GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
|
|
|
- Madeline Lloyd
- 5 years ago
- Views:
Transcription


1 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten



2 NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven
3 Who are we? Anton Wijs Assistant professor, Software Engineering & Technology, TU Eindhoven Developing and integrating formal methods for model driven software engineering Verification of model transformations Automatic generation of (correct) parallel software Accelerating formal methods with multi-/many-threading Muhammad Osama PhD student, Software Engineering & Technology, TU Eindhoven GEARS: GPU Enabled Accelerated Reasoning about System designs GPU Accelerated SAT solving
4 Schedule GPU Computing Tuesday 12 June Afternoon: Intro to GPU computing Wednesday 13 June Morning / Afternoon: Formal verification of GPU software Afternoon: Optimised GPU computing (to perform model checking)
5 Schedule of this afternoon 13:30 14:00 Introduction to GPU Computing 14:00 14:30 High-level intro to CUDA Programming Model 14:30 15:00 1 st Hands-on Session 15:00 15:15 Coffee break 15:15 15:30 Solution to first Hands-on Session 15:30 16:15 CUDA Programming model Part 2 with 2 nd Hands-on Session 16:15 16:40 CUDA Program execution
6 Before we start You can already do the following: Install VirtualBox (virtualbox.org) Download VM file: scp in terminal (Linux/Mac) or with WinSCP (Windows) Password: cuda (10 GB) Or copy from USB stick

7 We will cover approx. first five chapters
8 Introduction to GPU Computing

9 What is a GPU? Graphics Processing Unit The computer chip on a graphics card General Purpose GPU (GPGPU)

10 Graphics in 1980

11 Graphics in 2000

12 Graphics now



 GPUs are a gateway to the")

13 General Purpose Computing Graphics processing units (GPUs) Numerical simulation, media processing, medical imaging, machine learning, Communications of the ACM 59(9):14-16 (sep. 16) GPUs are a gateway to the future of computing Example: deep learning : GPUs dramatically increase performance
14 Compute performance (According to Nvidia)
15 GPUs vs supercomputers?


16 Oak Ridge s Titan Number 3 in top500 list: pflops peak, 8.2 MW power AMD Opteron processors x 16 cores = cores Nvidia Tesla K20X GPUs x 2688 cores = cores

17 CPU vs GPU Hardware Different goals produce different designs GPU assumes work load is highly parallel CPU must be good at everything, parallel or not CPU: minimize latency experienced by 1 thread Big on-chip caches Sophisticated control logic GPU: maximize throughput of all threads Multithreading can hide latency, so no big caches Control logic Much simpler Less: share control logic across many threads Control Core Core Cache Core Core

18 It's all about the memory
19 Many-core architectures From Wikipedia: A many-core processor is a multicore processor in which the number of cores is large enough that traditional multi-processor techniques are no longer efficient largely because of issues with congestion in supplying instructions and data to the many processors.


