Multithreaded Processors. Department of Electrical Engineering Stanford University
|
|
|
- Rolf Sanders
- 6 years ago
- Views:
Transcription
1 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University Lecture 12-1
2 The Big Picture Previous lectures: Core design for single-thread performance Focus on instruction level parallelism (ILP) Single-thread performance can't scale indefinitely! Hard to increase IPC or frequency Industry shift to architectures that exploit Thread-Level Parallelism (TLP) and Data-Level Parallelism (DLP) In the rest of the course: Multithreaded processors (today) Multicores GPUs Vector processors DLP TLP Lecture 12-2
3 Limits of Single-Thread Performance Fundamental ILP limitation in program Control dependences Data dependences Magnified by memory latency Power consumption ILP techniques must be energy-efficient Constrains clock frequency scaling Switching power = C(cap)*N(switch)*Vdd^2*F(freq) Complexity of advanced superscalar design with diminishing returns Higher design, verification, manufacturing costs Lecture 12-3

4 Limits of Single-Thread Performance Lecture 12-4
5 Thread-Level Parallelism Thread-Level Parallelism: Parallelism obtained by executing multiple instruction streams (threads) simultaneously Coarser grain Much easier to exploit than ILP Requires abundant threads software should be parallel Two benefits from having multiple threads: Parallel execution: Execute several threads in parallel (e.g. in different processors) Throughput improvement: Avoid idle time on a stall by switching to other thread Today's lecture: Exploiting TLP in a processor pipeline Lecture 12-5
6 Reminder: Processes and threads Process: An instance of a program executing in a system OS supports concurrent execution of multiple processes Each process has its own address space A process can have one or more threads Threads in the same process share its address space Two different processes can partially share their address spaces to communicate Thread: An independent control stream within a process Private state: PC, registers (integer, FP), stack, thread-local storage Shared state: Heap, address space (VM structures) Lecture 12-6
7 Reminder: Classic OS Context Switch OS context-switch: Timer interrupt stops a program mid-execution (precise) OS saves the context of the stopped thread PC, GPRs, and more Shared state such as physical pages are not saved OS restores the context of a previously stopped thread (all except PC) OS uses a return from exception to jump to the restarting PC The restored thread has no idea it was interrupted, removed, later restored and restarted Take a few hundred cycles per switch Amortized over the execution quantum What latencies can you hide using OS context switching for threads? How much faster would a user-level thread switch be? What are the implications? Lecture 12-7
 Improves throughput & HW utilization Does not improve single thread latency Need hardware support for fast")
8 Multithreaded processors Motivation: HW underutilized on stalls Memory accesses (misses) Pipeline hazards Control hazards Synchronization I/O Instead of reducing stalls, switch to running a different thread while the original thread is stalled Latency tolerance (vs avoidance) Improves throughput & HW utilization Does not improve single thread latency Need hardware support for fast contextswitching Lecture 12-8

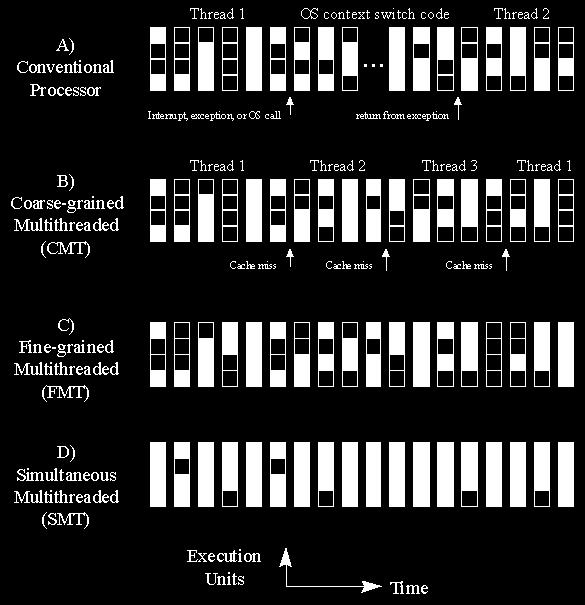
9 HW Support for Multithreading: the Options Lecture 12-9
10 Coarse Grain MT Lead : a processor becomes idle when a thread runs into a cache miss Why not switch to another thread? Problem: SW switch takes hundreds to thousands of cycles Solution: faster context switch in hardware Replicate hardware context registers: PC, GPRs, cntrl/status, PT base ptr Eliminates copying Share some resources with tagging thread id Cache, BTB and TLB match tags Eliminates cold starts Hardware context switch takes only a few cycles Flush the pipeline Choose the next ready thread as the currently active one Start fetching instructions from this thread Where does the penalty come from? Can it be eliminated? Lecture 12-10
11 Simple Multithreaded Processor Multiple threads supported in hardware With multiple hardware contexts Context switch events: With coarse-grain MT, High latency event cache miss, I/O operations Max cycle count for fairness Lecture 12-11
