CIS 612 Advanced Topics in Database Big Data Project Lawrence Ni, Priya Patil, James Tench
|
|
|
- Paul Trevor Ray
- 5 years ago
- Views:
Transcription
1 CIS 612 Advanced Topics in Database Big Data Project Lawrence Ni, Priya Patil, James Tench
2 Abstract Implementing a Hadoop-based system for processing big data and doing analytics is a topic which has been completed by many others in the past, and there is ample amount of documentation regarding the process. From the perspective of a beginner, or even someone with little knowledge of implementing a big data system from scratch, the process can be a overwhelming. Wading through the documentation, making mistakes along the way, and correcting those mistakes are considered by many part of the learning process. This paper will share our experiences with the installation of Hadoop on an Amazon Web Services cluster and analyzing this data in a meaningful way. The goal is to share areas where we encountered trouble so the reader may benefit from our learning. Introduction The Hadoop based installation was implemented by Lawrence Ni, Priya Patil, and James Tench as a group by working on the project over a series of Sunday afternoons. In addition, between meetings the individual members performed additional research to prepare for the following meeting. The Hadoop installation on Amazon Web Services (AWS) consisted of four servers hosted on micro EC2 instances. The cluster was setup in with one NameNode and three Data Nodes. In a real implementation, multiple Name Nodes would have been implemented to account for any machine failures. In addition to running Hadoop, the NameNode ran Hive as its NoSQL database to query the data. In addition to processing data on the AWS cluster, every step was first implemented on a local machine to test prior to running any job. On our local machines we ran MongoDb to query json data in an easy manner. In addition, the team implemented a custom Flume Agent to handle streaming data from Twitter s firehose. AWS Amazon Web Services offers various products that can be used in a cloud environment. Running an entire cluster of hardware in the cloud is referred to platform as a service. To get started with setting up a cloud infrastructure you begin by creating an account with AWS. AWS offers a free level, which is basically low end machines. For our implementation, these low end machines served our needs. After creating an account with AWS, the documentation for creating an EC2 instance is the place to start. An EC2 instance is the standard type of machine that can be launched in the cloud. The entire set up for AWS was as easy as following a wizard to launch the instances. Configuration After successfully launching 4 instances, to get the machines running Hadoop it is necessary to download the Hadoop files and configure each node. This is the first spot where the group encountered configuration issues. The trouble was minor and easy to resolve, but it was more about remembering the installation steps for Hadoop in pseudo mode. Hadoop communicates via SSH and must be able to do so without being prompted for a password. For AWS machines to communicate, it must be done via SSH and you must have your digitally
3 signed key available. To remedy the communication problem, a copy of the PEM file that is used locally was copied to each machine. Once the file was copied to each machine, a connection entry was made in the ~/.ssh config file with the ip address info for the other nodes. The next step after configuring the connection settings with SSH was to setup each of the Hadoop config files. Again, this process was straight-forward. Following the documentation on the Apache Hadoop website was all that was needed to set up the configuration. The key differences between installing on a cluster vs. pseudo mode were creating a slaves file, setting the replication factor, and adding the IP addresses of the data nodes. Flume The Twitter firehose API was chosen as the datasource for our project. The firehose is a stream of tweets coming from twitter live. To connect to the API, it is necessary to go to Twitter s developer page and register as a developer. Upon registration you may create an app and obtain an API key for the app. This