Pipelined Datapath. Reading. Sections Practice Problems: 1, 3, 8, 12
|
|
|
- Clarissa Newton
- 5 years ago
- Views:
Transcription
1 Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections Practice Problems:, 3, 8, 2 ing Note: Appendices A-E in the hardcopy text correspond to chapters 7- in the online text. (2)
 Pipeline Performance Single-cycle (T c = 8ps) Pipelined (T c= 2ps) (4)")
2 Assume time for stages is Pipeline Performance ps for register read or write 2ps for other stages Compare pipelined path with singlecycle path Instr Instr fetch Register read ALU op emory access Register write Total time lw 2ps ps 2ps 2ps ps 8ps sw 2ps ps 2ps 2ps 7ps R-format 2ps ps 2ps ps 6ps beq 2ps ps 2ps 5ps (3) Pipeline Performance Single-cycle (T c = 8ps) Pipelined (T c= 2ps) (4) 2
 does not decrease (5) Basic Idea All instructions are 32-bits Few & regular instruction formats Alignment of memory operands")
3 Pipeline Speedup If all stages are balanced i.e., all take the same time Inter instruction gap pipelined = Inter instruction gap nonpipelined number of stages If not balanced, speedup is less Speedup due to increased throughput Latency (time for each instruction) does not decrease (5) Basic Idea All instructions are 32-bits Few & regular instruction formats Alignment of memory operands (6) 3

4 What makes it easy All instructions are the same length Pipelining Simple instruction formats emory operands appear only in loads and stores What makes it hard? structural hazards: suppose we had only one memory control hazards: need to worry about branch instructions hazards: an instruction depends on a preious instruction What really makes it hard: exception handling trying to improe performance with out-of-order execution, etc. (7) Need registers between stages Pipeline registers To hold information produced in preious cycle Pipeline stage execution time (8) 4
5 Graphically Representing Pipelines Time lw IF ID EX E WB add IF ID EX E WB Shading indicates the unit is being used by the instruction Shading on the right half of the register file (ID or WB) or memory means the element is being read in that stage Shading on the left half means the element is being written in that stage (9) Graphically Representing Pipelines Program execution order (in instructions) lw$, 2($) Time (in clockcycles) CC CC2 CC3 CC4 CC5 CC6 I Reg ALU D Reg sub $, $2, $3 I Reg ALU D Reg Can help with answering questions like: how many cycles does it take to execute this code? what is the ALU doing during cycle 4? use this representation to help understand paths () 5
 IF for Load, Store, Pipeline stage execution time (2)")
6 Structural Hazard Time lw IF ID EX E WB add IF ID EX E WB sub IF ID EX E WB add IF ID EX E WB Need to separate instruction and memory () IF for Load, Store, Pipeline stage execution time (2) 6
 EX for Load Pipeline stage execution time (4)")
7 ID for Load, Store, Pipeline stage execution time (3) EX for Load Pipeline stage execution time (4) 7
 WB for Load Wrong register number (6)")
8 E for Load Pipeline stage execution time (5) WB for Load Wrong register number (6) 8

 9")
9 Corrected Datapath for Load Pipeline stage execution time (7) EX for Store Pipeline stage execution time (8) 9

")
10 E for Store Pipeline stage execution time (9) WB for Store Pipeline stage execution time (2)

![Pipeline stage execution time memory register register 2 Registers 2 register [2 6] [5 ] 6 Sign](/docs-images/96/127723494/images/11-1.jpg "extend 32 u x u x RegDst Zero ALU ALU result ress Data memory (2) Pipelined Control")
11 Pipelining Example add $4, $5, $6 lw $3, 24($) add $2, $3, $4 sub $, $2, $3 lw $, 2($) u x Note what is happening in the register file IF/ID ID/EX EX/E E/WB 4 result Shift left 2 PC ress Pipeline stage execution time memory register register 2 Registers 2 register [2 6] [5 ] 6 Sign extend 32 u x u x RegDst Zero ALU ALU result ress Data memory (2) Pipelined Control (Simplified) (22)




12 Pipelined Control Execution/ress Calculation stage control lines emory access stage control lines -back stage control lines Reg Dst ALU Op ALU Op ALU Src Branch em em Reg write em to Reg R-format lw sw X X beq X X Control signals deried from instruction As in single-cycle implementation Pass control signals along like (23) Pipelined Control (24) 2
13 Datapath with Control IF: lw $, 9($) PCSrc Control ID/EX WB EX/E WB E/WB IF/ID EX WB PC 4 ress memory register Reg register 2 Registers 2 register Shift left 2 result ALUSrc Zero ALU ALU result Branch ress Data memory em emtoreg [5 ] 6 32 Sign extend 6 ALU control em [2 6] [5 ] RegDst ALUOp (25) Datapath with Control IF: sub $, $2, $3 ID: lw $, 9($) PCSrc lw ID/EX WB Control EX/E WB E/WB IF/ID E X WB PC 4 ress memory register Reg register 2 Registers 2 register Shift left 2 result ALUSrc Zero ALU ALU result Branch ress Data memory em emtoreg [5 ] 6 32 Sign extend 6 ALU control em [2 6] [5 ] RegDst ALUOp (26) 3
14 Datapath with Control IF: and $2, $4, $5 PCSrc ID: sub $, $2, $3 EX: lw $, 9($) IF/ID sub ID/EX WB Control EX EX/E WB E/WB WB PC 4 ress memory register Reg register 2 Registers 2 register Shift left 2 result ALUSrc Zero ALU ALU result Branch ress Data memory em emtoreg [5 ] 6 32 Sign extend 6 ALU control em [2 6] [5 ] RegDst ALUOp (27) Datapath with Control IF: or $3, $6, $7 PCSrc ID: and $2, $4, $5 EX: sub $, $2, $3 E: lw $, 9($) IF/ID and ID/EX WB Control EX EX/E WB E/WB WB PC 4 ress memory register Reg register 2 Registers 2 register Shift left 2 result ALUSrc Zero ALU ALU result Branch ress Data memory em emtoreg [5 ] 6 32 Sign extend 6 ALU control em [2 6] [5 ] RegDst ALUOp (28) 4
15 Datapath with Control IF: add $4, $8, $9 PCSrc ID: or $3, $6, $7 EX: and $2, $4, $5 E: sub $,.. WB: lw $, 9($) IF/ID or ID/EX WB Control EX EX/E WB E/WB WB PC 4 ress memory register Reg register 2 Registers 2 register Shift left 2 result ALUSrc Zero ALU ALU result Branch ress Data memory em emtoreg [5 ] 6 32 Sign extend 6 ALU control em [2 6] [5 ] RegDst ALUOp (29) Datapath with Control IF: xxxx PCSrc ID: add $4, $8, $9 EX: or $3, $6, $7 E: and $2 WB: sub $,.. IF/ID add ID/EX WB Control EX EX/E WB E/WB WB PC 4 ress memory register Reg register 2 Registers 2 register Shift left 2 result ALUSrc Zero ALU ALU result Branch ress Data memory em emtoreg [5 ] 6 32 Sign extend 6 ALU control em [2 6] [5 ] RegDst ALUOp (3) 5
16 Datapath with Control IF: xxxx PCSrc ID: xxxx EX: add $4, $8, $9 E: or $3,.. WB: and $2 IF/ID Control ID/EX WB EX EX/E WB E/WB WB PC 4 ress memory register Reg register 2 Registers 2 register Shift left 2 result ALUSrc Zero ALU ALU result Branch ress Data memory em emtoreg [5 ] 6 32 Sign extend 6 ALU control em [2 6] [5 ] RegDst ALUOp (3) Datapath with Control IF: xxxx PCSrc ID: xxxx EX: xxxx E: add $4,.. WB: or $3 IF/ID Control ID/EX WB EX EX/E WB E/WB WB PC 4 ress memory register Reg register 2 Registers 2 register Shift left 2 result ALUSrc Zero ALU ALU result Branch ress Data memory em emtoreg [5 ] 6 32 Sign extend 6 ALU control em [2 6] [5 ] RegDst ALUOp (32) 6

![left 2 result ALUSrc Zero ALU ALU result Branch ress Data memory em emtoreg [5 ] 6 32 Sign extend 6 ALU control em](/docs-images/96/127723494/images/17-1.jpg "[2 6] [5 ] RegDst ALUOp (33) Data Hazards (4.")
17 Datapath with Control IF: xxxx PCSrc ID: xxxx EX: xxxx E: xxxx WB: add $4.. IF/ID Control ID/EX WB EX EX/E WB E/WB WB PC 4 ress memory register Reg register 2 Registers 2 register Shift left 2 result ALUSrc Zero ALU ALU result Branch ress Data memory em emtoreg [5 ] 6 32 Sign extend 6 ALU control em [2 6] [5 ] RegDst ALUOp (33) Data Hazards (4.7) An instruction depends on completion of access by a preious instruction add $s, $t, $t sub $t2, $s, $t3 (34) 7
18 Problem with starting next instruction before first is finished Dependencies dependencies that go backward in time are hazards Time (in clock cycles) Value of register $2: Program execution order (in instructions) sub $2, $, $3 CC CC 2 CC 3 CC 4 CC 5 CC 6 I Reg CC 7 CC 8 CC 9 / D Reg and $2, $2, $5 I Reg D Reg or $3, $6, $2 I Reg D Reg add $4, $2, $2 I Reg D Reg sw $5, ($2) I Reg D Reg (35) Hae compiler guarantee no hazards Where do we insert the nops? sub $2, $, $3 and $2, $2, $5 or $3, $6, $2 add $4, $2, $2 sw $5, ($2) Software Solution Problem: this really slows us down! (36) 8
19 A Better Solution Consider this sequence: sub $2, $,$3 and $2,$2,$5 or $3,$6,$2 add $4,$2,$2 sw $5,($2) We can resole hazards with forwarding How do we detect when to forward? (37) Dependencies & Forwarding Do not wait for results to be written to the register file find them in the pipeline à forward to ALU (38) 9
20 Forwarding IF: add $4, $8, $9 PCSrc ID: or $3, $6, $7 EX: and $6, $4, $5 E: sub $,.. WB: lw $, 9($) IF/ID or ID/EX WB Control EX EX/E WB E/WB WB PC 4 ress memory register Reg register 2 Registers 2 register Shift left 2 result ALUSrc Zero ALU ALU result Branch ress Data memory em emtoreg [5 ] 6 32 Sign extend 6 ALU control em [2 6] [5 ] RegDst ALUOp (39) Forwarding (simplified) ID/EX EX/E E/WB Register File ALU Data emory UX (4) 2
21 Forwarding (from EX/E) ID/EX EX/E E/WB UX Register File ALU UX Data emory UX (4) Forwarding (from E/WB) ID/EX EX/E E/WB UX Register File ALU UX Data emory UX (42) 2
22 Forwarding (operand selection) ID/EX EX/E E/WB UX Register File ALU UX Data emory UX Forwarding Unit (43) Forwarding (operand propagation) ID/EX EX/E E/WB Register File UX ALU UX Data emory UX Rd Rt UX Rt Rs Forwarding Unit EX/E Rd E/WB Rd Combinational Logic! (44) 22
23 Detecting the Need to Forward Pass register numbers along pipeline e.g., ID/EX.RegisterRs = register number for Rs sitting in ID/EX pipeline register ALU operand register numbers in EX stage are gien by ID/EX.RegisterRs, ID/EX.RegisterRt Data hazards when a. EX/E.RegisterRd = ID/EX.RegisterRs b. EX/E.RegisterRd = ID/EX.RegisterRt Fwd from EX/E pipeline reg 2a. E/WB.RegisterRd = ID/EX.RegisterRs 2b. E/WB.RegisterRd = ID/EX.RegisterRt Fwd from E/WB pipeline reg (45) Detecting the Need to Forward But only if forwarding instruction will write to a register! EX/E.Reg, E/WB.Reg And only if Rd for that instruction is not $zero EX/E.RegisterRd, E/WB.RegisterRd (46) 23
 and (E/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = if (E/WB.Reg and (E/WB.RegisterRd ) and (E/WB.RegisterRd = ID/EX.RegisterRt)) ForwardB = (48) 24")
24 Forwarding Paths (47) Forwarding Conditions EX hazard if (EX/E.Reg and (EX/E.RegisterRd ) and (EX/E.RegisterRd = ID/EX.RegisterRs)) ForwardA = if (EX/E.Reg and (EX/E.RegisterRd ) and (EX/E.RegisterRd = ID/EX.RegisterRt)) ForwardB = E hazard if (E/WB.Reg and (E/WB.RegisterRd ) and (E/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = if (E/WB.Reg and (E/WB.RegisterRd ) and (E/WB.RegisterRd = ID/EX.RegisterRt)) ForwardB = (48) 24
25 Consider the sequence: add $,$,$2 add $,$,$3 add $,$,$4 Both hazards occur Want to use the most recent Double Data Hazard Reise E hazard condition Only forward if EX hazard condition isn t true (49) E hazard Reised Forwarding Condition if (E/WB.Reg and (E/WB.RegisterRd ) and not (EX/E.Reg and (EX/E.RegisterRd ) and (EX/E.RegisterRd = ID/EX.RegisterRs)) and (E/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = if (E/WB.Reg and (E/WB.RegisterRd ) and not (EX/E.Reg and (EX/E.RegisterRd ) and (EX/E.RegisterRd = ID/EX.RegisterRt)) and (E/WB.RegisterRd = ID/EX.RegisterRt)) ForwardB = Checking precedence of EX hazard (5) 25

 We will come across other types of")
26 Datapath with Forwarding (5) Concurrent Execution Correct execution is about managing dependencies Producer-consumer Structural (using the same hardware component) We will come across other types of dependencies later! (52) 26
27 Load-Use Data Hazard Need to stall for one cycle (53) Forwarding IF: add $4, $8, $9 PCSrc ID: or $3, $6, $7 EX: and $6, $4, $ E: lw $, ($2) WB: lw $, 9($) IF/ID or ID/EX WB Control EX EX/E WB E/WB WB PC 4 ress memory register Reg register 2 Registers 2 register Shift left 2 result ALUSrc Zero ALU ALU result Branch ress Data memory em emtoreg [5 ] 6 32 Sign extend 6 ALU control em [2 6] [5 ] RegDst ALUOp (54) 27
28 Load-Use Hazard Detection Check when using instruction is decoded in ID stage ALU operand register numbers in ID stage are gien by IF/ID.RegisterRs, IF/ID.RegisterRt Load-use hazard when ID/EX.em and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or (ID/EX.RegisterRt = IF/ID.RegisterRt)) If detected, stall and insert bubble (55) Code Scheduling to Aoid Stalls Reorder code to aoid use of load result in the next instruction C code for A = B + E; C = B + F; stall stall lw $t, ($t) lw $t2, 4($t) add $t3, $t, $t2 sw $t3, 2($t) lw $t4, 8($t) add $t5, $t, $t4 sw $t5, 6($t) 3 cycles lw $t, ($t) lw $t2, 4($t) lw $t4, 8($t) add $t3, $t, $t2 sw $t3, 2($t) add $t5, $t, $t4 sw $t5, 6($t) cycles (56) 28
 Stall/Bubble in the Pipeline Stall inserted here (58)")
29 How to Stall the Pipeline Force control alues in ID/EX register to EX, E and WB perform a nop (no-operation) Preent update of PC and IF/ID register Using instruction is decoded again Following instruction is fetched again -cycle stall allows E to read for lw o Can subsequently forward to EX stage (57) Stall/Bubble in the Pipeline Stall inserted here (58) 29
 Datapath with")

30 Stall/Bubble in the Pipeline Or, more accurately (59) Datapath with Hazard Detection Pipeline stage execution time ALUSrc m is missing! (6) 3
 Branch instruction determines flow of control Fetching next instruction depends on branch")
 Branch Hazards If")
31 Control Hazards (4.8) Branch instruction determines flow of control Fetching next instruction depends on branch outcome Pipeline cannot always fetch correct instruction o Still working on ID stage of branch In IPS pipeline Need to compare registers and determine the branch condition (6) Branch Hazards If branch outcome determined in E Flush these instructions (Set control alues to ) PC (62) 3

32 Reducing Branch Delay oe hardware to determine outcome to ID stage Target address adder Register comparator IF.Flush signal to squash IF/ID register Example: branch taken 36: sub $, $4, $8 4: beq $, $3, 72 44: and $2, $2, $5 48: or $3, $2, $6 52: add $4, $4, $2 56: slt $5, $6, $ : lw $4, 5($7) (63) Example: Branch Taken (64) 32


33 Example: Branch Taken (65) Data Hazards for Branches If a comparison register is a destination of 2 nd or 3 rd preceding ALU instruction add $, $2, $3 IF ID EX E WB add $4, $5, $6 IF ID EX E WB IF ID EX E WB beq $, $4, target IF ID EX E WB n Can resole using forwarding to ID n Need to add forwarding logic! (66) 33
34 Data Hazards for Branches If a comparison register is a destination of preceding ALU instruction or 2 nd preceding load instruction Need stall cycle lw $, addr add $4, $5, $6 IF ID EX E WB IF ID EX E WB beq stalled IF ID beq $, $4, target ID EX E WB (67) Data Hazards for Branches If a comparison register is a destination of immediately preceding load instruction Need 2 stall cycles lw $, addr IF ID EX E WB beq stalled IF ID beq stalled ID beq $, $, target ID EX E WB (68) 34
35 Delay Slot (IPS) Expose pipeline Load and jump/branch entail a delay slot The instruction right after the jump or branch is executed before the jump/branch jal add lw function_a $4, $5, $6 ; executed before jmp $2, 8($4) ; executed after return Jump/branch and the delay slot instruction are considered indiisible In the delay slot, the compiler needs to schedule A useful instruction (either before the jmp, or after the jmp w/o side effect) otherwise a NOP (69) Branch Prediction Longer pipelines cannot readily determine branch outcome early Stall penalty becomes unacceptable Predict outcome of branch Only stall if prediction is wrong In IPS pipeline Can predict branches not taken Fetch instruction after branch, with no delay (7) 35


36 IPS with Predict Not Taken Prediction correct Prediction incorrect (7) -Bit Predictor: Shortcoming Inner loop branches mispredicted twice! outer: inner: beq,, inner beq,, outer n n ispredict as taken on last iteration of inner loop Then mispredict as not taken on first iteration of inner loop next time around (72) 36

37 2-Bit Predictor: State achine Only change prediction on two successie mispredictions (73) ore-realistic Branch Prediction Static branch prediction Based on typical branch behaior Example: loop and if-statement branches o Predict backward branches taken o Predict forward branches not taken Dynamic branch prediction Hardware measures actual branch behaior o e.g., record recent history of each branch Assume future behaior will continue the trend o When wrong, stall while re-fetching, and update history (74) 37
 Later in")
 Intel Sandy Bridge bdti.")
38 AD Bobcat ECE 6 Later in this course ECE 6 Leel Parallelism (ILP) Later in this course (75) Intel Sandy Bridge bdti.com (76) 38
39 Exceptions and Interrupts (4.9) Unexpected eents requiring change in flow of control Different ISAs use the terms differently Exception Arises within the CPU o e.g., undefined opcode, oerflow, syscall, Interrupt From an external I/O controller Updates to the path Recording the cause of the exception and transferring control to the OS Consider the impact of hardware modifications on the critical path (77) Handling Exceptions In IPS, exceptions managed by a System Control Coprocessor (CP) Sae PC of offending (or interrupted) instruction In IPS: Exception Program Counter (EPC) Sae indication of the problem In IPS: Cause register We ll assume -bit o for undefined opcode, for oerflow Jump to handler at 88 (78) 39
40 Exception Handling: Operations two registers to the path EPC and Cause registers a state for each exception condition Use the ALU to compute the EPC contents the Cause register with exception condition Update the PC with OS handler address Generate control signals for each operation See Appendix A.7 for details of IPS 2/3 implementation (79) The OS Interactions The IPS 32 Status and Cause Registers Status Register Interrupt ask User mode Excep leel int enable Cause Register Branch Delay Pending Interrupts Exception Code Operating System handlers interrogate these registers anage all state saing requirements example in A.7 (8) 4
41 An Alternate echanism Vectored Interrupts Handler address determined by the cause Example: Undefined opcode: C Oerflow: C 2 : C 4 s either Deal with the interrupt, or Jump to real handler (8) Handler Actions cause, and transfer to releant handler Determine action required If restartable Take correctie action use EPC to return to program Otherwise Terminate program Report error using EPC, cause, (82) 4

 Pipeline with Exceptions")
42 Another form of control hazard Exceptions in a Pipeline Consider oerflow on add in EX stage add $, $2, $ Preent $ from being clobbered Complete preious instructions Flush add and subsequent instructions Set Cause and EPC register alues Transfer control to handler Similar to mispredicted branch Use much of the same hardware (83) Pipeline with Exceptions (84) 42
43 Exception Properties Restartable exceptions Pipeline can flush the instruction Handler executes, then returns to the instruction o Re-fetched and executed from scratch PC saed in EPC register Identifies causing instruction Actually PC + 4 is saed o Handler must adjust (85) Exception Example Exception on add in 4 sub $, $2, $4 44 and $2, $2, $5 48 or $3, $2, $6 4C add $, $2, $ 5 slt $5, $6, $7 54 lw $6, 5($7) Handler 88 sw $25, ($) 884 sw $26, 4($) (86) 43

 44")
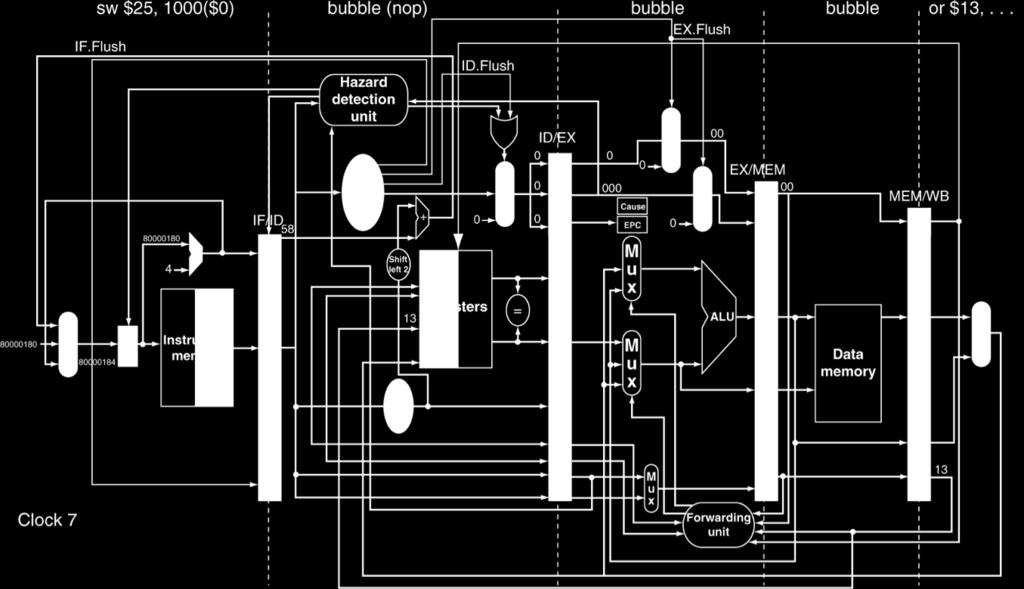
44 Exception Example (87) Exception Example (88) 44
45 ultiple Exceptions Pipelining oerlaps multiple instructions Could hae multiple exceptions at once Simple approach: deal with exception from earliest instruction Flush subsequent instructions Precise exceptions In complex pipelines ultiple instructions issued per cycle Out-of-order completion aintaining precise exceptions is difficult! (89) Just stop pipeline and sae state Including exception cause(s) Let the handler work out Which instruction(s) had exceptions Which to complete or flush o ay require manual completion Imprecise Exceptions Simplifies hardware, but more complex handler software Not feasible for complex multiple-issue out-of-order pipelines (9) 45
46 Performance How do we assess the impact of stall cycles? How close do we approach the ideal of one instruction per cycle execution time? Back to the CPI model! (9) Recall: Program Execution time Number of instruction classes # n & ExecutionTime = % C i CPI ( i= i cycle_time $ % '( ~= _count * CPI ag * clock_cycle_time algorithms/compiler architecture technology Clock Cycles CPI ag = Count = n i= " CPI i Count % i $ ' # Count & Relatie frequency (92) 46
47 Study Guide Gien a code block, and initial register alues (those that are accessed) be able to determine state of all pipeline registers at some future clock cycle. Determine the size of each pipeline register Track pipeline state in the case of forwarding and branches Compute the number of cycles to execute a code block odify the path to include forwarding and hazard detection for branches (this is trickier and time consuming but well worth it) (93) Study Guide (cont.) Schedule code (manually) to improe performance, for example to eliminate hazards and fill delay slots odify the path to add new instructions such as j odify the path to accommodate a two cycle memory access, i.e., the memory itself is a two cycle pipeline odify the forwarding and hazard control logic Gien a code sequence, be able to compute the number of stall cycles (94) 47
48 Study Guide (cont.) Track the state of the 2-bit branch predictor oer a sequence of branches in a code segment, for example a for-loop Show the pipeline state before and after an exception has taken place. (95) Glossary Branch prediction Branch hazards Branch delay Control hazard Data hazard Delay slot Dynamic instruction issue Forwarding Imprecise exception scheduling leel parallelism (ILP) Load-to-use hazard Pipeline bubbles Stall cycles Static instruction issue Structural hazard (96) 48
Pipelined Datapath. Reading. Sections Practice Problems: 1, 3, 8, 12 (2) Lecture notes from MKP, H. H. Lee and S.
 Lecture notes from MKP, H. H. Lee and S.") Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing (2) Pipeline Performance Assume time for stages is ps for register read or write
Pipelined Datapath Lecture notes from KP, H. H. Lee and S. Yalamanchili Sections 4.5 4. Practice Problems:, 3, 8, 2 ing (2) Pipeline Performance Assume time for stages is ps for register read or write
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Pipelining Analogy. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop: Speedup = 8/3.5 = 2.3.
 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Processor (II) - pipelining. Hwansoo Han
 - pipelining. Hwansoo Han") Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
The Processor (3) Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University") The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Chapter 4. The Processor
 Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Chapter 4 The Processor 1. Chapter 4B. The Processor
 Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
EIE/ENE 334 Microprocessors
 EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Outline. A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception
 hazards Exception") Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
The Processor: Improving the performance - Control Hazards
 The Processor: Improving the performance - Control Hazards Wednesday 14 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary
The Processor: Improving the performance - Control Hazards Wednesday 14 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary
Chapter 4. The Processor
 Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 (Part II) Sequential Laundry
 Sequential Laundry") Chapter 4 (Part II) The Processor Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Sequential Laundry 6 P 7 8 9 10 11 12 1 2 A T a s k O r d e r A B C D 30 30 30 30 30 30 30 30 30 30
Chapter 4 (Part II) The Processor Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Sequential Laundry 6 P 7 8 9 10 11 12 1 2 A T a s k O r d e r A B C D 30 30 30 30 30 30 30 30 30 30
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
Chapter 4. The Processor. Jiang Jiang
 Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
What do we have so far? Multi-Cycle Datapath (Textbook Version)
") What do we have so far? ulti-cycle Datapath (Textbook Version) CPI: R-Type = 4, Load = 5, Store 4, Branch = 3 Only one instruction being processed in datapath How to lower CPI further? #1 Lec # 8 Summer2001
What do we have so far? ulti-cycle Datapath (Textbook Version) CPI: R-Type = 4, Load = 5, Store 4, Branch = 3 Only one instruction being processed in datapath How to lower CPI further? #1 Lec # 8 Summer2001
PS Midterm 2. Pipelining
 PS idterm 2 Pipelining Seqential Landry 6 P 7 8 9 idnight Time T a s k O r d e r A B C D 3 4 2 3 4 2 3 4 2 3 4 2 Seqential landry takes 6 hors for 4 loads If they learned pipelining, how long wold landry
PS idterm 2 Pipelining Seqential Landry 6 P 7 8 9 idnight Time T a s k O r d e r A B C D 3 4 2 3 4 2 3 4 2 3 4 2 Seqential landry takes 6 hors for 4 loads If they learned pipelining, how long wold landry
14:332:331 Pipelined Datapath
 14:332:331 Pipelined Datapath I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Inst 4 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be timed to accommodate
14:332:331 Pipelined Datapath I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 Inst 4 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be timed to accommodate
Improve performance by increasing instruction throughput
 Improve performance by increasing instruction throughput Program execution order Time (in instructions) lw $1, 100($0) fetch 2 4 6 8 10 12 14 16 18 ALU Data access lw $2, 200($0) 8ns fetch ALU Data access
Improve performance by increasing instruction throughput Program execution order Time (in instructions) lw $1, 100($0) fetch 2 4 6 8 10 12 14 16 18 ALU Data access lw $2, 200($0) 8ns fetch ALU Data access
TDT4255 Friday the 21st of October. Real world examples of pipelining? How does pipelining influence instruction
 Review Friday the 2st of October Real world eamples of pipelining? How does pipelining pp inflence instrction latency? How does pipelining inflence instrction throghpt? What are the three types of hazard
Review Friday the 2st of October Real world eamples of pipelining? How does pipelining pp inflence instrction latency? How does pipelining inflence instrction throghpt? What are the three types of hazard
Pipelining. Ideal speedup is number of stages in the pipeline. Do we achieve this? 2. Improve performance by increasing instruction throughput ...
 CHAPTER 6 1 Pipelining Instruction class Instruction memory ister read ALU Data memory ister write Total (in ps) Load word 200 100 200 200 100 800 Store word 200 100 200 200 700 R-format 200 100 200 100
CHAPTER 6 1 Pipelining Instruction class Instruction memory ister read ALU Data memory ister write Total (in ps) Load word 200 100 200 200 100 800 Store word 200 100 200 200 700 R-format 200 100 200 100
Lecture Topics. Announcements. Today: Data and Control Hazards (P&H ) Next: continued. Exam #1 returned. Milestone #5 (due 2/27)
 Next: continued. Exam #1 returned. Milestone #5 (due 2/27)") Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
T = I x CPI x C. Both effective CPI and clock cycle C are heavily influenced by CPU design. CPI increased (3-5) bad Shorter cycle good
 bad Shorter cycle good") CPU performance equation: T = I x CPI x C Both effective CPI and clock cycle C are heavily influenced by CPU design. For single-cycle CPU: CPI = 1 good Long cycle time bad On the other hand, for multi-cycle
CPU performance equation: T = I x CPI x C Both effective CPI and clock cycle C are heavily influenced by CPU design. For single-cycle CPU: CPI = 1 good Long cycle time bad On the other hand, for multi-cycle
The Processor. Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut. CSE3666: Introduction to Computer Architecture
 The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
1 Hazards COMP2611 Fall 2015 Pipelined Processor
 1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Chapter 4. The Processor
 Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
CENG 3420 Lecture 06: Pipeline
 CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor? Chapter 4 The Processor 2 Introduction We will learn How the ISA determines many aspects
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor? Chapter 4 The Processor 2 Introduction We will learn How the ISA determines many aspects
Chapter 4 The Processor 1. Chapter 4A. The Processor
 Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
ECE260: Fundamentals of Computer Engineering
 Data Hazards in a Pipelined Datapath James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Data
Data Hazards in a Pipelined Datapath James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Data
MIPS An ISA for Pipelining
 Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
COMP2611: Computer Organization. The Pipelined Processor
 COMP2611: Computer Organization The 1 2 Background 2 High-Performance Processors 3 Two techniques for designing high-performance processors by exploiting parallelism: Multiprocessing: parallelism among
COMP2611: Computer Organization The 1 2 Background 2 High-Performance Processors 3 Two techniques for designing high-performance processors by exploiting parallelism: Multiprocessing: parallelism among
DEE 1053 Computer Organization Lecture 6: Pipelining
 Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
ECE Exam II - Solutions November 8 th, 2017
 ECE 3056 Exam II - Solutions November 8 th, 2017 1. (15 pts) To the base pipeline we add data forwarding to EX, data hazard detection and stall generation, and branches implemented in MEM and predicted
ECE 3056 Exam II - Solutions November 8 th, 2017 1. (15 pts) To the base pipeline we add data forwarding to EX, data hazard detection and stall generation, and branches implemented in MEM and predicted
Lecture 8: Data Hazard and Resolution. James C. Hoe Department of ECE Carnegie Mellon University
 18 447 Lecture 8: Data Hazard and Resolution James C. Hoe Department of ECE Carnegie ellon University 18 447 S18 L08 S1, James C. Hoe, CU/ECE/CALC, 2018 Your goal today Housekeeping detect and resolve
18 447 Lecture 8: Data Hazard and Resolution James C. Hoe Department of ECE Carnegie ellon University 18 447 S18 L08 S1, James C. Hoe, CU/ECE/CALC, 2018 Your goal today Housekeeping detect and resolve
LECTURE 9. Pipeline Hazards
 LECTURE 9 Pipeline Hazards PIPELINED DATAPATH AND CONTROL In the previous lecture, we finalized the pipelined datapath for instruction sequences which do not include hazards of any kind. Remember that
LECTURE 9 Pipeline Hazards PIPELINED DATAPATH AND CONTROL In the previous lecture, we finalized the pipelined datapath for instruction sequences which do not include hazards of any kind. Remember that
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Chapter Six. Dataı access. Reg. Instructionı. fetch. Dataı. Reg. access. Dataı. Reg. access. Dataı. Instructionı fetch. 2 ns 2 ns 2 ns 2 ns 2 ns
 Chapter Si Pipelining Improve perfomance by increasing instruction throughput eecutionı Time lw $, ($) 2 6 8 2 6 8 access lw $2, 2($) 8 ns access lw $3, 3($) eecutionı Time lw $, ($) lw $2, 2($) 2 ns 8
Chapter Si Pipelining Improve perfomance by increasing instruction throughput eecutionı Time lw $, ($) 2 6 8 2 6 8 access lw $2, 2($) 8 ns access lw $3, 3($) eecutionı Time lw $, ($) lw $2, 2($) 2 ns 8
Lecture 9 Pipeline and Cache
 Lecture 9 Pipeline and Cache Peng Liu liupeng@zju.edu.cn 1 What makes it easy Pipelining Review all instructions are the same length just a few instruction formats memory operands appear only in loads
Lecture 9 Pipeline and Cache Peng Liu liupeng@zju.edu.cn 1 What makes it easy Pipelining Review all instructions are the same length just a few instruction formats memory operands appear only in loads
Lecture 9. Pipeline Hazards. Christos Kozyrakis Stanford University
 Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
5 th Edition. The Processor We will examine two MIPS implementations A simplified version A more realistic pipelined version
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
Comp 303 Computer Architecture A Pipelined Datapath Control. Lecture 13
 Comp 33 Compter Architectre A Pipelined path Lectre 3 Pipelined path with Signals PCSrc IF/ ID ID/ EX EX / E E / Add PC 4 Address Instrction emory RegWr ra rb rw Registers bsw [5-] [2-6] [5-] bsa bsb Sign
Comp 33 Compter Architectre A Pipelined path Lectre 3 Pipelined path with Signals PCSrc IF/ ID ID/ EX EX / E E / Add PC 4 Address Instrction emory RegWr ra rb rw Registers bsw [5-] [2-6] [5-] bsa bsb Sign
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining
 Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Designing a Pipelined CPU
 Designing a Pipelined CPU CSE 4, S2'6 Review -- Single Cycle CPU CSE 4, S2'6 Review -- ultiple Cycle CPU CSE 4, S2'6 Review -- Instruction Latencies Single-Cycle CPU Load Ifetch /Dec Exec em Wr ultiple
Designing a Pipelined CPU CSE 4, S2'6 Review -- Single Cycle CPU CSE 4, S2'6 Review -- ultiple Cycle CPU CSE 4, S2'6 Review -- Instruction Latencies Single-Cycle CPU Load Ifetch /Dec Exec em Wr ultiple
Computer Organization and Structure
 Computer Organization and Structure 1. Assuming the following repeating pattern (e.g., in a loop) of branch outcomes: Branch outcomes a. T, T, NT, T b. T, T, T, NT, NT Homework #4 Due: 2014/12/9 a. What
Computer Organization and Structure 1. Assuming the following repeating pattern (e.g., in a loop) of branch outcomes: Branch outcomes a. T, T, NT, T b. T, T, T, NT, NT Homework #4 Due: 2014/12/9 a. What
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 27: Midterm2 review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Midterm 2 Review Midterm will cover Section 1.6: Processor
ECE331: Hardware Organization and Design Lecture 27: Midterm2 review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Midterm 2 Review Midterm will cover Section 1.6: Processor
Processor Design CSCE Instructor: Saraju P. Mohanty, Ph. D. NOTE: The figures, text etc included in slides are borrowed
 Lecture 3: General Purpose Processor Design CSCE 665 Advanced VLSI Systems Instructor: Saraju P. ohanty, Ph. D. NOTE: The figures, tet etc included in slides are borrowed from various books, websites,
Lecture 3: General Purpose Processor Design CSCE 665 Advanced VLSI Systems Instructor: Saraju P. ohanty, Ph. D. NOTE: The figures, tet etc included in slides are borrowed from various books, websites,
Solutions for Chapter 6 Exercises
 Soltions for Chapter 6 Eercises Soltions for Chapter 6 Eercises 6. 6.2 a. Shortening the ALU operation will not affect the speedp obtained from pipelining. It wold not affect the clock cycle. b. If the
Soltions for Chapter 6 Eercises Soltions for Chapter 6 Eercises 6. 6.2 a. Shortening the ALU operation will not affect the speedp obtained from pipelining. It wold not affect the clock cycle. b. If the
ECS 154B Computer Architecture II Spring 2009
 ECS 154B Computer Architecture II Spring 2009 Pipelining Datapath and Control 6.2-6.3 Partially adapted from slides by Mary Jane Irwin, Penn State And Kurtis Kredo, UCD Pipelined CPU Break execution into
ECS 154B Computer Architecture II Spring 2009 Pipelining Datapath and Control 6.2-6.3 Partially adapted from slides by Mary Jane Irwin, Penn State And Kurtis Kredo, UCD Pipelined CPU Break execution into
Advanced Computer Architecture Pipelining
 Advanced Computer Architecture Pipelining Dr. Shadrokh Samavi Some slides are from the instructors resources which accompany the 6 th and previous editions of the textbook. Some slides are from David Patterson,
Advanced Computer Architecture Pipelining Dr. Shadrokh Samavi Some slides are from the instructors resources which accompany the 6 th and previous editions of the textbook. Some slides are from David Patterson,
Lecture 6: Pipelining
 Lecture 6: Pipelining i CSCE 26 Computer Organization Instructor: Saraju P. ohanty, Ph. D. NOTE: The figures, text etc included in slides are borrowed from various books, websites, authors pages, and other
Lecture 6: Pipelining i CSCE 26 Computer Organization Instructor: Saraju P. ohanty, Ph. D. NOTE: The figures, text etc included in slides are borrowed from various books, websites, authors pages, and other
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard
 Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
CSE 2021 Computer Organization. Hugh Chesser, CSEB 1012U W12-M
 CSE 22 Computer Organization Hugh Chesser, CSEB 2U W2- Graphical Representation Time 2 6 8 add $s, $t, $t IF ID E E Decode / Execute emory Back fetch from / stage into the instruction register file. Shading
CSE 22 Computer Organization Hugh Chesser, CSEB 2U W2- Graphical Representation Time 2 6 8 add $s, $t, $t IF ID E E Decode / Execute emory Back fetch from / stage into the instruction register file. Shading
COMPUTER ORGANIZATION AND DESIGN
 ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some
ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some
1048: Computer Organization
 8: Compter Organization Lectre 6 Pipelining Lectre6 - pipelining (cwli@twins.ee.nct.ed.tw) 6- Otline An overview of pipelining A pipelined path Pipelined control Data hazards and forwarding Data hazards
8: Compter Organization Lectre 6 Pipelining Lectre6 - pipelining (cwli@twins.ee.nct.ed.tw) 6- Otline An overview of pipelining A pipelined path Pipelined control Data hazards and forwarding Data hazards
Lecture 2: Processor and Pipelining 1
 The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
Instruction word R0 R1 R2 R3 R4 R5 R6 R8 R12 R31
 4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
ECE154A Introduction to Computer Architecture. Homework 4 solution
 ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
cs470 - Computer Architecture 1 Spring 2002 Final Exam open books, open notes
 1 of 7 ay 13, 2002 v2 Spring 2002 Final Exam open books, open notes Starts: 7:30 pm Ends: 9:30 pm Name: (please print) ID: Problem ax points Your mark Comments 1 10 5+5 2 40 10+5+5+10+10 3 15 5+10 4 10
1 of 7 ay 13, 2002 v2 Spring 2002 Final Exam open books, open notes Starts: 7:30 pm Ends: 9:30 pm Name: (please print) ID: Problem ax points Your mark Comments 1 10 5+5 2 40 10+5+5+10+10 3 15 5+10 4 10
EE557--FALL 1999 MAKE-UP MIDTERM 1. Closed books, closed notes
 NAME: STUDENT NUMBER: EE557--FALL 1999 MAKE-UP MIDTERM 1 Closed books, closed notes Q1: /1 Q2: /1 Q3: /1 Q4: /1 Q5: /15 Q6: /1 TOTAL: /65 Grade: /25 1 QUESTION 1(Performance evaluation) 1 points We are
NAME: STUDENT NUMBER: EE557--FALL 1999 MAKE-UP MIDTERM 1 Closed books, closed notes Q1: /1 Q2: /1 Q3: /1 Q4: /1 Q5: /15 Q6: /1 TOTAL: /65 Grade: /25 1 QUESTION 1(Performance evaluation) 1 points We are
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards
 CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
Processor (I) - datapath & control. Hwansoo Han
 - datapath & control. Hwansoo Han") Processor (I) - datapath & control Hwansoo Han Introduction CPU performance factors Instruction count - Determined by ISA and compiler CPI and Cycle time - Determined by CPU hardware We will examine two
Processor (I) - datapath & control Hwansoo Han Introduction CPU performance factors Instruction count - Determined by ISA and compiler CPI and Cycle time - Determined by CPU hardware We will examine two
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
EC 413 Computer Organization - Fall 2017 Problem Set 3 Problem Set 3 Solution
 EC 413 Computer Organization - Fall 2017 Problem Set 3 Problem Set 3 Solution Important guidelines: Always state your assumptions and clearly explain your answers. Please upload your solution document
EC 413 Computer Organization - Fall 2017 Problem Set 3 Problem Set 3 Solution Important guidelines: Always state your assumptions and clearly explain your answers. Please upload your solution document
Chapter 3 & Appendix C Pipelining Part A: Basic and Intermediate Concepts
 CS359: Compter Architectre Chapter 3 & Appendi C Pipelining Part A: Basic and Intermediate Concepts Yanyan Shen Department of Compter Science and Engineering Shanghai Jiao Tong University 1 Otline Introdction
CS359: Compter Architectre Chapter 3 & Appendi C Pipelining Part A: Basic and Intermediate Concepts Yanyan Shen Department of Compter Science and Engineering Shanghai Jiao Tong University 1 Otline Introdction
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
Lecture 4: Review of MIPS. Instruction formats, impl. of control and datapath, pipelined impl.
 Lecture 4: Review of MIPS Instruction formats, impl. of control and datapath, pipelined impl. 1 MIPS Instruction Types Data transfer: Load and store Integer arithmetic/logic Floating point arithmetic Control
Lecture 4: Review of MIPS Instruction formats, impl. of control and datapath, pipelined impl. 1 MIPS Instruction Types Data transfer: Load and store Integer arithmetic/logic Floating point arithmetic Control
Improving Performance: Pipelining
 Improving Performance: Pipelining Memory General registers Memory ID EXE MEM WB Instruction Fetch (includes PC increment) ID Instruction Decode + fetching values from general purpose registers EXE EXEcute
Improving Performance: Pipelining Memory General registers Memory ID EXE MEM WB Instruction Fetch (includes PC increment) ID Instruction Decode + fetching values from general purpose registers EXE EXEcute
CS 251, Winter 2019, Assignment % of course mark
 CS 251, Winter 2019, Assignment 5.1.1 3% of course mark Due Wednesday, March 27th, 5:30PM Lates accepted until 1:00pm March 28th with a 15% penalty 1. (10 points) The code sequence below executes on a
CS 251, Winter 2019, Assignment 5.1.1 3% of course mark Due Wednesday, March 27th, 5:30PM Lates accepted until 1:00pm March 28th with a 15% penalty 1. (10 points) The code sequence below executes on a
Basic Instruction Timings. Pipelining 1. How long would it take to execute the following sequence of instructions?
 Basic Instruction Timings Pipelining 1 Making some assumptions regarding the operation times for some of the basic hardware units in our datapath, we have the following timings: Instruction class Instruction
Basic Instruction Timings Pipelining 1 Making some assumptions regarding the operation times for some of the basic hardware units in our datapath, we have the following timings: Instruction class Instruction
Basic Pipelining Concepts
 Basic ipelining oncepts Appendix A (recommended reading, not everything will be covered today) Basic pipelining ipeline hazards Data hazards ontrol hazards Structural hazards Multicycle operations Execution
Basic ipelining oncepts Appendix A (recommended reading, not everything will be covered today) Basic pipelining ipeline hazards Data hazards ontrol hazards Structural hazards Multicycle operations Execution
EE557--FALL 1999 MIDTERM 1. Closed books, closed notes
 NAME: SOLUTIONS STUDENT NUMBER: EE557--FALL 1999 MIDTERM 1 Closed books, closed notes GRADING POLICY: The front page of your exam shows your total numerical score out of 75. The highest numerical score
NAME: SOLUTIONS STUDENT NUMBER: EE557--FALL 1999 MIDTERM 1 Closed books, closed notes GRADING POLICY: The front page of your exam shows your total numerical score out of 75. The highest numerical score
CS 251, Winter 2018, Assignment % of course mark
 CS 251, Winter 2018, Assignment 5.0.4 3% of course mark Due Wednesday, March 21st, 4:30PM Lates accepted until 10:00am March 22nd with a 15% penalty 1. (10 points) The code sequence below executes on a
CS 251, Winter 2018, Assignment 5.0.4 3% of course mark Due Wednesday, March 21st, 4:30PM Lates accepted until 10:00am March 22nd with a 15% penalty 1. (10 points) The code sequence below executes on a
What do we have so far? Multi-Cycle Datapath
 What do we have so far? lti-cycle Datapath CPI: R-Type = 4, Load = 5, Store 4, Branch = 3 Only one instrction being processed in datapath How to lower CPI frther? #1 Lec # 8 Spring2 4-11-2 Pipelining pipelining
What do we have so far? lti-cycle Datapath CPI: R-Type = 4, Load = 5, Store 4, Branch = 3 Only one instrction being processed in datapath How to lower CPI frther? #1 Lec # 8 Spring2 4-11-2 Pipelining pipelining
Pipelined Processor Design
 Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Indian Institute of Science Bangalore virendra@computer.org Lecture 20 SE-273: Processor Design Courtesy: Prof. Vishwani Agrawal
Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Indian Institute of Science Bangalore virendra@computer.org Lecture 20 SE-273: Processor Design Courtesy: Prof. Vishwani Agrawal
Lecture 7 Pipelining. Peng Liu.
 Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Single Cycle Datapath
 Single Cycle atapath Lecture notes from MKP, H. H. Lee and S. Yalamanchili Section 4.1-4.4 Appendices B.3, B.7, B.8, B.11,.2 ing Note: Appendices A-E in the hardcopy text correspond to chapters 7-11 in
Single Cycle atapath Lecture notes from MKP, H. H. Lee and S. Yalamanchili Section 4.1-4.4 Appendices B.3, B.7, B.8, B.11,.2 ing Note: Appendices A-E in the hardcopy text correspond to chapters 7-11 in