OpenFOAM + GPGPU. İbrahim Özküçük
|
|
|
- David Palmer
- 6 years ago
- Views:
Transcription
1 OpenFOAM + GPGPU İbrahim Özküçük
2 Outline GPGPU vs CPU GPGPU plugins for OpenFOAM Overview of Discretization CUDA for FOAM Link (cufflink) Cusp & Thrust Libraries How Cufflink Works Performance data of Cufflink solvers CUDA Solvers in foam-extend-3.0 Considerations about future Linear System Solvers in OpenFOAM 2


3 GPGPU vs CPU Taken from reference (1) 3


4 GPGPU vs CPU Taken from reference (1) 4
5 OpenFOAM GPGPU Solvers SpeedIT Plugin to OpenFOAM - Conjugate Gradient & BiConjugate Gradient Further ofgpu, GPU Linear Solvers for OpenFOAM Further Culises - GPU power for OpenFOAM Further 5
6 Overview of Discretization The term discretization means approximation of a problem into discrete quantities. The FV method and others, such as the finite element and finite difference methods, all discretize the problem as follows: Spatial discretization Defining the solution domain by a set of points that fill and bound a region of space when connected; Temporal discretization (For transient problems) dividing the time domain into into a finite number of time intervals, or steps; Equation discretization Generating a system of algebraic equations in terms of discrete quantities defined at specific locations in the domain, from the PDEs that characterize the problem. 6
7 Linear System Solvers in OpenFOAM PBiCG - preconditioned bi-conjugate gradient solver for asymmetric matrices; PCG - preconditioned conjugate gradient solver for symmetric matrices; GAMG - generalized geometric-algebraic multi-grid solver smoothsolver - solver using a smoother for both symmetric and asymmetric matrices diagonalsolver - diagonal solver for both symmetric and asymmetric matrices 7
8 Linear System Solvers in OpenFOAM Preconditioners Diagonal incomplete-cholesky (DIC) Diagonal incomplete LU (DILU) GAMG preconditioner Smoothers Diagonal incomplete-cholesky (DIC) Diagonal incomplete LU (DILU) Gauss-Seidel Variants of DIC and DILU exist with additional Gauss-Seidel smoothing 8
9 Interface for Linear System Solvers OpenFOAM GPGPU Linear ldumatrix Class A b System Solver =? A x b x_solution 9
10 CUDA for FOAM Link (cufflink) Cuda For FOAM Link (cufflink) is an open-source library for linking numerical methods based on Nvidia's Compute Unified Device Architecture (CUDA ) C/C++ programming language and OpenFOAM. Currently, the library utilizes the sparse linear solvers of Cusp and methods from Thrust to solve the linear Ax = b system derived from OpenFOAM's ldumatrix class and return the solution vector. Cufflink is designed to utilize the course-grained parallelism of OpenFOAM (via domain decomposition) to allow multi-gpu parallelism at the level of the linear system solver. Currently only supports the OpenFOAM-extend fork of the OpenFOAM code. 10
11 CUSP A C++ Templated Sparse Matrix Library cusp-library Cusp is a library for sparse linear algebra and graph computations on CUDA. Cusp provides a flexible, high-level interface for manipulating sparse matrices and solving sparse linear systems. [2] Provided Template Solvers: (Bi-) Conjugate Gradient (-Stabilized) GMRES Matrix Storage CSR, COO, HYB, DIA Provided Preconditioners Jacobi (diagonal) preconditioners Sparse Approximate inverse preconditioner Smoothed-Aggregation Algebraic Multigrid preconditioner 11


12 Thrust Thrust is a CUDA library of parallel algorithms with an interface resembling the C++ Standard Template Library (STL). Thrust provides a flexible high-levelinterface for GPU programming that greatly enhances developer productivity. [3] 12
13 How Cufflink Works OpenFOAM ldumatrix Class Thrust Methods = A x b Cusp Solver on GPU = A x b Cusp Methods 13
14 How Cufflink Works OpenFOAM ldumatrix Class = Thrust Methods thrust::copy method converts ldumatrix data into COO format. A x b Cusp Solver on GPU = A x b Cusp Methods 14
15 How Cufflink Works OpenFOAM ldumatrix Class = Thrust Methods thrust::copy method converts ldumatrix data into COO format. A x b Data in COO format is transfered to GPU memory by using CUDA code. Cusp Solver on GPU = A x b Cusp Methods 15
16 How Cufflink Works OpenFOAM ldumatrix Class = Thrust Methods thrust::copy method converts ldumatrix data into COO format. A x b Data in COO format is transfered to GPU memory by using CUDA code. Cusp Solver on GPU = Data in COO format is changed into different formats in GPU and passed into CUSPbased solver along with a convergence criteria A x b Cusp Methods 16
17 How Cufflink Works OpenFOAM ldumatrix Class = Thrust Methods thrust::copy method converts ldumatrix data into COO format. A x b Cusp Solver on GPU = A x b Data in COO format is transfered to GPU memory by using CUDA code. Data in COO format is changed into different formats in GPU and passed into CUSPbased solver along with a convergence criteria Residuals are calculated based on OpenFOAM s normalized residual method Cusp Methods 17
18 How Cufflink Works OpenFOAM ldumatrix Class Thrust Methods = A x b Pass X solution vector back to OpenFOAM by using thrust methods along with GPU solver performance data. Cusp Solver on GPU = A x b 18
19 Current Cufflink Solvers cufflink_ainvpbicgstab cufflink_ainvpcg cufflink_cg cufflink_diagpbicgstab These solvers also have their parallel versions which works in multi-gpu setups by using OpenFOAM s domain decomposition methods. cufflink_diagpcg cufflink_smapcg 19

20 Performance Data taken from Optimization, HPC, and Pre- and Post-Processing I Session. 6th OpenFOAM Workshop Penn State University. June 15th 2011 Preliminary Results A test Problem. 2D Heat Equation 2 T = 0 Vary N from where N 2 = ncells 20
21 Performance Data taken from Optimization, HPC, and Pre- and Post-Processing I Session. 6th OpenFOAM Workshop Penn State University. June 15th 2011 Preliminary Results Solver Settings All CG solvers Tolerance = 1e-10; MaxIter 1000; solver GAMG; tolerance 1e-10; smoother GaussSeidel; npresweeps 0; npostsweeps 2; cacheagglomeration true; ncellsincoarsestlevel sqrt(ncells); agglomerator faceareapair; mergelevels 1; 21
22 Performance Data taken from Optimization, HPC, and Pre- and Post-Processing I Session. 6th OpenFOAM Workshop Penn State University. June 15th 2011 Preliminary Results Setup CUDA version 4.0 CUSP version 0.2 Thrust version 1.4 Ubuntu CPU: Dual Intel Xeon Quad Core E GHz Motherboard: Tyan S5396 RAM: 24 gig GPU: Tesla C2050 3GB DDR5 515 Gflops peak double precision 1.03 Tflops Peak single precision 14 MP * 32 cores/mp = 448 cores Host-device memory bw = 1566 MB/sec (Motherboard specific) 22
23 Performance Data taken from Optimization, HPC, and Pre- and Post-Processing I Session. 6th OpenFOAM Workshop Penn State University. June 15th Solve() Time Comparison Time [seconds] cusplink_smapcg GAMG cusplink_dpcg cusplink_cg DPCG-parallel4 DPCG-parallel6-s231 DPCG CG ncells 23
24 Performance Data taken from Optimization, HPC, and Pre- and Post-Processing I Session. 6th OpenFOAM Workshop Penn State University. June 15th Speedup Comparison 16 Speedup = Ts/Tp = T OFCG /T other 14 Speedup DPCG DPCG-parallel4 DPCG-parallel6-s231 DPCG-parallel6-s161 cusplink_dpcg cusplink_cg ncells 24
25 Performance Data taken from Optimization, HPC, and Pre- and Post-Processing I Session. 6th OpenFOAM Workshop Penn State University. June 15th 2011 Speedup Speedup Comparison DPCG DPCG-parallel4 DPCG-parallel6-s231 DPCG-parallel6-s161 cusplink_cg cusplink_dpcg GAMG GAMG6 cusplink_smapcg Speedup = Ts/Tp = T OFCG /T other ncells 25
26 Performance Data taken from Optimization, HPC, and Pre- and Post-Processing I Session. 6th OpenFOAM Workshop Penn State University. June 15th 2011 Speedup Comparison Speedup DPCG DPCG-parallel4 DPCG-parallel6-s231 DPCG-parallel6-s161 cusplink_cg cusplink_dpcg GAMG6 GAMG cusplink_smapcg Speedup = Ts/Tp = T OFCG /T other ncells
27 CUDA Solvers in foam-extend-3.0 Cufflink library is built-in since foam-extend-3.0. Right now, compiling CUDA solvers in foam-extend-3.0 is very hard due to lack of knowledge and tutorials about it. In near future, improvements on GPGPU solvers in foam-extend fork of OpenFOAM is expected by the community of foam-extend. It includes the following solvers: cudabicgstab, cudacg 27
28 Considerations about Future Improvements on Cusp based solvers which would decrease the effect of memory bottleneck between GPU and main memory. Different open-source sparse-matrix linear equations solver can replace the Cusp based ones for performance improvement. However, this is not a trivial task! Right now, multi-gpu on one node is supported, but developments of multi-node gpus would be better for very large scale simulations where one node would not be enough. Problem size must be big enough for compensating GPU memory bottleneck overhead. 28

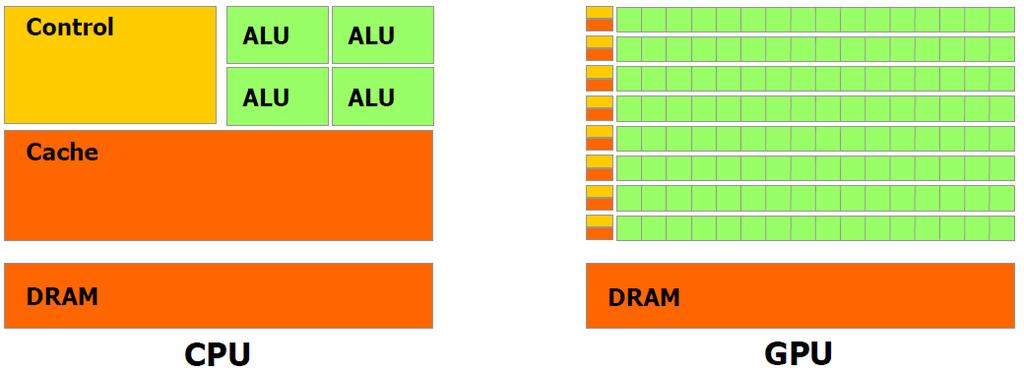
29 GPGPU vs CPU 29
30 GPGPU vs CPU Taken from reference (1) 30
31 GPGPU vs CPU Taken from reference (1) 31


32 GPGPU vs CPU Taken from reference (1) 32
")
33 GPGPU vs CPU Taken from reference (1) 33
34 Q & A
35 References 1. Karl Rupp. CPU, GPU and MIC Hardware Characteristics over Time. retrieved from on date Daniel P. Combest, Dr. P.A. Ramachandran, Dr. M.P. Dudukovic. Implementing Fast Parallel Linear System Solvers In OpenFOAM based on CUDA. 6th OpenFOAM Workshop Penn State University. June 15th The OpenFOAM Extend Project tutorials
Application of GPU technology to OpenFOAM simulations
 Application of GPU technology to OpenFOAM simulations Jakub Poła, Andrzej Kosior, Łukasz Miroslaw jakub.pola@vratis.com, www.vratis.com Wroclaw, Poland Agenda Motivation Partial acceleration SpeedIT OpenFOAM
Application of GPU technology to OpenFOAM simulations Jakub Poła, Andrzej Kosior, Łukasz Miroslaw jakub.pola@vratis.com, www.vratis.com Wroclaw, Poland Agenda Motivation Partial acceleration SpeedIT OpenFOAM
This offering is not approved or endorsed by OpenCFD Limited, the producer of the OpenFOAM software and owner of the OPENFOAM and OpenCFD trade marks.
 Disclaimer This offering is not approved or endorsed by OpenCFD Limited, the producer of the OpenFOAM software and owner of the OPENFOAM and OpenCFD trade marks. Introductory OpenFOAM Course From 8 th
Disclaimer This offering is not approved or endorsed by OpenCFD Limited, the producer of the OpenFOAM software and owner of the OPENFOAM and OpenCFD trade marks. Introductory OpenFOAM Course From 8 th
OPENFOAM ON GPUS USING AMGX
 OPENFOAM ON GPUS USING AMGX Thilina Rathnayake Sanath Jayasena Mahinsasa Narayana ABSTRACT Field Operation and Manipulation (OpenFOAM) is a free, open-source, feature-rich Computational Fluid Dynamics
OPENFOAM ON GPUS USING AMGX Thilina Rathnayake Sanath Jayasena Mahinsasa Narayana ABSTRACT Field Operation and Manipulation (OpenFOAM) is a free, open-source, feature-rich Computational Fluid Dynamics
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER PROF. BRYANT PROF. KAYVON 15618: PARALLEL COMPUTER ARCHITECTURE
 HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU. Robert Strzodka NVAMG Project Lead
 Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
Optimization of parameter settings for GAMG solver in simple solver
 Optimization of parameter settings for GAMG solver in simple solver Masashi Imano (OCAEL Co.Ltd.) Aug. 26th 2012 OpenFOAM Study Meeting for beginner @ Kanto Test cluster condition Hardware: SGI Altix ICE8200
Optimization of parameter settings for GAMG solver in simple solver Masashi Imano (OCAEL Co.Ltd.) Aug. 26th 2012 OpenFOAM Study Meeting for beginner @ Kanto Test cluster condition Hardware: SGI Altix ICE8200
Multi-GPU simulations in OpenFOAM with SpeedIT technology.
 Multi-GPU simulations in OpenFOAM with SpeedIT technology. Attempt I: SpeedIT GPU-based library of iterative solvers for Sparse Linear Algebra and CFD. Current version: 2.2. Version 1.0 in 2008. CMRS format
Multi-GPU simulations in OpenFOAM with SpeedIT technology. Attempt I: SpeedIT GPU-based library of iterative solvers for Sparse Linear Algebra and CFD. Current version: 2.2. Version 1.0 in 2008. CMRS format
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Iterative Sparse Triangular Solves for Preconditioning
 Euro-Par 2015, Vienna Aug 24-28, 2015 Iterative Sparse Triangular Solves for Preconditioning Hartwig Anzt, Edmond Chow and Jack Dongarra Incomplete Factorization Preconditioning Incomplete LU factorizations
Euro-Par 2015, Vienna Aug 24-28, 2015 Iterative Sparse Triangular Solves for Preconditioning Hartwig Anzt, Edmond Chow and Jack Dongarra Incomplete Factorization Preconditioning Incomplete LU factorizations
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
PARALUTION - a Library for Iterative Sparse Methods on CPU and GPU
 - a Library for Iterative Sparse Methods on CPU and GPU Dimitar Lukarski Division of Scientific Computing Department of Information Technology Uppsala Programming for Multicore Architectures Research Center
- a Library for Iterative Sparse Methods on CPU and GPU Dimitar Lukarski Division of Scientific Computing Department of Information Technology Uppsala Programming for Multicore Architectures Research Center
AMS526: Numerical Analysis I (Numerical Linear Algebra)
") AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 20: Sparse Linear Systems; Direct Methods vs. Iterative Methods Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 26
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 20: Sparse Linear Systems; Direct Methods vs. Iterative Methods Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 26
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016
 ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
OpenFOAM on GPUs. 3rd Northern germany OpenFoam User meeting. Institute of Scientific Computing. September 24th 2015
 OpenFOAM on GPUs 3rd Northern germany OpenFoam User meeting September 24th 2015 Haus der Wissenschaften, Braunschweig Overview HPC on GPGPUs OpenFOAM on GPUs 2013 OpenFOAM on GPUs 2015 BiCGstab/IDR(s)
OpenFOAM on GPUs 3rd Northern germany OpenFoam User meeting September 24th 2015 Haus der Wissenschaften, Braunschweig Overview HPC on GPGPUs OpenFOAM on GPUs 2013 OpenFOAM on GPUs 2015 BiCGstab/IDR(s)
Performance of Implicit Solver Strategies on GPUs
 9. LS-DYNA Forum, Bamberg 2010 IT / Performance Performance of Implicit Solver Strategies on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Abstract: The increasing power of GPUs can be used
9. LS-DYNA Forum, Bamberg 2010 IT / Performance Performance of Implicit Solver Strategies on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Abstract: The increasing power of GPUs can be used
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS. Kyle Spagnoli. Research EM Photonics 3/20/2013
 GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
Contents. I The Basic Framework for Stationary Problems 1
 page v Preface xiii I The Basic Framework for Stationary Problems 1 1 Some model PDEs 3 1.1 Laplace s equation; elliptic BVPs... 3 1.1.1 Physical experiments modeled by Laplace s equation... 5 1.2 Other
page v Preface xiii I The Basic Framework for Stationary Problems 1 1 Some model PDEs 3 1.1 Laplace s equation; elliptic BVPs... 3 1.1.1 Physical experiments modeled by Laplace s equation... 5 1.2 Other
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015
 AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
Structure-preserving Smoothing for Seismic Amplitude Data by Anisotropic Diffusion using GPGPU
 GPU Technology Conference 2016 April, 4-7 San Jose, CA, USA Structure-preserving Smoothing for Seismic Amplitude Data by Anisotropic Diffusion using GPGPU Joner Duarte jduartejr@tecgraf.puc-rio.br Outline
GPU Technology Conference 2016 April, 4-7 San Jose, CA, USA Structure-preserving Smoothing for Seismic Amplitude Data by Anisotropic Diffusion using GPGPU Joner Duarte jduartejr@tecgraf.puc-rio.br Outline
Algorithms, System and Data Centre Optimisation for Energy Efficient HPC
 2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND
 Student Submission for the 5 th OpenFOAM User Conference 2017, Wiesbaden - Germany: SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND TESSA UROIĆ Faculty of Mechanical Engineering and Naval Architecture, Ivana
Student Submission for the 5 th OpenFOAM User Conference 2017, Wiesbaden - Germany: SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND TESSA UROIĆ Faculty of Mechanical Engineering and Naval Architecture, Ivana
GPU-based Parallel Reservoir Simulators
 GPU-based Parallel Reservoir Simulators Zhangxin Chen 1, Hui Liu 1, Song Yu 1, Ben Hsieh 1 and Lei Shao 1 Key words: GPU computing, reservoir simulation, linear solver, parallel 1 Introduction Nowadays
GPU-based Parallel Reservoir Simulators Zhangxin Chen 1, Hui Liu 1, Song Yu 1, Ben Hsieh 1 and Lei Shao 1 Key words: GPU computing, reservoir simulation, linear solver, parallel 1 Introduction Nowadays
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Lecture 15: More Iterative Ideas
 Lecture 15: More Iterative Ideas David Bindel 15 Mar 2010 Logistics HW 2 due! Some notes on HW 2. Where we are / where we re going More iterative ideas. Intro to HW 3. More HW 2 notes See solution code!
Lecture 15: More Iterative Ideas David Bindel 15 Mar 2010 Logistics HW 2 due! Some notes on HW 2. Where we are / where we re going More iterative ideas. Intro to HW 3. More HW 2 notes See solution code!
CUDA Accelerated Compute Libraries. M. Naumov
 CUDA Accelerated Compute Libraries M. Naumov Outline Motivation Why should you use libraries? CUDA Toolkit Libraries Overview of performance CUDA Proprietary Libraries Address specific markets Third Party
CUDA Accelerated Compute Libraries M. Naumov Outline Motivation Why should you use libraries? CUDA Toolkit Libraries Overview of performance CUDA Proprietary Libraries Address specific markets Third Party
Optimizing Data Locality for Iterative Matrix Solvers on CUDA
 Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
EFFICIENT SOLVER FOR LINEAR ALGEBRAIC EQUATIONS ON PARALLEL ARCHITECTURE USING MPI
 EFFICIENT SOLVER FOR LINEAR ALGEBRAIC EQUATIONS ON PARALLEL ARCHITECTURE USING MPI 1 Akshay N. Panajwar, 2 Prof.M.A.Shah Department of Computer Science and Engineering, Walchand College of Engineering,
EFFICIENT SOLVER FOR LINEAR ALGEBRAIC EQUATIONS ON PARALLEL ARCHITECTURE USING MPI 1 Akshay N. Panajwar, 2 Prof.M.A.Shah Department of Computer Science and Engineering, Walchand College of Engineering,
GPU Implementation of Elliptic Solvers in NWP. Numerical Weather- and Climate- Prediction
 1/8 GPU Implementation of Elliptic Solvers in Numerical Weather- and Climate- Prediction Eike Hermann Müller, Robert Scheichl Department of Mathematical Sciences EHM, Xu Guo, Sinan Shi and RS: http://arxiv.org/abs/1302.7193
1/8 GPU Implementation of Elliptic Solvers in Numerical Weather- and Climate- Prediction Eike Hermann Müller, Robert Scheichl Department of Mathematical Sciences EHM, Xu Guo, Sinan Shi and RS: http://arxiv.org/abs/1302.7193
Matrix-free multi-gpu Implementation of Elliptic Solvers for strongly anisotropic PDEs
 Iterative Solvers Numerical Results Conclusion and outlook 1/18 Matrix-free multi-gpu Implementation of Elliptic Solvers for strongly anisotropic PDEs Eike Hermann Müller, Robert Scheichl, Eero Vainikko
Iterative Solvers Numerical Results Conclusion and outlook 1/18 Matrix-free multi-gpu Implementation of Elliptic Solvers for strongly anisotropic PDEs Eike Hermann Müller, Robert Scheichl, Eero Vainikko
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid. Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014
 Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
Accelerating GPU computation through mixed-precision methods. Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University
 Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs
 Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
The Visual Computing Company
 The Visual Computing Company GPU Acceleration Benefits for Applied CAE Axel Koehler, Senior Solutions Architect HPC, NVIDIA HPC Advisory Council Meeting, April 2014, Lugano Outline General overview about
The Visual Computing Company GPU Acceleration Benefits for Applied CAE Axel Koehler, Senior Solutions Architect HPC, NVIDIA HPC Advisory Council Meeting, April 2014, Lugano Outline General overview about
NEW ADVANCES IN GPU LINEAR ALGEBRA
 GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
GPU-Accelerated Algebraic Multigrid for Commercial Applications. Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA
 GPU-Accelerated Algebraic Multigrid for Commercial Applications Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA ANSYS Fluent 2 Fluent control flow Accelerate this first Non-linear iterations Assemble
GPU-Accelerated Algebraic Multigrid for Commercial Applications Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA ANSYS Fluent 2 Fluent control flow Accelerate this first Non-linear iterations Assemble
Report of Linear Solver Implementation on GPU
 Report of Linear Solver Implementation on GPU XIANG LI Abstract As the development of technology and the linear equation solver is used in many aspects such as smart grid, aviation and chemical engineering,
Report of Linear Solver Implementation on GPU XIANG LI Abstract As the development of technology and the linear equation solver is used in many aspects such as smart grid, aviation and chemical engineering,
Sparse Matrices. This means that for increasing problem size the matrices become sparse and sparser. O. Rheinbach, TU Bergakademie Freiberg
 Sparse Matrices Many matrices in computing only contain a very small percentage of nonzeros. Such matrices are called sparse ( dünn besetzt ). Often, an upper bound on the number of nonzeros in a row can
Sparse Matrices Many matrices in computing only contain a very small percentage of nonzeros. Such matrices are called sparse ( dünn besetzt ). Often, an upper bound on the number of nonzeros in a row can
Distributed NVAMG. Design and Implementation of a Scalable Algebraic Multigrid Framework for a Cluster of GPUs
 Distributed NVAMG Design and Implementation of a Scalable Algebraic Multigrid Framework for a Cluster of GPUs Istvan Reguly (istvan.reguly at oerc.ox.ac.uk) Oxford e-research Centre NVIDIA Summer Internship
Distributed NVAMG Design and Implementation of a Scalable Algebraic Multigrid Framework for a Cluster of GPUs Istvan Reguly (istvan.reguly at oerc.ox.ac.uk) Oxford e-research Centre NVIDIA Summer Internship
High Performance Iterative Solver for Linear System using Multi GPU )
") High Performance Iterative Solver for Linear System using Multi GPU ) Soichiro IKUNO 1), Norihisa FUJITA 1), Yuki KAWAGUCHI 1),TakuITOH 2), Susumu NAKATA 3), Kota WATANABE 4) and Hiroyuki NAKAMURA 5) 1)
High Performance Iterative Solver for Linear System using Multi GPU ) Soichiro IKUNO 1), Norihisa FUJITA 1), Yuki KAWAGUCHI 1),TakuITOH 2), Susumu NAKATA 3), Kota WATANABE 4) and Hiroyuki NAKAMURA 5) 1)
Accelerating the Conjugate Gradient Algorithm with GPUs in CFD Simulations
 Accelerating the Conjugate Gradient Algorithm with GPUs in CFD Simulations Hartwig Anzt 1, Marc Baboulin 2, Jack Dongarra 1, Yvan Fournier 3, Frank Hulsemann 3, Amal Khabou 2, and Yushan Wang 2 1 University
Accelerating the Conjugate Gradient Algorithm with GPUs in CFD Simulations Hartwig Anzt 1, Marc Baboulin 2, Jack Dongarra 1, Yvan Fournier 3, Frank Hulsemann 3, Amal Khabou 2, and Yushan Wang 2 1 University
Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA. NVIDIA Corporation
 Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA NVIDIA Corporation Outline! Overview of CG benchmark! Overview of CUDA Libraries! CUSPARSE! CUBLAS! Porting Sequence! Algorithm Analysis! Data/Code
Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA NVIDIA Corporation Outline! Overview of CG benchmark! Overview of CUDA Libraries! CUSPARSE! CUBLAS! Porting Sequence! Algorithm Analysis! Data/Code
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
Highly Parallel Multigrid Solvers for Multicore and Manycore Processors
 Highly Parallel Multigrid Solvers for Multicore and Manycore Processors Oleg Bessonov (B) Institute for Problems in Mechanics of the Russian Academy of Sciences, 101, Vernadsky Avenue, 119526 Moscow, Russia
Highly Parallel Multigrid Solvers for Multicore and Manycore Processors Oleg Bessonov (B) Institute for Problems in Mechanics of the Russian Academy of Sciences, 101, Vernadsky Avenue, 119526 Moscow, Russia
Accelerating a Simulation of Type I X ray Bursts from Accreting Neutron Stars Mark Mackey Professor Alexander Heger
 Accelerating a Simulation of Type I X ray Bursts from Accreting Neutron Stars Mark Mackey Professor Alexander Heger The goal of my project was to develop an optimized linear system solver to shorten the
Accelerating a Simulation of Type I X ray Bursts from Accreting Neutron Stars Mark Mackey Professor Alexander Heger The goal of my project was to develop an optimized linear system solver to shorten the
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
A Comparison of Algebraic Multigrid Preconditioners using Graphics Processing Units and Multi-Core Central Processing Units
 A Comparison of Algebraic Multigrid Preconditioners using Graphics Processing Units and Multi-Core Central Processing Units Markus Wagner, Karl Rupp,2, Josef Weinbub Institute for Microelectronics, TU
A Comparison of Algebraic Multigrid Preconditioners using Graphics Processing Units and Multi-Core Central Processing Units Markus Wagner, Karl Rupp,2, Josef Weinbub Institute for Microelectronics, TU
Performance of PETSc GPU Implementation with Sparse Matrix Storage Schemes
 Performance of PETSc GPU Implementation with Sparse Matrix Storage Schemes Pramod Kumbhar August 19, 2011 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2011 Abstract
Performance of PETSc GPU Implementation with Sparse Matrix Storage Schemes Pramod Kumbhar August 19, 2011 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2011 Abstract
GPU PROGRESS AND DIRECTIONS IN APPLIED CFD
 Eleventh International Conference on CFD in the Minerals and Process Industries CSIRO, Melbourne, Australia 7-9 December 2015 GPU PROGRESS AND DIRECTIONS IN APPLIED CFD Stan POSEY 1*, Simon SEE 2, and
Eleventh International Conference on CFD in the Minerals and Process Industries CSIRO, Melbourne, Australia 7-9 December 2015 GPU PROGRESS AND DIRECTIONS IN APPLIED CFD Stan POSEY 1*, Simon SEE 2, and
3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs
 3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs H. Knibbe, C. W. Oosterlee, C. Vuik Abstract We are focusing on an iterative solver for the three-dimensional
3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs H. Knibbe, C. W. Oosterlee, C. Vuik Abstract We are focusing on an iterative solver for the three-dimensional
OpenFOAM on GPUs. Thilina Rathnayake R. Department of Computer Science & Engineering. University of Moratuwa Sri Lanka
 OpenFOAM on GPUs Thilina Rathnayake 158034R Thesis/Dissertation submitted in partial fulfillment of the requirements for the degree Master of Science in Computer Science and Engineering Department of Computer
OpenFOAM on GPUs Thilina Rathnayake 158034R Thesis/Dissertation submitted in partial fulfillment of the requirements for the degree Master of Science in Computer Science and Engineering Department of Computer
Proceedings of the First International Workshop on Sustainable Ultrascale Computing Systems (NESUS 2014) Porto, Portugal
 Porto, Portugal") Proceedings of the First International Workshop on Sustainable Ultrascale Computing Systems (NESUS 2014) Porto, Portugal Jesus Carretero, Javier Garcia Blas Jorge Barbosa, Ricardo Morla (Editors) August
Proceedings of the First International Workshop on Sustainable Ultrascale Computing Systems (NESUS 2014) Porto, Portugal Jesus Carretero, Javier Garcia Blas Jorge Barbosa, Ricardo Morla (Editors) August
GPU-Acceleration of CAE Simulations. Bhushan Desam NVIDIA Corporation
 GPU-Acceleration of CAE Simulations Bhushan Desam NVIDIA Corporation bdesam@nvidia.com 1 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications
GPU-Acceleration of CAE Simulations Bhushan Desam NVIDIA Corporation bdesam@nvidia.com 1 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications
Studies of the ERCOFTAC Centrifugal Pump with OpenFOAM
 Title 1/20 Studies of the ERCOFTAC Centrifugal Pump with OpenFOAM Olivier Petit Håkan Nilsson Outline Outline Geometry Boundary conditions Method and cases Comparison of numerical results with the available
Title 1/20 Studies of the ERCOFTAC Centrifugal Pump with OpenFOAM Olivier Petit Håkan Nilsson Outline Outline Geometry Boundary conditions Method and cases Comparison of numerical results with the available
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM
 Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Introduction to fluid mechanics simulation using the OpenFOAM technology
 Introduction to fluid mechanics simulation using the OpenFOAM technology «Simulation in porous media from pore to large scale» Part II: Mesh complex geometries, application to the evaluation of permeability,
Introduction to fluid mechanics simulation using the OpenFOAM technology «Simulation in porous media from pore to large scale» Part II: Mesh complex geometries, application to the evaluation of permeability,
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Outlining Midterm Projects Topic 3: GPU-based FEA Topic 4: GPU Direct Solver for Sparse Linear Algebra March 01, 2011 Dan Negrut, 2011 ME964
ME964 High Performance Computing for Engineering Applications Outlining Midterm Projects Topic 3: GPU-based FEA Topic 4: GPU Direct Solver for Sparse Linear Algebra March 01, 2011 Dan Negrut, 2011 ME964
Matrix-free IPM with GPU acceleration
 Matrix-free IPM with GPU acceleration Julian Hall, Edmund Smith and Jacek Gondzio School of Mathematics University of Edinburgh jajhall@ed.ac.uk 29th June 2011 Linear programming theory Primal-dual pair
Matrix-free IPM with GPU acceleration Julian Hall, Edmund Smith and Jacek Gondzio School of Mathematics University of Edinburgh jajhall@ed.ac.uk 29th June 2011 Linear programming theory Primal-dual pair
Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC
 Fourth Workshop on Accelerator Programming Using Directives (WACCPD), Nov. 13, 2017 Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC Takuma
Fourth Workshop on Accelerator Programming Using Directives (WACCPD), Nov. 13, 2017 Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC Takuma
(Sparse) Linear Solvers
 Linear Solvers") (Sparse) Linear Solvers Ax = B Why? Many geometry processing applications boil down to: solve one or more linear systems Parameterization Editing Reconstruction Fairing Morphing 2 Don t you just invert
(Sparse) Linear Solvers Ax = B Why? Many geometry processing applications boil down to: solve one or more linear systems Parameterization Editing Reconstruction Fairing Morphing 2 Don t you just invert
Efficient multigrid solvers for strongly anisotropic PDEs in atmospheric modelling
 Iterative Solvers Numerical Results Conclusion and outlook 1/22 Efficient multigrid solvers for strongly anisotropic PDEs in atmospheric modelling Part II: GPU Implementation and Scaling on Titan Eike
Iterative Solvers Numerical Results Conclusion and outlook 1/22 Efficient multigrid solvers for strongly anisotropic PDEs in atmospheric modelling Part II: GPU Implementation and Scaling on Titan Eike
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
How to Optimize Geometric Multigrid Methods on GPUs
 How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Exploiting GPU Caches in Sparse Matrix Vector Multiplication. Yusuke Nagasaka Tokyo Institute of Technology
 Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
CUDA Toolkit 5.0 Performance Report. January 2013
 CUDA Toolkit 5.0 Performance Report January 2013 CUDA Math Libraries High performance math routines for your applications: cufft Fast Fourier Transforms Library cublas Complete BLAS Library cusparse Sparse
CUDA Toolkit 5.0 Performance Report January 2013 CUDA Math Libraries High performance math routines for your applications: cufft Fast Fourier Transforms Library cublas Complete BLAS Library cusparse Sparse
CUDA 6.0 Performance Report. April 2014
 CUDA 6. Performance Report April 214 1 CUDA 6 Performance Report CUDART CUDA Runtime Library cufft Fast Fourier Transforms Library cublas Complete BLAS Library cusparse Sparse Matrix Library curand Random
CUDA 6. Performance Report April 214 1 CUDA 6 Performance Report CUDART CUDA Runtime Library cufft Fast Fourier Transforms Library cublas Complete BLAS Library cusparse Sparse Matrix Library curand Random
3D ADI Method for Fluid Simulation on Multiple GPUs. Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA
 3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms
 Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms H. Anzt, V. Heuveline Karlsruhe Institute of Technology, Germany
Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms H. Anzt, V. Heuveline Karlsruhe Institute of Technology, Germany
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers
 Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
A Parallel Solver for Laplacian Matrices. Tristan Konolige (me) and Jed Brown
 and Jed Brown") A Parallel Solver for Laplacian Matrices Tristan Konolige (me) and Jed Brown Graph Laplacian Matrices Covered by other speakers (hopefully) Useful in a variety of areas Graphs are getting very big Facebook
A Parallel Solver for Laplacian Matrices Tristan Konolige (me) and Jed Brown Graph Laplacian Matrices Covered by other speakers (hopefully) Useful in a variety of areas Graphs are getting very big Facebook
Figure 6.1: Truss topology optimization diagram.
 6 Implementation 6.1 Outline This chapter shows the implementation details to optimize the truss, obtained in the ground structure approach, according to the formulation presented in previous chapters.
6 Implementation 6.1 Outline This chapter shows the implementation details to optimize the truss, obtained in the ground structure approach, according to the formulation presented in previous chapters.
High Performance Computing for PDE Some numerical aspects of Petascale Computing
 High Performance Computing for PDE Some numerical aspects of Petascale Computing S. Turek, D. Göddeke with support by: Chr. Becker, S. Buijssen, M. Grajewski, H. Wobker Institut für Angewandte Mathematik,
High Performance Computing for PDE Some numerical aspects of Petascale Computing S. Turek, D. Göddeke with support by: Chr. Becker, S. Buijssen, M. Grajewski, H. Wobker Institut für Angewandte Mathematik,
Super Matrix Solver-P-ICCG:
 Super Matrix Solver-P-ICCG: February 2011 VINAS Co., Ltd. Project Development Dept. URL: http://www.vinas.com All trademarks and trade names in this document are properties of their respective owners.
Super Matrix Solver-P-ICCG: February 2011 VINAS Co., Ltd. Project Development Dept. URL: http://www.vinas.com All trademarks and trade names in this document are properties of their respective owners.
The Fermi GPU and HPC Application Breakthroughs
 The Fermi GPU and HPC Application Breakthroughs Peng Wang, PhD HPC Developer Technology Group Stan Posey HPC Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA Corporation 2009 Overview GPU Computing:
The Fermi GPU and HPC Application Breakthroughs Peng Wang, PhD HPC Developer Technology Group Stan Posey HPC Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA Corporation 2009 Overview GPU Computing:
S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS
 S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS John R Appleyard Jeremy D Appleyard Polyhedron Software with acknowledgements to Mark A Wakefield Garf Bowen Schlumberger Outline of Talk Reservoir
S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS John R Appleyard Jeremy D Appleyard Polyhedron Software with acknowledgements to Mark A Wakefield Garf Bowen Schlumberger Outline of Talk Reservoir
Iterative solution of linear systems in electromagnetics (and not only): experiences with CUDA
: experiences with CUDA") How to cite this paper: D. De Donno, A. Esposito, G. Monti, and L. Tarricone, Iterative Solution of Linear Systems in Electromagnetics (and not only): Experiences with CUDA, Euro-Par 2010 Parallel Processing
How to cite this paper: D. De Donno, A. Esposito, G. Monti, and L. Tarricone, Iterative Solution of Linear Systems in Electromagnetics (and not only): Experiences with CUDA, Euro-Par 2010 Parallel Processing
(Sparse) Linear Solvers
 Linear Solvers") (Sparse) Linear Solvers Ax = B Why? Many geometry processing applications boil down to: solve one or more linear systems Parameterization Editing Reconstruction Fairing Morphing 1 Don t you just invert
(Sparse) Linear Solvers Ax = B Why? Many geometry processing applications boil down to: solve one or more linear systems Parameterization Editing Reconstruction Fairing Morphing 1 Don t you just invert
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
Automated Finite Element Computations in the FEniCS Framework using GPUs
 Automated Finite Element Computations in the FEniCS Framework using GPUs Florian Rathgeber (f.rathgeber10@imperial.ac.uk) Advanced Modelling and Computation Group (AMCG) Department of Earth Science & Engineering
Automated Finite Element Computations in the FEniCS Framework using GPUs Florian Rathgeber (f.rathgeber10@imperial.ac.uk) Advanced Modelling and Computation Group (AMCG) Department of Earth Science & Engineering
PROGRAMMING OF MULTIGRID METHODS
 PROGRAMMING OF MULTIGRID METHODS LONG CHEN In this note, we explain the implementation detail of multigrid methods. We will use the approach by space decomposition and subspace correction method; see Chapter:
PROGRAMMING OF MULTIGRID METHODS LONG CHEN In this note, we explain the implementation detail of multigrid methods. We will use the approach by space decomposition and subspace correction method; see Chapter:
Numerical Algorithms on Multi-GPU Architectures
 Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Very fast simulation of nonlinear water waves in very large numerical wave tanks on affordable graphics cards
 Very fast simulation of nonlinear water waves in very large numerical wave tanks on affordable graphics cards By Allan P. Engsig-Karup, Morten Gorm Madsen and Stefan L. Glimberg DTU Informatics Workshop
Very fast simulation of nonlinear water waves in very large numerical wave tanks on affordable graphics cards By Allan P. Engsig-Karup, Morten Gorm Madsen and Stefan L. Glimberg DTU Informatics Workshop
Available online at ScienceDirect. Parallel Computational Fluid Dynamics Conference (ParCFD2013)
") Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 61 ( 2013 ) 81 86 Parallel Computational Fluid Dynamics Conference (ParCFD2013) An OpenCL-based parallel CFD code for simulations
Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 61 ( 2013 ) 81 86 Parallel Computational Fluid Dynamics Conference (ParCFD2013) An OpenCL-based parallel CFD code for simulations
PhD Student. Associate Professor, Co-Director, Center for Computational Earth and Environmental Science. Abdulrahman Manea.
 Abdulrahman Manea PhD Student Hamdi Tchelepi Associate Professor, Co-Director, Center for Computational Earth and Environmental Science Energy Resources Engineering Department School of Earth Sciences
Abdulrahman Manea PhD Student Hamdi Tchelepi Associate Professor, Co-Director, Center for Computational Earth and Environmental Science Energy Resources Engineering Department School of Earth Sciences
smooth coefficients H. Köstler, U. Rüde
 A robust multigrid solver for the optical flow problem with non- smooth coefficients H. Köstler, U. Rüde Overview Optical Flow Problem Data term and various regularizers A Robust Multigrid Solver Galerkin
A robust multigrid solver for the optical flow problem with non- smooth coefficients H. Köstler, U. Rüde Overview Optical Flow Problem Data term and various regularizers A Robust Multigrid Solver Galerkin
Efficient AMG on Hybrid GPU Clusters. ScicomP Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann. Fraunhofer SCAI
 Efficient AMG on Hybrid GPU Clusters ScicomP 2012 Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann Fraunhofer SCAI Illustration: Darin McInnis Motivation Sparse iterative solvers benefit from
Efficient AMG on Hybrid GPU Clusters ScicomP 2012 Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann Fraunhofer SCAI Illustration: Darin McInnis Motivation Sparse iterative solvers benefit from
Effects of Solvers on Finite Element Analysis in COMSOL MULTIPHYSICS
 Effects of Solvers on Finite Element Analysis in COMSOL MULTIPHYSICS Chethan Ravi B.R Dr. Venkateswaran P Corporate Technology - Research and Technology Center Siemens Technology and Services Private Limited
Effects of Solvers on Finite Element Analysis in COMSOL MULTIPHYSICS Chethan Ravi B.R Dr. Venkateswaran P Corporate Technology - Research and Technology Center Siemens Technology and Services Private Limited
Krishnan Suresh Associate Professor Mechanical Engineering
 Large Scale FEA on the GPU Krishnan Suresh Associate Professor Mechanical Engineering High-Performance Trick Computations (i.e., 3.4*1.22): essentially free Memory access determines speed of code Pick
Large Scale FEA on the GPU Krishnan Suresh Associate Professor Mechanical Engineering High-Performance Trick Computations (i.e., 3.4*1.22): essentially free Memory access determines speed of code Pick
Introduction to Multigrid and its Parallelization
 Introduction to Multigrid and its Parallelization! Thomas D. Economon Lecture 14a May 28, 2014 Announcements 2 HW 1 & 2 have been returned. Any questions? Final projects are due June 11, 5 pm. If you are
Introduction to Multigrid and its Parallelization! Thomas D. Economon Lecture 14a May 28, 2014 Announcements 2 HW 1 & 2 have been returned. Any questions? Final projects are due June 11, 5 pm. If you are
Mixed Precision Methods
 Mixed Precision Methods Mixed precision, use the lowest precision required to achieve a given accuracy outcome " Improves runtime, reduce power consumption, lower data movement " Reformulate to find correction
Mixed Precision Methods Mixed precision, use the lowest precision required to achieve a given accuracy outcome " Improves runtime, reduce power consumption, lower data movement " Reformulate to find correction
Large Displacement Optical Flow & Applications
 Large Displacement Optical Flow & Applications Narayanan Sundaram, Kurt Keutzer (Parlab) In collaboration with Thomas Brox (University of Freiburg) Michael Tao (University of California Berkeley) Parlab
Large Displacement Optical Flow & Applications Narayanan Sundaram, Kurt Keutzer (Parlab) In collaboration with Thomas Brox (University of Freiburg) Michael Tao (University of California Berkeley) Parlab
Porting, optimization and bottleneck of OpenFOAM in KNL environment
 Porting, optimization and bottleneck of OpenFOAM in KNL environment I. Spissoa, G. Amatib, V. Ruggierob, C. Fiorinac a) SuperCompunting Application and Innovation Department, Cineca, Via Magnanelli 6/3,
Porting, optimization and bottleneck of OpenFOAM in KNL environment I. Spissoa, G. Amatib, V. Ruggierob, C. Fiorinac a) SuperCompunting Application and Innovation Department, Cineca, Via Magnanelli 6/3,
GPU Cluster Computing for FEM
 GPU Cluster Computing for FEM Dominik Göddeke Sven H.M. Buijssen, Hilmar Wobker and Stefan Turek Angewandte Mathematik und Numerik TU Dortmund, Germany dominik.goeddeke@math.tu-dortmund.de GPU Computing
GPU Cluster Computing for FEM Dominik Göddeke Sven H.M. Buijssen, Hilmar Wobker and Stefan Turek Angewandte Mathematik und Numerik TU Dortmund, Germany dominik.goeddeke@math.tu-dortmund.de GPU Computing
On the Comparative Performance of Parallel Algorithms on Small GPU/CUDA Clusters
 1 On the Comparative Performance of Parallel Algorithms on Small GPU/CUDA Clusters N. P. Karunadasa & D. N. Ranasinghe University of Colombo School of Computing, Sri Lanka nishantha@opensource.lk, dnr@ucsc.cmb.ac.lk
1 On the Comparative Performance of Parallel Algorithms on Small GPU/CUDA Clusters N. P. Karunadasa & D. N. Ranasinghe University of Colombo School of Computing, Sri Lanka nishantha@opensource.lk, dnr@ucsc.cmb.ac.lk
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Generic Programming Experiments for SPn and SN transport codes
 Generic Programming Experiments for SPn and SN transport codes 10 mai 200 Laurent Plagne Angélique Ponçot Generic Programming Experiments for SPn and SN transport codes p1/26 Plan 1 Introduction How to
Generic Programming Experiments for SPn and SN transport codes 10 mai 200 Laurent Plagne Angélique Ponçot Generic Programming Experiments for SPn and SN transport codes p1/26 Plan 1 Introduction How to
GPUML: Graphical processors for speeding up kernel machines
 GPUML: Graphical processors for speeding up kernel machines http://www.umiacs.umd.edu/~balajiv/gpuml.htm Balaji Vasan Srinivasan, Qi Hu, Ramani Duraiswami Department of Computer Science, University of
GPUML: Graphical processors for speeding up kernel machines http://www.umiacs.umd.edu/~balajiv/gpuml.htm Balaji Vasan Srinivasan, Qi Hu, Ramani Duraiswami Department of Computer Science, University of
Implicit schemes for wave models
 Implicit schemes for wave models Mathieu Dutour Sikirić Rudjer Bo sković Institute, Croatia and Universität Rostock April 17, 2013 I. Wave models Stochastic wave modelling Oceanic models are using grids
Implicit schemes for wave models Mathieu Dutour Sikirić Rudjer Bo sković Institute, Croatia and Universität Rostock April 17, 2013 I. Wave models Stochastic wave modelling Oceanic models are using grids
Auto-tuning Multigrid with PetaBricks
 Auto-tuning with PetaBricks Cy Chan Joint Work with: Jason Ansel Yee Lok Wong Saman Amarasinghe Alan Edelman Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
Auto-tuning with PetaBricks Cy Chan Joint Work with: Jason Ansel Yee Lok Wong Saman Amarasinghe Alan Edelman Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology