CME 213 S PRING Eric Darve
|
|
|
- Abel Jackson
- 6 years ago
- Views:
Transcription
1 CME 213 S PRING 2017 Eric Darve
2 Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and scheduling (static, dynamic) Reduction and atomic Data layout and vectorization (SoA vs AoS) Arithmetic intensity and roofline model NUMA and first-touch allocation
3 GPU computing!
4 Performance numbers (Karl Rupp) Years of Microprocessor Trend Data Transistors (thousands) Single-Thread Performance (SpecINT x 10 3 ) Frequency (MHz) Typical Power (Watts) Number of Logical Cores Year Original data up to the year 2010 collected and plotted by M. Horowitz, F. Labonte, O. Shacham, K. Olukotun, L. Hammond, and C. Batten New plot and data collected for by K. Rupp
5 Key to performance: lots of cores! 10 2 Number of Physical Cores/Multiprocessors, High-End Hardware Xeon Phi 7120 (KNC) Xeon Phi 7290 (KNL) Physical Cores/Multiprocessors GTS HD 3870 GTX 280 HD 4870 GTX 285 HD 5870 HD 6970 GTX 580 X5680 HD 6970 HD 7970 GHz Ed. HD 8970 GTX 580 GTX 680 GTX Titan X5690 E E v2 FirePro W9100 E v3 FirePro S9150 GTX Titan X Tesla K40 E v3 Tesla P100 E v X5482 X5492 W5590 INTEL Xeon CPUs NVIDIA GeForce GPUs AMD Radeon GPUs INTEL Xeon Phis End of Year
6 Peak performance: single precision GFLOP/sec GTS HD 3870 X5482 HD 4870 HD 5870 GTX 280 GTX 285 X5492 W5590 Theoretical Peak Performance, Single Precision HD 6970 GTX 580 X5680 HD 6970 HD 7970 GHz Ed. GTX 580 GTX 680 X5690 E GTX Titan HD 8970 FirePro W9100 E v2 Tesla K40 Xeon Phi 7120 (KNC) E v3 FirePro S9150 E v3 INTEL Xeon CPUs NVIDIA GeForce GPUs GTX Titan X NVIDIA Titan X Xeon Phi 7290 (KNL) E v4 AMD Radeon GPUs INTEL Xeon Phis End of Year
7 Memory is key for many applications GB/sec HD 3870 X5482 HD 4870 HD 5870 Tesla C1060 X5492 Theoretical Peak Memory Bandwidth Comparison HD 6970 Tesla C1060 Tesla C2050Tesla M2090 W5590 X5680 HD 6970HD 7970 GHz Ed. X End of Year Tesla K20 E HD 8970 FirePro W9100 E v2 E v3 Tesla K40 Xeon Phi 7120 (KNC) Tesla K20X FirePro S9150 E v3 INTEL Xeon CPUs NVIDIA Tesla GPUs AMD Radeon GPUs INTEL Xeon Phis Tesla P100 Xeon Phi 7290 (KNL) E v4
8 To build supercomputers, perf/watt is the relevant metric 10 2 Theoretical Peak Floating Point Operations per Watt, Single Precision GFLOP/sec per Watt 10 1 HD GTS HD 4870 GTX 280 HD 5870 GTX 285 HD 6970 GTX 580 HD 6970 HD 7970 GHz Ed. GTX Titan GTX 580 GTX 680 E E v2 Tesla K40 HD 8970 FirePro W9100 FirePro S9150 Xeon Phi 7120 (KNC) E v3 GTX Titan XNVIDIA Titan X Xeon Phi 7290 (KNL) E v3 E v X5482 X5492 W5590 X5680 X5690 INTEL Xeon CPUs NVIDIA GeForce GPUs AMD Radeon GPUs INTEL Xeon Phis End of Year
9 Arithmetic intensity: are you memory or compute bound? Theoretical Peak Floating Point Operations per Byte, Double Precision FLOP per Byte 10 1 Xeon Phi 7120 (KNC) X5482 HD 5870 HD 6970 X5492 Tesla C2050 HD 6970 Tesla M2090 Tesla K20 E v3 HD 3870 HD 4870 FirePro W9100 W5590 Tesla K20X E v3 E v2 E FirePro S9150 X5680 E v4 X5690 HD 7970 GHz Ed. Tesla C1060 HD 8970 Tesla K40 Tesla P100 Tesla C1060 Tesla K40 Xeon Phi 7290 (KNL) INTEL Xeon CPUs NVIDIA Tesla GPUs AMD Radeon GPUs INTEL Xeon Phis End of Year
10 pol

11

12 Performance for scientific applications Example: Tesla P teraflops double-precision performance 10.6 teraflops single-precision performance 732 GB/sec memory bandwidth
13 Performance of P100 Deep Learning Quantum Mechanics Particle Weather Quantum ChromoDynamics Molecular Dynamics Cosmology
14 Alphago 1,202 CPUs and 176 GPUs
15 What is the technology behind GPU processors?

16 It s started with 3D graphics
17 Parallelism For graphics rendering, GPUs can reach amazing performance. Characteristics of calculations: Simple arithmetic operations at each pixel Large amounts of parallelism Same operation needs to be performed on many different elements Graphics processing sounds a lot like scientific computing!

18 Multicore processors The mean giant. A fast processor because: Pipelining of execution Out of order execution Branch prediction Pre-fetching Large amount of multilevel cache Hyperthreading Fast and general; does not assume anything about the computation.

19 Streaming processors, e.g., GPUs The ants model Many computing units operating in parallel Ideal for simple but repetitive tasks. Example: Dense linear algebra Finite-difference Finite-element Neural network Large data set processing Bad when calculation involves significant branching, e.g., each thread is doing something different
20 How is this possible? There has to be a trade-off. More computing units means you need to give up something: No processor space is dedicated to complex optimizations, e.g., outof-order execution Cache space is limited because it has to be shared amongst the threads Light threads: hardware supports the ability to switch threads every cycle; this allows a large number of threads in-flight or live Limited logic for program control: 32 threads are grouped into warps; all threads in warp execute the same instruction at the same time. Each computing unit is less powerful but there are more of them.
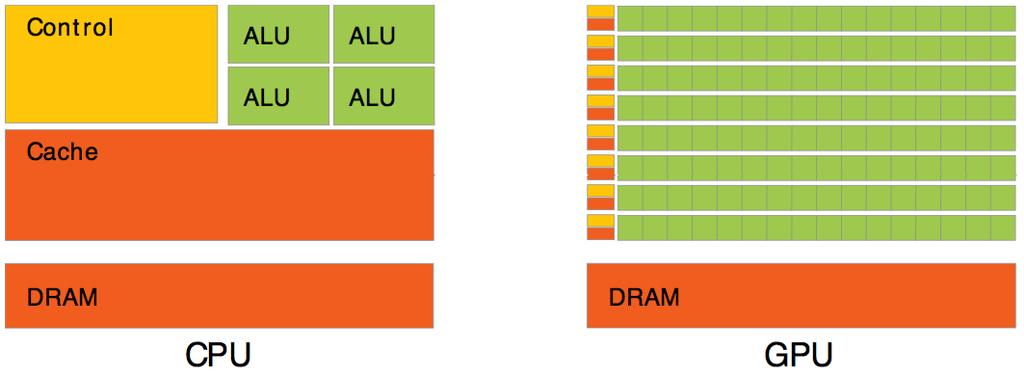
21
22 Modern processors Intel Xeon Specialization Intel Xeon Phi Performance NVIDIA Tesla
23 Short History of NVIDIA GPU architectures G70: 2006 Tesla: 2006 Fermi: 2010 Kepler: 2012 Maxwell: 2014 Pascal: 2016

24

25 Certainty What we have: Fermi M2050; 4 GPUs/node Release date: July 2011 Clock rate: GHz 14 multiprocessors 448 cores Total global memory: 2.8 GB Bandwidth: 148 GB/sec Peak performance: single 1.03 Tflop/sec; double 515 Gflop/sec Compute capability: 2.0
26 Host and coprocessor Xeon Phi accelerators support a full-fledged operating system like Linux. NVIDIA GPUs are different. They only work as a co-processor. This means you need a host processor (e.g., Intel Xeon). Your program runs on the host and uses the CUDA API to move data back and forth to the GPU and run programs on the GPU. You cannot log on the GPU directly or run an OS on the GPU.





