Master Informatics Eng.
|
|
|
- Charity Washington
- 5 years ago
- Views:
Transcription
1 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The CUDA programming model Compute Unified Device Architecture CUDA is a recent programming model, designed for a multicore CPU host coupled to a many-core device, where devices have wide SIMD/SIMT parallelism, and the host and the device do not share memory CUDA provides: a thread abstraction to deal with SIMD synchr. & data sharing between small groups of threads CUDA programs are written in C with extensions OpenCL inspired by CUDA, but hw & sw vendor neutral programming model essentially identical AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 2
2 CUDA Devices and Threads A compute device is a coprocessor to the CPU or host ( memory has its own DRAM (device runs many threads in parallel is typically a GPU but can also be another type of parallel processing device Data-parallel portions of an application are expressed as device kernels which run on many threads - SIMT Differences between GPU and CPU threads GPU threads are extremely lightweight very little creation overhead, requires LARGE register bank GPU needs 1000s of threads for full efficiency multi-core CPU needs only a few AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 3 David Kirk/NVIDIA and Wen-mei W. Hwu, ECE 498AL, University of Illinois, Urbana-Champaign CUDA basic model: Single-Program Multiple-Data (SPMD) CUDA integrated CPU + GPU application C program Serial C code executes on CPU Parallel Kernel C code executes on GPU thread blocks GPU Parallel Kernel KernelA<<< nblk, ntid >>>(args); GPU Parallel Kernel KernelB<<< nblk, ntid >>>(args); CPU Code CPU Code Grid 0 AJProença, Advanced Architectures, MiEI, UMinho, 2018/ Grid 1 David Kirk/NVIDIA and Wen-mei W. Hwu, ECE 498AL, University of Illinois, Urbana-Champaign
 Single instruction are executed on multiple threads (SIMD) Warp size defines SIMD granularity (32 threads) Synchronization within a block")

3 Programming Model: SPMD + SIMT/SIMD Hierarchy Device => Grids Grid => Blocks Block => Warps Warp => Threads Single kernel runs on multiple blocks (SPMD) Threads within a warp are executed in a lock-step way called singleinstruction multiple-thread (SIMT) Single instruction are executed on multiple threads (SIMD) Warp size defines SIMD granularity (32 threads) Synchronization within a block uses shared memory Courtesy NVIDIA AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 5 The Computational Grid: Block IDs and Thread IDs A kernel runs on a computational grid of thread blocks Threads share global memory Each thread uses IDs to decide what data to work on Block ID: 1D or 2D Thread ID: 1D, 2D, or 3D A thread block is a batch of threads that can cooperate by: Sync their execution w/ barrier Efficiently sharing data through a low latency shared memory Two threads from two different blocks cannot cooperate AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 6 David Kirk/NVIDIA and Wen-mei W. Hwu, ECE 498AL, University of Illinois, Urbana-Champaign