20 Integration into host system PCI-e 3.0 achieves about 16 GB/s Comparison: GPU device memory bandwidth is 320 GB/s for GTX1080
21 Why GPUs? Performance Large scale parallelism Power Efficiency Use transistors more efficiently #1 in green 500 uses NVIDIA Tesla P100 Price (GPUs) Huge market Mass production, economy of scale Gamers pay for our HPC needs!
22 When to use GPU Computing? When: Thousands or even millions of elements that can be processed in parallel Very efficient for algorithms that: have high arithmetic intensity (lots of computations per element) have regular data access patterns do not have a lot of data dependencies between elements do the same set of instructions for all elements
23 A high-level intro to the CUDA Programming Model
24 CUDA Programming Model Before we start: I m going to explain the CUDA Programming model I ll try to avoid talking about the hardware as much as possible For the moment, make no assumptions about the backend or how the program is executed by the hardware I will be using the term thread a lot, this stands for thread of execution and should be seen as a parallel programming concept. Do not compare them to CPU threads.
25 CUDA Programming Model The CUDA programming model separates a program into a host (CPU) and a device (GPU) part. The host part: allocates memory and transfers data between host and device memory, and starts GPU functions The device part consists of functions that will execute on the GPU, which are called kernels Kernels are executed by huge amounts of threads at the same time The data-parallel workload is divided among these threads The CUDA programming model allows you to code for each thread individually
26 Data management The GPU is located on a separate device The host program manages the allocation and freeing of GPU memory Host program also copies data between different physical memories CPU GPU Host memory Device memory Host PCI Express link Device
27 Thread Hierarchy Kernels are executed in parallel by possibly millions of threads, so it makes sense to try to organize them in some manner Grid (0, 0) (1, 0) (2, 0) (0, 1) (1, 1) (2, 1) Thread block (0,0,0) (1,0,0) (2,0,0) (0,1,0) (1,1,0) (2,1,0) Typical block sizes: 256, 512, 1024
28 Threads In the CUDA programming model a thread is the most fine-grained entity that performs computations Threads direct themselves to different parts of memory using their built-in variables threadidx.x, y, z (thread index within the thread block) Example: Create a single thread block of N threads: Effectively the loop is unrolled and spread across N threads Single Instruction Multiple Data (SIMD) principle
29 Thread blocks Threads are grouped in thread blocks, allowing you to work on problems larger than the maximum thread block size Thread blocks are also numbered, using the built-in variables containing the index of each block within the grid. Total number of threads created is always a multiple of the thread block size, possibly not exactly equal to the problem size Other built-in variables are used to describe the thread block dimensions and grid dimensions
30 Mapping to hardware
31 Starting a kernel The host program sets the number of threads and thread blocks when it launches the kernel
32 CUDA function declarations device float DeviceFunc() global void KernelFunc() host float HostFunc() defines a kernel function Each consists of two underscore characters A kernel function must return and can be used together is optional if used alone
 or with WinSCP (Windows) Password: cuda2018 https://tinyurl.")
33 Setup hands-on session You can already do the following: Install VirtualBox (virtualbox.org) Download VM file: scp in terminal (Linux/Mac) or with WinSCP (Windows) Password: cuda (10 GB) Or copy from USB stick

34 Setup hands-on session Import file as Appliance in VirtualBox Start the machine Login name: gpuser Login password: cuda2018 Launch NSight

35 First hands-on session Start with project vector_add in left pane Configure: right click vector_add -> Properties; go to Build -> Target Systems -> Manage Also update Project Path

36 First hands-on session Configure: go to Run/Debug Settings. Click the configuration -> Edit. Select the remote connection, and set Remote executable folder Do these steps for the four projects in the left pane, and restart Nsight
37 1 st Hands-on Session Make sure you understand everything in the code, and complete the exercise! Hints: Look at how the kernel is launched in the host program is the thread index within the thread block is the block index within the grid is the dimension of the thread block
38 Hint blockidx.x thread block 0 thread block 1 thread block 2 threadidx.x blockdim.x?
39 Solution CPU implementation: GPU implementation: Create a N threads using multiple thread blocks: Single Instruction Multiple Data (SIMD) principle
40 CUDA Programming model Part 2




")
41 CUDA memory hierarchy Registers Thread Shared memory Thread Block Global memory Constant memory Grid (0, 0) (1, 0)

