CS 152 Computer Architecture and Engineering
|
|
|
- Lambert Nash
- 6 years ago
- Views:
Transcription
1 CS 152 Computer Architecture and Engineering Lecture 19 Advanced Processors III John Lazzaro ( TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/ 1
2 Last Time: Dynamic Scheduling Fetch up to 8 instructions per cycle. Dispatch up to 5 instructions per cycle Execute up to 8 instructions per cycle Branch redirects Out-of-order processing Instruction fetch IF IC BP Branch MP ISS RF EX pipeline Load/store WB Xfer pipeline MP ISS RF EA DC Fmt WB Xfer CP D0 D1 D2 D3 Xfer GD Group formation and instruction decode MP ISS RF EX Fixed-point WB Xfer pipeline MP ISS RF Interrupts and flushes Up to 200 instructions in flight. CS 152 L18: Advanced Processors II 240 physical registers (120 int FP) F6 Floatingpoint WB pipeline Xfer A thread may commit up to 5 instructions per cycle. 2
3 Today: Throughput and multiple threads Goal: Use multiple instruction streams to improve (1) throughput of machines that run many programs (2) multi-threaded program execution time. Example: Sun Niagara (32 instruction streams on a chip). Difficulties: Gaining full advantage requires rewriting applications, OS, libraries. Ultimate limiter: Amdahl s law (application dependent). Memory system performance. 3
4 Throughput Computing Multithreading: Interleave instructions from separate threads on the same hardware. Seen by OS as several CPUs. Multi-core: Integrating several processors that (partially) share a memory system on the same chip 4
5 Multi-Threading (Static Pipelines) 5
6 Recall: Bypass network prevents stalls Instead of bypass: Interleave threads on the pipeline to prevent stalls... IR ID (Decode) IR EX IR MEM IR WE, MemToReg WB Mux,Logic From WB 32 op rs1 rs2 RegFile rd1 A 32 A L U 32 Y Data Memory Addr Dout Din WE MemToReg R ws wd WE rd2 M M Ext B 6
7 Introduced in 1964 by Seymour Cray Interleave 4 threads, T1-T4, on non-bypassed 5-stage pipe T1: LW r1, 0(r2) T2: ADD r7, r1, r4 T3: XORI r5, r4, #12 T4: SW 0(r7), r5 T1: LW r5, 12(r1) t0 t1 t2 t3 t4 t5 t6 t7 t8 F D X M W F D X M W F D X M W F D X M W F D X M W t9 Last instruction in a thread always completes writeback before next instruction in same thread reads regfile 4 CPUs, each run at 1/4 clock PC PC PC 1 PC I$ IR GPR1 GPR1 GPR1 GPR1 X Y D$ +1 2 Thread select 2 Many variants... 7
8 Multi-Threading (Dynamic Scheduling) 8


9 Power 4 (predates Power 5 shown Tuesday) Single-threaded predecessor to Power 5. 8 execution units in out-of-order engine, each may issue an instruction each cycle. Branch redirects Out-of-order processing Instruction fetch BR MP ISS RF EX WB Xfer LD/ST IF IC BP MP ISS RF EA DC Fmt WB Xfer CP D0 D1 D2 D3 Xfer GD MP ISS RF EX FX WB Xfer Instruction crack and group formation MP ISS RF FP F6 WB Xfer Interrupts and flushes 9
10 For most apps, most execution units lie idle Observation: Most hardware in an out-of-order CPU concerns physical registers. Could several Percent of Total Issue Cycles For an 8-way superscalar. memory conflict long fp short fp long integer short integer load delays control hazards branch misprediction dcache miss icache miss dtlb miss itlb miss processor busy instruction threads share this hardware? alvinn doduc eqntott espresso fpppp hydro2d li mdljdp2 mdljsp2 nasa7 ora Applications su2cor swm tomcatv composite From: Tullsen, Eggers, and Levy, Simultaneous Multithreading: Maximizing Onchip Parallelism, ISCA
11 Simultaneous Multi-threading... One thread, 8 units Cycle M M FX FX FP FP BR CC Two threads, 8 units Cycle M M FX FX FP FP BR CC M = Load/Store, FX = Fixed Point, FP = Floating Point, BR = Branch, CC = Condition Codes 11

12 Branch redirects Power 4 Out-of-order processing Instruction fetch IF IC BP MP ISS RF EX BR WB LD/ST MP ISS RF EA DC Fmt WB Xfer Xfer CP D0 D1 D2 D3 Xfer GD MP ISS RF EX FX WB Xfer Instruction crack and group formation MP ISS RF FP F6 WB Xfer Interrupts and flushes Branch redirects Instruction fetch IF IC BP D0 D1 D2 D3 Xfer GD Interrupts and flushes Power 5 Group formation and instruction decode 2 fetch (PC), 2 initial decodes Out-of-order processing Branch MP ISS RF EX pipeline Load/store WB Xfer pipeline MP ISS RF EA DC Fmt WB Xfer MP ISS RF EX Fixed-point WB Xfer pipeline MP ISS RF F6 Floatingpoint WB pipeline 2 commits (architected register sets) Xfer CP 12