4 Multiply two vectors of length 8192 Code that works over all elements is the grid Example Thread blocks break this down into manageable sizes 512 threads per block SIMD instruction executes 32 elements at a time Thus grid size = 16 blocks Block is analogous to a strip-mined vector loop with vector length of 32 Block is assigned to a multithreaded SIMD processor by the thread block scheduler Current-generation GPUs (Fermi) have 7-16 multithreaded SIMD processors Graphical Processing Units Copyright 2012, Elsevier Inc. All rights reserved. AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 7 AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 8
5 Terminology (and in NVidia) Threads of SIMD instructions (warps) Each has its own IP (up to 48/64 per SIMD processor, Fermi/Kepler) Thread scheduler uses scoreboard to dispatch No data dependencies between threads! Threads are organized into blocks & executed in groups of 32 threads (thread block) Blocks are organized into a grid The thread block scheduler schedules blocks to SIMD processors (Streaming Multiprocessors) Within each SIMD processor: 32 SIMD lanes (thread processors) Wide and shallow compared to vector processors Graphical Processing Units Copyright 2012, Elsevier Inc. All rights reserved. AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 9 CUDA Thread Block Programmer declares (Thread) Block: Block size 1 to 512 concurrent threads Block shape 1D, 2D, or 3D Block dimensions in threads All threads in a Block execute the same thread program Threads share data and synchronize while doing their share of the work Threads have thread id numbers within Block Thread program uses thread id to select work and address shared data threadid CUDA Thread Block AJProença, Advanced Architectures, MiEI, UMinho, 2018/ float x = input[threadid]; float y = func(x); output[threadid] = y; David Kirk/NVIDIA and Wen-mei W. Hwu, ECE 498AL, University of Illinois, Urbana-Champaign
6 Parallel Sharing Thread Block Grid 0 Grid 1 Local Shared Local : per-thread Private per thread Auto variables, register spill Shared : per-block Shared by threads of the same block Inter-thread communication Global : per-application Shared by all threads Inter-Grid communication Global Sequential Grids in Time AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 11 David Kirk/NVIDIA and Wen-mei W. Hwu, ECE 498AL, University of Illinois, Urbana-Champaign CUDA Model Overview Each thread can: R/W per-thread registers R/W per-thread local memory R/W per-block shared memory R/W per-grid global memory Read only per-grid constant memory Read only per-grid texture memory The host can R/W global, constant, and texture memories Host (Device) Grid Block (0, 0) Local Global Constant Texture Shared Thread (0, 0) Thread (1, 0) Local Block (1, 0) Local Shared Thread (0, 0) Thread (1, 0) Local AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 12 David Kirk/NVIDIA and Wen-mei W. Hwu, ECE 498AL, University of Illinois, Urbana-Champaign
7 Hardware Implementation: Architecture Device memory (DRAM) Slow (2~300 cycles) Local, global, constant, and texture memory On-chip memory Fast (1 cycle), shared memory, constant/texture cache Device Multiprocessor N Multiprocessor 2 Multiprocessor 1 Processor 1 Shared Processor 2 Constant Cache Texture Cache Processor M Instruction Unit Device memory Courtesy NVIDIA AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 13 Example Graphical Processing Units Copyright 2012, Elsevier Inc. All rights reserved. AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 14
8 Vector Processor versus CUDA core Graphical Processing Units Copyright 2012, Elsevier Inc. All rights reserved. AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 15 Conditional Branching Like vector architectures, GPU branch hardware uses internal masks Also uses Branch synchronization stack Entries consist of masks for each SIMD lane I.e. which threads commit their results (all threads execute) Instruction markers to manage when a branch diverges into multiple execution paths Push on divergent branch and when paths converge Act as barriers Pops stack Graphical Processing Units Per-thread-lane 1-bit predicate register, specified by programmer Copyright 2012, Elsevier Inc. All rights reserved. AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 16
9 Beyond Vector/SIMD architectures Vector/SIMD-extended architectures are hybrid approaches mix (super)scalar + vector op capabilities on a single device highly pipelined approach to reduce memory access penalty tightly-closed access to shared memory: lower latency Evolution of Vector/SIMD-extended architectures PU (Processing Unit) cores with wider vector units x86 many-core: Intel MIC / Xeon KNL (more slides later) other many-core: IBM Power BlueGene/Q Compute, ShenWay 260 coprocessors (require a host scalar processor): accelerator devices on disjoint physical memories (e.g., Xeon KNC with PCI-Expr, PEZY-SC) ISA-free architectures, code compiled to silica: FPGA focus on SIMT/SIMD to hide memory latency: GPU-type approach focus on tensor/neural nets cores: NVidia, IBM, Intel NNP, Google TPU heterogeneous PUs in a SoC: multicore PUs with GPU-cores AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 17 Machine learning w/ neural nets & deep learning... Key algorithms to train & classify use matrix products, but require lower precision numbers! AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 18

")
 256 outputs (neurons) RAM w/ data")


10 For each SM: 8x 64 FMA ops/cycle 1k FLOPS/cycle! AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 19 NVidia competitors with neural net features: IBM TrueNorth chip array (August 2014) TrueNorth Chip: 4096 neurosynaptic cores Each core: 256 inputs (axons) 256 outputs (neurons) RAM w/ data for each neuron router (any neuron to any axon) AJProença, Advanced Architectures, MiEI, UMinho, 2018/ NVidia Volta Architecture: the new Tensor Cores

 separate pipelines for computation and data management Loihi proprietary numeric format Flexpoint in-between floating point and fixed point")

11 NVidia competitors with neural net features: the IBM TrueNorth architecture AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 21 History Nervana Engine announced in May 16 Key features: ASIC chip, focused on matrix multiplication,convolutions,... (for neural nets) HBM2: 4x 8GB in-package storage & 1TB/sec memory access b/w no h/w managed cache hierarchy (saves die area, higher compute density) built-in networking (6 bi-directional high-b/w links) separate pipelines for computation and data management Loihi proprietary numeric format Flexpoint in-between floating point and fixed point precision Nervana acquired by Intel in August 2016: renamed the project to Lake Crest later to Nervana NNP, launched in October 17 Loihi test chip w/ self-learning capabilities announced in Sept 17, to be launched in 2018 AJProença, Advanced Architectures, MiEI, UMinho, 2018/ NVidia competitors with neural net features: Intel Nervana Neural Network Processor, NNP
 AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 23 Chip floor")

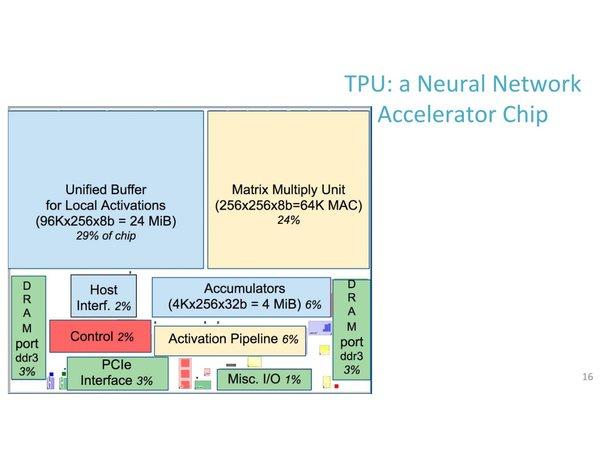
12 NVidia competitors with neural net features: Google Tensor Processing Unit, TPU (April 17) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 23 Chip floor plan NVidia competitors with neural net features: Google Tensor Processing Unit, TPU (April 17) TPUs are intensively used by Google, namely in RankBrain, StreetView & Google Translate AJProença, Advanced Architectures, MiEI, UMinho, 2018/
scalar + vector op capabilities on a single device highly pipelined approach to reduce memory access penalty tightly-closed access to shared memory:")
13 NVidia competitors with neural net features: Google TPUv2 (September 17) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 25 Beyond Vector/SIMD architectures Vector/SIMD-extended architectures are hybrid approaches mix (super)scalar + vector op capabilities on a single device highly pipelined approach to reduce memory access penalty tightly-closed access to shared memory: lower latency Evolution of Vector/SIMD-extended architectures PU (Processing Unit) cores with wider vector units x86 many-core: Intel MIC / Xeon KNL other many-core: IBM Power BlueGene/Q Compute, ShenWay 260 coprocessors (require a host scalar processor): accelerator devices on disjoint physical memories (e.g., Xeon KNC with PCI-Expr, PEZY-SC) ISA-free architectures, code compiled to silica: FPGA focus on SIMT/SIMD to hide memory latency: GPU-type approach focus on tensor/neural nets cores: NVidia, IBM, Intel NNP, Google TPU heterogeneous PUs in a SoC: multicore PUs with GPU-cores x86 multicore coupled with SIMT/SIMD cores: Intel i5/i7 ARMv8 cores coupled with SIMT/SIMD cores: NVidia Tegra AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 26
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA (1 of n*)
") Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
Arquitetura e Organização de Computadores 2
 Arquitetura e Organização de Computadores 2 Paralelismo em Nível de Dados Graphical Processing Units - GPUs Graphical Processing Units Given the hardware invested to do graphics well, how can be supplement
Arquitetura e Organização de Computadores 2 Paralelismo em Nível de Dados Graphical Processing Units - GPUs Graphical Processing Units Given the hardware invested to do graphics well, how can be supplement
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Introduction to CUDA (1 of n*)
") Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Module 2: Introduction to CUDA C
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Module 2: Introduction to CUDA C. Objective
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
Improving Performance of Machine Learning Workloads
 Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
Lecture 5. Performance programming for stencil methods Vectorization Computing with GPUs
 Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
Lecture 2: Introduction to CUDA C
 CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
HPC COMPUTING WITH CUDA AND TESLA HARDWARE. Timothy Lanfear, NVIDIA
 HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COSC 6339 Accelerators in Big Data
 COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
CSE 160 Lecture 24. Graphical Processing Units
 CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
Handout 3. HSAIL and A SIMT GPU Simulator
 Handout 3 HSAIL and A SIMT GPU Simulator 1 Outline Heterogeneous System Introduction of HSA Intermediate Language (HSAIL) A SIMT GPU Simulator Summary 2 Heterogeneous System CPU & GPU CPU GPU CPU wants
Handout 3 HSAIL and A SIMT GPU Simulator 1 Outline Heterogeneous System Introduction of HSA Intermediate Language (HSAIL) A SIMT GPU Simulator Summary 2 Heterogeneous System CPU & GPU CPU GPU CPU wants
VOLTA: PROGRAMMABILITY AND PERFORMANCE. Jack Choquette NVIDIA Hot Chips 2017
 VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
Data Parallel Execution Model
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
General Purpose GPU programming (GP-GPU) with Nvidia CUDA. Libby Shoop
 with Nvidia CUDA. Libby Shoop") General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 30: GP-GPU Programming. Lecturer: Alan Christopher
 Lecture 30: GP-GPU Programming. Lecturer: Alan Christopher") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 30: GP-GPU Programming Lecturer: Alan Christopher Overview GP-GPU: What and why OpenCL, CUDA, and programming GPUs GPU Performance
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 30: GP-GPU Programming Lecturer: Alan Christopher Overview GP-GPU: What and why OpenCL, CUDA, and programming GPUs GPU Performance
Lecture 1: Gentle Introduction to GPUs
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Programmer's View of Execution Teminology Summary
 CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 28: GP-GPU Programming GPUs Hardware specialized for graphics calculations Originally developed to facilitate the use of CAD programs
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 28: GP-GPU Programming GPUs Hardware specialized for graphics calculations Originally developed to facilitate the use of CAD programs
