|
|
|
- April Washington
- 6 years ago
- Views:
Transcription
1 UNIT -3 SYNTAX ANALYSIS 3.1 ROLE OF THE PARSER Parser obtains a string of tokens from the lexical analyzer and verifies that it can be generated by the language for the source program. The parser should report any syntax errors in an intelligible fashion. The two types of parsers employed are: 1.Top down parser: which build parse trees from top(root) to bottom(leaves) 2.Bottom up parser: which build parse trees from leaves and work up the root. Therefore there are two types of parsing methods top-down parsing and bottom-up parsing 3.2 TOP-DOWN PARSING A program that performs syntax analysis is called a parser. A syntax analyzer takes tokens as input and output error message if the program syntax is wrong. The parser uses symbol-lookahead and an approach called top-down parsing without backtracking. Top-downparsers check to see if a string can be generated by a grammar by creating a parse tree starting from the initial symbol and working down. Bottom-up parsers, however, check to see a string can be generated from a grammar by creating a parse tree from the leaves, and working up. Early parser generators such as YACC creates bottom-up parsers whereas many of Java parser generators such as JavaCC create top-down parsers. 3.3RECURSIVE DESCENT PARSING Typically, top-down parsers are implemented as a set of recursive functions that descent through a parse tree for a string. This approach is known as recursive descent parsing, also known as LL(k) parsing where the first L stands for left-to-right, the second L stands for
2 leftmost-derivation, and k indicates k-symbol lookahead. Therefore, a parser using the single symbol look-ahead method and top-down parsing without backtracking is called LL(1) parser. In the following sections, we will also use an extended BNF notation in which some regulation expression operators are to be incorporated. A syntax expression defines sentences of the form, or. A syntax of the form defines sentences that consist of a sentence of the form followed by a sentence of the form followed by a sentence of the form. A syntax of the form defines zero or one occurrence of the form. A syntax of the form defines zero or more occurrences of the form. A usual implementation of an LL(1) parser is: initialize its data structures, get the lookahead token by calling scanner routines, and call the routine that implements the start symbol. Here is an example. proc syntaxanalysis() begin initialize(); // initialize global data and structures nexttoken(); // get the lookahead token program(); // parser routine that implements the start symbol end; 3.4 FIRST AND FOLLOW To compute FIRST(X) for all grammar symbols X, apply the following rules until no more terminals or e can be added to any FIRST set. 1. If X is terminal, then FIRST(X) is {X}. 2. If X->e is a production, then add e to FIRST(X). 3. If X is nonterminal and X->Y1Y2...Yk is a production, then place a in FIRST(X) if for some i, a is in FIRST(Yi) and e is in all of FIRST(Y1),...,FIRST(Yi-1) that is, Y1...Yi- 1 =*>e. If e is in FIRST(Yj) for all j=1,2,...,k, then add e to FIRST(X). For example, everything in FIRST(Yj) is surely in FIRST(X). If y1 does not derive e, then we add nothing more to FIRST(X), but if Y1=*>e, then we add FIRST(Y2) and so on.
3 To compute the FIRST(A) for all nonterminals A, apply the following rules until nothing can be added to any FOLLOW set. 1. Place $ in FOLLOW(S), where S is the start symbol and $ in the input right endmarker. 2. If there is a production A=>aBs where FIRST(s) except e is placed in FOLLOW(B). 3. If there is aproduction A->aB or a production A->aBs where FIRST(s) contains e, then everything in FOLLOW(A) is in FOLLOW(B). Consider the following example to understand the concept of First and Follow.Find the first and follow of all nonterminals in the Grammar- E -> TE' E'-> +TE' e T -> FT' T'-> *FT' e F -> (E) id Then: FIRST(E)=FIRST(T)=FIRST(F)={(,id} FIRST(E')={+,e} FIRST(T')={*,e} FOLLOW(E)=FOLLOW(E')={),$} FOLLOW(T)=FOLLOW(T')={+,),$} FOLLOW(F)={+,*,),$} For example, id and left parenthesis are added to FIRST(F) by rule 3 in definition of FIRST with i=1 in each case, since FIRST(id)=(id) and FIRST('(')= {(} by rule 1. Then by rule 3 with i=1, the production T -> FT' implies that id and left parenthesis belong to FIRST(T) also. To compute FOLLOW,we put $ in FOLLOW(E) by rule 1 for FOLLOW. By rule 2 applied toproduction F-> (E), right parenthesis is also in FOLLOW(E). By rule 3 applied to production E-> TE', $ and right parenthesis are in FOLLOW(E').
4 3.5 CONSTRUCTION OF PREDICTIVE PARSING TABLES For any grammar G, the following algorithm can be used to construct the predictive parsing table. The algorithm is Input : Grammar G Output : Parsing table M Method 1. 1.For each production A-> a of the grammar, do steps 2 and For each terminal a in FIRST(a), add A->a, to M[A,a]. 3. If e is in First(a), add A->a to M[A,b] for each terminal b in FOLLOW(A). If e is in FIRST(a) and $ is in FOLLOW(A), add A->a to M[A,$]. 4. Make each undefined entry of M be error. 3.6.LL(1) GRAMMAR The above algorithm can be applied to any grammar G to produce a parsing table M. For some Grammars, for example if G is left recursive or ambiguous, then M will have at least one multiply-defined entry. A grammar whose parsing table has no multiply defined entries is said to be LL(1). It can be shown that the above algorithm can be used to produce for every LL(1) grammar G a parsing table M that parses all and only the sentences of G. LL(1) grammars have several distinctive properties. No ambiguous or left recursive grammar can be LL(1). There remains a question of what should be done in case of multiply defined entries. One easy solution is to eliminate all left recursion and left factoring, hoping to produce a grammar which will produce no multiply defined entries in the parse tables. Unfortunately there are some grammars which will give an LL(1) grammar after any kind of alteration. In general, there are no universal rules to convert multiply defined entries into single valued entries without affecting the language recognized by the parser. The main difficulty in using predictive parsing is in writing a grammar for the source language such that a predictive parser can be constructed from the grammar. Although left recursion elimination and left factoring are easy to do, they make the resulting grammar hard to read and difficult to use the translation purposes. To alleviate some of this difficulty, a common organization for a parser in a compiler is to use a predictive parser for control
5 constructs and to use operator precedence for expressions.however, if an lr parser generator is available, one can get all the benefits of predictive parsing and operator precedence automatically. 3.7.ERROR RECOVERY IN PREDICTIVE PARSING The stack of a nonrecursive predictive parser makes explicit the terminals and nonterminals that the parser hopes to match with the remainder of the input. We shall therefore refer to symbols on the parser stack in the following discussion. An error is detected during predictive parsing when the terminal on top of the stack does not match the next input symbol or when nonterminal A is on top of the stack, a is the next input symbol, and the parsing table entry M[A,a] is empty. Panic-mode error recovery is based on the idea of skipping symbols on the input until a token in a selected set of synchronizing tokens appears. Its effectiveness depends on the choice of synchronizing set. The sets should be chosen so that the parser recovers quickly from errors that are likely to occur in practice. Some heuristics are as follows As a starting point, we can place all symbols in FOLLOW(A) into the synchronizing set for nonterminal A. If we skip tokens until an element of FOLLOW(A) is seen and pop A from the stack, it is likely that parsing can continue. It is not enough to use FOLLOW(A) as the synchronizingset for A. Fo example, if semicolons terminate statements, as in C, then keywords that begin statements may not appear in the FOLLOW set of the nonterminal generating expressions. A missing semicolon after an assignment may therefore result in the keyword beginning the next statement being skipped. Often, there is a hierarchica structure on constructs in a language; e.g., expressions appear within statement, which appear within bblocks,and so on. We can add to the synchronizing set of a lower construct the symbols that begin higher constructs. For example, we might add keywords that begin statements to the synchronizing sets for the nonterminals generaitn expressions. If we add symbols in FIRST(A) to the synchronizing set for nonterminal A, then it may be possible to resume parsing according to A if a symbol in FIRST(A) appears in the input.
6 If a nonterminal can generate the empty string, then the production deriving e can be used as a default. Doing so may postpone some error detection, but cannot cause an error to be missed. This approach reduces the number of nonterminals that have to be considered during error recovery. If a terminal on top of the stack cannot be matched, a simple idea is to pop the terminal, issue a message saying that the terminal was inserted, and continue parsing. In effect, this approach takes the synchronizing set of a token to consist of all other tokens. 3.8 LR PARSING INTRODUCTION The "L" is for left-to-right scanning of the input and the "R" is for constructing a rightmost derivation in reverse. WHY LR PARSING: LR parsers can be constructed to recognize virtually all programming-language constructs for which context-free grammars can be written. The LR parsing method is the most general non-backtracking shift-reduce parsing method known, yet it can be implemented as efficiently as other shift-reduce methods. The class of grammars that can be parsed using LR methods is a proper subset of the class of grammars that can be parsed with predictive parsers. An LR parser can detect a syntactic error as soon as it is possible to do so on a leftto- right scan of the input.
