ChunkStash: Speeding Up Storage Deduplication using Flash Memory
|
|
|
- Alice Alisha Shields
- 6 years ago
- Views:
Transcription
 + Univ.")
1 ChunkStash: Speeding Up Storage Deduplication using Flash Memory Biplob Debnath +, Sudipta Sengupta *, Jin Li * * Microsoft Research, Redmond (USA) + Univ. of Minnesota, Twin Cities (USA)
2 Deduplication of Storage Detect and remove duplicate data in storage systems e.g., Across multiple full backups Storage space savings Faster backup completion: Disk I/O and Network bandwidth savings Feature offering in many storage systems products Data Domain, EMC, NetApp Backups need to complete over windows of few hours Throughput (MB/sec) important performance metric High-level techniques Content based chunking, detect/store unique chunks only Object/File level, Differential encoding



3 Impact of Dedup Savings Across Full Backups Source: Data Domain white paper
4 Deduplication of Storage Detect and remove duplicate data in storage systems e.g., Across full backups Storage space savings Faster backup completion: Disk I/O and Network bandwidth savings Feature offering in many storage systems products Data Domain, EMC, NetApp Backups need to complete over windows of few hours Throughput (MB/sec) important performance metric High-level techniques Content based chunking, detect/store unique chunks only Object/File level, Differential encoding
5 Content based Chunking Calculate Rabin fingerprint hash for each sliding window (16 byte)
6 Content based Chunking Calculate Rabin fingerprint hash for each sliding window (16 byte)
7 Content based Chunking Calculate Rabin fingerprint hash for each sliding window (16 byte) Hash
8 Content based Chunking Calculate Rabin fingerprint hash for each sliding window (16 byte) Hash
9 Content based Chunking Calculate Rabin fingerprint hash for each sliding window (16 byte) Hash
10 Content based Chunking Calculate Rabin fingerprint hash for each sliding window (16 byte) Hash
11 Content based Chunking Calculate Rabin fingerprint hash for each sliding window (16 byte) Hash
12 Content based Chunking Calculate Rabin fingerprint hash for each sliding window (16 byte) Hash
13 Content based Chunking Calculate Rabin fingerprint hash for each sliding window (16 byte) If Hash matches a particular pattern, Declare a chunk boundary Hash
14 Content based Chunking Calculate Rabin fingerprint hash for each sliding window (16 byte) If Hash matches a particular pattern, Declare a chunk boundary Hash
15 Content based Chunking Calculate Rabin fingerprint hash for each sliding window (16 byte) If Hash matches a particular pattern, Declare a chunk boundary Hash
16 Content based Chunking Calculate Rabin fingerprint hash for each sliding window (16 byte) If Hash matches a particular pattern, Declare a chunk boundary Hash
17 Content based Chunking Calculate Rabin fingerprint hash for each sliding window (16 byte) Chunks If Hash matches a particular pattern, Declare a chunk boundary Hash
18 How to Obtain Chunk Boundaries? Content dependent chunking When last n bits of Rabin hash = 0, declare chunk boundary Average chunk size = 2 n bytes When data changes over time, new chunks correspond to new data regions only Compare with fixed size chunks (e.g., disk blocks) Even unchanged data could be detected as new because of shifting How are chunks compared for equality? 20-byte SHA-1 hash (or, 32-byte SHA-256) Probability of collisions is less than that of hardware error by many orders of magnitude
19 Container Store and Chunk Parameters Chunks are written to disk in groups of containers Each container contains 1023 chunks New chunks added into currently open container, which is sealed when full Average chunk size = 8KB, Typical chunk compression ratio of 2:1 Average container size 4MB Data Container Container Store Chunk A Chunk B... Chunk X Chunk Y... Chunk A Chunk B chunks Slide 19
20 Index for Detecting Duplicate Chunks Chunk hash index for identifying duplicate chunks Key = 20-byte SHA-1 hash (or, 32-byte SHA-256) Value = chunk metadata, e.g., length, location on disk Key + Value 64 bytes Essential Operations Lookup (Get) Insert (Set) Need a high performance indexing scheme Chunk metadata too big to fit in RAM Disk IOPS is a bottleneck for disk-based index Duplicate chunk detection bottlenecked by hard disk seek times (~10 msec)
21 Disk Bottleneck for Identifying Duplicate Chunks 20 TB of unique data, average 8 KB chunk size 160 GB of storage for full index ( unique bytes per chunk metadata) Not cost effective to keep all of this huge index in RAM Backup throughput limited by disk seek times for index lookups 10ms seek time => chunk lookups per second => 800 KB/sec backup throughput Container No locality in the key space for chunk hash lookups Prefetching into RAM index mappings for entire container... to exploit sequential predictability of lookups during 2 nd and subsequent full backups (Zhu et al., FAST 2008)
22 Storage Deduplication Process Schematic Chunk (RAM) (Chunks in currently open container) (RAM) Chunk Index Index on on Flash HDD HDD HDD
23 Speedup Potential of a Flash based Index RAM hit ratio of 99% (using chunk metadata prefetching techniques) Average lookup time with on-disk index Average lookup time with on-flash index Potential of up to 50x speedup with index lookups served from flash


24 ChunkStash: Chunk Metadata Store on Flash Flash aware data structures and algorithms Random writes, in-place updates are expensive on flash memory Sequential writes, Random/Sequential reads great! Use flash in a log-structured manner Low RAM footprint Order of few bytes in RAM for each key-value pair stored on flash FusionIO 160GB iodrive 3x
25 ChunkStash Architecture RAM write buffer for chunk mappings in currently open container Chunk metadata organized on flash in logstructured manner in groups of 1023 chunks => 64 KB logical page metadata/ chunk) Prefetch cache for chunk metadata in RAM for sequential predictability of chunk lookups Chunk metadata indexed in RAM using a specialized space efficient hash table Slide 25
26 Low RAM Usage: Cuckoo Hashing High hash table load factors while keeping lookup times fast Collisions resolved using cuckoo hashing Key can be in one of K candidate positions Later inserted keys can relocate earlier keys to their other candidate positions K candidate positions for key x obtained using K hash functions h 1 (x),, h K (x) In practice, two hash functions can simulate K hash functions using h i (x) = g 1 (x) + i*g 2 (x) System uses value of K=16 and targets 90% hash table load factor Insert X
27 Low RAM Usage: Compact Key Signatures Compact key signatures stored in hash table 2-byte key signature (vs. 20-byte SHA-1 hash) Key x stored at its candidate position i derives its signature from h i (x) False flash read probability < 0.01% Total 6-10 bytes per entry (4-8 byte flash pointer) Related work on key-value stores on flash media MicroHash, FlashDB, FAWN, BufferHash Slide 27
28 RAM and Flash Capacity Considerations Whether RAM of flash size becomes bottleneck for store capacity depends on key-value size At 64 bytes per key-value pair, RAM is the bottleneck Example 4GB of RAM 716 million key-value pairs bytes of RAM per entry At 8KB average chunk size, this corresponds to 6TB of deduplicated data At 64 bytes of metadata per chunk on flash, this uses 45GB of flash Larger chunk sizes => larger datasets for same amount of RAM and flash (but may tradeoff with dedup quality) Slide 28
29 Further Reducing RAM Usage in ChunkStash Approach 1: Reduce the RAM requirements of the keyvalue store (work in progress) Approach 2: Deduplication application specific Index in RAM only a small fraction of the chunks in each container (sample and index every i-th chunk) Flash still holds the metadata for all chunks in the system Prefetch chunk metadata into RAM as before Incur some loss in deduplication quality Fraction of chunks indexed is a powerful knob for tradeoff between RAM usage and dedup quality Index 10% chunks => 90% reduction in RAM usage => less than 1-byte of RAM usage per chunk metadata stored on flash And negligible loss in dedup quality!
