Bridging the Particle Physics and Big Data Worlds
|
|
|
- Basil O’Connor’
- 6 years ago
- Views:
Transcription



1 Bridging the Particle Physics and Big Data Worlds Jim Pivarski Princeton University DIANA-HEP October 25, / 29
2 Particle physics: the original Big Data For decades, our computing needs were unique: large datasets complex structure has to be reduced to be modeled (too big for one computer: a moving definition!), (nested data, web of relationships within each event), (aggregated, by histogramming, usually) (fitting to extract physics results). 2 / 29
3 Particle physics: the original Big Data For decades, our computing needs were unique: large datasets complex structure has to be reduced to be modeled (too big for one computer: a moving definition!), (nested data, web of relationships within each event), (aggregated, by histogramming, usually) (fitting to extract physics results). Today these criteria apply equally, or more so, to web scale data. 2 / 29


4 200 PB is a lot of data 3 / 29
5 200 PB is a lot of data, but for Amazon, it s two truckloads 3 / 29
6 Also a much larger community Rate of web searches for ROOT TTree vs. Spark DataFrame (Google Trends): 4 / 29
7 Also a much larger community Rate of web searches for ROOT TTree vs. Spark DataFrame (Google Trends): Similarly for question-and-answer sites: RootTalk: 14,399 threads in (15 years) StackOverflow questions tagged #spark: 26,155 in the 3.3 years the tag has existed. (Not counting CrossValidated, Spark Developer and User mailing lists... ) 4 / 29
8 Also a much larger community Rate of web searches for ROOT TTree vs. Spark DataFrame (Google Trends): Similarly for question-and-answer sites: RootTalk: 14,399 threads in (15 years) StackOverflow questions tagged #spark: 26,155 in the 3.3 years the tag has existed. (Not counting CrossValidated, Spark Developer and User mailing lists... ) More users to talk to; more developers adding features/fixing bugs. 4 / 29
9 Particle physics is a special case Particle physics Events (modulo cosmics vetos or time-dependent calibrations) may be processed in isolation; embarrassingly parallel. Big Data All-to-all problems are common, such as matching a customer s purchases with all other purchases to make a recommendation. 5 / 29
10 Particle physics is a special case Particle physics Events (modulo cosmics vetos or time-dependent calibrations) may be processed in isolation; embarrassingly parallel. Once collected, physics datasets are immutable (with revisions). Big Data All-to-all problems are common, such as matching a customer s purchases with all other purchases to make a recommendation. Transactions accumulate in the database during analysis. 5 / 29
11 Particle physics is a special case Particle physics Events (modulo cosmics vetos or time-dependent calibrations) may be processed in isolation; embarrassingly parallel. Once collected, physics datasets are immutable (with revisions). Often fitting a model with a small number of parameters. Big Data All-to-all problems are common, such as matching a customer s purchases with all other purchases to make a recommendation. Transactions accumulate in the database during analysis. Modeling human behavior, more interested in predictions than description, so models may have thousands of free parameters. 5 / 29


12 Our software is largely isolated from these developments 6 / 29
13 Who am I? Why am I giving this talk? Jim Pivarski 5 years CLEO (9 GeV e + e ) 5 years CMS (7 TeV pp) 5 years Open Data Group 2 years Project DIANA-HEP 7 / 29
14 Who am I? Why am I giving this talk? Jim Pivarski 5 years CLEO (9 GeV e + e ) 5 years CMS (7 TeV pp) 5 years Open Data Group 2 years Project DIANA-HEP hyperspectral imagery automobile traffic network security Twitter sentiment Google n-grams DNA sequence analysis credit card fraud detection and Big Data tools 7 / 29
 5 years CMS (7 TeV pp) 5 years Open Data Group 2 years Project DIANA-HEP hyperspectral imagery automobile traffic network security Twitter sentiment Google")
15 Who am I? Why am I giving this talk? Jim Pivarski 5 years CLEO (9 GeV e + e ) 5 years CMS (7 TeV pp) 5 years Open Data Group 2 years Project DIANA-HEP hyperspectral imagery automobile traffic network security Twitter sentiment Google n-grams DNA sequence analysis credit card fraud detection and Big Data tools My goal within DIANA-HEP is to make it easier for physicists to use Big Data tools in their analyses, particularly for interactive, exploratory analysis. 7 / 29
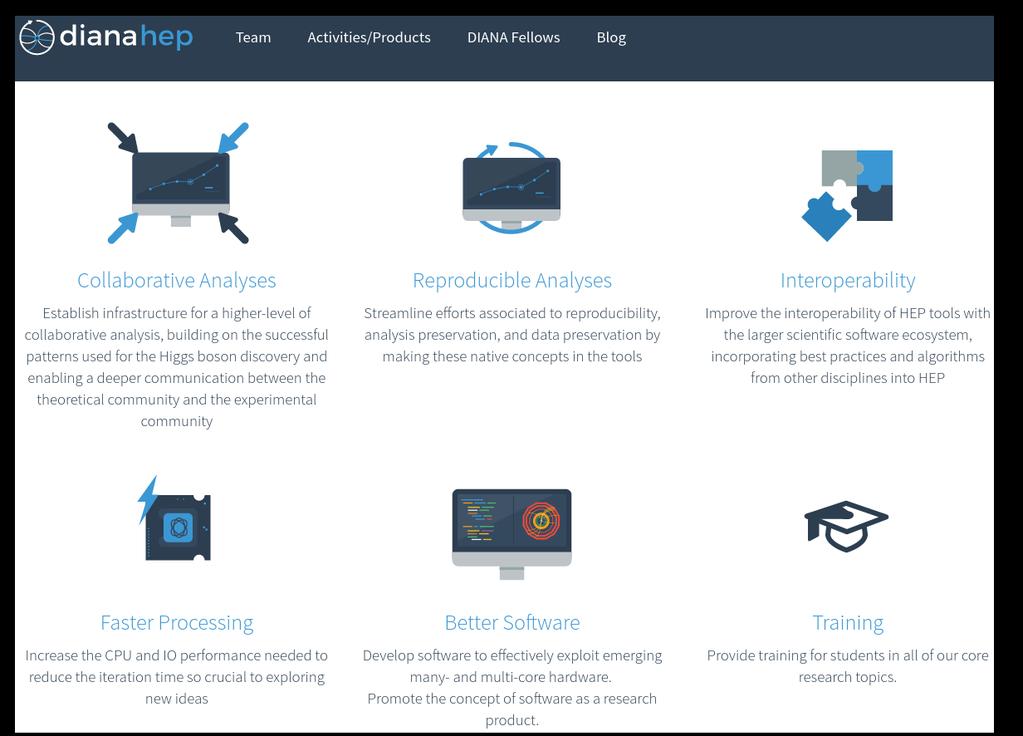
16 8 / 29

17 8 / 29
18 What to do with physics software: three cases Case I: Physics software that serves the same function as software in the Big Data community. Case II: Domain-specific software for our analyses. Example: HiggsCombiner. Case III: Physics software or concepts that would benefit the Big Data community. 9 / 29
19 What to do with physics software: three cases Case I: Physics software that serves the same function as software in the Big Data community. Case II: Domain-specific software for our analyses. Example: HiggsCombiner. Case III: Physics software or concepts that would benefit the Big Data community. Big Data community has better resources for maintaining code catching bugs revising bad designs. 9 / 29
20 What to do with physics software: three cases Case I: Physics software that serves the same function as software in the Big Data community. Case II: Domain-specific software for our analyses. Example: HiggsCombiner. Case III: Physics software or concepts that would benefit the Big Data community. Big Data community has better resources for maintaining code catching bugs revising bad designs. Obviously. This really is a unique problem. 9 / 29



21 What to do with physics software: three cases Case I: Physics software that serves the same function as software in the Big Data community. Case II: Domain-specific software for our analyses. Example: HiggsCombiner. Case III: Physics software or concepts that would benefit the Big Data community. Big Data community has better resources for maintaining code catching bugs revising bad designs. Obviously. This really is a unique problem. Cultural exchange goes in both directions. 9 / 29
22 All three cases in a single story: porting an analysis from ROOT to Spark. 10 / 29

23 CMS Big Data Project Oliver Gutsche, Matteo Cremonesi, Cristina Suárez (Fermilab) wanted to try their CMS dark matter search on Spark. My first DIANA-HEP project: I joined to plow through technical issues before the analysts hit them / 29
24 How to get the data into Spark (which runs in Java) A year of trial-and-error in one slide 1. Java Native Interface (JNI) No! This ought to be the right solution, but Java and ROOT are both large, complex applications with their own memory management: couldn t keep them from interfering (segmentation faults). process Java Virtual Machine Spark ROOT 2. Python as glue: PyROOT and PySpark in the same process PySpark is a low-performance solution: all data must be passed over a text-based socket and interpreted by Python. process 1 process 2 Python Java Virtual Machine PyROOT PySpark socket Spark ROOT 3. Convert to a Spark-friendly format, like Apache Avro We used this for most of the year. Efficient after conversion, but conversion step is awkward. Avro s C library is difficult to deploy. 12 / 29
25 How to get the data into Spark (which runs in Java) A year of trial-and-error in one slide process 1. Java Native Interface (JNI) Java Virtual Machine No! This ought to be the right solution, but Java Spark and ROOT are both large, complex applications ROOT with their own memory management: couldn t keep them from interfering (segmentation faults). This problem is incidental, not essential. Industry-standard formats 2. Python like Avro as glue: andpyroot Parquetand canpyspark store in complex the samephysics process events; process 1 process 2 we PySpark just happen is a low-performance to have a lot of data in ROOT files. Python Java Virtual Machine socket PyROOT PySpark Spark solution: all data must be passed over a text-based socket and interpreted by Python. ROOT 3. Convert to a Spark-friendly format, like Apache Avro We used this for most of the year. Efficient after conversion, but conversion step is awkward. Avro s C library is difficult to deploy. 12 / 29
 over a decade before it was reinvented at Google.")
26 This was a missed opportunity for exporting physics solutions! ROOT was storing nested data structures in a columnar format (for faster access) over a decade before it was reinvented at Google. Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis. Dremel: Interactive Analysis of Web-Scale Datasets (2010). 13 / 29
27 Easiest solution: reimplement ROOT I/O in Java root4j/ spark-root Java/Scala For Spark and other Big Data projects that run on Java. Started by Tony Johnson in 2001, updated by Viktor Khristenko. 14 / 29
28 Easiest solution: reimplement ROOT I/O in Java, JS root4j/ spark-root Java/Scala For Spark and other Big Data projects that run on Java. Started by Tony Johnson in 2001, updated by Viktor Khristenko. JsRoot Javascript For interacting with ROOT in web browsers or standalone. Sergey Linev 14 / 29
29 Easiest solution: reimplement ROOT I/O in Java, JS, Go root4j/ spark-root Java/Scala For Spark and other Big Data projects that run on Java. Started by Tony Johnson in 2001, updated by Viktor Khristenko. JsRoot Javascript For interacting with ROOT in web browsers or standalone. Sergey Linev rootio Go go-hep ecosystem in Go. Sebastien Binet 14 / 29
30 Easiest solution: reimplement ROOT I/O in Java, JS, Go, Python root4j/ spark-root Java/Scala For Spark and other Big Data projects that run on Java. Started by Tony Johnson in 2001, updated by Viktor Khristenko. JsRoot Javascript For interacting with ROOT in web browsers or standalone. Sergey Linev rootio Go go-hep ecosystem in Go. Sebastien Binet uproot Python For quickly getting ROOT data into Numpy and Pandas for machine learning. Jim Pivarski (me) 14 / 29
31 Easiest solution: reimplement ROOT I/O in Java, JS, Go, Python root4j/ spark-root Java/Scala For Spark and other Big Data projects that run on Java. Started by Tony Johnson in 2001, updated by Viktor Khristenko. JsRoot Javascript For interacting with ROOT in web browsers or standalone. Sergey Linev rootio Go go-hep ecosystem in Go. Sebastien Binet uproot Python For quickly getting ROOT data into Numpy and Pandas for machine learning. Jim Pivarski (me) Rust? 14 / 29
32 Example session (native Spark, which is Scala) Launch Spark with packages from Maven Central. spark-shell --packages org.diana-hep:spark-root_2.11:x.y.z, \ org.diana-hep:histogrammar_2.11:1.0.4 Read ROOT files like any other DataFrame input source. val df = spark.sqlcontext.read.root( "hdfs://path/to/files/*.root") df.printschema() root -- met: float (nullable = false) -- muons: array (nullable = false) -- element: struct (containsnull = false) -- pt: float (nullable = false) -- eta: float (nullable = false) -- phi: float (nullable = false) -- jets: array (nullable = false) 15 / 29
33 Example session (PySpark in Python) Launch Spark with packages from Maven Central. pyspark --packages org.diana-hep:spark-root_2.11:x.y.z, \ org.diana-hep:histogrammar_2.11:1.0.4 Read ROOT files like any other DataFrame input source. df = sqlcontext.read.format("org.dianahep.sparkroot") \.load("hdfs://path/to/files/*.root") df.printschema() root -- met: float (nullable = false) -- muons: array (nullable = false) -- element: struct (containsnull = false) -- pt: float (nullable = false) -- eta: float (nullable = false) -- phi: float (nullable = false) -- jets: array (nullable = false) 15 / 29
34 Example session (native Spark and PySpark) df.show() met muons jets [[ , [[ , [] [[ , [[ , [[ , [[ , [[ , [] [[ , [[ , [[ , [[ , [[ , [] [[ , [[ , [[ , [] [[ , only showing top 10 rows 16 / 29
35 Example session (Spark) // Bring dollar-sign notation into scope. import spark.sqlcontext.implicits._ // Compute event weight with columns and constants. df.select(($"lumi"*xsec/ngen) * $"LHE_weight"(309)).show() // Pre-defined function (notation s a little weird). val isgoodevent = ( ($"evthasgoodvtx" === 1) && ($"evthastrg" === 1) && ($"tkmet" >= 25.0) && ($"Mu_pt" >= 30.0) && ($"W_mt" >= 30.0)) // Use it. println("%d events pass".format( df.where(isgoodevent).count())) 17 / 29
36 Example session (PySpark) # Python trick: make columns Python variables. for name in df.schema.names: exec("{0} = df[ {0} ]".format(name)) # Look at a few event weights. df.select((lumi*xsec/ngen) * LHE_weight[309]).show() # Pre-defined function (notation s a little different). isgoodevent = ( (evthasgoodvtx == 1) & (evthastrg == 1) & (tkmet >= 25.0) & (Mu_pt >= 30.0) & (W_mt >= 30.0)) # Use it. print "{} events pass".format( df.where(isgoodevent).count()) 17 / 29
37 Example session (Spark) // Use Histogrammar to make histograms. import org.dianahep.histogrammar._ import org.dianahep.histogrammar.sparksql._ import org.dianahep.histogrammar.bokeh._ // Define histogram functions with SparkSQL Columns. val h = df.label( "muon pt" -> Bin(100, 0.0, 50.0, $"Mu_pt"), "W mt" -> Bin(100, 0.0, 120.0, $"W_mt")) // Plot the histograms with Bokeh. val bokehhist = h.get("muon pt").bokeh() plot(bokehhist) val bokehhist2 = h.get("w mt").bokeh() plot(bokehhist2) 18 / 29
38 Example session (PySpark) # Use Histogrammar to make histograms. from histogrammar import * import histogrammar.sparksql histogrammar.sparksql.addmethods(df) # Define histogram functions with SparkSQL Columns. h = df.label( muon_pt = Bin(100, 0.0, 50.0, Mu_pt), W_mt = Bin(100, 0.0, 120.0, W_mt)) # Plot the histograms with PyROOT. roothist = h.get("muon_pt").plot.root("muon pt") roothist.draw() roothist2 = h.get("w_mt").plot.root("w mt") roothist2.draw() 18 / 29
39 Example session (PySpark) # Use Histogrammar to make histograms. from histogrammar import * import histogrammar.sparksql histogrammar.sparksql.addmethods(df) # Define histogram functions with SparkSQL Columns. h = df.label( muon_pt = Bin(100, 0.0, 50.0, Mu_pt), W_mt = Bin(100, 0.0, 120.0, W_mt)) # Plot the histograms with PyROOT. roothist = h.get("muon_pt").plot.root("muon pt") roothist.draw() roothist2 = h.get("w_mt").plot.root("w mt") roothist2.draw() 18 / 29
40 Speaking of plots... Spark and Big Data in general are weak in plotting. 19 / 29
41 Speaking of plots... Spark and Big Data in general are weak in plotting. They have fancy visualizations (d3), but lack convenient workaday routines for quick histograms, profiles, heatmaps, lego plots, etc. 19 / 29
42 Speaking of plots... Spark and Big Data in general are weak in plotting. They have fancy visualizations (d3), but lack convenient workaday routines for quick histograms, profiles, heatmaps, lego plots, etc. (Exception: Python and R have good interactive graphics for in-memory analytics.) 19 / 29
 three = one.join(two) four = three.map((x, y) => (y, x)).cache() five = four.reduce((x, y) => x + y) six = five.saveastextfile(\"other.")
43 Analysis in Spark is a chain of higher-order functions In Spark, you submit work by passing functions in a chain: one = source1.textfile("some.txt").map(x => x.upper()) two = source2.cassandratable.filter(x => x.field > 3) three = one.join(two) four = three.map((x, y) => (y, x)).cache() five = four.reduce((x, y) => x + y) six = five.saveastextfile("other.txt") Thus, the code doesn t depend on whether or not it s parallelized (so it can be massively parallelized). 20 / 29
44 ROOT histogram API is cumbersome in this setting ROOT (or any HBOOK-style) histograms x = Histogram(100, -5.0, 5.0) for event in events: x.fill(event.calcx()) x.plot() Using them in Spark x = events.aggregate( Histogram(100, -5.0, 5.0), lambda h, event: ( h.fill(event.calcx())), lambda h1, h2: ( h1 + h2)) x.plot() 21 / 29
45 ROOT histogram API is cumbersome in this setting ROOT (or any HBOOK-style) histograms x = Histogram(100, -5.0, 5.0) y = Histogram(100, -5.0, 5.0) for event in events: x.fill(event.calcx()) y.fill(event.calcy()) x.plot() y.plot() Using them in Spark x, y = events.aggregate( (Histogram(100, -5.0, 5.0), Histogram(100, -5.0, 5.0)), lambda hs, event: ( hs[0].fill(event.calcx()), hs[1].fill(event.calcy())), lambda hs1, hs2: ( hs1[0] + hs2[0], hs1[1] + hs2[1])) x.plot() y.plot() 22 / 29
46 ROOT histogram API is cumbersome in this setting ROOT (or any HBOOK-style) histograms x = Histogram(100, -5.0, 5.0) y = Histogram(100, -5.0, 5.0) z = Histogram(100, -5.0, 5.0) for event in events: x.fill(event.calcx()) y.fill(event.calcy()) z.fill(event.calcz()) x.plot() y.plot() z.plot() Using them in Spark x, y, z = events.aggregate( (Histogram(100, -5.0, 5.0), Histogram(100, -5.0, 5.0), Histogram(100, -5.0, 5.0)), lambda hs, event: ( hs[0].fill(event.calcx()), hs[1].fill(event.calcy()), hs[2].fill(event.calcz())), lambda hs1, hs2: ( hs1[0] + hs2[0], hs1[1] + hs2[1], hs1[2] + hs2[2])) x.plot() y.plot() z.plot() 23 / 29
47 Solution: make the histograms functional, like the rest of Spark Histogram constructor as a higher-order function: h = Histogram(numBins, lowedge, highedge, fillrule) where fillrule is a function : data R that determines which bin an element of data increments. 24 / 29
48 Solution: make the histograms functional, like the rest of Spark Histogram constructor as a higher-order function: h = Histogram(numBins, lowedge, highedge, fillrule) where fillrule is a function : data R that determines which bin an element of data increments. All domain-specific knowledge is in the constructor. The filling function may now be generic (and automated). h.fill(datum) # calls fillrule(datum) internally 24 / 29
49 Familiar histogram types are now generated by combinators Histograms: Bin(num, low, high, fillrule, Count()) Two-dimensional histograms: Bin(xnum, xlow, xhigh, xfill, Bin(ynum, ylow, yhigh, yfill, Count())) Profile plots: Bin(xnum, xlow, xhigh, xfill, Deviate(yfill)) where Deviate aggregates a mean and standard deviation. Mix and match binning methods: IrregularlyBin([-2.4, -2.1, -1.5, 0.0, 1.5, 2.1, 2.4], filleta, Bin(314, -3.14, 3.14, fillphi, Count())) SparselyBin(0.01, filleta, Bin(314, -3.14, 3.14, fillphi, Count())) Categorize(fillByName, Bin(314, -3.14, 3.14, fillphi, Count())) 25 / 29
50 It all got mathematical pretty fast... For transparent parallelization, combinators must be additive: independent of whether datasets are partitioned. fill(data 1 + data 2 ) = fill(data 1 ) + fill(data 2 ) be homogeneous in the weights: fill weight 0.0 corresponds to no fill, 1.0 to simple fill, 2.0 to double-fill,... fill(data, weight) = fill(data) weight be associative: independent of where datasets get partitioned. (h 1 + h 2 ) + h 3 = h 1 + (h 2 + h 3 ) have an identity: for both the fill and + methods. h + 0 = h, 0 + h = h, fill(data, 0) = 0 linear monoid 26 / 29
51 (Get it?) 27 / 29
52 Other projects in development uproot: fast reading of ROOT files into Numpy/Pandas/Apache Arrow. Arrowed: transpiling complex analysis functions to skip object materialization (like SQL term rewriting, but for objects in Arrow format). Extending ROOT to use an object store database instead of seek points in a file (the petabyte ROOT file project). Speeding up analysis cuts with database-style indexing. Femtocode: Domain Specific Language (DSL) for particle physics queries. 28 / 29
53 Other projects in development uproot: fast reading of ROOT files into Numpy/Pandas/Apache Arrow. Arrowed: transpiling complex analysis functions to skip object materialization (like SQL term rewriting, but for objects in Arrow format). Extending ROOT to use an object store database instead of seek points in a file (the petabyte ROOT file project). Speeding up analysis cuts with database-style indexing. Femtocode: Domain Specific Language (DSL) for particle physics queries. All of the above are parts of the following: To develop a centralized query service that is as responsive as a private skim: to eliminate the need to copy data just to analyze it. 28 / 29
54 Conclusions we are here effort we could be here 29 / 29
55 Conclusions we are here building bridges effort we could be here 29 / 29
Survey of data formats and conversion tools
 Survey of data formats and conversion tools Jim Pivarski Princeton University DIANA May 23, 2017 1 / 28 The landscape of generic containers By generic, I mean file formats that define general structures
Survey of data formats and conversion tools Jim Pivarski Princeton University DIANA May 23, 2017 1 / 28 The landscape of generic containers By generic, I mean file formats that define general structures
Plotting data in a GPU with Histogrammar
 Plotting data in a GPU with Histogrammar Jim Pivarski Princeton DIANA September 30, 2016 1 / 20 Practical introduction Problem: You re developing a numerical algorithm for GPUs (tracking). If you were
Plotting data in a GPU with Histogrammar Jim Pivarski Princeton DIANA September 30, 2016 1 / 20 Practical introduction Problem: You re developing a numerical algorithm for GPUs (tracking). If you were
Data Analysis R&D. Jim Pivarski. February 5, Princeton University DIANA-HEP
 Data Analysis R&D Jim Pivarski Princeton University DIANA-HEP February 5, 2018 1 / 20 Tools for data analysis Eventual goal Query-based analysis: let physicists do their analysis by querying a central
Data Analysis R&D Jim Pivarski Princeton University DIANA-HEP February 5, 2018 1 / 20 Tools for data analysis Eventual goal Query-based analysis: let physicists do their analysis by querying a central
Big Data Software in Particle Physics
 Big Data Software in Particle Physics Jim Pivarski Princeton University DIANA-HEP August 2, 2018 1 / 24 What software should you use in your analysis? Sometimes considered as a vacuous question, like What
Big Data Software in Particle Physics Jim Pivarski Princeton University DIANA-HEP August 2, 2018 1 / 24 What software should you use in your analysis? Sometimes considered as a vacuous question, like What
Toward real-time data query systems in HEP
 Toward real-time data query systems in HEP Jim Pivarski Princeton University DIANA August 22, 2017 1 / 39 The dream... LHC experiments centrally manage data from readout to Analysis Object Datasets (AODs),
Toward real-time data query systems in HEP Jim Pivarski Princeton University DIANA August 22, 2017 1 / 39 The dream... LHC experiments centrally manage data from readout to Analysis Object Datasets (AODs),
Spark and HPC for High Energy Physics Data Analyses
 Spark and HPC for High Energy Physics Data Analyses Marc Paterno, Jim Kowalkowski, and Saba Sehrish 2017 IEEE International Workshop on High-Performance Big Data Computing Introduction High energy physics
Spark and HPC for High Energy Physics Data Analyses Marc Paterno, Jim Kowalkowski, and Saba Sehrish 2017 IEEE International Workshop on High-Performance Big Data Computing Introduction High energy physics
Rapidly moving data from ROOT to Numpy and Pandas
 Rapidly moving data from ROOT to Numpy and Pandas Jim Pivarski Princeton University DIANA-HEP February 28, 2018 1 / 32 The what and why of uproot What is uproot? A pure Python + Numpy implementation of
Rapidly moving data from ROOT to Numpy and Pandas Jim Pivarski Princeton University DIANA-HEP February 28, 2018 1 / 32 The what and why of uproot What is uproot? A pure Python + Numpy implementation of
Apache Drill. Interactive Analysis of Large-Scale Datasets. Tomer Shiran
 Apache Drill Interactive Analysis of Large-Scale Datasets Tomer Shiran Latency Matters Ad-hoc analysis with interactive tools Real-time dashboards Event/trend detection Network intrusions Fraud Failures
Apache Drill Interactive Analysis of Large-Scale Datasets Tomer Shiran Latency Matters Ad-hoc analysis with interactive tools Real-time dashboards Event/trend detection Network intrusions Fraud Failures
Dremel: Interactice Analysis of Web-Scale Datasets
 Dremel: Interactice Analysis of Web-Scale Datasets By Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis Presented by: Alex Zahdeh 1 / 32 Overview
Dremel: Interactice Analysis of Web-Scale Datasets By Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis Presented by: Alex Zahdeh 1 / 32 Overview
Dremel: Interactive Analysis of Web-Scale Datasets
 Dremel: Interactive Analysis of Web-Scale Datasets Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis Presented by: Sameer Agarwal sameerag@cs.berkeley.edu
Dremel: Interactive Analysis of Web-Scale Datasets Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis Presented by: Sameer Agarwal sameerag@cs.berkeley.edu
Striped Data Server for Scalable Parallel Data Analysis
 Journal of Physics: Conference Series PAPER OPEN ACCESS Striped Data Server for Scalable Parallel Data Analysis To cite this article: Jin Chang et al 2018 J. Phys.: Conf. Ser. 1085 042035 View the article
Journal of Physics: Conference Series PAPER OPEN ACCESS Striped Data Server for Scalable Parallel Data Analysis To cite this article: Jin Chang et al 2018 J. Phys.: Conf. Ser. 1085 042035 View the article
Employing HPC DEEP-EST for HEP Data Analysis. Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN)
, Maria Girone (CERN)") Employing HPC DEEP-EST for HEP Data Analysis Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN) 1 Outline The DEEP-EST Project Goals and Motivation HEP Data Analysis on HPC with Apache Spark on HPC
Employing HPC DEEP-EST for HEP Data Analysis Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN) 1 Outline The DEEP-EST Project Goals and Motivation HEP Data Analysis on HPC with Apache Spark on HPC
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Large Scale OLAP. Yifu Huang. 2014/11/4 MAST Scientific English Writing Report
 Large Scale OLAP Yifu Huang 2014/11/4 MAST612117 Scientific English Writing Report 2014 1 Preliminaries OLAP On-Line Analytical Processing Traditional solutions: data warehouses built by parallel databases
Large Scale OLAP Yifu Huang 2014/11/4 MAST612117 Scientific English Writing Report 2014 1 Preliminaries OLAP On-Line Analytical Processing Traditional solutions: data warehouses built by parallel databases
Greenplum-Spark Connector Examples Documentation. kong-yew,chan
 Greenplum-Spark Connector Examples Documentation kong-yew,chan Dec 10, 2018 Contents 1 Overview 1 1.1 Pivotal Greenplum............................................ 1 1.2 Pivotal Greenplum-Spark Connector...................................
Greenplum-Spark Connector Examples Documentation kong-yew,chan Dec 10, 2018 Contents 1 Overview 1 1.1 Pivotal Greenplum............................................ 1 1.2 Pivotal Greenplum-Spark Connector...................................
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Pandas UDF Scalable Analysis with Python and PySpark. Li Jin, Two Sigma Investments
 Pandas UDF Scalable Analysis with Python and PySpark Li Jin, Two Sigma Investments About Me Li Jin (icexelloss) Software Engineer @ Two Sigma Investments Analytics Tools Smith Apache Arrow Committer Other
Pandas UDF Scalable Analysis with Python and PySpark Li Jin, Two Sigma Investments About Me Li Jin (icexelloss) Software Engineer @ Two Sigma Investments Analytics Tools Smith Apache Arrow Committer Other
Blurring the Line Between Developer and Data Scientist
 Blurring the Line Between Developer and Data Scientist Notebooks with PixieDust va barbosa va@us.ibm.com Developer Advocacy IBM Watson Data Platform WHY ARE YOU HERE? More companies making bet-the-business
Blurring the Line Between Developer and Data Scientist Notebooks with PixieDust va barbosa va@us.ibm.com Developer Advocacy IBM Watson Data Platform WHY ARE YOU HERE? More companies making bet-the-business
Data in the Cloud and Analytics in the Lake
 Data in the Cloud and Analytics in the Lake Introduction Working in Analytics for over 5 years Part the digital team at BNZ for 3 years Based in the Auckland office Preferred Languages SQL Python (PySpark)
Data in the Cloud and Analytics in the Lake Introduction Working in Analytics for over 5 years Part the digital team at BNZ for 3 years Based in the Auckland office Preferred Languages SQL Python (PySpark)
Event Displays and LArg
 Event Displays and LArg Columbia U. / Nevis Labs Slide 1 Introduction Displays are needed in various ways at different stages of the experiment: Software development: understanding offline & trigger algorithms
Event Displays and LArg Columbia U. / Nevis Labs Slide 1 Introduction Displays are needed in various ways at different stages of the experiment: Software development: understanding offline & trigger algorithms
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Flexible Network Analytics in the Cloud. Jon Dugan & Peter Murphy ESnet Software Engineering Group October 18, 2017 TechEx 2017, San Francisco
 Flexible Network Analytics in the Cloud Jon Dugan & Peter Murphy ESnet Software Engineering Group October 18, 2017 TechEx 2017, San Francisco Introduction Harsh realities of network analytics netbeam Demo
Flexible Network Analytics in the Cloud Jon Dugan & Peter Murphy ESnet Software Engineering Group October 18, 2017 TechEx 2017, San Francisco Introduction Harsh realities of network analytics netbeam Demo
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
How to discover the Higgs Boson in an Oracle database. Maaike Limper
 How to discover the Higgs Boson in an Oracle database Maaike Limper 2 Introduction CERN openlab is a unique public-private partnership between CERN and leading ICT companies. Its mission is to accelerate
How to discover the Higgs Boson in an Oracle database Maaike Limper 2 Introduction CERN openlab is a unique public-private partnership between CERN and leading ICT companies. Its mission is to accelerate
Analyzing Flight Data
 IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
Pyspark standalone code
 COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
Spark 2. Alexey Zinovyev, Java/BigData Trainer in EPAM
 Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
New Developments in Spark
 New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
Apache Drill: interactive query and analysis on large-scale datasets
 Apache Drill: interactive query and analysis on large-scale datasets Michael Hausenblas, Chief Data Engineer EMEA, MapR NoSQL matters Training Day, 2013-04-25 Agenda Introduction round (15min) Overview
Apache Drill: interactive query and analysis on large-scale datasets Michael Hausenblas, Chief Data Engineer EMEA, MapR NoSQL matters Training Day, 2013-04-25 Agenda Introduction round (15min) Overview
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Expressing Parallelism with ROOT
 Expressing Parallelism with ROOT https://root.cern D. Piparo (CERN) for the ROOT team CHEP 2016 2 This Talk ROOT helps scientists to express parallelism Adopting multi-threading (MT) and multi-processing
Expressing Parallelism with ROOT https://root.cern D. Piparo (CERN) for the ROOT team CHEP 2016 2 This Talk ROOT helps scientists to express parallelism Adopting multi-threading (MT) and multi-processing
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
Command Line and Python Introduction. Jennifer Helsby, Eric Potash Computation for Public Policy Lecture 2: January 7, 2016
 Command Line and Python Introduction Jennifer Helsby, Eric Potash Computation for Public Policy Lecture 2: January 7, 2016 Today Assignment #1! Computer architecture Basic command line skills Python fundamentals
Command Line and Python Introduction Jennifer Helsby, Eric Potash Computation for Public Policy Lecture 2: January 7, 2016 Today Assignment #1! Computer architecture Basic command line skills Python fundamentals
ROOT: An object-orientated analysis framework
 C++ programming for physicists ROOT: An object-orientated analysis framework PD Dr H Kroha, Dr J Dubbert, Dr M Flowerdew 1 Kroha, Dubbert, Flowerdew 14/04/11 What is ROOT? An object-orientated framework
C++ programming for physicists ROOT: An object-orientated analysis framework PD Dr H Kroha, Dr J Dubbert, Dr M Flowerdew 1 Kroha, Dubbert, Flowerdew 14/04/11 What is ROOT? An object-orientated framework
Mobile Computing Professor Pushpendra Singh Indraprastha Institute of Information Technology Delhi Java Basics Lecture 02
 Mobile Computing Professor Pushpendra Singh Indraprastha Institute of Information Technology Delhi Java Basics Lecture 02 Hello, in this lecture we will learn about some fundamentals concepts of java.
Mobile Computing Professor Pushpendra Singh Indraprastha Institute of Information Technology Delhi Java Basics Lecture 02 Hello, in this lecture we will learn about some fundamentals concepts of java.
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Dremel: Interactive Analysis of Web- Scale Datasets
 Dremel: Interactive Analysis of Web- Scale Datasets S. Melnik, A. Gubarev, J. Long, G. Romer, S. Shivakumar, M. Tolton Google Inc. VLDB 200 Presented by Ke Hong (slide adapted from Melnik s) Outline Problem
Dremel: Interactive Analysis of Web- Scale Datasets S. Melnik, A. Gubarev, J. Long, G. Romer, S. Shivakumar, M. Tolton Google Inc. VLDB 200 Presented by Ke Hong (slide adapted from Melnik s) Outline Problem
SciSpark 201. Searching for MCCs
 SciSpark 201 Searching for MCCs Agenda for 201: Access your SciSpark & Notebook VM (personal sandbox) Quick recap. of SciSpark Project What is Spark? SciSpark Extensions scitensor: N-dimensional arrays
SciSpark 201 Searching for MCCs Agenda for 201: Access your SciSpark & Notebook VM (personal sandbox) Quick recap. of SciSpark Project What is Spark? SciSpark Extensions scitensor: N-dimensional arrays
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Data Formats. for Data Science. Valerio Maggio Data Scientist and Researcher Fondazione Bruno Kessler (FBK) Trento, Italy.
 Trento, Italy.") Data Formats for Data Science Valerio Maggio Data Scientist and Researcher Fondazione Bruno Kessler (FBK) Trento, Italy @leriomaggio About me kidding, that s me!-) Post Doc Researcher @ FBK Complex Data
Data Formats for Data Science Valerio Maggio Data Scientist and Researcher Fondazione Bruno Kessler (FBK) Trento, Italy @leriomaggio About me kidding, that s me!-) Post Doc Researcher @ FBK Complex Data
Big Data Analytics Tools. Applied to ATLAS Event Data
 Big Data Analytics Tools Applied to ATLAS Event Data Ilija Vukotic University of Chicago CHEP 2016, San Francisco Idea Big Data technologies have proven to be very useful for storage, visualization and
Big Data Analytics Tools Applied to ATLAS Event Data Ilija Vukotic University of Chicago CHEP 2016, San Francisco Idea Big Data technologies have proven to be very useful for storage, visualization and
Higher level data processing in Apache Spark
 Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Data Analysis in ATLAS. Graeme Stewart with thanks to Attila Krasznahorkay and Johannes Elmsheuser
 Data Analysis in ATLAS Graeme Stewart with thanks to Attila Krasznahorkay and Johannes Elmsheuser 1 ATLAS Data Flow into Analysis RAW detector data and simulated RDO data are reconstructed into our xaod
Data Analysis in ATLAS Graeme Stewart with thanks to Attila Krasznahorkay and Johannes Elmsheuser 1 ATLAS Data Flow into Analysis RAW detector data and simulated RDO data are reconstructed into our xaod
Index. bfs() function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225
 function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225") Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Declara've Parallel Analysis in ROOT: TDataFrame
 Declara've Parallel Analysis in ROOT: TDataFrame D. Piparo For the ROOT Team CERN EP-SFT Introduction Novel way to interact with ROOT columnar format Inspired by tools such as Pandas or Spark Analysis
Declara've Parallel Analysis in ROOT: TDataFrame D. Piparo For the ROOT Team CERN EP-SFT Introduction Novel way to interact with ROOT columnar format Inspired by tools such as Pandas or Spark Analysis
DATA FORMATS FOR DATA SCIENCE Remastered
 Budapest BI FORUM 2016 DATA FORMATS FOR DATA SCIENCE Remastered Valerio Maggio @leriomaggio Data Scientist and Researcher Fondazione Bruno Kessler (FBK) Trento, Italy WhoAmI Post Doc Researcher @ FBK Interested
Budapest BI FORUM 2016 DATA FORMATS FOR DATA SCIENCE Remastered Valerio Maggio @leriomaggio Data Scientist and Researcher Fondazione Bruno Kessler (FBK) Trento, Italy WhoAmI Post Doc Researcher @ FBK Interested
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
HEP data analysis using ROOT
 HEP data analysis using ROOT week I ROOT, CLING and the command line Histograms, Graphs and Trees Mark Hodgkinson Course contents ROOT, CLING and the command line Histograms, Graphs and Trees File I/O,
HEP data analysis using ROOT week I ROOT, CLING and the command line Histograms, Graphs and Trees Mark Hodgkinson Course contents ROOT, CLING and the command line Histograms, Graphs and Trees File I/O,
Scalable Tools - Part I Introduction to Scalable Tools
 Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Apache Beam. Modèle de programmation unifié pour Big Data
 Apache Beam Modèle de programmation unifié pour Big Data Who am I? Jean-Baptiste Onofre @jbonofre http://blog.nanthrax.net Member of the Apache Software Foundation
Apache Beam Modèle de programmation unifié pour Big Data Who am I? Jean-Baptiste Onofre @jbonofre http://blog.nanthrax.net Member of the Apache Software Foundation
Machine Learning for Large-Scale Data Analysis and Decision Making A. Distributed Machine Learning Week #9
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Distributed Machine Learning Week #9 Today Distributed computing for machine learning Background MapReduce/Hadoop & Spark Theory
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Distributed Machine Learning Week #9 Today Distributed computing for machine learning Background MapReduce/Hadoop & Spark Theory
Scaling Marketplaces at Thumbtack QCon SF 2017
 Scaling Marketplaces at Thumbtack QCon SF 2017 Nate Kupp Technical Infrastructure Data Eng, Experimentation, Platform Infrastructure, Security, Dev Tools Infrastructure from early beginnings You see that?
Scaling Marketplaces at Thumbtack QCon SF 2017 Nate Kupp Technical Infrastructure Data Eng, Experimentation, Platform Infrastructure, Security, Dev Tools Infrastructure from early beginnings You see that?
Spark and Spark SQL. Amir H. Payberah. SICS Swedish ICT. Amir H. Payberah (SICS) Spark and Spark SQL June 29, / 71
 Spark and Spark SQL June 29, / 71") Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Interactive Debugging for Big Data Analytics
 Interactive Debugging for Big Data Analytics Muhammad Ali Gulzar, Xueyuan Han, Matteo Interlandi, Shaghayegh Mardani, Sai Deep Tetali, Tyson Condie, Todd Millstein, Miryung Kim University of California,
Interactive Debugging for Big Data Analytics Muhammad Ali Gulzar, Xueyuan Han, Matteo Interlandi, Shaghayegh Mardani, Sai Deep Tetali, Tyson Condie, Todd Millstein, Miryung Kim University of California,
Putting A Spark in Web Apps
 Putting A Spark in Web Apps Apache Big Data, Seville ES, 2016 David Fallside Intro Web app development has moved from Java etc to Node.js and JavaScript JS environment relatively simple and very rich,
Putting A Spark in Web Apps Apache Big Data, Seville ES, 2016 David Fallside Intro Web app development has moved from Java etc to Node.js and JavaScript JS environment relatively simple and very rich,
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
POLICY diffusion occurs when government decisions in a
 2016 IEEE International Conference on Big Data (Big Data) Large-scale text processing pipeline with Apache Spark A. Svyatkovskiy, K. Imai, M. Kroeger, Y. Shiraito Princeton University Abstract In this
2016 IEEE International Conference on Big Data (Big Data) Large-scale text processing pipeline with Apache Spark A. Svyatkovskiy, K. Imai, M. Kroeger, Y. Shiraito Princeton University Abstract In this
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
DATABASE SYSTEMS. Introduction to MySQL. Database System Course, 2016
 DATABASE SYSTEMS Introduction to MySQL Database System Course, 2016 AGENDA FOR TODAY Administration Database Architecture on the web Database history in a brief Databases today MySQL What is it How to
DATABASE SYSTEMS Introduction to MySQL Database System Course, 2016 AGENDA FOR TODAY Administration Database Architecture on the web Database history in a brief Databases today MySQL What is it How to
Mothra: A Large-Scale Data Processing Platform for Network Security Analysis
 Mothra: A Large-Scale Data Processing Platform for Network Security Analysis Tony Cebzanov Software Engineering Institute Carnegie Mellon University Pittsburgh, PA 15213 REV-03.18.2016.0 1 Agenda Introduction
Mothra: A Large-Scale Data Processing Platform for Network Security Analysis Tony Cebzanov Software Engineering Institute Carnegie Mellon University Pittsburgh, PA 15213 REV-03.18.2016.0 1 Agenda Introduction
Introduction to ROOT. M. Eads PHYS 474/790B. Friday, January 17, 14
 Introduction to ROOT What is ROOT? ROOT is a software framework containing a large number of utilities useful for particle physics: More stuff than you can ever possibly need (or want)! 2 ROOT is written
Introduction to ROOT What is ROOT? ROOT is a software framework containing a large number of utilities useful for particle physics: More stuff than you can ever possibly need (or want)! 2 ROOT is written
Dremel: Interac-ve Analysis of Web- Scale Datasets
 Dremel: Interac-ve Analysis of Web- Scale Datasets Google Inc VLDB 2010 presented by Arka BhaEacharya some slides adapted from various Dremel presenta-ons on the internet The Problem: Interactive data
Dremel: Interac-ve Analysis of Web- Scale Datasets Google Inc VLDB 2010 presented by Arka BhaEacharya some slides adapted from various Dremel presenta-ons on the internet The Problem: Interactive data
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION
 Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Apache Kylin. OLAP on Hadoop
 Apache Kylin OLAP on Hadoop Agenda What s Apache Kylin? Tech Highlights Performance Roadmap Q & A http://kylin.io What s Kylin kylin / ˈkiːˈlɪn / 麒麟 --n. (in Chinese art) a mythical animal of composite
Apache Kylin OLAP on Hadoop Agenda What s Apache Kylin? Tech Highlights Performance Roadmap Q & A http://kylin.io What s Kylin kylin / ˈkiːˈlɪn / 麒麟 --n. (in Chinese art) a mythical animal of composite
OREKIT IN PYTHON ACCESS THE PYTHON SCIENTIFIC ECOSYSTEM. Petrus Hyvönen
 OREKIT IN PYTHON ACCESS THE PYTHON SCIENTIFIC ECOSYSTEM Petrus Hyvönen 2017-11-27 SSC ACTIVITIES Public Science Services Satellite Management Services Engineering Services 2 INITIAL REASON OF PYTHON WRAPPED
OREKIT IN PYTHON ACCESS THE PYTHON SCIENTIFIC ECOSYSTEM Petrus Hyvönen 2017-11-27 SSC ACTIVITIES Public Science Services Satellite Management Services Engineering Services 2 INITIAL REASON OF PYTHON WRAPPED
Lightning Fast Cluster Computing. Michael Armbrust Reflections Projections 2015 Michast
 Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Security analytics: From data to action Visual and analytical approaches to detecting modern adversaries
 Security analytics: From data to action Visual and analytical approaches to detecting modern adversaries Chris Calvert, CISSP, CISM Director of Solutions Innovation Copyright 2013 Hewlett-Packard Development
Security analytics: From data to action Visual and analytical approaches to detecting modern adversaries Chris Calvert, CISSP, CISM Director of Solutions Innovation Copyright 2013 Hewlett-Packard Development
Databricks, an Introduction
 Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
CSE 190D Spring 2017 Final Exam Answers
 CSE 190D Spring 2017 Final Exam Answers Q 1. [20pts] For the following questions, clearly circle True or False. 1. The hash join algorithm always has fewer page I/Os compared to the block nested loop join
CSE 190D Spring 2017 Final Exam Answers Q 1. [20pts] For the following questions, clearly circle True or False. 1. The hash join algorithm always has fewer page I/Os compared to the block nested loop join
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
SQL Server Machine Learning Marek Chmel & Vladimir Muzny
 SQL Server Machine Learning Marek Chmel & Vladimir Muzny @VladimirMuzny & @MarekChmel MCTs, MVPs, MCSEs Data Enthusiasts! vladimir@datascienceteam.cz marek@datascienceteam.cz Session Agenda Machine learning
SQL Server Machine Learning Marek Chmel & Vladimir Muzny @VladimirMuzny & @MarekChmel MCTs, MVPs, MCSEs Data Enthusiasts! vladimir@datascienceteam.cz marek@datascienceteam.cz Session Agenda Machine learning
Big Data Tools as Applied to ATLAS Event Data
 Big Data Tools as Applied to ATLAS Event Data I Vukotic 1, R W Gardner and L A Bryant University of Chicago, 5620 S Ellis Ave. Chicago IL 60637, USA ivukotic@uchicago.edu ATL-SOFT-PROC-2017-001 03 January
Big Data Tools as Applied to ATLAS Event Data I Vukotic 1, R W Gardner and L A Bryant University of Chicago, 5620 S Ellis Ave. Chicago IL 60637, USA ivukotic@uchicago.edu ATL-SOFT-PROC-2017-001 03 January
Deep Learning Frameworks with Spark and GPUs
 Deep Learning Frameworks with Spark and GPUs Abstract Spark is a powerful, scalable, real-time data analytics engine that is fast becoming the de facto hub for data science and big data. However, in parallel,
Deep Learning Frameworks with Spark and GPUs Abstract Spark is a powerful, scalable, real-time data analytics engine that is fast becoming the de facto hub for data science and big data. However, in parallel,
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Python, PySpark and Riak TS. Stephen Etheridge Lead Solution Architect, EMEA
 Python, PySpark and Riak TS Stephen Etheridge Lead Solution Architect, EMEA Agenda Introduction to Riak TS The Riak Python client The Riak Spark connector and PySpark CONFIDENTIAL Basho Technologies 3
Python, PySpark and Riak TS Stephen Etheridge Lead Solution Architect, EMEA Agenda Introduction to Riak TS The Riak Python client The Riak Spark connector and PySpark CONFIDENTIAL Basho Technologies 3
Introduction to Programming in C Department of Computer Science and Engineering. Lecture No. #16 Loops: Matrix Using Nested for Loop
 Introduction to Programming in C Department of Computer Science and Engineering Lecture No. #16 Loops: Matrix Using Nested for Loop In this section, we will use the, for loop to code of the matrix problem.
Introduction to Programming in C Department of Computer Science and Engineering Lecture No. #16 Loops: Matrix Using Nested for Loop In this section, we will use the, for loop to code of the matrix problem.
Collider analysis recasting with Rivet & Contur. Andy Buckley, University of Glasgow Jon Butterworth, University College London MC4BSM, 20 April 2018
 Collider analysis recasting with Rivet & Contur Andy Buckley, University of Glasgow Jon Butterworth, University College London MC4BSM, 20 April 2018 Rivet Rivet is an analysis system for MC events, and
Collider analysis recasting with Rivet & Contur Andy Buckley, University of Glasgow Jon Butterworth, University College London MC4BSM, 20 April 2018 Rivet Rivet is an analysis system for MC events, and
Data Analyst Nanodegree Syllabus
 Data Analyst Nanodegree Syllabus Discover Insights from Data with Python, R, SQL, and Tableau Before You Start Prerequisites : In order to succeed in this program, we recommend having experience working
Data Analyst Nanodegree Syllabus Discover Insights from Data with Python, R, SQL, and Tableau Before You Start Prerequisites : In order to succeed in this program, we recommend having experience working
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
Databases and Big Data Today. CS634 Class 22
 Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Department of Electrical Engineering and Computer Science MASSACHUSETTS INSTITUTE OF TECHNOLOGY
 Department of Electrical Engineering and Computer Science MASSACHUSETTS INSTITUTE OF TECHNOLOGY 6.095: Introduction to Computer Science and Programming Quiz I In order to receive credit you must answer
Department of Electrical Engineering and Computer Science MASSACHUSETTS INSTITUTE OF TECHNOLOGY 6.095: Introduction to Computer Science and Programming Quiz I In order to receive credit you must answer
Compile-Time Code Generation for Embedded Data-Intensive Query Languages
 Compile-Time Code Generation for Embedded Data-Intensive Query Languages Leonidas Fegaras University of Texas at Arlington http://lambda.uta.edu/ Outline Emerging DISC (Data-Intensive Scalable Computing)
Compile-Time Code Generation for Embedded Data-Intensive Query Languages Leonidas Fegaras University of Texas at Arlington http://lambda.uta.edu/ Outline Emerging DISC (Data-Intensive Scalable Computing)
Towards Practical Differential Privacy for SQL Queries. Noah Johnson, Joseph P. Near, Dawn Song UC Berkeley
 Towards Practical Differential Privacy for SQL Queries Noah Johnson, Joseph P. Near, Dawn Song UC Berkeley Outline 1. Discovering real-world requirements 2. Elastic sensitivity & calculating sensitivity
Towards Practical Differential Privacy for SQL Queries Noah Johnson, Joseph P. Near, Dawn Song UC Berkeley Outline 1. Discovering real-world requirements 2. Elastic sensitivity & calculating sensitivity
High-Performance Distributed DBMS for Analytics
 1 High-Performance Distributed DBMS for Analytics 2 About me Developer, hardware engineering background Head of Analytic Products Department in Yandex jkee@yandex-team.ru 3 About Yandex One of the largest
1 High-Performance Distributed DBMS for Analytics 2 About me Developer, hardware engineering background Head of Analytic Products Department in Yandex jkee@yandex-team.ru 3 About Yandex One of the largest
Lambda Architecture for Batch and Stream Processing. October 2018
 Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
PyROOT: Seamless Melting of C++ and Python. Pere MATO, Danilo PIPARO on behalf of the ROOT Team
 PyROOT: Seamless Melting of C++ and Python Pere MATO, Danilo PIPARO on behalf of the ROOT Team ROOT At the root of the experiments, project started in 1995 Open Source project (LGPL2) mainly written in
PyROOT: Seamless Melting of C++ and Python Pere MATO, Danilo PIPARO on behalf of the ROOT Team ROOT At the root of the experiments, project started in 1995 Open Source project (LGPL2) mainly written in
Using the Force of Python and SAS Viya on Star Wars Fan Posts
 SESUG Paper BB-170-2017 Using the Force of Python and SAS Viya on Star Wars Fan Posts Grace Heyne, Zencos Consulting, LLC ABSTRACT The wealth of information available on the Internet includes useful and
SESUG Paper BB-170-2017 Using the Force of Python and SAS Viya on Star Wars Fan Posts Grace Heyne, Zencos Consulting, LLC ABSTRACT The wealth of information available on the Internet includes useful and