CS 152 Computer Architecture and Engineering. Lecture 16: Graphics Processing Units (GPUs)
") CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Lecture 1: Introduction and Computational Thinking
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2)
") 1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
COMP 322: Fundamentals of Parallel Programming. Flynn s Taxonomy for Parallel Computers
 COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
An Introduction to GPU Architecture and CUDA C/C++ Programming. Bin Chen April 4, 2018 Research Computing Center
 An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
From Application to Technology OpenCL Application Processors Chung-Ho Chen
 From Application to Technology OpenCL Application Processors Chung-Ho Chen Computer Architecture and System Laboratory (CASLab) Department of Electrical Engineering and Institute of Computer and Communication
From Application to Technology OpenCL Application Processors Chung-Ho Chen Computer Architecture and System Laboratory (CASLab) Department of Electrical Engineering and Institute of Computer and Communication
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
Deep Learning Accelerators
 Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Introduction to GPU programming with CUDA
 Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Design of Digital Circuits Lecture 21: GPUs. Prof. Onur Mutlu ETH Zurich Spring May 2017
 Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
GPUs have enormous power that is enormously difficult to use
 524 GPUs GPUs have enormous power that is enormously difficult to use Nvidia GP100-5.3TFlops of double precision This is equivalent to the fastest super computer in the world in 2001; put a single rack
524 GPUs GPUs have enormous power that is enormously difficult to use Nvidia GP100-5.3TFlops of double precision This is equivalent to the fastest super computer in the world in 2001; put a single rack
Spring Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC.
 David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Advanced CUDA Optimization 1. Introduction
 Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA
 Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA Shane Ryoo, Christopher I. Rodrigues, Sara S. Baghsorkhi, Sam S. Stone, David B. Kirk, and Wen-mei H. Hwu
Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA Shane Ryoo, Christopher I. Rodrigues, Sara S. Baghsorkhi, Sam S. Stone, David B. Kirk, and Wen-mei H. Hwu
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
Vector Processors and Graphics Processing Units (GPUs)
") Vector Processors and Graphics Processing Units (GPUs) Many slides from: Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley TA Evaluations Please fill out your
Vector Processors and Graphics Processing Units (GPUs) Many slides from: Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley TA Evaluations Please fill out your
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
L17: CUDA, cont. 11/3/10. Final Project Purpose: October 28, Next Wednesday, November 3. Example Projects
 L17: CUDA, cont. October 28, 2010 Final Project Purpose: - A chance to dig in deeper into a parallel programming model and explore concepts. - Present results to work on communication of technical ideas
L17: CUDA, cont. October 28, 2010 Final Project Purpose: - A chance to dig in deeper into a parallel programming model and explore concepts. - Present results to work on communication of technical ideas
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
General introduction: GPUs and the realm of parallel architectures
 General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
Chapter 3 Parallel Software
 Chapter 3 Parallel Software Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Chapter 3 Parallel Software Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
CS 179 Lecture 4. GPU Compute Architecture
 CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
Real-Time Rendering Architectures
 Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Computer Architecture 计算机体系结构. Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Thread, Multithreading, SMT CMP and multicore Benefits of
Computer Architecture 计算机体系结构 Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Thread, Multithreading, SMT CMP and multicore Benefits of
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
CIS 665: GPU Programming. Lecture 2: The CUDA Programming Model
 CIS 665: GPU Programming Lecture 2: The CUDA Programming Model 1 Slides References Nvidia (Kitchen) David Kirk + Wen-Mei Hwu (UIUC) Gary Katz and Joe Kider 2 3D 3D API: API: OpenGL OpenGL or or Direct3D
CIS 665: GPU Programming Lecture 2: The CUDA Programming Model 1 Slides References Nvidia (Kitchen) David Kirk + Wen-Mei Hwu (UIUC) Gary Katz and Joe Kider 2 3D 3D API: API: OpenGL OpenGL or or Direct3D
GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS
 CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU