Shared Task Introduction
|
|
|
- Andrew Hardy
- 5 years ago
- Views:
Transcription
1 Shared Task Introduction Learning Machine Learning Nils Reiter September 26-27, 2018 Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
2 Outline Shared Tasks Data and Annotations Hackatorial Setup Concrete steps Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
3 Shared Tasks Shared Tasks Established framework in NLP Driver of innovation in the past decade (e.g., machine translation) Competitive, winners are highly respected Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
4 Shared Tasks Shared Tasks Established framework in NLP Driver of innovation in the past decade (e.g., machine translation) Competitive, winners are highly respected Past STs Chunking Sang and Buchholz (2000) Clause identification Sang and Déjean (2001) Language-independent named entity recognition Tjong Kim Sang and De Meulder (2003) Syntactic parsing either multilingually or for specific languages Buchholz and Marsi (2006), Kübler (2008), and Nivre et al. (2007) semantic representation/role labeling Bos (2008), Carreras and Màrquez (2004), and Carreras and Màrquez (2005) Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
5 Shared Tasks Shared Tasks Workflow Organizers define a task and provide a data set with annotations Participants develop (automatic) systems to solve the task 2: Previously unknown test data is published (without annotations), participants apply their systems to this data set 1: Participants upload/send the results of their systems to the organizers : Organizers evaluate each system s results against a (secret) gold standard, results are published + 1: Gold standard is published, papers written, workshops held Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
6 Data and Annotations Section 2 Data and Annotations Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
7 Data and Annotations Corpus Title Description Werther Goethe s ; pistolary novel, published 1774/1787 Bundestagsdebatten Debates from the German federal parliament; stenographic minutes Parzival Middle High German Arthurian Romance; written 12th/13th century CE; verse Table: Corpus overview Heterogeneous with respect to content and form German/Middle High German Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
8 Data and Annotations Background: Research interests Werther (Modern German Literature) Successful novel, a large number of adaptations have been published What makes a Werther adaptation ( Wertheriade ) recognizable as an adaptation (e.g., Wertherness?) Three characters in a triadic relationship (Werther, Lotte, Albert) Importance of nature (e.g., certain lakes or forest clearings) Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
9 Data and Annotations Background: Research interests Werther (Modern German Literature) Successful novel, a large number of adaptations have been published What makes a Werther adaptation ( Wertheriade ) recognizable as an adaptation (e.g., Wertherness?) Three characters in a triadic relationship (Werther, Lotte, Albert) Importance of nature (e.g., certain lakes or forest clearings) Parliamentary debates (Social Sciences) Relation of armed conflicts and identity building Who mentions which institution in what context? Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
10 Data and Annotations Background: Research interests Werther (Modern German Literature) Successful novel, a large number of adaptations have been published What makes a Werther adaptation ( Wertheriade ) recognizable as an adaptation (e.g., Wertherness?) Three characters in a triadic relationship (Werther, Lotte, Albert) Importance of nature (e.g., certain lakes or forest clearings) Parliamentary debates (Social Sciences) Relation of armed conflicts and identity building Who mentions which institution in what context? Parzival 16 volumes, many characters and places Social relations between characters and/or places Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
11 Data and Annotations Background: Research Interests Common interest CRETA works on methods/concepts/workflows that are relevant for multiple disciplines/research questions In this case: Entities! Werther: Characters and locations Parliamentary debates: Persons, organizations, locations, dates Parzival: Characters and locations Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
12 Data and Annotations Annotations Conceptual Overview Text Figure: Entity references and entities Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
13 Data and Annotations Annotations Conceptual Overview Text World Figure: Entity references and entities Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
14 Data and Annotations Annotations Conceptual Overview Persons Locations Text World Figure: Entity references and entities Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
15 Data and Annotations Annotations Guidelines Entity references Proper names ( Werther ) Appellative noun phrases ( the knight ) if they refer Groups: the two knights Addresses: My dear friend Generic expressions: the chancellor is elected by the parliament Pronouns are Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
16 Data and Annotations Annotations Guidelines How do we annotate? Maximal noun phrases, including relative clauses: the chancellor, who has in Berlin at this time appositions: Wilhelm, my friend If determiner and preposition are contracted, the contracted form is included in [dem Land], [im Land] Embedded phrases are annotated [Wolfram von [Eschenbach] LOC ] PER ST data: Only the longest annotation matters Entity type is annotated in context I always wanted to go to [Europe] LOC. [Europe] ORG is forcing Greece to take a hard austerity course. Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
17 Data and Annotations Annotations Examples Text Classes Examples Werther Bundestagsdebatten Parzival Person Werther, liebster Wilhelm, die Kinder aus dem Dorfe Location Die Schweiz, dem Dorfe Work Emilia Galotti Person Location Organization Person Location Angela Merkel, die Abgeordneten Großbritannien, das Land, Europa SPD, die Union, Europa Parzival, der ritter, die tafelrunde Nantes, der wald Brazilian, der palas Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
18 Data and Annotations Annotations Text-specific properties Werther 1878: old language Epistolary novel: First-person narrator Emotional style: Long sentences, interjections, Bundestagsdebatten Non-narrative text, logged direct speech Contemporary text: Style and content Parzival Middle High German Proper nouns are upper cased Almost all other words are lower cased Segmentation in 30 verses: Each first row upper case Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
19 Data and Annotations Annotations and Data Summary Three text types with different properties Annotated entity references (according to guidelines) Files are split into training and test set Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
20 Hackatorial Setup Section 3 Hackatorial Setup Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
21 Hackatorial Setup Hackatorial Overview test evaluation Mary 0.4 Peter 0.6 upload results feature set train train.py test.py prints accuracy, log files, errors edit inspect Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
22 Hackatorial Setup Hackatorial Playground options Choose a data set Werther, Parzival, Bundestagsdebatten Choose a classifier Decision tree, naive bayes Edit the feature set Turn features on/off, add additional features Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
23 Hackatorial Setup Concrete steps Hackatorial Navigate to the correct folder Where did you save the hackatorial folder? Open a Terminal/Eingabeaufforderung Use cd path/to/hackatorial/code to navigate into the folder Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
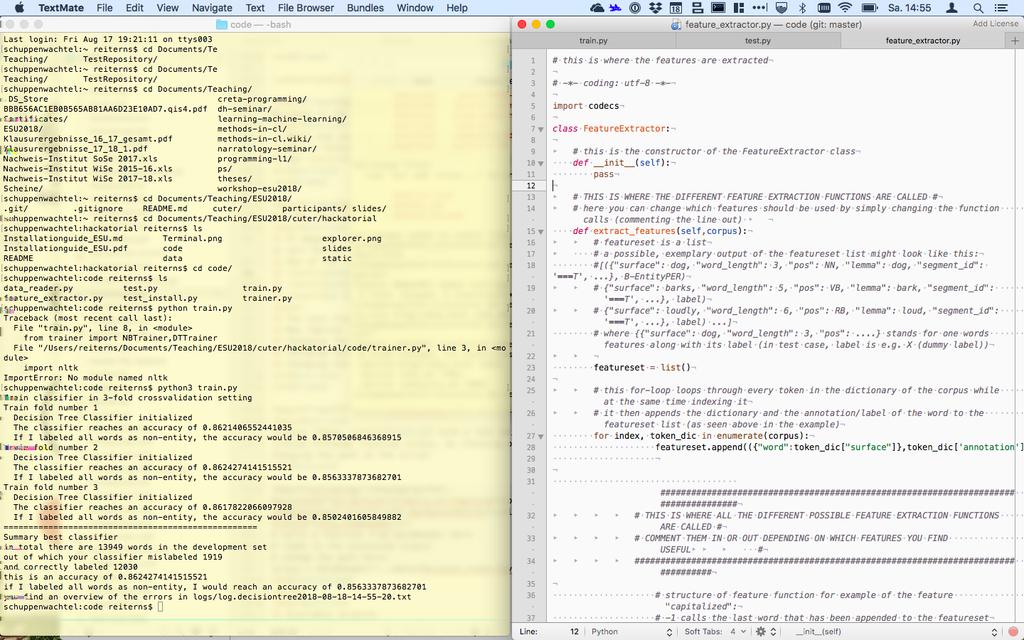

24
25 Hackatorial Setup Concrete steps Hackatorial Run the train script using Python It depends on your operating system and version, but you can try the following commands to call Python: py, python, python3 One of the following should work: python train.py python3 train.py py train.py Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
26 Hackatorial Setup Concrete steps Hackatorial Run the train script using Python It depends on your operating system and version, but you can try the following commands to call Python: py, python, python3 One of the following should work: python train.py python3 train.py py train.py You just trained your first machine learning model! Now improve its performance by Changing the data set Changing the algorithm Changing the feature set Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
27 Hackatorial Setup Concrete steps Hackatorial How to change the data set tep 1 Open train.py with a text editor (e.g. Notepad++) tep 2 Change training corpus, by choosing one of the available corpora listed below and changing the path in the script # calls a function from DataReader here # reads in the annotated corpus # change the path here: corpus = DataReader("../ data/parzival_train.tsv"). read_corpus() Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
28 Hackatorial Setup Concrete steps Hackatorial How to change the data set tep 1 Open train.py with a text editor (e.g. Notepad++) tep 2 Change training corpus, by choosing one of the available corpora listed below and changing the path in the script # calls a function from DataReader here # reads in the annotated corpus # change the path here: corpus = DataReader("../ data/parzival_train.tsv"). read_corpus() Available corpora: Parzival_train.tsv Werther_train.tsv Bundestag_train.tsv Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
29 Hackatorial Setup Concrete steps Hackatorial How to change the features tep 1 Open feature_extractor.py with a text editor tep 2 Comment or uncomment the features Commenting out (disable): Putting a # in front of the line Uncomment (enable the feature): Removing the #... #################################################################################### # THIS IS WHERE ALL THE DIFFERENT POSSIBLE FEATURE EXTRACTION FUNCTIONS ARE CALLED # # COMMENT THEM IN OR OUT DEPENDING ON WHICH FEATURES YOU FIND USEFUL # #################################################################################### # structure of feature function for example of the feature "capitalized": # -1 calls the last word that has been appended to the featureset # 0 accesses the dictionary which is the first element of the tupel # "capitalized" is the feature name featureset[-1][0]["pos"] = self.pos(token_dic) #featureset[-1][0]["surface"] = self.surface(token_dic) #featureset[-1][0]["surface_backwards"] = self.surface_backwards(token_dic)... The full feature list is available as a PDF (with examples). Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
30 Hackatorial Setup Concrete steps Hackatorial What do features mean? Available features and their meaning are listed in the table that you got on paper and further below in feature_extractor.py ##################################################################### # THESE ARE ALL THE DIFFERENT POSSIBLE FEATURE EXTRACTION FUNCTIONS # ##################################################################### # This function returns the part of speech tag of the word def pos(self, word_dic): return word_dic["pos"] # This function returns the word itself def surface(self, word_dic): return word_dic["surface"] # This function returns the word backwards def surface_backwards(self, word_dic): return word_dic["surface"][::-1]... Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
31 Hackatorial Setup Concrete steps Hackatorial How to change the training algorithm tep 1 Open train.py with a text editor tep 2 Comment out one of the lines starting with trainer = # THIS IS WHERE YOU CAN CHANGE THE ML ALGORITHM# # change this line for another ML algorithm (remove the # infront of a line to uncomment) # DTTrainer is the trainer for a Decision Tree classifier # NBTrainer is the trainer for a Naive Bayes classifier # trainer = DTTrainer(traincv) #trainer = NBTrainer(traincv) Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
32 Hackatorial Setup Concrete steps Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
33 Hackatorial Setup Concrete steps References I Bos, Johan. Introduction to the Shared Task on Comparing Semantic Representations. In:. Ed. by Johan Bos and Rodolfo Delmonte. Vol. 1. Research in Computational Semantics. College Publications, 2008, pp Buchholz, Sabine and Erwin Marsi. CoNLL-X Shared Task on Multilingual Dependency Parsing. In:. New York City: Association for Computational Linguistics, June 2006, pp Carreras, Xavier and Lluís Màrquez. Introduction to the CoNLL-2004 Shared Task: Semantic Role Labeling. In:. Ed. by Hwee Tou Ng and Ellen Riloff. Boston, Massachusetts, USA: Association for Computational Linguistics, May 2004, pp Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
34 Hackatorial Setup Concrete steps References II Carreras, Xavier and Lluıś Màrquez. Introduction to the CoNLL-2005 Shared Task: Semantic Role Labeling. In:. Ann Arbor, Michigan: Association for Computational Linguistics, June 2005, pp Kübler, Sandra. The PaGe 2008 Shared Task on Parsing German. In:. Columbus, Ohio: Association for Computational Linguistics, June 2008, pp Nivre, Joakim, Johan Hall, Sandra Kübler, Ryan McDonald, Jens Nilsson, Sebastian Riedel, and Deniz Yuret. The CoNLL 2007 Shared Task on Dependency Parsing. In:. Prague, Czech Republic: Association for Computational Linguistics, June 2007, pp Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
35 Hackatorial Setup Concrete steps References III Sang, Erik F. Tjong Kim and Sabine Buchholz. Introduction to the CoNLL-2000 Shared Task: Chunking. In:. Lisbon, Portugal: Association for Computational Linguistics, Sept Sang, Erik F. Tjong Kim and Hervé Déjean. Introduction to the CoNLL-2001 shared task: clause identification. In: Tjong Kim Sang, Erik F. and Fien De Meulder. Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition. In:. Ed. by Walter Daelemans and Miles Osborne. 2003, pp Nils Reiter (CRETA) Shared Task Introduction September 26-27, / 28
Managing a Multilingual Treebank Project
 Managing a Multilingual Treebank Project Milan Souček Timo Järvinen Adam LaMontagne Lionbridge Finland {milan.soucek,timo.jarvinen,adam.lamontagne}@lionbridge.com Abstract This paper describes the work
Managing a Multilingual Treebank Project Milan Souček Timo Järvinen Adam LaMontagne Lionbridge Finland {milan.soucek,timo.jarvinen,adam.lamontagne}@lionbridge.com Abstract This paper describes the work
Hybrid Combination of Constituency and Dependency Trees into an Ensemble Dependency Parser
 Hybrid Combination of Constituency and Dependency Trees into an Ensemble Dependency Parser Nathan David Green and Zdeněk Žabokrtský Charles University in Prague Institute of Formal and Applied Linguistics
Hybrid Combination of Constituency and Dependency Trees into an Ensemble Dependency Parser Nathan David Green and Zdeněk Žabokrtský Charles University in Prague Institute of Formal and Applied Linguistics
A Quick Guide to MaltParser Optimization
 A Quick Guide to MaltParser Optimization Joakim Nivre Johan Hall 1 Introduction MaltParser is a system for data-driven dependency parsing, which can be used to induce a parsing model from treebank data
A Quick Guide to MaltParser Optimization Joakim Nivre Johan Hall 1 Introduction MaltParser is a system for data-driven dependency parsing, which can be used to induce a parsing model from treebank data
Introduction to Data-Driven Dependency Parsing
 Introduction to Data-Driven Dependency Parsing Introductory Course, ESSLLI 2007 Ryan McDonald 1 Joakim Nivre 2 1 Google Inc., New York, USA E-mail: ryanmcd@google.com 2 Uppsala University and Växjö University,
Introduction to Data-Driven Dependency Parsing Introductory Course, ESSLLI 2007 Ryan McDonald 1 Joakim Nivre 2 1 Google Inc., New York, USA E-mail: ryanmcd@google.com 2 Uppsala University and Växjö University,
An Adaptive Framework for Named Entity Combination
 An Adaptive Framework for Named Entity Combination Bogdan Sacaleanu 1, Günter Neumann 2 1 IMC AG, 2 DFKI GmbH 1 New Business Department, 2 Language Technology Department Saarbrücken, Germany E-mail: Bogdan.Sacaleanu@im-c.de,
An Adaptive Framework for Named Entity Combination Bogdan Sacaleanu 1, Günter Neumann 2 1 IMC AG, 2 DFKI GmbH 1 New Business Department, 2 Language Technology Department Saarbrücken, Germany E-mail: Bogdan.Sacaleanu@im-c.de,
Dependency Parsing. Ganesh Bhosale Neelamadhav G Nilesh Bhosale Pranav Jawale under the guidance of
 Dependency Parsing Ganesh Bhosale - 09305034 Neelamadhav G. - 09305045 Nilesh Bhosale - 09305070 Pranav Jawale - 09307606 under the guidance of Prof. Pushpak Bhattacharyya Department of Computer Science
Dependency Parsing Ganesh Bhosale - 09305034 Neelamadhav G. - 09305045 Nilesh Bhosale - 09305070 Pranav Jawale - 09307606 under the guidance of Prof. Pushpak Bhattacharyya Department of Computer Science
TectoMT: Modular NLP Framework
 : Modular NLP Framework Martin Popel, Zdeněk Žabokrtský ÚFAL, Charles University in Prague IceTAL, 7th International Conference on Natural Language Processing August 17, 2010, Reykjavik Outline Motivation
: Modular NLP Framework Martin Popel, Zdeněk Žabokrtský ÚFAL, Charles University in Prague IceTAL, 7th International Conference on Natural Language Processing August 17, 2010, Reykjavik Outline Motivation
A Multilingual Social Media Linguistic Corpus
 A Multilingual Social Media Linguistic Corpus Luis Rei 1,2 Dunja Mladenić 1,2 Simon Krek 1 1 Artificial Intelligence Laboratory Jožef Stefan Institute 2 Jožef Stefan International Postgraduate School 4th
A Multilingual Social Media Linguistic Corpus Luis Rei 1,2 Dunja Mladenić 1,2 Simon Krek 1 1 Artificial Intelligence Laboratory Jožef Stefan Institute 2 Jožef Stefan International Postgraduate School 4th
AT&T: The Tag&Parse Approach to Semantic Parsing of Robot Spatial Commands
 AT&T: The Tag&Parse Approach to Semantic Parsing of Robot Spatial Commands Svetlana Stoyanchev, Hyuckchul Jung, John Chen, Srinivas Bangalore AT&T Labs Research 1 AT&T Way Bedminster NJ 07921 {sveta,hjung,jchen,srini}@research.att.com
AT&T: The Tag&Parse Approach to Semantic Parsing of Robot Spatial Commands Svetlana Stoyanchev, Hyuckchul Jung, John Chen, Srinivas Bangalore AT&T Labs Research 1 AT&T Way Bedminster NJ 07921 {sveta,hjung,jchen,srini}@research.att.com
Dependency Parsing. Johan Aulin D03 Department of Computer Science Lund University, Sweden
 Dependency Parsing Johan Aulin D03 Department of Computer Science Lund University, Sweden d03jau@student.lth.se Carl-Ola Boketoft ID03 Department of Computing Science Umeå University, Sweden calle_boketoft@hotmail.com
Dependency Parsing Johan Aulin D03 Department of Computer Science Lund University, Sweden d03jau@student.lth.se Carl-Ola Boketoft ID03 Department of Computing Science Umeå University, Sweden calle_boketoft@hotmail.com
Refresher on Dependency Syntax and the Nivre Algorithm
 Refresher on Dependency yntax and Nivre Algorithm Richard Johansson 1 Introduction This document gives more details about some important topics that re discussed very quickly during lecture: dependency
Refresher on Dependency yntax and Nivre Algorithm Richard Johansson 1 Introduction This document gives more details about some important topics that re discussed very quickly during lecture: dependency
Constructing a Japanese Basic Named Entity Corpus of Various Genres
 Constructing a Japanese Basic Named Entity Corpus of Various Genres Tomoya Iwakura 1, Ryuichi Tachibana 2, and Kanako Komiya 3 1 Fujitsu Laboratories Ltd. 2 Commerce Link Inc. 3 Ibaraki University Abstract
Constructing a Japanese Basic Named Entity Corpus of Various Genres Tomoya Iwakura 1, Ryuichi Tachibana 2, and Kanako Komiya 3 1 Fujitsu Laboratories Ltd. 2 Commerce Link Inc. 3 Ibaraki University Abstract
EFFICIENT INTEGRATION OF SEMANTIC TECHNOLOGIES FOR PROFESSIONAL IMAGE ANNOTATION AND SEARCH
 EFFICIENT INTEGRATION OF SEMANTIC TECHNOLOGIES FOR PROFESSIONAL IMAGE ANNOTATION AND SEARCH Andreas Walter FZI Forschungszentrum Informatik, Haid-und-Neu-Straße 10-14, 76131 Karlsruhe, Germany, awalter@fzi.de
EFFICIENT INTEGRATION OF SEMANTIC TECHNOLOGIES FOR PROFESSIONAL IMAGE ANNOTATION AND SEARCH Andreas Walter FZI Forschungszentrum Informatik, Haid-und-Neu-Straße 10-14, 76131 Karlsruhe, Germany, awalter@fzi.de
Statistical Dependency Parsing
 Statistical Dependency Parsing The State of the Art Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Dependency Parsing 1(29) Introduction
Statistical Dependency Parsing The State of the Art Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Dependency Parsing 1(29) Introduction
MaltOptimizer: A System for MaltParser Optimization
 MaltOptimizer: A System for MaltParser Optimization Miguel Ballesteros Joakim Nivre Universidad Complutense de Madrid, Spain miballes@fdi.ucm.es Uppsala University, Sweden joakim.nivre@lingfil.uu.se Abstract
MaltOptimizer: A System for MaltParser Optimization Miguel Ballesteros Joakim Nivre Universidad Complutense de Madrid, Spain miballes@fdi.ucm.es Uppsala University, Sweden joakim.nivre@lingfil.uu.se Abstract
Voting between Multiple Data Representations for Text Chunking
 Voting between Multiple Data Representations for Text Chunking Hong Shen and Anoop Sarkar School of Computing Science Simon Fraser University Burnaby, BC V5A 1S6, Canada {hshen,anoop}@cs.sfu.ca Abstract.
Voting between Multiple Data Representations for Text Chunking Hong Shen and Anoop Sarkar School of Computing Science Simon Fraser University Burnaby, BC V5A 1S6, Canada {hshen,anoop}@cs.sfu.ca Abstract.
Shrey Patel B.E. Computer Engineering, Gujarat Technological University, Ahmedabad, Gujarat, India
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
Transliteration as Constrained Optimization
 EMNLP 08 Transliteration as Constrained Optimization Dan Goldwasser Dan Roth Department of Computer Science University of Illinois Urbana, IL 61801 {goldwas1,danr}@uiuc.edu Abstract This paper introduces
EMNLP 08 Transliteration as Constrained Optimization Dan Goldwasser Dan Roth Department of Computer Science University of Illinois Urbana, IL 61801 {goldwas1,danr}@uiuc.edu Abstract This paper introduces
EDAN20 Language Technology Chapter 13: Dependency Parsing
 EDAN20 Language Technology http://cs.lth.se/edan20/ Pierre Nugues Lund University Pierre.Nugues@cs.lth.se http://cs.lth.se/pierre_nugues/ September 19, 2016 Pierre Nugues EDAN20 Language Technology http://cs.lth.se/edan20/
EDAN20 Language Technology http://cs.lth.se/edan20/ Pierre Nugues Lund University Pierre.Nugues@cs.lth.se http://cs.lth.se/pierre_nugues/ September 19, 2016 Pierre Nugues EDAN20 Language Technology http://cs.lth.se/edan20/
Transition-Based Dependency Parsing with MaltParser
 Transition-Based Dependency Parsing with MaltParser Joakim Nivre Uppsala University and Växjö University Transition-Based Dependency Parsing 1(13) Introduction Outline Goals of the workshop Transition-based
Transition-Based Dependency Parsing with MaltParser Joakim Nivre Uppsala University and Växjö University Transition-Based Dependency Parsing 1(13) Introduction Outline Goals of the workshop Transition-based
Online Service for Polish Dependency Parsing and Results Visualisation
 Online Service for Polish Dependency Parsing and Results Visualisation Alina Wróblewska and Piotr Sikora Institute of Computer Science, Polish Academy of Sciences, Warsaw, Poland alina@ipipan.waw.pl,piotr.sikora@student.uw.edu.pl
Online Service for Polish Dependency Parsing and Results Visualisation Alina Wróblewska and Piotr Sikora Institute of Computer Science, Polish Academy of Sciences, Warsaw, Poland alina@ipipan.waw.pl,piotr.sikora@student.uw.edu.pl
The Dictionary Parsing Project: Steps Toward a Lexicographer s Workstation
 The Dictionary Parsing Project: Steps Toward a Lexicographer s Workstation Ken Litkowski ken@clres.com http://www.clres.com http://www.clres.com/dppdemo/index.html Dictionary Parsing Project Purpose: to
The Dictionary Parsing Project: Steps Toward a Lexicographer s Workstation Ken Litkowski ken@clres.com http://www.clres.com http://www.clres.com/dppdemo/index.html Dictionary Parsing Project Purpose: to
2 Features
 BRAT: a Web-based Tool for NLP-Assisted Text Annotation Pontus Stenetorp 1 Sampo Pyysalo 2,3 Goran Topić 1 Tomoko Ohta 1,2,3 Sophia Ananiadou 2,3 and Jun ichi Tsujii 4 1 Department of Computer Science,
BRAT: a Web-based Tool for NLP-Assisted Text Annotation Pontus Stenetorp 1 Sampo Pyysalo 2,3 Goran Topić 1 Tomoko Ohta 1,2,3 Sophia Ananiadou 2,3 and Jun ichi Tsujii 4 1 Department of Computer Science,
NLP in practice, an example: Semantic Role Labeling
 NLP in practice, an example: Semantic Role Labeling Anders Björkelund Lund University, Dept. of Computer Science anders.bjorkelund@cs.lth.se October 15, 2010 Anders Björkelund NLP in practice, an example:
NLP in practice, an example: Semantic Role Labeling Anders Björkelund Lund University, Dept. of Computer Science anders.bjorkelund@cs.lth.se October 15, 2010 Anders Björkelund NLP in practice, an example:
Annotating Spatio-Temporal Information in Documents
 Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
An Integrated Digital Tool for Accessing Language Resources
 An Integrated Digital Tool for Accessing Language Resources Anil Kumar Singh, Bharat Ram Ambati Langauge Technologies Research Centre, International Institute of Information Technology Hyderabad, India
An Integrated Digital Tool for Accessing Language Resources Anil Kumar Singh, Bharat Ram Ambati Langauge Technologies Research Centre, International Institute of Information Technology Hyderabad, India
WebAnno: a flexible, web-based annotation tool for CLARIN
 WebAnno: a flexible, web-based annotation tool for CLARIN Richard Eckart de Castilho, Chris Biemann, Iryna Gurevych, Seid Muhie Yimam #WebAnno This work is licensed under a Attribution-NonCommercial-ShareAlike
WebAnno: a flexible, web-based annotation tool for CLARIN Richard Eckart de Castilho, Chris Biemann, Iryna Gurevych, Seid Muhie Yimam #WebAnno This work is licensed under a Attribution-NonCommercial-ShareAlike
Knowledge Engineering with Semantic Web Technologies
 This file is licensed under the Creative Commons Attribution-NonCommercial 3.0 (CC BY-NC 3.0) Knowledge Engineering with Semantic Web Technologies Lecture 5: Ontological Engineering 5.3 Ontology Learning
This file is licensed under the Creative Commons Attribution-NonCommercial 3.0 (CC BY-NC 3.0) Knowledge Engineering with Semantic Web Technologies Lecture 5: Ontological Engineering 5.3 Ontology Learning
Towards Domain Independent Named Entity Recognition
 38 Computer Science 5 Towards Domain Independent Named Entity Recognition Fredrick Edward Kitoogo, Venansius Baryamureeba and Guy De Pauw Named entity recognition is a preprocessing tool to many natural
38 Computer Science 5 Towards Domain Independent Named Entity Recognition Fredrick Edward Kitoogo, Venansius Baryamureeba and Guy De Pauw Named entity recognition is a preprocessing tool to many natural
Sorting Out Dependency Parsing
 Sorting Out Dependency Parsing Joakim Nivre Uppsala University and Växjö University Sorting Out Dependency Parsing 1(38) Introduction Introduction Syntactic parsing of natural language: Who does what to
Sorting Out Dependency Parsing Joakim Nivre Uppsala University and Växjö University Sorting Out Dependency Parsing 1(38) Introduction Introduction Syntactic parsing of natural language: Who does what to
Automatic Discovery of Feature Sets for Dependency Parsing
 Automatic Discovery of Feature Sets for Dependency Parsing Peter Nilsson Pierre Nugues Department of Computer Science Lund University peter.nilsson.lund@telia.com Pierre.Nugues@cs.lth.se Abstract This
Automatic Discovery of Feature Sets for Dependency Parsing Peter Nilsson Pierre Nugues Department of Computer Science Lund University peter.nilsson.lund@telia.com Pierre.Nugues@cs.lth.se Abstract This
Sorting Out Dependency Parsing
 Sorting Out Dependency Parsing Joakim Nivre Uppsala University and Växjö University Sorting Out Dependency Parsing 1(38) Introduction Introduction Syntactic parsing of natural language: Who does what to
Sorting Out Dependency Parsing Joakim Nivre Uppsala University and Växjö University Sorting Out Dependency Parsing 1(38) Introduction Introduction Syntactic parsing of natural language: Who does what to
Morpho-syntactic Analysis with the Stanford CoreNLP
 Morpho-syntactic Analysis with the Stanford CoreNLP Danilo Croce croce@info.uniroma2.it WmIR 2015/2016 Objectives of this tutorial Use of a Natural Language Toolkit CoreNLP toolkit Morpho-syntactic analysis
Morpho-syntactic Analysis with the Stanford CoreNLP Danilo Croce croce@info.uniroma2.it WmIR 2015/2016 Objectives of this tutorial Use of a Natural Language Toolkit CoreNLP toolkit Morpho-syntactic analysis
Final Project Discussion. Adam Meyers Montclair State University
 Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
NLP Final Project Fall 2015, Due Friday, December 18
 NLP Final Project Fall 2015, Due Friday, December 18 For the final project, everyone is required to do some sentiment classification and then choose one of the other three types of projects: annotation,
NLP Final Project Fall 2015, Due Friday, December 18 For the final project, everyone is required to do some sentiment classification and then choose one of the other three types of projects: annotation,
A Dynamic Confusion Score for Dependency Arc Labels
 A Dynamic Confusion Score for Dependency Arc Labels Sambhav Jain and Bhasha Agrawal Language Technologies Research Center IIIT-Hyderabad, India {sambhav.jain, bhasha.agrawal}@research.iiit.ac.in Abstract
A Dynamic Confusion Score for Dependency Arc Labels Sambhav Jain and Bhasha Agrawal Language Technologies Research Center IIIT-Hyderabad, India {sambhav.jain, bhasha.agrawal}@research.iiit.ac.in Abstract
Tekniker för storskalig parsning: Dependensparsning 2
 Tekniker för storskalig parsning: Dependensparsning 2 Joakim Nivre Uppsala Universitet Institutionen för lingvistik och filologi joakim.nivre@lingfil.uu.se Dependensparsning 2 1(45) Data-Driven Dependency
Tekniker för storskalig parsning: Dependensparsning 2 Joakim Nivre Uppsala Universitet Institutionen för lingvistik och filologi joakim.nivre@lingfil.uu.se Dependensparsning 2 1(45) Data-Driven Dependency
Token Gazetteer and Character Gazetteer for Named Entity Recognition
 Token Gazetteer and Character Gazetteer for Named Entity Recognition Giang Nguyen, Štefan Dlugolinský, Michal Laclavík, Martin Šeleng Institute of Informatics, Slovak Academy of Sciences Dúbravská cesta
Token Gazetteer and Character Gazetteer for Named Entity Recognition Giang Nguyen, Štefan Dlugolinský, Michal Laclavík, Martin Šeleng Institute of Informatics, Slovak Academy of Sciences Dúbravská cesta
Question Answering Using XML-Tagged Documents
 Question Answering Using XML-Tagged Documents Ken Litkowski ken@clres.com http://www.clres.com http://www.clres.com/trec11/index.html XML QA System P Full text processing of TREC top 20 documents Sentence
Question Answering Using XML-Tagged Documents Ken Litkowski ken@clres.com http://www.clres.com http://www.clres.com/trec11/index.html XML QA System P Full text processing of TREC top 20 documents Sentence
JU_CSE_TE: System Description 2010 ResPubliQA
 JU_CSE_TE: System Description QA@CLEF 2010 ResPubliQA Partha Pakray 1, Pinaki Bhaskar 1, Santanu Pal 1, Dipankar Das 1, Sivaji Bandyopadhyay 1, Alexander Gelbukh 2 Department of Computer Science & Engineering
JU_CSE_TE: System Description QA@CLEF 2010 ResPubliQA Partha Pakray 1, Pinaki Bhaskar 1, Santanu Pal 1, Dipankar Das 1, Sivaji Bandyopadhyay 1, Alexander Gelbukh 2 Department of Computer Science & Engineering
Exploring Automatic Feature Selection for Transition-Based Dependency Parsing
 Procesamiento del Lenguaje Natural, Revista nº 51, septiembre de 2013, pp 119-126 recibido 18-04-2013 revisado 16-06-2013 aceptado 21-06-2013 Exploring Automatic Feature Selection for Transition-Based
Procesamiento del Lenguaje Natural, Revista nº 51, septiembre de 2013, pp 119-126 recibido 18-04-2013 revisado 16-06-2013 aceptado 21-06-2013 Exploring Automatic Feature Selection for Transition-Based
Reducing Human Effort in Named Entity Corpus Construction Based on Ensemble Learning and Annotation Categorization
 Reducing Human Effort in Named Entity Corpus Construction Based on Ensemble Learning and Annotation Categorization Tingming Lu 1,2, Man Zhu 3, and Zhiqiang Gao 1,2( ) 1 Key Lab of Computer Network and
Reducing Human Effort in Named Entity Corpus Construction Based on Ensemble Learning and Annotation Categorization Tingming Lu 1,2, Man Zhu 3, and Zhiqiang Gao 1,2( ) 1 Key Lab of Computer Network and
CS395T Project 2: Shift-Reduce Parsing
 CS395T Project 2: Shift-Reduce Parsing Due date: Tuesday, October 17 at 9:30am In this project you ll implement a shift-reduce parser. First you ll implement a greedy model, then you ll extend that model
CS395T Project 2: Shift-Reduce Parsing Due date: Tuesday, October 17 at 9:30am In this project you ll implement a shift-reduce parser. First you ll implement a greedy model, then you ll extend that model
Chunking with Support Vector Machines
 Chunking with Support Vector Machines Taku Kudo and Yuji Matsumoto Graduate School of Information Science, Nara Institute of Science and Technology {taku-ku,matsu}@is.aist-nara.ac.jp Abstract We apply
Chunking with Support Vector Machines Taku Kudo and Yuji Matsumoto Graduate School of Information Science, Nara Institute of Science and Technology {taku-ku,matsu}@is.aist-nara.ac.jp Abstract We apply
WebLicht: Web-based LRT Services in a Distributed escience Infrastructure
 WebLicht: Web-based LRT Services in a Distributed escience Infrastructure Marie Hinrichs, Thomas Zastrow, Erhard Hinrichs Seminar für Sprachwissenschaft, University of Tübingen Wilhelmstr. 19, 72074 Tübingen
WebLicht: Web-based LRT Services in a Distributed escience Infrastructure Marie Hinrichs, Thomas Zastrow, Erhard Hinrichs Seminar für Sprachwissenschaft, University of Tübingen Wilhelmstr. 19, 72074 Tübingen
Langforia: Language Pipelines for Annotating Large Collections of Documents
 Langforia: Language Pipelines for Annotating Large Collections of Documents Marcus Klang Lund University Department of Computer Science Lund, Sweden Marcus.Klang@cs.lth.se Pierre Nugues Lund University
Langforia: Language Pipelines for Annotating Large Collections of Documents Marcus Klang Lund University Department of Computer Science Lund, Sweden Marcus.Klang@cs.lth.se Pierre Nugues Lund University
NLP Lab Session Week 9, October 28, 2015 Classification and Feature Sets in the NLTK, Part 1. Getting Started
 NLP Lab Session Week 9, October 28, 2015 Classification and Feature Sets in the NLTK, Part 1 Getting Started For this lab session download the examples: LabWeek9classifynames.txt and put it in your class
NLP Lab Session Week 9, October 28, 2015 Classification and Feature Sets in the NLTK, Part 1 Getting Started For this lab session download the examples: LabWeek9classifynames.txt and put it in your class
An Empirical Study of Semi-supervised Structured Conditional Models for Dependency Parsing
 An Empirical Study of Semi-supervised Structured Conditional Models for Dependency Parsing Jun Suzuki, Hideki Isozaki NTT CS Lab., NTT Corp. Kyoto, 619-0237, Japan jun@cslab.kecl.ntt.co.jp isozaki@cslab.kecl.ntt.co.jp
An Empirical Study of Semi-supervised Structured Conditional Models for Dependency Parsing Jun Suzuki, Hideki Isozaki NTT CS Lab., NTT Corp. Kyoto, 619-0237, Japan jun@cslab.kecl.ntt.co.jp isozaki@cslab.kecl.ntt.co.jp
Treex: Modular NLP Framework
 : Modular NLP Framework Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague September 2015, Prague, MT Marathon Outline Motivation, vs. architecture internals Future
: Modular NLP Framework Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague September 2015, Prague, MT Marathon Outline Motivation, vs. architecture internals Future
Question Answering Approach Using a WordNet-based Answer Type Taxonomy
 Question Answering Approach Using a WordNet-based Answer Type Taxonomy Seung-Hoon Na, In-Su Kang, Sang-Yool Lee, Jong-Hyeok Lee Department of Computer Science and Engineering, Electrical and Computer Engineering
Question Answering Approach Using a WordNet-based Answer Type Taxonomy Seung-Hoon Na, In-Su Kang, Sang-Yool Lee, Jong-Hyeok Lee Department of Computer Science and Engineering, Electrical and Computer Engineering
Transition-based Dependency Parsing with Rich Non-local Features
 Transition-based Dependency Parsing with Rich Non-local Features Yue Zhang University of Cambridge Computer Laboratory yue.zhang@cl.cam.ac.uk Joakim Nivre Uppsala University Department of Linguistics and
Transition-based Dependency Parsing with Rich Non-local Features Yue Zhang University of Cambridge Computer Laboratory yue.zhang@cl.cam.ac.uk Joakim Nivre Uppsala University Department of Linguistics and
Using Search-Logs to Improve Query Tagging
 Using Search-Logs to Improve Query Tagging Kuzman Ganchev Keith Hall Ryan McDonald Slav Petrov Google, Inc. {kuzman kbhall ryanmcd slav}@google.com Abstract Syntactic analysis of search queries is important
Using Search-Logs to Improve Query Tagging Kuzman Ganchev Keith Hall Ryan McDonald Slav Petrov Google, Inc. {kuzman kbhall ryanmcd slav}@google.com Abstract Syntactic analysis of search queries is important
LASH: Large-Scale Sequence Mining with Hierarchies
 LASH: Large-Scale Sequence Mining with Hierarchies Kaustubh Beedkar and Rainer Gemulla Data and Web Science Group University of Mannheim June 2 nd, 2015 SIGMOD 2015 Kaustubh Beedkar and Rainer Gemulla
LASH: Large-Scale Sequence Mining with Hierarchies Kaustubh Beedkar and Rainer Gemulla Data and Web Science Group University of Mannheim June 2 nd, 2015 SIGMOD 2015 Kaustubh Beedkar and Rainer Gemulla
Learning Latent Linguistic Structure to Optimize End Tasks. David A. Smith with Jason Naradowsky and Xiaoye Tiger Wu
 Learning Latent Linguistic Structure to Optimize End Tasks David A. Smith with Jason Naradowsky and Xiaoye Tiger Wu 12 October 2012 Learning Latent Linguistic Structure to Optimize End Tasks David A. Smith
Learning Latent Linguistic Structure to Optimize End Tasks David A. Smith with Jason Naradowsky and Xiaoye Tiger Wu 12 October 2012 Learning Latent Linguistic Structure to Optimize End Tasks David A. Smith
Information Extraction
 Information Extraction Tutor: Rahmad Mahendra rahmad.mahendra@cs.ui.ac.id Slide by: Bayu Distiawan Trisedya Main Reference: Stanford University Natural Language Processing & Text Mining Short Course Pusat
Information Extraction Tutor: Rahmad Mahendra rahmad.mahendra@cs.ui.ac.id Slide by: Bayu Distiawan Trisedya Main Reference: Stanford University Natural Language Processing & Text Mining Short Course Pusat
Building trainable taggers in a web-based, UIMA-supported NLP workbench
 Building trainable taggers in a web-based, UIMA-supported NLP workbench Rafal Rak, BalaKrishna Kolluru and Sophia Ananiadou National Centre for Text Mining School of Computer Science, University of Manchester
Building trainable taggers in a web-based, UIMA-supported NLP workbench Rafal Rak, BalaKrishna Kolluru and Sophia Ananiadou National Centre for Text Mining School of Computer Science, University of Manchester
Exam III March 17, 2010
 CIS 4930 NLP Print Your Name Exam III March 17, 2010 Total Score Your work is to be done individually. The exam is worth 106 points (six points of extra credit are available throughout the exam) and it
CIS 4930 NLP Print Your Name Exam III March 17, 2010 Total Score Your work is to be done individually. The exam is worth 106 points (six points of extra credit are available throughout the exam) and it
The GeoTALP-IR System at GeoCLEF-2005: Experiments Using a QA-based IR System, Linguistic Analysis, and a Geographical Thesaurus
 The GeoTALP-IR System at GeoCLEF-2005: Experiments Using a QA-based IR System, Linguistic Analysis, and a Geographical Thesaurus Daniel Ferrés, Alicia Ageno, and Horacio Rodríguez TALP Research Center
The GeoTALP-IR System at GeoCLEF-2005: Experiments Using a QA-based IR System, Linguistic Analysis, and a Geographical Thesaurus Daniel Ferrés, Alicia Ageno, and Horacio Rodríguez TALP Research Center
Frame Semantic Structure Extraction
 Frame Semantic Structure Extraction Organizing team: Collin Baker, Michael Ellsworth (International Computer Science Institute, Berkeley), Katrin Erk(U Texas, Austin) October 4, 2006 1 Description of task
Frame Semantic Structure Extraction Organizing team: Collin Baker, Michael Ellsworth (International Computer Science Institute, Berkeley), Katrin Erk(U Texas, Austin) October 4, 2006 1 Description of task
Named Entity Detection and Entity Linking in the Context of Semantic Web
 [1/52] Concordia Seminar - December 2012 Named Entity Detection and in the Context of Semantic Web Exploring the ambiguity question. Eric Charton, Ph.D. [2/52] Concordia Seminar - December 2012 Challenge
[1/52] Concordia Seminar - December 2012 Named Entity Detection and in the Context of Semantic Web Exploring the ambiguity question. Eric Charton, Ph.D. [2/52] Concordia Seminar - December 2012 Challenge
An UIMA based Tool Suite for Semantic Text Processing
 An UIMA based Tool Suite for Semantic Text Processing Katrin Tomanek, Ekaterina Buyko, Udo Hahn Jena University Language & Information Engineering Lab StemNet Knowledge Management for Immunology in life
An UIMA based Tool Suite for Semantic Text Processing Katrin Tomanek, Ekaterina Buyko, Udo Hahn Jena University Language & Information Engineering Lab StemNet Knowledge Management for Immunology in life
Language Resources and Linked Data
 Integrating NLP with Linked Data: the NIF Format Milan Dojchinovski @EKAW 2014 November 24-28, 2014, Linkoping, Sweden milan.dojchinovski@fit.cvut.cz - @m1ci - http://dojchinovski.mk Web Intelligence Research
Integrating NLP with Linked Data: the NIF Format Milan Dojchinovski @EKAW 2014 November 24-28, 2014, Linkoping, Sweden milan.dojchinovski@fit.cvut.cz - @m1ci - http://dojchinovski.mk Web Intelligence Research
University of Sheffield, NLP. Chunking Practical Exercise
 Chunking Practical Exercise Chunking for NER Chunking, as we saw at the beginning, means finding parts of text This task is often called Named Entity Recognition (NER), in the context of finding person
Chunking Practical Exercise Chunking for NER Chunking, as we saw at the beginning, means finding parts of text This task is often called Named Entity Recognition (NER), in the context of finding person
Homework 2: Parsing and Machine Learning
 Homework 2: Parsing and Machine Learning COMS W4705_001: Natural Language Processing Prof. Kathleen McKeown, Fall 2017 Due: Saturday, October 14th, 2017, 2:00 PM This assignment will consist of tasks in
Homework 2: Parsing and Machine Learning COMS W4705_001: Natural Language Processing Prof. Kathleen McKeown, Fall 2017 Due: Saturday, October 14th, 2017, 2:00 PM This assignment will consist of tasks in
Module 3: GATE and Social Media. Part 4. Named entities
 Module 3: GATE and Social Media Part 4. Named entities The 1995-2018 This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs Licence Named Entity Recognition Texts frequently
Module 3: GATE and Social Media Part 4. Named entities The 1995-2018 This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs Licence Named Entity Recognition Texts frequently
Discriminative Training with Perceptron Algorithm for POS Tagging Task
 Discriminative Training with Perceptron Algorithm for POS Tagging Task Mahsa Yarmohammadi Center for Spoken Language Understanding Oregon Health & Science University Portland, Oregon yarmoham@ohsu.edu
Discriminative Training with Perceptron Algorithm for POS Tagging Task Mahsa Yarmohammadi Center for Spoken Language Understanding Oregon Health & Science University Portland, Oregon yarmoham@ohsu.edu
Projective Dependency Parsing with Perceptron
 Projective Dependency Parsing with Perceptron Xavier Carreras, Mihai Surdeanu, and Lluís Màrquez Technical University of Catalonia {carreras,surdeanu,lluism}@lsi.upc.edu 8th June 2006 Outline Introduction
Projective Dependency Parsing with Perceptron Xavier Carreras, Mihai Surdeanu, and Lluís Màrquez Technical University of Catalonia {carreras,surdeanu,lluism}@lsi.upc.edu 8th June 2006 Outline Introduction
Syntactic N-grams as Machine Learning. Features for Natural Language Processing. Marvin Gülzow. Basics. Approach. Results.
 s Table of Contents s 1 s 2 3 4 5 6 TL;DR s Introduce n-grams Use them for authorship attribution Compare machine learning approaches s J48 (decision tree) SVM + S work well Section 1 s s Definition n-gram:
s Table of Contents s 1 s 2 3 4 5 6 TL;DR s Introduce n-grams Use them for authorship attribution Compare machine learning approaches s J48 (decision tree) SVM + S work well Section 1 s s Definition n-gram:
A bit of theory: Algorithms
 A bit of theory: Algorithms There are different kinds of algorithms Vector space models. e.g. support vector machines Decision trees, e.g. C45 Probabilistic models, e.g. Naive Bayes Neural networks, e.g.
A bit of theory: Algorithms There are different kinds of algorithms Vector space models. e.g. support vector machines Decision trees, e.g. C45 Probabilistic models, e.g. Naive Bayes Neural networks, e.g.
Information Extraction Techniques in Terrorism Surveillance
 Information Extraction Techniques in Terrorism Surveillance Roman Tekhov Abstract. The article gives a brief overview of what information extraction is and how it might be used for the purposes of counter-terrorism
Information Extraction Techniques in Terrorism Surveillance Roman Tekhov Abstract. The article gives a brief overview of what information extraction is and how it might be used for the purposes of counter-terrorism
Tokenization and Sentence Segmentation. Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017
 Tokenization and Sentence Segmentation Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017 Outline 1 Tokenization Introduction Exercise Evaluation Summary 2 Sentence segmentation
Tokenization and Sentence Segmentation Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017 Outline 1 Tokenization Introduction Exercise Evaluation Summary 2 Sentence segmentation
Progress Report STEVIN Projects
 Progress Report STEVIN Projects Project Name Large Scale Syntactic Annotation of Written Dutch Project Number STE05020 Reporting Period October 2009 - March 2010 Participants KU Leuven, University of Groningen
Progress Report STEVIN Projects Project Name Large Scale Syntactic Annotation of Written Dutch Project Number STE05020 Reporting Period October 2009 - March 2010 Participants KU Leuven, University of Groningen
Medical Event Extraction using the Swedish FrameNet, a pilot study
 Medical Event Extraction using the Swedish FrameNet, a pilot study DIMITRIOS KOKKINAKIS Centre for Language Technology University of Gothenburg Sweden dimitrios.kokkinakis@svenska.gu.se Overview From entities
Medical Event Extraction using the Swedish FrameNet, a pilot study DIMITRIOS KOKKINAKIS Centre for Language Technology University of Gothenburg Sweden dimitrios.kokkinakis@svenska.gu.se Overview From entities
Corpus Linguistics. Seminar Resources for Computational Linguists SS Magdalena Wolska & Michaela Regneri
 Seminar Resources for Computational Linguists SS 2007 Magdalena Wolska & Michaela Regneri Armchair Linguists vs. Corpus Linguists Competence Performance 2 Motivation (for ) 3 Outline Corpora Annotation
Seminar Resources for Computational Linguists SS 2007 Magdalena Wolska & Michaela Regneri Armchair Linguists vs. Corpus Linguists Competence Performance 2 Motivation (for ) 3 Outline Corpora Annotation
Privacy and Security in Online Social Networks Department of Computer Science and Engineering Indian Institute of Technology, Madras
 Privacy and Security in Online Social Networks Department of Computer Science and Engineering Indian Institute of Technology, Madras Lecture - 25 Tutorial 5: Analyzing text using Python NLTK Hi everyone,
Privacy and Security in Online Social Networks Department of Computer Science and Engineering Indian Institute of Technology, Madras Lecture - 25 Tutorial 5: Analyzing text using Python NLTK Hi everyone,
Parmenides. Semi-automatic. Ontology. construction and maintenance. Ontology. Document convertor/basic processing. Linguistic. Background knowledge
 Discover hidden information from your texts! Information overload is a well known issue in the knowledge industry. At the same time most of this information becomes available in natural language which
Discover hidden information from your texts! Information overload is a well known issue in the knowledge industry. At the same time most of this information becomes available in natural language which
Recent Developments in the Czech National Corpus
 Recent Developments in the Czech National Corpus Michal Křen Charles University in Prague 3 rd Workshop on the Challenges in the Management of Large Corpora Lancaster 20 July 2015 Introduction of the project
Recent Developments in the Czech National Corpus Michal Křen Charles University in Prague 3 rd Workshop on the Challenges in the Management of Large Corpora Lancaster 20 July 2015 Introduction of the project
Natural Language Processing SoSe Question Answering. (based on the slides of Dr. Saeedeh Momtazi) )
 )") Natural Language Processing SoSe 2014 Question Answering Dr. Mariana Neves June 25th, 2014 (based on the slides of Dr. Saeedeh Momtazi) ) Outline 2 Introduction History QA Architecture Natural Language
Natural Language Processing SoSe 2014 Question Answering Dr. Mariana Neves June 25th, 2014 (based on the slides of Dr. Saeedeh Momtazi) ) Outline 2 Introduction History QA Architecture Natural Language
Natural Language Processing. SoSe Question Answering
 Natural Language Processing SoSe 2017 Question Answering Dr. Mariana Neves July 5th, 2017 Motivation Find small segments of text which answer users questions (http://start.csail.mit.edu/) 2 3 Motivation
Natural Language Processing SoSe 2017 Question Answering Dr. Mariana Neves July 5th, 2017 Motivation Find small segments of text which answer users questions (http://start.csail.mit.edu/) 2 3 Motivation
A Textual Entailment System using Web based Machine Translation System
 A Textual Entailment System using Web based Machine Translation System Partha Pakray 1, Snehasis Neogi 1, Sivaji Bandyopadhyay 1, Alexander Gelbukh 2 1 Computer Science and Engineering Department, Jadavpur
A Textual Entailment System using Web based Machine Translation System Partha Pakray 1, Snehasis Neogi 1, Sivaji Bandyopadhyay 1, Alexander Gelbukh 2 1 Computer Science and Engineering Department, Jadavpur
Question Answering Systems
 Question Answering Systems An Introduction Potsdam, Germany, 14 July 2011 Saeedeh Momtazi Information Systems Group Outline 2 1 Introduction Outline 2 1 Introduction 2 History Outline 2 1 Introduction
Question Answering Systems An Introduction Potsdam, Germany, 14 July 2011 Saeedeh Momtazi Information Systems Group Outline 2 1 Introduction Outline 2 1 Introduction 2 History Outline 2 1 Introduction
Using Linked Data to Reduce Learning Latency for e-book Readers
 Using Linked Data to Reduce Learning Latency for e-book Readers Julien Robinson, Johann Stan, and Myriam Ribière Alcatel-Lucent Bell Labs France, 91620 Nozay, France, Julien.Robinson@alcatel-lucent.com
Using Linked Data to Reduce Learning Latency for e-book Readers Julien Robinson, Johann Stan, and Myriam Ribière Alcatel-Lucent Bell Labs France, 91620 Nozay, France, Julien.Robinson@alcatel-lucent.com
Agenda for today. Homework questions, issues? Non-projective dependencies Spanning tree algorithm for non-projective parsing
 Agenda for today Homework questions, issues? Non-projective dependencies Spanning tree algorithm for non-projective parsing 1 Projective vs non-projective dependencies If we extract dependencies from trees,
Agenda for today Homework questions, issues? Non-projective dependencies Spanning tree algorithm for non-projective parsing 1 Projective vs non-projective dependencies If we extract dependencies from trees,
clarin:el an infrastructure for documenting, sharing and processing language data
 clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
The Goal of this Document. Where to Start?
 A QUICK INTRODUCTION TO THE SEMILAR APPLICATION Mihai Lintean, Rajendra Banjade, and Vasile Rus vrus@memphis.edu linteam@gmail.com rbanjade@memphis.edu The Goal of this Document This document introduce
A QUICK INTRODUCTION TO THE SEMILAR APPLICATION Mihai Lintean, Rajendra Banjade, and Vasile Rus vrus@memphis.edu linteam@gmail.com rbanjade@memphis.edu The Goal of this Document This document introduce
Enhancing applications with Cognitive APIs IBM Corporation
 Enhancing applications with Cognitive APIs After you complete this section, you should understand: The Watson Developer Cloud offerings and APIs The benefits of commonly used Cognitive services 2 Watson
Enhancing applications with Cognitive APIs After you complete this section, you should understand: The Watson Developer Cloud offerings and APIs The benefits of commonly used Cognitive services 2 Watson
Fast and Effective System for Name Entity Recognition on Big Data
 International Journal of Computer Sciences and Engineering Open Access Research Paper Volume-3, Issue-2 E-ISSN: 2347-2693 Fast and Effective System for Name Entity Recognition on Big Data Jigyasa Nigam
International Journal of Computer Sciences and Engineering Open Access Research Paper Volume-3, Issue-2 E-ISSN: 2347-2693 Fast and Effective System for Name Entity Recognition on Big Data Jigyasa Nigam
Natural Language Processing SoSe Question Answering. (based on the slides of Dr. Saeedeh Momtazi)
") Natural Language Processing SoSe 2015 Question Answering Dr. Mariana Neves July 6th, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline 2 Introduction History QA Architecture Outline 3 Introduction
Natural Language Processing SoSe 2015 Question Answering Dr. Mariana Neves July 6th, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline 2 Introduction History QA Architecture Outline 3 Introduction
A Named Entity Recognition Method based on Decomposition and Concatenation of Word Chunks
 A Named Entity Recognition Method based on Decomposition and Concatenation of Word Chunks Tomoya Iwakura Hiroya Takamura Manabu Okumura Fujitsu Laboratories Ltd. iwakura.tomoya@jp.fujitsu.com Precision
A Named Entity Recognition Method based on Decomposition and Concatenation of Word Chunks Tomoya Iwakura Hiroya Takamura Manabu Okumura Fujitsu Laboratories Ltd. iwakura.tomoya@jp.fujitsu.com Precision
Meaning Banking and Beyond
 Meaning Banking and Beyond Valerio Basile Wimmics, Inria November 18, 2015 Semantics is a well-kept secret in texts, accessible only to humans. Anonymous I BEG TO DIFFER Surface Meaning Step by step analysis
Meaning Banking and Beyond Valerio Basile Wimmics, Inria November 18, 2015 Semantics is a well-kept secret in texts, accessible only to humans. Anonymous I BEG TO DIFFER Surface Meaning Step by step analysis
Projektgruppe. Michael Meier. Named-Entity-Recognition Pipeline
 Projektgruppe Michael Meier Named-Entity-Recognition Pipeline What is Named-Entitiy-Recognition? Named-Entity Nameable objects in the world, e.g.: Person: Albert Einstein Organization: Deutsche Bank Location:
Projektgruppe Michael Meier Named-Entity-Recognition Pipeline What is Named-Entitiy-Recognition? Named-Entity Nameable objects in the world, e.g.: Person: Albert Einstein Organization: Deutsche Bank Location:
Intra-sentence Punctuation Insertion in Natural Language Generation
 Intra-sentence Punctuation Insertion in Natural Language Generation Zhu ZHANG, Michael GAMON, Simon CORSTON-OLIVER, Eric RINGGER School of Information Microsoft Research University of Michigan One Microsoft
Intra-sentence Punctuation Insertion in Natural Language Generation Zhu ZHANG, Michael GAMON, Simon CORSTON-OLIVER, Eric RINGGER School of Information Microsoft Research University of Michigan One Microsoft
A DOMAIN INDEPENDENT APPROACH FOR ONTOLOGY SEMANTIC ENRICHMENT
 A DOMAIN INDEPENDENT APPROACH FOR ONTOLOGY SEMANTIC ENRICHMENT ABSTRACT Tahar Guerram and Nacima Mellal Departement of Mathematics and Computer Science, University Larbi Ben M hidi of Oum El Bouaghi -
A DOMAIN INDEPENDENT APPROACH FOR ONTOLOGY SEMANTIC ENRICHMENT ABSTRACT Tahar Guerram and Nacima Mellal Departement of Mathematics and Computer Science, University Larbi Ben M hidi of Oum El Bouaghi -
Let s get parsing! Each component processes the Doc object, then passes it on. doc.is_parsed attribute checks whether a Doc object has been parsed
 Let s get parsing! SpaCy default model includes tagger, parser and entity recognizer nlp = spacy.load('en ) tells spacy to use "en" with ["tagger", "parser", "ner"] Each component processes the Doc object,
Let s get parsing! SpaCy default model includes tagger, parser and entity recognizer nlp = spacy.load('en ) tells spacy to use "en" with ["tagger", "parser", "ner"] Each component processes the Doc object,
ANC2Go: A Web Application for Customized Corpus Creation
 ANC2Go: A Web Application for Customized Corpus Creation Nancy Ide, Keith Suderman, Brian Simms Department of Computer Science, Vassar College Poughkeepsie, New York 12604 USA {ide, suderman, brsimms}@cs.vassar.edu
ANC2Go: A Web Application for Customized Corpus Creation Nancy Ide, Keith Suderman, Brian Simms Department of Computer Science, Vassar College Poughkeepsie, New York 12604 USA {ide, suderman, brsimms}@cs.vassar.edu
A Short Introduction to CATMA
 A Short Introduction to CATMA Outline: I. Getting Started II. Analyzing Texts - Search Queries in CATMA III. Annotating Texts (collaboratively) with CATMA IV. Further Search Queries: Analyze Your Annotations
A Short Introduction to CATMA Outline: I. Getting Started II. Analyzing Texts - Search Queries in CATMA III. Annotating Texts (collaboratively) with CATMA IV. Further Search Queries: Analyze Your Annotations
Australian Journal of Basic and Applied Sciences. Named Entity Recognition from Biomedical Abstracts An Information Extraction Task
 ISSN:1991-8178 Australian Journal of Basic and Applied Sciences Journal home page: www.ajbasweb.com Named Entity Recognition from Biomedical Abstracts An Information Extraction Task 1 N. Kanya and 2 Dr.
ISSN:1991-8178 Australian Journal of Basic and Applied Sciences Journal home page: www.ajbasweb.com Named Entity Recognition from Biomedical Abstracts An Information Extraction Task 1 N. Kanya and 2 Dr.
Automatic Text Summarization System Using Extraction Based Technique
 Automatic Text Summarization System Using Extraction Based Technique 1 Priyanka Gonnade, 2 Disha Gupta 1,2 Assistant Professor 1 Department of Computer Science and Engineering, 2 Department of Computer
Automatic Text Summarization System Using Extraction Based Technique 1 Priyanka Gonnade, 2 Disha Gupta 1,2 Assistant Professor 1 Department of Computer Science and Engineering, 2 Department of Computer
Natural Language Processing: Programming Project II PoS tagging
 Natural Language Processing: Programming Project II PoS tagging Reykjavik University School of Computer Science November 2009 1 Pre-processing (20%) In this project you experiment with part-of-speech (PoS)
Natural Language Processing: Programming Project II PoS tagging Reykjavik University School of Computer Science November 2009 1 Pre-processing (20%) In this project you experiment with part-of-speech (PoS)
A Method for Semi-Automatic Ontology Acquisition from a Corporate Intranet
 A Method for Semi-Automatic Ontology Acquisition from a Corporate Intranet Joerg-Uwe Kietz, Alexander Maedche, Raphael Volz Swisslife Information Systems Research Lab, Zuerich, Switzerland fkietz, volzg@swisslife.ch
A Method for Semi-Automatic Ontology Acquisition from a Corporate Intranet Joerg-Uwe Kietz, Alexander Maedche, Raphael Volz Swisslife Information Systems Research Lab, Zuerich, Switzerland fkietz, volzg@swisslife.ch