13 Power 5 data flow... Program counter Instruction cache Instruction translation Alternate Branch history tables Instruction buffer 0 Instruction buffer 1 Branch prediction Return stack Thread priority Target cache Group formation Instruction decode Dispatch Sharedregister mappers Dynamic instruction selection Shared issue queues Read sharedregister files Shared execution units LSU0 FXU0 LSU1 FXU1 FPU0 FPU1 BXU CRL Write sharedregister files Data Translation Group completion Data translation Data Cache Store queue Data cache L2 cache Shared by two threads Thread 0 resources Thread 1 resources Why only 2 threads? With 4, one of the shared resources (physical registers, cache, memory bandwidth) would be prone to bottleneck. 13
 Single-thread mode 0,7 2,7 1,6 4,7 3,6 2,5 1,4 6,7 7,7 7,6 5,6 4,5 3,4 2,3 2,1 6,6 5,5 4,4 3,3 2,2 6,5 5,4 4,3 3,2 2,1 7,4 6,3 5,2 4,1 7,2 6,1 Thread 0 priority, thread 1")
14 Power 5 thread performance... Relative priority of each thread controllable in hardware. For balanced operation, both threads run slower than if they owned the machine. Instructions per cycle (IPC) Single-thread mode 0,7 2,7 1,6 4,7 3,6 2,5 1,4 6,7 7,7 7,6 5,6 4,5 3,4 2,3 2,1 6,6 5,5 4,4 3,3 2,2 6,5 5,4 4,3 3,2 2,1 7,4 6,3 5,2 4,1 7,2 6,1 Thread 0 priority, thread 1 priority 7,0 1,1 0,1 1,0 Power save mode Thread 0 IPC Thread 1 IPC 14
15 This Friday: Memory System Checkoff T e s t V e c t o r s IC Bus Instruction Cache Data Cache IM Bus Run your test vector suite on the Calinx board, display results on LEDs DC Bus DM Bus D R A M C o n t r o l l e r D R A M CS 152 L14: Cache II 15
16 Multi-Core 16
17 Recall: Superscalar utilization by a thread Percent of Total Issue Cycles For an 8-way superscalar. memory conflict long fp short fp long integer short integer load delays control hazards branch misprediction dcache miss icache miss dtlb miss itlb miss processor busy Observation: In many cases, the on-chip cache and DRAM I/O bandwidth is also underutilized 20 by one CPU. 10 So, let 2 cores 0 alvinn doduc eqntott espresso fpppp hydro2d li mdljdp2 mdljsp2 nasa7 ora Applications su2cor swm tomcatv composite share them. 17

18 Most of Power 5 die is shared hardware Core #1 Shared Components L2 Cache L3 Cache Control Core #2 DRAM Controller 18
19 Core-to-core interactions stay on chip (1) Threads on two cores that use shared libraries conserve L2 memory. (2) Threads on two cores share memory via L2 cache operations. Much faster than 2 CPUs on 2 chips. 19

20 Coming in 2007: 4 cores per die... Current products from Intel and AMD use 2 CPU cores. Both are planning 4-core designs. 20
21 Sun Niagara 21

22 The case for Sun s Niagara... Percent of Total Issue Cycles For an 8-way superscalar. memory conflict long fp short fp long integer short integer load delays control hazards branch misprediction dcache miss icache miss dtlb miss itlb miss processor busy Observation: Some apps struggle to reach a CPI == 1. For throughput on these apps, a large number 20 of single-issue 10 cores is better 0 alvinn doduc eqntott espresso fpppp hydro2d li mdljdp2 mdljsp2 nasa7 ora Applications su2cor swm tomcatv composite than a few superscalars. 22

23 Niagara: 32 threads on one chip 8 cores: Single-issue, 1.2 GHz 6-stage pipeline 4-way multi-threaded Fast crypto support Die size: 340 mm² in 90 nm. Power: W Shared resources: 3MB on-chip cache 4 DDR2 interfaces 32G DRAM, 20 Gb/s 1 shared FP unit GB Ethernet ports Sources: Hot Chips, via EE Times, Infoworld. J Schwartz weblog (Sun COO) 23


24 The board that booted Niagara first-silicon Source: J Schwartz weblog (then Sun COO, now CEO) 24



25 Used in Sun Fire T2000: Coolthreads Claim: server uses 1/3 the power of competing servers. Web server benchmarks used to position the T2000 in the market. 25

26 Project Blackbox A data center in a 20-ft shipping container. Servers, CS 152 L19: Advanced air-conditioners, Processors III power distribution. 26

27 Just hook up network, power, and water... 27

28 28


29 Holds 250 T1000 servers CPU cores, 8000 threads. 29

30 30


31 Cell: The PS3 chip 31

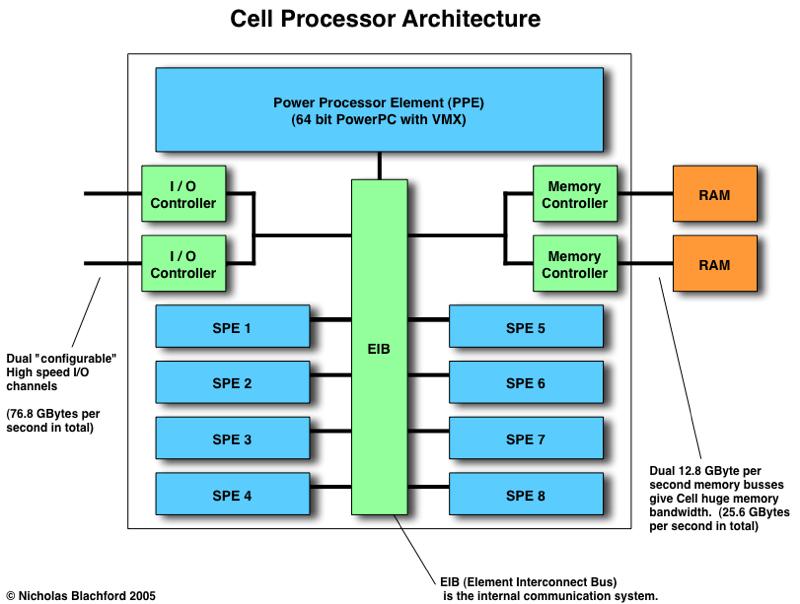
32 L2 Cache 512 KB PowerPC Synergistic Processing Units (SPUs) PowerPC manages the 8 SPUs, also runs serial code. 2X area of Pentium GHz+ cycle time 32
33 33
34 Synergistic Processing Units (SPUs) 8 cores using local memory, not traditional caches 34
 to 7 execution units SPU fills Local Store using DMA to DRAM and")
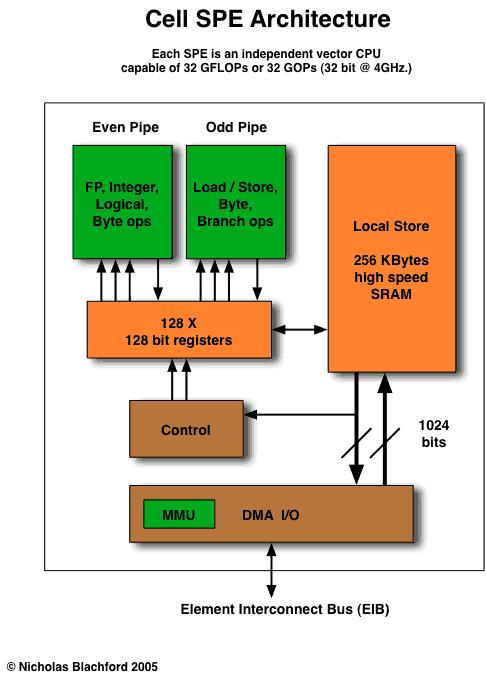
35 One Synergistic Processing Unit (SPU) Programmers manage caching explicitly 256 KB Local Store and bit Registers SPU issues 2 inst/cycle (in order) to 7 execution units SPU fills Local Store using DMA to DRAM and network 35
36 36