27 CPU GPU Allocate memory on GPU Allocation Copy data Launch kernel Copy data Asynchronous Host to Device Kernel execution Free memory on GPU Device to Host
28 GPU architecture You cannot program a GPU without understanding the architecture of the processor.
 Shared")
29 1 instruction buffer + warp scheduler Large register file 32 cores Maxwell architecture Maxwell Streaming Multiprocessor (SM) Shared memory
 x 8 x 4 = 2,048 cores!")
30 Global view Common L2 cache No. of cores: (8x4x2) x 8 x 4 = 2,048 cores! To memory To memory
31 Basic breakdown To program GPUs you need to understand the basic breakdown, at least as a programming model: Bottom-most level: 32 cores = 32 threads, grouped in a warp. The hardware is optimized to have all threads in a warp execute the same instruction at the same time. SIMT (single instruction multiple threads) model. Groups of warps form a block. A block executes on 1 SM (streaming multiprocessor). Threads within a block have some ability to exchange data and synchronize. All the blocks constitute the entire dataset that will be operated on by a kernel.

32

33
34 Execution model Calculations on a GPU always follow the same model. This is very constrained. GPUs run kernels that are designed to execute calculations in the following way. Input Output
35 Code example Let s start with a very basic example firstprogram.cu.bashrc: # User specific aliases and functions module load null module load gnu/4.9.2 module load cuda/7.5.18
36 Code overview
37 Function to execute Input variables Number of threads to use
38 Device kernels
39 global host device What are these mysterious keywords? global kernel will be Executed on the device Callable from the host host kernel will be Executed on the host Callable from the host device kernel will be Executed on the device Callable from the device only Compiled for host Compiled for device

40 We will see on Wednesday how to use more threads and run larger cases.
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
ENDURING DIFFERENTIATION Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION. Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Improving Performance of Machine Learning Workloads
 Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
GPU Basics. Introduction to GPU. S. Sundar and M. Panchatcharam. GPU Basics. S. Sundar & M. Panchatcharam. Super Computing GPU.
 Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8
Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Chapter 6. Parallel Processors from Client to Cloud. Copyright 2014 Elsevier Inc. All rights reserved.
 Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
GPU Programming. Lecture 1: Introduction. Miaoqing Huang University of Arkansas 1 / 27
 1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen
 Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen GPU Computing Applications Here's what Nvidia says its Tesla K20(X) card excels at doing - Seismic processing, CFD, CAE, Financial computing,
Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen GPU Computing Applications Here's what Nvidia says its Tesla K20(X) card excels at doing - Seismic processing, CFD, CAE, Financial computing,
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
GPU for HPC. October 2010
 GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort
 Rob van Nieuwpoort") PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
CUDA Experiences: Over-Optimization and Future HPC
 CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
GPU 101. Mike Bailey. Oregon State University. Oregon State University. Computer Graphics gpu101.pptx. mjb April 23, 2017
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
GPU 101. Mike Bailey. Oregon State University
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
General introduction: GPUs and the realm of parallel architectures
 General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Introduction to tuning on many core platforms. Gilles Gouaillardet RIST
 Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
HPC trends (Myths about) accelerator cards & more. June 24, Martin Schreiber,
 accelerator cards & more. June 24, Martin Schreiber,") HPC trends (Myths about) accelerator cards & more June 24, 2015 - Martin Schreiber, M.Schreiber@exeter.ac.uk Outline HPC & current architectures Performance: Programming models: OpenCL & OpenMP Some applications:
HPC trends (Myths about) accelerator cards & more June 24, 2015 - Martin Schreiber, M.Schreiber@exeter.ac.uk Outline HPC & current architectures Performance: Programming models: OpenCL & OpenMP Some applications:
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
NVidia s GPU Microarchitectures. By Stephen Lucas and Gerald Kotas
 NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
GPU ARCHITECTURE Chris Schultz, June 2017
 GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G
 Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Review Secret behind GPU performance: simple cores but a large number of them; even more threads can exist live on the hardware (10k 20k threads live). Important performance
CME 213 S PRING 2017 Eric Darve Review Secret behind GPU performance: simple cores but a large number of them; even more threads can exist live on the hardware (10k 20k threads live). Important performance
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
Towards Exascale Computing with the Atmospheric Model NUMA
 Towards Exascale Computing with the Atmospheric Model NUMA Andreas Müller, Daniel S. Abdi, Michal Kopera, Lucas Wilcox, Francis X. Giraldo Department of Applied Mathematics Naval Postgraduate School, Monterey
Towards Exascale Computing with the Atmospheric Model NUMA Andreas Müller, Daniel S. Abdi, Michal Kopera, Lucas Wilcox, Francis X. Giraldo Department of Applied Mathematics Naval Postgraduate School, Monterey
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
PARALLEL PROGRAMMING MANY-CORE COMPUTING: THE LOFAR SOFTWARE TELESCOPE (5/5)
") PARALLEL PROGRAMMING MANY-CORE COMPUTING: THE LOFAR SOFTWARE TELESCOPE (5/5) Rob van Nieuwpoort Vrije Universiteit Amsterdam & Astron, the Netherlands Institute for Radio Astronomy Why Radio? Credit: NASA/IPAC
PARALLEL PROGRAMMING MANY-CORE COMPUTING: THE LOFAR SOFTWARE TELESCOPE (5/5) Rob van Nieuwpoort Vrije Universiteit Amsterdam & Astron, the Netherlands Institute for Radio Astronomy Why Radio? Credit: NASA/IPAC
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP
 GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Lecture 1: an introduction to CUDA
 Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
Parallel Systems I The GPU architecture. Jan Lemeire
 Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Fra superdatamaskiner til grafikkprosessorer og
 Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CUDA Introduction Part I PATC GPU Programming Course 2017
 CUDA Introduction Part I PATC GPU Programming Course 2017 Andreas Herten, Forschungszentrum Jülich, 24 April 2017 Handout Version Outline Introduction GPU History Architecture Comparison Jülich Systems
CUDA Introduction Part I PATC GPU Programming Course 2017 Andreas Herten, Forschungszentrum Jülich, 24 April 2017 Handout Version Outline Introduction GPU History Architecture Comparison Jülich Systems
Cartoon parallel architectures; CPUs and GPUs
 Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CS 179 Lecture 4. GPU Compute Architecture
 CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
MANY-CORE COMPUTING. 7-Oct Ana Lucia Varbanescu, UvA. Original slides: Rob van Nieuwpoort, escience Center
 MANY-CORE COMPUTING 7-Oct-2013 Ana Lucia Varbanescu, UvA Original slides: Rob van Nieuwpoort, escience Center Schedule 2 1. Introduction, performance metrics & analysis 2. Programming: basics (10-10-2013)
MANY-CORE COMPUTING 7-Oct-2013 Ana Lucia Varbanescu, UvA Original slides: Rob van Nieuwpoort, escience Center Schedule 2 1. Introduction, performance metrics & analysis 2. Programming: basics (10-10-2013)
Evaluation Of The Performance Of GPU Global Memory Coalescing
 Evaluation Of The Performance Of GPU Global Memory Coalescing Dae-Hwan Kim Department of Computer and Information, Suwon Science College, 288 Seja-ro, Jeongnam-myun, Hwaseong-si, Gyeonggi-do, Rep. of Korea
Evaluation Of The Performance Of GPU Global Memory Coalescing Dae-Hwan Kim Department of Computer and Information, Suwon Science College, 288 Seja-ro, Jeongnam-myun, Hwaseong-si, Gyeonggi-do, Rep. of Korea
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
Exotic Methods in Parallel Computing [GPU Computing]
![Exotic Methods in Parallel Computing [GPU Computing]](/thumbs/79/80141987.jpg "Exotic Methods in Parallel Computing [GPU Computing]") Exotic Methods in Parallel Computing [GPU Computing] Frank Feinbube Exotic Methods in Parallel Computing Dr. Peter Tröger Exotic Methods in Parallel Computing FF 2012 Architectural Shift 2 Exotic Methods
Exotic Methods in Parallel Computing [GPU Computing] Frank Feinbube Exotic Methods in Parallel Computing Dr. Peter Tröger Exotic Methods in Parallel Computing FF 2012 Architectural Shift 2 Exotic Methods
Scientific Computing on GPUs: GPU Architecture Overview
 Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Trends in the Infrastructure of Computing
 Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
POST-SIEVING ON GPUs
 POST-SIEVING ON GPUs Andrea Miele 1, Joppe W Bos 2, Thorsten Kleinjung 1, Arjen K Lenstra 1 1 LACAL, EPFL, Lausanne, Switzerland 2 NXP Semiconductors, Leuven, Belgium 1/18 NUMBER FIELD SIEVE (NFS) Asymptotically
POST-SIEVING ON GPUs Andrea Miele 1, Joppe W Bos 2, Thorsten Kleinjung 1, Arjen K Lenstra 1 1 LACAL, EPFL, Lausanne, Switzerland 2 NXP Semiconductors, Leuven, Belgium 1/18 NUMBER FIELD SIEVE (NFS) Asymptotically
Parallel Algorithm Engineering
 Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework and numa control Examples
Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework and numa control Examples
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
From Shader Code to a Teraflop: How GPU Shader Cores Work. Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian)
") From Shader Code to a Teraflop: How GPU Shader Cores Work Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian) 1 This talk Three major ideas that make GPU processing cores run fast Closer look at real
From Shader Code to a Teraflop: How GPU Shader Cores Work Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian) 1 This talk Three major ideas that make GPU processing cores run fast Closer look at real
GPU A rchitectures Architectures Patrick Neill May
 GPU Architectures Patrick Neill May 30, 2014 Outline CPU versus GPU CUDA GPU Why are they different? Terminology Kepler/Maxwell Graphics Tiled deferred rendering Opportunities What skills you should know
GPU Architectures Patrick Neill May 30, 2014 Outline CPU versus GPU CUDA GPU Why are they different? Terminology Kepler/Maxwell Graphics Tiled deferred rendering Opportunities What skills you should know
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
CUDA. GPU Computing. K. Cooper 1. 1 Department of Mathematics. Washington State University
 GPU Computing K. Cooper 1 1 Department of Mathematics Washington State University 2014 Review of Parallel Paradigms MIMD Computing Multiple Instruction Multiple Data Several separate program streams, each
GPU Computing K. Cooper 1 1 Department of Mathematics Washington State University 2014 Review of Parallel Paradigms MIMD Computing Multiple Instruction Multiple Data Several separate program streams, each
A NEW COMPUTING ERA JENSEN HUANG, FOUNDER & CEO GTC CHINA 2017
 A NEW COMPUTING ERA JENSEN HUANG, FOUNDER & CEO GTC CHINA 2017 TWO FORCES DRIVING THE FUTURE OF COMPUTING 10 7 Transistors (thousands) 10 6 10 5 1.1X per year 10 4 10 3 10 2 1.5X per year Single-threaded
A NEW COMPUTING ERA JENSEN HUANG, FOUNDER & CEO GTC CHINA 2017 TWO FORCES DRIVING THE FUTURE OF COMPUTING 10 7 Transistors (thousands) 10 6 10 5 1.1X per year 10 4 10 3 10 2 1.5X per year Single-threaded
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Day 6: Optimization on Parallel Intel Architectures
 Day 6: Optimization on Parallel Intel Architectures Lecture day 6 Ryo Asai Colfax International colfaxresearch.com April 2017 colfaxresearch.com/ Welcome Colfax International, 2013 2017 Disclaimer 2 While
Day 6: Optimization on Parallel Intel Architectures Lecture day 6 Ryo Asai Colfax International colfaxresearch.com April 2017 colfaxresearch.com/ Welcome Colfax International, 2013 2017 Disclaimer 2 While
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
Real-Time Rendering Architectures
 Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Using Graphics Chips for General Purpose Computation
 White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
CS 179: GPU Computing
 CS 179: GPU Computing LECTURE 2: INTRO TO THE SIMD LIFESTYLE AND GPU INTERNALS Recap Can use GPU to solve highly parallelizable problems Straightforward extension to C++ Separate CUDA code into.cu and.cuh
CS 179: GPU Computing LECTURE 2: INTRO TO THE SIMD LIFESTYLE AND GPU INTERNALS Recap Can use GPU to solve highly parallelizable problems Straightforward extension to C++ Separate CUDA code into.cu and.cuh