key is used to connect, and download data from the various Twitter APIs. Because of the streaming nature of the data (vs. connecting to a REST API), a method for moving the data from the stream to HDFS is needed. Flume provides this API. Flume works by using sinks, channels and sources. A sink is a data source, and in our case is the streaming API. A channel is the method it will use to store data as it moves to permanent storage. For this project, memory is used as the channel. Finally the sink is where data is stored. In our case, we are storing data in HDFS. Flume is also very well documented, and the documentation will guide you through the majority of the process for creating a Flume Agent. One area documented on the Flume website references the Twitter API and warns the user that to code is experimental and subject to change. This was the first area of configuring Flume where trouble was encountered. For the most part, the Apache Flume example worked for downloading data and storing it in HDFS. However, the Twitter API allows for filtering of the data via keywords passed with the API request. The default Apache implementation did not implement the ability to pass keywords, so there was no filter. To get around this problem, there is a well documented java class from Cloudera that includes the ability to use a Flume Agent with a filter condition. For our project we elected to copy the Apache implementation, and modify it by adding in the filter code from Cloudera. Once we had this in place, Flume was streaming data from to HDFS. After a few minutes letting Flume run on a local machine, the program began throwing exceptions, and the exceptions starting increasing. To solve this problem it was necessary to modify the Flume Agent config files so that the memory channel was flushed to disc often enough. After modifying the transaction capacity setting, and some trial and error the Flume Agent began running without exceptions. The key to getting the program to run without exception was to set the transaction capacity higher than the batch size. Once this was working as desired, the Flume Agent was copied to the Namenode on AWS. The Namenode launched the Flume Agent, was allowed to download data for days. Flume Java code
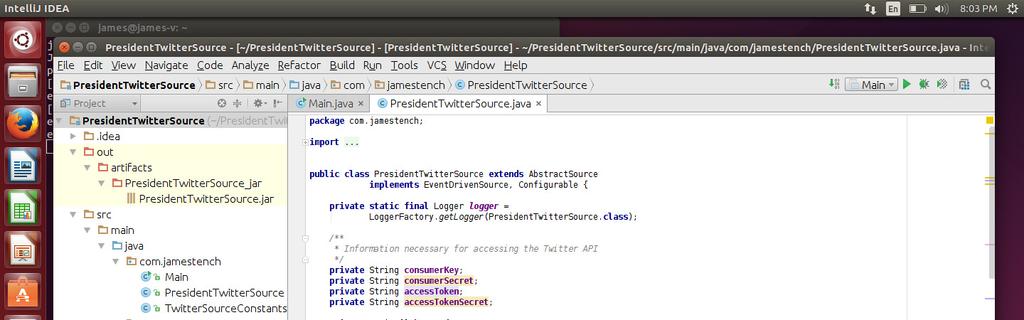
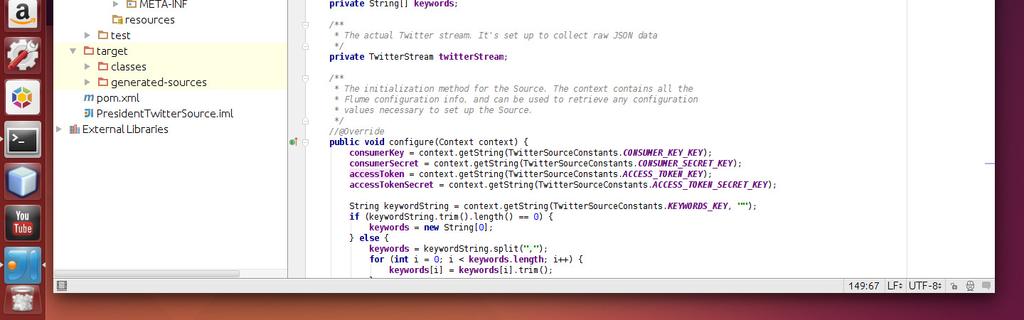
4


5 MongoDb The Twitter API sends data in JSON format. MongoDb handles JSON naturally because it stores data in a binary JSON format called BSON. For these reasons, we used MongoDb on a local machine to understand the raw data better. Sample files were copied from the AWS cluster to a local machine. The files were imported into MongoDb via the mongoimport command. Once

6 the data was loaded, querying to view to format of the tweets, test for valid data, and review simple aggregations was done with the mongo query language. Realizing we wanted a method to process large amounts of data directly on HDFS the group decided that MongoDb would not be our best choice for direct manipulation of the data on HDFS. For those reasons, the extent of the MongoDb usage was limited to only analyzing and reviewing sample data. MapReduce The first attempt to process large queries on the Hadoop cluster involved writing a MapReduce job. The JSONObject library created by Douglas Crockford was used to parse the raw JSON and extract the components being aggregated. MapReduce for finding one summary metric was easily implemented by using the JSONObject library to extract screen_name as the key, and the followers_count as the value for our MapReduce Job. Once again, the job was tested locally first, then processed on the cluster. With about 3.6 gb of data, the cluster process our count job in about 90 seconds. We did not consider this bad performance for 4 low end machines processing almost 4gig of data. Although the MapReduce job was not difficult to create in Java, it lacked the flexibility of running various ad hoc queries at will. This lead to the next phase of processing our data on the cluster. mapreduce code



7 HIVE Apache Hive, like the other products mentioned prior was also very well documented and easy to install on the cluster following the standard docs. Moving data into hive proved to be the challenge.
8 For HIVE to process data it needs a method for serializing and deserializing data when you send a query request. This is referred to as a Serde. Finding a JSON Serde was the easy part. We used the Hive-JSON-Serde from user rcongiu on github. The initial trouble with setting up the hive table was telling the Serde file what the format of the data would look like. Typically a create table statement needs to be generated to define what each field looks like inside the nested JSON document. During the development and implementation of the table, many of the data fields that we expected to hold a value were returning null. This is where we learned that in order for the Serde to work properly, the table definition needed to be very precise. Because each tweet from twitter did not alway contain complete data, our original implementation was failing. To create the perfect schema definition, another library called hive-json-schema by user quux00 on github was used. This tool was very good at auto generating a hive schema if you provided it with a single sample JSON document. After using the tool to generate the create table statement, the data was tested again. Once again, the data was returning null values for fields that should have had values. This ended up being one of the most tedious areas of the project to debug. After spending time researching and debugging, the problem was discovered. The problem once again stemmed back to twitter data sometimes being incomplete. Because of this, the sample tweet that was used by the tool to generate the create table statement was not complete. To correct this problem, a sample tweet was reconstructed with dummy data in any field that we found to be missing. We used the Twitter API to validate what each field should look like in terms of data types and nested structures. After making a few typos, we finally got it right and constructed a full tweet. Using this new Tweet sample a create table statement was generated with the same tool. Queries began returning expected values! hive code
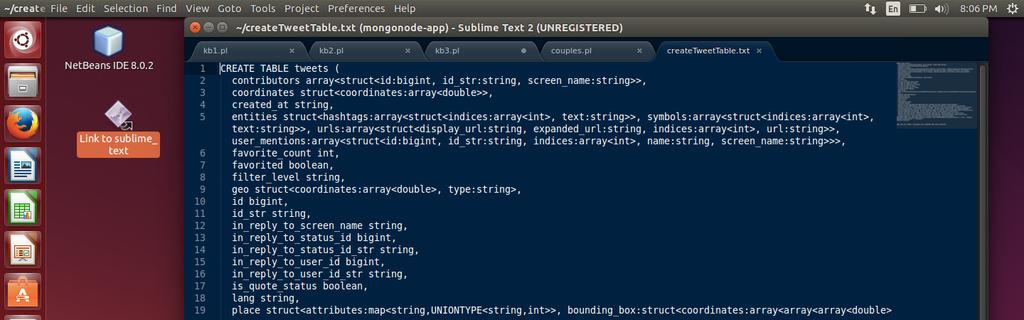
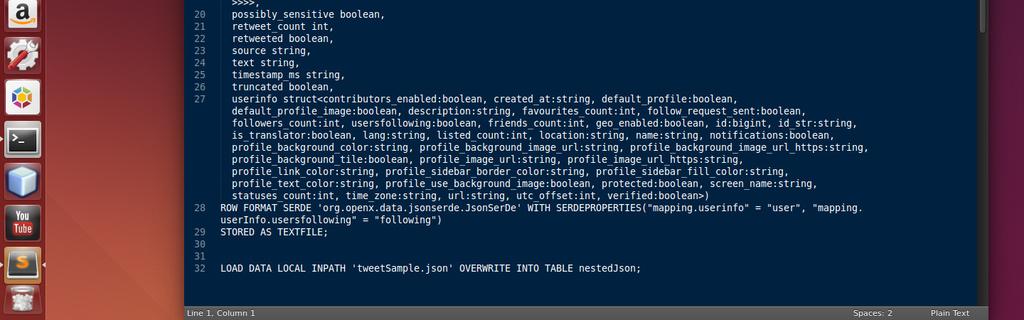
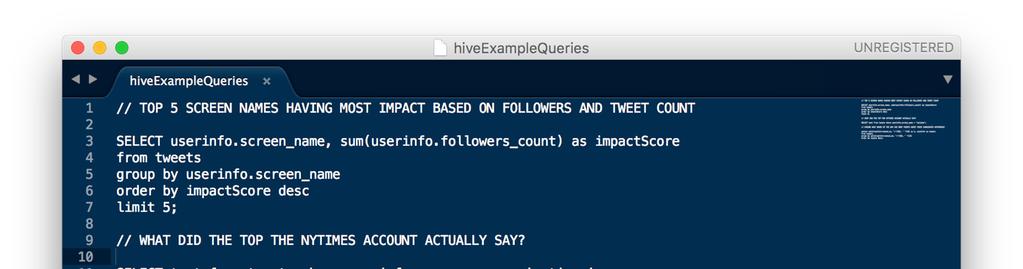
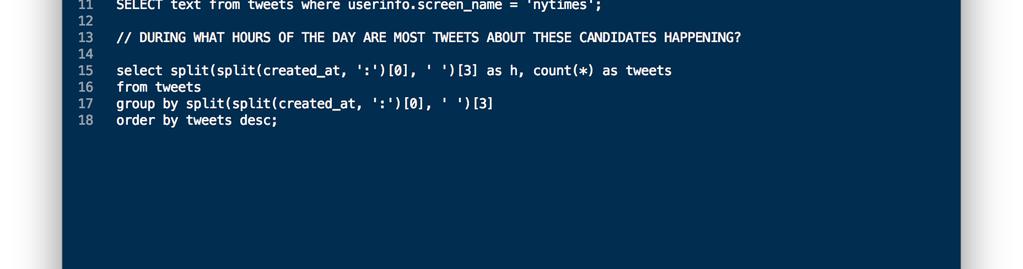

9


10 python code Queries & Visualization Now that we had HIVE up and running, we generated some sample queries that aggregated the data in various ways. Creating HIVE queries is just like creating standard SQL queries. In addition, it was easy to use Java style string manipulation to aid in processing the data.