12 Coarse-grain Multithreading: Thread States 4 potential states: {Ready/not-ready} x {using HW context, swapped out} User-level runtime or OS can manage swapping Based on readiness, fairness, or priorities Lecture 12-12
13 Fine Grain Multithreading Lead : when pipelined processor stalls due to RAW dependence, the execution stage is idling Why not switch to another thread? Problem: Context-switching must be instantaneous to have any advantage Solution : 1-cycle context switch Multiple hardware contexts Instruction buffer To dispatch instruction from another thread at the next cycle Multiple threads co-exist in the pipeline Lecture 12-13
14 Example: Tera MTA Instruction latency hiding Worst case instruction latency is 128 cycles (may need 128 threads!!) On every cycle, select a ready thread (i.e. last instruction has finished) from a pool of up to 128 threads Benefits : no forward logic, no interlock, and no cache Problem : Single thread performance H Inst T1 A B C D E E G H Inst T2 A B C D E F G Inst T3 Inst A B C D E F G H A B C D E F G H T4 Inst T5 A B C D E F G H Inst T6 A B C D E F G H Inst T7 A B C D E F G H Inst T8 A B C D E F G H Inst T1 A B C D E F G H Lecture 12-14

15 Example: Sun UltraSparc T1 A fine-grain multithreaded system With multiple processors on a chip 4-threads per CPU, round-robin switch Thread blocked on stalls, mul, div, loads, Lecture 12-15

16 Example: Sun UltraSparc T2 Similar to T1, but 8-way threaded 8-stage dual pipeline can execute 2 threads at the time Fetch, cache, pick, decode, execute, memory, bypass, writeback Lecture 12-16

17 UltraSparc T2: Instruction Fetch Logic Fetch up to 4 instructions from $I Priority to least-recently fetched ready thread Predict not-taken (5 cycle penalty) Threads separated into two groups 1 instruction issued per group Priority to least-recently picked ready thread Decode stage resolves LSU conflicts Lecture 12-17
18 UltraSparc T2: Further Details Load miss queue One miss per thread Store buffer 8 stores per thread (write-through L1 cache) MMU can handle up to 8 TLB misses For instructions or data for each thread Hardware page table walk Lecture 12-18
19 Simultaneous Multithreading (SMT, aka HyperThreading) Lead : not all resources on all stages are busy in a superscalar processor. Why not execute multiple threads in the same pipeline stage? Problem : how can we support multiple active threads? Solution : variety of design options What pipeline stages to share? The rest of the stages are replicated How to share resources? Time sharing: one thread at a cycle Spatial partition: dedicate a portion of resource to a thread Lecture 12-19

20 Regular OOO Vs. SMT OOO: the Alpha Approach Lecture 12-20

21 SMT Resource Sharing What are the tradeoffs here? Complexity, resource utilization, interference Lecture 12-21
22 SMT Design Options (1) Fetch How many threads to fetch from each cycle? If >1, Multi-ported I-cache I-fetch buffer replication From which threads to fetch? Branch predictor: BTB is shared BHR and RAS are replicated. Why? Decode Share decoding logic O(n^2) for dependence check Spatial partition at the cost of single thread performance Lecture 12-22
23 SMT Design Options (2) Rename / RF Need per-thread map tables More architectural registers Larger (A)RF Sharing registers? Multi-ported register file same as in non-smt superscalar Issue Share wakeup logic for arguments O(n^2) for instruction selection Spatial partition at the cost of single thread performance Execution Very natural to share Pipeline vs. dedicate multi-cycle ALUs Lecture 12-23
24 SMT Design Options (3) Memory Multi-ported L1D? Separate load/store queues? Load forwarding/bypassing must be thread-aware Retire Separate reorder buffers? Per-thread instruction retirement Lecture 12-24
25 SMT Design Options: How Many Threads? As the number of HW threads increases: Need larger register file Resources statically partitioned/replicated Lower utilization, lower single-thread performance Shared resources Better utilization, but interference and fairness issues More threads!= Higher aggregate throughput! Scheduling optimizations: Adapt number of running threads depending on interference Co-schedule threads that have good interference behavior (symbiotic threads) Lecture 12-25
26 SMT Processors Alpha EV8: would be the 1 st SMT CPU if not cancelled 8-wide superscalar with support for 4-way SMT SMT mode: like 4 CPUs with shared caches and TLBs Replicated HW: PCs, registers (different maps, shared physical regs) Shared: instruction queue, caches, TLBs, branch predictors, Pentium 4 HT: 1 st commercial SMT CPU (2 threads) SMT threads share: caches, FUs, predictors (5% area increase) Statically partitioned IW & ROB Replicated RAS, 1 st level global branch history table Shared second-level branch history table, tagged with logical processor IDs IBM Power5, IBM Power 6: 2-way SMT Intel Nehalem (Core i7): 4-wide superscalar, 2-way SMT Lecture 12-26
27 Fetch Policies for SMT Fetch polices try to identify the best thread to fetch from. Policies: Least unresolved branches (BRCOUNT) Least misses in-flight (MISSCOUNT) Least instructions in decode/rename/issue stages (ICOUNT) Motivation for each policy? ICOUNT typically does best. Reasons: Gives priority to more efficient threads Avoids thread starvation Lecture 12-27
28 Long-latency stall tolerance with SMT SMT does not necessarily work well for long-latency stalls E.g. a thread misses to main memory (around 300 cycles) CPU continues issuing instructions from stalled thread, eventually clogging IW Improved policies: Detect long-latency stall Completely stop issuing instructions Flush instructions from stalled thread (works surprisingly well) Lecture 12-28
29 Summary Multithreaded processors implement hardware support to share pipeline across multiple threads Stall tolerance Better resource utilization 3 types of multithreading: Coarse grain (switch on long-latency stalls) Fine-grain (switch every cycle) Simultaneous (instrs from multiple threads each cycle) Design options in SMT processors Lecture 12-29
EECS 452 Lecture 9 TLP Thread-Level Parallelism
 EECS 452 Lecture 9 TLP Thread-Level Parallelism Instructor: Gokhan Memik EECS Dept., Northwestern University The lecture is adapted from slides by Iris Bahar (Brown), James Hoe (CMU), and John Shen (CMU
EECS 452 Lecture 9 TLP Thread-Level Parallelism Instructor: Gokhan Memik EECS Dept., Northwestern University The lecture is adapted from slides by Iris Bahar (Brown), James Hoe (CMU), and John Shen (CMU
Lecture 11: SMT and Caching Basics. Today: SMT, cache access basics (Sections 3.5, 5.1)
") Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
250P: Computer Systems Architecture. Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019
 Anton Burtsev February, 2019") 250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Simultaneous Multithreading Architecture
 Simultaneous Multithreading Architecture Virendra Singh Indian Institute of Science Bangalore Lecture-32 SE-273: Processor Design For most apps, most execution units lie idle For an 8-way superscalar.
Simultaneous Multithreading Architecture Virendra Singh Indian Institute of Science Bangalore Lecture-32 SE-273: Processor Design For most apps, most execution units lie idle For an 8-way superscalar.
Lecture 18: Multithreading and Multicores
 S 09 L18-1 18-447 Lecture 18: Multithreading and Multicores James C. Hoe Dept of ECE, CMU April 1, 2009 Announcements: Handouts: Handout #13 Project 4 (On Blackboard) Design Challenges of Technology Scaling,
S 09 L18-1 18-447 Lecture 18: Multithreading and Multicores James C. Hoe Dept of ECE, CMU April 1, 2009 Announcements: Handouts: Handout #13 Project 4 (On Blackboard) Design Challenges of Technology Scaling,
Lecture: SMT, Cache Hierarchies. Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1)
") Lecture: SMT, Cache Hierarchies Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized
Lecture: SMT, Cache Hierarchies Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
" # " $ % & ' ( ) * + $ " % '* + * ' "
 * + $ % '* + * '") ! )! # & ) * + * + * & *,+,- Update Instruction Address IA Instruction Fetch IF Instruction Decode ID Execute EX Memory Access ME Writeback Results WB Program Counter Instruction Register Register File
! )! # & ) * + * + * & *,+,- Update Instruction Address IA Instruction Fetch IF Instruction Decode ID Execute EX Memory Access ME Writeback Results WB Program Counter Instruction Register Register File
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Lecture: SMT, Cache Hierarchies. Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.
 Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 0 Consider the following LSQ and when operands are
Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 0 Consider the following LSQ and when operands are
ILP Ends TLP Begins. ILP Limits via an Oracle
 ILP Ends TLP Begins Today s topics: Explore a perfect machine unlimited budget to see where ILP goes answer: not far enough Look to TLP & multi-threading for help everything has it s issues we ll look
ILP Ends TLP Begins Today s topics: Explore a perfect machine unlimited budget to see where ILP goes answer: not far enough Look to TLP & multi-threading for help everything has it s issues we ll look
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
EECS 470. Lecture 18. Simultaneous Multithreading. Fall 2018 Jon Beaumont
 Lecture 18 Simultaneous Multithreading Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi,
Lecture 18 Simultaneous Multithreading Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi,
Lecture: SMT, Cache Hierarchies. Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.
 Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 1 Consider the following LSQ and when operands are
Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 1 Consider the following LSQ and when operands are
CS 152 Computer Architecture and Engineering. Lecture 18: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
 1 cycle per instruction I
1 cycle per instruction I CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Limitations of Scalar Pipelines
 Limitations of Scalar Pipelines Superscalar Organization Modern Processor Design: Fundamentals of Superscalar Processors Scalar upper bound on throughput IPC = 1 Inefficient unified pipeline
Limitations of Scalar Pipelines Superscalar Organization Modern Processor Design: Fundamentals of Superscalar Processors Scalar upper bound on throughput IPC = 1 Inefficient unified pipeline
Multithreading: Exploiting Thread-Level Parallelism within a Processor
 Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Lecture: SMT, Cache Hierarchies. Topics: memory dependence wrap-up, SMT processors, cache access basics (Sections B.1-B.3, 2.1)
") Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics (Sections B.1-B.3, 2.1) 1 Problem 3 Consider the following LSQ and when operands are available. Estimate
Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics (Sections B.1-B.3, 2.1) 1 Problem 3 Consider the following LSQ and when operands are available. Estimate
CS 152 Computer Architecture and Engineering. Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Multithreading Processors and Static Optimization Review. Adapted from Bhuyan, Patterson, Eggers, probably others
 Multithreading Processors and Static Optimization Review Adapted from Bhuyan, Patterson, Eggers, probably others Schedule of things to do By Wednesday the 9 th at 9pm Please send a milestone report (as
Multithreading Processors and Static Optimization Review Adapted from Bhuyan, Patterson, Eggers, probably others Schedule of things to do By Wednesday the 9 th at 9pm Please send a milestone report (as
Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
Kaisen Lin and Michael Conley
 Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
TDT 4260 lecture 7 spring semester 2015
 1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
Computer Systems Architecture I. CSE 560M Lecture 10 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 10 Prof. Patrick Crowley Plan for Today Questions Dynamic Execution III discussion Multiple Issue Static multiple issue (+ examples) Dynamic multiple issue
Computer Systems Architecture I CSE 560M Lecture 10 Prof. Patrick Crowley Plan for Today Questions Dynamic Execution III discussion Multiple Issue Static multiple issue (+ examples) Dynamic multiple issue
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Simultaneous Multithreading (SMT)
") Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue
Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue
Hyperthreading Technology
 Hyperthreading Technology Aleksandar Milenkovic Electrical and Computer Engineering Department University of Alabama in Huntsville milenka@ece.uah.edu www.ece.uah.edu/~milenka/ Outline What is hyperthreading?
Hyperthreading Technology Aleksandar Milenkovic Electrical and Computer Engineering Department University of Alabama in Huntsville milenka@ece.uah.edu www.ece.uah.edu/~milenka/ Outline What is hyperthreading?
Lecture 16: Checkpointed Processors. Department of Electrical Engineering Stanford University
 Lecture 16: Checkpointed Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 18-1 Announcements Reading for today: class notes Your main focus:
Lecture 16: Checkpointed Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 18-1 Announcements Reading for today: class notes Your main focus:
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Simultaneous Multithreading (SMT)
") Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue
Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue
Simultaneous Multithreading Processor
 Simultaneous Multithreading Processor Paper presented: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor James Lue Some slides are modified from http://hassan.shojania.com/pdf/smt_presentation.pdf
Simultaneous Multithreading Processor Paper presented: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor James Lue Some slides are modified from http://hassan.shojania.com/pdf/smt_presentation.pdf
Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov
 ECE 154B Dmitri Strukov") Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov Dealing With Control Hazards Simplest solution to stall pipeline until branch is resolved and target address is calculated
Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov Dealing With Control Hazards Simplest solution to stall pipeline until branch is resolved and target address is calculated
Spring 2010 Prof. Hyesoon Kim. Thanks to Prof. Loh & Prof. Prvulovic
 Spring 2010 Prof. Hyesoon Kim Thanks to Prof. Loh & Prof. Prvulovic C/C++ program Compiler Assembly Code (binary) Processor 0010101010101011110 Memory MAR MDR INPUT Processing Unit OUTPUT ALU TEMP PC Control
Spring 2010 Prof. Hyesoon Kim Thanks to Prof. Loh & Prof. Prvulovic C/C++ program Compiler Assembly Code (binary) Processor 0010101010101011110 Memory MAR MDR INPUT Processing Unit OUTPUT ALU TEMP PC Control
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling)
") 18-447 Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling) Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 2/13/2015 Agenda for Today & Next Few Lectures
18-447 Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling) Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 2/13/2015 Agenda for Today & Next Few Lectures
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University
 Prof. Onur Mutlu Carnegie Mellon University") Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 9: Multithreading
Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 9: Multithreading
The University of Texas at Austin
 EE382 (20): Computer Architecture - Parallelism and Locality Lecture 4 Parallelism in Hardware Mattan Erez The University of Texas at Austin EE38(20) (c) Mattan Erez 1 Outline 2 Principles of parallel
EE382 (20): Computer Architecture - Parallelism and Locality Lecture 4 Parallelism in Hardware Mattan Erez The University of Texas at Austin EE38(20) (c) Mattan Erez 1 Outline 2 Principles of parallel
Lecture 9: More ILP. Today: limits of ILP, case studies, boosting ILP (Sections )
") Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
EE382A Lecture 7: Dynamic Scheduling. Department of Electrical Engineering Stanford University
 EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
Lecture 26: Parallel Processing. Spring 2018 Jason Tang
 Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Simultaneous Multithreading (SMT)
") #1 Lec # 2 Fall 2003 9-10-2003 Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing
#1 Lec # 2 Fall 2003 9-10-2003 Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Pipelining to Superscalar
 Pipelining to Superscalar ECE/CS 752 Fall 207 Prof. Mikko H. Lipasti University of Wisconsin-Madison Pipelining to Superscalar Forecast Limits of pipelining The case for superscalar Instruction-level parallel
Pipelining to Superscalar ECE/CS 752 Fall 207 Prof. Mikko H. Lipasti University of Wisconsin-Madison Pipelining to Superscalar Forecast Limits of pipelining The case for superscalar Instruction-level parallel
Control Hazards. Branch Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Simultaneous Multithreading (SMT)
") Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1996 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue
Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1996 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Computer Architecture Lecture 14: Out-of-Order Execution. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/18/2013
 18-447 Computer Architecture Lecture 14: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/18/2013 Reminder: Homework 3 Homework 3 Due Feb 25 REP MOVS in Microprogrammed
18-447 Computer Architecture Lecture 14: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/18/2013 Reminder: Homework 3 Homework 3 Due Feb 25 REP MOVS in Microprogrammed
Processor Architecture
 Processor Architecture Advanced Dynamic Scheduling Techniques M. Schölzel Content Tomasulo with speculative execution Introducing superscalarity into the instruction pipeline Multithreading Content Tomasulo
Processor Architecture Advanced Dynamic Scheduling Techniques M. Schölzel Content Tomasulo with speculative execution Introducing superscalarity into the instruction pipeline Multithreading Content Tomasulo
Pentium IV-XEON. Computer architectures M
 Pentium IV-XEON Computer architectures M 1 Pentium IV block scheme 4 32 bytes parallel Four access ports to the EU 2 Pentium IV block scheme Address Generation Unit BTB Branch Target Buffer I-TLB Instruction
Pentium IV-XEON Computer architectures M 1 Pentium IV block scheme 4 32 bytes parallel Four access ports to the EU 2 Pentium IV block scheme Address Generation Unit BTB Branch Target Buffer I-TLB Instruction
15-740/ Computer Architecture Lecture 10: Out-of-Order Execution. Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 10/3/2011
 5-740/8-740 Computer Architecture Lecture 0: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Fall 20, 0/3/20 Review: Solutions to Enable Precise Exceptions Reorder buffer History buffer
5-740/8-740 Computer Architecture Lecture 0: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Fall 20, 0/3/20 Review: Solutions to Enable Precise Exceptions Reorder buffer History buffer
ECSE 425 Lecture 25: Mul1- threading
 ECSE 425 Lecture 25: Mul1- threading H&P Chapter 3 Last Time Theore1cal and prac1cal limits of ILP Instruc1on window Branch predic1on Register renaming 2 Today Mul1- threading Chapter 3.5 Summary of ILP:
ECSE 425 Lecture 25: Mul1- threading H&P Chapter 3 Last Time Theore1cal and prac1cal limits of ILP Instruc1on window Branch predic1on Register renaming 2 Today Mul1- threading Chapter 3.5 Summary of ILP:
Introducing Multi-core Computing / Hyperthreading
 Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
CS 152 Computer Architecture and Engineering. Lecture 12 - Advanced Out-of-Order Superscalars
 CS 152 Computer Architecture and Engineering Lecture 12 - Advanced Out-of-Order Superscalars Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
CS 152 Computer Architecture and Engineering Lecture 12 - Advanced Out-of-Order Superscalars Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
Control Hazards. Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
CMSC22200 Computer Architecture Lecture 8: Out-of-Order Execution. Prof. Yanjing Li University of Chicago
 CMSC22200 Computer Architecture Lecture 8: Out-of-Order Execution Prof. Yanjing Li University of Chicago Administrative Stuff! Lab2 due tomorrow " 2 free late days! Lab3 is out " Start early!! My office
CMSC22200 Computer Architecture Lecture 8: Out-of-Order Execution Prof. Yanjing Li University of Chicago Administrative Stuff! Lab2 due tomorrow " 2 free late days! Lab3 is out " Start early!! My office
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
CS 152 Computer Architecture and Engineering. Lecture 10 - Complex Pipelines, Out-of-Order Issue, Register Renaming
 CS 152 Computer Architecture and Engineering Lecture 10 - Complex Pipelines, Out-of-Order Issue, Register Renaming John Wawrzynek Electrical Engineering and Computer Sciences University of California at
CS 152 Computer Architecture and Engineering Lecture 10 - Complex Pipelines, Out-of-Order Issue, Register Renaming John Wawrzynek Electrical Engineering and Computer Sciences University of California at
Beyond ILP. Hemanth M Bharathan Balaji. Hemanth M & Bharathan Balaji
 Beyond ILP Hemanth M Bharathan Balaji Multiscalar Processors Gurindar S Sohi Scott E Breach T N Vijaykumar Control Flow Graph (CFG) Each node is a basic block in graph CFG divided into a collection of
Beyond ILP Hemanth M Bharathan Balaji Multiscalar Processors Gurindar S Sohi Scott E Breach T N Vijaykumar Control Flow Graph (CFG) Each node is a basic block in graph CFG divided into a collection of
CS 654 Computer Architecture Summary. Peter Kemper
 CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
Simultaneous Multithreading on Pentium 4
 Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
ECE/CS 552: Pipelining to Superscalar Prof. Mikko Lipasti
 ECE/CS 552: Pipelining to Superscalar Prof. Mikko Lipasti Lecture notes based in part on slides created by Mark Hill, David Wood, Guri Sohi, John Shen and Jim Smith Pipelining to Superscalar Forecast Real
ECE/CS 552: Pipelining to Superscalar Prof. Mikko Lipasti Lecture notes based in part on slides created by Mark Hill, David Wood, Guri Sohi, John Shen and Jim Smith Pipelining to Superscalar Forecast Real
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
TDT 4260 TDT ILP Chap 2, App. C
 TDT 4260 ILP Chap 2, App. C Intro Ian Bratt (ianbra@idi.ntnu.no) ntnu no) Instruction level parallelism (ILP) A program is sequence of instructions typically written to be executed one after the other
TDT 4260 ILP Chap 2, App. C Intro Ian Bratt (ianbra@idi.ntnu.no) ntnu no) Instruction level parallelism (ILP) A program is sequence of instructions typically written to be executed one after the other
Superscalar Processors Ch 14
 Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]
![Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]](/thumbs/83/88761675.jpg "Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]") Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
Superscalar Processing (5) Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?
 Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?") Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Computer Architecture 计算机体系结构. Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Reorder Buffer Implementation (Pentium Pro) Reorder Buffer Implementation (Pentium Pro)
 Reorder Buffer Implementation (Pentium Pro)") Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
CPU Architecture Overview. Varun Sampath CIS 565 Spring 2012
 CPU Architecture Overview Varun Sampath CIS 565 Spring 2012 Objectives Performance tricks of a modern CPU Pipelining Branch Prediction Superscalar Out-of-Order (OoO) Execution Memory Hierarchy Vector Operations
CPU Architecture Overview Varun Sampath CIS 565 Spring 2012 Objectives Performance tricks of a modern CPU Pipelining Branch Prediction Superscalar Out-of-Order (OoO) Execution Memory Hierarchy Vector Operations
Precise Exceptions and Out-of-Order Execution. Samira Khan
 Precise Exceptions and Out-of-Order Execution Samira Khan Multi-Cycle Execution Not all instructions take the same amount of time for execution Idea: Have multiple different functional units that take
Precise Exceptions and Out-of-Order Execution Samira Khan Multi-Cycle Execution Not all instructions take the same amount of time for execution Idea: Have multiple different functional units that take
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
Lecture 25: Board Notes: Threads and GPUs
 Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
Superscalar Processors
 Superscalar Processors Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any a performance
Superscalar Processors Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any a performance
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Lecture: Out-of-order Processors. Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ
 Lecture: Out-of-order Processors Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB)
Lecture: Out-of-order Processors Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB)
LIMITS OF ILP. B649 Parallel Architectures and Programming
 LIMITS OF ILP B649 Parallel Architectures and Programming A Perfect Processor Register renaming infinite number of registers hence, avoids all WAW and WAR hazards Branch prediction perfect prediction Jump
LIMITS OF ILP B649 Parallel Architectures and Programming A Perfect Processor Register renaming infinite number of registers hence, avoids all WAW and WAR hazards Branch prediction perfect prediction Jump
An Overview of MIPS Multi-Threading. White Paper
 Public Imagination Technologies An Overview of MIPS Multi-Threading White Paper Copyright Imagination Technologies Limited. All Rights Reserved. This document is Public. This publication contains proprietary
Public Imagination Technologies An Overview of MIPS Multi-Threading White Paper Copyright Imagination Technologies Limited. All Rights Reserved. This document is Public. This publication contains proprietary
Multi-threaded processors. Hung-Wei Tseng x Dean Tullsen
 Multi-threaded processors Hung-Wei Tseng x Dean Tullsen OoO SuperScalar Processor Fetch instructions in the instruction window Register renaming to eliminate false dependencies edule an instruction to
Multi-threaded processors Hung-Wei Tseng x Dean Tullsen OoO SuperScalar Processor Fetch instructions in the instruction window Register renaming to eliminate false dependencies edule an instruction to
Assuming ideal conditions (perfect pipelining and no hazards), how much time would it take to execute the same program in: b) A 5-stage pipeline?
, how much time would it take to execute the same program in: b) A 5-stage pipeline?") 1. Imagine we have a non-pipelined processor running at 1MHz and want to run a program with 1000 instructions. a) How much time would it take to execute the program? 1 instruction per cycle. 1MHz clock
1. Imagine we have a non-pipelined processor running at 1MHz and want to run a program with 1000 instructions. a) How much time would it take to execute the program? 1 instruction per cycle. 1MHz clock
CS 252 Graduate Computer Architecture. Lecture 4: Instruction-Level Parallelism
 CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Lecture 9: Dynamic ILP. Topics: out-of-order processors (Sections )
") Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
Ron Kalla, Balaram Sinharoy, Joel Tendler IBM Systems Group
 Simultaneous Multi-threading Implementation in POWER5 -- IBM's Next Generation POWER Microprocessor Ron Kalla, Balaram Sinharoy, Joel Tendler IBM Systems Group Outline Motivation Background Threading Fundamentals
Simultaneous Multi-threading Implementation in POWER5 -- IBM's Next Generation POWER Microprocessor Ron Kalla, Balaram Sinharoy, Joel Tendler IBM Systems Group Outline Motivation Background Threading Fundamentals