30 Compare with Sparse Indexing Scheme Sparse indexing scheme (FAST 2009) Chop incoming stream into multi-mb segments, select chunk hooks in each segment using random sampling Use these hooks to find few segments seen in the recent past that share many chunks How does ChunkStash differ? Uniform interval sampling No concept of segment; all incoming chunks looked up in index Match incoming chunks with sampled chunks in all containers stored in the system, not just those see in recent past Slide 30
 ChunkStash on hard disk (ChunkStash-HDD) Prefetching of chunk metadata in all systems Three datasets, 2 full backups for each BerkeleyDB used as the")
31 Performance Evaluation Comparison with disk index based system Disk based index (Zhu08-BDB-HDD) SSD replacement (Zhu08-BDB-SSD) SSD replacement + ChunkStash (ChunkStash-SSD) ChunkStash on hard disk (ChunkStash-HDD) Prefetching of chunk metadata in all systems Three datasets, 2 full backups for each BerkeleyDB used as the index on HDD/SSD

32 Performance Evaluation Dataset 2 1.2x 65x 3.5x 1.8x 25x 3x Slide 32


33 Performance Evaluation Dataset 3 Slide 33
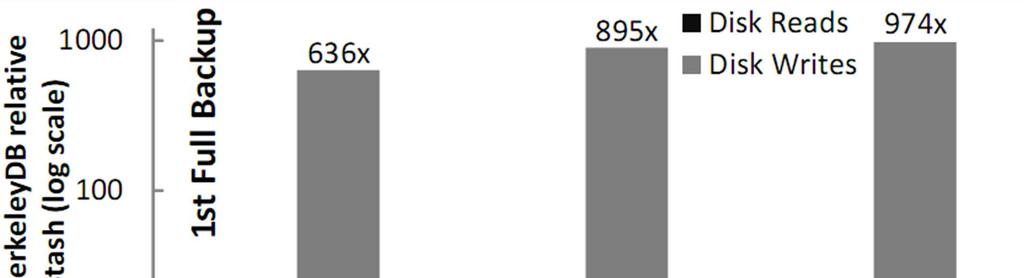

34 Performance Evaluation Disk IOPS Slide 34


 (1/8)")
35 Indexing Chunk Samples in ChunkStash: Deduplication Quality (1/64) (1/16) (1/8) Slide 35



36 Indexing Chunk Samples in ChunkStash: Backup Throughput Slide 36
37 Flash Memory Cost Considerations Chunks occupy an average of 4KB on hard disk Store compressed chunks on hard disk Typical compression ratio of 2:1 Flash storage is 1/64-th of hard disk storage 64-byte metadata on flash per 4KB occupies space on hard disk Flash investment is about 16% of hard disk cost 1/64-th additional cost = 16% additional cost Performance/dollar improvement of 22x 25x performance at 1.16x cost Further cost reduction by amortizing flash across datasets Store chunk metadata on HDD and preload to flash Slide 37
38 Summary Backup throughput in inline deduplication systems limited by chunk hash index lookups Flash-assisted storage deduplication system Chunk metadata store on flash Flash aware data structures and algorithms Low RAM footprint Significant backup throughput improvements 7x-60x over over HDD index based system (BerkeleyDB) 2x-4x over flash index based (but flash unaware) system (BerkeleyDB) Performance/dollar improvement of 22x (over HDD index) Reduce RAM usage further by 90-99% Index small fraction of chunks in each container Negligible to marginal loss in deduplication quality
Speeding Up Cloud/Server Applications Using Flash Memory
 Speeding Up Cloud/Server Applications Using Flash Memory Sudipta Sengupta and Jin Li Microsoft Research, Redmond, WA, USA Contains work that is joint with Biplob Debnath (Univ. of Minnesota) Flash Memory
Speeding Up Cloud/Server Applications Using Flash Memory Sudipta Sengupta and Jin Li Microsoft Research, Redmond, WA, USA Contains work that is joint with Biplob Debnath (Univ. of Minnesota) Flash Memory
Reducing Replication Bandwidth for Distributed Document Databases
 Reducing Replication Bandwidth for Distributed Document Databases Lianghong Xu 1, Andy Pavlo 1, Sudipta Sengupta 2 Jin Li 2, Greg Ganger 1 Carnegie Mellon University 1, Microsoft Research 2 Document-oriented
Reducing Replication Bandwidth for Distributed Document Databases Lianghong Xu 1, Andy Pavlo 1, Sudipta Sengupta 2 Jin Li 2, Greg Ganger 1 Carnegie Mellon University 1, Microsoft Research 2 Document-oriented
DELL EMC DATA DOMAIN SISL SCALING ARCHITECTURE
 WHITEPAPER DELL EMC DATA DOMAIN SISL SCALING ARCHITECTURE A Detailed Review ABSTRACT While tape has been the dominant storage medium for data protection for decades because of its low cost, it is steadily
WHITEPAPER DELL EMC DATA DOMAIN SISL SCALING ARCHITECTURE A Detailed Review ABSTRACT While tape has been the dominant storage medium for data protection for decades because of its low cost, it is steadily
Part II: Data Center Software Architecture: Topic 2: Key-value Data Management Systems. SkimpyStash: Key Value Store on Flash-based Storage
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 2: Key-value Data Management Systems SkimpyStash: Key Value
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 2: Key-value Data Management Systems SkimpyStash: Key Value
A DEDUPLICATION-INSPIRED FAST DELTA COMPRESSION APPROACH W EN XIA, HONG JIANG, DA N FENG, LEI T I A N, M I N FU, YUKUN Z HOU
 A DEDUPLICATION-INSPIRED FAST DELTA COMPRESSION APPROACH W EN XIA, HONG JIANG, DA N FENG, LEI T I A N, M I N FU, YUKUN Z HOU PRESENTED BY ROMAN SHOR Overview Technics of data reduction in storage systems:
A DEDUPLICATION-INSPIRED FAST DELTA COMPRESSION APPROACH W EN XIA, HONG JIANG, DA N FENG, LEI T I A N, M I N FU, YUKUN Z HOU PRESENTED BY ROMAN SHOR Overview Technics of data reduction in storage systems:
Integrating Flash Memory into the Storage Hierarchy
 Integrating Flash Memory into the Storage Hierarchy A DISSERTATION SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL OF THE UNIVERSITY OF MINNESOTA BY Biplob Kumar Debnath IN PARTIAL FULFILLMENT OF THE REQUIREMENTS
Integrating Flash Memory into the Storage Hierarchy A DISSERTATION SUBMITTED TO THE FACULTY OF THE GRADUATE SCHOOL OF THE UNIVERSITY OF MINNESOTA BY Biplob Kumar Debnath IN PARTIAL FULFILLMENT OF THE REQUIREMENTS
Deduplication Storage System
 Deduplication Storage System Kai Li Charles Fitzmorris Professor, Princeton University & Chief Scientist and Co-Founder, Data Domain, Inc. 03/11/09 The World Is Becoming Data-Centric CERN Tier 0 Business
Deduplication Storage System Kai Li Charles Fitzmorris Professor, Princeton University & Chief Scientist and Co-Founder, Data Domain, Inc. 03/11/09 The World Is Becoming Data-Centric CERN Tier 0 Business
Design Tradeoffs for Data Deduplication Performance in Backup Workloads
 Design Tradeoffs for Data Deduplication Performance in Backup Workloads Min Fu,DanFeng,YuHua,XubinHe, Zuoning Chen *, Wen Xia,YuchengZhang,YujuanTan Huazhong University of Science and Technology Virginia
Design Tradeoffs for Data Deduplication Performance in Backup Workloads Min Fu,DanFeng,YuHua,XubinHe, Zuoning Chen *, Wen Xia,YuchengZhang,YujuanTan Huazhong University of Science and Technology Virginia
Sparse Indexing: Large-Scale, Inline Deduplication Using Sampling and Locality
 Sparse Indexing: Large-Scale, Inline Deduplication Using Sampling and Locality Mark Lillibridge, Kave Eshghi, Deepavali Bhagwat, Vinay Deolalikar, Greg Trezise, and Peter Camble Work done at Hewlett-Packard
Sparse Indexing: Large-Scale, Inline Deduplication Using Sampling and Locality Mark Lillibridge, Kave Eshghi, Deepavali Bhagwat, Vinay Deolalikar, Greg Trezise, and Peter Camble Work done at Hewlett-Packard
Deduplication File System & Course Review
 Deduplication File System & Course Review Kai Li 12/13/13 Topics u Deduplication File System u Review 12/13/13 2 Storage Tiers of A Tradi/onal Data Center $$$$ Mirrored storage $$$ Dedicated Fibre Clients
Deduplication File System & Course Review Kai Li 12/13/13 Topics u Deduplication File System u Review 12/13/13 2 Storage Tiers of A Tradi/onal Data Center $$$$ Mirrored storage $$$ Dedicated Fibre Clients
Scalable and Secure Internet Services and Architecture PRESENTATION REPORT Semester: Winter 2015 Course: ECE 7650
 Scalable and Secure Internet Services and Architecture PRESENTATION REPORT Semester: Winter 2015 Course: ECE 7650 SUBMITTED BY: Yashwanth Boddu fq9316@wayne.edu (1) Our base design uses less than 1 byte
Scalable and Secure Internet Services and Architecture PRESENTATION REPORT Semester: Winter 2015 Course: ECE 7650 SUBMITTED BY: Yashwanth Boddu fq9316@wayne.edu (1) Our base design uses less than 1 byte
Purity: building fast, highly-available enterprise flash storage from commodity components
 Purity: building fast, highly-available enterprise flash storage from commodity components J. Colgrove, J. Davis, J. Hayes, E. Miller, C. Sandvig, R. Sears, A. Tamches, N. Vachharajani, and F. Wang 0 Gala
Purity: building fast, highly-available enterprise flash storage from commodity components J. Colgrove, J. Davis, J. Hayes, E. Miller, C. Sandvig, R. Sears, A. Tamches, N. Vachharajani, and F. Wang 0 Gala
dedupv1: Improving Deduplication Throughput using Solid State Drives (SSD)
") University Paderborn Paderborn Center for Parallel Computing Technical Report dedupv1: Improving Deduplication Throughput using Solid State Drives (SSD) Dirk Meister Paderborn Center for Parallel Computing
University Paderborn Paderborn Center for Parallel Computing Technical Report dedupv1: Improving Deduplication Throughput using Solid State Drives (SSD) Dirk Meister Paderborn Center for Parallel Computing
COS 318: Operating Systems. NSF, Snapshot, Dedup and Review
 COS 318: Operating Systems NSF, Snapshot, Dedup and Review Topics! NFS! Case Study: NetApp File System! Deduplication storage system! Course review 2 Network File System! Sun introduced NFS v2 in early
COS 318: Operating Systems NSF, Snapshot, Dedup and Review Topics! NFS! Case Study: NetApp File System! Deduplication storage system! Course review 2 Network File System! Sun introduced NFS v2 in early
SHHC: A Scalable Hybrid Hash Cluster for Cloud Backup Services in Data Centers
 2011 31st International Conference on Distributed Computing Systems Workshops SHHC: A Scalable Hybrid Hash Cluster for Cloud Backup Services in Data Centers Lei Xu, Jian Hu, Stephen Mkandawire and Hong
2011 31st International Conference on Distributed Computing Systems Workshops SHHC: A Scalable Hybrid Hash Cluster for Cloud Backup Services in Data Centers Lei Xu, Jian Hu, Stephen Mkandawire and Hong
Delta Compressed and Deduplicated Storage Using Stream-Informed Locality
 Delta Compressed and Deduplicated Storage Using Stream-Informed Locality Philip Shilane, Grant Wallace, Mark Huang, and Windsor Hsu Backup Recovery Systems Division EMC Corporation Abstract For backup
Delta Compressed and Deduplicated Storage Using Stream-Informed Locality Philip Shilane, Grant Wallace, Mark Huang, and Windsor Hsu Backup Recovery Systems Division EMC Corporation Abstract For backup
Reducing Replication Bandwidth for Distributed Document Databases
 Reducing Replication Bandwidth for Distributed Document Databases Lianghong Xu Andrew Pavlo Sudipta Sengupta Jin Li Gregory R. Ganger Carnegie Mellon University, Microsoft Research Long Research Paper
Reducing Replication Bandwidth for Distributed Document Databases Lianghong Xu Andrew Pavlo Sudipta Sengupta Jin Li Gregory R. Ganger Carnegie Mellon University, Microsoft Research Long Research Paper
Data Reduction Meets Reality What to Expect From Data Reduction
 Data Reduction Meets Reality What to Expect From Data Reduction Doug Barbian and Martin Murrey Oracle Corporation Thursday August 11, 2011 9961: Data Reduction Meets Reality Introduction Data deduplication
Data Reduction Meets Reality What to Expect From Data Reduction Doug Barbian and Martin Murrey Oracle Corporation Thursday August 11, 2011 9961: Data Reduction Meets Reality Introduction Data deduplication
Reducing Replication Bandwidth for Distributed Document Databases
 Reducing Replication Bandwidth for Distributed Document Databases Lianghong Xu Andrew Pavlo Sudipta Sengupta Jin Li Gregory R. Ganger Carnegie Mellon University, Microsoft Research Abstract With the rise
Reducing Replication Bandwidth for Distributed Document Databases Lianghong Xu Andrew Pavlo Sudipta Sengupta Jin Li Gregory R. Ganger Carnegie Mellon University, Microsoft Research Abstract With the rise
The What, Why and How of the Pure Storage Enterprise Flash Array. Ethan L. Miller (and a cast of dozens at Pure Storage)
") The What, Why and How of the Pure Storage Enterprise Flash Array Ethan L. Miller (and a cast of dozens at Pure Storage) Enterprise storage: $30B market built on disk Key players: EMC, NetApp, HP, etc.
The What, Why and How of the Pure Storage Enterprise Flash Array Ethan L. Miller (and a cast of dozens at Pure Storage) Enterprise storage: $30B market built on disk Key players: EMC, NetApp, HP, etc.
WAN Optimized Replication of Backup Datasets Using Stream-Informed Delta Compression
 WAN Optimized Replication of Backup Datasets Using Stream-Informed Delta Compression Philip Shilane, Mark Huang, Grant Wallace, & Windsor Hsu Backup Recovery Systems Division EMC Corporation Introduction
WAN Optimized Replication of Backup Datasets Using Stream-Informed Delta Compression Philip Shilane, Mark Huang, Grant Wallace, & Windsor Hsu Backup Recovery Systems Division EMC Corporation Introduction
The Logic of Physical Garbage Collection in Deduplicating Storage
 The Logic of Physical Garbage Collection in Deduplicating Storage Fred Douglis Abhinav Duggal Philip Shilane Tony Wong Dell EMC Shiqin Yan University of Chicago Fabiano Botelho Rubrik 1 Deduplication in
The Logic of Physical Garbage Collection in Deduplicating Storage Fred Douglis Abhinav Duggal Philip Shilane Tony Wong Dell EMC Shiqin Yan University of Chicago Fabiano Botelho Rubrik 1 Deduplication in
Parallelizing Inline Data Reduction Operations for Primary Storage Systems
 Parallelizing Inline Data Reduction Operations for Primary Storage Systems Jeonghyeon Ma ( ) and Chanik Park Department of Computer Science and Engineering, POSTECH, Pohang, South Korea {doitnow0415,cipark}@postech.ac.kr
Parallelizing Inline Data Reduction Operations for Primary Storage Systems Jeonghyeon Ma ( ) and Chanik Park Department of Computer Science and Engineering, POSTECH, Pohang, South Korea {doitnow0415,cipark}@postech.ac.kr
Rethinking Deduplication Scalability
 Rethinking Deduplication Scalability Petros Efstathopoulos Petros Efstathopoulos@symantec.com Fanglu Guo Fanglu Guo@symantec.com Symantec Research Labs Symantec Corporation, Culver City, CA, USA 1 ABSTRACT
Rethinking Deduplication Scalability Petros Efstathopoulos Petros Efstathopoulos@symantec.com Fanglu Guo Fanglu Guo@symantec.com Symantec Research Labs Symantec Corporation, Culver City, CA, USA 1 ABSTRACT
Design Tradeoffs for Data Deduplication Performance in Backup Workloads
 Design Tradeoffs for Data Deduplication Performance in Backup Workloads Min Fu, Dan Feng, and Yu Hua, Huazhong University of Science and Technology; Xubin He, Virginia Commonwealth University; Zuoning
Design Tradeoffs for Data Deduplication Performance in Backup Workloads Min Fu, Dan Feng, and Yu Hua, Huazhong University of Science and Technology; Xubin He, Virginia Commonwealth University; Zuoning
BloomStore: Bloom-Filter based Memory-efficient Key-Value Store for Indexing of Data Deduplication on Flash
 BloomStore: Bloom-Filter based Memory-efficient Key-Value Store for Indexing of Data Deduplication on Flash Guanlin Lu EMC 2 Santa Clara, CA Guanlin.Lu@emc.com Young Jin Nam Daegu University Gyeongbuk,
BloomStore: Bloom-Filter based Memory-efficient Key-Value Store for Indexing of Data Deduplication on Flash Guanlin Lu EMC 2 Santa Clara, CA Guanlin.Lu@emc.com Young Jin Nam Daegu University Gyeongbuk,
Azor: Using Two-level Block Selection to Improve SSD-based I/O caches
 Azor: Using Two-level Block Selection to Improve SSD-based I/O caches Yannis Klonatos, Thanos Makatos, Manolis Marazakis, Michail D. Flouris, Angelos Bilas {klonatos, makatos, maraz, flouris, bilas}@ics.forth.gr
Azor: Using Two-level Block Selection to Improve SSD-based I/O caches Yannis Klonatos, Thanos Makatos, Manolis Marazakis, Michail D. Flouris, Angelos Bilas {klonatos, makatos, maraz, flouris, bilas}@ics.forth.gr
Reducing The De-linearization of Data Placement to Improve Deduplication Performance
 Reducing The De-linearization of Data Placement to Improve Deduplication Performance Yujuan Tan 1, Zhichao Yan 2, Dan Feng 2, E. H.-M. Sha 1,3 1 School of Computer Science & Technology, Chongqing University
Reducing The De-linearization of Data Placement to Improve Deduplication Performance Yujuan Tan 1, Zhichao Yan 2, Dan Feng 2, E. H.-M. Sha 1,3 1 School of Computer Science & Technology, Chongqing University
CS3600 SYSTEMS AND NETWORKS
 CS3600 SYSTEMS AND NETWORKS NORTHEASTERN UNIVERSITY Lecture 11: File System Implementation Prof. Alan Mislove (amislove@ccs.neu.edu) File-System Structure File structure Logical storage unit Collection
CS3600 SYSTEMS AND NETWORKS NORTHEASTERN UNIVERSITY Lecture 11: File System Implementation Prof. Alan Mislove (amislove@ccs.neu.edu) File-System Structure File structure Logical storage unit Collection
Lazy Exact Deduplication
 Lazy Exact Deduplication JINGWEI MA, REBECCA J. STONES, YUXIANG MA, JINGUI WANG, JUNJIE REN, GANG WANG, and XIAOGUANG LIU, College of Computer and Control Engineering, Nankai University 11 Deduplication
Lazy Exact Deduplication JINGWEI MA, REBECCA J. STONES, YUXIANG MA, JINGUI WANG, JUNJIE REN, GANG WANG, and XIAOGUANG LIU, College of Computer and Control Engineering, Nankai University 11 Deduplication
Zero-Chunk: An Efficient Cache Algorithm to Accelerate the I/O Processing of Data Deduplication
 2016 IEEE 22nd International Conference on Parallel and Distributed Systems Zero-Chunk: An Efficient Cache Algorithm to Accelerate the I/O Processing of Data Deduplication Hongyuan Gao 1, Chentao Wu 1,
2016 IEEE 22nd International Conference on Parallel and Distributed Systems Zero-Chunk: An Efficient Cache Algorithm to Accelerate the I/O Processing of Data Deduplication Hongyuan Gao 1, Chentao Wu 1,
Understanding Primary Storage Optimization Options Jered Floyd Permabit Technology Corp.
 Understanding Primary Storage Optimization Options Jered Floyd Permabit Technology Corp. Primary Storage Optimization Technologies that let you store more data on the same storage Thin provisioning Copy-on-write
Understanding Primary Storage Optimization Options Jered Floyd Permabit Technology Corp. Primary Storage Optimization Technologies that let you store more data on the same storage Thin provisioning Copy-on-write
NetApp Data Compression, Deduplication, and Data Compaction
 Technical Report NetApp Data Compression, Deduplication, and Data Compaction Data ONTAP 8.3.1 and Later Karthik Viswanath, NetApp February 2018 TR-4476 Abstract This technical report focuses on implementing
Technical Report NetApp Data Compression, Deduplication, and Data Compaction Data ONTAP 8.3.1 and Later Karthik Viswanath, NetApp February 2018 TR-4476 Abstract This technical report focuses on implementing
HPDedup: A Hybrid Prioritized Data Deduplication Mechanism for Primary Storage in the Cloud
 HPDedup: A Hybrid Prioritized Data Deduplication Mechanism for Primary Storage in the Cloud Huijun Wu 1,4, Chen Wang 2, Yinjin Fu 3, Sherif Sakr 1, Liming Zhu 1,2 and Kai Lu 4 The University of New South
HPDedup: A Hybrid Prioritized Data Deduplication Mechanism for Primary Storage in the Cloud Huijun Wu 1,4, Chen Wang 2, Yinjin Fu 3, Sherif Sakr 1, Liming Zhu 1,2 and Kai Lu 4 The University of New South
The Effectiveness of Deduplication on Virtual Machine Disk Images
 The Effectiveness of Deduplication on Virtual Machine Disk Images Keren Jin & Ethan L. Miller Storage Systems Research Center University of California, Santa Cruz Motivation Virtualization is widely deployed
The Effectiveness of Deduplication on Virtual Machine Disk Images Keren Jin & Ethan L. Miller Storage Systems Research Center University of California, Santa Cruz Motivation Virtualization is widely deployed
Can t We All Get Along? Redesigning Protection Storage for Modern Workloads
 Can t We All Get Along? Redesigning Protection Storage for Modern Workloads Yamini Allu, Fred Douglis, Mahesh Kamat, Ramya Prabhakar, Philip Shilane, and Rahul Ugale, Dell EMC https://www.usenix.org/conference/atc18/presentation/allu
Can t We All Get Along? Redesigning Protection Storage for Modern Workloads Yamini Allu, Fred Douglis, Mahesh Kamat, Ramya Prabhakar, Philip Shilane, and Rahul Ugale, Dell EMC https://www.usenix.org/conference/atc18/presentation/allu
DEBAR: A Scalable High-Performance Deduplication Storage System for Backup and Archiving
 University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln CSE Technical reports Computer Science and Engineering, Department of 1-5-29 DEBAR: A Scalable High-Performance Deduplication
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln CSE Technical reports Computer Science and Engineering, Department of 1-5-29 DEBAR: A Scalable High-Performance Deduplication
A study of practical deduplication
 A study of practical deduplication Dutch T. Meyer University of British Columbia Microsoft Research Intern William Bolosky Microsoft Research Why Dutch is Not Here A study of practical deduplication Dutch
A study of practical deduplication Dutch T. Meyer University of British Columbia Microsoft Research Intern William Bolosky Microsoft Research Why Dutch is Not Here A study of practical deduplication Dutch
LSM-trie: An LSM-tree-based Ultra-Large Key-Value Store for Small Data
 LSM-trie: An LSM-tree-based Ultra-Large Key-Value Store for Small Data Xingbo Wu Yuehai Xu Song Jiang Zili Shao The Hong Kong Polytechnic University The Challenge on Today s Key-Value Store Trends on workloads
LSM-trie: An LSM-tree-based Ultra-Large Key-Value Store for Small Data Xingbo Wu Yuehai Xu Song Jiang Zili Shao The Hong Kong Polytechnic University The Challenge on Today s Key-Value Store Trends on workloads
Storage Efficiency Opportunities and Analysis for Video Repositories
 Storage Efficiency Opportunities and Analysis for Video Repositories Suganthi Dewakar Sethuraman Subbiah Gokul Soundararajan Mike Wilson Mark W. Storer Box Inc. Kishore Udayashankar Exablox Kaladhar Voruganti
Storage Efficiency Opportunities and Analysis for Video Repositories Suganthi Dewakar Sethuraman Subbiah Gokul Soundararajan Mike Wilson Mark W. Storer Box Inc. Kishore Udayashankar Exablox Kaladhar Voruganti
SILT: A Memory-Efficient, High- Performance Key-Value Store
 SILT: A Memory-Efficient, High- Performance Key-Value Store SOSP 11 Presented by Fan Ni March, 2016 SILT is Small Index Large Tables which is a memory efficient high performance key value store system
SILT: A Memory-Efficient, High- Performance Key-Value Store SOSP 11 Presented by Fan Ni March, 2016 SILT is Small Index Large Tables which is a memory efficient high performance key value store system
Improving throughput for small disk requests with proximal I/O
 Improving throughput for small disk requests with proximal I/O Jiri Schindler with Sandip Shete & Keith A. Smith Advanced Technology Group 2/16/2011 v.1.3 Important Workload in Datacenters Serial reads
Improving throughput for small disk requests with proximal I/O Jiri Schindler with Sandip Shete & Keith A. Smith Advanced Technology Group 2/16/2011 v.1.3 Important Workload in Datacenters Serial reads
Flashed-Optimized VPSA. Always Aligned with your Changing World
 Flashed-Optimized VPSA Always Aligned with your Changing World Yair Hershko Co-founder, VP Engineering, Zadara Storage 3 Modern Data Storage for Modern Computing Innovating data services to meet modern
Flashed-Optimized VPSA Always Aligned with your Changing World Yair Hershko Co-founder, VP Engineering, Zadara Storage 3 Modern Data Storage for Modern Computing Innovating data services to meet modern
Using Transparent Compression to Improve SSD-based I/O Caches
 Using Transparent Compression to Improve SSD-based I/O Caches Thanos Makatos, Yannis Klonatos, Manolis Marazakis, Michail D. Flouris, and Angelos Bilas {mcatos,klonatos,maraz,flouris,bilas}@ics.forth.gr
Using Transparent Compression to Improve SSD-based I/O Caches Thanos Makatos, Yannis Klonatos, Manolis Marazakis, Michail D. Flouris, and Angelos Bilas {mcatos,klonatos,maraz,flouris,bilas}@ics.forth.gr
Contents Part I Traditional Deduplication Techniques and Solutions Introduction Existing Deduplication Techniques
 Contents Part I Traditional Deduplication Techniques and Solutions 1 Introduction... 3 1.1 Data Explosion... 3 1.2 Redundancies... 4 1.3 Existing Deduplication Solutions to Remove Redundancies... 5 1.4
Contents Part I Traditional Deduplication Techniques and Solutions 1 Introduction... 3 1.1 Data Explosion... 3 1.2 Redundancies... 4 1.3 Existing Deduplication Solutions to Remove Redundancies... 5 1.4
Accelerating Restore and Garbage Collection in Deduplication-based Backup Systems via Exploiting Historical Information
 Accelerating Restore and Garbage Collection in Deduplication-based Backup Systems via Exploiting Historical Information Min Fu, Dan Feng, Yu Hua, Xubin He, Zuoning Chen *, Wen Xia, Fangting Huang, Qing
Accelerating Restore and Garbage Collection in Deduplication-based Backup Systems via Exploiting Historical Information Min Fu, Dan Feng, Yu Hua, Xubin He, Zuoning Chen *, Wen Xia, Fangting Huang, Qing
In-line Deduplication for Cloud storage to Reduce Fragmentation by using Historical Knowledge
 In-line Deduplication for Cloud storage to Reduce Fragmentation by using Historical Knowledge Smitha.M. S, Prof. Janardhan Singh Mtech Computer Networking, Associate Professor Department of CSE, Cambridge
In-line Deduplication for Cloud storage to Reduce Fragmentation by using Historical Knowledge Smitha.M. S, Prof. Janardhan Singh Mtech Computer Networking, Associate Professor Department of CSE, Cambridge
International Journal of Computer Engineering and Applications, Volume XII, Special Issue, March 18, ISSN
 International Journal of Computer Engineering and Applications, Volume XII, Special Issue, March 18, www.ijcea.com ISSN 2321-3469 SECURE DATA DEDUPLICATION FOR CLOUD STORAGE: A SURVEY Vidya Kurtadikar
International Journal of Computer Engineering and Applications, Volume XII, Special Issue, March 18, www.ijcea.com ISSN 2321-3469 SECURE DATA DEDUPLICATION FOR CLOUD STORAGE: A SURVEY Vidya Kurtadikar
DASH COPY GUIDE. Published On: 11/19/2013 V10 Service Pack 4A Page 1 of 31
 DASH COPY GUIDE Published On: 11/19/2013 V10 Service Pack 4A Page 1 of 31 DASH Copy Guide TABLE OF CONTENTS OVERVIEW GETTING STARTED ADVANCED BEST PRACTICES FAQ TROUBLESHOOTING DASH COPY PERFORMANCE TUNING
DASH COPY GUIDE Published On: 11/19/2013 V10 Service Pack 4A Page 1 of 31 DASH Copy Guide TABLE OF CONTENTS OVERVIEW GETTING STARTED ADVANCED BEST PRACTICES FAQ TROUBLESHOOTING DASH COPY PERFORMANCE TUNING
PS2 out today. Lab 2 out today. Lab 1 due today - how was it?
 6.830 Lecture 7 9/25/2017 PS2 out today. Lab 2 out today. Lab 1 due today - how was it? Project Teams Due Wednesday Those of you who don't have groups -- send us email, or hand in a sheet with just your
6.830 Lecture 7 9/25/2017 PS2 out today. Lab 2 out today. Lab 1 due today - how was it? Project Teams Due Wednesday Those of you who don't have groups -- send us email, or hand in a sheet with just your
FGDEFRAG: A Fine-Grained Defragmentation Approach to Improve Restore Performance
 FGDEFRAG: A Fine-Grained Defragmentation Approach to Improve Restore Performance Yujuan Tan, Jian Wen, Zhichao Yan, Hong Jiang, Witawas Srisa-an, Baiping Wang, Hao Luo Outline Background and Motivation
FGDEFRAG: A Fine-Grained Defragmentation Approach to Improve Restore Performance Yujuan Tan, Jian Wen, Zhichao Yan, Hong Jiang, Witawas Srisa-an, Baiping Wang, Hao Luo Outline Background and Motivation
SSDs in the Cloud Dave Wright, CEO SolidFire, Inc.
 SSDs in the Cloud Dave Wright, CEO SolidFire, Inc. Storage in the Cloud Local Storage Swap Temp Files Data Processing WD Seagate FusionIO Bulk Object Storage Media Files Content Distribution Backup Archival
SSDs in the Cloud Dave Wright, CEO SolidFire, Inc. Storage in the Cloud Local Storage Swap Temp Files Data Processing WD Seagate FusionIO Bulk Object Storage Media Files Content Distribution Backup Archival
C has been and will always remain on top for performancecritical
 Check out this link: http://spectrum.ieee.org/static/interactive-the-top-programminglanguages-2016 C has been and will always remain on top for performancecritical applications: Implementing: Databases
Check out this link: http://spectrum.ieee.org/static/interactive-the-top-programminglanguages-2016 C has been and will always remain on top for performancecritical applications: Implementing: Databases
Introducing Tegile. Company Overview. Product Overview. Solutions & Use Cases. Partnering with Tegile
 Tegile Systems 1 Introducing Tegile Company Overview Product Overview Solutions & Use Cases Partnering with Tegile 2 Company Overview Company Overview Te gile - [tey-jile] Tegile = technology + agile Founded
Tegile Systems 1 Introducing Tegile Company Overview Product Overview Solutions & Use Cases Partnering with Tegile 2 Company Overview Company Overview Te gile - [tey-jile] Tegile = technology + agile Founded
White paper ETERNUS CS800 Data Deduplication Background
 White paper ETERNUS CS800 - Data Deduplication Background This paper describes the process of Data Deduplication inside of ETERNUS CS800 in detail. The target group consists of presales, administrators,
White paper ETERNUS CS800 - Data Deduplication Background This paper describes the process of Data Deduplication inside of ETERNUS CS800 in detail. The target group consists of presales, administrators,
Database Architecture 2 & Storage. Instructor: Matei Zaharia cs245.stanford.edu
 Database Architecture 2 & Storage Instructor: Matei Zaharia cs245.stanford.edu Summary from Last Time System R mostly matched the architecture of a modern RDBMS» SQL» Many storage & access methods» Cost-based
Database Architecture 2 & Storage Instructor: Matei Zaharia cs245.stanford.edu Summary from Last Time System R mostly matched the architecture of a modern RDBMS» SQL» Many storage & access methods» Cost-based
Cheap and Large CAMs for High Performance Data-Intensive Networked Systems- The Bufferhash KV Store
 Cheap and Large CAMs for High Performance Data-Intensive Networked Systems- The Bufferhash KV Store Presented by Akhila Nookala M.S EE Wayne State University ECE7650 Scalable and Secure Internet Services
Cheap and Large CAMs for High Performance Data-Intensive Networked Systems- The Bufferhash KV Store Presented by Akhila Nookala M.S EE Wayne State University ECE7650 Scalable and Secure Internet Services
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 25 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Q 2 Data and Metadata
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 25 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Q 2 Data and Metadata
Distributed caching for cloud computing
 Distributed caching for cloud computing Maxime Lorrillere, Julien Sopena, Sébastien Monnet et Pierre Sens February 11, 2013 Maxime Lorrillere (LIP6/UPMC/CNRS) February 11, 2013 1 / 16 Introduction Context
Distributed caching for cloud computing Maxime Lorrillere, Julien Sopena, Sébastien Monnet et Pierre Sens February 11, 2013 Maxime Lorrillere (LIP6/UPMC/CNRS) February 11, 2013 1 / 16 Introduction Context
HICAMP Bitmap. A Space-Efficient Updatable Bitmap Index for In-Memory Databases! Bo Wang, Heiner Litz, David R. Cheriton Stanford University DAMON 14
 HICAMP Bitmap A Space-Efficient Updatable Bitmap Index for In-Memory Databases! Bo Wang, Heiner Litz, David R. Cheriton Stanford University DAMON 14 Database Indexing Databases use precomputed indexes
HICAMP Bitmap A Space-Efficient Updatable Bitmap Index for In-Memory Databases! Bo Wang, Heiner Litz, David R. Cheriton Stanford University DAMON 14 Database Indexing Databases use precomputed indexes
Main Memory (Part II)
") Main Memory (Part II) Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Main Memory 1393/8/17 1 / 50 Reminder Amir H. Payberah
Main Memory (Part II) Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Main Memory 1393/8/17 1 / 50 Reminder Amir H. Payberah
CSE 4/521 Introduction to Operating Systems. Lecture 23 File System Implementation II (Allocation Methods, Free-Space Management) Summer 2018
 Summer 2018") CSE 4/521 Introduction to Operating Systems Lecture 23 File System Implementation II (Allocation Methods, Free-Space Management) Summer 2018 Overview Objective: To discuss how the disk is managed for a
CSE 4/521 Introduction to Operating Systems Lecture 23 File System Implementation II (Allocation Methods, Free-Space Management) Summer 2018 Overview Objective: To discuss how the disk is managed for a
Disks and Files. Storage Structures Introduction Chapter 8 (3 rd edition) Why Not Store Everything in Main Memory?
 Why Not Store Everything in Main Memory?") Why Not Store Everything in Main Memory? Storage Structures Introduction Chapter 8 (3 rd edition) Sharma Chakravarthy UT Arlington sharma@cse.uta.edu base Management Systems: Sharma Chakravarthy Costs
Why Not Store Everything in Main Memory? Storage Structures Introduction Chapter 8 (3 rd edition) Sharma Chakravarthy UT Arlington sharma@cse.uta.edu base Management Systems: Sharma Chakravarthy Costs
System and Algorithmic Adaptation for Flash
 System and Algorithmic Adaptation for Flash The FAWN Perspective David G. Andersen, Vijay Vasudevan, Michael Kaminsky* Amar Phanishayee, Jason Franklin, Iulian Moraru, Lawrence Tan Carnegie Mellon University
System and Algorithmic Adaptation for Flash The FAWN Perspective David G. Andersen, Vijay Vasudevan, Michael Kaminsky* Amar Phanishayee, Jason Franklin, Iulian Moraru, Lawrence Tan Carnegie Mellon University
An Application Awareness Local Source and Global Source De-Duplication with Security in resource constraint based Cloud backup services
 An Application Awareness Local Source and Global Source De-Duplication with Security in resource constraint based Cloud backup services S.Meghana Assistant Professor, Dept. of IT, Vignana Bharathi Institute
An Application Awareness Local Source and Global Source De-Duplication with Security in resource constraint based Cloud backup services S.Meghana Assistant Professor, Dept. of IT, Vignana Bharathi Institute
CHAPTER 11: IMPLEMENTING FILE SYSTEMS (COMPACT) By I-Chen Lin Textbook: Operating System Concepts 9th Ed.