11 After we queried data and aggregated it in different ways we moved the aggregated data to summary files. The aggregated data included information about who tweeted, how often they tweeted, and even the hours of the day users were most actively sending tweets. Watching HIVE generate MapReduce jobs in the terminal window was fun the first one or two times, but then we realized we should find a way to better represent our data. The final piece of software we used to process our data was called Plotly. Plotly is a Python library that offers multiple graphing options. To process and use Plotly, you need a developer account. Once you create an account, you use Python to define your data set and format the data set based on the graph or chart you intend to create. The library then generates a custom URL that can be used to view the data in chart form via a web browser. Conclusion From the perspective of a beginner, it may seem very difficult and overwhelming to implement and configure a complex computer system. However, breaking down these complex systems into more manageable pieces makes it easier to understand how these different parts work and communicate with each other. This type of structured learning not only helps you understand the material but also makes debugging issues a lot easier. While configuring and installing our various systems, we encountered a variety of different issues. Whether it be environment variables not being set or jar files that are no longer compatible with your current software, these issues were easier to debug because we were able to break down the different parts and localize the error. Experiencing errors/bugs when setting up these complex systems is when the learning truly begins. Having to break down the error messages and think about the different moving parts helps you develop a deeper understanding of how these different aspects work and interact as a whole.
12 References The Apache Software Foundation. Apache Hadooop, The Apache Software Foundation. Apache HIVE, The Apache Software Foundation. Apache Flume, Cloudera. Cloudera Engineering Blog, Analyzing Twitter Data with Hadoop. JSON-Hive Serde. JSON-Hive-schema. Plotly The Online Chart Maker.
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Question: 1 You need to place the results of a PigLatin script into an HDFS output directory. What is the correct syntax in Apache Pig?
 Volume: 72 Questions Question: 1 You need to place the results of a PigLatin script into an HDFS output directory. What is the correct syntax in Apache Pig? A. update hdfs set D as./output ; B. store D
Volume: 72 Questions Question: 1 You need to place the results of a PigLatin script into an HDFS output directory. What is the correct syntax in Apache Pig? A. update hdfs set D as./output ; B. store D
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
1Z Oracle Big Data 2017 Implementation Essentials Exam Summary Syllabus Questions
 1Z0-449 Oracle Big Data 2017 Implementation Essentials Exam Summary Syllabus Questions Table of Contents Introduction to 1Z0-449 Exam on Oracle Big Data 2017 Implementation Essentials... 2 Oracle 1Z0-449
1Z0-449 Oracle Big Data 2017 Implementation Essentials Exam Summary Syllabus Questions Table of Contents Introduction to 1Z0-449 Exam on Oracle Big Data 2017 Implementation Essentials... 2 Oracle 1Z0-449
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
AWS Serverless Architecture Think Big
 MAKING BIG DATA COME ALIVE AWS Serverless Architecture Think Big Garrett Holbrook, Data Engineer Feb 1 st, 2017 Agenda What is Think Big? Example Project Walkthrough AWS Serverless 2 Think Big, a Teradata
MAKING BIG DATA COME ALIVE AWS Serverless Architecture Think Big Garrett Holbrook, Data Engineer Feb 1 st, 2017 Agenda What is Think Big? Example Project Walkthrough AWS Serverless 2 Think Big, a Teradata
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Data in the Cloud and Analytics in the Lake
 Data in the Cloud and Analytics in the Lake Introduction Working in Analytics for over 5 years Part the digital team at BNZ for 3 years Based in the Auckland office Preferred Languages SQL Python (PySpark)
Data in the Cloud and Analytics in the Lake Introduction Working in Analytics for over 5 years Part the digital team at BNZ for 3 years Based in the Auckland office Preferred Languages SQL Python (PySpark)
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
SOLUTION TRACK Finding the Needle in a Big Data Innovator & Problem Solver Cloudera
 SOLUTION TRACK Finding the Needle in a Big Data Haystack @EvaAndreasson, Innovator & Problem Solver Cloudera Agenda Problem (Solving) Apache Solr + Apache Hadoop et al Real-world examples Q&A Problem Solving
SOLUTION TRACK Finding the Needle in a Big Data Haystack @EvaAndreasson, Innovator & Problem Solver Cloudera Agenda Problem (Solving) Apache Solr + Apache Hadoop et al Real-world examples Q&A Problem Solving
Hadoop, Yarn and Beyond
 Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
2013 AWS Worldwide Public Sector Summit Washington, D.C.
 2013 AWS Worldwide Public Sector Summit Washington, D.C. EMR for Fun and for Profit Ben Butler Sr. Manager, Big Data butlerb@amazon.com @bensbutler Overview 1. What is big data? 2. What is AWS Elastic
2013 AWS Worldwide Public Sector Summit Washington, D.C. EMR for Fun and for Profit Ben Butler Sr. Manager, Big Data butlerb@amazon.com @bensbutler Overview 1. What is big data? 2. What is AWS Elastic
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation)
 (Development, Administration & REAL TIME Projects Implementation)") HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
Social Network Analytics on Cray Urika-XA
 Social Network Analytics on Cray Urika-XA Mike Hinchey, mhinchey@cray.com Technical Solutions Architect Cray Inc, Analytics Products Group April, 2015 Agenda 1. Introduce platform Urika-XA 2. Technology
Social Network Analytics on Cray Urika-XA Mike Hinchey, mhinchey@cray.com Technical Solutions Architect Cray Inc, Analytics Products Group April, 2015 Agenda 1. Introduce platform Urika-XA 2. Technology
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Deployment Planning Guide
 Deployment Planning Guide Community 1.5.1 release The purpose of this document is to educate the user about the different strategies that can be adopted to optimize the usage of Jumbune on Hadoop and also
Deployment Planning Guide Community 1.5.1 release The purpose of this document is to educate the user about the different strategies that can be adopted to optimize the usage of Jumbune on Hadoop and also
/ Cloud Computing. Recitation 8 October 18, 2016
 15-319 / 15-619 Cloud Computing Recitation 8 October 18, 2016 1 Overview Administrative issues Office Hours, Piazza guidelines Last week s reflection Project 3.2, OLI Unit 3, Module 13, Quiz 6 This week
15-319 / 15-619 Cloud Computing Recitation 8 October 18, 2016 1 Overview Administrative issues Office Hours, Piazza guidelines Last week s reflection Project 3.2, OLI Unit 3, Module 13, Quiz 6 This week
Prototyping Data Intensive Apps: TrendingTopics.org
 Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
What is Cloud Computing? What are the Private and Public Clouds? What are IaaS, PaaS, and SaaS? What is the Amazon Web Services (AWS)?
?") What is Cloud Computing? What are the Private and Public Clouds? What are IaaS, PaaS, and SaaS? What is the Amazon Web Services (AWS)? What is Amazon Machine Image (AMI)? Amazon Elastic Compute Cloud (EC2)?
What is Cloud Computing? What are the Private and Public Clouds? What are IaaS, PaaS, and SaaS? What is the Amazon Web Services (AWS)? What is Amazon Machine Image (AMI)? Amazon Elastic Compute Cloud (EC2)?
Lambda Architecture for Batch and Stream Processing. October 2018
 Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
Hadoop. Introduction to BIGDATA and HADOOP
 Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Scalable Tools - Part I Introduction to Scalable Tools
 Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
/ Cloud Computing. Recitation 7 October 10, 2017
 15-319 / 15-619 Cloud Computing Recitation 7 October 10, 2017 Overview Last week s reflection Project 3.1 OLI Unit 3 - Module 10, 11, 12 Quiz 5 This week s schedule OLI Unit 3 - Module 13 Quiz 6 Project
15-319 / 15-619 Cloud Computing Recitation 7 October 10, 2017 Overview Last week s reflection Project 3.1 OLI Unit 3 - Module 10, 11, 12 Quiz 5 This week s schedule OLI Unit 3 - Module 13 Quiz 6 Project
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect
 Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES
 1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
Hadoop Online Training
 Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
MongoDB - a No SQL Database What you need to know as an Oracle DBA
 MongoDB - a No SQL Database What you need to know as an Oracle DBA David Burnham Aims of this Presentation To introduce NoSQL database technology specifically using MongoDB as an example To enable the
MongoDB - a No SQL Database What you need to know as an Oracle DBA David Burnham Aims of this Presentation To introduce NoSQL database technology specifically using MongoDB as an example To enable the
SQLite vs. MongoDB for Big Data
 SQLite vs. MongoDB for Big Data In my latest tutorial I walked readers through a Python script designed to download tweets by a set of Twitter users and insert them into an SQLite database. In this post
SQLite vs. MongoDB for Big Data In my latest tutorial I walked readers through a Python script designed to download tweets by a set of Twitter users and insert them into an SQLite database. In this post
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Hadoop & Big Data Analytics Complete Practical & Real-time Training
 An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Percona Live September 21-23, 2015 Mövenpick Hotel Amsterdam
 Percona Live 2015 September 21-23, 2015 Mövenpick Hotel Amsterdam MongoDB, Elastic, and Hadoop: The What, When, and How Kimberly Wilkins Principal Engineer/Database Denizen ObjectRocket/Rackspace kimberly@objectrocket.com
Percona Live 2015 September 21-23, 2015 Mövenpick Hotel Amsterdam MongoDB, Elastic, and Hadoop: The What, When, and How Kimberly Wilkins Principal Engineer/Database Denizen ObjectRocket/Rackspace kimberly@objectrocket.com
Processing 11 billions events a day with Spark. Alexander Krasheninnikov
 Processing 11 billions events a day with Spark Alexander Krasheninnikov Badoo facts 46 languages 10M Photos added daily 320M registered users 190 countries 21M daily active users 3000+ servers 2 data-centers
Processing 11 billions events a day with Spark Alexander Krasheninnikov Badoo facts 46 languages 10M Photos added daily 320M registered users 190 countries 21M daily active users 3000+ servers 2 data-centers
SAP VORA 1.4 on AWS - MARKETPLACE EDITION FREQUENTLY ASKED QUESTIONS
 SAP VORA 1.4 on AWS - MARKETPLACE EDITION FREQUENTLY ASKED QUESTIONS 1. What is SAP Vora? SAP Vora is an in-memory, distributed computing solution that helps organizations uncover actionable business insights
SAP VORA 1.4 on AWS - MARKETPLACE EDITION FREQUENTLY ASKED QUESTIONS 1. What is SAP Vora? SAP Vora is an in-memory, distributed computing solution that helps organizations uncover actionable business insights
Course Content MongoDB
 Course Content MongoDB 1. Course introduction and mongodb Essentials (basics) 2. Introduction to NoSQL databases What is NoSQL? Why NoSQL? Difference Between RDBMS and NoSQL Databases Benefits of NoSQL
Course Content MongoDB 1. Course introduction and mongodb Essentials (basics) 2. Introduction to NoSQL databases What is NoSQL? Why NoSQL? Difference Between RDBMS and NoSQL Databases Benefits of NoSQL
Evolution of Big Data Facebook. Architecture Summit, Shenzhen, August 2012 Ashish Thusoo
 Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
Expert Lecture plan proposal Hadoop& itsapplication
 Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
DATA MINING II - 1DL460
 DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
Activity 03 AWS MapReduce
 Implementation Activity: A03 (version: 1.0; date: 04/15/2013) 1 6 Activity 03 AWS MapReduce Purpose 1. To be able describe the MapReduce computational model 2. To be able to solve simple problems with
Implementation Activity: A03 (version: 1.0; date: 04/15/2013) 1 6 Activity 03 AWS MapReduce Purpose 1. To be able describe the MapReduce computational model 2. To be able to solve simple problems with
Configuring and Deploying Hadoop Cluster Deployment Templates
 Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
New Approaches to Big Data Processing and Analytics
 New Approaches to Big Data Processing and Analytics Contributing authors: David Floyer, David Vellante Original publication date: February 12, 2013 There are number of approaches to processing and analyzing
New Approaches to Big Data Processing and Analytics Contributing authors: David Floyer, David Vellante Original publication date: February 12, 2013 There are number of approaches to processing and analyzing
Verarbeitung von Vektor- und Rasterdaten auf der Hadoop Plattform DOAG Spatial and Geodata Day 2016
 Verarbeitung von Vektor- und Rasterdaten auf der Hadoop Plattform DOAG Spatial and Geodata Day 2016 Hans Viehmann Product Manager EMEA ORACLE Corporation 12. Mai 2016 Safe Harbor Statement The following
Verarbeitung von Vektor- und Rasterdaten auf der Hadoop Plattform DOAG Spatial and Geodata Day 2016 Hans Viehmann Product Manager EMEA ORACLE Corporation 12. Mai 2016 Safe Harbor Statement The following
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
DATABASE DESIGN II - 1DL400
 DATABASE DESIGN II - 1DL400 Fall 2016 A second course in database systems http://www.it.uu.se/research/group/udbl/kurser/dbii_ht16 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATABASE DESIGN II - 1DL400 Fall 2016 A second course in database systems http://www.it.uu.se/research/group/udbl/kurser/dbii_ht16 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
MIS Database Systems.
 MIS 335 - Database Systems http://www.mis.boun.edu.tr/durahim/ Ahmet Onur Durahim Learning Objectives Database systems concepts Designing and implementing a database application Life of a Query in a Database
MIS 335 - Database Systems http://www.mis.boun.edu.tr/durahim/ Ahmet Onur Durahim Learning Objectives Database systems concepts Designing and implementing a database application Life of a Query in a Database
BIS Database Management Systems.
 BIS 512 - Database Management Systems http://www.mis.boun.edu.tr/durahim/ Ahmet Onur Durahim Learning Objectives Database systems concepts Designing and implementing a database application Life of a Query
BIS 512 - Database Management Systems http://www.mis.boun.edu.tr/durahim/ Ahmet Onur Durahim Learning Objectives Database systems concepts Designing and implementing a database application Life of a Query
Real-time Data Engineering in the Cloud Exercise Guide
 Real-time Data Engineering in the Cloud Exercise Guide Jesse Anderson 2017 SMOKING HAND LLC ALL RIGHTS RESERVED Version 1.12.a9779239 1 Contents 1 Lab Notes 3 2 Kafka HelloWorld 6 3 Streaming ETL 8 4 Advanced
Real-time Data Engineering in the Cloud Exercise Guide Jesse Anderson 2017 SMOKING HAND LLC ALL RIGHTS RESERVED Version 1.12.a9779239 1 Contents 1 Lab Notes 3 2 Kafka HelloWorld 6 3 Streaming ETL 8 4 Advanced
IBM Big SQL Partner Application Verification Quick Guide
 IBM Big SQL Partner Application Verification Quick Guide VERSION: 1.6 DATE: Sept 13, 2017 EDITORS: R. Wozniak D. Rangarao Table of Contents 1 Overview of the Application Verification Process... 3 2 Platform
IBM Big SQL Partner Application Verification Quick Guide VERSION: 1.6 DATE: Sept 13, 2017 EDITORS: R. Wozniak D. Rangarao Table of Contents 1 Overview of the Application Verification Process... 3 2 Platform
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Presented by Sunnie S Chung CIS 612
 By Yasin N. Silva, Arizona State University Presented by Sunnie S Chung CIS 612 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. See http://creativecommons.org/licenses/by-nc-sa/4.0/
By Yasin N. Silva, Arizona State University Presented by Sunnie S Chung CIS 612 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. See http://creativecommons.org/licenses/by-nc-sa/4.0/
Hortonworks Data Platform
 Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Big Data Development HADOOP Training - Workshop. FEB 12 to (5 days) 9 am to 5 pm HOTEL DUBAI GRAND DUBAI
 9 am to 5 pm HOTEL DUBAI GRAND DUBAI") Big Data Development HADOOP Training - Workshop FEB 12 to 16 2017 (5 days) 9 am to 5 pm HOTEL DUBAI GRAND DUBAI ISIDUS TECH TEAM FZE PO Box 9798 Dubai UAE, email training-coordinator@isidusnet M: +97150
Big Data Development HADOOP Training - Workshop FEB 12 to 16 2017 (5 days) 9 am to 5 pm HOTEL DUBAI GRAND DUBAI ISIDUS TECH TEAM FZE PO Box 9798 Dubai UAE, email training-coordinator@isidusnet M: +97150
Data Analytics Job Guarantee Program
 Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Oracle Big Data SQL High Performance Data Virtualization Explained
 Keywords: Oracle Big Data SQL High Performance Data Virtualization Explained Jean-Pierre Dijcks Oracle Redwood City, CA, USA Big Data SQL, SQL, Big Data, Hadoop, NoSQL Databases, Relational Databases,
Keywords: Oracle Big Data SQL High Performance Data Virtualization Explained Jean-Pierre Dijcks Oracle Redwood City, CA, USA Big Data SQL, SQL, Big Data, Hadoop, NoSQL Databases, Relational Databases,
Big Data on AWS. Peter-Mark Verwoerd Solutions Architect
 Big Data on AWS Peter-Mark Verwoerd Solutions Architect What to get out of this talk Non-technical: Big Data processing stages: ingest, store, process, visualize Hot vs. Cold data Low latency processing
Big Data on AWS Peter-Mark Verwoerd Solutions Architect What to get out of this talk Non-technical: Big Data processing stages: ingest, store, process, visualize Hot vs. Cold data Low latency processing
Verteego VDS Documentation
 Verteego VDS Documentation Release 1.0 Verteego May 31, 2017 Installation 1 Getting started 3 2 Ansible 5 2.1 1. Install Ansible............................................. 5 2.2 2. Clone installation
Verteego VDS Documentation Release 1.0 Verteego May 31, 2017 Installation 1 Getting started 3 2 Ansible 5 2.1 1. Install Ansible............................................. 5 2.2 2. Clone installation
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Data Storage Infrastructure at Facebook
 Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Top 25 Big Data Interview Questions And Answers
 Top 25 Big Data Interview Questions And Answers By: Neeru Jain - Big Data The era of big data has just begun. With more companies inclined towards big data to run their operations, the demand for talent
Top 25 Big Data Interview Questions And Answers By: Neeru Jain - Big Data The era of big data has just begun. With more companies inclined towards big data to run their operations, the demand for talent
MapR Enterprise Hadoop
 2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
A Review Paper on Big data & Hadoop
 A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
A Review Paper on Big data & Hadoop Rupali Jagadale MCA Department, Modern College of Engg. Modern College of Engginering Pune,India rupalijagadale02@gmail.com Pratibha Adkar MCA Department, Modern College
SQT03 Big Data and Hadoop with Azure HDInsight Andrew Brust. Senior Director, Technical Product Marketing and Evangelism
 Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Documentation. This PDF was generated for your convenience. For the latest documentation, always see
 Management Pack for AWS 1.50 Table of Contents Home... 1 Release Notes... 3 What's New in Release 1.50... 4 Known Problems and Workarounds... 5 Get started... 7 Key concepts... 8 Install... 10 Installation
Management Pack for AWS 1.50 Table of Contents Home... 1 Release Notes... 3 What's New in Release 1.50... 4 Known Problems and Workarounds... 5 Get started... 7 Key concepts... 8 Install... 10 Installation
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Amazon Search Services. Christoph Schmitter
 Amazon Search Services Christoph Schmitter csc@amazon.de What we'll cover Overview of Amazon Search Services Understand the difference between Cloudsearch and Amazon ElasticSearch Service Q&A Amazon Search
Amazon Search Services Christoph Schmitter csc@amazon.de What we'll cover Overview of Amazon Search Services Understand the difference between Cloudsearch and Amazon ElasticSearch Service Q&A Amazon Search
COSC 416 NoSQL Databases. NoSQL Databases Overview. Dr. Ramon Lawrence University of British Columbia Okanagan
 COSC 416 NoSQL Databases NoSQL Databases Overview Dr. Ramon Lawrence University of British Columbia Okanagan ramon.lawrence@ubc.ca Databases Brought Back to Life!!! Image copyright: www.dragoart.com Image
COSC 416 NoSQL Databases NoSQL Databases Overview Dr. Ramon Lawrence University of British Columbia Okanagan ramon.lawrence@ubc.ca Databases Brought Back to Life!!! Image copyright: www.dragoart.com Image
A Survey on Big Data
 A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
A Survey on Big Data D.Prudhvi 1, D.Jaswitha 2, B. Mounika 3, Monika Bagal 4 1 2 3 4 B.Tech Final Year, CSE, Dadi Institute of Engineering & Technology,Andhra Pradesh,INDIA ---------------------------------------------------------------------***---------------------------------------------------------------------
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI
 DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI Department of Information Technology IT6701 - INFORMATION MANAGEMENT Anna University 2 & 16 Mark Questions & Answers Year / Semester: IV / VII Regulation: 2013
DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI Department of Information Technology IT6701 - INFORMATION MANAGEMENT Anna University 2 & 16 Mark Questions & Answers Year / Semester: IV / VII Regulation: 2013
Big Data Infrastructure at Spotify
 Big Data Infrastructure at Spotify Wouter de Bie Team Lead Data Infrastructure September 26, 2013 2 Who am I? According to ZDNet: "The work they have done to improve the Apache Hive data warehouse system
Big Data Infrastructure at Spotify Wouter de Bie Team Lead Data Infrastructure September 26, 2013 2 Who am I? According to ZDNet: "The work they have done to improve the Apache Hive data warehouse system
CIS 601 Graduate Seminar. Dr. Sunnie S. Chung Dhruv Patel ( ) Kalpesh Sharma ( )
 Kalpesh Sharma ( )") Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL