FCN DilatedNet Holistic DilatedNet Table 6. Semantic segmentation results on SIFT-Flow. miu over the state-of-the-art method, FCN-32s + RGB + HHA [26], which utilizes both the color and depth information. It again verifies the effectiveness of holistic filtering and our two-stream network architecture SIFT-Flow Dataset. The SIFT-Flow dataset contains 2,688 images thoroughly annotated by LabelMe users [20, 21] with 33 semantic pixel labels (e.g., mountain, sun, bridge, etc). We use the same split as [20, 21] 2,488 images for training and 200 images for testing. Evaluation. We compare our networks with state-ofthe-art approaches in Table 6. The results show that our holistic filtering networks perform the best over all the compared methods. Note that current state-of-the-art FCN- 8s [26] leverages the available pixel-wise geometric labels (i.e., horizontal, vertical and sky) as extra supervision, whereas our networks do not use them. These observations show the utility of our networks in semantic segmentation. It is worth mentioning that a competitive method on the SIFT-Flow dataset is proposed by Lin et al. [19], achieving 88.1% pacc, 53.4% macc and 44.9% miu. However, this method up-samples training and testing images by a factor of two, and benefits from the high-resolution images to obtain superior performance. On the other hand, all other methods including our networks do not up-sample images, and thus are not directly comparable with [19] PASCAL-Context ADE20K miu pacc miu pacc FCN+ Holistic FCN+ Holistic FCN+ w. ground truth Figure 5. The pacc and miu performance of FCN +, Holistic FCN + and Holisitic FCN + with ground truth on PASCAL- Context and ADE20K Analysis All the above experiments show that semantic segmentation benefits from holistic information and holistic filtering. However, by no means would we claim that our holistic branch is perfect. For example, when applying a threshold of 0 on the image label confidences from the holistic information derived by Holistic FCN +, we observe 90.93% recall and 46.75% precision on PASCAL-Context, and 69.07% recall and 47.59% precision on ADE20K. Thus, an interesting question to raise is: How well our networks could perform if we have a perfect holistic branch with % recall and % precision? We answer this question by leveraging ground-truth image labels in Holistic FCN +. We implement it by replacing our holistic branch with a static process that returns groundtruth image label confidences, taking the value of infinity if a label is present in the image; and negative infinity otherwise. We keep the rest of the network the same as Holistic FCN +, and train it end-to-end towards optimizing the segmentation loss (see Section 4.3 for details of the loss). We compare the pacc and miu performance of FCN +, Holistic FCN +, and Holistic FCN + with ground truth in Figure 5. It clearly shows that Holistic FCN + with ground truth significantly boosts semantic segmentation for example, the miu values are improved to 63.61% on PASCAL-Context and 54.26% on ADE20K. We believe Holistic FCN + with ground truth provides the upper-bound on performance we could have achieved with holistic filtering, and we would gradually approach this upper-bound as we obtain a better and better holistic analysis models in our two-stream network architecture. This opens up a promising direction for further research.
9 8s FCN + 16s 32s up-sampling Conv & Pooling Conv Conv Non-Linear Pixel Classifier image Non-Linear Pixel Classifier Non-Linear Pixel Classifier Non-Linear Pixel Classifier full segmentation map Conv 3x3 (dilation = 2, channel = 512) ReLU DilatedNet + up-sampling Conv 1x1 (classifier) Conv & Pooling Dilated Conv Dilated Conv Non-Linear Pixel Classifier image full segmentation map Figure 6. The network architectures of FCN + and DilatedNet +. Note that the only modification from FCN [26] and DilatedNet [3] is to use our non-linear pixel classifier to generate segmentation maps. More details are described in the text. 6. Conclusion This paper is motivated by the benefit of holistic information in semantic segmentation. We have presented empirical analysis to support our intuition, and proposed a twostream neural network architecture as an implementation. Our network includes a holistic branch to recall holistic information by inspecting location-aware image patches. We also have a segmentation branch that leverages holistic filtering to filter out noisy pixel predictions. Experiments on four benchmark datasets show the effectiveness of the proposed method, which achieves state-of-art performance on PASCAL-Context and NYUDv2, as well as competitive results on ADE20K and SIFT-Flow. Our method that leverages holistic information from images is general and could be applied to many other applications, for example, improving object detection with holistic image labels, locating actions with holistic video activity annotations, and so on. Appendix A. FCN + and DilatedNet + As mentioned in Section 4.2, the pixel network in our segmentation branch is responsible for generating a segmentation map based on the feature map obtained from the feature network. We have implemented two variants as our pixel network in our segmentation branch. Specifically, we have FCN + derived from FCN [26] and DilatedNet + derived from DilatedNet [3]. We show the network architectures in Figure 6, and describe the details in the following. FCN + has a similar structure as FCN [26]: it first uses skip features to generate three segmentation maps of various down-sampling rates (8s, 16s and 32s), then fuses them together, and finally up-samples to the original image size for semantic segmentation. The only modification is that FCN + applies our designed non-linear pixel classifier to generate a segmentation map from the input feature map. The non-linear pixel classifier leverages non-linearity and dilated convolution to model pixel labeling. It consists of a dilated convolutional layer [32, 3] to summarize image information, a ReLU layer for non-linearity, as well as a one-by-one convolutional layer to predict the segmentation map. In our experiments, we apply 3 by 3 convolutional kernels in the dilated convolutional layer, using a dilation rate of 2 under 512 channels. Our DilatedNet + is derived from DilatedNet [3] with the same modification we apply our non-linear pixel classifier on the feature map (obtained after dilated convolutions) to generate the segmentation map. The rest of the structure is kept the same as [3]. Note that our experimental results verify the utility of our non-linear pixel classifier. See Tables 2, 3, 5, and 6 for detailed comparison between FCN + and FCN, and between DilatedNet + and DilatedNet.
10 Feature Network pacc macc miu fwiu FCN + VGGNet Holistic FCN + VGGNet DilatedNet + VGGNet Holistic DilatedNet + VGGNet FCN + ResNet Holistic FCN + ResNet DilatedNet + ResNet Holistic DilatedNet + ResNet Table 7. Ablation study of feature networks on the PASCAL-Context dataset [23]. We highlight the best performance in red and boldfaced, and the second best in blue and underline. Appendix B. Precision and Recall Setup In Section 3.2, we experimented with the holistic filtering methods with various precision and recall settings of ground-truth labels in holistic information. The detailed experimental setup is as follows. To degrade the precision, we have added in n p {1, 2,, 10} noisy labels per image. Similarly, to degrade the recall, we have removed n r {1, 2,, 10} groundtruth labels per image (if there are fewer than n r groundtruth labels in an image, we just remove them all). Note that n p and n r can be set as fractional values to further refine the numerical accuracy of precision and recall. For example, setting n r = 2.3 means that we will first remove 2 (the integer part of n r ) ground-truth labels on each image, and then randomly pick up 30% (the decimal part of n r ) of the images to remove one more ground-truth label each. With this trick, we also tried n r {0.2, 0.4, 0.6, 0.8} in our experiment. We conduct holistic filtering for semantic segmentation with an exhaustive grid search of n p and n r values. Note that each combination of n p and n r produces holistic information with certain precision and recall of ground-truth labels (by averaging over all images). We plot the mean IU performance in Figure 2. Appendix C. Data Augmentation Strategy It has been shown that data augmentation is a practical technique to boost semantic segmentation performance. In our experiments, we have applied horizontal flipping as well as scale augmentation when training our networks. For scale augmentation, we randomly pick a scale factor in the set {0.7, 0.8, 0.9, 1.0, 1.1, 1.2, 1.3} to scale each image. Appendix D. Feature Network Ablation Study As promised in Section 5, we have conducted experiments to study the flexibility of our network architecture in taking various feature networks. In detail, we have tried the 16-layer VGGNet [28] and the 152-layer ResNet [11] respectively as the feature network, by removing the top fullyconnected layers and keeping the convolutional and pooling layers. We evaluate our networks (i.e., Holistic FCN + and Holistic DilatedNet + ) and our baselines (i.e., FCN + and DilatedNet + ) using the two feature network variants. The comparison results on the PASCAL-Context [23] dataset is reported in Table 7. The table clearly shows that our holistic filtering networks improve over the baselines, using either VGGNet or ResNet. It verifies that our network architecture can flexibly adopt various feature networks to improve semantic segmentation. This flexibility enables our network to take advantage of the continual improvement in CNN architectures. Furthermore, it is beneficial to use ResNet as our feature network as it consistently outperforms the VGGNet counterpart. It is reasonable since ResNet employs a deeper structure than VGGNet to capture rich image features. Appendix E. Visualizations We select sample images from PASCAL-Context and ADE20K, and visualize the semantic segmentation results in Figures 7 and 8. As a comparison with existing methods, we have also provided the FCN [26] results on PASCAL- Context and the DilatedNet [35] results on ADE20K. The qualitative results verify the usage of holistic filtering in semantic segmentation recalling holistic information to filter out noisy pixel predictions is a practical strategy for semantic segmentation. References [1] M. R. Amer, D. Xie, M. Zhao, S. Todorovic, and S.-C. Zhu. Cost-sensitive top-down/bottom-up inference for multiscale activity recognition. In ECCV, [2] A. Arnab, S. Jayasumana, S. Zheng, and P. H. S. Torr. Higher order conditional random fields in deep neural networks. In ECCV, [3] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. Yuille. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. arxiv Preprint, abs/ , , 4, 5, 6, 7, 9 [4] J. Dai, K. He, and J. Sun. BoxSup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In ICCV,
![Image FCN [26] Holistic FCN+](/docs-images/75/72258621/images/11-0.jpg "Ground Truth Ground Truth")

















![In CVPR, 2013. 7 [10] S.](/docs-images/75/72258621/images/11-18.jpg "Gupta, R. Girshick, P.")





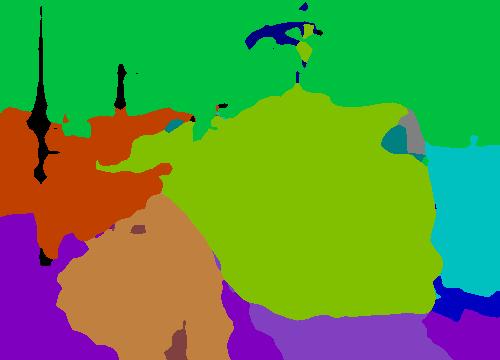






11 Image FCN [26] Holistic FCN+ Ground Truth Image FCN [26] Holistic FCN+ Ground Truth Figure 7. Visualization of the semantic segmentation results on sample PASCAL-Context images. We compare our Holistic FCN+ with the FCN method of [26]. We also show the origin images and the ground-truth annotations for reference. [5] J. Dai, K. He, and J. Sun. Convolutional feature masking for joint object and stuff segmentation. In CVPR, , 7 [6] J. Deng, N. Ding, Y. Jia, A. Frome, K. Murphy, S. Bengio, Y. Li, H. Neven, and H. Adam. Large-scale object classification using label relation graphs. In ECCV, [7] C. Farabet, C. Couprie, L. Najman, and Y. LeCun. Learning hierarchical features for scene labeling. IEEE T-PAMI, 35(8): , [8] G. Gkioxari, R. Girshick, and J. Malik. Contextual action recognition with R*CNN. In ICCV, [9] S. Gupta, P. Arbelaez, and J. Malik. Perceptual organization and recognition of indoor scenes from RGB-D images. In CVPR, [10] S. Gupta, R. Girshick, P. Arbela ez, and J. Malik. Learning rich features from RGB-D images for object detection and segmentation. In ECCV, [11] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, , 2, 4, 6, 10 [12] X. He, R. S. Zemel, and M. A. Carreira-Perpin a n. Multiscale conditional random fields for image labeling. In CVPR, [13] H. Hu, G.-T. Zhou, Z. Deng, Z. Liao, and G. Mori. Learning structured inference neural networks with label relations. In CVPR, , 5 [14] A. Jain, A. R. Zamir, S. Savarese, and A. Saxena. StructuralRNN: Deep learning on spatio-temporal graphs. In CVPR, [15] P. Kra henbu hl and V. Koltun. Efficient inference in fully connected CRFs with Gaussian edge potentials. In NIPS, [16] A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, , 2

![[35] DilatedNet](/docs-images/75/72258621/images/12-1.jpg "+ Ground Truth")






![method of [35].](/docs-images/75/72258621/images/12-8.jpg "We also show the")






























12 Holistic Holistic Image DilatedNet [35] DilatedNet + Ground Truth Image DilatedNet [35] DilatedNet + Ground Truth Figure 8. Visualization of the semantic segmentation results on sample ADE20K images. We compare our Holistic DilatedNet + with the DilatedNet method of [35]. We also show the origin images and the ground-truth annotations for reference. [17] M. P. Kumar, P. H. S. Torr, and A. Zisserman. OBJ CUT. In CVPR, [18] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradientbased learning applied to document recognition. Proceedings of the IEEE, 86(11): , [19] G. Lin, C. Shen, I. Reid, and A. van den Hengel. Efficient piecewise training of deep structured models for semantic segmentation. In CVPR, , 8 [20] C. Liu, J. Yuen, and A. Torralba. Nonparametric scene parsing via label transfer. IEEE T-PAMI, 33(12): , , 6, 8 [21] C. Liu, J. Yuen, and A. Torralba. SIFT flow: Dense correspondence across scenes and its applications. IEEE T-PAMI, 33(5): , [22] W. Liu, A. Rabinovich, and A. C. Berg. ParseNet: Looking wider to see better. In ICLR Workshop, , 8 [23] R. Mottaghi, X. Chen, X. Liu, N.-G. Cho, S.-W. Lee, S. Fidler, R. Urtasun, and A. Yuille. The role of context for object
13 detection and semantic segmentation in the wild. In CVPR, , 6, 10 [24] P. H. O. Pinheiro and R. Collobert. Recurrent convolutional neural networks for scene labeling. In ICML, [25] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet large scale visual recognition challenge. IJCV, 115(3): , [26] E. Shelhamer, J. Long, and T. Darrell. Fully convolutional networks for semantic segmentation. IEEE T-PAMI, , 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 [27] N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. Indoor segmentation and support inference from RGBD images. In ECCV, , 6 [28] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, , 2, 4, 6, 10 [29] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. E. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In CVPR, [30] J. Tighe and S. Lazebnik. Finding things: Image parsing with regions and per-exemplar detectors. In CVPR, [31] B. Wu and R. Nevatia. Simultaneous object detection and segmentation by boosting local shape feature based classifier. In CVPR, [32] F. Yu and V. Koltun. Multi-scale context aggregation by dilated convolutions. In ICLR, , 4, 5, 6, 9 [33] H. Zhao, J. Shi, X. Qi, X. Wang, T. Xiao, and J. Jia. Understanding scene in the wild. ECCV Workshop Presentation, [34] S. Zheng, S. Jayasumana, B. Romera-Paredes, V. Vineet, Z. Su, D. Du, C. Huang, and P. H. S. Torr. Conditional random fields as recurrent neural networks. In ICCV, , 7 [35] B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba. Semantic understanding of scenes through the ADE20K dataset. arxiv Preprint, abs/ , , 3, 4, 6, 7, 10, 12
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deconvolutions in Convolutional Neural Networks
 Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
arxiv: v2 [cs.cv] 18 Jul 2017
![arxiv: v2 [cs.cv] 18 Jul 2017](/thumbs/72/67294650.jpg "arxiv: v2 [cs.cv] 18 Jul 2017") PHAM, ITO, KOZAKAYA: BISEG 1 arxiv:1706.02135v2 [cs.cv] 18 Jul 2017 BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks Viet-Quoc Pham quocviet.pham@toshiba.co.jp
PHAM, ITO, KOZAKAYA: BISEG 1 arxiv:1706.02135v2 [cs.cv] 18 Jul 2017 BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks Viet-Quoc Pham quocviet.pham@toshiba.co.jp
arxiv: v4 [cs.cv] 6 Jul 2016
![arxiv: v4 [cs.cv] 6 Jul 2016](/thumbs/93/112985717.jpg "arxiv: v4 [cs.cv] 6 Jul 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION
 HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
 : Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1,2, Anton Milan 1, Chunhua Shen 1,2, Ian Reid 1,2 1 The University of Adelaide, 2 Australian Centre for Robotic
: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1,2, Anton Milan 1, Chunhua Shen 1,2, Ian Reid 1,2 1 The University of Adelaide, 2 Australian Centre for Robotic
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
 : Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1 Anton Milan 2 Chunhua Shen 2,3 Ian Reid 2,3 1 Nanyang Technological University 2 University of Adelaide 3 Australian
: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1 Anton Milan 2 Chunhua Shen 2,3 Ian Reid 2,3 1 Nanyang Technological University 2 University of Adelaide 3 Australian
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
arxiv: v1 [cs.cv] 1 Feb 2018
![arxiv: v1 [cs.cv] 1 Feb 2018](/thumbs/89/100586364.jpg "arxiv: v1 [cs.cv] 1 Feb 2018") Learning Semantic Segmentation with Diverse Supervision Linwei Ye University of Manitoba yel3@cs.umanitoba.ca Zhi Liu Shanghai University liuzhi@staff.shu.edu.cn Yang Wang University of Manitoba ywang@cs.umanitoba.ca
Learning Semantic Segmentation with Diverse Supervision Linwei Ye University of Manitoba yel3@cs.umanitoba.ca Zhi Liu Shanghai University liuzhi@staff.shu.edu.cn Yang Wang University of Manitoba ywang@cs.umanitoba.ca
Scene Parsing with Global Context Embedding
 Scene Parsing with Global Context Embedding Wei-Chih Hung 1, Yi-Hsuan Tsai 1,2, Xiaohui Shen 3, Zhe Lin 3, Kalyan Sunkavalli 3, Xin Lu 3, Ming-Hsuan Yang 1 1 University of California, Merced 2 NEC Laboratories
Scene Parsing with Global Context Embedding Wei-Chih Hung 1, Yi-Hsuan Tsai 1,2, Xiaohui Shen 3, Zhe Lin 3, Kalyan Sunkavalli 3, Xin Lu 3, Ming-Hsuan Yang 1 1 University of California, Merced 2 NEC Laboratories
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
arxiv: v1 [cs.cv] 24 May 2016
![arxiv: v1 [cs.cv] 24 May 2016](/thumbs/80/80473828.jpg "arxiv: v1 [cs.cv] 24 May 2016") Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
Conditional Random Fields as Recurrent Neural Networks
 BIL722 - Deep Learning for Computer Vision Conditional Random Fields as Recurrent Neural Networks S. Zheng, S. Jayasumana, B. Romera-Paredes V. Vineet, Z. Su, D. Du, C. Huang, P.H.S. Torr Introduction
BIL722 - Deep Learning for Computer Vision Conditional Random Fields as Recurrent Neural Networks S. Zheng, S. Jayasumana, B. Romera-Paredes V. Vineet, Z. Su, D. Du, C. Huang, P.H.S. Torr Introduction
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Building Damage Assessment Using Deep Learning and Ground-Level Image Data
 Building Damage Assessment Using Deep Learning and Ground-Level Image Data Karoon Rashedi Nia School of Computing Science Simon Fraser University Burnaby, Canada krashedi@sfu.ca Greg Mori School of Computing
Building Damage Assessment Using Deep Learning and Ground-Level Image Data Karoon Rashedi Nia School of Computing Science Simon Fraser University Burnaby, Canada krashedi@sfu.ca Greg Mori School of Computing
arxiv: v1 [cs.cv] 5 Oct 2015
![arxiv: v1 [cs.cv] 5 Oct 2015](/thumbs/71/66021937.jpg "arxiv: v1 [cs.cv] 5 Oct 2015") Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Dense Image Labeling Using Deep Convolutional Neural Networks
 Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Amodal and Panoptic Segmentation. Stephanie Liu, Andrew Zhou
 Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Semantic Segmentation
 Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Classification of objects from Video Data (Group 30)
") Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Elastic Neural Networks for Classification
 Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Team G-RMI: Google Research & Machine Intelligence
 Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation
 BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation Jifeng Dai Kaiming He Jian Sun Microsoft Research {jifdai,kahe,jiansun}@microsoft.com Abstract Recent leading
BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation Jifeng Dai Kaiming He Jian Sun Microsoft Research {jifdai,kahe,jiansun}@microsoft.com Abstract Recent leading
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
 Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute of Advanced Industrial Science and Technology (AIST) Tsukuba,
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute of Advanced Industrial Science and Technology (AIST) Tsukuba,
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
Pixel Offset Regression (POR) for Single-shot Instance Segmentation
 for Single-shot Instance Segmentation") Pixel Offset Regression (POR) for Single-shot Instance Segmentation Yuezun Li 1, Xiao Bian 2, Ming-ching Chang 1, Longyin Wen 2 and Siwei Lyu 1 1 University at Albany, State University of New York, NY,
Pixel Offset Regression (POR) for Single-shot Instance Segmentation Yuezun Li 1, Xiao Bian 2, Ming-ching Chang 1, Longyin Wen 2 and Siwei Lyu 1 1 University at Albany, State University of New York, NY,
arxiv: v1 [cs.cv] 26 Jun 2017
![arxiv: v1 [cs.cv] 26 Jun 2017](/thumbs/80/82184026.jpg "arxiv: v1 [cs.cv] 26 Jun 2017") Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
In Defense of Fully Connected Layers in Visual Representation Transfer
 In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
arxiv: v1 [cs.cv] 14 Jul 2017
![arxiv: v1 [cs.cv] 14 Jul 2017](/thumbs/74/70463879.jpg "arxiv: v1 [cs.cv] 14 Jul 2017") Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Learning Fully Dense Neural Networks for Image Semantic Segmentation
 Learning Fully Dense Neural Networks for Image Semantic Segmentation Mingmin Zhen 1, Jinglu Wang 2, Lei Zhou 1, Tian Fang 3, Long Quan 1 1 Hong Kong University of Science and Technology, 2 Microsoft Research
Learning Fully Dense Neural Networks for Image Semantic Segmentation Mingmin Zhen 1, Jinglu Wang 2, Lei Zhou 1, Tian Fang 3, Long Quan 1 1 Hong Kong University of Science and Technology, 2 Microsoft Research
Depth-aware CNN for RGB-D Segmentation
 Depth-aware CNN for RGB-D Segmentation Weiyue Wang [0000 0002 8114 8271] and Ulrich Neumann University of Southern California, Los Angeles, California {weiyuewa,uneumann}@usc.edu Abstract. Convolutional
Depth-aware CNN for RGB-D Segmentation Weiyue Wang [0000 0002 8114 8271] and Ulrich Neumann University of Southern California, Los Angeles, California {weiyuewa,uneumann}@usc.edu Abstract. Convolutional
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Learning Deep Structured Models for Semantic Segmentation. Guosheng Lin
 Learning Deep Structured Models for Semantic Segmentation Guosheng Lin Semantic Segmentation Outline Exploring Context with Deep Structured Models Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel;
Learning Deep Structured Models for Semantic Segmentation Guosheng Lin Semantic Segmentation Outline Exploring Context with Deep Structured Models Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel;
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Supervised Learning of Classifiers
 Supervised Learning of Classifiers Carlo Tomasi Supervised learning is the problem of computing a function from a feature (or input) space X to an output space Y from a training set T of feature-output
Supervised Learning of Classifiers Carlo Tomasi Supervised learning is the problem of computing a function from a feature (or input) space X to an output space Y from a training set T of feature-output
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Depth Estimation from Single Image Using CNN-Residual Network
 Depth Estimation from Single Image Using CNN-Residual Network Xiaobai Ma maxiaoba@stanford.edu Zhenglin Geng zhenglin@stanford.edu Zhi Bie zhib@stanford.edu Abstract In this project, we tackle the problem
Depth Estimation from Single Image Using CNN-Residual Network Xiaobai Ma maxiaoba@stanford.edu Zhenglin Geng zhenglin@stanford.edu Zhi Bie zhib@stanford.edu Abstract In this project, we tackle the problem
arxiv: v1 [cs.cv] 8 Mar 2017 Abstract
![arxiv: v1 [cs.cv] 8 Mar 2017 Abstract](/thumbs/74/70449616.jpg "arxiv: v1 [cs.cv] 8 Mar 2017 Abstract") Large Kernel Matters Improve Semantic Segmentation by Global Convolutional Network Chao Peng Xiangyu Zhang Gang Yu Guiming Luo Jian Sun School of Software, Tsinghua University, {pengc14@mails.tsinghua.edu.cn,
Large Kernel Matters Improve Semantic Segmentation by Global Convolutional Network Chao Peng Xiangyu Zhang Gang Yu Guiming Luo Jian Sun School of Software, Tsinghua University, {pengc14@mails.tsinghua.edu.cn,
LSTM and its variants for visual recognition. Xiaodan Liang Sun Yat-sen University
 LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
arxiv: v4 [cs.cv] 12 Aug 2015
![arxiv: v4 [cs.cv] 12 Aug 2015](/thumbs/88/115589297.jpg "arxiv: v4 [cs.cv] 12 Aug 2015") CAESAR ET AL.: JOINT CALIBRATION FOR SEMANTIC SEGMENTATION 1 arxiv:1507.01581v4 [cs.cv] 12 Aug 2015 Joint Calibration for Semantic Segmentation Holger Caesar holger.caesar@ed.ac.uk Jasper Uijlings jrr.uijlings@ed.ac.uk
CAESAR ET AL.: JOINT CALIBRATION FOR SEMANTIC SEGMENTATION 1 arxiv:1507.01581v4 [cs.cv] 12 Aug 2015 Joint Calibration for Semantic Segmentation Holger Caesar holger.caesar@ed.ac.uk Jasper Uijlings jrr.uijlings@ed.ac.uk
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
Pseudo Mask Augmented Object Detection
 Pseudo Mask Augmented Object Detection Xiangyun Zhao Northwestern University zhaoxiangyun915@gmail.com Shuang Liang Tongji University shuangliang@tongji.edu.cn Yichen Wei Microsoft Research yichenw@microsoft.com
Pseudo Mask Augmented Object Detection Xiangyun Zhao Northwestern University zhaoxiangyun915@gmail.com Shuang Liang Tongji University shuangliang@tongji.edu.cn Yichen Wei Microsoft Research yichenw@microsoft.com
arxiv: v1 [cs.cv] 26 Jul 2018
![arxiv: v1 [cs.cv] 26 Jul 2018](/thumbs/88/117269915.jpg "arxiv: v1 [cs.cv] 26 Jul 2018") A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
LARGE-SCALE PERSON RE-IDENTIFICATION AS RETRIEVAL
 LARGE-SCALE PERSON RE-IDENTIFICATION AS RETRIEVAL Hantao Yao 1,2, Shiliang Zhang 3, Dongming Zhang 1, Yongdong Zhang 1,2, Jintao Li 1, Yu Wang 4, Qi Tian 5 1 Key Lab of Intelligent Information Processing
LARGE-SCALE PERSON RE-IDENTIFICATION AS RETRIEVAL Hantao Yao 1,2, Shiliang Zhang 3, Dongming Zhang 1, Yongdong Zhang 1,2, Jintao Li 1, Yu Wang 4, Qi Tian 5 1 Key Lab of Intelligent Information Processing
arxiv: v2 [cs.cv] 23 May 2016
![arxiv: v2 [cs.cv] 23 May 2016](/thumbs/88/115196824.jpg "arxiv: v2 [cs.cv] 23 May 2016") Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition arxiv:1605.06217v2 [cs.cv] 23 May 2016 Xiao Liu Jiang Wang Shilei Wen Errui Ding Yuanqing Lin Baidu Research
Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition arxiv:1605.06217v2 [cs.cv] 23 May 2016 Xiao Liu Jiang Wang Shilei Wen Errui Ding Yuanqing Lin Baidu Research
Fully Convolutional Network for Depth Estimation and Semantic Segmentation
 Fully Convolutional Network for Depth Estimation and Semantic Segmentation Yokila Arora ICME Stanford University yarora@stanford.edu Ishan Patil Department of Electrical Engineering Stanford University
Fully Convolutional Network for Depth Estimation and Semantic Segmentation Yokila Arora ICME Stanford University yarora@stanford.edu Ishan Patil Department of Electrical Engineering Stanford University
arxiv: v1 [cs.cv] 6 Jul 2015
![arxiv: v1 [cs.cv] 6 Jul 2015](/thumbs/77/75402517.jpg "arxiv: v1 [cs.cv] 6 Jul 2015") CAESAR ET AL.: JOINT CALIBRATION FOR SEMANTIC SEGMENTATION 1 arxiv:1507.01581v1 [cs.cv] 6 Jul 2015 Joint Calibration for Semantic Segmentation Holger Caesar holger.caesar@ed.ac.uk Jasper Uijlings jrr.uijlings@ed.ac.uk
CAESAR ET AL.: JOINT CALIBRATION FOR SEMANTIC SEGMENTATION 1 arxiv:1507.01581v1 [cs.cv] 6 Jul 2015 Joint Calibration for Semantic Segmentation Holger Caesar holger.caesar@ed.ac.uk Jasper Uijlings jrr.uijlings@ed.ac.uk
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks
 Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors
![[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors](/thumbs/89/97941029.jpg "[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors") [Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation
 LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation Abhishek Chaurasia School of Electrical and Computer Engineering Purdue University West Lafayette, USA Email: aabhish@purdue.edu
LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation Abhishek Chaurasia School of Electrical and Computer Engineering Purdue University West Lafayette, USA Email: aabhish@purdue.edu
arxiv: v1 [cs.cv] 11 Apr 2018
![arxiv: v1 [cs.cv] 11 Apr 2018](/thumbs/89/99253021.jpg "arxiv: v1 [cs.cv] 11 Apr 2018") arxiv:1804.03821v1 [cs.cv] 11 Apr 2018 ExFuse: Enhancing Feature Fusion for Semantic Segmentation Zhenli Zhang 1, Xiangyu Zhang 2, Chao Peng 2, Dazhi Cheng 3, Jian Sun 2 1 Fudan University, 2 Megvii Inc.
arxiv:1804.03821v1 [cs.cv] 11 Apr 2018 ExFuse: Enhancing Feature Fusion for Semantic Segmentation Zhenli Zhang 1, Xiangyu Zhang 2, Chao Peng 2, Dazhi Cheng 3, Jian Sun 2 1 Fudan University, 2 Megvii Inc.
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
RDFNet: RGB-D Multi-level Residual Feature Fusion for Indoor Semantic Segmentation
 RDFNet: RGB-D Multi-level Residual Feature Fusion for Indoor Semantic Segmentation Seong-Jin Park POSTECH Ki-Sang Hong POSTECH {windray,hongks,leesy}@postech.ac.kr Seungyong Lee POSTECH Abstract In multi-class
RDFNet: RGB-D Multi-level Residual Feature Fusion for Indoor Semantic Segmentation Seong-Jin Park POSTECH Ki-Sang Hong POSTECH {windray,hongks,leesy}@postech.ac.kr Seungyong Lee POSTECH Abstract In multi-class
arxiv: v2 [cs.cv] 16 Sep 2018
![arxiv: v2 [cs.cv] 16 Sep 2018](/thumbs/90/104336455.jpg "arxiv: v2 [cs.cv] 16 Sep 2018") Dual Attention Network for Scene Segmentation Jun Fu, Jing Liu, Haijie Tian, Zhiwei Fang, Hanqing Lu CASIA IVA {jun.fu, jliu, zhiwei.fang, luhq}@nlpr.ia.ac.cn,{hjtian bit}@63.com arxiv:809.0983v [cs.cv]
Dual Attention Network for Scene Segmentation Jun Fu, Jing Liu, Haijie Tian, Zhiwei Fang, Hanqing Lu CASIA IVA {jun.fu, jliu, zhiwei.fang, luhq}@nlpr.ia.ac.cn,{hjtian bit}@63.com arxiv:809.0983v [cs.cv]
Joint Calibration for Semantic Segmentation
 CAESAR ET AL.: JOINT CALIBRATION FOR SEMANTIC SEGMENTATION 1 Joint Calibration for Semantic Segmentation Holger Caesar holger.caesar@ed.ac.uk Jasper Uijlings jrr.uijlings@ed.ac.uk Vittorio Ferrari vittorio.ferrari@ed.ac.uk
CAESAR ET AL.: JOINT CALIBRATION FOR SEMANTIC SEGMENTATION 1 Joint Calibration for Semantic Segmentation Holger Caesar holger.caesar@ed.ac.uk Jasper Uijlings jrr.uijlings@ed.ac.uk Vittorio Ferrari vittorio.ferrari@ed.ac.uk
Unified, real-time object detection
 Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
arxiv: v1 [cs.cv] 29 Nov 2017
![arxiv: v1 [cs.cv] 29 Nov 2017](/thumbs/94/122233241.jpg "arxiv: v1 [cs.cv] 29 Nov 2017") Detection-aided liver lesion segmentation using deep learning arxiv:1711.11069v1 [cs.cv] 29 Nov 2017 Míriam Bellver, Kevis-Kokitsi Maninis, Jordi Pont-Tuset, Xavier Giró-i-Nieto, Jordi Torres,, Luc Van
Detection-aided liver lesion segmentation using deep learning arxiv:1711.11069v1 [cs.cv] 29 Nov 2017 Míriam Bellver, Kevis-Kokitsi Maninis, Jordi Pont-Tuset, Xavier Giró-i-Nieto, Jordi Torres,, Luc Van
Supplementary material for Analyzing Filters Toward Efficient ConvNet
 Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
arxiv: v2 [cs.cv] 24 Jul 2018
![arxiv: v2 [cs.cv] 24 Jul 2018](/thumbs/94/120067817.jpg "arxiv: v2 [cs.cv] 24 Jul 2018") arxiv:1803.05549v2 [cs.cv] 24 Jul 2018 Object Detection in Video with Spatiotemporal Sampling Networks Gedas Bertasius 1, Lorenzo Torresani 2, and Jianbo Shi 1 1 University of Pennsylvania, 2 Dartmouth
arxiv:1803.05549v2 [cs.cv] 24 Jul 2018 Object Detection in Video with Spatiotemporal Sampling Networks Gedas Bertasius 1, Lorenzo Torresani 2, and Jianbo Shi 1 1 University of Pennsylvania, 2 Dartmouth
Towards Real-Time Automatic Number Plate. Detection: Dots in the Search Space
 Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Deep Learning. Visualizing and Understanding Convolutional Networks. Christopher Funk. Pennsylvania State University.
 Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
arxiv: v2 [cs.cv] 10 Apr 2017
![arxiv: v2 [cs.cv] 10 Apr 2017](/thumbs/80/82485703.jpg "arxiv: v2 [cs.cv] 10 Apr 2017") Fully Convolutional Instance-aware Semantic Segmentation Yi Li 1,2 Haozhi Qi 2 Jifeng Dai 2 Xiangyang Ji 1 Yichen Wei 2 1 Tsinghua University 2 Microsoft Research Asia {liyi14,xyji}@tsinghua.edu.cn, {v-haoq,jifdai,yichenw}@microsoft.com
Fully Convolutional Instance-aware Semantic Segmentation Yi Li 1,2 Haozhi Qi 2 Jifeng Dai 2 Xiangyang Ji 1 Yichen Wei 2 1 Tsinghua University 2 Microsoft Research Asia {liyi14,xyji}@tsinghua.edu.cn, {v-haoq,jifdai,yichenw}@microsoft.com
Deep Neural Networks:
 Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
CS 2750: Machine Learning. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh April 13, 2016
 CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik Presented by Pandian Raju and Jialin Wu Last class SGD for Document
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik Presented by Pandian Raju and Jialin Wu Last class SGD for Document
Know your data - many types of networks
 Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
A MULTI-RESOLUTION FUSION MODEL INCORPORATING COLOR AND ELEVATION FOR SEMANTIC SEGMENTATION
 A MULTI-RESOLUTION FUSION MODEL INCORPORATING COLOR AND ELEVATION FOR SEMANTIC SEGMENTATION Wenkai Zhang a, b, Hai Huang c, *, Matthias Schmitz c, Xian Sun a, Hongqi Wang a, Helmut Mayer c a Key Laboratory
A MULTI-RESOLUTION FUSION MODEL INCORPORATING COLOR AND ELEVATION FOR SEMANTIC SEGMENTATION Wenkai Zhang a, b, Hai Huang c, *, Matthias Schmitz c, Xian Sun a, Hongqi Wang a, Helmut Mayer c a Key Laboratory