Batch Systems. Running your jobs on an HPC machine
|
|
|
- Nickolas Mills
- 6 years ago
- Views:
Transcription
1 Batch Systems Running your jobs on an HPC machine

2 Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. This means you are free to copy and redistribute the material and adapt and build on the material under the following terms: You must give appropriate credit, provide a link to the license and indicate if changes were made. If you adapt or build on the material you must distribute your work under the same license as the original. Note that this presentation contains images owned by others. Please seek their permission before reusing these images.
3 Outline What is a batch system and why do we need them? How do I use a batch system to run my jobs? Concepts Resource scheduling and job execution Job submission scripts Interactive jobs Scheduling Best practice Common batch systems Converting between different batch systems
4 Batch Systems What are they and why do we need them?
5 What is a batch system? Mechanism to control access by many users to shared computing resources Queuing / scheduling system for users jobs Manages the reservation of resources and job execution Allows users to fire and forget large, long calculations or many jobs ( production runs )
6 Why do we need a batch system? Ensure all users get a fair share of compute resources (demand usually exceeds supply) To ensure the machine is utilised as efficiently as possible To track usage - for accounting and budget control To mediate access to other resources e.g. software licences
7 Using batch systems How can I use them to run and manage my jobs?
8 How to use a batch system 1. Set up a job, consisting of: Commands that run one or more calculations / simulations Specification of compute resources needed to do this 2. Submit your job to the batch system Job is placed in a queue by the scheduler Will be executed when there is space and time on the machine Job runs until it finishes successfully, is terminated due to errors, or exceeds a time limit 3. Examine outputs and any error messages
9 Batch system flow Job Submit Command Job Delete Command Write Job Script Job Queued Job Executes Job Finished Allocated Job ID Job Status Command Output Files (& Errors) Status
10 Resource scheduling & job execution When you submit a job to a batch system you specify the resources it requires (number of nodes / cores, job time, etc.) The batch system schedules a block of resources that meet these requirements to become available for your job to use When it runs your job can use these resources however it likes (specified in advance in your job script): Run a single calculation / simulation that spans all cores and full time Run multiple shorter calculations / simulations in sequence Run multiple smaller calculations / simulations running in parallel for the full time
11 Batch system concepts Queue a logical scheduling category that may correspond to a portion of the machine: Different time constraints Nodes with special features such as large memory, different processor architecture or accelerators such as GPUs, etc. Nodes reserved for access by a subset of users (e.g. for training) Generally have a small number of defined queues Jobs contend for resources within the queue in which they sit E.g. on ARCHER: standard queue (24 hour limit, no limit on number of nodes) short queue (max 20 minutes & 8 nodes, weekdays 08:00-22:00 only)
12 Batch system concepts Priority numerical ranking of a job by the scheduler that influences how soon it will start (higher priority more likely to start sooner) Account name / budget code identifier used to charge ( ) time used Jobs may be rejected when you submit with insufficient budget Walltime the time a job takes (or is expected to take)
13 Batch system commands & job states PBS (ARCHER & Cirrus) SLURM Job submit command qsub myjob.pbs sbatch myjob_sbatch Job status command qstat u $USER squeue u $USER Job delete command qdel ######## scancel ######## PBS job state (ARCHER & Cirrus) Q R E H Meaning The job is queued and waiting to start The job is currently running The job is currently exiting The job is held and not eligible to run
14 Parallel application launcher commands Use these commands inside a job script to launch a parallel executable Parallel application launcher commands aprun n 48 N 12 d 2 my_program mpiexec_mpt n 48 ppn 24 my_program mpirun ppn 12 np 48 my_program mpiexec n 48 my_program (ARCHER) (Cirrus)
15 Job submission scripts PBS example: #!/bin/bash login #PBS -N Weather1 #PBS -l select=200 #PBS -l walltime=1:00:00 #PBS q short cd $PBS_O_WORKDIR aprun n 4800 weathersim Linux shell to run job script in Job name Number of nodes requested Requested job duration Queue to submit job to Changing to directory to run in Parallel job launcher Number of parallel instances of program to launch Program name
16 Job submission scripts SLURM example: #!/bin/bash #SBATCH J Weather1 #SBATCH --nodes=2 #SBATCH --time=12:00:00 #SBATCH --ntasks=24 #SBATCH p tesla mpirun np 24 weathersim Linux shell to run job script in Job name Number of nodes requested Requested job duration Number of parallel tasks Queue to submit job to (GPU queue) Parallel job launcher Number of parallel instances of program to launch Program name
17 Interactive jobs Most HPC machines allow both batch and interactive jobs Batch jobs are non-interactive. You write a job submission script to run your job Jobs run without user intervention and you collect results at the end Interactive jobs allow you to use compute resources interactively For testing, debugging/profiling, software development work For visualisation and data analysis How these are set up and charged varies from machine to machine
18 Interactive jobs If using the same compute resource as batch jobs then need to request interactive jobs from the batch scheduler Use same resource request variables as batch jobs (duration, size) Wait until job runs to get an interactive session Within interactive session run serial code or parallel programs using parallel launcher as for batch jobs May have a small part of the HPC machine dedicated to interactive jobs Typically for visualisation & postprocessing / data analysis May bypass the batch scheduler for instant access May be limited in performance, available libraries, parallelism, etc.
19 Scheduling of jobs A brief look under the hood at when jobs are run
20 Scheduling Complex scheduling algorithms try to run many jobs of different sizes on system to ensure maximum utilisation and minimum wait time Batch schedulers can implement scheduling policy that varies from machine to machine by allowing control over the relative importance to job prioritisation of: Waiting times Large vs small jobs Long vs short jobs Power consumption
21 Scheduling Backfilling: Assign all jobs priority according to policy & scheduling algorithm Starting with highest priority job, run each lesser priority job that can run with current free resources For the highest priority job A that can not currently run, calculate when the required resources will become available and schedule job A to run at this time. Until such time, run any less high priority jobs that will complete before job A starts and for which sufficient resources are currently available This fills gaps and improves resource utilisation Active area of research For example on ARCHER you can view detailed statistics on this How long until my job executes? Not always an easy question to answer!