37 L2 Cache PowerPC 37

38 Example: Using Cell to Decode HDTV 38

39 39
40 Conclusions: Throughput processing Simultaneous Multithreading: Instructions streams can share an out-of-order engine economically. Multi-core: Once instruction-level parallelism run dry, thread-level parallelism is a good use of die area. 40
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 22 Advanced Processors III 2005-4-12 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 22 Advanced Processors III 2005-4-12 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 22 Advanced Processors III 2004-11-18 Dave Patterson (www.cs.berkeley.edu/~patterson) John Lazzaro (www.cs.berkeley.edu/~lazzaro) www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 22 Advanced Processors III 2004-11-18 Dave Patterson (www.cs.berkeley.edu/~patterson) John Lazzaro (www.cs.berkeley.edu/~lazzaro) www-inst.eecs.berkeley.edu/~cs152/
CS Digital Systems Project Laboratory. Lecture 10: Advanced Processors II
 CS 194-6 Digital Systems Project Laboratory Lecture 10: Advanced Processors II 2008-11-24 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TA: Greg Gibeling www-inst.eecs.berkeley.edu/~cs194-6/
CS 194-6 Digital Systems Project Laboratory Lecture 10: Advanced Processors II 2008-11-24 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TA: Greg Gibeling www-inst.eecs.berkeley.edu/~cs194-6/
Multi-Threading. Last Time: Dynamic Scheduling. Recall: Throughput and multiple threads. This Time: Throughput Computing
 CS Computer Architecture and Engineering Lecture Advanced Processors III -- Dave Patterson (www.cs.berkeley.edu/~patterson) John Lazzaro (www.cs.berkeley.edu/~lazzaro) www-inst.eecs.berkeley.edu/~cs/ Last
CS Computer Architecture and Engineering Lecture Advanced Processors III -- Dave Patterson (www.cs.berkeley.edu/~patterson) John Lazzaro (www.cs.berkeley.edu/~lazzaro) www-inst.eecs.berkeley.edu/~cs/ Last
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 17 Advanced Processors I 2005-10-27 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 17 Advanced Processors I 2005-10-27 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 20 Advanced Processors I 2005-4-5 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last
CS 152 Computer Architecture and Engineering Lecture 20 Advanced Processors I 2005-4-5 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 18 Advanced Processors II 2006-10-31 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 18 Advanced Processors II 2006-10-31 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 7 Pipelining I 2005-9-20 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/ Office Hours
CS 152 Computer Architecture and Engineering Lecture 7 Pipelining I 2005-9-20 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/ Office Hours
IBM's POWER5 Micro Processor Design and Methodology
 IBM's POWER5 Micro Processor Design and Methodology Ron Kalla IBM Systems Group Outline POWER5 Overview Design Process Power POWER Server Roadmap 2001 POWER4 2002-3 POWER4+ 2004* POWER5 2005* POWER5+ 2006*
IBM's POWER5 Micro Processor Design and Methodology Ron Kalla IBM Systems Group Outline POWER5 Overview Design Process Power POWER Server Roadmap 2001 POWER4 2002-3 POWER4+ 2004* POWER5 2005* POWER5+ 2006*
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 7 Pipelining I 2006-9-19 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/ Last Time: ipod
CS 152 Computer Architecture and Engineering Lecture 7 Pipelining I 2006-9-19 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/ Last Time: ipod
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Lecture 19: Memory Hierarchy Five Ways to Reduce Miss Penalty (Second Level Cache) Admin
 Admin") Lecture 19: Memory Hierarchy Five Ways to Reduce Miss Penalty (Second Level Cache) Professor Alvin R. Lebeck Computer Science 220 Fall 1999 Exam Average 76 90-100 4 80-89 3 70-79 3 60-69 5 < 60 1 Admin
Lecture 19: Memory Hierarchy Five Ways to Reduce Miss Penalty (Second Level Cache) Professor Alvin R. Lebeck Computer Science 220 Fall 1999 Exam Average 76 90-100 4 80-89 3 70-79 3 60-69 5 < 60 1 Admin
CS 152 Computer Architecture and Engineering. Lecture 18: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
PowerPC 620 Case Study
 Chapter 6: The PowerPC 60 Modern Processor Design: Fundamentals of Superscalar Processors PowerPC 60 Case Study First-generation out-of-order processor Developed as part of Apple-IBM-Motorola alliance
Chapter 6: The PowerPC 60 Modern Processor Design: Fundamentals of Superscalar Processors PowerPC 60 Case Study First-generation out-of-order processor Developed as part of Apple-IBM-Motorola alliance
Chapter-5 Memory Hierarchy Design
 Chapter-5 Memory Hierarchy Design Unlimited amount of fast memory - Economical solution is memory hierarchy - Locality - Cost performance Principle of locality - most programs do not access all code or
Chapter-5 Memory Hierarchy Design Unlimited amount of fast memory - Economical solution is memory hierarchy - Locality - Cost performance Principle of locality - most programs do not access all code or
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Virtual memory why? Virtual memory parameters Compared to first-level cache Parameter First-level cache Virtual memory. Virtual memory concepts
 Lecture 16 Virtual memory why? Virtual memory: Virtual memory concepts (5.10) Protection (5.11) The memory hierarchy of Alpha 21064 (5.13) Virtual address space proc 0? s space proc 1 Physical memory Virtual
Lecture 16 Virtual memory why? Virtual memory: Virtual memory concepts (5.10) Protection (5.11) The memory hierarchy of Alpha 21064 (5.13) Virtual address space proc 0? s space proc 1 Physical memory Virtual
CSE 502 Graduate Computer Architecture. Lec 11 Simultaneous Multithreading
 CSE 502 Graduate Computer Architecture Lec 11 Simultaneous Multithreading Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from David Patterson,
CSE 502 Graduate Computer Architecture Lec 11 Simultaneous Multithreading Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from David Patterson,
IBM POWER5 CHIP: A DUAL-CORE MULTITHREADED PROCESSOR
 IBM POWER5 CHIP: A DUAL-CORE MULTITHREADED PROCESSOR FEATURING SINGLE- AND MULTITHREADED EXECUTION, THE POWER5 PROVIDES HIGHER PERFORMANCE IN THE SINGLE-THREADED MODE THAN ITS POWER4 PREDECESSOR AT EQUIVALENT
IBM POWER5 CHIP: A DUAL-CORE MULTITHREADED PROCESSOR FEATURING SINGLE- AND MULTITHREADED EXECUTION, THE POWER5 PROVIDES HIGHER PERFORMANCE IN THE SINGLE-THREADED MODE THAN ITS POWER4 PREDECESSOR AT EQUIVALENT
CS 152 Computer Architecture and Engineering
 CS 52 Computer Architecture and Engineering Lecture 26 Mid-Term II Review 26--3 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs52/ CS 52 L26: Mid-Term
CS 52 Computer Architecture and Engineering Lecture 26 Mid-Term II Review 26--3 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs52/ CS 52 L26: Mid-Term
CS 152 Computer Architecture and Engineering. Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 14 - Cache Design and Coherence 2014-3-6 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: 1 Today:
CS 152 Computer Architecture and Engineering Lecture 14 - Cache Design and Coherence 2014-3-6 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: 1 Today:
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 7 Performance 2005-2-8 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last Time: Tips
CS 152 Computer Architecture and Engineering Lecture 7 Performance 2005-2-8 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last Time: Tips
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
Case Study IBM PowerPC 620
 Case Study IBM PowerPC 620 year shipped: 1995 allowing out-of-order execution (dynamic scheduling) and in-order commit (hardware speculation). using a reorder buffer to track when instruction can commit,
Case Study IBM PowerPC 620 year shipped: 1995 allowing out-of-order execution (dynamic scheduling) and in-order commit (hardware speculation). using a reorder buffer to track when instruction can commit,
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Cache Performance! ! Memory system and processor performance:! ! Improving memory hierarchy performance:! CPU time = IC x CPI x Clock time
 Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Multithreading Processors and Static Optimization Review. Adapted from Bhuyan, Patterson, Eggers, probably others
 Multithreading Processors and Static Optimization Review Adapted from Bhuyan, Patterson, Eggers, probably others Schedule of things to do By Wednesday the 9 th at 9pm Please send a milestone report (as
Multithreading Processors and Static Optimization Review Adapted from Bhuyan, Patterson, Eggers, probably others Schedule of things to do By Wednesday the 9 th at 9pm Please send a milestone report (as
Predict Not Taken. Revisiting Branch Hazard Solutions. Filling the delay slot (e.g., in the compiler) Delayed Branch
 Delayed Branch") branch taken Revisiting Branch Hazard Solutions Stall Predict Not Taken Predict Taken Branch Delay Slot Branch I+1 I+2 I+3 Predict Not Taken branch not taken Branch I+1 IF (bubble) (bubble) (bubble) (bubble)
branch taken Revisiting Branch Hazard Solutions Stall Predict Not Taken Predict Taken Branch Delay Slot Branch I+1 I+2 I+3 Predict Not Taken branch not taken Branch I+1 IF (bubble) (bubble) (bubble) (bubble)
Ron Kalla, Balaram Sinharoy, Joel Tendler IBM Systems Group
 Simultaneous Multi-threading Implementation in POWER5 -- IBM's Next Generation POWER Microprocessor Ron Kalla, Balaram Sinharoy, Joel Tendler IBM Systems Group Outline Motivation Background Threading Fundamentals
Simultaneous Multi-threading Implementation in POWER5 -- IBM's Next Generation POWER Microprocessor Ron Kalla, Balaram Sinharoy, Joel Tendler IBM Systems Group Outline Motivation Background Threading Fundamentals
Cache Performance! ! Memory system and processor performance:! ! Improving memory hierarchy performance:! CPU time = IC x CPI x Clock time
 Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Improving Cache Performance. Dr. Yitzhak Birk Electrical Engineering Department, Technion
 Improving Cache Performance Dr. Yitzhak Birk Electrical Engineering Department, Technion 1 Cache Performance CPU time = (CPU execution clock cycles + Memory stall clock cycles) x clock cycle time Memory
Improving Cache Performance Dr. Yitzhak Birk Electrical Engineering Department, Technion 1 Cache Performance CPU time = (CPU execution clock cycles + Memory stall clock cycles) x clock cycle time Memory
CS 252 Graduate Computer Architecture. Lecture 4: Instruction-Level Parallelism
 CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
Dynamic Hardware Prediction. Basic Branch Prediction Buffers. N-bit Branch Prediction Buffers
 Dynamic Hardware Prediction Importance of control dependences Branches and jumps are frequent Limiting factor as ILP increases (Amdahl s law) Schemes to attack control dependences Static Basic (stall the
Dynamic Hardware Prediction Importance of control dependences Branches and jumps are frequent Limiting factor as ILP increases (Amdahl s law) Schemes to attack control dependences Static Basic (stall the
Advanced processor designs
 Advanced processor designs We ve only scratched the surface of CPU design. Today we ll briefly introduce some of the big ideas and big words behind modern processors by looking at two example CPUs. The
Advanced processor designs We ve only scratched the surface of CPU design. Today we ll briefly introduce some of the big ideas and big words behind modern processors by looking at two example CPUs. The
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Memory Hierarchy 3 Cs and 6 Ways to Reduce Misses
 Memory Hierarchy 3 Cs and 6 Ways to Reduce Misses Soner Onder Michigan Technological University Randy Katz & David A. Patterson University of California, Berkeley Four Questions for Memory Hierarchy Designers
Memory Hierarchy 3 Cs and 6 Ways to Reduce Misses Soner Onder Michigan Technological University Randy Katz & David A. Patterson University of California, Berkeley Four Questions for Memory Hierarchy Designers
EECS Digital Design
 EECS 150 -- Digital Design Lecture 11-- Processor Pipelining 2010-2-23 John Wawrzynek Today s lecture by John Lazzaro www-inst.eecs.berkeley.edu/~cs150 1 Today: Pipelining How to apply the performance
EECS 150 -- Digital Design Lecture 11-- Processor Pipelining 2010-2-23 John Wawrzynek Today s lecture by John Lazzaro www-inst.eecs.berkeley.edu/~cs150 1 Today: Pipelining How to apply the performance
Instruction Level Parallelism
 Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Multiple Issue ILP Processors. Summary of discussions
 Summary of discussions Multiple Issue ILP Processors ILP processors - VLIW/EPIC, Superscalar Superscalar has hardware logic for extracting parallelism - Solutions for stalls etc. must be provided in hardware
Summary of discussions Multiple Issue ILP Processors ILP processors - VLIW/EPIC, Superscalar Superscalar has hardware logic for extracting parallelism - Solutions for stalls etc. must be provided in hardware
EC 513 Computer Architecture
 EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
TDT 4260 lecture 7 spring semester 2015
 1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW. Computer Architectures S
 Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
Review: Evaluating Branch Alternatives. Lecture 3: Introduction to Advanced Pipelining. Review: Evaluating Branch Prediction
 Review: Evaluating Branch Alternatives Lecture 3: Introduction to Advanced Pipelining Two part solution: Determine branch taken or not sooner, AND Compute taken branch address earlier Pipeline speedup
Review: Evaluating Branch Alternatives Lecture 3: Introduction to Advanced Pipelining Two part solution: Determine branch taken or not sooner, AND Compute taken branch address earlier Pipeline speedup
Lecture 9: Multiple Issue (Superscalar and VLIW)
") Lecture 9: Multiple Issue (Superscalar and VLIW) Iakovos Mavroidis Computer Science Department University of Crete Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Lecture 9: Multiple Issue (Superscalar and VLIW) Iakovos Mavroidis Computer Science Department University of Crete Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Lecture 5: VLIW, Software Pipelining, and Limits to ILP. Review: Tomasulo
 Lecture 5: VLIW, Software Pipelining, and Limits to ILP Professor David A. Patterson Computer Science 252 Spring 1998 DAP.F96 1 Review: Tomasulo Prevents Register as bottleneck Avoids WAR, WAW hazards
Lecture 5: VLIW, Software Pipelining, and Limits to ILP Professor David A. Patterson Computer Science 252 Spring 1998 DAP.F96 1 Review: Tomasulo Prevents Register as bottleneck Avoids WAR, WAW hazards
UC Berkeley CS61C : Machine Structures
 inst.eecs.berkeley.edu/~cs61c UC Berkeley CS61C : Machine Structures Lecture 40 Hardware Parallel Computing 2006-12-06 Thanks to John Lazarro for his CS152 slides inst.eecs.berkeley.edu/~cs152/ Head TA
inst.eecs.berkeley.edu/~cs61c UC Berkeley CS61C : Machine Structures Lecture 40 Hardware Parallel Computing 2006-12-06 Thanks to John Lazarro for his CS152 slides inst.eecs.berkeley.edu/~cs152/ Head TA
Outline. Lecture 40 Hardware Parallel Computing Thanks to John Lazarro for his CS152 slides inst.eecs.berkeley.
 CS61C L40 Hardware Parallel Computing (1) inst.eecs.berkeley.edu/~cs61c UC Berkeley CS61C : Machine Structures Lecture 40 Hardware Parallel Computing 2006-12-06 Thanks to John Lazarro for his CS152 slides
CS61C L40 Hardware Parallel Computing (1) inst.eecs.berkeley.edu/~cs61c UC Berkeley CS61C : Machine Structures Lecture 40 Hardware Parallel Computing 2006-12-06 Thanks to John Lazarro for his CS152 slides
Functional Units. Registers. The Big Picture: Where are We Now? The Five Classic Components of a Computer Processor Input Control Memory
 The Big Picture: Where are We Now? CS152 Computer Architecture and Engineering Lecture 18 The Five Classic Components of a Computer Processor Input Control Dynamic Scheduling (Cont), Speculation, and ILP
The Big Picture: Where are We Now? CS152 Computer Architecture and Engineering Lecture 18 The Five Classic Components of a Computer Processor Input Control Dynamic Scheduling (Cont), Speculation, and ILP
Appendix C. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Appendix C Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure C.2 The pipeline can be thought of as a series of data paths shifted in time. This shows
Appendix C Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure C.2 The pipeline can be thought of as a series of data paths shifted in time. This shows
Power 7. Dan Christiani Kyle Wieschowski
 Power 7 Dan Christiani Kyle Wieschowski History 1980-2000 1980 RISC Prototype 1990 POWER1 (Performance Optimization With Enhanced RISC) (1 um) 1993 IBM launches 66MHz POWER2 (.35 um) 1997 POWER2 Super
Power 7 Dan Christiani Kyle Wieschowski History 1980-2000 1980 RISC Prototype 1990 POWER1 (Performance Optimization With Enhanced RISC) (1 um) 1993 IBM launches 66MHz POWER2 (.35 um) 1997 POWER2 Super
Simultaneous Multithreading Architecture
 Simultaneous Multithreading Architecture Virendra Singh Indian Institute of Science Bangalore Lecture-32 SE-273: Processor Design For most apps, most execution units lie idle For an 8-way superscalar.
Simultaneous Multithreading Architecture Virendra Singh Indian Institute of Science Bangalore Lecture-32 SE-273: Processor Design For most apps, most execution units lie idle For an 8-way superscalar.
CS 152 Exam #2 Solutions
 University of California, Berkeley College of Engineering Department of Electrical Engineering and Computer Sciences all 2004 Instructors: Dave Patterson and John Lazzaro November 23 rd, 2004 CS 152 Exam
University of California, Berkeley College of Engineering Department of Electrical Engineering and Computer Sciences all 2004 Instructors: Dave Patterson and John Lazzaro November 23 rd, 2004 CS 152 Exam
Cache performance Outline
 Cache performance 1 Outline Metrics Performance characterization Cache optimization techniques 2 Page 1 Cache Performance metrics (1) Miss rate: Neglects cycle time implications Average memory access time
Cache performance 1 Outline Metrics Performance characterization Cache optimization techniques 2 Page 1 Cache Performance metrics (1) Miss rate: Neglects cycle time implications Average memory access time
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Computer Science 146. Computer Architecture
 Computer Architecture Spring 2004 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 9: Limits of ILP, Case Studies Lecture Outline Speculative Execution Implementing Precise Interrupts
Computer Architecture Spring 2004 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 9: Limits of ILP, Case Studies Lecture Outline Speculative Execution Implementing Precise Interrupts
Pipelining. Ideal speedup is number of stages in the pipeline. Do we achieve this? 2. Improve performance by increasing instruction throughput ...
 CHAPTER 6 1 Pipelining Instruction class Instruction memory ister read ALU Data memory ister write Total (in ps) Load word 200 100 200 200 100 800 Store word 200 100 200 200 700 R-format 200 100 200 100
CHAPTER 6 1 Pipelining Instruction class Instruction memory ister read ALU Data memory ister write Total (in ps) Load word 200 100 200 200 100 800 Store word 200 100 200 200 700 R-format 200 100 200 100
Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov
 ECE 154B Dmitri Strukov") Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov Dealing With Control Hazards Simplest solution to stall pipeline until branch is resolved and target address is calculated
Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov Dealing With Control Hazards Simplest solution to stall pipeline until branch is resolved and target address is calculated
Metodologie di Progettazione Hardware-Software
 Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
CISC 662 Graduate Computer Architecture Lecture 18 - Cache Performance. Why More on Memory Hierarchy?
 CISC 662 Graduate Computer Architecture Lecture 18 - Cache Performance Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture, 4th edition ---- Additional
CISC 662 Graduate Computer Architecture Lecture 18 - Cache Performance Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture, 4th edition ---- Additional
Reference. T1 Architecture. T1 ( Niagara ) Case Study of a Multi-core, Multithreaded
 Case Study of a Multi-core, Multithreaded") Reference Case Study of a Multi-core, Multithreaded Processor The Sun T ( Niagara ) Computer Architecture, A Quantitative Approach, Fourth Edition, by John Hennessy and David Patterson, chapter. :/C:8
Reference Case Study of a Multi-core, Multithreaded Processor The Sun T ( Niagara ) Computer Architecture, A Quantitative Approach, Fourth Edition, by John Hennessy and David Patterson, chapter. :/C:8
NOW Handout Page # Why More on Memory Hierarchy? CISC 662 Graduate Computer Architecture Lecture 18 - Cache Performance
 CISC 66 Graduate Computer Architecture Lecture 8 - Cache Performance Michela Taufer Performance Why More on Memory Hierarchy?,,, Processor Memory Processor-Memory Performance Gap Growing Powerpoint Lecture
CISC 66 Graduate Computer Architecture Lecture 8 - Cache Performance Michela Taufer Performance Why More on Memory Hierarchy?,,, Processor Memory Processor-Memory Performance Gap Growing Powerpoint Lecture
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
Hardware Speculation Support
 Hardware Speculation Support Conditional instructions Most common form is conditional move BNEZ R1, L ;if MOV R2, R3 ;then CMOVZ R2,R3, R1 L: ;else Other variants conditional loads and stores nullification
Hardware Speculation Support Conditional instructions Most common form is conditional move BNEZ R1, L ;if MOV R2, R3 ;then CMOVZ R2,R3, R1 L: ;else Other variants conditional loads and stores nullification
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 152 Computer Architecture and Engineering Lecture 4 Pipelining
 CS 152 Computer rchitecture and Engineering Lecture 4 Pipelining 2014-1-30 John Lazzaro (not a prof - John is always OK) T: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: 1 otorola 68000 Next week
CS 152 Computer rchitecture and Engineering Lecture 4 Pipelining 2014-1-30 John Lazzaro (not a prof - John is always OK) T: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: 1 otorola 68000 Next week
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Lecture 5: VLIW, Software Pipelining, and Limits to ILP Professor David A. Patterson Computer Science 252 Spring 1998
 Lecture 5: VLIW, Software Pipelining, and Limits to ILP Professor David A. Patterson Computer Science 252 Spring 1998 DAP.F96 1 Review: Tomasulo Prevents Register as bottleneck Avoids WAR, WAW hazards
Lecture 5: VLIW, Software Pipelining, and Limits to ILP Professor David A. Patterson Computer Science 252 Spring 1998 DAP.F96 1 Review: Tomasulo Prevents Register as bottleneck Avoids WAR, WAW hazards
Improving Performance: Pipelining
 Improving Performance: Pipelining Memory General registers Memory ID EXE MEM WB Instruction Fetch (includes PC increment) ID Instruction Decode + fetching values from general purpose registers EXE EXEcute
Improving Performance: Pipelining Memory General registers Memory ID EXE MEM WB Instruction Fetch (includes PC increment) ID Instruction Decode + fetching values from general purpose registers EXE EXEcute
Classification Steady-State Cache Misses: Techniques To Improve Cache Performance:
 #1 Lec # 9 Winter 2003 1-21-2004 Classification Steady-State Cache Misses: The Three C s of cache Misses: Compulsory Misses Capacity Misses Conflict Misses Techniques To Improve Cache Performance: Reduce
#1 Lec # 9 Winter 2003 1-21-2004 Classification Steady-State Cache Misses: The Three C s of cache Misses: Compulsory Misses Capacity Misses Conflict Misses Techniques To Improve Cache Performance: Reduce
Pentium IV-XEON. Computer architectures M
 Pentium IV-XEON Computer architectures M 1 Pentium IV block scheme 4 32 bytes parallel Four access ports to the EU 2 Pentium IV block scheme Address Generation Unit BTB Branch Target Buffer I-TLB Instruction
Pentium IV-XEON Computer architectures M 1 Pentium IV block scheme 4 32 bytes parallel Four access ports to the EU 2 Pentium IV block scheme Address Generation Unit BTB Branch Target Buffer I-TLB Instruction
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Lecture 19: Instruction Level Parallelism -- Dynamic Scheduling, Multiple Issue, and Speculation
 Lecture 19: Instruction Level Parallelism -- Dynamic Scheduling, Multiple Issue, and Speculation CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu
Lecture 19: Instruction Level Parallelism -- Dynamic Scheduling, Multiple Issue, and Speculation CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu
Review Tomasulo. Lecture 17: ILP and Dynamic Execution #2: Branch Prediction, Multiple Issue. Tomasulo Algorithm and Branch Prediction
 CS252 Graduate Computer Architecture Lecture 17: ILP and Dynamic Execution #2: Branch Prediction, Multiple Issue March 23, 01 Prof. David A. Patterson Computer Science 252 Spring 01 Review Tomasulo Reservations
CS252 Graduate Computer Architecture Lecture 17: ILP and Dynamic Execution #2: Branch Prediction, Multiple Issue March 23, 01 Prof. David A. Patterson Computer Science 252 Spring 01 Review Tomasulo Reservations
OPENSPARC T1 OVERVIEW
 Chapter Four OPENSPARC T1 OVERVIEW Denis Sheahan Distinguished Engineer Niagara Architecture Group Sun Microsystems Creative Commons 3.0United United States License Creative CommonsAttribution-Share Attribution-Share
Chapter Four OPENSPARC T1 OVERVIEW Denis Sheahan Distinguished Engineer Niagara Architecture Group Sun Microsystems Creative Commons 3.0United United States License Creative CommonsAttribution-Share Attribution-Share
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 6 Superpipelining + Branch Prediction 2014-2-6 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play:
CS 152 Computer Architecture and Engineering Lecture 6 Superpipelining + Branch Prediction 2014-2-6 John Lazzaro (not a prof - John is always OK) TA: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play:
Beyond ILP. Hemanth M Bharathan Balaji. Hemanth M & Bharathan Balaji
 Beyond ILP Hemanth M Bharathan Balaji Multiscalar Processors Gurindar S Sohi Scott E Breach T N Vijaykumar Control Flow Graph (CFG) Each node is a basic block in graph CFG divided into a collection of
Beyond ILP Hemanth M Bharathan Balaji Multiscalar Processors Gurindar S Sohi Scott E Breach T N Vijaykumar Control Flow Graph (CFG) Each node is a basic block in graph CFG divided into a collection of
ECE 571 Advanced Microprocessor-Based Design Lecture 4
 ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
CS 152, Spring 2012 Section 8
 CS 152, Spring 2012 Section 8 Christopher Celio University of California, Berkeley Agenda More Out- of- Order Intel Core 2 Duo (Penryn) Vs. NVidia GTX 280 Intel Core 2 Duo (Penryn) dual- core 2007+ 45nm
CS 152, Spring 2012 Section 8 Christopher Celio University of California, Berkeley Agenda More Out- of- Order Intel Core 2 Duo (Penryn) Vs. NVidia GTX 280 Intel Core 2 Duo (Penryn) dual- core 2007+ 45nm
CS252 Graduate Computer Architecture Lecture 6. Recall: Software Pipelining Example
 CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
What SMT can do for You. John Hague, IBM Consultant Oct 06
 What SMT can do for ou John Hague, IBM Consultant Oct 06 100.000 European Centre for Medium Range Weather Forecasting (ECMWF): Growth in HPC performance 10.000 teraflops sustained 1.000 0.100 0.010 VPP700
What SMT can do for ou John Hague, IBM Consultant Oct 06 100.000 European Centre for Medium Range Weather Forecasting (ECMWF): Growth in HPC performance 10.000 teraflops sustained 1.000 0.100 0.010 VPP700
LSU EE 4720 Dynamic Scheduling Study Guide Fall David M. Koppelman. 1.1 Introduction. 1.2 Summary of Dynamic Scheduling Method 3
 PR 0,0 ID:incmb PR ID:St: C,X LSU EE 4720 Dynamic Scheduling Study Guide Fall 2005 1.1 Introduction David M. Koppelman The material on dynamic scheduling is not covered in detail in the text, which is
PR 0,0 ID:incmb PR ID:St: C,X LSU EE 4720 Dynamic Scheduling Study Guide Fall 2005 1.1 Introduction David M. Koppelman The material on dynamic scheduling is not covered in detail in the text, which is
CS 110 Computer Architecture. Pipelining. Guest Lecture: Shu Yin. School of Information Science and Technology SIST
 CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards
 CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CS 61C: Great Ideas in Computer Architecture. Lecture 13: Pipelining. Krste Asanović & Randy Katz
 CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type
CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type