7 The disadvantage is that it takes too much work to constuct an LR parser by hand for a typical programming-language grammar. But there are lots of LR parser generators available to make this task easy. MODELS OF LR PARSERS The schematic form of an LR parser is shown below. The program uses a stack to store a string of the form s0x1s1x2...xmsm where sm is on top. Each Xi is a grammar symbol and each si is a symbol representing a state. Each state symbol summarizes the information contained in the stack below it. The combination of the state symbol on top of the stack and the current input symbol are used to index the parsing table and determine the shiftreduce parsing decision. The parsing table consists of two parts: a parsing action function action and a goto function goto. The program driving the LR parser behaves as follows: It determines sm the state currently on top of the stack and ai the current input symbol. It then consults action[sm,ai], which can have one of four values: shift s, where s is a state reduce by a grammar production A -> b
8 accept error The function goto takes a state and grammar symbol as arguments and produces a state. For a parsing table constructed for a grammar G, the goto table is the transition function of a deterministic finite automaton that recognizes the viable prefixes of G. Recall that the viable prefixes of G are those prefixes of right-sentential forms that can appear on the stack of a shiftreduce parser because they do not extend past the rightmost handle. A configuration of an LR parser is a pair whose first component is the stack contents and whose second component is the unexpended input: (s0 X1 s1 X2 s2... Xm sm, ai ai+1... an$) This configuration represents the right-sentential form X1 X1... Xm ai ai+1...an in essentially the same way a shift-reduce parser would; only the presence of the states on the stack is new. Recall the sample parse we did (see Example 1: Sample bottom-up parse) in which we assembled the right-sentential form by concatenating the remainder of the input buffer to the top of the stack. The next move of the parser is determined by reading ai and sm, and consulting the parsing action table entry action[sm, ai]. Note that we are just looking at the state here and no symbol below it. We'll see how this actually works later. The configurations resulting after each of the four types of move are as follows: If action[sm, ai] = shift s, the parser executes a shift move entering the configuration (s0 X1 s1 X2 s2... Xm sm ai s, ai+1... an$) Here the parser has shifted both the current input symbol ai and the next symbol. If action[sm, ai] = reduce A -> b, then the parser executes a reduce move, entering the configuration, (s0 X1 s1 X2 s2... Xm-r sm-r A s, ai ai+1... an$) where s = goto[sm-r, A] and r is the length of b, the right side of the production. The parser first popped 2r symbols off the stack (r state symbols and r grammar symbols), exposing state sm-r. The parser then pushed both A, the left side of the production, and s, the entry for goto[sm-r, A], onto the stack. The current input symbol is not changed in a reduce move. The output of an LR parser is generated after a reduce move by executing the semantic action associated with the reducing production. For example, we might just print out the production
9 reduced. If action[sm, ai] = accept, parsing is completed. 3.9 SHIFT REDUCE PARSING A shift-reduce parser uses a parse stack which (conceptually) contains grammar symbols. During the operation of the parser, symbols from the input are shifted onto the stack. If a prefix of the symbols on top of the stack matches the RHS of a grammar rule which is the correct rule to use within the current context, then the parser reduces the RHS of the rule to its LHS,replacing the RHS symbols on top of the stack with the nonterminal occurring on the LHS of the rule. This shift-reduce process continues until the parser terminates, reporting either success or failure. It terminates with success when the input is legal and is accepted by the parser. It terminates with failure if an error is detected in the input. The parser is nothing but a stack automaton which may be in one of several discrete states. A state is usually represented simply as an integer. In reality, the parse stack contains states, rather than grammar symbols. However, since each state corresponds to a unique grammar symbol, the state stack can be mapped onto the grammar symbol stack mentioned earlier. The operation of the parser is controlled by a couple of tables: ACTION TABLE The action table is a table with rows indexed by states and columns indexed by terminal symbols. When the parser is in some state s and the current lookahead terminal is t, the action taken by the parser depends on the contents of action[s][t], which can contain four different kinds of entries: Shift s' Shift state s' onto the parse stack. Reduce r Reduce by rule r. This is explained in more detail below. Accept Terminate the parse with success, accepting the input. Error Signal a parse error GOTO TABLE The goto table is a table with rows indexed by states and columns indexed by nonterminal
10 symbols. When the parser is in state s immediately after reducing by rule N, then the next state to enter is given by goto[s][n]. The current state of a shift-reduce parser is the state on top of the state stack. The detailed operation of such a parser is as follows: 1. Initialize the parse stack to contain a single state s0, where s0 is the distinguished initial state of the parser. 2. Use the state s on top of the parse stack and the current lookahead t to consult the action table entry action[s][t]: If the action table entry is shift s' then push state s' onto the stack and advance the input so that the lookahead is set to the next token. If the action table entry is reduce r and rule r has m symbols in its RHS, then pop m symbols off the parse stack. Let s' be the state now revealed on top of the parse stack and N be the LHS nonterminal for rule r. Then consult the goto table and push the state given by goto[s'][n] onto the stack. The lookahead token is not changed by this step. If the action table entry is accept, then terminate the parse with success. If the action table entry is error, then signal an error. 3. Repeat step (2) until the parser terminates. For example, consider the following simple grammar 0) $S: stmt <EOF> 1) stmt: ID ':=' expr 2) expr: expr '+' ID 3) expr: expr '-' ID 4) expr: ID which describes assignment statements like a:= b + c - d. (Rule 0 is a special augmenting production added to the grammar). One possible set of shift-reduce parsing tables is shown below (sn denotes shift n, rn denotes reduce n, acc denotes accept and blank entries denote error entries): Parser Tables
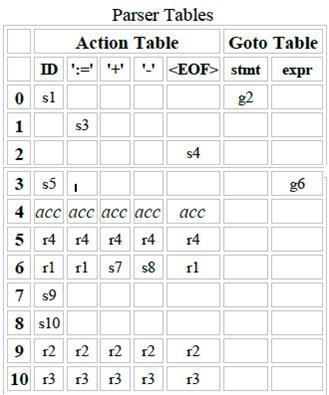
11


12 3.10 SLR PARSER An LR(0) item (or just item) of a grammar G is a production of G with a dot at some position of the right side indicating how much of a production we have seen up to a given point. For example, for the production E -> E + T we would have the following items: [E ->.E + T] [E -> E. + T] [E -> E +. T] [E -> E + T.]
13 CONSTRUCTING THE SLR PARSING TABLE To construct the parser table we must convert our NFA into a DFA. The states in the LR table will be the e-closures of the states corresponding to the items SO...the process of creating the LR state table parallels the process of constructing an equivalent DFA from a machine with e-transitions. Been there, done that - this is essentially the subset construction algorithm so we are in familiar territory here. We need two operations: closure() and goto(). closure() If I is a set of items for a grammar G, then closure(i) is the set of items constructed from I by the two rules: Initially every item in I is added to closure(i) If A -> a.bb is in closure(i), and B -> g is a production, then add the initial item [B ->.g] to I, if it is not already there. Apply this rule until no more new items can be added to closure(i). From our grammar above, if I is the set of one item {[E'->.E]}, then closure(i) contains: I0: E' ->.E E ->.E + T E ->.T T ->.T * F T ->.F F ->.(E) F ->.id goto() goto(i, X), where I is a set of items and X is a grammar symbol, is defined to be the closure of the set of all items [A -> ax.b] such that [A -> a.xb] is in I. The idea here is fairly intuitive: if I is the set of items that are valid for some viable prefix g, then goto(i, X) is the set of items that are valid for the viable prefix gx. SETS-OF-ITEMS-CONSTRUCTION To construct the canonical collection of sets of LR(0) items for augmented grammar G'. procedure items(g') begin
14 C := {closure({[s' ->.S]})}; repeat for each set of items in C and each grammar symbol X such that goto(i, X) is not empty and not in C do add goto(i, X) to C; until no more sets of items can be added to C end; ALGORITHM FOR CONSTRUCTING AN SLR PARSING TABLE Input: augmented grammar G' Output: SLR parsing table functions action and goto for G' Method: Construct C = {I0, I1,..., In} the collection of sets of LR(0) items for G'. State i is constructed from Ii: if [A -> a.ab] is in Ii and goto(ii, a) = Ij, then set action[i, a] to "shift j". Here a must be a terminal. if [A -> a.] is in Ii, then set action[i, a] to "reduce A -> a" for all a in FOLLOW(A). Here A may not be S'. if [S' -> S.] is in Ii, then set action[i, $] to "accept" If any conflicting actions are generated by these rules, the grammar is not SLR(1) and the algorithm fails to produce a parser. The goto transitions for state i are constructed for all nonterminals A using the rule: If goto(ii, A)= Ij, then goto[i, A] = j. All entries not defined by rules 2 and 3 are made "error". The inital state of the parser is the one constructed from the set of items containing [S' ->.S]. Let's work an example to get a feel for what is going on, An Example (1) E -> E * B (2) E -> E + B (3) E -> B (4) B -> 0 (5) B -> 1
 parsing have the same set of core (or first) components and differ only in their second component, the lookahead symbol.")
15 The Action and Goto Table The two LR(0) parsing tables for this grammar look as follows: 3.11 LALR PARSER: We begin with two observations. First, some of the states generated for LR(1) parsing have the same set of core (or first) components and differ only in their second component, the lookahead symbol. Our intuition is that we should be able to merge these states and reduce the number of states we have, getting close to the number of states that would be generated for LR(0) parsing. This observation suggests a hybrid approach: We can construct the canonical LR(1) sets of items and then look for sets of items having the same core. We merge these sets with common cores into one set of items. The merging of states with common cores can never produce a shift/reduce conflict that was not present in one of the original states because shift actions depend only on the core, not the lookahead. But it is possible for the merger to produce a reduce/reduce conflict. Our second observation is that we are really only interested in the lookahead symbol in places where there is a problem. So our next thought is to take the LR(0) set of items and add lookaheads only where they are needed. This leads to a more efficient, but much more complicated method.
16 ALGORITHM FOR EASY CONSTRUCTION OF AN LALR TABLE Input: G' Output: LALR parsing table functions with action and goto for G'. Method: 1. Construct C = {I0, I1,..., In} the collection of sets of LR(1) items for G'. 2. For each core present among the set of LR(1) items, find all sets having that core and replace these sets by the union. 3. Let C' = {J0, J1,..., Jm} be the resulting sets of LR(1) items. The parsing actions for state i are constructed from Ji in the same manner as in the construction of the canonical LR parsing table. 4. If there is a conflict, the grammar is not LALR(1) and the algorithm fails. 5. The goto table is constructed as follows: If J is the union of one or more sets of LR(1) items, that is, J = I0U I1 U... U Ik, then the cores of goto(i0, X), goto(i1, X),..., goto(ik, X) are the same, since I0, I1,..., Ik all have the same core. Let K be the union of all sets of items having the same core asgoto(i1, X). 6. Then goto(j, X) = K. Consider the above example, I3 & I6 can be replaced by their union I36:C->c.C,c/d/$ C->.Cc,C/D/$ C->.d,c/d/$ I47:C->d.,c/d/$ I89:C->Cc.,c/d/$ Parsing Table state c d $ S C 0 S36 S Accept 2 S36 S47 5
17 36 S36 S R3 R3 5 R1 89 R2 R2 R2 HANDLING ERRORS The LALR parser may continue to do reductions after the LR parser would have spotted an error, but the LALR parser will never do a shift after the point the LR parser would have discovered the error and will eventually find the error LR ERROR RECOVERY An LR parser will detect an error when it consults the parsing action table and find a blank or error entry. Errors are never detected by consulting the goto table. An LR parser will detect an error as soon as there is no valid continuation for the portion of the input thus far scanned. A canonical LR parser will not make even a single reduction before announcing the error. SLR and LALR parsers may make several reductions before detecting an error, but they will never shift an erroneous input symbol onto the stack PANIC-MODE ERROR RECOVERY We can implement panic-mode error recovery by scanning down the stack until a state s with a goto on a particular nonterminal A is found. Zero or more input symbols are then discarded until a symbol a is found that can legitimately follow The situation might exist where there is more than one choice for the nonterminal A. Normally these would be nonterminals representing major program pieces, e.g. an expression, a statement, or a block. For example, if A is the nonterminal stmt, a might be semicolon or }, which marks the end of a statement sequence. This method of error recovery attempts to eliminate the phrase containing the syntactic error. The parser determines that a string derivable from A contains an error. Part of that string has already been processed, and the result of this processing is a sequence of states on top of the stack. The remainder of the string is still in the input, and the parser attempts to skip over the remainder of this string by looking for a symbol on the input that can legitimately follow A. By removing states from the stack, skipping over the input, and pushing GOTO(s, A) on the stack, the parser pretends that if has found an instance of A and resumes normal parsing.
18 PHRASE-LEVEL RECOVERY Phrase-level recovery is implemented by examining each error entry in the LR action table and deciding on the basis of language usage the most likely programmer error that would give rise to that error. An appropriate recovery procedure can then be constructed; presumably the top of the stack and/or first input symbol would be modified in a way deemed appropriate for each error entry. In designing specific error-handling routines for an LR parser, we can fill in each blank entry in the action field with a pointer to an error routine that will take the appropriate action selected by the compiler designer. The actions may include insertion or deletion of symbols from the stack or the input or both, or alteration and transposition of input symbols. We must make our choices so that the LR parser will not get into an infinite loop. A safe strategy will assure that at least one input symbol will be removed or shifted eventually, or that the stack will eventually shrink if the end of the input has been reached. Popping a stack state that covers a non terminal should be avoided, because this modification eliminates from the stack a construct that has already been successfully parsed.
UNIT OVERVIEW OF LANGUAGE PROCESSING SYSTEM 1.3 COMPILER
 UNIT -1 1.1 OVERVIEW OF LANGUAGE PROCESSING SYSTEM 1.2 Preprocessor A preprocessor produce input to compilers. They may perform the following functions. 1. Macro processing: A preprocessor may allow a
UNIT -1 1.1 OVERVIEW OF LANGUAGE PROCESSING SYSTEM 1.2 Preprocessor A preprocessor produce input to compilers. They may perform the following functions. 1. Macro processing: A preprocessor may allow a
COMPILER DESIGN LECTURE NOTES
 COMPILER DESIGN LECTURE NOTES -1- UNIT -1 1.1 OVERVIEW OF LANGUAGE PROCESSING SYSTEM 1.2 Preprocessor A preprocessor produce input to compilers. They may perform the following functions. 1. Macro processing:
COMPILER DESIGN LECTURE NOTES -1- UNIT -1 1.1 OVERVIEW OF LANGUAGE PROCESSING SYSTEM 1.2 Preprocessor A preprocessor produce input to compilers. They may perform the following functions. 1. Macro processing:
Context-free grammars
 Context-free grammars Section 4.2 Formal way of specifying rules about the structure/syntax of a program terminals - tokens non-terminals - represent higher-level structures of a program start symbol,
Context-free grammars Section 4.2 Formal way of specifying rules about the structure/syntax of a program terminals - tokens non-terminals - represent higher-level structures of a program start symbol,
Compiler Construction: Parsing
 Compiler Construction: Parsing Mandar Mitra Indian Statistical Institute M. Mitra (ISI) Parsing 1 / 33 Context-free grammars. Reference: Section 4.2 Formal way of specifying rules about the structure/syntax
Compiler Construction: Parsing Mandar Mitra Indian Statistical Institute M. Mitra (ISI) Parsing 1 / 33 Context-free grammars. Reference: Section 4.2 Formal way of specifying rules about the structure/syntax
BVRIT HYDERABAD College of Engineering for Women Department of Computer Science and Engineering. Course Hand Out
 BVRIT HYDERABAD College of Engineering for Women Department of Computer Science and Engineering Course Hand Out Subject Name : Compiler Design Prepared by : Mr.K.Rajesh, Assistant Professor, CSE Year,
BVRIT HYDERABAD College of Engineering for Women Department of Computer Science and Engineering Course Hand Out Subject Name : Compiler Design Prepared by : Mr.K.Rajesh, Assistant Professor, CSE Year,
 SYNTAX ANALYSIS 1. Define parser. Hierarchical analysis is one in which the tokens are grouped hierarchically into nested collections with collective meaning. Also termed as Parsing. 2. Mention the basic
SYNTAX ANALYSIS 1. Define parser. Hierarchical analysis is one in which the tokens are grouped hierarchically into nested collections with collective meaning. Also termed as Parsing. 2. Mention the basic
3. Syntax Analysis. Andrea Polini. Formal Languages and Compilers Master in Computer Science University of Camerino
 3. Syntax Analysis Andrea Polini Formal Languages and Compilers Master in Computer Science University of Camerino (Formal Languages and Compilers) 3. Syntax Analysis CS@UNICAM 1 / 54 Syntax Analysis: the
3. Syntax Analysis Andrea Polini Formal Languages and Compilers Master in Computer Science University of Camerino (Formal Languages and Compilers) 3. Syntax Analysis CS@UNICAM 1 / 54 Syntax Analysis: the
LALR Parsing. What Yacc and most compilers employ.
 LALR Parsing Canonical sets of LR(1) items Number of states much larger than in the SLR construction LR(1) = Order of thousands for a standard prog. Lang. SLR(1) = order of hundreds for a standard prog.
LALR Parsing Canonical sets of LR(1) items Number of states much larger than in the SLR construction LR(1) = Order of thousands for a standard prog. Lang. SLR(1) = order of hundreds for a standard prog.
LR Parsing Techniques
 LR Parsing Techniques Introduction Bottom-Up Parsing LR Parsing as Handle Pruning Shift-Reduce Parser LR(k) Parsing Model Parsing Table Construction: SLR, LR, LALR 1 Bottom-UP Parsing A bottom-up parser
LR Parsing Techniques Introduction Bottom-Up Parsing LR Parsing as Handle Pruning Shift-Reduce Parser LR(k) Parsing Model Parsing Table Construction: SLR, LR, LALR 1 Bottom-UP Parsing A bottom-up parser
UNIT III & IV. Bottom up parsing
 UNIT III & IV Bottom up parsing 5.0 Introduction Given a grammar and a sentence belonging to that grammar, if we have to show that the given sentence belongs to the given grammar, there are two methods.
UNIT III & IV Bottom up parsing 5.0 Introduction Given a grammar and a sentence belonging to that grammar, if we have to show that the given sentence belongs to the given grammar, there are two methods.
PART 3 - SYNTAX ANALYSIS. F. Wotawa TU Graz) Compiler Construction Summer term / 309
 Compiler Construction Summer term / 309") PART 3 - SYNTAX ANALYSIS F. Wotawa (IST @ TU Graz) Compiler Construction Summer term 2016 64 / 309 Goals Definition of the syntax of a programming language using context free grammars Methods for parsing
PART 3 - SYNTAX ANALYSIS F. Wotawa (IST @ TU Graz) Compiler Construction Summer term 2016 64 / 309 Goals Definition of the syntax of a programming language using context free grammars Methods for parsing
Bottom up parsing. The sentential forms happen to be a right most derivation in the reverse order. S a A B e a A d e. a A d e a A B e S.
 Bottom up parsing Construct a parse tree for an input string beginning at leaves and going towards root OR Reduce a string w of input to start symbol of grammar Consider a grammar S aabe A Abc b B d And
Bottom up parsing Construct a parse tree for an input string beginning at leaves and going towards root OR Reduce a string w of input to start symbol of grammar Consider a grammar S aabe A Abc b B d And
UNIT-III BOTTOM-UP PARSING
 UNIT-III BOTTOM-UP PARSING Constructing a parse tree for an input string beginning at the leaves and going towards the root is called bottom-up parsing. A general type of bottom-up parser is a shift-reduce
UNIT-III BOTTOM-UP PARSING Constructing a parse tree for an input string beginning at the leaves and going towards the root is called bottom-up parsing. A general type of bottom-up parser is a shift-reduce
Parsing. Handle, viable prefix, items, closures, goto s LR(k): SLR(1), LR(1), LALR(1)
: SLR(1), LR(1), LALR(1)") TD parsing - LL(1) Parsing First and Follow sets Parse table construction BU Parsing Handle, viable prefix, items, closures, goto s LR(k): SLR(1), LR(1), LALR(1) Problems with SLR Aho, Sethi, Ullman, Compilers
TD parsing - LL(1) Parsing First and Follow sets Parse table construction BU Parsing Handle, viable prefix, items, closures, goto s LR(k): SLR(1), LR(1), LALR(1) Problems with SLR Aho, Sethi, Ullman, Compilers
Bottom-up parsing. Bottom-Up Parsing. Recall. Goal: For a grammar G, withstartsymbols, any string α such that S α is called a sentential form
 Bottom-up parsing Bottom-up parsing Recall Goal: For a grammar G, withstartsymbols, any string α such that S α is called a sentential form If α V t,thenα is called a sentence in L(G) Otherwise it is just
Bottom-up parsing Bottom-up parsing Recall Goal: For a grammar G, withstartsymbols, any string α such that S α is called a sentential form If α V t,thenα is called a sentence in L(G) Otherwise it is just
MODULE 14 SLR PARSER LR(0) ITEMS
 ITEMS") MODULE 14 SLR PARSER LR(0) ITEMS In this module we shall discuss one of the LR type parser namely SLR parser. The various steps involved in the SLR parser will be discussed with a focus on the construction
MODULE 14 SLR PARSER LR(0) ITEMS In this module we shall discuss one of the LR type parser namely SLR parser. The various steps involved in the SLR parser will be discussed with a focus on the construction
Section A. A grammar that produces more than one parse tree for some sentences is said to be ambiguous.
 Section A 1. What do you meant by parser and its types? A parser for grammar G is a program that takes as input a string w and produces as output either a parse tree for w, if w is a sentence of G, or
Section A 1. What do you meant by parser and its types? A parser for grammar G is a program that takes as input a string w and produces as output either a parse tree for w, if w is a sentence of G, or
Let us construct the LR(1) items for the grammar given below to construct the LALR parsing table.
 items for the grammar given below to construct the LALR parsing table.") MODULE 18 LALR parsing After understanding the most powerful CALR parser, in this module we will learn to construct the LALR parser. The CALR parser has a large set of items and hence the LALR parser is
MODULE 18 LALR parsing After understanding the most powerful CALR parser, in this module we will learn to construct the LALR parser. The CALR parser has a large set of items and hence the LALR parser is
Syntax Analysis. Amitabha Sanyal. (www.cse.iitb.ac.in/ as) Department of Computer Science and Engineering, Indian Institute of Technology, Bombay
 Department of Computer Science and Engineering, Indian Institute of Technology, Bombay") Syntax Analysis (www.cse.iitb.ac.in/ as) Department of Computer Science and Engineering, Indian Institute of Technology, Bombay September 2007 College of Engineering, Pune Syntax Analysis: 2/124 Syntax
Syntax Analysis (www.cse.iitb.ac.in/ as) Department of Computer Science and Engineering, Indian Institute of Technology, Bombay September 2007 College of Engineering, Pune Syntax Analysis: 2/124 Syntax
Compiler Construction 2016/2017 Syntax Analysis
 Compiler Construction 2016/2017 Syntax Analysis Peter Thiemann November 2, 2016 Outline 1 Syntax Analysis Recursive top-down parsing Nonrecursive top-down parsing Bottom-up parsing Syntax Analysis tokens
Compiler Construction 2016/2017 Syntax Analysis Peter Thiemann November 2, 2016 Outline 1 Syntax Analysis Recursive top-down parsing Nonrecursive top-down parsing Bottom-up parsing Syntax Analysis tokens
Parsing. Roadmap. > Context-free grammars > Derivations and precedence > Top-down parsing > Left-recursion > Look-ahead > Table-driven parsing
 Roadmap > Context-free grammars > Derivations and precedence > Top-down parsing > Left-recursion > Look-ahead > Table-driven parsing The role of the parser > performs context-free syntax analysis > guides
Roadmap > Context-free grammars > Derivations and precedence > Top-down parsing > Left-recursion > Look-ahead > Table-driven parsing The role of the parser > performs context-free syntax analysis > guides
MIT Parse Table Construction. Martin Rinard Laboratory for Computer Science Massachusetts Institute of Technology
 MIT 6.035 Parse Table Construction Martin Rinard Laboratory for Computer Science Massachusetts Institute of Technology Parse Tables (Review) ACTION Goto State ( ) $ X s0 shift to s2 error error goto s1
MIT 6.035 Parse Table Construction Martin Rinard Laboratory for Computer Science Massachusetts Institute of Technology Parse Tables (Review) ACTION Goto State ( ) $ X s0 shift to s2 error error goto s1
Formal Languages and Compilers Lecture VII Part 3: Syntactic A
 Formal Languages and Compilers Lecture VII Part 3: Syntactic Analysis Free University of Bozen-Bolzano Faculty of Computer Science POS Building, Room: 2.03 artale@inf.unibz.it http://www.inf.unibz.it/
Formal Languages and Compilers Lecture VII Part 3: Syntactic Analysis Free University of Bozen-Bolzano Faculty of Computer Science POS Building, Room: 2.03 artale@inf.unibz.it http://www.inf.unibz.it/
Parsing Wrapup. Roadmap (Where are we?) Last lecture Shift-reduce parser LR(1) parsing. This lecture LR(1) parsing
 Last lecture Shift-reduce parser LR(1) parsing. This lecture LR(1) parsing") Parsing Wrapup Roadmap (Where are we?) Last lecture Shift-reduce parser LR(1) parsing LR(1) items Computing closure Computing goto LR(1) canonical collection This lecture LR(1) parsing Building ACTION
Parsing Wrapup Roadmap (Where are we?) Last lecture Shift-reduce parser LR(1) parsing LR(1) items Computing closure Computing goto LR(1) canonical collection This lecture LR(1) parsing Building ACTION
Monday, September 13, Parsers
 Parsers Agenda Terminology LL(1) Parsers Overview of LR Parsing Terminology Grammar G = (Vt, Vn, S, P) Vt is the set of terminals Vn is the set of non-terminals S is the start symbol P is the set of productions
Parsers Agenda Terminology LL(1) Parsers Overview of LR Parsing Terminology Grammar G = (Vt, Vn, S, P) Vt is the set of terminals Vn is the set of non-terminals S is the start symbol P is the set of productions
VIVA QUESTIONS WITH ANSWERS
 VIVA QUESTIONS WITH ANSWERS 1. What is a compiler? A compiler is a program that reads a program written in one language the source language and translates it into an equivalent program in another language-the
VIVA QUESTIONS WITH ANSWERS 1. What is a compiler? A compiler is a program that reads a program written in one language the source language and translates it into an equivalent program in another language-the
CSE P 501 Compilers. LR Parsing Hal Perkins Spring UW CSE P 501 Spring 2018 D-1
 CSE P 501 Compilers LR Parsing Hal Perkins Spring 2018 UW CSE P 501 Spring 2018 D-1 Agenda LR Parsing Table-driven Parsers Parser States Shift-Reduce and Reduce-Reduce conflicts UW CSE P 501 Spring 2018
CSE P 501 Compilers LR Parsing Hal Perkins Spring 2018 UW CSE P 501 Spring 2018 D-1 Agenda LR Parsing Table-driven Parsers Parser States Shift-Reduce and Reduce-Reduce conflicts UW CSE P 501 Spring 2018
EDAN65: Compilers, Lecture 06 A LR parsing. Görel Hedin Revised:
 EDAN65: Compilers, Lecture 06 A LR parsing Görel Hedin Revised: 2017-09-11 This lecture Regular expressions Context-free grammar Attribute grammar Lexical analyzer (scanner) Syntactic analyzer (parser)
EDAN65: Compilers, Lecture 06 A LR parsing Görel Hedin Revised: 2017-09-11 This lecture Regular expressions Context-free grammar Attribute grammar Lexical analyzer (scanner) Syntactic analyzer (parser)
Compiler Design 1. Bottom-UP Parsing. Goutam Biswas. Lect 6
 Compiler Design 1 Bottom-UP Parsing Compiler Design 2 The Process The parse tree is built starting from the leaf nodes labeled by the terminals (tokens). The parser tries to discover appropriate reductions,
Compiler Design 1 Bottom-UP Parsing Compiler Design 2 The Process The parse tree is built starting from the leaf nodes labeled by the terminals (tokens). The parser tries to discover appropriate reductions,
Syntactic Analysis. Top-Down Parsing
 Syntactic Analysis Top-Down Parsing Copyright 2017, Pedro C. Diniz, all rights reserved. Students enrolled in Compilers class at University of Southern California (USC) have explicit permission to make
Syntactic Analysis Top-Down Parsing Copyright 2017, Pedro C. Diniz, all rights reserved. Students enrolled in Compilers class at University of Southern California (USC) have explicit permission to make
A left-sentential form is a sentential form that occurs in the leftmost derivation of some sentence.
 Bottom-up parsing Recall For a grammar G, with start symbol S, any string α such that S α is a sentential form If α V t, then α is a sentence in L(G) A left-sentential form is a sentential form that occurs
Bottom-up parsing Recall For a grammar G, with start symbol S, any string α such that S α is a sentential form If α V t, then α is a sentence in L(G) A left-sentential form is a sentential form that occurs
Wednesday, August 31, Parsers
 Parsers How do we combine tokens? Combine tokens ( words in a language) to form programs ( sentences in a language) Not all combinations of tokens are correct programs (not all sentences are grammatically
Parsers How do we combine tokens? Combine tokens ( words in a language) to form programs ( sentences in a language) Not all combinations of tokens are correct programs (not all sentences are grammatically
Syntax Analysis. Martin Sulzmann. Martin Sulzmann Syntax Analysis 1 / 38
 Syntax Analysis Martin Sulzmann Martin Sulzmann Syntax Analysis 1 / 38 Syntax Analysis Objective Recognize individual tokens as sentences of a language (beyond regular languages). Example 1 (OK) Program
Syntax Analysis Martin Sulzmann Martin Sulzmann Syntax Analysis 1 / 38 Syntax Analysis Objective Recognize individual tokens as sentences of a language (beyond regular languages). Example 1 (OK) Program
Wednesday, September 9, 15. Parsers
 Parsers What is a parser A parser has two jobs: 1) Determine whether a string (program) is valid (think: grammatically correct) 2) Determine the structure of a program (think: diagramming a sentence) Agenda
Parsers What is a parser A parser has two jobs: 1) Determine whether a string (program) is valid (think: grammatically correct) 2) Determine the structure of a program (think: diagramming a sentence) Agenda
Parsers. What is a parser. Languages. Agenda. Terminology. Languages. A parser has two jobs:
 What is a parser Parsers A parser has two jobs: 1) Determine whether a string (program) is valid (think: grammatically correct) 2) Determine the structure of a program (think: diagramming a sentence) Agenda
What is a parser Parsers A parser has two jobs: 1) Determine whether a string (program) is valid (think: grammatically correct) 2) Determine the structure of a program (think: diagramming a sentence) Agenda
shift-reduce parsing
 Parsing #2 Bottom-up Parsing Rightmost derivations; use of rules from right to left Uses a stack to push symbols the concatenation of the stack symbols with the rest of the input forms a valid bottom-up
Parsing #2 Bottom-up Parsing Rightmost derivations; use of rules from right to left Uses a stack to push symbols the concatenation of the stack symbols with the rest of the input forms a valid bottom-up
S Y N T A X A N A L Y S I S LR
 LR parsing There are three commonly used algorithms to build tables for an LR parser: 1. SLR(1) = LR(0) plus use of FOLLOW set to select between actions smallest class of grammars smallest tables (number
LR parsing There are three commonly used algorithms to build tables for an LR parser: 1. SLR(1) = LR(0) plus use of FOLLOW set to select between actions smallest class of grammars smallest tables (number
Parsers. Xiaokang Qiu Purdue University. August 31, 2018 ECE 468
 Parsers Xiaokang Qiu Purdue University ECE 468 August 31, 2018 What is a parser A parser has two jobs: 1) Determine whether a string (program) is valid (think: grammatically correct) 2) Determine the structure
Parsers Xiaokang Qiu Purdue University ECE 468 August 31, 2018 What is a parser A parser has two jobs: 1) Determine whether a string (program) is valid (think: grammatically correct) 2) Determine the structure
3. Parsing. Oscar Nierstrasz
 3. Parsing Oscar Nierstrasz Thanks to Jens Palsberg and Tony Hosking for their kind permission to reuse and adapt the CS132 and CS502 lecture notes. http://www.cs.ucla.edu/~palsberg/ http://www.cs.purdue.edu/homes/hosking/
3. Parsing Oscar Nierstrasz Thanks to Jens Palsberg and Tony Hosking for their kind permission to reuse and adapt the CS132 and CS502 lecture notes. http://www.cs.ucla.edu/~palsberg/ http://www.cs.purdue.edu/homes/hosking/
CS308 Compiler Principles Syntax Analyzer Li Jiang
 CS308 Syntax Analyzer Li Jiang Department of Computer Science and Engineering Shanghai Jiao Tong University Syntax Analyzer Syntax Analyzer creates the syntactic structure of the given source program.
CS308 Syntax Analyzer Li Jiang Department of Computer Science and Engineering Shanghai Jiao Tong University Syntax Analyzer Syntax Analyzer creates the syntactic structure of the given source program.
The analysis part breaks up the source program into constituent pieces and creates an intermediate representation of the source program.
 COMPILER DESIGN 1. What is a compiler? A compiler is a program that reads a program written in one language the source language and translates it into an equivalent program in another language-the target
COMPILER DESIGN 1. What is a compiler? A compiler is a program that reads a program written in one language the source language and translates it into an equivalent program in another language-the target
Formal Languages and Compilers Lecture VII Part 4: Syntactic A
 Formal Languages and Compilers Lecture VII Part 4: Syntactic Analysis Free University of Bozen-Bolzano Faculty of Computer Science POS Building, Room: 2.03 artale@inf.unibz.it http://www.inf.unibz.it/
Formal Languages and Compilers Lecture VII Part 4: Syntactic Analysis Free University of Bozen-Bolzano Faculty of Computer Science POS Building, Room: 2.03 artale@inf.unibz.it http://www.inf.unibz.it/
Lexical and Syntax Analysis. Bottom-Up Parsing
 Lexical and Syntax Analysis Bottom-Up Parsing Parsing There are two ways to construct derivation of a grammar. Top-Down: begin with start symbol; repeatedly replace an instance of a production s LHS with
Lexical and Syntax Analysis Bottom-Up Parsing Parsing There are two ways to construct derivation of a grammar. Top-Down: begin with start symbol; repeatedly replace an instance of a production s LHS with
LR Parsing Techniques
 LR Parsing Techniques Bottom-Up Parsing - LR: a special form of BU Parser LR Parsing as Handle Pruning Shift-Reduce Parser (LR Implementation) LR(k) Parsing Model - k lookaheads to determine next action
LR Parsing Techniques Bottom-Up Parsing - LR: a special form of BU Parser LR Parsing as Handle Pruning Shift-Reduce Parser (LR Implementation) LR(k) Parsing Model - k lookaheads to determine next action
Concepts Introduced in Chapter 4
 Concepts Introduced in Chapter 4 Grammars Context-Free Grammars Derivations and Parse Trees Ambiguity, Precedence, and Associativity Top Down Parsing Recursive Descent, LL Bottom Up Parsing SLR, LR, LALR
Concepts Introduced in Chapter 4 Grammars Context-Free Grammars Derivations and Parse Trees Ambiguity, Precedence, and Associativity Top Down Parsing Recursive Descent, LL Bottom Up Parsing SLR, LR, LALR
CSE 401 Compilers. LR Parsing Hal Perkins Autumn /10/ Hal Perkins & UW CSE D-1
 CSE 401 Compilers LR Parsing Hal Perkins Autumn 2011 10/10/2011 2002-11 Hal Perkins & UW CSE D-1 Agenda LR Parsing Table-driven Parsers Parser States Shift-Reduce and Reduce-Reduce conflicts 10/10/2011
CSE 401 Compilers LR Parsing Hal Perkins Autumn 2011 10/10/2011 2002-11 Hal Perkins & UW CSE D-1 Agenda LR Parsing Table-driven Parsers Parser States Shift-Reduce and Reduce-Reduce conflicts 10/10/2011
CSC 4181 Compiler Construction. Parsing. Outline. Introduction
 CC 4181 Compiler Construction Parsing 1 Outline Top-down v.s. Bottom-up Top-down parsing Recursive-descent parsing LL1) parsing LL1) parsing algorithm First and follow sets Constructing LL1) parsing table
CC 4181 Compiler Construction Parsing 1 Outline Top-down v.s. Bottom-up Top-down parsing Recursive-descent parsing LL1) parsing LL1) parsing algorithm First and follow sets Constructing LL1) parsing table
8 Parsing. Parsing. Top Down Parsing Methods. Parsing complexity. Top down vs. bottom up parsing. Top down vs. bottom up parsing
 8 Parsing Parsing A grammar describes syntactically legal strings in a language A recogniser simply accepts or rejects strings A generator produces strings A parser constructs a parse tree for a string
8 Parsing Parsing A grammar describes syntactically legal strings in a language A recogniser simply accepts or rejects strings A generator produces strings A parser constructs a parse tree for a string
Downloaded from Page 1. LR Parsing
 Downloaded from http://himadri.cmsdu.org Page 1 LR Parsing We first understand Context Free Grammars. Consider the input string: x+2*y When scanned by a scanner, it produces the following stream of tokens:
Downloaded from http://himadri.cmsdu.org Page 1 LR Parsing We first understand Context Free Grammars. Consider the input string: x+2*y When scanned by a scanner, it produces the following stream of tokens:
CA Compiler Construction
 CA4003 - Compiler Construction David Sinclair A top-down parser starts with the root of the parse tree, labelled with the goal symbol of the grammar, and repeats the following steps until the fringe of
CA4003 - Compiler Construction David Sinclair A top-down parser starts with the root of the parse tree, labelled with the goal symbol of the grammar, and repeats the following steps until the fringe of
How do LL(1) Parsers Build Syntax Trees?
 Parsers Build Syntax Trees?") How do LL(1) Parsers Build Syntax Trees? So far our LL(1) parser has acted like a recognizer. It verifies that input token are syntactically correct, but it produces no output. Building complete (concrete)
How do LL(1) Parsers Build Syntax Trees? So far our LL(1) parser has acted like a recognizer. It verifies that input token are syntactically correct, but it produces no output. Building complete (concrete)
Top down vs. bottom up parsing
 Parsing A grammar describes the strings that are syntactically legal A recogniser simply accepts or rejects strings A generator produces sentences in the language described by the grammar A parser constructs
Parsing A grammar describes the strings that are syntactically legal A recogniser simply accepts or rejects strings A generator produces sentences in the language described by the grammar A parser constructs
Principle of Compilers Lecture IV Part 4: Syntactic Analysis. Alessandro Artale
 Free University of Bolzano Principles of Compilers Lecture IV Part 4, 2003/2004 AArtale (1) Principle of Compilers Lecture IV Part 4: Syntactic Analysis Alessandro Artale Faculty of Computer Science Free
Free University of Bolzano Principles of Compilers Lecture IV Part 4, 2003/2004 AArtale (1) Principle of Compilers Lecture IV Part 4: Syntactic Analysis Alessandro Artale Faculty of Computer Science Free
Bottom Up Parsing. Shift and Reduce. Sentential Form. Handle. Parse Tree. Bottom Up Parsing 9/26/2012. Also known as Shift-Reduce parsing
 Also known as Shift-Reduce parsing More powerful than top down Don t need left factored grammars Can handle left recursion Attempt to construct parse tree from an input string eginning at leaves and working
Also known as Shift-Reduce parsing More powerful than top down Don t need left factored grammars Can handle left recursion Attempt to construct parse tree from an input string eginning at leaves and working
Compilerconstructie. najaar Rudy van Vliet kamer 140 Snellius, tel rvvliet(at)liacs(dot)nl. college 3, vrijdag 22 september 2017
liacs(dot)nl. college 3, vrijdag 22 september 2017") Compilerconstructie najaar 2017 http://www.liacs.leidenuniv.nl/~vlietrvan1/coco/ Rudy van Vliet kamer 140 Snellius, tel. 071-527 2876 rvvliet(at)liacs(dot)nl college 3, vrijdag 22 september 2017 + werkcollege
Compilerconstructie najaar 2017 http://www.liacs.leidenuniv.nl/~vlietrvan1/coco/ Rudy van Vliet kamer 140 Snellius, tel. 071-527 2876 rvvliet(at)liacs(dot)nl college 3, vrijdag 22 september 2017 + werkcollege
Chapter 4. Lexical and Syntax Analysis
 Chapter 4 Lexical and Syntax Analysis Chapter 4 Topics Introduction Lexical Analysis The Parsing Problem Recursive-Descent Parsing Bottom-Up Parsing Copyright 2012 Addison-Wesley. All rights reserved.
Chapter 4 Lexical and Syntax Analysis Chapter 4 Topics Introduction Lexical Analysis The Parsing Problem Recursive-Descent Parsing Bottom-Up Parsing Copyright 2012 Addison-Wesley. All rights reserved.
Note that for recursive descent to work, if A ::= B1 B2 is a grammar rule we need First k (B1) disjoint from First k (B2).
 disjoint from First k (B2).") LL(k) Grammars We need a bunch of terminology. For any terminal string a we write First k (a) is the prefix of a of length k (or all of a if its length is less than k) For any string g of terminal and
LL(k) Grammars We need a bunch of terminology. For any terminal string a we write First k (a) is the prefix of a of length k (or all of a if its length is less than k) For any string g of terminal and
4. Lexical and Syntax Analysis
 4. Lexical and Syntax Analysis 4.1 Introduction Language implementation systems must analyze source code, regardless of the specific implementation approach Nearly all syntax analysis is based on a formal
4. Lexical and Syntax Analysis 4.1 Introduction Language implementation systems must analyze source code, regardless of the specific implementation approach Nearly all syntax analysis is based on a formal
Syntax Analysis. Chapter 4
 Syntax Analysis Chapter 4 Check (Important) http://www.engineersgarage.com/contributio n/difference-between-compiler-andinterpreter Introduction covers the major parsing methods that are typically used
Syntax Analysis Chapter 4 Check (Important) http://www.engineersgarage.com/contributio n/difference-between-compiler-andinterpreter Introduction covers the major parsing methods that are typically used
4. Lexical and Syntax Analysis
 4. Lexical and Syntax Analysis 4.1 Introduction Language implementation systems must analyze source code, regardless of the specific implementation approach Nearly all syntax analysis is based on a formal
4. Lexical and Syntax Analysis 4.1 Introduction Language implementation systems must analyze source code, regardless of the specific implementation approach Nearly all syntax analysis is based on a formal
Bottom-Up Parsing. Parser Generation. LR Parsing. Constructing LR Parser
 Parser Generation Main Problem: given a grammar G, how to build a top-down parser or a bottom-up parser for it? parser : a program that, given a sentence, reconstructs a derivation for that sentence ----
Parser Generation Main Problem: given a grammar G, how to build a top-down parser or a bottom-up parser for it? parser : a program that, given a sentence, reconstructs a derivation for that sentence ----
Principles of Programming Languages
 Principles of Programming Languages h"p://www.di.unipi.it/~andrea/dida2ca/plp- 14/ Prof. Andrea Corradini Department of Computer Science, Pisa Lesson 8! Bo;om- Up Parsing Shi?- Reduce LR(0) automata and
Principles of Programming Languages h"p://www.di.unipi.it/~andrea/dida2ca/plp- 14/ Prof. Andrea Corradini Department of Computer Science, Pisa Lesson 8! Bo;om- Up Parsing Shi?- Reduce LR(0) automata and
Table-driven using an explicit stack (no recursion!). Stack can be viewed as containing both terminals and non-terminals.
. Stack can be viewed as containing both terminals and non-terminals.") Bottom-up Parsing: Table-driven using an explicit stack (no recursion!). Stack can be viewed as containing both terminals and non-terminals. Basic operation is to shift terminals from the input to the
Bottom-up Parsing: Table-driven using an explicit stack (no recursion!). Stack can be viewed as containing both terminals and non-terminals. Basic operation is to shift terminals from the input to the
Introduction to parsers
 Syntax Analysis Introduction to parsers Context-free grammars Push-down automata Top-down parsing LL grammars and parsers Bottom-up parsing LR grammars and parsers Bison/Yacc - parser generators Error
Syntax Analysis Introduction to parsers Context-free grammars Push-down automata Top-down parsing LL grammars and parsers Bottom-up parsing LR grammars and parsers Bison/Yacc - parser generators Error
Parser Generation. Bottom-Up Parsing. Constructing LR Parser. LR Parsing. Construct parse tree bottom-up --- from leaves to the root
 Parser Generation Main Problem: given a grammar G, how to build a top-down parser or a bottom-up parser for it? parser : a program that, given a sentence, reconstructs a derivation for that sentence ----
Parser Generation Main Problem: given a grammar G, how to build a top-down parser or a bottom-up parser for it? parser : a program that, given a sentence, reconstructs a derivation for that sentence ----
Question Bank. 10CS63:Compiler Design
 Question Bank 10CS63:Compiler Design 1.Determine whether the following regular expressions define the same language? (ab)* and a*b* 2.List the properties of an operator grammar 3. Is macro processing a
Question Bank 10CS63:Compiler Design 1.Determine whether the following regular expressions define the same language? (ab)* and a*b* 2.List the properties of an operator grammar 3. Is macro processing a
Table-Driven Parsing
 Table-Driven Parsing It is possible to build a non-recursive predictive parser by maintaining a stack explicitly, rather than implicitly via recursive calls [1] The non-recursive parser looks up the production
Table-Driven Parsing It is possible to build a non-recursive predictive parser by maintaining a stack explicitly, rather than implicitly via recursive calls [1] The non-recursive parser looks up the production
LR Parsing. Leftmost and Rightmost Derivations. Compiler Design CSE 504. Derivations for id + id: T id = id+id. 1 Shift-Reduce Parsing.
 LR Parsing Compiler Design CSE 504 1 Shift-Reduce Parsing 2 LR Parsers 3 SLR and LR(1) Parsers Last modifled: Fri Mar 06 2015 at 13:50:06 EST Version: 1.7 16:58:46 2016/01/29 Compiled at 12:57 on 2016/02/26
LR Parsing Compiler Design CSE 504 1 Shift-Reduce Parsing 2 LR Parsers 3 SLR and LR(1) Parsers Last modifled: Fri Mar 06 2015 at 13:50:06 EST Version: 1.7 16:58:46 2016/01/29 Compiled at 12:57 on 2016/02/26
COP4020 Programming Languages. Syntax Prof. Robert van Engelen
 COP4020 Programming Languages Syntax Prof. Robert van Engelen Overview n Tokens and regular expressions n Syntax and context-free grammars n Grammar derivations n More about parse trees n Top-down and
COP4020 Programming Languages Syntax Prof. Robert van Engelen Overview n Tokens and regular expressions n Syntax and context-free grammars n Grammar derivations n More about parse trees n Top-down and
LR Parsers. Aditi Raste, CCOEW
 LR Parsers Aditi Raste, CCOEW 1 LR Parsers Most powerful shift-reduce parsers and yet efficient. LR(k) parsing L : left to right scanning of input R : constructing rightmost derivation in reverse k : number
LR Parsers Aditi Raste, CCOEW 1 LR Parsers Most powerful shift-reduce parsers and yet efficient. LR(k) parsing L : left to right scanning of input R : constructing rightmost derivation in reverse k : number
Compilers. Bottom-up Parsing. (original slides by Sam
 Compilers Bottom-up Parsing Yannis Smaragdakis U Athens Yannis Smaragdakis, U. Athens (original slides by Sam Guyer@Tufts) Bottom-Up Parsing More general than top-down parsing And just as efficient Builds
Compilers Bottom-up Parsing Yannis Smaragdakis U Athens Yannis Smaragdakis, U. Athens (original slides by Sam Guyer@Tufts) Bottom-Up Parsing More general than top-down parsing And just as efficient Builds
LR Parsing E T + E T 1 T
 LR Parsing 1 Introduction Before reading this quick JFLAP tutorial on parsing please make sure to look at a reference on LL parsing to get an understanding of how the First and Follow sets are defined.
LR Parsing 1 Introduction Before reading this quick JFLAP tutorial on parsing please make sure to look at a reference on LL parsing to get an understanding of how the First and Follow sets are defined.
CS 4120 Introduction to Compilers
 CS 4120 Introduction to Compilers Andrew Myers Cornell University Lecture 6: Bottom-Up Parsing 9/9/09 Bottom-up parsing A more powerful parsing technology LR grammars -- more expressive than LL can handle
CS 4120 Introduction to Compilers Andrew Myers Cornell University Lecture 6: Bottom-Up Parsing 9/9/09 Bottom-up parsing A more powerful parsing technology LR grammars -- more expressive than LL can handle
Lecture 7: Deterministic Bottom-Up Parsing
 Lecture 7: Deterministic Bottom-Up Parsing (From slides by G. Necula & R. Bodik) Last modified: Tue Sep 20 12:50:42 2011 CS164: Lecture #7 1 Avoiding nondeterministic choice: LR We ve been looking at general
Lecture 7: Deterministic Bottom-Up Parsing (From slides by G. Necula & R. Bodik) Last modified: Tue Sep 20 12:50:42 2011 CS164: Lecture #7 1 Avoiding nondeterministic choice: LR We ve been looking at general
Syntax Analysis Part I
 Syntax Analysis Part I Chapter 4: Context-Free Grammars Slides adapted from : Robert van Engelen, Florida State University Position of a Parser in the Compiler Model Source Program Lexical Analyzer Token,
Syntax Analysis Part I Chapter 4: Context-Free Grammars Slides adapted from : Robert van Engelen, Florida State University Position of a Parser in the Compiler Model Source Program Lexical Analyzer Token,
CS453 : JavaCUP and error recovery. CS453 Shift-reduce Parsing 1
 CS453 : JavaCUP and error recovery CS453 Shift-reduce Parsing 1 Shift-reduce parsing in an LR parser LR(k) parser Left-to-right parse Right-most derivation K-token look ahead LR parsing algorithm using
CS453 : JavaCUP and error recovery CS453 Shift-reduce Parsing 1 Shift-reduce parsing in an LR parser LR(k) parser Left-to-right parse Right-most derivation K-token look ahead LR parsing algorithm using
Lecture 8: Deterministic Bottom-Up Parsing
 Lecture 8: Deterministic Bottom-Up Parsing (From slides by G. Necula & R. Bodik) Last modified: Fri Feb 12 13:02:57 2010 CS164: Lecture #8 1 Avoiding nondeterministic choice: LR We ve been looking at general
Lecture 8: Deterministic Bottom-Up Parsing (From slides by G. Necula & R. Bodik) Last modified: Fri Feb 12 13:02:57 2010 CS164: Lecture #8 1 Avoiding nondeterministic choice: LR We ve been looking at general
Top-Down Parsing and Intro to Bottom-Up Parsing. Lecture 7
 Top-Down Parsing and Intro to Bottom-Up Parsing Lecture 7 1 Predictive Parsers Like recursive-descent but parser can predict which production to use Predictive parsers are never wrong Always able to guess
Top-Down Parsing and Intro to Bottom-Up Parsing Lecture 7 1 Predictive Parsers Like recursive-descent but parser can predict which production to use Predictive parsers are never wrong Always able to guess
Part III : Parsing. From Regular to Context-Free Grammars. Deriving a Parser from a Context-Free Grammar. Scanners and Parsers.
 Part III : Parsing From Regular to Context-Free Grammars Deriving a Parser from a Context-Free Grammar Scanners and Parsers A Parser for EBNF Left-Parsable Grammars Martin Odersky, LAMP/DI 1 From Regular
Part III : Parsing From Regular to Context-Free Grammars Deriving a Parser from a Context-Free Grammar Scanners and Parsers A Parser for EBNF Left-Parsable Grammars Martin Odersky, LAMP/DI 1 From Regular
Compilers. Predictive Parsing. Alex Aiken
 Compilers Like recursive-descent but parser can predict which production to use By looking at the next fewtokens No backtracking Predictive parsers accept LL(k) grammars L means left-to-right scan of input
Compilers Like recursive-descent but parser can predict which production to use By looking at the next fewtokens No backtracking Predictive parsers accept LL(k) grammars L means left-to-right scan of input
CSE 130 Programming Language Principles & Paradigms Lecture # 5. Chapter 4 Lexical and Syntax Analysis
 Chapter 4 Lexical and Syntax Analysis Introduction - Language implementation systems must analyze source code, regardless of the specific implementation approach - Nearly all syntax analysis is based on
Chapter 4 Lexical and Syntax Analysis Introduction - Language implementation systems must analyze source code, regardless of the specific implementation approach - Nearly all syntax analysis is based on
LL(k) Parsing. Predictive Parsers. LL(k) Parser Structure. Sample Parse Table. LL(1) Parsing Algorithm. Push RHS in Reverse Order 10/17/2012
 Parsing. Predictive Parsers. LL(k) Parser Structure. Sample Parse Table. LL(1) Parsing Algorithm. Push RHS in Reverse Order 10/17/2012") Predictive Parsers LL(k) Parsing Can we avoid backtracking? es, if for a given input symbol and given nonterminal, we can choose the alternative appropriately. his is possible if the first terminal of
Predictive Parsers LL(k) Parsing Can we avoid backtracking? es, if for a given input symbol and given nonterminal, we can choose the alternative appropriately. his is possible if the first terminal of
Bottom-Up Parsing. Lecture 11-12
 Bottom-Up Parsing Lecture 11-12 (From slides by G. Necula & R. Bodik) 9/22/06 Prof. Hilfinger CS164 Lecture 11 1 Bottom-Up Parsing Bottom-up parsing is more general than topdown parsing And just as efficient
Bottom-Up Parsing Lecture 11-12 (From slides by G. Necula & R. Bodik) 9/22/06 Prof. Hilfinger CS164 Lecture 11 1 Bottom-Up Parsing Bottom-up parsing is more general than topdown parsing And just as efficient
Top-Down Parsing and Intro to Bottom-Up Parsing. Lecture 7
 Top-Down Parsing and Intro to Bottom-Up Parsing Lecture 7 1 Predictive Parsers Like recursive-descent but parser can predict which production to use Predictive parsers are never wrong Always able to guess
Top-Down Parsing and Intro to Bottom-Up Parsing Lecture 7 1 Predictive Parsers Like recursive-descent but parser can predict which production to use Predictive parsers are never wrong Always able to guess
Chapter 4. Lexical and Syntax Analysis. Topics. Compilation. Language Implementation. Issues in Lexical and Syntax Analysis.
 Topics Chapter 4 Lexical and Syntax Analysis Introduction Lexical Analysis Syntax Analysis Recursive -Descent Parsing Bottom-Up parsing 2 Language Implementation Compilation There are three possible approaches
Topics Chapter 4 Lexical and Syntax Analysis Introduction Lexical Analysis Syntax Analysis Recursive -Descent Parsing Bottom-Up parsing 2 Language Implementation Compilation There are three possible approaches
Syn S t yn a t x a Ana x lysi y s si 1
 Syntax Analysis 1 Position of a Parser in the Compiler Model Source Program Lexical Analyzer Token, tokenval Get next token Parser and rest of front-end Intermediate representation Lexical error Syntax
Syntax Analysis 1 Position of a Parser in the Compiler Model Source Program Lexical Analyzer Token, tokenval Get next token Parser and rest of front-end Intermediate representation Lexical error Syntax
CS502: Compilers & Programming Systems
 CS502: Compilers & Programming Systems Top-down Parsing Zhiyuan Li Department of Computer Science Purdue University, USA There exist two well-known schemes to construct deterministic top-down parsers:
CS502: Compilers & Programming Systems Top-down Parsing Zhiyuan Li Department of Computer Science Purdue University, USA There exist two well-known schemes to construct deterministic top-down parsers:
Simple LR (SLR) LR(0) Drawbacks LR(1) SLR Parse. LR(1) Start State and Reduce. LR(1) Items 10/3/2012
 LR(0) Drawbacks LR(1) SLR Parse. LR(1) Start State and Reduce. LR(1) Items 10/3/2012") LR(0) Drawbacks Consider the unambiguous augmented grammar: 0.) S E $ 1.) E T + E 2.) E T 3.) T x If we build the LR(0) DFA table, we find that there is a shift-reduce conflict. This arises because the
LR(0) Drawbacks Consider the unambiguous augmented grammar: 0.) S E $ 1.) E T + E 2.) E T 3.) T x If we build the LR(0) DFA table, we find that there is a shift-reduce conflict. This arises because the
Bottom-Up Parsing II. Lecture 8
 Bottom-Up Parsing II Lecture 8 1 Review: Shift-Reduce Parsing Bottom-up parsing uses two actions: Shift ABC xyz ABCx yz Reduce Cbxy ijk CbA ijk 2 Recall: he Stack Left string can be implemented by a stack
Bottom-Up Parsing II Lecture 8 1 Review: Shift-Reduce Parsing Bottom-up parsing uses two actions: Shift ABC xyz ABCx yz Reduce Cbxy ijk CbA ijk 2 Recall: he Stack Left string can be implemented by a stack
CS143 Handout 20 Summer 2011 July 15 th, 2011 CS143 Practice Midterm and Solution
 CS143 Handout 20 Summer 2011 July 15 th, 2011 CS143 Practice Midterm and Solution Exam Facts Format Wednesday, July 20 th from 11:00 a.m. 1:00 p.m. in Gates B01 The exam is designed to take roughly 90
CS143 Handout 20 Summer 2011 July 15 th, 2011 CS143 Practice Midterm and Solution Exam Facts Format Wednesday, July 20 th from 11:00 a.m. 1:00 p.m. in Gates B01 The exam is designed to take roughly 90
Compilers. Yannis Smaragdakis, U. Athens (original slides by Sam
 Compilers Parsing Yannis Smaragdakis, U. Athens (original slides by Sam Guyer@Tufts) Next step text chars Lexical analyzer tokens Parser IR Errors Parsing: Organize tokens into sentences Do tokens conform
Compilers Parsing Yannis Smaragdakis, U. Athens (original slides by Sam Guyer@Tufts) Next step text chars Lexical analyzer tokens Parser IR Errors Parsing: Organize tokens into sentences Do tokens conform
VETRI VINAYAHA COLLEGE OF ENGINEERING AND TECHNOLOGY
 VETRI VINAYAHA COLLEGE OF ENGINEERING AND TECHNOLOGY DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING CS6660 COMPILER DESIGN III year/ VI sem CSE (Regulation 2013) UNIT I -INTRODUCTION TO COMPILER PART A
VETRI VINAYAHA COLLEGE OF ENGINEERING AND TECHNOLOGY DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING CS6660 COMPILER DESIGN III year/ VI sem CSE (Regulation 2013) UNIT I -INTRODUCTION TO COMPILER PART A
CS1622. Today. A Recursive Descent Parser. Preliminaries. Lecture 9 Parsing (4)
") CS1622 Lecture 9 Parsing (4) CS 1622 Lecture 9 1 Today Example of a recursive descent parser Predictive & LL(1) parsers Building parse tables CS 1622 Lecture 9 2 A Recursive Descent Parser. Preliminaries
CS1622 Lecture 9 Parsing (4) CS 1622 Lecture 9 1 Today Example of a recursive descent parser Predictive & LL(1) parsers Building parse tables CS 1622 Lecture 9 2 A Recursive Descent Parser. Preliminaries
Parsing. Note by Baris Aktemur: Our slides are adapted from Cooper and Torczon s slides that they prepared for COMP 412 at Rice.
 Parsing Note by Baris Aktemur: Our slides are adapted from Cooper and Torczon s slides that they prepared for COMP 412 at Rice. Copyright 2010, Keith D. Cooper & Linda Torczon, all rights reserved. Students
Parsing Note by Baris Aktemur: Our slides are adapted from Cooper and Torczon s slides that they prepared for COMP 412 at Rice. Copyright 2010, Keith D. Cooper & Linda Torczon, all rights reserved. Students
Bottom-Up Parsing II (Different types of Shift-Reduce Conflicts) Lecture 10. Prof. Aiken (Modified by Professor Vijay Ganesh.
 Lecture 10. Prof. Aiken (Modified by Professor Vijay Ganesh.") Bottom-Up Parsing II Different types of Shift-Reduce Conflicts) Lecture 10 Ganesh. Lecture 10) 1 Review: Bottom-Up Parsing Bottom-up parsing is more general than topdown parsing And just as efficient Doesn
Bottom-Up Parsing II Different types of Shift-Reduce Conflicts) Lecture 10 Ganesh. Lecture 10) 1 Review: Bottom-Up Parsing Bottom-up parsing is more general than topdown parsing And just as efficient Doesn
Bottom-Up Parsing LR Parsing
 Bottom-Up Parsing LR Parsing Maryam Siahbani 2/19/2016 1 What we need for LR parsing LR0) states: Describe all possible states in which parser can be Parsing table ransition between LR0) states Actions
Bottom-Up Parsing LR Parsing Maryam Siahbani 2/19/2016 1 What we need for LR parsing LR0) states: Describe all possible states in which parser can be Parsing table ransition between LR0) states Actions
Programming Language Syntax and Analysis
 Programming Language Syntax and Analysis 2017 Kwangman Ko (http://compiler.sangji.ac.kr, kkman@sangji.ac.kr) Dept. of Computer Engineering, Sangji University Introduction Syntax the form or structure of
Programming Language Syntax and Analysis 2017 Kwangman Ko (http://compiler.sangji.ac.kr, kkman@sangji.ac.kr) Dept. of Computer Engineering, Sangji University Introduction Syntax the form or structure of
Review: Shift-Reduce Parsing. Bottom-up parsing uses two actions: Bottom-Up Parsing II. Shift ABC xyz ABCx yz. Lecture 8. Reduce Cbxy ijk CbA ijk
 Review: Shift-Reduce Parsing Bottom-up parsing uses two actions: Bottom-Up Parsing II Lecture 8 Shift ABC xyz ABCx yz Reduce Cbxy ijk CbA ijk Prof. Aiken CS 13 Lecture 8 1 Prof. Aiken CS 13 Lecture 8 2
Review: Shift-Reduce Parsing Bottom-up parsing uses two actions: Bottom-Up Parsing II Lecture 8 Shift ABC xyz ABCx yz Reduce Cbxy ijk CbA ijk Prof. Aiken CS 13 Lecture 8 1 Prof. Aiken CS 13 Lecture 8 2
CS606- compiler instruction Solved MCQS From Midterm Papers
 CS606- compiler instruction Solved MCQS From Midterm Papers March 06,2014 MC100401285 Moaaz.pk@gmail.com Mc100401285@gmail.com PSMD01 Final Term MCQ s and Quizzes CS606- compiler instruction If X is a
CS606- compiler instruction Solved MCQS From Midterm Papers March 06,2014 MC100401285 Moaaz.pk@gmail.com Mc100401285@gmail.com PSMD01 Final Term MCQ s and Quizzes CS606- compiler instruction If X is a
Lecture Bottom-Up Parsing
 Lecture 14+15 Bottom-Up Parsing CS 241: Foundations of Sequential Programs Winter 2018 Troy Vasiga et al University of Waterloo 1 Example CFG 1. S S 2. S AyB 3. A ab 4. A cd 5. B z 6. B wz 2 Stacks in
Lecture 14+15 Bottom-Up Parsing CS 241: Foundations of Sequential Programs Winter 2018 Troy Vasiga et al University of Waterloo 1 Example CFG 1. S S 2. S AyB 3. A ab 4. A cd 5. B z 6. B wz 2 Stacks in