Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
|
|
|
- Neil Bell
- 6 years ago
- Views:
Transcription

1 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com
2 Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb 2006 Before Grid team, I worked on Yahoos WebMap VP of Apache for Hadoop Chair of Hadoop Program Management Committee Responsible for Building the Hadoop community Interfacing between the Hadoop PMC and the Apache Board
3 Problem How do you scale up applications? 100 s of terabytes of data Takes 11 days to read on 1 computer Need lots of cheap computers Fixes speed problem (15 minutes on 1000 computers), but Reliability problems In large clusters, computers fail every day Cluster size is not fixed Need common infrastructure Must be efficient and reliable
4 Solution Open Source Apache Project Hadoop Core includes: Distributed File System - distributes data Map/Reduce - distributes application Written in Java Runs on Linux, Mac OS/X, Windows, and Solaris Commodity hardware


5 Commodity Hardware Cluster Typically in 2 level architecture Nodes are commodity Linux PCs 40 nodes/rack Uplink from rack is 8 gigabit Rack-internal is 1 gigabit all-to-all
6 Distributed File System Single petabyte file system for entire cluster Managed by a single namenode. Files are written, read, renamed, deleted, but append-only. Optimized for streaming reads of large files. Files are broken in to large blocks. Transparent to the client Blocks are typically 128 MB Replicated to several datanodes, for reliability Client talks to both namenode and datanodes Data is not sent through the namenode. Throughput of file system scales nearly linearly. Access from Java, C, or command line.
7 Block Placement Default is 3 replicas, but settable Blocks are placed (writes are pipelined): On same node On different rack On the other rack Clients read from closest replica If the replication for a block drops below target, it is automatically re-replicated.

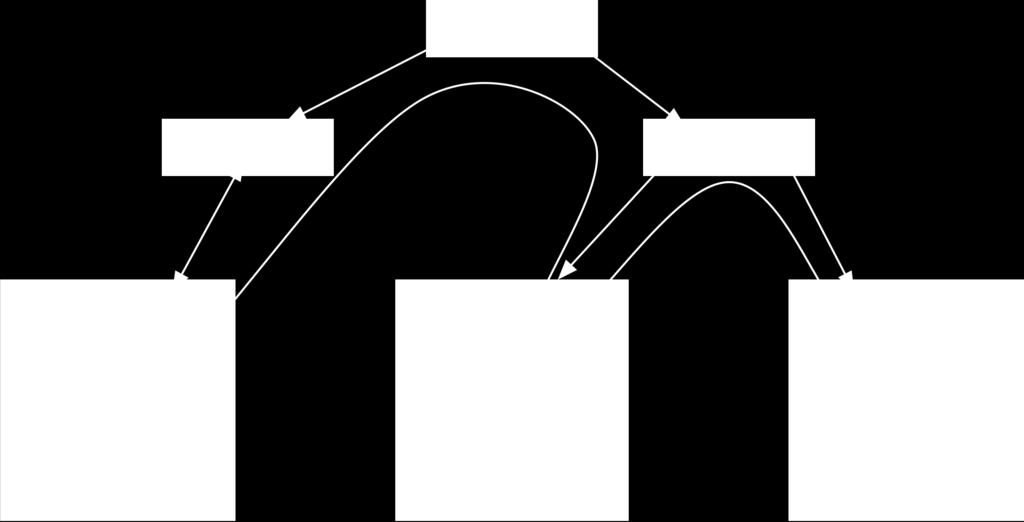
8 HDFS Dataflow
9 Data Correctness Data is checked with CRC32 File Creation Client computes checksum per 512 byte DataNode stores the checksum File access Client retrieves the data and checksum from DataNode If Validation fails, Client tries other replicas Periodic validation by DataNode
10 Map/Reduce Map/Reduce is a programming model for efficient distributed computing It works like a Unix pipeline: cat input grep sort uniq -c cat > output Input Map Shuffle & Sort Reduce Output Efficiency from Streaming through data, reducing seeks Pipelining A good fit for a lot of applications Log processing Web index building Data mining and machine learning
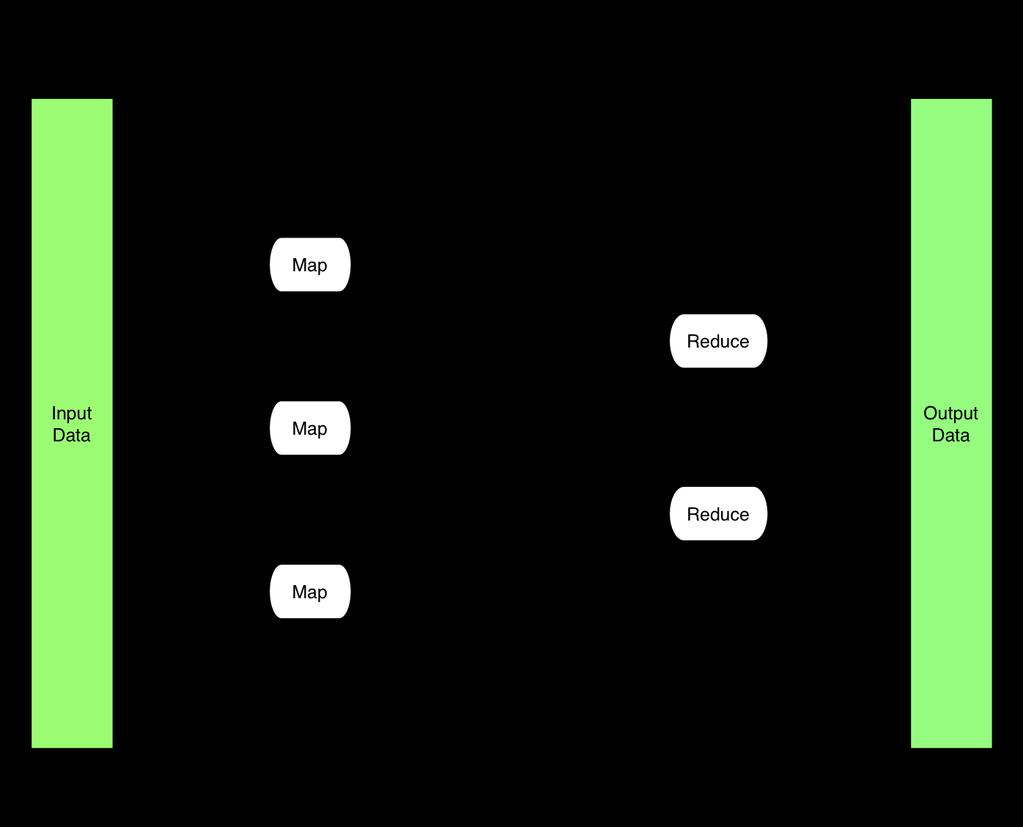
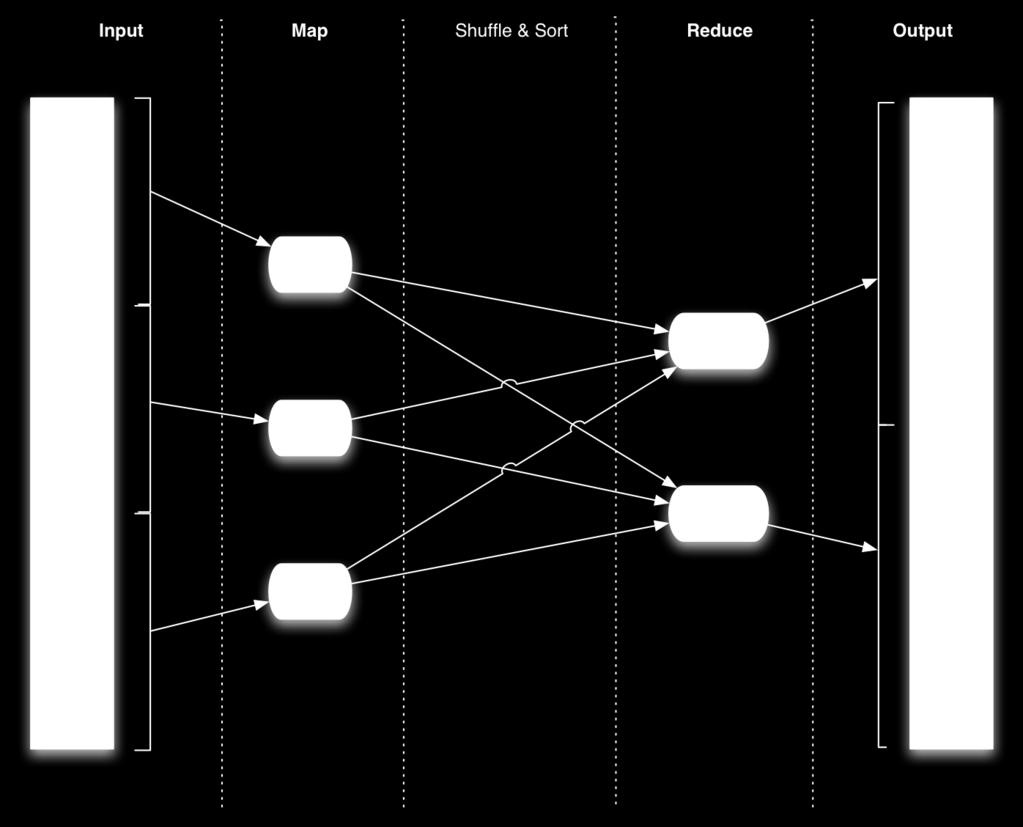
11 Map/Reduce Dataflow
12 Map/Reduce features Java, C++, and text-based APIs In Java use Objects and and C++ bytes Text-based (streaming) great for scripting or legacy apps Higher level interfaces: Pig, Hive, Jaql Automatic re-execution on failure In a large cluster, some nodes are always slow or flaky Framework re-executes failed tasks Locality optimizations With large data, bandwidth to data is a problem Map-Reduce queries HDFS for locations of input data Map tasks are scheduled close to the inputs when possible
13 Why Yahoo! is investing in Hadoop We started with building better applications Scale up web scale batch applications (search, ads, ) Factor out common code from existing systems, so new applications will be easier to write Manage the many clusters we have more easily The mission now includes research support Build a huge data warehouse with many Yahoo! data sets Couple it with a huge compute cluster and programming models to make using the data easy Provide this as a service to our researchers We are seeing great results! Experiments can be run much more quickly in this environment
14 Hadoop Timeline 2004 HDFS & map/reduce started in Nutch Dec 2005 Nutch ported to map/reduce Jan 2006 Doug Cutting joins Yahoo Feb 2006 Factored out of Nutch. Apr 2006 Sorts 1.9 TB on 188 nodes in 47 hours May 2006 Yahoo sets up research cluster Jan 2008 Hadoop is a top level Apache project Feb 2008 Yahoo creating Webmap with Hadoop Apr 2008 Wins Terabyte sort benchmark Aug 2008 Ran 4000 node Hadoop cluster
15 Running the Production WebMap Search needs a graph of the known web Invert edges, compute link text, whole graph heuristics Periodic batch job using Map/Reduce Uses a chain of ~100 map/reduce jobs Scale 100 billion nodes and 1 trillion edges Largest shuffle is 450 TB Final output is 300 TB compressed Runs on 10,000 cores Written mostly using Hadoop s C++ interface
16 Inverting the Webmap One job inverts all of the edges in the Webmap Finds the text in the links that point to each page. Input is cache of web pages Key: URL, Value: Page HTML Map output is Key: Target URL, Value: Source URL, Text from link Reduce adds column to URL table with set of linking pages and link text
17 Finding Duplicate Web Pages Find close textual matches in the corpus of web pages Use a loose hash based on visible text Input is same cache of web pages Key: URL; Value: Page HTML. Map output is Key: Page Text Hash, Goodness; Value: URL Reduce output is Key: Page Text Hash; Value: URL (best first) Second job resorts based on the URL Map output is URL, best URL Reduce creates a new column in URL table with best URL for duplicate pages
18 Research Clusters The grid team runs research clusters as a service to Yahoo researchers Analytics as a Service Mostly data mining/machine learning jobs Most research jobs are *not* Java: 42% Streaming Uses Unix text processing to define map and reduce 28% Pig Higher level dataflow scripting language 28% Java 2% C++
 We run hundreds of thousands of jobs every")
19 Hadoop clusters We have ~20,000 machines running Hadoop Our largest clusters are currently 2000 nodes Several petabytes of user data (compressed, unreplicated) We run hundreds of thousands of jobs every month

20 Research Cluster Usage

21 NY Times Needed offline conversion of public domain articles from Used Hadoop to convert scanned images to PDF Ran 100 Amazon EC2 instances for around 24 hours 4 TB of input 1.5 TB of output Published 1892, copyright New York Times
22 Terabyte Sort Benchmark Started by Jim Gray at Microsoft in 1998 Sorting 10 billion 100 byte records Hadoop won general category in 209 seconds (prev was 297 ) 910 nodes 2 quad-core 2.0Ghz / node 4 SATA disks / node 8 GB ram / node 1 gb ethernet / node and 8 gb ethernet uplink / rack 40 nodes / rack Only hard parts were: Getting a total order Converting the data generator to map/reduce
23 Hadoop Community Apache is focused on project communities Users Contributors write patches Committers can commit patches too Project Management Committee vote on new committers and releases too Apache is a meritocracy Use, contribution, and diversity is growing But we need and want more!

24 Size of Releases

25 Size of Developer Community

26 Size of User Community
27 Who Uses Hadoop? Amazon/A9 Facebook Google IBM Joost Last.fm New York Times PowerSet (now Microsoft) Quantcast Veoh Yahoo! More at
28 What s Next? 0.19 File Appends Total Order Sampler and Partitioner Pluggable scheduler 0.20 New map/reduce API Better scheduling for sharing between groups Splitting Core into sub-projects (HDFS, Map/Reduce, Hive) And beyond HDFS and Map/Reduce security High Availability via Zookeeper Get ready for Hadoop 1.0
29 Q&A For more information: Website: Mailing lists: IRC: #hadoop on irc.freenode.org
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Cloud Computing at Yahoo! Thomas Kwan Director, Research Operations Yahoo! Labs
 Cloud Computing at Yahoo! Thomas Kwan Director, Research Operations Yahoo! Labs Overview Cloud Strategy Cloud Services Cloud Research Partnerships - 2 - Yahoo! Cloud Strategy 1. Optimizing for Yahoo-scale
Cloud Computing at Yahoo! Thomas Kwan Director, Research Operations Yahoo! Labs Overview Cloud Strategy Cloud Services Cloud Research Partnerships - 2 - Yahoo! Cloud Strategy 1. Optimizing for Yahoo-scale
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Timeline Dec 2004: Dean/Ghemawat (Google) MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (
 MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (") HADOOP Lecture 5 Timeline Dec 2004: Dean/Ghemawat (Google) MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (the name is derived from Doug s son
HADOOP Lecture 5 Timeline Dec 2004: Dean/Ghemawat (Google) MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (the name is derived from Doug s son
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler
 The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Scalable Web Programming. CS193S - Jan Jannink - 2/25/10
 Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Apache Hadoop.Next What it takes and what it means
 Apache Hadoop.Next What it takes and what it means Arun C. Murthy Founder & Architect, Hortonworks @acmurthy (@hortonworks) Page 1 Hello! I m Arun Founder/Architect at Hortonworks Inc. Lead, Map-Reduce
Apache Hadoop.Next What it takes and what it means Arun C. Murthy Founder & Architect, Hortonworks @acmurthy (@hortonworks) Page 1 Hello! I m Arun Founder/Architect at Hortonworks Inc. Lead, Map-Reduce
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Data Analysis Using MapReduce in Hadoop Environment
 Data Analysis Using MapReduce in Hadoop Environment Muhammad Khairul Rijal Muhammad*, Saiful Adli Ismail, Mohd Nazri Kama, Othman Mohd Yusop, Azri Azmi Advanced Informatics School (UTM AIS), Universiti
Data Analysis Using MapReduce in Hadoop Environment Muhammad Khairul Rijal Muhammad*, Saiful Adli Ismail, Mohd Nazri Kama, Othman Mohd Yusop, Azri Azmi Advanced Informatics School (UTM AIS), Universiti
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Introduction to Hadoop. Scott Seighman Systems Engineer Sun Microsystems
 Introduction to Hadoop Scott Seighman Systems Engineer Sun Microsystems 1 Agenda Identify the Problem Hadoop Overview Target Workloads Hadoop Architecture Major Components > HDFS > Map/Reduce Demo Resources
Introduction to Hadoop Scott Seighman Systems Engineer Sun Microsystems 1 Agenda Identify the Problem Hadoop Overview Target Workloads Hadoop Architecture Major Components > HDFS > Map/Reduce Demo Resources
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
Cloud Programming. Programming Environment Oct 29, 2015 Osamu Tatebe
 Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Distributed Systems CS6421
 Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
A Survey on Big Data
 A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
HDFS Federation. Sanjay Radia Founder and Hortonworks. Page 1
 HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia,
 Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Big Data and Cloud Computing
 Big Data and Cloud Computing Presented at Faculty of Computer Science University of Murcia Presenter: Muhammad Fahim, PhD Department of Computer Eng. Istanbul S. Zaim University, Istanbul, Turkey About
Big Data and Cloud Computing Presented at Faculty of Computer Science University of Murcia Presenter: Muhammad Fahim, PhD Department of Computer Eng. Istanbul S. Zaim University, Istanbul, Turkey About
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Crossing the Chasm: Sneaking a parallel file system into Hadoop
 Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Introduction to MapReduce Algorithms and Analysis
 Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
HADOOP. K.Nagaraju B.Tech Student, Department of CSE, Sphoorthy Engineering College, Nadergul (Vill.), Sagar Road, Saroonagar (Mdl), R.R Dist.T.S.
, Sagar Road, Saroonagar (Mdl), R.R Dist.T.S.") K.Nagaraju B.Tech Student, HADOOP J.Deepthi Associate Professor & HOD, Mr.T.Pavan Kumar Assistant Professor, Apache Hadoop is an open-source software framework used for distributed storage and processing
K.Nagaraju B.Tech Student, HADOOP J.Deepthi Associate Professor & HOD, Mr.T.Pavan Kumar Assistant Professor, Apache Hadoop is an open-source software framework used for distributed storage and processing
Lecture 12 DATA ANALYTICS ON WEB SCALE
 Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Chase Wu New Jersey Institute of Technology
 CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
Apache BookKeeper. A High Performance and Low Latency Storage Service
 Apache BookKeeper A High Performance and Low Latency Storage Service Hello! I am Sijie Guo - PMC Chair of Apache BookKeeper Co-creator of Apache DistributedLog Twitter Messaging/Pub-Sub Team Yahoo! R&D
Apache BookKeeper A High Performance and Low Latency Storage Service Hello! I am Sijie Guo - PMC Chair of Apache BookKeeper Co-creator of Apache DistributedLog Twitter Messaging/Pub-Sub Team Yahoo! R&D
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin. Presented by: Suhua Wei Yong Yu
 CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop Distributed File System(HDFS)
") Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Hadoop Distributed File System(HDFS) Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Crossing the Chasm: Sneaking a parallel file system into Hadoop
 Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Jaql. Kevin Beyer, Vuk Ercegovac, Eugene Shekita, Jun Rao, Ning Li, Sandeep Tata. IBM Almaden Research Center
 Jaql Running Pipes in the Clouds Kevin Beyer, Vuk Ercegovac, Eugene Shekita, Jun Rao, Ning Li, Sandeep Tata IBM Almaden Research Center http://code.google.com/p/jaql/ 2009 IBM Corporation Motivating Scenarios
Jaql Running Pipes in the Clouds Kevin Beyer, Vuk Ercegovac, Eugene Shekita, Jun Rao, Ning Li, Sandeep Tata IBM Almaden Research Center http://code.google.com/p/jaql/ 2009 IBM Corporation Motivating Scenarios
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
A Review Paper on Big data & Hadoop
 A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
Large-scale Information Processing
 Sommer 2013 Large-scale Information Processing Ulf Brefeld Knowledge Mining & Assessment brefeld@kma.informatik.tu-darmstadt.de Anecdotal evidence... I think there is a world market for about five computers,
Sommer 2013 Large-scale Information Processing Ulf Brefeld Knowledge Mining & Assessment brefeld@kma.informatik.tu-darmstadt.de Anecdotal evidence... I think there is a world market for about five computers,
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
Performance Enhancement of Data Processing using Multiple Intelligent Cache in Hadoop
 Performance Enhancement of Data Processing using Multiple Intelligent Cache in Hadoop K. Senthilkumar PG Scholar Department of Computer Science and Engineering SRM University, Chennai, Tamilnadu, India
Performance Enhancement of Data Processing using Multiple Intelligent Cache in Hadoop K. Senthilkumar PG Scholar Department of Computer Science and Engineering SRM University, Chennai, Tamilnadu, India
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
MapReduce. Cloud Computing COMP / ECPE 293A
 Cloud Computing COMP / ECPE 293A MapReduce Jeffrey Dean and Sanjay Ghemawat, MapReduce: simplified data processing on large clusters, In Proceedings of the 6th conference on Symposium on Opera7ng Systems
Cloud Computing COMP / ECPE 293A MapReduce Jeffrey Dean and Sanjay Ghemawat, MapReduce: simplified data processing on large clusters, In Proceedings of the 6th conference on Symposium on Opera7ng Systems
Big Data Analytics Overview with Hadoop and Spark
 Big Data Analytics Overview with Hadoop and Spark Harrison Carranza, MSIS Marist College, USA, Harrison.Carranza2@marist.edu Mentor: Aparicio Carranza, PhD New York City College of Technology - CUNY, USA,
Big Data Analytics Overview with Hadoop and Spark Harrison Carranza, MSIS Marist College, USA, Harrison.Carranza2@marist.edu Mentor: Aparicio Carranza, PhD New York City College of Technology - CUNY, USA,
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
Google: A Computer Scientist s Playground
 Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Outline Mission, data, and scaling Systems infrastructure Parallel programming model: MapReduce Googles
Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Outline Mission, data, and scaling Systems infrastructure Parallel programming model: MapReduce Googles
Google: A Computer Scientist s Playground
 Outline Mission, data, and scaling Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Systems infrastructure Parallel programming model: MapReduce Googles
Outline Mission, data, and scaling Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Systems infrastructure Parallel programming model: MapReduce Googles
Map Reduce & Hadoop Recommended Text:
 Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Scaling Up 1 CSE 6242 / CX Duen Horng (Polo) Chau Georgia Tech. Hadoop, Pig
 Chau Georgia Tech. Hadoop, Pig") CSE 6242 / CX 4242 Scaling Up 1 Hadoop, Pig Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
CSE 6242 / CX 4242 Scaling Up 1 Hadoop, Pig Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but