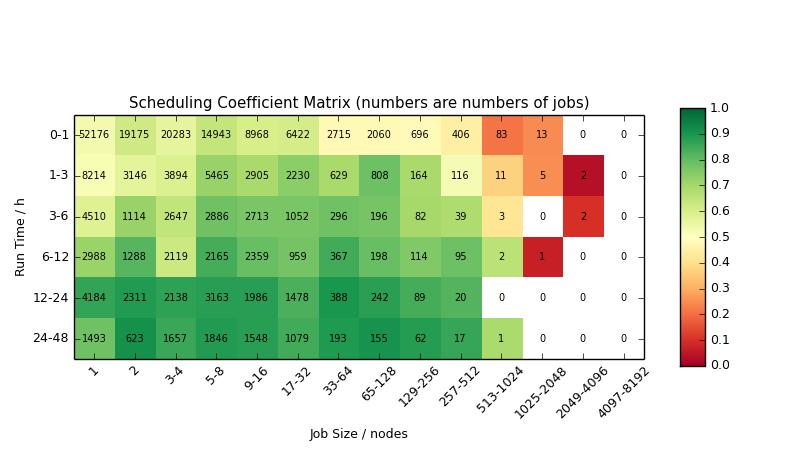
22 Scheduling
23 Best practice Tips for making the most effective use of batch systems
24 Best practice Run short tests using interactive jobs if possible Once you are happy the setup works write a short test job script and submit it to the batch system Finally, produce scripts for full production runs Remember you have the full functionality of the Linux command line (bash or other) available in scripts This allows for sophisticated scripts if you need them Can automate a lot of tedious data analysis and transformation be careful to test when moving, copying deleting important data it is very easy to lose the results of a large simulation due to a typo (or unforeseen error) in a script
25 Migrating Changing your scripts from one batch system to another
26 Batch systems PBS (on ARCHER and Cirrus), Torque Grid Engine SLURM LSF IBM Systems LoadLeveller IBM Systems It is not unusual for applications to run over many different HPC machines which might be using different queue systems You often see sets of submission scripts for different systems From a user s perspective different commands are used to submit and manage jobs
27 Submission script conversion Usually need to change the batch system options Sometimes need to change the commands in the script Particularly to different paths Usually the order (logic) of the commands remains the same Tends to be a fairly mechanical process and there are some utilities that can help Bolt from EPCC, generates job submission scripts for a variety of batch systems/hpc resources: HPC machine documentation often provides significant reference material Especially true for ARCHER and Cirrus
28 Summary
29 Summary Submitting jobs through a batch system represents a different way of interacting with a computer than you might be used to But this has a crucial role in enabling potentially thousands of users to easily run jobs on the same machine concurrently A number of different batch system technologies Fundamentally the same concepts, but different options and commands These are all well documented Many applications are shipped with submission scripts for multiple systems
Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine
 Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike
Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike
Batch Systems. Running calculations on HPC resources
 Batch Systems Running calculations on HPC resources Outline What is a batch system? How do I interact with the batch system Job submission scripts Interactive jobs Common batch systems Converting between
Batch Systems Running calculations on HPC resources Outline What is a batch system? How do I interact with the batch system Job submission scripts Interactive jobs Common batch systems Converting between
User Guide of High Performance Computing Cluster in School of Physics
 User Guide of High Performance Computing Cluster in School of Physics Prepared by Sue Yang (xue.yang@sydney.edu.au) This document aims at helping users to quickly log into the cluster, set up the software
User Guide of High Performance Computing Cluster in School of Physics Prepared by Sue Yang (xue.yang@sydney.edu.au) This document aims at helping users to quickly log into the cluster, set up the software
Sharpen Exercise: Using HPC resources and running parallel applications
 Sharpen Exercise: Using HPC resources and running parallel applications Contents 1 Aims 2 2 Introduction 2 3 Instructions 3 3.1 Log into ARCHER frontend nodes and run commands.... 3 3.2 Download and extract
Sharpen Exercise: Using HPC resources and running parallel applications Contents 1 Aims 2 2 Introduction 2 3 Instructions 3 3.1 Log into ARCHER frontend nodes and run commands.... 3 3.2 Download and extract
Quick Guide for the Torque Cluster Manager
 Quick Guide for the Torque Cluster Manager Introduction: One of the main purposes of the Aries Cluster is to accommodate especially long-running programs. Users who run long jobs (which take hours or days
Quick Guide for the Torque Cluster Manager Introduction: One of the main purposes of the Aries Cluster is to accommodate especially long-running programs. Users who run long jobs (which take hours or days
Sharpen Exercise: Using HPC resources and running parallel applications
 Sharpen Exercise: Using HPC resources and running parallel applications Andrew Turner, Dominic Sloan-Murphy, David Henty, Adrian Jackson Contents 1 Aims 2 2 Introduction 2 3 Instructions 3 3.1 Log into
Sharpen Exercise: Using HPC resources and running parallel applications Andrew Turner, Dominic Sloan-Murphy, David Henty, Adrian Jackson Contents 1 Aims 2 2 Introduction 2 3 Instructions 3 3.1 Log into
Job Management on LONI and LSU HPC clusters
 Job Management on LONI and LSU HPC clusters Le Yan HPC Consultant User Services @ LONI Outline Overview Batch queuing system Job queues on LONI clusters Basic commands The Cluster Environment Multiple
Job Management on LONI and LSU HPC clusters Le Yan HPC Consultant User Services @ LONI Outline Overview Batch queuing system Job queues on LONI clusters Basic commands The Cluster Environment Multiple
Introduction to GALILEO
 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Maurizio Cremonesi m.cremonesi@cineca.it
Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Maurizio Cremonesi m.cremonesi@cineca.it
PBS Pro Documentation
 Introduction Most jobs will require greater resources than are available on individual nodes. All jobs must be scheduled via the batch job system. The batch job system in use is PBS Pro. Jobs are submitted
Introduction Most jobs will require greater resources than are available on individual nodes. All jobs must be scheduled via the batch job system. The batch job system in use is PBS Pro. Jobs are submitted
Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat
 Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat Summary 1. Submitting Jobs: Batch mode - Interactive mode 2. Partition 3. Jobs: Serial, Parallel 4. Using generic resources Gres : GPUs, MICs.
Submitting and running jobs on PlaFRIM2 Redouane Bouchouirbat Summary 1. Submitting Jobs: Batch mode - Interactive mode 2. Partition 3. Jobs: Serial, Parallel 4. Using generic resources Gres : GPUs, MICs.
Slurm basics. Summer Kickstart June slide 1 of 49
 Slurm basics Summer Kickstart 2017 June 2017 slide 1 of 49 Triton layers Triton is a powerful but complex machine. You have to consider: Connecting (ssh) Data storage (filesystems and Lustre) Resource
Slurm basics Summer Kickstart 2017 June 2017 slide 1 of 49 Triton layers Triton is a powerful but complex machine. You have to consider: Connecting (ssh) Data storage (filesystems and Lustre) Resource
Image Sharpening. Practical Introduction to HPC Exercise. Instructions for Cirrus Tier-2 System
 Image Sharpening Practical Introduction to HPC Exercise Instructions for Cirrus Tier-2 System 2 1. Aims The aim of this exercise is to get you used to logging into an HPC resource, using the command line
Image Sharpening Practical Introduction to HPC Exercise Instructions for Cirrus Tier-2 System 2 1. Aims The aim of this exercise is to get you used to logging into an HPC resource, using the command line
NBIC TechTrack PBS Tutorial
 NBIC TechTrack PBS Tutorial by Marcel Kempenaar, NBIC Bioinformatics Research Support group, University Medical Center Groningen Visit our webpage at: http://www.nbic.nl/support/brs 1 NBIC PBS Tutorial
NBIC TechTrack PBS Tutorial by Marcel Kempenaar, NBIC Bioinformatics Research Support group, University Medical Center Groningen Visit our webpage at: http://www.nbic.nl/support/brs 1 NBIC PBS Tutorial
Compilation and Parallel Start
 Compiling MPI Programs Programming with MPI Compiling and running MPI programs Type to enter text Jan Thorbecke Delft University of Technology 2 Challenge the future Compiling and Starting MPI Jobs Compiling:
Compiling MPI Programs Programming with MPI Compiling and running MPI programs Type to enter text Jan Thorbecke Delft University of Technology 2 Challenge the future Compiling and Starting MPI Jobs Compiling:
Introduction to RCC. September 14, 2016 Research Computing Center
 Introduction to HPC @ RCC September 14, 2016 Research Computing Center What is HPC High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers
Introduction to HPC @ RCC September 14, 2016 Research Computing Center What is HPC High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers
Introduction to RCC. January 18, 2017 Research Computing Center
 Introduction to HPC @ RCC January 18, 2017 Research Computing Center What is HPC High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much
Introduction to HPC @ RCC January 18, 2017 Research Computing Center What is HPC High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much
Minnesota Supercomputing Institute Regents of the University of Minnesota. All rights reserved.
 Minnesota Supercomputing Institute Introduction to Job Submission and Scheduling Andrew Gustafson Interacting with MSI Systems Connecting to MSI SSH is the most reliable connection method Linux and Mac
Minnesota Supercomputing Institute Introduction to Job Submission and Scheduling Andrew Gustafson Interacting with MSI Systems Connecting to MSI SSH is the most reliable connection method Linux and Mac
Queue systems. and how to use Torque/Maui. Piero Calucci. Scuola Internazionale Superiore di Studi Avanzati Trieste
 Queue systems and how to use Torque/Maui Piero Calucci Scuola Internazionale Superiore di Studi Avanzati Trieste March 9th 2007 Advanced School in High Performance Computing Tools for e-science Outline
Queue systems and how to use Torque/Maui Piero Calucci Scuola Internazionale Superiore di Studi Avanzati Trieste March 9th 2007 Advanced School in High Performance Computing Tools for e-science Outline
NBIC TechTrack PBS Tutorial. by Marcel Kempenaar, NBIC Bioinformatics Research Support group, University Medical Center Groningen
 NBIC TechTrack PBS Tutorial by Marcel Kempenaar, NBIC Bioinformatics Research Support group, University Medical Center Groningen 1 NBIC PBS Tutorial This part is an introduction to clusters and the PBS
NBIC TechTrack PBS Tutorial by Marcel Kempenaar, NBIC Bioinformatics Research Support group, University Medical Center Groningen 1 NBIC PBS Tutorial This part is an introduction to clusters and the PBS
Introduction to PICO Parallel & Production Enviroment
 Introduction to PICO Parallel & Production Enviroment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Nicola Spallanzani n.spallanzani@cineca.it
Introduction to PICO Parallel & Production Enviroment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Nicola Spallanzani n.spallanzani@cineca.it
Reduces latency and buffer overhead. Messaging occurs at a speed close to the processors being directly connected. Less error detection
 Switching Operational modes: Store-and-forward: Each switch receives an entire packet before it forwards it onto the next switch - useful in a general purpose network (I.e. a LAN). usually, there is a
Switching Operational modes: Store-and-forward: Each switch receives an entire packet before it forwards it onto the next switch - useful in a general purpose network (I.e. a LAN). usually, there is a
and how to use TORQUE & Maui Piero Calucci
 Queue and how to use & Maui Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 We Are Trying to Solve 2 Using the Manager
Queue and how to use & Maui Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 We Are Trying to Solve 2 Using the Manager
Before We Start. Sign in hpcxx account slips Windows Users: Download PuTTY. Google PuTTY First result Save putty.exe to Desktop
 Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Introduction to SLURM & SLURM batch scripts
 Introduction to SLURM & SLURM batch scripts Anita Orendt Assistant Director Research Consulting & Faculty Engagement anita.orendt@utah.edu 6 February 2018 Overview of Talk Basic SLURM commands SLURM batch
Introduction to SLURM & SLURM batch scripts Anita Orendt Assistant Director Research Consulting & Faculty Engagement anita.orendt@utah.edu 6 February 2018 Overview of Talk Basic SLURM commands SLURM batch
How to run a job on a Cluster?
 How to run a job on a Cluster? Cluster Training Workshop Dr Samuel Kortas Computational Scientist KAUST Supercomputing Laboratory Samuel.kortas@kaust.edu.sa 17 October 2017 Outline 1. Resources available
How to run a job on a Cluster? Cluster Training Workshop Dr Samuel Kortas Computational Scientist KAUST Supercomputing Laboratory Samuel.kortas@kaust.edu.sa 17 October 2017 Outline 1. Resources available
OpenPBS Users Manual
 How to Write a PBS Batch Script OpenPBS Users Manual PBS scripts are rather simple. An MPI example for user your-user-name: Example: MPI Code PBS -N a_name_for_my_parallel_job PBS -l nodes=7,walltime=1:00:00
How to Write a PBS Batch Script OpenPBS Users Manual PBS scripts are rather simple. An MPI example for user your-user-name: Example: MPI Code PBS -N a_name_for_my_parallel_job PBS -l nodes=7,walltime=1:00:00
Introduction to the NCAR HPC Systems. 25 May 2018 Consulting Services Group Brian Vanderwende
 Introduction to the NCAR HPC Systems 25 May 2018 Consulting Services Group Brian Vanderwende Topics to cover Overview of the NCAR cluster resources Basic tasks in the HPC environment Accessing pre-built
Introduction to the NCAR HPC Systems 25 May 2018 Consulting Services Group Brian Vanderwende Topics to cover Overview of the NCAR cluster resources Basic tasks in the HPC environment Accessing pre-built
Introduction to SLURM on the High Performance Cluster at the Center for Computational Research
 Introduction to SLURM on the High Performance Cluster at the Center for Computational Research Cynthia Cornelius Center for Computational Research University at Buffalo, SUNY 701 Ellicott St Buffalo, NY
Introduction to SLURM on the High Performance Cluster at the Center for Computational Research Cynthia Cornelius Center for Computational Research University at Buffalo, SUNY 701 Ellicott St Buffalo, NY
Introduction to GALILEO
 November 27, 2016 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it SuperComputing Applications and Innovation Department
November 27, 2016 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it SuperComputing Applications and Innovation Department
High Performance Computing Cluster Advanced course
 High Performance Computing Cluster Advanced course Jeremie Vandenplas, Gwen Dawes 9 November 2017 Outline Introduction to the Agrogenomics HPC Submitting and monitoring jobs on the HPC Parallel jobs on
High Performance Computing Cluster Advanced course Jeremie Vandenplas, Gwen Dawes 9 November 2017 Outline Introduction to the Agrogenomics HPC Submitting and monitoring jobs on the HPC Parallel jobs on
Introduction to HPC Using the New Cluster at GACRC
 Introduction to HPC Using the New Cluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is the new cluster
Introduction to HPC Using the New Cluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is the new cluster
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Running in parallel. Total number of cores available after hyper threading (virtual cores)
") First at all, to know how many processors/cores you have available in your computer, type in the terminal: $> lscpu The output for this particular workstation is the following: Architecture: x86_64 CPU
First at all, to know how many processors/cores you have available in your computer, type in the terminal: $> lscpu The output for this particular workstation is the following: Architecture: x86_64 CPU
Duke Compute Cluster Workshop. 3/28/2018 Tom Milledge rc.duke.edu
 Duke Compute Cluster Workshop 3/28/2018 Tom Milledge rc.duke.edu rescomputing@duke.edu Outline of talk Overview of Research Computing resources Duke Compute Cluster overview Running interactive and batch
Duke Compute Cluster Workshop 3/28/2018 Tom Milledge rc.duke.edu rescomputing@duke.edu Outline of talk Overview of Research Computing resources Duke Compute Cluster overview Running interactive and batch
Introduction to HPC Using zcluster at GACRC
 Introduction to HPC Using zcluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is HPC Concept? What is
Introduction to HPC Using zcluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is HPC Concept? What is
New User Tutorial. OSU High Performance Computing Center
 New User Tutorial OSU High Performance Computing Center TABLE OF CONTENTS Logging In... 3-5 Windows... 3-4 Linux... 4 Mac... 4-5 Changing Password... 5 Using Linux Commands... 6 File Systems... 7 File
New User Tutorial OSU High Performance Computing Center TABLE OF CONTENTS Logging In... 3-5 Windows... 3-4 Linux... 4 Mac... 4-5 Changing Password... 5 Using Linux Commands... 6 File Systems... 7 File
Compiling applications for the Cray XC
 Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
UF Research Computing: Overview and Running STATA
 UF : Overview and Running STATA www.rc.ufl.edu Mission Improve opportunities for research and scholarship Improve competitiveness in securing external funding Matt Gitzendanner magitz@ufl.edu Provide high-performance
UF : Overview and Running STATA www.rc.ufl.edu Mission Improve opportunities for research and scholarship Improve competitiveness in securing external funding Matt Gitzendanner magitz@ufl.edu Provide high-performance
Introduction to GALILEO
 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Alessandro Grottesi a.grottesi@cineca.it SuperComputing Applications and
Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Alessandro Grottesi a.grottesi@cineca.it SuperComputing Applications and
Introduction to SLURM & SLURM batch scripts
 Introduction to SLURM & SLURM batch scripts Anita Orendt Assistant Director Research Consulting & Faculty Engagement anita.orendt@utah.edu 16 Feb 2017 Overview of Talk Basic SLURM commands SLURM batch
Introduction to SLURM & SLURM batch scripts Anita Orendt Assistant Director Research Consulting & Faculty Engagement anita.orendt@utah.edu 16 Feb 2017 Overview of Talk Basic SLURM commands SLURM batch
Introduction to Molecular Dynamics on ARCHER: Instructions for running parallel jobs on ARCHER
 Introduction to Molecular Dynamics on ARCHER: Instructions for running parallel jobs on ARCHER 1 Introduction This handout contains basic instructions for how to login in to ARCHER and submit jobs to the
Introduction to Molecular Dynamics on ARCHER: Instructions for running parallel jobs on ARCHER 1 Introduction This handout contains basic instructions for how to login in to ARCHER and submit jobs to the
How to run applications on Aziz supercomputer. Mohammad Rafi System Administrator Fujitsu Technology Solutions
 How to run applications on Aziz supercomputer Mohammad Rafi System Administrator Fujitsu Technology Solutions Agenda Overview Compute Nodes Storage Infrastructure Servers Cluster Stack Environment Modules
How to run applications on Aziz supercomputer Mohammad Rafi System Administrator Fujitsu Technology Solutions Agenda Overview Compute Nodes Storage Infrastructure Servers Cluster Stack Environment Modules
Content. MPIRUN Command Environment Variables LoadLeveler SUBMIT Command IBM Simple Scheduler. IBM PSSC Montpellier Customer Center
 Content IBM PSSC Montpellier Customer Center MPIRUN Command Environment Variables LoadLeveler SUBMIT Command IBM Simple Scheduler Control System Service Node (SN) An IBM system-p 64-bit system Control
Content IBM PSSC Montpellier Customer Center MPIRUN Command Environment Variables LoadLeveler SUBMIT Command IBM Simple Scheduler Control System Service Node (SN) An IBM system-p 64-bit system Control
Introduction to Joker Cyber Infrastructure Architecture Team CIA.NMSU.EDU
 Introduction to Joker Cyber Infrastructure Architecture Team CIA.NMSU.EDU What is Joker? NMSU s supercomputer. 238 core computer cluster. Intel E-5 Xeon CPUs and Nvidia K-40 GPUs. InfiniBand innerconnect.
Introduction to Joker Cyber Infrastructure Architecture Team CIA.NMSU.EDU What is Joker? NMSU s supercomputer. 238 core computer cluster. Intel E-5 Xeon CPUs and Nvidia K-40 GPUs. InfiniBand innerconnect.
Running applications on the Cray XC30
 Running applications on the Cray XC30 Running on compute nodes By default, users do not access compute nodes directly. Instead they launch jobs on compute nodes using one of three available modes: 1. Extreme
Running applications on the Cray XC30 Running on compute nodes By default, users do not access compute nodes directly. Instead they launch jobs on compute nodes using one of three available modes: 1. Extreme
Introduction to HPC Using zcluster at GACRC
 Introduction to HPC Using zcluster at GACRC On-class PBIO/BINF8350 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What
Introduction to HPC Using zcluster at GACRC On-class PBIO/BINF8350 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What
Fractals exercise. Investigating task farms and load imbalance
 Fractals exercise Investigating task farms and load imbalance Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Fractals exercise Investigating task farms and load imbalance Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Fractals. Investigating task farms and load imbalance
 Fractals Investigating task farms and load imbalance Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Fractals Investigating task farms and load imbalance Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
High Performance Computing (HPC) Using zcluster at GACRC
 Using zcluster at GACRC") High Performance Computing (HPC) Using zcluster at GACRC On-class STAT8060 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC?
High Performance Computing (HPC) Using zcluster at GACRC On-class STAT8060 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC?
Quick Start Guide. by Burak Himmetoglu. Supercomputing Consultant. Enterprise Technology Services & Center for Scientific Computing
 Quick Start Guide by Burak Himmetoglu Supercomputing Consultant Enterprise Technology Services & Center for Scientific Computing E-mail: bhimmetoglu@ucsb.edu Contents User access, logging in Linux/Unix
Quick Start Guide by Burak Himmetoglu Supercomputing Consultant Enterprise Technology Services & Center for Scientific Computing E-mail: bhimmetoglu@ucsb.edu Contents User access, logging in Linux/Unix
PRACTICAL MACHINE SPECIFIC COMMANDS KRAKEN
 PRACTICAL MACHINE SPECIFIC COMMANDS KRAKEN Myvizhi Esai Selvan Department of Chemical and Biomolecular Engineering University of Tennessee, Knoxville October, 2008 Machine: a Cray XT4 system with 4512
PRACTICAL MACHINE SPECIFIC COMMANDS KRAKEN Myvizhi Esai Selvan Department of Chemical and Biomolecular Engineering University of Tennessee, Knoxville October, 2008 Machine: a Cray XT4 system with 4512
Slurm Overview. Brian Christiansen, Marshall Garey, Isaac Hartung SchedMD SC17. Copyright 2017 SchedMD LLC
 Slurm Overview Brian Christiansen, Marshall Garey, Isaac Hartung SchedMD SC17 Outline Roles of a resource manager and job scheduler Slurm description and design goals Slurm architecture and plugins Slurm
Slurm Overview Brian Christiansen, Marshall Garey, Isaac Hartung SchedMD SC17 Outline Roles of a resource manager and job scheduler Slurm description and design goals Slurm architecture and plugins Slurm
June Workshop Series June 27th: All About SLURM University of Nebraska Lincoln Holland Computing Center. Carrie Brown, Adam Caprez
 June Workshop Series June 27th: All About SLURM University of Nebraska Lincoln Holland Computing Center Carrie Brown, Adam Caprez Setup Instructions Please complete these steps before the lessons start
June Workshop Series June 27th: All About SLURM University of Nebraska Lincoln Holland Computing Center Carrie Brown, Adam Caprez Setup Instructions Please complete these steps before the lessons start
Introduction to High Performance Computing (HPC) Resources at GACRC
 Resources at GACRC") Introduction to High Performance Computing (HPC) Resources at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu 1 Outline GACRC? High Performance
Introduction to High Performance Computing (HPC) Resources at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu 1 Outline GACRC? High Performance
Bash for SLURM. Author: Wesley Schaal Pharmaceutical Bioinformatics, Uppsala University
 Bash for SLURM Author: Wesley Schaal Pharmaceutical Bioinformatics, Uppsala University wesley.schaal@farmbio.uu.se Lab session: Pavlin Mitev (pavlin.mitev@kemi.uu.se) it i slides at http://uppmax.uu.se/support/courses
Bash for SLURM Author: Wesley Schaal Pharmaceutical Bioinformatics, Uppsala University wesley.schaal@farmbio.uu.se Lab session: Pavlin Mitev (pavlin.mitev@kemi.uu.se) it i slides at http://uppmax.uu.se/support/courses
Submitting batch jobs
 Submitting batch jobs SLURM on ECGATE Xavi Abellan Xavier.Abellan@ecmwf.int ECMWF February 20, 2017 Outline Interactive mode versus Batch mode Overview of the Slurm batch system on ecgate Batch basic concepts
Submitting batch jobs SLURM on ECGATE Xavi Abellan Xavier.Abellan@ecmwf.int ECMWF February 20, 2017 Outline Interactive mode versus Batch mode Overview of the Slurm batch system on ecgate Batch basic concepts
Lecture Topics. Announcements. Today: Advanced Scheduling (Stallings, chapter ) Next: Deadlock (Stallings, chapter
 Next: Deadlock (Stallings, chapter") Lecture Topics Today: Advanced Scheduling (Stallings, chapter 10.1-10.4) Next: Deadlock (Stallings, chapter 6.1-6.6) 1 Announcements Exam #2 returned today Self-Study Exercise #10 Project #8 (due 11/16)
Lecture Topics Today: Advanced Scheduling (Stallings, chapter 10.1-10.4) Next: Deadlock (Stallings, chapter 6.1-6.6) 1 Announcements Exam #2 returned today Self-Study Exercise #10 Project #8 (due 11/16)
Quick Start Guide. by Burak Himmetoglu. Supercomputing Consultant. Enterprise Technology Services & Center for Scientific Computing
 Quick Start Guide by Burak Himmetoglu Supercomputing Consultant Enterprise Technology Services & Center for Scientific Computing E-mail: bhimmetoglu@ucsb.edu Linux/Unix basic commands Basic command structure:
Quick Start Guide by Burak Himmetoglu Supercomputing Consultant Enterprise Technology Services & Center for Scientific Computing E-mail: bhimmetoglu@ucsb.edu Linux/Unix basic commands Basic command structure:
Intel Manycore Testing Lab (MTL) - Linux Getting Started Guide
 - Linux Getting Started Guide") Intel Manycore Testing Lab (MTL) - Linux Getting Started Guide Introduction What are the intended uses of the MTL? The MTL is prioritized for supporting the Intel Academic Community for the testing, validation
Intel Manycore Testing Lab (MTL) - Linux Getting Started Guide Introduction What are the intended uses of the MTL? The MTL is prioritized for supporting the Intel Academic Community for the testing, validation
COSC 6374 Parallel Computation. Debugging MPI applications. Edgar Gabriel. Spring 2008
 COSC 6374 Parallel Computation Debugging MPI applications Spring 2008 How to use a cluster A cluster usually consists of a front-end node and compute nodes Name of the front-end node: shark.cs.uh.edu You
COSC 6374 Parallel Computation Debugging MPI applications Spring 2008 How to use a cluster A cluster usually consists of a front-end node and compute nodes Name of the front-end node: shark.cs.uh.edu You
Introduction to SLURM & SLURM batch scripts
 Introduction to SLURM & SLURM batch scripts Anita Orendt Assistant Director Research Consulting & Faculty Engagement anita.orendt@utah.edu 23 June 2016 Overview of Talk Basic SLURM commands SLURM batch
Introduction to SLURM & SLURM batch scripts Anita Orendt Assistant Director Research Consulting & Faculty Engagement anita.orendt@utah.edu 23 June 2016 Overview of Talk Basic SLURM commands SLURM batch
Introduction to HPC Using zcluster at GACRC On-Class GENE 4220
 Introduction to HPC Using zcluster at GACRC On-Class GENE 4220 Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu Slides courtesy: Zhoufei Hou 1 OVERVIEW GACRC
Introduction to HPC Using zcluster at GACRC On-Class GENE 4220 Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu Slides courtesy: Zhoufei Hou 1 OVERVIEW GACRC
Moab Workload Manager on Cray XT3
 Moab Workload Manager on Cray XT3 presented by Don Maxwell (ORNL) Michael Jackson (Cluster Resources, Inc.) MOAB Workload Manager on Cray XT3 Why MOAB? Requirements Features Support/Futures 2 Why Moab?
Moab Workload Manager on Cray XT3 presented by Don Maxwell (ORNL) Michael Jackson (Cluster Resources, Inc.) MOAB Workload Manager on Cray XT3 Why MOAB? Requirements Features Support/Futures 2 Why Moab?
Introduction to HPC Using zcluster at GACRC
 Introduction to HPC Using zcluster at GACRC On-class STAT8330 Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu Slides courtesy: Zhoufei Hou 1 Outline What
Introduction to HPC Using zcluster at GACRC On-class STAT8330 Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu Slides courtesy: Zhoufei Hou 1 Outline What
Introduction to NCAR HPC. 25 May 2017 Consulting Services Group Brian Vanderwende
 Introduction to NCAR HPC 25 May 2017 Consulting Services Group Brian Vanderwende Topics we will cover Technical overview of our HPC systems The NCAR computing environment Accessing software on Cheyenne
Introduction to NCAR HPC 25 May 2017 Consulting Services Group Brian Vanderwende Topics we will cover Technical overview of our HPC systems The NCAR computing environment Accessing software on Cheyenne
SLURM Operation on Cray XT and XE
 SLURM Operation on Cray XT and XE Morris Jette jette@schedmd.com Contributors and Collaborators This work was supported by the Oak Ridge National Laboratory Extreme Scale Systems Center. Swiss National
SLURM Operation on Cray XT and XE Morris Jette jette@schedmd.com Contributors and Collaborators This work was supported by the Oak Ridge National Laboratory Extreme Scale Systems Center. Swiss National
Using ISMLL Cluster. Tutorial Lec 5. Mohsan Jameel, Information Systems and Machine Learning Lab, University of Hildesheim
 Using ISMLL Cluster Tutorial Lec 5 1 Agenda Hardware Useful command Submitting job 2 Computing Cluster http://www.admin-magazine.com/hpc/articles/building-an-hpc-cluster Any problem or query regarding
Using ISMLL Cluster Tutorial Lec 5 1 Agenda Hardware Useful command Submitting job 2 Computing Cluster http://www.admin-magazine.com/hpc/articles/building-an-hpc-cluster Any problem or query regarding
High Performance Computing Cluster Basic course
 High Performance Computing Cluster Basic course Jeremie Vandenplas, Gwen Dawes 30 October 2017 Outline Introduction to the Agrogenomics HPC Connecting with Secure Shell to the HPC Introduction to the Unix/Linux
High Performance Computing Cluster Basic course Jeremie Vandenplas, Gwen Dawes 30 October 2017 Outline Introduction to the Agrogenomics HPC Connecting with Secure Shell to the HPC Introduction to the Unix/Linux
Introduction to HPC Resources and Linux
 Introduction to HPC Resources and Linux Burak Himmetoglu Enterprise Technology Services & Center for Scientific Computing e-mail: bhimmetoglu@ucsb.edu Paul Weakliem California Nanosystems Institute & Center
Introduction to HPC Resources and Linux Burak Himmetoglu Enterprise Technology Services & Center for Scientific Computing e-mail: bhimmetoglu@ucsb.edu Paul Weakliem California Nanosystems Institute & Center
Introduction to Slurm
 Introduction to Slurm Tim Wickberg SchedMD Slurm User Group Meeting 2017 Outline Roles of resource manager and job scheduler Slurm description and design goals Slurm architecture and plugins Slurm configuration
Introduction to Slurm Tim Wickberg SchedMD Slurm User Group Meeting 2017 Outline Roles of resource manager and job scheduler Slurm description and design goals Slurm architecture and plugins Slurm configuration
Logging in to the CRAY
 Logging in to the CRAY 1. Open Terminal Cray Hostname: cray2.colostate.edu Cray IP address: 129.82.103.183 On a Mac 2. type ssh username@cray2.colostate.edu where username is your account name 3. enter
Logging in to the CRAY 1. Open Terminal Cray Hostname: cray2.colostate.edu Cray IP address: 129.82.103.183 On a Mac 2. type ssh username@cray2.colostate.edu where username is your account name 3. enter
Duke Compute Cluster Workshop. 11/10/2016 Tom Milledge h:ps://rc.duke.edu/
 Duke Compute Cluster Workshop 11/10/2016 Tom Milledge h:ps://rc.duke.edu/ rescompu>ng@duke.edu Outline of talk Overview of Research Compu>ng resources Duke Compute Cluster overview Running interac>ve and
Duke Compute Cluster Workshop 11/10/2016 Tom Milledge h:ps://rc.duke.edu/ rescompu>ng@duke.edu Outline of talk Overview of Research Compu>ng resources Duke Compute Cluster overview Running interac>ve and
Slurm at UPPMAX. How to submit jobs with our queueing system. Jessica Nettelblad sysadmin at UPPMAX
 Slurm at UPPMAX How to submit jobs with our queueing system Jessica Nettelblad sysadmin at UPPMAX Slurm at UPPMAX Intro Queueing with Slurm How to submit jobs Testing How to test your scripts before submission
Slurm at UPPMAX How to submit jobs with our queueing system Jessica Nettelblad sysadmin at UPPMAX Slurm at UPPMAX Intro Queueing with Slurm How to submit jobs Testing How to test your scripts before submission
Effective Use of CCV Resources
 Effective Use of CCV Resources Mark Howison User Services & Support This talk... Assumes you have some familiarity with a Unix shell Provides examples and best practices for typical usage of CCV systems
Effective Use of CCV Resources Mark Howison User Services & Support This talk... Assumes you have some familiarity with a Unix shell Provides examples and best practices for typical usage of CCV systems
Introduction to Discovery.
 Introduction to Discovery http://discovery.dartmouth.edu March 2014 The Discovery Cluster 2 Agenda Resource overview Logging on to the cluster with ssh Transferring files to and from the cluster The Environment
Introduction to Discovery http://discovery.dartmouth.edu March 2014 The Discovery Cluster 2 Agenda Resource overview Logging on to the cluster with ssh Transferring files to and from the cluster The Environment
Introduction to High-Performance Computing (HPC)
") Introduction to High-Performance Computing (HPC) Computer components CPU : Central Processing Unit cores : individual processing units within a CPU Storage : Disk drives HDD : Hard Disk Drive SSD : Solid
Introduction to High-Performance Computing (HPC) Computer components CPU : Central Processing Unit cores : individual processing units within a CPU Storage : Disk drives HDD : Hard Disk Drive SSD : Solid
Introduction to Discovery.
 Introduction to Discovery http://discovery.dartmouth.edu The Discovery Cluster 2 Agenda What is a cluster and why use it Overview of computer hardware in cluster Help Available to Discovery Users Logging
Introduction to Discovery http://discovery.dartmouth.edu The Discovery Cluster 2 Agenda What is a cluster and why use it Overview of computer hardware in cluster Help Available to Discovery Users Logging
Sequence Alignment. Practical Introduction to HPC Exercise
 1 Sequence Alignment Practical Introduction to HPC Exercise Aims The aims of this exercise are to get you used to logging on to an HPC machine, using the command line in a terminal window and an editor
1 Sequence Alignment Practical Introduction to HPC Exercise Aims The aims of this exercise are to get you used to logging on to an HPC machine, using the command line in a terminal window and an editor
Cluster Network Products
 Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Knights Landing production environment on MARCONI
 Knights Landing production environment on MARCONI Alessandro Marani - a.marani@cineca.it March 20th, 2017 Agenda In this presentation, we will discuss - How we interact with KNL environment on MARCONI
Knights Landing production environment on MARCONI Alessandro Marani - a.marani@cineca.it March 20th, 2017 Agenda In this presentation, we will discuss - How we interact with KNL environment on MARCONI
Introduction to Discovery.
 Introduction to Discovery http://discovery.dartmouth.edu The Discovery Cluster 2 Agenda What is a cluster and why use it Overview of computer hardware in cluster Help Available to Discovery Users Logging
Introduction to Discovery http://discovery.dartmouth.edu The Discovery Cluster 2 Agenda What is a cluster and why use it Overview of computer hardware in cluster Help Available to Discovery Users Logging
Sherlock for IBIIS. William Law Stanford Research Computing
 Sherlock for IBIIS William Law Stanford Research Computing Overview How we can help System overview Tech specs Signing on Batch submission Software environment Interactive jobs Next steps We are here to
Sherlock for IBIIS William Law Stanford Research Computing Overview How we can help System overview Tech specs Signing on Batch submission Software environment Interactive jobs Next steps We are here to
Minnesota Supercomputing Institute Regents of the University of Minnesota. All rights reserved.
 Minnesota Supercomputing Institute Introduction to MSI Systems Andrew Gustafson The Machines at MSI Machine Type: Cluster Source: http://en.wikipedia.org/wiki/cluster_%28computing%29 Machine Type: Cluster
Minnesota Supercomputing Institute Introduction to MSI Systems Andrew Gustafson The Machines at MSI Machine Type: Cluster Source: http://en.wikipedia.org/wiki/cluster_%28computing%29 Machine Type: Cluster
Using a Linux System 6
 Canaan User Guide Connecting to the Cluster 1 SSH (Secure Shell) 1 Starting an ssh session from a Mac or Linux system 1 Starting an ssh session from a Windows PC 1 Once you're connected... 1 Ending an
Canaan User Guide Connecting to the Cluster 1 SSH (Secure Shell) 1 Starting an ssh session from a Mac or Linux system 1 Starting an ssh session from a Windows PC 1 Once you're connected... 1 Ending an
Slurm and Abel job scripts. Katerina Michalickova The Research Computing Services Group SUF/USIT November 13, 2013
 Slurm and Abel job scripts Katerina Michalickova The Research Computing Services Group SUF/USIT November 13, 2013 Abel in numbers Nodes - 600+ Cores - 10000+ (1 node->2 processors->16 cores) Total memory
Slurm and Abel job scripts Katerina Michalickova The Research Computing Services Group SUF/USIT November 13, 2013 Abel in numbers Nodes - 600+ Cores - 10000+ (1 node->2 processors->16 cores) Total memory
Introduction to running C based MPI jobs on COGNAC. Paul Bourke November 2006
 Introduction to running C based MPI jobs on COGNAC. Paul Bourke November 2006 The following is a practical introduction to running parallel MPI jobs on COGNAC, the SGI Altix machine (160 Itanium2 cpus)
Introduction to running C based MPI jobs on COGNAC. Paul Bourke November 2006 The following is a practical introduction to running parallel MPI jobs on COGNAC, the SGI Altix machine (160 Itanium2 cpus)
Workshop Set up. Workshop website: Workshop project set up account at my.osc.edu PZS0724 Nq7sRoNrWnFuLtBm
 Workshop Set up Workshop website: https://khill42.github.io/osc_introhpc/ Workshop project set up account at my.osc.edu PZS0724 Nq7sRoNrWnFuLtBm If you already have an OSC account, sign in to my.osc.edu
Workshop Set up Workshop website: https://khill42.github.io/osc_introhpc/ Workshop project set up account at my.osc.edu PZS0724 Nq7sRoNrWnFuLtBm If you already have an OSC account, sign in to my.osc.edu
Slurm and Abel job scripts. Katerina Michalickova The Research Computing Services Group SUF/USIT October 23, 2012
 Slurm and Abel job scripts Katerina Michalickova The Research Computing Services Group SUF/USIT October 23, 2012 Abel in numbers Nodes - 600+ Cores - 10000+ (1 node->2 processors->16 cores) Total memory
Slurm and Abel job scripts Katerina Michalickova The Research Computing Services Group SUF/USIT October 23, 2012 Abel in numbers Nodes - 600+ Cores - 10000+ (1 node->2 processors->16 cores) Total memory
HPC DOCUMENTATION. 3. Node Names and IP addresses:- Node details with respect to their individual IP addresses are given below:-
 HPC DOCUMENTATION 1. Hardware Resource :- Our HPC consists of Blade chassis with 5 blade servers and one GPU rack server. a.total available cores for computing: - 96 cores. b.cores reserved and dedicated
HPC DOCUMENTATION 1. Hardware Resource :- Our HPC consists of Blade chassis with 5 blade servers and one GPU rack server. a.total available cores for computing: - 96 cores. b.cores reserved and dedicated
Parallel Programming. Libraries and implementations
 Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Guillimin HPC Users Meeting March 17, 2016
 Guillimin HPC Users Meeting March 17, 2016 guillimin@calculquebec.ca McGill University / Calcul Québec / Compute Canada Montréal, QC Canada Outline Compute Canada News System Status Software Updates Training
Guillimin HPC Users Meeting March 17, 2016 guillimin@calculquebec.ca McGill University / Calcul Québec / Compute Canada Montréal, QC Canada Outline Compute Canada News System Status Software Updates Training
Duke Compute Cluster Workshop. 10/04/2018 Tom Milledge rc.duke.edu
 Duke Compute Cluster Workshop 10/04/2018 Tom Milledge rc.duke.edu rescomputing@duke.edu Outline of talk Overview of Research Computing resources Duke Compute Cluster overview Running interactive and batch
Duke Compute Cluster Workshop 10/04/2018 Tom Milledge rc.duke.edu rescomputing@duke.edu Outline of talk Overview of Research Computing resources Duke Compute Cluster overview Running interactive and batch
SCALABLE HYBRID PROTOTYPE
 SCALABLE HYBRID PROTOTYPE Scalable Hybrid Prototype Part of the PRACE Technology Evaluation Objectives Enabling key applications on new architectures Familiarizing users and providing a research platform
SCALABLE HYBRID PROTOTYPE Scalable Hybrid Prototype Part of the PRACE Technology Evaluation Objectives Enabling key applications on new architectures Familiarizing users and providing a research platform
Installing and running COMSOL 4.3a on a Linux cluster COMSOL. All rights reserved.
 Installing and running COMSOL 4.3a on a Linux cluster 2012 COMSOL. All rights reserved. Introduction This quick guide explains how to install and operate COMSOL Multiphysics 4.3a on a Linux cluster. It
Installing and running COMSOL 4.3a on a Linux cluster 2012 COMSOL. All rights reserved. Introduction This quick guide explains how to install and operate COMSOL Multiphysics 4.3a on a Linux cluster. It
The DTU HPC system. and how to use TopOpt in PETSc on a HPC system, visualize and 3D print results.
 The DTU HPC system and how to use TopOpt in PETSc on a HPC system, visualize and 3D print results. Niels Aage Department of Mechanical Engineering Technical University of Denmark Email: naage@mek.dtu.dk
The DTU HPC system and how to use TopOpt in PETSc on a HPC system, visualize and 3D print results. Niels Aage Department of Mechanical Engineering Technical University of Denmark Email: naage@mek.dtu.dk
Introduction to High Performance Computing (HPC) Resources at GACRC
 Resources at GACRC") Introduction to High Performance Computing (HPC) Resources at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? Concept
Introduction to High Performance Computing (HPC) Resources at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? Concept
Graham vs legacy systems
 New User Seminar Graham vs legacy systems This webinar only covers topics pertaining to graham. For the introduction to our legacy systems (Orca etc.), please check the following recorded webinar: SHARCNet
New User Seminar Graham vs legacy systems This webinar only covers topics pertaining to graham. For the introduction to our legacy systems (Orca etc.), please check the following recorded webinar: SHARCNet
Batch environment PBS (Running applications on the Cray XC30) 1/18/2016
 1/18/2016") Batch environment PBS (Running applications on the Cray XC30) 1/18/2016 1 Running on compute nodes By default, users do not log in and run applications on the compute nodes directly. Instead they launch
Batch environment PBS (Running applications on the Cray XC30) 1/18/2016 1 Running on compute nodes By default, users do not log in and run applications on the compute nodes directly. Instead they launch
Introduction to CINECA Computer Environment
 Introduction to CINECA Computer Environment Today you will learn... Basic commands for UNIX environment @ CINECA How to submitt your job to the PBS queueing system on Eurora Tutorial #1: Example: launch
Introduction to CINECA Computer Environment Today you will learn... Basic commands for UNIX environment @ CINECA How to submitt your job to the PBS queueing system on Eurora Tutorial #1: Example: launch
Name Department/Research Area Have you used the Linux command line?
 Please log in with HawkID (IOWA domain) Macs are available at stations as marked To switch between the Windows and the Mac systems, press scroll lock twice 9/27/2018 1 Ben Rogers ITS-Research Services
Please log in with HawkID (IOWA domain) Macs are available at stations as marked To switch between the Windows and the Mac systems, press scroll lock twice 9/27/2018 1 Ben Rogers ITS-Research Services