 By I-Chen Lin Textbook: Operating System Concepts 9th Ed.") CHAPTER 11: IMPLEMENTING FILE SYSTEMS (COMPACT) By I-Chen Lin Textbook: Operating System Concepts 9th Ed. File-System Structure File structure Logical storage unit Collection of related information File
CHAPTER 11: IMPLEMENTING FILE SYSTEMS (COMPACT) By I-Chen Lin Textbook: Operating System Concepts 9th Ed. File-System Structure File structure Logical storage unit Collection of related information File
NVMFS: A New File System Designed Specifically to Take Advantage of Nonvolatile Memory
 NVMFS: A New File System Designed Specifically to Take Advantage of Nonvolatile Memory Dhananjoy Das, Sr. Systems Architect SanDisk Corp. 1 Agenda: Applications are KING! Storage landscape (Flash / NVM)
NVMFS: A New File System Designed Specifically to Take Advantage of Nonvolatile Memory Dhananjoy Das, Sr. Systems Architect SanDisk Corp. 1 Agenda: Applications are KING! Storage landscape (Flash / NVM)
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
A Scalable Inline Cluster Deduplication Framework for Big Data Protection
 University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln CSE Technical reports Computer Science and Engineering, Department of Summer 5-30-2012 A Scalable Inline Cluster Deduplication
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln CSE Technical reports Computer Science and Engineering, Department of Summer 5-30-2012 A Scalable Inline Cluster Deduplication
RPE: The Art of Data Deduplication
 RPE: The Art of Data Deduplication Dilip Simha Advisor: Professor Tzi-cker Chiueh Committee advisors: Professor Erez Zadok & Professor Donald Porter Department of Computer Science, StonyBrook University
RPE: The Art of Data Deduplication Dilip Simha Advisor: Professor Tzi-cker Chiueh Committee advisors: Professor Erez Zadok & Professor Donald Porter Department of Computer Science, StonyBrook University
Deduplication and Incremental Accelleration in Bacula with NetApp Technologies. Peter Buschman EMEA PS Consultant September 25th, 2012
 Deduplication and Incremental Accelleration in Bacula with NetApp Technologies Peter Buschman EMEA PS Consultant September 25th, 2012 1 NetApp and Bacula Systems Bacula Systems became a NetApp Developer
Deduplication and Incremental Accelleration in Bacula with NetApp Technologies Peter Buschman EMEA PS Consultant September 25th, 2012 1 NetApp and Bacula Systems Bacula Systems became a NetApp Developer
LEVERAGING FLASH MEMORY in ENTERPRISE STORAGE
 LEVERAGING FLASH MEMORY in ENTERPRISE STORAGE Luanne Dauber, Pure Storage Author: Matt Kixmoeller, Pure Storage SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless
LEVERAGING FLASH MEMORY in ENTERPRISE STORAGE Luanne Dauber, Pure Storage Author: Matt Kixmoeller, Pure Storage SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless
Data Storage and Query Answering. Data Storage and Disk Structure (2)
") Data Storage and Query Answering Data Storage and Disk Structure (2) Review: The Memory Hierarchy Swapping, Main-memory DBMS s Tertiary Storage: Tape, Network Backup 3,200 MB/s (DDR-SDRAM @200MHz) 6,400
Data Storage and Query Answering Data Storage and Disk Structure (2) Review: The Memory Hierarchy Swapping, Main-memory DBMS s Tertiary Storage: Tape, Network Backup 3,200 MB/s (DDR-SDRAM @200MHz) 6,400
Alternative Approaches for Deduplication in Cloud Storage Environment
 International Journal of Computational Intelligence Research ISSN 0973-1873 Volume 13, Number 10 (2017), pp. 2357-2363 Research India Publications http://www.ripublication.com Alternative Approaches for
International Journal of Computational Intelligence Research ISSN 0973-1873 Volume 13, Number 10 (2017), pp. 2357-2363 Research India Publications http://www.ripublication.com Alternative Approaches for
SoftNAS Cloud Performance Evaluation on AWS
 SoftNAS Cloud Performance Evaluation on AWS October 25, 2016 Contents SoftNAS Cloud Overview... 3 Introduction... 3 Executive Summary... 4 Key Findings for AWS:... 5 Test Methodology... 6 Performance Summary
SoftNAS Cloud Performance Evaluation on AWS October 25, 2016 Contents SoftNAS Cloud Overview... 3 Introduction... 3 Executive Summary... 4 Key Findings for AWS:... 5 Test Methodology... 6 Performance Summary
UCS Invicta: A New Generation of Storage Performance. Mazen Abou Najm DC Consulting Systems Engineer
 UCS Invicta: A New Generation of Storage Performance Mazen Abou Najm DC Consulting Systems Engineer HDDs Aren t Designed For High Performance Disk 101 Can t spin faster (200 IOPS/Drive) Can t seek faster
UCS Invicta: A New Generation of Storage Performance Mazen Abou Najm DC Consulting Systems Engineer HDDs Aren t Designed For High Performance Disk 101 Can t spin faster (200 IOPS/Drive) Can t seek faster
Banshee: Bandwidth-Efficient DRAM Caching via Software/Hardware Cooperation!
 Banshee: Bandwidth-Efficient DRAM Caching via Software/Hardware Cooperation! Xiangyao Yu 1, Christopher Hughes 2, Nadathur Satish 2, Onur Mutlu 3, Srinivas Devadas 1 1 MIT 2 Intel Labs 3 ETH Zürich 1 High-Bandwidth
Banshee: Bandwidth-Efficient DRAM Caching via Software/Hardware Cooperation! Xiangyao Yu 1, Christopher Hughes 2, Nadathur Satish 2, Onur Mutlu 3, Srinivas Devadas 1 1 MIT 2 Intel Labs 3 ETH Zürich 1 High-Bandwidth
File system internals Tanenbaum, Chapter 4. COMP3231 Operating Systems
 File system internals Tanenbaum, Chapter 4 COMP3231 Operating Systems Architecture of the OS storage stack Application File system: Hides physical location of data on the disk Exposes: directory hierarchy,
File system internals Tanenbaum, Chapter 4 COMP3231 Operating Systems Architecture of the OS storage stack Application File system: Hides physical location of data on the disk Exposes: directory hierarchy,
Improving Backup and Restore Performance for Deduplication-based Cloud Backup Services
 University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Computer Science and Engineering: Theses, Dissertations, and Student Research Computer Science and Engineering, Department
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Computer Science and Engineering: Theses, Dissertations, and Student Research Computer Science and Engineering, Department
I-CASH: Intelligently Coupled Array of SSD and HDD
 : Intelligently Coupled Array of SSD and HDD Jin Ren and Qing Yang Dept. of Electrical, Computer, and Biomedical Engineering University of Rhode Island, Kingston, RI 02881 (rjin,qyang)@ele.uri.edu Abstract
: Intelligently Coupled Array of SSD and HDD Jin Ren and Qing Yang Dept. of Electrical, Computer, and Biomedical Engineering University of Rhode Island, Kingston, RI 02881 (rjin,qyang)@ele.uri.edu Abstract
SoftNAS Cloud Performance Evaluation on Microsoft Azure
 SoftNAS Cloud Performance Evaluation on Microsoft Azure November 30, 2016 Contents SoftNAS Cloud Overview... 3 Introduction... 3 Executive Summary... 4 Key Findings for Azure:... 5 Test Methodology...
SoftNAS Cloud Performance Evaluation on Microsoft Azure November 30, 2016 Contents SoftNAS Cloud Overview... 3 Introduction... 3 Executive Summary... 4 Key Findings for Azure:... 5 Test Methodology...
P-Dedupe: Exploiting Parallelism in Data Deduplication System
 2012 IEEE Seventh International Conference on Networking, Architecture, and Storage P-Dedupe: Exploiting Parallelism in Data Deduplication System Wen Xia, Hong Jiang, Dan Feng,*, Lei Tian, Min Fu, Zhongtao
2012 IEEE Seventh International Conference on Networking, Architecture, and Storage P-Dedupe: Exploiting Parallelism in Data Deduplication System Wen Xia, Hong Jiang, Dan Feng,*, Lei Tian, Min Fu, Zhongtao
DEC: An Efficient Deduplication-Enhanced Compression Approach
 2016 IEEE 22nd International Conference on Parallel and Distributed Systems DEC: An Efficient Deduplication-Enhanced Compression Approach Zijin Han, Wen Xia, Yuchong Hu *, Dan Feng, Yucheng Zhang, Yukun
2016 IEEE 22nd International Conference on Parallel and Distributed Systems DEC: An Efficient Deduplication-Enhanced Compression Approach Zijin Han, Wen Xia, Yuchong Hu *, Dan Feng, Yucheng Zhang, Yukun
Application-Aware Big Data Deduplication in Cloud Environment
 IEEE TRANSACTIONS ON CLOUD COMPUTING 1 Application-Aware Big Data Deduplication in Cloud Environment Yinjin Fu, Nong Xiao, Hong Jiang, Fellow, IEEE, Guyu Hu, and Weiwei Chen Abstract Deduplication has
IEEE TRANSACTIONS ON CLOUD COMPUTING 1 Application-Aware Big Data Deduplication in Cloud Environment Yinjin Fu, Nong Xiao, Hong Jiang, Fellow, IEEE, Guyu Hu, and Weiwei Chen Abstract Deduplication has
Efficient Deduplication Techniques for Modern Backup Operation
 824 IEEE TRANSACTIONS ON COMPUTERS, VOL. 60, NO. 6, JUNE 2011 Efficient Deduplication Techniques for Modern Backup Operation Jaehong Min, Daeyoung Yoon, and Youjip Won Abstract In this work, we focus on
824 IEEE TRANSACTIONS ON COMPUTERS, VOL. 60, NO. 6, JUNE 2011 Efficient Deduplication Techniques for Modern Backup Operation Jaehong Min, Daeyoung Yoon, and Youjip Won Abstract In this work, we focus on
Online Deduplication for Databases
 Online Deduplication for Databases ABSTRACT Lianghong Xu Carnegie Mellon University lianghon@andrew.cmu.edu Sudipta Sengupta Microsoft Research sudipta@microsoft.com is a similarity-based deduplication
Online Deduplication for Databases ABSTRACT Lianghong Xu Carnegie Mellon University lianghon@andrew.cmu.edu Sudipta Sengupta Microsoft Research sudipta@microsoft.com is a similarity-based deduplication
Solid State Storage Technologies. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Solid State Storage Technologies Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu NVMe (1) NVM Express (NVMe) For accessing PCIe-based SSDs Bypass
Solid State Storage Technologies Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu NVMe (1) NVM Express (NVMe) For accessing PCIe-based SSDs Bypass
Operating Systems. Lecture File system implementation. Master of Computer Science PUF - Hồ Chí Minh 2016/2017
 Operating Systems Lecture 7.2 - File system implementation Adrien Krähenbühl Master of Computer Science PUF - Hồ Chí Minh 2016/2017 Design FAT or indexed allocation? UFS, FFS & Ext2 Journaling with Ext3
Operating Systems Lecture 7.2 - File system implementation Adrien Krähenbühl Master of Computer Science PUF - Hồ Chí Minh 2016/2017 Design FAT or indexed allocation? UFS, FFS & Ext2 Journaling with Ext3
TIBX NEXT-GENERATION ARCHIVE FORMAT IN ACRONIS BACKUP CLOUD
 TIBX NEXT-GENERATION ARCHIVE FORMAT IN ACRONIS BACKUP CLOUD 1 Backup Speed and Reliability Are the Top Data Protection Mandates What are the top data protection mandates from your organization s IT leadership?
TIBX NEXT-GENERATION ARCHIVE FORMAT IN ACRONIS BACKUP CLOUD 1 Backup Speed and Reliability Are the Top Data Protection Mandates What are the top data protection mandates from your organization s IT leadership?
MIGRATORY COMPRESSION Coarse-grained Data Reordering to Improve Compressibility
 MIGRATORY COMPRESSION Coarse-grained Data Reordering to Improve Compressibility Xing Lin *, Guanlin Lu, Fred Douglis, Philip Shilane, Grant Wallace * University of Utah EMC Corporation Data Protection
MIGRATORY COMPRESSION Coarse-grained Data Reordering to Improve Compressibility Xing Lin *, Guanlin Lu, Fred Douglis, Philip Shilane, Grant Wallace * University of Utah EMC Corporation Data Protection
Chapter 12: File System Implementation
 Chapter 12: File System Implementation Silberschatz, Galvin and Gagne 2013 Chapter 12: File System Implementation File-System Structure File-System Implementation Allocation Methods Free-Space Management
Chapter 12: File System Implementation Silberschatz, Galvin and Gagne 2013 Chapter 12: File System Implementation File-System Structure File-System Implementation Allocation Methods Free-Space Management
Presented by: Nafiseh Mahmoudi Spring 2017
 Presented by: Nafiseh Mahmoudi Spring 2017 Authors: Publication: Type: ACM Transactions on Storage (TOS), 2016 Research Paper 2 High speed data processing demands high storage I/O performance. Flash memory
Presented by: Nafiseh Mahmoudi Spring 2017 Authors: Publication: Type: ACM Transactions on Storage (TOS), 2016 Research Paper 2 High speed data processing demands high storage I/O performance. Flash memory
DBMS Data Loading: An Analysis on Modern Hardware. Adam Dziedzic, Manos Karpathiotakis*, Ioannis Alagiannis, Raja Appuswamy, Anastasia Ailamaki
 DBMS Data Loading: An Analysis on Modern Hardware Adam Dziedzic, Manos Karpathiotakis*, Ioannis Alagiannis, Raja Appuswamy, Anastasia Ailamaki Data loading: A necessary evil Volume => Expensive 4 zettabytes
DBMS Data Loading: An Analysis on Modern Hardware Adam Dziedzic, Manos Karpathiotakis*, Ioannis Alagiannis, Raja Appuswamy, Anastasia Ailamaki Data loading: A necessary evil Volume => Expensive 4 zettabytes
Che-Wei Chang Department of Computer Science and Information Engineering, Chang Gung University
 Che-Wei Chang chewei@mail.cgu.edu.tw Department of Computer Science and Information Engineering, Chang Gung University Chapter 10: File System Chapter 11: Implementing File-Systems Chapter 12: Mass-Storage
Che-Wei Chang chewei@mail.cgu.edu.tw Department of Computer Science and Information Engineering, Chang Gung University Chapter 10: File System Chapter 11: Implementing File-Systems Chapter 12: Mass-Storage
Functional Partitioning to Optimize End-to-End Performance on Many-core Architectures
 Functional Partitioning to Optimize End-to-End Performance on Many-core Architectures Min Li, Sudharshan S. Vazhkudai, Ali R. Butt, Fei Meng, Xiaosong Ma, Youngjae Kim,Christian Engelmann, and Galen Shipman
Functional Partitioning to Optimize End-to-End Performance on Many-core Architectures Min Li, Sudharshan S. Vazhkudai, Ali R. Butt, Fei Meng, Xiaosong Ma, Youngjae Kim,Christian Engelmann, and Galen Shipman
Benefits of Storage Capacity Optimization Methods (COMs) And. Performance Optimization Methods (POMs)
 And. Performance Optimization Methods (POMs)") Benefits of Storage Capacity Optimization Methods (COMs) And Performance Optimization Methods (POMs) Herb Tanzer & Chuck Paridon Storage Product & Storage Performance Architects Hewlett Packard Enterprise
Benefits of Storage Capacity Optimization Methods (COMs) And Performance Optimization Methods (POMs) Herb Tanzer & Chuck Paridon Storage Product & Storage Performance Architects Hewlett Packard Enterprise
Chapter 12: Query Processing
 Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Basic Steps in Query Processing 1. Parsing and translation 2. Optimization 3. Evaluation 12.2
Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Basic Steps in Query Processing 1. Parsing and translation 2. Optimization 3. Evaluation 12.2
April 2010 Rosen Shingle Creek Resort Orlando, Florida
 Data Reduction and File Systems Jeffrey Tofano Chief Technical Officer, Quantum Corporation Today s Agenda File Systems and Data Reduction Overview File System and Data Reduction Integration Issues Reviewing
Data Reduction and File Systems Jeffrey Tofano Chief Technical Officer, Quantum Corporation Today s Agenda File Systems and Data Reduction Overview File System and Data Reduction Integration Issues Reviewing
Memory management. Last modified: Adaptation of Silberschatz, Galvin, Gagne slides for the textbook Applied Operating Systems Concepts
 Memory management Last modified: 26.04.2016 1 Contents Background Logical and physical address spaces; address binding Overlaying, swapping Contiguous Memory Allocation Segmentation Paging Structure of
Memory management Last modified: 26.04.2016 1 Contents Background Logical and physical address spaces; address binding Overlaying, swapping Contiguous Memory Allocation Segmentation Paging Structure of
SMORE: A Cold Data Object Store for SMR Drives
 SMORE: A Cold Data Object Store for SMR Drives Peter Macko, Xiongzi Ge, John Haskins Jr.*, James Kelley, David Slik, Keith A. Smith, and Maxim G. Smith Advanced Technology Group NetApp, Inc. * Qualcomm
SMORE: A Cold Data Object Store for SMR Drives Peter Macko, Xiongzi Ge, John Haskins Jr.*, James Kelley, David Slik, Keith A. Smith, and Maxim G. Smith Advanced Technology Group NetApp, Inc. * Qualcomm