42 Hardware overview
43 Memory space: Registers Example: Registers Thread-local scalars or small constant size arrays are stored as registers Implicit in the programming model Behavior is very similar to normal local variables Not persistent, after the kernel has finished, values in registers are lost
44 Memory space: Global Example: Global memory Allocated by the host program using Initialized by the host program using or previous kernels Persistent, the values in global memory remain across kernel invocations Not coherent, writes by other threads will not be visible until kernel has finished
45 Memory space: Constant Constant memory Statically defined by the host program using qualifier Defined as a global variable Initialized by the host program using Read-only to the GPU, cannot be accessed directly by the host Values are cached in a special cache optimized for broadcast access by multiple threads simultaneously, access should not depend on
46 2 nd Hands-on Session Go to project reduction, look at the source files Make sure you understand everything in the code Task: Implement the kernel to perform a single iteration of parallel reduction Hints: It is assumed that enough threads are launched such that each thread only needs to compute the sum of two elements in the input array In each iteration, an array of size n is reduced into an array of size n/2 Each thread stores it result at a designated position in the output array
47 Hint Parallel Summation
48 Global synchronisation CUDA has no mechanism to indicate global synchronisation of all threads across the grid Instead, enforce synchronisation points by breaking down computation into multiple kernel launches Kernel launch 0 Kernel launch 1 Kernel launch 2 Kernel launch 3 Kernel launch 4
49 Barrier synchronisation Two forms: Global synchronisation: achieved between kernel launches Intra-block synchronisation: Contrary to global synchronisation, CUDA does provide a mechanism to synchronise all threads in the same block All threads in the same block must reach the before any of them can move on Best used to split up computation of each block in several phases Tightly linked to use of (block-local) shared memory, which we will address tomorrow afternoon
50 CUDA Program execution

51 Compilation CUDA program PTX assembly CUBIN bytecode Nvidia Compiler nvcc Machine-level binary Runtime compiler driver
52 Translation table CUDA OpenCL OpenACC OpenMP 4 Grid NDRange compute region parallel region Thread block Work group Gang Team Warp CL_KERNEL_PREFERRED _WORK_GROUP_SIZE_MU LTIPLE Worker SIMD Chunk Thread Work item Vector Thread or SIMD Note that for the mapping is actually implementation dependent for the open standards and may differ across computing platforms Not too sure about the OpenMP 4 naming scheme, please correct me if wrong
53 How threads are executed Remember: all threads in a CUDA kernel execute the exact same program Threads are actually executed in groups of (32) threads called warps (more on this tomorrow afternoon) Threads within a warp all execute one common instruction simultaneously The context of each thread is stored separately, as such the GPU stores the context of all currently active threads The GPU can switch between warps even after executing only 1 instruction, effectively hiding the long latency of instructions such as memory loads

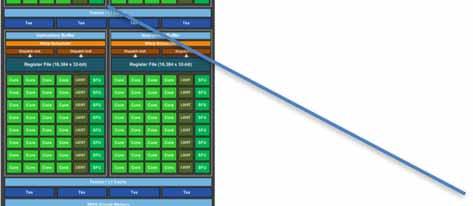

54 Maxwell Architecture Streaming multiprocessor (SM) 32 core block



55 Maxwell Architecture Register file block of 32 cores L1 Cache L1 Cache Shared memory

56 Resource partitioning The GPU consists of several (1 to 56) streaming multiprocessors (SMs) The SMs are fully independent Each SM contains several resources: Thread and Thread Block slots, Register file, and Shared memory SM Resources are dynamically partitioned among the thread blocks that execute concurrently on the SM, resulting in a certain occupancy Thread slots Register file Shared memory

57 Global Memory access Global memory is cached at L2, and for some GPUs also in L1 SM SM When a thread reads a value from global memory, think about: The total number of values that are accessed by the warp that the thread belongs to The cache line length and the number of cache lines that those values will belong to Alignment of the data accesses to that of the cache lines L1 L1 L2 GPU Device memory
58 Cached memory access The memory hierarchy is optimized for certain access patterns CPU All memory accesses happen through the cache Main memory Memory is optimized for reading in (rowwise) bursts Cache Cache fetches memory at the granularity of cache-lines
59 Overview Proving correctness tomorrow morning / afternoon! CUDA Programming model (API) threads Think in terms of threads Reason on program correctness warps GPU Hardware Think in terms of warps Reason on program performance Tomorrow in Part 2 of GPU Development!
60 To do: setup the VerCors tool See basic build: Clone the VerCors repository: Move into the cloned directory: Build VerCors with Ant: Test build: If this fails, there will be a VM with VerCors available tomorrow Do NOT delete your VM with Nsight, as we will use it again tomorrow afternoon!
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
GPU Programming Using NVIDIA CUDA
 GPU Programming Using NVIDIA CUDA Siddhante Nangla 1, Professor Chetna Achar 2 1, 2 MET s Institute of Computer Science, Bandra Mumbai University Abstract: GPGPU or General-Purpose Computing on Graphics
GPU Programming Using NVIDIA CUDA Siddhante Nangla 1, Professor Chetna Achar 2 1, 2 MET s Institute of Computer Science, Bandra Mumbai University Abstract: GPGPU or General-Purpose Computing on Graphics
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Reductions and Low-Level Performance Considerations CME343 / ME May David Tarjan NVIDIA Research
 Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Introduction to CUDA programming
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
GPU programming: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
CS 179 Lecture 4. GPU Compute Architecture
 CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
INTRODUCTION TO GPU COMPUTING WITH CUDA. Topi Siro
 INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
Learn CUDA in an Afternoon. Alan Gray EPCC The University of Edinburgh
 Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
Lecture 1: an introduction to CUDA
 Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
Introduction to GPU programming with CUDA
 Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Lecture 11: GPU programming
 Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
GPU 101. Mike Bailey. Oregon State University. Oregon State University. Computer Graphics gpu101.pptx. mjb April 23, 2017
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
GPU 101. Mike Bailey. Oregon State University
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Improving Performance of Machine Learning Workloads
 Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
Fundamental Optimizations
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer
 CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
GPU & High Performance Computing (by NVIDIA) CUDA. Compute Unified Device Architecture Florian Schornbaum
 CUDA. Compute Unified Device Architecture Florian Schornbaum") GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Recent Advances in Heterogeneous Computing using Charm++
 Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
CUDA Parallelism Model
 GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
Scientific Computing on GPUs: GPU Architecture Overview
 Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Parallel Systems Course: Chapter IV. GPU Programming. Jan Lemeire Dept. ETRO November 6th 2008
 Parallel Systems Course: Chapter IV GPU Programming Jan Lemeire Dept. ETRO November 6th 2008 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing Overview 1.
Parallel Systems Course: Chapter IV GPU Programming Jan Lemeire Dept. ETRO November 6th 2008 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing Overview 1.
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
CUDA Experiences: Over-Optimization and Future HPC
 CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
Supporting Data Parallelism in Matcloud: Final Report
 Supporting Data Parallelism in Matcloud: Final Report Yongpeng Zhang, Xing Wu 1 Overview Matcloud is an on-line service to run Matlab-like script on client s web browser. Internally it is accelerated by
Supporting Data Parallelism in Matcloud: Final Report Yongpeng Zhang, Xing Wu 1 Overview Matcloud is an on-line service to run Matlab-like script on client s web browser. Internally it is accelerated by
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Profiling of Data-Parallel Processors
 Profiling of Data-Parallel Processors Daniel Kruck 09/02/2014 09/02/2014 Profiling Daniel Kruck 1 / 41 Outline 1 Motivation 2 Background - GPUs 3 Profiler NVIDIA Tools Lynx 4 Optimizations 5 Conclusion
Profiling of Data-Parallel Processors Daniel Kruck 09/02/2014 09/02/2014 Profiling Daniel Kruck 1 / 41 Outline 1 Motivation 2 Background - GPUs 3 Profiler NVIDIA Tools Lynx 4 Optimizations 5 Conclusion
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES. Stephen Jones, GTC 2017
 CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES Stephen Jones, GTC 2017 The art of doing more with less 2 Performance RULE #1: DON T TRY TOO HARD Peak Performance Time 3 Unrealistic Effort/Reward Performance
CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES Stephen Jones, GTC 2017 The art of doing more with less 2 Performance RULE #1: DON T TRY TOO HARD Peak Performance Time 3 Unrealistic Effort/Reward Performance
 By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
OpenACC. Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer
 OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
Lecture 1: Introduction and Computational Thinking
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
Dense Linear Algebra. HPC - Algorithms and Applications
 Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler
 GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Sparse Linear Algebra in CUDA
 Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
Cartoon parallel architectures; CPUs and GPUs
 Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort
 Rob van Nieuwpoort") PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted: