Apache BookKeeper. A High Performance and Low Latency Storage Service
|
|
|
- Norah Chrystal Lewis
- 5 years ago
- Views:
Transcription
1 Apache BookKeeper A High Performance and Low Latency Storage Service

2 Hello! I am Sijie Guo - PMC Chair of Apache BookKeeper Co-creator of Apache DistributedLog Twitter Messaging/Pub-Sub Team Yahoo! R&D Beijing

3 Challenges in Distributed Systems

4 Expect Failures up to 10% annual failure rates for disks/servers
5 Symptoms
6 Problem 1: Not Available
7 Problem 1: Not Available
8 Problem 2: Inconsistencies
9 CAP
10 More Issues
11 Problem 3: Split Brain Writer A Two Writers Writer A Writer A Write A Write A
12 Problem 4: Failure Detection B A C
13 Problem 5: Recovery B A Consistency C Recovery Protocol
14 Solutions
15 Overview Enter Apache BookKeeper
16 BookKeeper - Durable Storage A building block for reliable systems Client Library Replication Consistency Durability Commodity Hardware Recovery

17 Ledger Abstraction
18 Ledger Segment Block / Object Append-Only File...
19 Guarantees If an entry has been acknowledged, it must be readable If an entry is read once, it must always be readable
20 History Initial Use Case - Hadoop NameNode HA 2008: Open Sourced Contrib of ZooKeeper 2011: Sub-Project of ZooKeeper 2012: Yahoo! Push Notification 2012~Now: DistributedLog, Pulsar, Majordodo 2015~Now: Salesforce Distributed Store
21 Details Inside of Apache BookKeeper
22 Architecture APP Client Metadata Store Ledger Bookie Bookie Bookie
23 Reliable Writes Bookie Store digest along with entry Fsync entries before responding Ack when Bookie Bookie All Previous Entries Accepted This Entry Quorum by
24 Consistency - LastAddPushed Writer Add entries LastAdd Pushed
25 Consistency - LastAddConfirmed Ownership Changed Writer Writer Add entries Ack Adds Fencing LastAdd Confirmed Reader LastAdd Confirmed Reader
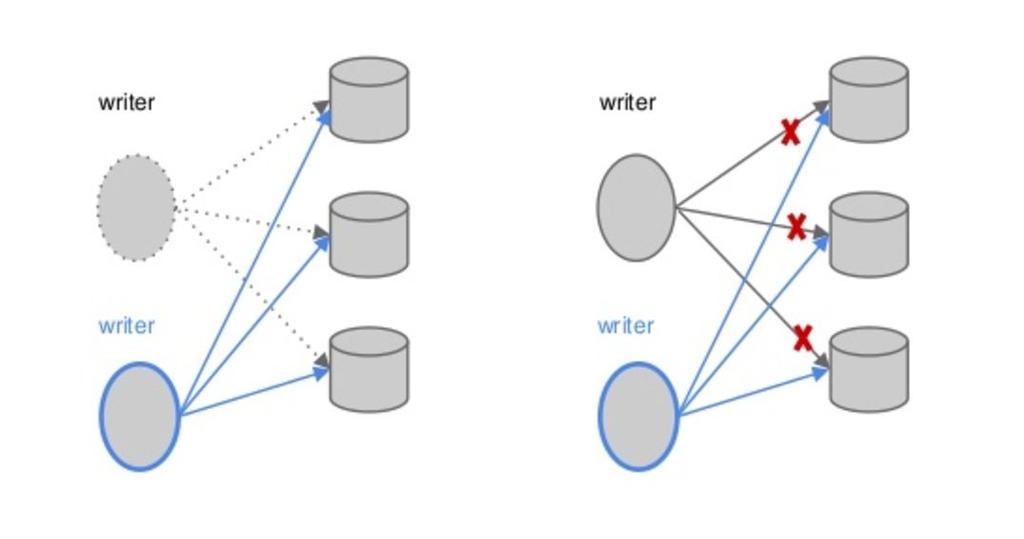
26 Fencing
27 Read Entry & Read LAC B1 Read Entry K Read LAC Client Client Speculative Reads On Timeouts Quorum Read B2 B3 B1 B2 B3
28 Long Poll Read Client Speculative Long Poll B1 Long Poll Read B2 B3

29 Inside a Bookie
30 Use Cases Apache BookKeeper as a Building Block
31 Projects built on BookKeeper Twitter: Apache DistributedLog Yahoo: Pulsar - Cloud Messaging Service Salesforce Distributed Store. Huawei - HDFS NameNode HA HubSpot - WAL Majordodo - Distributed Resource Manager

32 Apache DistributedLog (Twitter)
33 Apache DistributedLog Log Segment X Log Segment X+2 Log Segment X Oldest Newest Apache BookKeeper
34 Apache DistributedLog DBs - e.g., Twitter s Manhattan Deferred RPC (queuing) Metadata Store Write Proxy Log Streams Log Segment Store (BK) Self-serve Pub/Sub - Ownership Tracking - Batching, Compression - Abstraction & Naming - Data Management Stream Computing Cross DC Replication Record Cache Rate Limiting, Quota - Read Proxy - Efficient Write & Read - Intra-cluster & Geo Replication Cold Storage (HDFS) - Applications - Different Consumer models - Serving - Raw Streams - Segments
35 DistributedLog at Twitter Manhattan Key/Value Store - WAL Durable Deferred RPC - Journal Real-Time Search Indexing - Change Propagation Self-serve Pub/Sub - Message Delivery, Ads Pipeline Stream Computing Source & Sink Stateful Processing in Heron (coming soon) Reliable Cross Datacenter Replication
36 Scale DistributedLog at Twitter 1.5 trillion records/day, 17.5 petabytes/day O(10) thousands streams, O(1) million live ledgers O(10^2) bookies, O(10^3) proxies Records size from 100 bytes to 20 KB to even more Data is kept from hours to days, even up to a year Replication factor is 3 or 5. 9 or 15 for global use case.
37 DistributedLog Resources Website - Mail List dev@distributedlog.incubator.apache.org Project Ideas Paper - DistributedLog: A high performance replicated log service (ICDE 2017)
38 Yahoo! Pulsar (Cloud Messaging Service)
39 Yahoo! Pulsar Distributed Pub/Sub Messaging Platform Flexible Messaging Model - Topic and Queue Durable, Low Latency Strong Ordering and Consistency Guarantees Geo Replication Apache BookKeeper as Durable Message Store

40 Yahoo! Pulsar
41 Scale Pulsar at Yahoo! 100 billion messages per day More than 1.4 million topics Avg publish latency across services of less than 5ms 10+ data centers, cross-region replications

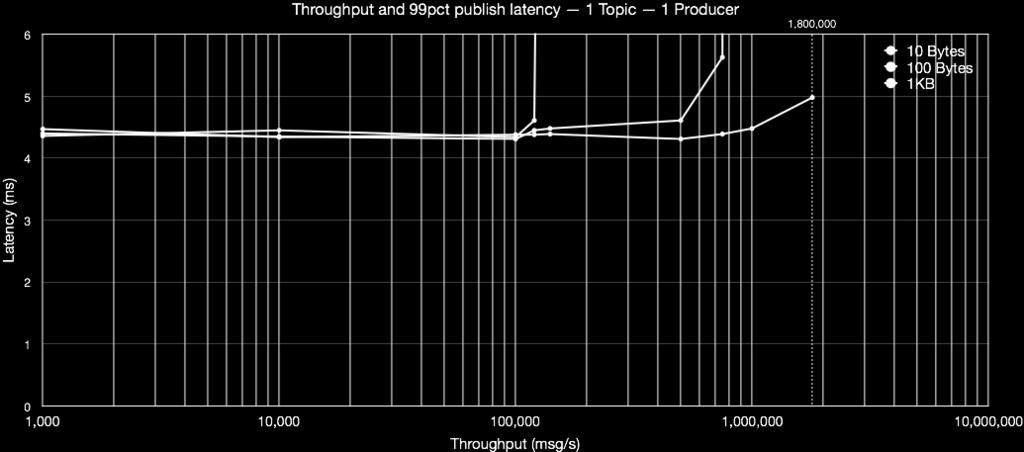

42 Pulsar Performance
43 Salesforce Distributed Store
44 Salesforce Application Storage Store for Persistent WAL, Data and Objects Low, Constant Write Latencies Low, Constant Random Read Latencies Highly Available, Consistent Distributed and Linearly Scalable On Commodity Hardware

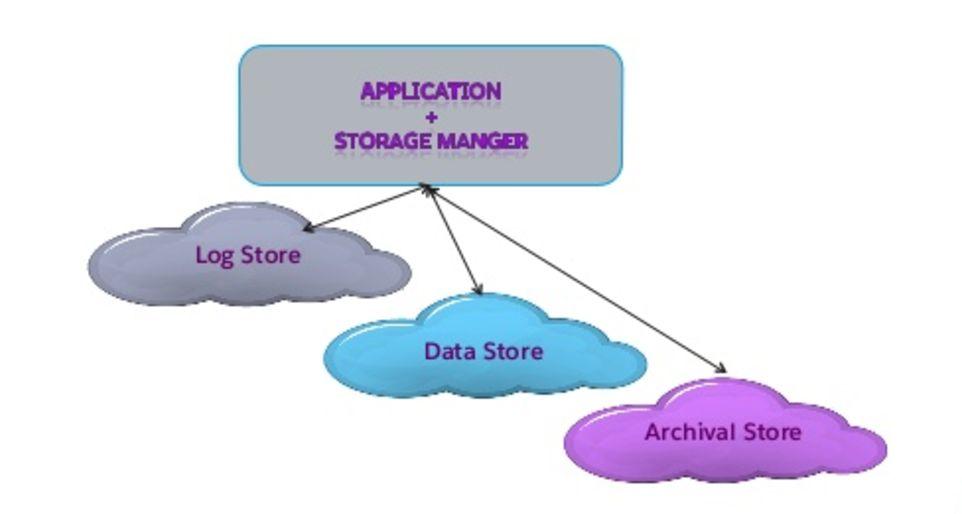
45 Heterogeneous Stores
46 Community Roadmap, Releases, Future
47 Community 7 PMC Members 10+ Committers 20+ Active Contributors 5+ Companies actively using/contributing Twitter Yahoo! Salesforce Huawei EMC
48 Release Netty 4 Upgrade - Performance Improvements Security (Authentication & Authorization) Support Explicit LAC Long Poll Read Support Auto Re-replication Improvements...
49 Future Scalable Segment Store Object, Log, File, Stream, Long Term Storage Disk Scrubber Better Lifecycle Management Beyond the limit 128 bits support Scalable metadata management
50 Thanks! Any questions? You can find me
Building Durable Real-time Data Pipeline
 Building Durable Real-time Data Pipeline Apache BookKeeper at Twitter @sijieg Twitter Background Layered Architecture Agenda Design Details Performance Scale @Twitter Q & A Publish-Subscribe Online services
Building Durable Real-time Data Pipeline Apache BookKeeper at Twitter @sijieg Twitter Background Layered Architecture Agenda Design Details Performance Scale @Twitter Q & A Publish-Subscribe Online services
Intra-cluster Replication for Apache Kafka. Jun Rao
 Intra-cluster Replication for Apache Kafka Jun Rao About myself Engineer at LinkedIn since 2010 Worked on Apache Kafka and Cassandra Database researcher at IBM Outline Overview of Kafka Kafka architecture
Intra-cluster Replication for Apache Kafka Jun Rao About myself Engineer at LinkedIn since 2010 Worked on Apache Kafka and Cassandra Database researcher at IBM Outline Overview of Kafka Kafka architecture
BookKeeper overview. Table of contents
 by Table of contents 1...2 1.1 BookKeeper introduction...2 1.2 In slightly more detail...2 1.3 Bookkeeper elements and concepts... 3 1.4 Bookkeeper initial design... 3 1.5 Bookkeeper metadata management...
by Table of contents 1...2 1.1 BookKeeper introduction...2 1.2 In slightly more detail...2 1.3 Bookkeeper elements and concepts... 3 1.4 Bookkeeper initial design... 3 1.5 Bookkeeper metadata management...
Namenode HA. Sanjay Radia - Hortonworks
 Namenode HA Sanjay Radia - Hortonworks Sanjay Radia - Background Working on Hadoop for the last 4 years Part of the original team at Yahoo Primarily worked on HDFS, MR Capacity scheduler wire protocols,
Namenode HA Sanjay Radia - Hortonworks Sanjay Radia - Background Working on Hadoop for the last 4 years Part of the original team at Yahoo Primarily worked on HDFS, MR Capacity scheduler wire protocols,
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduc)on to Apache Ka1a. Jun Rao Co- founder of Confluent
on to Apache Ka1a. Jun Rao Co- founder of Confluent") Introduc)on to Apache Ka1a Jun Rao Co- founder of Confluent Agenda Why people use Ka1a Technical overview of Ka1a What s coming What s Apache Ka1a Distributed, high throughput pub/sub system Ka1a Usage
Introduc)on to Apache Ka1a Jun Rao Co- founder of Confluent Agenda Why people use Ka1a Technical overview of Ka1a What s coming What s Apache Ka1a Distributed, high throughput pub/sub system Ka1a Usage
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
HDFS What is New and Futures
 HDFS What is New and Futures Sanjay Radia, Founder, Architect Suresh Srinivas, Founder, Architect Hortonworks Inc. Page 1 About me Founder, Architect, Hortonworks Part of the Hadoop team at Yahoo! since
HDFS What is New and Futures Sanjay Radia, Founder, Architect Suresh Srinivas, Founder, Architect Hortonworks Inc. Page 1 About me Founder, Architect, Hortonworks Part of the Hadoop team at Yahoo! since
Improving efficiency of Twitter Infrastructure using Chargeback
 Improving efficiency of Twitter Infrastructure using Chargeback @vinucharanya @micheal AGENDA Brief History Problem Chargeback Engineering Challenges The product Impact Future Getty Images from http://www.fifa.com/worldcup/news/y=2010/m=7/news=pride-for-africa-spain-strike-gold-2247372.html
Improving efficiency of Twitter Infrastructure using Chargeback @vinucharanya @micheal AGENDA Brief History Problem Chargeback Engineering Challenges The product Impact Future Getty Images from http://www.fifa.com/worldcup/news/y=2010/m=7/news=pride-for-africa-spain-strike-gold-2247372.html
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Tools for Social Networking Infrastructures
 Tools for Social Networking Infrastructures 1 Cassandra - a decentralised structured storage system Problem : Facebook Inbox Search hundreds of millions of users distributed infrastructure inbox changes
Tools for Social Networking Infrastructures 1 Cassandra - a decentralised structured storage system Problem : Facebook Inbox Search hundreds of millions of users distributed infrastructure inbox changes
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
Apache Hadoop Goes Realtime at Facebook. Himanshu Sharma
 Apache Hadoop Goes Realtime at Facebook Guide - Dr. Sunny S. Chung Presented By- Anand K Singh Himanshu Sharma Index Problem with Current Stack Apache Hadoop and Hbase Zookeeper Applications of HBase at
Apache Hadoop Goes Realtime at Facebook Guide - Dr. Sunny S. Chung Presented By- Anand K Singh Himanshu Sharma Index Problem with Current Stack Apache Hadoop and Hbase Zookeeper Applications of HBase at
4/9/2018 Week 13-A Sangmi Lee Pallickara. CS435 Introduction to Big Data Spring 2018 Colorado State University. FAQs. Architecture of GFS
 W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia,
 Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
The State of Apache HBase. Michael Stack
 The State of Apache HBase Michael Stack Michael Stack Chair of the Apache HBase PMC* Caretaker/Janitor Member of the Hadoop PMC Engineer at Cloudera in SF * Project Management
The State of Apache HBase Michael Stack Michael Stack Chair of the Apache HBase PMC* Caretaker/Janitor Member of the Hadoop PMC Engineer at Cloudera in SF * Project Management
Durability for Memory-Based Key-Value Stores
 Durability for Memory-Based Key-Value Stores Kiarash Rezahanjani Dissertation for European Master in Distributed Computing Programme Supervisor: Tutor: Flavio Junqueira Yolanda Becerra Júri President:
Durability for Memory-Based Key-Value Stores Kiarash Rezahanjani Dissertation for European Master in Distributed Computing Programme Supervisor: Tutor: Flavio Junqueira Yolanda Becerra Júri President:
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Automatic-Hot HA for HDFS NameNode Konstantin V Shvachko Ari Flink Timothy Coulter EBay Cisco Aisle Five. November 11, 2011
 Automatic-Hot HA for HDFS NameNode Konstantin V Shvachko Ari Flink Timothy Coulter EBay Cisco Aisle Five November 11, 2011 About Authors Konstantin Shvachko Hadoop Architect, ebay; Hadoop Committer Ari
Automatic-Hot HA for HDFS NameNode Konstantin V Shvachko Ari Flink Timothy Coulter EBay Cisco Aisle Five November 11, 2011 About Authors Konstantin Shvachko Hadoop Architect, ebay; Hadoop Committer Ari
Pulsar. Realtime Analytics At Scale. Wang Xinglang
 Pulsar Realtime Analytics At Scale Wang Xinglang Agenda Pulsar : Real Time Analytics At ebay Business Use Cases Product Requirements Pulsar : Technology Deep Dive 2 Pulsar Business Use Case: Behavioral
Pulsar Realtime Analytics At Scale Wang Xinglang Agenda Pulsar : Real Time Analytics At ebay Business Use Cases Product Requirements Pulsar : Technology Deep Dive 2 Pulsar Business Use Case: Behavioral
Using the SDACK Architecture to Build a Big Data Product. Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver
 Apache Big Data NA 2016 Vancouver") Using the SDACK Architecture to Build a Big Data Product Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver Outline A Threat Analytic Big Data product The SDACK Architecture Akka Streams and data
Using the SDACK Architecture to Build a Big Data Product Yu-hsin Yeh (Evans Ye) Apache Big Data NA 2016 Vancouver Outline A Threat Analytic Big Data product The SDACK Architecture Akka Streams and data
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
Cloud Computing at Yahoo! Thomas Kwan Director, Research Operations Yahoo! Labs
 Cloud Computing at Yahoo! Thomas Kwan Director, Research Operations Yahoo! Labs Overview Cloud Strategy Cloud Services Cloud Research Partnerships - 2 - Yahoo! Cloud Strategy 1. Optimizing for Yahoo-scale
Cloud Computing at Yahoo! Thomas Kwan Director, Research Operations Yahoo! Labs Overview Cloud Strategy Cloud Services Cloud Research Partnerships - 2 - Yahoo! Cloud Strategy 1. Optimizing for Yahoo-scale
A New Key-value Data Store For Heterogeneous Storage Architecture Intel APAC R&D Ltd.
 A New Key-value Data Store For Heterogeneous Storage Architecture Intel APAC R&D Ltd. 1 Agenda Introduction Background and Motivation Hybrid Key-Value Data Store Architecture Overview Design details Performance
A New Key-value Data Store For Heterogeneous Storage Architecture Intel APAC R&D Ltd. 1 Agenda Introduction Background and Motivation Hybrid Key-Value Data Store Architecture Overview Design details Performance
Distributed Systems. Tutorial 9 Windows Azure Storage
 Distributed Systems Tutorial 9 Windows Azure Storage written by Alex Libov Based on SOSP 2011 presentation winter semester, 2011-2012 Windows Azure Storage (WAS) A scalable cloud storage system In production
Distributed Systems Tutorial 9 Windows Azure Storage written by Alex Libov Based on SOSP 2011 presentation winter semester, 2011-2012 Windows Azure Storage (WAS) A scalable cloud storage system In production
Streaming Log Analytics with Kafka
 Streaming Log Analytics with Kafka Kresten Krab Thorup, Humio CTO Log Everything, Answer Anything, In Real-Time. Why this talk? Humio is a Log Analytics system Designed to run on-prem High volume, real
Streaming Log Analytics with Kafka Kresten Krab Thorup, Humio CTO Log Everything, Answer Anything, In Real-Time. Why this talk? Humio is a Log Analytics system Designed to run on-prem High volume, real
Apache Hadoop.Next What it takes and what it means
 Apache Hadoop.Next What it takes and what it means Arun C. Murthy Founder & Architect, Hortonworks @acmurthy (@hortonworks) Page 1 Hello! I m Arun Founder/Architect at Hortonworks Inc. Lead, Map-Reduce
Apache Hadoop.Next What it takes and what it means Arun C. Murthy Founder & Architect, Hortonworks @acmurthy (@hortonworks) Page 1 Hello! I m Arun Founder/Architect at Hortonworks Inc. Lead, Map-Reduce
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
CCA-410. Cloudera. Cloudera Certified Administrator for Apache Hadoop (CCAH)
") Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
11/5/2018 Week 12-A Sangmi Lee Pallickara. CS435 Introduction to Big Data FALL 2018 Colorado State University
 11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.0.0 CS435 Introduction to Big Data 11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.1 Consider a Graduate Degree in Computer Science
11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.0.0 CS435 Introduction to Big Data 11/5/2018 CS435 Introduction to Big Data - FALL 2018 W12.A.1 Consider a Graduate Degree in Computer Science
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
The Google File System Sanjay Ghemawat, Howard Gobioff and Shun Tak Leung Google* Shivesh Kumar Sharma fl4164@wayne.edu Fall 2015 004395771 Overview Google file system is a scalable distributed file system
GridGain and Apache Ignite In-Memory Performance with Durability of Disk
 GridGain and Apache Ignite In-Memory Performance with Durability of Disk Dmitriy Setrakyan Apache Ignite PMC GridGain Founder & CPO http://ignite.apache.org #apacheignite Agenda What is GridGain and Ignite
GridGain and Apache Ignite In-Memory Performance with Durability of Disk Dmitriy Setrakyan Apache Ignite PMC GridGain Founder & CPO http://ignite.apache.org #apacheignite Agenda What is GridGain and Ignite
Data Storage Revolution
 Data Storage Revolution Relational Databases Object Storage (put/get) Dynamo PNUTS CouchDB MemcacheDB Cassandra Speed Scalability Availability Throughput No Complexity Eventual Consistency Write Request
Data Storage Revolution Relational Databases Object Storage (put/get) Dynamo PNUTS CouchDB MemcacheDB Cassandra Speed Scalability Availability Throughput No Complexity Eventual Consistency Write Request
Kafka Connect the Dots
 Kafka Connect the Dots Building Oracle Change Data Capture Pipelines With Kafka Mike Donovan CTO Dbvisit Software Mike Donovan Chief Technology Officer, Dbvisit Software Multi-platform DBA, (Oracle, MSSQL..)
Kafka Connect the Dots Building Oracle Change Data Capture Pipelines With Kafka Mike Donovan CTO Dbvisit Software Mike Donovan Chief Technology Officer, Dbvisit Software Multi-platform DBA, (Oracle, MSSQL..)
CIT 668: System Architecture. Amazon Web Services
 CIT 668: System Architecture Amazon Web Services Topics 1. AWS Global Infrastructure 2. Foundation Services 1. Compute 2. Storage 3. Database 4. Network 3. AWS Economics Amazon Services Architecture Regions
CIT 668: System Architecture Amazon Web Services Topics 1. AWS Global Infrastructure 2. Foundation Services 1. Compute 2. Storage 3. Database 4. Network 3. AWS Economics Amazon Services Architecture Regions
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
PRESENTATION TITLE GOES HERE. Understanding Architectural Trade-offs in Object Storage Technologies
 Object Storage 201 PRESENTATION TITLE GOES HERE Understanding Architectural Trade-offs in Object Storage Technologies SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA
Object Storage 201 PRESENTATION TITLE GOES HERE Understanding Architectural Trade-offs in Object Storage Technologies SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA
ZooKeeper. Table of contents
 by Table of contents 1 ZooKeeper: A Distributed Coordination Service for Distributed Applications... 2 1.1 Design Goals... 2 1.2 Data model and the hierarchical namespace... 3 1.3 Nodes and ephemeral nodes...
by Table of contents 1 ZooKeeper: A Distributed Coordination Service for Distributed Applications... 2 1.1 Design Goals... 2 1.2 Data model and the hierarchical namespace... 3 1.3 Nodes and ephemeral nodes...
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
L5-6:Runtime Platforms Hadoop and HDFS
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences SE256:Jan16 (2:1) L5-6:Runtime Platforms Hadoop and HDFS Yogesh Simmhan 03/
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences SE256:Jan16 (2:1) L5-6:Runtime Platforms Hadoop and HDFS Yogesh Simmhan 03/
A Distributed System Case Study: Apache Kafka. High throughput messaging for diverse consumers
 A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
ZooKeeper & Curator. CS 475, Spring 2018 Concurrent & Distributed Systems
 ZooKeeper & Curator CS 475, Spring 2018 Concurrent & Distributed Systems Review: Agreement In distributed systems, we have multiple nodes that need to all agree that some object has some state Examples:
ZooKeeper & Curator CS 475, Spring 2018 Concurrent & Distributed Systems Review: Agreement In distributed systems, we have multiple nodes that need to all agree that some object has some state Examples:
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Yuval Carmel Tel-Aviv University "Advanced Topics in Storage Systems" - Spring 2013
 Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Yuval Carmel Tel-Aviv University "Advanced Topics in About & Keywords Motivation & Purpose Assumptions Architecture overview & Comparison Measurements How does it fit in? The Future 2 About & Keywords
Ambry: LinkedIn s Scalable Geo- Distributed Object Store
 Ambry: LinkedIn s Scalable Geo- Distributed Object Store Shadi A. Noghabi *, Sriram Subramanian +, Priyesh Narayanan +, Sivabalan Narayanan +, Gopalakrishna Holla +, Mammad Zadeh +, Tianwei Li +, Indranil
Ambry: LinkedIn s Scalable Geo- Distributed Object Store Shadi A. Noghabi *, Sriram Subramanian +, Priyesh Narayanan +, Sivabalan Narayanan +, Gopalakrishna Holla +, Mammad Zadeh +, Tianwei Li +, Indranil
Scaling for Humongous amounts of data with MongoDB
 Scaling for Humongous amounts of data with MongoDB Alvin Richards Technical Director, EMEA alvin@10gen.com @jonnyeight alvinonmongodb.com From here... http://bit.ly/ot71m4 ...to here... http://bit.ly/oxcsis
Scaling for Humongous amounts of data with MongoDB Alvin Richards Technical Director, EMEA alvin@10gen.com @jonnyeight alvinonmongodb.com From here... http://bit.ly/ot71m4 ...to here... http://bit.ly/oxcsis
! Design constraints. " Component failures are the norm. " Files are huge by traditional standards. ! POSIX-like
 Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
CSE-E5430 Scalable Cloud Computing Lecture 9
 CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
HDFS Design Principles
 HDFS Design Principles The Scale-out-Ability of Distributed Storage SVForum Software Architecture & Platform SIG Konstantin V. Shvachko May 23, 2012 Big Data Computations that need the power of many computers
HDFS Design Principles The Scale-out-Ability of Distributed Storage SVForum Software Architecture & Platform SIG Konstantin V. Shvachko May 23, 2012 Big Data Computations that need the power of many computers
YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores
 YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores Swapnil Patil Milo Polte, Wittawat Tantisiriroj, Kai Ren, Lin Xiao, Julio Lopez, Garth Gibson, Adam Fuchs *, Billie
YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores Swapnil Patil Milo Polte, Wittawat Tantisiriroj, Kai Ren, Lin Xiao, Julio Lopez, Garth Gibson, Adam Fuchs *, Billie
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
Data Storage Infrastructure at Facebook
 Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Strata: A Cross Media File System. Youngjin Kwon, Henrique Fingler, Tyler Hunt, Simon Peter, Emmett Witchel, Thomas Anderson
 A Cross Media File System Youngjin Kwon, Henrique Fingler, Tyler Hunt, Simon Peter, Emmett Witchel, Thomas Anderson 1 Let s build a fast server NoSQL store, Database, File server, Mail server Requirements
A Cross Media File System Youngjin Kwon, Henrique Fingler, Tyler Hunt, Simon Peter, Emmett Witchel, Thomas Anderson 1 Let s build a fast server NoSQL store, Database, File server, Mail server Requirements
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung December 2003 ACM symposium on Operating systems principles Publisher: ACM Nov. 26, 2008 OUTLINE INTRODUCTION DESIGN OVERVIEW
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler
 The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
The Hadoop Distributed File System Konstantin Shvachko Hairong Kuang Sanjay Radia Robert Chansler MSST 10 Hadoop in Perspective Hadoop scales computation capacity, storage capacity, and I/O bandwidth by
Look Up! Your Future is in the Cloud
 Look Up! Your Future is in the Cloud What is the Cloud? Data centers at scale networked elastic computation big data ISP Telecom ISP 2 Paradigm Shift Single computer to clusters + mobile 3 Batch and Interactive
Look Up! Your Future is in the Cloud What is the Cloud? Data centers at scale networked elastic computation big data ISP Telecom ISP 2 Paradigm Shift Single computer to clusters + mobile 3 Batch and Interactive
Before proceeding with this tutorial, you must have a good understanding of Core Java and any of the Linux flavors.
 About the Tutorial Storm was originally created by Nathan Marz and team at BackType. BackType is a social analytics company. Later, Storm was acquired and open-sourced by Twitter. In a short time, Apache
About the Tutorial Storm was originally created by Nathan Marz and team at BackType. BackType is a social analytics company. Later, Storm was acquired and open-sourced by Twitter. In a short time, Apache
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CGAR: Strong Consistency without Synchronous Replication. Seo Jin Park Advised by: John Ousterhout
 CGAR: Strong Consistency without Synchronous Replication Seo Jin Park Advised by: John Ousterhout Improved update performance of storage systems with master-back replication Fast: updates complete before
CGAR: Strong Consistency without Synchronous Replication Seo Jin Park Advised by: John Ousterhout Improved update performance of storage systems with master-back replication Fast: updates complete before
Transformation-free Data Pipelines by combining the Power of Apache Kafka and the Flexibility of the ESB's
 Building Agile and Resilient Schema Transformations using Apache Kafka and ESB's Transformation-free Data Pipelines by combining the Power of Apache Kafka and the Flexibility of the ESB's Ricardo Ferreira
Building Agile and Resilient Schema Transformations using Apache Kafka and ESB's Transformation-free Data Pipelines by combining the Power of Apache Kafka and the Flexibility of the ESB's Ricardo Ferreira
How we scaled push messaging for millions of Netflix devices. Susheel Aroskar Cloud Gateway
 How we scaled push messaging for millions of Netflix devices Susheel Aroskar Cloud Gateway Why do we need push? How I spend my time in Netflix application... What is push? What is push? How you can build
How we scaled push messaging for millions of Netflix devices Susheel Aroskar Cloud Gateway Why do we need push? How I spend my time in Netflix application... What is push? What is push? How you can build
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
Making Non-Distributed Databases, Distributed. Ioannis Papapanagiotou, PhD Shailesh Birari
 Making Non-Distributed Databases, Distributed Ioannis Papapanagiotou, PhD Shailesh Birari Dynomite Ecosystem Dynomite - Proxy layer Dyno - Client Dynomite-manager - Ecosystem orchestrator Dynomite-explorer
Making Non-Distributed Databases, Distributed Ioannis Papapanagiotou, PhD Shailesh Birari Dynomite Ecosystem Dynomite - Proxy layer Dyno - Client Dynomite-manager - Ecosystem orchestrator Dynomite-explorer
ECS ARCHITECTURE DEEP DIVE #EMCECS. Copyright 2015 EMC Corporation. All rights reserved.
 ECS ARCHITECTURE DEEP DIVE 1 BOOKING HOTEL IN 1960 2 TODAY! 3 MODERN APPS ARE CHANGING INDUSTRIES 4 @scale unstructured global accessible web many devices 5 MODERN APPS ARE CHANGING INDUSTRIES 6 MODERN
ECS ARCHITECTURE DEEP DIVE 1 BOOKING HOTEL IN 1960 2 TODAY! 3 MODERN APPS ARE CHANGING INDUSTRIES 4 @scale unstructured global accessible web many devices 5 MODERN APPS ARE CHANGING INDUSTRIES 6 MODERN
WHITE PAPER. Reference Guide for Deploying and Configuring Apache Kafka
 WHITE PAPER Reference Guide for Deploying and Configuring Apache Kafka Revised: 02/2015 Table of Content 1. Introduction 3 2. Apache Kafka Technology Overview 3 3. Common Use Cases for Kafka 4 4. Deploying
WHITE PAPER Reference Guide for Deploying and Configuring Apache Kafka Revised: 02/2015 Table of Content 1. Introduction 3 2. Apache Kafka Technology Overview 3 3. Common Use Cases for Kafka 4 4. Deploying
Dynamic Reconfiguration of Primary/Backup Clusters
 Dynamic Reconfiguration of Primary/Backup Clusters (Apache ZooKeeper) Alex Shraer Yahoo! Research In collaboration with: Benjamin Reed Dahlia Malkhi Flavio Junqueira Yahoo! Research Microsoft Research
Dynamic Reconfiguration of Primary/Backup Clusters (Apache ZooKeeper) Alex Shraer Yahoo! Research In collaboration with: Benjamin Reed Dahlia Malkhi Flavio Junqueira Yahoo! Research Microsoft Research
Microservices Lessons Learned From a Startup Perspective
 Microservices Lessons Learned From a Startup Perspective Susanne Kaiser @suksr CTO at Just Software @JustSocialApps Each journey is different People try to copy Netflix, but they can only copy what they
Microservices Lessons Learned From a Startup Perspective Susanne Kaiser @suksr CTO at Just Software @JustSocialApps Each journey is different People try to copy Netflix, but they can only copy what they
Engineering Goals. Scalability Availability. Transactional behavior Security EAI... CS530 S05
 Engineering Goals Scalability Availability Transactional behavior Security EAI... Scalability How much performance can you get by adding hardware ($)? Performance perfect acceptable unacceptable Processors
Engineering Goals Scalability Availability Transactional behavior Security EAI... Scalability How much performance can you get by adding hardware ($)? Performance perfect acceptable unacceptable Processors
EVCache: Lowering Costs for a Low Latency Cache with RocksDB. Scott Mansfield Vu Nguyen EVCache
 EVCache: Lowering Costs for a Low Latency Cache with RocksDB Scott Mansfield Vu Nguyen EVCache 90 seconds What do caches touch? Signing up* Logging in Choosing a profile Picking liked videos
EVCache: Lowering Costs for a Low Latency Cache with RocksDB Scott Mansfield Vu Nguyen EVCache 90 seconds What do caches touch? Signing up* Logging in Choosing a profile Picking liked videos
Apache Hadoop 3. Balazs Gaspar Sales Engineer CEE & CIS Cloudera, Inc. All rights reserved.
 Apache Hadoop 3 Balazs Gaspar Sales Engineer CEE & CIS balazs@cloudera.com 1 We believe data can make what is impossible today, possible tomorrow 2 We empower people to transform complex data into clear
Apache Hadoop 3 Balazs Gaspar Sales Engineer CEE & CIS balazs@cloudera.com 1 We believe data can make what is impossible today, possible tomorrow 2 We empower people to transform complex data into clear
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
PNUTS and Weighted Voting. Vijay Chidambaram CS 380 D (Feb 8)
") PNUTS and Weighted Voting Vijay Chidambaram CS 380 D (Feb 8) PNUTS Distributed database built by Yahoo Paper describes a production system Goals: Scalability Low latency, predictable latency Must handle
PNUTS and Weighted Voting Vijay Chidambaram CS 380 D (Feb 8) PNUTS Distributed database built by Yahoo Paper describes a production system Goals: Scalability Low latency, predictable latency Must handle
VOLTDB + HP VERTICA. page
 VOLTDB + HP VERTICA ARCHITECTURE FOR FAST AND BIG DATA ARCHITECTURE FOR FAST + BIG DATA FAST DATA Fast Serve Analytics BIG DATA BI Reporting Fast Operational Database Streaming Analytics Columnar Analytics
VOLTDB + HP VERTICA ARCHITECTURE FOR FAST AND BIG DATA ARCHITECTURE FOR FAST + BIG DATA FAST DATA Fast Serve Analytics BIG DATA BI Reporting Fast Operational Database Streaming Analytics Columnar Analytics
Building LinkedIn s Real-time Data Pipeline. Jay Kreps
 Building LinkedIn s Real-time Data Pipeline Jay Kreps What is a data pipeline? What data is there? Database data Activity data Page Views, Ad Impressions, etc Messaging JMS, AMQP, etc Application and
Building LinkedIn s Real-time Data Pipeline Jay Kreps What is a data pipeline? What data is there? Database data Activity data Page Views, Ad Impressions, etc Messaging JMS, AMQP, etc Application and
Big Data XML Parsing in Pentaho Data Integration (PDI)
") Big Data XML Parsing in Pentaho Data Integration (PDI) Change log (if you want to use it): Date Version Author Changes Contents Overview... 1 Before You Begin... 1 Terms You Should Know... 1 Selecting
Big Data XML Parsing in Pentaho Data Integration (PDI) Change log (if you want to use it): Date Version Author Changes Contents Overview... 1 Before You Begin... 1 Terms You Should Know... 1 Selecting
Rapid Automated Indication of Link-Loss
 Rapid Automated Indication of Link-Loss Fast recovery of failures is becoming a hot topic of discussion for many of today s Big Data applications such as Hadoop, HBase, Cassandra, MongoDB, MySQL, MemcacheD
Rapid Automated Indication of Link-Loss Fast recovery of failures is becoming a hot topic of discussion for many of today s Big Data applications such as Hadoop, HBase, Cassandra, MongoDB, MySQL, MemcacheD
RA-GRS, 130 replication support, ZRS, 130
 Index A, B Agile approach advantages, 168 continuous software delivery, 167 definition, 167 disadvantages, 169 sprints, 167 168 Amazon Web Services (AWS) failure, 88 CloudTrail Service, 21 CloudWatch Service,
Index A, B Agile approach advantages, 168 continuous software delivery, 167 definition, 167 disadvantages, 169 sprints, 167 168 Amazon Web Services (AWS) failure, 88 CloudTrail Service, 21 CloudWatch Service,
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
by Dhruba Borthakur Table of contents 1 Introduction...3 2 Assumptions and Goals...3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets...3 2.4 Simple Coherency Model... 4 2.5
PNUTS: Yahoo! s Hosted Data Serving Platform. Reading Review by: Alex Degtiar (adegtiar) /30/2013
 /30/2013") PNUTS: Yahoo! s Hosted Data Serving Platform Reading Review by: Alex Degtiar (adegtiar) 15-799 9/30/2013 What is PNUTS? Yahoo s NoSQL database Motivated by web applications Massively parallel Geographically
PNUTS: Yahoo! s Hosted Data Serving Platform Reading Review by: Alex Degtiar (adegtiar) 15-799 9/30/2013 What is PNUTS? Yahoo s NoSQL database Motivated by web applications Massively parallel Geographically
HDFS Federation. Sanjay Radia Founder and Hortonworks. Page 1
 HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
Distributed Systems CS6421
 Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Distributed Systems CS6421 Intro to Distributed Systems and the Cloud Prof. Tim Wood v I teach: Software Engineering, Operating Systems, Sr. Design I like: distributed systems, networks, building cool
Staggeringly Large Filesystems
 Staggeringly Large Filesystems Evan Danaher CS 6410 - October 27, 2009 Outline 1 Large Filesystems 2 GFS 3 Pond Outline 1 Large Filesystems 2 GFS 3 Pond Internet Scale Web 2.0 GFS Thousands of machines
Staggeringly Large Filesystems Evan Danaher CS 6410 - October 27, 2009 Outline 1 Large Filesystems 2 GFS 3 Pond Outline 1 Large Filesystems 2 GFS 3 Pond Internet Scale Web 2.0 GFS Thousands of machines
Machine Learning meets Databases. Ioannis Papapanagiotou Cloud Database Engineering
 Machine Learning meets Databases Ioannis Papapanagiotou Cloud Database Engineering Create Personalized Recommendations for discoveries of engaging video content that maximizes member joy. Personalize Everything
Machine Learning meets Databases Ioannis Papapanagiotou Cloud Database Engineering Create Personalized Recommendations for discoveries of engaging video content that maximizes member joy. Personalize Everything
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce